基于 LLM 大语言模型的知识库问答系统
+
+ 
+



+ +MaxKB = Max Knowledge Base,是一款基于 LLM 大语言模型的开源知识库问答系统,广泛应用于企业内部知识库、客户服务、学术研究与教育等场景。 + +- **开箱即用**:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好; +- **模型中立**:支持对接各种大语言模型,包括本地私有大模型(Llama 3 / Qwen 2 等)、国内公共大模型(通义千问 / 智谱 AI / 百度千帆 / Kimi / DeepSeek 等)和国外公共大模型(OpenAI / Azure OpenAI / Gemini 等); +- **灵活编排**:内置强大的工作流引擎,支持编排 AI 工作过程,满足复杂业务场景下的需求; +- **无缝嵌入**:支持零编码快速嵌入到第三方业务系统,让已有系统快速拥有智能问答能力,提高用户满意度。 + +## 快速开始 + +``` +docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages cr2.fit2cloud.com/1panel/maxkb + +# 用户名: admin +# 密码: MaxKB@123.. +``` + +- 你也可以通过 [1Panel 应用商店](https://apps.fit2cloud.com/1panel) 快速部署 MaxKB + Ollama + Llama 3,30 分钟内即可上线基于本地大模型的知识库问答系统,并嵌入到第三方业务系统中; +- 如果是内网环境,推荐使用 [离线安装包](https://community.fit2cloud.com/#/products/maxkb/downloads) 进行安装部署; +- 你也可以在线体验:[DataEase 小助手](https://dataease.io/docs/v2/),它是基于 MaxKB 搭建的智能问答系统,已经嵌入到 DataEase 产品及在线文档中; +- MaxKB 产品版本分为社区版和专业版,详情请参见:[MaxKB 产品版本对比](https://maxkb.cn/pricing.html)。 + +如你有更多问题,可以查看使用手册,或者通过论坛与我们交流。如果你需要搭建技术博客或者知识库,推荐使用 [Halo 开源建站工具](https://github.com/halo-dev/halo/),你可以体验下飞致云官方的 [技术博客](https://blog.fit2cloud.com/) 和 [知识库](https://kb.fit2cloud.com) 案例。 + +- [使用手册](https://maxkb.cn/docs/) +- [演示视频](https://www.bilibili.com/video/BV1BE421M7YM/) +- [论坛求助](https://bbs.fit2cloud.com/c/mk/11) +- 技术交流群 + +
+
+
+
+
+`
+const chatButtonHtml=
+`
+
+
+
+ 🌟 遇见问题,不再有障碍!
+ 你好,我是你的智能小助手。
+ 点我,开启高效解答模式,让问题变成过去式。
+ +
+
`
+
+
+
+const getChatContainerHtml=(protocol,host,token)=>{
+ return `
+
+/publish', views.Application.Publish.as_view()),
+ path('application//edit_icon', views.Application.EditIcon.as_view()),
+ path('application//statistics/customer_count',
+ views.ApplicationStatistics.CustomerCount.as_view()),
+ path('application//statistics/customer_count_trend',
+ views.ApplicationStatistics.CustomerCountTrend.as_view()),
+ path('application//statistics/chat_record_aggregate',
+ views.ApplicationStatistics.ChatRecordAggregate.as_view()),
+ path('application//statistics/chat_record_aggregate_trend',
+ views.ApplicationStatistics.ChatRecordAggregateTrend.as_view()),
+ path('application//model', views.Application.Model.as_view()),
+ path('application//function_lib', views.Application.FunctionLib.as_view()),
+ path('application//function_lib/',
+ views.Application.FunctionLib.Operate.as_view()),
+ path('application//model_params_form/',
+ views.Application.ModelParamsForm.as_view()),
+ path('application//hit_test', views.Application.HitTest.as_view()),
+ path('application//api_key', views.Application.ApplicationKey.as_view()),
+ path("application//api_key/",
+ views.Application.ApplicationKey.Operate.as_view()),
+ path('application/', views.Application.Operate.as_view(), name='application/operate'),
+ path('application//list_dataset', views.Application.ListApplicationDataSet.as_view(),
+ name='application/dataset'),
+ path('application//access_token', views.Application.AccessToken.as_view(),
+ name='application/access_token'),
+ path('application//', views.Application.Page.as_view(), name='application_page'),
+ path('application//chat/open', views.ChatView.Open.as_view(), name='application/open'),
+ path("application/chat/open", views.ChatView.OpenTemp.as_view()),
+ path("application/chat_workflow/open", views.ChatView.OpenWorkFlowTemp.as_view()),
+ path("application//chat/client//",
+ views.ChatView.ClientChatHistoryPage.as_view()),
+ path("application//chat/client/",
+ views.ChatView.ClientChatHistoryPage.Operate.as_view()),
+ path('application//chat/export', views.ChatView.Export.as_view(), name='export'),
+ path('application//chat', views.ChatView.as_view(), name='chats'),
+ path('application//chat//', views.ChatView.Page.as_view()),
+ path('application//chat/', views.ChatView.Operate.as_view()),
+ path('application//chat//chat_record/', views.ChatView.ChatRecord.as_view()),
+ path('application//chat//chat_record//',
+ views.ChatView.ChatRecord.Page.as_view()),
+ path('application//chat//chat_record/',
+ views.ChatView.ChatRecord.Operate.as_view()),
+ path('application//chat//chat_record//vote',
+ views.ChatView.ChatRecord.Vote.as_view(),
+ name=''),
+ path(
+ 'application//chat//chat_record//dataset//document_id//improve',
+ views.ChatView.ChatRecord.Improve.as_view(),
+ name=''),
+ path('application//chat//chat_record//improve',
+ views.ChatView.ChatRecord.ChatRecordImprove.as_view()),
+ path('application/chat_message/', views.ChatView.Message.as_view(), name='application/message'),
+ path(
+ 'application//chat//chat_record//dataset//document_id//improve/',
+ views.ChatView.ChatRecord.Improve.Operate.as_view(),
+ name='')
+
+]
diff --git a/src/MaxKB-1.5.1/apps/application/views/__init__.py b/src/MaxKB-1.5.1/apps/application/views/__init__.py
new file mode 100644
index 0000000..52d0040
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/application/views/__init__.py
@@ -0,0 +1,10 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/9/25 17:12
+ @desc:
+"""
+from .application_views import *
+from .chat_views import *
diff --git a/src/MaxKB-1.5.1/apps/application/views/application_views.py b/src/MaxKB-1.5.1/apps/application/views/application_views.py
new file mode 100644
index 0000000..560c69f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/application/views/application_views.py
@@ -0,0 +1,536 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: application_views.py
+ @date:2023/10/27 14:56
+ @desc:
+"""
+
+from django.core import cache
+from django.http import HttpResponse
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.parsers import MultiPartParser
+from rest_framework.request import Request
+from rest_framework.views import APIView
+
+from application.serializers.application_serializers import ApplicationSerializer
+from application.serializers.application_statistics_serializers import ApplicationStatisticsSerializer
+from application.swagger_api.application_api import ApplicationApi
+from application.swagger_api.application_statistics_api import ApplicationStatisticsApi
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import CompareConstants, PermissionConstants, Permission, Group, Operate, \
+ ViewPermission, RoleConstants
+from common.exception.app_exception import AppAuthenticationFailed
+from common.response import result
+from common.swagger_api.common_api import CommonApi
+from common.util.common import query_params_to_single_dict
+from dataset.serializers.dataset_serializers import DataSetSerializers
+from setting.swagger_api.provide_api import ProvideApi
+
+chat_cache = cache.caches['chat_cache']
+
+
+class ApplicationStatistics(APIView):
+ class CustomerCount(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="用户统计",
+ operation_id="用户统计",
+ tags=["应用/统计"],
+ manual_parameters=ApplicationStatisticsApi.get_request_params_api(),
+ responses=result.get_api_response(
+ ApplicationStatisticsApi.CustomerCount.get_response_body_api())
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationStatisticsSerializer(data={'application_id': application_id,
+ 'start_time': request.query_params.get(
+ 'start_time'),
+ 'end_time': request.query_params.get(
+ 'end_time')
+ }).get_customer_count())
+
+ class CustomerCountTrend(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="用户统计趋势",
+ operation_id="用户统计趋势",
+ tags=["应用/统计"],
+ manual_parameters=ApplicationStatisticsApi.get_request_params_api(),
+ responses=result.get_api_array_response(
+ ApplicationStatisticsApi.CustomerCountTrend.get_response_body_api()))
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationStatisticsSerializer(data={'application_id': application_id,
+ 'start_time': request.query_params.get(
+ 'start_time'),
+ 'end_time': request.query_params.get(
+ 'end_time')
+ }).get_customer_count_trend())
+
+ class ChatRecordAggregate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="对话相关统计",
+ operation_id="对话相关统计",
+ tags=["应用/统计"],
+ manual_parameters=ApplicationStatisticsApi.get_request_params_api(),
+ responses=result.get_api_response(
+ ApplicationStatisticsApi.ChatRecordAggregate.get_response_body_api())
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationStatisticsSerializer(data={'application_id': application_id,
+ 'start_time': request.query_params.get(
+ 'start_time'),
+ 'end_time': request.query_params.get(
+ 'end_time')
+ }).get_chat_record_aggregate())
+
+ class ChatRecordAggregateTrend(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="对话相关统计趋势",
+ operation_id="对话相关统计趋势",
+ tags=["应用/统计"],
+ manual_parameters=ApplicationStatisticsApi.get_request_params_api(),
+ responses=result.get_api_array_response(
+ ApplicationStatisticsApi.ChatRecordAggregate.get_response_body_api())
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationStatisticsSerializer(data={'application_id': application_id,
+ 'start_time': request.query_params.get(
+ 'start_time'),
+ 'end_time': request.query_params.get(
+ 'end_time')
+ }).get_chat_record_aggregate_trend())
+
+
+class Application(APIView):
+ authentication_classes = [TokenAuth]
+
+ class EditIcon(APIView):
+ authentication_classes = [TokenAuth]
+ parser_classes = [MultiPartParser]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改应用icon",
+ operation_id="修改应用icon",
+ tags=['应用'],
+ manual_parameters=ApplicationApi.EditApplicationIcon.get_request_params_api(),
+ request_body=ApplicationApi.Operate.get_request_body_api())
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND), PermissionConstants.APPLICATION_EDIT,
+ compare=CompareConstants.AND)
+ def put(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.IconOperate(
+ data={'application_id': application_id, 'user_id': request.user.id,
+ 'image': request.FILES.get('file')}).edit(request.data))
+
+ class Embed(APIView):
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="获取嵌入js",
+ operation_id="获取嵌入js",
+ tags=["应用"],
+ manual_parameters=ApplicationApi.ApiKey.get_request_params_api())
+ def get(self, request: Request):
+ return ApplicationSerializer.Embed(
+ data={'protocol': request.query_params.get('protocol'), 'token': request.query_params.get('token'),
+ 'host': request.query_params.get('host'), }).get_embed()
+
+ class Model(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型列表",
+ operation_id="获取模型列表",
+ tags=["应用"],
+ manual_parameters=ApplicationApi.Model.get_request_params_api())
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.Operate(
+ data={'application_id': application_id,
+ 'user_id': request.user.id}).list_model(request.query_params.get('model_type')))
+
+ class ModelParamsForm(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型参数表单",
+ operation_id="获取模型参数表单",
+ tags=["模型"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str, model_id: str):
+ return result.success(
+ ApplicationSerializer.Operate(
+ data={'application_id': application_id,
+ 'user_id': request.user.id}).get_model_params_form(model_id))
+
+ class FunctionLib(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="获取函数库列表",
+ operation_id="获取函数库列表",
+ tags=["应用"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.Operate(
+ data={'application_id': application_id,
+ 'user_id': request.user.id}).list_function_lib())
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="获取函数库列表",
+ operation_id="获取函数库列表",
+ tags=["应用"],
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str, function_lib_id: str):
+ return result.success(
+ ApplicationSerializer.Operate(
+ data={'application_id': application_id,
+ 'user_id': request.user.id}).get_function_lib(function_lib_id))
+
+ class Profile(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取应用相关信息",
+ operation_id="获取应用相关信息",
+ tags=["应用/会话"])
+ def get(self, request: Request):
+ if 'application_id' in request.auth.keywords:
+ return result.success(ApplicationSerializer.Operate(
+ data={'application_id': request.auth.keywords.get('application_id'),
+ 'user_id': request.user.id}).profile())
+ raise AppAuthenticationFailed(401, "身份异常")
+
+ class ApplicationKey(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="新增ApiKey",
+ operation_id="新增ApiKey",
+ tags=['应用/API_KEY'],
+ manual_parameters=ApplicationApi.ApiKey.get_request_params_api())
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def post(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.ApplicationKeySerializer(
+ data={'application_id': application_id, 'user_id': request.user.id}).generate())
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取应用API_KEY列表",
+ operation_id="获取应用API_KEY列表",
+ tags=['应用/API_KEY'],
+ manual_parameters=ApplicationApi.ApiKey.get_request_params_api()
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(ApplicationSerializer.ApplicationKeySerializer(
+ data={'application_id': application_id, 'user_id': request.user.id}).list())
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改应用API_KEY",
+ operation_id="修改应用API_KEY",
+ tags=['应用/API_KEY'],
+ manual_parameters=ApplicationApi.ApiKey.Operate.get_request_params_api(),
+ request_body=ApplicationApi.ApiKey.Operate.get_request_body_api())
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND), PermissionConstants.APPLICATION_EDIT,
+ compare=CompareConstants.AND)
+ def put(self, request: Request, application_id: str, api_key_id: str):
+ return result.success(
+ ApplicationSerializer.ApplicationKeySerializer.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id,
+ 'api_key_id': api_key_id}).edit(request.data))
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除应用API_KEY",
+ operation_id="删除应用API_KEY",
+ tags=['应用/API_KEY'],
+ manual_parameters=ApplicationApi.ApiKey.Operate.get_request_params_api())
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND), PermissionConstants.APPLICATION_DELETE,
+ compare=CompareConstants.AND)
+ def delete(self, request: Request, application_id: str, api_key_id: str):
+ return result.success(
+ ApplicationSerializer.ApplicationKeySerializer.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id,
+ 'api_key_id': api_key_id}).delete())
+
+ class AccessToken(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改 应用AccessToken",
+ operation_id="修改 应用AccessToken",
+ tags=['应用/公开访问'],
+ manual_parameters=ApplicationApi.AccessToken.get_request_params_api(),
+ request_body=ApplicationApi.AccessToken.get_request_body_api())
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def put(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.AccessTokenSerializer(data={'application_id': application_id}).edit(request.data))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取应用 AccessToken信息",
+ operation_id="获取应用 AccessToken信息",
+ manual_parameters=ApplicationApi.AccessToken.get_request_params_api(),
+ tags=['应用/公开访问'],
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.AccessTokenSerializer(data={'application_id': application_id}).one())
+
+ class Authentication(APIView):
+ @action(methods=['OPTIONS'], detail=False)
+ def options(self, request, *args, **kwargs):
+ return HttpResponse(headers={"Access-Control-Allow-Origin": "*", "Access-Control-Allow-Credentials": "true",
+ "Access-Control-Allow-Methods": "POST",
+ "Access-Control-Allow-Headers": "Origin,Content-Type,Cookie,Accept,Token"}, )
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="应用认证",
+ operation_id="应用认证",
+ request_body=ApplicationApi.Authentication.get_request_body_api(),
+ tags=["应用/认证"],
+ security=[])
+ def post(self, request: Request):
+ return result.success(
+ ApplicationSerializer.Authentication(data={'access_token': request.data.get("access_token")}).auth(
+ request),
+ headers={"Access-Control-Allow-Origin": "*", "Access-Control-Allow-Credentials": "true",
+ "Access-Control-Allow-Methods": "POST",
+ "Access-Control-Allow-Headers": "Origin,Content-Type,Cookie,Accept,Token"}
+ )
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建应用",
+ operation_id="创建应用",
+ request_body=ApplicationApi.Create.get_request_body_api(),
+ tags=['应用'])
+ @has_permissions(PermissionConstants.APPLICATION_CREATE, compare=CompareConstants.AND)
+ def post(self, request: Request):
+ return result.success(ApplicationSerializer.Create(data={'user_id': request.user.id}).insert(request.data))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取应用列表",
+ operation_id="获取应用列表",
+ manual_parameters=ApplicationApi.Query.get_request_params_api(),
+ responses=result.get_api_array_response(ApplicationApi.get_response_body_api()),
+ tags=['应用'])
+ @has_permissions(PermissionConstants.APPLICATION_READ, compare=CompareConstants.AND)
+ def get(self, request: Request):
+ return result.success(
+ ApplicationSerializer.Query(
+ data={**query_params_to_single_dict(request.query_params), 'user_id': request.user.id}).list())
+
+ class HitTest(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods="GET", detail=False)
+ @swagger_auto_schema(operation_summary="命中测试列表", operation_id="命中测试列表",
+ manual_parameters=CommonApi.HitTestApi.get_request_params_api(),
+ responses=result.get_api_array_response(CommonApi.HitTestApi.get_response_body_api()),
+ tags=["应用"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_ACCESS_TOKEN,
+ RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.HitTest(data={'id': application_id, 'user_id': request.user.id,
+ "query_text": request.query_params.get("query_text"),
+ "top_number": request.query_params.get("top_number"),
+ 'similarity': request.query_params.get('similarity'),
+ 'search_mode': request.query_params.get('search_mode')}).hit_test(
+ ))
+
+ class Publish(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="发布应用",
+ operation_id="发布应用",
+ manual_parameters=ApplicationApi.Operate.get_request_params_api(),
+ request_body=ApplicationApi.Publish.get_request_body_api(),
+ responses=result.get_default_response(),
+ tags=['应用'])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def put(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id}).publish(request.data))
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除应用",
+ operation_id="删除应用",
+ manual_parameters=ApplicationApi.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=['应用'])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND),
+ lambda r, k: Permission(group=Group.APPLICATION, operate=Operate.DELETE,
+ dynamic_tag=k.get('application_id')), compare=CompareConstants.AND)
+ def delete(self, request: Request, application_id: str):
+ return result.success(ApplicationSerializer.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id}).delete(
+ with_valid=True))
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改应用",
+ operation_id="修改应用",
+ manual_parameters=ApplicationApi.Operate.get_request_params_api(),
+ request_body=ApplicationApi.Edit.get_request_body_api(),
+ responses=result.get_api_array_response(ApplicationApi.get_response_body_api()),
+ tags=['应用'])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def put(self, request: Request, application_id: str):
+ return result.success(
+ ApplicationSerializer.Operate(data={'application_id': application_id, 'user_id': request.user.id}).edit(
+ request.data))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取应用详情",
+ operation_id="获取应用详情",
+ manual_parameters=ApplicationApi.Operate.get_request_params_api(),
+ responses=result.get_api_array_response(ApplicationApi.get_response_body_api()),
+ tags=['应用'])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_ACCESS_TOKEN,
+ RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(ApplicationSerializer.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id}).one())
+
+ class ListApplicationDataSet(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取当前应用可使用的知识库",
+ operation_id="获取当前应用可使用的知识库",
+ manual_parameters=ApplicationApi.Operate.get_request_params_api(),
+ responses=result.get_api_array_response(DataSetSerializers.Query.get_response_body_api()),
+ tags=['应用'])
+ @has_permissions(ViewPermission([RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, application_id: str):
+ return result.success(ApplicationSerializer.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id}).list_dataset())
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="分页获取应用列表",
+ operation_id="分页获取应用列表",
+ manual_parameters=result.get_page_request_params(
+ ApplicationApi.Query.get_request_params_api()),
+ responses=result.get_page_api_response(ApplicationApi.get_response_body_api()),
+ tags=['应用'])
+ @has_permissions(PermissionConstants.APPLICATION_READ, compare=CompareConstants.AND)
+ def get(self, request: Request, current_page: int, page_size: int):
+ return result.success(
+ ApplicationSerializer.Query(
+ data={**query_params_to_single_dict(request.query_params), 'user_id': request.user.id}).page(
+ current_page, page_size))
diff --git a/src/MaxKB-1.5.1/apps/application/views/chat_views.py b/src/MaxKB-1.5.1/apps/application/views/chat_views.py
new file mode 100644
index 0000000..f1882e4
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/application/views/chat_views.py
@@ -0,0 +1,383 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: chat_views.py
+ @date:2023/11/14 9:53
+ @desc:
+"""
+
+from django.http import JsonResponse
+from django.views import View
+import json
+
+
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.request import Request
+from rest_framework.views import APIView
+
+from application.serializers.chat_message_serializers import ChatMessageSerializer
+from application.serializers.chat_serializers import ChatSerializers, ChatRecordSerializer
+from application.swagger_api.chat_api import ChatApi, VoteApi, ChatRecordApi, ImproveApi, ChatRecordImproveApi, \
+ ChatClientHistoryApi
+from common.auth import TokenAuth, has_permissions
+from common.constants.authentication_type import AuthenticationType
+from common.constants.permission_constants import Permission, Group, Operate, \
+ RoleConstants, ViewPermission, CompareConstants
+from common.response import result
+from common.util.common import query_params_to_single_dict
+
+
+class ChatView(APIView):
+ authentication_classes = [TokenAuth]
+
+ class Export(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="导出对话",
+ operation_id="导出对话",
+ manual_parameters=ChatApi.get_request_params_api(),
+ tags=["应用/对话日志"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def get(self, request: Request, application_id: str):
+ return ChatSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'application_id': application_id,
+ 'user_id': request.user.id}).export()
+
+ class Open(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取会话id,根据应用id",
+ operation_id="获取会话id,根据应用id",
+ manual_parameters=ChatApi.OpenChat.get_request_params_api(),
+ tags=["应用/会话"])
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_ACCESS_TOKEN,
+ RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND)
+ )
+ def get(self, request: Request, application_id: str):
+ return result.success(ChatSerializers.OpenChat(
+ data={'user_id': request.user.id, 'application_id': application_id}).open())
+
+ class OpenWorkFlowTemp(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="获取工作流临时会话id",
+ operation_id="获取工作流临时会话id",
+ request_body=ChatApi.OpenWorkFlowTemp.get_request_body_api(),
+ tags=["应用/会话"])
+ def post(self, request: Request):
+ return result.success(ChatSerializers.OpenWorkFlowChat(
+ data={**request.data, 'user_id': request.user.id}).open())
+
+ class OpenTemp(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="获取会话id(根据模型id,知识库列表,是否多轮会话)",
+ operation_id="获取会话id",
+ request_body=ChatApi.OpenTempChat.get_request_body_api(),
+ tags=["应用/会话"])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def post(self, request: Request):
+ return result.success(ChatSerializers.OpenTempChat(
+ data={**request.data, 'user_id': request.user.id}).open())
+
+ class Message(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="对话",
+ operation_id="对话",
+ request_body=ChatApi.get_request_body_api(),
+ tags=["应用/会话"])
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY,
+ RoleConstants.APPLICATION_ACCESS_TOKEN],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def post(self, request: Request, chat_id: str):
+ return ChatMessageSerializer(data={'chat_id': chat_id, 'message': request.data.get('message'),
+ 're_chat': (request.data.get(
+ 're_chat') if 're_chat' in request.data else False),
+ 'stream': (request.data.get(
+ 'stream') if 'stream' in request.data else True),
+ 'application_id': (request.auth.keywords.get(
+ 'application_id') if request.auth.client_type == AuthenticationType.APPLICATION_ACCESS_TOKEN.value else None),
+ 'client_id': request.auth.client_id,
+ 'client_type': request.auth.client_type}).chat()
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取对话列表",
+ operation_id="获取对话列表",
+ manual_parameters=ChatApi.get_request_params_api(),
+ responses=result.get_api_array_response(ChatApi.get_response_body_api()),
+ tags=["应用/对话日志"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def get(self, request: Request, application_id: str):
+ return result.success(ChatSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'application_id': application_id,
+ 'user_id': request.user.id}).list())
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除对话",
+ operation_id="删除对话",
+ tags=["应用/对话日志"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND),
+ compare=CompareConstants.AND)
+ def delete(self, request: Request, application_id: str, chat_id: str):
+ return result.success(
+ ChatSerializers.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id,
+ 'chat_id': chat_id}).delete())
+
+ class ClientChatHistoryPage(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="分页获取客户端对话列表",
+ operation_id="分页获取客户端对话列表",
+ manual_parameters=result.get_page_request_params(
+ ChatClientHistoryApi.get_request_params_api()),
+ responses=result.get_page_api_response(ChatApi.get_response_body_api()),
+ tags=["应用/对话日志"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.APPLICATION_ACCESS_TOKEN],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def get(self, request: Request, application_id: str, current_page: int, page_size: int):
+ return result.success(ChatSerializers.ClientChatHistory(
+ data={'client_id': request.auth.client_id, 'application_id': application_id}).page(
+ current_page=current_page,
+ page_size=page_size))
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="客户端删除对话",
+ operation_id="客户端删除对话",
+ tags=["应用/对话日志"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.APPLICATION_ACCESS_TOKEN],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+ compare=CompareConstants.AND),
+ compare=CompareConstants.AND)
+ def delete(self, request: Request, application_id: str, chat_id: str):
+ return result.success(
+ ChatSerializers.Operate(
+ data={'application_id': application_id, 'user_id': request.user.id,
+ 'chat_id': chat_id}).logic_delete())
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="分页获取对话列表",
+ operation_id="分页获取对话列表",
+ manual_parameters=result.get_page_request_params(ChatApi.get_request_params_api()),
+ responses=result.get_page_api_response(ChatApi.get_response_body_api()),
+ tags=["应用/对话日志"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def get(self, request: Request, application_id: str, current_page: int, page_size: int):
+ return result.success(ChatSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'application_id': application_id,
+ 'user_id': request.user.id}).page(current_page=current_page,
+ page_size=page_size))
+
+ class ChatRecord(APIView):
+ authentication_classes = [TokenAuth]
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取对话记录详情",
+ operation_id="获取对话记录详情",
+ manual_parameters=ChatRecordApi.get_request_params_api(),
+ responses=result.get_api_array_response(ChatRecordApi.get_response_body_api()),
+ tags=["应用/对话日志"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY,
+ RoleConstants.APPLICATION_ACCESS_TOKEN],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def get(self, request: Request, application_id: str, chat_id: str, chat_record_id: str):
+ return result.success(ChatRecordSerializer.Operate(
+ data={'application_id': application_id,
+ 'chat_id': chat_id,
+ 'chat_record_id': chat_record_id}).one(request.auth.current_role))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取对话记录列表",
+ operation_id="获取对话记录列表",
+ manual_parameters=ChatRecordApi.get_request_params_api(),
+ responses=result.get_api_array_response(ChatRecordApi.get_response_body_api()),
+ tags=["应用/对话日志"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def get(self, request: Request, application_id: str, chat_id: str):
+ return result.success(ChatRecordSerializer.Query(
+ data={'application_id': application_id,
+ 'chat_id': chat_id, 'order_asc': request.query_params.get('order_asc')}).list())
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取对话记录列表",
+ operation_id="获取对话记录列表",
+ manual_parameters=result.get_page_request_params(
+ ChatRecordApi.get_request_params_api()),
+ responses=result.get_page_api_response(ChatRecordApi.get_response_body_api()),
+ tags=["应用/对话日志"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def get(self, request: Request, application_id: str, chat_id: str, current_page: int, page_size: int):
+ return result.success(ChatRecordSerializer.Query(
+ data={'application_id': application_id,
+ 'chat_id': chat_id, 'order_asc': request.query_params.get('order_asc')}).page(current_page,
+ page_size))
+
+ class Vote(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="点赞,点踩",
+ operation_id="点赞,点踩",
+ manual_parameters=VoteApi.get_request_params_api(),
+ request_body=VoteApi.get_request_body_api(),
+ responses=result.get_default_response(),
+ tags=["应用/会话"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER, RoleConstants.APPLICATION_KEY,
+ RoleConstants.APPLICATION_ACCESS_TOKEN],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))])
+ )
+ def put(self, request: Request, application_id: str, chat_id: str, chat_record_id: str):
+ return result.success(ChatRecordSerializer.Vote(
+ data={'vote_status': request.data.get('vote_status'), 'chat_id': chat_id,
+ 'chat_record_id': chat_record_id}).vote())
+
+ class ChatRecordImprove(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取标注段落列表信息",
+ operation_id="获取标注段落列表信息",
+ manual_parameters=ChatRecordImproveApi.get_request_params_api(),
+ responses=result.get_api_response(ChatRecordImproveApi.get_response_body_api()),
+ tags=["应用/对话日志/标注"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))]
+ ))
+ def get(self, request: Request, application_id: str, chat_id: str, chat_record_id: str):
+ return result.success(ChatRecordSerializer.ChatRecordImprove(
+ data={'chat_id': chat_id, 'chat_record_id': chat_record_id}).get())
+
+ class Improve(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="标注",
+ operation_id="标注",
+ manual_parameters=ImproveApi.get_request_params_api(),
+ request_body=ImproveApi.get_request_body_api(),
+ responses=result.get_api_response(ChatRecordApi.get_response_body_api()),
+ tags=["应用/对话日志/标注"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+
+ ), ViewPermission([RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.DATASET,
+ operate=Operate.MANAGE,
+ dynamic_tag=keywords.get(
+ 'dataset_id'))],
+ compare=CompareConstants.AND
+ ), compare=CompareConstants.AND)
+ def put(self, request: Request, application_id: str, chat_id: str, chat_record_id: str, dataset_id: str,
+ document_id: str):
+ return result.success(ChatRecordSerializer.Improve(
+ data={'chat_id': chat_id, 'chat_record_id': chat_record_id,
+ 'dataset_id': dataset_id, 'document_id': document_id}).improve(request.data))
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="标注",
+ operation_id="标注",
+ manual_parameters=ImproveApi.get_request_params_api(),
+ responses=result.get_api_response(ChatRecordApi.get_response_body_api()),
+ tags=["应用/对话日志/标注"]
+ )
+ @has_permissions(
+ ViewPermission([RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.APPLICATION, operate=Operate.USE,
+ dynamic_tag=keywords.get('application_id'))],
+
+ ), ViewPermission([RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.DATASET,
+ operate=Operate.MANAGE,
+ dynamic_tag=keywords.get(
+ 'dataset_id'))],
+ compare=CompareConstants.AND
+ ), compare=CompareConstants.AND)
+ def delete(self, request: Request, application_id: str, chat_id: str, chat_record_id: str,
+ dataset_id: str,
+ document_id: str, paragraph_id: str):
+ return result.success(ChatRecordSerializer.Improve.Operate(
+ data={'chat_id': chat_id, 'chat_record_id': chat_record_id,
+ 'dataset_id': dataset_id, 'document_id': document_id,
+ 'paragraph_id': paragraph_id}).delete())
diff --git a/src/MaxKB-1.5.1/apps/common/__init__.py b/src/MaxKB-1.5.1/apps/common/__init__.py
new file mode 100644
index 0000000..75ce08f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: smart-doc
+ @Author:虎
+ @file: __init__.py
+ @date:2023/9/14 16:22
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/common/auth/__init__.py b/src/MaxKB-1.5.1/apps/common/auth/__init__.py
new file mode 100644
index 0000000..ca866ce
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/auth/__init__.py
@@ -0,0 +1,10 @@
+# coding=utf-8
+"""
+ @project: smart-doc
+ @Author:虎
+ @file: __init__.py
+ @date:2023/9/14 19:44
+ @desc:
+"""
+from .authenticate import *
+from .authentication import *
diff --git a/src/MaxKB-1.5.1/apps/common/auth/authenticate.py b/src/MaxKB-1.5.1/apps/common/auth/authenticate.py
new file mode 100644
index 0000000..424f859
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/auth/authenticate.py
@@ -0,0 +1,72 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: authenticate.py
+ @date:2023/9/4 11:16
+ @desc: 认证类
+"""
+import traceback
+from importlib import import_module
+
+from django.conf import settings
+from django.core import cache
+from django.core import signing
+from rest_framework.authentication import TokenAuthentication
+
+from common.exception.app_exception import AppAuthenticationFailed, AppEmbedIdentityFailed, AppChatNumOutOfBoundsFailed
+
+token_cache = cache.caches['token_cache']
+
+
+class AnonymousAuthentication(TokenAuthentication):
+ def authenticate(self, request):
+ return None, None
+
+
+def new_instance_by_class_path(class_path: str):
+ parts = class_path.rpartition('.')
+ package_path = parts[0]
+ class_name = parts[2]
+ module = import_module(package_path)
+ HandlerClass = getattr(module, class_name)
+ return HandlerClass()
+
+
+handles = [new_instance_by_class_path(class_path) for class_path in settings.AUTH_HANDLES]
+
+
+class TokenDetails:
+ token_details = None
+ is_load = False
+
+ def __init__(self, token: str):
+ self.token = token
+
+ def get_token_details(self):
+ if self.token_details is None and not self.is_load:
+ try:
+ self.token_details = signing.loads(self.token)
+ except Exception as e:
+ self.is_load = True
+ return self.token_details
+
+
+class TokenAuth(TokenAuthentication):
+ # 重新 authenticate 方法,自定义认证规则
+ def authenticate(self, request):
+ auth = request.META.get('HTTP_AUTHORIZATION')
+ # 未认证
+ if auth is None:
+ raise AppAuthenticationFailed(1003, '未登录,请先登录')
+ try:
+ token_details = TokenDetails(auth)
+ for handle in handles:
+ if handle.support(request, auth, token_details.get_token_details):
+ return handle.handle(request, auth, token_details.get_token_details)
+ raise AppAuthenticationFailed(1002, "身份验证信息不正确!非法用户")
+ except Exception as e:
+ traceback.format_exc()
+ if isinstance(e, AppEmbedIdentityFailed) or isinstance(e, AppChatNumOutOfBoundsFailed):
+ raise e
+ raise AppAuthenticationFailed(1002, "身份验证信息不正确!非法用户")
diff --git a/src/MaxKB-1.5.1/apps/common/auth/authentication.py b/src/MaxKB-1.5.1/apps/common/auth/authentication.py
new file mode 100644
index 0000000..d692d61
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/auth/authentication.py
@@ -0,0 +1,98 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: authentication.py
+ @date:2023/9/13 15:00
+ @desc: 鉴权
+"""
+from typing import List
+
+from common.constants.permission_constants import ViewPermission, CompareConstants, RoleConstants, PermissionConstants, \
+ Permission
+from common.exception.app_exception import AppUnauthorizedFailed
+
+
+def exist_permissions_by_permission_constants(user_permission: List[PermissionConstants],
+ permission_list: List[PermissionConstants]):
+ """
+ 用户是否拥有 permission_list的权限
+ :param user_permission: 用户权限
+ :param permission_list: 需要的权限
+ :return: 是否拥有
+ """
+ return any(list(map(lambda up: permission_list.__contains__(up), user_permission)))
+
+
+def exist_role_by_role_constants(user_role: List[RoleConstants],
+ role_list: List[RoleConstants]):
+ """
+ 用户是否拥有这个角色
+ :param user_role: 用户角色
+ :param role_list: 需要拥有的角色
+ :return: 是否拥有
+ """
+ return any(list(map(lambda up: role_list.__contains__(up), user_role)))
+
+
+def exist_permissions_by_view_permission(user_role: List[RoleConstants],
+ user_permission: List[PermissionConstants | object],
+ permission: ViewPermission, request, **kwargs):
+ """
+ 用户是否存在这些权限
+ :param request:
+ :param user_role: 用户角色
+ :param user_permission: 用户权限
+ :param permission: 所属权限
+ :return: 是否存在 True False
+ """
+ role_ok = any(list(map(lambda ur: permission.roleList.__contains__(ur), user_role)))
+ permission_list = [user_p(request, kwargs) if callable(user_p) else user_p for user_p in
+ permission.permissionList
+ ]
+ permission_ok = any(list(map(lambda up: permission_list.__contains__(up),
+ user_permission)))
+ return role_ok | permission_ok if permission.compare == CompareConstants.OR else role_ok & permission_ok
+
+
+def exist_permissions(user_role: List[RoleConstants], user_permission: List[PermissionConstants], permission, request,
+ **kwargs):
+ if isinstance(permission, ViewPermission):
+ return exist_permissions_by_view_permission(user_role, user_permission, permission, request, **kwargs)
+ if isinstance(permission, RoleConstants):
+ return exist_role_by_role_constants(user_role, [permission])
+ if isinstance(permission, PermissionConstants):
+ return exist_permissions_by_permission_constants(user_permission, [permission])
+ if isinstance(permission, Permission):
+ return user_permission.__contains__(permission)
+ return False
+
+
+def exist(user_role: List[RoleConstants], user_permission: List[PermissionConstants], permission, request, **kwargs):
+ if callable(permission):
+ p = permission(request, kwargs)
+ return exist_permissions(user_role, user_permission, p, request)
+ return exist_permissions(user_role, user_permission, permission, request, **kwargs)
+
+
+def has_permissions(*permission, compare=CompareConstants.OR):
+ """
+ 权限 role or permission
+ :param compare: 比较符号
+ :param permission: 如果是角色 role:roleId
+ :return: 权限装饰器函数,用于判断用户是否有权限访问当前接口
+ """
+
+ def inner(func):
+ def run(view, request, **kwargs):
+ exit_list = list(
+ map(lambda p: exist(request.auth.role_list, request.auth.permission_list, p, request, **kwargs),
+ permission))
+ # 判断是否有权限
+ if any(exit_list) if compare == CompareConstants.OR else all(exit_list):
+ return func(view, request, **kwargs)
+ raise AppUnauthorizedFailed(403, "没有权限访问")
+
+ return run
+
+ return inner
diff --git a/src/MaxKB-1.5.1/apps/common/auth/handle/auth_base_handle.py b/src/MaxKB-1.5.1/apps/common/auth/handle/auth_base_handle.py
new file mode 100644
index 0000000..991256e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/auth/handle/auth_base_handle.py
@@ -0,0 +1,19 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: authenticate.py
+ @date:2024/3/14 03:02
+ @desc: 认证处理器
+"""
+from abc import ABC, abstractmethod
+
+
+class AuthBaseHandle(ABC):
+ @abstractmethod
+ def support(self, request, token: str, get_token_details):
+ pass
+
+ @abstractmethod
+ def handle(self, request, token: str, get_token_details):
+ pass
diff --git a/src/MaxKB-1.5.1/apps/common/auth/handle/impl/application_key.py b/src/MaxKB-1.5.1/apps/common/auth/handle/impl/application_key.py
new file mode 100644
index 0000000..b35ef80
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/auth/handle/impl/application_key.py
@@ -0,0 +1,43 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: authenticate.py
+ @date:2024/3/14 03:02
+ @desc: 应用api key认证
+"""
+from django.db.models import QuerySet
+
+from application.models.api_key_model import ApplicationApiKey
+from common.auth.handle.auth_base_handle import AuthBaseHandle
+from common.constants.authentication_type import AuthenticationType
+from common.constants.permission_constants import Permission, Group, Operate, RoleConstants, Auth
+from common.exception.app_exception import AppAuthenticationFailed
+
+
+class ApplicationKey(AuthBaseHandle):
+ def handle(self, request, token: str, get_token_details):
+ application_api_key = QuerySet(ApplicationApiKey).filter(secret_key=token).first()
+ if application_api_key is None:
+ raise AppAuthenticationFailed(500, "secret_key 无效")
+ if not application_api_key.is_active:
+ raise AppAuthenticationFailed(500, "secret_key 无效")
+ permission_list = [Permission(group=Group.APPLICATION,
+ operate=Operate.USE,
+ dynamic_tag=str(
+ application_api_key.application_id)),
+ Permission(group=Group.APPLICATION,
+ operate=Operate.MANAGE,
+ dynamic_tag=str(
+ application_api_key.application_id))
+ ]
+ return application_api_key.user, Auth(role_list=[RoleConstants.APPLICATION_KEY],
+ permission_list=permission_list,
+ application_id=application_api_key.application_id,
+ client_id=str(application_api_key.id),
+ client_type=AuthenticationType.API_KEY.value,
+ current_role=RoleConstants.APPLICATION_KEY
+ )
+
+ def support(self, request, token: str, get_token_details):
+ return str(token).startswith("application-")
diff --git a/src/MaxKB-1.5.1/apps/common/auth/handle/impl/public_access_token.py b/src/MaxKB-1.5.1/apps/common/auth/handle/impl/public_access_token.py
new file mode 100644
index 0000000..1655187
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/auth/handle/impl/public_access_token.py
@@ -0,0 +1,50 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: authenticate.py
+ @date:2024/3/14 03:02
+ @desc: 公共访问连接认证
+"""
+from django.db.models import QuerySet
+
+from application.models.api_key_model import ApplicationAccessToken
+from common.auth.handle.auth_base_handle import AuthBaseHandle
+from common.constants.authentication_type import AuthenticationType
+from common.constants.permission_constants import RoleConstants, Permission, Group, Operate, Auth
+from common.exception.app_exception import AppAuthenticationFailed
+
+
+class PublicAccessToken(AuthBaseHandle):
+ def support(self, request, token: str, get_token_details):
+ token_details = get_token_details()
+ if token_details is None:
+ return False
+ return (
+ 'application_id' in token_details and
+ 'access_token' in token_details and
+ token_details.get('type') == AuthenticationType.APPLICATION_ACCESS_TOKEN.value)
+
+ def handle(self, request, token: str, get_token_details):
+ auth_details = get_token_details()
+ application_access_token = QuerySet(ApplicationAccessToken).filter(
+ application_id=auth_details.get('application_id')).first()
+ if application_access_token is None:
+ raise AppAuthenticationFailed(1002, "身份验证信息不正确")
+ if not application_access_token.is_active:
+ raise AppAuthenticationFailed(1002, "身份验证信息不正确")
+ if not application_access_token.access_token == auth_details.get('access_token'):
+ raise AppAuthenticationFailed(1002, "身份验证信息不正确")
+
+ return application_access_token.application.user, Auth(
+ role_list=[RoleConstants.APPLICATION_ACCESS_TOKEN],
+ permission_list=[
+ Permission(group=Group.APPLICATION,
+ operate=Operate.USE,
+ dynamic_tag=str(
+ application_access_token.application_id))],
+ application_id=application_access_token.application_id,
+ client_id=auth_details.get('client_id'),
+ client_type=AuthenticationType.APPLICATION_ACCESS_TOKEN.value,
+ current_role=RoleConstants.APPLICATION_ACCESS_TOKEN
+ )
diff --git a/src/MaxKB-1.5.1/apps/common/auth/handle/impl/user_token.py b/src/MaxKB-1.5.1/apps/common/auth/handle/impl/user_token.py
new file mode 100644
index 0000000..6559797
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/auth/handle/impl/user_token.py
@@ -0,0 +1,47 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: authenticate.py
+ @date:2024/3/14 03:02
+ @desc: 用户认证
+"""
+from django.db.models import QuerySet
+
+from common.auth.handle.auth_base_handle import AuthBaseHandle
+from common.constants.authentication_type import AuthenticationType
+from common.constants.permission_constants import RoleConstants, get_permission_list_by_role, Auth
+from common.exception.app_exception import AppAuthenticationFailed
+from smartdoc.settings import JWT_AUTH
+from users.models import User
+from django.core import cache
+
+from users.models.user import get_user_dynamics_permission
+
+token_cache = cache.caches['token_cache']
+
+
+class UserToken(AuthBaseHandle):
+ def support(self, request, token: str, get_token_details):
+ auth_details = get_token_details()
+ if auth_details is None:
+ return False
+ return 'id' in auth_details and auth_details.get('type') == AuthenticationType.USER.value
+
+ def handle(self, request, token: str, get_token_details):
+ cache_token = token_cache.get(token)
+ if cache_token is None:
+ raise AppAuthenticationFailed(1002, "登录过期")
+ auth_details = get_token_details()
+ user = QuerySet(User).get(id=auth_details['id'])
+ # 续期
+ token_cache.touch(token, timeout=JWT_AUTH['JWT_EXPIRATION_DELTA'].total_seconds())
+ rule = RoleConstants[user.role]
+ permission_list = get_permission_list_by_role(RoleConstants[user.role])
+ # 获取用户的应用和知识库的权限
+ permission_list += get_user_dynamics_permission(str(user.id))
+ return user, Auth(role_list=[rule],
+ permission_list=permission_list,
+ client_id=str(user.id),
+ client_type=AuthenticationType.USER.value,
+ current_role=rule)
diff --git a/src/MaxKB-1.5.1/apps/common/cache/file_cache.py b/src/MaxKB-1.5.1/apps/common/cache/file_cache.py
new file mode 100644
index 0000000..4808b31
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/cache/file_cache.py
@@ -0,0 +1,79 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: file_cache.py
+ @date:2023/9/11 15:58
+ @desc: 文件缓存
+"""
+import datetime
+import math
+import os
+import time
+
+from diskcache import Cache
+from django.core.cache.backends.base import DEFAULT_TIMEOUT, BaseCache
+
+
+class FileCache(BaseCache):
+ def __init__(self, dir, params):
+ super().__init__(params)
+ self._dir = os.path.abspath(dir)
+ self._createdir()
+ self.cache = Cache(self._dir)
+
+ def _createdir(self):
+ old_umask = os.umask(0o077)
+ try:
+ os.makedirs(self._dir, 0o700, exist_ok=True)
+ finally:
+ os.umask(old_umask)
+
+ def add(self, key, value, timeout=DEFAULT_TIMEOUT, version=None):
+ expire = timeout if isinstance(timeout, int) or isinstance(timeout,
+ float) else timeout.total_seconds()
+ return self.cache.add(key, value=value, expire=expire)
+
+ def set(self, key, value, timeout=DEFAULT_TIMEOUT, version=None):
+ expire = timeout if isinstance(timeout, int) or isinstance(timeout,
+ float) else timeout.total_seconds()
+ return self.cache.set(key, value=value, expire=expire)
+
+ def get(self, key, default=None, version=None):
+ return self.cache.get(key, default=default)
+
+ def delete(self, key, version=None):
+ return self.cache.delete(key)
+
+ def touch(self, key, timeout=DEFAULT_TIMEOUT, version=None):
+ expire = timeout if isinstance(timeout, int) or isinstance(timeout,
+ float) else timeout.total_seconds()
+
+ return self.cache.touch(key, expire=expire)
+
+ def ttl(self, key):
+ """
+ 获取key的剩余时间
+ :param key: key
+ :return: 剩余时间
+ """
+ value, expire_time = self.cache.get(key, expire_time=True)
+ if value is None:
+ return None
+ return datetime.timedelta(seconds=math.ceil(expire_time - time.time()))
+
+ def clear_by_application_id(self, application_id):
+ delete_keys = []
+ for key in self.cache.iterkeys():
+ value = self.cache.get(key)
+ if (hasattr(value,
+ 'application') and value.application is not None and value.application.id is not None and
+ str(
+ value.application.id) == application_id):
+ delete_keys.append(key)
+ for key in delete_keys:
+ self.delete(key)
+
+ def clear_timeout_data(self):
+ for key in self.cache.iterkeys():
+ self.get(key)
diff --git a/src/MaxKB-1.5.1/apps/common/cache/mem_cache.py b/src/MaxKB-1.5.1/apps/common/cache/mem_cache.py
new file mode 100644
index 0000000..5afb1e5
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/cache/mem_cache.py
@@ -0,0 +1,47 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: mem_cache.py
+ @date:2024/3/6 11:20
+ @desc:
+"""
+from django.core.cache.backends.base import DEFAULT_TIMEOUT
+from django.core.cache.backends.locmem import LocMemCache
+
+
+class MemCache(LocMemCache):
+ def __init__(self, name, params):
+ super().__init__(name, params)
+
+ def set(self, key, value, timeout=DEFAULT_TIMEOUT, version=None):
+ key = self.make_and_validate_key(key, version=version)
+ pickled = value
+ with self._lock:
+ self._set(key, pickled, timeout)
+
+ def get(self, key, default=None, version=None):
+ key = self.make_and_validate_key(key, version=version)
+ with self._lock:
+ if self._has_expired(key):
+ self._delete(key)
+ return default
+ pickled = self._cache[key]
+ self._cache.move_to_end(key, last=False)
+ return pickled
+
+ def clear_by_application_id(self, application_id):
+ delete_keys = []
+ for key in self._cache.keys():
+ value = self._cache.get(key)
+ if (hasattr(value,
+ 'application') and value.application is not None and value.application.id is not None and
+ str(
+ value.application.id) == application_id):
+ delete_keys.append(key)
+ for key in delete_keys:
+ self._delete(key)
+
+ def clear_timeout_data(self):
+ for key in self._cache.keys():
+ self.get(key)
diff --git a/src/MaxKB-1.5.1/apps/common/cache_data/application_access_token_cache.py b/src/MaxKB-1.5.1/apps/common/cache_data/application_access_token_cache.py
new file mode 100644
index 0000000..54f2a7e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/cache_data/application_access_token_cache.py
@@ -0,0 +1,31 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: application_access_token_cache.py
+ @date:2024/7/25 11:34
+ @desc:
+"""
+from django.core.cache import cache
+from django.db.models import QuerySet
+
+from application.models.api_key_model import ApplicationAccessToken
+from common.constants.cache_code_constants import CacheCodeConstants
+from common.util.cache_util import get_cache
+
+
+@get_cache(cache_key=lambda access_token, use_get_data: access_token,
+ use_get_data=lambda access_token, use_get_data: use_get_data,
+ version=CacheCodeConstants.APPLICATION_ACCESS_TOKEN_CACHE.value)
+def get_application_access_token(access_token, use_get_data):
+ application_access_token = QuerySet(ApplicationAccessToken).filter(access_token=access_token).first()
+ if application_access_token is None:
+ return None
+ return {'white_active': application_access_token.white_active,
+ 'white_list': application_access_token.white_list,
+ 'application_icon': application_access_token.application.icon,
+ 'application_name': application_access_token.application.name}
+
+
+def del_application_access_token(access_token):
+ cache.delete(access_token, version=CacheCodeConstants.APPLICATION_ACCESS_TOKEN_CACHE.value)
diff --git a/src/MaxKB-1.5.1/apps/common/cache_data/application_api_key_cache.py b/src/MaxKB-1.5.1/apps/common/cache_data/application_api_key_cache.py
new file mode 100644
index 0000000..a7d810c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/cache_data/application_api_key_cache.py
@@ -0,0 +1,27 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: application_api_key_cache.py
+ @date:2024/7/25 11:30
+ @desc:
+"""
+from django.core.cache import cache
+from django.db.models import QuerySet
+
+from application.models.api_key_model import ApplicationApiKey
+from common.constants.cache_code_constants import CacheCodeConstants
+from common.util.cache_util import get_cache
+
+
+@get_cache(cache_key=lambda secret_key, use_get_data: secret_key,
+ use_get_data=lambda secret_key, use_get_data: use_get_data,
+ version=CacheCodeConstants.APPLICATION_API_KEY_CACHE.value)
+def get_application_api_key(secret_key, use_get_data):
+ application_api_key = QuerySet(ApplicationApiKey).filter(secret_key=secret_key).first()
+ return {'allow_cross_domain': application_api_key.allow_cross_domain,
+ 'cross_domain_list': application_api_key.cross_domain_list}
+
+
+def del_application_api_key(secret_key):
+ cache.delete(secret_key, version=CacheCodeConstants.APPLICATION_API_KEY_CACHE.value)
diff --git a/src/MaxKB-1.5.1/apps/common/cache_data/static_resource_cache.py b/src/MaxKB-1.5.1/apps/common/cache_data/static_resource_cache.py
new file mode 100644
index 0000000..1bb84e9
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/cache_data/static_resource_cache.py
@@ -0,0 +1,19 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: static_resource_cache.py
+ @date:2024/7/25 11:30
+ @desc:
+"""
+from common.constants.cache_code_constants import CacheCodeConstants
+from common.util.cache_util import get_cache
+
+
+@get_cache(cache_key=lambda index_path: index_path,
+ version=CacheCodeConstants.STATIC_RESOURCE_CACHE.value)
+def get_index_html(index_path):
+ file = open(index_path, "r", encoding='utf-8')
+ content = file.read()
+ file.close()
+ return content
diff --git a/src/MaxKB-1.5.1/apps/common/chunk/__init__.py b/src/MaxKB-1.5.1/apps/common/chunk/__init__.py
new file mode 100644
index 0000000..a4babde
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/chunk/__init__.py
@@ -0,0 +1,18 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: __init__.py
+ @date:2024/7/23 17:03
+ @desc:
+"""
+from common.chunk.impl.mark_chunk_handle import MarkChunkHandle
+
+handles = [MarkChunkHandle()]
+
+
+def text_to_chunk(text: str):
+ chunk_list = [text]
+ for handle in handles:
+ chunk_list = handle.handle(chunk_list)
+ return chunk_list
diff --git a/src/MaxKB-1.5.1/apps/common/chunk/i_chunk_handle.py b/src/MaxKB-1.5.1/apps/common/chunk/i_chunk_handle.py
new file mode 100644
index 0000000..d53575d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/chunk/i_chunk_handle.py
@@ -0,0 +1,16 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: i_chunk_handle.py
+ @date:2024/7/23 16:51
+ @desc:
+"""
+from abc import ABC, abstractmethod
+from typing import List
+
+
+class IChunkHandle(ABC):
+ @abstractmethod
+ def handle(self, chunk_list: List[str]):
+ pass
diff --git a/src/MaxKB-1.5.1/apps/common/chunk/impl/mark_chunk_handle.py b/src/MaxKB-1.5.1/apps/common/chunk/impl/mark_chunk_handle.py
new file mode 100644
index 0000000..9e5a66c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/chunk/impl/mark_chunk_handle.py
@@ -0,0 +1,37 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: mark_chunk_handle.py
+ @date:2024/7/23 16:52
+ @desc:
+"""
+import re
+from typing import List
+
+from common.chunk.i_chunk_handle import IChunkHandle
+
+split_chunk_pattern = "!|。|\n|;|;"
+min_chunk_len = 20
+
+
+class MarkChunkHandle(IChunkHandle):
+ def handle(self, chunk_list: List[str]):
+ result = []
+ for chunk in chunk_list:
+ base_chunk = re.split(split_chunk_pattern, chunk)
+ base_chunk = [chunk.strip() for chunk in base_chunk if len(chunk.strip()) > 0]
+ result_chunk = []
+ for c in base_chunk:
+ if len(result_chunk) == 0:
+ result_chunk.append(c)
+ else:
+ if len(result_chunk[-1]) < min_chunk_len:
+ result_chunk[-1] = result_chunk[-1] + c
+ else:
+ if len(c) < min_chunk_len:
+ result_chunk[-1] = result_chunk[-1] + c
+ else:
+ result_chunk.append(c)
+ result = [*result, *result_chunk]
+ return result
diff --git a/src/MaxKB-1.5.1/apps/common/config/embedding_config.py b/src/MaxKB-1.5.1/apps/common/config/embedding_config.py
new file mode 100644
index 0000000..a6e9ab9
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/config/embedding_config.py
@@ -0,0 +1,66 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: embedding_config.py
+ @date:2023/10/23 16:03
+ @desc:
+"""
+import threading
+import time
+
+from common.cache.mem_cache import MemCache
+
+lock = threading.Lock()
+
+
+class ModelManage:
+ cache = MemCache('model', {})
+ up_clear_time = time.time()
+
+ @staticmethod
+ def get_model(_id, get_model):
+ # 获取锁
+ lock.acquire()
+ try:
+ model_instance = ModelManage.cache.get(_id)
+ if model_instance is None or not model_instance.is_cache_model():
+ model_instance = get_model(_id)
+ ModelManage.cache.set(_id, model_instance, timeout=60 * 30)
+ return model_instance
+ # 续期
+ ModelManage.cache.touch(_id, timeout=60 * 30)
+ ModelManage.clear_timeout_cache()
+ return model_instance
+ finally:
+ # 释放锁
+ lock.release()
+
+ @staticmethod
+ def clear_timeout_cache():
+ if time.time() - ModelManage.up_clear_time > 60:
+ ModelManage.cache.clear_timeout_data()
+
+ @staticmethod
+ def delete_key(_id):
+ if ModelManage.cache.has_key(_id):
+ ModelManage.cache.delete(_id)
+
+
+class VectorStore:
+ from embedding.vector.pg_vector import PGVector
+ from embedding.vector.base_vector import BaseVectorStore
+ instance_map = {
+ 'pg_vector': PGVector,
+ }
+ instance = None
+
+ @staticmethod
+ def get_embedding_vector() -> BaseVectorStore:
+ from embedding.vector.pg_vector import PGVector
+ if VectorStore.instance is None:
+ from smartdoc.const import CONFIG
+ vector_store_class = VectorStore.instance_map.get(CONFIG.get("VECTOR_STORE_NAME"),
+ PGVector)
+ VectorStore.instance = vector_store_class()
+ return VectorStore.instance
diff --git a/src/MaxKB-1.5.1/apps/common/config/swagger_conf.py b/src/MaxKB-1.5.1/apps/common/config/swagger_conf.py
new file mode 100644
index 0000000..b3ba272
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/config/swagger_conf.py
@@ -0,0 +1,22 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: swagger_conf.py
+ @date:2023/9/5 14:01
+ @desc: 用于swagger 分组
+"""
+
+from drf_yasg.inspectors import SwaggerAutoSchema
+
+tags_dict = {
+ 'user': '用户'
+}
+
+
+class CustomSwaggerAutoSchema(SwaggerAutoSchema):
+ def get_tags(self, operation_keys=None):
+ tags = super().get_tags(operation_keys)
+ if "api" in tags and operation_keys:
+ return [tags_dict.get(operation_keys[1]) if operation_keys[1] in tags_dict else operation_keys[1]]
+ return tags
diff --git a/src/MaxKB-1.5.1/apps/common/config/tokenizer_manage_config.py b/src/MaxKB-1.5.1/apps/common/config/tokenizer_manage_config.py
new file mode 100644
index 0000000..1d3fa8d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/config/tokenizer_manage_config.py
@@ -0,0 +1,24 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: tokenizer_manage_config.py
+ @date:2024/4/28 10:17
+ @desc:
+"""
+
+
+class TokenizerManage:
+ tokenizer = None
+
+ @staticmethod
+ def get_tokenizer():
+ from transformers import GPT2TokenizerFast
+ if TokenizerManage.tokenizer is None:
+ TokenizerManage.tokenizer = GPT2TokenizerFast.from_pretrained(
+ 'gpt2',
+ cache_dir="/opt/maxkb/model/tokenizer",
+ local_files_only=True,
+ resume_download=False,
+ force_download=False)
+ return TokenizerManage.tokenizer
diff --git a/src/MaxKB-1.5.1/apps/common/constants/authentication_type.py b/src/MaxKB-1.5.1/apps/common/constants/authentication_type.py
new file mode 100644
index 0000000..3316300
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/constants/authentication_type.py
@@ -0,0 +1,18 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: authentication_type.py
+ @date:2023/11/14 20:03
+ @desc:
+"""
+from enum import Enum
+
+
+class AuthenticationType(Enum):
+ # 普通用户
+ USER = "USER"
+ # 公共访问链接
+ APPLICATION_ACCESS_TOKEN = "APPLICATION_ACCESS_TOKEN"
+ # key API
+ API_KEY = "API_KEY"
diff --git a/src/MaxKB-1.5.1/apps/common/constants/cache_code_constants.py b/src/MaxKB-1.5.1/apps/common/constants/cache_code_constants.py
new file mode 100644
index 0000000..dd64805
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/constants/cache_code_constants.py
@@ -0,0 +1,18 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: cache_code_constants.py
+ @date:2024/7/24 18:20
+ @desc:
+"""
+from enum import Enum
+
+
+class CacheCodeConstants(Enum):
+ # 应用ACCESS_TOKEN缓存
+ APPLICATION_ACCESS_TOKEN_CACHE = 'APPLICATION_ACCESS_TOKEN_CACHE'
+ # 静态资源缓存
+ STATIC_RESOURCE_CACHE = 'STATIC_RESOURCE_CACHE'
+ # 应用API_KEY缓存
+ APPLICATION_API_KEY_CACHE = 'APPLICATION_API_KEY_CACHE'
diff --git a/src/MaxKB-1.5.1/apps/common/constants/exception_code_constants.py b/src/MaxKB-1.5.1/apps/common/constants/exception_code_constants.py
new file mode 100644
index 0000000..ba7a810
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/constants/exception_code_constants.py
@@ -0,0 +1,39 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: exception_code_constants.py
+ @date:2023/9/4 14:09
+ @desc: 异常常量类
+"""
+from enum import Enum
+
+from common.exception.app_exception import AppApiException
+
+
+class ExceptionCodeConstantsValue:
+ def __init__(self, code, message):
+ self.code = code
+ self.message = message
+
+ def get_message(self):
+ return self.message
+
+ def get_code(self):
+ return self.code
+
+ def to_app_api_exception(self):
+ return AppApiException(code=self.code, message=self.message)
+
+
+class ExceptionCodeConstants(Enum):
+ INCORRECT_USERNAME_AND_PASSWORD = ExceptionCodeConstantsValue(1000, "用户名或者密码不正确")
+ NOT_AUTHENTICATION = ExceptionCodeConstantsValue(1001, "请先登录,并携带用户Token")
+ EMAIL_SEND_ERROR = ExceptionCodeConstantsValue(1002, "邮件发送失败")
+ EMAIL_FORMAT_ERROR = ExceptionCodeConstantsValue(1003, "邮箱格式错误")
+ EMAIL_IS_EXIST = ExceptionCodeConstantsValue(1004, "邮箱已经被注册,请勿重复注册")
+ EMAIL_IS_NOT_EXIST = ExceptionCodeConstantsValue(1005, "邮箱尚未注册,请先注册")
+ CODE_ERROR = ExceptionCodeConstantsValue(1005, "验证码不正确,或者验证码过期")
+ USERNAME_IS_EXIST = ExceptionCodeConstantsValue(1006, "用户名已被使用,请使用其他用户名")
+ USERNAME_ERROR = ExceptionCodeConstantsValue(1006, "用户名不能为空,并且长度在6-20")
+ PASSWORD_NOT_EQ_RE_PASSWORD = ExceptionCodeConstantsValue(1007, "密码与确认密码不一致")
diff --git a/src/MaxKB-1.5.1/apps/common/constants/permission_constants.py b/src/MaxKB-1.5.1/apps/common/constants/permission_constants.py
new file mode 100644
index 0000000..04f86bb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/constants/permission_constants.py
@@ -0,0 +1,176 @@
+"""
+ @project: qabot
+ @Author:虎
+ @file: permission_constants.py
+ @date:2023/9/13 18:23
+ @desc: 权限,角色 常量
+"""
+from enum import Enum
+from typing import List
+
+
+class Group(Enum):
+ """
+ 权限组 一个组一般对应前端一个菜单
+ """
+ USER = "USER"
+
+ DATASET = "DATASET"
+
+ APPLICATION = "APPLICATION"
+
+ SETTING = "SETTING"
+
+ MODEL = "MODEL"
+
+ TEAM = "TEAM"
+
+
+class Operate(Enum):
+ """
+ 一个权限组的操作权限
+ """
+ READ = 'READ'
+ EDIT = "EDIT"
+ CREATE = "CREATE"
+ DELETE = "DELETE"
+ """
+ 管理权限
+ """
+ MANAGE = "MANAGE"
+ """
+ 使用权限
+ """
+ USE = "USE"
+
+
+class RoleGroup(Enum):
+ USER = 'USER'
+ APPLICATION_KEY = "APPLICATION_KEY"
+ APPLICATION_ACCESS_TOKEN = "APPLICATION_ACCESS_TOKEN"
+
+
+class Role:
+ def __init__(self, name: str, decs: str, group: RoleGroup):
+ self.name = name
+ self.decs = decs
+ self.group = group
+
+
+class RoleConstants(Enum):
+ ADMIN = Role("管理员", "管理员,预制目前不会使用", RoleGroup.USER)
+ USER = Role("用户", "用户所有权限", RoleGroup.USER)
+ APPLICATION_ACCESS_TOKEN = Role("会话", "只拥有应用会话框接口权限", RoleGroup.APPLICATION_ACCESS_TOKEN),
+ APPLICATION_KEY = Role("应用私钥", "应用私钥", RoleGroup.APPLICATION_KEY)
+
+
+class Permission:
+ """
+ 权限信息
+ """
+
+ def __init__(self, group: Group, operate: Operate, roles=None, dynamic_tag=None):
+ if roles is None:
+ roles = []
+ self.group = group
+ self.operate = operate
+ self.roleList = roles
+ self.dynamic_tag = dynamic_tag
+
+ def __str__(self):
+ return self.group.value + ":" + self.operate.value + (
+ (":" + self.dynamic_tag) if self.dynamic_tag is not None else '')
+
+ def __eq__(self, other):
+ return str(self) == str(other)
+
+
+class PermissionConstants(Enum):
+ """
+ 权限枚举
+ """
+ USER_READ = Permission(group=Group.USER, operate=Operate.READ, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+ USER_EDIT = Permission(group=Group.USER, operate=Operate.EDIT, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+ USER_DELETE = Permission(group=Group.USER, operate=Operate.DELETE, roles=[RoleConstants.USER])
+
+ DATASET_CREATE = Permission(group=Group.DATASET, operate=Operate.CREATE,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ DATASET_READ = Permission(group=Group.DATASET, operate=Operate.READ,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ DATASET_EDIT = Permission(group=Group.DATASET, operate=Operate.EDIT,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ APPLICATION_READ = Permission(group=Group.APPLICATION, operate=Operate.READ,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ APPLICATION_CREATE = Permission(group=Group.APPLICATION, operate=Operate.CREATE,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ APPLICATION_DELETE = Permission(group=Group.APPLICATION, operate=Operate.DELETE,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ APPLICATION_EDIT = Permission(group=Group.APPLICATION, operate=Operate.EDIT,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ SETTING_READ = Permission(group=Group.SETTING, operate=Operate.READ,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ MODEL_READ = Permission(group=Group.MODEL, operate=Operate.READ, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ MODEL_EDIT = Permission(group=Group.MODEL, operate=Operate.EDIT, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ MODEL_DELETE = Permission(group=Group.MODEL, operate=Operate.DELETE,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+ MODEL_CREATE = Permission(group=Group.MODEL, operate=Operate.CREATE,
+ roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ TEAM_READ = Permission(group=Group.TEAM, operate=Operate.READ, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ TEAM_CREATE = Permission(group=Group.TEAM, operate=Operate.CREATE, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ TEAM_DELETE = Permission(group=Group.TEAM, operate=Operate.DELETE, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+ TEAM_EDIT = Permission(group=Group.TEAM, operate=Operate.EDIT, roles=[RoleConstants.ADMIN, RoleConstants.USER])
+
+
+def get_permission_list_by_role(role: RoleConstants):
+ """
+ 根据角色 获取角色对应的权限
+ :param role: 角色
+ :return: 权限
+ """
+ return list(map(lambda k: PermissionConstants[k],
+ list(filter(lambda k: PermissionConstants[k].value.roleList.__contains__(role),
+ PermissionConstants.__members__))))
+
+
+class Auth:
+ """
+ 用于存储当前用户的角色和权限
+ """
+
+ def __init__(self, role_list: List[RoleConstants], permission_list: List[PermissionConstants | Permission]
+ , client_id, client_type, current_role: RoleConstants, **keywords):
+ self.role_list = role_list
+ self.permission_list = permission_list
+ self.client_id = client_id
+ self.client_type = client_type
+ self.keywords = keywords
+ self.current_role = current_role
+
+
+class CompareConstants(Enum):
+ # 或者
+ OR = "OR"
+ # 并且
+ AND = "AND"
+
+
+class ViewPermission:
+ def __init__(self, roleList: List[RoleConstants], permissionList: List[PermissionConstants | object],
+ compare=CompareConstants.OR):
+ self.roleList = roleList
+ self.permissionList = permissionList
+ self.compare = compare
diff --git a/src/MaxKB-1.5.1/apps/common/db/compiler.py b/src/MaxKB-1.5.1/apps/common/db/compiler.py
new file mode 100644
index 0000000..69640c8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/db/compiler.py
@@ -0,0 +1,217 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: compiler.py
+ @date:2023/10/7 10:53
+ @desc:
+"""
+
+from django.core.exceptions import EmptyResultSet, FullResultSet
+from django.db import NotSupportedError
+from django.db.models.sql.compiler import SQLCompiler
+from django.db.transaction import TransactionManagementError
+
+
+class AppSQLCompiler(SQLCompiler):
+ def __init__(self, query, connection, using, elide_empty=True, field_replace_dict=None):
+ super().__init__(query, connection, using, elide_empty)
+ if field_replace_dict is None:
+ field_replace_dict = {}
+ self.field_replace_dict = field_replace_dict
+
+ def get_query_str(self, with_limits=True, with_table_name=False, with_col_aliases=False):
+ refcounts_before = self.query.alias_refcount.copy()
+ try:
+ combinator = self.query.combinator
+ extra_select, order_by, group_by = self.pre_sql_setup(
+ with_col_aliases=with_col_aliases or bool(combinator),
+ )
+ for_update_part = None
+ # Is a LIMIT/OFFSET clause needed?
+ with_limit_offset = with_limits and self.query.is_sliced
+ combinator = self.query.combinator
+ features = self.connection.features
+ if combinator:
+ if not getattr(features, "supports_select_{}".format(combinator)):
+ raise NotSupportedError(
+ "{} is not supported on this database backend.".format(
+ combinator
+ )
+ )
+ result, params = self.get_combinator_sql(
+ combinator, self.query.combinator_all
+ )
+ elif self.qualify:
+ result, params = self.get_qualify_sql()
+ order_by = None
+ else:
+ distinct_fields, distinct_params = self.get_distinct()
+ # This must come after 'select', 'ordering', and 'distinct'
+ # (see docstring of get_from_clause() for details).
+ from_, f_params = self.get_from_clause()
+ try:
+ where, w_params = (
+ self.compile(self.where) if self.where is not None else ("", [])
+ )
+ except EmptyResultSet:
+ if self.elide_empty:
+ raise
+ # Use a predicate that's always False.
+ where, w_params = "0 = 1", []
+ except FullResultSet:
+ where, w_params = "", []
+ try:
+ having, h_params = (
+ self.compile(self.having)
+ if self.having is not None
+ else ("", [])
+ )
+ except FullResultSet:
+ having, h_params = "", []
+ result = []
+ params = []
+
+ if self.query.distinct:
+ distinct_result, distinct_params = self.connection.ops.distinct_sql(
+ distinct_fields,
+ distinct_params,
+ )
+ result += distinct_result
+ params += distinct_params
+
+ out_cols = []
+ for _, (s_sql, s_params), alias in self.select + extra_select:
+ if alias:
+ s_sql = "%s AS %s" % (
+ s_sql,
+ self.connection.ops.quote_name(alias),
+ )
+ params.extend(s_params)
+ out_cols.append(s_sql)
+
+ params.extend(f_params)
+
+ if self.query.select_for_update and features.has_select_for_update:
+ if (
+ self.connection.get_autocommit()
+ # Don't raise an exception when database doesn't
+ # support transactions, as it's a noop.
+ and features.supports_transactions
+ ):
+ raise TransactionManagementError(
+ "select_for_update cannot be used outside of a transaction."
+ )
+
+ if (
+ with_limit_offset
+ and not features.supports_select_for_update_with_limit
+ ):
+ raise NotSupportedError(
+ "LIMIT/OFFSET is not supported with "
+ "select_for_update on this database backend."
+ )
+ nowait = self.query.select_for_update_nowait
+ skip_locked = self.query.select_for_update_skip_locked
+ of = self.query.select_for_update_of
+ no_key = self.query.select_for_no_key_update
+ # If it's a NOWAIT/SKIP LOCKED/OF/NO KEY query but the
+ # backend doesn't support it, raise NotSupportedError to
+ # prevent a possible deadlock.
+ if nowait and not features.has_select_for_update_nowait:
+ raise NotSupportedError(
+ "NOWAIT is not supported on this database backend."
+ )
+ elif skip_locked and not features.has_select_for_update_skip_locked:
+ raise NotSupportedError(
+ "SKIP LOCKED is not supported on this database backend."
+ )
+ elif of and not features.has_select_for_update_of:
+ raise NotSupportedError(
+ "FOR UPDATE OF is not supported on this database backend."
+ )
+ elif no_key and not features.has_select_for_no_key_update:
+ raise NotSupportedError(
+ "FOR NO KEY UPDATE is not supported on this "
+ "database backend."
+ )
+ for_update_part = self.connection.ops.for_update_sql(
+ nowait=nowait,
+ skip_locked=skip_locked,
+ of=self.get_select_for_update_of_arguments(),
+ no_key=no_key,
+ )
+
+ if for_update_part and features.for_update_after_from:
+ result.append(for_update_part)
+
+ if where:
+ result.append("WHERE %s" % where)
+ params.extend(w_params)
+
+ grouping = []
+ for g_sql, g_params in group_by:
+ grouping.append(g_sql)
+ params.extend(g_params)
+ if grouping:
+ if distinct_fields:
+ raise NotImplementedError(
+ "annotate() + distinct(fields) is not implemented."
+ )
+ order_by = order_by or self.connection.ops.force_no_ordering()
+ result.append("GROUP BY %s" % ", ".join(grouping))
+ if self._meta_ordering:
+ order_by = None
+ if having:
+ result.append("HAVING %s" % having)
+ params.extend(h_params)
+
+ if self.query.explain_info:
+ result.insert(
+ 0,
+ self.connection.ops.explain_query_prefix(
+ self.query.explain_info.format,
+ **self.query.explain_info.options,
+ ),
+ )
+
+ if order_by:
+ ordering = []
+ for _, (o_sql, o_params, _) in order_by:
+ ordering.append(o_sql)
+ params.extend(o_params)
+ order_by_sql = "ORDER BY %s" % ", ".join(ordering)
+ if combinator and features.requires_compound_order_by_subquery:
+ result = ["SELECT * FROM (", *result, ")", order_by_sql]
+ else:
+ result.append(order_by_sql)
+
+ if with_limit_offset:
+ result.append(
+ self.connection.ops.limit_offset_sql(
+ self.query.low_mark, self.query.high_mark
+ )
+ )
+
+ if for_update_part and not features.for_update_after_from:
+ result.append(for_update_part)
+
+ from_, f_params = self.get_from_clause()
+ sql = " ".join(result)
+ if not with_table_name:
+ for table_name in from_:
+ sql = sql.replace(table_name + ".", "")
+ for key in self.field_replace_dict.keys():
+ value = self.field_replace_dict.get(key)
+ sql = sql.replace(key, value)
+ return sql, tuple(params)
+ finally:
+ # Finally do cleanup - get rid of the joins we created above.
+ self.query.reset_refcounts(refcounts_before)
+
+ def as_sql(self, with_limits=True, with_col_aliases=False, select_string=None):
+ if select_string is None:
+ return super().as_sql(with_limits, with_col_aliases)
+ else:
+ sql, params = self.get_query_str(with_table_name=False)
+ return (select_string + " " + sql), params
diff --git a/src/MaxKB-1.5.1/apps/common/db/search.py b/src/MaxKB-1.5.1/apps/common/db/search.py
new file mode 100644
index 0000000..7636671
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/db/search.py
@@ -0,0 +1,176 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: search.py
+ @date:2023/10/7 18:20
+ @desc:
+"""
+from typing import Dict, Any
+
+from django.db import DEFAULT_DB_ALIAS, models, connections
+from django.db.models import QuerySet
+
+from common.db.compiler import AppSQLCompiler
+from common.db.sql_execute import select_one, select_list
+from common.response.result import Page
+
+
+def get_dynamics_model(attr: dict, table_name='dynamics'):
+ """
+ 获取一个动态的django模型
+ :param attr: 模型字段
+ :param table_name: 表名
+ :return: django 模型
+ """
+ attributes = {
+ "__module__": "dataset.models",
+ "Meta": type("Meta", (), {'db_table': table_name}),
+ **attr
+ }
+ return type('Dynamics', (models.Model,), attributes)
+
+
+def generate_sql_by_query_dict(queryset_dict: Dict[str, QuerySet], select_string: str,
+ field_replace_dict: None | Dict[str, Dict[str, str]] = None, with_table_name=False):
+ """
+ 生成 查询sql
+ :param with_table_name:
+ :param queryset_dict: 多条件 查询条件
+ :param select_string: 查询sql
+ :param field_replace_dict: 需要替换的查询字段,一般不需要传入如果有特殊的需要传入
+ :return: sql:需要查询的sql params: sql 参数
+ """
+
+ params_dict: Dict[int, Any] = {}
+ result_params = []
+ for key in queryset_dict.keys():
+ value = queryset_dict.get(key)
+ sql, params = compiler_queryset(value, None if field_replace_dict is None else field_replace_dict.get(key),
+ with_table_name)
+ params_dict = {**params_dict, select_string.index("${" + key + "}"): params}
+ select_string = select_string.replace("${" + key + "}", sql)
+
+ for key in sorted(list(params_dict.keys())):
+ result_params = [*result_params, *params_dict.get(key)]
+ return select_string, result_params
+
+
+def generate_sql_by_query(queryset: QuerySet, select_string: str,
+ field_replace_dict: None | Dict[str, str] = None, with_table_name=False):
+ """
+ 生成 查询sql
+ :param queryset: 查询条件
+ :param select_string: 原始sql
+ :param field_replace_dict: 需要替换的查询字段,一般不需要传入如果有特殊的需要传入
+ :return: sql:需要查询的sql params: sql 参数
+ """
+ sql, params = compiler_queryset(queryset, field_replace_dict, with_table_name)
+ return select_string + " " + sql, params
+
+
+def compiler_queryset(queryset: QuerySet, field_replace_dict: None | Dict[str, str] = None, with_table_name=False):
+ """
+ 解析 queryset查询对象
+ :param with_table_name:
+ :param queryset: 查询对象
+ :param field_replace_dict: 需要替换的查询字段,一般不需要传入如果有特殊的需要传入
+ :return: sql:需要查询的sql params: sql 参数
+ """
+ q = queryset.query
+ compiler = q.get_compiler(DEFAULT_DB_ALIAS)
+ if field_replace_dict is None:
+ field_replace_dict = get_field_replace_dict(queryset)
+ app_sql_compiler = AppSQLCompiler(q, using=DEFAULT_DB_ALIAS, connection=compiler.connection,
+ field_replace_dict=field_replace_dict)
+ sql, params = app_sql_compiler.get_query_str(with_table_name=with_table_name)
+ return sql, params
+
+
+def native_search(queryset: QuerySet | Dict[str, QuerySet], select_string: str,
+ field_replace_dict: None | Dict[str, Dict[str, str]] | Dict[str, str] = None,
+ with_search_one=False, with_table_name=False):
+ """
+ 复杂查询
+ :param with_table_name: 生成sql是否包含表名
+ :param queryset: 查询条件构造器
+ :param select_string: 查询前缀 不包括 where limit 等信息
+ :param field_replace_dict: 需要替换的字段
+ :param with_search_one: 查询
+ :return: 查询结果
+ """
+ if isinstance(queryset, Dict):
+ exec_sql, exec_params = generate_sql_by_query_dict(queryset, select_string, field_replace_dict, with_table_name)
+ else:
+ exec_sql, exec_params = generate_sql_by_query(queryset, select_string, field_replace_dict, with_table_name)
+ if with_search_one:
+ return select_one(exec_sql, exec_params)
+ else:
+ return select_list(exec_sql, exec_params)
+
+
+def page_search(current_page: int, page_size: int, queryset: QuerySet, post_records_handler):
+ """
+ 分页查询
+ :param current_page: 当前页
+ :param page_size: 每页大小
+ :param queryset: 查询条件
+ :param post_records_handler: 数据处理器
+ :return: 分页结果
+ """
+ total = QuerySet(query=queryset.query.clone(), model=queryset.model).count()
+ result = queryset.all()[((current_page - 1) * page_size):(current_page * page_size)]
+ return Page(total, list(map(post_records_handler, result)), current_page, page_size)
+
+
+def native_page_search(current_page: int, page_size: int, queryset: QuerySet | Dict[str, QuerySet], select_string: str,
+ field_replace_dict=None,
+ post_records_handler=lambda r: r,
+ with_table_name=False):
+ """
+ 复杂分页查询
+ :param with_table_name:
+ :param current_page: 当前页
+ :param page_size: 每页大小
+ :param queryset: 查询条件
+ :param select_string: 查询
+ :param field_replace_dict: 特殊字段替换
+ :param post_records_handler: 数据row处理器
+ :return: 分页结果
+ """
+ if isinstance(queryset, Dict):
+ exec_sql, exec_params = generate_sql_by_query_dict(queryset, select_string, field_replace_dict, with_table_name)
+ else:
+ exec_sql, exec_params = generate_sql_by_query(queryset, select_string, field_replace_dict, with_table_name)
+ total_sql = "SELECT \"count\"(*) FROM (%s) temp" % exec_sql
+ total = select_one(total_sql, exec_params)
+ limit_sql = connections[DEFAULT_DB_ALIAS].ops.limit_offset_sql(
+ ((current_page - 1) * page_size), (current_page * page_size)
+ )
+ page_sql = exec_sql + " " + limit_sql
+ result = select_list(page_sql, exec_params)
+ return Page(total.get("count"), list(map(post_records_handler, result)), current_page, page_size)
+
+
+def get_field_replace_dict(queryset: QuerySet):
+ """
+ 获取需要替换的字段 默认 “xxx.xxx”需要被替换成 “xxx”."xxx"
+ :param queryset: 查询对象
+ :return: 需要替换的字典
+ """
+ result = {}
+ for field in queryset.model._meta.local_fields:
+ if field.attname.__contains__("."):
+ replace_field = to_replace_field(field.attname)
+ result.__setitem__('"' + field.attname + '"', replace_field)
+ return result
+
+
+def to_replace_field(field: str):
+ """
+ 将field 转换为 需要替换的field “xxx.xxx”需要被替换成 “xxx”."xxx" 只替换 field包含.的字段
+ :param field: django field字段
+ :return: 替换字段
+ """
+ split_field = field.split(".")
+ return ".".join(list(map(lambda sf: '"' + sf + '"', split_field)))
diff --git a/src/MaxKB-1.5.1/apps/common/db/sql_execute.py b/src/MaxKB-1.5.1/apps/common/db/sql_execute.py
new file mode 100644
index 0000000..79e7de4
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/db/sql_execute.py
@@ -0,0 +1,66 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: sql_execute.py
+ @date:2023/9/25 20:05
+ @desc:
+"""
+from typing import List
+
+from django.db import connection
+
+
+def sql_execute(sql: str, params):
+ """
+ 执行一条sql
+ :param sql: 需要执行的sql
+ :param params: sql参数
+ :return: 执行结果
+ """
+ with connection.cursor() as cursor:
+ cursor.execute(sql, params)
+ columns = list(map(lambda d: d.name, cursor.description))
+ res = cursor.fetchall()
+ result = list(map(lambda row: dict(list(zip(columns, row))), res))
+ cursor.close()
+ return result
+
+
+def update_execute(sql: str, params):
+ """
+ 执行一条sql
+ :param sql: 需要执行的sql
+ :param params: sql参数
+ :return: 执行结果
+ """
+ with connection.cursor() as cursor:
+ cursor.execute(sql, params)
+ cursor.close()
+ return None
+
+
+def select_list(sql: str, params: List):
+ """
+ 执行sql 查询列表数据
+ :param sql: 需要执行的sql
+ :param params: sql的参数
+ :return: 查询结果
+ """
+ result_list = sql_execute(sql, params)
+ if result_list is None:
+ return []
+ return result_list
+
+
+def select_one(sql: str, params: List):
+ """
+ 执行sql 查询一条数据
+ :param sql: 需要执行的sql
+ :param params: 参数
+ :return: 查询结果
+ """
+ result_list = sql_execute(sql, params)
+ if result_list is None or len(result_list) == 0:
+ return None
+ return result_list[0]
diff --git a/src/MaxKB-1.5.1/apps/common/event/__init__.py b/src/MaxKB-1.5.1/apps/common/event/__init__.py
new file mode 100644
index 0000000..bd4d363
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/event/__init__.py
@@ -0,0 +1,17 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py
+ @date:2023/11/10 10:43
+ @desc:
+"""
+import setting.models
+from setting.models import Model
+from .listener_manage import *
+
+
+def run():
+ QuerySet(Document).filter(status__in=[Status.embedding, Status.queue_up]).update(**{'status': Status.error})
+ QuerySet(Model).filter(status=setting.models.Status.DOWNLOAD).update(status=setting.models.Status.ERROR,
+ meta={'message': "下载程序被中断,请重试"})
diff --git a/src/MaxKB-1.5.1/apps/common/event/common.py b/src/MaxKB-1.5.1/apps/common/event/common.py
new file mode 100644
index 0000000..a54d24d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/event/common.py
@@ -0,0 +1,50 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: common.py
+ @date:2023/11/10 10:41
+ @desc:
+"""
+from concurrent.futures import ThreadPoolExecutor
+
+from django.core.cache.backends.locmem import LocMemCache
+
+work_thread_pool = ThreadPoolExecutor(5)
+
+embedding_thread_pool = ThreadPoolExecutor(3)
+
+memory_cache = LocMemCache('task', {"OPTIONS": {"MAX_ENTRIES": 1000}})
+
+
+def poxy(poxy_function):
+ def inner(args, **keywords):
+ work_thread_pool.submit(poxy_function, args, **keywords)
+
+ return inner
+
+
+def get_cache_key(poxy_function, args):
+ return poxy_function.__name__ + str(args)
+
+
+def get_cache_poxy_function(poxy_function, cache_key):
+ def fun(args, **keywords):
+ try:
+ poxy_function(args, **keywords)
+ finally:
+ memory_cache.delete(cache_key)
+
+ return fun
+
+
+def embedding_poxy(poxy_function):
+ def inner(*args, **keywords):
+ key = get_cache_key(poxy_function, args)
+ if memory_cache.has_key(key):
+ return
+ memory_cache.add(key, None)
+ f = get_cache_poxy_function(poxy_function, key)
+ embedding_thread_pool.submit(f, args, **keywords)
+
+ return inner
diff --git a/src/MaxKB-1.5.1/apps/common/event/listener_manage.py b/src/MaxKB-1.5.1/apps/common/event/listener_manage.py
new file mode 100644
index 0000000..537677b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/event/listener_manage.py
@@ -0,0 +1,269 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: listener_manage.py
+ @date:2023/10/20 14:01
+ @desc:
+"""
+import datetime
+import logging
+import os
+import traceback
+from typing import List
+
+import django.db.models
+from django.db.models import QuerySet
+from langchain_core.embeddings import Embeddings
+
+from common.config.embedding_config import VectorStore
+from common.db.search import native_search, get_dynamics_model
+from common.event.common import embedding_poxy
+from common.util.file_util import get_file_content
+from common.util.lock import try_lock, un_lock
+from dataset.models import Paragraph, Status, Document, ProblemParagraphMapping
+from embedding.models import SourceType, SearchMode
+from smartdoc.conf import PROJECT_DIR
+
+max_kb_error = logging.getLogger(__file__)
+max_kb = logging.getLogger(__file__)
+
+
+class SyncWebDatasetArgs:
+ def __init__(self, lock_key: str, url: str, selector: str, handler):
+ self.lock_key = lock_key
+ self.url = url
+ self.selector = selector
+ self.handler = handler
+
+
+class SyncWebDocumentArgs:
+ def __init__(self, source_url_list: List[str], selector: str, handler):
+ self.source_url_list = source_url_list
+ self.selector = selector
+ self.handler = handler
+
+
+class UpdateProblemArgs:
+ def __init__(self, problem_id: str, problem_content: str, embedding_model: Embeddings):
+ self.problem_id = problem_id
+ self.problem_content = problem_content
+ self.embedding_model = embedding_model
+
+
+class UpdateEmbeddingDatasetIdArgs:
+ def __init__(self, paragraph_id_list: List[str], target_dataset_id: str):
+ self.paragraph_id_list = paragraph_id_list
+ self.target_dataset_id = target_dataset_id
+
+
+class UpdateEmbeddingDocumentIdArgs:
+ def __init__(self, paragraph_id_list: List[str], target_document_id: str, target_dataset_id: str,
+ target_embedding_model: Embeddings = None):
+ self.paragraph_id_list = paragraph_id_list
+ self.target_document_id = target_document_id
+ self.target_dataset_id = target_dataset_id
+ self.target_embedding_model = target_embedding_model
+
+
+class ListenerManagement:
+
+ @staticmethod
+ def embedding_by_problem(args, embedding_model: Embeddings):
+ VectorStore.get_embedding_vector().save(**args, embedding=embedding_model)
+
+ @staticmethod
+ def embedding_by_paragraph_list(paragraph_id_list, embedding_model: Embeddings):
+ try:
+ data_list = native_search(
+ {'problem': QuerySet(get_dynamics_model({'paragraph.id': django.db.models.CharField()})).filter(
+ **{'paragraph.id__in': paragraph_id_list}),
+ 'paragraph': QuerySet(Paragraph).filter(id__in=paragraph_id_list)},
+ select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "common", 'sql', 'list_embedding_text.sql')))
+ ListenerManagement.embedding_by_paragraph_data_list(data_list, paragraph_id_list=paragraph_id_list,
+ embedding_model=embedding_model)
+ except Exception as e:
+ max_kb_error.error(f'查询向量数据:{paragraph_id_list}出现错误{str(e)}{traceback.format_exc()}')
+
+ @staticmethod
+ def embedding_by_paragraph_data_list(data_list, paragraph_id_list, embedding_model: Embeddings):
+ max_kb.info(f'开始--->向量化段落:{paragraph_id_list}')
+ status = Status.success
+ try:
+ # 删除段落
+ VectorStore.get_embedding_vector().delete_by_paragraph_ids(paragraph_id_list)
+
+ def is_save_function():
+ return QuerySet(Paragraph).filter(id__in=paragraph_id_list).exists()
+
+ # 批量向量化
+ VectorStore.get_embedding_vector().batch_save(data_list, embedding_model, is_save_function)
+ except Exception as e:
+ max_kb_error.error(f'向量化段落:{paragraph_id_list}出现错误{str(e)}{traceback.format_exc()}')
+ status = Status.error
+ finally:
+ QuerySet(Paragraph).filter(id__in=paragraph_id_list).update(**{'status': status})
+ max_kb.info(f'结束--->向量化段落:{paragraph_id_list}')
+
+ @staticmethod
+ def embedding_by_paragraph(paragraph_id, embedding_model: Embeddings):
+ """
+ 向量化段落 根据段落id
+ @param paragraph_id: 段落id
+ @param embedding_model: 向量模型
+ """
+ max_kb.info(f"开始--->向量化段落:{paragraph_id}")
+ status = Status.success
+ try:
+ data_list = native_search(
+ {'problem': QuerySet(get_dynamics_model({'paragraph.id': django.db.models.CharField()})).filter(
+ **{'paragraph.id': paragraph_id}),
+ 'paragraph': QuerySet(Paragraph).filter(id=paragraph_id)},
+ select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "common", 'sql', 'list_embedding_text.sql')))
+ # 删除段落
+ VectorStore.get_embedding_vector().delete_by_paragraph_id(paragraph_id)
+
+ def is_save_function():
+ return QuerySet(Paragraph).filter(id=paragraph_id).exists()
+
+ # 批量向量化
+ VectorStore.get_embedding_vector().batch_save(data_list, embedding_model, is_save_function)
+ except Exception as e:
+ max_kb_error.error(f'向量化段落:{paragraph_id}出现错误{str(e)}{traceback.format_exc()}')
+ status = Status.error
+ finally:
+ QuerySet(Paragraph).filter(id=paragraph_id).update(**{'status': status})
+ max_kb.info(f'结束--->向量化段落:{paragraph_id}')
+
+ @staticmethod
+ def embedding_by_document(document_id, embedding_model: Embeddings):
+ """
+ 向量化文档
+ @param document_id: 文档id
+ @param embedding_model 向量模型
+ :return: None
+ """
+ if not try_lock('embedding' + str(document_id)):
+ return
+ max_kb.info(f"开始--->向量化文档:{document_id}")
+ QuerySet(Document).filter(id=document_id).update(**{'status': Status.embedding})
+ QuerySet(Paragraph).filter(document_id=document_id).update(**{'status': Status.embedding})
+ status = Status.success
+ try:
+ data_list = native_search(
+ {'problem': QuerySet(
+ get_dynamics_model({'paragraph.document_id': django.db.models.CharField()})).filter(
+ **{'paragraph.document_id': document_id}),
+ 'paragraph': QuerySet(Paragraph).filter(document_id=document_id)},
+ select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "common", 'sql', 'list_embedding_text.sql')))
+ # 删除文档向量数据
+ VectorStore.get_embedding_vector().delete_by_document_id(document_id)
+
+ def is_save_function():
+ return QuerySet(Document).filter(id=document_id).exists()
+
+ # 批量向量化
+ VectorStore.get_embedding_vector().batch_save(data_list, embedding_model, is_save_function)
+ except Exception as e:
+ max_kb_error.error(f'向量化文档:{document_id}出现错误{str(e)}{traceback.format_exc()}')
+ status = Status.error
+ finally:
+ # 修改状态
+ QuerySet(Document).filter(id=document_id).update(
+ **{'status': status, 'update_time': datetime.datetime.now()})
+ QuerySet(Paragraph).filter(document_id=document_id).update(**{'status': status})
+ max_kb.info(f"结束--->向量化文档:{document_id}")
+ un_lock('embedding' + str(document_id))
+
+ @staticmethod
+ def embedding_by_dataset(dataset_id, embedding_model: Embeddings):
+ """
+ 向量化知识库
+ @param dataset_id: 知识库id
+ @param embedding_model 向量模型
+ :return: None
+ """
+ max_kb.info(f"开始--->向量化数据集:{dataset_id}")
+ try:
+ ListenerManagement.delete_embedding_by_dataset(dataset_id)
+ document_list = QuerySet(Document).filter(dataset_id=dataset_id)
+ max_kb.info(f"数据集文档:{[d.name for d in document_list]}")
+ for document in document_list:
+ ListenerManagement.embedding_by_document(document.id, embedding_model=embedding_model)
+ except Exception as e:
+ max_kb_error.error(f'向量化数据集:{dataset_id}出现错误{str(e)}{traceback.format_exc()}')
+ finally:
+ max_kb.info(f"结束--->向量化数据集:{dataset_id}")
+
+ @staticmethod
+ def delete_embedding_by_document(document_id):
+ VectorStore.get_embedding_vector().delete_by_document_id(document_id)
+
+ @staticmethod
+ def delete_embedding_by_document_list(document_id_list: List[str]):
+ VectorStore.get_embedding_vector().delete_by_document_id_list(document_id_list)
+
+ @staticmethod
+ def delete_embedding_by_dataset(dataset_id):
+ VectorStore.get_embedding_vector().delete_by_dataset_id(dataset_id)
+
+ @staticmethod
+ def delete_embedding_by_paragraph(paragraph_id):
+ VectorStore.get_embedding_vector().delete_by_paragraph_id(paragraph_id)
+
+ @staticmethod
+ def delete_embedding_by_source(source_id):
+ VectorStore.get_embedding_vector().delete_by_source_id(source_id, SourceType.PROBLEM)
+
+ @staticmethod
+ def disable_embedding_by_paragraph(paragraph_id):
+ VectorStore.get_embedding_vector().update_by_paragraph_id(paragraph_id, {'is_active': False})
+
+ @staticmethod
+ def enable_embedding_by_paragraph(paragraph_id):
+ VectorStore.get_embedding_vector().update_by_paragraph_id(paragraph_id, {'is_active': True})
+
+ @staticmethod
+ def update_problem(args: UpdateProblemArgs):
+ problem_paragraph_mapping_list = QuerySet(ProblemParagraphMapping).filter(problem_id=args.problem_id)
+ embed_value = args.embedding_model.embed_query(args.problem_content)
+ VectorStore.get_embedding_vector().update_by_source_ids([v.id for v in problem_paragraph_mapping_list],
+ {'embedding': embed_value})
+
+ @staticmethod
+ def update_embedding_dataset_id(args: UpdateEmbeddingDatasetIdArgs):
+ VectorStore.get_embedding_vector().update_by_paragraph_ids(args.paragraph_id_list,
+ {'dataset_id': args.target_dataset_id})
+
+ @staticmethod
+ def update_embedding_document_id(args: UpdateEmbeddingDocumentIdArgs):
+ if args.target_embedding_model is None:
+ VectorStore.get_embedding_vector().update_by_paragraph_ids(args.paragraph_id_list,
+ {'document_id': args.target_document_id,
+ 'dataset_id': args.target_dataset_id})
+ else:
+ ListenerManagement.embedding_by_paragraph_list(args.paragraph_id_list,
+ embedding_model=args.target_embedding_model)
+
+ @staticmethod
+ def delete_embedding_by_source_ids(source_ids: List[str]):
+ VectorStore.get_embedding_vector().delete_by_source_ids(source_ids, SourceType.PROBLEM)
+
+ @staticmethod
+ def delete_embedding_by_paragraph_ids(paragraph_ids: List[str]):
+ VectorStore.get_embedding_vector().delete_by_paragraph_ids(paragraph_ids)
+
+ @staticmethod
+ def delete_embedding_by_dataset_id_list(source_ids: List[str]):
+ VectorStore.get_embedding_vector().delete_by_dataset_id_list(source_ids)
+
+ @staticmethod
+ def hit_test(query_text, dataset_id: list[str], exclude_document_id_list: list[str], top_number: int,
+ similarity: float,
+ search_mode: SearchMode,
+ embedding: Embeddings):
+ return VectorStore.get_embedding_vector().hit_test(query_text, dataset_id, exclude_document_id_list, top_number,
+ similarity, search_mode, embedding)
diff --git a/src/MaxKB-1.5.1/apps/common/exception/app_exception.py b/src/MaxKB-1.5.1/apps/common/exception/app_exception.py
new file mode 100644
index 0000000..3646efb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/exception/app_exception.py
@@ -0,0 +1,75 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: app_exception.py
+ @date:2023/9/4 14:04
+ @desc:
+"""
+from rest_framework import status
+
+
+class AppApiException(Exception):
+ """
+ 项目内异常
+ """
+ status_code = status.HTTP_200_OK
+
+ def __init__(self, code, message):
+ self.code = code
+ self.message = message
+
+
+class NotFound404(AppApiException):
+ """
+ 未认证(未登录)异常
+ """
+ status_code = status.HTTP_404_NOT_FOUND
+
+ def __init__(self, code, message):
+ self.code = code
+ self.message = message
+
+
+class AppAuthenticationFailed(AppApiException):
+ """
+ 未认证(未登录)异常
+ """
+ status_code = status.HTTP_401_UNAUTHORIZED
+
+ def __init__(self, code, message):
+ self.code = code
+ self.message = message
+
+
+class AppUnauthorizedFailed(AppApiException):
+ """
+ 未授权(没有权限)异常
+ """
+ status_code = status.HTTP_403_FORBIDDEN
+
+ def __init__(self, code, message):
+ self.code = code
+ self.message = message
+
+
+class AppEmbedIdentityFailed(AppApiException):
+ """
+ 嵌入cookie异常
+ """
+ status_code = 460
+
+ def __init__(self, code, message):
+ self.code = code
+ self.message = message
+
+
+class AppChatNumOutOfBoundsFailed(AppApiException):
+ """
+ 访问次数超过今日访问量
+ """
+ status_code = 461
+
+ def __init__(self, code, message):
+ self.code = code
+ self.message = message
diff --git a/src/MaxKB-1.5.1/apps/common/field/__init__.py b/src/MaxKB-1.5.1/apps/common/field/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/common/field/common.py b/src/MaxKB-1.5.1/apps/common/field/common.py
new file mode 100644
index 0000000..3025ec5
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/field/common.py
@@ -0,0 +1,65 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: common.py
+ @date:2024/1/11 18:44
+ @desc:
+"""
+from rest_framework import serializers
+
+
+class ObjectField(serializers.Field):
+ def __init__(self, model_type_list, **kwargs):
+ self.model_type_list = model_type_list
+ super().__init__(**kwargs)
+
+ def to_internal_value(self, data):
+ for model_type in self.model_type_list:
+ if isinstance(data, model_type):
+ return data
+ self.fail('message类型错误', value=data)
+
+ def to_representation(self, value):
+ return value
+
+
+class InstanceField(serializers.Field):
+ def __init__(self, model_type, **kwargs):
+ self.model_type = model_type
+ super().__init__(**kwargs)
+
+ def to_internal_value(self, data):
+ if not isinstance(data, self.model_type):
+ self.fail('message类型错误', value=data)
+ return data
+
+ def to_representation(self, value):
+ return value
+
+
+class FunctionField(serializers.Field):
+
+ def to_internal_value(self, data):
+ if not callable(data):
+ self.fail('不是一个函數', value=data)
+ return data
+
+ def to_representation(self, value):
+ return value
+
+
+class UploadedImageField(serializers.ImageField):
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def to_representation(self, value):
+ return value
+
+
+class UploadedFileField(serializers.FileField):
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+
+ def to_representation(self, value):
+ return value
diff --git a/src/MaxKB-1.5.1/apps/common/field/vector_field.py b/src/MaxKB-1.5.1/apps/common/field/vector_field.py
new file mode 100644
index 0000000..5916198
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/field/vector_field.py
@@ -0,0 +1,12 @@
+from django.db import models
+
+
+class VectorField(models.Field):
+
+ def db_type(self, connection):
+ return 'vector'
+
+
+class TsVectorField(models.Field):
+ def db_type(self, connection):
+ return 'tsvector'
diff --git a/src/MaxKB-1.5.1/apps/common/forms/__init__.py b/src/MaxKB-1.5.1/apps/common/forms/__init__.py
new file mode 100644
index 0000000..6095421
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/__init__.py
@@ -0,0 +1,24 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py
+ @date:2023/10/31 17:56
+ @desc:
+"""
+from .array_object_card import *
+from .base_field import *
+from .base_form import *
+from .multi_select import *
+from .object_card import *
+from .password_input import *
+from .radio_field import *
+from .single_select_field import *
+from .tab_card import *
+from .table_radio import *
+from .text_input_field import *
+from .radio_button_field import *
+from .table_checkbox import *
+from .radio_card_field import *
+from .label import *
+from .slider_field import *
diff --git a/src/MaxKB-1.5.1/apps/common/forms/array_object_card.py b/src/MaxKB-1.5.1/apps/common/forms/array_object_card.py
new file mode 100644
index 0000000..2dc71aa
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/array_object_card.py
@@ -0,0 +1,33 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: array_object_card.py
+ @date:2023/10/31 18:03
+ @desc:
+"""
+from typing import Dict
+
+from common.forms.base_field import BaseExecField, TriggerType
+
+
+class ArrayCard(BaseExecField):
+ """
+ 收集List[Object]
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("ArrayObjectCard", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
diff --git a/src/MaxKB-1.5.1/apps/common/forms/base_field.py b/src/MaxKB-1.5.1/apps/common/forms/base_field.py
new file mode 100644
index 0000000..dedd78d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/base_field.py
@@ -0,0 +1,156 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: base_field.py
+ @date:2023/10/31 18:07
+ @desc:
+"""
+from enum import Enum
+from typing import List, Dict
+
+from common.exception.app_exception import AppApiException
+from common.forms.label.base_label import BaseLabel
+
+
+class TriggerType(Enum):
+ # 执行函数获取 OptionList数据
+ OPTION_LIST = 'OPTION_LIST'
+ # 执行函数获取子表单
+ CHILD_FORMS = 'CHILD_FORMS'
+
+
+class BaseField:
+ def __init__(self,
+ input_type: str,
+ label: str or BaseLabel,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ """
+
+ :param input_type: 字段
+ :param label: 提示
+ :param default_value: 默认值
+ :param relation_show_field_dict: {field:field_value_list} 表示在 field有值 ,并且值在field_value_list中才显示
+ :param relation_trigger_field_dict: {field:field_value_list} 表示在 field有值 ,并且值在field_value_list中才 执行函数获取 数据
+ :param trigger_type: 执行器类型 OPTION_LIST请求Option_list数据 CHILD_FORMS请求子表单
+ :param attrs: 前端attr数据
+ :param props_info: 其他额外信息
+ """
+ if props_info is None:
+ props_info = {}
+ if attrs is None:
+ attrs = {}
+ self.label = label
+ self.attrs = attrs
+ self.props_info = props_info
+ self.default_value = default_value
+ self.input_type = input_type
+ self.relation_show_field_dict = {} if relation_show_field_dict is None else relation_show_field_dict
+ self.relation_trigger_field_dict = [] if relation_trigger_field_dict is None else relation_trigger_field_dict
+ self.required = required
+ self.trigger_type = trigger_type
+
+ def is_valid(self, value):
+ field_label = self.label.label if hasattr(self.label, 'to_dict') else self.label
+ if self.required and value is None:
+ raise AppApiException(500,
+ f"{field_label} 为必填参数")
+
+ def to_dict(self, **kwargs):
+ return {
+ 'input_type': self.input_type,
+ 'label': self.label.to_dict(**kwargs) if hasattr(self.label, 'to_dict') else self.label,
+ 'required': self.required,
+ 'default_value': self.default_value,
+ 'relation_show_field_dict': self.relation_show_field_dict,
+ 'relation_trigger_field_dict': self.relation_trigger_field_dict,
+ 'trigger_type': self.trigger_type.value,
+ 'attrs': self.attrs,
+ 'props_info': self.props_info,
+ **kwargs
+ }
+
+
+class BaseDefaultOptionField(BaseField):
+ def __init__(self, input_type: str,
+ label: str,
+ text_field: str,
+ value_field: str,
+ option_list: List[dict],
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict[str, object] = None,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ """
+
+ :param input_type: 字段
+ :param label: label
+ :param text_field: 文本字段
+ :param value_field: 值字段
+ :param option_list: 可选列表
+ :param required: 是否必填
+ :param default_value: 默认值
+ :param relation_show_field_dict: {field:field_value_list} 表示在 field有值 ,并且值在field_value_list中才显示
+ :param attrs: 前端attr数据
+ :param props_info: 其他额外信息
+ """
+ super().__init__(input_type, label, required, default_value, relation_show_field_dict,
+ {}, TriggerType.OPTION_LIST, attrs, props_info)
+ self.text_field = text_field
+ self.value_field = value_field
+ self.option_list = option_list
+
+ def to_dict(self, **kwargs):
+ return {**super().to_dict(**kwargs), 'text_field': self.text_field, 'value_field': self.value_field,
+ 'option_list': self.option_list}
+
+
+class BaseExecField(BaseField):
+ def __init__(self,
+ input_type: str,
+ label: str,
+ text_field: str,
+ value_field: str,
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ """
+
+ :param input_type: 字段
+ :param label: 提示
+ :param text_field: 文本字段
+ :param value_field: 值字段
+ :param provider: 指定供应商
+ :param method: 执行供应商函数 method
+ :param required: 是否必填
+ :param default_value: 默认值
+ :param relation_show_field_dict: {field:field_value_list} 表示在 field有值 ,并且值在field_value_list中才显示
+ :param relation_trigger_field_dict: {field:field_value_list} 表示在 field有值 ,并且值在field_value_list中才 执行函数获取 数据
+ :param trigger_type: 执行器类型 OPTION_LIST请求Option_list数据 CHILD_FORMS请求子表单
+ :param attrs: 前端attr数据
+ :param props_info: 其他额外信息
+ """
+ super().__init__(input_type, label, required, default_value, relation_show_field_dict,
+ relation_trigger_field_dict,
+ trigger_type, attrs, props_info)
+ self.text_field = text_field
+ self.value_field = value_field
+ self.provider = provider
+ self.method = method
+
+ def to_dict(self, **kwargs):
+ return {**super().to_dict(**kwargs), 'text_field': self.text_field, 'value_field': self.value_field,
+ 'provider': self.provider, 'method': self.method}
diff --git a/src/MaxKB-1.5.1/apps/common/forms/base_form.py b/src/MaxKB-1.5.1/apps/common/forms/base_form.py
new file mode 100644
index 0000000..5ef92c5
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/base_form.py
@@ -0,0 +1,30 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: base_form.py
+ @date:2023/11/1 16:04
+ @desc:
+"""
+from typing import Dict
+
+from common.forms import BaseField
+
+
+class BaseForm:
+ def to_form_list(self, **kwargs):
+ return [{**self.__getattribute__(key).to_dict(**kwargs), 'field': key} for key in
+ list(filter(lambda key: isinstance(self.__getattribute__(key), BaseField),
+ [attr for attr in vars(self.__class__) if not attr.startswith("__")]))]
+
+ def valid_form(self, form_data):
+ field_keys = list(filter(lambda key: isinstance(self.__getattribute__(key), BaseField),
+ [attr for attr in vars(self.__class__) if not attr.startswith("__")]))
+ for field_key in field_keys:
+ self.__getattribute__(field_key).is_valid(form_data.get(field_key))
+
+ def get_default_form_data(self):
+ return {key: self.__getattribute__(key).default_value for key in
+ [attr for attr in vars(self.__class__) if not attr.startswith("__")] if
+ isinstance(self.__getattribute__(key), BaseField) and self.__getattribute__(
+ key).default_value is not None}
diff --git a/src/MaxKB-1.5.1/apps/common/forms/label/__init__.py b/src/MaxKB-1.5.1/apps/common/forms/label/__init__.py
new file mode 100644
index 0000000..81c1b32
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/label/__init__.py
@@ -0,0 +1,10 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: __init__.py.py
+ @date:2024/8/22 17:19
+ @desc:
+"""
+from .base_label import *
+from .tooltip_label import *
diff --git a/src/MaxKB-1.5.1/apps/common/forms/label/base_label.py b/src/MaxKB-1.5.1/apps/common/forms/label/base_label.py
new file mode 100644
index 0000000..59e4d37
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/label/base_label.py
@@ -0,0 +1,28 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: base_label.py
+ @date:2024/8/22 17:11
+ @desc:
+"""
+
+
+class BaseLabel:
+ def __init__(self,
+ input_type: str,
+ label: str,
+ attrs=None,
+ props_info=None):
+ self.input_type = input_type
+ self.label = label
+ self.attrs = attrs
+ self.props_info = props_info
+
+ def to_dict(self, **kwargs):
+ return {
+ 'input_type': self.input_type,
+ 'label': self.label,
+ 'attrs': {} if self.attrs is None else self.attrs,
+ 'props_info': {} if self.props_info is None else self.props_info,
+ }
diff --git a/src/MaxKB-1.5.1/apps/common/forms/label/tooltip_label.py b/src/MaxKB-1.5.1/apps/common/forms/label/tooltip_label.py
new file mode 100644
index 0000000..885345d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/label/tooltip_label.py
@@ -0,0 +1,14 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: tooltip_label.py
+ @date:2024/8/22 17:19
+ @desc:
+"""
+from common.forms.label.base_label import BaseLabel
+
+
+class TooltipLabel(BaseLabel):
+ def __init__(self, label, tooltip):
+ super().__init__('TooltipLabel', label, attrs={'tooltip': tooltip}, props_info={})
diff --git a/src/MaxKB-1.5.1/apps/common/forms/multi_select.py b/src/MaxKB-1.5.1/apps/common/forms/multi_select.py
new file mode 100644
index 0000000..791c8e9
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/multi_select.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: multi_select.py
+ @date:2023/10/31 18:00
+ @desc:
+"""
+from typing import List, Dict
+
+from common.forms.base_field import BaseExecField, TriggerType
+
+
+class MultiSelect(BaseExecField):
+ """
+ 下拉单选
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ option_list: List[str:object],
+ provider: str = None,
+ method: str = None,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("MultiSelect", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
+ self.option_list = option_list
+
+ def to_dict(self):
+ return {**super().to_dict(), 'option_list': self.option_list}
diff --git a/src/MaxKB-1.5.1/apps/common/forms/object_card.py b/src/MaxKB-1.5.1/apps/common/forms/object_card.py
new file mode 100644
index 0000000..ddb192e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/object_card.py
@@ -0,0 +1,33 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: object_card.py
+ @date:2023/10/31 18:02
+ @desc:
+"""
+from typing import Dict
+
+from common.forms.base_field import BaseExecField, TriggerType
+
+
+class ObjectCard(BaseExecField):
+ """
+ 收集对象子表卡片
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("ObjectCard", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
diff --git a/src/MaxKB-1.5.1/apps/common/forms/password_input.py b/src/MaxKB-1.5.1/apps/common/forms/password_input.py
new file mode 100644
index 0000000..e7c7923
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/password_input.py
@@ -0,0 +1,26 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: password_input.py
+ @date:2023/11/1 14:48
+ @desc:
+"""
+from typing import Dict
+
+from common.forms import BaseField, TriggerType
+
+
+class PasswordInputField(BaseField):
+ """
+ 文本输入框
+ """
+
+ def __init__(self, label: str,
+ required: bool = False,
+ default_value=None,
+ relation_show_field_dict: Dict = None,
+ attrs=None, props_info=None):
+ super().__init__('PasswordInput', label, required, default_value, relation_show_field_dict,
+ {},
+ TriggerType.OPTION_LIST, attrs, props_info)
diff --git a/src/MaxKB-1.5.1/apps/common/forms/radio_button_field.py b/src/MaxKB-1.5.1/apps/common/forms/radio_button_field.py
new file mode 100644
index 0000000..aa69523
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/radio_button_field.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: radio_field.py
+ @date:2023/10/31 17:59
+ @desc:
+"""
+from typing import List, Dict
+
+from common.forms.base_field import BaseExecField, TriggerType
+
+
+class Radio(BaseExecField):
+ """
+ 下拉单选
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ option_list: List[str:object],
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("RadioButton", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
+ self.option_list = option_list
+
+ def to_dict(self):
+ return {**super().to_dict(), 'option_list': self.option_list}
diff --git a/src/MaxKB-1.5.1/apps/common/forms/radio_card_field.py b/src/MaxKB-1.5.1/apps/common/forms/radio_card_field.py
new file mode 100644
index 0000000..b3579b8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/radio_card_field.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: radio_field.py
+ @date:2023/10/31 17:59
+ @desc:
+"""
+from typing import List, Dict
+
+from common.forms.base_field import BaseExecField, TriggerType
+
+
+class Radio(BaseExecField):
+ """
+ 下拉单选
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ option_list: List[str:object],
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("RadioCard", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
+ self.option_list = option_list
+
+ def to_dict(self):
+ return {**super().to_dict(), 'option_list': self.option_list}
diff --git a/src/MaxKB-1.5.1/apps/common/forms/radio_field.py b/src/MaxKB-1.5.1/apps/common/forms/radio_field.py
new file mode 100644
index 0000000..94a016d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/radio_field.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: radio_field.py
+ @date:2023/10/31 17:59
+ @desc:
+"""
+from typing import List, Dict
+
+from common.forms.base_field import BaseExecField, TriggerType
+
+
+class Radio(BaseExecField):
+ """
+ 下拉单选
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ option_list: List[str:object],
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("Radio", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
+ self.option_list = option_list
+
+ def to_dict(self):
+ return {**super().to_dict(), 'option_list': self.option_list}
diff --git a/src/MaxKB-1.5.1/apps/common/forms/single_select_field.py b/src/MaxKB-1.5.1/apps/common/forms/single_select_field.py
new file mode 100644
index 0000000..cf3d504
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/single_select_field.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: single_select_field.py
+ @date:2023/10/31 18:00
+ @desc:
+"""
+from typing import List, Dict
+
+from common.forms.base_field import TriggerType, BaseExecField
+
+
+class SingleSelect(BaseExecField):
+ """
+ 下拉单选
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ option_list: List[str:object],
+ provider: str = None,
+ method: str = None,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("SingleSelect", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
+ self.option_list = option_list
+
+ def to_dict(self):
+ return {**super().to_dict(), 'option_list': self.option_list}
diff --git a/src/MaxKB-1.5.1/apps/common/forms/slider_field.py b/src/MaxKB-1.5.1/apps/common/forms/slider_field.py
new file mode 100644
index 0000000..6bf3625
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/slider_field.py
@@ -0,0 +1,58 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: slider_field.py
+ @date:2024/8/22 17:06
+ @desc:
+"""
+from typing import Dict
+
+from common.exception.app_exception import AppApiException
+from common.forms import BaseField, TriggerType, BaseLabel
+
+
+class SliderField(BaseField):
+ """
+ 滑块输入框
+ """
+
+ def __init__(self, label: str or BaseLabel,
+ _min,
+ _max,
+ _step,
+ precision,
+ required: bool = False,
+ default_value=None,
+ relation_show_field_dict: Dict = None,
+ attrs=None, props_info=None):
+ """
+ @param label: 提示
+ @param _min: 最小值
+ @param _max: 最大值
+ @param _step: 步长
+ @param precision: 保留多少小数
+ @param required: 是否必填
+ @param default_value: 默认值
+ @param relation_show_field_dict:
+ @param attrs:
+ @param props_info:
+ """
+ _attrs = {'min': _min, 'max': _max, 'step': _step,
+ 'precision': precision, 'show-input-controls': False, 'show-input': True}
+ if attrs is not None:
+ _attrs.update(attrs)
+ super().__init__('Slider', label, required, default_value, relation_show_field_dict,
+ {},
+ TriggerType.OPTION_LIST, _attrs, props_info)
+
+ def is_valid(self, value):
+ super().is_valid(value)
+ field_label = self.label.label if hasattr(self.label, 'to_dict') else self.label
+ if value is not None:
+ if value < self.attrs.get('min'):
+ raise AppApiException(500,
+ f"{field_label} 不能小于{self.attrs.get('min')}")
+ if value > self.attrs.get('max'):
+ raise AppApiException(500,
+ f"{field_label} 不能大于{self.attrs.get('max')}")
diff --git a/src/MaxKB-1.5.1/apps/common/forms/tab_card.py b/src/MaxKB-1.5.1/apps/common/forms/tab_card.py
new file mode 100644
index 0000000..7907714
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/tab_card.py
@@ -0,0 +1,33 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: tab_card.py
+ @date:2023/10/31 18:03
+ @desc:
+"""
+from typing import Dict
+
+from common.forms.base_field import BaseExecField, TriggerType
+
+
+class TabCard(BaseExecField):
+ """
+ 收集 Tab类型数据 tab1:{},tab2:{}
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("TabCard", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
diff --git a/src/MaxKB-1.5.1/apps/common/forms/table_checkbox.py b/src/MaxKB-1.5.1/apps/common/forms/table_checkbox.py
new file mode 100644
index 0000000..e01f14d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/table_checkbox.py
@@ -0,0 +1,33 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: table_radio.py
+ @date:2023/10/31 18:01
+ @desc:
+"""
+from typing import Dict
+
+from common.forms.base_field import TriggerType, BaseExecField
+
+
+class TableRadio(BaseExecField):
+ """
+ table 单选
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("TableCheckbox", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
diff --git a/src/MaxKB-1.5.1/apps/common/forms/table_radio.py b/src/MaxKB-1.5.1/apps/common/forms/table_radio.py
new file mode 100644
index 0000000..3b4c2bf
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/table_radio.py
@@ -0,0 +1,33 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: table_radio.py
+ @date:2023/10/31 18:01
+ @desc:
+"""
+from typing import Dict
+
+from common.forms.base_field import TriggerType, BaseExecField
+
+
+class TableRadio(BaseExecField):
+ """
+ table 单选
+ """
+
+ def __init__(self,
+ label: str,
+ text_field: str,
+ value_field: str,
+ provider: str,
+ method: str,
+ required: bool = False,
+ default_value: object = None,
+ relation_show_field_dict: Dict = None,
+ relation_trigger_field_dict: Dict = None,
+ trigger_type: TriggerType = TriggerType.OPTION_LIST,
+ attrs: Dict[str, object] = None,
+ props_info: Dict[str, object] = None):
+ super().__init__("TableRadio", label, text_field, value_field, provider, method, required, default_value,
+ relation_show_field_dict, relation_trigger_field_dict, trigger_type, attrs, props_info)
diff --git a/src/MaxKB-1.5.1/apps/common/forms/text_input_field.py b/src/MaxKB-1.5.1/apps/common/forms/text_input_field.py
new file mode 100644
index 0000000..28a821e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/forms/text_input_field.py
@@ -0,0 +1,27 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: text_input_field.py
+ @date:2023/10/31 17:58
+ @desc:
+"""
+from typing import Dict
+
+from common.forms.base_field import BaseField, TriggerType
+
+
+class TextInputField(BaseField):
+ """
+ 文本输入框
+ """
+
+ def __init__(self, label: str,
+ required: bool = False,
+ default_value=None,
+ relation_show_field_dict: Dict = None,
+
+ attrs=None, props_info=None):
+ super().__init__('TextInput', label, required, default_value, relation_show_field_dict,
+ {},
+ TriggerType.OPTION_LIST, attrs, props_info)
diff --git a/src/MaxKB-1.5.1/apps/common/handle/__init__.py b/src/MaxKB-1.5.1/apps/common/handle/__init__.py
new file mode 100644
index 0000000..ad09602
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/9/6 10:09
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/common/handle/base_parse_qa_handle.py b/src/MaxKB-1.5.1/apps/common/handle/base_parse_qa_handle.py
new file mode 100644
index 0000000..e65807c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/base_parse_qa_handle.py
@@ -0,0 +1,52 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: base_parse_qa_handle.py
+ @date:2024/5/21 14:56
+ @desc:
+"""
+from abc import ABC, abstractmethod
+
+
+def get_row_value(row, title_row_index_dict, field):
+ index = title_row_index_dict.get(field)
+ if index is None:
+ return None
+ if (len(row) - 1) >= index:
+ return row[index]
+ return None
+
+
+def get_title_row_index_dict(title_row_list):
+ title_row_index_dict = {}
+ if len(title_row_list) == 1:
+ title_row_index_dict['content'] = 0
+ elif len(title_row_list) == 1:
+ title_row_index_dict['title'] = 0
+ title_row_index_dict['content'] = 1
+ else:
+ title_row_index_dict['title'] = 0
+ title_row_index_dict['content'] = 1
+ title_row_index_dict['problem_list'] = 2
+ for index in range(len(title_row_list)):
+ title_row = title_row_list[index]
+ if title_row is None:
+ title_row = ''
+ if title_row.startswith('分段标题'):
+ title_row_index_dict['title'] = index
+ if title_row.startswith('分段内容'):
+ title_row_index_dict['content'] = index
+ if title_row.startswith('问题'):
+ title_row_index_dict['problem_list'] = index
+ return title_row_index_dict
+
+
+class BaseParseQAHandle(ABC):
+ @abstractmethod
+ def support(self, file, get_buffer):
+ pass
+
+ @abstractmethod
+ def handle(self, file, get_buffer):
+ pass
diff --git a/src/MaxKB-1.5.1/apps/common/handle/base_split_handle.py b/src/MaxKB-1.5.1/apps/common/handle/base_split_handle.py
new file mode 100644
index 0000000..f9b573f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/base_split_handle.py
@@ -0,0 +1,20 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: base_split_handle.py
+ @date:2024/3/27 18:13
+ @desc:
+"""
+from abc import ABC, abstractmethod
+from typing import List
+
+
+class BaseSplitHandle(ABC):
+ @abstractmethod
+ def support(self, file, get_buffer):
+ pass
+
+ @abstractmethod
+ def handle(self, file, pattern_list: List, with_filter: bool, limit: int, get_buffer, save_image):
+ pass
diff --git a/src/MaxKB-1.5.1/apps/common/handle/handle_exception.py b/src/MaxKB-1.5.1/apps/common/handle/handle_exception.py
new file mode 100644
index 0000000..bff0c4c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/handle_exception.py
@@ -0,0 +1,91 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: handle_exception.py
+ @date:2023/9/5 19:29
+ @desc:
+"""
+import logging
+import traceback
+
+from rest_framework.exceptions import ValidationError, ErrorDetail, APIException
+from rest_framework.views import exception_handler
+
+from common.exception.app_exception import AppApiException
+from common.response import result
+
+
+def to_result(key, args, parent_key=None):
+ """
+ 将校验异常 args转换为统一数据
+ :param key: 校验key
+ :param args: 校验异常参数
+ :param parent_key 父key
+ :return: 接口响应对象
+ """
+ error_detail = list(filter(
+ lambda d: True if isinstance(d, ErrorDetail) else True if isinstance(d, dict) and len(
+ d.keys()) > 0 else False,
+ (args[0] if len(args) > 0 else {key: [ErrorDetail('未知异常', code='unknown')]}).get(key)))[0]
+
+ if isinstance(error_detail, dict):
+ return list(map(lambda k: to_result(k, args=[error_detail],
+ parent_key=key if parent_key is None else parent_key + '.' + key),
+ error_detail.keys() if len(error_detail) > 0 else []))[0]
+
+ return result.Result(500 if isinstance(error_detail.code, str) else error_detail.code,
+ message=f"【{key if parent_key is None else parent_key + '.' + key}】为必填参数" if str(
+ error_detail) == "This field is required." else error_detail)
+
+
+def validation_error_to_result(exc: ValidationError):
+ """
+ 校验异常转响应对象
+ :param exc: 校验异常
+ :return: 接口响应对象
+ """
+ try:
+ v = find_err_detail(exc.detail)
+ if v is None:
+ return result.error(str(exc.detail))
+ return result.error(str(v))
+ except Exception as e:
+ return result.error(str(exc.detail))
+
+
+def find_err_detail(exc_detail):
+ if isinstance(exc_detail, ErrorDetail):
+ return exc_detail
+ if isinstance(exc_detail, dict):
+ keys = exc_detail.keys()
+ for key in keys:
+ _value = exc_detail[key]
+ if isinstance(_value, list):
+ return find_err_detail(_value)
+ if isinstance(_value, ErrorDetail):
+ return _value
+ if isinstance(_value, dict) and len(_value.keys()) > 0:
+ return find_err_detail(_value)
+ if isinstance(exc_detail, list):
+ for v in exc_detail:
+ r = find_err_detail(v)
+ if r is not None:
+ return r
+
+
+def handle_exception(exc, context):
+ exception_class = exc.__class__
+ # 先调用REST framework默认的异常处理方法获得标准错误响应对象
+ response = exception_handler(exc, context)
+ # 在此处补充自定义的异常处理
+ if issubclass(exception_class, ValidationError):
+ return validation_error_to_result(exc)
+ if issubclass(exception_class, AppApiException):
+ return result.Result(exc.code, exc.message, response_status=exc.status_code)
+ if issubclass(exception_class, APIException):
+ return result.error(exc.detail)
+ if response is None:
+ logging.getLogger("max_kb_error").error(f'{str(exc)}:{traceback.format_exc()}')
+ return result.error(str(exc))
+ return response
diff --git a/src/MaxKB-1.5.1/apps/common/handle/impl/doc_split_handle.py b/src/MaxKB-1.5.1/apps/common/handle/impl/doc_split_handle.py
new file mode 100644
index 0000000..8cd08d7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/impl/doc_split_handle.py
@@ -0,0 +1,155 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: text_split_handle.py
+ @date:2024/3/27 18:19
+ @desc:
+"""
+import io
+import re
+import traceback
+import uuid
+from typing import List
+
+from docx import Document, ImagePart
+from docx.table import Table
+from docx.text.paragraph import Paragraph
+
+from common.handle.base_split_handle import BaseSplitHandle
+from common.util.split_model import SplitModel
+from dataset.models import Image
+
+default_pattern_list = [re.compile('(?<=^)# .*|(?<=\\n)# .*'),
+ re.compile('(?<=\\n)(? 0:
+ return "".join(
+ [item for item in [image_to_mode(image, doc, images_list, get_image_id) for image in images] if
+ item is not None])
+ elif paragraph_element.text is not None:
+ return paragraph_element.text
+ return ""
+ except Exception as e:
+ print(e)
+ return ""
+
+
+def get_paragraph_txt(paragraph: Paragraph, doc: Document, images_list, get_image_id):
+ try:
+ return "".join([get_paragraph_element_txt(e, doc, images_list, get_image_id) for e in paragraph._element])
+ except Exception as e:
+ return ""
+
+
+def get_cell_text(cell, doc: Document, images_list, get_image_id):
+ try:
+ return "".join(
+ [get_paragraph_txt(paragraph, doc, images_list, get_image_id) for paragraph in cell.paragraphs]).replace(
+ "\n", '')
+ except Exception as e:
+ return ""
+
+
+def get_image_id_func():
+ image_map = {}
+
+ def get_image_id(image_id):
+ _v = image_map.get(image_id)
+ if _v is None:
+ image_map[image_id] = uuid.uuid1()
+ return image_map.get(image_id)
+ return _v
+
+ return get_image_id
+
+
+class DocSplitHandle(BaseSplitHandle):
+ @staticmethod
+ def paragraph_to_md(paragraph: Paragraph, doc: Document, images_list, get_image_id):
+ try:
+ psn = paragraph.style.name
+ if psn.startswith('Heading'):
+ return "".join(["#" for i in range(int(psn.replace("Heading ", '')))]) + " " + paragraph.text
+ except Exception as e:
+ return paragraph.text
+ return get_paragraph_txt(paragraph, doc, images_list, get_image_id)
+
+ @staticmethod
+ def table_to_md(table, doc: Document, images_list, get_image_id):
+ rows = table.rows
+
+ # 创建 Markdown 格式的表格
+ md_table = '| ' + ' | '.join(
+ [get_cell_text(cell, doc, images_list, get_image_id) for cell in rows[0].cells]) + ' |\n'
+ md_table += '| ' + ' | '.join(['---' for i in range(len(rows[0].cells))]) + ' |\n'
+ for row in rows[1:]:
+ md_table += '| ' + ' | '.join(
+ [get_cell_text(cell, doc, images_list, get_image_id) for cell in row.cells]) + ' |\n'
+ return md_table
+
+ def to_md(self, doc, images_list, get_image_id):
+ elements = []
+ for element in doc.element.body:
+ if element.tag.endswith('tbl'):
+ # 处理表格
+ table = Table(element, doc)
+ elements.append(table)
+ elif element.tag.endswith('p'):
+ # 处理段落
+ paragraph = Paragraph(element, doc)
+ elements.append(paragraph)
+ return "\n".join(
+ [self.paragraph_to_md(element, doc, images_list, get_image_id) if isinstance(element,
+ Paragraph) else self.table_to_md(
+ element,
+ doc,
+ images_list, get_image_id)
+ for element
+ in elements])
+
+ def handle(self, file, pattern_list: List, with_filter: bool, limit: int, get_buffer, save_image):
+ try:
+ image_list = []
+ buffer = get_buffer(file)
+ doc = Document(io.BytesIO(buffer))
+ content = self.to_md(doc, image_list, get_image_id_func())
+ if len(image_list) > 0:
+ save_image(image_list)
+ if pattern_list is not None and len(pattern_list) > 0:
+ split_model = SplitModel(pattern_list, with_filter, limit)
+ else:
+ split_model = SplitModel(default_pattern_list, with_filter=with_filter, limit=limit)
+ except BaseException as e:
+ traceback.print_exception(e)
+ return {'name': file.name,
+ 'content': []}
+ return {'name': file.name,
+ 'content': split_model.parse(content)
+ }
+
+ def support(self, file, get_buffer):
+ file_name: str = file.name.lower()
+ if file_name.endswith(".docx") or file_name.endswith(".doc") or file_name.endswith(
+ ".DOC") or file_name.endswith(".DOCX"):
+ return True
+ return False
diff --git a/src/MaxKB-1.5.1/apps/common/handle/impl/html_split_handle.py b/src/MaxKB-1.5.1/apps/common/handle/impl/html_split_handle.py
new file mode 100644
index 0000000..878d9ed
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/impl/html_split_handle.py
@@ -0,0 +1,61 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: html_split_handle.py
+ @date:2024/5/23 10:58
+ @desc:
+"""
+import re
+from typing import List
+
+from bs4 import BeautifulSoup
+from charset_normalizer import detect
+from html2text import html2text
+
+from common.handle.base_split_handle import BaseSplitHandle
+from common.util.split_model import SplitModel
+
+default_pattern_list = [re.compile('(?<=^)# .*|(?<=\\n)# .*'),
+ re.compile('(?<=\\n)(? 0:
+ charset = charset_list[0]
+ return charset
+ return detect(buffer)['encoding']
+
+
+class HTMLSplitHandle(BaseSplitHandle):
+ def support(self, file, get_buffer):
+ file_name: str = file.name.lower()
+ if file_name.endswith(".html") or file_name.endswith(".HTML"):
+ return True
+ return False
+
+ def handle(self, file, pattern_list: List, with_filter: bool, limit: int, get_buffer, save_image):
+ buffer = get_buffer(file)
+
+ if pattern_list is not None and len(pattern_list) > 0:
+ split_model = SplitModel(pattern_list, with_filter, limit)
+ else:
+ split_model = SplitModel(default_pattern_list, with_filter=with_filter, limit=limit)
+ try:
+ encoding = get_encoding(buffer)
+ content = buffer.decode(encoding)
+ content = html2text(content)
+ except BaseException as e:
+ return {'name': file.name,
+ 'content': []}
+ return {'name': file.name,
+ 'content': split_model.parse(content)
+ }
diff --git a/src/MaxKB-1.5.1/apps/common/handle/impl/pdf_split_handle.py b/src/MaxKB-1.5.1/apps/common/handle/impl/pdf_split_handle.py
new file mode 100644
index 0000000..b242292
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/impl/pdf_split_handle.py
@@ -0,0 +1,102 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: text_split_handle.py
+ @date:2024/3/27 18:19
+ @desc:
+"""
+import re
+from typing import List
+
+import fitz
+import os
+import tempfile
+import logging
+from langchain_community.document_loaders import PyPDFLoader
+
+from common.handle.base_split_handle import BaseSplitHandle
+from common.util.split_model import SplitModel
+
+import time
+
+default_pattern_list = [re.compile('(?<=^)# .*|(?<=\\n)# .*'),
+ re.compile('(?<=\\n)(? 0:
+ split_model = SplitModel(pattern_list, with_filter, limit)
+ else:
+ split_model = SplitModel(default_pattern_list, with_filter=with_filter, limit=limit)
+
+
+ except BaseException as e:
+ max_kb.error(f"File: {file.name}, error: {e}")
+ return {'name': file.name,
+ 'content': []}
+ finally:
+ pdf_document.close()
+ # 处理完后可以删除临时文件
+ os.remove(temp_file_path)
+
+ return {'name': file.name,
+ 'content': split_model.parse(content)
+ }
+
+ def support(self, file, get_buffer):
+ file_name: str = file.name.lower()
+ if file_name.endswith(".pdf") or file_name.endswith(".PDF"):
+ return True
+ return False
diff --git a/src/MaxKB-1.5.1/apps/common/handle/impl/qa/csv_parse_qa_handle.py b/src/MaxKB-1.5.1/apps/common/handle/impl/qa/csv_parse_qa_handle.py
new file mode 100644
index 0000000..30fe3d7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/impl/qa/csv_parse_qa_handle.py
@@ -0,0 +1,59 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: csv_parse_qa_handle.py
+ @date:2024/5/21 14:59
+ @desc:
+"""
+import csv
+import io
+
+from charset_normalizer import detect
+
+from common.handle.base_parse_qa_handle import BaseParseQAHandle, get_title_row_index_dict, get_row_value
+
+
+def read_csv_standard(file_path):
+ data = []
+ with open(file_path, 'r') as file:
+ reader = csv.reader(file)
+ for row in reader:
+ data.append(row)
+ return data
+
+
+class CsvParseQAHandle(BaseParseQAHandle):
+ def support(self, file, get_buffer):
+ file_name: str = file.name.lower()
+ if file_name.endswith(".csv"):
+ return True
+ return False
+
+ def handle(self, file, get_buffer):
+ buffer = get_buffer(file)
+ try:
+ reader = csv.reader(io.TextIOWrapper(io.BytesIO(buffer), encoding=detect(buffer)['encoding']))
+ try:
+ title_row_list = reader.__next__()
+ except Exception as e:
+ return [{'name': file.name, 'paragraphs': []}]
+ if len(title_row_list) == 0:
+ return [{'name': file.name, 'paragraphs': []}]
+ title_row_index_dict = get_title_row_index_dict(title_row_list)
+ paragraph_list = []
+ for row in reader:
+ content = get_row_value(row, title_row_index_dict, 'content')
+ if content is None:
+ continue
+ problem = get_row_value(row, title_row_index_dict, 'problem_list')
+ problem = str(problem) if problem is not None else ''
+ problem_list = [{'content': p[0:255]} for p in problem.split('\n') if len(p.strip()) > 0]
+ title = get_row_value(row, title_row_index_dict, 'title')
+ title = str(title) if title is not None else ''
+ paragraph_list.append({'title': title[0:255],
+ 'content': content[0:4096],
+ 'problem_list': problem_list})
+ return [{'name': file.name, 'paragraphs': paragraph_list}]
+ except Exception as e:
+ return [{'name': file.name, 'paragraphs': []}]
diff --git a/src/MaxKB-1.5.1/apps/common/handle/impl/qa/xls_parse_qa_handle.py b/src/MaxKB-1.5.1/apps/common/handle/impl/qa/xls_parse_qa_handle.py
new file mode 100644
index 0000000..1d1660e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/impl/qa/xls_parse_qa_handle.py
@@ -0,0 +1,61 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: xls_parse_qa_handle.py
+ @date:2024/5/21 14:59
+ @desc:
+"""
+
+import xlrd
+
+from common.handle.base_parse_qa_handle import BaseParseQAHandle, get_title_row_index_dict, get_row_value
+
+
+def handle_sheet(file_name, sheet):
+ rows = iter([sheet.row_values(i) for i in range(sheet.nrows)])
+ try:
+ title_row_list = next(rows)
+ except Exception as e:
+ return {'name': file_name, 'paragraphs': []}
+ if len(title_row_list) == 0:
+ return {'name': file_name, 'paragraphs': []}
+ title_row_index_dict = get_title_row_index_dict(title_row_list)
+ paragraph_list = []
+ for row in rows:
+ content = get_row_value(row, title_row_index_dict, 'content')
+ if content is None:
+ continue
+ problem = get_row_value(row, title_row_index_dict, 'problem_list')
+ problem = str(problem) if problem is not None else ''
+ problem_list = [{'content': p[0:255]} for p in problem.split('\n') if len(p.strip()) > 0]
+ title = get_row_value(row, title_row_index_dict, 'title')
+ title = str(title) if title is not None else ''
+ content = str(content)
+ paragraph_list.append({'title': title[0:255],
+ 'content': content[0:4096],
+ 'problem_list': problem_list})
+ return {'name': file_name, 'paragraphs': paragraph_list}
+
+
+class XlsParseQAHandle(BaseParseQAHandle):
+ def support(self, file, get_buffer):
+ file_name: str = file.name.lower()
+ buffer = get_buffer(file)
+ if file_name.endswith(".xls") and xlrd.inspect_format(content=buffer):
+ return True
+ return False
+
+ def handle(self, file, get_buffer):
+ buffer = get_buffer(file)
+ try:
+ workbook = xlrd.open_workbook(file_contents=buffer)
+ worksheets = workbook.sheets()
+ worksheets_size = len(worksheets)
+ return [row for row in
+ [handle_sheet(file.name,
+ sheet) if worksheets_size == 1 and sheet.name == 'Sheet1' else handle_sheet(
+ sheet.name, sheet) for sheet
+ in worksheets] if row is not None]
+ except Exception as e:
+ return [{'name': file.name, 'paragraphs': []}]
diff --git a/src/MaxKB-1.5.1/apps/common/handle/impl/qa/xlsx_parse_qa_handle.py b/src/MaxKB-1.5.1/apps/common/handle/impl/qa/xlsx_parse_qa_handle.py
new file mode 100644
index 0000000..a32b5f0
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/impl/qa/xlsx_parse_qa_handle.py
@@ -0,0 +1,62 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: xlsx_parse_qa_handle.py
+ @date:2024/5/21 14:59
+ @desc:
+"""
+import io
+
+import openpyxl
+
+from common.handle.base_parse_qa_handle import BaseParseQAHandle, get_title_row_index_dict, get_row_value
+
+
+def handle_sheet(file_name, sheet):
+ rows = sheet.rows
+ try:
+ title_row_list = next(rows)
+ title_row_list = [row.value for row in title_row_list]
+ except Exception as e:
+ return {'name': file_name, 'paragraphs': []}
+ if len(title_row_list) == 0:
+ return {'name': file_name, 'paragraphs': []}
+ title_row_index_dict = get_title_row_index_dict(title_row_list)
+ paragraph_list = []
+ for row in rows:
+ content = get_row_value(row, title_row_index_dict, 'content')
+ if content is None or content.value is None:
+ continue
+ problem = get_row_value(row, title_row_index_dict, 'problem_list')
+ problem = str(problem.value) if problem is not None and problem.value is not None else ''
+ problem_list = [{'content': p[0:255]} for p in problem.split('\n') if len(p.strip()) > 0]
+ title = get_row_value(row, title_row_index_dict, 'title')
+ title = str(title.value) if title is not None and title.value is not None else ''
+ content = str(content.value)
+ paragraph_list.append({'title': title[0:255],
+ 'content': content[0:4096],
+ 'problem_list': problem_list})
+ return {'name': file_name, 'paragraphs': paragraph_list}
+
+
+class XlsxParseQAHandle(BaseParseQAHandle):
+ def support(self, file, get_buffer):
+ file_name: str = file.name.lower()
+ if file_name.endswith(".xlsx"):
+ return True
+ return False
+
+ def handle(self, file, get_buffer):
+ buffer = get_buffer(file)
+ try:
+ workbook = openpyxl.load_workbook(io.BytesIO(buffer))
+ worksheets = workbook.worksheets
+ worksheets_size = len(worksheets)
+ return [row for row in
+ [handle_sheet(file.name,
+ sheet) if worksheets_size == 1 and sheet.title == 'Sheet1' else handle_sheet(
+ sheet.title, sheet) for sheet
+ in worksheets] if row is not None]
+ except Exception as e:
+ return [{'name': file.name, 'paragraphs': []}]
diff --git a/src/MaxKB-1.5.1/apps/common/handle/impl/text_split_handle.py b/src/MaxKB-1.5.1/apps/common/handle/impl/text_split_handle.py
new file mode 100644
index 0000000..467607f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/handle/impl/text_split_handle.py
@@ -0,0 +1,51 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: text_split_handle.py
+ @date:2024/3/27 18:19
+ @desc:
+"""
+import re
+from typing import List
+
+from charset_normalizer import detect
+
+from common.handle.base_split_handle import BaseSplitHandle
+from common.util.split_model import SplitModel
+
+default_pattern_list = [re.compile('(?<=^)# .*|(?<=\\n)# .*'),
+ re.compile('(?<=\\n)(? 0.5:
+ return True
+ return False
+
+ def handle(self, file, pattern_list: List, with_filter: bool, limit: int, get_buffer, save_image):
+ buffer = get_buffer(file)
+ if pattern_list is not None and len(pattern_list) > 0:
+ split_model = SplitModel(pattern_list, with_filter, limit)
+ else:
+ split_model = SplitModel(default_pattern_list, with_filter=with_filter, limit=limit)
+ try:
+ content = buffer.decode(detect(buffer)['encoding'])
+ except BaseException as e:
+ return {'name': file.name,
+ 'content': []}
+ return {'name': file.name,
+ 'content': split_model.parse(content)
+ }
diff --git a/src/MaxKB-1.5.1/apps/common/init/init_doc.py b/src/MaxKB-1.5.1/apps/common/init/init_doc.py
new file mode 100644
index 0000000..5a60e55
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/init/init_doc.py
@@ -0,0 +1,92 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: init_doc.py
+ @date:2024/5/24 14:11
+ @desc:
+"""
+import hashlib
+
+from django.urls import re_path, path, URLPattern
+from drf_yasg import openapi
+from drf_yasg.views import get_schema_view
+from rest_framework import permissions
+
+from common.auth import AnonymousAuthentication
+from smartdoc.const import CONFIG
+
+
+def init_app_doc(application_urlpatterns):
+ schema_view = get_schema_view(
+ openapi.Info(
+ title="Python API",
+ default_version='v1',
+ description="智能客服平台",
+ ),
+ public=True,
+ permission_classes=[permissions.AllowAny],
+ authentication_classes=[AnonymousAuthentication]
+ )
+ application_urlpatterns += [
+ re_path(r'^doc(?P\.json|\.yaml)$', schema_view.without_ui(cache_timeout=0),
+ name='schema-json'), # 导出
+ path('doc/', schema_view.with_ui('swagger', cache_timeout=0), name='schema-swagger-ui'),
+ path('redoc/', schema_view.with_ui('redoc', cache_timeout=0), name='schema-redoc'),
+ ]
+
+
+def init_chat_doc(application_urlpatterns, patterns):
+ chat_schema_view = get_schema_view(
+ openapi.Info(
+ title="Python API",
+ default_version='/chat',
+ description="智能客服平台",
+ ),
+ public=True,
+ permission_classes=[permissions.AllowAny],
+ authentication_classes=[AnonymousAuthentication],
+ patterns=[
+ URLPattern(pattern='api/' + str(url.pattern), callback=url.callback, default_args=url.default_args,
+ name=url.name)
+ for url in patterns if
+ url.name is not None and ['application/message', 'application/open',
+ 'application/profile'].__contains__(
+ url.name)]
+ )
+
+ application_urlpatterns += [
+ path('doc/chat/', chat_schema_view.with_ui('swagger', cache_timeout=0), name='schema-swagger-ui'),
+ path('redoc/chat/', chat_schema_view.with_ui('redoc', cache_timeout=0), name='schema-redoc'),
+ ]
+
+
+def encrypt(text):
+ md5 = hashlib.md5()
+ md5.update(text.encode())
+ result = md5.hexdigest()
+ return result
+
+
+def get_call(application_urlpatterns, patterns, params, func):
+ def run():
+ if params['valid']():
+ func(*params['get_params'](application_urlpatterns, patterns))
+
+ return run
+
+
+init_list = [(init_app_doc, {'valid': lambda: CONFIG.get('DOC_PASSWORD') is not None and encrypt(
+ CONFIG.get('DOC_PASSWORD')) == 'd4fc097197b4b90a122b92cbd5bbe867',
+ 'get_call': get_call,
+ 'get_params': lambda application_urlpatterns, patterns: (application_urlpatterns,)}),
+ (init_chat_doc, {'valid': lambda: CONFIG.get('DOC_PASSWORD') is not None and encrypt(
+ CONFIG.get('DOC_PASSWORD')) == 'd4fc097197b4b90a122b92cbd5bbe867' or True, 'get_call': get_call,
+ 'get_params': lambda application_urlpatterns, patterns: (
+ application_urlpatterns, patterns)})]
+
+
+def init_doc(application_urlpatterns, patterns):
+ for init, params in init_list:
+ if params['valid']():
+ get_call(application_urlpatterns, patterns, params, init)()
diff --git a/src/MaxKB-1.5.1/apps/common/job/__init__.py b/src/MaxKB-1.5.1/apps/common/job/__init__.py
new file mode 100644
index 0000000..895bf7f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/job/__init__.py
@@ -0,0 +1,13 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py
+ @date:2024/3/14 11:54
+ @desc:
+"""
+from .client_access_num_job import *
+
+
+def run():
+ client_access_num_job.run()
diff --git a/src/MaxKB-1.5.1/apps/common/job/client_access_num_job.py b/src/MaxKB-1.5.1/apps/common/job/client_access_num_job.py
new file mode 100644
index 0000000..9d91054
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/job/client_access_num_job.py
@@ -0,0 +1,39 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: client_access_num_job.py
+ @date:2024/3/14 11:56
+ @desc:
+"""
+import logging
+
+from apscheduler.schedulers.background import BackgroundScheduler
+from django.db.models import QuerySet
+from django_apscheduler.jobstores import DjangoJobStore
+
+from application.models.api_key_model import ApplicationPublicAccessClient
+from common.lock.impl.file_lock import FileLock
+
+scheduler = BackgroundScheduler()
+scheduler.add_jobstore(DjangoJobStore(), "default")
+lock = FileLock()
+
+
+def client_access_num_reset_job():
+ logging.getLogger("max_kb").info('开始重置access_num')
+ QuerySet(ApplicationPublicAccessClient).update(intraday_access_num=0)
+ logging.getLogger("max_kb").info('结束重置access_num')
+
+
+def run():
+ if lock.try_lock('client_access_num_reset_job', 30 * 30):
+ try:
+ scheduler.start()
+ access_num_reset = scheduler.get_job(job_id='access_num_reset')
+ if access_num_reset is not None:
+ access_num_reset.remove()
+ scheduler.add_job(client_access_num_reset_job, 'cron', hour='0', minute='0', second='0',
+ id='access_num_reset')
+ finally:
+ lock.un_lock('client_access_num_reset_job')
diff --git a/src/MaxKB-1.5.1/apps/common/lock/base_lock.py b/src/MaxKB-1.5.1/apps/common/lock/base_lock.py
new file mode 100644
index 0000000..2ca5b21
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/lock/base_lock.py
@@ -0,0 +1,20 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: base_lock.py
+ @date:2024/8/20 10:33
+ @desc:
+"""
+
+from abc import ABC, abstractmethod
+
+
+class BaseLock(ABC):
+ @abstractmethod
+ def try_lock(self, key, timeout):
+ pass
+
+ @abstractmethod
+ def un_lock(self, key):
+ pass
diff --git a/src/MaxKB-1.5.1/apps/common/lock/impl/file_lock.py b/src/MaxKB-1.5.1/apps/common/lock/impl/file_lock.py
new file mode 100644
index 0000000..f8ea639
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/lock/impl/file_lock.py
@@ -0,0 +1,77 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: file_lock.py
+ @date:2024/8/20 10:48
+ @desc:
+"""
+import errno
+import hashlib
+import os
+import time
+
+import six
+
+from common.lock.base_lock import BaseLock
+from smartdoc.const import PROJECT_DIR
+
+
+def key_to_lock_name(key):
+ """
+ Combine part of a key with its hash to prevent very long filenames
+ """
+ MAX_LENGTH = 50
+ key_hash = hashlib.md5(six.b(key)).hexdigest()
+ lock_name = key[:MAX_LENGTH - len(key_hash) - 1] + '_' + key_hash
+ return lock_name
+
+
+class FileLock(BaseLock):
+ """
+ File locking backend.
+ """
+
+ def __init__(self, settings=None):
+ if settings is None:
+ settings = {}
+ self.location = settings.get('location')
+ if self.location is None:
+ self.location = os.path.join(PROJECT_DIR, 'data', 'lock')
+ try:
+ os.makedirs(self.location)
+ except OSError as error:
+ # Directory exists?
+ if error.errno != errno.EEXIST:
+ # Re-raise unexpected OSError
+ raise
+
+ def _get_lock_path(self, key):
+ lock_name = key_to_lock_name(key)
+ return os.path.join(self.location, lock_name)
+
+ def try_lock(self, key, timeout):
+ lock_path = self._get_lock_path(key)
+ try:
+ # 创建锁文件,如果没创建成功则拿不到
+ fd = os.open(lock_path, os.O_CREAT | os.O_EXCL)
+ except OSError as error:
+ if error.errno == errno.EEXIST:
+ # File already exists, check its modification time
+ mtime = os.path.getmtime(lock_path)
+ ttl = mtime + timeout - time.time()
+ if ttl > 0:
+ return False
+ else:
+ # 如果超时时间已到,直接上锁成功继续执行
+ os.utime(lock_path, None)
+ return True
+ else:
+ return False
+ else:
+ os.close(fd)
+ return True
+
+ def un_lock(self, key):
+ lock_path = self._get_lock_path(key)
+ os.remove(lock_path)
diff --git a/src/MaxKB-1.5.1/apps/common/management/__init__.py b/src/MaxKB-1.5.1/apps/common/management/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/__init__.py b/src/MaxKB-1.5.1/apps/common/management/commands/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/celery.py b/src/MaxKB-1.5.1/apps/common/management/commands/celery.py
new file mode 100644
index 0000000..a26b435
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/celery.py
@@ -0,0 +1,46 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: celery.py
+ @date:2024/8/19 11:57
+ @desc:
+"""
+import os
+import subprocess
+
+from django.core.management.base import BaseCommand
+
+from smartdoc.const import BASE_DIR
+
+
+class Command(BaseCommand):
+ help = 'celery'
+
+ def add_arguments(self, parser):
+ parser.add_argument(
+ 'service', nargs='+', type=str, choices=("celery", "model"), help='Service',
+ )
+
+ def handle(self, *args, **options):
+ service = options.get('service')
+ os.environ.setdefault('CELERY_NAME', ','.join(service))
+ server_hostname = os.environ.get("SERVER_HOSTNAME")
+ if hasattr(os, 'getuid') and os.getuid() == 0:
+ os.environ.setdefault('C_FORCE_ROOT', '1')
+ if not server_hostname:
+ server_hostname = '%h'
+ cmd = [
+ 'celery',
+ '-A', 'ops',
+ 'worker',
+ '-P', 'threads',
+ '-l', 'info',
+ '-c', '10',
+ '-Q', ','.join(service),
+ '--heartbeat-interval', '10',
+ '-n', f'{",".join(service)}@{server_hostname}',
+ '--without-mingle',
+ ]
+ kwargs = {'cwd': BASE_DIR}
+ subprocess.run(cmd, **kwargs)
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/restart.py b/src/MaxKB-1.5.1/apps/common/management/commands/restart.py
new file mode 100644
index 0000000..57285f9
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/restart.py
@@ -0,0 +1,6 @@
+from .services.command import BaseActionCommand, Action
+
+
+class Command(BaseActionCommand):
+ help = 'Restart services'
+ action = Action.restart.value
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/__init__.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/command.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/command.py
new file mode 100644
index 0000000..c5b7192
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/command.py
@@ -0,0 +1,131 @@
+from django.core.management.base import BaseCommand
+from django.db.models import TextChoices
+
+from .hands import *
+from .utils import ServicesUtil
+import os
+
+
+class Services(TextChoices):
+ gunicorn = 'gunicorn', 'gunicorn'
+ celery_default = 'celery_default', 'celery_default'
+ local_model = 'local_model', 'local_model'
+ web = 'web', 'web'
+ celery = 'celery', 'celery'
+ celery_model = 'celery_model', 'celery_model'
+ task = 'task', 'task'
+ all = 'all', 'all'
+
+ @classmethod
+ def get_service_object_class(cls, name):
+ from . import services
+ services_map = {
+ cls.gunicorn.value: services.GunicornService,
+ cls.celery_default: services.CeleryDefaultService,
+ cls.local_model: services.GunicornLocalModelService
+ }
+ return services_map.get(name)
+
+ @classmethod
+ def web_services(cls):
+ return [cls.gunicorn, cls.local_model]
+
+ @classmethod
+ def celery_services(cls):
+ return [cls.celery_default, cls.celery_model]
+
+ @classmethod
+ def task_services(cls):
+ return cls.celery_services()
+
+ @classmethod
+ def all_services(cls):
+ return cls.web_services() + cls.task_services()
+
+ @classmethod
+ def export_services_values(cls):
+ return [cls.all.value, cls.web.value, cls.task.value] + [s.value for s in cls.all_services()]
+
+ @classmethod
+ def get_service_objects(cls, service_names, **kwargs):
+ services = set()
+ for name in service_names:
+ method_name = f'{name}_services'
+ if hasattr(cls, method_name):
+ _services = getattr(cls, method_name)()
+ elif hasattr(cls, name):
+ _services = [getattr(cls, name)]
+ else:
+ continue
+ services.update(set(_services))
+
+ service_objects = []
+ for s in services:
+ service_class = cls.get_service_object_class(s.value)
+ if not service_class:
+ continue
+ kwargs.update({
+ 'name': s.value
+ })
+ service_object = service_class(**kwargs)
+ service_objects.append(service_object)
+ return service_objects
+
+
+class Action(TextChoices):
+ start = 'start', 'start'
+ status = 'status', 'status'
+ stop = 'stop', 'stop'
+ restart = 'restart', 'restart'
+
+
+class BaseActionCommand(BaseCommand):
+ help = 'Service Base Command'
+
+ action = None
+ util = None
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ def add_arguments(self, parser):
+ parser.add_argument(
+ 'services', nargs='+', choices=Services.export_services_values(), help='Service',
+ )
+ parser.add_argument('-d', '--daemon', nargs="?", const=True)
+ parser.add_argument('-w', '--worker', type=int, nargs="?", default=3 if os.cpu_count() > 3 else os.cpu_count())
+ parser.add_argument('-f', '--force', nargs="?", const=True)
+
+ def initial_util(self, *args, **options):
+ service_names = options.get('services')
+ service_kwargs = {
+ 'worker_gunicorn': options.get('worker')
+ }
+ services = Services.get_service_objects(service_names=service_names, **service_kwargs)
+
+ kwargs = {
+ 'services': services,
+ 'run_daemon': options.get('daemon', False),
+ 'stop_daemon': self.action == Action.stop.value and Services.all.value in service_names,
+ 'force_stop': options.get('force') or False,
+ }
+ self.util = ServicesUtil(**kwargs)
+
+ def handle(self, *args, **options):
+ self.initial_util(*args, **options)
+ assert self.action in Action.values, f'The action {self.action} is not in the optional list'
+ _handle = getattr(self, f'_handle_{self.action}', lambda: None)
+ _handle()
+
+ def _handle_start(self):
+ self.util.start_and_watch()
+ os._exit(0)
+
+ def _handle_stop(self):
+ self.util.stop()
+
+ def _handle_restart(self):
+ self.util.restart()
+
+ def _handle_status(self):
+ self.util.show_status()
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/hands.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/hands.py
new file mode 100644
index 0000000..8244702
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/hands.py
@@ -0,0 +1,26 @@
+import logging
+import os
+import sys
+
+from smartdoc.const import CONFIG, PROJECT_DIR
+
+try:
+ from apps.smartdoc import const
+
+ __version__ = const.VERSION
+except ImportError as e:
+ print("Not found __version__: {}".format(e))
+ print("Python is: ")
+ logging.info(sys.executable)
+ __version__ = 'Unknown'
+ sys.exit(1)
+
+HTTP_HOST = '0.0.0.0'
+HTTP_PORT = CONFIG.HTTP_LISTEN_PORT or 8080
+DEBUG = CONFIG.DEBUG or False
+
+LOG_DIR = os.path.join(PROJECT_DIR, 'data', 'logs')
+APPS_DIR = os.path.join(PROJECT_DIR, 'apps')
+TMP_DIR = os.path.join(PROJECT_DIR, 'tmp')
+if not os.path.exists(TMP_DIR):
+ os.makedirs(TMP_DIR)
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/services/__init__.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/__init__.py
new file mode 100644
index 0000000..1027392
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/__init__.py
@@ -0,0 +1,3 @@
+from .celery_default import *
+from .gunicorn import *
+from .local_model import *
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/services/base.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/base.py
new file mode 100644
index 0000000..ddcb4fe
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/base.py
@@ -0,0 +1,207 @@
+import abc
+import time
+import shutil
+import psutil
+import datetime
+import threading
+import subprocess
+from ..hands import *
+
+
+class BaseService(object):
+
+ def __init__(self, **kwargs):
+ self.name = kwargs['name']
+ self._process = None
+ self.STOP_TIMEOUT = 10
+ self.max_retry = 0
+ self.retry = 3
+ self.LOG_KEEP_DAYS = 7
+ self.EXIT_EVENT = threading.Event()
+
+ @property
+ @abc.abstractmethod
+ def cmd(self):
+ return []
+
+ @property
+ @abc.abstractmethod
+ def cwd(self):
+ return ''
+
+ @property
+ def is_running(self):
+ if self.pid == 0:
+ return False
+ try:
+ os.kill(self.pid, 0)
+ except (OSError, ProcessLookupError):
+ return False
+ else:
+ return True
+
+ def show_status(self):
+ if self.is_running:
+ msg = f'{self.name} is running: {self.pid}.'
+ else:
+ msg = f'{self.name} is stopped.'
+ if DEBUG:
+ msg = '\033[31m{} is stopped.\033[0m\nYou can manual start it to find the error: \n' \
+ ' $ cd {}\n' \
+ ' $ {}'.format(self.name, self.cwd, ' '.join(self.cmd))
+
+ print(msg)
+
+ # -- log --
+ @property
+ def log_filename(self):
+ return f'{self.name}.log'
+
+ @property
+ def log_filepath(self):
+ return os.path.join(LOG_DIR, self.log_filename)
+
+ @property
+ def log_file(self):
+ return open(self.log_filepath, 'a')
+
+ @property
+ def log_dir(self):
+ return os.path.dirname(self.log_filepath)
+ # -- end log --
+
+ # -- pid --
+ @property
+ def pid_filepath(self):
+ return os.path.join(TMP_DIR, f'{self.name}.pid')
+
+ @property
+ def pid(self):
+ if not os.path.isfile(self.pid_filepath):
+ return 0
+ with open(self.pid_filepath) as f:
+ try:
+ pid = int(f.read().strip())
+ except ValueError:
+ pid = 0
+ return pid
+
+ def write_pid(self):
+ with open(self.pid_filepath, 'w') as f:
+ f.write(str(self.process.pid))
+
+ def remove_pid(self):
+ if os.path.isfile(self.pid_filepath):
+ os.unlink(self.pid_filepath)
+ # -- end pid --
+
+ # -- process --
+ @property
+ def process(self):
+ if not self._process:
+ try:
+ self._process = psutil.Process(self.pid)
+ except:
+ pass
+ return self._process
+
+ # -- end process --
+
+ # -- action --
+ def open_subprocess(self):
+ kwargs = {'cwd': self.cwd, 'stderr': self.log_file, 'stdout': self.log_file}
+ self._process = subprocess.Popen(self.cmd, **kwargs)
+
+ def start(self):
+ if self.is_running:
+ self.show_status()
+ return
+ self.remove_pid()
+ self.open_subprocess()
+ self.write_pid()
+ self.start_other()
+
+ def start_other(self):
+ pass
+
+ def stop(self, force=False):
+ if not self.is_running:
+ self.show_status()
+ # self.remove_pid()
+ return
+
+ print(f'Stop service: {self.name}', end='')
+ sig = 9 if force else 15
+ os.kill(self.pid, sig)
+
+ if self.process is None:
+ print("\033[31m No process found\033[0m")
+ return
+ try:
+ self.process.wait(1)
+ except:
+ pass
+
+ for i in range(self.STOP_TIMEOUT):
+ if i == self.STOP_TIMEOUT - 1:
+ print("\033[31m Error\033[0m")
+ if not self.is_running:
+ print("\033[32m Ok\033[0m")
+ self.remove_pid()
+ break
+ else:
+ continue
+
+ def watch(self):
+ self._check()
+ if not self.is_running:
+ self._restart()
+ self._rotate_log()
+
+ def _check(self):
+ now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
+ print(f"{now} Check service status: {self.name} -> ", end='')
+ if self.process:
+ try:
+ self.process.wait(1) # 不wait,子进程可能无法回收
+ except:
+ pass
+
+ if self.is_running:
+ print(f'running at {self.pid}')
+ else:
+ print(f'stopped at {self.pid}')
+
+ def _restart(self):
+ if self.retry > self.max_retry:
+ logging.info("Service start failed, exit: {}".format(self.name))
+ self.EXIT_EVENT.set()
+ return
+ self.retry += 1
+ logging.info(f'> Find {self.name} stopped, retry {self.retry}, {self.pid}')
+ self.start()
+
+ def _rotate_log(self):
+ now = datetime.datetime.now()
+ _time = now.strftime('%H:%M')
+ if _time != '23:59':
+ return
+
+ backup_date = now.strftime('%Y-%m-%d')
+ backup_log_dir = os.path.join(self.log_dir, backup_date)
+ if not os.path.exists(backup_log_dir):
+ os.mkdir(backup_log_dir)
+
+ backup_log_path = os.path.join(backup_log_dir, self.log_filename)
+ if os.path.isfile(self.log_filepath) and not os.path.isfile(backup_log_path):
+ logging.info(f'Rotate log file: {self.log_filepath} => {backup_log_path}')
+ shutil.copy(self.log_filepath, backup_log_path)
+ with open(self.log_filepath, 'w') as f:
+ pass
+
+ to_delete_date = now - datetime.timedelta(days=self.LOG_KEEP_DAYS)
+ to_delete_dir = os.path.join(LOG_DIR, to_delete_date.strftime('%Y-%m-%d'))
+ if os.path.exists(to_delete_dir):
+ logging.info(f'Remove old log: {to_delete_dir}')
+ shutil.rmtree(to_delete_dir, ignore_errors=True)
+ # -- end action --
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/services/celery_base.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/celery_base.py
new file mode 100644
index 0000000..0ae219b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/celery_base.py
@@ -0,0 +1,45 @@
+from django.conf import settings
+
+from .base import BaseService
+from ..hands import *
+
+
+class CeleryBaseService(BaseService):
+
+ def __init__(self, queue, num=10, **kwargs):
+ super().__init__(**kwargs)
+ self.queue = queue
+ self.num = num
+
+ @property
+ def cmd(self):
+ print('\n- Start Celery as Distributed Task Queue: {}'.format(self.queue.capitalize()))
+
+ os.environ.setdefault('LC_ALL', 'C.UTF-8')
+ os.environ.setdefault('PYTHONOPTIMIZE', '1')
+ os.environ.setdefault('ANSIBLE_FORCE_COLOR', 'True')
+ os.environ.setdefault('PYTHONPATH', settings.APPS_DIR)
+
+ if os.getuid() == 0:
+ os.environ.setdefault('C_FORCE_ROOT', '1')
+ server_hostname = os.environ.get("SERVER_HOSTNAME")
+ if not server_hostname:
+ server_hostname = '%h'
+
+ cmd = [
+ 'celery',
+ '-A', 'ops',
+ 'worker',
+ '-P', 'threads',
+ '-l', 'error',
+ '-c', str(self.num),
+ '-Q', self.queue,
+ '--heartbeat-interval', '10',
+ '-n', f'{self.queue}@{server_hostname}',
+ '--without-mingle',
+ ]
+ return cmd
+
+ @property
+ def cwd(self):
+ return APPS_DIR
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/services/celery_default.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/celery_default.py
new file mode 100644
index 0000000..5d3e6d7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/celery_default.py
@@ -0,0 +1,10 @@
+from .celery_base import CeleryBaseService
+
+__all__ = ['CeleryDefaultService']
+
+
+class CeleryDefaultService(CeleryBaseService):
+
+ def __init__(self, **kwargs):
+ kwargs['queue'] = 'celery'
+ super().__init__(**kwargs)
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/services/gunicorn.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/gunicorn.py
new file mode 100644
index 0000000..cc42c4f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/gunicorn.py
@@ -0,0 +1,36 @@
+from .base import BaseService
+from ..hands import *
+
+__all__ = ['GunicornService']
+
+
+class GunicornService(BaseService):
+
+ def __init__(self, **kwargs):
+ self.worker = kwargs['worker_gunicorn']
+ super().__init__(**kwargs)
+
+ @property
+ def cmd(self):
+ print("\n- Start Gunicorn WSGI HTTP Server")
+
+ log_format = '%(h)s %(t)s %(L)ss "%(r)s" %(s)s %(b)s '
+ bind = f'{HTTP_HOST}:{HTTP_PORT}'
+ cmd = [
+ 'gunicorn', 'smartdoc.wsgi:application',
+ '-b', bind,
+ '-k', 'gthread',
+ '--threads', '200',
+ '-w', str(self.worker),
+ '--max-requests', '10240',
+ '--max-requests-jitter', '2048',
+ '--access-logformat', log_format,
+ '--access-logfile', '-'
+ ]
+ if DEBUG:
+ cmd.append('--reload')
+ return cmd
+
+ @property
+ def cwd(self):
+ return APPS_DIR
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/services/local_model.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/local_model.py
new file mode 100644
index 0000000..4511f8f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/services/local_model.py
@@ -0,0 +1,44 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: local_model.py
+ @date:2024/8/21 13:28
+ @desc:
+"""
+from .base import BaseService
+from ..hands import *
+
+__all__ = ['GunicornLocalModelService']
+
+
+class GunicornLocalModelService(BaseService):
+
+ def __init__(self, **kwargs):
+ self.worker = kwargs['worker_gunicorn']
+ super().__init__(**kwargs)
+
+ @property
+ def cmd(self):
+ print("\n- Start Gunicorn Local Model WSGI HTTP Server")
+ os.environ.setdefault('SERVER_NAME', 'local_model')
+ log_format = '%(h)s %(t)s %(L)ss "%(r)s" %(s)s %(b)s '
+ bind = f'{CONFIG.get("LOCAL_MODEL_HOST")}:{CONFIG.get("LOCAL_MODEL_PORT")}'
+ cmd = [
+ 'gunicorn', 'smartdoc.wsgi:application',
+ '-b', bind,
+ '-k', 'gthread',
+ '--threads', '200',
+ '-w', "1",
+ '--max-requests', '10240',
+ '--max-requests-jitter', '2048',
+ '--access-logformat', log_format,
+ '--access-logfile', '-'
+ ]
+ if DEBUG:
+ cmd.append('--reload')
+ return cmd
+
+ @property
+ def cwd(self):
+ return APPS_DIR
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/services/utils.py b/src/MaxKB-1.5.1/apps/common/management/commands/services/utils.py
new file mode 100644
index 0000000..2426758
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/services/utils.py
@@ -0,0 +1,140 @@
+import threading
+import signal
+import time
+import daemon
+from daemon import pidfile
+from .hands import *
+from .hands import __version__
+from .services.base import BaseService
+
+
+class ServicesUtil(object):
+
+ def __init__(self, services, run_daemon=False, force_stop=False, stop_daemon=False):
+ self._services = services
+ self.run_daemon = run_daemon
+ self.force_stop = force_stop
+ self.stop_daemon = stop_daemon
+ self.EXIT_EVENT = threading.Event()
+ self.check_interval = 30
+ self.files_preserve_map = {}
+
+ def restart(self):
+ self.stop()
+ time.sleep(5)
+ self.start_and_watch()
+
+ def start_and_watch(self):
+ logging.info(time.ctime())
+ logging.info(f'MaxKB version {__version__}, more see https://www.jumpserver.org')
+ self.start()
+ if self.run_daemon:
+ self.show_status()
+ with self.daemon_context:
+ self.watch()
+ else:
+ self.watch()
+
+ def start(self):
+ for service in self._services:
+ service: BaseService
+ service.start()
+ self.files_preserve_map[service.name] = service.log_file
+
+ time.sleep(1)
+
+ def stop(self):
+ for service in self._services:
+ service: BaseService
+ service.stop(force=self.force_stop)
+
+ if self.stop_daemon:
+ self._stop_daemon()
+
+ # -- watch --
+ def watch(self):
+ while not self.EXIT_EVENT.is_set():
+ try:
+ _exit = self._watch()
+ if _exit:
+ break
+ time.sleep(self.check_interval)
+ except KeyboardInterrupt:
+ print('Start stop services')
+ break
+ self.clean_up()
+
+ def _watch(self):
+ for service in self._services:
+ service: BaseService
+ service.watch()
+ if service.EXIT_EVENT.is_set():
+ self.EXIT_EVENT.set()
+ return True
+ return False
+ # -- end watch --
+
+ def clean_up(self):
+ if not self.EXIT_EVENT.is_set():
+ self.EXIT_EVENT.set()
+ self.stop()
+
+ def show_status(self):
+ for service in self._services:
+ service: BaseService
+ service.show_status()
+
+ # -- daemon --
+ def _stop_daemon(self):
+ if self.daemon_pid and self.daemon_is_running:
+ os.kill(self.daemon_pid, 15)
+ self.remove_daemon_pid()
+
+ def remove_daemon_pid(self):
+ if os.path.isfile(self.daemon_pid_filepath):
+ os.unlink(self.daemon_pid_filepath)
+
+ @property
+ def daemon_pid(self):
+ if not os.path.isfile(self.daemon_pid_filepath):
+ return 0
+ with open(self.daemon_pid_filepath) as f:
+ try:
+ pid = int(f.read().strip())
+ except ValueError:
+ pid = 0
+ return pid
+
+ @property
+ def daemon_is_running(self):
+ try:
+ os.kill(self.daemon_pid, 0)
+ except (OSError, ProcessLookupError):
+ return False
+ else:
+ return True
+
+ @property
+ def daemon_pid_filepath(self):
+ return os.path.join(TMP_DIR, 'mk.pid')
+
+ @property
+ def daemon_log_filepath(self):
+ return os.path.join(LOG_DIR, 'mk.log')
+
+ @property
+ def daemon_context(self):
+ daemon_log_file = open(self.daemon_log_filepath, 'a')
+ context = daemon.DaemonContext(
+ pidfile=pidfile.TimeoutPIDLockFile(self.daemon_pid_filepath),
+ signal_map={
+ signal.SIGTERM: lambda x, y: self.clean_up(),
+ signal.SIGHUP: 'terminate',
+ },
+ stdout=daemon_log_file,
+ stderr=daemon_log_file,
+ files_preserve=list(self.files_preserve_map.values()),
+ detach_process=True,
+ )
+ return context
+ # -- end daemon --
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/start.py b/src/MaxKB-1.5.1/apps/common/management/commands/start.py
new file mode 100644
index 0000000..4c078a8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/start.py
@@ -0,0 +1,6 @@
+from .services.command import BaseActionCommand, Action
+
+
+class Command(BaseActionCommand):
+ help = 'Start services'
+ action = Action.start.value
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/status.py b/src/MaxKB-1.5.1/apps/common/management/commands/status.py
new file mode 100644
index 0000000..36f0d36
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/status.py
@@ -0,0 +1,6 @@
+from .services.command import BaseActionCommand, Action
+
+
+class Command(BaseActionCommand):
+ help = 'Show services status'
+ action = Action.status.value
diff --git a/src/MaxKB-1.5.1/apps/common/management/commands/stop.py b/src/MaxKB-1.5.1/apps/common/management/commands/stop.py
new file mode 100644
index 0000000..a79a533
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/management/commands/stop.py
@@ -0,0 +1,6 @@
+from .services.command import BaseActionCommand, Action
+
+
+class Command(BaseActionCommand):
+ help = 'Stop services'
+ action = Action.stop.value
diff --git a/src/MaxKB-1.5.1/apps/common/middleware/cross_domain_middleware.py b/src/MaxKB-1.5.1/apps/common/middleware/cross_domain_middleware.py
new file mode 100644
index 0000000..06c0a6a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/middleware/cross_domain_middleware.py
@@ -0,0 +1,40 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: cross_domain_middleware.py
+ @date:2024/5/8 13:36
+ @desc:
+"""
+from django.http import HttpResponse
+from django.utils.deprecation import MiddlewareMixin
+
+from common.cache_data.application_api_key_cache import get_application_api_key
+
+
+class CrossDomainMiddleware(MiddlewareMixin):
+
+ def process_request(self, request):
+ if request.method == 'OPTIONS':
+ return HttpResponse(status=200,
+ headers={
+ "Access-Control-Allow-Origin": "*",
+ "Access-Control-Allow-Methods": "GET,POST,DELETE,PUT",
+ "Access-Control-Allow-Headers": "Origin,X-Requested-With,Content-Type,Accept,Authorization,token"})
+
+ def process_response(self, request, response):
+ auth = request.META.get('HTTP_AUTHORIZATION')
+ origin = request.META.get('HTTP_ORIGIN')
+ if auth is not None and str(auth).startswith("application-") and origin is not None:
+ application_api_key = get_application_api_key(str(auth), True)
+ cross_domain_list = application_api_key.get('cross_domain_list', [])
+ allow_cross_domain = application_api_key.get('allow_cross_domain', False)
+ if allow_cross_domain:
+ response['Access-Control-Allow-Methods'] = 'GET,POST,DELETE,PUT'
+ response[
+ 'Access-Control-Allow-Headers'] = "Origin,X-Requested-With,Content-Type,Accept,Authorization,token"
+ if cross_domain_list is None or len(cross_domain_list) == 0:
+ response['Access-Control-Allow-Origin'] = "*"
+ elif cross_domain_list.__contains__(origin):
+ response['Access-Control-Allow-Origin'] = origin
+ return response
diff --git a/src/MaxKB-1.5.1/apps/common/middleware/static_headers_middleware.py b/src/MaxKB-1.5.1/apps/common/middleware/static_headers_middleware.py
new file mode 100644
index 0000000..f5afcfb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/middleware/static_headers_middleware.py
@@ -0,0 +1,33 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: static_headers_middleware.py
+ @date:2024/3/13 18:26
+ @desc:
+"""
+from django.utils.deprecation import MiddlewareMixin
+
+from common.cache_data.application_access_token_cache import get_application_access_token
+
+
+class StaticHeadersMiddleware(MiddlewareMixin):
+ def process_response(self, request, response):
+ if request.path.startswith('/ui/chat/'):
+ access_token = request.path.replace('/ui/chat/', '')
+ application_access_token = get_application_access_token(access_token, True)
+ if application_access_token is not None:
+ white_active = application_access_token.get('white_active', False)
+ white_list = application_access_token.get('white_list', [])
+ application_icon = application_access_token.get('application_icon')
+ application_name = application_access_token.get('application_name')
+ if white_active:
+ # 添加自定义的响应头
+ response[
+ 'Content-Security-Policy'] = f'frame-ancestors {" ".join(white_list)}'
+ response.content = (response.content.decode('utf-8').replace(
+ '',
+ f'')
+ .replace('MaxKB ', f'{application_name} ').encode(
+ "utf-8"))
+ return response
diff --git a/src/MaxKB-1.5.1/apps/common/mixins/api_mixin.py b/src/MaxKB-1.5.1/apps/common/mixins/api_mixin.py
new file mode 100644
index 0000000..d2625a0
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/mixins/api_mixin.py
@@ -0,0 +1,24 @@
+# coding=utf-8
+"""
+ @project: smart-doc
+ @Author:虎
+ @file: api_mixin.py
+ @date:2023/9/14 17:50
+ @desc:
+"""
+from rest_framework import serializers
+
+
+class ApiMixin(serializers.Serializer):
+
+ @staticmethod
+ def get_request_params_api():
+ pass
+
+ @staticmethod
+ def get_request_body_api():
+ pass
+
+ @staticmethod
+ def get_response_body_api():
+ pass
diff --git a/src/MaxKB-1.5.1/apps/common/mixins/app_model_mixin.py b/src/MaxKB-1.5.1/apps/common/mixins/app_model_mixin.py
new file mode 100644
index 0000000..412dbae
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/mixins/app_model_mixin.py
@@ -0,0 +1,18 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: app_model_mixin.py
+ @date:2023/9/21 9:41
+ @desc:
+"""
+from django.db import models
+
+
+class AppModelMixin(models.Model):
+ create_time = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
+ update_time = models.DateTimeField(verbose_name="修改时间", auto_now=True)
+
+ class Meta:
+ abstract = True
+ ordering = ['create_time']
diff --git a/src/MaxKB-1.5.1/apps/common/response/result.py b/src/MaxKB-1.5.1/apps/common/response/result.py
new file mode 100644
index 0000000..bb2ba0f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/response/result.py
@@ -0,0 +1,166 @@
+from typing import List
+
+from django.http import JsonResponse
+from drf_yasg import openapi
+from rest_framework import status
+
+
+class Page(dict):
+ """
+ 分页对象
+ """
+
+ def __init__(self, total: int, records: List, current_page: int, page_size: int, **kwargs):
+ super().__init__(**{'total': total, 'records': records, 'current': current_page, 'size': page_size})
+
+
+class Result(JsonResponse):
+ charset = 'utf-8'
+ """
+ 接口统一返回对象
+ """
+
+ def __init__(self, code=200, message="成功", data=None, response_status=status.HTTP_200_OK, **kwargs):
+ back_info_dict = {"code": code, "message": message, 'data': data}
+ super().__init__(data=back_info_dict, status=response_status, **kwargs)
+
+
+def get_page_request_params(other_request_params=None):
+ if other_request_params is None:
+ other_request_params = []
+ current_page = openapi.Parameter(name='current_page',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_INTEGER,
+ required=True,
+ description='当前页')
+
+ page_size = openapi.Parameter(name='page_size',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_INTEGER,
+ required=True,
+ description='每页大小')
+ result = [current_page, page_size]
+ for other_request_param in other_request_params:
+ result.append(other_request_param)
+ return result
+
+
+def get_page_api_response(response_data_schema: openapi.Schema):
+ """
+ 获取统一返回 响应Api
+ """
+ return openapi.Responses(responses={200: openapi.Response(description="响应参数",
+ schema=openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'code': openapi.Schema(
+ type=openapi.TYPE_INTEGER,
+ title="响应码",
+ default=200,
+ description="成功:200 失败:其他"),
+ "message": openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="提示",
+ default='成功',
+ description="错误提示"),
+ "data": openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'total': openapi.Schema(
+ type=openapi.TYPE_INTEGER,
+ title="总条数",
+ default=1,
+ description="数据总条数"),
+ "records": openapi.Schema(
+ type=openapi.TYPE_ARRAY,
+ items=response_data_schema),
+ "current": openapi.Schema(
+ type=openapi.TYPE_INTEGER,
+ title="当前页",
+ default=1,
+ description="当前页"),
+ "size": openapi.Schema(
+ type=openapi.TYPE_INTEGER,
+ title="每页大小",
+ default=10,
+ description="每页大小")
+
+ }
+ )
+
+ }
+ ),
+ )})
+
+
+def get_api_response(response_data_schema: openapi.Schema):
+ """
+ 获取统一返回 响应Api
+ """
+ return openapi.Responses(responses={200: openapi.Response(description="响应参数",
+ schema=openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'code': openapi.Schema(
+ type=openapi.TYPE_INTEGER,
+ title="响应码",
+ default=200,
+ description="成功:200 失败:其他"),
+ "message": openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="提示",
+ default='成功',
+ description="错误提示"),
+ "data": response_data_schema
+
+ }
+ ),
+ )})
+
+
+def get_default_response():
+ return get_api_response(openapi.Schema(type=openapi.TYPE_BOOLEAN))
+
+
+def get_api_array_response(response_data_schema: openapi.Schema):
+ """
+ 获取统一返回 响应Api
+ """
+ return openapi.Responses(responses={200: openapi.Response(description="响应参数",
+ schema=openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'code': openapi.Schema(
+ type=openapi.TYPE_INTEGER,
+ title="响应码",
+ default=200,
+ description="成功:200 失败:其他"),
+ "message": openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="提示",
+ default='成功',
+ description="错误提示"),
+ "data": openapi.Schema(type=openapi.TYPE_ARRAY,
+ items=response_data_schema)
+
+ }
+ ),
+ )})
+
+
+def success(data, **kwargs):
+ """
+ 获取一个成功的响应对象
+ :param data: 接口响应数据
+ :return: 请求响应对象
+ """
+ return Result(data=data, **kwargs)
+
+
+def error(message):
+ """
+ 获取一个失败的响应对象
+ :param message: 错误提示
+ :return: 接口响应对象
+ """
+ return Result(code=500, message=message)
diff --git a/src/MaxKB-1.5.1/apps/common/sql/list_embedding_text.sql b/src/MaxKB-1.5.1/apps/common/sql/list_embedding_text.sql
new file mode 100644
index 0000000..ac0dc7b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/sql/list_embedding_text.sql
@@ -0,0 +1,27 @@
+SELECT
+ problem_paragraph_mapping."id" AS "source_id",
+ paragraph.document_id AS document_id,
+ paragraph."id" AS paragraph_id,
+ problem.dataset_id AS dataset_id,
+ 0 AS source_type,
+ problem."content" AS "text",
+ paragraph.is_active AS is_active
+FROM
+ problem problem
+ LEFT JOIN problem_paragraph_mapping problem_paragraph_mapping ON problem_paragraph_mapping.problem_id=problem."id"
+ LEFT JOIN paragraph paragraph ON paragraph."id" = problem_paragraph_mapping.paragraph_id
+ ${problem}
+
+UNION
+SELECT
+ paragraph."id" AS "source_id",
+ paragraph.document_id AS document_id,
+ paragraph."id" AS paragraph_id,
+ paragraph.dataset_id AS dataset_id,
+ 1 AS source_type,
+ concat_ws(E'\n',paragraph.title,paragraph."content") AS "text",
+ paragraph.is_active AS is_active
+FROM
+ paragraph paragraph
+
+ ${paragraph}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/common/swagger_api/common_api.py b/src/MaxKB-1.5.1/apps/common/swagger_api/common_api.py
new file mode 100644
index 0000000..c3d8be6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/swagger_api/common_api.py
@@ -0,0 +1,85 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: common.py
+ @date:2023/12/25 16:17
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class CommonApi:
+ class HitTestApi(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [
+ openapi.Parameter(name='query_text',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='问题文本'),
+ openapi.Parameter(name='top_number',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_NUMBER,
+ default=10,
+ required=True,
+ description='topN'),
+ openapi.Parameter(name='similarity',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_NUMBER,
+ default=0.6,
+ required=True,
+ description='相关性'),
+ openapi.Parameter(name='search_mode',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ default="embedding",
+ required=True,
+ description='检索模式embedding|keywords|blend'
+ )
+ ]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'content', 'hit_num', 'star_num', 'trample_num', 'is_active', 'dataset_id',
+ 'document_id', 'title',
+ 'similarity', 'comprehensive_score',
+ 'create_time', 'update_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'content': openapi.Schema(type=openapi.TYPE_STRING, title="段落内容",
+ description="段落内容", default='段落内容'),
+ 'title': openapi.Schema(type=openapi.TYPE_STRING, title="标题",
+ description="标题", default="xxx的描述"),
+ 'hit_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="命中数量", description="命中数量",
+ default=1),
+ 'star_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="点赞数量",
+ description="点赞数量", default=1),
+ 'trample_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="点踩数量",
+ description="点踩数", default=1),
+ 'dataset_id': openapi.Schema(type=openapi.TYPE_STRING, title="知识库id",
+ description="知识库id", default='xxx'),
+ 'document_id': openapi.Schema(type=openapi.TYPE_STRING, title="文档id",
+ description="文档id", default='xxx'),
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否可用",
+ description="是否可用", default=True),
+ 'similarity': openapi.Schema(type=openapi.TYPE_NUMBER, title="相关性得分",
+ description="相关性得分", default=True),
+ 'comprehensive_score': openapi.Schema(type=openapi.TYPE_NUMBER, title="综合得分,用于排序",
+ description="综合得分,用于排序", default=True),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ ),
+
+ }
+ )
diff --git a/src/MaxKB-1.5.1/apps/common/task/__init__.py b/src/MaxKB-1.5.1/apps/common/task/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/common/template/email_template.html b/src/MaxKB-1.5.1/apps/common/template/email_template.html
new file mode 100644
index 0000000..0647d3c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/template/email_template.html
@@ -0,0 +1,122 @@
+
+
+
+
+
+
+
+
+
+
+ ', views.Dataset.Operate.as_view(), name="dataset_key"),
+ path('dataset//export', views.Dataset.Export.as_view(), name="export"),
+ path('dataset//re_embedding', views.Dataset.Embedding.as_view(), name="dataset_key"),
+ path('dataset//application', views.Dataset.Application.as_view()),
+ path('dataset//', views.Dataset.Page.as_view(), name="dataset"),
+ path('dataset//sync_web', views.Dataset.SyncWeb.as_view()),
+ path('dataset//hit_test', views.Dataset.HitTest.as_view()),
+ path('dataset//document', views.Document.as_view(), name='document'),
+ path('dataset/document/template/export', views.Template.as_view()),
+ path('dataset//document/web', views.WebDocument.as_view()),
+ path('dataset//document/qa', views.QaDocument.as_view()),
+ path('dataset//document/_bach', views.Document.Batch.as_view()),
+ path('dataset//document/batch_hit_handling', views.Document.BatchEditHitHandling.as_view()),
+ path('dataset//document//', views.Document.Page.as_view()),
+ path('dataset//document/', views.Document.Operate.as_view(),
+ name="document_operate"),
+ path('dataset/document/split', views.Document.Split.as_view(),
+ name="document_operate"),
+ path('dataset/document/split_pattern', views.Document.SplitPattern.as_view(),
+ name="document_operate"),
+ path('dataset//document/migrate/', views.Document.Migrate.as_view()),
+ path('dataset//document//export', views.Document.Export.as_view(),
+ name="document_export"),
+ path('dataset//document//sync', views.Document.SyncWeb.as_view()),
+ path('dataset//document//refresh', views.Document.Refresh.as_view()),
+ path('dataset//document//paragraph', views.Paragraph.as_view()),
+ path(
+ 'dataset//document//paragraph/migrate/dataset//document/',
+ views.Paragraph.BatchMigrate.as_view()),
+ path('dataset//document//paragraph/_batch', views.Paragraph.Batch.as_view()),
+ path('dataset//document//paragraph//',
+ views.Paragraph.Page.as_view(), name='paragraph_page'),
+ path('dataset//document//paragraph/',
+ views.Paragraph.Operate.as_view()),
+ path('dataset//document//paragraph//problem',
+ views.Paragraph.Problem.as_view()),
+ path(
+ 'dataset//document//paragraph//problem//un_association',
+ views.Paragraph.Problem.UnAssociation.as_view()),
+ path(
+ 'dataset//document//paragraph//problem//association',
+ views.Paragraph.Problem.Association.as_view()),
+ path('dataset//problem', views.Problem.as_view()),
+ path('dataset//problem/_batch', views.Problem.OperateBatch.as_view()),
+ path('dataset//problem//', views.Problem.Page.as_view()),
+ path('dataset//problem/', views.Problem.Operate.as_view()),
+ path('dataset//problem//paragraph', views.Problem.Paragraph.as_view()),
+ path('image/', views.Image.Operate.as_view()),
+ path('image', views.Image.as_view()),
+ path('file/', views.FileView.Operate.as_view()),
+ path('file', views.FileView.as_view())
+]
diff --git a/src/MaxKB-1.5.1/apps/dataset/views/__init__.py b/src/MaxKB-1.5.1/apps/dataset/views/__init__.py
new file mode 100644
index 0000000..e434cec
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/views/__init__.py
@@ -0,0 +1,14 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py
+ @date:2023/9/21 9:32
+ @desc:
+"""
+from .dataset import *
+from .document import *
+from .paragraph import *
+from .problem import *
+from .image import *
+from .file import *
diff --git a/src/MaxKB-1.5.1/apps/dataset/views/dataset.py b/src/MaxKB-1.5.1/apps/dataset/views/dataset.py
new file mode 100644
index 0000000..adf10e3
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/views/dataset.py
@@ -0,0 +1,225 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: dataset.py
+ @date:2023/9/21 15:52
+ @desc:
+"""
+
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.parsers import MultiPartParser
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import PermissionConstants, CompareConstants, Permission, Group, Operate, \
+ ViewPermission, RoleConstants
+from common.response import result
+from common.response.result import get_page_request_params, get_page_api_response, get_api_response
+from common.swagger_api.common_api import CommonApi
+from dataset.serializers.dataset_serializers import DataSetSerializers
+
+
+class Dataset(APIView):
+ authentication_classes = [TokenAuth]
+
+ class SyncWeb(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="同步Web站点知识库",
+ operation_id="同步Web站点知识库",
+ manual_parameters=DataSetSerializers.SyncWeb.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN, RoleConstants.USER],
+ [lambda r, keywords: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('dataset_id'))],
+ compare=CompareConstants.AND), PermissionConstants.DATASET_EDIT,
+ compare=CompareConstants.AND)
+ def put(self, request: Request, dataset_id: str):
+ return result.success(DataSetSerializers.SyncWeb(
+ data={'sync_type': request.query_params.get('sync_type'), 'id': dataset_id,
+ 'user_id': str(request.user.id)}).sync())
+
+ class CreateQADataset(APIView):
+ authentication_classes = [TokenAuth]
+ parser_classes = [MultiPartParser]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建QA知识库",
+ operation_id="创建QA知识库",
+ manual_parameters=DataSetSerializers.Create.CreateQASerializers.get_request_params_api(),
+ responses=get_api_response(
+ DataSetSerializers.Create.CreateQASerializers.get_response_body_api()),
+ tags=["知识库"]
+ )
+ @has_permissions(PermissionConstants.DATASET_CREATE, compare=CompareConstants.AND)
+ def post(self, request: Request):
+ return result.success(DataSetSerializers.Create(data={'user_id': request.user.id}).save_qa({
+ 'file_list': request.FILES.getlist('file'),
+ 'name': request.data.get('name'),
+ 'desc': request.data.get('desc')
+ }))
+
+ class CreateWebDataset(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建web站点知识库",
+ operation_id="创建web站点知识库",
+ request_body=DataSetSerializers.Create.CreateWebSerializers.get_request_body_api(),
+ responses=get_api_response(
+ DataSetSerializers.Create.CreateWebSerializers.get_response_body_api()),
+ tags=["知识库"]
+ )
+ @has_permissions(PermissionConstants.DATASET_CREATE, compare=CompareConstants.AND)
+ def post(self, request: Request):
+ return result.success(DataSetSerializers.Create(data={'user_id': request.user.id}).save_web(request.data))
+
+ class Application(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取知识库可用应用列表",
+ operation_id="获取知识库可用应用列表",
+ manual_parameters=DataSetSerializers.Application.get_request_params_api(),
+ responses=result.get_api_array_response(
+ DataSetSerializers.Application.get_response_body_api()),
+ tags=["知识库"])
+ def get(self, request: Request, dataset_id: str):
+ return result.success(DataSetSerializers.Operate(
+ data={'id': dataset_id, 'user_id': str(request.user.id)}).list_application())
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取知识库列表",
+ operation_id="获取知识库列表",
+ manual_parameters=DataSetSerializers.Query.get_request_params_api(),
+ responses=result.get_api_array_response(DataSetSerializers.Query.get_response_body_api()),
+ tags=["知识库"])
+ @has_permissions(PermissionConstants.DATASET_READ, compare=CompareConstants.AND)
+ def get(self, request: Request):
+ d = DataSetSerializers.Query(data={**request.query_params, 'user_id': str(request.user.id)})
+ d.is_valid()
+ return result.success(d.list())
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建知识库",
+ operation_id="创建知识库",
+ request_body=DataSetSerializers.Create.get_request_body_api(),
+ responses=get_api_response(DataSetSerializers.Create.get_response_body_api()),
+ tags=["知识库"]
+ )
+ @has_permissions(PermissionConstants.DATASET_CREATE, compare=CompareConstants.AND)
+ def post(self, request: Request):
+ return result.success(DataSetSerializers.Create(data={'user_id': request.user.id}).save(request.data))
+
+ class HitTest(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods="GET", detail=False)
+ @swagger_auto_schema(operation_summary="命中测试列表", operation_id="命中测试列表",
+ manual_parameters=CommonApi.HitTestApi.get_request_params_api(),
+ responses=result.get_api_array_response(CommonApi.HitTestApi.get_response_body_api()),
+ tags=["知识库"])
+ @has_permissions(lambda r, keywords: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=keywords.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str):
+ return result.success(
+ DataSetSerializers.HitTest(data={'id': dataset_id, 'user_id': request.user.id,
+ "query_text": request.query_params.get("query_text"),
+ "top_number": request.query_params.get("top_number"),
+ 'similarity': request.query_params.get('similarity'),
+ 'search_mode': request.query_params.get('search_mode')}).hit_test(
+ ))
+
+ class Embedding(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods="PUT", detail=False)
+ @swagger_auto_schema(operation_summary="重新向量化", operation_id="重新向量化",
+ manual_parameters=DataSetSerializers.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库"]
+ )
+ @has_permissions(lambda r, keywords: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str):
+ return result.success(
+ DataSetSerializers.Operate(data={'id': dataset_id, 'user_id': request.user.id}).re_embedding())
+
+ class Export(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods="GET", detail=False)
+ @swagger_auto_schema(operation_summary="导出知识库", operation_id="导出知识库",
+ manual_parameters=DataSetSerializers.Operate.get_request_params_api(),
+ tags=["知识库"]
+ )
+ @has_permissions(lambda r, keywords: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str):
+ return DataSetSerializers.Operate(data={'id': dataset_id, 'user_id': request.user.id}).export_excel()
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods="DELETE", detail=False)
+ @swagger_auto_schema(operation_summary="删除知识库", operation_id="删除知识库",
+ manual_parameters=DataSetSerializers.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库"])
+ @has_permissions(lambda r, keywords: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('dataset_id')),
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.DELETE,
+ dynamic_tag=k.get('dataset_id')), compare=CompareConstants.AND)
+ def delete(self, request: Request, dataset_id: str):
+ operate = DataSetSerializers.Operate(data={'id': dataset_id})
+ return result.success(operate.delete())
+
+ @action(methods="GET", detail=False)
+ @swagger_auto_schema(operation_summary="查询知识库详情根据知识库id", operation_id="查询知识库详情根据知识库id",
+ manual_parameters=DataSetSerializers.Operate.get_request_params_api(),
+ responses=get_api_response(DataSetSerializers.Operate.get_response_body_api()),
+ tags=["知识库"])
+ @has_permissions(lambda r, keywords: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=keywords.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str):
+ return result.success(DataSetSerializers.Operate(data={'id': dataset_id, 'user_id': request.user.id}).one(
+ user_id=request.user.id))
+
+ @action(methods="PUT", detail=False)
+ @swagger_auto_schema(operation_summary="修改知识库信息", operation_id="修改知识库信息",
+ manual_parameters=DataSetSerializers.Operate.get_request_params_api(),
+ request_body=DataSetSerializers.Operate.get_request_body_api(),
+ responses=get_api_response(DataSetSerializers.Operate.get_response_body_api()),
+ tags=["知识库"]
+ )
+ @has_permissions(lambda r, keywords: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=keywords.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str):
+ return result.success(
+ DataSetSerializers.Operate(data={'id': dataset_id, 'user_id': request.user.id}).edit(request.data,
+ user_id=request.user.id))
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取知识库分页列表",
+ operation_id="获取知识库分页列表",
+ manual_parameters=get_page_request_params(
+ DataSetSerializers.Query.get_request_params_api()),
+ responses=get_page_api_response(DataSetSerializers.Query.get_response_body_api()),
+ tags=["知识库"]
+ )
+ @has_permissions(PermissionConstants.DATASET_READ, compare=CompareConstants.AND)
+ def get(self, request: Request, current_page, page_size):
+ d = DataSetSerializers.Query(
+ data={'name': request.query_params.get('name', None), 'desc': request.query_params.get("desc", None),
+ 'user_id': str(request.user.id)})
+ d.is_valid()
+ return result.success(d.page(current_page, page_size))
diff --git a/src/MaxKB-1.5.1/apps/dataset/views/document.py b/src/MaxKB-1.5.1/apps/dataset/views/document.py
new file mode 100644
index 0000000..f522d01
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/views/document.py
@@ -0,0 +1,345 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: document.py
+ @date:2023/9/22 11:32
+ @desc:
+"""
+
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.parsers import MultiPartParser
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import Permission, Group, Operate, CompareConstants
+from common.response import result
+from common.util.common import query_params_to_single_dict
+from dataset.serializers.common_serializers import BatchSerializer
+from dataset.serializers.document_serializers import DocumentSerializers, DocumentWebInstanceSerializer
+from dataset.swagger_api.document_api import DocumentApi
+
+
+class Template(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取QA模版",
+ operation_id="获取QA模版",
+ manual_parameters=DocumentSerializers.Export.get_request_params_api(),
+ tags=["知识库/文档"])
+ def get(self, request: Request):
+ return DocumentSerializers.Export(data={'type': request.query_params.get('type')}).export(with_valid=True)
+
+
+class WebDocument(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建Web站点文档",
+ operation_id="创建Web站点文档",
+ request_body=DocumentWebInstanceSerializer.get_request_body_api(),
+ manual_parameters=DocumentSerializers.Create.get_request_params_api(),
+ responses=result.get_api_response(DocumentSerializers.Operate.get_response_body_api()),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def post(self, request: Request, dataset_id: str):
+ return result.success(
+ DocumentSerializers.Create(data={'dataset_id': dataset_id}).save_web(request.data, with_valid=True))
+
+
+class QaDocument(APIView):
+ authentication_classes = [TokenAuth]
+ parser_classes = [MultiPartParser]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="导入QA并创建文档",
+ operation_id="导入QA并创建文档",
+ manual_parameters=DocumentWebInstanceSerializer.get_request_params_api(),
+ responses=result.get_api_response(DocumentSerializers.Create.get_response_body_api()),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def post(self, request: Request, dataset_id: str):
+ return result.success(
+ DocumentSerializers.Create(data={'dataset_id': dataset_id}).save_qa(
+ {'file_list': request.FILES.getlist('file')},
+ with_valid=True))
+
+
+class Document(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建文档",
+ operation_id="创建文档",
+ request_body=DocumentSerializers.Create.get_request_body_api(),
+ manual_parameters=DocumentSerializers.Create.get_request_params_api(),
+ responses=result.get_api_response(DocumentSerializers.Operate.get_response_body_api()),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def post(self, request: Request, dataset_id: str):
+ return result.success(
+ DocumentSerializers.Create(data={'dataset_id': dataset_id}).save(request.data, with_valid=True))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="文档列表",
+ operation_id="文档列表",
+ manual_parameters=DocumentSerializers.Query.get_request_params_api(),
+ responses=result.get_api_response(DocumentSerializers.Query.get_response_body_api()),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str):
+ d = DocumentSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id})
+ d.is_valid(raise_exception=True)
+ return result.success(d.list())
+
+ class BatchEditHitHandling(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="批量修改文档命中处理方式",
+ operation_id="批量修改文档命中处理方式",
+ request_body=
+ DocumentApi.BatchEditHitHandlingApi.get_request_body_api(),
+ manual_parameters=DocumentSerializers.Create.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str):
+ return result.success(
+ DocumentSerializers.Batch(data={'dataset_id': dataset_id}).batch_edit_hit_handling(request.data))
+
+ class Batch(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="批量创建文档",
+ operation_id="批量创建文档",
+ request_body=
+ DocumentSerializers.Batch.get_request_body_api(),
+ manual_parameters=DocumentSerializers.Create.get_request_params_api(),
+ responses=result.get_api_array_response(
+ DocumentSerializers.Operate.get_response_body_api()),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def post(self, request: Request, dataset_id: str):
+ return result.success(DocumentSerializers.Batch(data={'dataset_id': dataset_id}).batch_save(request.data))
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="批量同步文档",
+ operation_id="批量同步文档",
+ request_body=
+ BatchSerializer.get_request_body_api(),
+ manual_parameters=DocumentSerializers.Create.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str):
+ return result.success(DocumentSerializers.Batch(data={'dataset_id': dataset_id}).batch_sync(request.data))
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="批量删除文档",
+ operation_id="批量删除文档",
+ request_body=
+ BatchSerializer.get_request_body_api(),
+ manual_parameters=DocumentSerializers.Create.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def delete(self, request: Request, dataset_id: str):
+ return result.success(DocumentSerializers.Batch(data={'dataset_id': dataset_id}).batch_delete(request.data))
+
+ class SyncWeb(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="同步web站点类型",
+ operation_id="同步web站点类型",
+ manual_parameters=DocumentSerializers.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档"]
+ )
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str, document_id: str):
+ return result.success(
+ DocumentSerializers.Sync(data={'document_id': document_id, 'dataset_id': dataset_id}).sync(
+ ))
+
+ class Refresh(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="刷新文档向量库",
+ operation_id="刷新文档向量库",
+ manual_parameters=DocumentSerializers.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档"]
+ )
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str, document_id: str):
+ return result.success(
+ DocumentSerializers.Operate(data={'document_id': document_id, 'dataset_id': dataset_id}).refresh(
+ ))
+
+ class Migrate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="批量迁移文档",
+ operation_id="批量迁移文档",
+ manual_parameters=DocumentSerializers.Migrate.get_request_params_api(),
+ request_body=DocumentSerializers.Migrate.get_request_body_api(),
+ responses=result.get_api_response(DocumentSerializers.Operate.get_response_body_api()),
+ tags=["知识库/文档"]
+ )
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')),
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('target_dataset_id')),
+ compare=CompareConstants.AND
+ )
+ def put(self, request: Request, dataset_id: str, target_dataset_id: str):
+ return result.success(
+ DocumentSerializers.Migrate(
+ data={'dataset_id': dataset_id, 'target_dataset_id': target_dataset_id,
+ 'document_id_list': request.data}).migrate(
+
+ ))
+
+ class Export(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="导出文档",
+ operation_id="导出文档",
+ manual_parameters=DocumentSerializers.Operate.get_request_params_api(),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, document_id: str):
+ return DocumentSerializers.Operate(data={'document_id': document_id, 'dataset_id': dataset_id}).export()
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取文档详情",
+ operation_id="获取文档详情",
+ manual_parameters=DocumentSerializers.Operate.get_request_params_api(),
+ responses=result.get_api_response(DocumentSerializers.Operate.get_response_body_api()),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, document_id: str):
+ operate = DocumentSerializers.Operate(data={'document_id': document_id, 'dataset_id': dataset_id})
+ operate.is_valid(raise_exception=True)
+ return result.success(operate.one())
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改文档",
+ operation_id="修改文档",
+ manual_parameters=DocumentSerializers.Operate.get_request_params_api(),
+ request_body=DocumentSerializers.Operate.get_request_body_api(),
+ responses=result.get_api_response(DocumentSerializers.Operate.get_response_body_api()),
+ tags=["知识库/文档"]
+ )
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str, document_id: str):
+ return result.success(
+ DocumentSerializers.Operate(data={'document_id': document_id, 'dataset_id': dataset_id}).edit(
+ request.data,
+ with_valid=True))
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除文档",
+ operation_id="删除文档",
+ manual_parameters=DocumentSerializers.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def delete(self, request: Request, dataset_id: str, document_id: str):
+ operate = DocumentSerializers.Operate(data={'document_id': document_id, 'dataset_id': dataset_id})
+ operate.is_valid(raise_exception=True)
+ return result.success(operate.delete())
+
+ class SplitPattern(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取分段标识列表",
+ operation_id="获取分段标识列表",
+ tags=["知识库/文档"])
+ def get(self, request: Request):
+ return result.success(DocumentSerializers.SplitPattern.list())
+
+ class Split(APIView):
+ authentication_classes = [TokenAuth]
+ parser_classes = [MultiPartParser]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="分段文档",
+ operation_id="分段文档",
+ manual_parameters=DocumentSerializers.Split.get_request_params_api(),
+ tags=["知识库/文档"])
+ def post(self, request: Request):
+ split_data = {'file': request.FILES.getlist('file')}
+ request_data = request.data
+ if 'patterns' in request.data and request.data.get('patterns') is not None and len(
+ request.data.get('patterns')) > 0:
+ split_data.__setitem__('patterns', request_data.getlist('patterns'))
+ if 'limit' in request.data:
+ split_data.__setitem__('limit', request_data.get('limit'))
+ if 'with_filter' in request.data:
+ split_data.__setitem__('with_filter', request_data.get('with_filter'))
+ ds = DocumentSerializers.Split(
+ data=split_data)
+ ds.is_valid(raise_exception=True)
+ return result.success(ds.parse())
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取知识库分页列表",
+ operation_id="获取知识库分页列表",
+ manual_parameters=DocumentSerializers.Query.get_request_params_api(),
+ responses=result.get_page_api_response(DocumentSerializers.Query.get_response_body_api()),
+ tags=["知识库/文档"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, current_page, page_size):
+ d = DocumentSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id})
+ d.is_valid(raise_exception=True)
+ return result.success(d.page(current_page, page_size))
diff --git a/src/MaxKB-1.5.1/apps/dataset/views/file.py b/src/MaxKB-1.5.1/apps/dataset/views/file.py
new file mode 100644
index 0000000..7ec437d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/views/file.py
@@ -0,0 +1,43 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: image.py
+ @date:2024/4/22 16:23
+ @desc:
+"""
+from drf_yasg import openapi
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.parsers import MultiPartParser
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth
+from common.response import result
+from dataset.serializers.file_serializers import FileSerializer
+
+
+class FileView(APIView):
+ authentication_classes = [TokenAuth]
+ parser_classes = [MultiPartParser]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="上传文件",
+ operation_id="上传文件",
+ manual_parameters=[openapi.Parameter(name='file',
+ in_=openapi.IN_FORM,
+ type=openapi.TYPE_FILE,
+ required=True,
+ description='上传文件')],
+ tags=["文件"])
+ def post(self, request: Request):
+ return result.success(FileSerializer(data={'file': request.FILES.get('file')}).upload())
+
+ class Operate(APIView):
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取图片",
+ operation_id="获取图片",
+ tags=["文件"])
+ def get(self, request: Request, file_id: str):
+ return FileSerializer.Operate(data={'id': file_id}).get()
diff --git a/src/MaxKB-1.5.1/apps/dataset/views/image.py b/src/MaxKB-1.5.1/apps/dataset/views/image.py
new file mode 100644
index 0000000..124336f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/views/image.py
@@ -0,0 +1,43 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: image.py
+ @date:2024/4/22 16:23
+ @desc:
+"""
+from drf_yasg import openapi
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.parsers import MultiPartParser
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth
+from common.response import result
+from dataset.serializers.image_serializers import ImageSerializer
+
+
+class Image(APIView):
+ authentication_classes = [TokenAuth]
+ parser_classes = [MultiPartParser]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="上传图片",
+ operation_id="上传图片",
+ manual_parameters=[openapi.Parameter(name='file',
+ in_=openapi.IN_FORM,
+ type=openapi.TYPE_FILE,
+ required=True,
+ description='上传文件')],
+ tags=["图片"])
+ def post(self, request: Request):
+ return result.success(ImageSerializer(data={'image': request.FILES.get('file')}).upload())
+
+ class Operate(APIView):
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取图片",
+ operation_id="获取图片",
+ tags=["图片"])
+ def get(self, request: Request, image_id: str):
+ return ImageSerializer.Operate(data={'id': image_id}).get()
diff --git a/src/MaxKB-1.5.1/apps/dataset/views/paragraph.py b/src/MaxKB-1.5.1/apps/dataset/views/paragraph.py
new file mode 100644
index 0000000..af968b8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/views/paragraph.py
@@ -0,0 +1,234 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: paragraph_serializers.py
+ @date:2023/10/16 15:51
+ @desc:
+"""
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import Permission, Group, Operate, CompareConstants
+from common.response import result
+from common.util.common import query_params_to_single_dict
+from dataset.serializers.common_serializers import BatchSerializer
+from dataset.serializers.paragraph_serializers import ParagraphSerializers
+
+
+class Paragraph(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="段落列表",
+ operation_id="段落列表",
+ manual_parameters=ParagraphSerializers.Query.get_request_params_api(),
+ responses=result.get_api_array_response(ParagraphSerializers.Query.get_response_body_api()),
+ tags=["知识库/文档/段落"]
+ )
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, document_id: str):
+ q = ParagraphSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id,
+ 'document_id': document_id})
+ q.is_valid(raise_exception=True)
+ return result.success(q.list())
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建段落",
+ operation_id="创建段落",
+ manual_parameters=ParagraphSerializers.Create.get_request_params_api(),
+ request_body=ParagraphSerializers.Create.get_request_body_api(),
+ responses=result.get_api_response(ParagraphSerializers.Query.get_response_body_api()),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def post(self, request: Request, dataset_id: str, document_id: str):
+ return result.success(
+ ParagraphSerializers.Create(data={'dataset_id': dataset_id, 'document_id': document_id}).save(request.data))
+
+ class Problem(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="添加关联问题",
+ operation_id="添加段落关联问题",
+ manual_parameters=ParagraphSerializers.Problem.get_request_params_api(),
+ request_body=ParagraphSerializers.Problem.get_request_body_api(),
+ responses=result.get_api_response(ParagraphSerializers.Problem.get_response_body_api()),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def post(self, request: Request, dataset_id: str, document_id: str, paragraph_id: str):
+ return result.success(ParagraphSerializers.Problem(
+ data={"dataset_id": dataset_id, 'document_id': document_id, 'paragraph_id': paragraph_id}).save(
+ request.data, with_valid=True))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取段落问题列表",
+ operation_id="获取段落问题列表",
+ manual_parameters=ParagraphSerializers.Problem.get_request_params_api(),
+ responses=result.get_api_array_response(
+ ParagraphSerializers.Problem.get_response_body_api()),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, document_id: str, paragraph_id: str):
+ return result.success(ParagraphSerializers.Problem(
+ data={"dataset_id": dataset_id, 'document_id': document_id, 'paragraph_id': paragraph_id}).list(
+ with_valid=True))
+
+ class UnAssociation(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="解除关联问题",
+ operation_id="解除关联问题",
+ manual_parameters=ParagraphSerializers.Association.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str, document_id: str, paragraph_id: str, problem_id: str):
+ return result.success(ParagraphSerializers.Association(
+ data={'dataset_id': dataset_id, 'document_id': document_id, 'paragraph_id': paragraph_id,
+ 'problem_id': problem_id}).un_association())
+
+ class Association(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="关联问题",
+ operation_id="关联问题",
+ manual_parameters=ParagraphSerializers.Association.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str, document_id: str, paragraph_id: str, problem_id: str):
+ return result.success(ParagraphSerializers.Association(
+ data={'dataset_id': dataset_id, 'document_id': document_id, 'paragraph_id': paragraph_id,
+ 'problem_id': problem_id}).association())
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['UPDATE'], detail=False)
+ @swagger_auto_schema(operation_summary="修改段落数据",
+ operation_id="修改段落数据",
+ manual_parameters=ParagraphSerializers.Operate.get_request_params_api(),
+ request_body=ParagraphSerializers.Operate.get_request_body_api(),
+ responses=result.get_api_response(ParagraphSerializers.Operate.get_response_body_api())
+ , tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str, document_id: str, paragraph_id: str):
+ o = ParagraphSerializers.Operate(
+ data={"paragraph_id": paragraph_id, 'dataset_id': dataset_id, 'document_id': document_id})
+ o.is_valid(raise_exception=True)
+ return result.success(o.edit(request.data))
+
+ @action(methods=['UPDATE'], detail=False)
+ @swagger_auto_schema(operation_summary="获取段落详情",
+ operation_id="获取段落详情",
+ manual_parameters=ParagraphSerializers.Operate.get_request_params_api(),
+ responses=result.get_api_response(ParagraphSerializers.Operate.get_response_body_api()),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, document_id: str, paragraph_id: str):
+ o = ParagraphSerializers.Operate(
+ data={"dataset_id": dataset_id, 'document_id': document_id, "paragraph_id": paragraph_id})
+ o.is_valid(raise_exception=True)
+ return result.success(o.one())
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除段落",
+ operation_id="删除段落",
+ manual_parameters=ParagraphSerializers.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def delete(self, request: Request, dataset_id: str, document_id: str, paragraph_id: str):
+ o = ParagraphSerializers.Operate(
+ data={"dataset_id": dataset_id, 'document_id': document_id, "paragraph_id": paragraph_id})
+ o.is_valid(raise_exception=True)
+ return result.success(o.delete())
+
+ class Batch(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="批量删除段落",
+ operation_id="批量删除段落",
+ request_body=
+ BatchSerializer.get_request_body_api(),
+ manual_parameters=ParagraphSerializers.Create.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def delete(self, request: Request, dataset_id: str, document_id: str):
+ return result.success(ParagraphSerializers.Batch(
+ data={"dataset_id": dataset_id, 'document_id': document_id}).batch_delete(request.data))
+
+ class BatchMigrate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="批量迁移段落",
+ operation_id="批量迁移段落",
+ manual_parameters=ParagraphSerializers.Migrate.get_request_params_api(),
+ request_body=ParagraphSerializers.Migrate.get_request_body_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档/段落"]
+ )
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')),
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('target_dataset_id')),
+ compare=CompareConstants.AND
+ )
+ def put(self, request: Request, dataset_id: str, target_dataset_id: str, document_id: str, target_document_id):
+ return result.success(
+ ParagraphSerializers.Migrate(
+ data={'dataset_id': dataset_id, 'target_dataset_id': target_dataset_id,
+ 'document_id': document_id,
+ 'target_document_id': target_document_id,
+ 'paragraph_id_list': request.data}).migrate())
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="分页获取段落列表",
+ operation_id="分页获取段落列表",
+ manual_parameters=result.get_page_request_params(
+ ParagraphSerializers.Query.get_request_params_api()),
+ responses=result.get_page_api_response(ParagraphSerializers.Query.get_response_body_api()),
+ tags=["知识库/文档/段落"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, document_id: str, current_page, page_size):
+ d = ParagraphSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id,
+ 'document_id': document_id})
+ d.is_valid(raise_exception=True)
+ return result.success(d.page(current_page, page_size))
diff --git a/src/MaxKB-1.5.1/apps/dataset/views/problem.py b/src/MaxKB-1.5.1/apps/dataset/views/problem.py
new file mode 100644
index 0000000..beebcc6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/views/problem.py
@@ -0,0 +1,140 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: problem.py
+ @date:2023/10/23 13:54
+ @desc:
+"""
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import Permission, Group, Operate
+from common.response import result
+from common.util.common import query_params_to_single_dict
+from dataset.serializers.problem_serializers import ProblemSerializers
+from dataset.swagger_api.problem_api import ProblemApi
+
+
+class Problem(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="问题列表",
+ operation_id="问题列表",
+ manual_parameters=ProblemApi.Query.get_request_params_api(),
+ responses=result.get_api_array_response(ProblemApi.get_response_body_api()),
+ tags=["知识库/文档/段落/问题"]
+ )
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str):
+ q = ProblemSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id})
+ q.is_valid(raise_exception=True)
+ return result.success(q.list())
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建问题",
+ operation_id="创建问题",
+ manual_parameters=ProblemApi.BatchCreate.get_request_params_api(),
+ request_body=ProblemApi.BatchCreate.get_request_body_api(),
+ responses=result.get_api_response(ProblemApi.Query.get_response_body_api()),
+ tags=["知识库/文档/段落/问题"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def post(self, request: Request, dataset_id: str):
+ return result.success(
+ ProblemSerializers.Create(
+ data={'dataset_id': dataset_id, 'problem_list': request.data}).batch())
+
+ class Paragraph(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取关联段落列表",
+ operation_id="获取关联段落列表",
+ manual_parameters=ProblemApi.Paragraph.get_request_params_api(),
+ responses=result.get_api_array_response(ProblemApi.Paragraph.get_response_body_api()),
+ tags=["知识库/文档/段落/问题"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, problem_id: str):
+ return result.success(ProblemSerializers.Operate(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id,
+ 'problem_id': problem_id}).list_paragraph())
+
+ class OperateBatch(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="批量删除问题",
+ operation_id="批量删除问题",
+ request_body=
+ ProblemApi.BatchOperate.get_request_body_api(),
+ manual_parameters=ProblemApi.BatchOperate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档/段落/问题"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def delete(self, request: Request, dataset_id: str):
+ return result.success(
+ ProblemSerializers.BatchOperate(data={'dataset_id': dataset_id}).delete(request.data))
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除问题",
+ operation_id="删除问题",
+ manual_parameters=ProblemApi.Operate.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["知识库/文档/段落/问题"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def delete(self, request: Request, dataset_id: str, problem_id: str):
+ return result.success(ProblemSerializers.Operate(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id,
+ 'problem_id': problem_id}).delete())
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改问题",
+ operation_id="修改问题",
+ manual_parameters=ProblemApi.Operate.get_request_params_api(),
+ request_body=ProblemApi.Operate.get_request_body_api(),
+ responses=result.get_api_response(ProblemApi.get_response_body_api()),
+ tags=["知识库/文档/段落/问题"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.MANAGE,
+ dynamic_tag=k.get('dataset_id')))
+ def put(self, request: Request, dataset_id: str, problem_id: str):
+ return result.success(ProblemSerializers.Operate(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id,
+ 'problem_id': problem_id}).edit(request.data))
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="分页获取问题列表",
+ operation_id="分页获取问题列表",
+ manual_parameters=result.get_page_request_params(
+ ProblemApi.Query.get_request_params_api()),
+ responses=result.get_page_api_response(ProblemApi.get_response_body_api()),
+ tags=["知识库/文档/段落/问题"])
+ @has_permissions(
+ lambda r, k: Permission(group=Group.DATASET, operate=Operate.USE,
+ dynamic_tag=k.get('dataset_id')))
+ def get(self, request: Request, dataset_id: str, current_page, page_size):
+ d = ProblemSerializers.Query(
+ data={**query_params_to_single_dict(request.query_params), 'dataset_id': dataset_id})
+ d.is_valid(raise_exception=True)
+ return result.success(d.page(current_page, page_size))
diff --git a/src/MaxKB-1.5.1/apps/embedding/__init__.py b/src/MaxKB-1.5.1/apps/embedding/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/embedding/admin.py b/src/MaxKB-1.5.1/apps/embedding/admin.py
new file mode 100644
index 0000000..8c38f3f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/admin.py
@@ -0,0 +1,3 @@
+from django.contrib import admin
+
+# Register your models here.
diff --git a/src/MaxKB-1.5.1/apps/embedding/apps.py b/src/MaxKB-1.5.1/apps/embedding/apps.py
new file mode 100644
index 0000000..45a5d88
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/apps.py
@@ -0,0 +1,6 @@
+from django.apps import AppConfig
+
+
+class EmbeddingConfig(AppConfig):
+ default_auto_field = 'django.db.models.BigAutoField'
+ name = 'embedding'
diff --git a/src/MaxKB-1.5.1/apps/embedding/migrations/0001_initial.py b/src/MaxKB-1.5.1/apps/embedding/migrations/0001_initial.py
new file mode 100644
index 0000000..82e850e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/migrations/0001_initial.py
@@ -0,0 +1,35 @@
+# Generated by Django 4.1.10 on 2024-03-18 17:48
+
+import common.field.vector_field
+from django.db import migrations, models
+import django.db.models.deletion
+
+
+class Migration(migrations.Migration):
+
+ initial = True
+
+ dependencies = [
+ ('dataset', '0001_initial'),
+ ]
+
+ operations = [
+ migrations.CreateModel(
+ name='Embedding',
+ fields=[
+ ('id', models.CharField(max_length=128, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('source_id', models.CharField(max_length=128, verbose_name='资源id')),
+ ('source_type', models.CharField(choices=[('0', '问题'), ('1', '段落'), ('2', '标题')], default='0', max_length=5, verbose_name='资源类型')),
+ ('is_active', models.BooleanField(default=True, max_length=1, verbose_name='是否可用')),
+ ('embedding', common.field.vector_field.VectorField(verbose_name='向量')),
+ ('meta', models.JSONField(default=dict, verbose_name='元数据')),
+ ('dataset', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.dataset', verbose_name='文档关联')),
+ ('document', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.document', verbose_name='文档关联')),
+ ('paragraph', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.paragraph', verbose_name='段落关联')),
+ ],
+ options={
+ 'db_table': 'embedding',
+ 'unique_together': {('source_id', 'source_type')},
+ },
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/embedding/migrations/0002_embedding_search_vector.py b/src/MaxKB-1.5.1/apps/embedding/migrations/0002_embedding_search_vector.py
new file mode 100644
index 0000000..c73a5a0
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/migrations/0002_embedding_search_vector.py
@@ -0,0 +1,65 @@
+# Generated by Django 4.1.13 on 2024-04-16 11:43
+import threading
+
+import django.contrib.postgres.search
+from django.db import migrations
+
+from common.util.common import sub_array
+from common.util.ts_vecto_util import to_ts_vector
+from dataset.models import Status
+from embedding.models import Embedding
+
+
+def update_embedding_search_vector(embedding, paragraph_list):
+ paragraphs = [paragraph for paragraph in paragraph_list if paragraph.id == embedding.get('paragraph')]
+ if len(paragraphs) > 0:
+ content = paragraphs[0].title + paragraphs[0].content
+ return Embedding(id=embedding.get('id'), search_vector=to_ts_vector(content))
+ return Embedding(id=embedding.get('id'), search_vector="")
+
+
+def save_keywords(apps, schema_editor):
+ try:
+ document = apps.get_model("dataset", "Document")
+ embedding = apps.get_model("embedding", "Embedding")
+ paragraph = apps.get_model('dataset', 'Paragraph')
+ db_alias = schema_editor.connection.alias
+ document_list = document.objects.using(db_alias).all()
+ for document in document_list:
+ document.status = Status.embedding
+ document.save()
+ paragraph_list = paragraph.objects.using(db_alias).filter(document=document).all()
+ embedding_list = embedding.objects.using(db_alias).filter(document=document).values('id', 'search_vector',
+ 'paragraph')
+ embedding_update_list = [update_embedding_search_vector(embedding, paragraph_list) for embedding
+ in embedding_list]
+ child_array = sub_array(embedding_update_list, 50)
+ for c in child_array:
+ try:
+ embedding.objects.using(db_alias).bulk_update(c, ['search_vector'])
+ except Exception as e:
+ print(e)
+ document.status = Status.success
+ document.save()
+ except Exception as e:
+ print(e)
+
+
+def async_save_keywords(apps, schema_editor):
+ thread = threading.Thread(target=save_keywords, args=(apps, schema_editor))
+ thread.start()
+
+
+class Migration(migrations.Migration):
+ dependencies = [
+ ('embedding', '0001_initial'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='embedding',
+ name='search_vector',
+ field=django.contrib.postgres.search.SearchVectorField(default='', verbose_name='分词'),
+ ),
+ migrations.RunPython(async_save_keywords)
+ ]
diff --git a/src/MaxKB-1.5.1/apps/embedding/migrations/0003_alter_embedding_unique_together.py b/src/MaxKB-1.5.1/apps/embedding/migrations/0003_alter_embedding_unique_together.py
new file mode 100644
index 0000000..9cb4506
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/migrations/0003_alter_embedding_unique_together.py
@@ -0,0 +1,17 @@
+# Generated by Django 4.2.14 on 2024-07-23 18:14
+
+from django.db import migrations
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('embedding', '0002_embedding_search_vector'),
+ ]
+
+ operations = [
+ migrations.AlterUniqueTogether(
+ name='embedding',
+ unique_together=set(),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/embedding/migrations/__init__.py b/src/MaxKB-1.5.1/apps/embedding/migrations/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/embedding/sql/blend_search.sql b/src/MaxKB-1.5.1/apps/embedding/sql/blend_search.sql
new file mode 100644
index 0000000..afb1f00
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/sql/blend_search.sql
@@ -0,0 +1,26 @@
+SELECT
+ paragraph_id,
+ comprehensive_score,
+ comprehensive_score AS similarity
+FROM
+ (
+ SELECT DISTINCT ON
+ ( "paragraph_id" ) ( similarity ),* ,
+ similarity AS comprehensive_score
+ FROM
+ (
+ SELECT
+ *,
+ (( 1 - ( embedding.embedding <=> %s ) )+ts_rank_cd( embedding.search_vector, websearch_to_tsquery('simple', %s ), 32 )) AS similarity
+ FROM
+ embedding ${embedding_query}
+ ) TEMP
+ ORDER BY
+ paragraph_id,
+ similarity DESC
+ ) DISTINCT_TEMP
+WHERE
+ comprehensive_score >%s
+ORDER BY
+ comprehensive_score DESC
+ LIMIT %s
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/embedding/sql/embedding_search.sql b/src/MaxKB-1.5.1/apps/embedding/sql/embedding_search.sql
new file mode 100644
index 0000000..ce3d4a5
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/sql/embedding_search.sql
@@ -0,0 +1,17 @@
+SELECT
+ paragraph_id,
+ comprehensive_score,
+ comprehensive_score as similarity
+FROM
+ (
+ SELECT DISTINCT ON
+ ("paragraph_id") ( similarity ),* ,similarity AS comprehensive_score
+ FROM
+ ( SELECT *, ( 1 - ( embedding.embedding <=> %s ) ) AS similarity FROM embedding ${embedding_query}) TEMP
+ ORDER BY
+ paragraph_id,
+ similarity DESC
+ ) DISTINCT_TEMP
+WHERE comprehensive_score>%s
+ORDER BY comprehensive_score DESC
+LIMIT %s
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/embedding/sql/hit_test.sql b/src/MaxKB-1.5.1/apps/embedding/sql/hit_test.sql
new file mode 100644
index 0000000..8feffc8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/sql/hit_test.sql
@@ -0,0 +1,17 @@
+SELECT
+ paragraph_id,
+ comprehensive_score,
+ comprehensive_score as similarity
+FROM
+ (
+ SELECT DISTINCT ON
+ ("paragraph_id") ( similarity ),* ,similarity AS comprehensive_score
+ FROM
+ ( SELECT *, ( 1 - ( embedding.embedding <=> %s ) ) AS similarity FROM embedding ${embedding_query} ) TEMP
+ ORDER BY
+ paragraph_id,
+ similarity DESC
+ ) DISTINCT_TEMP
+WHERE comprehensive_score>%s
+ORDER BY comprehensive_score DESC
+LIMIT %s
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/embedding/sql/keywords_search.sql b/src/MaxKB-1.5.1/apps/embedding/sql/keywords_search.sql
new file mode 100644
index 0000000..a27d0a6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/sql/keywords_search.sql
@@ -0,0 +1,17 @@
+SELECT
+ paragraph_id,
+ comprehensive_score,
+ comprehensive_score as similarity
+FROM
+ (
+ SELECT DISTINCT ON
+ ("paragraph_id") ( similarity ),* ,similarity AS comprehensive_score
+ FROM
+ ( SELECT *,ts_rank_cd(embedding.search_vector,websearch_to_tsquery('simple',%s),32) AS similarity FROM embedding ${keywords_query}) TEMP
+ ORDER BY
+ paragraph_id,
+ similarity DESC
+ ) DISTINCT_TEMP
+WHERE comprehensive_score>%s
+ORDER BY comprehensive_score DESC
+LIMIT %s
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/embedding/task/__init__.py b/src/MaxKB-1.5.1/apps/embedding/task/__init__.py
new file mode 100644
index 0000000..e5e7dd3
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/task/__init__.py
@@ -0,0 +1 @@
+from .embedding import *
diff --git a/src/MaxKB-1.5.1/apps/embedding/task/embedding.py b/src/MaxKB-1.5.1/apps/embedding/task/embedding.py
new file mode 100644
index 0000000..779969c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/task/embedding.py
@@ -0,0 +1,229 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/8/19 14:13
+ @desc:
+"""
+
+import logging
+import traceback
+from typing import List
+
+from celery_once import QueueOnce
+from django.db.models import QuerySet
+
+from common.config.embedding_config import ModelManage
+from common.event import ListenerManagement, UpdateProblemArgs, UpdateEmbeddingDatasetIdArgs, \
+ UpdateEmbeddingDocumentIdArgs
+from dataset.models import Document
+from ops import celery_app
+from setting.models import Model
+from setting.models_provider import get_model
+
+max_kb_error = logging.getLogger("max_kb_error")
+max_kb = logging.getLogger("max_kb")
+
+
+def get_embedding_model(model_id):
+ model = QuerySet(Model).filter(id=model_id).first()
+ embedding_model = ModelManage.get_model(model_id,
+ lambda _id: get_model(model))
+ return embedding_model
+
+
+@celery_app.task(base=QueueOnce, once={'keys': ['paragraph_id']}, name='celery:embedding_by_paragraph')
+def embedding_by_paragraph(paragraph_id, model_id):
+ embedding_model = get_embedding_model(model_id)
+ ListenerManagement.embedding_by_paragraph(paragraph_id, embedding_model)
+
+
+@celery_app.task(base=QueueOnce, once={'keys': ['paragraph_id_list']}, name='celery:embedding_by_paragraph_data_list')
+def embedding_by_paragraph_data_list(data_list, paragraph_id_list, model_id):
+ embedding_model = get_embedding_model(model_id)
+ ListenerManagement.embedding_by_paragraph_data_list(data_list, paragraph_id_list, embedding_model)
+
+
+@celery_app.task(base=QueueOnce, once={'keys': ['paragraph_id_list']}, name='celery:embedding_by_paragraph_list')
+def embedding_by_paragraph_list(paragraph_id_list, model_id):
+ embedding_model = get_embedding_model(model_id)
+ ListenerManagement.embedding_by_paragraph_list(paragraph_id_list, embedding_model)
+
+
+@celery_app.task(base=QueueOnce, once={'keys': ['document_id']}, name='celery:embedding_by_document')
+def embedding_by_document(document_id, model_id):
+ """
+ 向量化文档
+ @param document_id: 文档id
+ @param model_id 向量模型
+ :return: None
+ """
+ embedding_model = get_embedding_model(model_id)
+ ListenerManagement.embedding_by_document(document_id, embedding_model)
+
+
+@celery_app.task(name='celery:embedding_by_document_list')
+def embedding_by_document_list(document_id_list, model_id):
+ """
+ 向量化文档
+ @param document_id_list: 文档id列表
+ @param model_id 向量模型
+ :return: None
+ """
+ print(document_id_list)
+ for document_id in document_id_list:
+ embedding_by_document.delay(document_id, model_id)
+
+
+@celery_app.task(base=QueueOnce, once={'keys': ['dataset_id']}, name='celery:embedding_by_dataset')
+def embedding_by_dataset(dataset_id, model_id):
+ """
+ 向量化知识库
+ @param dataset_id: 知识库id
+ @param model_id 向量模型
+ :return: None
+ """
+ max_kb.info(f"开始--->向量化数据集:{dataset_id}")
+ try:
+ ListenerManagement.delete_embedding_by_dataset(dataset_id)
+ document_list = QuerySet(Document).filter(dataset_id=dataset_id)
+ max_kb.info(f"数据集文档:{[d.name for d in document_list]}")
+ for document in document_list:
+ try:
+ embedding_by_document.delay(document.id, model_id)
+ except Exception as e:
+ pass
+ except Exception as e:
+ max_kb_error.error(f'向量化数据集:{dataset_id}出现错误{str(e)}{traceback.format_exc()}')
+ finally:
+ max_kb.info(f"结束--->向量化数据集:{dataset_id}")
+
+
+def embedding_by_problem(args, model_id):
+ """
+ 向量话问题
+ @param args: 问题对象
+ @param model_id: 模型id
+ @return:
+ """
+ embedding_model = get_embedding_model(model_id)
+ ListenerManagement.embedding_by_problem(args, embedding_model)
+
+
+def delete_embedding_by_document(document_id):
+ """
+ 删除指定文档id的向量
+ @param document_id: 文档id
+ @return: None
+ """
+
+ ListenerManagement.delete_embedding_by_document(document_id)
+
+
+def delete_embedding_by_document_list(document_id_list: List[str]):
+ """
+ 删除指定文档列表的向量数据
+ @param document_id_list: 文档id列表
+ @return: None
+ """
+ ListenerManagement.delete_embedding_by_document_list(document_id_list)
+
+
+def delete_embedding_by_dataset(dataset_id):
+ """
+ 删除指定数据集向量数据
+ @param dataset_id: 数据集id
+ @return: None
+ """
+ ListenerManagement.delete_embedding_by_dataset(dataset_id)
+
+
+def delete_embedding_by_paragraph(paragraph_id):
+ """
+ 删除指定段落的向量数据
+ @param paragraph_id: 段落id
+ @return: None
+ """
+ ListenerManagement.delete_embedding_by_paragraph(paragraph_id)
+
+
+def delete_embedding_by_source(source_id):
+ """
+ 删除指定资源id的向量数据
+ @param source_id: 资源id
+ @return: None
+ """
+ ListenerManagement.delete_embedding_by_source(source_id)
+
+
+def disable_embedding_by_paragraph(paragraph_id):
+ """
+ 禁用某个段落id的向量
+ @param paragraph_id: 段落id
+ @return: None
+ """
+ ListenerManagement.disable_embedding_by_paragraph(paragraph_id)
+
+
+def enable_embedding_by_paragraph(paragraph_id):
+ """
+ 开启某个段落id的向量数据
+ @param paragraph_id: 段落id
+ @return: None
+ """
+ ListenerManagement.enable_embedding_by_paragraph(paragraph_id)
+
+
+def delete_embedding_by_source_ids(source_ids: List[str]):
+ """
+ 删除向量根据source_id_list
+ @param source_ids:
+ @return:
+ """
+ ListenerManagement.delete_embedding_by_source_ids(source_ids)
+
+
+def update_problem_embedding(problem_id: str, problem_content: str, model_id):
+ """
+ 更新问题
+ @param problem_id:
+ @param problem_content:
+ @param model_id:
+ @return:
+ """
+ model = get_embedding_model(model_id)
+ ListenerManagement.update_problem(UpdateProblemArgs(problem_id, problem_content, model))
+
+
+def update_embedding_dataset_id(paragraph_id_list, target_dataset_id):
+ """
+ 修改向量数据到指定知识库
+ @param paragraph_id_list: 指定段落的向量数据
+ @param target_dataset_id: 知识库id
+ @return:
+ """
+
+ ListenerManagement.update_embedding_dataset_id(
+ UpdateEmbeddingDatasetIdArgs(paragraph_id_list, target_dataset_id))
+
+
+def delete_embedding_by_paragraph_ids(paragraph_ids: List[str]):
+ """
+ 删除指定段落列表的向量数据
+ @param paragraph_ids: 段落列表
+ @return: None
+ """
+ ListenerManagement.delete_embedding_by_paragraph_ids(paragraph_ids)
+
+
+def update_embedding_document_id(paragraph_id_list, target_document_id, target_dataset_id,
+ target_embedding_model_id=None):
+ target_embedding_model = get_embedding_model(
+ target_embedding_model_id) if target_embedding_model_id is not None else None
+ ListenerManagement.update_embedding_document_id(
+ UpdateEmbeddingDocumentIdArgs(paragraph_id_list, target_document_id, target_dataset_id, target_embedding_model))
+
+
+def delete_embedding_by_dataset_id_list(dataset_id_list):
+ ListenerManagement.delete_embedding_by_dataset_id_list(dataset_id_list)
diff --git a/src/MaxKB-1.5.1/apps/embedding/tests.py b/src/MaxKB-1.5.1/apps/embedding/tests.py
new file mode 100644
index 0000000..7ce503c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/tests.py
@@ -0,0 +1,3 @@
+from django.test import TestCase
+
+# Create your tests here.
diff --git a/src/MaxKB-1.5.1/apps/embedding/vector/base_vector.py b/src/MaxKB-1.5.1/apps/embedding/vector/base_vector.py
new file mode 100644
index 0000000..f9ef23d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/vector/base_vector.py
@@ -0,0 +1,193 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: base_vector.py
+ @date:2023/10/18 19:16
+ @desc:
+"""
+import threading
+from abc import ABC, abstractmethod
+from functools import reduce
+from typing import List, Dict
+
+from langchain_core.embeddings import Embeddings
+
+from common.chunk import text_to_chunk
+from common.util.common import sub_array
+from embedding.models import SourceType, SearchMode
+
+lock = threading.Lock()
+
+
+def chunk_data(data: Dict):
+ if str(data.get('source_type')) == SourceType.PARAGRAPH.value:
+ text = data.get('text')
+ chunk_list = text_to_chunk(text)
+ return [{**data, 'text': chunk} for chunk in chunk_list]
+ return [data]
+
+
+def chunk_data_list(data_list: List[Dict]):
+ result = [chunk_data(data) for data in data_list]
+ return reduce(lambda x, y: [*x, *y], result, [])
+
+
+class BaseVectorStore(ABC):
+ vector_exists = False
+
+ @abstractmethod
+ def vector_is_create(self) -> bool:
+ """
+ 判断向量库是否创建
+ :return: 是否创建向量库
+ """
+ pass
+
+ @abstractmethod
+ def vector_create(self):
+ """
+ 创建 向量库
+ :return:
+ """
+ pass
+
+ def save_pre_handler(self):
+ """
+ 插入前置处理器 主要是判断向量库是否创建
+ :return: True
+ """
+ if not BaseVectorStore.vector_exists:
+ if not self.vector_is_create():
+ self.vector_create()
+ BaseVectorStore.vector_exists = True
+ return True
+
+ def save(self, text, source_type: SourceType, dataset_id: str, document_id: str, paragraph_id: str, source_id: str,
+ is_active: bool,
+ embedding: Embeddings):
+ """
+ 插入向量数据
+ :param source_id: 资源id
+ :param dataset_id: 知识库id
+ :param text: 文本
+ :param source_type: 资源类型
+ :param document_id: 文档id
+ :param is_active: 是否禁用
+ :param embedding: 向量化处理器
+ :param paragraph_id 段落id
+ :return: bool
+ """
+ self.save_pre_handler()
+ data = {'document_id': document_id, 'paragraph_id': paragraph_id, 'dataset_id': dataset_id,
+ 'is_active': is_active, 'source_id': source_id, 'source_type': source_type, 'text': text}
+ chunk_list = chunk_data(data)
+ result = sub_array(chunk_list)
+ for child_array in result:
+ self._batch_save(child_array, embedding, lambda: True)
+
+ def batch_save(self, data_list: List[Dict], embedding: Embeddings, is_save_function):
+ # 获取锁
+ lock.acquire()
+ try:
+ """
+ 批量插入
+ :param data_list: 数据列表
+ :param embedding: 向量化处理器
+ :return: bool
+ """
+ self.save_pre_handler()
+ chunk_list = chunk_data_list(data_list)
+ result = sub_array(chunk_list)
+ for child_array in result:
+ if is_save_function():
+ self._batch_save(child_array, embedding, is_save_function)
+ else:
+ break
+ finally:
+ # 释放锁
+ lock.release()
+ return True
+
+ @abstractmethod
+ def _save(self, text, source_type: SourceType, dataset_id: str, document_id: str, paragraph_id: str, source_id: str,
+ is_active: bool,
+ embedding: Embeddings):
+ pass
+
+ @abstractmethod
+ def _batch_save(self, text_list: List[Dict], embedding: Embeddings, is_save_function):
+ pass
+
+ def search(self, query_text, dataset_id_list: list[str], exclude_document_id_list: list[str],
+ exclude_paragraph_list: list[str],
+ is_active: bool,
+ embedding: Embeddings):
+ if dataset_id_list is None or len(dataset_id_list) == 0:
+ return []
+ embedding_query = embedding.embed_query(query_text)
+ result = self.query(embedding_query, dataset_id_list, exclude_document_id_list, exclude_paragraph_list,
+ is_active, 1, 3, 0.65)
+ return result[0]
+
+ @abstractmethod
+ def query(self, query_text: str, query_embedding: List[float], dataset_id_list: list[str],
+ exclude_document_id_list: list[str],
+ exclude_paragraph_list: list[str], is_active: bool, top_n: int, similarity: float,
+ search_mode: SearchMode):
+ pass
+
+ @abstractmethod
+ def hit_test(self, query_text, dataset_id: list[str], exclude_document_id_list: list[str], top_number: int,
+ similarity: float,
+ search_mode: SearchMode,
+ embedding: Embeddings):
+ pass
+
+ @abstractmethod
+ def update_by_paragraph_id(self, paragraph_id: str, instance: Dict):
+ pass
+
+ @abstractmethod
+ def update_by_paragraph_ids(self, paragraph_ids: str, instance: Dict):
+ pass
+
+ @abstractmethod
+ def update_by_source_id(self, source_id: str, instance: Dict):
+ pass
+
+ @abstractmethod
+ def update_by_source_ids(self, source_ids: List[str], instance: Dict):
+ pass
+
+ @abstractmethod
+ def delete_by_dataset_id(self, dataset_id: str):
+ pass
+
+ @abstractmethod
+ def delete_by_document_id(self, document_id: str):
+ pass
+
+ @abstractmethod
+ def delete_by_document_id_list(self, document_id_list: List[str]):
+ pass
+
+ @abstractmethod
+ def delete_by_dataset_id_list(self, dataset_id_list: List[str]):
+ pass
+
+ @abstractmethod
+ def delete_by_source_id(self, source_id: str, source_type: str):
+ pass
+
+ @abstractmethod
+ def delete_by_source_ids(self, source_ids: List[str], source_type: str):
+ pass
+
+ @abstractmethod
+ def delete_by_paragraph_id(self, paragraph_id: str):
+ pass
+
+ @abstractmethod
+ def delete_by_paragraph_ids(self, paragraph_ids: List[str]):
+ pass
diff --git a/src/MaxKB-1.5.1/apps/embedding/vector/pg_vector.py b/src/MaxKB-1.5.1/apps/embedding/vector/pg_vector.py
new file mode 100644
index 0000000..8cd2146
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/vector/pg_vector.py
@@ -0,0 +1,220 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: pg_vector.py
+ @date:2023/10/19 15:28
+ @desc:
+"""
+import json
+import os
+import uuid
+from abc import ABC, abstractmethod
+from typing import Dict, List
+
+from django.db.models import QuerySet
+from langchain_core.embeddings import Embeddings
+
+from common.db.search import generate_sql_by_query_dict
+from common.db.sql_execute import select_list
+from common.util.file_util import get_file_content
+from common.util.ts_vecto_util import to_ts_vector, to_query
+from embedding.models import Embedding, SourceType, SearchMode
+from embedding.vector.base_vector import BaseVectorStore
+from smartdoc.conf import PROJECT_DIR
+
+
+class PGVector(BaseVectorStore):
+
+ def delete_by_source_ids(self, source_ids: List[str], source_type: str):
+ if len(source_ids) == 0:
+ return
+ QuerySet(Embedding).filter(source_id__in=source_ids, source_type=source_type).delete()
+
+ def update_by_source_ids(self, source_ids: List[str], instance: Dict):
+ QuerySet(Embedding).filter(source_id__in=source_ids).update(**instance)
+
+ def vector_is_create(self) -> bool:
+ # 项目启动默认是创建好的 不需要再创建
+ return True
+
+ def vector_create(self):
+ return True
+
+ def _save(self, text, source_type: SourceType, dataset_id: str, document_id: str, paragraph_id: str, source_id: str,
+ is_active: bool,
+ embedding: Embeddings):
+ text_embedding = embedding.embed_query(text)
+ embedding = Embedding(id=uuid.uuid1(),
+ dataset_id=dataset_id,
+ document_id=document_id,
+ is_active=is_active,
+ paragraph_id=paragraph_id,
+ source_id=source_id,
+ embedding=text_embedding,
+ source_type=source_type,
+ search_vector=to_ts_vector(text))
+ embedding.save()
+ return True
+
+ def _batch_save(self, text_list: List[Dict], embedding: Embeddings, is_save_function):
+ texts = [row.get('text') for row in text_list]
+ embeddings = embedding.embed_documents(texts)
+ embedding_list = [Embedding(id=uuid.uuid1(),
+ document_id=text_list[index].get('document_id'),
+ paragraph_id=text_list[index].get('paragraph_id'),
+ dataset_id=text_list[index].get('dataset_id'),
+ is_active=text_list[index].get('is_active', True),
+ source_id=text_list[index].get('source_id'),
+ source_type=text_list[index].get('source_type'),
+ embedding=embeddings[index],
+ search_vector=to_ts_vector(text_list[index]['text'])) for index in
+ range(0, len(texts))]
+ if is_save_function():
+ QuerySet(Embedding).bulk_create(embedding_list) if len(embedding_list) > 0 else None
+ return True
+
+ def hit_test(self, query_text, dataset_id_list: list[str], exclude_document_id_list: list[str], top_number: int,
+ similarity: float,
+ search_mode: SearchMode,
+ embedding: Embeddings):
+ if dataset_id_list is None or len(dataset_id_list) == 0:
+ return []
+ exclude_dict = {}
+ embedding_query = embedding.embed_query(query_text)
+ query_set = QuerySet(Embedding).filter(dataset_id__in=dataset_id_list, is_active=True)
+ if exclude_document_id_list is not None and len(exclude_document_id_list) > 0:
+ exclude_dict.__setitem__('document_id__in', exclude_document_id_list)
+ query_set = query_set.exclude(**exclude_dict)
+ for search_handle in search_handle_list:
+ if search_handle.support(search_mode):
+ return search_handle.handle(query_set, query_text, embedding_query, top_number, similarity, search_mode)
+
+ def query(self, query_text: str, query_embedding: List[float], dataset_id_list: list[str],
+ exclude_document_id_list: list[str],
+ exclude_paragraph_list: list[str], is_active: bool, top_n: int, similarity: float,
+ search_mode: SearchMode):
+ exclude_dict = {}
+ if dataset_id_list is None or len(dataset_id_list) == 0:
+ return []
+ query_set = QuerySet(Embedding).filter(dataset_id__in=dataset_id_list, is_active=is_active)
+ if exclude_document_id_list is not None and len(exclude_document_id_list) > 0:
+ query_set = query_set.exclude(document_id__in=exclude_document_id_list)
+ if exclude_paragraph_list is not None and len(exclude_paragraph_list) > 0:
+ query_set = query_set.exclude(paragraph_id__in=exclude_paragraph_list)
+ query_set = query_set.exclude(**exclude_dict)
+ for search_handle in search_handle_list:
+ if search_handle.support(search_mode):
+ return search_handle.handle(query_set, query_text, query_embedding, top_n, similarity, search_mode)
+
+ def update_by_source_id(self, source_id: str, instance: Dict):
+ QuerySet(Embedding).filter(source_id=source_id).update(**instance)
+
+ def update_by_paragraph_id(self, paragraph_id: str, instance: Dict):
+ QuerySet(Embedding).filter(paragraph_id=paragraph_id).update(**instance)
+
+ def update_by_paragraph_ids(self, paragraph_id: str, instance: Dict):
+ QuerySet(Embedding).filter(paragraph_id__in=paragraph_id).update(**instance)
+
+ def delete_by_dataset_id(self, dataset_id: str):
+ QuerySet(Embedding).filter(dataset_id=dataset_id).delete()
+
+ def delete_by_dataset_id_list(self, dataset_id_list: List[str]):
+ QuerySet(Embedding).filter(dataset_id__in=dataset_id_list).delete()
+
+ def delete_by_document_id(self, document_id: str):
+ QuerySet(Embedding).filter(document_id=document_id).delete()
+ return True
+
+ def delete_by_document_id_list(self, document_id_list: List[str]):
+ if len(document_id_list) == 0:
+ return True
+ return QuerySet(Embedding).filter(document_id__in=document_id_list).delete()
+
+ def delete_by_source_id(self, source_id: str, source_type: str):
+ QuerySet(Embedding).filter(source_id=source_id, source_type=source_type).delete()
+ return True
+
+ def delete_by_paragraph_id(self, paragraph_id: str):
+ QuerySet(Embedding).filter(paragraph_id=paragraph_id).delete()
+
+ def delete_by_paragraph_ids(self, paragraph_ids: List[str]):
+ QuerySet(Embedding).filter(paragraph_id__in=paragraph_ids).delete()
+
+
+class ISearch(ABC):
+ @abstractmethod
+ def support(self, search_mode: SearchMode):
+ pass
+
+ @abstractmethod
+ def handle(self, query_set, query_text, query_embedding, top_number: int,
+ similarity: float, search_mode: SearchMode):
+ pass
+
+
+class EmbeddingSearch(ISearch):
+ def handle(self,
+ query_set,
+ query_text,
+ query_embedding,
+ top_number: int,
+ similarity: float,
+ search_mode: SearchMode):
+ exec_sql, exec_params = generate_sql_by_query_dict({'embedding_query': query_set},
+ select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "embedding", 'sql',
+ 'embedding_search.sql')),
+ with_table_name=True)
+ embedding_model = select_list(exec_sql,
+ [json.dumps(query_embedding), *exec_params, similarity, top_number])
+ return embedding_model
+
+ def support(self, search_mode: SearchMode):
+ return search_mode.value == SearchMode.embedding.value
+
+
+class KeywordsSearch(ISearch):
+ def handle(self,
+ query_set,
+ query_text,
+ query_embedding,
+ top_number: int,
+ similarity: float,
+ search_mode: SearchMode):
+ exec_sql, exec_params = generate_sql_by_query_dict({'keywords_query': query_set},
+ select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "embedding", 'sql',
+ 'keywords_search.sql')),
+ with_table_name=True)
+ embedding_model = select_list(exec_sql,
+ [to_query(query_text), *exec_params, similarity, top_number])
+ return embedding_model
+
+ def support(self, search_mode: SearchMode):
+ return search_mode.value == SearchMode.keywords.value
+
+
+class BlendSearch(ISearch):
+ def handle(self,
+ query_set,
+ query_text,
+ query_embedding,
+ top_number: int,
+ similarity: float,
+ search_mode: SearchMode):
+ exec_sql, exec_params = generate_sql_by_query_dict({'embedding_query': query_set},
+ select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "embedding", 'sql',
+ 'blend_search.sql')),
+ with_table_name=True)
+ embedding_model = select_list(exec_sql,
+ [json.dumps(query_embedding), to_query(query_text), *exec_params, similarity,
+ top_number])
+ return embedding_model
+
+ def support(self, search_mode: SearchMode):
+ return search_mode.value == SearchMode.blend.value
+
+
+search_handle_list = [EmbeddingSearch(), KeywordsSearch(), BlendSearch()]
diff --git a/src/MaxKB-1.5.1/apps/embedding/views.py b/src/MaxKB-1.5.1/apps/embedding/views.py
new file mode 100644
index 0000000..91ea44a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/embedding/views.py
@@ -0,0 +1,3 @@
+from django.shortcuts import render
+
+# Create your views here.
diff --git a/src/MaxKB-1.5.1/apps/function_lib/__init__.py b/src/MaxKB-1.5.1/apps/function_lib/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/function_lib/admin.py b/src/MaxKB-1.5.1/apps/function_lib/admin.py
new file mode 100644
index 0000000..8c38f3f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/admin.py
@@ -0,0 +1,3 @@
+from django.contrib import admin
+
+# Register your models here.
diff --git a/src/MaxKB-1.5.1/apps/function_lib/apps.py b/src/MaxKB-1.5.1/apps/function_lib/apps.py
new file mode 100644
index 0000000..11957d6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/apps.py
@@ -0,0 +1,6 @@
+from django.apps import AppConfig
+
+
+class FunctionLibConfig(AppConfig):
+ default_auto_field = 'django.db.models.BigAutoField'
+ name = 'function_lib'
diff --git a/src/MaxKB-1.5.1/apps/function_lib/migrations/0001_initial.py b/src/MaxKB-1.5.1/apps/function_lib/migrations/0001_initial.py
new file mode 100644
index 0000000..bb2fd60
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/migrations/0001_initial.py
@@ -0,0 +1,34 @@
+# Generated by Django 4.2.15 on 2024-08-13 10:04
+
+import django.contrib.postgres.fields
+from django.db import migrations, models
+import django.db.models.deletion
+import uuid
+
+
+class Migration(migrations.Migration):
+
+ initial = True
+
+ dependencies = [
+ ('users', '0004_alter_user_email'),
+ ]
+
+ operations = [
+ migrations.CreateModel(
+ name='FunctionLib',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('name', models.CharField(max_length=64, verbose_name='函数名称')),
+ ('desc', models.CharField(max_length=128, verbose_name='描述')),
+ ('code', models.CharField(max_length=102400, verbose_name='python代码')),
+ ('input_field_list', django.contrib.postgres.fields.ArrayField(base_field=models.JSONField(default=dict, verbose_name='输入字段'), default=list, size=None, verbose_name='输入字段列表')),
+ ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='users.user', verbose_name='用户id')),
+ ],
+ options={
+ 'db_table': 'function_lib',
+ },
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/function_lib/migrations/__init__.py b/src/MaxKB-1.5.1/apps/function_lib/migrations/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/function_lib/serializers/function_lib_serializer.py b/src/MaxKB-1.5.1/apps/function_lib/serializers/function_lib_serializer.py
new file mode 100644
index 0000000..468b07b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/serializers/function_lib_serializer.py
@@ -0,0 +1,206 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: function_lib_serializer.py
+ @date:2024/8/2 17:35
+ @desc:
+"""
+import json
+import re
+import uuid
+
+from django.core import validators
+from django.db.models import QuerySet
+from rest_framework import serializers
+
+from common.db.search import page_search
+from common.exception.app_exception import AppApiException
+from common.util.field_message import ErrMessage
+from common.util.function_code import FunctionExecutor
+from function_lib.models.function import FunctionLib
+from smartdoc.const import CONFIG
+
+function_executor = FunctionExecutor(CONFIG.get('SANDBOX'))
+
+
+class FunctionLibModelSerializer(serializers.ModelSerializer):
+ class Meta:
+ model = FunctionLib
+ fields = ['id', 'name', 'desc', 'code', 'input_field_list',
+ 'create_time', 'update_time']
+
+
+class FunctionLibInputField(serializers.Serializer):
+ name = serializers.CharField(required=True, error_messages=ErrMessage.char('变量名'))
+ is_required = serializers.BooleanField(required=True, error_messages=ErrMessage.boolean("是否必填"))
+ type = serializers.CharField(required=True, error_messages=ErrMessage.char("类型"), validators=[
+ validators.RegexValidator(regex=re.compile("^string|int|dict|array|float$"),
+ message="字段只支持string|int|dict|array|float", code=500)
+ ])
+ source = serializers.CharField(required=True, error_messages=ErrMessage.char("来源"), validators=[
+ validators.RegexValidator(regex=re.compile("^custom|reference$"),
+ message="字段只支持custom|reference", code=500)
+ ])
+
+
+class DebugField(serializers.Serializer):
+ name = serializers.CharField(required=True, error_messages=ErrMessage.char('变量名'))
+ value = serializers.CharField(required=False, allow_blank=True, allow_null=True,
+ error_messages=ErrMessage.char("变量值"))
+
+
+class DebugInstance(serializers.Serializer):
+ debug_field_list = DebugField(required=True, many=True)
+ input_field_list = FunctionLibInputField(required=True, many=True)
+ code = serializers.CharField(required=True, error_messages=ErrMessage.char("函数内容"))
+
+
+class EditFunctionLib(serializers.Serializer):
+ name = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("函数名称"))
+
+ desc = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("函数描述"))
+
+ code = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("函数内容"))
+
+ input_field_list = FunctionLibInputField(required=False, many=True)
+
+
+class CreateFunctionLib(serializers.Serializer):
+ name = serializers.CharField(required=True, error_messages=ErrMessage.char("函数名称"))
+
+ desc = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("函数描述"))
+
+ code = serializers.CharField(required=True, error_messages=ErrMessage.char("函数内容"))
+
+ input_field_list = FunctionLibInputField(required=True, many=True)
+
+
+class FunctionLibSerializer(serializers.Serializer):
+ class Query(serializers.Serializer):
+ name = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("函数名称"))
+
+ desc = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("函数描述"))
+
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ def get_query_set(self):
+ query_set = QuerySet(FunctionLib).filter(user_id=self.data.get('user_id'))
+ if self.data.get('name') is not None:
+ query_set = query_set.filter(name__contains=self.data.get('name'))
+ if self.data.get('desc') is not None:
+ query_set = query_set.filter(desc__contains=self.data.get('desc'))
+ query_set = query_set.order_by("-create_time")
+ return query_set
+
+ def list(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ return [FunctionLibModelSerializer(item).data for item in self.get_query_set()]
+
+ def page(self, current_page: int, page_size: int, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ return page_search(current_page, page_size, self.get_query_set(),
+ post_records_handler=lambda row: FunctionLibModelSerializer(row).data)
+
+ class Create(serializers.Serializer):
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ def insert(self, instance, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ CreateFunctionLib(data=instance).is_valid(raise_exception=True)
+ function_lib = FunctionLib(id=uuid.uuid1(), name=instance.get('name'), desc=instance.get('desc'),
+ code=instance.get('code'),
+ user_id=self.data.get('user_id'),
+ input_field_list=instance.get('input_field_list'))
+ function_lib.save()
+ return FunctionLibModelSerializer(function_lib).data
+
+ class Debug(serializers.Serializer):
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ def debug(self, debug_instance, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ DebugInstance(data=debug_instance).is_valid(raise_exception=True)
+ input_field_list = debug_instance.get('input_field_list')
+ code = debug_instance.get('code')
+ debug_field_list = debug_instance.get('debug_field_list')
+ params = {field.get('name'): self.convert_value(field.get('name'), field.get('value'), field.get('type'),
+ field.get('is_required'))
+ for field in
+ [{'value': self.get_field_value(debug_field_list, field.get('name'), field.get('is_required')),
+ **field} for field in
+ input_field_list]}
+ return function_executor.exec_code(code, params)
+
+ @staticmethod
+ def get_field_value(debug_field_list, name, is_required):
+ result = [field for field in debug_field_list if field.get('name') == name]
+ if len(result) > 0:
+ return result[-1].get('value')
+ if is_required:
+ raise AppApiException(500, f"{name}字段未设置值")
+ return None
+
+ @staticmethod
+ def convert_value(name: str, value: str, _type: str, is_required: bool):
+ if not is_required and value is None:
+ return None
+ try:
+ if _type == 'int':
+ return int(value)
+ if _type == 'float':
+ return float(value)
+ if _type == 'dict':
+ v = json.loads(value)
+ if isinstance(v, dict):
+ return v
+ raise Exception("类型错误")
+ if _type == 'array':
+ v = json.loads(value)
+ if isinstance(v, list):
+ return v
+ raise Exception("类型错误")
+ return value
+ except Exception as e:
+ raise AppApiException(500, f'字段:{name}类型:{_type}值:{value}类型转换错误')
+
+ class Operate(serializers.Serializer):
+ id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("函数id"))
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(FunctionLib).filter(id=self.data.get('id'), user_id=self.data.get('user_id')).exists():
+ raise AppApiException(500, '函数不存在')
+
+ def delete(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ QuerySet(FunctionLib).filter(id=self.data.get('id')).delete()
+ return True
+
+ def edit(self, instance, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ EditFunctionLib(data=instance).is_valid(raise_exception=True)
+ edit_field_list = ['name', 'desc', 'code', 'input_field_list']
+ edit_dict = {field: instance.get(field) for field in edit_field_list if (
+ field in instance and instance.get(field) is not None)}
+ QuerySet(FunctionLib).filter(id=self.data.get('id')).update(**edit_dict)
+ return self.one(False)
+
+ def one(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ function_lib = QuerySet(FunctionLib).filter(id=self.data.get('id')).first()
+ return FunctionLibModelSerializer(function_lib).data
diff --git a/src/MaxKB-1.5.1/apps/function_lib/swagger_api/function_lib_api.py b/src/MaxKB-1.5.1/apps/function_lib/swagger_api/function_lib_api.py
new file mode 100644
index 0000000..ce396c6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/swagger_api/function_lib_api.py
@@ -0,0 +1,168 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: function_lib_api.py
+ @date:2024/8/2 17:11
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class FunctionLibApi(ApiMixin):
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'name', 'desc', 'code', 'input_field_list', 'create_time',
+ 'update_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="", description="主键id"),
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="函数名称", description="函数名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="函数描述", description="函数描述"),
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="函数内容", description="函数内容"),
+ 'input_field_list': openapi.Schema(type=openapi.TYPE_STRING, title="输入字段", description="输入字段"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间", description="创建时间"),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间", description="修改时间"),
+ }
+ )
+
+ class Query(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='name',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='函数名称'),
+ openapi.Parameter(name='desc',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='函数描述')
+ ]
+
+ class Debug(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=[],
+ properties={
+ 'debug_field_list': openapi.Schema(type=openapi.TYPE_ARRAY,
+ description="输入变量列表",
+ items=openapi.Schema(type=openapi.TYPE_OBJECT,
+ required=[],
+ properties={
+ 'name': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="变量名",
+ description="变量名"),
+ 'value': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="变量值",
+ description="变量值"),
+ })),
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="函数内容", description="函数内容"),
+ 'input_field_list': openapi.Schema(type=openapi.TYPE_ARRAY,
+ description="输入变量列表",
+ items=openapi.Schema(type=openapi.TYPE_OBJECT,
+ required=['name', 'is_required', 'source'],
+ properties={
+ 'name': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="变量名",
+ description="变量名"),
+ 'is_required': openapi.Schema(
+ type=openapi.TYPE_BOOLEAN,
+ title="是否必填",
+ description="是否必填"),
+ 'type': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="字段类型",
+ description="字段类型 string|int|dict|array|float"
+ ),
+ 'source': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="来源",
+ description="来源只支持custom|reference"),
+
+ }))
+ }
+ )
+
+ class Edit(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=[],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="函数名称", description="函数名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="函数描述", description="函数描述"),
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="函数内容", description="函数内容"),
+ 'input_field_list': openapi.Schema(type=openapi.TYPE_ARRAY,
+ description="输入变量列表",
+ items=openapi.Schema(type=openapi.TYPE_OBJECT,
+ required=[],
+ properties={
+ 'name': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="变量名",
+ description="变量名"),
+ 'is_required': openapi.Schema(
+ type=openapi.TYPE_BOOLEAN,
+ title="是否必填",
+ description="是否必填"),
+ 'type': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="字段类型",
+ description="字段类型 string|int|dict|array|float"
+ ),
+ 'source': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="来源",
+ description="来源只支持custom|reference"),
+
+ }))
+ }
+ )
+
+ class Create(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['name', 'code', 'input_field_list'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="函数名称", description="函数名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="函数描述", description="函数描述"),
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="函数内容", description="函数内容"),
+ 'input_field_list': openapi.Schema(type=openapi.TYPE_ARRAY,
+ description="输入变量列表",
+ items=openapi.Schema(type=openapi.TYPE_OBJECT,
+ required=['name', 'is_required', 'source'],
+ properties={
+ 'name': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="变量名",
+ description="变量名"),
+ 'is_required': openapi.Schema(
+ type=openapi.TYPE_BOOLEAN,
+ title="是否必填",
+ description="是否必填"),
+ 'type': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="字段类型",
+ description="字段类型 string|int|dict|array|float"
+ ),
+ 'source': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="来源",
+ description="来源只支持custom|reference"),
+
+ }))
+ }
+ )
diff --git a/src/MaxKB-1.5.1/apps/function_lib/task/__init__.py b/src/MaxKB-1.5.1/apps/function_lib/task/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/function_lib/tests.py b/src/MaxKB-1.5.1/apps/function_lib/tests.py
new file mode 100644
index 0000000..7ce503c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/tests.py
@@ -0,0 +1,3 @@
+from django.test import TestCase
+
+# Create your tests here.
diff --git a/src/MaxKB-1.5.1/apps/function_lib/urls.py b/src/MaxKB-1.5.1/apps/function_lib/urls.py
new file mode 100644
index 0000000..a393fd5
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/urls.py
@@ -0,0 +1,12 @@
+from django.urls import path
+
+from . import views
+
+app_name = "function_lib"
+urlpatterns = [
+ path('function_lib', views.FunctionLibView.as_view()),
+ path('function_lib/debug', views.FunctionLibView.Debug.as_view()),
+ path('function_lib/', views.FunctionLibView.Operate.as_view()),
+ path("function_lib//", views.FunctionLibView.Page.as_view(),
+ name="function_lib_page"),
+]
diff --git a/src/MaxKB-1.5.1/apps/function_lib/views/__init__.py b/src/MaxKB-1.5.1/apps/function_lib/views/__init__.py
new file mode 100644
index 0000000..aadec35
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/views/__init__.py
@@ -0,0 +1,9 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: __init__.py
+ @date:2024/8/2 14:53
+ @desc:
+"""
+from .function_lib_views import *
diff --git a/src/MaxKB-1.5.1/apps/function_lib/views/function_lib_views.py b/src/MaxKB-1.5.1/apps/function_lib/views/function_lib_views.py
new file mode 100644
index 0000000..7589a60
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/function_lib/views/function_lib_views.py
@@ -0,0 +1,109 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: function_lib_views.py
+ @date:2024/8/2 17:08
+ @desc:
+"""
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.request import Request
+from rest_framework.views import APIView
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import RoleConstants
+from common.response import result
+from function_lib.serializers.function_lib_serializer import FunctionLibSerializer
+from function_lib.swagger_api.function_lib_api import FunctionLibApi
+
+
+class FunctionLibView(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=["GET"], detail=False)
+ @swagger_auto_schema(operation_summary="获取函数列表",
+ operation_id="获取函数列表",
+ tags=["函数库"],
+ manual_parameters=FunctionLibApi.Query.get_request_params_api())
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def get(self, request: Request):
+ return result.success(
+ FunctionLibSerializer.Query(
+ data={'name': request.query_params.get('name'),
+ 'desc': request.query_params.get('desc'),
+ 'user_id': request.user.id}).list())
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建函数",
+ operation_id="创建函数",
+ request_body=FunctionLibApi.Create.get_request_body_api(),
+ tags=['函数库'])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def post(self, request: Request):
+ return result.success(FunctionLibSerializer.Create(data={'user_id': request.user.id}).insert(request.data))
+
+ class Debug(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="调试函数",
+ operation_id="调试函数",
+ request_body=FunctionLibApi.Debug.get_request_body_api(),
+ tags=['函数库'])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def post(self, request: Request):
+ return result.success(
+ FunctionLibSerializer.Debug(data={'user_id': request.user.id}).debug(
+ request.data))
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改函数",
+ operation_id="修改函数",
+ request_body=FunctionLibApi.Edit.get_request_body_api(),
+ tags=['函数库'])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def put(self, request: Request, function_lib_id: str):
+ return result.success(
+ FunctionLibSerializer.Operate(data={'user_id': request.user.id, 'id': function_lib_id}).edit(
+ request.data))
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除函数",
+ operation_id="删除函数",
+ tags=['函数库'])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def delete(self, request: Request, function_lib_id: str):
+ return result.success(
+ FunctionLibSerializer.Operate(data={'user_id': request.user.id, 'id': function_lib_id}).delete())
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取函数详情",
+ operation_id="获取函数详情",
+ tags=['函数库'])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def get(self, request: Request, function_lib_id: str):
+ return result.success(
+ FunctionLibSerializer.Operate(data={'user_id': request.user.id, 'id': function_lib_id}).one())
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="分页获取函数列表",
+ operation_id="分页获取函数列表",
+ manual_parameters=result.get_page_request_params(
+ FunctionLibApi.Query.get_request_params_api()),
+ responses=result.get_page_api_response(FunctionLibApi.get_response_body_api()),
+ tags=['函数库'])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def get(self, request: Request, current_page: int, page_size: int):
+ return result.success(
+ FunctionLibSerializer.Query(
+ data={'name': request.query_params.get('name'),
+ 'desc': request.query_params.get('desc'),
+ 'user_id': request.user.id}).page(
+ current_page, page_size))
diff --git a/src/MaxKB-1.5.1/apps/manage.py b/src/MaxKB-1.5.1/apps/manage.py
new file mode 100644
index 0000000..dc30985
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/manage.py
@@ -0,0 +1,22 @@
+#!/usr/bin/env python
+"""Django's command-line utility for administrative tasks."""
+import os
+import sys
+
+
+def main():
+ """Run administrative tasks."""
+ os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'smartdoc.settings')
+ try:
+ from django.core.management import execute_from_command_line
+ except ImportError as exc:
+ raise ImportError(
+ "Couldn't import Django. Are you sure it's installed and "
+ "available on your PYTHONPATH environment variable? Did you "
+ "forget to activate a virtual environment?"
+ ) from exc
+ execute_from_command_line(sys.argv)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/src/MaxKB-1.5.1/apps/ops/__init__.py b/src/MaxKB-1.5.1/apps/ops/__init__.py
new file mode 100644
index 0000000..a02f13a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/__init__.py
@@ -0,0 +1,9 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: __init__.py.py
+ @date:2024/8/16 14:47
+ @desc:
+"""
+from .celery import app as celery_app
diff --git a/src/MaxKB-1.5.1/apps/ops/celery/__init__.py b/src/MaxKB-1.5.1/apps/ops/celery/__init__.py
new file mode 100644
index 0000000..55e727b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/celery/__init__.py
@@ -0,0 +1,33 @@
+# -*- coding: utf-8 -*-
+
+import os
+
+from celery import Celery
+from celery.schedules import crontab
+from kombu import Exchange, Queue
+from smartdoc import settings
+from .heatbeat import *
+
+# set the default Django settings module for the 'celery' program.
+os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'smartdoc.settings')
+
+app = Celery('MaxKB')
+
+configs = {k: v for k, v in settings.__dict__.items() if k.startswith('CELERY')}
+configs['worker_concurrency'] = 5
+# Using a string here means the worker will not have to
+# pickle the object when using Windows.
+# app.config_from_object('django.conf:settings', namespace='CELERY')
+
+configs["task_queues"] = [
+ Queue("celery", Exchange("celery"), routing_key="celery"),
+ Queue("model", Exchange("model"), routing_key="model")
+]
+app.namespace = 'CELERY'
+app.conf.update(
+ {key.replace('CELERY_', '') if key.replace('CELERY_', '').lower() == key.replace('CELERY_',
+ '') else key: configs.get(
+ key) for
+ key
+ in configs.keys()})
+app.autodiscover_tasks(lambda: [app_config.split('.')[0] for app_config in settings.INSTALLED_APPS])
diff --git a/src/MaxKB-1.5.1/apps/ops/celery/const.py b/src/MaxKB-1.5.1/apps/ops/celery/const.py
new file mode 100644
index 0000000..2f88702
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/celery/const.py
@@ -0,0 +1,4 @@
+# -*- coding: utf-8 -*-
+#
+
+CELERY_LOG_MAGIC_MARK = b'\x00\x00\x00\x00\x00'
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/ops/celery/decorator.py b/src/MaxKB-1.5.1/apps/ops/celery/decorator.py
new file mode 100644
index 0000000..317a7f7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/celery/decorator.py
@@ -0,0 +1,104 @@
+# -*- coding: utf-8 -*-
+#
+from functools import wraps
+
+_need_registered_period_tasks = []
+_after_app_ready_start_tasks = []
+_after_app_shutdown_clean_periodic_tasks = []
+
+
+def add_register_period_task(task):
+ _need_registered_period_tasks.append(task)
+
+
+def get_register_period_tasks():
+ return _need_registered_period_tasks
+
+
+def add_after_app_shutdown_clean_task(name):
+ _after_app_shutdown_clean_periodic_tasks.append(name)
+
+
+def get_after_app_shutdown_clean_tasks():
+ return _after_app_shutdown_clean_periodic_tasks
+
+
+def add_after_app_ready_task(name):
+ _after_app_ready_start_tasks.append(name)
+
+
+def get_after_app_ready_tasks():
+ return _after_app_ready_start_tasks
+
+
+def register_as_period_task(
+ crontab=None, interval=None, name=None,
+ args=(), kwargs=None,
+ description=''):
+ """
+ Warning: Task must have not any args and kwargs
+ :param crontab: "* * * * *"
+ :param interval: 60*60*60
+ :param args: ()
+ :param kwargs: {}
+ :param description: "
+ :param name: ""
+ :return:
+ """
+ if crontab is None and interval is None:
+ raise SyntaxError("Must set crontab or interval one")
+
+ def decorate(func):
+ if crontab is None and interval is None:
+ raise SyntaxError("Interval and crontab must set one")
+
+ # Because when this decorator run, the task was not created,
+ # So we can't use func.name
+ task = '{func.__module__}.{func.__name__}'.format(func=func)
+ _name = name if name else task
+ add_register_period_task({
+ _name: {
+ 'task': task,
+ 'interval': interval,
+ 'crontab': crontab,
+ 'args': args,
+ 'kwargs': kwargs if kwargs else {},
+ 'description': description
+ }
+ })
+
+ @wraps(func)
+ def wrapper(*args, **kwargs):
+ return func(*args, **kwargs)
+
+ return wrapper
+
+ return decorate
+
+
+def after_app_ready_start(func):
+ # Because when this decorator run, the task was not created,
+ # So we can't use func.name
+ name = '{func.__module__}.{func.__name__}'.format(func=func)
+ if name not in _after_app_ready_start_tasks:
+ add_after_app_ready_task(name)
+
+ @wraps(func)
+ def decorate(*args, **kwargs):
+ return func(*args, **kwargs)
+
+ return decorate
+
+
+def after_app_shutdown_clean_periodic(func):
+ # Because when this decorator run, the task was not created,
+ # So we can't use func.name
+ name = '{func.__module__}.{func.__name__}'.format(func=func)
+ if name not in _after_app_shutdown_clean_periodic_tasks:
+ add_after_app_shutdown_clean_task(name)
+
+ @wraps(func)
+ def decorate(*args, **kwargs):
+ return func(*args, **kwargs)
+
+ return decorate
diff --git a/src/MaxKB-1.5.1/apps/ops/celery/heatbeat.py b/src/MaxKB-1.5.1/apps/ops/celery/heatbeat.py
new file mode 100644
index 0000000..339a3c6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/celery/heatbeat.py
@@ -0,0 +1,25 @@
+from pathlib import Path
+
+from celery.signals import heartbeat_sent, worker_ready, worker_shutdown
+
+
+@heartbeat_sent.connect
+def heartbeat(sender, **kwargs):
+ worker_name = sender.eventer.hostname.split('@')[0]
+ heartbeat_path = Path('/tmp/worker_heartbeat_{}'.format(worker_name))
+ heartbeat_path.touch()
+
+
+@worker_ready.connect
+def worker_ready(sender, **kwargs):
+ worker_name = sender.hostname.split('@')[0]
+ ready_path = Path('/tmp/worker_ready_{}'.format(worker_name))
+ ready_path.touch()
+
+
+@worker_shutdown.connect
+def worker_shutdown(sender, **kwargs):
+ worker_name = sender.hostname.split('@')[0]
+ for signal in ['ready', 'heartbeat']:
+ path = Path('/tmp/worker_{}_{}'.format(signal, worker_name))
+ path.unlink(missing_ok=True)
diff --git a/src/MaxKB-1.5.1/apps/ops/celery/logger.py b/src/MaxKB-1.5.1/apps/ops/celery/logger.py
new file mode 100644
index 0000000..bdadc56
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/celery/logger.py
@@ -0,0 +1,223 @@
+from logging import StreamHandler
+from threading import get_ident
+
+from celery import current_task
+from celery.signals import task_prerun, task_postrun
+from django.conf import settings
+from kombu import Connection, Exchange, Queue, Producer
+from kombu.mixins import ConsumerMixin
+
+from .utils import get_celery_task_log_path
+from .const import CELERY_LOG_MAGIC_MARK
+
+routing_key = 'celery_log'
+celery_log_exchange = Exchange('celery_log_exchange', type='direct')
+celery_log_queue = [Queue('celery_log', celery_log_exchange, routing_key=routing_key)]
+
+
+class CeleryLoggerConsumer(ConsumerMixin):
+ def __init__(self):
+ self.connection = Connection(settings.CELERY_LOG_BROKER_URL)
+
+ def get_consumers(self, Consumer, channel):
+ return [Consumer(queues=celery_log_queue,
+ accept=['pickle', 'json'],
+ callbacks=[self.process_task])
+ ]
+
+ def handle_task_start(self, task_id, message):
+ pass
+
+ def handle_task_end(self, task_id, message):
+ pass
+
+ def handle_task_log(self, task_id, msg, message):
+ pass
+
+ def process_task(self, body, message):
+ action = body.get('action')
+ task_id = body.get('task_id')
+ msg = body.get('msg')
+ if action == CeleryLoggerProducer.ACTION_TASK_LOG:
+ self.handle_task_log(task_id, msg, message)
+ elif action == CeleryLoggerProducer.ACTION_TASK_START:
+ self.handle_task_start(task_id, message)
+ elif action == CeleryLoggerProducer.ACTION_TASK_END:
+ self.handle_task_end(task_id, message)
+
+
+class CeleryLoggerProducer:
+ ACTION_TASK_START, ACTION_TASK_LOG, ACTION_TASK_END = range(3)
+
+ def __init__(self):
+ self.connection = Connection(settings.CELERY_LOG_BROKER_URL)
+
+ @property
+ def producer(self):
+ return Producer(self.connection)
+
+ def publish(self, payload):
+ self.producer.publish(
+ payload, serializer='json', exchange=celery_log_exchange,
+ declare=[celery_log_exchange], routing_key=routing_key
+ )
+
+ def log(self, task_id, msg):
+ payload = {'task_id': task_id, 'msg': msg, 'action': self.ACTION_TASK_LOG}
+ return self.publish(payload)
+
+ def read(self):
+ pass
+
+ def flush(self):
+ pass
+
+ def task_end(self, task_id):
+ payload = {'task_id': task_id, 'action': self.ACTION_TASK_END}
+ return self.publish(payload)
+
+ def task_start(self, task_id):
+ payload = {'task_id': task_id, 'action': self.ACTION_TASK_START}
+ return self.publish(payload)
+
+
+class CeleryTaskLoggerHandler(StreamHandler):
+ terminator = '\r\n'
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+ task_prerun.connect(self.on_task_start)
+ task_postrun.connect(self.on_start_end)
+
+ @staticmethod
+ def get_current_task_id():
+ if not current_task:
+ return
+ task_id = current_task.request.root_id
+ return task_id
+
+ def on_task_start(self, sender, task_id, **kwargs):
+ return self.handle_task_start(task_id)
+
+ def on_start_end(self, sender, task_id, **kwargs):
+ return self.handle_task_end(task_id)
+
+ def after_task_publish(self, sender, body, **kwargs):
+ pass
+
+ def emit(self, record):
+ task_id = self.get_current_task_id()
+ if not task_id:
+ return
+ try:
+ self.write_task_log(task_id, record)
+ self.flush()
+ except Exception:
+ self.handleError(record)
+
+ def write_task_log(self, task_id, msg):
+ pass
+
+ def handle_task_start(self, task_id):
+ pass
+
+ def handle_task_end(self, task_id):
+ pass
+
+
+class CeleryThreadingLoggerHandler(CeleryTaskLoggerHandler):
+ @staticmethod
+ def get_current_thread_id():
+ return str(get_ident())
+
+ def emit(self, record):
+ thread_id = self.get_current_thread_id()
+ try:
+ self.write_thread_task_log(thread_id, record)
+ self.flush()
+ except ValueError:
+ self.handleError(record)
+
+ def write_thread_task_log(self, thread_id, msg):
+ pass
+
+ def handle_task_start(self, task_id):
+ pass
+
+ def handle_task_end(self, task_id):
+ pass
+
+ def handleError(self, record) -> None:
+ pass
+
+
+class CeleryTaskMQLoggerHandler(CeleryTaskLoggerHandler):
+ def __init__(self):
+ self.producer = CeleryLoggerProducer()
+ super().__init__(stream=None)
+
+ def write_task_log(self, task_id, record):
+ msg = self.format(record)
+ self.producer.log(task_id, msg)
+
+ def flush(self):
+ self.producer.flush()
+
+
+class CeleryTaskFileHandler(CeleryTaskLoggerHandler):
+ def __init__(self, *args, **kwargs):
+ self.f = None
+ super().__init__(*args, **kwargs)
+
+ def emit(self, record):
+ msg = self.format(record)
+ if not self.f or self.f.closed:
+ return
+ self.f.write(msg)
+ self.f.write(self.terminator)
+ self.flush()
+
+ def flush(self):
+ self.f and self.f.flush()
+
+ def handle_task_start(self, task_id):
+ log_path = get_celery_task_log_path(task_id)
+ self.f = open(log_path, 'a')
+
+ def handle_task_end(self, task_id):
+ self.f and self.f.close()
+
+
+class CeleryThreadTaskFileHandler(CeleryThreadingLoggerHandler):
+ def __init__(self, *args, **kwargs):
+ self.thread_id_fd_mapper = {}
+ self.task_id_thread_id_mapper = {}
+ super().__init__(*args, **kwargs)
+
+ def write_thread_task_log(self, thread_id, record):
+ f = self.thread_id_fd_mapper.get(thread_id, None)
+ if not f:
+ raise ValueError('Not found thread task file')
+ msg = self.format(record)
+ f.write(msg.encode())
+ f.write(self.terminator.encode())
+ f.flush()
+
+ def flush(self):
+ for f in self.thread_id_fd_mapper.values():
+ f.flush()
+
+ def handle_task_start(self, task_id):
+ log_path = get_celery_task_log_path(task_id)
+ thread_id = self.get_current_thread_id()
+ self.task_id_thread_id_mapper[task_id] = thread_id
+ f = open(log_path, 'ab')
+ self.thread_id_fd_mapper[thread_id] = f
+
+ def handle_task_end(self, task_id):
+ ident_id = self.task_id_thread_id_mapper.get(task_id, '')
+ f = self.thread_id_fd_mapper.pop(ident_id, None)
+ if f and not f.closed:
+ f.write(CELERY_LOG_MAGIC_MARK)
+ f.close()
+ self.task_id_thread_id_mapper.pop(task_id, None)
diff --git a/src/MaxKB-1.5.1/apps/ops/celery/signal_handler.py b/src/MaxKB-1.5.1/apps/ops/celery/signal_handler.py
new file mode 100644
index 0000000..90ed624
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/celery/signal_handler.py
@@ -0,0 +1,63 @@
+# -*- coding: utf-8 -*-
+#
+import logging
+import os
+
+from celery import subtask
+from celery.signals import (
+ worker_ready, worker_shutdown, after_setup_logger
+)
+from django.core.cache import cache
+from django_celery_beat.models import PeriodicTask
+
+from .decorator import get_after_app_ready_tasks, get_after_app_shutdown_clean_tasks
+from .logger import CeleryThreadTaskFileHandler
+
+logger = logging.getLogger(__file__)
+safe_str = lambda x: x
+
+
+@worker_ready.connect
+def on_app_ready(sender=None, headers=None, **kwargs):
+ if cache.get("CELERY_APP_READY", 0) == 1:
+ return
+ cache.set("CELERY_APP_READY", 1, 10)
+ tasks = get_after_app_ready_tasks()
+ logger.debug("Work ready signal recv")
+ logger.debug("Start need start task: [{}]".format(", ".join(tasks)))
+ for task in tasks:
+ periodic_task = PeriodicTask.objects.filter(task=task).first()
+ if periodic_task and not periodic_task.enabled:
+ logger.debug("Periodic task [{}] is disabled!".format(task))
+ continue
+ subtask(task).delay()
+
+
+def delete_files(directory):
+ if os.path.isdir(directory):
+ for filename in os.listdir(directory):
+ file_path = os.path.join(directory, filename)
+ if os.path.isfile(file_path):
+ os.remove(file_path)
+
+
+@worker_shutdown.connect
+def after_app_shutdown_periodic_tasks(sender=None, **kwargs):
+ if cache.get("CELERY_APP_SHUTDOWN", 0) == 1:
+ return
+ cache.set("CELERY_APP_SHUTDOWN", 1, 10)
+ tasks = get_after_app_shutdown_clean_tasks()
+ logger.debug("Worker shutdown signal recv")
+ logger.debug("Clean period tasks: [{}]".format(', '.join(tasks)))
+ PeriodicTask.objects.filter(name__in=tasks).delete()
+
+
+@after_setup_logger.connect
+def add_celery_logger_handler(sender=None, logger=None, loglevel=None, format=None, **kwargs):
+ if not logger:
+ return
+ task_handler = CeleryThreadTaskFileHandler()
+ task_handler.setLevel(loglevel)
+ formatter = logging.Formatter(format)
+ task_handler.setFormatter(formatter)
+ logger.addHandler(task_handler)
diff --git a/src/MaxKB-1.5.1/apps/ops/celery/utils.py b/src/MaxKB-1.5.1/apps/ops/celery/utils.py
new file mode 100644
index 0000000..288089f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/ops/celery/utils.py
@@ -0,0 +1,68 @@
+# -*- coding: utf-8 -*-
+#
+import logging
+import os
+import uuid
+
+from django.conf import settings
+from django_celery_beat.models import (
+ PeriodicTasks
+)
+
+from smartdoc.const import PROJECT_DIR
+
+logger = logging.getLogger(__file__)
+
+
+def disable_celery_periodic_task(task_name):
+ from django_celery_beat.models import PeriodicTask
+ PeriodicTask.objects.filter(name=task_name).update(enabled=False)
+ PeriodicTasks.update_changed()
+
+
+def delete_celery_periodic_task(task_name):
+ from django_celery_beat.models import PeriodicTask
+ PeriodicTask.objects.filter(name=task_name).delete()
+ PeriodicTasks.update_changed()
+
+
+def get_celery_periodic_task(task_name):
+ from django_celery_beat.models import PeriodicTask
+ task = PeriodicTask.objects.filter(name=task_name).first()
+ return task
+
+
+def make_dirs(name, mode=0o755, exist_ok=False):
+ """ 默认权限设置为 0o755 """
+ return os.makedirs(name, mode=mode, exist_ok=exist_ok)
+
+
+def get_task_log_path(base_path, task_id, level=2):
+ task_id = str(task_id)
+ try:
+ uuid.UUID(task_id)
+ except:
+ return os.path.join(PROJECT_DIR, 'data', 'caution.txt')
+
+ rel_path = os.path.join(*task_id[:level], task_id + '.log')
+ path = os.path.join(base_path, rel_path)
+ make_dirs(os.path.dirname(path), exist_ok=True)
+ return path
+
+
+def get_celery_task_log_path(task_id):
+ return get_task_log_path(settings.CELERY_LOG_DIR, task_id)
+
+
+def get_celery_status():
+ from . import app
+ i = app.control.inspect()
+ ping_data = i.ping() or {}
+ active_nodes = [k for k, v in ping_data.items() if v.get('ok') == 'pong']
+ active_queue_worker = set([n.split('@')[0] for n in active_nodes if n])
+ # Celery Worker 数量: 2
+ if len(active_queue_worker) < 2:
+ print("Not all celery worker worked")
+ return False
+ else:
+ return True
diff --git a/src/MaxKB-1.5.1/apps/setting/__init__.py b/src/MaxKB-1.5.1/apps/setting/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/setting/admin.py b/src/MaxKB-1.5.1/apps/setting/admin.py
new file mode 100644
index 0000000..8c38f3f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/admin.py
@@ -0,0 +1,3 @@
+from django.contrib import admin
+
+# Register your models here.
diff --git a/src/MaxKB-1.5.1/apps/setting/apps.py b/src/MaxKB-1.5.1/apps/setting/apps.py
new file mode 100644
index 0000000..57d346a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/apps.py
@@ -0,0 +1,6 @@
+from django.apps import AppConfig
+
+
+class SettingConfig(AppConfig):
+ default_auto_field = 'django.db.models.BigAutoField'
+ name = 'setting'
diff --git a/src/MaxKB-1.5.1/apps/setting/migrations/0001_initial.py b/src/MaxKB-1.5.1/apps/setting/migrations/0001_initial.py
new file mode 100644
index 0000000..f6900dc
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/migrations/0001_initial.py
@@ -0,0 +1,95 @@
+# Generated by Django 4.1.10 on 2024-03-18 16:02
+
+import django.contrib.postgres.fields
+from django.db import migrations, models
+import django.db.models.deletion
+import uuid
+
+
+def insert_default_data(apps, schema_editor):
+ TeamModel = apps.get_model('setting', 'Team')
+ TeamModel.objects.create(user_id='f0dd8f71-e4ee-11ee-8c84-a8a1595801ab', name='admin的团队')
+
+
+class Migration(migrations.Migration):
+ initial = True
+
+ dependencies = [
+ ('users', '0001_initial'),
+ ]
+
+ operations = [
+ migrations.CreateModel(
+ name='Team',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('user',
+ models.OneToOneField(on_delete=django.db.models.deletion.DO_NOTHING, primary_key=True, serialize=False,
+ to='users.user', verbose_name='团队所有者')),
+ ('name', models.CharField(max_length=128, verbose_name='团队名称')),
+ ],
+ options={
+ 'db_table': 'team',
+ },
+ ),
+ migrations.RunPython(insert_default_data),
+ migrations.CreateModel(
+ name='TeamMember',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False,
+ verbose_name='主键id')),
+ ('team', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='setting.team',
+ verbose_name='团队id')),
+ ('user', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='users.user',
+ verbose_name='成员用户id')),
+ ],
+ options={
+ 'db_table': 'team_member',
+ },
+ ),
+ migrations.CreateModel(
+ name='TeamMemberPermission',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False,
+ verbose_name='主键id')),
+ ('auth_target_type',
+ models.CharField(choices=[('DATASET', '数据集'), ('APPLICATION', '应用')], default='DATASET',
+ max_length=128, verbose_name='授权目标')),
+ ('target', models.UUIDField(verbose_name='数据集/应用id')),
+ ('operate', django.contrib.postgres.fields.ArrayField(
+ base_field=models.CharField(blank=True, choices=[('MANAGE', '管理'), ('USE', '使用')],
+ default='USE', max_length=256), size=None,
+ verbose_name='权限操作列表')),
+ ('member', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='setting.teammember',
+ verbose_name='团队成员')),
+ ],
+ options={
+ 'db_table': 'team_member_permission',
+ },
+ ),
+ migrations.CreateModel(
+ name='Model',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False,
+ verbose_name='主键id')),
+ ('name', models.CharField(max_length=128, verbose_name='名称')),
+ ('model_type', models.CharField(max_length=128, verbose_name='模型类型')),
+ ('model_name', models.CharField(max_length=128, verbose_name='模型名称')),
+ ('provider', models.CharField(max_length=128, verbose_name='供应商')),
+ ('credential', models.CharField(max_length=5120, verbose_name='模型认证信息')),
+ ('user', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='users.user',
+ verbose_name='成员用户id')),
+ ],
+ options={
+ 'db_table': 'model',
+ 'unique_together': {('name', 'user_id')},
+ },
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/migrations/0002_systemsetting.py b/src/MaxKB-1.5.1/apps/setting/migrations/0002_systemsetting.py
new file mode 100644
index 0000000..5c2972f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/migrations/0002_systemsetting.py
@@ -0,0 +1,24 @@
+# Generated by Django 4.1.10 on 2024-03-19 16:51
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+ dependencies = [
+ ('setting', '0001_initial'),
+ ]
+
+ operations = [
+ migrations.CreateModel(
+ name='SystemSetting',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('type', models.IntegerField(choices=[(0, '邮箱'), (1, '私钥秘钥')], default=0, primary_key=True, serialize=False, verbose_name='设置类型')),
+ ('meta', models.JSONField(default=dict, verbose_name='配置数据')),
+ ],
+ options={
+ 'db_table': 'system_setting',
+ },
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/migrations/0003_model_meta_model_status.py b/src/MaxKB-1.5.1/apps/setting/migrations/0003_model_meta_model_status.py
new file mode 100644
index 0000000..f4956e8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/migrations/0003_model_meta_model_status.py
@@ -0,0 +1,23 @@
+# Generated by Django 4.1.13 on 2024-03-22 17:51
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('setting', '0002_systemsetting'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='model',
+ name='meta',
+ field=models.JSONField(default=dict, verbose_name='模型元数据,用于存储下载,或者错误信息'),
+ ),
+ migrations.AddField(
+ model_name='model',
+ name='status',
+ field=models.CharField(choices=[('SUCCESS', '成功'), ('ERROR', '失败'), ('DOWNLOAD', '下载中')], default='SUCCESS', max_length=20, verbose_name='设置类型'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/migrations/0004_alter_model_credential.py b/src/MaxKB-1.5.1/apps/setting/migrations/0004_alter_model_credential.py
new file mode 100644
index 0000000..4b5e488
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/migrations/0004_alter_model_credential.py
@@ -0,0 +1,18 @@
+# Generated by Django 4.1.13 on 2024-04-28 18:06
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('setting', '0003_model_meta_model_status'),
+ ]
+
+ operations = [
+ migrations.AlterField(
+ model_name='model',
+ name='credential',
+ field=models.CharField(max_length=102400, verbose_name='模型认证信息'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/migrations/0005_model_permission_type.py b/src/MaxKB-1.5.1/apps/setting/migrations/0005_model_permission_type.py
new file mode 100644
index 0000000..dba081a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/migrations/0005_model_permission_type.py
@@ -0,0 +1,46 @@
+# Generated by Django 4.2.13 on 2024-07-15 15:23
+import json
+
+from django.db import migrations, models
+from django.db.models import QuerySet
+
+from common.util.rsa_util import rsa_long_encrypt
+from setting.models import Status, PermissionType
+from smartdoc.const import CONFIG
+
+default_embedding_model_id = '42f63a3d-427e-11ef-b3ec-a8a1595801ab'
+
+
+def save_default_embedding_model(apps, schema_editor):
+ ModelModel = apps.get_model('setting', 'Model')
+ cache_folder = CONFIG.get('EMBEDDING_MODEL_PATH')
+ model_name = CONFIG.get('EMBEDDING_MODEL_NAME')
+ credential = {'cache_folder': cache_folder}
+ model_credential_str = json.dumps(credential)
+ model = ModelModel(id=default_embedding_model_id, name='maxkb-embedding', status=Status.SUCCESS,
+ model_type="EMBEDDING", model_name=model_name, user_id='f0dd8f71-e4ee-11ee-8c84-a8a1595801ab',
+ provider='model_local_provider',
+ credential=rsa_long_encrypt(model_credential_str), meta={},
+ permission_type=PermissionType.PUBLIC)
+ model.save()
+
+
+def reverse_code_embedding_model(apps, schema_editor):
+ ModelModel = apps.get_model('setting', 'Model')
+ QuerySet(ModelModel).filter(id=default_embedding_model_id).delete()
+
+
+class Migration(migrations.Migration):
+ dependencies = [
+ ('setting', '0004_alter_model_credential'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='model',
+ name='permission_type',
+ field=models.CharField(choices=[('PUBLIC', '公开'), ('PRIVATE', '私有')], default='PRIVATE', max_length=20,
+ verbose_name='权限类型'),
+ ),
+ migrations.RunPython(save_default_embedding_model, reverse_code_embedding_model)
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/migrations/0006_alter_model_status.py b/src/MaxKB-1.5.1/apps/setting/migrations/0006_alter_model_status.py
new file mode 100644
index 0000000..209f57c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/migrations/0006_alter_model_status.py
@@ -0,0 +1,18 @@
+# Generated by Django 4.2.14 on 2024-07-23 18:14
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('setting', '0005_model_permission_type'),
+ ]
+
+ operations = [
+ migrations.AlterField(
+ model_name='model',
+ name='status',
+ field=models.CharField(choices=[('SUCCESS', '成功'), ('ERROR', '失败'), ('DOWNLOAD', '下载中'), ('PAUSE_DOWNLOAD', '暂停下载')], default='SUCCESS', max_length=20, verbose_name='设置类型'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/migrations/__init__.py b/src/MaxKB-1.5.1/apps/setting/migrations/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/__init__.py
new file mode 100644
index 0000000..7f573ec
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/__init__.py
@@ -0,0 +1,94 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/10/31 17:16
+ @desc:
+"""
+import json
+from typing import Dict
+
+from common.util.rsa_util import rsa_long_decrypt
+from setting.models_provider.constants.model_provider_constants import ModelProvideConstants
+
+
+def get_model_(provider, model_type, model_name, credential, model_id, use_local=False, **kwargs):
+ """
+ 获取模型实例
+ @param provider: 供应商
+ @param model_type: 模型类型
+ @param model_name: 模型名称
+ @param credential: 认证信息
+ @param model_id: 模型id
+ @param use_local: 是否调用本地模型 只适用于本地供应商
+ @return: 模型实例
+ """
+ model = get_provider(provider).get_model(model_type, model_name,
+ json.loads(
+ rsa_long_decrypt(credential)),
+ model_id=model_id,
+ use_local=use_local,
+ streaming=True, **kwargs)
+ return model
+
+
+def get_model(model, **kwargs):
+ """
+ 获取模型实例
+ @param model: model 数据库Model实例对象
+ @return: 模型实例
+ """
+ return get_model_(model.provider, model.model_type, model.model_name, model.credential, str(model.id), **kwargs)
+
+
+def get_provider(provider):
+ """
+ 获取供应商实例
+ @param provider: 供应商字符串
+ @return: 供应商实例
+ """
+ return ModelProvideConstants[provider].value
+
+
+def get_model_list(provider, model_type):
+ """
+ 获取模型列表
+ @param provider: 供应商字符串
+ @param model_type: 模型类型
+ @return: 模型列表
+ """
+ return get_provider(provider).get_model_list(model_type)
+
+
+def get_model_credential(provider, model_type, model_name):
+ """
+ 获取模型认证实例
+ @param provider: 供应商字符串
+ @param model_type: 模型类型
+ @param model_name: 模型名称
+ @return: 认证实例对象
+ """
+ return get_provider(provider).get_model_credential(model_type, model_name)
+
+
+def get_model_type_list(provider):
+ """
+ 获取模型类型列表
+ @param provider: 供应商字符串
+ @return: 模型类型列表
+ """
+ return get_provider(provider).get_model_type_list()
+
+
+def is_valid_credential(provider, model_type, model_name, model_credential: Dict[str, object], raise_exception=False):
+ """
+ 校验模型认证参数
+ @param provider: 供应商字符串
+ @param model_type: 模型类型
+ @param model_name: 模型名称
+ @param model_credential: 模型认证数据
+ @param raise_exception: 是否抛出错误
+ @return: True|False
+ """
+ return get_provider(provider).is_valid_credential(model_type, model_name, model_credential, raise_exception)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/base_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/base_model_provider.py
new file mode 100644
index 0000000..6b33139
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/base_model_provider.py
@@ -0,0 +1,250 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: base_model_provider.py
+ @date:2023/10/31 16:19
+ @desc:
+"""
+from abc import ABC, abstractmethod
+from enum import Enum
+from functools import reduce
+from typing import Dict, Iterator, Type, List
+
+from pydantic.v1 import BaseModel
+
+from common.exception.app_exception import AppApiException
+
+
+class DownModelChunkStatus(Enum):
+ success = "success"
+ error = "error"
+ pulling = "pulling"
+ unknown = 'unknown'
+
+
+class ValidCode(Enum):
+ valid_error = 500
+ model_not_fount = 404
+
+
+class DownModelChunk:
+ def __init__(self, status: DownModelChunkStatus, digest: str, progress: int, details: str, index: int):
+ self.details = details
+ self.status = status
+ self.digest = digest
+ self.progress = progress
+ self.index = index
+
+ def to_dict(self):
+ return {
+ "details": self.details,
+ "status": self.status.value,
+ "digest": self.digest,
+ "progress": self.progress,
+ "index": self.index
+ }
+
+
+class IModelProvider(ABC):
+ @abstractmethod
+ def get_model_info_manage(self):
+ pass
+
+ @abstractmethod
+ def get_model_provide_info(self):
+ pass
+
+ def get_model_type_list(self):
+ return self.get_model_info_manage().get_model_type_list()
+
+ def get_model_list(self, model_type):
+ if model_type is None:
+ raise AppApiException(500, '模型类型不能为空')
+ return self.get_model_info_manage().get_model_list_by_model_type(model_type)
+
+ def get_model_credential(self, model_type, model_name):
+ model_info = self.get_model_info_manage().get_model_info(model_type, model_name)
+ return model_info.model_credential
+
+ def is_valid_credential(self, model_type, model_name, model_credential: Dict[str, object], raise_exception=False):
+ model_info = self.get_model_info_manage().get_model_info(model_type, model_name)
+ return model_info.model_credential.is_valid(model_type, model_name, model_credential, self,
+ raise_exception=raise_exception)
+
+ def get_model(self, model_type, model_name, model_credential: Dict[str, object], **model_kwargs) -> BaseModel:
+ model_info = self.get_model_info_manage().get_model_info(model_type, model_name)
+ return model_info.model_class.new_instance(model_type, model_name, model_credential, **model_kwargs)
+
+ def get_dialogue_number(self):
+ return 3
+
+ def down_model(self, model_type: str, model_name, model_credential: Dict[str, object]) -> Iterator[DownModelChunk]:
+ raise AppApiException(500, "当前平台不支持下载模型")
+
+
+class MaxKBBaseModel(ABC):
+ @staticmethod
+ @abstractmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ pass
+
+ @staticmethod
+ def is_cache_model():
+ return True
+
+
+class BaseModelCredential(ABC):
+
+ @abstractmethod
+ def is_valid(self, model_type: str, model_name, model: Dict[str, object], provider, raise_exception=True):
+ pass
+
+ @abstractmethod
+ def encryption_dict(self, model_info: Dict[str, object]):
+ """
+ :param model_info: 模型数据
+ :return: 加密后数据
+ """
+ pass
+
+ def get_model_params_setting_form(self, model_name):
+ """
+ 模型参数设置表单
+ :return:
+ """
+ pass
+
+ @staticmethod
+ def encryption(message: str):
+ """
+ 加密敏感字段数据 加密方式是 如果密码是 1234567890 那么给前端则是 123******890
+ :param message:
+ :return:
+ """
+ max_pre_len = 8
+ max_post_len = 4
+ message_len = len(message)
+ pre_len = int(message_len / 5 * 2)
+ post_len = int(message_len / 5 * 1)
+ pre_str = "".join([message[index] for index in
+ range(0, max_pre_len if pre_len > max_pre_len else 1 if pre_len <= 0 else int(pre_len))])
+ end_str = "".join(
+ [message[index] for index in
+ range(message_len - (int(post_len) if pre_len < max_post_len else max_post_len), message_len)])
+ content = "***************"
+ return pre_str + content + end_str
+
+
+class ModelTypeConst(Enum):
+ LLM = {'code': 'LLM', 'message': '大语言模型'}
+ EMBEDDING = {'code': 'EMBEDDING', 'message': '向量模型'}
+
+
+class ModelInfo:
+ def __init__(self, name: str, desc: str, model_type: ModelTypeConst, model_credential: BaseModelCredential,
+ model_class: Type[MaxKBBaseModel],
+ **keywords):
+ self.name = name
+ self.desc = desc
+ self.model_type = model_type.name
+ self.model_credential = model_credential
+ self.model_class = model_class
+ if keywords is not None:
+ for key in keywords.keys():
+ self.__setattr__(key, keywords.get(key))
+
+ def get_name(self):
+ """
+ 获取模型名称
+ :return: 模型名称
+ """
+ return self.name
+
+ def get_desc(self):
+ """
+ 获取模型描述
+ :return: 模型描述
+ """
+ return self.desc
+
+ def get_model_type(self):
+ return self.model_type
+
+ def get_model_class(self):
+ return self.model_class
+
+ def to_dict(self):
+ return reduce(lambda x, y: {**x, **y},
+ [{attr: self.__getattribute__(attr)} for attr in vars(self) if
+ not attr.startswith("__") and not attr == 'model_credential' and not attr == 'model_class'], {})
+
+
+class ModelInfoManage:
+ def __init__(self):
+ self.model_dict = {}
+ self.model_list = []
+ self.default_model_list = []
+ self.default_model_dict = {}
+
+ def append_model_info(self, model_info: ModelInfo):
+ self.model_list.append(model_info)
+ model_type_dict = self.model_dict.get(model_info.model_type)
+ if model_type_dict is None:
+ self.model_dict[model_info.model_type] = {model_info.name: model_info}
+ else:
+ model_type_dict[model_info.name] = model_info
+
+ def append_default_model_info(self, model_info: ModelInfo):
+ self.default_model_list.append(model_info)
+ self.default_model_dict[model_info.model_type] = model_info
+
+ def get_model_list(self):
+ return [model.to_dict() for model in self.model_list]
+
+ def get_model_list_by_model_type(self, model_type):
+ return [model.to_dict() for model in self.model_list if model.model_type == model_type]
+
+ def get_model_type_list(self):
+ return [{'key': _type.value.get('message'), 'value': _type.value.get('code')} for _type in ModelTypeConst if
+ len([model for model in self.model_list if model.model_type == _type.name]) > 0]
+
+ def get_model_info(self, model_type, model_name) -> ModelInfo:
+ model_info = self.model_dict.get(model_type, {}).get(model_name, self.default_model_dict.get(model_type))
+ if model_info is None:
+ raise AppApiException(500, '模型不支持')
+ return model_info
+
+ class builder:
+ def __init__(self):
+ self.modelInfoManage = ModelInfoManage()
+
+ def append_model_info(self, model_info: ModelInfo):
+ self.modelInfoManage.append_model_info(model_info)
+ return self
+
+ def append_model_info_list(self, model_info_list: List[ModelInfo]):
+ for model_info in model_info_list:
+ self.modelInfoManage.append_model_info(model_info)
+ return self
+
+ def append_default_model_info(self, model_info: ModelInfo):
+ self.modelInfoManage.append_default_model_info(model_info)
+ return self
+
+ def build(self):
+ return self.modelInfoManage
+
+
+class ModelProvideInfo:
+ def __init__(self, provider: str, name: str, icon: str):
+ self.provider = provider
+
+ self.name = name
+
+ self.icon = icon
+
+ def to_dict(self):
+ return reduce(lambda x, y: {**x, **y},
+ [{attr: self.__getattribute__(attr)} for attr in vars(self) if
+ not attr.startswith("__")], {})
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/constants/model_provider_constants.py b/src/MaxKB-1.5.1/apps/setting/models_provider/constants/model_provider_constants.py
new file mode 100644
index 0000000..13e43a2
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/constants/model_provider_constants.py
@@ -0,0 +1,46 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: model_provider_constants.py
+ @date:2023/11/2 14:55
+ @desc:
+"""
+from enum import Enum
+
+from setting.models_provider.impl.aws_bedrock_model_provider.aws_bedrock_model_provider import BedrockModelProvider
+from setting.models_provider.impl.azure_model_provider.azure_model_provider import AzureModelProvider
+from setting.models_provider.impl.deepseek_model_provider.deepseek_model_provider import DeepSeekModelProvider
+from setting.models_provider.impl.gemini_model_provider.gemini_model_provider import GeminiModelProvider
+from setting.models_provider.impl.kimi_model_provider.kimi_model_provider import KimiModelProvider
+from setting.models_provider.impl.ollama_model_provider.ollama_model_provider import OllamaModelProvider
+from setting.models_provider.impl.openai_model_provider.openai_model_provider import OpenAIModelProvider
+from setting.models_provider.impl.qwen_model_provider.qwen_model_provider import QwenModelProvider
+from setting.models_provider.impl.tencent_model_provider.tencent_model_provider import TencentModelProvider
+from setting.models_provider.impl.vllm_model_provider.vllm_model_provider import VllmModelProvider
+from setting.models_provider.impl.volcanic_engine_model_provider.volcanic_engine_model_provider import \
+ VolcanicEngineModelProvider
+from setting.models_provider.impl.wenxin_model_provider.wenxin_model_provider import WenxinModelProvider
+from setting.models_provider.impl.xf_model_provider.xf_model_provider import XunFeiModelProvider
+from setting.models_provider.impl.xinference_model_provider.xinference_model_provider import XinferenceModelProvider
+from setting.models_provider.impl.zhipu_model_provider.zhipu_model_provider import ZhiPuModelProvider
+from setting.models_provider.impl.local_model_provider.local_model_provider import LocalModelProvider
+
+
+class ModelProvideConstants(Enum):
+ model_azure_provider = AzureModelProvider()
+ model_wenxin_provider = WenxinModelProvider()
+ model_ollama_provider = OllamaModelProvider()
+ model_openai_provider = OpenAIModelProvider()
+ model_kimi_provider = KimiModelProvider()
+ model_qwen_provider = QwenModelProvider()
+ model_zhipu_provider = ZhiPuModelProvider()
+ model_xf_provider = XunFeiModelProvider()
+ model_deepseek_provider = DeepSeekModelProvider()
+ model_gemini_provider = GeminiModelProvider()
+ model_volcanic_engine_provider = VolcanicEngineModelProvider()
+ model_tencent_provider = TencentModelProvider()
+ model_aws_bedrock_provider = BedrockModelProvider()
+ model_local_provider = LocalModelProvider()
+ model_xinference_provider = XinferenceModelProvider()
+ model_vllm_provider = VllmModelProvider()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/__init__.py
new file mode 100644
index 0000000..8cb7f45
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/__init__.py
@@ -0,0 +1,2 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/aws_bedrock_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/aws_bedrock_model_provider.py
new file mode 100644
index 0000000..c15bdf7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/aws_bedrock_model_provider.py
@@ -0,0 +1,144 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+
+import os
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import (
+ IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, ModelInfoManage
+)
+from setting.models_provider.impl.aws_bedrock_model_provider.credential.llm import BedrockLLMModelCredential
+from setting.models_provider.impl.aws_bedrock_model_provider.model.llm import BedrockModel
+from setting.models_provider.impl.tencent_model_provider.credential.embedding import TencentEmbeddingCredential
+from setting.models_provider.impl.tencent_model_provider.credential.llm import TencentLLMModelCredential
+from setting.models_provider.impl.tencent_model_provider.model.embedding import TencentEmbeddingModel
+from setting.models_provider.impl.tencent_model_provider.model.llm import TencentModel
+from smartdoc.conf import PROJECT_DIR
+
+
+def _create_model_info(model_name, description, model_type, credential_class, model_class):
+ return ModelInfo(
+ name=model_name,
+ desc=description,
+ model_type=model_type,
+ model_credential=credential_class(),
+ model_class=model_class
+ )
+
+
+def _get_aws_bedrock_icon_path():
+ return os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'aws_bedrock_model_provider',
+ 'icon', 'bedrock_icon_svg')
+
+
+def _initialize_model_info():
+ model_info_list = [
+ _create_model_info(
+ 'anthropic.claude-v2:1',
+ 'Claude 2 的更新,采用双倍的上下文窗口,并在长文档和 RAG 上下文中提高可靠性、幻觉率和循证准确性。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel
+ ),
+ _create_model_info(
+ 'anthropic.claude-v2',
+ 'Anthropic 功能强大的模型,可处理各种任务,从复杂的对话和创意内容生成到详细的指令服从。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel
+ ),
+ _create_model_info(
+ 'anthropic.claude-3-haiku-20240307-v1:0',
+ 'Claude 3 Haiku 是 Anthropic 最快速、最紧凑的模型,具有近乎即时的响应能力。该模型可以快速回答简单的查询和请求。客户将能够构建模仿人类交互的无缝人工智能体验。 Claude 3 Haiku 可以处理图像和返回文本输出,并且提供 200K 上下文窗口。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel
+ ),
+ _create_model_info(
+ 'anthropic.claude-3-sonnet-20240229-v1:0',
+ 'Anthropic 推出的 Claude 3 Sonnet 模型在智能和速度之间取得理想的平衡,尤其是在处理企业工作负载方面。该模型提供最大的效用,同时价格低于竞争产品,并且其经过精心设计,是大规模部署人工智能的可靠选择。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel
+ ),
+ _create_model_info(
+ 'anthropic.claude-3-5-sonnet-20240620-v1:0',
+ 'Claude 3.5 Sonnet提高了智能的行业标准,在广泛的评估中超越了竞争对手的型号和Claude 3 Opus,具有我们中端型号的速度和成本效益。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel
+ ),
+ _create_model_info(
+ 'anthropic.claude-instant-v1',
+ '一种更快速、更实惠但仍然非常强大的模型,它可以处理一系列任务,包括随意对话、文本分析、摘要和文档问题回答。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel
+ ),
+ _create_model_info(
+ 'amazon.titan-text-premier-v1:0',
+ 'Titan Text Premier 是 Titan Text 系列中功能强大且先进的型号,旨在为各种企业应用程序提供卓越的性能。凭借其尖端功能,它提供了更高的准确性和出色的结果,使其成为寻求一流文本处理解决方案的组织的绝佳选择。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel
+ ),
+ _create_model_info(
+ 'amazon.titan-text-lite-v1',
+ 'Amazon Titan Text Lite 是一种轻量级的高效模型,非常适合英语任务的微调,包括摘要和文案写作等,在这种场景下,客户需要更小、更经济高效且高度可定制的模型',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel),
+ _create_model_info(
+ 'amazon.titan-text-express-v1',
+ 'Amazon Titan Text Express 的上下文长度长达 8000 个令牌,因而非常适合各种高级常规语言任务,例如开放式文本生成和对话式聊天,以及检索增强生成(RAG)中的支持。在发布时,该模型针对英语进行了优化,但也支持其他语言。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel),
+ _create_model_info(
+ 'mistral.mistral-7b-instruct-v0:2',
+ '7B 密集型转换器,可快速部署,易于定制。体积虽小,但功能强大,适用于各种用例。支持英语和代码,以及 32k 的上下文窗口。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel),
+ _create_model_info(
+ 'mistral.mistral-large-2402-v1:0',
+ '先进的 Mistral AI 大型语言模型,能够处理任何语言任务,包括复杂的多语言推理、文本理解、转换和代码生成。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel),
+ _create_model_info(
+ 'meta.llama3-70b-instruct-v1:0',
+ '非常适合内容创作、会话式人工智能、语言理解、研发和企业应用',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel),
+ _create_model_info(
+ 'meta.llama3-8b-instruct-v1:0',
+ '非常适合有限的计算能力和资源、边缘设备和更快的训练时间。',
+ ModelTypeConst.LLM,
+ BedrockLLMModelCredential,
+ BedrockModel),
+ ]
+
+ model_info_manage = ModelInfoManage.builder() \
+ .append_model_info_list(model_info_list) \
+ .append_default_model_info(model_info_list[0]) \
+ .build()
+
+ return model_info_manage
+
+
+class BedrockModelProvider(IModelProvider):
+ def __init__(self):
+ self._model_info_manage = _initialize_model_info()
+
+ def get_model_info_manage(self):
+ return self._model_info_manage
+
+ def get_model_provide_info(self):
+ icon_path = _get_aws_bedrock_icon_path()
+ icon_data = get_file_content(icon_path)
+ return ModelProvideInfo(
+ provider='model_aws_bedrock_provider',
+ name='Amazon Bedrock',
+ icon=icon_data
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/credential/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/credential/embedding.py
new file mode 100644
index 0000000..40e36ca
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/credential/embedding.py
@@ -0,0 +1,64 @@
+import json
+from typing import Dict
+
+from tencentcloud.common import credential
+from tencentcloud.common.profile.client_profile import ClientProfile
+from tencentcloud.common.profile.http_profile import HttpProfile
+from tencentcloud.hunyuan.v20230901 import hunyuan_client, models
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class TencentEmbeddingCredential(BaseForm, BaseModelCredential):
+ @classmethod
+ def _validate_model_type(cls, model_type: str, provider) -> bool:
+ model_type_list = provider.get_model_type_list()
+ if not any(mt.get('value') == model_type for mt in model_type_list):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ return True
+
+ @classmethod
+ def _validate_credential(cls, model_credential: Dict[str, object]) -> credential.Credential:
+ for key in ['SecretId', 'SecretKey']:
+ if key not in model_credential:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ return credential.Credential(model_credential['SecretId'], model_credential['SecretKey'])
+
+ @classmethod
+ def _test_credentials(cls, client, model_name: str):
+ req = models.GetEmbeddingRequest()
+ params = {
+ "Model": model_name,
+ "Input": "测试"
+ }
+ req.from_json_string(json.dumps(params))
+ try:
+ res = client.GetEmbedding(req)
+ print(res.to_json_string())
+ except Exception as e:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=True) -> bool:
+ try:
+ self._validate_model_type(model_type, provider)
+ cred = self._validate_credential(model_credential)
+ httpProfile = HttpProfile(endpoint="hunyuan.tencentcloudapi.com")
+ clientProfile = ClientProfile(httpProfile=httpProfile)
+ client = hunyuan_client.HunyuanClient(cred, "", clientProfile)
+ self._test_credentials(client, model_name)
+ return True
+ except AppApiException as e:
+ if raise_exception:
+ raise e
+ return False
+
+ def encryption_dict(self, model: Dict[str, object]) -> Dict[str, object]:
+ encrypted_secret_key = super().encryption(model.get('SecretKey', ''))
+ return {**model, 'SecretKey': encrypted_secret_key}
+
+ SecretId = forms.PasswordInputField('SecretId', required=True)
+ SecretKey = forms.PasswordInputField('SecretKey', required=True)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/credential/llm.py
new file mode 100644
index 0000000..2392d3d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/credential/llm.py
@@ -0,0 +1,84 @@
+import os
+import re
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import ValidCode, BaseModelCredential
+
+
+class BedrockLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.7,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=1024,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class BedrockLLMModelCredential(BaseForm, BaseModelCredential):
+
+ @staticmethod
+ def _update_aws_credentials(profile_name, access_key_id, secret_access_key):
+ credentials_path = os.path.join(os.path.expanduser("~"), ".aws", "credentials")
+ os.makedirs(os.path.dirname(credentials_path), exist_ok=True)
+
+ content = open(credentials_path, 'r').read() if os.path.exists(credentials_path) else ''
+ pattern = rf'\n*\[{profile_name}\]\n*(aws_access_key_id = .*)\n*(aws_secret_access_key = .*)\n*'
+ content = re.sub(pattern, '', content, flags=re.DOTALL)
+
+ if not re.search(rf'\[{profile_name}\]', content):
+ content += f"\n[{profile_name}]\naws_access_key_id = {access_key_id}\naws_secret_access_key = {secret_access_key}\n"
+
+ with open(credentials_path, 'w') as file:
+ file.write(content)
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(mt.get('value') == model_type for mt in model_type_list):
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ return False
+
+ required_keys = ['region_name', 'access_key_id', 'secret_access_key']
+ if not all(key in model_credential for key in required_keys):
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'以下字段为必填字段: {", ".join(required_keys)}')
+ return False
+
+ try:
+ self._update_aws_credentials('aws-profile', model_credential['access_key_id'],
+ model_credential['secret_access_key'])
+ model_credential['credentials_profile_name'] = 'aws-profile'
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except AppApiException:
+ raise
+ except Exception as e:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ return False
+
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'secret_access_key': super().encryption(model.get('secret_access_key', ''))}
+
+ region_name = forms.TextInputField('Region Name', required=True)
+ access_key_id = forms.TextInputField('Access Key ID', required=True)
+ secret_access_key = forms.PasswordInputField('Secret Access Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return BedrockLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/icon/bedrock_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/icon/bedrock_icon_svg
new file mode 100644
index 0000000..5f176a7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/icon/bedrock_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/model/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/model/embedding.py
new file mode 100644
index 0000000..a5bd033
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/model/embedding.py
@@ -0,0 +1,25 @@
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from typing import Dict
+import requests
+
+
+class TencentEmbeddingModel(MaxKBBaseModel):
+ def __init__(self, secret_id: str, secret_key: str, api_base: str, model_name: str):
+ self.secret_id = secret_id
+ self.secret_key = secret_key
+ self.api_base = api_base
+ self.model_name = model_name
+
+ @staticmethod
+ def new_instance(model_type: str, model_name: str, model_credential: Dict[str, str], **model_kwargs):
+ return TencentEmbeddingModel(
+ secret_id=model_credential.get('SecretId'),
+ secret_key=model_credential.get('SecretKey'),
+ api_base=model_credential.get('api_base'),
+ model_name=model_name,
+ )
+
+
+ def _generate_auth_token(self):
+ # Example method to generate an authentication token for the model API
+ return f"{self.secret_id}:{self.secret_key}"
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/model/llm.py
new file mode 100644
index 0000000..510ef13
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/aws_bedrock_model_provider/model/llm.py
@@ -0,0 +1,54 @@
+from typing import List, Dict
+from langchain_community.chat_models import BedrockChat
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+def get_max_tokens_keyword(model_name):
+ """
+ 根据模型名称返回正确的 max_tokens 关键字。
+
+ :param model_name: 模型名称字符串
+ :return: 对应的 max_tokens 关键字字符串
+ """
+ if 'amazon' in model_name:
+ return 'maxTokenCount'
+ elif 'anthropic' in model_name:
+ return 'max_tokens_to_sample'
+ elif 'ai21' in model_name:
+ return 'maxTokens'
+ elif 'cohere' in model_name or 'mistral' in model_name:
+ return 'max_tokens'
+ elif 'meta' in model_name:
+ return 'max_gen_len'
+ else:
+ raise ValueError("Unsupported model supplier in model_name.")
+
+
+class BedrockModel(MaxKBBaseModel, BedrockChat):
+
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ def __init__(self, model_id: str, region_name: str, credentials_profile_name: str,
+ streaming: bool = False, **kwargs):
+ super().__init__(model_id=model_id, region_name=region_name,
+ credentials_profile_name=credentials_profile_name, streaming=streaming, **kwargs)
+
+ @classmethod
+ def new_instance(cls, model_type: str, model_name: str, model_credential: Dict[str, str],
+ **model_kwargs) -> 'BedrockModel':
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ keyword = get_max_tokens_keyword(model_name)
+ optional_params[keyword] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+
+ return cls(
+ model_id=model_name,
+ region_name=model_credential['region_name'],
+ credentials_profile_name=model_credential['credentials_profile_name'],
+ streaming=model_kwargs.pop('streaming', True),
+ model_kwargs=optional_params
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/__init__.py
new file mode 100644
index 0000000..53b7001
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/10/31 17:16
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/azure_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/azure_model_provider.py
new file mode 100644
index 0000000..8b95dfe
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/azure_model_provider.py
@@ -0,0 +1,36 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: azure_model_provider.py
+ @date:2023/10/31 16:19
+ @desc:
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, \
+ ModelTypeConst, ModelInfoManage
+from setting.models_provider.impl.azure_model_provider.credential.llm import AzureLLMModelCredential
+from setting.models_provider.impl.azure_model_provider.model.azure_chat_model import AzureChatModel
+from smartdoc.conf import PROJECT_DIR
+
+base_azure_llm_model_credential = AzureLLMModelCredential()
+
+default_model_info = ModelInfo('Azure OpenAI', '具体的基础模型由部署名决定', ModelTypeConst.LLM,
+ base_azure_llm_model_credential, AzureChatModel, api_version='2024-02-15-preview'
+ )
+
+model_info_manage = ModelInfoManage.builder().append_default_model_info(default_model_info).append_model_info(
+ default_model_info).build()
+
+
+class AzureModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_azure_provider', name='Azure OpenAI', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'azure_model_provider', 'icon',
+ 'azure_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/credential/llm.py
new file mode 100644
index 0000000..1906d20
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/credential/llm.py
@@ -0,0 +1,75 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 17:08
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class AzureLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.7,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=800,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class AzureLLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['api_base', 'api_key', 'deployment_name', 'api_version']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, '校验失败,请检查参数是否正确')
+ else:
+ return False
+
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_version = forms.TextInputField("API 版本 (api_version)", required=True)
+
+ api_base = forms.TextInputField('API 域名 (azure_endpoint)', required=True)
+
+ api_key = forms.PasswordInputField("API Key (api_key)", required=True)
+
+ deployment_name = forms.TextInputField("部署名 (deployment_name)", required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return AzureLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/icon/azure_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/icon/azure_icon_svg
new file mode 100644
index 0000000..e5a2f98
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/icon/azure_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/model/azure_chat_model.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/model/azure_chat_model.py
new file mode 100644
index 0000000..110d72d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/azure_model_provider/model/azure_chat_model.py
@@ -0,0 +1,57 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: azure_chat_model.py
+ @date:2024/4/28 11:45
+ @desc:
+"""
+
+from typing import List, Dict, Optional, Any, Iterator, Type
+
+from langchain_core.callbacks import CallbackManagerForLLMRun
+from langchain_core.messages import BaseMessage, get_buffer_string, BaseMessageChunk, AIMessageChunk
+from langchain_core.outputs import ChatGenerationChunk
+from langchain_openai import AzureChatOpenAI
+from langchain_openai.chat_models.base import _convert_delta_to_message_chunk
+
+from common.config.tokenizer_manage_config import TokenizerManage
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class AzureChatModel(MaxKBBaseModel, AzureChatOpenAI):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+
+ return AzureChatModel(
+ azure_endpoint=model_credential.get('api_base'),
+ openai_api_version=model_credential.get('api_version', '2024-02-15-preview'),
+ deployment_name=model_credential.get('deployment_name'),
+ openai_api_key=model_credential.get('api_key'),
+ openai_api_type="azure",
+ **optional_params,
+ streaming=True,
+ )
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ try:
+ return super().get_num_tokens_from_messages(messages)
+ except Exception as e:
+ tokenizer = TokenizerManage.get_tokenizer()
+ return sum([len(tokenizer.encode(get_buffer_string([m]))) for m in messages])
+
+ def get_num_tokens(self, text: str) -> int:
+ try:
+ return super().get_num_tokens(text)
+ except Exception as e:
+ tokenizer = TokenizerManage.get_tokenizer()
+ return len(tokenizer.encode(text))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/base_chat_open_ai.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/base_chat_open_ai.py
new file mode 100644
index 0000000..b0d5f3b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/base_chat_open_ai.py
@@ -0,0 +1,78 @@
+# coding=utf-8
+
+from typing import List, Dict, Optional, Any, Iterator, Type
+from langchain_core.callbacks import CallbackManagerForLLMRun
+from langchain_core.messages import BaseMessage, AIMessageChunk, BaseMessageChunk
+from langchain_core.outputs import ChatGenerationChunk
+from langchain_openai import ChatOpenAI
+from langchain_openai.chat_models.base import _convert_delta_to_message_chunk
+
+
+class BaseChatOpenAI(ChatOpenAI):
+
+ def get_last_generation_info(self) -> Optional[Dict[str, Any]]:
+ return self.__dict__.get('_last_generation_info')
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ return self.get_last_generation_info().get('prompt_tokens', 0)
+
+ def get_num_tokens(self, text: str) -> int:
+ return self.get_last_generation_info().get('completion_tokens', 0)
+
+ def _stream(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ **kwargs: Any,
+ ) -> Iterator[ChatGenerationChunk]:
+ kwargs["stream"] = True
+ kwargs["stream_options"] = {"include_usage": True}
+ payload = self._get_request_payload(messages, stop=stop, **kwargs)
+ default_chunk_class: Type[BaseMessageChunk] = AIMessageChunk
+ if self.include_response_headers:
+ raw_response = self.client.with_raw_response.create(**payload)
+ response = raw_response.parse()
+ base_generation_info = {"headers": dict(raw_response.headers)}
+ else:
+ response = self.client.create(**payload)
+ base_generation_info = {}
+ with response:
+ is_first_chunk = True
+ for chunk in response:
+ if not isinstance(chunk, dict):
+ chunk = chunk.model_dump()
+ if (len(chunk["choices"]) == 0 or chunk["choices"][0]["finish_reason"] == "length" or
+ chunk["choices"][0]["finish_reason"] == "stop") and chunk.get("usage") is not None:
+ if token_usage := chunk.get("usage"):
+ self.__dict__.setdefault('_last_generation_info', {}).update(token_usage)
+ logprobs = None
+ continue
+ else:
+ choice = chunk["choices"][0]
+ if choice["delta"] is None:
+ continue
+ message_chunk = _convert_delta_to_message_chunk(
+ choice["delta"], default_chunk_class
+ )
+ generation_info = {**base_generation_info} if is_first_chunk else {}
+ if finish_reason := choice.get("finish_reason"):
+ generation_info["finish_reason"] = finish_reason
+ if model_name := chunk.get("model"):
+ generation_info["model_name"] = model_name
+ if system_fingerprint := chunk.get("system_fingerprint"):
+ generation_info["system_fingerprint"] = system_fingerprint
+
+ logprobs = choice.get("logprobs")
+ if logprobs:
+ generation_info["logprobs"] = logprobs
+ default_chunk_class = message_chunk.__class__
+ generation_chunk = ChatGenerationChunk(
+ message=message_chunk, generation_info=generation_info or None
+ )
+ if run_manager:
+ run_manager.on_llm_new_token(
+ generation_chunk.text, chunk=generation_chunk, logprobs=logprobs
+ )
+ is_first_chunk = False
+ yield generation_chunk
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/__init__.py
new file mode 100644
index 0000000..ee456da
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/__init__.py
@@ -0,0 +1,8 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+"""
+@Project :MaxKB
+@File :__init__.py.py
+@Author :Brian Yang
+@Date :5/12/24 7:38 AM
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/credential/llm.py
new file mode 100644
index 0000000..72f101c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/credential/llm.py
@@ -0,0 +1,68 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 17:51
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class DeepSeekLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.7,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=800,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class DeepSeekLLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return DeepSeekLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/deepseek_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/deepseek_model_provider.py
new file mode 100644
index 0000000..f60f26f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/deepseek_model_provider.py
@@ -0,0 +1,41 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+"""
+@Project :MaxKB
+@File :deepseek_model_provider.py
+@Author :Brian Yang
+@Date :5/12/24 7:40 AM
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, \
+ ModelInfoManage
+from setting.models_provider.impl.deepseek_model_provider.credential.llm import DeepSeekLLMModelCredential
+from setting.models_provider.impl.deepseek_model_provider.model.llm import DeepSeekChatModel
+from smartdoc.conf import PROJECT_DIR
+
+deepseek_llm_model_credential = DeepSeekLLMModelCredential()
+
+deepseek_chat = ModelInfo('deepseek-chat', '擅长通用对话任务,支持 32K 上下文', ModelTypeConst.LLM,
+ deepseek_llm_model_credential, DeepSeekChatModel
+ )
+
+deepseek_coder = ModelInfo('deepseek-coder', '擅长处理编程任务,支持 16K 上下文', ModelTypeConst.LLM,
+ deepseek_llm_model_credential,
+ DeepSeekChatModel)
+
+model_info_manage = ModelInfoManage.builder().append_model_info(deepseek_chat).append_model_info(
+ deepseek_coder).append_default_model_info(
+ deepseek_coder).build()
+
+
+class DeepSeekModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_deepseek_provider', name='DeepSeek', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'deepseek_model_provider', 'icon',
+ 'deepseek_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/icon/deepseek_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/icon/deepseek_icon_svg
new file mode 100644
index 0000000..6ace891
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/icon/deepseek_icon_svg
@@ -0,0 +1,6 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/model/llm.py
new file mode 100644
index 0000000..94c7d48
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/deepseek_model_provider/model/llm.py
@@ -0,0 +1,36 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+"""
+@Project :MaxKB
+@File :llm.py
+@Author :Brian Yang
+@Date :5/12/24 7:44 AM
+"""
+from typing import List, Dict
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from setting.models_provider.impl.base_chat_open_ai import BaseChatOpenAI
+
+
+class DeepSeekChatModel(MaxKBBaseModel, BaseChatOpenAI):
+
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+
+ deepseek_chat_open_ai = DeepSeekChatModel(
+ model=model_name,
+ openai_api_base='https://api.deepseek.com',
+ openai_api_key=model_credential.get('api_key'),
+ **optional_params
+ )
+ return deepseek_chat_open_ai
+
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/__init__.py
new file mode 100644
index 0000000..43fd3dd
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/__init__.py
@@ -0,0 +1,8 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+"""
+@Project :MaxKB
+@File :__init__.py.py
+@Author :Brian Yang
+@Date :5/13/24 7:40 AM
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/credential/llm.py
new file mode 100644
index 0000000..77e01df
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/credential/llm.py
@@ -0,0 +1,69 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 17:57
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class GeminiLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.7,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=800,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class GeminiLLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ res = model.invoke([HumanMessage(content='你好')])
+ print(res)
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return GeminiLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/gemini_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/gemini_model_provider.py
new file mode 100644
index 0000000..b6dd442
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/gemini_model_provider.py
@@ -0,0 +1,42 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+"""
+@Project :MaxKB
+@File :gemini_model_provider.py
+@Author :Brian Yang
+@Date :5/13/24 7:47 AM
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, \
+ ModelInfoManage
+from setting.models_provider.impl.gemini_model_provider.credential.llm import GeminiLLMModelCredential
+from setting.models_provider.impl.gemini_model_provider.model.llm import GeminiChatModel
+from smartdoc.conf import PROJECT_DIR
+
+gemini_llm_model_credential = GeminiLLMModelCredential()
+
+gemini_1_pro = ModelInfo('gemini-1.0-pro', '最新的Gemini 1.0 Pro模型,随Google更新而更新',
+ ModelTypeConst.LLM,
+ gemini_llm_model_credential,
+ GeminiChatModel)
+
+gemini_1_pro_vision = ModelInfo('gemini-1.0-pro-vision', '最新的Gemini 1.0 Pro Vision模型,随Google更新而更新',
+ ModelTypeConst.LLM,
+ gemini_llm_model_credential,
+ GeminiChatModel)
+
+model_info_manage = ModelInfoManage.builder().append_model_info(gemini_1_pro).append_model_info(
+ gemini_1_pro_vision).append_default_model_info(gemini_1_pro).build()
+
+
+class GeminiModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_gemini_provider', name='Gemini', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'gemini_model_provider', 'icon',
+ 'gemini_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/icon/gemini_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/icon/gemini_icon_svg
new file mode 100644
index 0000000..00c48a3
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/icon/gemini_icon_svg
@@ -0,0 +1,10 @@
+
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/model/llm.py
new file mode 100644
index 0000000..e9174d3
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/gemini_model_provider/model/llm.py
@@ -0,0 +1,91 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+"""
+@Project :MaxKB
+@File :llm.py
+@Author :Brian Yang
+@Date :5/13/24 7:40 AM
+"""
+from typing import List, Dict, Optional, Sequence, Union, Any, Iterator, cast
+
+from google.ai.generativelanguage_v1 import GenerateContentResponse
+from google.generativeai.responder import ToolDict
+from google.generativeai.types import FunctionDeclarationType, SafetySettingDict
+from langchain_core.callbacks import CallbackManagerForLLMRun
+from langchain_core.messages import BaseMessage, get_buffer_string
+from langchain_core.outputs import ChatGenerationChunk
+from langchain_google_genai import ChatGoogleGenerativeAI
+from langchain_google_genai._function_utils import _ToolConfigDict
+from langchain_google_genai.chat_models import _chat_with_retry, _response_to_result
+from google.generativeai.types import Tool as GoogleTool
+from common.config.tokenizer_manage_config import TokenizerManage
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class GeminiChatModel(MaxKBBaseModel, ChatGoogleGenerativeAI):
+
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'temperature' in model_kwargs:
+ optional_params['temperature'] = model_kwargs['temperature']
+ if 'max_tokens' in model_kwargs:
+ optional_params['max_output_tokens'] = model_kwargs['max_tokens']
+
+ gemini_chat = GeminiChatModel(
+ model=model_name,
+ google_api_key=model_credential.get('api_key'),
+ **optional_params
+ )
+ return gemini_chat
+
+ def get_last_generation_info(self) -> Optional[Dict[str, Any]]:
+ return self.__dict__.get('_last_generation_info')
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ return self.get_last_generation_info().get('input_tokens', 0)
+
+ def get_num_tokens(self, text: str) -> int:
+ return self.get_last_generation_info().get('output_tokens', 0)
+
+ def _stream(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ *,
+ tools: Optional[Sequence[Union[ToolDict, GoogleTool]]] = None,
+ functions: Optional[Sequence[FunctionDeclarationType]] = None,
+ safety_settings: Optional[SafetySettingDict] = None,
+ tool_config: Optional[Union[Dict, _ToolConfigDict]] = None,
+ generation_config: Optional[Dict[str, Any]] = None,
+ **kwargs: Any,
+ ) -> Iterator[ChatGenerationChunk]:
+ request = self._prepare_request(
+ messages,
+ stop=stop,
+ tools=tools,
+ functions=functions,
+ safety_settings=safety_settings,
+ tool_config=tool_config,
+ generation_config=generation_config,
+ )
+ response: GenerateContentResponse = _chat_with_retry(
+ request=request,
+ generation_method=self.client.stream_generate_content,
+ **kwargs,
+ metadata=self.default_metadata,
+ )
+ for chunk in response:
+ _chat_result = _response_to_result(chunk, stream=True)
+ gen = cast(ChatGenerationChunk, _chat_result.generations[0])
+ if gen.message:
+ token_usage = gen.message.usage_metadata
+ self.__dict__.setdefault('_last_generation_info', {}).update(token_usage)
+ if run_manager:
+ run_manager.on_llm_new_token(gen.text)
+ yield gen
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/__init__.py
new file mode 100644
index 0000000..53b7001
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/10/31 17:16
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/credential/llm.py
new file mode 100644
index 0000000..ef2aeb1
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/credential/llm.py
@@ -0,0 +1,69 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 18:06
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class KimiLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.3,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=1024,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class KimiLLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['api_base', 'api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_base = forms.TextInputField('API 域名', required=True)
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return KimiLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/icon/kimi_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/icon/kimi_icon_svg
new file mode 100644
index 0000000..8bd2a78
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/icon/kimi_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/kimi_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/kimi_model_provider.py
new file mode 100644
index 0000000..1347df4
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/kimi_model_provider.py
@@ -0,0 +1,42 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: kimi_model_provider.py
+ @date:2024/3/28 16:26
+ @desc:
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, \
+ ModelTypeConst, ModelInfoManage
+from setting.models_provider.impl.kimi_model_provider.credential.llm import KimiLLMModelCredential
+from setting.models_provider.impl.kimi_model_provider.model.llm import KimiChatModel
+from smartdoc.conf import PROJECT_DIR
+
+kimi_llm_model_credential = KimiLLMModelCredential()
+
+moonshot_v1_8k = ModelInfo('moonshot-v1-8k', '', ModelTypeConst.LLM, kimi_llm_model_credential,
+ KimiChatModel)
+moonshot_v1_32k = ModelInfo('moonshot-v1-32k', '', ModelTypeConst.LLM, kimi_llm_model_credential,
+ KimiChatModel)
+moonshot_v1_128k = ModelInfo('moonshot-v1-128k', '', ModelTypeConst.LLM, kimi_llm_model_credential,
+ KimiChatModel)
+
+model_info_manage = ModelInfoManage.builder().append_model_info(moonshot_v1_8k).append_model_info(
+ moonshot_v1_32k).append_default_model_info(moonshot_v1_128k).append_default_model_info(moonshot_v1_8k).build()
+
+
+class KimiModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_dialogue_number(self):
+ return 3
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_kimi_provider', name='Kimi', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'kimi_model_provider', 'icon',
+ 'kimi_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/model/llm.py
new file mode 100644
index 0000000..2dd117f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/kimi_model_provider/model/llm.py
@@ -0,0 +1,35 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: llm.py
+ @date:2023/11/10 17:45
+ @desc:
+"""
+from typing import List, Dict
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from setting.models_provider.impl.base_chat_open_ai import BaseChatOpenAI
+
+
+class KimiChatModel(MaxKBBaseModel, BaseChatOpenAI):
+
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+
+ kimi_chat_open_ai = KimiChatModel(
+ openai_api_base=model_credential['api_base'],
+ openai_api_key=model_credential['api_key'],
+ model_name=model_name,
+ **optional_params
+ )
+ return kimi_chat_open_ai
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/__init__.py
new file mode 100644
index 0000000..90a8d72
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: __init__.py
+ @date:2024/7/10 17:48
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/credential/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/credential/embedding.py
new file mode 100644
index 0000000..a631196
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/credential/embedding.py
@@ -0,0 +1,45 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/7/11 11:06
+ @desc:
+"""
+from typing import Dict
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+from setting.models_provider.impl.local_model_provider.model.embedding import LocalEmbedding
+
+
+class LocalEmbeddingCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ if not model_type == 'EMBEDDING':
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ for key in ['cache_folder']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model: LocalEmbedding = provider.get_model(model_type, model_name, model_credential)
+ model.embed_query('你好')
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return model
+
+ cache_folder = forms.TextInputField('模型目录', required=True)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/icon/local_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/icon/local_icon_svg
new file mode 100644
index 0000000..62930fa
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/icon/local_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/local_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/local_model_provider.py
new file mode 100644
index 0000000..65cc573
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/local_model_provider.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: zhipu_model_provider.py
+ @date:2024/04/19 13:5
+ @desc:
+"""
+import os
+from typing import Dict
+
+from pydantic import BaseModel
+
+from common.exception.app_exception import AppApiException
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import ModelProvideInfo, ModelTypeConst, ModelInfo, IModelProvider, \
+ ModelInfoManage
+from setting.models_provider.impl.local_model_provider.credential.embedding import LocalEmbeddingCredential
+from setting.models_provider.impl.local_model_provider.model.embedding import LocalEmbedding
+from smartdoc.conf import PROJECT_DIR
+
+embedding_text2vec_base_chinese = ModelInfo('shibing624/text2vec-base-chinese', '', ModelTypeConst.EMBEDDING,
+ LocalEmbeddingCredential(), LocalEmbedding)
+
+model_info_manage = (ModelInfoManage.builder().append_model_info(embedding_text2vec_base_chinese)
+ .append_default_model_info(embedding_text2vec_base_chinese)
+ .build())
+
+
+class LocalModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_local_provider', name='本地模型', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'local_model_provider', 'icon',
+ 'local_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/model/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/model/embedding.py
new file mode 100644
index 0000000..38cf1ae
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/local_model_provider/model/embedding.py
@@ -0,0 +1,62 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/7/11 14:06
+ @desc:
+"""
+from typing import Dict, List
+
+import requests
+from langchain_core.embeddings import Embeddings
+from langchain_core.pydantic_v1 import BaseModel
+from langchain_huggingface import HuggingFaceEmbeddings
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from smartdoc.const import CONFIG
+
+
+class WebLocalEmbedding(MaxKBBaseModel, BaseModel, Embeddings):
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ pass
+
+ model_id: str = None
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+ self.model_id = kwargs.get('model_id', None)
+
+ def embed_query(self, text: str) -> List[float]:
+ bind = f'{CONFIG.get("LOCAL_MODEL_HOST")}:{CONFIG.get("LOCAL_MODEL_PORT")}'
+ res = requests.post(f'{CONFIG.get("LOCAL_MODEL_PROTOCOL")}://{bind}/api/model/{self.model_id}/embed_query',
+ {'text': text})
+ result = res.json()
+ if result.get('code', 500) == 200:
+ return result.get('data')
+ raise Exception(result.get('msg'))
+
+ def embed_documents(self, texts: List[str]) -> List[List[float]]:
+ bind = f'{CONFIG.get("LOCAL_MODEL_HOST")}:{CONFIG.get("LOCAL_MODEL_PORT")}'
+ res = requests.post(f'{CONFIG.get("LOCAL_MODEL_PROTOCOL")}://{bind}/api/model/{self.model_id}/embed_documents',
+ {'texts': texts})
+ result = res.json()
+ if result.get('code', 500) == 200:
+ return result.get('data')
+ raise Exception(result.get('msg'))
+
+
+class LocalEmbedding(MaxKBBaseModel, HuggingFaceEmbeddings):
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ if model_kwargs.get('use_local', True):
+ return LocalEmbedding(model_name=model_name, cache_folder=model_credential.get('cache_folder'),
+ model_kwargs={'device': model_credential.get('device')},
+ encode_kwargs={'normalize_embeddings': True}
+ )
+ return WebLocalEmbedding(model_name=model_name, cache_folder=model_credential.get('cache_folder'),
+ model_kwargs={'device': model_credential.get('device')},
+ encode_kwargs={'normalize_embeddings': True},
+ **model_kwargs)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/__init__.py
new file mode 100644
index 0000000..6da6cdb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2024/3/5 17:20
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/credential/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/credential/embedding.py
new file mode 100644
index 0000000..e0eeabe
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/credential/embedding.py
@@ -0,0 +1,45 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/7/12 15:10
+ @desc:
+"""
+from typing import Dict
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+from setting.models_provider.impl.local_model_provider.model.embedding import LocalEmbedding
+
+
+class OllamaEmbeddingModelCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ try:
+ model_list = provider.get_base_model_list(model_credential.get('api_base'))
+ except Exception as e:
+ raise AppApiException(ValidCode.valid_error.value, "API 域名无效")
+ exist = [model for model in (model_list.get('models') if model_list.get('models') is not None else []) if
+ model.get('model') == model_name or model.get('model').replace(":latest", "") == model_name]
+ if len(exist) == 0:
+ raise AppApiException(ValidCode.model_not_fount, "模型不存在,请先下载模型")
+ model: LocalEmbedding = provider.get_model(model_type, model_name, model_credential)
+ model.embed_query('你好')
+ return True
+
+ def encryption_dict(self, model_info: Dict[str, object]):
+ return model_info
+
+ def build_model(self, model_info: Dict[str, object]):
+ for key in ['model']:
+ if key not in model_info:
+ raise AppApiException(500, f'{key} 字段为必填字段')
+ return self
+
+ api_base = forms.TextInputField('API 域名', required=True)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/credential/llm.py
new file mode 100644
index 0000000..14634b4
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/credential/llm.py
@@ -0,0 +1,64 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 18:19
+ @desc:
+"""
+from typing import Dict
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class OllamaLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.3,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=1024,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class OllamaLLMModelCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ try:
+ model_list = provider.get_base_model_list(model_credential.get('api_base'))
+ except Exception as e:
+ raise AppApiException(ValidCode.valid_error.value, "API 域名无效")
+ exist = [model for model in (model_list.get('models') if model_list.get('models') is not None else []) if
+ model.get('model') == model_name or model.get('model').replace(":latest", "") == model_name]
+ if len(exist) == 0:
+ raise AppApiException(ValidCode.model_not_fount, "模型不存在,请先下载模型")
+ return True
+
+ def encryption_dict(self, model_info: Dict[str, object]):
+ return {**model_info, 'api_key': super().encryption(model_info.get('api_key', ''))}
+
+ def build_model(self, model_info: Dict[str, object]):
+ for key in ['api_key', 'model']:
+ if key not in model_info:
+ raise AppApiException(500, f'{key} 字段为必填字段')
+ self.api_key = model_info.get('api_key')
+ return self
+
+ api_base = forms.TextInputField('API 域名', required=True)
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return OllamaLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/icon/ollama_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/icon/ollama_icon_svg
new file mode 100644
index 0000000..ba96d43
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/icon/ollama_icon_svg
@@ -0,0 +1,3 @@
+
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/model/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/model/embedding.py
new file mode 100644
index 0000000..d1a68eb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/model/embedding.py
@@ -0,0 +1,48 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/7/12 15:02
+ @desc:
+"""
+from typing import Dict, List
+
+from langchain_community.embeddings import OllamaEmbeddings
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class OllamaEmbedding(MaxKBBaseModel, OllamaEmbeddings):
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ return OllamaEmbedding(
+ model=model_name,
+ base_url=model_credential.get('api_base'),
+ )
+
+ def embed_documents(self, texts: List[str]) -> List[List[float]]:
+ """Embed documents using an Ollama deployed embedding model.
+
+ Args:
+ texts: The list of texts to embed.
+
+ Returns:
+ List of embeddings, one for each text.
+ """
+ instruction_pairs = [f"{text}" for text in texts]
+ embeddings = self._embed(instruction_pairs)
+ return embeddings
+
+ def embed_query(self, text: str) -> List[float]:
+ """Embed a query using a Ollama deployed embedding model.
+
+ Args:
+ text: The text to embed.
+
+ Returns:
+ Embeddings for the text.
+ """
+ instruction_pair = f"{text}"
+ embedding = self._embed([instruction_pair])[0]
+ return embedding
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/model/llm.py
new file mode 100644
index 0000000..abb5fcb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/model/llm.py
@@ -0,0 +1,53 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: llm.py
+ @date:2024/3/6 11:48
+ @desc:
+"""
+from typing import List, Dict
+from urllib.parse import urlparse, ParseResult
+
+from langchain_core.messages import BaseMessage, get_buffer_string
+from langchain_openai.chat_models import ChatOpenAI
+
+from common.config.tokenizer_manage_config import TokenizerManage
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+def get_base_url(url: str):
+ parse = urlparse(url)
+ result_url = ParseResult(scheme=parse.scheme, netloc=parse.netloc, path=parse.path, params='',
+ query='',
+ fragment='').geturl()
+ return result_url[:-1] if result_url.endswith("/") else result_url
+
+
+class OllamaChatModel(MaxKBBaseModel, ChatOpenAI):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ api_base = model_credential.get('api_base', '')
+ base_url = get_base_url(api_base)
+ base_url = base_url if base_url.endswith('/v1') else (base_url + '/v1')
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+
+ return OllamaChatModel(model=model_name, openai_api_base=base_url,
+ openai_api_key=model_credential.get('api_key'),
+ stream_usage=True, **optional_params)
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ tokenizer = TokenizerManage.get_tokenizer()
+ return sum([len(tokenizer.encode(get_buffer_string([m]))) for m in messages])
+
+ def get_num_tokens(self, text: str) -> int:
+ tokenizer = TokenizerManage.get_tokenizer()
+ return len(tokenizer.encode(text))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/ollama_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/ollama_model_provider.py
new file mode 100644
index 0000000..6f0fc94
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/ollama_model_provider/ollama_model_provider.py
@@ -0,0 +1,186 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: ollama_model_provider.py
+ @date:2024/3/5 17:23
+ @desc:
+"""
+import json
+import os
+from typing import Dict, Iterator
+from urllib.parse import urlparse, ParseResult
+
+import requests
+from langchain.chat_models.base import BaseChatModel
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, \
+ BaseModelCredential, DownModelChunk, DownModelChunkStatus, ValidCode, ModelInfoManage
+from setting.models_provider.impl.ollama_model_provider.credential.embedding import OllamaEmbeddingModelCredential
+from setting.models_provider.impl.ollama_model_provider.credential.llm import OllamaLLMModelCredential
+from setting.models_provider.impl.ollama_model_provider.model.embedding import OllamaEmbedding
+from setting.models_provider.impl.ollama_model_provider.model.llm import OllamaChatModel
+from smartdoc.conf import PROJECT_DIR
+
+""
+
+ollama_llm_model_credential = OllamaLLMModelCredential()
+model_info_list = [
+ ModelInfo(
+ 'llama2',
+ 'Llama 2 是一组经过预训练和微调的生成文本模型,其规模从 70 亿到 700 亿个不等。这是 7B 预训练模型的存储库。其他模型的链接可以在底部的索引中找到。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'llama2:13b',
+ 'Llama 2 是一组经过预训练和微调的生成文本模型,其规模从 70 亿到 700 亿个不等。这是 13B 预训练模型的存储库。其他模型的链接可以在底部的索引中找到。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'llama2:70b',
+ 'Llama 2 是一组经过预训练和微调的生成文本模型,其规模从 70 亿到 700 亿个不等。这是 70B 预训练模型的存储库。其他模型的链接可以在底部的索引中找到。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'llama2-chinese:13b',
+ '由于Llama2本身的中文对齐较弱,我们采用中文指令集,对meta-llama/Llama-2-13b-chat-hf进行LoRA微调,使其具备较强的中文对话能力。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'llama3:8b',
+ 'Meta Llama 3:迄今为止最有能力的公开产品LLM。80亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'llama3:70b',
+ 'Meta Llama 3:迄今为止最有能力的公开产品LLM。700亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'qwen:0.5b',
+ 'qwen 1.5 0.5b 相较于以往版本,模型与人类偏好的对齐程度以及多语言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。5亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'qwen:1.8b',
+ 'qwen 1.5 1.8b 相较于以往版本,模型与人类偏好的对齐程度以及多语言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。18亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'qwen:4b',
+ 'qwen 1.5 4b 相较于以往版本,模型与人类偏好的对齐程度以及多语言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。40亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+
+ ModelInfo(
+ 'qwen:7b',
+ 'qwen 1.5 7b 相较于以往版本,模型与人类偏好的对齐程度以及多语1言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。70亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'qwen:14b',
+ 'qwen 1.5 14b 相较于以往版本,模型与人类偏好的对齐程度以及多语言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。140亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'qwen:32b',
+ 'qwen 1.5 32b 相较于以往版本,模型与人类偏好的对齐程度以及多语言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。320亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'qwen:72b',
+ 'qwen 1.5 72b 相较于以往版本,模型与人类偏好的对齐程度以及多语言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。720亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'qwen:110b',
+ 'qwen 1.5 110b 相较于以往版本,模型与人类偏好的对齐程度以及多语言处理能力上有显著增强。所有规模的模型都支持32768个tokens的上下文长度。1100亿参数。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+ ModelInfo(
+ 'phi3',
+ 'Phi-3 Mini是Microsoft的3.8B参数,轻量级,最先进的开放模型。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel),
+]
+ollama_embedding_model_credential = OllamaEmbeddingModelCredential()
+embedding_model_info = [
+ ModelInfo(
+ 'nomic-embed-text',
+ '一个具有大令牌上下文窗口的高性能开放嵌入模型。',
+ ModelTypeConst.EMBEDDING, ollama_embedding_model_credential, OllamaEmbedding),
+]
+
+model_info_manage = ModelInfoManage.builder().append_model_info_list(model_info_list).append_model_info_list(
+ embedding_model_info).append_default_model_info(
+ ModelInfo(
+ 'phi3',
+ 'Phi-3 Mini是Microsoft的3.8B参数,轻量级,最先进的开放模型。',
+ ModelTypeConst.LLM, ollama_llm_model_credential, OllamaChatModel)).append_default_model_info(ModelInfo(
+ 'nomic-embed-text',
+ '一个具有大令牌上下文窗口的高性能开放嵌入模型。',
+ ModelTypeConst.EMBEDDING, ollama_embedding_model_credential, OllamaEmbedding), ).build()
+
+
+def get_base_url(url: str):
+ parse = urlparse(url)
+ result_url = ParseResult(scheme=parse.scheme, netloc=parse.netloc, path=parse.path, params='',
+ query='',
+ fragment='').geturl()
+ return result_url[:-1] if result_url.endswith("/") else result_url
+
+
+def convert_to_down_model_chunk(row_str: str, chunk_index: int):
+ row = json.loads(row_str)
+ status = DownModelChunkStatus.unknown
+ digest = ""
+ progress = 100
+ if 'status' in row:
+ digest = row.get('status')
+ if row.get('status') == 'success':
+ status = DownModelChunkStatus.success
+ if row.get('status').__contains__("pulling"):
+ progress = 0
+ status = DownModelChunkStatus.pulling
+ if 'total' in row and 'completed' in row:
+ progress = (row.get('completed') / row.get('total') * 100)
+ elif 'error' in row:
+ status = DownModelChunkStatus.error
+ digest = row.get('error')
+ return DownModelChunk(status=status, digest=digest, progress=progress, details=row_str, index=chunk_index)
+
+
+def convert(response_stream) -> Iterator[DownModelChunk]:
+ temp = ""
+ index = 0
+ for c in response_stream:
+ index += 1
+ row_content = c.decode()
+ temp += row_content
+ if row_content.endswith('}') or row_content.endswith('\n'):
+ rows = [t for t in temp.split("\n") if len(t) > 0]
+ for row in rows:
+ yield convert_to_down_model_chunk(row, index)
+ temp = ""
+
+ if len(temp) > 0:
+ rows = [t for t in temp.split("\n") if len(t) > 0]
+ for row in rows:
+ yield convert_to_down_model_chunk(row, index)
+
+
+class OllamaModelProvider(IModelProvider):
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_ollama_provider', name='Ollama', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'ollama_model_provider', 'icon',
+ 'ollama_icon_svg')))
+
+ @staticmethod
+ def get_base_model_list(api_base):
+ base_url = get_base_url(api_base)
+ r = requests.request(method="GET", url=f"{base_url}/api/tags", timeout=5)
+ r.raise_for_status()
+ return r.json()
+
+ def down_model(self, model_type: str, model_name, model_credential: Dict[str, object]) -> Iterator[DownModelChunk]:
+ api_base = model_credential.get('api_base', '')
+ base_url = get_base_url(api_base)
+ r = requests.request(
+ method="POST",
+ url=f"{base_url}/api/pull",
+ data=json.dumps({"name": model_name}).encode(),
+ stream=True,
+ )
+ return convert(r)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/__init__.py
new file mode 100644
index 0000000..2dc4ab1
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2024/3/28 16:25
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/credential/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/credential/embedding.py
new file mode 100644
index 0000000..d49d22e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/credential/embedding.py
@@ -0,0 +1,46 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/7/12 16:45
+ @desc:
+"""
+from typing import Dict
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class OpenAIEmbeddingCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=True):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['api_base', 'api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.embed_query('你好')
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_base = forms.TextInputField('API 域名', required=True)
+ api_key = forms.PasswordInputField('API Key', required=True)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/credential/llm.py
new file mode 100644
index 0000000..f7d244a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/credential/llm.py
@@ -0,0 +1,69 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 18:32
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class OpenAILLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.7,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=800,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class OpenAILLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['api_base', 'api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_base = forms.TextInputField('API 域名', required=True)
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return OpenAILLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/icon/openai_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/icon/openai_icon_svg
new file mode 100644
index 0000000..da75338
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/icon/openai_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/model/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/model/embedding.py
new file mode 100644
index 0000000..5ac1f8e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/model/embedding.py
@@ -0,0 +1,23 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/7/12 17:44
+ @desc:
+"""
+from typing import Dict
+
+from langchain_community.embeddings import OpenAIEmbeddings
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class OpenAIEmbeddingModel(MaxKBBaseModel, OpenAIEmbeddings):
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ return OpenAIEmbeddingModel(
+ api_key=model_credential.get('api_key'),
+ model=model_name,
+ openai_api_base=model_credential.get('api_base'),
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/model/llm.py
new file mode 100644
index 0000000..cdd187d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/model/llm.py
@@ -0,0 +1,59 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: llm.py
+ @date:2024/4/18 15:28
+ @desc:
+"""
+from typing import List, Dict
+
+from langchain_core.messages import BaseMessage, get_buffer_string
+from langchain_openai.chat_models import ChatOpenAI
+
+from common.config.tokenizer_manage_config import TokenizerManage
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+def custom_get_token_ids(text: str):
+ tokenizer = TokenizerManage.get_tokenizer()
+ return tokenizer.encode(text)
+
+
+class OpenAIChatModel(MaxKBBaseModel, ChatOpenAI):
+
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+ azure_chat_open_ai = OpenAIChatModel(
+ model=model_name,
+ openai_api_base=model_credential.get('api_base'),
+ openai_api_key=model_credential.get('api_key'),
+ **optional_params,
+ streaming=True,
+ stream_usage=True,
+ custom_get_token_ids=custom_get_token_ids
+ )
+ return azure_chat_open_ai
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ try:
+ return super().get_num_tokens_from_messages(messages)
+ except Exception as e:
+ tokenizer = TokenizerManage.get_tokenizer()
+ return sum([len(tokenizer.encode(get_buffer_string([m]))) for m in messages])
+
+ def get_num_tokens(self, text: str) -> int:
+ try:
+ return super().get_num_tokens(text)
+ except Exception as e:
+ tokenizer = TokenizerManage.get_tokenizer()
+ return len(tokenizer.encode(text))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/openai_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/openai_model_provider.py
new file mode 100644
index 0000000..fb4c89d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/openai_model_provider/openai_model_provider.py
@@ -0,0 +1,84 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: openai_model_provider.py
+ @date:2024/3/28 16:26
+ @desc:
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, \
+ ModelTypeConst, ModelInfoManage
+from setting.models_provider.impl.openai_model_provider.credential.embedding import OpenAIEmbeddingCredential
+from setting.models_provider.impl.openai_model_provider.credential.llm import OpenAILLMModelCredential
+from setting.models_provider.impl.openai_model_provider.model.embedding import OpenAIEmbeddingModel
+from setting.models_provider.impl.openai_model_provider.model.llm import OpenAIChatModel
+from smartdoc.conf import PROJECT_DIR
+
+openai_llm_model_credential = OpenAILLMModelCredential()
+model_info_list = [
+ ModelInfo('gpt-3.5-turbo', '最新的gpt-3.5-turbo,随OpenAI调整而更新', ModelTypeConst.LLM,
+ openai_llm_model_credential, OpenAIChatModel
+ ),
+ ModelInfo('gpt-4', '最新的gpt-4,随OpenAI调整而更新', ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-4o', '最新的GPT-4o,比gpt-4-turbo更便宜、更快,随OpenAI调整而更新',
+ ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-4-turbo', '最新的gpt-4-turbo,随OpenAI调整而更新', ModelTypeConst.LLM,
+ openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-4-turbo-preview', '最新的gpt-4-turbo-preview,随OpenAI调整而更新',
+ ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-3.5-turbo-0125',
+ '2024年1月25日的gpt-3.5-turbo快照,支持上下文长度16,385 tokens', ModelTypeConst.LLM,
+ openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-3.5-turbo-1106',
+ '2023年11月6日的gpt-3.5-turbo快照,支持上下文长度16,385 tokens', ModelTypeConst.LLM,
+ openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-3.5-turbo-0613',
+ '[Legacy] 2023年6月13日的gpt-3.5-turbo快照,将于2024年6月13日弃用',
+ ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-4o-2024-05-13',
+ '2024年5月13日的gpt-4o快照,支持上下文长度128,000 tokens',
+ ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-4-turbo-2024-04-09',
+ '2024年4月9日的gpt-4-turbo快照,支持上下文长度128,000 tokens',
+ ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-4-0125-preview', '2024年1月25日的gpt-4-turbo快照,支持上下文长度128,000 tokens',
+ ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel),
+ ModelInfo('gpt-4-1106-preview', '2023年11月6日的gpt-4-turbo快照,支持上下文长度128,000 tokens',
+ ModelTypeConst.LLM, openai_llm_model_credential,
+ OpenAIChatModel)
+]
+open_ai_embedding_credential = OpenAIEmbeddingCredential()
+model_info_embedding_list = [
+ ModelInfo('text-embedding-ada-002', '',
+ ModelTypeConst.EMBEDDING, open_ai_embedding_credential,
+ OpenAIEmbeddingModel)]
+
+model_info_manage = ModelInfoManage.builder().append_model_info_list(model_info_list).append_default_model_info(
+ ModelInfo('gpt-3.5-turbo', '最新的gpt-3.5-turbo,随OpenAI调整而更新', ModelTypeConst.LLM,
+ openai_llm_model_credential, OpenAIChatModel
+ )).append_model_info_list(model_info_embedding_list).append_default_model_info(
+ model_info_embedding_list[0]).build()
+
+
+class OpenAIModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_openai_provider', name='OpenAI', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'openai_model_provider', 'icon',
+ 'openai_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/__init__.py
new file mode 100644
index 0000000..53b7001
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/10/31 17:16
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/credential/llm.py
new file mode 100644
index 0000000..7ad0684
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/credential/llm.py
@@ -0,0 +1,67 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 18:41
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class QwenModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=1.0,
+ _min=0.1,
+ _max=1.9,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=800,
+ _min=1,
+ _max=2048,
+ _step=1,
+ precision=0)
+
+
+class OpenAILLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ for key in ['api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return QwenModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/icon/qwen_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/icon/qwen_icon_svg
new file mode 100644
index 0000000..cb9a718
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/icon/qwen_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/model/llm.py
new file mode 100644
index 0000000..a1af92c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/model/llm.py
@@ -0,0 +1,85 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: llm.py
+ @date:2024/4/28 11:44
+ @desc:
+"""
+from typing import List, Dict, Optional, Iterator, Any
+
+from langchain_community.chat_models import ChatTongyi
+from langchain_community.llms.tongyi import generate_with_last_element_mark
+from langchain_core.callbacks import CallbackManagerForLLMRun
+from langchain_core.messages import BaseMessage, get_buffer_string
+from langchain_core.outputs import ChatGenerationChunk
+
+from common.config.tokenizer_manage_config import TokenizerManage
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class QwenChatModel(MaxKBBaseModel, ChatTongyi):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+ chat_tong_yi = QwenChatModel(
+ model_name=model_name,
+ dashscope_api_key=model_credential.get('api_key'),
+ model_kwargs=optional_params,
+ )
+ return chat_tong_yi
+
+ def get_last_generation_info(self) -> Optional[Dict[str, Any]]:
+ return self.__dict__.get('_last_generation_info')
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ return self.get_last_generation_info().get('input_tokens', 0)
+
+ def get_num_tokens(self, text: str) -> int:
+ return self.get_last_generation_info().get('output_tokens', 0)
+
+ def _stream(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ **kwargs: Any,
+ ) -> Iterator[ChatGenerationChunk]:
+ params: Dict[str, Any] = self._invocation_params(
+ messages=messages, stop=stop, stream=True, **kwargs
+ )
+
+ for stream_resp, is_last_chunk in generate_with_last_element_mark(
+ self.stream_completion_with_retry(**params)
+ ):
+ choice = stream_resp["output"]["choices"][0]
+ message = choice["message"]
+ if (
+ choice["finish_reason"] == "stop"
+ and message["content"] == ""
+ ) or (choice["finish_reason"] == "length"):
+ token_usage = stream_resp["usage"]
+ self.__dict__.setdefault('_last_generation_info', {}).update(token_usage)
+ if (
+ choice["finish_reason"] == "null"
+ and message["content"] == ""
+ and "tool_calls" not in message
+ ):
+ continue
+
+ chunk = ChatGenerationChunk(
+ **self._chat_generation_from_qwen_resp(
+ stream_resp, is_chunk=True, is_last_chunk=is_last_chunk
+ )
+ )
+ if run_manager:
+ run_manager.on_llm_new_token(chunk.text, chunk=chunk)
+ yield chunk
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/qwen_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/qwen_model_provider.py
new file mode 100644
index 0000000..dd0a924
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/qwen_model_provider/qwen_model_provider.py
@@ -0,0 +1,39 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: qwen_model_provider.py
+ @date:2023/10/31 16:19
+ @desc:
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import ModelProvideInfo, ModelTypeConst, ModelInfo, IModelProvider, \
+ ModelInfoManage
+from setting.models_provider.impl.qwen_model_provider.credential.llm import OpenAILLMModelCredential
+
+from setting.models_provider.impl.qwen_model_provider.model.llm import QwenChatModel
+from smartdoc.conf import PROJECT_DIR
+
+qwen_model_credential = OpenAILLMModelCredential()
+
+module_info_list = [
+ ModelInfo('qwen-turbo', '', ModelTypeConst.LLM, qwen_model_credential, QwenChatModel),
+ ModelInfo('qwen-plus', '', ModelTypeConst.LLM, qwen_model_credential, QwenChatModel),
+ ModelInfo('qwen-max', '', ModelTypeConst.LLM, qwen_model_credential, QwenChatModel)
+]
+
+model_info_manage = ModelInfoManage.builder().append_model_info_list(module_info_list).append_default_model_info(
+ ModelInfo('qwen-turbo', '', ModelTypeConst.LLM, qwen_model_credential, QwenChatModel)).build()
+
+
+class QwenModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_qwen_provider', name='通义千问', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'qwen_model_provider', 'icon',
+ 'qwen_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/__init__.py
new file mode 100644
index 0000000..8cb7f45
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/__init__.py
@@ -0,0 +1,2 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/credential/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/credential/embedding.py
new file mode 100644
index 0000000..40e36ca
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/credential/embedding.py
@@ -0,0 +1,64 @@
+import json
+from typing import Dict
+
+from tencentcloud.common import credential
+from tencentcloud.common.profile.client_profile import ClientProfile
+from tencentcloud.common.profile.http_profile import HttpProfile
+from tencentcloud.hunyuan.v20230901 import hunyuan_client, models
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class TencentEmbeddingCredential(BaseForm, BaseModelCredential):
+ @classmethod
+ def _validate_model_type(cls, model_type: str, provider) -> bool:
+ model_type_list = provider.get_model_type_list()
+ if not any(mt.get('value') == model_type for mt in model_type_list):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ return True
+
+ @classmethod
+ def _validate_credential(cls, model_credential: Dict[str, object]) -> credential.Credential:
+ for key in ['SecretId', 'SecretKey']:
+ if key not in model_credential:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ return credential.Credential(model_credential['SecretId'], model_credential['SecretKey'])
+
+ @classmethod
+ def _test_credentials(cls, client, model_name: str):
+ req = models.GetEmbeddingRequest()
+ params = {
+ "Model": model_name,
+ "Input": "测试"
+ }
+ req.from_json_string(json.dumps(params))
+ try:
+ res = client.GetEmbedding(req)
+ print(res.to_json_string())
+ except Exception as e:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=True) -> bool:
+ try:
+ self._validate_model_type(model_type, provider)
+ cred = self._validate_credential(model_credential)
+ httpProfile = HttpProfile(endpoint="hunyuan.tencentcloudapi.com")
+ clientProfile = ClientProfile(httpProfile=httpProfile)
+ client = hunyuan_client.HunyuanClient(cred, "", clientProfile)
+ self._test_credentials(client, model_name)
+ return True
+ except AppApiException as e:
+ if raise_exception:
+ raise e
+ return False
+
+ def encryption_dict(self, model: Dict[str, object]) -> Dict[str, object]:
+ encrypted_secret_key = super().encryption(model.get('SecretKey', ''))
+ return {**model, 'SecretKey': encrypted_secret_key}
+
+ SecretId = forms.PasswordInputField('SecretId', required=True)
+ SecretKey = forms.PasswordInputField('SecretKey', required=True)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/credential/llm.py
new file mode 100644
index 0000000..20b1bf8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/credential/llm.py
@@ -0,0 +1,60 @@
+# coding=utf-8
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class TencentLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.5,
+ _min=0.1,
+ _max=2.0,
+ _step=0.01,
+ precision=2)
+
+
+class TencentLLMModelCredential(BaseForm, BaseModelCredential):
+ REQUIRED_FIELDS = ['hunyuan_app_id', 'hunyuan_secret_id', 'hunyuan_secret_key']
+
+ @classmethod
+ def _validate_model_type(cls, model_type, provider, raise_exception=False):
+ if not any(mt['value'] == model_type for mt in provider.get_model_type_list()):
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ return False
+ return True
+
+ @classmethod
+ def _validate_credential_fields(cls, model_credential, raise_exception=False):
+ missing_keys = [key for key in cls.REQUIRED_FIELDS if key not in model_credential]
+ if missing_keys:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{", ".join(missing_keys)} 字段为必填字段')
+ return False
+ return True
+
+ def is_valid(self, model_type, model_name, model_credential, provider, raise_exception=False):
+ if not (self._validate_model_type(model_type, provider, raise_exception) and
+ self._validate_credential_fields(model_credential, raise_exception)):
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ return False
+ return True
+
+ def encryption_dict(self, model):
+ return {**model, 'hunyuan_secret_key': super().encryption(model.get('hunyuan_secret_key', ''))}
+
+ hunyuan_app_id = forms.TextInputField('APP ID', required=True)
+ hunyuan_secret_id = forms.PasswordInputField('SecretId', required=True)
+ hunyuan_secret_key = forms.PasswordInputField('SecretKey', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return TencentLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/icon/tencent_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/icon/tencent_icon_svg
new file mode 100644
index 0000000..6cec08b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/icon/tencent_icon_svg
@@ -0,0 +1,5 @@
+
+
+
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/embedding.py
new file mode 100644
index 0000000..a5bd033
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/embedding.py
@@ -0,0 +1,25 @@
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from typing import Dict
+import requests
+
+
+class TencentEmbeddingModel(MaxKBBaseModel):
+ def __init__(self, secret_id: str, secret_key: str, api_base: str, model_name: str):
+ self.secret_id = secret_id
+ self.secret_key = secret_key
+ self.api_base = api_base
+ self.model_name = model_name
+
+ @staticmethod
+ def new_instance(model_type: str, model_name: str, model_credential: Dict[str, str], **model_kwargs):
+ return TencentEmbeddingModel(
+ secret_id=model_credential.get('SecretId'),
+ secret_key=model_credential.get('SecretKey'),
+ api_base=model_credential.get('api_base'),
+ model_name=model_name,
+ )
+
+
+ def _generate_auth_token(self):
+ # Example method to generate an authentication token for the model API
+ return f"{self.secret_id}:{self.secret_key}"
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/hunyuan.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/hunyuan.py
new file mode 100644
index 0000000..2199201
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/hunyuan.py
@@ -0,0 +1,278 @@
+import json
+import logging
+from typing import Any, Dict, Iterator, List, Mapping, Optional, Type
+
+from langchain_core.callbacks import CallbackManagerForLLMRun
+from langchain_core.language_models.chat_models import (
+ BaseChatModel,
+ generate_from_stream,
+)
+from langchain_core.messages import (
+ AIMessage,
+ AIMessageChunk,
+ BaseMessage,
+ BaseMessageChunk,
+ ChatMessage,
+ ChatMessageChunk,
+ HumanMessage,
+ HumanMessageChunk,
+)
+from langchain_core.outputs import ChatGeneration, ChatGenerationChunk, ChatResult
+from langchain_core.pydantic_v1 import Field, SecretStr, root_validator
+from langchain_core.utils import (
+ convert_to_secret_str,
+ get_from_dict_or_env,
+ get_pydantic_field_names,
+ pre_init,
+)
+
+logger = logging.getLogger(__name__)
+
+
+def _convert_message_to_dict(message: BaseMessage) -> dict:
+ message_dict: Dict[str, Any]
+ if isinstance(message, ChatMessage):
+ message_dict = {"Role": message.role, "Content": message.content}
+ elif isinstance(message, HumanMessage):
+ message_dict = {"Role": "user", "Content": message.content}
+ elif isinstance(message, AIMessage):
+ message_dict = {"Role": "assistant", "Content": message.content}
+ else:
+ raise TypeError(f"Got unknown type {message}")
+
+ return message_dict
+
+
+def _convert_dict_to_message(_dict: Mapping[str, Any]) -> BaseMessage:
+ role = _dict["Role"]
+ if role == "user":
+ return HumanMessage(content=_dict["Content"])
+ elif role == "assistant":
+ return AIMessage(content=_dict.get("Content", "") or "")
+ else:
+ return ChatMessage(content=_dict["Content"], role=role)
+
+
+def _convert_delta_to_message_chunk(
+ _dict: Mapping[str, Any], default_class: Type[BaseMessageChunk]
+) -> BaseMessageChunk:
+ role = _dict.get("Role")
+ content = _dict.get("Content") or ""
+
+ if role == "user" or default_class == HumanMessageChunk:
+ return HumanMessageChunk(content=content)
+ elif role == "assistant" or default_class == AIMessageChunk:
+ return AIMessageChunk(content=content)
+ elif role or default_class == ChatMessageChunk:
+ return ChatMessageChunk(content=content, role=role) # type: ignore[arg-type]
+ else:
+ return default_class(content=content) # type: ignore[call-arg]
+
+
+def _create_chat_result(response: Mapping[str, Any]) -> ChatResult:
+ generations = []
+ for choice in response["Choices"]:
+ message = _convert_dict_to_message(choice["Message"])
+ generations.append(ChatGeneration(message=message))
+
+ token_usage = response["Usage"]
+ llm_output = {"token_usage": token_usage}
+ return ChatResult(generations=generations, llm_output=llm_output)
+
+
+class ChatHunyuan(BaseChatModel):
+ """Tencent Hunyuan chat models API by Tencent.
+
+ For more information, see https://cloud.tencent.com/document/product/1729
+ """
+
+ @property
+ def lc_secrets(self) -> Dict[str, str]:
+ return {
+ "hunyuan_app_id": "HUNYUAN_APP_ID",
+ "hunyuan_secret_id": "HUNYUAN_SECRET_ID",
+ "hunyuan_secret_key": "HUNYUAN_SECRET_KEY",
+ }
+
+ @property
+ def lc_serializable(self) -> bool:
+ return True
+
+ hunyuan_app_id: Optional[int] = None
+ """Hunyuan App ID"""
+ hunyuan_secret_id: Optional[str] = None
+ """Hunyuan Secret ID"""
+ hunyuan_secret_key: Optional[SecretStr] = None
+ """Hunyuan Secret Key"""
+ streaming: bool = False
+ """Whether to stream the results or not."""
+ request_timeout: int = 60
+ """Timeout for requests to Hunyuan API. Default is 60 seconds."""
+ temperature: float = 1.0
+ """What sampling temperature to use."""
+ top_p: float = 1.0
+ """What probability mass to use."""
+ model: str = "hunyuan-lite"
+ """What Model to use.
+ Optional model:
+ - hunyuan-lite、
+ - hunyuan-standard
+ - hunyuan-standard-256K
+ - hunyuan-pro
+ - hunyuan-code
+ - hunyuan-role
+ - hunyuan-functioncall
+ - hunyuan-vision
+ """
+ stream_moderation: bool = False
+ """Whether to review the results or not when streaming is true."""
+ enable_enhancement: bool = True
+ """Whether to enhancement the results or not."""
+
+ model_kwargs: Dict[str, Any] = Field(default_factory=dict)
+ """Holds any model parameters valid for API call not explicitly specified."""
+
+ class Config:
+ """Configuration for this pydantic object."""
+
+ allow_population_by_field_name = True
+
+ @root_validator(pre=True)
+ def build_extra(cls, values: Dict[str, Any]) -> Dict[str, Any]:
+ """Build extra kwargs from additional params that were passed in."""
+ all_required_field_names = get_pydantic_field_names(cls)
+ extra = values.get("model_kwargs", {})
+ for field_name in list(values):
+ if field_name in extra:
+ raise ValueError(f"Found {field_name} supplied twice.")
+ if field_name not in all_required_field_names:
+ logger.warning(
+ f"""WARNING! {field_name} is not default parameter.
+ {field_name} was transferred to model_kwargs.
+ Please confirm that {field_name} is what you intended."""
+ )
+ extra[field_name] = values.pop(field_name)
+
+ invalid_model_kwargs = all_required_field_names.intersection(extra.keys())
+ if invalid_model_kwargs:
+ raise ValueError(
+ f"Parameters {invalid_model_kwargs} should be specified explicitly. "
+ f"Instead they were passed in as part of `model_kwargs` parameter."
+ )
+
+ values["model_kwargs"] = extra
+ return values
+
+ @pre_init
+ def validate_environment(cls, values: Dict) -> Dict:
+ values["hunyuan_app_id"] = get_from_dict_or_env(
+ values,
+ "hunyuan_app_id",
+ "HUNYUAN_APP_ID",
+ )
+ values["hunyuan_secret_id"] = get_from_dict_or_env(
+ values,
+ "hunyuan_secret_id",
+ "HUNYUAN_SECRET_ID",
+ )
+ values["hunyuan_secret_key"] = convert_to_secret_str(
+ get_from_dict_or_env(
+ values,
+ "hunyuan_secret_key",
+ "HUNYUAN_SECRET_KEY",
+ )
+ )
+ return values
+
+ @property
+ def _default_params(self) -> Dict[str, Any]:
+ """Get the default parameters for calling Hunyuan API."""
+ normal_params = {
+ "Temperature": self.temperature,
+ "TopP": self.top_p,
+ "Model": self.model,
+ "Stream": self.streaming,
+ "StreamModeration": self.stream_moderation,
+ "EnableEnhancement": self.enable_enhancement,
+ }
+ return {**normal_params, **self.model_kwargs}
+
+ def _generate(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ **kwargs: Any,
+ ) -> ChatResult:
+ if self.streaming:
+ stream_iter = self._stream(
+ messages=messages, stop=stop, run_manager=run_manager, **kwargs
+ )
+ return generate_from_stream(stream_iter)
+
+ res = self._chat(messages, **kwargs)
+ return _create_chat_result(json.loads(res.to_json_string()))
+
+ def _stream(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ **kwargs: Any,
+ ) -> Iterator[ChatGenerationChunk]:
+ res = self._chat(messages, **kwargs)
+
+ default_chunk_class = AIMessageChunk
+ for chunk in res:
+ chunk = chunk.get("data", "")
+ if len(chunk) == 0:
+ continue
+ response = json.loads(chunk)
+ if "error" in response:
+ raise ValueError(f"Error from Hunyuan api response: {response}")
+
+ for choice in response["Choices"]:
+ chunk = _convert_delta_to_message_chunk(
+ choice["Delta"], default_chunk_class
+ )
+ default_chunk_class = chunk.__class__
+ # FinishReason === stop
+ if choice.get("FinishReason") == "stop":
+ self.__dict__.setdefault("_last_generation_info", {}).update(
+ response.get("Usage", {})
+ )
+ cg_chunk = ChatGenerationChunk(message=chunk)
+ if run_manager:
+ run_manager.on_llm_new_token(chunk.content, chunk=cg_chunk)
+ yield cg_chunk
+
+ def _chat(self, messages: List[BaseMessage], **kwargs: Any) -> Any:
+ if self.hunyuan_secret_key is None:
+ raise ValueError("Hunyuan secret key is not set.")
+
+ try:
+ from tencentcloud.common import credential
+ from tencentcloud.hunyuan.v20230901 import hunyuan_client, models
+ except ImportError:
+ raise ImportError(
+ "Could not import tencentcloud python package. "
+ "Please install it with `pip install tencentcloud-sdk-python`."
+ )
+
+ parameters = {**self._default_params, **kwargs}
+ cred = credential.Credential(
+ self.hunyuan_secret_id, str(self.hunyuan_secret_key.get_secret_value())
+ )
+ client = hunyuan_client.HunyuanClient(cred, "")
+ req = models.ChatCompletionsRequest()
+ params = {
+ "Messages": [_convert_message_to_dict(m) for m in messages],
+ **parameters,
+ }
+ req.from_json_string(json.dumps(params))
+ resp = client.ChatCompletions(req)
+ return resp
+
+ @property
+ def _llm_type(self) -> str:
+ return "hunyuan-chat"
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/llm.py
new file mode 100644
index 0000000..0f879f7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/model/llm.py
@@ -0,0 +1,47 @@
+# coding=utf-8
+
+from typing import List, Dict, Optional, Any
+
+from langchain_core.messages import BaseMessage, get_buffer_string
+from common.config.tokenizer_manage_config import TokenizerManage
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from setting.models_provider.impl.tencent_model_provider.model.hunyuan import ChatHunyuan
+
+
+class TencentModel(MaxKBBaseModel, ChatHunyuan):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ def __init__(self, model_name: str, credentials: Dict[str, str], streaming: bool = False, **kwargs):
+ hunyuan_app_id = credentials.get('hunyuan_app_id')
+ hunyuan_secret_id = credentials.get('hunyuan_secret_id')
+ hunyuan_secret_key = credentials.get('hunyuan_secret_key')
+
+ optional_params = {}
+ if 'temperature' in kwargs:
+ optional_params['temperature'] = kwargs['temperature']
+
+ if not all([hunyuan_app_id, hunyuan_secret_id, hunyuan_secret_key]):
+ raise ValueError(
+ "All of 'hunyuan_app_id', 'hunyuan_secret_id', and 'hunyuan_secret_key' must be provided in credentials.")
+
+ super().__init__(model=model_name, hunyuan_app_id=hunyuan_app_id, hunyuan_secret_id=hunyuan_secret_id,
+ hunyuan_secret_key=hunyuan_secret_key, streaming=streaming,
+ temperature=optional_params.get('temperature', 1.0)
+ )
+
+ @staticmethod
+ def new_instance(model_type: str, model_name: str, model_credential: Dict[str, object],
+ **model_kwargs) -> 'TencentModel':
+ streaming = model_kwargs.pop('streaming', False)
+ return TencentModel(model_name=model_name, credentials=model_credential, streaming=streaming, **model_kwargs)
+
+ def get_last_generation_info(self) -> Optional[Dict[str, Any]]:
+ return self.__dict__.get('_last_generation_info')
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ return self.get_last_generation_info().get('PromptTokens', 0)
+
+ def get_num_tokens(self, text: str) -> int:
+ return self.get_last_generation_info().get('CompletionTokens', 0)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/tencent_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/tencent_model_provider.py
new file mode 100644
index 0000000..572ff94
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/tencent_model_provider/tencent_model_provider.py
@@ -0,0 +1,103 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+
+import os
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import (
+ IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, ModelInfoManage
+)
+from setting.models_provider.impl.tencent_model_provider.credential.embedding import TencentEmbeddingCredential
+from setting.models_provider.impl.tencent_model_provider.credential.llm import TencentLLMModelCredential
+from setting.models_provider.impl.tencent_model_provider.model.embedding import TencentEmbeddingModel
+from setting.models_provider.impl.tencent_model_provider.model.llm import TencentModel
+from smartdoc.conf import PROJECT_DIR
+
+
+def _create_model_info(model_name, description, model_type, credential_class, model_class):
+ return ModelInfo(
+ name=model_name,
+ desc=description,
+ model_type=model_type,
+ model_credential=credential_class(),
+ model_class=model_class
+ )
+
+
+def _get_tencent_icon_path():
+ return os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'tencent_model_provider',
+ 'icon', 'tencent_icon_svg')
+
+
+def _initialize_model_info():
+ model_info_list = [_create_model_info(
+ 'hunyuan-pro',
+ '当前混元模型中效果最优版本,万亿级参数规模 MOE-32K 长文模型。在各种 benchmark 上达到绝对领先的水平,复杂指令和推理,具备复杂数学能力,支持 functioncall,在多语言翻译、金融法律医疗等领域应用重点优化',
+ ModelTypeConst.LLM,
+ TencentLLMModelCredential,
+ TencentModel
+ ),
+ _create_model_info(
+ 'hunyuan-standard',
+ '采用更优的路由策略,同时缓解了负载均衡和专家趋同的问题。长文方面,大海捞针指标达到99.9%',
+ ModelTypeConst.LLM,
+ TencentLLMModelCredential,
+ TencentModel),
+ _create_model_info(
+ 'hunyuan-lite',
+ '升级为 MOE 结构,上下文窗口为 256k ,在 NLP,代码,数学,行业等多项评测集上领先众多开源模型',
+ ModelTypeConst.LLM,
+ TencentLLMModelCredential,
+ TencentModel),
+ _create_model_info(
+ 'hunyuan-role',
+ '混元最新版角色扮演模型,混元官方精调训练推出的角色扮演模型,基于混元模型结合角色扮演场景数据集进行增训,在角色扮演场景具有更好的基础效果',
+ ModelTypeConst.LLM,
+ TencentLLMModelCredential,
+ TencentModel),
+ _create_model_info(
+ 'hunyuan-functioncall ',
+ '混元最新 MOE 架构 FunctionCall 模型,经过高质量的 FunctionCall 数据训练,上下文窗口达 32K,在多个维度的评测指标上处于领先。',
+ ModelTypeConst.LLM,
+ TencentLLMModelCredential,
+ TencentModel),
+ _create_model_info(
+ 'hunyuan-code',
+ '混元最新代码生成模型,经过 200B 高质量代码数据增训基座模型,迭代半年高质量 SFT 数据训练,上下文长窗口长度增大到 8K,五大语言代码生成自动评测指标上位居前列;五大语言10项考量各方面综合代码任务人工高质量评测上,性能处于第一梯队',
+ ModelTypeConst.LLM,
+ TencentLLMModelCredential,
+ TencentModel),
+ ]
+
+ tencent_embedding_model_info = _create_model_info(
+ 'hunyuan-embedding',
+ '',
+ ModelTypeConst.EMBEDDING,
+ TencentEmbeddingCredential,
+ TencentEmbeddingModel
+ )
+
+ model_info_embedding_list = [tencent_embedding_model_info]
+
+ model_info_manage = ModelInfoManage.builder() \
+ .append_model_info_list(model_info_list) \
+ .append_default_model_info(model_info_list[0]) \
+ .build()
+
+ return model_info_manage
+
+
+class TencentModelProvider(IModelProvider):
+ def __init__(self):
+ self._model_info_manage = _initialize_model_info()
+
+ def get_model_info_manage(self):
+ return self._model_info_manage
+
+ def get_model_provide_info(self):
+ icon_path = _get_tencent_icon_path()
+ icon_data = get_file_content(icon_path)
+ return ModelProvideInfo(
+ provider='model_tencent_provider',
+ name='腾讯混元',
+ icon=icon_data
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/__init__.py
new file mode 100644
index 0000000..9bad579
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/__init__.py
@@ -0,0 +1 @@
+# coding=utf-8
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/credential/llm.py
new file mode 100644
index 0000000..7ea3cab
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/credential/llm.py
@@ -0,0 +1,65 @@
+# coding=utf-8
+
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class VLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.7,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=800,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class VLLMModelCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ try:
+ model_list = provider.get_base_model_list(model_credential.get('api_base'))
+ except Exception as e:
+ raise AppApiException(ValidCode.valid_error.value, "API 域名无效")
+ exist = provider.get_model_info_by_name(model_list, model_name)
+ if len(exist) == 0:
+ raise AppApiException(ValidCode.valid_error.value, "模型不存在,请先下载模型")
+ model = provider.get_model(model_type, model_name, model_credential)
+ try:
+ res = model.invoke([HumanMessage(content='你好')])
+ print(res)
+ except Exception as e:
+ print(e)
+ return True
+
+ def encryption_dict(self, model_info: Dict[str, object]):
+ return {**model_info, 'api_key': super().encryption(model_info.get('api_key', ''))}
+
+ def build_model(self, model_info: Dict[str, object]):
+ for key in ['api_key', 'model']:
+ if key not in model_info:
+ raise AppApiException(500, f'{key} 字段为必填字段')
+ self.api_key = model_info.get('api_key')
+ return self
+
+ api_base = forms.TextInputField('API 域名', required=True)
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return VLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/icon/vllm_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/icon/vllm_icon_svg
new file mode 100644
index 0000000..1ad7d0a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/icon/vllm_icon_svg
@@ -0,0 +1,5 @@
+
+
+
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/model/llm.py
new file mode 100644
index 0000000..5c498f8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/model/llm.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+
+from typing import List, Dict
+from urllib.parse import urlparse, ParseResult
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from setting.models_provider.impl.base_chat_open_ai import BaseChatOpenAI
+
+
+def get_base_url(url: str):
+ parse = urlparse(url)
+ result_url = ParseResult(scheme=parse.scheme, netloc=parse.netloc, path=parse.path, params='',
+ query='',
+ fragment='').geturl()
+ return result_url[:-1] if result_url.endswith("/") else result_url
+
+
+class VllmChatModel(MaxKBBaseModel, BaseChatOpenAI):
+
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+ vllm_chat_open_ai = VllmChatModel(
+ model=model_name,
+ openai_api_base=model_credential.get('api_base'),
+ openai_api_key=model_credential.get('api_key'),
+ **optional_params,
+ streaming=True,
+ stream_usage=True,
+ )
+ return vllm_chat_open_ai
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/vllm_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/vllm_model_provider.py
new file mode 100644
index 0000000..42ba361
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/vllm_model_provider/vllm_model_provider.py
@@ -0,0 +1,59 @@
+# coding=utf-8
+import os
+from urllib.parse import urlparse, ParseResult
+
+import requests
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, \
+ ModelInfoManage
+from setting.models_provider.impl.vllm_model_provider.credential.llm import VLLMModelCredential
+from setting.models_provider.impl.vllm_model_provider.model.llm import VllmChatModel
+from smartdoc.conf import PROJECT_DIR
+
+v_llm_model_credential = VLLMModelCredential()
+model_info_list = [
+ ModelInfo('facebook/opt-125m', 'Facebook的125M参数模型', ModelTypeConst.LLM, v_llm_model_credential, VllmChatModel),
+ ModelInfo('BAAI/Aquila-7B', 'BAAI的7B参数模型', ModelTypeConst.LLM, v_llm_model_credential, VllmChatModel),
+ ModelInfo('BAAI/AquilaChat-7B', 'BAAI的13B参数模型', ModelTypeConst.LLM, v_llm_model_credential, VllmChatModel),
+
+]
+
+model_info_manage = (ModelInfoManage.builder().append_model_info_list(model_info_list).append_default_model_info(
+ ModelInfo(
+ 'facebook/opt-125m',
+ 'Facebook的125M参数模型',
+ ModelTypeConst.LLM, v_llm_model_credential, VllmChatModel))
+ .build())
+
+
+def get_base_url(url: str):
+ parse = urlparse(url)
+ result_url = ParseResult(scheme=parse.scheme, netloc=parse.netloc, path=parse.path, params='',
+ query='',
+ fragment='').geturl()
+ return result_url[:-1] if result_url.endswith("/") else result_url
+
+
+class VllmModelProvider(IModelProvider):
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_vllm_provider', name='vLLM', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'vllm_model_provider', 'icon',
+ 'vllm_icon_svg')))
+
+ @staticmethod
+ def get_base_model_list(api_base):
+ base_url = get_base_url(api_base)
+ base_url = base_url if base_url.endswith('/v1') else (base_url + '/v1')
+ r = requests.request(method="GET", url=f"{base_url}/models", timeout=5)
+ r.raise_for_status()
+ return r.json().get('data')
+
+ @staticmethod
+ def get_model_info_by_name(model_list, model_name):
+ if model_list is None:
+ return []
+ return [model for model in model_list if model.get('id') == model_name]
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/__init__.py
new file mode 100644
index 0000000..8cb7f45
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/__init__.py
@@ -0,0 +1,2 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/credential/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/credential/embedding.py
new file mode 100644
index 0000000..d49d22e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/credential/embedding.py
@@ -0,0 +1,46 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: embedding.py
+ @date:2024/7/12 16:45
+ @desc:
+"""
+from typing import Dict
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class OpenAIEmbeddingCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=True):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['api_base', 'api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.embed_query('你好')
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_base = forms.TextInputField('API 域名', required=True)
+ api_key = forms.PasswordInputField('API Key', required=True)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/credential/llm.py
new file mode 100644
index 0000000..f918b43
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/credential/llm.py
@@ -0,0 +1,70 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/11 17:57
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class VolcanicEngineLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.3,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=1024,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class VolcanicEngineLLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['access_key_id', 'secret_access_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ res = model.invoke([HumanMessage(content='你好')])
+ print(res)
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'access_key_id': super().encryption(model.get('access_key_id', ''))}
+
+ access_key_id = forms.PasswordInputField('Access Key ID', required=True)
+ secret_access_key = forms.PasswordInputField('Secret Access Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return VolcanicEngineLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/icon/volcanic_engine_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/icon/volcanic_engine_icon_svg
new file mode 100644
index 0000000..05a1279
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/icon/volcanic_engine_icon_svg
@@ -0,0 +1,5 @@
+
+
+
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/model/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/model/embedding.py
new file mode 100644
index 0000000..b7307a0
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/model/embedding.py
@@ -0,0 +1,15 @@
+from typing import Dict
+
+from langchain_community.embeddings import VolcanoEmbeddings
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class VolcanicEngineEmbeddingModel(MaxKBBaseModel, VolcanoEmbeddings):
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ return VolcanicEngineEmbeddingModel(
+ api_key=model_credential.get('api_key'),
+ model=model_name,
+ openai_api_base=model_credential.get('api_base'),
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/model/llm.py
new file mode 100644
index 0000000..c549710
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/model/llm.py
@@ -0,0 +1,25 @@
+from typing import List, Dict
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+from setting.models_provider.impl.base_chat_open_ai import BaseChatOpenAI
+
+
+class VolcanicEngineChatModel(MaxKBBaseModel, BaseChatOpenAI):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+ return VolcanicEngineChatModel(
+ model=model_name,
+ openai_api_base=model_credential.get('api_base'),
+ openai_api_key=model_credential.get('api_key'),
+ **optional_params
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/volcanic_engine_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/volcanic_engine_model_provider.py
new file mode 100644
index 0000000..48802f6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/volcanic_engine_model_provider/volcanic_engine_model_provider.py
@@ -0,0 +1,51 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+"""
+@Project :MaxKB
+@File :gemini_model_provider.py
+@Author :Brian Yang
+@Date :5/13/24 7:47 AM
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, \
+ ModelInfoManage
+from setting.models_provider.impl.openai_model_provider.credential.embedding import OpenAIEmbeddingCredential
+from setting.models_provider.impl.openai_model_provider.credential.llm import OpenAILLMModelCredential
+from setting.models_provider.impl.openai_model_provider.model.embedding import OpenAIEmbeddingModel
+from setting.models_provider.impl.volcanic_engine_model_provider.model.llm import VolcanicEngineChatModel
+
+from smartdoc.conf import PROJECT_DIR
+
+volcanic_engine_llm_model_credential = OpenAILLMModelCredential()
+
+model_info_list = [
+ ModelInfo('ep-xxxxxxxxxx-yyyy',
+ '用户前往火山方舟的模型推理页面创建推理接入点,这里需要输入ep-xxxxxxxxxx-yyyy进行调用',
+ ModelTypeConst.LLM,
+ volcanic_engine_llm_model_credential, VolcanicEngineChatModel
+ )
+]
+
+open_ai_embedding_credential = OpenAIEmbeddingCredential()
+model_info_embedding_list = [
+ ModelInfo('ep-xxxxxxxxxx-yyyy',
+ '用户前往火山方舟的模型推理页面创建推理接入点,这里需要输入ep-xxxxxxxxxx-yyyy进行调用',
+ ModelTypeConst.EMBEDDING, open_ai_embedding_credential,
+ OpenAIEmbeddingModel)]
+
+model_info_manage = ModelInfoManage.builder().append_model_info_list(model_info_list).append_default_model_info(
+ model_info_list[0]).build()
+
+
+class VolcanicEngineModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_volcanic_engine_provider', name='火山引擎', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'volcanic_engine_model_provider',
+ 'icon',
+ 'volcanic_engine_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/__init__.py
new file mode 100644
index 0000000..53b7001
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/10/31 17:16
+ @desc:
+"""
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/credential/llm.py
new file mode 100644
index 0000000..be294e8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/credential/llm.py
@@ -0,0 +1,75 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/12 10:19
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class WenxinLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.95,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=1024,
+ _min=2,
+ _max=2048,
+ _step=1,
+ precision=0)
+
+
+class WenxinLLMModelCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ model = provider.get_model(model_type, model_name, model_credential)
+ model_info = [model.lower() for model in model.client.models()]
+ if not model_info.__contains__(model_name.lower()):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_name} 模型不支持')
+ for key in ['api_key', 'secret_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model.invoke(
+ [HumanMessage(content='你好')])
+ except Exception as e:
+ raise e
+ return True
+
+ def encryption_dict(self, model_info: Dict[str, object]):
+ return {**model_info, 'secret_key': super().encryption(model_info.get('secret_key', ''))}
+
+ def build_model(self, model_info: Dict[str, object]):
+ for key in ['api_key', 'secret_key', 'model']:
+ if key not in model_info:
+ raise AppApiException(500, f'{key} 字段为必填字段')
+ self.api_key = model_info.get('api_key')
+ self.secret_key = model_info.get('secret_key')
+ return self
+
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ secret_key = forms.PasswordInputField("Secret Key", required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return WenxinLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/icon/azure_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/icon/azure_icon_svg
new file mode 100644
index 0000000..4added8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/icon/azure_icon_svg
@@ -0,0 +1,5 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/model/llm.py
new file mode 100644
index 0000000..fc5b533
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/model/llm.py
@@ -0,0 +1,78 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: llm.py
+ @date:2023/11/10 17:45
+ @desc:
+"""
+import uuid
+from typing import List, Dict, Optional, Any, Iterator
+
+from langchain_community.chat_models.baidu_qianfan_endpoint import _convert_dict_to_message, QianfanChatEndpoint
+from langchain_core.callbacks import CallbackManagerForLLMRun
+from langchain_core.outputs import ChatGenerationChunk
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from langchain_core.messages import (
+ AIMessageChunk,
+ BaseMessage,
+)
+
+
+class QianfanChatModel(MaxKBBaseModel, QianfanChatEndpoint):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_output_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+ return QianfanChatModel(model=model_name,
+ qianfan_ak=model_credential.get('api_key'),
+ qianfan_sk=model_credential.get('secret_key'),
+ streaming=model_kwargs.get('streaming', False),
+ init_kwargs=optional_params)
+
+ def get_last_generation_info(self) -> Optional[Dict[str, Any]]:
+ return self.__dict__.get('_last_generation_info')
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ return self.get_last_generation_info().get('prompt_tokens', 0)
+
+ def get_num_tokens(self, text: str) -> int:
+ return self.get_last_generation_info().get('completion_tokens', 0)
+
+ def _stream(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ **kwargs: Any,
+ ) -> Iterator[ChatGenerationChunk]:
+ kwargs = {**self.init_kwargs, **kwargs}
+ params = self._convert_prompt_msg_params(messages, **kwargs)
+ params["stop"] = stop
+ params["stream"] = True
+ for res in self.client.do(**params):
+ if res:
+ msg = _convert_dict_to_message(res)
+ additional_kwargs = msg.additional_kwargs.get("function_call", {})
+ if msg.content == "" or res.get("body").get("is_end"):
+ token_usage = res.get("body").get("usage")
+ self.__dict__.setdefault('_last_generation_info', {}).update(token_usage)
+ chunk = ChatGenerationChunk(
+ text=res["result"],
+ message=AIMessageChunk( # type: ignore[call-arg]
+ content=msg.content,
+ role="assistant",
+ additional_kwargs=additional_kwargs,
+ ),
+ generation_info=msg.additional_kwargs,
+ )
+ if run_manager:
+ run_manager.on_llm_new_token(chunk.text, chunk=chunk)
+ yield chunk
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/wenxin_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/wenxin_model_provider.py
new file mode 100644
index 0000000..92e955f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/wenxin_model_provider/wenxin_model_provider.py
@@ -0,0 +1,61 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: wenxin_model_provider.py
+ @date:2023/10/31 16:19
+ @desc:
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import ModelProvideInfo, ModelTypeConst, ModelInfo, IModelProvider, \
+ ModelInfoManage
+from setting.models_provider.impl.wenxin_model_provider.credential.llm import WenxinLLMModelCredential
+from setting.models_provider.impl.wenxin_model_provider.model.llm import QianfanChatModel
+from smartdoc.conf import PROJECT_DIR
+
+win_xin_llm_model_credential = WenxinLLMModelCredential()
+model_info_list = [ModelInfo('ERNIE-Bot-4',
+ 'ERNIE-Bot-4是百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel),
+ ModelInfo('ERNIE-Bot',
+ 'ERNIE-Bot是百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel),
+ ModelInfo('ERNIE-Bot-turbo',
+ 'ERNIE-Bot-turbo是百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力,响应速度更快。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel),
+ ModelInfo('BLOOMZ-7B',
+ 'BLOOMZ-7B是业内知名的大语言模型,由BigScience研发并开源,能够以46种语言和13种编程语言输出文本。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel),
+ ModelInfo('Llama-2-7b-chat',
+ 'Llama-2-7b-chat由Meta AI研发并开源,在编码、推理及知识应用等场景表现优秀,Llama-2-7b-chat是高性能原生开源版本,适用于对话场景。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel),
+ ModelInfo('Llama-2-13b-chat',
+ 'Llama-2-13b-chat由Meta AI研发并开源,在编码、推理及知识应用等场景表现优秀,Llama-2-13b-chat是性能与效果均衡的原生开源版本,适用于对话场景。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel),
+ ModelInfo('Llama-2-70b-chat',
+ 'Llama-2-70b-chat由Meta AI研发并开源,在编码、推理及知识应用等场景表现优秀,Llama-2-70b-chat是高精度效果的原生开源版本。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel),
+ ModelInfo('Qianfan-Chinese-Llama-2-7B',
+ '千帆团队在Llama-2-7b基础上的中文增强版本,在CMMLU、C-EVAL等中文知识库上表现优异。',
+ ModelTypeConst.LLM, win_xin_llm_model_credential, QianfanChatModel)
+ ]
+
+model_info_manage = ModelInfoManage.builder().append_model_info_list(model_info_list).append_default_model_info(
+ ModelInfo('ERNIE-Bot-4',
+ 'ERNIE-Bot-4是百度自行研发的大语言模型,覆盖海量中文数据,具有更强的对话问答、内容创作生成等能力。',
+ ModelTypeConst.LLM,
+ win_xin_llm_model_credential,
+ QianfanChatModel)).build()
+
+
+class WenxinModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_wenxin_provider', name='千帆大模型', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'wenxin_model_provider', 'icon',
+ 'azure_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/__init__.py
new file mode 100644
index 0000000..c743b4e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/__init__.py
@@ -0,0 +1,8 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2024/04/19 15:55
+ @desc:
+"""
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/credential/llm.py
new file mode 100644
index 0000000..770aff2
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/credential/llm.py
@@ -0,0 +1,90 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/12 10:29
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class XunFeiLLMModelGeneralParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.5,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=4096,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class XunFeiLLMModelProParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.5,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=4096,
+ _min=1,
+ _max=8192,
+ _step=1,
+ precision=0)
+
+
+class XunFeiLLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+
+ for key in ['spark_api_url', 'spark_app_id', 'spark_api_key', 'spark_api_secret']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'spark_api_secret': super().encryption(model.get('spark_api_secret', ''))}
+
+ spark_api_url = forms.TextInputField('API 域名', required=True)
+ spark_app_id = forms.TextInputField('APP ID', required=True)
+ spark_api_key = forms.PasswordInputField("API Key", required=True)
+ spark_api_secret = forms.PasswordInputField('API Secret', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ if model_name == 'general' or model_name == 'pro-128k':
+ return XunFeiLLMModelGeneralParams()
+ return XunFeiLLMModelProParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/icon/xf_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/icon/xf_icon_svg
new file mode 100644
index 0000000..b74e351
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/icon/xf_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/model/llm.py
new file mode 100644
index 0000000..f8d55ac
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/model/llm.py
@@ -0,0 +1,81 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2024/04/19 15:55
+ @desc:
+"""
+import json
+from typing import List, Optional, Any, Iterator, Dict
+
+from langchain_community.chat_models.sparkllm import _convert_message_to_dict, _convert_delta_to_message_chunk, \
+ ChatSparkLLM
+from langchain_core.callbacks import CallbackManagerForLLMRun
+from langchain_core.messages import BaseMessage, AIMessageChunk
+from langchain_core.outputs import ChatGenerationChunk
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class XFChatSparkLLM(MaxKBBaseModel, ChatSparkLLM):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+ return XFChatSparkLLM(
+ spark_app_id=model_credential.get('spark_app_id'),
+ spark_api_key=model_credential.get('spark_api_key'),
+ spark_api_secret=model_credential.get('spark_api_secret'),
+ spark_api_url=model_credential.get('spark_api_url'),
+ spark_llm_domain=model_name,
+ streaming=model_kwargs.get('streaming', False),
+ **optional_params
+ )
+
+ def get_last_generation_info(self) -> Optional[Dict[str, Any]]:
+ return self.__dict__.get('_last_generation_info')
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ return self.get_last_generation_info().get('prompt_tokens', 0)
+
+ def get_num_tokens(self, text: str) -> int:
+ return self.get_last_generation_info().get('completion_tokens', 0)
+
+ def _stream(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ **kwargs: Any,
+ ) -> Iterator[ChatGenerationChunk]:
+ default_chunk_class = AIMessageChunk
+
+ self.client.arun(
+ [_convert_message_to_dict(m) for m in messages],
+ self.spark_user_id,
+ self.model_kwargs,
+ True,
+ )
+ for content in self.client.subscribe(timeout=self.request_timeout):
+ if "data" in content:
+ delta = content["data"]
+ chunk = _convert_delta_to_message_chunk(delta, default_chunk_class)
+ cg_chunk = ChatGenerationChunk(message=chunk)
+ elif "usage" in content:
+ generation_info = content["usage"]
+ self.__dict__.setdefault('_last_generation_info', {}).update(generation_info)
+ continue
+ else:
+ continue
+ if cg_chunk is not None:
+ if run_manager:
+ run_manager.on_llm_new_token(str(cg_chunk.message.content), chunk=cg_chunk)
+ yield cg_chunk
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/xf_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/xf_model_provider.py
new file mode 100644
index 0000000..d33b944
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xf_model_provider/xf_model_provider.py
@@ -0,0 +1,39 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: xf_model_provider.py
+ @date:2024/04/19 14:47
+ @desc:
+"""
+import os
+import ssl
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import ModelProvideInfo, ModelTypeConst, ModelInfo, IModelProvider, \
+ ModelInfoManage
+from setting.models_provider.impl.xf_model_provider.credential.llm import XunFeiLLMModelCredential
+from setting.models_provider.impl.xf_model_provider.model.llm import XFChatSparkLLM
+from smartdoc.conf import PROJECT_DIR
+
+ssl._create_default_https_context = ssl.create_default_context()
+
+qwen_model_credential = XunFeiLLMModelCredential()
+model_info_list = [ModelInfo('generalv3.5', '', ModelTypeConst.LLM, qwen_model_credential, XFChatSparkLLM),
+ ModelInfo('generalv3', '', ModelTypeConst.LLM, qwen_model_credential, XFChatSparkLLM),
+ ModelInfo('generalv2', '', ModelTypeConst.LLM, qwen_model_credential, XFChatSparkLLM)
+ ]
+
+model_info_manage = ModelInfoManage.builder().append_model_info_list(model_info_list).append_default_model_info(
+ ModelInfo('generalv3.5', '', ModelTypeConst.LLM, qwen_model_credential, XFChatSparkLLM)).build()
+
+
+class XunFeiModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_xf_provider', name='讯飞星火', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'xf_model_provider', 'icon',
+ 'xf_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/__init__.py
new file mode 100644
index 0000000..9bad579
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/__init__.py
@@ -0,0 +1 @@
+# coding=utf-8
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/credential/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/credential/embedding.py
new file mode 100644
index 0000000..200183e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/credential/embedding.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+from typing import Dict
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+from setting.models_provider.impl.local_model_provider.model.embedding import LocalEmbedding
+
+
+class XinferenceEmbeddingModelCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ try:
+ model_list = provider.get_base_model_list(model_credential.get('api_base'), 'embedding')
+ except Exception as e:
+ raise AppApiException(ValidCode.valid_error.value, "API 域名无效")
+ exist = provider.get_model_info_by_name(model_list, model_name)
+ model: LocalEmbedding = provider.get_model(model_type, model_name, model_credential)
+ if len(exist) == 0:
+ model.start_down_model_thread()
+ raise AppApiException(ValidCode.model_not_fount, "模型不存在,请先下载模型")
+ model.embed_query('你好')
+ return True
+
+ def encryption_dict(self, model_info: Dict[str, object]):
+ return model_info
+
+ def build_model(self, model_info: Dict[str, object]):
+ for key in ['model']:
+ if key not in model_info:
+ raise AppApiException(500, f'{key} 字段为必填字段')
+ return self
+
+ api_base = forms.TextInputField('API 域名', required=True)
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/credential/llm.py
new file mode 100644
index 0000000..bb17e5c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/credential/llm.py
@@ -0,0 +1,61 @@
+# coding=utf-8
+
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class XinferenceLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.7,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=800,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class XinferenceLLMModelCredential(BaseForm, BaseModelCredential):
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ try:
+ model_list = provider.get_base_model_list(model_credential.get('api_base'), model_type)
+ except Exception as e:
+ raise AppApiException(ValidCode.valid_error.value, "API 域名无效")
+ exist = provider.get_model_info_by_name(model_list, model_name)
+ if len(exist) == 0:
+ raise AppApiException(ValidCode.valid_error.value, "模型不存在,请先下载模型")
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ return True
+
+ def encryption_dict(self, model_info: Dict[str, object]):
+ return {**model_info, 'api_key': super().encryption(model_info.get('api_key', ''))}
+
+ def build_model(self, model_info: Dict[str, object]):
+ for key in ['api_key', 'model']:
+ if key not in model_info:
+ raise AppApiException(500, f'{key} 字段为必填字段')
+ self.api_key = model_info.get('api_key')
+ return self
+
+ api_base = forms.TextInputField('API 域名', required=True)
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return XinferenceLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/icon/xinference_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/icon/xinference_icon_svg
new file mode 100644
index 0000000..fc553ee
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/icon/xinference_icon_svg
@@ -0,0 +1,5 @@
+
+
+
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/model/embedding.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/model/embedding.py
new file mode 100644
index 0000000..1cf34aa
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/model/embedding.py
@@ -0,0 +1,24 @@
+# coding=utf-8
+import threading
+from typing import Dict
+
+from langchain_community.embeddings import XinferenceEmbeddings
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+
+
+class XinferenceEmbedding(MaxKBBaseModel, XinferenceEmbeddings):
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ return XinferenceEmbedding(
+ model_uid=model_name,
+ server_url=model_credential.get('api_base'),
+ )
+
+ def down_model(self):
+ self.client.launch_model(model_name=self.model_uid, model_type="embedding")
+
+ def start_down_model_thread(self):
+ thread = threading.Thread(target=self.down_model)
+ thread.daemon = True
+ thread.start()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/model/llm.py
new file mode 100644
index 0000000..b0fb4d1
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/model/llm.py
@@ -0,0 +1,39 @@
+# coding=utf-8
+
+from typing import Dict
+from urllib.parse import urlparse, ParseResult
+
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+from setting.models_provider.impl.base_chat_open_ai import BaseChatOpenAI
+
+
+def get_base_url(url: str):
+ parse = urlparse(url)
+ result_url = ParseResult(scheme=parse.scheme, netloc=parse.netloc, path=parse.path, params='',
+ query='',
+ fragment='').geturl()
+ return result_url[:-1] if result_url.endswith("/") else result_url
+
+
+class XinferenceChatModel(MaxKBBaseModel, BaseChatOpenAI):
+
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ api_base = model_credential.get('api_base', '')
+ base_url = get_base_url(api_base)
+ base_url = base_url if base_url.endswith('/v1') else (base_url + '/v1')
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+ return XinferenceChatModel(
+ model=model_name,
+ openai_api_base=base_url,
+ openai_api_key=model_credential.get('api_key'),
+ **optional_params
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/xinference_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/xinference_model_provider.py
new file mode 100644
index 0000000..d751fa7
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/xinference_model_provider/xinference_model_provider.py
@@ -0,0 +1,528 @@
+# coding=utf-8
+import os
+from urllib.parse import urlparse, ParseResult
+
+import requests
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import IModelProvider, ModelProvideInfo, ModelInfo, ModelTypeConst, \
+ ModelInfoManage
+from setting.models_provider.impl.xinference_model_provider.credential.embedding import \
+ XinferenceEmbeddingModelCredential
+from setting.models_provider.impl.xinference_model_provider.credential.llm import XinferenceLLMModelCredential
+from setting.models_provider.impl.xinference_model_provider.model.embedding import XinferenceEmbedding
+from setting.models_provider.impl.xinference_model_provider.model.llm import XinferenceChatModel
+from smartdoc.conf import PROJECT_DIR
+
+xinference_llm_model_credential = XinferenceLLMModelCredential()
+model_info_list = [
+ ModelInfo(
+ 'aquila2',
+ 'Aquila2 是一个具有 340 亿参数的大规模语言模型,支持中英文双语。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'aquila2-chat',
+ 'Aquila2 Chat 是一个聊天模型版本的 Aquila2,支持中英文双语。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'aquila2-chat-16k',
+ 'Aquila2 Chat 16K 是一个聊天模型版本的 Aquila2,支持长达 16K 令牌的上下文。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'baichuan',
+ 'Baichuan 是一个大规模语言模型,具有 130 亿参数。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'baichuan-2',
+ 'Baichuan 2 是 Baichuan 的更新版本,具有更高的性能。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'baichuan-2-chat',
+ 'Baichuan 2 Chat 是一个聊天模型版本的 Baichuan 2。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'baichuan-chat',
+ 'Baichuan Chat 是一个聊天模型版本的 Baichuan。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'c4ai-command-r-v01',
+ 'C4AI Command R V01 是一个用于执行命令的语言模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'chatglm',
+ 'ChatGLM 是一个聊天模型,特别擅长中文对话。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'chatglm2',
+ 'ChatGLM2 是 ChatGLM 的更新版本,具有更好的性能。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'chatglm2-32k',
+ 'ChatGLM2 32K 是一个聊天模型版本的 ChatGLM2,支持长达 32K 令牌的上下文。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'chatglm3',
+ 'ChatGLM3 是 ChatGLM 的第三个版本,具有更高的性能。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'chatglm3-128k',
+ 'ChatGLM3 128K 是一个聊天模型版本的 ChatGLM3,支持长达 128K 令牌的上下文。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'chatglm3-32k',
+ 'ChatGLM3 32K 是一个聊天模型版本的 ChatGLM3,支持长达 32K 令牌的上下文。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'code-llama',
+ 'Code Llama 是一个专门用于代码生成的语言模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'code-llama-instruct',
+ 'Code Llama Instruct 是 Code Llama 的指令微调版本,专为执行特定任务而设计。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'code-llama-python',
+ 'Code Llama Python 是一个专门用于 Python 代码生成的语言模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'codegeex4',
+ 'CodeGeeX4 是一个用于代码生成的语言模型,具有较高的性能。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'codeqwen1.5',
+ 'CodeQwen 1.5 是一个用于代码生成的语言模型,具有较高的性能。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'codeqwen1.5-chat',
+ 'CodeQwen 1.5 Chat 是一个聊天模型版本的 CodeQwen 1.5。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'codeshell',
+ 'CodeShell 是一个用于代码生成的语言模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'codeshell-chat',
+ 'CodeShell Chat 是一个聊天模型版本的 CodeShell。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'codestral-v0.1',
+ 'CodeStral V0.1 是一个用于代码生成的语言模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'cogvlm2',
+ 'CogVLM2 是一个视觉语言模型,能够处理图像和文本输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'csg-wukong-chat-v0.1',
+ 'CSG Wukong Chat V0.1 是一个聊天模型版本的 CSG Wukong。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'deepseek',
+ 'Deepseek 是一个大规模语言模型,具有 130 亿参数。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'deepseek-chat',
+ 'Deepseek Chat 是一个聊天模型版本的 Deepseek。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'deepseek-coder',
+ 'Deepseek Coder 是一个专为代码生成设计的模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'deepseek-coder-instruct',
+ 'Deepseek Coder Instruct 是 Deepseek Coder 的指令微调版本,专为执行特定任务而设计。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'deepseek-vl-chat',
+ 'Deepseek VL Chat 是 Deepseek 的视觉语言聊天模型版本,能够处理图像和文本输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'falcon',
+ 'Falcon 是一个开源的 Transformer 解码器模型,具有 400 亿参数,旨在生成高质量的文本。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'falcon-instruct',
+ 'Falcon Instruct 是 Falcon 语言模型的指令微调版本,专为执行特定任务而设计。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'gemma-2-it',
+ 'GEMMA-2-IT 是一个基于 GEMMA-2 的意大利语模型,具有 130 亿参数。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'gemma-it',
+ 'GEMMA-IT 是一个基于 GEMMA 的意大利语模型,具有 130 亿参数。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'gpt-3.5-turbo',
+ 'GPT-3.5 Turbo 是一个高效能的通用语言模型,适用于多种应用场景。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'gpt-4',
+ 'GPT-4 是一个强大的多模态模型,不仅支持文本输入,还支持图像输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'gpt-4-vision-preview',
+ 'GPT-4 Vision Preview 是 GPT-4 的视觉预览版本,支持图像输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'gpt4all',
+ 'GPT4All 是一个开源的多模态模型,支持文本和图像输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'llama2',
+ 'Llama2 是一个具有 700 亿参数的大规模语言模型,支持多种语言。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'llama2-chat',
+ 'Llama2 Chat 是一个聊天模型版本的 Llama2,支持多种语言。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'llama2-chat-32k',
+ 'Llama2 Chat 32K 是一个聊天模型版本的 Llama2,支持长达 32K 令牌的上下文。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'moss',
+ 'MOSS 是一个大规模语言模型,具有 130 亿参数。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'moss-chat',
+ 'MOSS Chat 是一个聊天模型版本的 MOSS。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'qwen',
+ 'Qwen 是一个大规模语言模型,具有 130 亿参数。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'qwen-chat',
+ 'Qwen Chat 是一个聊天模型版本的 Qwen。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'qwen-chat-32k',
+ 'Qwen Chat 32K 是一个聊天模型版本的 Qwen,支持长达 32K 令牌的上下文。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'qwen-code',
+ 'Qwen Code 是一个专门用于代码生成的语言模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'qwen-code-chat',
+ 'Qwen Code Chat 是一个聊天模型版本的 Qwen Code。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'qwen-vl',
+ 'Qwen VL 是 Qwen 的视觉语言模型版本,能够处理图像和文本输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'qwen-vl-chat',
+ 'Qwen VL Chat 是 Qwen VL 的聊天模型版本,能够处理图像和文本输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'spark2',
+ 'Spark2 是一个大规模语言模型,具有 130 亿参数。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'spark2-chat',
+ 'Spark2 Chat 是一个聊天模型版本的 Spark2。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'spark2-chat-32k',
+ 'Spark2 Chat 32K 是一个聊天模型版本的 Spark2,支持长达 32K 令牌的上下文。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'spark2-code',
+ 'Spark2 Code 是一个专门用于代码生成的语言模型。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'spark2-code-chat',
+ 'Spark2 Code Chat 是一个聊天模型版本的 Spark2 Code。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'spark2-vl',
+ 'Spark2 VL 是 Spark2 的视觉语言模型版本,能够处理图像和文本输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+ ModelInfo(
+ 'spark2-vl-chat',
+ 'Spark2 VL Chat 是 Spark2 VL 的聊天模型版本,能够处理图像和文本输入。',
+ ModelTypeConst.LLM,
+ xinference_llm_model_credential,
+ XinferenceChatModel
+ ),
+]
+
+xinference_embedding_model_credential = XinferenceEmbeddingModelCredential()
+
+# 生成embedding_model_info列表
+embedding_model_info = [
+ ModelInfo('bce-embedding-base_v1', 'BCE 嵌入模型的基础版本。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-base-en', 'BGE 英语基础版本的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-base-en-v1.5', 'BGE 英语基础版本 1.5 的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-base-zh', 'BGE 中文基础版本的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-base-zh-v1.5', 'BGE 中文基础版本 1.5 的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-large-en', 'BGE 英语大型版本的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-large-en-v1.5', 'BGE 英语大型版本 1.5 的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-large-zh', 'BGE 中文大型版本的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-large-zh-noinstruct', 'BGE 中文大型版本的嵌入模型,无指令调整。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-large-zh-v1.5', 'BGE 中文大型版本 1.5 的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-m3', 'BGE M3 版本的嵌入模型。', ModelTypeConst.EMBEDDING, xinference_embedding_model_credential,
+ XinferenceEmbedding),
+ ModelInfo('bge-small-en-v1.5', 'BGE 英语小型版本 1.5 的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-small-zh', 'BGE 中文小型版本的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('bge-small-zh-v1.5', 'BGE 中文小型版本 1.5 的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('e5-large-v2', 'E5 大型版本 2 的嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('gte-base', 'GTE 基础版本的嵌入模型。', ModelTypeConst.EMBEDDING, xinference_embedding_model_credential,
+ XinferenceEmbedding),
+ ModelInfo('gte-large', 'GTE 大型版本的嵌入模型。', ModelTypeConst.EMBEDDING, xinference_embedding_model_credential,
+ XinferenceEmbedding),
+ ModelInfo('jina-embeddings-v2-base-en', 'Jina 嵌入模型的英语基础版本 2。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('jina-embeddings-v2-base-zh', 'Jina 嵌入模型的中文基础版本 2。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('jina-embeddings-v2-small-en', 'Jina 嵌入模型的英语小型版本 2。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('m3e-base', 'M3E 基础版本的嵌入模型。', ModelTypeConst.EMBEDDING, xinference_embedding_model_credential,
+ XinferenceEmbedding),
+ ModelInfo('m3e-large', 'M3E 大型版本的嵌入模型。', ModelTypeConst.EMBEDDING, xinference_embedding_model_credential,
+ XinferenceEmbedding),
+ ModelInfo('m3e-small', 'M3E 小型版本的嵌入模型。', ModelTypeConst.EMBEDDING, xinference_embedding_model_credential,
+ XinferenceEmbedding),
+ ModelInfo('multilingual-e5-large', '多语言大型版本的 E5 嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('text2vec-base-chinese', 'Text2Vec 的中文基础版本嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('text2vec-base-chinese-paraphrase', 'Text2Vec 的中文基础版本的同义句嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('text2vec-base-chinese-sentence', 'Text2Vec 的中文基础版本的句子嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('text2vec-base-multilingual', 'Text2Vec 的多语言基础版本嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+ ModelInfo('text2vec-large-chinese', 'Text2Vec 的中文大型版本嵌入模型。', ModelTypeConst.EMBEDDING,
+ xinference_embedding_model_credential, XinferenceEmbedding),
+]
+
+model_info_manage = (ModelInfoManage.builder().append_model_info_list(model_info_list).append_default_model_info(
+ ModelInfo(
+ 'phi3',
+ 'Phi-3 Mini是Microsoft的3.8B参数,轻量级,最先进的开放模型。',
+ ModelTypeConst.LLM, xinference_llm_model_credential, XinferenceChatModel))
+ .append_model_info_list(
+ embedding_model_info).append_default_model_info(
+ ModelInfo(
+ '',
+ '',
+ ModelTypeConst.EMBEDDING, xinference_embedding_model_credential, XinferenceEmbedding))
+ .build())
+
+
+def get_base_url(url: str):
+ parse = urlparse(url)
+ result_url = ParseResult(scheme=parse.scheme, netloc=parse.netloc, path=parse.path, params='',
+ query='',
+ fragment='').geturl()
+ return result_url[:-1] if result_url.endswith("/") else result_url
+
+
+class XinferenceModelProvider(IModelProvider):
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_xinference_provider', name='Xorbits Inference', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'xinference_model_provider', 'icon',
+ 'xinference_icon_svg')))
+
+ @staticmethod
+ def get_base_model_list(api_base, model_type):
+ base_url = get_base_url(api_base)
+ base_url = base_url if base_url.endswith('/v1') else (base_url + '/v1')
+ r = requests.request(method="GET", url=f"{base_url}/models", timeout=5)
+ r.raise_for_status()
+ model_list = r.json().get('data')
+ return [model for model in model_list if model.get('model_type') == model_type]
+
+ @staticmethod
+ def get_model_info_by_name(model_list, model_name):
+ if model_list is None:
+ return []
+ return [model for model in model_list if model.get('model_name') == model_name]
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/__init__.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/credential/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/credential/llm.py
new file mode 100644
index 0000000..aee7441
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/credential/llm.py
@@ -0,0 +1,67 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: llm.py
+ @date:2024/7/12 10:46
+ @desc:
+"""
+from typing import Dict
+
+from langchain_core.messages import HumanMessage
+
+from common import forms
+from common.exception.app_exception import AppApiException
+from common.forms import BaseForm, TooltipLabel
+from setting.models_provider.base_model_provider import BaseModelCredential, ValidCode
+
+
+class ZhiPuLLMModelParams(BaseForm):
+ temperature = forms.SliderField(TooltipLabel('温度', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=0.95,
+ _min=0.1,
+ _max=1.0,
+ _step=0.01,
+ precision=2)
+
+ max_tokens = forms.SliderField(
+ TooltipLabel('输出最大Tokens', '较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定'),
+ required=True, default_value=1024,
+ _min=1,
+ _max=4096,
+ _step=1,
+ precision=0)
+
+
+class ZhiPuLLMModelCredential(BaseForm, BaseModelCredential):
+
+ def is_valid(self, model_type: str, model_name, model_credential: Dict[str, object], provider,
+ raise_exception=False):
+ model_type_list = provider.get_model_type_list()
+ if not any(list(filter(lambda mt: mt.get('value') == model_type, model_type_list))):
+ raise AppApiException(ValidCode.valid_error.value, f'{model_type} 模型类型不支持')
+ for key in ['api_key']:
+ if key not in model_credential:
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'{key} 字段为必填字段')
+ else:
+ return False
+ try:
+ model = provider.get_model(model_type, model_name, model_credential)
+ model.invoke([HumanMessage(content='你好')])
+ except Exception as e:
+ if isinstance(e, AppApiException):
+ raise e
+ if raise_exception:
+ raise AppApiException(ValidCode.valid_error.value, f'校验失败,请检查参数是否正确: {str(e)}')
+ else:
+ return False
+ return True
+
+ def encryption_dict(self, model: Dict[str, object]):
+ return {**model, 'api_key': super().encryption(model.get('api_key', ''))}
+
+ api_key = forms.PasswordInputField('API Key', required=True)
+
+ def get_model_params_setting_form(self, model_name):
+ return ZhiPuLLMModelParams()
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/icon/zhipuai_icon_svg b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/icon/zhipuai_icon_svg
new file mode 100644
index 0000000..f39fedc
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/icon/zhipuai_icon_svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/model/llm.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/model/llm.py
new file mode 100644
index 0000000..5722aea
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/model/llm.py
@@ -0,0 +1,107 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: llm.py
+ @date:2024/4/28 11:42
+ @desc:
+"""
+
+from langchain_community.chat_models import ChatZhipuAI
+from langchain_community.chat_models.zhipuai import _truncate_params, _get_jwt_token, connect_sse, \
+ _convert_delta_to_message_chunk
+from setting.models_provider.base_model_provider import MaxKBBaseModel
+import json
+from collections.abc import Iterator
+from typing import Any, Dict, List, Optional
+
+from langchain_core.callbacks import (
+ CallbackManagerForLLMRun,
+)
+
+from langchain_core.messages import (
+ AIMessageChunk,
+ BaseMessage
+)
+from langchain_core.outputs import ChatGenerationChunk
+
+
+class ZhipuChatModel(MaxKBBaseModel, ChatZhipuAI):
+ @staticmethod
+ def is_cache_model():
+ return False
+
+ @staticmethod
+ def new_instance(model_type, model_name, model_credential: Dict[str, object], **model_kwargs):
+ optional_params = {}
+ if 'max_tokens' in model_kwargs and model_kwargs['max_tokens'] is not None:
+ optional_params['max_tokens'] = model_kwargs['max_tokens']
+ if 'temperature' in model_kwargs and model_kwargs['temperature'] is not None:
+ optional_params['temperature'] = model_kwargs['temperature']
+
+ zhipuai_chat = ZhipuChatModel(
+ api_key=model_credential.get('api_key'),
+ model=model_name,
+ streaming=model_kwargs.get('streaming', False),
+ **optional_params
+ )
+ return zhipuai_chat
+
+ def get_last_generation_info(self) -> Optional[Dict[str, Any]]:
+ return self.__dict__.get('_last_generation_info')
+
+ def get_num_tokens_from_messages(self, messages: List[BaseMessage]) -> int:
+ return self.get_last_generation_info().get('prompt_tokens', 0)
+
+ def get_num_tokens(self, text: str) -> int:
+ return self.get_last_generation_info().get('completion_tokens', 0)
+
+ def _stream(
+ self,
+ messages: List[BaseMessage],
+ stop: Optional[List[str]] = None,
+ run_manager: Optional[CallbackManagerForLLMRun] = None,
+ **kwargs: Any,
+ ) -> Iterator[ChatGenerationChunk]:
+ """Stream the chat response in chunks."""
+ if self.zhipuai_api_key is None:
+ raise ValueError("Did not find zhipuai_api_key.")
+ if self.zhipuai_api_base is None:
+ raise ValueError("Did not find zhipu_api_base.")
+ message_dicts, params = self._create_message_dicts(messages, stop)
+ payload = {**params, **kwargs, "messages": message_dicts, "stream": True}
+ _truncate_params(payload)
+ headers = {
+ "Authorization": _get_jwt_token(self.zhipuai_api_key),
+ "Accept": "application/json",
+ }
+
+ default_chunk_class = AIMessageChunk
+ import httpx
+
+ with httpx.Client(headers=headers, timeout=60) as client:
+ with connect_sse(
+ client, "POST", self.zhipuai_api_base, json=payload
+ ) as event_source:
+ for sse in event_source.iter_sse():
+ chunk = json.loads(sse.data)
+ if len(chunk["choices"]) == 0:
+ continue
+ choice = chunk["choices"][0]
+ generation_info = {}
+ if "usage" in chunk:
+ generation_info = chunk["usage"]
+ self.__dict__.setdefault('_last_generation_info', {}).update(generation_info)
+ chunk = _convert_delta_to_message_chunk(
+ choice["delta"], default_chunk_class
+ )
+ finish_reason = choice.get("finish_reason", None)
+
+ chunk = ChatGenerationChunk(
+ message=chunk, generation_info=generation_info
+ )
+ yield chunk
+ if run_manager:
+ run_manager.on_llm_new_token(chunk.text, chunk=chunk)
+ if finish_reason is not None:
+ break
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/zhipu_model_provider.py b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/zhipu_model_provider.py
new file mode 100644
index 0000000..ab19b15
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/impl/zhipu_model_provider/zhipu_model_provider.py
@@ -0,0 +1,36 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: zhipu_model_provider.py
+ @date:2024/04/19 13:5
+ @desc:
+"""
+import os
+
+from common.util.file_util import get_file_content
+from setting.models_provider.base_model_provider import ModelProvideInfo, ModelTypeConst, ModelInfo, IModelProvider, \
+ ModelInfoManage
+from setting.models_provider.impl.zhipu_model_provider.credential.llm import ZhiPuLLMModelCredential
+from setting.models_provider.impl.zhipu_model_provider.model.llm import ZhipuChatModel
+from smartdoc.conf import PROJECT_DIR
+
+qwen_model_credential = ZhiPuLLMModelCredential()
+model_info_list = [
+ ModelInfo('glm-4', '', ModelTypeConst.LLM, qwen_model_credential, ZhipuChatModel),
+ ModelInfo('glm-4v', '', ModelTypeConst.LLM, qwen_model_credential, ZhipuChatModel),
+ ModelInfo('glm-3-turbo', '', ModelTypeConst.LLM, qwen_model_credential, ZhipuChatModel)
+]
+model_info_manage = ModelInfoManage.builder().append_model_info_list(model_info_list).append_default_model_info(
+ ModelInfo('glm-4', '', ModelTypeConst.LLM, qwen_model_credential, ZhipuChatModel)).build()
+
+
+class ZhiPuModelProvider(IModelProvider):
+
+ def get_model_info_manage(self):
+ return model_info_manage
+
+ def get_model_provide_info(self):
+ return ModelProvideInfo(provider='model_zhipu_provider', name='智谱AI', icon=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'models_provider', 'impl', 'zhipu_model_provider', 'icon',
+ 'zhipuai_icon_svg')))
diff --git a/src/MaxKB-1.5.1/apps/setting/models_provider/tools.py b/src/MaxKB-1.5.1/apps/setting/models_provider/tools.py
new file mode 100644
index 0000000..6606043
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/models_provider/tools.py
@@ -0,0 +1,33 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: tools.py
+ @date:2024/7/22 11:18
+ @desc:
+"""
+from django.db.models import QuerySet
+
+from common.config.embedding_config import ModelManage
+from setting.models import Model
+from setting.models_provider import get_model
+
+
+def get_model_by_id(_id, user_id):
+ model = QuerySet(Model).filter(id=_id).first()
+ if model is None:
+ raise Exception("模型不存在")
+ if model.permission_type == 'PRIVATE' and str(model.user_id) != str(user_id):
+ raise Exception(f"无权限使用此模型:{model.name}")
+ return model
+
+
+def get_model_instance_by_model_user_id(model_id, user_id, **kwargs):
+ """
+ 获取模型实例,根据模型相关数据
+ @param model_id: 模型id
+ @param user_id: 用户id
+ @return: 模型实例
+ """
+ model = get_model_by_id(model_id, user_id)
+ return ModelManage.get_model(model_id, lambda _id: get_model(model, **kwargs))
diff --git a/src/MaxKB-1.5.1/apps/setting/serializers/model_apply_serializers.py b/src/MaxKB-1.5.1/apps/setting/serializers/model_apply_serializers.py
new file mode 100644
index 0000000..2177b5f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/serializers/model_apply_serializers.py
@@ -0,0 +1,53 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: model_apply_serializers.py
+ @date:2024/8/20 20:39
+ @desc:
+"""
+from django.db.models import QuerySet
+from rest_framework import serializers
+
+from common.config.embedding_config import ModelManage
+from common.util.field_message import ErrMessage
+from setting.models import Model
+from setting.models_provider import get_model
+
+
+def get_embedding_model(model_id):
+ model = QuerySet(Model).filter(id=model_id).first()
+ embedding_model = ModelManage.get_model(model_id,
+ lambda _id: get_model(model, use_local=True))
+ return embedding_model
+
+
+class EmbedDocuments(serializers.Serializer):
+ texts = serializers.ListField(required=True, child=serializers.CharField(required=True,
+ error_messages=ErrMessage.char(
+ "向量文本")),
+ error_messages=ErrMessage.list("向量文本列表"))
+
+
+class EmbedQuery(serializers.Serializer):
+ text = serializers.CharField(required=True, error_messages=ErrMessage.char("向量文本"))
+
+
+class ModelApplySerializers(serializers.Serializer):
+ model_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("模型id"))
+
+ def embed_documents(self, instance, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ EmbedDocuments(data=instance).is_valid(raise_exception=True)
+
+ model = get_embedding_model(self.data.get('model_id'))
+ return model.embed_documents(instance.getlist('texts'))
+
+ def embed_query(self, instance, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ EmbedQuery(data=instance).is_valid(raise_exception=True)
+
+ model = get_embedding_model(self.data.get('model_id'))
+ return model.embed_query(instance.get('text'))
diff --git a/src/MaxKB-1.5.1/apps/setting/serializers/provider_serializers.py b/src/MaxKB-1.5.1/apps/setting/serializers/provider_serializers.py
new file mode 100644
index 0000000..fcd04e9
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/serializers/provider_serializers.py
@@ -0,0 +1,336 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: provider_serializers.py
+ @date:2023/11/2 14:01
+ @desc:
+"""
+import json
+import re
+import threading
+import time
+import uuid
+from typing import Dict
+
+from django.core import validators
+from django.db.models import QuerySet, Q
+from rest_framework import serializers
+
+from application.models import Application
+from common.config.embedding_config import ModelManage
+from common.exception.app_exception import AppApiException
+from common.util.field_message import ErrMessage
+from common.util.rsa_util import rsa_long_decrypt, rsa_long_encrypt
+from dataset.models import DataSet
+from setting.models.model_management import Model, Status, PermissionType
+from setting.models_provider import get_model, get_model_credential
+from setting.models_provider.base_model_provider import ValidCode, DownModelChunkStatus
+from setting.models_provider.constants.model_provider_constants import ModelProvideConstants
+
+
+class ModelPullManage:
+
+ @staticmethod
+ def pull(model: Model, credential: Dict):
+ try:
+ response = ModelProvideConstants[model.provider].value.down_model(model.model_type, model.model_name,
+ credential)
+ down_model_chunk = {}
+ timestamp = time.time()
+ for chunk in response:
+ down_model_chunk[chunk.digest] = chunk.to_dict()
+ if time.time() - timestamp > 5:
+ model_new = QuerySet(Model).filter(id=model.id).first()
+ if model_new.status == Status.PAUSE_DOWNLOAD:
+ return
+ QuerySet(Model).filter(id=model.id).update(
+ meta={"down_model_chunk": list(down_model_chunk.values())})
+ timestamp = time.time()
+ status = Status.ERROR
+ message = ""
+ down_model_chunk_list = list(down_model_chunk.values())
+ for chunk in down_model_chunk_list:
+ if chunk.get('status') == DownModelChunkStatus.success.value:
+ status = Status.SUCCESS
+ if chunk.get('status') == DownModelChunkStatus.error.value:
+ message = chunk.get("digest")
+ QuerySet(Model).filter(id=model.id).update(meta={"down_model_chunk": [], "message": message},
+ status=status)
+ except Exception as e:
+ QuerySet(Model).filter(id=model.id).update(meta={"down_model_chunk": [], "message": str(e)},
+ status=Status.ERROR)
+
+
+class ModelSerializer(serializers.Serializer):
+ class Query(serializers.Serializer):
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ name = serializers.CharField(required=False, max_length=64,
+ error_messages=ErrMessage.char("模型名称"))
+
+ model_type = serializers.CharField(required=False, error_messages=ErrMessage.char("模型类型"))
+
+ model_name = serializers.CharField(required=False, error_messages=ErrMessage.char("基础模型"))
+
+ provider = serializers.CharField(required=False, error_messages=ErrMessage.char("供应商"))
+
+ def list(self, with_valid):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ user_id = self.data.get('user_id')
+ name = self.data.get('name')
+ model_query_set = QuerySet(Model).filter((Q(user_id=user_id) | Q(permission_type='PUBLIC')))
+ query_params = {}
+ if name is not None:
+ query_params['name__contains'] = name
+ if self.data.get('model_type') is not None:
+ query_params['model_type'] = self.data.get('model_type')
+ if self.data.get('model_name') is not None:
+ query_params['model_name'] = self.data.get('model_name')
+ if self.data.get('provider') is not None:
+ query_params['provider'] = self.data.get('provider')
+
+ return [
+ {'id': str(model.id), 'provider': model.provider, 'name': model.name, 'model_type': model.model_type,
+ 'model_name': model.model_name, 'status': model.status, 'meta': model.meta,
+ 'permission_type': model.permission_type, 'user_id': model.user_id} for model in
+ model_query_set.filter(**query_params).order_by("-create_time")]
+
+ class Edit(serializers.Serializer):
+ user_id = serializers.CharField(required=False, error_messages=ErrMessage.uuid("用户id"))
+
+ name = serializers.CharField(required=False, max_length=64,
+ error_messages=ErrMessage.char("模型名称"))
+
+ model_type = serializers.CharField(required=False, error_messages=ErrMessage.char("模型类型"))
+
+ permission_type = serializers.CharField(required=False, error_messages=ErrMessage.char("权限"), validators=[
+ validators.RegexValidator(regex=re.compile("^PUBLIC|PRIVATE$"),
+ message="权限只支持PUBLIC|PRIVATE", code=500)
+ ])
+
+ model_name = serializers.CharField(required=False, error_messages=ErrMessage.char("模型类型"))
+
+ credential = serializers.DictField(required=False, error_messages=ErrMessage.dict("认证信息"))
+
+ def is_valid(self, model=None, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ filter_params = {'user_id': self.data.get('user_id')}
+ if 'name' in self.data and self.data.get('name') is not None:
+ filter_params['name'] = self.data.get('name')
+ if QuerySet(Model).exclude(id=model.id).filter(**filter_params).exists():
+ raise AppApiException(500, f'模型名称【{self.data.get("name")}】已存在')
+
+ ModelSerializer.model_to_dict(model)
+
+ provider = model.provider
+ model_type = self.data.get('model_type')
+ model_name = self.data.get(
+ 'model_name')
+ credential = self.data.get('credential')
+ provider_handler = ModelProvideConstants[provider].value
+ model_credential = ModelProvideConstants[provider].value.get_model_credential(model_type,
+ model_name)
+ source_model_credential = json.loads(rsa_long_decrypt(model.credential))
+ source_encryption_model_credential = model_credential.encryption_dict(source_model_credential)
+ if credential is not None:
+ for k in source_encryption_model_credential.keys():
+ if credential[k] == source_encryption_model_credential[k]:
+ credential[k] = source_model_credential[k]
+ return credential, model_credential, provider_handler
+
+ class Create(serializers.Serializer):
+ user_id = serializers.CharField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ name = serializers.CharField(required=True, max_length=64, error_messages=ErrMessage.char("模型名称"))
+
+ provider = serializers.CharField(required=True, error_messages=ErrMessage.char("供应商"))
+
+ model_type = serializers.CharField(required=True, error_messages=ErrMessage.char("模型类型"))
+
+ permission_type = serializers.CharField(required=True, error_messages=ErrMessage.char("权限"), validators=[
+ validators.RegexValidator(regex=re.compile("^PUBLIC|PRIVATE$"),
+ message="权限只支持PUBLIC|PRIVATE", code=500)
+ ])
+
+ model_name = serializers.CharField(required=True, error_messages=ErrMessage.char("基础模型"))
+
+ credential = serializers.DictField(required=True, error_messages=ErrMessage.dict("认证信息"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if QuerySet(Model).filter(user_id=self.data.get('user_id'),
+ name=self.data.get('name')).exists():
+ raise AppApiException(500, f'模型名称【{self.data.get("name")}】已存在')
+ ModelProvideConstants[self.data.get('provider')].value.is_valid_credential(self.data.get('model_type'),
+ self.data.get('model_name'),
+ self.data.get('credential'),
+ raise_exception=True
+ )
+
+ def insert(self, user_id, with_valid=False):
+ status = Status.SUCCESS
+ if with_valid:
+ try:
+ self.is_valid(raise_exception=True)
+ except AppApiException as e:
+ if e.code == ValidCode.model_not_fount:
+ status = Status.DOWNLOAD
+ else:
+ raise e
+ credential = self.data.get('credential')
+ name = self.data.get('name')
+ provider = self.data.get('provider')
+ model_type = self.data.get('model_type')
+ model_name = self.data.get('model_name')
+ permission_type = self.data.get('permission_type')
+ model_credential_str = json.dumps(credential)
+ model = Model(id=uuid.uuid1(), status=status, user_id=user_id, name=name,
+ credential=rsa_long_encrypt(model_credential_str),
+ provider=provider, model_type=model_type, model_name=model_name,
+ permission_type=permission_type)
+ model.save()
+ if status == Status.DOWNLOAD:
+ thread = threading.Thread(target=ModelPullManage.pull, args=(model, credential))
+ thread.start()
+ return ModelSerializer.Operate(data={'id': model.id, 'user_id': user_id}).one(with_valid=True)
+
+ @staticmethod
+ def model_to_dict(model: Model):
+ credential = json.loads(rsa_long_decrypt(model.credential))
+ return {'id': str(model.id), 'provider': model.provider, 'name': model.name, 'model_type': model.model_type,
+ 'model_name': model.model_name,
+ 'status': model.status,
+ 'meta': model.meta,
+ 'credential': ModelProvideConstants[model.provider].value.get_model_credential(model.model_type,
+ model.model_name).encryption_dict(
+ credential),
+ 'permission_type': model.permission_type}
+
+ class ModelParams(serializers.Serializer):
+ id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("模型id"))
+
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ model = QuerySet(Model).filter(id=self.data.get("id")).first()
+ if model is None:
+ raise AppApiException(500, '模型不存在')
+ if model.permission_type == PermissionType.PRIVATE and self.data.get('user_id') != str(model.user_id):
+ raise AppApiException(500, '没有权限访问到此模型')
+
+ def get_model_params(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ model_id = self.data.get('id')
+ model = QuerySet(Model).filter(id=model_id).first()
+ credential = get_model_credential(model.provider, model.model_type, model.model_name)
+ return credential.get_model_params_setting_form(model.model_name).to_form_list()
+
+ class Operate(serializers.Serializer):
+ id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("模型id"))
+
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("用户id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ model = QuerySet(Model).filter(id=self.data.get("id"), user_id=self.data.get("user_id")).first()
+ if model is None:
+ raise AppApiException(500, '模型不存在')
+
+ def one(self, with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ model = QuerySet(Model).get(id=self.data.get('id'), user_id=self.data.get('user_id'))
+ return ModelSerializer.model_to_dict(model)
+
+ def one_meta(self, with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ model = QuerySet(Model).get(id=self.data.get('id'), user_id=self.data.get('user_id'))
+ return {'id': str(model.id), 'provider': model.provider, 'name': model.name, 'model_type': model.model_type,
+ 'model_name': model.model_name,
+ 'status': model.status,
+ 'meta': model.meta
+ }
+
+ def delete(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ model_id = self.data.get('id')
+ model = Model.objects.filter(id=model_id).first()
+ if not model:
+ # 模型不存在,直接返回或抛出异常
+ raise AppApiException(500, "模型不存在")
+ if model.model_type == 'LLM':
+ application_count = Application.objects.filter(model_id=model_id).count()
+ if application_count > 0:
+ raise AppApiException(500, f"该模型关联了{application_count} 个应用,无法删除该模型。")
+ elif model.model_type == 'EMBEDDING':
+ dataset_count = DataSet.objects.filter(embedding_mode_id=model_id).count()
+ if dataset_count > 0:
+ raise AppApiException(500, f"该模型关联了{dataset_count} 个知识库,无法删除该模型。")
+ model.delete()
+ return True
+
+ def pause_download(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ QuerySet(Model).filter(id=self.data.get('id')).update(status=Status.PAUSE_DOWNLOAD)
+ return True
+
+ def edit(self, instance: Dict, user_id: str, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ model = QuerySet(Model).filter(id=self.data.get('id')).first()
+
+ if model is None:
+ raise AppApiException(500, '不存在的id')
+ else:
+ credential, model_credential, provider_handler = ModelSerializer.Edit(
+ data={**instance, 'user_id': user_id}).is_valid(
+ model=model)
+ try:
+ model.status = Status.SUCCESS
+ # 校验模型认证数据
+ provider_handler.is_valid_credential(model.model_type,
+ instance.get("model_name"),
+ credential,
+ raise_exception=True)
+
+ except AppApiException as e:
+ if e.code == ValidCode.model_not_fount:
+ model.status = Status.DOWNLOAD
+ else:
+ raise e
+ update_keys = ['credential', 'name', 'model_type', 'model_name', 'permission_type']
+ for update_key in update_keys:
+ if update_key in instance and instance.get(update_key) is not None:
+ if update_key == 'credential':
+ model_credential_str = json.dumps(credential)
+ model.__setattr__(update_key, rsa_long_encrypt(model_credential_str))
+ else:
+ model.__setattr__(update_key, instance.get(update_key))
+ # 修改模型时候删除缓存
+ ModelManage.delete_key(str(model.id))
+ model.save()
+ if model.status == Status.DOWNLOAD:
+ thread = threading.Thread(target=ModelPullManage.pull, args=(model, credential))
+ thread.start()
+ return self.one(with_valid=False)
+
+
+class ProviderSerializer(serializers.Serializer):
+ provider = serializers.CharField(required=True, error_messages=ErrMessage.char("供应商"))
+
+ method = serializers.CharField(required=True, error_messages=ErrMessage.char("执行函数名称"))
+
+ def exec(self, exec_params: Dict[str, object], with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+
+ provider = self.data.get('provider')
+ method = self.data.get('method')
+ return getattr(ModelProvideConstants[provider].value, method)(exec_params)
diff --git a/src/MaxKB-1.5.1/apps/setting/serializers/system_setting.py b/src/MaxKB-1.5.1/apps/setting/serializers/system_setting.py
new file mode 100644
index 0000000..a66b158
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/serializers/system_setting.py
@@ -0,0 +1,67 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: system_setting.py
+ @date:2024/3/19 16:29
+ @desc:
+"""
+from django.core.mail.backends.smtp import EmailBackend
+from django.db.models import QuerySet
+from rest_framework import serializers
+
+from common.exception.app_exception import AppApiException
+from common.util.field_message import ErrMessage
+from setting.models.system_management import SystemSetting, SettingType
+
+
+class SystemSettingSerializer(serializers.Serializer):
+ class EmailSerializer(serializers.Serializer):
+ @staticmethod
+ def one():
+ system_setting = QuerySet(SystemSetting).filter(type=SettingType.EMAIL.value).first()
+ if system_setting is None:
+ return {}
+ return system_setting.meta
+
+ class Create(serializers.Serializer):
+ email_host = serializers.CharField(required=True, error_messages=ErrMessage.char("SMTP 主机"))
+ email_port = serializers.IntegerField(required=True, error_messages=ErrMessage.char("SMTP 端口"))
+ email_host_user = serializers.CharField(required=True, error_messages=ErrMessage.char("发件人邮箱"))
+ email_host_password = serializers.CharField(required=True, error_messages=ErrMessage.char("密码"))
+ email_use_tls = serializers.BooleanField(required=True, error_messages=ErrMessage.char("是否开启TLS"))
+ email_use_ssl = serializers.BooleanField(required=True, error_messages=ErrMessage.char("是否开启SSL"))
+ from_email = serializers.EmailField(required=True, error_messages=ErrMessage.char("发送人邮箱"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ try:
+ EmailBackend(self.data.get("email_host"),
+ self.data.get("email_port"),
+ self.data.get("email_host_user"),
+ self.data.get("email_host_password"),
+ self.data.get("email_use_tls"),
+ False,
+ self.data.get("email_use_ssl")
+ ).open()
+ except Exception as e:
+ raise AppApiException(1004, "邮箱校验失败")
+
+ def update_or_save(self):
+ self.is_valid(raise_exception=True)
+ system_setting = QuerySet(SystemSetting).filter(type=SettingType.EMAIL.value).first()
+ if system_setting is None:
+ system_setting = SystemSetting(type=SettingType.EMAIL.value)
+ system_setting.meta = self.to_email_meta()
+ system_setting.save()
+ return system_setting.meta
+
+ def to_email_meta(self):
+ return {'email_host': self.data.get('email_host'),
+ 'email_port': self.data.get('email_port'),
+ 'email_host_user': self.data.get('email_host_user'),
+ 'email_host_password': self.data.get('email_host_password'),
+ 'email_use_tls': self.data.get('email_use_tls'),
+ 'email_use_ssl': self.data.get('email_use_ssl'),
+ 'from_email': self.data.get('from_email')
+ }
diff --git a/src/MaxKB-1.5.1/apps/setting/serializers/team_serializers.py b/src/MaxKB-1.5.1/apps/setting/serializers/team_serializers.py
new file mode 100644
index 0000000..46266bb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/serializers/team_serializers.py
@@ -0,0 +1,320 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: team_serializers.py
+ @date:2023/9/5 16:32
+ @desc:
+"""
+import itertools
+import json
+import os
+import uuid
+from typing import Dict, List
+
+from django.core import cache
+from django.db import transaction
+from django.db.models import QuerySet, Q
+from drf_yasg import openapi
+from rest_framework import serializers
+
+from common.constants.permission_constants import Operate
+from common.db.sql_execute import select_list
+from common.exception.app_exception import AppApiException
+from common.mixins.api_mixin import ApiMixin
+from common.response.result import get_api_response
+from common.util.field_message import ErrMessage
+from common.util.file_util import get_file_content
+from setting.models import TeamMember, TeamMemberPermission, Team
+from smartdoc.conf import PROJECT_DIR
+from users.models.user import User
+from users.serializers.user_serializers import UserSerializer
+
+user_cache = cache.caches['user_cache']
+
+
+def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'username', 'email', 'role', 'is_active', 'team_id', 'member_id'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="用户id", description="用户id"),
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'role': openapi.Schema(type=openapi.TYPE_STRING, title="角色", description="角色"),
+ 'is_active': openapi.Schema(type=openapi.TYPE_STRING, title="是否可用", description="是否可用"),
+ 'team_id': openapi.Schema(type=openapi.TYPE_STRING, title="团队id", description="团队id"),
+ 'member_id': openapi.Schema(type=openapi.TYPE_STRING, title="成员id", description="成员id"),
+ }
+ )
+
+
+class TeamMemberPermissionOperate(ApiMixin, serializers.Serializer):
+ USE = serializers.BooleanField(required=True, error_messages=ErrMessage.boolean("使用"))
+ MANAGE = serializers.BooleanField(required=True, error_messages=ErrMessage.boolean("管理"))
+
+ def get_request_body_api(self):
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="类型",
+ description="操作权限USE,MANAGE权限",
+ properties={
+ 'USE': openapi.Schema(type=openapi.TYPE_BOOLEAN,
+ title="使用权限",
+ description="使用权限 True|False"),
+ 'MANAGE': openapi.Schema(type=openapi.TYPE_BOOLEAN,
+ title="管理权限",
+ description="管理权限 True|False")
+ }
+ )
+
+
+class UpdateTeamMemberItemPermissionSerializer(ApiMixin, serializers.Serializer):
+ target_id = serializers.CharField(required=True, error_messages=ErrMessage.char("目标id"))
+ type = serializers.CharField(required=True, error_messages=ErrMessage.char("目标类型"))
+ operate = TeamMemberPermissionOperate(required=True, many=False)
+
+ def get_request_body_api(self):
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'type', 'operate'],
+ properties={
+ 'target_id': openapi.Schema(type=openapi.TYPE_STRING, title="知识库/应用id",
+ description="知识库或者应用的id"),
+ 'type': openapi.Schema(type=openapi.TYPE_STRING,
+ title="类型",
+ description="DATASET|APPLICATION",
+ ),
+ 'operate': TeamMemberPermissionOperate().get_request_body_api()
+ }
+ )
+
+
+class UpdateTeamMemberPermissionSerializer(ApiMixin, serializers.Serializer):
+ team_member_permission_list = UpdateTeamMemberItemPermissionSerializer(required=True, many=True)
+
+ def is_valid(self, *, user_id=None):
+ super().is_valid(raise_exception=True)
+ permission_list = self.data.get("team_member_permission_list")
+ illegal_target_id_list = select_list(
+ get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "setting", 'sql', 'check_member_permission_target_exists.sql')),
+ [json.dumps(permission_list), user_id, user_id])
+ if illegal_target_id_list is not None and len(illegal_target_id_list) > 0:
+ raise AppApiException(500, '不存在的 应用|知识库id[' + str(illegal_target_id_list) + ']')
+
+ def update_or_save(self, member_id: str):
+ team_member_permission_list = self.data.get("team_member_permission_list")
+ # 获取数据库已有权限 从而判断是否是插入还是更新
+ team_member_permission_exist_list = QuerySet(TeamMemberPermission).filter(
+ member_id=member_id)
+ update_list = []
+ save_list = []
+ for item in team_member_permission_list:
+ exist_list = list(
+ filter(lambda use: str(use.target) == item.get('target_id'), team_member_permission_exist_list))
+ if len(exist_list) > 0:
+ exist_list[0].operate = list(
+ filter(lambda key: item.get('operate').get(key),
+ item.get('operate').keys()))
+ update_list.append(exist_list[0])
+ else:
+ save_list.append(TeamMemberPermission(target=item.get('target_id'), auth_target_type=item.get('type'),
+ operate=list(
+ filter(lambda key: item.get('operate').get(key),
+ item.get('operate').keys())),
+ member_id=member_id))
+ # 批量更新
+ QuerySet(TeamMemberPermission).bulk_update(update_list, ['operate'])
+ # 批量插入
+ QuerySet(TeamMemberPermission).bulk_create(save_list)
+
+ def get_request_body_api(self):
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id'],
+ properties={
+ 'team_member_permission_list':
+ openapi.Schema(type=openapi.TYPE_ARRAY, title="权限数据",
+ description="权限数据",
+ items=UpdateTeamMemberItemPermissionSerializer().get_request_body_api()
+ ),
+ }
+ )
+
+
+class TeamMemberSerializer(ApiMixin, serializers.Serializer):
+ team_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("团队id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+
+ @staticmethod
+ def get_bach_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_ARRAY,
+ title="用户id列表",
+ description="用户id列表",
+ items=openapi.Schema(type=openapi.TYPE_STRING)
+ )
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['username_or_email'],
+ properties={
+ 'username_or_email': openapi.Schema(type=openapi.TYPE_STRING, title="用户名或者邮箱",
+ description="用户名或者邮箱"),
+
+ }
+ )
+
+ @transaction.atomic
+ def batch_add_member(self, user_id_list: List[str], with_valid=True):
+ """
+ 批量添加成员
+ :param user_id_list: 用户id列表
+ :param with_valid: 是否校验
+ :return: 成员列表
+ """
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ use_user_id_list = [str(u.id) for u in QuerySet(User).filter(id__in=user_id_list)]
+
+ team_member_user_id_list = [str(team_member.user_id) for team_member in
+ QuerySet(TeamMember).filter(team_id=self.data.get('team_id'))]
+ team_id = self.data.get("team_id")
+ create_team_member_list = [
+ self.to_member_model(add_user_id, team_member_user_id_list, use_user_id_list, team_id) for add_user_id in
+ user_id_list]
+ QuerySet(TeamMember).bulk_create(create_team_member_list) if len(create_team_member_list) > 0 else None
+ return TeamMemberSerializer(
+ data={'team_id': self.data.get("team_id")}).list_member()
+
+ def to_member_model(self, add_user_id, team_member_user_id_list, use_user_id_list, user_id):
+ if use_user_id_list.__contains__(add_user_id):
+ if team_member_user_id_list.__contains__(add_user_id) or user_id == add_user_id:
+ raise AppApiException(500, "团队中已存在当前成员,不要重复添加")
+ else:
+ return TeamMember(team_id=self.data.get("team_id"), user_id=add_user_id)
+ else:
+ raise AppApiException(500, "不存在的用户")
+
+ def add_member(self, username_or_email: str, with_valid=True):
+ """
+ 添加一个成员
+ :param with_valid: 是否校驗參數
+ :param username_or_email: 添加成员的邮箱或者用户名
+ :return: 成员列表
+ """
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ if username_or_email is None:
+ raise AppApiException(500, "用户名或者邮箱必填")
+ user = QuerySet(User).filter(
+ Q(username=username_or_email) | Q(email=username_or_email)).first()
+ if user is None:
+ raise AppApiException(500, "不存在的用户")
+ if QuerySet(TeamMember).filter(Q(team_id=self.data.get('team_id')) & Q(user=user)).exists() or self.data.get(
+ "team_id") == str(user.id):
+ raise AppApiException(500, "团队中已存在当前成员,不要重复添加")
+ TeamMember(team_id=self.data.get("team_id"), user=user).save()
+ return self.list_member(with_valid=False)
+
+ def list_member(self, with_valid=True):
+ """
+ 获取 团队中的成员列表
+ :return: 成员列表
+ """
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ # 普通成員列表
+ member_list = list(map(lambda t: {"id": t.id, 'email': t.user.email, 'username': t.user.username,
+ 'team_id': self.data.get("team_id"), 'user_id': t.user.id,
+ 'type': 'member'},
+ QuerySet(TeamMember).filter(team_id=self.data.get("team_id"))))
+ # 管理員成員
+ manage_member = QuerySet(User).get(id=self.data.get('team_id'))
+ return [{'id': 'root', 'email': manage_member.email, 'username': manage_member.username,
+ 'team_id': self.data.get("team_id"), 'user_id': manage_member.id, 'type': 'manage'
+ }, *member_list]
+
+ def get_response_body_api(self):
+ return get_api_response(openapi.Schema(
+ type=openapi.TYPE_ARRAY, title="成员列表", description="成员列表",
+ items=UserSerializer().get_response_body_api()
+ ))
+
+ class Operate(ApiMixin, serializers.Serializer):
+ # 团队 成员id
+ member_id = serializers.CharField(required=True, error_messages=ErrMessage.char("成员id"))
+ # 团队id
+ team_id = serializers.CharField(required=True, error_messages=ErrMessage.char("团队id"))
+
+ def is_valid(self, *, raise_exception=True):
+ super().is_valid(raise_exception=True)
+ if self.data.get('member_id') != 'root' and not QuerySet(TeamMember).filter(
+ team_id=self.data.get('team_id'),
+ id=self.data.get('member_id')).exists():
+ raise AppApiException(500, "不存在的成员,请先添加成员")
+
+ return True
+
+ def list_member_permission(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ team_id = self.data.get('team_id')
+ member_id = self.data.get("member_id")
+ # 查询当前团队成员所有的知识库和应用的权限 注意 operate为null是为设置权限 默认值都是false
+ member_permission_list = select_list(
+ get_file_content(os.path.join(PROJECT_DIR, "apps", "setting", 'sql', 'get_member_permission.sql')),
+ [team_id, team_id, (member_id if member_id != 'root' else uuid.uuid1())])
+
+ # 如果是管理员 则拥有所有权限 默认赋值
+ if member_id == 'root':
+ member_permission_list = list(
+ map(lambda row: {**row, 'operate': {Operate.USE.value: True, Operate.MANAGE.value: True}},
+ member_permission_list))
+ # 分为 APPLICATION DATASET俩组
+ groups = itertools.groupby(
+ sorted(list(map(lambda m: {**m, 'member_id': member_id,
+ 'operate': dict(
+ map(lambda key: (key, True if m.get('operate') is not None and m.get(
+ 'operate').__contains__(key) else False),
+ [Operate.USE.value, Operate.MANAGE.value]))},
+ member_permission_list)), key=lambda x: x.get('type')),
+ key=lambda x: x.get('type'))
+ return dict([(key, list(group)) for key, group in groups])
+
+ def edit(self, member_permission: Dict):
+ self.is_valid(raise_exception=True)
+ member_id = self.data.get("member_id")
+ if member_id == 'root':
+ raise AppApiException(500, "管理员权限不允许修改")
+ s = UpdateTeamMemberPermissionSerializer(data=member_permission)
+ s.is_valid(user_id=self.data.get("team_id"))
+ s.update_or_save(member_id)
+ return self.list_member_permission(with_valid=False)
+
+ def delete(self):
+ """
+ 移除成员
+ :return:
+ """
+ self.is_valid(raise_exception=True)
+ member_id = self.data.get("member_id")
+ if member_id == 'root':
+ raise AppApiException(500, "无法移除团队管理员")
+ # 删除成员权限
+ QuerySet(TeamMemberPermission).filter(member_id=member_id).delete()
+ # 删除成员
+ QuerySet(TeamMember).filter(id=member_id).delete()
+ return True
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='member_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='团队成员id')]
diff --git a/src/MaxKB-1.5.1/apps/setting/serializers/valid_serializers.py b/src/MaxKB-1.5.1/apps/setting/serializers/valid_serializers.py
new file mode 100644
index 0000000..71c7d21
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/serializers/valid_serializers.py
@@ -0,0 +1,50 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: valid_serializers.py
+ @date:2024/7/8 18:00
+ @desc:
+"""
+import re
+
+from django.core import validators
+from django.db.models import QuerySet
+from rest_framework import serializers
+
+from application.models import Application
+from common.exception.app_exception import AppApiException
+from common.util.field_message import ErrMessage
+from dataset.models import DataSet
+from smartdoc import settings
+from users.models import User
+
+model_message_dict = {
+ 'dataset': {'model': DataSet, 'count': 50,
+ 'message': '社区版最多支持 50 个知识库,如需拥有更多知识库,请联系我们(https://fit2cloud.com/)。'},
+ 'application': {'model': Application, 'count': 5,
+ 'message': '社区版最多支持 5 个应用,如需拥有更多应用,请联系我们(https://fit2cloud.com/)。'},
+ 'user': {'model': User, 'count': 2,
+ 'message': '社区版最多支持 2 个用户,如需拥有更多用户,请联系我们(https://fit2cloud.com/)。'}
+}
+
+
+class ValidSerializer(serializers.Serializer):
+ valid_type = serializers.CharField(required=True, error_messages=ErrMessage.char("类型"), validators=[
+ validators.RegexValidator(regex=re.compile("^application|dataset|user$"),
+ message="类型只支持:application|dataset|user", code=500)
+ ])
+ valid_count = serializers.IntegerField(required=True, error_messages=ErrMessage.integer("校验数量"))
+
+ def valid(self, is_valid=True):
+ if is_valid:
+ self.is_valid(raise_exception=True)
+ model_value = model_message_dict.get(self.data.get('valid_type'))
+ if not (settings.XPACK_LICENSE_IS_VALID if hasattr(settings,
+ 'XPACK_LICENSE_IS_VALID') else None):
+ if self.data.get('valid_count') != model_value.get('count'):
+ raise AppApiException(400, model_value.get('message'))
+ if QuerySet(
+ model_value.get('model')).count() >= model_value.get('count'):
+ raise AppApiException(400, model_value.get('message'))
+ return True
diff --git a/src/MaxKB-1.5.1/apps/setting/sql/check_member_permission_target_exists.sql b/src/MaxKB-1.5.1/apps/setting/sql/check_member_permission_target_exists.sql
new file mode 100644
index 0000000..13c1aaa
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/sql/check_member_permission_target_exists.sql
@@ -0,0 +1,32 @@
+SELECT
+ static_temp."target_id"::text
+FROM
+ (SELECT * FROM json_to_recordset(
+ %s
+ ) AS x(target_id uuid,type text)) static_temp
+ LEFT JOIN (
+ SELECT
+ "id",
+ 'DATASET' AS "type",
+ user_id,
+ ARRAY [ 'MANAGE',
+ 'USE',
+ 'DELETE' ] AS "operate"
+ FROM
+ dataset
+ WHERE
+ "user_id" = %s UNION
+ SELECT
+ "id",
+ 'APPLICATION' AS "type",
+ user_id,
+ ARRAY [ 'MANAGE',
+ 'USE',
+ 'DELETE' ] AS "operate"
+ FROM
+ application
+ WHERE
+ "user_id" = %s
+ ) "app_and_dataset_temp"
+ ON "app_and_dataset_temp"."id" = static_temp."target_id" and app_and_dataset_temp."type"=static_temp."type"
+ WHERE app_and_dataset_temp.id is NULL ;
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/sql/get_member_permission.sql b/src/MaxKB-1.5.1/apps/setting/sql/get_member_permission.sql
new file mode 100644
index 0000000..f6b2d95
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/sql/get_member_permission.sql
@@ -0,0 +1,26 @@
+SELECT
+ app_or_dataset.*,
+ team_member_permission.member_id,
+ team_member_permission.operate
+FROM
+ (
+ SELECT
+ "id",
+ "name",
+ 'DATASET' AS "type",
+ user_id
+ FROM
+ dataset
+ WHERE
+ "user_id" = %s UNION
+ SELECT
+ "id",
+ "name",
+ 'APPLICATION' AS "type",
+ user_id
+ FROM
+ application
+ WHERE
+ "user_id" = %s
+ ) app_or_dataset
+ LEFT JOIN ( SELECT * FROM team_member_permission WHERE member_id = %s ) team_member_permission ON team_member_permission.target = app_or_dataset."id"
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/sql/get_user_permission.sql b/src/MaxKB-1.5.1/apps/setting/sql/get_user_permission.sql
new file mode 100644
index 0000000..c50e5ea
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/sql/get_user_permission.sql
@@ -0,0 +1,30 @@
+SELECT
+ "id",
+ 'DATASET' AS "type",
+ user_id,
+ ARRAY [ 'MANAGE',
+ 'USE','DELETE' ] AS "operate"
+FROM
+ dataset
+WHERE
+ "user_id" = %s UNION
+SELECT
+ "id",
+ 'APPLICATION' AS "type",
+ user_id,
+ ARRAY [ 'MANAGE',
+ 'USE','DELETE' ] AS "operate"
+FROM
+ application
+WHERE
+ "user_id" = %s UNION
+SELECT
+ team_member_permission.target AS "id",
+ team_member_permission.auth_target_type AS "type",
+ team_member.user_id AS user_id,
+ team_member_permission.operate AS "operate"
+FROM
+ team_member team_member
+ LEFT JOIN team_member_permission team_member_permission ON team_member.ID = team_member_permission.member_id
+WHERE
+ team_member.user_id = %s AND team_member_permission.target IS NOT NULL
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/setting/swagger_api/provide_api.py b/src/MaxKB-1.5.1/apps/setting/swagger_api/provide_api.py
new file mode 100644
index 0000000..7544fdf
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/swagger_api/provide_api.py
@@ -0,0 +1,188 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: provide_api.py
+ @date:2023/11/2 14:25
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class ModelQueryApi(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='name',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='模型名称'),
+ openapi.Parameter(name='model_type', in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='模型类型'),
+ openapi.Parameter(name='model_name', in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='基础模型名称'),
+ openapi.Parameter(name='provider',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='供应名称')
+ ]
+
+
+class ModelEditApi(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="调用函数所需要的参数",
+ description="调用函数所需要的参数",
+ required=['provide', 'model_info'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING,
+ title="模型名称",
+ description="模型名称"),
+ 'model_type': openapi.Schema(type=openapi.TYPE_STRING,
+ title="供应商",
+ description="供应商"),
+ 'model_name': openapi.Schema(type=openapi.TYPE_STRING,
+ title="供应商",
+ description="供应商"),
+ 'credential': openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="模型证书信息",
+ description="模型证书信息")
+ }
+ )
+
+
+class ModelCreateApi(ApiMixin):
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="调用函数所需要的参数",
+ description="调用函数所需要的参数",
+ required=['provide', 'model_info'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING,
+ title="模型名称",
+ description="模型名称"),
+ 'provider': openapi.Schema(type=openapi.TYPE_STRING,
+ title="供应商",
+ description="供应商"),
+ 'permission_type': openapi.Schema(type=openapi.TYPE_STRING, title="权限",
+ description="PUBLIC|PRIVATE"),
+ 'model_type': openapi.Schema(type=openapi.TYPE_STRING,
+ title="供应商",
+ description="供应商"),
+ 'model_name': openapi.Schema(type=openapi.TYPE_STRING,
+ title="供应商",
+ description="供应商"),
+ 'credential': openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="模型证书信息",
+ description="模型证书信息"),
+
+ }
+ )
+
+
+class ProvideApi(ApiMixin):
+ class ModelTypeList(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='provider',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='供应名称'),
+ ]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['key', 'value'],
+ properties={
+ 'key': openapi.Schema(type=openapi.TYPE_STRING, title="模型类型描述",
+ description="模型类型描述", default="大语言模型"),
+ 'value': openapi.Schema(type=openapi.TYPE_STRING, title="模型类型值",
+ description="模型类型值", default="LLM"),
+
+ }
+ )
+
+ class ModelList(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='provider',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='供应名称'),
+ openapi.Parameter(name='model_type',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='模型类型'),
+ ]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['name', 'desc', 'model_type'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="模型名称",
+ description="模型名称", default="模型名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="模型描述",
+ description="模型描述", default="xxx模型"),
+ 'model_type': openapi.Schema(type=openapi.TYPE_STRING, title="模型类型值",
+ description="模型类型值", default="LLM"),
+
+ }
+ )
+
+ class ModelForm(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='provider',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='供应名称'),
+ openapi.Parameter(name='model_type',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='模型类型'),
+ openapi.Parameter(name='model_name',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='模型名称'),
+ ]
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='provider',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='供应商'),
+ openapi.Parameter(name='method',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='需要执行的函数'),
+ ]
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="调用函数所需要的参数",
+ description="调用函数所需要的参数",
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/swagger_api/system_setting.py b/src/MaxKB-1.5.1/apps/setting/swagger_api/system_setting.py
new file mode 100644
index 0000000..1246ff2
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/swagger_api/system_setting.py
@@ -0,0 +1,77 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: system_setting.py
+ @date:2024/3/19 16:05
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class SystemSettingEmailApi(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="邮箱相关参数",
+ description="邮箱相关参数",
+ required=['email_host', 'email_port', 'email_host_user', 'email_host_password',
+ 'email_use_tls', 'email_use_ssl', 'from_email'],
+ properties={
+ 'email_host': openapi.Schema(type=openapi.TYPE_STRING,
+ title="SMTP 主机",
+ description="SMTP 主机"),
+ 'email_port': openapi.Schema(type=openapi.TYPE_NUMBER,
+ title="SMTP 端口",
+ description="SMTP 端口"),
+ 'email_host_user': openapi.Schema(type=openapi.TYPE_STRING,
+ title="发件人邮箱",
+ description="发件人邮箱"),
+ 'email_host_password': openapi.Schema(type=openapi.TYPE_STRING,
+ title="密码",
+ description="密码"),
+ 'email_use_tls': openapi.Schema(type=openapi.TYPE_BOOLEAN,
+ title="是否开启TLS",
+ description="是否开启TLS"),
+ 'email_use_ssl': openapi.Schema(type=openapi.TYPE_BOOLEAN,
+ title="是否开启SSL",
+ description="是否开启SSL"),
+ 'from_email': openapi.Schema(type=openapi.TYPE_STRING,
+ title="发送人邮箱",
+ description="发送人邮箱")
+ }
+ )
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ title="邮箱相关参数",
+ description="邮箱相关参数",
+ required=['email_host', 'email_port', 'email_host_user', 'email_host_password',
+ 'email_use_tls', 'email_use_ssl', 'from_email'],
+ properties={
+ 'email_host': openapi.Schema(type=openapi.TYPE_STRING,
+ title="SMTP 主机",
+ description="SMTP 主机"),
+ 'email_port': openapi.Schema(type=openapi.TYPE_NUMBER,
+ title="SMTP 端口",
+ description="SMTP 端口"),
+ 'email_host_user': openapi.Schema(type=openapi.TYPE_STRING,
+ title="发件人邮箱",
+ description="发件人邮箱"),
+ 'email_host_password': openapi.Schema(type=openapi.TYPE_STRING,
+ title="密码",
+ description="密码"),
+ 'email_use_tls': openapi.Schema(type=openapi.TYPE_BOOLEAN,
+ title="是否开启TLS",
+ description="是否开启TLS"),
+ 'email_use_ssl': openapi.Schema(type=openapi.TYPE_BOOLEAN,
+ title="是否开启SSL",
+ description="是否开启SSL"),
+ 'from_email': openapi.Schema(type=openapi.TYPE_STRING,
+ title="发送人邮箱",
+ description="发送人邮箱")
+ }
+ )
diff --git a/src/MaxKB-1.5.1/apps/setting/swagger_api/valid_api.py b/src/MaxKB-1.5.1/apps/setting/swagger_api/valid_api.py
new file mode 100644
index 0000000..4fad9e8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/swagger_api/valid_api.py
@@ -0,0 +1,27 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: valid_api.py
+ @date:2024/7/8 17:52
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class ValidApi(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='valid_type',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='校验类型:application|dataset|user'),
+ openapi.Parameter(name='valid_count',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='校验数量')
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/tests.py b/src/MaxKB-1.5.1/apps/setting/tests.py
new file mode 100644
index 0000000..7ce503c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/tests.py
@@ -0,0 +1,3 @@
+from django.test import TestCase
+
+# Create your tests here.
diff --git a/src/MaxKB-1.5.1/apps/setting/urls.py b/src/MaxKB-1.5.1/apps/setting/urls.py
new file mode 100644
index 0000000..557edcc
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/urls.py
@@ -0,0 +1,34 @@
+import os
+
+from django.urls import path
+
+from . import views
+
+app_name = "team"
+urlpatterns = [
+ path('team/member', views.TeamMember.as_view(), name="team"),
+ path('team/member/_batch', views.TeamMember.Batch.as_view()),
+ path('team/member/', views.TeamMember.Operate.as_view(), name='member'),
+ path('provider//', views.Provide.Exec.as_view(), name='provide_exec'),
+ path('provider', views.Provide.as_view(), name='provide'),
+ path('provider/model_type_list', views.Provide.ModelTypeList.as_view(), name="provider/model_type_list"),
+ path('provider/model_list', views.Provide.ModelList.as_view(),
+ name="provider/model_name_list"),
+ path('provider/model_form', views.Provide.ModelForm.as_view(),
+ name="provider/model_form"),
+ path('model', views.Model.as_view(), name='model'),
+ path('model//model_params_form', views.Model.ModelParamsForm.as_view(), name='model/model_params_form'),
+ path('model/', views.Model.Operate.as_view(), name='model/operate'),
+ path('model//pause_download', views.Model.PauseDownload.as_view(), name='model/operate'),
+ path('model//meta', views.Model.ModelMeta.as_view(), name='model/operate/meta'),
+ path('email_setting', views.SystemSetting.Email.as_view(), name='email_setting'),
+ path('valid//', views.Valid.as_view())
+
+]
+if os.environ.get('SERVER_NAME', 'web') == 'local_model':
+ urlpatterns += [
+ path('model//embed_documents', views.ModelApply.EmbedDocuments.as_view(),
+ name='model/embed_documents'),
+ path('model//embed_query', views.ModelApply.EmbedQuery.as_view(),
+ name='model/embed_query'),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/setting/views/Team.py b/src/MaxKB-1.5.1/apps/setting/views/Team.py
new file mode 100644
index 0000000..71710e3
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/views/Team.py
@@ -0,0 +1,90 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: Team.py
+ @date:2023/9/25 17:13
+ @desc:
+"""
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import PermissionConstants
+from common.response import result
+from setting.serializers.team_serializers import TeamMemberSerializer, get_response_body_api, \
+ UpdateTeamMemberPermissionSerializer
+
+
+class TeamMember(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取团队成员列表",
+ operation_id="获取团员成员列表",
+ responses=result.get_api_response(get_response_body_api()),
+ tags=["团队"])
+ @has_permissions(PermissionConstants.TEAM_READ)
+ def get(self, request: Request):
+ return result.success(TeamMemberSerializer(data={'team_id': str(request.user.id)}).list_member())
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="添加成员",
+ operation_id="添加成员",
+ request_body=TeamMemberSerializer().get_request_body_api(),
+ tags=["团队"])
+ @has_permissions(PermissionConstants.TEAM_CREATE)
+ def post(self, request: Request):
+ team = TeamMemberSerializer(data={'team_id': str(request.user.id)})
+ return result.success((team.add_member(**request.data)))
+
+ class Batch(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="批量添加成员",
+ operation_id="批量添加成员",
+ request_body=TeamMemberSerializer.get_bach_request_body_api(),
+ tags=["团队"])
+ @has_permissions(PermissionConstants.TEAM_CREATE)
+ def post(self, request: Request):
+ return result.success(
+ TeamMemberSerializer(data={'team_id': request.user.id}).batch_add_member(request.data))
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取团队成员权限",
+ operation_id="获取团队成员权限",
+ manual_parameters=TeamMemberSerializer.Operate.get_request_params_api(),
+ tags=["团队"])
+ @has_permissions(PermissionConstants.TEAM_READ)
+ def get(self, request: Request, member_id: str):
+ return result.success(TeamMemberSerializer.Operate(
+ data={'member_id': member_id, 'team_id': str(request.user.id)}).list_member_permission())
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改团队成员权限",
+ operation_id="修改团队成员权限",
+ request_body=UpdateTeamMemberPermissionSerializer().get_request_body_api(),
+ manual_parameters=TeamMemberSerializer.Operate.get_request_params_api(),
+ tags=["团队"]
+ )
+ @has_permissions(PermissionConstants.TEAM_EDIT)
+ def put(self, request: Request, member_id: str):
+ return result.success(TeamMemberSerializer.Operate(
+ data={'member_id': member_id, 'team_id': str(request.user.id)}).edit(request.data))
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="移除成员",
+ operation_id="移除成员",
+ manual_parameters=TeamMemberSerializer.Operate.get_request_params_api(),
+ tags=["团队"]
+ )
+ @has_permissions(PermissionConstants.TEAM_DELETE)
+ def delete(self, request: Request, member_id: str):
+ return result.success(TeamMemberSerializer.Operate(
+ data={'member_id': member_id, 'team_id': str(request.user.id)}).delete())
diff --git a/src/MaxKB-1.5.1/apps/setting/views/__init__.py b/src/MaxKB-1.5.1/apps/setting/views/__init__.py
new file mode 100644
index 0000000..4fe5056
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/views/__init__.py
@@ -0,0 +1,13 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/9/25 17:12
+ @desc:
+"""
+from .Team import *
+from .model import *
+from .system_setting import *
+from .valid import *
+from .model_apply import *
diff --git a/src/MaxKB-1.5.1/apps/setting/views/model.py b/src/MaxKB-1.5.1/apps/setting/views/model.py
new file mode 100644
index 0000000..d57a194
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/views/model.py
@@ -0,0 +1,205 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: model.py
+ @date:2023/11/2 13:55
+ @desc:
+"""
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import PermissionConstants
+from common.response import result
+from common.util.common import query_params_to_single_dict
+from setting.models_provider.constants.model_provider_constants import ModelProvideConstants
+from setting.serializers.provider_serializers import ProviderSerializer, ModelSerializer
+from setting.swagger_api.provide_api import ProvideApi, ModelCreateApi, ModelQueryApi, ModelEditApi
+
+
+class Model(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="创建模型",
+ operation_id="创建模型",
+ request_body=ModelCreateApi.get_request_body_api()
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_CREATE)
+ def post(self, request: Request):
+ return result.success(
+ ModelSerializer.Create(data={**request.data, 'user_id': str(request.user.id)}).insert(request.user.id,
+ with_valid=True))
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="下载模型,只试用与Ollama平台",
+ operation_id="下载模型,只试用与Ollama平台",
+ request_body=ModelCreateApi.get_request_body_api()
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_CREATE)
+ def put(self, request: Request):
+ return result.success(
+ ModelSerializer.Create(data={**request.data, 'user_id': str(request.user.id)}).insert(request.user.id,
+ with_valid=True))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型列表",
+ operation_id="获取模型列表",
+ manual_parameters=ModelQueryApi.get_request_params_api()
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request):
+ return result.success(
+ ModelSerializer.Query(
+ data={**query_params_to_single_dict(request.query_params), 'user_id': request.user.id}).list(
+ with_valid=True))
+
+ class ModelMeta(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="查询模型meta信息,该接口不携带认证信息",
+ operation_id="查询模型meta信息,该接口不携带认证信息",
+ tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request, model_id: str):
+ return result.success(
+ ModelSerializer.Operate(data={'id': model_id, 'user_id': request.user.id}).one_meta(with_valid=True))
+
+ class PauseDownload(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="暂停模型下载",
+ operation_id="暂停模型下载",
+ tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_CREATE)
+ def put(self, request: Request, model_id: str):
+ return result.success(
+ ModelSerializer.Operate(data={'id': model_id, 'user_id': request.user.id}).pause_download())
+
+ class ModelParamsForm(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型参数表单",
+ operation_id="获取模型参数表单",
+ manual_parameters=ProvideApi.ModelForm.get_request_params_api(),
+ tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request, model_id: str):
+ return result.success(
+ ModelSerializer.ModelParams(data={'id': model_id, 'user_id': request.user.id}).get_model_params())
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改模型",
+ operation_id="修改模型",
+ request_body=ModelEditApi.get_request_body_api()
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_CREATE)
+ def put(self, request: Request, model_id: str):
+ return result.success(
+ ModelSerializer.Operate(data={'id': model_id, 'user_id': request.user.id}).edit(request.data,
+ str(request.user.id)))
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除模型",
+ operation_id="删除模型",
+ responses=result.get_default_response()
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_DELETE)
+ def delete(self, request: Request, model_id: str):
+ return result.success(
+ ModelSerializer.Operate(data={'id': model_id, 'user_id': request.user.id}).delete())
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="查询模型详细信息",
+ operation_id="查询模型详细信息",
+ tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request, model_id: str):
+ return result.success(
+ ModelSerializer.Operate(data={'id': model_id, 'user_id': request.user.id}).one(with_valid=True))
+
+
+class Provide(APIView):
+ authentication_classes = [TokenAuth]
+
+ class Exec(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="调用供应商函数,获取表单数据",
+ operation_id="调用供应商函数,获取表单数据",
+ manual_parameters=ProvideApi.get_request_params_api(),
+ request_body=ProvideApi.get_request_body_api()
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def post(self, request: Request, provider: str, method: str):
+ return result.success(
+ ProviderSerializer(data={'provider': provider, 'method': method}).exec(request.data, with_valid=True))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型供应商数据",
+ operation_id="获取模型供应商列表"
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request):
+ return result.success(
+ [ModelProvideConstants[key].value.get_model_provide_info().to_dict() for key in
+ ModelProvideConstants.__members__])
+
+ class ModelTypeList(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型类型列表",
+ operation_id="获取模型类型类型列表",
+ manual_parameters=ProvideApi.ModelTypeList.get_request_params_api(),
+ responses=result.get_api_array_response(ProvideApi.ModelTypeList.get_response_body_api())
+ , tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request):
+ provider = request.query_params.get('provider')
+ return result.success(ModelProvideConstants[provider].value.get_model_type_list())
+
+ class ModelList(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型列表",
+ operation_id="获取模型创建表单",
+ manual_parameters=ProvideApi.ModelList.get_request_params_api(),
+ responses=result.get_api_array_response(ProvideApi.ModelList.get_response_body_api())
+ , tags=["模型"]
+ )
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request):
+ provider = request.query_params.get('provider')
+ model_type = request.query_params.get('model_type')
+
+ return result.success(
+ ModelProvideConstants[provider].value.get_model_list(
+ model_type))
+
+ class ModelForm(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取模型创建表单",
+ operation_id="获取模型创建表单",
+ manual_parameters=ProvideApi.ModelForm.get_request_params_api(),
+ tags=["模型"])
+ @has_permissions(PermissionConstants.MODEL_READ)
+ def get(self, request: Request):
+ provider = request.query_params.get('provider')
+ model_type = request.query_params.get('model_type')
+ model_name = request.query_params.get('model_name')
+ return result.success(
+ ModelProvideConstants[provider].value.get_model_credential(model_type, model_name).to_form_list())
diff --git a/src/MaxKB-1.5.1/apps/setting/views/model_apply.py b/src/MaxKB-1.5.1/apps/setting/views/model_apply.py
new file mode 100644
index 0000000..4a4e613
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/views/model_apply.py
@@ -0,0 +1,38 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: model_apply.py
+ @date:2024/8/20 20:38
+ @desc:
+"""
+from urllib.request import Request
+
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.views import APIView
+
+from common.response import result
+from setting.serializers.model_apply_serializers import ModelApplySerializers
+
+
+class ModelApply(APIView):
+ class EmbedDocuments(APIView):
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="向量化文档",
+ operation_id="向量化文档",
+ responses=result.get_default_response(),
+ tags=["模型"])
+ def post(self, request: Request, model_id):
+ return result.success(
+ ModelApplySerializers(data={'model_id': model_id}).embed_documents(request.data))
+
+ class EmbedQuery(APIView):
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="向量化文档",
+ operation_id="向量化文档",
+ responses=result.get_default_response(),
+ tags=["模型"])
+ def post(self, request: Request, model_id):
+ return result.success(
+ ModelApplySerializers(data={'model_id': model_id}).embed_query(request.data))
diff --git a/src/MaxKB-1.5.1/apps/setting/views/system_setting.py b/src/MaxKB-1.5.1/apps/setting/views/system_setting.py
new file mode 100644
index 0000000..e08a470
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/views/system_setting.py
@@ -0,0 +1,57 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: system_setting.py
+ @date:2024/3/19 16:01
+ @desc:
+"""
+
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.request import Request
+from rest_framework.views import APIView
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import RoleConstants
+from common.response import result
+from setting.serializers.system_setting import SystemSettingSerializer
+from setting.swagger_api.system_setting import SystemSettingEmailApi
+
+
+class SystemSetting(APIView):
+ class Email(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="创建或者修改邮箱设置",
+ operation_id="创建或者修改邮箱设置",
+ request_body=SystemSettingEmailApi.get_request_body_api(), tags=["邮箱设置"],
+ responses=result.get_api_response(SystemSettingEmailApi.get_response_body_api()))
+ @has_permissions(RoleConstants.ADMIN)
+ def put(self, request: Request):
+ return result.success(
+ SystemSettingSerializer.EmailSerializer.Create(
+ data=request.data).update_or_save())
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="测试邮箱设置",
+ operation_id="测试邮箱设置",
+ request_body=SystemSettingEmailApi.get_request_body_api(),
+ responses=result.get_default_response(),
+ tags=["邮箱设置"])
+ @has_permissions(RoleConstants.ADMIN)
+ def post(self, request: Request):
+ return result.success(
+ SystemSettingSerializer.EmailSerializer.Create(
+ data=request.data).is_valid())
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取邮箱设置",
+ operation_id="获取邮箱设置",
+ responses=result.get_api_response(SystemSettingEmailApi.get_response_body_api()),
+ tags=["邮箱设置"])
+ @has_permissions(RoleConstants.ADMIN)
+ def get(self, request: Request):
+ return result.success(
+ SystemSettingSerializer.EmailSerializer.one())
diff --git a/src/MaxKB-1.5.1/apps/setting/views/valid.py b/src/MaxKB-1.5.1/apps/setting/views/valid.py
new file mode 100644
index 0000000..f88c589
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/setting/views/valid.py
@@ -0,0 +1,32 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: valid.py
+ @date:2024/7/8 17:50
+ @desc:
+"""
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.request import Request
+from rest_framework.views import APIView
+
+from common.auth import TokenAuth, has_permissions
+from common.constants.permission_constants import RoleConstants
+from common.response import result
+from setting.serializers.valid_serializers import ValidSerializer
+from setting.swagger_api.valid_api import ValidApi
+
+
+class Valid(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取校验结果",
+ operation_id="获取校验结果",
+ manual_parameters=ValidApi.get_request_params_api(),
+ responses=result.get_default_response()
+ , tags=["校验"])
+ @has_permissions(RoleConstants.ADMIN, RoleConstants.USER)
+ def get(self, request: Request, valid_type: str, valid_count: int):
+ return result.success(ValidSerializer(data={'valid_type': valid_type, 'valid_count': valid_count}).valid())
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/__init__.py b/src/MaxKB-1.5.1/apps/smartdoc/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/asgi.py b/src/MaxKB-1.5.1/apps/smartdoc/asgi.py
new file mode 100644
index 0000000..e68e6ce
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/asgi.py
@@ -0,0 +1,16 @@
+"""
+ASGI config for apps project.
+
+It exposes the ASGI callable as a module-level variable named ``application``.
+
+For more information on this file, see
+https://docs.djangoproject.com/en/4.2/howto/deployment/asgi/
+"""
+
+import os
+
+from django.core.asgi import get_asgi_application
+
+os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'smartdoc.settings')
+
+application = get_asgi_application()
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/conf.py b/src/MaxKB-1.5.1/apps/smartdoc/conf.py
new file mode 100644
index 0000000..0349739
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/conf.py
@@ -0,0 +1,225 @@
+# !/usr/bin/env python3
+# -*- coding: utf-8 -*-
+#
+"""
+配置分类:
+1. Django使用的配置文件,写到settings中
+2. 程序需要, 用户不需要更改的写到settings中
+3. 程序需要, 用户需要更改的写到本config中
+"""
+import errno
+import logging
+import os
+import re
+from importlib import import_module
+from urllib.parse import urljoin, urlparse
+
+import yaml
+
+BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+PROJECT_DIR = os.path.dirname(BASE_DIR)
+logger = logging.getLogger('smartdoc.conf')
+
+
+def import_string(dotted_path):
+ try:
+ module_path, class_name = dotted_path.rsplit('.', 1)
+ except ValueError as err:
+ raise ImportError("%s doesn't look like a module path" % dotted_path) from err
+
+ module = import_module(module_path)
+
+ try:
+ return getattr(module, class_name)
+ except AttributeError as err:
+ raise ImportError(
+ 'Module "%s" does not define a "%s" attribute/class' %
+ (module_path, class_name)) from err
+
+
+def is_absolute_uri(uri):
+ """ 判断一个uri是否是绝对地址 """
+ if not isinstance(uri, str):
+ return False
+
+ result = re.match(r'^http[s]?://.*', uri)
+ if result is None:
+ return False
+
+ return True
+
+
+def build_absolute_uri(base, uri):
+ """ 构建绝对uri地址 """
+ if uri is None:
+ return base
+
+ if isinstance(uri, int):
+ uri = str(uri)
+
+ if not isinstance(uri, str):
+ return base
+
+ if is_absolute_uri(uri):
+ return uri
+
+ parsed_base = urlparse(base)
+ url = "{}://{}".format(parsed_base.scheme, parsed_base.netloc)
+ path = '{}/{}/'.format(parsed_base.path.strip('/'), uri.strip('/'))
+ return urljoin(url, path)
+
+
+class DoesNotExist(Exception):
+ pass
+
+
+class Config(dict):
+ defaults = {
+ # 数据库相关配置
+ "DB_HOST": "127.0.0.1",
+ "DB_PORT": 5432,
+ "DB_USER": "root",
+ "DB_PASSWORD": "Password123@postgres",
+ "DB_ENGINE": "django.db.backends.postgresql_psycopg2",
+ # 向量模型
+ "EMBEDDING_MODEL_NAME": "shibing624/text2vec-base-chinese",
+ "EMBEDDING_DEVICE": "cpu",
+ "EMBEDDING_MODEL_PATH": os.path.join(PROJECT_DIR, 'models'),
+ # 向量库配置
+ "VECTOR_STORE_NAME": 'pg_vector',
+ "DEBUG": False,
+ 'SANDBOX': False,
+ 'LOCAL_MODEL_HOST': '127.0.0.1',
+ 'LOCAL_MODEL_PORT': '11636',
+ 'LOCAL_MODEL_PROTOCOL': "http"
+
+ }
+
+ def get_debug(self) -> bool:
+ return self.get('DEBUG') if 'DEBUG' in self else True
+
+ def get_time_zone(self) -> str:
+ return self.get('TIME_ZONE') if 'TIME_ZONE' in self else 'Asia/Shanghai'
+
+ def get_db_setting(self) -> dict:
+ return {
+ "NAME": self.get('DB_NAME'),
+ "HOST": self.get('DB_HOST'),
+ "PORT": self.get('DB_PORT'),
+ "USER": self.get('DB_USER'),
+ "PASSWORD": self.get('DB_PASSWORD'),
+ "ENGINE": self.get('DB_ENGINE')
+ }
+
+ def __init__(self, *args):
+ super().__init__(*args)
+
+ def __repr__(self):
+ return '<%s %s>' % (self.__class__.__name__, dict.__repr__(self))
+
+ def __getitem__(self, item):
+ return self.get(item)
+
+ def __getattr__(self, item):
+ return self.get(item)
+
+
+class ConfigManager:
+ config_class = Config
+
+ def __init__(self, root_path=None):
+ self.root_path = root_path
+ self.config = self.config_class()
+ for key in self.config_class.defaults:
+ self.config[key] = self.config_class.defaults[key]
+
+ def from_mapping(self, *mapping, **kwargs):
+ """Updates the config like :meth:`update` ignoring items with non-upper
+ keys.
+
+ .. versionadded:: 0.11
+ """
+ mappings = []
+ if len(mapping) == 1:
+ if hasattr(mapping[0], 'items'):
+ mappings.append(mapping[0].items())
+ else:
+ mappings.append(mapping[0])
+ elif len(mapping) > 1:
+ raise TypeError(
+ 'expected at most 1 positional argument, got %d' % len(mapping)
+ )
+ mappings.append(kwargs.items())
+ for mapping in mappings:
+ for (key, value) in mapping:
+ if key.isupper():
+ self.config[key] = value
+ return True
+
+ def from_yaml(self, filename, silent=False):
+ if self.root_path:
+ filename = os.path.join(self.root_path, filename)
+ try:
+ with open(filename, 'rt', encoding='utf8') as f:
+ obj = yaml.safe_load(f)
+ except IOError as e:
+ if silent and e.errno in (errno.ENOENT, errno.EISDIR):
+ return False
+ e.strerror = 'Unable to load configuration file (%s)' % e.strerror
+ raise
+ if obj:
+ return self.from_mapping(obj)
+ return True
+
+ def load_from_yml(self):
+ for i in ['config_example.yml', 'config.yaml', 'config.yml']:
+ if not os.path.isfile(os.path.join(self.root_path, i)):
+ continue
+ loaded = self.from_yaml(i)
+ if loaded:
+ return True
+ msg = f"""
+
+ Error: No config file found.
+
+ You can run `cp config_example.yml {self.root_path}/config.yml`, and edit it.
+
+ """
+ raise ImportError(msg)
+
+ def load_from_env(self):
+ keys = os.environ.keys()
+ config = {key.replace('MAXKB_', ''): os.environ.get(key) for key in keys if key.startswith('MAXKB_')}
+ if len(config.keys()) <= 1:
+ msg = f"""
+
+ Error: No config env found.
+
+ Please set environment variables
+ MAXKB_CONFIG_TYPE: 配置文件读取方式 FILE: 使用配置文件配置 ENV: 使用ENV配置
+ MAXKB_DB_NAME: 数据库名称
+ MAXKB_DB_HOST: 数据库主机
+ MAXKB_DB_PORT: 数据库端口
+ MAXKB_DB_USER: 数据库用户名
+ MAXKB_DB_PASSWORD: 数据库密码
+ MAXKB_EMBEDDING_MODEL_PATH: 向量模型目录
+ MAXKB_EMBEDDING_MODEL_NAME: 向量模型名称
+ """
+ raise ImportError(msg)
+ self.from_mapping(config)
+ return True
+
+ @classmethod
+ def load_user_config(cls, root_path=None, config_class=None):
+ config_class = config_class or Config
+ cls.config_class = config_class
+ if not root_path:
+ root_path = PROJECT_DIR
+ manager = cls(root_path=root_path)
+ config_type = os.environ.get('MAXKB_CONFIG_TYPE')
+ if config_type is None or config_type != 'ENV':
+ manager.load_from_yml()
+ else:
+ manager.load_from_env()
+ config = manager.config
+ return config
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/const.py b/src/MaxKB-1.5.1/apps/smartdoc/const.py
new file mode 100644
index 0000000..9b1159a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/const.py
@@ -0,0 +1,12 @@
+# -*- coding: utf-8 -*-
+#
+import os
+
+from .conf import ConfigManager
+
+__all__ = ['BASE_DIR', 'PROJECT_DIR', 'VERSION', 'CONFIG']
+
+BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+PROJECT_DIR = os.path.dirname(BASE_DIR)
+VERSION = '1.0.0'
+CONFIG = ConfigManager.load_user_config(root_path=os.path.abspath('/opt/maxkb/conf'))
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/settings/__init__.py b/src/MaxKB-1.5.1/apps/smartdoc/settings/__init__.py
new file mode 100644
index 0000000..4e7ea78
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/settings/__init__.py
@@ -0,0 +1,12 @@
+# coding=utf-8
+"""
+ @project: smart-doc
+ @Author:虎
+ @file: __init__.py
+ @date:2023/9/14 15:45
+ @desc:
+"""
+from .base import *
+from .logging import *
+from .auth import *
+from .lib import *
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/settings/auth.py b/src/MaxKB-1.5.1/apps/smartdoc/settings/auth.py
new file mode 100644
index 0000000..077f98b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/settings/auth.py
@@ -0,0 +1,19 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: auth.py
+ @date:2024/7/9 18:47
+ @desc:
+"""
+USER_TOKEN_AUTH = 'common.auth.handle.impl.user_token.UserToken'
+
+PUBLIC_ACCESS_TOKEN_AUTH = 'common.auth.handle.impl.public_access_token.PublicAccessToken'
+
+APPLICATION_KEY_AUTH = 'common.auth.handle.impl.application_key.ApplicationKey'
+
+AUTH_HANDLES = [
+ USER_TOKEN_AUTH,
+ PUBLIC_ACCESS_TOKEN_AUTH,
+ APPLICATION_KEY_AUTH
+]
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/settings/base.py b/src/MaxKB-1.5.1/apps/smartdoc/settings/base.py
new file mode 100644
index 0000000..c6b2188
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/settings/base.py
@@ -0,0 +1,185 @@
+import datetime
+import mimetypes
+import os
+from pathlib import Path
+
+from PIL import Image
+
+from ..const import CONFIG, PROJECT_DIR
+
+mimetypes.add_type("text/css", ".css", True)
+mimetypes.add_type("text/javascript", ".js", True)
+# Build paths inside the project like this: BASE_DIR / 'subdir'.
+BASE_DIR = Path(__file__).resolve().parent.parent
+Image.MAX_IMAGE_PIXELS = 20000000000
+# Quick-start development settings - unsuitable for production
+# See https://docs.djangoproject.com/en/4.2/howto/deployment/checklist/
+
+# SECURITY WARNING: keep the secret key used in production secret!
+SECRET_KEY = 'django-insecure-g1u*$)1ddn20_3orw^f+g4(i(2dacj^awe*2vh-$icgqwfnbq('
+# SECURITY WARNING: don't run with debug turned on in production!
+DEBUG = CONFIG.get_debug()
+
+ALLOWED_HOSTS = ['*']
+
+DATABASES = {
+ 'default': CONFIG.get_db_setting()
+}
+
+# Application definition
+
+INSTALLED_APPS = [
+ 'users.apps.UsersConfig',
+ 'setting',
+ 'dataset',
+ 'application',
+ 'embedding',
+ 'django.contrib.contenttypes',
+ 'django.contrib.messages',
+ 'django.contrib.staticfiles',
+ 'rest_framework',
+ "drf_yasg", # swagger 接口
+ 'django_filters', # 条件过滤
+ 'django_apscheduler',
+ 'common',
+ 'function_lib',
+ 'django_celery_beat'
+
+]
+
+MIDDLEWARE = [
+ 'django.middleware.security.SecurityMiddleware',
+ 'django.contrib.sessions.middleware.SessionMiddleware',
+ 'django.middleware.common.CommonMiddleware',
+ 'django.contrib.messages.middleware.MessageMiddleware',
+ 'common.middleware.static_headers_middleware.StaticHeadersMiddleware',
+ 'common.middleware.cross_domain_middleware.CrossDomainMiddleware'
+
+]
+
+JWT_AUTH = {
+ 'JWT_EXPIRATION_DELTA': datetime.timedelta(seconds=60 * 60 * 2) # <-- 设置token有效时间
+}
+
+APPS_DIR = os.path.join(PROJECT_DIR, 'apps')
+ROOT_URLCONF = 'smartdoc.urls'
+# FORCE_SCRIPT_NAME
+TEMPLATES = [
+ {
+ 'BACKEND': 'django.template.backends.django.DjangoTemplates',
+ 'DIRS': ['apps/static/ui'],
+ 'APP_DIRS': True,
+ 'OPTIONS': {
+ 'context_processors': [
+ 'django.template.context_processors.debug',
+ 'django.template.context_processors.request',
+ 'django.contrib.auth.context_processors.auth',
+ 'django.contrib.messages.context_processors.messages',
+ ],
+ },
+ },
+]
+
+SWAGGER_SETTINGS = {
+ 'DEFAULT_AUTO_SCHEMA_CLASS': 'common.config.swagger_conf.CustomSwaggerAutoSchema',
+ "DEFAULT_MODEL_RENDERING": "example",
+ 'USE_SESSION_AUTH': False,
+ 'SECURITY_DEFINITIONS': {
+ 'Bearer': {
+ 'type': 'apiKey',
+ 'name': 'AUTHORIZATION',
+ 'in': 'header',
+ }
+ }
+}
+
+# 缓存配置
+CACHES = {
+ "default": {
+ 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
+ 'LOCATION': 'unique-snowflake',
+ 'TIMEOUT': 60 * 30,
+ 'OPTIONS': {
+ 'MAX_ENTRIES': 150,
+ 'CULL_FREQUENCY': 5,
+ }
+ },
+ 'chat_cache': {
+ 'BACKEND': 'common.cache.file_cache.FileCache',
+ 'LOCATION': os.path.join(PROJECT_DIR, 'data', 'cache', "chat_cache") # 文件夹路径
+ },
+ # 存储用户信息
+ 'user_cache': {
+ 'BACKEND': 'common.cache.file_cache.FileCache',
+ 'LOCATION': os.path.join(PROJECT_DIR, 'data', 'cache', "user_cache") # 文件夹路径
+ },
+ # 存储用户Token
+ "token_cache": {
+ 'BACKEND': 'common.cache.file_cache.FileCache',
+ 'LOCATION': os.path.join(PROJECT_DIR, 'data', 'cache', "token_cache") # 文件夹路径
+ }
+}
+
+REST_FRAMEWORK = {
+ 'EXCEPTION_HANDLER': 'common.handle.handle_exception.handle_exception',
+ 'DEFAULT_AUTHENTICATION_CLASSES': ['common.auth.authenticate.AnonymousAuthentication']
+
+}
+STATICFILES_DIRS = [(os.path.join(PROJECT_DIR, 'ui', 'dist'))]
+
+STATIC_ROOT = os.path.join(BASE_DIR.parent, 'static')
+
+WSGI_APPLICATION = 'smartdoc.wsgi.application'
+
+# 邮件配置
+EMAIL_ADDRESS = CONFIG.get('EMAIL_ADDRESS')
+EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'
+EMAIL_USE_TLS = CONFIG.get('EMAIL_USE_TLS') # 是否使用TLS安全传输协议(用于在两个通信应用程序之间提供保密性和数据完整性。)
+EMAIL_USE_SSL = CONFIG.get('EMAIL_USE_SSL') # 是否使用SSL加密,qq企业邮箱要求使用
+EMAIL_HOST = CONFIG.get('EMAIL_HOST') # 发送邮件的邮箱 的 SMTP服务器,这里用了163邮箱
+EMAIL_PORT = CONFIG.get('EMAIL_PORT') # 发件箱的SMTP服务器端口
+EMAIL_HOST_USER = CONFIG.get('EMAIL_HOST_USER') # 发送邮件的邮箱地址
+EMAIL_HOST_PASSWORD = CONFIG.get('EMAIL_HOST_PASSWORD') # 发送邮件的邮箱密码(这里使用的是授权码)
+
+# Database
+# https://docs.djangoproject.com/en/4.2/ref/settings/#databases
+
+
+# Password validation
+# https://docs.djangoproject.com/en/4.2/ref/settings/#auth-password-validators
+
+AUTH_PASSWORD_VALIDATORS = [
+ {
+ 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
+ },
+ {
+ 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
+ },
+ {
+ 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
+ },
+ {
+ 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
+ },
+]
+
+# Internationalization
+# https://docs.djangoproject.com/en/4.2/topics/i18n/
+
+LANGUAGE_CODE = 'en-us'
+
+TIME_ZONE = CONFIG.get_time_zone()
+
+USE_I18N = True
+
+USE_TZ = False
+
+# Static files (CSS, JavaScript, Images)
+# https://docs.djangoproject.com/en/4.2/howto/static-files/
+
+STATIC_URL = 'static/'
+
+# Default primary key field type
+# https://docs.djangoproject.com/en/4.2/ref/settings/#default-auto-field
+
+DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/settings/lib.py b/src/MaxKB-1.5.1/apps/smartdoc/settings/lib.py
new file mode 100644
index 0000000..e7b6d39
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/settings/lib.py
@@ -0,0 +1,40 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: lib.py
+ @date:2024/8/16 17:12
+ @desc:
+"""
+import os
+
+from smartdoc.const import CONFIG, PROJECT_DIR
+
+# celery相关配置
+celery_data_dir = os.path.join(PROJECT_DIR, 'data', 'celery_task')
+if not os.path.exists(celery_data_dir) or not os.path.isdir(celery_data_dir):
+ os.makedirs(celery_data_dir)
+broker_path = os.path.join(celery_data_dir, "celery_db.sqlite3")
+backend_path = os.path.join(celery_data_dir, "celery_results.sqlite3")
+# 使用sql_lite 当做broker 和 响应接收
+CELERY_BROKER_URL = f'sqla+sqlite:///{broker_path}'
+CELERY_result_backend = f'db+sqlite:///{backend_path}'
+CELERY_timezone = CONFIG.TIME_ZONE
+CELERY_ENABLE_UTC = False
+CELERY_task_serializer = 'pickle'
+CELERY_result_serializer = 'pickle'
+CELERY_accept_content = ['json', 'pickle']
+CELERY_RESULT_EXPIRES = 600
+CELERY_WORKER_TASK_LOG_FORMAT = '%(asctime).19s %(message)s'
+CELERY_WORKER_LOG_FORMAT = '%(asctime).19s %(message)s'
+CELERY_TASK_EAGER_PROPAGATES = True
+CELERY_WORKER_REDIRECT_STDOUTS = True
+CELERY_WORKER_REDIRECT_STDOUTS_LEVEL = "INFO"
+CELERY_TASK_SOFT_TIME_LIMIT = 3600
+CELERY_WORKER_CANCEL_LONG_RUNNING_TASKS_ON_CONNECTION_LOSS = True
+CELERY_ONCE = {
+ 'backend': 'celery_once.backends.File',
+ 'settings': {'location': os.path.join(celery_data_dir, "celery_once")}
+}
+CELERY_BROKER_CONNECTION_RETRY_ON_STARTUP = True
+CELERY_LOG_DIR = os.path.join(PROJECT_DIR, 'logs', 'celery')
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/settings/logging.py b/src/MaxKB-1.5.1/apps/smartdoc/settings/logging.py
new file mode 100644
index 0000000..9c3df8c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/settings/logging.py
@@ -0,0 +1,128 @@
+# -*- coding: utf-8 -*-
+#
+import os
+
+from ..const import PROJECT_DIR, CONFIG
+
+LOG_DIR = os.path.join(PROJECT_DIR, 'data', 'logs')
+MAX_KB_LOG_FILE = os.path.join(LOG_DIR, 'max_kb.log')
+DRF_EXCEPTION_LOG_FILE = os.path.join(LOG_DIR, 'drf_exception.log')
+UNEXPECTED_EXCEPTION_LOG_FILE = os.path.join(LOG_DIR, 'unexpected_exception.log')
+LOG_LEVEL = "DEBUG"
+
+LOGGING = {
+ 'version': 1,
+ 'disable_existing_loggers': False,
+ 'formatters': {
+ 'verbose': {
+ 'format': '%(levelname)s %(asctime)s %(module)s %(process)d %(thread)d %(message)s'
+ },
+ 'main': {
+ 'datefmt': '%Y-%m-%d %H:%M:%S',
+ 'format': '%(asctime)s [%(module)s %(levelname)s] %(message)s',
+ },
+ 'exception': {
+ 'datefmt': '%Y-%m-%d %H:%M:%S',
+ 'format': '\n%(asctime)s [%(levelname)s] %(message)s',
+ },
+ 'simple': {
+ 'format': '%(levelname)s %(message)s'
+ },
+ 'syslog': {
+ 'format': 'jumpserver: %(message)s'
+ },
+ 'msg': {
+ 'format': '%(message)s'
+ }
+ },
+ 'handlers': {
+ 'null': {
+ 'level': 'DEBUG',
+ 'class': 'logging.NullHandler',
+ },
+ 'console': {
+ 'level': 'DEBUG',
+ 'class': 'logging.StreamHandler',
+ 'formatter': 'main'
+ },
+ 'file': {
+ 'encoding': 'utf8',
+ 'level': 'DEBUG',
+ 'class': 'logging.handlers.RotatingFileHandler',
+ 'maxBytes': 1024 * 1024 * 100,
+ 'backupCount': 7,
+ 'formatter': 'main',
+ 'filename': MAX_KB_LOG_FILE,
+ },
+ 'drf_exception': {
+ 'encoding': 'utf8',
+ 'level': 'DEBUG',
+ 'class': 'logging.handlers.RotatingFileHandler',
+ 'formatter': 'exception',
+ 'maxBytes': 1024 * 1024 * 100,
+ 'backupCount': 7,
+ 'filename': DRF_EXCEPTION_LOG_FILE,
+ },
+ 'unexpected_exception': {
+ 'encoding': 'utf8',
+ 'level': 'DEBUG',
+ 'class': 'logging.handlers.RotatingFileHandler',
+ 'formatter': 'exception',
+ 'maxBytes': 1024 * 1024 * 100,
+ 'backupCount': 7,
+ 'filename': UNEXPECTED_EXCEPTION_LOG_FILE,
+ },
+ 'syslog': {
+ 'level': 'INFO',
+ 'class': 'logging.NullHandler',
+ 'formatter': 'syslog'
+ },
+ },
+ 'loggers': {
+ 'django': {
+ 'handlers': ['null'],
+ 'propagate': False,
+ 'level': LOG_LEVEL,
+ },
+ 'django.request': {
+ 'handlers': ['console', 'file', 'syslog'],
+ 'level': LOG_LEVEL,
+ 'propagate': False,
+ },
+ 'sqlalchemy': {
+ 'handlers': ['console', 'file', 'syslog'],
+ 'level': "ERROR",
+ 'propagate': False,
+ },
+ 'django.db.backends': {
+ 'handlers': ['console', 'file', 'syslog'],
+ 'propagate': False,
+ 'level': LOG_LEVEL,
+ },
+ 'django.server': {
+ 'handlers': ['console', 'file', 'syslog'],
+ 'level': LOG_LEVEL,
+ 'propagate': False,
+ },
+ 'max_kb_error': {
+ 'handlers': ['console', 'unexpected_exception'],
+ 'level': LOG_LEVEL,
+ 'propagate': False,
+ },
+ 'max_kb': {
+ 'handlers': ['console', 'file'],
+ 'level': LOG_LEVEL,
+ 'propagate': False,
+ },
+ 'common.event': {
+ 'handlers': ['console', 'file'],
+ 'level': "DEBUG",
+ 'propagate': False,
+ },
+ }
+}
+
+SYSLOG_ENABLE = CONFIG.SYSLOG_ENABLE
+
+if not os.path.isdir(LOG_DIR):
+ os.makedirs(LOG_DIR, mode=0o755)
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/urls.py b/src/MaxKB-1.5.1/apps/smartdoc/urls.py
new file mode 100644
index 0000000..aa3b563
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/urls.py
@@ -0,0 +1,74 @@
+"""
+URL configuration for apps project.
+
+The `urlpatterns` list routes URLs to views. For more information please see:
+ https://docs.djangoproject.com/en/4.2/topics/http/urls/
+Examples:
+Function views
+ 1. Add an import: forms my_app import views
+ 2. Add a URL to urlpatterns: path('', views.home, name='home')
+Class-based views
+ 1. Add an import: forms other_app.views import Home
+ 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
+Including another URLconf
+ 1. Import the include() function_lib: forms django.urls import include, path
+ 2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
+"""
+import os
+
+from django.http import HttpResponse
+from django.urls import path, re_path, include
+from django.views import static
+from rest_framework import status
+
+from application.urls import urlpatterns as application_urlpatterns
+from common.cache_data.static_resource_cache import get_index_html
+from common.constants.cache_code_constants import CacheCodeConstants
+from common.init.init_doc import init_doc
+from common.response.result import Result
+from common.util.cache_util import get_cache
+from smartdoc import settings
+from smartdoc.conf import PROJECT_DIR
+
+urlpatterns = [
+ path("api/", include("users.urls")),
+ path("api/", include("dataset.urls")),
+ path("api/", include("setting.urls")),
+ path("api/", include("application.urls")),
+ path("api/", include("function_lib.urls"))
+]
+
+
+def pro():
+ # 暴露静态主要是swagger资源
+ urlpatterns.append(
+ re_path(r'^static/(?P.*)$', static.serve, {'document_root': settings.STATIC_ROOT}, name='static'),
+ )
+ # 暴露ui静态资源
+ urlpatterns.append(
+ re_path(r'^ui/(?P.*)$', static.serve, {'document_root': os.path.join(settings.STATIC_ROOT, "ui")},
+ name='ui'),
+ )
+
+
+if not settings.DEBUG:
+ pro()
+
+
+def page_not_found(request, exception):
+ """
+ 页面不存在处理
+ """
+ if request.path.startswith("/api/"):
+ return Result(response_status=status.HTTP_404_NOT_FOUND, code=404, message="找不到接口")
+ index_path = os.path.join(PROJECT_DIR, 'apps', "static", 'ui', 'index.html')
+ if not os.path.exists(index_path):
+ return HttpResponse("页面不存在", status=404)
+ content = get_index_html(index_path)
+ if request.path.startswith('/ui/chat/'):
+ return HttpResponse(content, status=200)
+ return HttpResponse(content, status=200, headers={'X-Frame-Options': 'DENY'})
+
+
+handler404 = page_not_found
+init_doc(urlpatterns, application_urlpatterns)
diff --git a/src/MaxKB-1.5.1/apps/smartdoc/wsgi.py b/src/MaxKB-1.5.1/apps/smartdoc/wsgi.py
new file mode 100644
index 0000000..6c7c681
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/smartdoc/wsgi.py
@@ -0,0 +1,28 @@
+"""
+WSGI config for apps project.
+
+It exposes the WSGI callable as a module-level variable named ``application``.
+
+For more information on this file, see
+https://docs.djangoproject.com/en/4.2/howto/deployment/wsgi/
+"""
+
+import os
+
+from django.core.wsgi import get_wsgi_application
+
+os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'smartdoc.settings')
+
+application = get_wsgi_application()
+
+
+def post_handler():
+ from common import event
+ from common import job
+ from common.models.db_model_manage import DBModelManage
+ event.run()
+ job.run()
+ DBModelManage.init()
+
+
+post_handler()
diff --git a/src/MaxKB-1.5.1/apps/users/__init__.py b/src/MaxKB-1.5.1/apps/users/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/users/apps.py b/src/MaxKB-1.5.1/apps/users/apps.py
new file mode 100644
index 0000000..8e08561
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/apps.py
@@ -0,0 +1,9 @@
+from django.apps import AppConfig
+
+
+class UsersConfig(AppConfig):
+ default_auto_field = 'django.db.models.BigAutoField'
+ name = 'users'
+
+ def ready(self):
+ from ops.celery import signal_handler
diff --git a/src/MaxKB-1.5.1/apps/users/migrations/0001_initial.py b/src/MaxKB-1.5.1/apps/users/migrations/0001_initial.py
new file mode 100644
index 0000000..9565efa
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/migrations/0001_initial.py
@@ -0,0 +1,44 @@
+# Generated by Django 4.1.10 on 2024-03-18 16:02
+
+from django.db import migrations, models
+import uuid
+
+from common.constants.permission_constants import RoleConstants
+from users.models import password_encrypt
+
+
+def insert_default_data(apps, schema_editor):
+ UserModel = apps.get_model('users', 'User')
+ UserModel.objects.create(id='f0dd8f71-e4ee-11ee-8c84-a8a1595801ab', email='', username='admin',
+ nick_name="系统管理员",
+ password=password_encrypt('MaxKB@123..'),
+ role=RoleConstants.ADMIN.name,
+ is_active=True)
+
+
+class Migration(migrations.Migration):
+ initial = True
+
+ dependencies = [
+ ]
+
+ operations = [
+ migrations.CreateModel(
+ name='User',
+ fields=[
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False,
+ verbose_name='主键id')),
+ ('email', models.EmailField(max_length=254, unique=True, verbose_name='邮箱')),
+ ('phone', models.CharField(default='', max_length=20, verbose_name='电话')),
+ ('nick_name', models.CharField(default='', max_length=150, verbose_name='昵称')),
+ ('username', models.CharField(max_length=150, unique=True, verbose_name='用户名')),
+ ('password', models.CharField(max_length=150, verbose_name='密码')),
+ ('role', models.CharField(max_length=150, verbose_name='角色')),
+ ('is_active', models.BooleanField(default=True)),
+ ],
+ options={
+ 'db_table': 'user',
+ },
+ ),
+ migrations.RunPython(insert_default_data)
+ ]
diff --git a/src/MaxKB-1.5.1/apps/users/migrations/0002_user_create_time_user_update_time.py b/src/MaxKB-1.5.1/apps/users/migrations/0002_user_create_time_user_update_time.py
new file mode 100644
index 0000000..68baae0
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/migrations/0002_user_create_time_user_update_time.py
@@ -0,0 +1,23 @@
+# Generated by Django 4.1.13 on 2024-03-20 12:27
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('users', '0001_initial'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='user',
+ name='create_time',
+ field=models.DateTimeField(auto_now_add=True, null=True, verbose_name='创建时间'),
+ ),
+ migrations.AddField(
+ model_name='user',
+ name='update_time',
+ field=models.DateTimeField(auto_now=True, null=True, verbose_name='修改时间'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/users/migrations/0003_user_source.py b/src/MaxKB-1.5.1/apps/users/migrations/0003_user_source.py
new file mode 100644
index 0000000..7292cc1
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/migrations/0003_user_source.py
@@ -0,0 +1,18 @@
+# Generated by Django 4.2.13 on 2024-07-11 19:16
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('users', '0002_user_create_time_user_update_time'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='user',
+ name='source',
+ field=models.CharField(default='LOCAL', max_length=10, verbose_name='来源'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/users/migrations/0004_alter_user_email.py b/src/MaxKB-1.5.1/apps/users/migrations/0004_alter_user_email.py
new file mode 100644
index 0000000..c77416b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/migrations/0004_alter_user_email.py
@@ -0,0 +1,18 @@
+# Generated by Django 4.2.13 on 2024-07-16 17:03
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('users', '0003_user_source'),
+ ]
+
+ operations = [
+ migrations.AlterField(
+ model_name='user',
+ name='email',
+ field=models.EmailField(blank=True, max_length=254, null=True, unique=True, verbose_name='邮箱'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/users/migrations/__init__.py b/src/MaxKB-1.5.1/apps/users/migrations/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/users/serializers/user_serializers.py b/src/MaxKB-1.5.1/apps/users/serializers/user_serializers.py
new file mode 100644
index 0000000..5401b8a
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/serializers/user_serializers.py
@@ -0,0 +1,783 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: team_serializers.py
+ @date:2023/9/5 16:32
+ @desc:
+"""
+import datetime
+import os
+import random
+import re
+import uuid
+
+from django.conf import settings
+from django.core import validators, signing, cache
+from django.core.mail import send_mail
+from django.core.mail.backends.smtp import EmailBackend
+from django.db import transaction
+from django.db.models import Q, QuerySet
+from drf_yasg import openapi
+from rest_framework import serializers
+
+from application.models import Application
+from common.constants.authentication_type import AuthenticationType
+from common.constants.exception_code_constants import ExceptionCodeConstants
+from common.constants.permission_constants import RoleConstants, get_permission_list_by_role
+from common.db.search import page_search
+from common.exception.app_exception import AppApiException
+from common.mixins.api_mixin import ApiMixin
+from common.response.result import get_api_response
+from common.util.common import valid_license
+from common.util.field_message import ErrMessage
+from common.util.lock import lock
+from dataset.models import DataSet, Document, Paragraph, Problem, ProblemParagraphMapping
+from embedding.task import delete_embedding_by_dataset_id_list
+from setting.models import Team, SystemSetting, SettingType, Model, TeamMember, TeamMemberPermission
+from smartdoc.conf import PROJECT_DIR
+from users.models.user import User, password_encrypt, get_user_dynamics_permission
+
+user_cache = cache.caches['user_cache']
+
+
+class SystemSerializer(ApiMixin, serializers.Serializer):
+ @staticmethod
+ def get_profile():
+ version = os.environ.get('MAXKB_VERSION')
+ return {'version': version, 'IS_XPACK': hasattr(settings, 'IS_XPACK'),
+ 'XPACK_LICENSE_IS_VALID': (settings.XPACK_LICENSE_IS_VALID if hasattr(settings,
+ 'XPACK_LICENSE_IS_VALID') else False)}
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=[],
+ properties={
+ 'version': openapi.Schema(type=openapi.TYPE_STRING, title="系统版本号", description="系统版本号"),
+ }
+ )
+
+
+class LoginSerializer(ApiMixin, serializers.Serializer):
+ username = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("用户名"))
+
+ password = serializers.CharField(required=True, error_messages=ErrMessage.char("密码"))
+
+ def is_valid(self, *, raise_exception=False):
+ """
+ 校验参数
+ :param raise_exception: 是否抛出异常 只能是True
+ :return: 用户信息
+ """
+ super().is_valid(raise_exception=True)
+ username = self.data.get("username")
+ password = password_encrypt(self.data.get("password"))
+ user = QuerySet(User).filter(Q(username=username,
+ password=password) | Q(email=username,
+ password=password)).first()
+ if user is None:
+ raise ExceptionCodeConstants.INCORRECT_USERNAME_AND_PASSWORD.value.to_app_api_exception()
+ if not user.is_active:
+ raise AppApiException(1005, "用户已被禁用,请联系管理员!")
+ return user
+
+ def get_user_token(self):
+ """
+ 获取用户Token
+ :return: 用户Token(认证信息)
+ """
+ user = self.is_valid()
+ token = signing.dumps({'username': user.username, 'id': str(user.id), 'email': user.email,
+ 'type': AuthenticationType.USER.value})
+ return token
+
+ class Meta:
+ model = User
+ fields = '__all__'
+
+ def get_request_body_api(self):
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['username', 'password'],
+ properties={
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'password': openapi.Schema(type=openapi.TYPE_STRING, title="密码", description="密码")
+ }
+ )
+
+ def get_response_body_api(self):
+ return get_api_response(openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="token",
+ default="xxxx",
+ description="认证token"
+ ))
+
+
+class RegisterSerializer(ApiMixin, serializers.Serializer):
+ """
+ 注册请求对象
+ """
+ email = serializers.EmailField(
+ required=True,
+ error_messages=ErrMessage.char("邮箱"),
+ validators=[validators.EmailValidator(message=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.message,
+ code=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.code)])
+
+ username = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("用户名"),
+ max_length=20,
+ min_length=6,
+ validators=[
+ validators.RegexValidator(regex=re.compile("^[a-zA-Z][a-zA-Z0-9_]{5,20}$"),
+ message="用户名字符数为 6-20 个字符,必须以字母开头,可使用字母、数字、下划线等")
+ ])
+ password = serializers.CharField(required=True, error_messages=ErrMessage.char("密码"),
+ validators=[validators.RegexValidator(regex=re.compile(
+ "^(?![a-zA-Z]+$)(?![A-Z0-9]+$)(?![A-Z_!@#$%^&*`~.()-+=]+$)(?![a-z0-9]+$)(?![a-z_!@#$%^&*`~()-+=]+$)"
+ "(?![0-9_!@#$%^&*`~()-+=]+$)[a-zA-Z0-9_!@#$%^&*`~.()-+=]{6,20}$")
+ , message="密码长度6-20个字符,必须字母、数字、特殊字符组合")])
+
+ re_password = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("确认密码"),
+ validators=[validators.RegexValidator(regex=re.compile(
+ "^(?![a-zA-Z]+$)(?![A-Z0-9]+$)(?![A-Z_!@#$%^&*`~.()-+=]+$)(?![a-z0-9]+$)(?![a-z_!@#$%^&*`~()-+=]+$)"
+ "(?![0-9_!@#$%^&*`~()-+=]+$)[a-zA-Z0-9_!@#$%^&*`~.()-+=]{6,20}$")
+ , message="确认密码长度6-20个字符,必须字母、数字、特殊字符组合")])
+
+ code = serializers.CharField(required=True, error_messages=ErrMessage.char("验证码"))
+
+ class Meta:
+ model = User
+ fields = '__all__'
+
+ @lock(lock_key=lambda this, raise_exception: (
+ this.initial_data.get("email") + ":register"
+
+ ))
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if self.data.get('password') != self.data.get('re_password'):
+ raise ExceptionCodeConstants.PASSWORD_NOT_EQ_RE_PASSWORD.value.to_app_api_exception()
+ username = self.data.get("username")
+ email = self.data.get("email")
+ code = self.data.get("code")
+ code_cache_key = email + ":register"
+ cache_code = user_cache.get(code_cache_key)
+ if code != cache_code:
+ raise ExceptionCodeConstants.CODE_ERROR.value.to_app_api_exception()
+ u = QuerySet(User).filter(Q(username=username) | Q(email=email)).first()
+ if u is not None:
+ if u.email == email:
+ raise ExceptionCodeConstants.EMAIL_IS_EXIST.value.to_app_api_exception()
+ if u.username == username:
+ raise ExceptionCodeConstants.USERNAME_IS_EXIST.value.to_app_api_exception()
+
+ return True
+
+ @valid_license(model=User, count=2,
+ message='社区版最多支持 2 个用户,如需拥有更多用户,请联系我们(https://fit2cloud.com/)。')
+ @transaction.atomic
+ def save(self, **kwargs):
+ m = User(
+ **{'id': uuid.uuid1(), 'email': self.data.get("email"), 'username': self.data.get("username"),
+ 'role': RoleConstants.USER.name})
+ m.set_password(self.data.get("password"))
+ # 插入用户
+ m.save()
+ # 初始化用户团队
+ Team(**{'user': m, 'name': m.username + '的团队'}).save()
+ email = self.data.get("email")
+ code_cache_key = email + ":register"
+ # 删除验证码缓存
+ user_cache.delete(code_cache_key)
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['username', 'email', 'password', 're_password', 'code'],
+ properties={
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'password': openapi.Schema(type=openapi.TYPE_STRING, title="密码", description="密码"),
+ 're_password': openapi.Schema(type=openapi.TYPE_STRING, title="确认密码", description="确认密码"),
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="验证码", description="验证码")
+ }
+ )
+
+
+class CheckCodeSerializer(ApiMixin, serializers.Serializer):
+ """
+ 校验验证码
+ """
+ email = serializers.EmailField(
+ required=True,
+ error_messages=ErrMessage.char("邮箱"),
+ validators=[validators.EmailValidator(message=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.message,
+ code=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.code)])
+ code = serializers.CharField(required=True, error_messages=ErrMessage.char("验证码"))
+
+ type = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("类型"),
+ validators=[
+ validators.RegexValidator(regex=re.compile("^register|reset_password$"),
+ message="类型只支持register|reset_password", code=500)
+ ])
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid()
+ value = user_cache.get(self.data.get("email") + ":" + self.data.get("type"))
+ if value is None or value != self.data.get("code"):
+ raise ExceptionCodeConstants.CODE_ERROR.value.to_app_api_exception()
+ return True
+
+ class Meta:
+ model = User
+ fields = '__all__'
+
+ def get_request_body_api(self):
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['email', 'code', 'type'],
+ properties={
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="验证码", description="验证码"),
+ 'type': openapi.Schema(type=openapi.TYPE_STRING, title="类型", description="register|reset_password")
+ }
+ )
+
+ def get_response_body_api(self):
+ return get_api_response(openapi.Schema(
+ type=openapi.TYPE_BOOLEAN,
+ title="是否成功",
+ default=True,
+ description="错误提示"))
+
+
+class RePasswordSerializer(ApiMixin, serializers.Serializer):
+ email = serializers.EmailField(
+ required=True,
+ error_messages=ErrMessage.char("邮箱"),
+ validators=[validators.EmailValidator(message=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.message,
+ code=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.code)])
+
+ code = serializers.CharField(required=True, error_messages=ErrMessage.char("验证码"))
+
+ password = serializers.CharField(required=True, error_messages=ErrMessage.char("密码"),
+ validators=[validators.RegexValidator(regex=re.compile(
+ "^(?![a-zA-Z]+$)(?![A-Z0-9]+$)(?![A-Z_!@#$%^&*`~.()-+=]+$)(?![a-z0-9]+$)(?![a-z_!@#$%^&*`~()-+=]+$)"
+ "(?![0-9_!@#$%^&*`~()-+=]+$)[a-zA-Z0-9_!@#$%^&*`~.()-+=]{6,20}$")
+ , message="确认密码长度6-20个字符,必须字母、数字、特殊字符组合")])
+
+ re_password = serializers.CharField(required=True, error_messages=ErrMessage.char("确认密码"),
+ validators=[validators.RegexValidator(regex=re.compile(
+ "^(?![a-zA-Z]+$)(?![A-Z0-9]+$)(?![A-Z_!@#$%^&*`~.()-+=]+$)(?![a-z0-9]+$)(?![a-z_!@#$%^&*`~()-+=]+$)"
+ "(?![0-9_!@#$%^&*`~()-+=]+$)[a-zA-Z0-9_!@#$%^&*`~.()-+=]{6,20}$")
+ , message="确认密码长度6-20个字符,必须字母、数字、特殊字符组合")]
+ )
+
+ class Meta:
+ model = User
+ fields = '__all__'
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ email = self.data.get("email")
+ cache_code = user_cache.get(email + ':reset_password')
+ if self.data.get('password') != self.data.get('re_password'):
+ raise AppApiException(ExceptionCodeConstants.PASSWORD_NOT_EQ_RE_PASSWORD.value.code,
+ ExceptionCodeConstants.PASSWORD_NOT_EQ_RE_PASSWORD.value.message)
+ if cache_code != self.data.get('code'):
+ raise AppApiException(ExceptionCodeConstants.CODE_ERROR.value.code,
+ ExceptionCodeConstants.CODE_ERROR.value.message)
+ return True
+
+ def reset_password(self):
+ """
+ 修改密码
+ :return: 是否成功
+ """
+ if self.is_valid():
+ email = self.data.get("email")
+ QuerySet(User).filter(email=email).update(
+ password=password_encrypt(self.data.get('password')))
+ code_cache_key = email + ":reset_password"
+ # 删除验证码缓存
+ user_cache.delete(code_cache_key)
+ return True
+
+ def get_request_body_api(self):
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['email', 'code', "password", 're_password'],
+ properties={
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="验证码", description="验证码"),
+ 'password': openapi.Schema(type=openapi.TYPE_STRING, title="密码", description="密码"),
+ 're_password': openapi.Schema(type=openapi.TYPE_STRING, title="确认密码", description="确认密码")
+ }
+ )
+
+
+class SendEmailSerializer(ApiMixin, serializers.Serializer):
+ email = serializers.EmailField(
+ required=True
+ , error_messages=ErrMessage.char("邮箱"),
+ validators=[validators.EmailValidator(message=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.message,
+ code=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.code)])
+
+ type = serializers.CharField(required=True, error_messages=ErrMessage.char("类型"), validators=[
+ validators.RegexValidator(regex=re.compile("^register|reset_password$"),
+ message="类型只支持register|reset_password", code=500)
+ ])
+
+ class Meta:
+ model = User
+ fields = '__all__'
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=raise_exception)
+ user_exists = QuerySet(User).filter(email=self.data.get('email')).exists()
+ if not user_exists and self.data.get('type') == 'reset_password':
+ raise ExceptionCodeConstants.EMAIL_IS_NOT_EXIST.value.to_app_api_exception()
+ elif user_exists and self.data.get('type') == 'register':
+ raise ExceptionCodeConstants.EMAIL_IS_EXIST.value.to_app_api_exception()
+ code_cache_key = self.data.get('email') + ":" + self.data.get("type")
+ code_cache_key_lock = code_cache_key + "_lock"
+ ttl = user_cache.ttl(code_cache_key_lock)
+ if ttl is not None:
+ raise AppApiException(500, f"{ttl.total_seconds()}秒内请勿重复发送邮件")
+ return True
+
+ def send(self):
+ """
+ 发送邮件
+ :return: 是否发送成功
+ :exception 发送失败异常
+ """
+ email = self.data.get("email")
+ state = self.data.get("type")
+ # 生成随机验证码
+ code = "".join(list(map(lambda i: random.choice(['1', '2', '3', '4', '5', '6', '7', '8', '9', '0'
+ ]), range(6))))
+ # 获取邮件模板
+ file = open(os.path.join(PROJECT_DIR, "apps", "common", 'template', 'email_template.html'), "r",
+ encoding='utf-8')
+ content = file.read()
+ file.close()
+ code_cache_key = email + ":" + state
+ code_cache_key_lock = code_cache_key + "_lock"
+ # 设置缓存
+ user_cache.set(code_cache_key_lock, code, timeout=datetime.timedelta(minutes=1))
+ system_setting = QuerySet(SystemSetting).filter(type=SettingType.EMAIL.value).first()
+ if system_setting is None:
+ user_cache.delete(code_cache_key_lock)
+ raise AppApiException(1004, "邮箱未设置,请联系管理员设置")
+ try:
+ connection = EmailBackend(system_setting.meta.get("email_host"),
+ system_setting.meta.get('email_port'),
+ system_setting.meta.get('email_host_user'),
+ system_setting.meta.get('email_host_password'),
+ system_setting.meta.get('email_use_tls'),
+ False,
+ system_setting.meta.get('email_use_ssl')
+ )
+ # 发送邮件
+ send_mail(f'【MaxKB 智能知识库-{"用户注册" if state == "register" else "修改密码"}】',
+ '',
+ html_message=f'{content.replace("${code}", code)}',
+ from_email=system_setting.meta.get('from_email'),
+ recipient_list=[email], fail_silently=False, connection=connection)
+ except Exception as e:
+ user_cache.delete(code_cache_key_lock)
+ raise AppApiException(500, f"{str(e)}邮件发送失败")
+ user_cache.set(code_cache_key, code, timeout=datetime.timedelta(minutes=30))
+ return True
+
+ def get_request_body_api(self):
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['email', 'type'],
+ properties={
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'type': openapi.Schema(type=openapi.TYPE_STRING, title="类型", description="register|reset_password")
+ }
+ )
+
+ def get_response_body_api(self):
+ return get_api_response(openapi.Schema(type=openapi.TYPE_STRING, default=True))
+
+
+class UserProfile(ApiMixin):
+
+ @staticmethod
+ def get_user_profile(user: User):
+ """
+ 获取用户详情
+ :param user: 用户对象
+ :return:
+ """
+ permission_list = get_user_dynamics_permission(str(user.id))
+ permission_list += [p.value for p in get_permission_list_by_role(RoleConstants[user.role])]
+ return {'id': user.id, 'username': user.username, 'email': user.email, 'role': user.role,
+ 'permissions': [str(p) for p in permission_list],
+ 'is_edit_password': user.password == 'd880e722c47a34d8e9fce789fc62389d' if user.role == 'ADMIN' else False}
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'username', 'email', 'role', 'is_active'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="用户id", description="用户id"),
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'role': openapi.Schema(type=openapi.TYPE_STRING, title="角色", description="角色"),
+ 'is_active': openapi.Schema(type=openapi.TYPE_STRING, title="是否可用", description="是否可用"),
+ "permissions": openapi.Schema(type=openapi.TYPE_ARRAY, title="权限列表", description="权限列表",
+ items=openapi.Schema(type=openapi.TYPE_STRING))
+ }
+ )
+
+
+class UserSerializer(ApiMixin, serializers.ModelSerializer):
+ class Meta:
+ model = User
+ fields = ["email", "id",
+ "username", ]
+
+ def get_response_body_api(self):
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'username', 'email', 'role', 'is_active'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="用户id", description="用户id"),
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'role': openapi.Schema(type=openapi.TYPE_STRING, title="角色", description="角色"),
+ 'is_active': openapi.Schema(type=openapi.TYPE_STRING, title="是否可用", description="是否可用")
+ }
+ )
+
+ class Query(ApiMixin, serializers.Serializer):
+ email_or_username = serializers.CharField(required=True)
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='email_or_username',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='邮箱或者用户名')]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['username', 'email', 'id'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title='用户主键id', description="用户主键id"),
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址")
+ }
+ )
+
+ def list(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ email_or_username = self.data.get('email_or_username')
+ return [{'id': user_model.id, 'username': user_model.username, 'email': user_model.email} for user_model in
+ QuerySet(User).filter(Q(username=email_or_username) | Q(email=email_or_username))]
+
+
+class UserInstanceSerializer(ApiMixin, serializers.ModelSerializer):
+ class Meta:
+ model = User
+ fields = ['id', 'username', 'email', 'phone', 'is_active', 'role', 'nick_name', 'create_time', 'update_time',
+ 'source']
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'username', 'email', 'phone', 'is_active', 'role', 'nick_name', 'create_time',
+ 'update_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="用户id", description="用户id"),
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'phone': openapi.Schema(type=openapi.TYPE_STRING, title="手机号", description="手机号"),
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否激活", description="是否激活"),
+ 'role': openapi.Schema(type=openapi.TYPE_STRING, title="角色", description="角色"),
+ 'source': openapi.Schema(type=openapi.TYPE_STRING, title="来源", description="来源"),
+ 'nick_name': openapi.Schema(type=openapi.TYPE_STRING, title="姓名", description="姓名"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间", description="修改时间"),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间", description="修改时间")
+ }
+ )
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='user_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='用户名id')
+
+ ]
+
+
+class UserManageSerializer(serializers.Serializer):
+ class Query(ApiMixin, serializers.Serializer):
+ email_or_username = serializers.CharField(required=False, allow_null=True,
+ error_messages=ErrMessage.char("邮箱或者用户名"))
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='email_or_username',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='邮箱或者用户名')]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['username', 'email', 'id'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title='用户主键id', description="用户主键id"),
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址")
+ }
+ )
+
+ def get_query_set(self):
+ email_or_username = self.data.get('email_or_username')
+ query_set = QuerySet(User)
+ if email_or_username is not None:
+ query_set = query_set.filter(
+ Q(username__contains=email_or_username) | Q(email__contains=email_or_username))
+ query_set = query_set.order_by("-create_time")
+ return query_set
+
+ def list(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ return [{'id': user_model.id, 'username': user_model.username, 'email': user_model.email} for user_model in
+ self.get_query_set()]
+
+ def page(self, current_page: int, page_size: int, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ return page_search(current_page, page_size,
+ self.get_query_set(),
+ post_records_handler=lambda u: UserInstanceSerializer(u).data)
+
+ class UserInstance(ApiMixin, serializers.Serializer):
+ email = serializers.EmailField(
+ required=True,
+ error_messages=ErrMessage.char("邮箱"),
+ validators=[validators.EmailValidator(message=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.message,
+ code=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.code)])
+
+ username = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("用户名"),
+ max_length=20,
+ min_length=6,
+ validators=[
+ validators.RegexValidator(regex=re.compile("^[a-zA-Z][a-zA-Z0-9_]{5,20}$"),
+ message="用户名字符数为 6-20 个字符,必须以字母开头,可使用字母、数字、下划线等")
+ ])
+ password = serializers.CharField(required=True, error_messages=ErrMessage.char("密码"),
+ validators=[validators.RegexValidator(regex=re.compile(
+ "^(?![a-zA-Z]+$)(?![A-Z0-9]+$)(?![A-Z_!@#$%^&*`~.()-+=]+$)(?![a-z0-9]+$)(?![a-z_!@#$%^&*`~()-+=]+$)"
+ "(?![0-9_!@#$%^&*`~()-+=]+$)[a-zA-Z0-9_!@#$%^&*`~.()-+=]{6,20}$")
+ , message="密码长度6-20个字符,必须字母、数字、特殊字符组合")])
+
+ nick_name = serializers.CharField(required=False, error_messages=ErrMessage.char("姓名"), max_length=64,
+ allow_null=True, allow_blank=True)
+ phone = serializers.CharField(required=False, error_messages=ErrMessage.char("手机号"), max_length=20,
+ allow_null=True, allow_blank=True)
+
+ def is_valid(self, *, raise_exception=True):
+ super().is_valid(raise_exception=True)
+ username = self.data.get('username')
+ email = self.data.get('email')
+ u = QuerySet(User).filter(Q(username=username) | Q(email=email)).first()
+ if u is not None:
+ if u.email == email:
+ raise ExceptionCodeConstants.EMAIL_IS_EXIST.value.to_app_api_exception()
+ if u.username == username:
+ raise ExceptionCodeConstants.USERNAME_IS_EXIST.value.to_app_api_exception()
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['username', 'email', 'password'],
+ properties={
+ 'username': openapi.Schema(type=openapi.TYPE_STRING, title="用户名", description="用户名"),
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱地址"),
+ 'password': openapi.Schema(type=openapi.TYPE_STRING, title="密码", description="密码"),
+ 'phone': openapi.Schema(type=openapi.TYPE_STRING, title="手机号", description="手机号"),
+ 'nick_name': openapi.Schema(type=openapi.TYPE_STRING, title="姓名", description="姓名")
+ }
+ )
+
+ class UserEditInstance(ApiMixin, serializers.Serializer):
+ email = serializers.EmailField(
+ required=False,
+ error_messages=ErrMessage.char("邮箱"),
+ validators=[validators.EmailValidator(message=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.message,
+ code=ExceptionCodeConstants.EMAIL_FORMAT_ERROR.value.code)])
+
+ nick_name = serializers.CharField(required=False, error_messages=ErrMessage.char("姓名"), max_length=64,
+ allow_null=True, allow_blank=True)
+ phone = serializers.CharField(required=False, error_messages=ErrMessage.char("手机号"), max_length=20,
+ allow_null=True, allow_blank=True)
+ is_active = serializers.BooleanField(required=False, error_messages=ErrMessage.char("是否可用"))
+
+ def is_valid(self, *, user_id=None, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if self.data.get('email') is not None and QuerySet(User).filter(email=self.data.get('email')).exclude(
+ id=user_id).exists():
+ raise AppApiException(1004, "邮箱已经被使用")
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'email': openapi.Schema(type=openapi.TYPE_STRING, title="邮箱", description="邮箱"),
+ 'nick_name': openapi.Schema(type=openapi.TYPE_STRING, title="姓名", description="姓名"),
+ 'phone': openapi.Schema(type=openapi.TYPE_STRING, title="手机号", description="手机号"),
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否可用", description="是否可用"),
+ }
+ )
+
+ class RePasswordInstance(ApiMixin, serializers.Serializer):
+ password = serializers.CharField(required=True, error_messages=ErrMessage.char("密码"),
+ validators=[validators.RegexValidator(regex=re.compile(
+ "^(?![a-zA-Z]+$)(?![A-Z0-9]+$)(?![A-Z_!@#$%^&*`~.()-+=]+$)(?![a-z0-9]+$)(?![a-z_!@#$%^&*`~()-+=]+$)"
+ "(?![0-9_!@#$%^&*`~()-+=]+$)[a-zA-Z0-9_!@#$%^&*`~.()-+=]{6,20}$")
+ , message="密码长度6-20个字符,必须字母、数字、特殊字符组合")])
+ re_password = serializers.CharField(required=True, error_messages=ErrMessage.char("确认密码"),
+ validators=[validators.RegexValidator(regex=re.compile(
+ "^(?![a-zA-Z]+$)(?![A-Z0-9]+$)(?![A-Z_!@#$%^&*`~.()-+=]+$)(?![a-z0-9]+$)(?![a-z_!@#$%^&*`~()-+=]+$)"
+ "(?![0-9_!@#$%^&*`~()-+=]+$)[a-zA-Z0-9_!@#$%^&*`~.()-+=]{6,20}$")
+ , message="确认密码长度6-20个字符,必须字母、数字、特殊字符组合")]
+ )
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['password', 're_password'],
+ properties={
+ 'password': openapi.Schema(type=openapi.TYPE_STRING, title="密码", description="密码"),
+ 're_password': openapi.Schema(type=openapi.TYPE_STRING, title="确认密码",
+ description="确认密码"),
+ }
+ )
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if self.data.get('password') != self.data.get('re_password'):
+ raise ExceptionCodeConstants.PASSWORD_NOT_EQ_RE_PASSWORD.value.to_app_api_exception()
+
+ @valid_license(model=User, count=2,
+ message='社区版最多支持 2 个用户,如需拥有更多用户,请联系我们(https://fit2cloud.com/)。')
+ @transaction.atomic
+ def save(self, instance, with_valid=True):
+ if with_valid:
+ UserManageSerializer.UserInstance(data=instance).is_valid(raise_exception=True)
+
+ user = User(id=uuid.uuid1(), email=instance.get('email'),
+ phone="" if instance.get('phone') is None else instance.get('phone'),
+ nick_name="" if instance.get('nick_name') is None else instance.get('nick_name')
+ , username=instance.get('username'), password=password_encrypt(instance.get('password')),
+ role=RoleConstants.USER.name, source="LOCAL",
+ is_active=True)
+ user.save()
+ # 初始化用户团队
+ Team(**{'user': user, 'name': user.username + '的团队'}).save()
+ return UserInstanceSerializer(user).data
+
+ class Operate(serializers.Serializer):
+ id = serializers.UUIDField(required=True, error_messages=ErrMessage.char("用户id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(User).filter(id=self.data.get('id')).exists():
+ raise AppApiException(1004, "用户不存在")
+
+ @transaction.atomic
+ def delete(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ user = QuerySet(User).filter(id=self.data.get('id')).first()
+ if user.role == RoleConstants.ADMIN.name:
+ raise AppApiException(1004, "无法删除管理员")
+ user_id = self.data.get('id')
+
+ team_member_list = QuerySet(TeamMember).filter(Q(user_id=user_id) | Q(team_id=user_id))
+ # 删除团队成员权限
+ QuerySet(TeamMemberPermission).filter(
+ member_id__in=[team_member.id for team_member in team_member_list]).delete()
+ # 删除团队成员
+ team_member_list.delete()
+ # 删除应用相关 因为应用相关都是级联删除所以不需要手动删除
+ QuerySet(Application).filter(user_id=self.data.get('id')).delete()
+ # 删除数据集相关
+ dataset_list = QuerySet(DataSet).filter(user_id=self.data.get('id'))
+ dataset_id_list = [str(dataset.id) for dataset in dataset_list]
+ QuerySet(Document).filter(dataset_id__in=dataset_id_list).delete()
+ QuerySet(Paragraph).filter(dataset_id__in=dataset_id_list).delete()
+ QuerySet(ProblemParagraphMapping).filter(dataset_id__in=dataset_id_list).delete()
+ QuerySet(Problem).filter(dataset_id__in=dataset_id_list).delete()
+ delete_embedding_by_dataset_id_list(dataset_id_list)
+ dataset_list.delete()
+ # 删除团队
+ QuerySet(Team).filter(user_id=self.data.get('id')).delete()
+ # 删除模型
+ QuerySet(Model).filter(user_id=self.data.get('id')).delete()
+ # 删除用户
+ QuerySet(User).filter(id=self.data.get('id')).delete()
+ return True
+
+ def edit(self, instance, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ UserManageSerializer.UserEditInstance(data=instance).is_valid(user_id=self.data.get('id'),
+ raise_exception=True)
+
+ user = QuerySet(User).filter(id=self.data.get('id')).first()
+ if user.role == RoleConstants.ADMIN.name and 'is_active' in instance and instance.get(
+ 'is_active') is not None:
+ raise AppApiException(1004, "不能修改管理员状态")
+ update_keys = ['email', 'nick_name', 'phone', 'is_active']
+ for update_key in update_keys:
+ if update_key in instance and instance.get(update_key) is not None:
+ user.__setattr__(update_key, instance.get(update_key))
+ user.save()
+ return UserInstanceSerializer(user).data
+
+ def one(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ user = QuerySet(User).filter(id=self.data.get('id')).first()
+ return UserInstanceSerializer(user).data
+
+ def re_password(self, instance, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ UserManageSerializer.RePasswordInstance(data=instance).is_valid(raise_exception=True)
+ user = QuerySet(User).filter(id=self.data.get('id')).first()
+ user.password = password_encrypt(instance.get('password'))
+ user.save()
+ return True
diff --git a/src/MaxKB-1.5.1/apps/users/task/__init__.py b/src/MaxKB-1.5.1/apps/users/task/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/users/urls.py b/src/MaxKB-1.5.1/apps/users/urls.py
new file mode 100644
index 0000000..55388d8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/urls.py
@@ -0,0 +1,24 @@
+from django.urls import path
+
+from . import views
+
+app_name = "user"
+urlpatterns = [
+ path('profile', views.Profile.as_view()),
+ path('user', views.User.as_view(), name="profile"),
+ path('user/list', views.User.Query.as_view()),
+ path('user/login', views.Login.as_view(), name='login'),
+ path('user/logout', views.Logout.as_view(), name='logout'),
+ # path('user/register', views.Register.as_view(), name="register"),
+ path("user/send_email", views.SendEmail.as_view(), name='send_email'),
+ path("user/check_code", views.CheckCode.as_view(), name='check_code'),
+ path("user/re_password", views.RePasswordView.as_view(), name='re_password'),
+ path("user/current/send_email", views.SendEmailToCurrentUserView.as_view(), name="send_email_current"),
+ path("user/current/reset_password", views.ResetCurrentUserPasswordView.as_view(), name="reset_password_current"),
+ path("user_manage", views.UserManage.as_view(), name="user_manage"),
+ path("user_manage/", views.UserManage.Operate.as_view(), name="user_manage_operate"),
+ path("user_manage//re_password", views.UserManage.RePassword.as_view(),
+ name="user_manage_re_password"),
+ path("user_manage//", views.UserManage.Page.as_view(),
+ name="user_manage_re_password"),
+]
diff --git a/src/MaxKB-1.5.1/apps/users/views/__init__.py b/src/MaxKB-1.5.1/apps/users/views/__init__.py
new file mode 100644
index 0000000..ee3becc
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/views/__init__.py
@@ -0,0 +1,9 @@
+# coding=utf-8
+"""
+ @project: smart-doc
+ @Author:虎
+ @file: __init__.py.py
+ @date:2023/9/14 19:01
+ @desc:
+"""
+from .user import *
diff --git a/src/MaxKB-1.5.1/apps/users/views/user.py b/src/MaxKB-1.5.1/apps/users/views/user.py
new file mode 100644
index 0000000..e691ff4
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/users/views/user.py
@@ -0,0 +1,303 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: user.py
+ @date:2023/9/4 10:57
+ @desc:
+"""
+from django.core import cache
+from drf_yasg import openapi
+from drf_yasg.utils import swagger_auto_schema
+from rest_framework.decorators import action
+from rest_framework.decorators import permission_classes
+from rest_framework.permissions import AllowAny
+from rest_framework.views import APIView
+from rest_framework.views import Request
+
+from common.auth.authenticate import TokenAuth
+from common.auth.authentication import has_permissions
+from common.constants.permission_constants import PermissionConstants, CompareConstants, ViewPermission, RoleConstants
+from common.response import result
+from smartdoc.settings import JWT_AUTH
+from users.serializers.user_serializers import RegisterSerializer, LoginSerializer, CheckCodeSerializer, \
+ RePasswordSerializer, \
+ SendEmailSerializer, UserProfile, UserSerializer, UserManageSerializer, UserInstanceSerializer, SystemSerializer
+
+user_cache = cache.caches['user_cache']
+token_cache = cache.caches['token_cache']
+
+
+class Profile(APIView):
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取MaxKB相关信息",
+ operation_id="获取MaxKB相关信息",
+ responses=result.get_api_response(SystemSerializer.get_response_body_api()),
+ tags=['系统参数'])
+ def get(self, request: Request):
+ return result.success(SystemSerializer.get_profile())
+
+
+class User(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取当前用户信息",
+ operation_id="获取当前用户信息",
+ responses=result.get_api_response(UserProfile.get_response_body_api()),
+ tags=['用户'])
+ @has_permissions(PermissionConstants.USER_READ)
+ def get(self, request: Request):
+ return result.success(UserProfile.get_user_profile(request.user))
+
+ class Query(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取用户列表",
+ operation_id="获取用户列表",
+ manual_parameters=UserSerializer.Query.get_request_params_api(),
+ responses=result.get_api_array_response(UserSerializer.Query.get_response_body_api()),
+ tags=['用户'])
+ @has_permissions(PermissionConstants.USER_READ)
+ def get(self, request: Request):
+ return result.success(
+ UserSerializer.Query(data={'email_or_username': request.query_params.get('email_or_username')}).list())
+
+
+class ResetCurrentUserPasswordView(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="修改当前用户密码",
+ operation_id="修改当前用户密码",
+ request_body=openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['email', 'code', "password", 're_password'],
+ properties={
+ 'code': openapi.Schema(type=openapi.TYPE_STRING, title="验证码", description="验证码"),
+ 'password': openapi.Schema(type=openapi.TYPE_STRING, title="密码", description="密码"),
+ 're_password': openapi.Schema(type=openapi.TYPE_STRING, title="密码",
+ description="密码")
+ }
+ ),
+ responses=RePasswordSerializer().get_response_body_api(),
+ tags=['用户'])
+ def post(self, request: Request):
+ data = {'email': request.user.email}
+ data.update(request.data)
+ serializer_obj = RePasswordSerializer(data=data)
+ if serializer_obj.reset_password():
+ token_cache.delete(request.META.get('HTTP_AUTHORIZATION'))
+ return result.success(True)
+ return result.error("修改密码失败")
+
+
+class SendEmailToCurrentUserView(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @permission_classes((AllowAny,))
+ @swagger_auto_schema(operation_summary="发送邮件到当前用户",
+ operation_id="发送邮件到当前用户",
+ responses=SendEmailSerializer().get_response_body_api(),
+ tags=['用户'])
+ def post(self, request: Request):
+ serializer_obj = SendEmailSerializer(data={'email': request.user.email, 'type': "reset_password"})
+ if serializer_obj.is_valid(raise_exception=True):
+ return result.success(serializer_obj.send())
+
+
+class Logout(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @permission_classes((AllowAny,))
+ @swagger_auto_schema(operation_summary="登出",
+ operation_id="登出",
+ responses=SendEmailSerializer().get_response_body_api(),
+ tags=['用户'])
+ def post(self, request: Request):
+ token_cache.delete(request.META.get('HTTP_AUTHORIZATION'))
+ return result.success(True)
+
+
+class Login(APIView):
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="登录",
+ operation_id="登录",
+ request_body=LoginSerializer().get_request_body_api(),
+ responses=LoginSerializer().get_response_body_api(),
+ security=[],
+ tags=['用户'])
+ def post(self, request: Request):
+ login_request = LoginSerializer(data=request.data)
+ # 校验请求参数
+ user = login_request.is_valid(raise_exception=True)
+ token = login_request.get_user_token()
+ token_cache.set(token, user, timeout=JWT_AUTH['JWT_EXPIRATION_DELTA'])
+ return result.success(token)
+
+
+class Register(APIView):
+
+ @action(methods=['POST'], detail=False)
+ @permission_classes((AllowAny,))
+ @swagger_auto_schema(operation_summary="用户注册",
+ operation_id="用户注册",
+ request_body=RegisterSerializer().get_request_body_api(),
+ responses=RegisterSerializer().get_response_body_api(),
+ security=[],
+ tags=['用户'])
+ def post(self, request: Request):
+ serializer_obj = RegisterSerializer(data=request.data)
+ if serializer_obj.is_valid(raise_exception=True):
+ serializer_obj.save()
+ return result.success("注册成功")
+
+
+class RePasswordView(APIView):
+
+ @action(methods=['POST'], detail=False)
+ @permission_classes((AllowAny,))
+ @swagger_auto_schema(operation_summary="修改密码",
+ operation_id="修改密码",
+ request_body=RePasswordSerializer().get_request_body_api(),
+ responses=RePasswordSerializer().get_response_body_api(),
+ security=[],
+ tags=['用户'])
+ def post(self, request: Request):
+ serializer_obj = RePasswordSerializer(data=request.data)
+ return result.success(serializer_obj.reset_password())
+
+
+class CheckCode(APIView):
+
+ @action(methods=['POST'], detail=False)
+ @permission_classes((AllowAny,))
+ @swagger_auto_schema(operation_summary="校验验证码是否正确",
+ operation_id="校验验证码是否正确",
+ request_body=CheckCodeSerializer().get_request_body_api(),
+ responses=CheckCodeSerializer().get_response_body_api(),
+ security=[],
+ tags=['用户'])
+ def post(self, request: Request):
+ return result.success(CheckCodeSerializer(data=request.data).is_valid(raise_exception=True))
+
+
+class SendEmail(APIView):
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="发送邮件",
+ operation_id="发送邮件",
+ request_body=SendEmailSerializer().get_request_body_api(),
+ responses=SendEmailSerializer().get_response_body_api(),
+ security=[],
+ tags=['用户'])
+ def post(self, request: Request):
+ serializer_obj = SendEmailSerializer(data=request.data)
+ if serializer_obj.is_valid(raise_exception=True):
+ return result.success(serializer_obj.send())
+
+
+class UserManage(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['POST'], detail=False)
+ @swagger_auto_schema(operation_summary="添加用户",
+ operation_id="添加用户",
+ request_body=UserManageSerializer.UserInstance.get_request_body_api(),
+ responses=result.get_api_response(UserInstanceSerializer.get_response_body_api()),
+ tags=["用户管理"]
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN],
+ [PermissionConstants.USER_READ],
+ compare=CompareConstants.AND))
+ def post(self, request: Request):
+ return result.success(UserManageSerializer().save(request.data))
+
+ class Page(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取用户分页列表",
+ operation_id="获取用户分页列表",
+ tags=["用户管理"],
+ manual_parameters=UserManageSerializer.Query.get_request_params_api(),
+ responses=result.get_page_api_response(UserInstanceSerializer.get_response_body_api()),
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN],
+ [PermissionConstants.USER_READ],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, current_page, page_size):
+ d = UserManageSerializer.Query(
+ data={'email_or_username': request.query_params.get('email_or_username', None),
+ 'user_id': str(request.user.id)})
+ return result.success(d.page(current_page, page_size))
+
+ class RePassword(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改密码",
+ operation_id="修改密码",
+ manual_parameters=UserInstanceSerializer.get_request_params_api(),
+ request_body=UserManageSerializer.RePasswordInstance.get_request_body_api(),
+ responses=result.get_default_response(),
+ tags=["用户管理"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN],
+ [PermissionConstants.USER_READ],
+ compare=CompareConstants.AND))
+ def put(self, request: Request, user_id):
+ return result.success(
+ UserManageSerializer.Operate(data={'id': user_id}).re_password(request.data, with_valid=True))
+
+ class Operate(APIView):
+ authentication_classes = [TokenAuth]
+
+ @action(methods=['DELETE'], detail=False)
+ @swagger_auto_schema(operation_summary="删除用户",
+ operation_id="删除用户",
+ manual_parameters=UserInstanceSerializer.get_request_params_api(),
+ responses=result.get_default_response(),
+ tags=["用户管理"])
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN],
+ [PermissionConstants.USER_READ],
+ compare=CompareConstants.AND))
+ def delete(self, request: Request, user_id):
+ return result.success(UserManageSerializer.Operate(data={'id': user_id}).delete(with_valid=True))
+
+ @action(methods=['GET'], detail=False)
+ @swagger_auto_schema(operation_summary="获取用户信息",
+ operation_id="获取用户信息",
+ manual_parameters=UserInstanceSerializer.get_request_params_api(),
+ responses=result.get_api_response(UserInstanceSerializer.get_response_body_api()),
+ tags=["用户管理"]
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN],
+ [PermissionConstants.USER_READ],
+ compare=CompareConstants.AND))
+ def get(self, request: Request, user_id):
+ return result.success(UserManageSerializer.Operate(data={'id': user_id}).one(with_valid=True))
+
+ @action(methods=['PUT'], detail=False)
+ @swagger_auto_schema(operation_summary="修改用户信息",
+ operation_id="修改用户信息",
+ manual_parameters=UserInstanceSerializer.get_request_params_api(),
+ request_body=UserManageSerializer.UserEditInstance.get_request_body_api(),
+ responses=result.get_api_response(UserInstanceSerializer.get_response_body_api()),
+ tags=["用户管理"]
+ )
+ @has_permissions(ViewPermission(
+ [RoleConstants.ADMIN],
+ [PermissionConstants.USER_READ],
+ compare=CompareConstants.AND))
+ def put(self, request: Request, user_id):
+ return result.success(
+ UserManageSerializer.Operate(data={'id': user_id}).edit(request.data, with_valid=True))
diff --git a/src/MaxKB-1.5.1/config_example.yml b/src/MaxKB-1.5.1/config_example.yml
new file mode 100644
index 0000000..e262de1
--- /dev/null
+++ b/src/MaxKB-1.5.1/config_example.yml
@@ -0,0 +1,11 @@
+# 数据库链接信息
+DB_NAME: maxkb
+DB_HOST: localhost
+DB_PORT: 5432
+DB_USER: root
+DB_PASSWORD: xxxxxxx
+DB_ENGINE: django.db.backends.postgresql_psycopg2
+
+DEBUG: false
+
+TIME_ZONE: Asia/Shanghai
diff --git a/src/MaxKB-1.5.1/installer/Dockerfile b/src/MaxKB-1.5.1/installer/Dockerfile
new file mode 100644
index 0000000..937e72e
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/Dockerfile
@@ -0,0 +1,71 @@
+FROM ghcr.io/1panel-dev/maxkb-vector-model:v1.0.1 AS vector-model
+FROM node:18-alpine3.18 AS web-build
+COPY ui ui
+RUN cd ui && \
+ npm install && \
+ npm run build && \
+ rm -rf ./node_modules
+FROM ghcr.io/1panel-dev/maxkb-python-pg:python3.11-pg15.6 AS stage-build
+
+ARG DEPENDENCIES=" \
+ python3-pip"
+
+RUN apt-get update && \
+ apt-get install -y --no-install-recommends $DEPENDENCIES && \
+ apt-get clean all && \
+ rm -rf /var/lib/apt/lists/*
+
+COPY . /opt/maxkb/app
+RUN mkdir -p /opt/maxkb/app /opt/maxkb/model /opt/maxkb/conf && \
+ rm -rf /opt/maxkb/app/ui
+
+COPY --from=web-build ui /opt/maxkb/app/ui
+WORKDIR /opt/maxkb/app
+RUN python3 -m venv /opt/py3 && \
+ pip install poetry --break-system-packages && \
+ poetry config virtualenvs.create false && \
+ . /opt/py3/bin/activate && \
+ if [ "$(uname -m)" = "x86_64" ]; then sed -i 's/^torch.*/torch = {version = "^2.2.1+cpu", source = "pytorch"}/g' pyproject.toml; fi && \
+ poetry install
+
+FROM ghcr.io/1panel-dev/maxkb-python-pg:python3.11-pg15.6
+ARG DOCKER_IMAGE_TAG=dev \
+ BUILD_AT \
+ GITHUB_COMMIT
+
+ENV MAXKB_VERSION="${DOCKER_IMAGE_TAG} (build at ${BUILD_AT}, commit: ${GITHUB_COMMIT})" \
+ MAXKB_CONFIG_TYPE=ENV \
+ MAXKB_DB_NAME=maxkb \
+ MAXKB_DB_HOST=127.0.0.1 \
+ MAXKB_DB_PORT=5432 \
+ MAXKB_DB_USER=root \
+ MAXKB_DB_PASSWORD=Password123@postgres \
+ MAXKB_EMBEDDING_MODEL_NAME=/opt/maxkb/model/embedding/shibing624_text2vec-base-chinese \
+ MAXKB_EMBEDDING_MODEL_PATH=/opt/maxkb/model/embedding \
+ MAXKB_SANDBOX=true \
+ LANG=en_US.UTF-8 \
+ PATH=/opt/py3/bin:$PATH \
+ POSTGRES_USER=root \
+ POSTGRES_PASSWORD=Password123@postgres \
+ PIP_TARGET=/opt/maxkb/app/sandbox/python-packages \
+ PYTHONPATH=/opt/maxkb/app/sandbox/python-packages \
+ PYTHONUNBUFFERED=1
+
+WORKDIR /opt/maxkb/app
+COPY --from=stage-build /opt/maxkb /opt/maxkb
+COPY --from=stage-build /opt/py3 /opt/py3
+COPY --from=vector-model /opt/maxkb/app/model /opt/maxkb/model
+
+RUN chmod 755 /opt/maxkb/app/installer/run-maxkb.sh && \
+ cp -r /opt/maxkb/model/base/hub /opt/maxkb/model/tokenizer && \
+ cp -f /opt/maxkb/app/installer/run-maxkb.sh /usr/bin/run-maxkb.sh && \
+ cp -f /opt/maxkb/app/installer/init.sql /docker-entrypoint-initdb.d && \
+ mkdir -p /opt/maxkb/app/sandbox/python-packages && \
+ useradd --no-create-home --home /opt/maxkb/app/sandbox --shell /bin/bash sandbox && \
+ chown sandbox:sandbox /opt/maxkb/app/sandbox
+
+
+EXPOSE 8080
+
+ENTRYPOINT ["bash", "-c"]
+CMD [ "/usr/bin/run-maxkb.sh" ]
diff --git a/src/MaxKB-1.5.1/installer/Dockerfile-python-pg b/src/MaxKB-1.5.1/installer/Dockerfile-python-pg
new file mode 100644
index 0000000..eb25014
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/Dockerfile-python-pg
@@ -0,0 +1,14 @@
+FROM postgres:15.6-bookworm
+
+ARG DEPENDENCIES=" \
+ curl \
+ vim \
+ python3.11-mini \
+ python3.11-venv \
+ postgresql-15-pgvector"
+
+RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \
+ echo "Asia/Shanghai" > /etc/timezone && \
+ apt-get update && apt-get install -y --no-install-recommends $DEPENDENCIES && \
+ apt-get clean all && \
+ rm -rf /var/lib/apt/lists/*
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/installer/Dockerfile-vector-model b/src/MaxKB-1.5.1/installer/Dockerfile-vector-model
new file mode 100644
index 0000000..a732661
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/Dockerfile-vector-model
@@ -0,0 +1,10 @@
+FROM python:3.11-slim-bookworm AS vector-model
+
+COPY installer/install_model.py install_model.py
+RUN pip3 install --upgrade pip setuptools && \
+ pip install pycrawlers && \
+ pip install transformers && \
+ python3 install_model.py
+
+FROM scratch
+COPY --from=vector-model model /opt/maxkb/app/model
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/installer/config.yaml b/src/MaxKB-1.5.1/installer/config.yaml
new file mode 100644
index 0000000..c9f45db
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/config.yaml
@@ -0,0 +1,20 @@
+# 邮箱配置
+EMAIL_ADDRESS: ${EMAIL_ADDRESS}
+EMAIL_USE_TLS: ${EMAIL_USE_TLS}
+EMAIL_USE_SSL: ${EMAIL_USE_SSL}
+EMAIL_HOST: ${EMAIL_HOST}
+EMAIL_PORT: ${EMAIL_PORT}
+EMAIL_HOST_USER: ${EMAIL_HOST_USER}
+EMAIL_HOST_PASSWORD: ${EMAIL_HOST_PASSWORD}
+
+# 数据库链接信息
+DB_NAME: maxkb
+DB_HOST: 127.0.0.1
+DB_PORT: 5432
+DB_USER: root
+DB_PASSWORD: Password123@postgres
+DB_ENGINE: django.db.backends.postgresql_psycopg2
+EMBEDDING_MODEL_PATH: /opt/maxkb/model/embedding
+EMBEDDING_MODEL_NAME: /opt/maxkb/model/embedding/shibing624_text2vec-base-chinese
+
+DEBUG: false
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/installer/init.sql b/src/MaxKB-1.5.1/installer/init.sql
new file mode 100644
index 0000000..dfc30f9
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/init.sql
@@ -0,0 +1,5 @@
+CREATE DATABASE "maxkb";
+
+\c "maxkb";
+
+CREATE EXTENSION "vector";
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/installer/install_model.py b/src/MaxKB-1.5.1/installer/install_model.py
new file mode 100644
index 0000000..fb46461
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/install_model.py
@@ -0,0 +1,69 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: install_model.py
+ @date:2023/12/18 14:02
+ @desc:
+"""
+import json
+import os.path
+from pycrawlers import huggingface
+from transformers import GPT2TokenizerFast
+hg = huggingface()
+prefix_dir = "./model"
+model_config = [
+ {
+ 'download_params': {
+ 'cache_dir': os.path.join(prefix_dir, 'base/hub'),
+ 'pretrained_model_name_or_path': 'gpt2'
+ },
+ 'download_function': GPT2TokenizerFast.from_pretrained
+ },
+ {
+ 'download_params': {
+ 'cache_dir': os.path.join(prefix_dir, 'base/hub'),
+ 'pretrained_model_name_or_path': 'gpt2-medium'
+ },
+ 'download_function': GPT2TokenizerFast.from_pretrained
+ },
+ {
+ 'download_params': {
+ 'cache_dir': os.path.join(prefix_dir, 'base/hub'),
+ 'pretrained_model_name_or_path': 'gpt2-large'
+ },
+ 'download_function': GPT2TokenizerFast.from_pretrained
+ },
+ {
+ 'download_params': {
+ 'cache_dir': os.path.join(prefix_dir, 'base/hub'),
+ 'pretrained_model_name_or_path': 'gpt2-xl'
+ },
+ 'download_function': GPT2TokenizerFast.from_pretrained
+ },
+ {
+ 'download_params': {
+ 'cache_dir': os.path.join(prefix_dir, 'base/hub'),
+ 'pretrained_model_name_or_path': 'distilgpt2'
+ },
+ 'download_function': GPT2TokenizerFast.from_pretrained
+ },
+ {
+ 'download_params': {
+ 'urls': ["https://huggingface.co/shibing624/text2vec-base-chinese/tree/main"],
+ 'file_save_paths': [os.path.join(prefix_dir, 'embedding',"shibing624_text2vec-base-chinese")]
+ },
+ 'download_function': hg.get_batch_data
+ }
+
+]
+
+
+def install():
+ for model in model_config:
+ print(json.dumps(model.get('download_params')))
+ model.get('download_function')(**model.get('download_params'))
+
+
+if __name__ == '__main__':
+ install()
diff --git a/src/MaxKB-1.5.1/installer/run-maxkb.sh b/src/MaxKB-1.5.1/installer/run-maxkb.sh
new file mode 100644
index 0000000..43374df
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/run-maxkb.sh
@@ -0,0 +1,10 @@
+#!/bin/bash
+rm -f /opt/maxkb/app/tmp/*.pid
+# Start postgresql
+docker-entrypoint.sh postgres &
+sleep 10
+# Wait postgresql
+until pg_isready --host=127.0.0.1; do sleep 1 && echo "waiting for postgres"; done
+
+# Start MaxKB
+python /opt/maxkb/app/main.py start
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/installer/start-maxkb.sh b/src/MaxKB-1.5.1/installer/start-maxkb.sh
new file mode 100644
index 0000000..4e88eff
--- /dev/null
+++ b/src/MaxKB-1.5.1/installer/start-maxkb.sh
@@ -0,0 +1,3 @@
+#!/bin/bash
+rm -f /opt/maxkb/app/tmp/*.pid
+python /opt/maxkb/app/main.py start
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/main.py b/src/MaxKB-1.5.1/main.py
new file mode 100644
index 0000000..a8bd74a
--- /dev/null
+++ b/src/MaxKB-1.5.1/main.py
@@ -0,0 +1,122 @@
+import argparse
+import logging
+import os
+import sys
+import time
+
+import django
+from django.core import management
+
+BASE_DIR = os.path.dirname(os.path.abspath(__file__))
+APP_DIR = os.path.join(BASE_DIR, 'apps')
+
+os.chdir(BASE_DIR)
+sys.path.insert(0, APP_DIR)
+os.environ.setdefault("DJANGO_SETTINGS_MODULE", "smartdoc.settings")
+django.setup()
+
+
+def collect_static():
+ """
+ 收集静态文件到指定目录
+ 本项目主要是将前端vue/dist的前端项目放到静态目录下面
+ :return:
+ """
+ logging.info("Collect static files")
+ try:
+ management.call_command('collectstatic', '--no-input', '-c', verbosity=0, interactive=False)
+ logging.info("Collect static files done")
+ except:
+ pass
+
+
+def perform_db_migrate():
+ """
+ 初始化数据库表
+ """
+ logging.info("Check database structure change ...")
+ logging.info("Migrate model change to database ...")
+ try:
+ management.call_command('migrate')
+ except Exception as e:
+ logging.error('Perform migrate failed, exit', exc_info=True)
+ sys.exit(11)
+
+
+def start_services():
+ services = args.services if isinstance(args.services, list) else [args.services]
+ start_args = []
+ if args.daemon:
+ start_args.append('--daemon')
+ if args.force:
+ start_args.append('--force')
+ if args.worker:
+ start_args.extend(['--worker', str(args.worker)])
+ else:
+ worker = os.environ.get('CORE_WORKER')
+ if isinstance(worker, str) and worker.isdigit():
+ start_args.extend(['--worker', worker])
+
+ try:
+ management.call_command(action, *services, *start_args)
+ except KeyboardInterrupt:
+ logging.info('Cancel ...')
+ time.sleep(2)
+ except Exception as exc:
+ logging.error("Start service error {}: {}".format(services, exc))
+ time.sleep(2)
+
+
+def dev():
+ services = args.services if isinstance(args.services, list) else args.services
+ if services.__contains__('web'):
+ management.call_command('runserver', "0.0.0.0:8080")
+ elif services.__contains__('celery'):
+ management.call_command('celery', 'celery')
+ elif services.__contains__('local_model'):
+ os.environ.setdefault('SERVER_NAME', 'local_model')
+ from smartdoc.const import CONFIG
+ bind = f'{CONFIG.get("LOCAL_MODEL_HOST")}:{CONFIG.get("LOCAL_MODEL_PORT")}'
+ management.call_command('runserver', bind)
+
+
+if __name__ == '__main__':
+ os.environ['HF_HOME'] = '/opt/maxkb/model/base'
+ parser = argparse.ArgumentParser(
+ description="""
+ qabot service control tools;
+
+ Example: \r\n
+
+ %(prog)s start all -d;
+ """
+ )
+ parser.add_argument(
+ 'action', type=str,
+ choices=("start", "dev", "upgrade_db", "collect_static"),
+ help="Action to run"
+ )
+ args, e = parser.parse_known_args()
+ parser.add_argument(
+ "services", type=str, default='all' if args.action == 'start' else 'web', nargs="*",
+ choices=("all", "web", "task") if args.action == 'start' else ("web", "celery", 'local_model'),
+ help="The service to start",
+ )
+
+ parser.add_argument('-d', '--daemon', nargs="?", const=True)
+ parser.add_argument('-w', '--worker', type=int, nargs="?")
+ parser.add_argument('-f', '--force', nargs="?", const=True)
+ args = parser.parse_args()
+ action = args.action
+ if action == "upgrade_db":
+ perform_db_migrate()
+ elif action == "collect_static":
+ collect_static()
+ elif action == 'dev':
+ collect_static()
+ perform_db_migrate()
+ dev()
+ else:
+ collect_static()
+ perform_db_migrate()
+ start_services()
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/nanoid b/src/MaxKB-1.5.1/node_modules/.bin/nanoid
new file mode 100644
index 0000000..46220bd
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/nanoid
@@ -0,0 +1,16 @@
+#!/bin/sh
+basedir=$(dirname "$(echo "$0" | sed -e 's,\\,/,g')")
+
+case `uname` in
+ *CYGWIN*|*MINGW*|*MSYS*)
+ if command -v cygpath > /dev/null 2>&1; then
+ basedir=`cygpath -w "$basedir"`
+ fi
+ ;;
+esac
+
+if [ -x "$basedir/node" ]; then
+ exec "$basedir/node" "$basedir/../nanoid/bin/nanoid.cjs" "$@"
+else
+ exec node "$basedir/../nanoid/bin/nanoid.cjs" "$@"
+fi
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/nanoid.cmd b/src/MaxKB-1.5.1/node_modules/.bin/nanoid.cmd
new file mode 100644
index 0000000..9c40107
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/nanoid.cmd
@@ -0,0 +1,17 @@
+@ECHO off
+GOTO start
+:find_dp0
+SET dp0=%~dp0
+EXIT /b
+:start
+SETLOCAL
+CALL :find_dp0
+
+IF EXIST "%dp0%\node.exe" (
+ SET "_prog=%dp0%\node.exe"
+) ELSE (
+ SET "_prog=node"
+ SET PATHEXT=%PATHEXT:;.JS;=;%
+)
+
+endLocal & goto #_undefined_# 2>NUL || title %COMSPEC% & "%_prog%" "%dp0%\..\nanoid\bin\nanoid.cjs" %*
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/nanoid.ps1 b/src/MaxKB-1.5.1/node_modules/.bin/nanoid.ps1
new file mode 100644
index 0000000..d8a4d7a
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/nanoid.ps1
@@ -0,0 +1,28 @@
+#!/usr/bin/env pwsh
+$basedir=Split-Path $MyInvocation.MyCommand.Definition -Parent
+
+$exe=""
+if ($PSVersionTable.PSVersion -lt "6.0" -or $IsWindows) {
+ # Fix case when both the Windows and Linux builds of Node
+ # are installed in the same directory
+ $exe=".exe"
+}
+$ret=0
+if (Test-Path "$basedir/node$exe") {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "$basedir/node$exe" "$basedir/../nanoid/bin/nanoid.cjs" $args
+ } else {
+ & "$basedir/node$exe" "$basedir/../nanoid/bin/nanoid.cjs" $args
+ }
+ $ret=$LASTEXITCODE
+} else {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "node$exe" "$basedir/../nanoid/bin/nanoid.cjs" $args
+ } else {
+ & "node$exe" "$basedir/../nanoid/bin/nanoid.cjs" $args
+ }
+ $ret=$LASTEXITCODE
+}
+exit $ret
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/parser b/src/MaxKB-1.5.1/node_modules/.bin/parser
new file mode 100644
index 0000000..7696ad4
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/parser
@@ -0,0 +1,16 @@
+#!/bin/sh
+basedir=$(dirname "$(echo "$0" | sed -e 's,\\,/,g')")
+
+case `uname` in
+ *CYGWIN*|*MINGW*|*MSYS*)
+ if command -v cygpath > /dev/null 2>&1; then
+ basedir=`cygpath -w "$basedir"`
+ fi
+ ;;
+esac
+
+if [ -x "$basedir/node" ]; then
+ exec "$basedir/node" "$basedir/../@babel/parser/bin/babel-parser.js" "$@"
+else
+ exec node "$basedir/../@babel/parser/bin/babel-parser.js" "$@"
+fi
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/parser.cmd b/src/MaxKB-1.5.1/node_modules/.bin/parser.cmd
new file mode 100644
index 0000000..1ad5c81
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/parser.cmd
@@ -0,0 +1,17 @@
+@ECHO off
+GOTO start
+:find_dp0
+SET dp0=%~dp0
+EXIT /b
+:start
+SETLOCAL
+CALL :find_dp0
+
+IF EXIST "%dp0%\node.exe" (
+ SET "_prog=%dp0%\node.exe"
+) ELSE (
+ SET "_prog=node"
+ SET PATHEXT=%PATHEXT:;.JS;=;%
+)
+
+endLocal & goto #_undefined_# 2>NUL || title %COMSPEC% & "%_prog%" "%dp0%\..\@babel\parser\bin\babel-parser.js" %*
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/parser.ps1 b/src/MaxKB-1.5.1/node_modules/.bin/parser.ps1
new file mode 100644
index 0000000..8926517
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/parser.ps1
@@ -0,0 +1,28 @@
+#!/usr/bin/env pwsh
+$basedir=Split-Path $MyInvocation.MyCommand.Definition -Parent
+
+$exe=""
+if ($PSVersionTable.PSVersion -lt "6.0" -or $IsWindows) {
+ # Fix case when both the Windows and Linux builds of Node
+ # are installed in the same directory
+ $exe=".exe"
+}
+$ret=0
+if (Test-Path "$basedir/node$exe") {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "$basedir/node$exe" "$basedir/../@babel/parser/bin/babel-parser.js" $args
+ } else {
+ & "$basedir/node$exe" "$basedir/../@babel/parser/bin/babel-parser.js" $args
+ }
+ $ret=$LASTEXITCODE
+} else {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "node$exe" "$basedir/../@babel/parser/bin/babel-parser.js" $args
+ } else {
+ & "node$exe" "$basedir/../@babel/parser/bin/babel-parser.js" $args
+ }
+ $ret=$LASTEXITCODE
+}
+exit $ret
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix
new file mode 100644
index 0000000..a4fe91d
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix
@@ -0,0 +1,16 @@
+#!/bin/sh
+basedir=$(dirname "$(echo "$0" | sed -e 's,\\,/,g')")
+
+case `uname` in
+ *CYGWIN*|*MINGW*|*MSYS*)
+ if command -v cygpath > /dev/null 2>&1; then
+ basedir=`cygpath -w "$basedir"`
+ fi
+ ;;
+esac
+
+if [ -x "$basedir/node" ]; then
+ exec "$basedir/node" "$basedir/../vue-demi/bin/vue-demi-fix.js" "$@"
+else
+ exec node "$basedir/../vue-demi/bin/vue-demi-fix.js" "$@"
+fi
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix.cmd b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix.cmd
new file mode 100644
index 0000000..cb05986
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix.cmd
@@ -0,0 +1,17 @@
+@ECHO off
+GOTO start
+:find_dp0
+SET dp0=%~dp0
+EXIT /b
+:start
+SETLOCAL
+CALL :find_dp0
+
+IF EXIST "%dp0%\node.exe" (
+ SET "_prog=%dp0%\node.exe"
+) ELSE (
+ SET "_prog=node"
+ SET PATHEXT=%PATHEXT:;.JS;=;%
+)
+
+endLocal & goto #_undefined_# 2>NUL || title %COMSPEC% & "%_prog%" "%dp0%\..\vue-demi\bin\vue-demi-fix.js" %*
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix.ps1 b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix.ps1
new file mode 100644
index 0000000..adecc34
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-fix.ps1
@@ -0,0 +1,28 @@
+#!/usr/bin/env pwsh
+$basedir=Split-Path $MyInvocation.MyCommand.Definition -Parent
+
+$exe=""
+if ($PSVersionTable.PSVersion -lt "6.0" -or $IsWindows) {
+ # Fix case when both the Windows and Linux builds of Node
+ # are installed in the same directory
+ $exe=".exe"
+}
+$ret=0
+if (Test-Path "$basedir/node$exe") {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "$basedir/node$exe" "$basedir/../vue-demi/bin/vue-demi-fix.js" $args
+ } else {
+ & "$basedir/node$exe" "$basedir/../vue-demi/bin/vue-demi-fix.js" $args
+ }
+ $ret=$LASTEXITCODE
+} else {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "node$exe" "$basedir/../vue-demi/bin/vue-demi-fix.js" $args
+ } else {
+ & "node$exe" "$basedir/../vue-demi/bin/vue-demi-fix.js" $args
+ }
+ $ret=$LASTEXITCODE
+}
+exit $ret
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch
new file mode 100644
index 0000000..2bcb66e
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch
@@ -0,0 +1,16 @@
+#!/bin/sh
+basedir=$(dirname "$(echo "$0" | sed -e 's,\\,/,g')")
+
+case `uname` in
+ *CYGWIN*|*MINGW*|*MSYS*)
+ if command -v cygpath > /dev/null 2>&1; then
+ basedir=`cygpath -w "$basedir"`
+ fi
+ ;;
+esac
+
+if [ -x "$basedir/node" ]; then
+ exec "$basedir/node" "$basedir/../vue-demi/bin/vue-demi-switch.js" "$@"
+else
+ exec node "$basedir/../vue-demi/bin/vue-demi-switch.js" "$@"
+fi
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch.cmd b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch.cmd
new file mode 100644
index 0000000..a685a41
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch.cmd
@@ -0,0 +1,17 @@
+@ECHO off
+GOTO start
+:find_dp0
+SET dp0=%~dp0
+EXIT /b
+:start
+SETLOCAL
+CALL :find_dp0
+
+IF EXIST "%dp0%\node.exe" (
+ SET "_prog=%dp0%\node.exe"
+) ELSE (
+ SET "_prog=node"
+ SET PATHEXT=%PATHEXT:;.JS;=;%
+)
+
+endLocal & goto #_undefined_# 2>NUL || title %COMSPEC% & "%_prog%" "%dp0%\..\vue-demi\bin\vue-demi-switch.js" %*
diff --git a/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch.ps1 b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch.ps1
new file mode 100644
index 0000000..fbb4d69
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.bin/vue-demi-switch.ps1
@@ -0,0 +1,28 @@
+#!/usr/bin/env pwsh
+$basedir=Split-Path $MyInvocation.MyCommand.Definition -Parent
+
+$exe=""
+if ($PSVersionTable.PSVersion -lt "6.0" -or $IsWindows) {
+ # Fix case when both the Windows and Linux builds of Node
+ # are installed in the same directory
+ $exe=".exe"
+}
+$ret=0
+if (Test-Path "$basedir/node$exe") {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "$basedir/node$exe" "$basedir/../vue-demi/bin/vue-demi-switch.js" $args
+ } else {
+ & "$basedir/node$exe" "$basedir/../vue-demi/bin/vue-demi-switch.js" $args
+ }
+ $ret=$LASTEXITCODE
+} else {
+ # Support pipeline input
+ if ($MyInvocation.ExpectingInput) {
+ $input | & "node$exe" "$basedir/../vue-demi/bin/vue-demi-switch.js" $args
+ } else {
+ & "node$exe" "$basedir/../vue-demi/bin/vue-demi-switch.js" $args
+ }
+ $ret=$LASTEXITCODE
+}
+exit $ret
diff --git a/src/MaxKB-1.5.1/node_modules/.package-lock.json b/src/MaxKB-1.5.1/node_modules/.package-lock.json
new file mode 100644
index 0000000..2f057bc
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/.package-lock.json
@@ -0,0 +1,477 @@
+{
+ "name": "MaxKB-1.5.1",
+ "lockfileVersion": 3,
+ "requires": true,
+ "packages": {
+ "node_modules/@babel/helper-string-parser": {
+ "version": "7.25.7",
+ "resolved": "https://registry.npmmirror.com/@babel/helper-string-parser/-/helper-string-parser-7.25.7.tgz",
+ "integrity": "sha512-CbkjYdsJNHFk8uqpEkpCvRs3YRp9tY6FmFY7wLMSYuGYkrdUi7r2lc4/wqsvlHoMznX3WJ9IP8giGPq68T/Y6g==",
+ "license": "MIT",
+ "peer": true,
+ "engines": {
+ "node": ">=6.9.0"
+ }
+ },
+ "node_modules/@babel/helper-validator-identifier": {
+ "version": "7.25.7",
+ "resolved": "https://registry.npmmirror.com/@babel/helper-validator-identifier/-/helper-validator-identifier-7.25.7.tgz",
+ "integrity": "sha512-AM6TzwYqGChO45oiuPqwL2t20/HdMC1rTPAesnBCgPCSF1x3oN9MVUwQV2iyz4xqWrctwK5RNC8LV22kaQCNYg==",
+ "license": "MIT",
+ "peer": true,
+ "engines": {
+ "node": ">=6.9.0"
+ }
+ },
+ "node_modules/@babel/parser": {
+ "version": "7.25.8",
+ "resolved": "https://registry.npmmirror.com/@babel/parser/-/parser-7.25.8.tgz",
+ "integrity": "sha512-HcttkxzdPucv3nNFmfOOMfFf64KgdJVqm1KaCm25dPGMLElo9nsLvXeJECQg8UzPuBGLyTSA0ZzqCtDSzKTEoQ==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/types": "^7.25.8"
+ },
+ "bin": {
+ "parser": "bin/babel-parser.js"
+ },
+ "engines": {
+ "node": ">=6.0.0"
+ }
+ },
+ "node_modules/@babel/types": {
+ "version": "7.25.8",
+ "resolved": "https://registry.npmmirror.com/@babel/types/-/types-7.25.8.tgz",
+ "integrity": "sha512-JWtuCu8VQsMladxVz/P4HzHUGCAwpuqacmowgXFs5XjxIgKuNjnLokQzuVjlTvIzODaDmpjT3oxcC48vyk9EWg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/helper-string-parser": "^7.25.7",
+ "@babel/helper-validator-identifier": "^7.25.7",
+ "to-fast-properties": "^2.0.0"
+ },
+ "engines": {
+ "node": ">=6.9.0"
+ }
+ },
+ "node_modules/@jridgewell/sourcemap-codec": {
+ "version": "1.5.0",
+ "resolved": "https://registry.npmmirror.com/@jridgewell/sourcemap-codec/-/sourcemap-codec-1.5.0.tgz",
+ "integrity": "sha512-gv3ZRaISU3fjPAgNsriBRqGWQL6quFx04YMPW/zD8XMLsU32mhCCbfbO6KZFLjvYpCZ8zyDEgqsgf+PwPaM7GQ==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/@vue/compiler-core": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-core/-/compiler-core-3.5.12.tgz",
+ "integrity": "sha512-ISyBTRMmMYagUxhcpyEH0hpXRd/KqDU4ymofPgl2XAkY9ZhQ+h0ovEZJIiPop13UmR/54oA2cgMDjgroRelaEw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/parser": "^7.25.3",
+ "@vue/shared": "3.5.12",
+ "entities": "^4.5.0",
+ "estree-walker": "^2.0.2",
+ "source-map-js": "^1.2.0"
+ }
+ },
+ "node_modules/@vue/compiler-dom": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-dom/-/compiler-dom-3.5.12.tgz",
+ "integrity": "sha512-9G6PbJ03uwxLHKQ3P42cMTi85lDRvGLB2rSGOiQqtXELat6uI4n8cNz9yjfVHRPIu+MsK6TE418Giruvgptckg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-core": "3.5.12",
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/compiler-sfc": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-sfc/-/compiler-sfc-3.5.12.tgz",
+ "integrity": "sha512-2k973OGo2JuAa5+ZlekuQJtitI5CgLMOwgl94BzMCsKZCX/xiqzJYzapl4opFogKHqwJk34vfsaKpfEhd1k5nw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/parser": "^7.25.3",
+ "@vue/compiler-core": "3.5.12",
+ "@vue/compiler-dom": "3.5.12",
+ "@vue/compiler-ssr": "3.5.12",
+ "@vue/shared": "3.5.12",
+ "estree-walker": "^2.0.2",
+ "magic-string": "^0.30.11",
+ "postcss": "^8.4.47",
+ "source-map-js": "^1.2.0"
+ }
+ },
+ "node_modules/@vue/compiler-ssr": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-ssr/-/compiler-ssr-3.5.12.tgz",
+ "integrity": "sha512-eLwc7v6bfGBSM7wZOGPmRavSWzNFF6+PdRhE+VFJhNCgHiF8AM7ccoqcv5kBXA2eWUfigD7byekvf/JsOfKvPA==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-dom": "3.5.12",
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/reactivity": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/reactivity/-/reactivity-3.5.12.tgz",
+ "integrity": "sha512-UzaN3Da7xnJXdz4Okb/BGbAaomRHc3RdoWqTzlvd9+WBR5m3J39J1fGcHes7U3za0ruYn/iYy/a1euhMEHvTAg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/runtime-core": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/runtime-core/-/runtime-core-3.5.12.tgz",
+ "integrity": "sha512-hrMUYV6tpocr3TL3Ad8DqxOdpDe4zuQY4HPY3X/VRh+L2myQO8MFXPAMarIOSGNu0bFAjh1yBkMPXZBqCk62Uw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/reactivity": "3.5.12",
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/runtime-dom": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/runtime-dom/-/runtime-dom-3.5.12.tgz",
+ "integrity": "sha512-q8VFxR9A2MRfBr6/55Q3umyoN7ya836FzRXajPB6/Vvuv0zOPL+qltd9rIMzG/DbRLAIlREmnLsplEF/kotXKA==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/reactivity": "3.5.12",
+ "@vue/runtime-core": "3.5.12",
+ "@vue/shared": "3.5.12",
+ "csstype": "^3.1.3"
+ }
+ },
+ "node_modules/@vue/server-renderer": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/server-renderer/-/server-renderer-3.5.12.tgz",
+ "integrity": "sha512-I3QoeDDeEPZm8yR28JtY+rk880Oqmj43hreIBVTicisFTx/Dl7JpG72g/X7YF8hnQD3IFhkky5i2bPonwrTVPg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-ssr": "3.5.12",
+ "@vue/shared": "3.5.12"
+ },
+ "peerDependencies": {
+ "vue": "3.5.12"
+ }
+ },
+ "node_modules/@vue/shared": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/shared/-/shared-3.5.12.tgz",
+ "integrity": "sha512-L2RPSAwUFbgZH20etwrXyVyCBu9OxRSi8T/38QsvnkJyvq2LufW2lDCOzm7t/U9C1mkhJGWYfCuFBCmIuNivrg==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/asynckit": {
+ "version": "0.4.0",
+ "resolved": "https://registry.npmmirror.com/asynckit/-/asynckit-0.4.0.tgz",
+ "integrity": "sha512-Oei9OH4tRh0YqU3GxhX79dM/mwVgvbZJaSNaRk+bshkj0S5cfHcgYakreBjrHwatXKbz+IoIdYLxrKim2MjW0Q==",
+ "license": "MIT"
+ },
+ "node_modules/axios": {
+ "version": "1.7.7",
+ "resolved": "https://registry.npmmirror.com/axios/-/axios-1.7.7.tgz",
+ "integrity": "sha512-S4kL7XrjgBmvdGut0sN3yJxqYzrDOnivkBiN0OFs6hLiUam3UPvswUo0kqGyhqUZGEOytHyumEdXsAkgCOUf3Q==",
+ "license": "MIT",
+ "dependencies": {
+ "follow-redirects": "^1.15.6",
+ "form-data": "^4.0.0",
+ "proxy-from-env": "^1.1.0"
+ }
+ },
+ "node_modules/combined-stream": {
+ "version": "1.0.8",
+ "resolved": "https://registry.npmmirror.com/combined-stream/-/combined-stream-1.0.8.tgz",
+ "integrity": "sha512-FQN4MRfuJeHf7cBbBMJFXhKSDq+2kAArBlmRBvcvFE5BB1HZKXtSFASDhdlz9zOYwxh8lDdnvmMOe/+5cdoEdg==",
+ "license": "MIT",
+ "dependencies": {
+ "delayed-stream": "~1.0.0"
+ },
+ "engines": {
+ "node": ">= 0.8"
+ }
+ },
+ "node_modules/csstype": {
+ "version": "3.1.3",
+ "resolved": "https://registry.npmmirror.com/csstype/-/csstype-3.1.3.tgz",
+ "integrity": "sha512-M1uQkMl8rQK/szD0LNhtqxIPLpimGm8sOBwU7lLnCpSbTyY3yeU1Vc7l4KT5zT4s/yOxHH5O7tIuuLOCnLADRw==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/delayed-stream": {
+ "version": "1.0.0",
+ "resolved": "https://registry.npmmirror.com/delayed-stream/-/delayed-stream-1.0.0.tgz",
+ "integrity": "sha512-ZySD7Nf91aLB0RxL4KGrKHBXl7Eds1DAmEdcoVawXnLD7SDhpNgtuII2aAkg7a7QS41jxPSZ17p4VdGnMHk3MQ==",
+ "license": "MIT",
+ "engines": {
+ "node": ">=0.4.0"
+ }
+ },
+ "node_modules/echarts": {
+ "version": "5.5.1",
+ "resolved": "https://registry.npmmirror.com/echarts/-/echarts-5.5.1.tgz",
+ "integrity": "sha512-Fce8upazaAXUVUVsjgV6mBnGuqgO+JNDlcgF79Dksy4+wgGpQB2lmYoO4TSweFg/mZITdpGHomw/cNBJZj1icA==",
+ "license": "Apache-2.0",
+ "dependencies": {
+ "tslib": "2.3.0",
+ "zrender": "5.6.0"
+ }
+ },
+ "node_modules/entities": {
+ "version": "4.5.0",
+ "resolved": "https://registry.npmmirror.com/entities/-/entities-4.5.0.tgz",
+ "integrity": "sha512-V0hjH4dGPh9Ao5p0MoRY6BVqtwCjhz6vI5LT8AJ55H+4g9/4vbHx1I54fS0XuclLhDHArPQCiMjDxjaL8fPxhw==",
+ "license": "BSD-2-Clause",
+ "peer": true,
+ "engines": {
+ "node": ">=0.12"
+ },
+ "funding": {
+ "url": "https://github.com/fb55/entities?sponsor=1"
+ }
+ },
+ "node_modules/estree-walker": {
+ "version": "2.0.2",
+ "resolved": "https://registry.npmmirror.com/estree-walker/-/estree-walker-2.0.2.tgz",
+ "integrity": "sha512-Rfkk/Mp/DL7JVje3u18FxFujQlTNR2q6QfMSMB7AvCBx91NGj/ba3kCfza0f6dVDbw7YlRf/nDrn7pQrCCyQ/w==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/follow-redirects": {
+ "version": "1.15.9",
+ "resolved": "https://registry.npmmirror.com/follow-redirects/-/follow-redirects-1.15.9.tgz",
+ "integrity": "sha512-gew4GsXizNgdoRyqmyfMHyAmXsZDk6mHkSxZFCzW9gwlbtOW44CDtYavM+y+72qD/Vq2l550kMF52DT8fOLJqQ==",
+ "funding": [
+ {
+ "type": "individual",
+ "url": "https://github.com/sponsors/RubenVerborgh"
+ }
+ ],
+ "license": "MIT",
+ "engines": {
+ "node": ">=4.0"
+ },
+ "peerDependenciesMeta": {
+ "debug": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/form-data": {
+ "version": "4.0.1",
+ "resolved": "https://registry.npmmirror.com/form-data/-/form-data-4.0.1.tgz",
+ "integrity": "sha512-tzN8e4TX8+kkxGPK8D5u0FNmjPUjw3lwC9lSLxxoB/+GtsJG91CO8bSWy73APlgAZzZbXEYZJuxjkHH2w+Ezhw==",
+ "license": "MIT",
+ "dependencies": {
+ "asynckit": "^0.4.0",
+ "combined-stream": "^1.0.8",
+ "mime-types": "^2.1.12"
+ },
+ "engines": {
+ "node": ">= 6"
+ }
+ },
+ "node_modules/magic-string": {
+ "version": "0.30.12",
+ "resolved": "https://registry.npmmirror.com/magic-string/-/magic-string-0.30.12.tgz",
+ "integrity": "sha512-Ea8I3sQMVXr8JhN4z+H/d8zwo+tYDgHE9+5G4Wnrwhs0gaK9fXTKx0Tw5Xwsd/bCPTTZNRAdpyzvoeORe9LYpw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@jridgewell/sourcemap-codec": "^1.5.0"
+ }
+ },
+ "node_modules/mime-db": {
+ "version": "1.52.0",
+ "resolved": "https://registry.npmmirror.com/mime-db/-/mime-db-1.52.0.tgz",
+ "integrity": "sha512-sPU4uV7dYlvtWJxwwxHD0PuihVNiE7TyAbQ5SWxDCB9mUYvOgroQOwYQQOKPJ8CIbE+1ETVlOoK1UC2nU3gYvg==",
+ "license": "MIT",
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
+ "node_modules/mime-types": {
+ "version": "2.1.35",
+ "resolved": "https://registry.npmmirror.com/mime-types/-/mime-types-2.1.35.tgz",
+ "integrity": "sha512-ZDY+bPm5zTTF+YpCrAU9nK0UgICYPT0QtT1NZWFv4s++TNkcgVaT0g6+4R2uI4MjQjzysHB1zxuWL50hzaeXiw==",
+ "license": "MIT",
+ "dependencies": {
+ "mime-db": "1.52.0"
+ },
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
+ "node_modules/nanoid": {
+ "version": "3.3.7",
+ "resolved": "https://registry.npmmirror.com/nanoid/-/nanoid-3.3.7.tgz",
+ "integrity": "sha512-eSRppjcPIatRIMC1U6UngP8XFcz8MQWGQdt1MTBQ7NaAmvXDfvNxbvWV3x2y6CdEUciCSsDHDQZbhYaB8QEo2g==",
+ "funding": [
+ {
+ "type": "github",
+ "url": "https://github.com/sponsors/ai"
+ }
+ ],
+ "license": "MIT",
+ "peer": true,
+ "bin": {
+ "nanoid": "bin/nanoid.cjs"
+ },
+ "engines": {
+ "node": "^10 || ^12 || ^13.7 || ^14 || >=15.0.1"
+ }
+ },
+ "node_modules/picocolors": {
+ "version": "1.1.0",
+ "resolved": "https://registry.npmmirror.com/picocolors/-/picocolors-1.1.0.tgz",
+ "integrity": "sha512-TQ92mBOW0l3LeMeyLV6mzy/kWr8lkd/hp3mTg7wYK7zJhuBStmGMBG0BdeDZS/dZx1IukaX6Bk11zcln25o1Aw==",
+ "license": "ISC",
+ "peer": true
+ },
+ "node_modules/postcss": {
+ "version": "8.4.47",
+ "resolved": "https://registry.npmmirror.com/postcss/-/postcss-8.4.47.tgz",
+ "integrity": "sha512-56rxCq7G/XfB4EkXq9Egn5GCqugWvDFjafDOThIdMBsI15iqPqR5r15TfSr1YPYeEI19YeaXMCbY6u88Y76GLQ==",
+ "funding": [
+ {
+ "type": "opencollective",
+ "url": "https://opencollective.com/postcss/"
+ },
+ {
+ "type": "tidelift",
+ "url": "https://tidelift.com/funding/github/npm/postcss"
+ },
+ {
+ "type": "github",
+ "url": "https://github.com/sponsors/ai"
+ }
+ ],
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "nanoid": "^3.3.7",
+ "picocolors": "^1.1.0",
+ "source-map-js": "^1.2.1"
+ },
+ "engines": {
+ "node": "^10 || ^12 || >=14"
+ }
+ },
+ "node_modules/proxy-from-env": {
+ "version": "1.1.0",
+ "resolved": "https://registry.npmmirror.com/proxy-from-env/-/proxy-from-env-1.1.0.tgz",
+ "integrity": "sha512-D+zkORCbA9f1tdWRK0RaCR3GPv50cMxcrz4X8k5LTSUD1Dkw47mKJEZQNunItRTkWwgtaUSo1RVFRIG9ZXiFYg==",
+ "license": "MIT"
+ },
+ "node_modules/source-map-js": {
+ "version": "1.2.1",
+ "resolved": "https://registry.npmmirror.com/source-map-js/-/source-map-js-1.2.1.tgz",
+ "integrity": "sha512-UXWMKhLOwVKb728IUtQPXxfYU+usdybtUrK/8uGE8CQMvrhOpwvzDBwj0QhSL7MQc7vIsISBG8VQ8+IDQxpfQA==",
+ "license": "BSD-3-Clause",
+ "peer": true,
+ "engines": {
+ "node": ">=0.10.0"
+ }
+ },
+ "node_modules/to-fast-properties": {
+ "version": "2.0.0",
+ "resolved": "https://registry.npmmirror.com/to-fast-properties/-/to-fast-properties-2.0.0.tgz",
+ "integrity": "sha512-/OaKK0xYrs3DmxRYqL/yDc+FxFUVYhDlXMhRmv3z915w2HF1tnN1omB354j8VUGO/hbRzyD6Y3sA7v7GS/ceog==",
+ "license": "MIT",
+ "peer": true,
+ "engines": {
+ "node": ">=4"
+ }
+ },
+ "node_modules/tslib": {
+ "version": "2.3.0",
+ "resolved": "https://registry.npmmirror.com/tslib/-/tslib-2.3.0.tgz",
+ "integrity": "sha512-N82ooyxVNm6h1riLCoyS9e3fuJ3AMG2zIZs2Gd1ATcSFjSA23Q0fzjjZeh0jbJvWVDZ0cJT8yaNNaaXHzueNjg==",
+ "license": "0BSD"
+ },
+ "node_modules/vue": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/vue/-/vue-3.5.12.tgz",
+ "integrity": "sha512-CLVZtXtn2ItBIi/zHZ0Sg1Xkb7+PU32bJJ8Bmy7ts3jxXTcbfsEfBivFYYWz1Hur+lalqGAh65Coin0r+HRUfg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-dom": "3.5.12",
+ "@vue/compiler-sfc": "3.5.12",
+ "@vue/runtime-dom": "3.5.12",
+ "@vue/server-renderer": "3.5.12",
+ "@vue/shared": "3.5.12"
+ },
+ "peerDependencies": {
+ "typescript": "*"
+ },
+ "peerDependenciesMeta": {
+ "typescript": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/vue-demi": {
+ "version": "0.13.11",
+ "resolved": "https://registry.npmmirror.com/vue-demi/-/vue-demi-0.13.11.tgz",
+ "integrity": "sha512-IR8HoEEGM65YY3ZJYAjMlKygDQn25D5ajNFNoKh9RSDMQtlzCxtfQjdQgv9jjK+m3377SsJXY8ysq8kLCZL25A==",
+ "hasInstallScript": true,
+ "license": "MIT",
+ "bin": {
+ "vue-demi-fix": "bin/vue-demi-fix.js",
+ "vue-demi-switch": "bin/vue-demi-switch.js"
+ },
+ "engines": {
+ "node": ">=12"
+ },
+ "funding": {
+ "url": "https://github.com/sponsors/antfu"
+ },
+ "peerDependencies": {
+ "@vue/composition-api": "^1.0.0-rc.1",
+ "vue": "^3.0.0-0 || ^2.6.0"
+ },
+ "peerDependenciesMeta": {
+ "@vue/composition-api": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/vue-echarts": {
+ "version": "7.0.3",
+ "resolved": "https://registry.npmmirror.com/vue-echarts/-/vue-echarts-7.0.3.tgz",
+ "integrity": "sha512-/jSxNwOsw5+dYAUcwSfkLwKPuzTQ0Cepz1LxCOpj2QcHrrmUa/Ql0eQqMmc1rTPQVrh2JQ29n2dhq75ZcHvRDw==",
+ "license": "MIT",
+ "dependencies": {
+ "vue-demi": "^0.13.11"
+ },
+ "peerDependencies": {
+ "@vue/runtime-core": "^3.0.0",
+ "echarts": "^5.5.1",
+ "vue": "^2.7.0 || ^3.1.1"
+ },
+ "peerDependenciesMeta": {
+ "@vue/runtime-core": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/zrender": {
+ "version": "5.6.0",
+ "resolved": "https://registry.npmmirror.com/zrender/-/zrender-5.6.0.tgz",
+ "integrity": "sha512-uzgraf4njmmHAbEUxMJ8Oxg+P3fT04O+9p7gY+wJRVxo8Ge+KmYv0WJev945EH4wFuc4OY2NLXz46FZrWS9xJg==",
+ "license": "BSD-3-Clause",
+ "dependencies": {
+ "tslib": "2.3.0"
+ }
+ }
+ }
+}
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/LICENSE b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/LICENSE
new file mode 100644
index 0000000..f31575e
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/LICENSE
@@ -0,0 +1,22 @@
+MIT License
+
+Copyright (c) 2014-present Sebastian McKenzie and other contributors
+
+Permission is hereby granted, free of charge, to any person obtaining
+a copy of this software and associated documentation files (the
+"Software"), to deal in the Software without restriction, including
+without limitation the rights to use, copy, modify, merge, publish,
+distribute, sublicense, and/or sell copies of the Software, and to
+permit persons to whom the Software is furnished to do so, subject to
+the following conditions:
+
+The above copyright notice and this permission notice shall be
+included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
+LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
+WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/README.md b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/README.md
new file mode 100644
index 0000000..771b470
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/README.md
@@ -0,0 +1,19 @@
+# @babel/helper-string-parser
+
+> A utility package to parse strings
+
+See our website [@babel/helper-string-parser](https://babeljs.io/docs/babel-helper-string-parser) for more information.
+
+## Install
+
+Using npm:
+
+```sh
+npm install --save @babel/helper-string-parser
+```
+
+or using yarn:
+
+```sh
+yarn add @babel/helper-string-parser
+```
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/package.json b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/package.json
new file mode 100644
index 0000000..39fb92d
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/package.json
@@ -0,0 +1,31 @@
+{
+ "name": "@babel/helper-string-parser",
+ "version": "7.25.7",
+ "description": "A utility package to parse strings",
+ "repository": {
+ "type": "git",
+ "url": "https://github.com/babel/babel.git",
+ "directory": "packages/babel-helper-string-parser"
+ },
+ "homepage": "https://babel.dev/docs/en/next/babel-helper-string-parser",
+ "license": "MIT",
+ "publishConfig": {
+ "access": "public"
+ },
+ "main": "./lib/index.js",
+ "devDependencies": {
+ "charcodes": "^0.2.0"
+ },
+ "engines": {
+ "node": ">=6.9.0"
+ },
+ "author": "The Babel Team (https://babel.dev/team)",
+ "exports": {
+ ".": {
+ "types": "./lib/index.d.ts",
+ "default": "./lib/index.js"
+ },
+ "./package.json": "./package.json"
+ },
+ "type": "commonjs"
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/tsconfig.json b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/tsconfig.json
new file mode 100644
index 0000000..0d16490
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/tsconfig.json
@@ -0,0 +1,13 @@
+/* This file is automatically generated by scripts/generators/tsconfig.js */
+{
+ "extends": [
+ "../../tsconfig.base.json",
+ "../../tsconfig.paths.json"
+ ],
+ "include": [
+ "../../packages/babel-helper-string-parser/src/**/*.ts",
+ "../../lib/globals.d.ts",
+ "../../scripts/repo-utils/*.d.ts"
+ ],
+ "references": []
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/tsconfig.tsbuildinfo b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/tsconfig.tsbuildinfo
new file mode 100644
index 0000000..8ff0d19
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-string-parser/tsconfig.tsbuildinfo
@@ -0,0 +1 @@
+{"fileNames":["../../node_modules/typescript/lib/lib.es5.d.ts","../../node_modules/typescript/lib/lib.es2015.d.ts","../../node_modules/typescript/lib/lib.es2016.d.ts","../../node_modules/typescript/lib/lib.es2017.d.ts","../../node_modules/typescript/lib/lib.es2018.d.ts","../../node_modules/typescript/lib/lib.es2019.d.ts","../../node_modules/typescript/lib/lib.es2020.d.ts","../../node_modules/typescript/lib/lib.es2021.d.ts","../../node_modules/typescript/lib/lib.es2022.d.ts","../../node_modules/typescript/lib/lib.es2023.d.ts","../../node_modules/typescript/lib/lib.esnext.d.ts","../../node_modules/typescript/lib/lib.es2015.core.d.ts","../../node_modules/typescript/lib/lib.es2015.collection.d.ts","../../node_modules/typescript/lib/lib.es2015.generator.d.ts","../../node_modules/typescript/lib/lib.es2015.iterable.d.ts","../../node_modules/typescript/lib/lib.es2015.promise.d.ts","../../node_modules/typescript/lib/lib.es2015.proxy.d.ts","../../node_modules/typescript/lib/lib.es2015.reflect.d.ts","../../node_modules/typescript/lib/lib.es2015.symbol.d.ts","../../node_modules/typescript/lib/lib.es2015.symbol.wellknown.d.ts","../../node_modules/typescript/lib/lib.es2016.array.include.d.ts","../../node_modules/typescript/lib/lib.es2016.intl.d.ts","../../node_modules/typescript/lib/lib.es2017.date.d.ts","../../node_modules/typescript/lib/lib.es2017.object.d.ts","../../node_modules/typescript/lib/lib.es2017.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2017.string.d.ts","../../node_modules/typescript/lib/lib.es2017.intl.d.ts","../../node_modules/typescript/lib/lib.es2017.typedarrays.d.ts","../../node_modules/typescript/lib/lib.es2018.asyncgenerator.d.ts","../../node_modules/typescript/lib/lib.es2018.asynciterable.d.ts","../../node_modules/typescript/lib/lib.es2018.intl.d.ts","../../node_modules/typescript/lib/lib.es2018.promise.d.ts","../../node_modules/typescript/lib/lib.es2018.regexp.d.ts","../../node_modules/typescript/lib/lib.es2019.array.d.ts","../../node_modules/typescript/lib/lib.es2019.object.d.ts","../../node_modules/typescript/lib/lib.es2019.string.d.ts","../../node_modules/typescript/lib/lib.es2019.symbol.d.ts","../../node_modules/typescript/lib/lib.es2019.intl.d.ts","../../node_modules/typescript/lib/lib.es2020.bigint.d.ts","../../node_modules/typescript/lib/lib.es2020.date.d.ts","../../node_modules/typescript/lib/lib.es2020.promise.d.ts","../../node_modules/typescript/lib/lib.es2020.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2020.string.d.ts","../../node_modules/typescript/lib/lib.es2020.symbol.wellknown.d.ts","../../node_modules/typescript/lib/lib.es2020.intl.d.ts","../../node_modules/typescript/lib/lib.es2020.number.d.ts","../../node_modules/typescript/lib/lib.es2021.promise.d.ts","../../node_modules/typescript/lib/lib.es2021.string.d.ts","../../node_modules/typescript/lib/lib.es2021.weakref.d.ts","../../node_modules/typescript/lib/lib.es2021.intl.d.ts","../../node_modules/typescript/lib/lib.es2022.array.d.ts","../../node_modules/typescript/lib/lib.es2022.error.d.ts","../../node_modules/typescript/lib/lib.es2022.intl.d.ts","../../node_modules/typescript/lib/lib.es2022.object.d.ts","../../node_modules/typescript/lib/lib.es2022.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2022.string.d.ts","../../node_modules/typescript/lib/lib.es2022.regexp.d.ts","../../node_modules/typescript/lib/lib.es2023.array.d.ts","../../node_modules/typescript/lib/lib.es2023.collection.d.ts","../../node_modules/typescript/lib/lib.es2023.intl.d.ts","../../node_modules/typescript/lib/lib.esnext.array.d.ts","../../node_modules/typescript/lib/lib.esnext.collection.d.ts","../../node_modules/typescript/lib/lib.esnext.intl.d.ts","../../node_modules/typescript/lib/lib.esnext.disposable.d.ts","../../node_modules/typescript/lib/lib.esnext.string.d.ts","../../node_modules/typescript/lib/lib.esnext.promise.d.ts","../../node_modules/typescript/lib/lib.esnext.decorators.d.ts","../../node_modules/typescript/lib/lib.esnext.object.d.ts","../../node_modules/typescript/lib/lib.esnext.regexp.d.ts","../../node_modules/typescript/lib/lib.esnext.iterator.d.ts","../../node_modules/typescript/lib/lib.decorators.d.ts","../../node_modules/typescript/lib/lib.decorators.legacy.d.ts","../../node_modules/@types/charcodes/index.d.ts","./src/index.ts","../../lib/globals.d.ts","../../node_modules/@types/color-name/index.d.ts","../../node_modules/@types/convert-source-map/index.d.ts","../../node_modules/@types/debug/index.d.ts","../../node_modules/@types/eslint/helpers.d.ts","../../node_modules/@types/estree/index.d.ts","../../node_modules/@types/json-schema/index.d.ts","../../node_modules/@types/eslint/index.d.ts","../../node_modules/@types/eslint-scope/index.d.ts","../../node_modules/@types/fs-readdir-recursive/index.d.ts","../../node_modules/@types/gensync/index.d.ts","../../node_modules/@types/node/assert.d.ts","../../node_modules/@types/node/assert/strict.d.ts","../../node_modules/buffer/index.d.ts","../../node_modules/undici-types/header.d.ts","../../node_modules/undici-types/readable.d.ts","../../node_modules/undici-types/file.d.ts","../../node_modules/undici-types/fetch.d.ts","../../node_modules/undici-types/formdata.d.ts","../../node_modules/undici-types/connector.d.ts","../../node_modules/undici-types/client.d.ts","../../node_modules/undici-types/errors.d.ts","../../node_modules/undici-types/dispatcher.d.ts","../../node_modules/undici-types/global-dispatcher.d.ts","../../node_modules/undici-types/global-origin.d.ts","../../node_modules/undici-types/pool-stats.d.ts","../../node_modules/undici-types/pool.d.ts","../../node_modules/undici-types/handlers.d.ts","../../node_modules/undici-types/balanced-pool.d.ts","../../node_modules/undici-types/agent.d.ts","../../node_modules/undici-types/mock-interceptor.d.ts","../../node_modules/undici-types/mock-agent.d.ts","../../node_modules/undici-types/mock-client.d.ts","../../node_modules/undici-types/mock-pool.d.ts","../../node_modules/undici-types/mock-errors.d.ts","../../node_modules/undici-types/proxy-agent.d.ts","../../node_modules/undici-types/env-http-proxy-agent.d.ts","../../node_modules/undici-types/retry-handler.d.ts","../../node_modules/undici-types/retry-agent.d.ts","../../node_modules/undici-types/api.d.ts","../../node_modules/undici-types/interceptors.d.ts","../../node_modules/undici-types/util.d.ts","../../node_modules/undici-types/cookies.d.ts","../../node_modules/undici-types/patch.d.ts","../../node_modules/undici-types/websocket.d.ts","../../node_modules/undici-types/eventsource.d.ts","../../node_modules/undici-types/filereader.d.ts","../../node_modules/undici-types/diagnostics-channel.d.ts","../../node_modules/undici-types/content-type.d.ts","../../node_modules/undici-types/cache.d.ts","../../node_modules/undici-types/index.d.ts","../../node_modules/@types/node/globals.d.ts","../../node_modules/@types/node/async_hooks.d.ts","../../node_modules/@types/node/buffer.d.ts","../../node_modules/@types/node/child_process.d.ts","../../node_modules/@types/node/cluster.d.ts","../../node_modules/@types/node/console.d.ts","../../node_modules/@types/node/constants.d.ts","../../node_modules/@types/node/crypto.d.ts","../../node_modules/@types/node/dgram.d.ts","../../node_modules/@types/node/diagnostics_channel.d.ts","../../node_modules/@types/node/dns.d.ts","../../node_modules/@types/node/dns/promises.d.ts","../../node_modules/@types/node/domain.d.ts","../../node_modules/@types/node/dom-events.d.ts","../../node_modules/@types/node/events.d.ts","../../node_modules/@types/node/fs.d.ts","../../node_modules/@types/node/fs/promises.d.ts","../../node_modules/@types/node/http.d.ts","../../node_modules/@types/node/http2.d.ts","../../node_modules/@types/node/https.d.ts","../../node_modules/@types/node/inspector.d.ts","../../node_modules/@types/node/module.d.ts","../../node_modules/@types/node/net.d.ts","../../node_modules/@types/node/os.d.ts","../../node_modules/@types/node/path.d.ts","../../node_modules/@types/node/perf_hooks.d.ts","../../node_modules/@types/node/process.d.ts","../../node_modules/@types/node/punycode.d.ts","../../node_modules/@types/node/querystring.d.ts","../../node_modules/@types/node/readline.d.ts","../../node_modules/@types/node/readline/promises.d.ts","../../node_modules/@types/node/repl.d.ts","../../node_modules/@types/node/sea.d.ts","../../node_modules/@types/node/sqlite.d.ts","../../node_modules/@types/node/stream.d.ts","../../node_modules/@types/node/stream/promises.d.ts","../../node_modules/@types/node/stream/consumers.d.ts","../../node_modules/@types/node/stream/web.d.ts","../../node_modules/@types/node/string_decoder.d.ts","../../node_modules/@types/node/test.d.ts","../../node_modules/@types/node/timers.d.ts","../../node_modules/@types/node/timers/promises.d.ts","../../node_modules/@types/node/tls.d.ts","../../node_modules/@types/node/trace_events.d.ts","../../node_modules/@types/node/tty.d.ts","../../node_modules/@types/node/url.d.ts","../../node_modules/@types/node/util.d.ts","../../node_modules/@types/node/v8.d.ts","../../node_modules/@types/node/vm.d.ts","../../node_modules/@types/node/wasi.d.ts","../../node_modules/@types/node/worker_threads.d.ts","../../node_modules/@types/node/zlib.d.ts","../../node_modules/@types/node/globals.global.d.ts","../../node_modules/@types/node/index.d.ts","../../node_modules/@types/minimatch/index.d.ts","../../node_modules/@types/glob/index.d.ts","../../node_modules/@types/istanbul-lib-coverage/index.d.ts","../../node_modules/@types/istanbul-lib-report/index.d.ts","../../node_modules/@types/istanbul-reports/index.d.ts","../../node_modules/@types/jest/node_modules/@jest/expect-utils/build/index.d.ts","../../node_modules/@types/jest/node_modules/chalk/index.d.ts","../../node_modules/@sinclair/typebox/typebox.d.ts","../../node_modules/@jest/schemas/build/index.d.ts","../../node_modules/jest-diff/node_modules/pretty-format/build/index.d.ts","../../node_modules/jest-diff/build/index.d.ts","../../node_modules/@types/jest/node_modules/jest-matcher-utils/build/index.d.ts","../../node_modules/@types/jest/node_modules/expect/build/index.d.ts","../../node_modules/@types/jest/node_modules/pretty-format/build/index.d.ts","../../node_modules/@types/jest/index.d.ts","../../node_modules/@types/jsesc/index.d.ts","../../node_modules/@types/json5/index.d.ts","../../node_modules/@types/lru-cache/index.d.ts","../../node_modules/@types/normalize-package-data/index.d.ts","../../node_modules/@types/resolve/index.d.ts","../../node_modules/@types/semver/classes/semver.d.ts","../../node_modules/@types/semver/functions/parse.d.ts","../../node_modules/@types/semver/functions/valid.d.ts","../../node_modules/@types/semver/functions/clean.d.ts","../../node_modules/@types/semver/functions/inc.d.ts","../../node_modules/@types/semver/functions/diff.d.ts","../../node_modules/@types/semver/functions/major.d.ts","../../node_modules/@types/semver/functions/minor.d.ts","../../node_modules/@types/semver/functions/patch.d.ts","../../node_modules/@types/semver/functions/prerelease.d.ts","../../node_modules/@types/semver/functions/compare.d.ts","../../node_modules/@types/semver/functions/rcompare.d.ts","../../node_modules/@types/semver/functions/compare-loose.d.ts","../../node_modules/@types/semver/functions/compare-build.d.ts","../../node_modules/@types/semver/functions/sort.d.ts","../../node_modules/@types/semver/functions/rsort.d.ts","../../node_modules/@types/semver/functions/gt.d.ts","../../node_modules/@types/semver/functions/lt.d.ts","../../node_modules/@types/semver/functions/eq.d.ts","../../node_modules/@types/semver/functions/neq.d.ts","../../node_modules/@types/semver/functions/gte.d.ts","../../node_modules/@types/semver/functions/lte.d.ts","../../node_modules/@types/semver/functions/cmp.d.ts","../../node_modules/@types/semver/functions/coerce.d.ts","../../node_modules/@types/semver/classes/comparator.d.ts","../../node_modules/@types/semver/classes/range.d.ts","../../node_modules/@types/semver/functions/satisfies.d.ts","../../node_modules/@types/semver/ranges/max-satisfying.d.ts","../../node_modules/@types/semver/ranges/min-satisfying.d.ts","../../node_modules/@types/semver/ranges/to-comparators.d.ts","../../node_modules/@types/semver/ranges/min-version.d.ts","../../node_modules/@types/semver/ranges/valid.d.ts","../../node_modules/@types/semver/ranges/outside.d.ts","../../node_modules/@types/semver/ranges/gtr.d.ts","../../node_modules/@types/semver/ranges/ltr.d.ts","../../node_modules/@types/semver/ranges/intersects.d.ts","../../node_modules/@types/semver/ranges/simplify.d.ts","../../node_modules/@types/semver/ranges/subset.d.ts","../../node_modules/@types/semver/internals/identifiers.d.ts","../../node_modules/@types/semver/index.d.ts","../../node_modules/@types/stack-utils/index.d.ts","../../node_modules/@types/v8flags/index.d.ts","../../node_modules/@types/yargs-parser/index.d.ts","../../node_modules/@types/yargs/index.d.ts"],"fileIdsList":[[187],[80,82],[79,80,81],[140,141,179,180],[182],[183],[189,192],[127,179,185,191],[186,190],[188],[86],[127],[128,133,163],[129,134,140,141,148,160,171],[129,130,140,148],[131,172],[132,133,141,149],[133,160,168],[134,136,140,148],[127,135],[136,137],[140],[138,140],[127,140],[140,141,142,160,171],[140,141,142,155,160,163],[125,176],[125,136,140,143,148,160,171],[140,141,143,144,148,160,168,171],[143,145,160,168,171],[86,87,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178],[140,146],[147,171,176],[136,140,148,160],[149],[150],[127,151],[86,87,127,128,129,130,131,132,133,134,135,136,137,138,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177],[153],[154],[140,155,156],[155,157,172,174],[128,140,160,161,162,163],[128,160,162],[160,161],[163],[164],[86,160],[140,166,167],[166,167],[133,148,160,168],[169],[148,170],[128,143,154,171],[133,172],[160,173],[147,174],[175],[128,133,140,142,151,160,171,174,176],[160,177],[200,239],[200,224,239],[239],[200],[200,225,239],[200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238],[225,239],[242],[189],[97,101,171],[97,160,171],[92],[94,97,168,171],[148,168],[179],[92,179],[94,97,148,171],[89,90,93,96,128,140,160,171],[97,104],[89,95],[97,118,119],[93,97,128,163,171,179],[128,179],[118,128,179],[91,92,179],[97],[91,92,93,94,95,96,97,98,99,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,119,120,121,122,123,124],[97,112],[97,104,105],[95,97,105,106],[96],[89,92,97],[97,101,105,106],[101],[95,97,100,171],[89,94,97,104],[128,160],[92,97,118,128,176,179],[73]],"fileInfos":[{"version":"44e584d4f6444f58791784f1d530875970993129442a847597db702a073ca68c","affectsGlobalScope":true,"impliedFormat":1},{"version":"45b7ab580deca34ae9729e97c13cfd999df04416a79116c3bfb483804f85ded4","impliedFormat":1},{"version":"3facaf05f0c5fc569c5649dd359892c98a85557e3e0c847964caeb67076f4d75","impliedFormat":1},{"version":"9a68c0c07ae2fa71b44384a839b7b8d81662a236d4b9ac30916718f7510b1b2d","impliedFormat":1},{"version":"5e1c4c362065a6b95ff952c0eab010f04dcd2c3494e813b493ecfd4fcb9fc0d8","impliedFormat":1},{"version":"68d73b4a11549f9c0b7d352d10e91e5dca8faa3322bfb77b661839c42b1ddec7","impliedFormat":1},{"version":"5efce4fc3c29ea84e8928f97adec086e3dc876365e0982cc8479a07954a3efd4","impliedFormat":1},{"version":"feecb1be483ed332fad555aff858affd90a48ab19ba7272ee084704eb7167569","impliedFormat":1},{"version":"5514e54f17d6d74ecefedc73c504eadffdeda79c7ea205cf9febead32d45c4bc","impliedFormat":1},{"version":"27bdc30a0e32783366a5abeda841bc22757c1797de8681bbe81fbc735eeb1c10","impliedFormat":1},{"version":"abee51ebffafd50c07d76be5848a34abfe4d791b5745ef1e5648718722fab924","impliedFormat":1},{"version":"6920e1448680767498a0b77c6a00a8e77d14d62c3da8967b171f1ddffa3c18e4","affectsGlobalScope":true,"impliedFormat":1},{"version":"dc2df20b1bcdc8c2d34af4926e2c3ab15ffe1160a63e58b7e09833f616efff44","affectsGlobalScope":true,"impliedFormat":1},{"version":"515d0b7b9bea2e31ea4ec968e9edd2c39d3eebf4a2d5cbd04e88639819ae3b71","affectsGlobalScope":true,"impliedFormat":1},{"version":"45d8ccb3dfd57355eb29749919142d4321a0aa4df6acdfc54e30433d7176600a","affectsGlobalScope":true,"impliedFormat":1},{"version":"0dc1e7ceda9b8b9b455c3a2d67b0412feab00bd2f66656cd8850e8831b08b537","affectsGlobalScope":true,"impliedFormat":1},{"version":"ce691fb9e5c64efb9547083e4a34091bcbe5bdb41027e310ebba8f7d96a98671","affectsGlobalScope":true,"impliedFormat":1},{"version":"8d697a2a929a5fcb38b7a65594020fcef05ec1630804a33748829c5ff53640d0","affectsGlobalScope":true,"impliedFormat":1},{"version":"4ff2a353abf8a80ee399af572debb8faab2d33ad38c4b4474cff7f26e7653b8d","affectsGlobalScope":true,"impliedFormat":1},{"version":"93495ff27b8746f55d19fcbcdbaccc99fd95f19d057aed1bd2c0cafe1335fbf0","affectsGlobalScope":true,"impliedFormat":1},{"version":"6fc23bb8c3965964be8c597310a2878b53a0306edb71d4b5a4dfe760186bcc01","affectsGlobalScope":true,"impliedFormat":1},{"version":"ea011c76963fb15ef1cdd7ce6a6808b46322c527de2077b6cfdf23ae6f5f9ec7","affectsGlobalScope":true,"impliedFormat":1},{"version":"38f0219c9e23c915ef9790ab1d680440d95419ad264816fa15009a8851e79119","affectsGlobalScope":true,"impliedFormat":1},{"version":"69ab18c3b76cd9b1be3d188eaf8bba06112ebbe2f47f6c322b5105a6fbc45a2e","affectsGlobalScope":true,"impliedFormat":1},{"version":"4738f2420687fd85629c9efb470793bb753709c2379e5f85bc1815d875ceadcd","affectsGlobalScope":true,"impliedFormat":1},{"version":"2f11ff796926e0832f9ae148008138ad583bd181899ab7dd768a2666700b1893","affectsGlobalScope":true,"impliedFormat":1},{"version":"4de680d5bb41c17f7f68e0419412ca23c98d5749dcaaea1896172f06435891fc","affectsGlobalScope":true,"impliedFormat":1},{"version":"9fc46429fbe091ac5ad2608c657201eb68b6f1b8341bd6d670047d32ed0a88fa","affectsGlobalScope":true,"impliedFormat":1},{"version":"ac9538681b19688c8eae65811b329d3744af679e0bdfa5d842d0e32524c73e1c","affectsGlobalScope":true,"impliedFormat":1},{"version":"0a969edff4bd52585473d24995c5ef223f6652d6ef46193309b3921d65dd4376","affectsGlobalScope":true,"impliedFormat":1},{"version":"9e9fbd7030c440b33d021da145d3232984c8bb7916f277e8ffd3dc2e3eae2bdb","affectsGlobalScope":true,"impliedFormat":1},{"version":"811ec78f7fefcabbda4bfa93b3eb67d9ae166ef95f9bff989d964061cbf81a0c","affectsGlobalScope":true,"impliedFormat":1},{"version":"717937616a17072082152a2ef351cb51f98802fb4b2fdabd32399843875974ca","affectsGlobalScope":true,"impliedFormat":1},{"version":"d7e7d9b7b50e5f22c915b525acc5a49a7a6584cf8f62d0569e557c5cfc4b2ac2","affectsGlobalScope":true,"impliedFormat":1},{"version":"71c37f4c9543f31dfced6c7840e068c5a5aacb7b89111a4364b1d5276b852557","affectsGlobalScope":true,"impliedFormat":1},{"version":"576711e016cf4f1804676043e6a0a5414252560eb57de9faceee34d79798c850","affectsGlobalScope":true,"impliedFormat":1},{"version":"89c1b1281ba7b8a96efc676b11b264de7a8374c5ea1e6617f11880a13fc56dc6","affectsGlobalScope":true,"impliedFormat":1},{"version":"74f7fa2d027d5b33eb0471c8e82a6c87216223181ec31247c357a3e8e2fddc5b","affectsGlobalScope":true,"impliedFormat":1},{"version":"1a94697425a99354df73d9c8291e2ecd4dddd370aed4023c2d6dee6cccb32666","affectsGlobalScope":true,"impliedFormat":1},{"version":"063600664504610fe3e99b717a1223f8b1900087fab0b4cad1496a114744f8df","affectsGlobalScope":true,"impliedFormat":1},{"version":"934019d7e3c81950f9a8426d093458b65d5aff2c7c1511233c0fd5b941e608ab","affectsGlobalScope":true,"impliedFormat":1},{"version":"bf14a426dbbf1022d11bd08d6b8e709a2e9d246f0c6c1032f3b2edb9a902adbe","affectsGlobalScope":true,"impliedFormat":1},{"version":"e3f9fc0ec0b96a9e642f11eda09c0be83a61c7b336977f8b9fdb1e9788e925fe","affectsGlobalScope":true,"impliedFormat":1},{"version":"59fb2c069260b4ba00b5643b907ef5d5341b167e7d1dbf58dfd895658bda2867","affectsGlobalScope":true,"impliedFormat":1},{"version":"479553e3779be7d4f68e9f40cdb82d038e5ef7592010100410723ceced22a0f7","affectsGlobalScope":true,"impliedFormat":1},{"version":"368af93f74c9c932edd84c58883e736c9e3d53cec1fe24c0b0ff451f529ceab1","affectsGlobalScope":true,"impliedFormat":1},{"version":"af3dd424cf267428f30ccfc376f47a2c0114546b55c44d8c0f1d57d841e28d74","affectsGlobalScope":true,"impliedFormat":1},{"version":"995c005ab91a498455ea8dfb63aa9f83fa2ea793c3d8aa344be4a1678d06d399","affectsGlobalScope":true,"impliedFormat":1},{"version":"d3d7b04b45033f57351c8434f60b6be1ea71a2dfec2d0a0c3c83badbb0e3e693","affectsGlobalScope":true,"impliedFormat":1},{"version":"956d27abdea9652e8368ce029bb1e0b9174e9678a273529f426df4b3d90abd60","affectsGlobalScope":true,"impliedFormat":1},{"version":"4fa6ed14e98aa80b91f61b9805c653ee82af3502dc21c9da5268d3857772ca05","affectsGlobalScope":true,"impliedFormat":1},{"version":"e6633e05da3ff36e6da2ec170d0d03ccf33de50ca4dc6f5aeecb572cedd162fb","affectsGlobalScope":true,"impliedFormat":1},{"version":"15c1c3d7b2e46e0025417ed6d5f03f419e57e6751f87925ca19dc88297053fe6","affectsGlobalScope":true,"impliedFormat":1},{"version":"8444af78980e3b20b49324f4a16ba35024fef3ee069a0eb67616ea6ca821c47a","affectsGlobalScope":true,"impliedFormat":1},{"version":"caccc56c72713969e1cfe5c3d44e5bab151544d9d2b373d7dbe5a1e4166652be","affectsGlobalScope":true,"impliedFormat":1},{"version":"3287d9d085fbd618c3971944b65b4be57859f5415f495b33a6adc994edd2f004","affectsGlobalScope":true,"impliedFormat":1},{"version":"b4b67b1a91182421f5df999988c690f14d813b9850b40acd06ed44691f6727ad","affectsGlobalScope":true,"impliedFormat":1},{"version":"9d540251809289a05349b70ab5f4b7b99f922af66ab3c39ba56a475dcf95d5ff","affectsGlobalScope":true,"impliedFormat":1},{"version":"436aaf437562f276ec2ddbee2f2cdedac7664c1e4c1d2c36839ddd582eeb3d0a","affectsGlobalScope":true,"impliedFormat":1},{"version":"8e3c06ea092138bf9fa5e874a1fdbc9d54805d074bee1de31b99a11e2fec239d","affectsGlobalScope":true,"impliedFormat":1},{"version":"0b11f3ca66aa33124202c80b70cd203219c3d4460cfc165e0707aa9ec710fc53","affectsGlobalScope":true,"impliedFormat":1},{"version":"6a3f5a0129cc80cf439ab71164334d649b47059a4f5afca90282362407d0c87f","affectsGlobalScope":true,"impliedFormat":1},{"version":"811c71eee4aa0ac5f7adf713323a5c41b0cf6c4e17367a34fbce379e12bbf0a4","affectsGlobalScope":true,"impliedFormat":1},{"version":"51ad4c928303041605b4d7ae32e0c1ee387d43a24cd6f1ebf4a2699e1076d4fa","affectsGlobalScope":true,"impliedFormat":1},{"version":"0a6282c8827e4b9a95f4bf4f5c205673ada31b982f50572d27103df8ceb8013c","affectsGlobalScope":true,"impliedFormat":1},{"version":"ac77cb3e8c6d3565793eb90a8373ee8033146315a3dbead3bde8db5eaf5e5ec6","affectsGlobalScope":true,"impliedFormat":1},{"version":"d4b1d2c51d058fc21ec2629fff7a76249dec2e36e12960ea056e3ef89174080f","affectsGlobalScope":true,"impliedFormat":1},{"version":"2fef54945a13095fdb9b84f705f2b5994597640c46afeb2ce78352fab4cb3279","affectsGlobalScope":true,"impliedFormat":1},{"version":"56e4ed5aab5f5920980066a9409bfaf53e6d21d3f8d020c17e4de584d29600ad","affectsGlobalScope":true,"impliedFormat":1},{"version":"61d6a2092f48af66dbfb220e31eea8b10bc02b6932d6e529005fd2d7b3281290","affectsGlobalScope":true,"impliedFormat":1},{"version":"33358442698bb565130f52ba79bfd3d4d484ac85fe33f3cb1759c54d18201393","affectsGlobalScope":true,"impliedFormat":1},{"version":"782dec38049b92d4e85c1585fbea5474a219c6984a35b004963b00beb1aab538","affectsGlobalScope":true,"impliedFormat":1},{"version":"b7589677bd27b038f8aae8afeb030e554f1d5ff29dc4f45854e2cb7e5095d59a","impliedFormat":1},{"version":"aa0aa9c785df8942a0c0474ea22e93925d81a79310daec3990a747011e4b5bdd","signature":"186139eb9963554412f6fb33b35aabee1acdaa644b365de5c38fbd9123bdbe45"},{"version":"f0b6690984c3a44b15740ac24bfb63853617731c0f40c87a956ce537c4b50969","affectsGlobalScope":true},{"version":"f0cb4b3ab88193e3e51e9e2622e4c375955003f1f81239d72c5b7a95415dad3e","impliedFormat":1},{"version":"13d94ac3ee5780f99988ae4cce0efd139598ca159553bc0100811eba74fc2351","impliedFormat":1},{"version":"3cf5f191d75bbe7c92f921e5ae12004ac672266e2be2ece69f40b1d6b1b678f9","impliedFormat":1},{"version":"64d4b35c5456adf258d2cf56c341e203a073253f229ef3208fc0d5020253b241","affectsGlobalScope":true,"impliedFormat":1},{"version":"ee7d8894904b465b072be0d2e4b45cf6b887cdba16a467645c4e200982ece7ea","impliedFormat":1},{"version":"f3d8c757e148ad968f0d98697987db363070abada5f503da3c06aefd9d4248c1","impliedFormat":1},{"version":"0c5a621a8cf10464c2020f05c99a86d8ac6875d9e17038cb8522cc2f604d539f","impliedFormat":1},{"version":"e050a0afcdbb269720a900c85076d18e0c1ab73e580202a2bf6964978181222a","impliedFormat":1},{"version":"1d78c35b7e8ce86a188e3e5528cc5d1edfc85187a85177458d26e17c8b48105f","impliedFormat":1},{"version":"bde8c75c442f701f7c428265ecad3da98023b6152db9ca49552304fd19fdba38","impliedFormat":1},{"version":"e142fda89ed689ea53d6f2c93693898464c7d29a0ae71c6dc8cdfe5a1d76c775","impliedFormat":1},{"version":"7394959e5a741b185456e1ef5d64599c36c60a323207450991e7a42e08911419","impliedFormat":1},{"version":"4967529644e391115ca5592184d4b63980569adf60ee685f968fd59ab1557188","impliedFormat":1},{"version":"5929864ce17fba74232584d90cb721a89b7ad277220627cc97054ba15a98ea8f","impliedFormat":1},{"version":"24bd580b5743dc56402c440dc7f9a4f5d592ad7a419f25414d37a7bfe11e342b","impliedFormat":1},{"version":"25c8056edf4314820382a5fdb4bb7816999acdcb929c8f75e3f39473b87e85bc","impliedFormat":1},{"version":"c464d66b20788266e5353b48dc4aa6bc0dc4a707276df1e7152ab0c9ae21fad8","impliedFormat":1},{"version":"78d0d27c130d35c60b5e5566c9f1e5be77caf39804636bc1a40133919a949f21","impliedFormat":1},{"version":"c6fd2c5a395f2432786c9cb8deb870b9b0e8ff7e22c029954fabdd692bff6195","impliedFormat":1},{"version":"1d6e127068ea8e104a912e42fc0a110e2aa5a66a356a917a163e8cf9a65e4a75","impliedFormat":1},{"version":"5ded6427296cdf3b9542de4471d2aa8d3983671d4cac0f4bf9c637208d1ced43","impliedFormat":1},{"version":"6bdc71028db658243775263e93a7db2fd2abfce3ca569c3cca5aee6ed5eb186d","impliedFormat":1},{"version":"cadc8aced301244057c4e7e73fbcae534b0f5b12a37b150d80e5a45aa4bebcbd","impliedFormat":1},{"version":"385aab901643aa54e1c36f5ef3107913b10d1b5bb8cbcd933d4263b80a0d7f20","impliedFormat":1},{"version":"9670d44354bab9d9982eca21945686b5c24a3f893db73c0dae0fd74217a4c219","impliedFormat":1},{"version":"0b8a9268adaf4da35e7fa830c8981cfa22adbbe5b3f6f5ab91f6658899e657a7","impliedFormat":1},{"version":"11396ed8a44c02ab9798b7dca436009f866e8dae3c9c25e8c1fbc396880bf1bb","impliedFormat":1},{"version":"ba7bc87d01492633cb5a0e5da8a4a42a1c86270e7b3d2dea5d156828a84e4882","impliedFormat":1},{"version":"4893a895ea92c85345017a04ed427cbd6a1710453338df26881a6019432febdd","impliedFormat":1},{"version":"c21dc52e277bcfc75fac0436ccb75c204f9e1b3fa5e12729670910639f27343e","impliedFormat":1},{"version":"13f6f39e12b1518c6650bbb220c8985999020fe0f21d818e28f512b7771d00f9","impliedFormat":1},{"version":"9b5369969f6e7175740bf51223112ff209f94ba43ecd3bb09eefff9fd675624a","impliedFormat":1},{"version":"4fe9e626e7164748e8769bbf74b538e09607f07ed17c2f20af8d680ee49fc1da","impliedFormat":1},{"version":"24515859bc0b836719105bb6cc3d68255042a9f02a6022b3187948b204946bd2","impliedFormat":1},{"version":"ea0148f897b45a76544ae179784c95af1bd6721b8610af9ffa467a518a086a43","impliedFormat":1},{"version":"24c6a117721e606c9984335f71711877293a9651e44f59f3d21c1ea0856f9cc9","impliedFormat":1},{"version":"dd3273ead9fbde62a72949c97dbec2247ea08e0c6952e701a483d74ef92d6a17","impliedFormat":1},{"version":"405822be75ad3e4d162e07439bac80c6bcc6dbae1929e179cf467ec0b9ee4e2e","impliedFormat":1},{"version":"0db18c6e78ea846316c012478888f33c11ffadab9efd1cc8bcc12daded7a60b6","impliedFormat":1},{"version":"4d2b0eb911816f66abe4970898f97a2cfc902bcd743cbfa5017fad79f7ef90d8","impliedFormat":1},{"version":"bd0532fd6556073727d28da0edfd1736417a3f9f394877b6d5ef6ad88fba1d1a","impliedFormat":1},{"version":"89167d696a849fce5ca508032aabfe901c0868f833a8625d5a9c6e861ef935d2","impliedFormat":1},{"version":"e53a3c2a9f624d90f24bf4588aacd223e7bec1b9d0d479b68d2f4a9e6011147f","impliedFormat":1},{"version":"24b8685c62562f5d98615c5a0c1d05f297cf5065f15246edfe99e81ec4c0e011","impliedFormat":1},{"version":"93507c745e8f29090efb99399c3f77bec07db17acd75634249dc92f961573387","impliedFormat":1},{"version":"339dc5265ee5ed92e536a93a04c4ebbc2128f45eeec6ed29f379e0085283542c","impliedFormat":1},{"version":"4732aec92b20fb28c5fe9ad99521fb59974289ed1e45aecb282616202184064f","impliedFormat":1},{"version":"2e85db9e6fd73cfa3d7f28e0ab6b55417ea18931423bd47b409a96e4a169e8e6","impliedFormat":1},{"version":"c46e079fe54c76f95c67fb89081b3e399da2c7d109e7dca8e4b58d83e332e605","impliedFormat":1},{"version":"bf67d53d168abc1298888693338cb82854bdb2e69ef83f8a0092093c2d562107","impliedFormat":1},{"version":"964f307d249df0d7e8eb16d594536c0ac6cc63c8d467edf635d05542821dec8e","affectsGlobalScope":true,"impliedFormat":1},{"version":"db3ec8993b7596a4ef47f309c7b25ee2505b519c13050424d9c34701e5973315","impliedFormat":1},{"version":"6a1ebd564896d530364f67b3257c62555b61d60494a73dfe8893274878c6589d","affectsGlobalScope":true,"impliedFormat":1},{"version":"af49b066a76ce26673fe49d1885cc6b44153f1071ed2d952f2a90fccba1095c9","impliedFormat":1},{"version":"f22fd1dc2df53eaf5ce0ff9e0a3326fc66f880d6a652210d50563ae72625455f","impliedFormat":1},{"version":"3ddbdb519e87a7827c4f0c4007013f3628ca0ebb9e2b018cf31e5b2f61c593f1","affectsGlobalScope":true,"impliedFormat":1},{"version":"a40826e8476694e90da94aa008283a7de50d1dafd37beada623863f1901cb7fb","impliedFormat":1},{"version":"6d498d4fd8036ea02a4edcae10375854a0eb1df0496cf0b9d692577d3c0fd603","affectsGlobalScope":true,"impliedFormat":1},{"version":"24642567d3729bcc545bacb65ee7c0db423400c7f1ef757cab25d05650064f98","impliedFormat":1},{"version":"fd09b892597ab93e7f79745ce725a3aaf6dd005e8db20f0c63a5d10984cba328","impliedFormat":1},{"version":"a3be878ff1e1964ab2dc8e0a3b67087cf838731c7f3d8f603337e7b712fdd558","impliedFormat":1},{"version":"5433f7f77cd1fd53f45bd82445a4e437b2f6a72a32070e907530a4fea56c30c8","impliedFormat":1},{"version":"9be74296ee565af0c12d7071541fdd23260f53c3da7731fb6361f61150a791f6","impliedFormat":1},{"version":"ee1ee365d88c4c6c0c0a5a5701d66ebc27ccd0bcfcfaa482c6e2e7fe7b98edf7","affectsGlobalScope":true,"impliedFormat":1},{"version":"f501a53b94ba382d9ba396a5c486969a3abc68309828fa67f916035f5d37fe2b","affectsGlobalScope":true,"impliedFormat":1},{"version":"aa658b5d765f630c312ac9202d110bbaf2b82d180376457f0a9d57b42629714a","impliedFormat":1},{"version":"312ac7cbd070107766a9886fd27f9faad997ef57d93fdfb4095df2c618ac8162","impliedFormat":1},{"version":"2e9b4e7f9942af902eb85bae6066d04ef1afee51d61554a62d144df3da7dec94","impliedFormat":1},{"version":"672ad3045f329e94002256f8ed460cfd06173a50c92cde41edaadfacffd16808","impliedFormat":1},{"version":"64da4965d1e0559e134d9c1621ae400279a216f87ed00c4cce4f2c7c78021712","impliedFormat":1},{"version":"2205527b976f4f1844adc46a3f0528729fb68cac70027a5fb13c49ca23593797","impliedFormat":1},{"version":"0166fce1204d520fdfd6b5febb3cda3deee438bcbf8ce9ffeb2b1bcde7155346","affectsGlobalScope":true,"impliedFormat":1},{"version":"d8b13eab85b532285031b06a971fa051bf0175d8fff68065a24a6da9c1c986cf","impliedFormat":1},{"version":"50c382ba1827988c59aa9cc9d046e386d55d70f762e9e352e95ee8cb7337cdb8","impliedFormat":1},{"version":"bb9627ab9d078c79bb5623de4ac8e5d08f806ec9b970962dfc83b3211373690d","impliedFormat":1},{"version":"21d7e87f271e72d02f8d167edc902f90b04525edc7918f00f01dd0bd00599f7e","affectsGlobalScope":true,"impliedFormat":1},{"version":"6f6abdaf8764ef01a552a958f45e795b5e79153b87ddad3af5264b86d2681b72","affectsGlobalScope":true,"impliedFormat":1},{"version":"a215554477f7629e3dcbc8cde104bec036b78673650272f5ffdc5a2cee399a0a","impliedFormat":1},{"version":"c3497fc242aabfedcd430b5932412f94f157b5906568e737f6a18cc77b36a954","impliedFormat":1},{"version":"cdc1de3b672f9ef03ff15c443aa1b631edca35b6ae6970a7da6400647ff74d95","impliedFormat":1},{"version":"139ad1dc93a503da85b7a0d5f615bddbae61ad796bc68fedd049150db67a1e26","impliedFormat":1},{"version":"bf01fdd3b93cf633b3f7420718457af19c57ab8cbfea49268df60bae2e84d627","impliedFormat":1},{"version":"15c5e91b5f08be34a78e3d976179bf5b7a9cc28dc0ef1ffebffeb3c7812a2dca","impliedFormat":1},{"version":"5f461d6f5d9ff474f1121cc3fd86aa3cd67476c701f55c306d323c5112201207","impliedFormat":1},{"version":"65b39cc6b610a4a4aecc321f6efb436f10c0509d686124795b4c36a5e915b89e","impliedFormat":1},{"version":"269929a24b2816343a178008ac9ae9248304d92a8ba8e233055e0ed6dbe6ef71","impliedFormat":1},{"version":"93452d394fdd1dc551ec62f5042366f011a00d342d36d50793b3529bfc9bd633","impliedFormat":1},{"version":"83fe38aa2243059ea859325c006da3964ead69b773429fe049ebb0426e75424d","affectsGlobalScope":true,"impliedFormat":1},{"version":"d3edb86744e2c19f2c1503849ac7594a5e06024f2451bacae032390f2e20314a","impliedFormat":1},{"version":"e501cbca25bd54f0bcb89c00f092d3cae227e970b93fd76207287fd8110b123d","affectsGlobalScope":true,"impliedFormat":1},{"version":"8a3e61347b8f80aa5af532094498bceb0c0b257b25a6aa8ab4880fd6ed57c95a","affectsGlobalScope":true,"impliedFormat":1},{"version":"98e00f3613402504bc2a2c9a621800ab48e0a463d1eed062208a4ae98ad8f84c","impliedFormat":1},{"version":"950f6810f7c80e0cffefcf1bcc6ade3485c94394720e334c3c2be3c16b6922fb","impliedFormat":1},{"version":"5475df7cfc493a08483c9d7aa61cc04791aecba9d0a2efc213f23c4006d4d3cd","impliedFormat":1},{"version":"000720870b275764c65e9f28ac97cc9e4d9e4a36942d4750ca8603e416e9c57c","impliedFormat":1},{"version":"54412c70bacb9ed547ed6caae8836f712a83ccf58d94466f3387447ec4e82dc3","affectsGlobalScope":true,"impliedFormat":1},{"version":"e74e7b0baa7a24f073080091427d36a75836d584b9393e6ac2b1daf1647fe65a","affectsGlobalScope":true,"impliedFormat":1},{"version":"4c48e931a72f6971b5add7fdb1136be1d617f124594e94595f7114af749395e0","impliedFormat":1},{"version":"478eb5c32250678a906d91e0529c70243fc4d75477a08f3da408e2615396f558","impliedFormat":1},{"version":"e686a88c9ee004c8ba12ffc9d674ca3192a4c50ed0ca6bd5b2825c289e2b2bfe","impliedFormat":1},{"version":"0d27932df2fbc3728e78b98892540e24084424ce12d3bd32f62a23cf307f411f","affectsGlobalScope":true,"impliedFormat":1},{"version":"4423fb3d6abe6eefb8d7f79eb2df9510824a216ec1c6feee46718c9b18e6d89f","impliedFormat":1},{"version":"ab9b9a36e5284fd8d3bf2f7d5fcbc60052f25f27e4d20954782099282c60d23e","affectsGlobalScope":true,"impliedFormat":1},{"version":"01c47d1c006b3a15b51d89d7764fff7e4fabc4e412b3a61ee5357bd74b822879","impliedFormat":1},{"version":"8841e2aa774b89bd23302dede20663306dc1b9902431ac64b24be8b8d0e3f649","impliedFormat":1},{"version":"fd326577c62145816fe1acc306c734c2396487f76719d3785d4e825b34540b33","impliedFormat":1},{"version":"9e951ec338c4232d611552a1be7b4ecec79a8c2307a893ce39701316fe2374bd","impliedFormat":1},{"version":"70c61ff569aabdf2b36220da6c06caaa27e45cd7acac81a1966ab4ee2eadc4f2","impliedFormat":1},{"version":"905c3e8f7ddaa6c391b60c05b2f4c3931d7127ad717a080359db3df510b7bdab","impliedFormat":1},{"version":"6c1e688f95fcaf53b1e41c0fdadf2c1cfc96fa924eaf7f9fdb60f96deb0a4986","impliedFormat":1},{"version":"0d14fa22c41fdc7277e6f71473b20ebc07f40f00e38875142335d5b63cdfc9d2","impliedFormat":1},{"version":"c085e9aa62d1ae1375794c1fb927a445fa105fed891a7e24edbb1c3300f7384a","impliedFormat":1},{"version":"f315e1e65a1f80992f0509e84e4ae2df15ecd9ef73df975f7c98813b71e4c8da","impliedFormat":1},{"version":"5b9586e9b0b6322e5bfbd2c29bd3b8e21ab9d871f82346cb71020e3d84bae73e","impliedFormat":1},{"version":"3e70a7e67c2cb16f8cd49097360c0309fe9d1e3210ff9222e9dac1f8df9d4fb6","impliedFormat":1},{"version":"ab68d2a3e3e8767c3fba8f80de099a1cfc18c0de79e42cb02ae66e22dfe14a66","impliedFormat":1},{"version":"6d969939c4a63f70f2aa49e88da6f64b655c8e6799612807bef41ccff6ea0da9","impliedFormat":1},{"version":"5b9586e9b0b6322e5bfbd2c29bd3b8e21ab9d871f82346cb71020e3d84bae73e","impliedFormat":1},{"version":"46894b2a21a60f8449ca6b2b7223b7179bba846a61b1434bed77b34b2902c306","affectsGlobalScope":true,"impliedFormat":1},{"version":"84a805c22a49922085dc337ca71ac0b85aad6d4dba6b01cee5bd5776ff54df39","impliedFormat":1},{"version":"96d14f21b7652903852eef49379d04dbda28c16ed36468f8c9fa08f7c14c9538","impliedFormat":1},{"version":"6d727c1f6a7122c04e4f7c164c5e6f460c21ada618856894cdaa6ac25e95f38c","impliedFormat":1},{"version":"22293bd6fa12747929f8dfca3ec1684a3fe08638aa18023dd286ab337e88a592","impliedFormat":1},{"version":"8baa5d0febc68db886c40bf341e5c90dc215a90cd64552e47e8184be6b7e3358","impliedFormat":1},{"version":"cf3d384d082b933d987c4e2fe7bfb8710adfd9dc8155190056ed6695a25a559e","impliedFormat":1},{"version":"9871b7ee672bc16c78833bdab3052615834b08375cb144e4d2cba74473f4a589","impliedFormat":1},{"version":"c863198dae89420f3c552b5a03da6ed6d0acfa3807a64772b895db624b0de707","impliedFormat":1},{"version":"8b03a5e327d7db67112ebbc93b4f744133eda2c1743dbb0a990c61a8007823ef","impliedFormat":1},{"version":"86c73f2ee1752bac8eeeece234fd05dfcf0637a4fbd8032e4f5f43102faa8eec","impliedFormat":1},{"version":"42fad1f540271e35ca37cecda12c4ce2eef27f0f5cf0f8dd761d723c744d3159","impliedFormat":1},{"version":"ff3743a5de32bee10906aff63d1de726f6a7fd6ee2da4b8229054dfa69de2c34","impliedFormat":1},{"version":"83acd370f7f84f203e71ebba33ba61b7f1291ca027d7f9a662c6307d74e4ac22","impliedFormat":1},{"version":"1445cec898f90bdd18b2949b9590b3c012f5b7e1804e6e329fb0fe053946d5ec","impliedFormat":1},{"version":"0e5318ec2275d8da858b541920d9306650ae6ac8012f0e872fe66eb50321a669","impliedFormat":1},{"version":"cf530297c3fb3a92ec9591dd4fa229d58b5981e45fe6702a0bd2bea53a5e59be","impliedFormat":1},{"version":"c1f6f7d08d42148ddfe164d36d7aba91f467dbcb3caa715966ff95f55048b3a4","impliedFormat":1},{"version":"f4e9bf9103191ef3b3612d3ec0044ca4044ca5be27711fe648ada06fad4bcc85","impliedFormat":1},{"version":"0c1ee27b8f6a00097c2d6d91a21ee4d096ab52c1e28350f6362542b55380059a","impliedFormat":1},{"version":"7677d5b0db9e020d3017720f853ba18f415219fb3a9597343b1b1012cfd699f7","impliedFormat":1},{"version":"bc1c6bc119c1784b1a2be6d9c47addec0d83ef0d52c8fbe1f14a51b4dfffc675","impliedFormat":1},{"version":"52cf2ce99c2a23de70225e252e9822a22b4e0adb82643ab0b710858810e00bf1","impliedFormat":1},{"version":"770625067bb27a20b9826255a8d47b6b5b0a2d3dfcbd21f89904c731f671ba77","impliedFormat":1},{"version":"d1ed6765f4d7906a05968fb5cd6d1db8afa14dbe512a4884e8ea5c0f5e142c80","impliedFormat":1},{"version":"799c0f1b07c092626cf1efd71d459997635911bb5f7fc1196efe449bba87e965","impliedFormat":1},{"version":"2a184e4462b9914a30b1b5c41cf80c6d3428f17b20d3afb711fff3f0644001fd","impliedFormat":1},{"version":"9eabde32a3aa5d80de34af2c2206cdc3ee094c6504a8d0c2d6d20c7c179503cc","impliedFormat":1},{"version":"397c8051b6cfcb48aa22656f0faca2553c5f56187262135162ee79d2b2f6c966","impliedFormat":1},{"version":"a8ead142e0c87dcd5dc130eba1f8eeed506b08952d905c47621dc2f583b1bff9","impliedFormat":1},{"version":"a02f10ea5f73130efca046429254a4e3c06b5475baecc8f7b99a0014731be8b3","impliedFormat":1},{"version":"c2576a4083232b0e2d9bd06875dd43d371dee2e090325a9eac0133fd5650c1cb","impliedFormat":1},{"version":"4c9a0564bb317349de6a24eb4efea8bb79898fa72ad63a1809165f5bd42970dd","impliedFormat":1},{"version":"f40ac11d8859092d20f953aae14ba967282c3bb056431a37fced1866ec7a2681","impliedFormat":1},{"version":"cc11e9e79d4746cc59e0e17473a59d6f104692fd0eeea1bdb2e206eabed83b03","impliedFormat":1},{"version":"b444a410d34fb5e98aa5ee2b381362044f4884652e8bc8a11c8fe14bbd85518e","impliedFormat":1},{"version":"c35808c1f5e16d2c571aa65067e3cb95afeff843b259ecfa2fc107a9519b5392","impliedFormat":1},{"version":"14d5dc055143e941c8743c6a21fa459f961cbc3deedf1bfe47b11587ca4b3ef5","impliedFormat":1},{"version":"a3ad4e1fc542751005267d50a6298e6765928c0c3a8dce1572f2ba6ca518661c","impliedFormat":1},{"version":"f237e7c97a3a89f4591afd49ecb3bd8d14f51a1c4adc8fcae3430febedff5eb6","impliedFormat":1},{"version":"3ffdfbec93b7aed71082af62b8c3e0cc71261cc68d796665faa1e91604fbae8f","impliedFormat":1},{"version":"662201f943ed45b1ad600d03a90dffe20841e725203ced8b708c91fcd7f9379a","impliedFormat":1},{"version":"c9ef74c64ed051ea5b958621e7fb853fe3b56e8787c1587aefc6ea988b3c7e79","impliedFormat":1},{"version":"2462ccfac5f3375794b861abaa81da380f1bbd9401de59ffa43119a0b644253d","impliedFormat":1},{"version":"34baf65cfee92f110d6653322e2120c2d368ee64b3c7981dff08ed105c4f19b0","impliedFormat":1},{"version":"7d8ddf0f021c53099e34ee831a06c394d50371816caa98684812f089b4c6b3d4","impliedFormat":1},{"version":"c6c4fea9acc55d5e38ff2b70d57ab0b5cdbd08f8bc5d7a226e322cea128c5b57","impliedFormat":1},{"version":"9ad8802fd8850d22277c08f5653e69e551a2e003a376ce0afb3fe28474b51d65","impliedFormat":1},{"version":"fdfbe321c556c39a2ecf791d537b999591d0849e971dd938d88f460fea0186f6","impliedFormat":1},{"version":"105b9a2234dcb06ae922f2cd8297201136d416503ff7d16c72bfc8791e9895c1","impliedFormat":1}],"root":[74,75],"options":{"allowImportingTsExtensions":true,"composite":true,"declaration":true,"declarationDir":"../../dts","declarationMap":true,"emitDeclarationOnly":true,"esModuleInterop":true,"module":200,"noImplicitAny":true,"noImplicitThis":true,"rootDir":"../..","skipLibCheck":true,"strictBindCallApply":true,"target":99},"referencedMap":[[188,1],[83,2],[82,3],[181,4],[183,5],[184,6],[194,7],[192,8],[191,9],[193,10],[86,11],[87,11],[127,12],[128,13],[129,14],[130,15],[131,16],[132,17],[133,18],[134,19],[135,20],[136,21],[137,21],[139,22],[138,23],[140,24],[141,25],[142,26],[126,27],[143,28],[144,29],[145,30],[179,31],[146,32],[147,33],[148,34],[149,35],[150,36],[151,37],[152,38],[153,39],[154,40],[155,41],[156,41],[157,42],[160,43],[162,44],[161,45],[163,46],[164,47],[165,48],[166,49],[167,50],[168,51],[169,52],[170,53],[171,54],[172,55],[173,56],[174,57],[175,58],[176,59],[177,60],[224,61],[225,62],[200,63],[203,63],[222,61],[223,61],[213,61],[212,64],[210,61],[205,61],[218,61],[216,61],[220,61],[204,61],[217,61],[221,61],[206,61],[207,61],[219,61],[201,61],[208,61],[209,61],[211,61],[215,61],[226,65],[214,61],[202,61],[239,66],[233,65],[235,67],[234,65],[227,65],[228,65],[230,65],[232,65],[236,67],[237,67],[229,67],[231,67],[243,68],[190,69],[189,10],[104,70],[114,71],[103,70],[124,72],[95,73],[94,74],[123,75],[117,76],[122,77],[97,78],[111,79],[96,80],[120,81],[92,82],[91,83],[121,84],[93,85],[98,86],[102,86],[125,87],[115,88],[106,89],[107,90],[109,91],[105,92],[108,93],[118,75],[100,94],[101,95],[110,96],[90,97],[113,88],[112,86],[119,98],[74,99]],"latestChangedDtsFile":"../../dts/packages/babel-helper-string-parser/src/index.d.ts","version":"5.6.2"}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/LICENSE b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/LICENSE
new file mode 100644
index 0000000..f31575e
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/LICENSE
@@ -0,0 +1,22 @@
+MIT License
+
+Copyright (c) 2014-present Sebastian McKenzie and other contributors
+
+Permission is hereby granted, free of charge, to any person obtaining
+a copy of this software and associated documentation files (the
+"Software"), to deal in the Software without restriction, including
+without limitation the rights to use, copy, modify, merge, publish,
+distribute, sublicense, and/or sell copies of the Software, and to
+permit persons to whom the Software is furnished to do so, subject to
+the following conditions:
+
+The above copyright notice and this permission notice shall be
+included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
+LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
+WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/README.md b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/README.md
new file mode 100644
index 0000000..05c19e6
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/README.md
@@ -0,0 +1,19 @@
+# @babel/helper-validator-identifier
+
+> Validate identifier/keywords name
+
+See our website [@babel/helper-validator-identifier](https://babeljs.io/docs/babel-helper-validator-identifier) for more information.
+
+## Install
+
+Using npm:
+
+```sh
+npm install --save @babel/helper-validator-identifier
+```
+
+or using yarn:
+
+```sh
+yarn add @babel/helper-validator-identifier
+```
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/package.json b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/package.json
new file mode 100644
index 0000000..c7f90c8
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/package.json
@@ -0,0 +1,31 @@
+{
+ "name": "@babel/helper-validator-identifier",
+ "version": "7.25.7",
+ "description": "Validate identifier/keywords name",
+ "repository": {
+ "type": "git",
+ "url": "https://github.com/babel/babel.git",
+ "directory": "packages/babel-helper-validator-identifier"
+ },
+ "license": "MIT",
+ "publishConfig": {
+ "access": "public"
+ },
+ "main": "./lib/index.js",
+ "exports": {
+ ".": {
+ "types": "./lib/index.d.ts",
+ "default": "./lib/index.js"
+ },
+ "./package.json": "./package.json"
+ },
+ "devDependencies": {
+ "@unicode/unicode-16.0.0": "^1.0.0",
+ "charcodes": "^0.2.0"
+ },
+ "engines": {
+ "node": ">=6.9.0"
+ },
+ "author": "The Babel Team (https://babel.dev/team)",
+ "type": "commonjs"
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/scripts/generate-identifier-regex.cjs b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/scripts/generate-identifier-regex.cjs
new file mode 100644
index 0000000..62b16e6
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/scripts/generate-identifier-regex.cjs
@@ -0,0 +1,73 @@
+"use strict";
+
+// Always use the latest available version of Unicode!
+// https://tc39.github.io/ecma262/#sec-conformance
+const version = "16.0.0";
+
+const start = require(
+ "@unicode/unicode-" + version + "/Binary_Property/ID_Start/code-points.js"
+).filter(function (ch) {
+ return ch > 0x7f;
+});
+let last = -1;
+const cont = require(
+ "@unicode/unicode-" + version + "/Binary_Property/ID_Continue/code-points.js"
+).filter(function (ch) {
+ return ch > 0x7f && search(start, ch, last + 1) === -1;
+});
+
+function search(arr, ch, starting) {
+ for (let i = starting; arr[i] <= ch && i < arr.length; last = i++) {
+ if (arr[i] === ch) return i;
+ }
+ return -1;
+}
+
+function pad(str, width) {
+ while (str.length < width) str = "0" + str;
+ return str;
+}
+
+function esc(code) {
+ const hex = code.toString(16);
+ if (hex.length <= 2) return "\\x" + pad(hex, 2);
+ else return "\\u" + pad(hex, 4);
+}
+
+function generate(chars) {
+ const astral = [];
+ let re = "";
+ for (let i = 0, at = 0x10000; i < chars.length; i++) {
+ const from = chars[i];
+ let to = from;
+ while (i < chars.length - 1 && chars[i + 1] === to + 1) {
+ i++;
+ to++;
+ }
+ if (to <= 0xffff) {
+ if (from === to) re += esc(from);
+ else if (from + 1 === to) re += esc(from) + esc(to);
+ else re += esc(from) + "-" + esc(to);
+ } else {
+ astral.push(from - at, to - from);
+ at = to;
+ }
+ }
+ return { nonASCII: re, astral: astral };
+}
+
+const startData = generate(start);
+const contData = generate(cont);
+
+console.log("/* prettier-ignore */");
+console.log('let nonASCIIidentifierStartChars = "' + startData.nonASCII + '";');
+console.log("/* prettier-ignore */");
+console.log('let nonASCIIidentifierChars = "' + contData.nonASCII + '";');
+console.log("/* prettier-ignore */");
+console.log(
+ "const astralIdentifierStartCodes = " + JSON.stringify(startData.astral) + ";"
+);
+console.log("/* prettier-ignore */");
+console.log(
+ "const astralIdentifierCodes = " + JSON.stringify(contData.astral) + ";"
+);
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/tsconfig.json b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/tsconfig.json
new file mode 100644
index 0000000..394a919
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/tsconfig.json
@@ -0,0 +1,13 @@
+/* This file is automatically generated by scripts/generators/tsconfig.js */
+{
+ "extends": [
+ "../../tsconfig.base.json",
+ "../../tsconfig.paths.json"
+ ],
+ "include": [
+ "../../packages/babel-helper-validator-identifier/src/**/*.ts",
+ "../../lib/globals.d.ts",
+ "../../scripts/repo-utils/*.d.ts"
+ ],
+ "references": []
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/tsconfig.tsbuildinfo b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/tsconfig.tsbuildinfo
new file mode 100644
index 0000000..1ea689c
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/helper-validator-identifier/tsconfig.tsbuildinfo
@@ -0,0 +1 @@
+{"fileNames":["../../node_modules/typescript/lib/lib.es5.d.ts","../../node_modules/typescript/lib/lib.es2015.d.ts","../../node_modules/typescript/lib/lib.es2016.d.ts","../../node_modules/typescript/lib/lib.es2017.d.ts","../../node_modules/typescript/lib/lib.es2018.d.ts","../../node_modules/typescript/lib/lib.es2019.d.ts","../../node_modules/typescript/lib/lib.es2020.d.ts","../../node_modules/typescript/lib/lib.es2021.d.ts","../../node_modules/typescript/lib/lib.es2022.d.ts","../../node_modules/typescript/lib/lib.es2023.d.ts","../../node_modules/typescript/lib/lib.esnext.d.ts","../../node_modules/typescript/lib/lib.es2015.core.d.ts","../../node_modules/typescript/lib/lib.es2015.collection.d.ts","../../node_modules/typescript/lib/lib.es2015.generator.d.ts","../../node_modules/typescript/lib/lib.es2015.iterable.d.ts","../../node_modules/typescript/lib/lib.es2015.promise.d.ts","../../node_modules/typescript/lib/lib.es2015.proxy.d.ts","../../node_modules/typescript/lib/lib.es2015.reflect.d.ts","../../node_modules/typescript/lib/lib.es2015.symbol.d.ts","../../node_modules/typescript/lib/lib.es2015.symbol.wellknown.d.ts","../../node_modules/typescript/lib/lib.es2016.array.include.d.ts","../../node_modules/typescript/lib/lib.es2016.intl.d.ts","../../node_modules/typescript/lib/lib.es2017.date.d.ts","../../node_modules/typescript/lib/lib.es2017.object.d.ts","../../node_modules/typescript/lib/lib.es2017.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2017.string.d.ts","../../node_modules/typescript/lib/lib.es2017.intl.d.ts","../../node_modules/typescript/lib/lib.es2017.typedarrays.d.ts","../../node_modules/typescript/lib/lib.es2018.asyncgenerator.d.ts","../../node_modules/typescript/lib/lib.es2018.asynciterable.d.ts","../../node_modules/typescript/lib/lib.es2018.intl.d.ts","../../node_modules/typescript/lib/lib.es2018.promise.d.ts","../../node_modules/typescript/lib/lib.es2018.regexp.d.ts","../../node_modules/typescript/lib/lib.es2019.array.d.ts","../../node_modules/typescript/lib/lib.es2019.object.d.ts","../../node_modules/typescript/lib/lib.es2019.string.d.ts","../../node_modules/typescript/lib/lib.es2019.symbol.d.ts","../../node_modules/typescript/lib/lib.es2019.intl.d.ts","../../node_modules/typescript/lib/lib.es2020.bigint.d.ts","../../node_modules/typescript/lib/lib.es2020.date.d.ts","../../node_modules/typescript/lib/lib.es2020.promise.d.ts","../../node_modules/typescript/lib/lib.es2020.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2020.string.d.ts","../../node_modules/typescript/lib/lib.es2020.symbol.wellknown.d.ts","../../node_modules/typescript/lib/lib.es2020.intl.d.ts","../../node_modules/typescript/lib/lib.es2020.number.d.ts","../../node_modules/typescript/lib/lib.es2021.promise.d.ts","../../node_modules/typescript/lib/lib.es2021.string.d.ts","../../node_modules/typescript/lib/lib.es2021.weakref.d.ts","../../node_modules/typescript/lib/lib.es2021.intl.d.ts","../../node_modules/typescript/lib/lib.es2022.array.d.ts","../../node_modules/typescript/lib/lib.es2022.error.d.ts","../../node_modules/typescript/lib/lib.es2022.intl.d.ts","../../node_modules/typescript/lib/lib.es2022.object.d.ts","../../node_modules/typescript/lib/lib.es2022.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2022.string.d.ts","../../node_modules/typescript/lib/lib.es2022.regexp.d.ts","../../node_modules/typescript/lib/lib.es2023.array.d.ts","../../node_modules/typescript/lib/lib.es2023.collection.d.ts","../../node_modules/typescript/lib/lib.es2023.intl.d.ts","../../node_modules/typescript/lib/lib.esnext.array.d.ts","../../node_modules/typescript/lib/lib.esnext.collection.d.ts","../../node_modules/typescript/lib/lib.esnext.intl.d.ts","../../node_modules/typescript/lib/lib.esnext.disposable.d.ts","../../node_modules/typescript/lib/lib.esnext.string.d.ts","../../node_modules/typescript/lib/lib.esnext.promise.d.ts","../../node_modules/typescript/lib/lib.esnext.decorators.d.ts","../../node_modules/typescript/lib/lib.esnext.object.d.ts","../../node_modules/typescript/lib/lib.esnext.regexp.d.ts","../../node_modules/typescript/lib/lib.esnext.iterator.d.ts","../../node_modules/typescript/lib/lib.decorators.d.ts","../../node_modules/typescript/lib/lib.decorators.legacy.d.ts","../../node_modules/@types/charcodes/index.d.ts","./src/identifier.ts","./src/keyword.ts","./src/index.ts","../../lib/globals.d.ts","../../node_modules/@types/color-name/index.d.ts","../../node_modules/@types/convert-source-map/index.d.ts","../../node_modules/@types/debug/index.d.ts","../../node_modules/@types/eslint/helpers.d.ts","../../node_modules/@types/estree/index.d.ts","../../node_modules/@types/json-schema/index.d.ts","../../node_modules/@types/eslint/index.d.ts","../../node_modules/@types/eslint-scope/index.d.ts","../../node_modules/@types/fs-readdir-recursive/index.d.ts","../../node_modules/@types/gensync/index.d.ts","../../node_modules/@types/node/assert.d.ts","../../node_modules/@types/node/assert/strict.d.ts","../../node_modules/buffer/index.d.ts","../../node_modules/undici-types/header.d.ts","../../node_modules/undici-types/readable.d.ts","../../node_modules/undici-types/file.d.ts","../../node_modules/undici-types/fetch.d.ts","../../node_modules/undici-types/formdata.d.ts","../../node_modules/undici-types/connector.d.ts","../../node_modules/undici-types/client.d.ts","../../node_modules/undici-types/errors.d.ts","../../node_modules/undici-types/dispatcher.d.ts","../../node_modules/undici-types/global-dispatcher.d.ts","../../node_modules/undici-types/global-origin.d.ts","../../node_modules/undici-types/pool-stats.d.ts","../../node_modules/undici-types/pool.d.ts","../../node_modules/undici-types/handlers.d.ts","../../node_modules/undici-types/balanced-pool.d.ts","../../node_modules/undici-types/agent.d.ts","../../node_modules/undici-types/mock-interceptor.d.ts","../../node_modules/undici-types/mock-agent.d.ts","../../node_modules/undici-types/mock-client.d.ts","../../node_modules/undici-types/mock-pool.d.ts","../../node_modules/undici-types/mock-errors.d.ts","../../node_modules/undici-types/proxy-agent.d.ts","../../node_modules/undici-types/env-http-proxy-agent.d.ts","../../node_modules/undici-types/retry-handler.d.ts","../../node_modules/undici-types/retry-agent.d.ts","../../node_modules/undici-types/api.d.ts","../../node_modules/undici-types/interceptors.d.ts","../../node_modules/undici-types/util.d.ts","../../node_modules/undici-types/cookies.d.ts","../../node_modules/undici-types/patch.d.ts","../../node_modules/undici-types/websocket.d.ts","../../node_modules/undici-types/eventsource.d.ts","../../node_modules/undici-types/filereader.d.ts","../../node_modules/undici-types/diagnostics-channel.d.ts","../../node_modules/undici-types/content-type.d.ts","../../node_modules/undici-types/cache.d.ts","../../node_modules/undici-types/index.d.ts","../../node_modules/@types/node/globals.d.ts","../../node_modules/@types/node/async_hooks.d.ts","../../node_modules/@types/node/buffer.d.ts","../../node_modules/@types/node/child_process.d.ts","../../node_modules/@types/node/cluster.d.ts","../../node_modules/@types/node/console.d.ts","../../node_modules/@types/node/constants.d.ts","../../node_modules/@types/node/crypto.d.ts","../../node_modules/@types/node/dgram.d.ts","../../node_modules/@types/node/diagnostics_channel.d.ts","../../node_modules/@types/node/dns.d.ts","../../node_modules/@types/node/dns/promises.d.ts","../../node_modules/@types/node/domain.d.ts","../../node_modules/@types/node/dom-events.d.ts","../../node_modules/@types/node/events.d.ts","../../node_modules/@types/node/fs.d.ts","../../node_modules/@types/node/fs/promises.d.ts","../../node_modules/@types/node/http.d.ts","../../node_modules/@types/node/http2.d.ts","../../node_modules/@types/node/https.d.ts","../../node_modules/@types/node/inspector.d.ts","../../node_modules/@types/node/module.d.ts","../../node_modules/@types/node/net.d.ts","../../node_modules/@types/node/os.d.ts","../../node_modules/@types/node/path.d.ts","../../node_modules/@types/node/perf_hooks.d.ts","../../node_modules/@types/node/process.d.ts","../../node_modules/@types/node/punycode.d.ts","../../node_modules/@types/node/querystring.d.ts","../../node_modules/@types/node/readline.d.ts","../../node_modules/@types/node/readline/promises.d.ts","../../node_modules/@types/node/repl.d.ts","../../node_modules/@types/node/sea.d.ts","../../node_modules/@types/node/sqlite.d.ts","../../node_modules/@types/node/stream.d.ts","../../node_modules/@types/node/stream/promises.d.ts","../../node_modules/@types/node/stream/consumers.d.ts","../../node_modules/@types/node/stream/web.d.ts","../../node_modules/@types/node/string_decoder.d.ts","../../node_modules/@types/node/test.d.ts","../../node_modules/@types/node/timers.d.ts","../../node_modules/@types/node/timers/promises.d.ts","../../node_modules/@types/node/tls.d.ts","../../node_modules/@types/node/trace_events.d.ts","../../node_modules/@types/node/tty.d.ts","../../node_modules/@types/node/url.d.ts","../../node_modules/@types/node/util.d.ts","../../node_modules/@types/node/v8.d.ts","../../node_modules/@types/node/vm.d.ts","../../node_modules/@types/node/wasi.d.ts","../../node_modules/@types/node/worker_threads.d.ts","../../node_modules/@types/node/zlib.d.ts","../../node_modules/@types/node/globals.global.d.ts","../../node_modules/@types/node/index.d.ts","../../node_modules/@types/minimatch/index.d.ts","../../node_modules/@types/glob/index.d.ts","../../node_modules/@types/istanbul-lib-coverage/index.d.ts","../../node_modules/@types/istanbul-lib-report/index.d.ts","../../node_modules/@types/istanbul-reports/index.d.ts","../../node_modules/@types/jest/node_modules/@jest/expect-utils/build/index.d.ts","../../node_modules/@types/jest/node_modules/chalk/index.d.ts","../../node_modules/@sinclair/typebox/typebox.d.ts","../../node_modules/@jest/schemas/build/index.d.ts","../../node_modules/jest-diff/node_modules/pretty-format/build/index.d.ts","../../node_modules/jest-diff/build/index.d.ts","../../node_modules/@types/jest/node_modules/jest-matcher-utils/build/index.d.ts","../../node_modules/@types/jest/node_modules/expect/build/index.d.ts","../../node_modules/@types/jest/node_modules/pretty-format/build/index.d.ts","../../node_modules/@types/jest/index.d.ts","../../node_modules/@types/jsesc/index.d.ts","../../node_modules/@types/json5/index.d.ts","../../node_modules/@types/lru-cache/index.d.ts","../../node_modules/@types/normalize-package-data/index.d.ts","../../node_modules/@types/resolve/index.d.ts","../../node_modules/@types/semver/classes/semver.d.ts","../../node_modules/@types/semver/functions/parse.d.ts","../../node_modules/@types/semver/functions/valid.d.ts","../../node_modules/@types/semver/functions/clean.d.ts","../../node_modules/@types/semver/functions/inc.d.ts","../../node_modules/@types/semver/functions/diff.d.ts","../../node_modules/@types/semver/functions/major.d.ts","../../node_modules/@types/semver/functions/minor.d.ts","../../node_modules/@types/semver/functions/patch.d.ts","../../node_modules/@types/semver/functions/prerelease.d.ts","../../node_modules/@types/semver/functions/compare.d.ts","../../node_modules/@types/semver/functions/rcompare.d.ts","../../node_modules/@types/semver/functions/compare-loose.d.ts","../../node_modules/@types/semver/functions/compare-build.d.ts","../../node_modules/@types/semver/functions/sort.d.ts","../../node_modules/@types/semver/functions/rsort.d.ts","../../node_modules/@types/semver/functions/gt.d.ts","../../node_modules/@types/semver/functions/lt.d.ts","../../node_modules/@types/semver/functions/eq.d.ts","../../node_modules/@types/semver/functions/neq.d.ts","../../node_modules/@types/semver/functions/gte.d.ts","../../node_modules/@types/semver/functions/lte.d.ts","../../node_modules/@types/semver/functions/cmp.d.ts","../../node_modules/@types/semver/functions/coerce.d.ts","../../node_modules/@types/semver/classes/comparator.d.ts","../../node_modules/@types/semver/classes/range.d.ts","../../node_modules/@types/semver/functions/satisfies.d.ts","../../node_modules/@types/semver/ranges/max-satisfying.d.ts","../../node_modules/@types/semver/ranges/min-satisfying.d.ts","../../node_modules/@types/semver/ranges/to-comparators.d.ts","../../node_modules/@types/semver/ranges/min-version.d.ts","../../node_modules/@types/semver/ranges/valid.d.ts","../../node_modules/@types/semver/ranges/outside.d.ts","../../node_modules/@types/semver/ranges/gtr.d.ts","../../node_modules/@types/semver/ranges/ltr.d.ts","../../node_modules/@types/semver/ranges/intersects.d.ts","../../node_modules/@types/semver/ranges/simplify.d.ts","../../node_modules/@types/semver/ranges/subset.d.ts","../../node_modules/@types/semver/internals/identifiers.d.ts","../../node_modules/@types/semver/index.d.ts","../../node_modules/@types/stack-utils/index.d.ts","../../node_modules/@types/v8flags/index.d.ts","../../node_modules/@types/yargs-parser/index.d.ts","../../node_modules/@types/yargs/index.d.ts"],"fileIdsList":[[189],[82,84],[81,82,83],[142,143,181,182],[184],[185],[191,194],[129,181,187,193],[188,192],[190],[88],[129],[130,135,165],[131,136,142,143,150,162,173],[131,132,142,150],[133,174],[134,135,143,151],[135,162,170],[136,138,142,150],[129,137],[138,139],[142],[140,142],[129,142],[142,143,144,162,173],[142,143,144,157,162,165],[127,178],[127,138,142,145,150,162,173],[142,143,145,146,150,162,170,173],[145,147,162,170,173],[88,89,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180],[142,148],[149,173,178],[138,142,150,162],[151],[152],[129,153],[88,89,129,130,131,132,133,134,135,136,137,138,139,140,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179],[155],[156],[142,157,158],[157,159,174,176],[130,142,162,163,164,165],[130,162,164],[162,163],[165],[166],[88,162],[142,168,169],[168,169],[135,150,162,170],[171],[150,172],[130,145,156,173],[135,174],[162,175],[149,176],[177],[130,135,142,144,153,162,173,176,178],[162,179],[202,241],[202,226,241],[241],[202],[202,227,241],[202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239,240],[227,241],[244],[191],[99,103,173],[99,162,173],[94],[96,99,170,173],[150,170],[181],[94,181],[96,99,150,173],[91,92,95,98,130,142,162,173],[99,106],[91,97],[99,120,121],[95,99,130,165,173,181],[130,181],[120,130,181],[93,94,181],[99],[93,94,95,96,97,98,99,100,101,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,121,122,123,124,125,126],[99,114],[99,106,107],[97,99,107,108],[98],[91,94,99],[99,103,107,108],[103],[97,99,102,173],[91,96,99,106],[130,162],[94,99,120,130,178,181],[73],[74,75]],"fileInfos":[{"version":"44e584d4f6444f58791784f1d530875970993129442a847597db702a073ca68c","affectsGlobalScope":true,"impliedFormat":1},{"version":"45b7ab580deca34ae9729e97c13cfd999df04416a79116c3bfb483804f85ded4","impliedFormat":1},{"version":"3facaf05f0c5fc569c5649dd359892c98a85557e3e0c847964caeb67076f4d75","impliedFormat":1},{"version":"9a68c0c07ae2fa71b44384a839b7b8d81662a236d4b9ac30916718f7510b1b2d","impliedFormat":1},{"version":"5e1c4c362065a6b95ff952c0eab010f04dcd2c3494e813b493ecfd4fcb9fc0d8","impliedFormat":1},{"version":"68d73b4a11549f9c0b7d352d10e91e5dca8faa3322bfb77b661839c42b1ddec7","impliedFormat":1},{"version":"5efce4fc3c29ea84e8928f97adec086e3dc876365e0982cc8479a07954a3efd4","impliedFormat":1},{"version":"feecb1be483ed332fad555aff858affd90a48ab19ba7272ee084704eb7167569","impliedFormat":1},{"version":"5514e54f17d6d74ecefedc73c504eadffdeda79c7ea205cf9febead32d45c4bc","impliedFormat":1},{"version":"27bdc30a0e32783366a5abeda841bc22757c1797de8681bbe81fbc735eeb1c10","impliedFormat":1},{"version":"abee51ebffafd50c07d76be5848a34abfe4d791b5745ef1e5648718722fab924","impliedFormat":1},{"version":"6920e1448680767498a0b77c6a00a8e77d14d62c3da8967b171f1ddffa3c18e4","affectsGlobalScope":true,"impliedFormat":1},{"version":"dc2df20b1bcdc8c2d34af4926e2c3ab15ffe1160a63e58b7e09833f616efff44","affectsGlobalScope":true,"impliedFormat":1},{"version":"515d0b7b9bea2e31ea4ec968e9edd2c39d3eebf4a2d5cbd04e88639819ae3b71","affectsGlobalScope":true,"impliedFormat":1},{"version":"45d8ccb3dfd57355eb29749919142d4321a0aa4df6acdfc54e30433d7176600a","affectsGlobalScope":true,"impliedFormat":1},{"version":"0dc1e7ceda9b8b9b455c3a2d67b0412feab00bd2f66656cd8850e8831b08b537","affectsGlobalScope":true,"impliedFormat":1},{"version":"ce691fb9e5c64efb9547083e4a34091bcbe5bdb41027e310ebba8f7d96a98671","affectsGlobalScope":true,"impliedFormat":1},{"version":"8d697a2a929a5fcb38b7a65594020fcef05ec1630804a33748829c5ff53640d0","affectsGlobalScope":true,"impliedFormat":1},{"version":"4ff2a353abf8a80ee399af572debb8faab2d33ad38c4b4474cff7f26e7653b8d","affectsGlobalScope":true,"impliedFormat":1},{"version":"93495ff27b8746f55d19fcbcdbaccc99fd95f19d057aed1bd2c0cafe1335fbf0","affectsGlobalScope":true,"impliedFormat":1},{"version":"6fc23bb8c3965964be8c597310a2878b53a0306edb71d4b5a4dfe760186bcc01","affectsGlobalScope":true,"impliedFormat":1},{"version":"ea011c76963fb15ef1cdd7ce6a6808b46322c527de2077b6cfdf23ae6f5f9ec7","affectsGlobalScope":true,"impliedFormat":1},{"version":"38f0219c9e23c915ef9790ab1d680440d95419ad264816fa15009a8851e79119","affectsGlobalScope":true,"impliedFormat":1},{"version":"69ab18c3b76cd9b1be3d188eaf8bba06112ebbe2f47f6c322b5105a6fbc45a2e","affectsGlobalScope":true,"impliedFormat":1},{"version":"4738f2420687fd85629c9efb470793bb753709c2379e5f85bc1815d875ceadcd","affectsGlobalScope":true,"impliedFormat":1},{"version":"2f11ff796926e0832f9ae148008138ad583bd181899ab7dd768a2666700b1893","affectsGlobalScope":true,"impliedFormat":1},{"version":"4de680d5bb41c17f7f68e0419412ca23c98d5749dcaaea1896172f06435891fc","affectsGlobalScope":true,"impliedFormat":1},{"version":"9fc46429fbe091ac5ad2608c657201eb68b6f1b8341bd6d670047d32ed0a88fa","affectsGlobalScope":true,"impliedFormat":1},{"version":"ac9538681b19688c8eae65811b329d3744af679e0bdfa5d842d0e32524c73e1c","affectsGlobalScope":true,"impliedFormat":1},{"version":"0a969edff4bd52585473d24995c5ef223f6652d6ef46193309b3921d65dd4376","affectsGlobalScope":true,"impliedFormat":1},{"version":"9e9fbd7030c440b33d021da145d3232984c8bb7916f277e8ffd3dc2e3eae2bdb","affectsGlobalScope":true,"impliedFormat":1},{"version":"811ec78f7fefcabbda4bfa93b3eb67d9ae166ef95f9bff989d964061cbf81a0c","affectsGlobalScope":true,"impliedFormat":1},{"version":"717937616a17072082152a2ef351cb51f98802fb4b2fdabd32399843875974ca","affectsGlobalScope":true,"impliedFormat":1},{"version":"d7e7d9b7b50e5f22c915b525acc5a49a7a6584cf8f62d0569e557c5cfc4b2ac2","affectsGlobalScope":true,"impliedFormat":1},{"version":"71c37f4c9543f31dfced6c7840e068c5a5aacb7b89111a4364b1d5276b852557","affectsGlobalScope":true,"impliedFormat":1},{"version":"576711e016cf4f1804676043e6a0a5414252560eb57de9faceee34d79798c850","affectsGlobalScope":true,"impliedFormat":1},{"version":"89c1b1281ba7b8a96efc676b11b264de7a8374c5ea1e6617f11880a13fc56dc6","affectsGlobalScope":true,"impliedFormat":1},{"version":"74f7fa2d027d5b33eb0471c8e82a6c87216223181ec31247c357a3e8e2fddc5b","affectsGlobalScope":true,"impliedFormat":1},{"version":"1a94697425a99354df73d9c8291e2ecd4dddd370aed4023c2d6dee6cccb32666","affectsGlobalScope":true,"impliedFormat":1},{"version":"063600664504610fe3e99b717a1223f8b1900087fab0b4cad1496a114744f8df","affectsGlobalScope":true,"impliedFormat":1},{"version":"934019d7e3c81950f9a8426d093458b65d5aff2c7c1511233c0fd5b941e608ab","affectsGlobalScope":true,"impliedFormat":1},{"version":"bf14a426dbbf1022d11bd08d6b8e709a2e9d246f0c6c1032f3b2edb9a902adbe","affectsGlobalScope":true,"impliedFormat":1},{"version":"e3f9fc0ec0b96a9e642f11eda09c0be83a61c7b336977f8b9fdb1e9788e925fe","affectsGlobalScope":true,"impliedFormat":1},{"version":"59fb2c069260b4ba00b5643b907ef5d5341b167e7d1dbf58dfd895658bda2867","affectsGlobalScope":true,"impliedFormat":1},{"version":"479553e3779be7d4f68e9f40cdb82d038e5ef7592010100410723ceced22a0f7","affectsGlobalScope":true,"impliedFormat":1},{"version":"368af93f74c9c932edd84c58883e736c9e3d53cec1fe24c0b0ff451f529ceab1","affectsGlobalScope":true,"impliedFormat":1},{"version":"af3dd424cf267428f30ccfc376f47a2c0114546b55c44d8c0f1d57d841e28d74","affectsGlobalScope":true,"impliedFormat":1},{"version":"995c005ab91a498455ea8dfb63aa9f83fa2ea793c3d8aa344be4a1678d06d399","affectsGlobalScope":true,"impliedFormat":1},{"version":"d3d7b04b45033f57351c8434f60b6be1ea71a2dfec2d0a0c3c83badbb0e3e693","affectsGlobalScope":true,"impliedFormat":1},{"version":"956d27abdea9652e8368ce029bb1e0b9174e9678a273529f426df4b3d90abd60","affectsGlobalScope":true,"impliedFormat":1},{"version":"4fa6ed14e98aa80b91f61b9805c653ee82af3502dc21c9da5268d3857772ca05","affectsGlobalScope":true,"impliedFormat":1},{"version":"e6633e05da3ff36e6da2ec170d0d03ccf33de50ca4dc6f5aeecb572cedd162fb","affectsGlobalScope":true,"impliedFormat":1},{"version":"15c1c3d7b2e46e0025417ed6d5f03f419e57e6751f87925ca19dc88297053fe6","affectsGlobalScope":true,"impliedFormat":1},{"version":"8444af78980e3b20b49324f4a16ba35024fef3ee069a0eb67616ea6ca821c47a","affectsGlobalScope":true,"impliedFormat":1},{"version":"caccc56c72713969e1cfe5c3d44e5bab151544d9d2b373d7dbe5a1e4166652be","affectsGlobalScope":true,"impliedFormat":1},{"version":"3287d9d085fbd618c3971944b65b4be57859f5415f495b33a6adc994edd2f004","affectsGlobalScope":true,"impliedFormat":1},{"version":"b4b67b1a91182421f5df999988c690f14d813b9850b40acd06ed44691f6727ad","affectsGlobalScope":true,"impliedFormat":1},{"version":"9d540251809289a05349b70ab5f4b7b99f922af66ab3c39ba56a475dcf95d5ff","affectsGlobalScope":true,"impliedFormat":1},{"version":"436aaf437562f276ec2ddbee2f2cdedac7664c1e4c1d2c36839ddd582eeb3d0a","affectsGlobalScope":true,"impliedFormat":1},{"version":"8e3c06ea092138bf9fa5e874a1fdbc9d54805d074bee1de31b99a11e2fec239d","affectsGlobalScope":true,"impliedFormat":1},{"version":"0b11f3ca66aa33124202c80b70cd203219c3d4460cfc165e0707aa9ec710fc53","affectsGlobalScope":true,"impliedFormat":1},{"version":"6a3f5a0129cc80cf439ab71164334d649b47059a4f5afca90282362407d0c87f","affectsGlobalScope":true,"impliedFormat":1},{"version":"811c71eee4aa0ac5f7adf713323a5c41b0cf6c4e17367a34fbce379e12bbf0a4","affectsGlobalScope":true,"impliedFormat":1},{"version":"51ad4c928303041605b4d7ae32e0c1ee387d43a24cd6f1ebf4a2699e1076d4fa","affectsGlobalScope":true,"impliedFormat":1},{"version":"0a6282c8827e4b9a95f4bf4f5c205673ada31b982f50572d27103df8ceb8013c","affectsGlobalScope":true,"impliedFormat":1},{"version":"ac77cb3e8c6d3565793eb90a8373ee8033146315a3dbead3bde8db5eaf5e5ec6","affectsGlobalScope":true,"impliedFormat":1},{"version":"d4b1d2c51d058fc21ec2629fff7a76249dec2e36e12960ea056e3ef89174080f","affectsGlobalScope":true,"impliedFormat":1},{"version":"2fef54945a13095fdb9b84f705f2b5994597640c46afeb2ce78352fab4cb3279","affectsGlobalScope":true,"impliedFormat":1},{"version":"56e4ed5aab5f5920980066a9409bfaf53e6d21d3f8d020c17e4de584d29600ad","affectsGlobalScope":true,"impliedFormat":1},{"version":"61d6a2092f48af66dbfb220e31eea8b10bc02b6932d6e529005fd2d7b3281290","affectsGlobalScope":true,"impliedFormat":1},{"version":"33358442698bb565130f52ba79bfd3d4d484ac85fe33f3cb1759c54d18201393","affectsGlobalScope":true,"impliedFormat":1},{"version":"782dec38049b92d4e85c1585fbea5474a219c6984a35b004963b00beb1aab538","affectsGlobalScope":true,"impliedFormat":1},{"version":"b7589677bd27b038f8aae8afeb030e554f1d5ff29dc4f45854e2cb7e5095d59a","impliedFormat":1},{"version":"a69a9a388d4b0900f9841d53e1115eeff5369d33ec4e9fbd65de5c6b48d6f1f5","signature":"603a6a23fb575101f92bb7c9d9f70e149b923b0b64b8da3bff10b76dad968f73"},{"version":"ba047e49d1eac4a6da39da7b05c2cd77e498a771b1bddd35760742bf93aa4d0e","signature":"a04503349c00a0421942bb14d5e9eea391fa1633d867b13fe5125f7df8355962"},{"version":"cef698f00f85277f0b2d4beb2fd7a69e9d223afa7c259daf47c4c4c392772473","signature":"e81bb81b21289ef6653935d1dbadedd907b857ada80f9221b260a33e311c9ea1"},{"version":"f0b6690984c3a44b15740ac24bfb63853617731c0f40c87a956ce537c4b50969","affectsGlobalScope":true},{"version":"f0cb4b3ab88193e3e51e9e2622e4c375955003f1f81239d72c5b7a95415dad3e","impliedFormat":1},{"version":"13d94ac3ee5780f99988ae4cce0efd139598ca159553bc0100811eba74fc2351","impliedFormat":1},{"version":"3cf5f191d75bbe7c92f921e5ae12004ac672266e2be2ece69f40b1d6b1b678f9","impliedFormat":1},{"version":"64d4b35c5456adf258d2cf56c341e203a073253f229ef3208fc0d5020253b241","affectsGlobalScope":true,"impliedFormat":1},{"version":"ee7d8894904b465b072be0d2e4b45cf6b887cdba16a467645c4e200982ece7ea","impliedFormat":1},{"version":"f3d8c757e148ad968f0d98697987db363070abada5f503da3c06aefd9d4248c1","impliedFormat":1},{"version":"0c5a621a8cf10464c2020f05c99a86d8ac6875d9e17038cb8522cc2f604d539f","impliedFormat":1},{"version":"e050a0afcdbb269720a900c85076d18e0c1ab73e580202a2bf6964978181222a","impliedFormat":1},{"version":"1d78c35b7e8ce86a188e3e5528cc5d1edfc85187a85177458d26e17c8b48105f","impliedFormat":1},{"version":"bde8c75c442f701f7c428265ecad3da98023b6152db9ca49552304fd19fdba38","impliedFormat":1},{"version":"e142fda89ed689ea53d6f2c93693898464c7d29a0ae71c6dc8cdfe5a1d76c775","impliedFormat":1},{"version":"7394959e5a741b185456e1ef5d64599c36c60a323207450991e7a42e08911419","impliedFormat":1},{"version":"4967529644e391115ca5592184d4b63980569adf60ee685f968fd59ab1557188","impliedFormat":1},{"version":"5929864ce17fba74232584d90cb721a89b7ad277220627cc97054ba15a98ea8f","impliedFormat":1},{"version":"24bd580b5743dc56402c440dc7f9a4f5d592ad7a419f25414d37a7bfe11e342b","impliedFormat":1},{"version":"25c8056edf4314820382a5fdb4bb7816999acdcb929c8f75e3f39473b87e85bc","impliedFormat":1},{"version":"c464d66b20788266e5353b48dc4aa6bc0dc4a707276df1e7152ab0c9ae21fad8","impliedFormat":1},{"version":"78d0d27c130d35c60b5e5566c9f1e5be77caf39804636bc1a40133919a949f21","impliedFormat":1},{"version":"c6fd2c5a395f2432786c9cb8deb870b9b0e8ff7e22c029954fabdd692bff6195","impliedFormat":1},{"version":"1d6e127068ea8e104a912e42fc0a110e2aa5a66a356a917a163e8cf9a65e4a75","impliedFormat":1},{"version":"5ded6427296cdf3b9542de4471d2aa8d3983671d4cac0f4bf9c637208d1ced43","impliedFormat":1},{"version":"6bdc71028db658243775263e93a7db2fd2abfce3ca569c3cca5aee6ed5eb186d","impliedFormat":1},{"version":"cadc8aced301244057c4e7e73fbcae534b0f5b12a37b150d80e5a45aa4bebcbd","impliedFormat":1},{"version":"385aab901643aa54e1c36f5ef3107913b10d1b5bb8cbcd933d4263b80a0d7f20","impliedFormat":1},{"version":"9670d44354bab9d9982eca21945686b5c24a3f893db73c0dae0fd74217a4c219","impliedFormat":1},{"version":"0b8a9268adaf4da35e7fa830c8981cfa22adbbe5b3f6f5ab91f6658899e657a7","impliedFormat":1},{"version":"11396ed8a44c02ab9798b7dca436009f866e8dae3c9c25e8c1fbc396880bf1bb","impliedFormat":1},{"version":"ba7bc87d01492633cb5a0e5da8a4a42a1c86270e7b3d2dea5d156828a84e4882","impliedFormat":1},{"version":"4893a895ea92c85345017a04ed427cbd6a1710453338df26881a6019432febdd","impliedFormat":1},{"version":"c21dc52e277bcfc75fac0436ccb75c204f9e1b3fa5e12729670910639f27343e","impliedFormat":1},{"version":"13f6f39e12b1518c6650bbb220c8985999020fe0f21d818e28f512b7771d00f9","impliedFormat":1},{"version":"9b5369969f6e7175740bf51223112ff209f94ba43ecd3bb09eefff9fd675624a","impliedFormat":1},{"version":"4fe9e626e7164748e8769bbf74b538e09607f07ed17c2f20af8d680ee49fc1da","impliedFormat":1},{"version":"24515859bc0b836719105bb6cc3d68255042a9f02a6022b3187948b204946bd2","impliedFormat":1},{"version":"ea0148f897b45a76544ae179784c95af1bd6721b8610af9ffa467a518a086a43","impliedFormat":1},{"version":"24c6a117721e606c9984335f71711877293a9651e44f59f3d21c1ea0856f9cc9","impliedFormat":1},{"version":"dd3273ead9fbde62a72949c97dbec2247ea08e0c6952e701a483d74ef92d6a17","impliedFormat":1},{"version":"405822be75ad3e4d162e07439bac80c6bcc6dbae1929e179cf467ec0b9ee4e2e","impliedFormat":1},{"version":"0db18c6e78ea846316c012478888f33c11ffadab9efd1cc8bcc12daded7a60b6","impliedFormat":1},{"version":"4d2b0eb911816f66abe4970898f97a2cfc902bcd743cbfa5017fad79f7ef90d8","impliedFormat":1},{"version":"bd0532fd6556073727d28da0edfd1736417a3f9f394877b6d5ef6ad88fba1d1a","impliedFormat":1},{"version":"89167d696a849fce5ca508032aabfe901c0868f833a8625d5a9c6e861ef935d2","impliedFormat":1},{"version":"e53a3c2a9f624d90f24bf4588aacd223e7bec1b9d0d479b68d2f4a9e6011147f","impliedFormat":1},{"version":"24b8685c62562f5d98615c5a0c1d05f297cf5065f15246edfe99e81ec4c0e011","impliedFormat":1},{"version":"93507c745e8f29090efb99399c3f77bec07db17acd75634249dc92f961573387","impliedFormat":1},{"version":"339dc5265ee5ed92e536a93a04c4ebbc2128f45eeec6ed29f379e0085283542c","impliedFormat":1},{"version":"4732aec92b20fb28c5fe9ad99521fb59974289ed1e45aecb282616202184064f","impliedFormat":1},{"version":"2e85db9e6fd73cfa3d7f28e0ab6b55417ea18931423bd47b409a96e4a169e8e6","impliedFormat":1},{"version":"c46e079fe54c76f95c67fb89081b3e399da2c7d109e7dca8e4b58d83e332e605","impliedFormat":1},{"version":"bf67d53d168abc1298888693338cb82854bdb2e69ef83f8a0092093c2d562107","impliedFormat":1},{"version":"964f307d249df0d7e8eb16d594536c0ac6cc63c8d467edf635d05542821dec8e","affectsGlobalScope":true,"impliedFormat":1},{"version":"db3ec8993b7596a4ef47f309c7b25ee2505b519c13050424d9c34701e5973315","impliedFormat":1},{"version":"6a1ebd564896d530364f67b3257c62555b61d60494a73dfe8893274878c6589d","affectsGlobalScope":true,"impliedFormat":1},{"version":"af49b066a76ce26673fe49d1885cc6b44153f1071ed2d952f2a90fccba1095c9","impliedFormat":1},{"version":"f22fd1dc2df53eaf5ce0ff9e0a3326fc66f880d6a652210d50563ae72625455f","impliedFormat":1},{"version":"3ddbdb519e87a7827c4f0c4007013f3628ca0ebb9e2b018cf31e5b2f61c593f1","affectsGlobalScope":true,"impliedFormat":1},{"version":"a40826e8476694e90da94aa008283a7de50d1dafd37beada623863f1901cb7fb","impliedFormat":1},{"version":"6d498d4fd8036ea02a4edcae10375854a0eb1df0496cf0b9d692577d3c0fd603","affectsGlobalScope":true,"impliedFormat":1},{"version":"24642567d3729bcc545bacb65ee7c0db423400c7f1ef757cab25d05650064f98","impliedFormat":1},{"version":"fd09b892597ab93e7f79745ce725a3aaf6dd005e8db20f0c63a5d10984cba328","impliedFormat":1},{"version":"a3be878ff1e1964ab2dc8e0a3b67087cf838731c7f3d8f603337e7b712fdd558","impliedFormat":1},{"version":"5433f7f77cd1fd53f45bd82445a4e437b2f6a72a32070e907530a4fea56c30c8","impliedFormat":1},{"version":"9be74296ee565af0c12d7071541fdd23260f53c3da7731fb6361f61150a791f6","impliedFormat":1},{"version":"ee1ee365d88c4c6c0c0a5a5701d66ebc27ccd0bcfcfaa482c6e2e7fe7b98edf7","affectsGlobalScope":true,"impliedFormat":1},{"version":"f501a53b94ba382d9ba396a5c486969a3abc68309828fa67f916035f5d37fe2b","affectsGlobalScope":true,"impliedFormat":1},{"version":"aa658b5d765f630c312ac9202d110bbaf2b82d180376457f0a9d57b42629714a","impliedFormat":1},{"version":"312ac7cbd070107766a9886fd27f9faad997ef57d93fdfb4095df2c618ac8162","impliedFormat":1},{"version":"2e9b4e7f9942af902eb85bae6066d04ef1afee51d61554a62d144df3da7dec94","impliedFormat":1},{"version":"672ad3045f329e94002256f8ed460cfd06173a50c92cde41edaadfacffd16808","impliedFormat":1},{"version":"64da4965d1e0559e134d9c1621ae400279a216f87ed00c4cce4f2c7c78021712","impliedFormat":1},{"version":"2205527b976f4f1844adc46a3f0528729fb68cac70027a5fb13c49ca23593797","impliedFormat":1},{"version":"0166fce1204d520fdfd6b5febb3cda3deee438bcbf8ce9ffeb2b1bcde7155346","affectsGlobalScope":true,"impliedFormat":1},{"version":"d8b13eab85b532285031b06a971fa051bf0175d8fff68065a24a6da9c1c986cf","impliedFormat":1},{"version":"50c382ba1827988c59aa9cc9d046e386d55d70f762e9e352e95ee8cb7337cdb8","impliedFormat":1},{"version":"bb9627ab9d078c79bb5623de4ac8e5d08f806ec9b970962dfc83b3211373690d","impliedFormat":1},{"version":"21d7e87f271e72d02f8d167edc902f90b04525edc7918f00f01dd0bd00599f7e","affectsGlobalScope":true,"impliedFormat":1},{"version":"6f6abdaf8764ef01a552a958f45e795b5e79153b87ddad3af5264b86d2681b72","affectsGlobalScope":true,"impliedFormat":1},{"version":"a215554477f7629e3dcbc8cde104bec036b78673650272f5ffdc5a2cee399a0a","impliedFormat":1},{"version":"c3497fc242aabfedcd430b5932412f94f157b5906568e737f6a18cc77b36a954","impliedFormat":1},{"version":"cdc1de3b672f9ef03ff15c443aa1b631edca35b6ae6970a7da6400647ff74d95","impliedFormat":1},{"version":"139ad1dc93a503da85b7a0d5f615bddbae61ad796bc68fedd049150db67a1e26","impliedFormat":1},{"version":"bf01fdd3b93cf633b3f7420718457af19c57ab8cbfea49268df60bae2e84d627","impliedFormat":1},{"version":"15c5e91b5f08be34a78e3d976179bf5b7a9cc28dc0ef1ffebffeb3c7812a2dca","impliedFormat":1},{"version":"5f461d6f5d9ff474f1121cc3fd86aa3cd67476c701f55c306d323c5112201207","impliedFormat":1},{"version":"65b39cc6b610a4a4aecc321f6efb436f10c0509d686124795b4c36a5e915b89e","impliedFormat":1},{"version":"269929a24b2816343a178008ac9ae9248304d92a8ba8e233055e0ed6dbe6ef71","impliedFormat":1},{"version":"93452d394fdd1dc551ec62f5042366f011a00d342d36d50793b3529bfc9bd633","impliedFormat":1},{"version":"83fe38aa2243059ea859325c006da3964ead69b773429fe049ebb0426e75424d","affectsGlobalScope":true,"impliedFormat":1},{"version":"d3edb86744e2c19f2c1503849ac7594a5e06024f2451bacae032390f2e20314a","impliedFormat":1},{"version":"e501cbca25bd54f0bcb89c00f092d3cae227e970b93fd76207287fd8110b123d","affectsGlobalScope":true,"impliedFormat":1},{"version":"8a3e61347b8f80aa5af532094498bceb0c0b257b25a6aa8ab4880fd6ed57c95a","affectsGlobalScope":true,"impliedFormat":1},{"version":"98e00f3613402504bc2a2c9a621800ab48e0a463d1eed062208a4ae98ad8f84c","impliedFormat":1},{"version":"950f6810f7c80e0cffefcf1bcc6ade3485c94394720e334c3c2be3c16b6922fb","impliedFormat":1},{"version":"5475df7cfc493a08483c9d7aa61cc04791aecba9d0a2efc213f23c4006d4d3cd","impliedFormat":1},{"version":"000720870b275764c65e9f28ac97cc9e4d9e4a36942d4750ca8603e416e9c57c","impliedFormat":1},{"version":"54412c70bacb9ed547ed6caae8836f712a83ccf58d94466f3387447ec4e82dc3","affectsGlobalScope":true,"impliedFormat":1},{"version":"e74e7b0baa7a24f073080091427d36a75836d584b9393e6ac2b1daf1647fe65a","affectsGlobalScope":true,"impliedFormat":1},{"version":"4c48e931a72f6971b5add7fdb1136be1d617f124594e94595f7114af749395e0","impliedFormat":1},{"version":"478eb5c32250678a906d91e0529c70243fc4d75477a08f3da408e2615396f558","impliedFormat":1},{"version":"e686a88c9ee004c8ba12ffc9d674ca3192a4c50ed0ca6bd5b2825c289e2b2bfe","impliedFormat":1},{"version":"0d27932df2fbc3728e78b98892540e24084424ce12d3bd32f62a23cf307f411f","affectsGlobalScope":true,"impliedFormat":1},{"version":"4423fb3d6abe6eefb8d7f79eb2df9510824a216ec1c6feee46718c9b18e6d89f","impliedFormat":1},{"version":"ab9b9a36e5284fd8d3bf2f7d5fcbc60052f25f27e4d20954782099282c60d23e","affectsGlobalScope":true,"impliedFormat":1},{"version":"01c47d1c006b3a15b51d89d7764fff7e4fabc4e412b3a61ee5357bd74b822879","impliedFormat":1},{"version":"8841e2aa774b89bd23302dede20663306dc1b9902431ac64b24be8b8d0e3f649","impliedFormat":1},{"version":"fd326577c62145816fe1acc306c734c2396487f76719d3785d4e825b34540b33","impliedFormat":1},{"version":"9e951ec338c4232d611552a1be7b4ecec79a8c2307a893ce39701316fe2374bd","impliedFormat":1},{"version":"70c61ff569aabdf2b36220da6c06caaa27e45cd7acac81a1966ab4ee2eadc4f2","impliedFormat":1},{"version":"905c3e8f7ddaa6c391b60c05b2f4c3931d7127ad717a080359db3df510b7bdab","impliedFormat":1},{"version":"6c1e688f95fcaf53b1e41c0fdadf2c1cfc96fa924eaf7f9fdb60f96deb0a4986","impliedFormat":1},{"version":"0d14fa22c41fdc7277e6f71473b20ebc07f40f00e38875142335d5b63cdfc9d2","impliedFormat":1},{"version":"c085e9aa62d1ae1375794c1fb927a445fa105fed891a7e24edbb1c3300f7384a","impliedFormat":1},{"version":"f315e1e65a1f80992f0509e84e4ae2df15ecd9ef73df975f7c98813b71e4c8da","impliedFormat":1},{"version":"5b9586e9b0b6322e5bfbd2c29bd3b8e21ab9d871f82346cb71020e3d84bae73e","impliedFormat":1},{"version":"3e70a7e67c2cb16f8cd49097360c0309fe9d1e3210ff9222e9dac1f8df9d4fb6","impliedFormat":1},{"version":"ab68d2a3e3e8767c3fba8f80de099a1cfc18c0de79e42cb02ae66e22dfe14a66","impliedFormat":1},{"version":"6d969939c4a63f70f2aa49e88da6f64b655c8e6799612807bef41ccff6ea0da9","impliedFormat":1},{"version":"5b9586e9b0b6322e5bfbd2c29bd3b8e21ab9d871f82346cb71020e3d84bae73e","impliedFormat":1},{"version":"46894b2a21a60f8449ca6b2b7223b7179bba846a61b1434bed77b34b2902c306","affectsGlobalScope":true,"impliedFormat":1},{"version":"84a805c22a49922085dc337ca71ac0b85aad6d4dba6b01cee5bd5776ff54df39","impliedFormat":1},{"version":"96d14f21b7652903852eef49379d04dbda28c16ed36468f8c9fa08f7c14c9538","impliedFormat":1},{"version":"6d727c1f6a7122c04e4f7c164c5e6f460c21ada618856894cdaa6ac25e95f38c","impliedFormat":1},{"version":"22293bd6fa12747929f8dfca3ec1684a3fe08638aa18023dd286ab337e88a592","impliedFormat":1},{"version":"8baa5d0febc68db886c40bf341e5c90dc215a90cd64552e47e8184be6b7e3358","impliedFormat":1},{"version":"cf3d384d082b933d987c4e2fe7bfb8710adfd9dc8155190056ed6695a25a559e","impliedFormat":1},{"version":"9871b7ee672bc16c78833bdab3052615834b08375cb144e4d2cba74473f4a589","impliedFormat":1},{"version":"c863198dae89420f3c552b5a03da6ed6d0acfa3807a64772b895db624b0de707","impliedFormat":1},{"version":"8b03a5e327d7db67112ebbc93b4f744133eda2c1743dbb0a990c61a8007823ef","impliedFormat":1},{"version":"86c73f2ee1752bac8eeeece234fd05dfcf0637a4fbd8032e4f5f43102faa8eec","impliedFormat":1},{"version":"42fad1f540271e35ca37cecda12c4ce2eef27f0f5cf0f8dd761d723c744d3159","impliedFormat":1},{"version":"ff3743a5de32bee10906aff63d1de726f6a7fd6ee2da4b8229054dfa69de2c34","impliedFormat":1},{"version":"83acd370f7f84f203e71ebba33ba61b7f1291ca027d7f9a662c6307d74e4ac22","impliedFormat":1},{"version":"1445cec898f90bdd18b2949b9590b3c012f5b7e1804e6e329fb0fe053946d5ec","impliedFormat":1},{"version":"0e5318ec2275d8da858b541920d9306650ae6ac8012f0e872fe66eb50321a669","impliedFormat":1},{"version":"cf530297c3fb3a92ec9591dd4fa229d58b5981e45fe6702a0bd2bea53a5e59be","impliedFormat":1},{"version":"c1f6f7d08d42148ddfe164d36d7aba91f467dbcb3caa715966ff95f55048b3a4","impliedFormat":1},{"version":"f4e9bf9103191ef3b3612d3ec0044ca4044ca5be27711fe648ada06fad4bcc85","impliedFormat":1},{"version":"0c1ee27b8f6a00097c2d6d91a21ee4d096ab52c1e28350f6362542b55380059a","impliedFormat":1},{"version":"7677d5b0db9e020d3017720f853ba18f415219fb3a9597343b1b1012cfd699f7","impliedFormat":1},{"version":"bc1c6bc119c1784b1a2be6d9c47addec0d83ef0d52c8fbe1f14a51b4dfffc675","impliedFormat":1},{"version":"52cf2ce99c2a23de70225e252e9822a22b4e0adb82643ab0b710858810e00bf1","impliedFormat":1},{"version":"770625067bb27a20b9826255a8d47b6b5b0a2d3dfcbd21f89904c731f671ba77","impliedFormat":1},{"version":"d1ed6765f4d7906a05968fb5cd6d1db8afa14dbe512a4884e8ea5c0f5e142c80","impliedFormat":1},{"version":"799c0f1b07c092626cf1efd71d459997635911bb5f7fc1196efe449bba87e965","impliedFormat":1},{"version":"2a184e4462b9914a30b1b5c41cf80c6d3428f17b20d3afb711fff3f0644001fd","impliedFormat":1},{"version":"9eabde32a3aa5d80de34af2c2206cdc3ee094c6504a8d0c2d6d20c7c179503cc","impliedFormat":1},{"version":"397c8051b6cfcb48aa22656f0faca2553c5f56187262135162ee79d2b2f6c966","impliedFormat":1},{"version":"a8ead142e0c87dcd5dc130eba1f8eeed506b08952d905c47621dc2f583b1bff9","impliedFormat":1},{"version":"a02f10ea5f73130efca046429254a4e3c06b5475baecc8f7b99a0014731be8b3","impliedFormat":1},{"version":"c2576a4083232b0e2d9bd06875dd43d371dee2e090325a9eac0133fd5650c1cb","impliedFormat":1},{"version":"4c9a0564bb317349de6a24eb4efea8bb79898fa72ad63a1809165f5bd42970dd","impliedFormat":1},{"version":"f40ac11d8859092d20f953aae14ba967282c3bb056431a37fced1866ec7a2681","impliedFormat":1},{"version":"cc11e9e79d4746cc59e0e17473a59d6f104692fd0eeea1bdb2e206eabed83b03","impliedFormat":1},{"version":"b444a410d34fb5e98aa5ee2b381362044f4884652e8bc8a11c8fe14bbd85518e","impliedFormat":1},{"version":"c35808c1f5e16d2c571aa65067e3cb95afeff843b259ecfa2fc107a9519b5392","impliedFormat":1},{"version":"14d5dc055143e941c8743c6a21fa459f961cbc3deedf1bfe47b11587ca4b3ef5","impliedFormat":1},{"version":"a3ad4e1fc542751005267d50a6298e6765928c0c3a8dce1572f2ba6ca518661c","impliedFormat":1},{"version":"f237e7c97a3a89f4591afd49ecb3bd8d14f51a1c4adc8fcae3430febedff5eb6","impliedFormat":1},{"version":"3ffdfbec93b7aed71082af62b8c3e0cc71261cc68d796665faa1e91604fbae8f","impliedFormat":1},{"version":"662201f943ed45b1ad600d03a90dffe20841e725203ced8b708c91fcd7f9379a","impliedFormat":1},{"version":"c9ef74c64ed051ea5b958621e7fb853fe3b56e8787c1587aefc6ea988b3c7e79","impliedFormat":1},{"version":"2462ccfac5f3375794b861abaa81da380f1bbd9401de59ffa43119a0b644253d","impliedFormat":1},{"version":"34baf65cfee92f110d6653322e2120c2d368ee64b3c7981dff08ed105c4f19b0","impliedFormat":1},{"version":"7d8ddf0f021c53099e34ee831a06c394d50371816caa98684812f089b4c6b3d4","impliedFormat":1},{"version":"c6c4fea9acc55d5e38ff2b70d57ab0b5cdbd08f8bc5d7a226e322cea128c5b57","impliedFormat":1},{"version":"9ad8802fd8850d22277c08f5653e69e551a2e003a376ce0afb3fe28474b51d65","impliedFormat":1},{"version":"fdfbe321c556c39a2ecf791d537b999591d0849e971dd938d88f460fea0186f6","impliedFormat":1},{"version":"105b9a2234dcb06ae922f2cd8297201136d416503ff7d16c72bfc8791e9895c1","impliedFormat":1}],"root":[[74,77]],"options":{"allowImportingTsExtensions":true,"composite":true,"declaration":true,"declarationDir":"../../dts","declarationMap":true,"emitDeclarationOnly":true,"esModuleInterop":true,"module":200,"noImplicitAny":true,"noImplicitThis":true,"rootDir":"../..","skipLibCheck":true,"strictBindCallApply":true,"target":99},"referencedMap":[[190,1],[85,2],[84,3],[183,4],[185,5],[186,6],[196,7],[194,8],[193,9],[195,10],[88,11],[89,11],[129,12],[130,13],[131,14],[132,15],[133,16],[134,17],[135,18],[136,19],[137,20],[138,21],[139,21],[141,22],[140,23],[142,24],[143,25],[144,26],[128,27],[145,28],[146,29],[147,30],[181,31],[148,32],[149,33],[150,34],[151,35],[152,36],[153,37],[154,38],[155,39],[156,40],[157,41],[158,41],[159,42],[162,43],[164,44],[163,45],[165,46],[166,47],[167,48],[168,49],[169,50],[170,51],[171,52],[172,53],[173,54],[174,55],[175,56],[176,57],[177,58],[178,59],[179,60],[226,61],[227,62],[202,63],[205,63],[224,61],[225,61],[215,61],[214,64],[212,61],[207,61],[220,61],[218,61],[222,61],[206,61],[219,61],[223,61],[208,61],[209,61],[221,61],[203,61],[210,61],[211,61],[213,61],[217,61],[228,65],[216,61],[204,61],[241,66],[235,65],[237,67],[236,65],[229,65],[230,65],[232,65],[234,65],[238,67],[239,67],[231,67],[233,67],[245,68],[192,69],[191,10],[106,70],[116,71],[105,70],[126,72],[97,73],[96,74],[125,75],[119,76],[124,77],[99,78],[113,79],[98,80],[122,81],[94,82],[93,83],[123,84],[95,85],[100,86],[104,86],[127,87],[117,88],[108,89],[109,90],[111,91],[107,92],[110,93],[120,75],[102,94],[103,95],[112,96],[92,97],[115,88],[114,86],[121,98],[74,99],[76,100]],"latestChangedDtsFile":"../../dts/packages/babel-helper-validator-identifier/src/index.d.ts","version":"5.6.2"}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/parser/CHANGELOG.md b/src/MaxKB-1.5.1/node_modules/@babel/parser/CHANGELOG.md
new file mode 100644
index 0000000..b3840ac
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/parser/CHANGELOG.md
@@ -0,0 +1,1073 @@
+# Changelog
+
+> **Tags:**
+> - :boom: [Breaking Change]
+> - :eyeglasses: [Spec Compliance]
+> - :rocket: [New Feature]
+> - :bug: [Bug Fix]
+> - :memo: [Documentation]
+> - :house: [Internal]
+> - :nail_care: [Polish]
+
+> Semver Policy: https://github.com/babel/babel/tree/main/packages/babel-parser#semver
+
+_Note: Gaps between patch versions are faulty, broken or test releases._
+
+See the [Babel Changelog](https://github.com/babel/babel/blob/main/CHANGELOG.md) for the pre-6.8.0 version Changelog.
+
+## 6.17.1 (2017-05-10)
+
+### :bug: Bug Fix
+ * Fix typo in flow spread operator error (Brian Ng)
+ * Fixed invalid number literal parsing ([#473](https://github.com/babel/babylon/pull/473)) (Alex Kuzmenko)
+ * Fix number parser ([#433](https://github.com/babel/babylon/pull/433)) (Alex Kuzmenko)
+ * Ensure non pattern shorthand props are checked for reserved words ([#479](https://github.com/babel/babylon/pull/479)) (Brian Ng)
+ * Remove jsx context when parsing arrow functions ([#475](https://github.com/babel/babylon/pull/475)) (Brian Ng)
+ * Allow super in class properties ([#499](https://github.com/babel/babylon/pull/499)) (Brian Ng)
+ * Allow flow class field to be named constructor ([#510](https://github.com/babel/babylon/pull/510)) (Brian Ng)
+
+## 6.17.0 (2017-04-20)
+
+### :bug: Bug Fix
+ * Cherry-pick #418 to 6.x ([#476](https://github.com/babel/babylon/pull/476)) (Sebastian McKenzie)
+ * Add support for invalid escapes in tagged templates ([#274](https://github.com/babel/babylon/pull/274)) (Kevin Gibbons)
+ * Throw error if new.target is used outside of a function ([#402](https://github.com/babel/babylon/pull/402)) (Brian Ng)
+ * Fix parsing of class properties ([#351](https://github.com/babel/babylon/pull/351)) (Kevin Gibbons)
+ * Fix parsing yield with dynamicImport ([#383](https://github.com/babel/babylon/pull/383)) (Brian Ng)
+ * Ensure consistent start args for parseParenItem ([#386](https://github.com/babel/babylon/pull/386)) (Brian Ng)
+
+## 7.0.0-beta.8 (2017-04-04)
+
+### New Feature
+* Add support for flow type spread (#418) (Conrad Buck)
+* Allow statics in flow interfaces (#427) (Brian Ng)
+
+### Bug Fix
+* Fix predicate attachment to match flow parser (#428) (Brian Ng)
+* Add extra.raw back to JSXText and JSXAttribute (#344) (Alex Rattray)
+* Fix rest parameters with array and objects (#424) (Brian Ng)
+* Fix number parser (#433) (Alex Kuzmenko)
+
+### Docs
+* Fix CONTRIBUTING.md [skip ci] (#432) (Alex Kuzmenko)
+
+### Internal
+* Use babel-register script when running babel smoke tests (#442) (Brian Ng)
+
+## 7.0.0-beta.7 (2017-03-22)
+
+### Spec Compliance
+* Remove babylon plugin for template revision since it's stage-4 (#426) (Henry Zhu)
+
+### Bug Fix
+
+* Fix push-pop logic in flow (#405) (Daniel Tschinder)
+
+## 7.0.0-beta.6 (2017-03-21)
+
+### New Feature
+* Add support for invalid escapes in tagged templates (#274) (Kevin Gibbons)
+
+### Polish
+* Improves error message when super is called outside of constructor (#408) (Arshabh Kumar Agarwal)
+
+### Docs
+
+* [7.0] Moved value field in spec from ObjectMember to ObjectProperty as ObjectMethod's don't have it (#415) [skip ci] (James Browning)
+
+## 7.0.0-beta.5 (2017-03-21)
+
+### Bug Fix
+* Throw error if new.target is used outside of a function (#402) (Brian Ng)
+* Fix parsing of class properties (#351) (Kevin Gibbons)
+
+### Other
+ * Test runner: Detect extra property in 'actual' but not in 'expected'. (#407) (Andy)
+ * Optimize travis builds (#419) (Daniel Tschinder)
+ * Update codecov to 2.0 (#412) (Daniel Tschinder)
+ * Fix spec for ClassMethod: It doesn't have a function, it *is* a function. (#406) [skip ci] (Andy)
+ * Changed Non-existent RestPattern to RestElement which is what is actually parsed (#409) [skip ci] (James Browning)
+ * Upgrade flow to 0.41 (Daniel Tschinder)
+ * Fix watch command (#403) (Brian Ng)
+ * Update yarn lock (Daniel Tschinder)
+ * Fix watch command (#403) (Brian Ng)
+ * chore(package): update flow-bin to version 0.41.0 (#395) (greenkeeper[bot])
+ * Add estree test for correct order of directives (Daniel Tschinder)
+ * Add DoExpression to spec (#364) (Alex Kuzmenko)
+ * Mention cloning of repository in CONTRIBUTING.md (#391) [skip ci] (Sumedh Nimkarde)
+ * Explain how to run only one test (#389) [skip ci] (Aaron Ang)
+
+ ## 7.0.0-beta.4 (2017-03-01)
+
+* Don't consume async when checking for async func decl (#377) (Brian Ng)
+* add `ranges` option [skip ci] (Henry Zhu)
+* Don't parse class properties without initializers when classProperties is disabled and Flow is enabled (#300) (Andrew Levine)
+
+## 7.0.0-beta.3 (2017-02-28)
+
+- [7.0] Change RestProperty/SpreadProperty to RestElement/SpreadElement (#384)
+- Merge changes from 6.x
+
+## 7.0.0-beta.2 (2017-02-20)
+
+- estree: correctly change literals in all cases (#368) (Daniel Tschinder)
+
+## 7.0.0-beta.1 (2017-02-20)
+
+- Fix negative number literal typeannotations (#366) (Daniel Tschinder)
+- Update contributing with more test info [skip ci] (#355) (Brian Ng)
+
+## 7.0.0-beta.0 (2017-02-15)
+
+- Reintroduce Variance node (#333) (Daniel Tschinder)
+- Rename NumericLiteralTypeAnnotation to NumberLiteralTypeAnnotation (#332) (Charles Pick)
+- [7.0] Remove ForAwaitStatement, add await flag to ForOfStatement (#349) (Brandon Dail)
+- chore(package): update ava to version 0.18.0 (#345) (greenkeeper[bot])
+- chore(package): update babel-plugin-istanbul to version 4.0.0 (#350) (greenkeeper[bot])
+- Change location of ObjectTypeIndexer to match flow (#228) (Daniel Tschinder)
+- Rename flow AST Type ExistentialTypeParam to ExistsTypeAnnotation (#322) (Toru Kobayashi)
+- Revert "Temporary rollback for erroring on trailing comma with spread (#154)" (#290) (Daniel Tschinder)
+- Remove classConstructorCall plugin (#291) (Brian Ng)
+- Update yarn.lock (Daniel Tschinder)
+- Update cross-env to 3.x (Daniel Tschinder)
+- [7.0] Remove node 0.10, 0.12 and 5 from Travis (#284) (Sergey Rubanov)
+- Remove `String.fromCodePoint` shim (#279) (Mathias Bynens)
+
+## 6.16.1 (2017-02-23)
+
+### :bug: Regression
+
+- Revert "Fix export default async function to be FunctionDeclaration" ([#375](https://github.com/babel/babylon/pull/375))
+
+Need to modify Babel for this AST node change, so moving to 7.0.
+
+- Revert "Don't parse class properties without initializers when classProperties plugin is disabled, and Flow is enabled" ([#376](https://github.com/babel/babylon/pull/376))
+
+[react-native](https://github.com/facebook/react-native/issues/12542) broke with this so we reverted.
+
+## 6.16.0 (2017-02-23)
+
+### :rocket: New Feature
+
+***ESTree*** compatibility as plugin ([#277](https://github.com/babel/babylon/pull/277)) (Daniel Tschinder)
+
+We finally introduce a new compatibility layer for ESTree. To put babylon into ESTree-compatible mode the new plugin `estree` can be enabled. In this mode the parser will output an AST that is compliant to the specs of [ESTree](https://github.com/estree/estree/)
+
+We highly recommend everyone who uses babylon outside of babel to use this plugin. This will make it much easier for users to switch between different ESTree-compatible parsers. We so far tested several projects with different parsers and exchanged their parser to babylon and in nearly all cases it worked out of the box. Some other estree-compatible parsers include `acorn`, `esprima`, `espree`, `flow-parser`, etc.
+
+To enable `estree` mode simply add the plugin in the config:
+```json
+{
+ "plugins": [ "estree" ]
+}
+```
+
+If you want to migrate your project from non-ESTree mode to ESTree, have a look at our [Readme](https://github.com/babel/babylon/#output), where all deviations are mentioned.
+
+Add a parseExpression public method ([#213](https://github.com/babel/babylon/pull/213)) (jeromew)
+
+Babylon exports a new function to parse a single expression
+
+```js
+import { parseExpression } from 'babylon';
+
+const ast = parseExpression('x || y && z', options);
+```
+
+The returned AST will only consist of the expression. The options are the same as for `parse()`
+
+Add startLine option ([#346](https://github.com/babel/babylon/pull/346)) (Raphael Mu)
+
+A new option was added to babylon allowing to change the initial linenumber for the first line which is usually `1`.
+Changing this for example to `100` will make line `1` of the input source to be marked as line `100`, line `2` as `101`, line `3` as `102`, ...
+
+Function predicate declaration ([#103](https://github.com/babel/babylon/pull/103)) (Panagiotis Vekris)
+
+Added support for function predicates which flow introduced in version 0.33.0
+
+```js
+declare function is_number(x: mixed): boolean %checks(typeof x === "number");
+```
+
+Allow imports in declare module ([#315](https://github.com/babel/babylon/pull/315)) (Daniel Tschinder)
+
+Added support for imports within module declarations which flow introduced in version 0.37.0
+
+```js
+declare module "C" {
+ import type { DT } from "D";
+ declare export type CT = { D: DT };
+}
+```
+
+### :eyeglasses: Spec Compliance
+
+Forbid semicolons after decorators in classes ([#352](https://github.com/babel/babylon/pull/352)) (Kevin Gibbons)
+
+This example now correctly throws an error when there is a semicolon after the decorator:
+
+```js
+class A {
+@a;
+foo(){}
+}
+```
+
+Keywords are not allowed as local specifier ([#307](https://github.com/babel/babylon/pull/307)) (Daniel Tschinder)
+
+Using keywords in imports is not allowed anymore:
+
+```js
+import { default } from "foo";
+import { a as debugger } from "foo";
+```
+
+Do not allow overwritting of primitive types ([#314](https://github.com/babel/babylon/pull/314)) (Daniel Tschinder)
+
+In flow it is now forbidden to overwrite the primitive types `"any"`, `"mixed"`, `"empty"`, `"bool"`, `"boolean"`, `"number"`, `"string"`, `"void"` and `"null"` with your own type declaration.
+
+Disallow import type { type a } from … ([#305](https://github.com/babel/babylon/pull/305)) (Daniel Tschinder)
+
+The following code now correctly throws an error
+
+```js
+import type { type a } from "foo";
+```
+
+Don't parse class properties without initializers when classProperties is disabled and Flow is enabled ([#300](https://github.com/babel/babylon/pull/300)) (Andrew Levine)
+
+Ensure that you enable the `classProperties` plugin in order to enable correct parsing of class properties. Prior to this version it was possible to parse them by enabling the `flow` plugin but this was not intended the behaviour.
+
+If you enable the flow plugin you can only define the type of the class properties, but not initialize them.
+
+Fix export default async function to be FunctionDeclaration ([#324](https://github.com/babel/babylon/pull/324)) (Daniel Tschinder)
+
+Parsing the following code now returns a `FunctionDeclaration` AST node instead of `FunctionExpression`.
+
+```js
+export default async function bar() {};
+```
+
+### :nail_care: Polish
+
+Improve error message on attempt to destructure named import ([#288](https://github.com/babel/babylon/pull/288)) (Brian Ng)
+
+### :bug: Bug Fix
+
+Fix negative number literal typeannotations ([#366](https://github.com/babel/babylon/pull/366)) (Daniel Tschinder)
+
+Ensure takeDecorators is called on exported class ([#358](https://github.com/babel/babylon/pull/358)) (Brian Ng)
+
+ESTree: correctly change literals in all cases ([#368](https://github.com/babel/babylon/pull/368)) (Daniel Tschinder)
+
+Correctly convert RestProperty to Assignable ([#339](https://github.com/babel/babylon/pull/339)) (Daniel Tschinder)
+
+Fix #321 by allowing question marks in type params ([#338](https://github.com/babel/babylon/pull/338)) (Daniel Tschinder)
+
+Fix #336 by correctly setting arrow-param ([#337](https://github.com/babel/babylon/pull/337)) (Daniel Tschinder)
+
+Fix parse error when destructuring `set` with default value ([#317](https://github.com/babel/babylon/pull/317)) (Brian Ng)
+
+Fix ObjectTypeCallProperty static ([#298](https://github.com/babel/babylon/pull/298)) (Dan Harper)
+
+
+### :house: Internal
+
+Fix generator-method-with-computed-name spec ([#360](https://github.com/babel/babylon/pull/360)) (Alex Rattray)
+
+Fix flow type-parameter-declaration test with unintended semantic ([#361](https://github.com/babel/babylon/pull/361)) (Alex Rattray)
+
+Cleanup and splitup parser functions ([#295](https://github.com/babel/babylon/pull/295)) (Daniel Tschinder)
+
+chore(package): update flow-bin to version 0.38.0 ([#313](https://github.com/babel/babylon/pull/313)) (greenkeeper[bot])
+
+Call inner function instead of 1:1 copy to plugin ([#294](https://github.com/babel/babylon/pull/294)) (Daniel Tschinder)
+
+Update eslint-config-babel to the latest version 🚀 ([#299](https://github.com/babel/babylon/pull/299)) (greenkeeper[bot])
+
+Update eslint-config-babel to the latest version 🚀 ([#293](https://github.com/babel/babylon/pull/293)) (greenkeeper[bot])
+
+devDeps: remove eslint-plugin-babel ([#292](https://github.com/babel/babylon/pull/292)) (Kai Cataldo)
+
+Correct indent eslint rule config ([#276](https://github.com/babel/babylon/pull/276)) (Daniel Tschinder)
+
+Fail tests that have expected.json and throws-option ([#285](https://github.com/babel/babylon/pull/285)) (Daniel Tschinder)
+
+### :memo: Documentation
+
+Update contributing with more test info [skip ci] ([#355](https://github.com/babel/babylon/pull/355)) (Brian Ng)
+
+Update API documentation ([#330](https://github.com/babel/babylon/pull/330)) (Timothy Gu)
+
+Added keywords to package.json ([#323](https://github.com/babel/babylon/pull/323)) (Dmytro)
+
+AST spec: fix casing of `RegExpLiteral` ([#318](https://github.com/babel/babylon/pull/318)) (Mathias Bynens)
+
+## 6.15.0 (2017-01-10)
+
+### :eyeglasses: Spec Compliance
+
+Add support for Flow shorthand import type ([#267](https://github.com/babel/babylon/pull/267)) (Jeff Morrison)
+
+This change implements flows new shorthand import syntax
+and where previously you had to write this code:
+
+```js
+import {someValue} from "blah";
+import type {someType} from "blah";
+import typeof {someOtherValue} from "blah";
+```
+
+you can now write it like this:
+
+```js
+import {
+ someValue,
+ type someType,
+ typeof someOtherValue,
+} from "blah";
+```
+
+For more information look at [this](https://github.com/facebook/flow/pull/2890) pull request.
+
+flow: allow leading pipes in all positions ([#256](https://github.com/babel/babylon/pull/256)) (Vladimir Kurchatkin)
+
+This change now allows a leading pipe everywhere types can be used:
+```js
+var f = (x): | 1 | 2 => 1;
+```
+
+Throw error when exporting non-declaration ([#241](https://github.com/babel/babylon/pull/241)) (Kai Cataldo)
+
+Previously babylon parsed the following exports, although they are not valid:
+```js
+export typeof foo;
+export new Foo();
+export function() {};
+export for (;;);
+export while(foo);
+```
+
+### :bug: Bug Fix
+
+Don't set inType flag when parsing property names ([#266](https://github.com/babel/babylon/pull/266)) (Vladimir Kurchatkin)
+
+This fixes parsing of this case:
+
+```js
+const map = {
+ [age <= 17] : 'Too young'
+};
+```
+
+Fix source location for JSXEmptyExpression nodes (fixes #248) ([#249](https://github.com/babel/babylon/pull/249)) (James Long)
+
+The following case produced an invalid AST
+```js
+(): void;
+ static foobar(): void;
+}
+```
+
+Allow keyword in object/class property names with Flow type parameters ([#145](https://github.com/babel/babylon/pull/145)) (Dan Harper)
+
+```js
+class Foo {
+ delete(item: T): T {
+ return item;
+ }
+}
+```
+
+Allow typeAnnotations for yield expressions ([#174](https://github.com/babel/babylon/pull/174))) (Daniel Tschinder)
+
+```js
+function *foo() {
+ const x = (yield 5: any);
+}
+```
+
+### :nail_care: Polish
+
+Annotate more errors with expected token ([#172](https://github.com/babel/babylon/pull/172))) (Moti Zilberman)
+
+```js
+// Unexpected token, expected ; (1:6)
+{ set 1 }
+```
+
+### :house: Internal
+
+Remove kcheck ([#173](https://github.com/babel/babylon/pull/173))) (Daniel Tschinder)
+
+Also run flow, linting, babel tests on separate instances (add back node 0.10)
+
+## v6.11.6 (2016-10-12)
+
+### :bug: Bug Fix/Regression
+
+Fix crash when exporting with destructuring and sparse array ([#170](https://github.com/babel/babylon/pull/170)) (Jeroen Engels)
+
+```js
+// was failing with `Cannot read property 'type' of null` because of null identifiers
+export const { foo: [ ,, qux7 ] } = bar;
+```
+
+## v6.11.5 (2016-10-12)
+
+### :eyeglasses: Spec Compliance
+
+Fix: Check for duplicate named exports in exported destructuring assignments ([#144](https://github.com/babel/babylon/pull/144)) (Kai Cataldo)
+
+```js
+// `foo` has already been exported. Exported identifiers must be unique. (2:20)
+export function foo() {};
+export const { a: [{foo}] } = bar;
+```
+
+Fix: Check for duplicate named exports in exported rest elements/properties ([#164](https://github.com/babel/babylon/pull/164)) (Kai Cataldo)
+
+```js
+// `foo` has already been exported. Exported identifiers must be unique. (2:22)
+export const foo = 1;
+export const [bar, ...foo] = baz;
+```
+
+### :bug: Bug Fix
+
+Fix: Allow identifier `async` for default param in arrow expression ([#165](https://github.com/babel/babylon/pull/165)) (Kai Cataldo)
+
+```js
+// this is ok now
+const test = ({async = true}) => {};
+```
+
+### :nail_care: Polish
+
+Babylon will now print out the token it's expecting if there's a `SyntaxError` ([#150](https://github.com/babel/babylon/pull/150)) (Daniel Tschinder)
+
+```bash
+# So in the case of a missing ending curly (`}`)
+Module build failed: SyntaxError: Unexpected token, expected } (30:0)
+ 28 | }
+ 29 |
+> 30 |
+ | ^
+```
+
+## v6.11.4 (2016-10-03)
+
+Temporary rollback for erroring on trailing comma with spread (#154) (Henry Zhu)
+
+## v6.11.3 (2016-10-01)
+
+### :eyeglasses: Spec Compliance
+
+Add static errors for object rest (#149) ([@danez](https://github.com/danez))
+
+> https://github.com/sebmarkbage/ecmascript-rest-spread
+
+Object rest copies the *rest* of properties from the right hand side `obj` starting from the left to right.
+
+```js
+let { x, y, ...z } = { x: 1, y: 2, z: 3 };
+// x = 1
+// y = 2
+// z = { z: 3 }
+```
+
+#### New Syntax Errors:
+
+**SyntaxError**: The rest element has to be the last element when destructuring (1:10)
+```bash
+> 1 | let { ...x, y, z } = { x: 1, y: 2, z: 3};
+ | ^
+# Previous behavior:
+# x = { x: 1, y: 2, z: 3 }
+# y = 2
+# z = 3
+```
+
+Before, this was just a more verbose way of shallow copying `obj` since it doesn't actually do what you think.
+
+**SyntaxError**: Cannot have multiple rest elements when destructuring (1:13)
+
+```bash
+> 1 | let { x, ...y, ...z } = { x: 1, y: 2, z: 3};
+ | ^
+# Previous behavior:
+# x = 1
+# y = { y: 2, z: 3 }
+# z = { y: 2, z: 3 }
+```
+
+Before y and z would just be the same value anyway so there is no reason to need to have both.
+
+**SyntaxError**: A trailing comma is not permitted after the rest element (1:16)
+
+```js
+let { x, y, ...z, } = obj;
+```
+
+The rationale for this is that the use case for trailing comma is that you can add something at the end without affecting the line above. Since a RestProperty always has to be the last property it doesn't make sense.
+
+---
+
+get / set are valid property names in default assignment (#142) ([@jezell](https://github.com/jezell))
+
+```js
+// valid
+function something({ set = null, get = null }) {}
+```
+
+## v6.11.2 (2016-09-23)
+
+### Bug Fix
+
+- [#139](https://github.com/babel/babylon/issues/139) Don't do the duplicate check if not an identifier (#140) @hzoo
+
+```js
+// regression with duplicate export check
+SyntaxError: ./typography.js: `undefined` has already been exported. Exported identifiers must be unique. (22:13)
+ 20 |
+ 21 | export const { rhythm } = typography;
+> 22 | export const { TypographyStyle } = typography
+```
+
+Bail out for now, and make a change to account for destructuring in the next release.
+
+## 6.11.1 (2016-09-22)
+
+### Bug Fix
+- [#137](https://github.com/babel/babylon/pull/137) - Fix a regression with duplicate exports - it was erroring on all keys in `Object.prototype`. @danez
+
+```javascript
+export toString from './toString';
+```
+
+```bash
+`toString` has already been exported. Exported identifiers must be unique. (1:7)
+> 1 | export toString from './toString';
+ | ^
+ 2 |
+```
+
+## 6.11.0 (2016-09-22)
+
+### Spec Compliance (will break CI)
+
+- Disallow duplicate named exports ([#107](https://github.com/babel/babylon/pull/107)) @kaicataldo
+
+```js
+// Only one default export allowed per module. (2:9)
+export default function() {};
+export { foo as default };
+
+// Only one default export allowed per module. (2:0)
+export default {};
+export default function() {};
+
+// `Foo` has already been exported. Exported identifiers must be unique. (2:0)
+export { Foo };
+export class Foo {};
+```
+
+### New Feature (Syntax)
+
+- Add support for computed class property names ([#121](https://github.com/babel/babylon/pull/121)) @motiz88
+
+```js
+// AST
+interface ClassProperty <: Node {
+ type: "ClassProperty";
+ key: Identifier;
+ value: Expression;
+ computed: boolean; // added
+}
+```
+
+```js
+// with "plugins": ["classProperties"]
+class Foo {
+ [x]
+ ['y']
+}
+
+class Bar {
+ [p]
+ [m] () {}
+}
+ ```
+
+### Bug Fix
+
+- Fix `static` property falling through in the declare class Flow AST ([#135](https://github.com/babel/babylon/pull/135)) @danharper
+
+```js
+declare class X {
+ a: number;
+ static b: number; // static
+ c: number; // this was being marked as static in the AST as well
+}
+```
+
+### Polish
+
+- Rephrase "assigning/binding to rvalue" errors to include context ([#119](https://github.com/babel/babylon/pull/119)) @motiz88
+
+```js
+// Used to error with:
+// SyntaxError: Assigning to rvalue (1:0)
+
+// Now:
+// Invalid left-hand side in assignment expression (1:0)
+3 = 4
+
+// Invalid left-hand side in for-in statement (1:5)
+for (+i in {});
+```
+
+### Internal
+
+- Fix call to `this.parseMaybeAssign` with correct arguments ([#133](https://github.com/babel/babylon/pull/133)) @danez
+- Add semver note to changelog ([#131](https://github.com/babel/babylon/pull/131)) @hzoo
+
+## 6.10.0 (2016-09-19)
+
+> We plan to include some spec compliance bugs in patch versions. An example was the multiple default exports issue.
+
+### Spec Compliance
+
+* Implement ES2016 check for simple parameter list in strict mode ([#106](https://github.com/babel/babylon/pull/106)) (Timothy Gu)
+
+> It is a Syntax Error if ContainsUseStrict of FunctionBody is true and IsSimpleParameterList of FormalParameters is false. https://tc39.github.io/ecma262/2016/#sec-function-definitions-static-semantics-early-errors
+
+More Context: [tc39-notes](https://github.com/rwaldron/tc39-notes/blob/master/es7/2015-07/july-29.md#611-the-scope-of-use-strict-with-respect-to-destructuring-in-parameter-lists)
+
+For example:
+
+```js
+// this errors because it uses destructuring and default parameters
+// in a function with a "use strict" directive
+function a([ option1, option2 ] = []) {
+ "use strict";
+}
+ ```
+
+The solution would be to use a top level "use strict" or to remove the destructuring or default parameters when using a function + "use strict" or to.
+
+### New Feature
+
+* Exact object type annotations for Flow plugin ([#104](https://github.com/babel/babylon/pull/104)) (Basil Hosmer)
+
+Added to flow in https://github.com/facebook/flow/commit/c710c40aa2a115435098d6c0dfeaadb023cd39b8
+
+Looks like:
+
+```js
+var a : {| x: number, y: string |} = { x: 0, y: 'foo' };
+```
+
+### Bug Fixes
+
+* Include `typeParameter` location in `ArrowFunctionExpression` ([#126](https://github.com/babel/babylon/pull/126)) (Daniel Tschinder)
+* Error on invalid flow type annotation with default assignment ([#122](https://github.com/babel/babylon/pull/122)) (Dan Harper)
+* Fix Flow return types on arrow functions ([#124](https://github.com/babel/babylon/pull/124)) (Dan Harper)
+
+### Misc
+
+* Add tests for export extensions ([#127](https://github.com/babel/babylon/pull/127)) (Daniel Tschinder)
+* Fix Contributing guidelines [skip ci] (Daniel Tschinder)
+
+## 6.9.2 (2016-09-09)
+
+The only change is to remove the `babel-runtime` dependency by compiling with Babel's ES2015 loose mode. So using babylon standalone should be smaller.
+
+## 6.9.1 (2016-08-23)
+
+This release contains mainly small bugfixes but also updates babylons default mode to es2017. The features for `exponentiationOperator`, `asyncFunctions` and `trailingFunctionCommas` which previously needed to be activated via plugin are now enabled by default and the plugins are now no-ops.
+
+### Bug Fixes
+
+- Fix issues with default object params in async functions ([#96](https://github.com/babel/babylon/pull/96)) @danez
+- Fix issues with flow-types and async function ([#95](https://github.com/babel/babylon/pull/95)) @danez
+- Fix arrow functions with destructuring, types & default value ([#94](https://github.com/babel/babylon/pull/94)) @danharper
+- Fix declare class with qualified type identifier ([#97](https://github.com/babel/babylon/pull/97)) @danez
+- Remove exponentiationOperator, asyncFunctions, trailingFunctionCommas plugins and enable them by default ([#98](https://github.com/babel/babylon/pull/98)) @danez
+
+## 6.9.0 (2016-08-16)
+
+### New syntax support
+
+- Add JSX spread children ([#42](https://github.com/babel/babylon/pull/42)) @calebmer
+
+(Be aware that React is not going to support this syntax)
+
+```js
+(x: T): T => x;` ([#54](https://github.com/babel/babylon/pull/54)) @gabelevi
+
+### Documentation
+
+- Document AST differences from ESTree ([#41](https://github.com/babel/babylon/pull/41)) @nene
+- Move ast spec from babel/babel ([#46](https://github.com/babel/babylon/pull/46)) @hzoo
+
+### Internal
+
+- Enable skipped tests ([#16](https://github.com/babel/babylon/pull/16)) @danez
+- Add script to test latest version of babylon with babel ([#21](https://github.com/babel/babylon/pull/21)) @danez
+- Upgrade test runner ava @kittens
+- Add missing generate-identifier-regex script @kittens
+- Rename parser context types @kittens
+- Add node v6 to travis testing @hzoo
+- Update to Unicode v9 ([#45](https://github.com/babel/babylon/pull/45)) @mathiasbynens
+
+## 6.8.1 (2016-06-06)
+
+### New Feature
+
+- Parse type parameter declarations with defaults like `type Foo = T`
+
+### Bug Fixes
+- Type parameter declarations need 1 or more type parameters.
+- The existential type `*` is not a valid type parameter.
+- The existential type `*` is a primary type
+
+### Spec Compliance
+- The param list for type parameter declarations now consists of `TypeParameter` nodes
+- New `TypeParameter` AST Node (replaces using the `Identifier` node before)
+
+```
+interface TypeParameter <: Node {
+ bound: TypeAnnotation;
+ default: TypeAnnotation;
+ name: string;
+ variance: "plus" | "minus";
+}
+```
+
+## 6.8.0 (2016-05-02)
+
+#### New Feature
+
+##### Parse Method Parameter Decorators ([#12](https://github.com/babel/babylon/pull/12))
+
+> [Method Parameter Decorators](https://goo.gl/8MmCMG) is now a TC39 [stage 0 proposal](https://github.com/tc39/ecma262/blob/master/stage0.md).
+
+Examples:
+
+```js
+class Foo {
+ constructor(@foo() x, @bar({ a: 123 }) @baz() y) {}
+}
+
+export default function func(@foo() x, @bar({ a: 123 }) @baz() y) {}
+
+var obj = {
+ method(@foo() x, @bar({ a: 123 }) @baz() y) {}
+};
+```
+
+##### Parse for-await statements (w/ `asyncGenerators` plugin) ([#17](https://github.com/babel/babylon/pull/17))
+
+There is also a new node type, `ForAwaitStatement`.
+
+> [Async generators and for-await](https://github.com/tc39/proposal-async-iteration) are now a [stage 2 proposal](https://github.com/tc39/ecma262#current-proposals).
+
+Example:
+
+```js
+async function f() {
+ for await (let x of y);
+}
+```
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/parser/LICENSE b/src/MaxKB-1.5.1/node_modules/@babel/parser/LICENSE
new file mode 100644
index 0000000..d4c7fc5
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/parser/LICENSE
@@ -0,0 +1,19 @@
+Copyright (C) 2012-2014 by various contributors (see AUTHORS)
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/parser/README.md b/src/MaxKB-1.5.1/node_modules/@babel/parser/README.md
new file mode 100644
index 0000000..a9463e8
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/parser/README.md
@@ -0,0 +1,19 @@
+# @babel/parser
+
+> A JavaScript parser
+
+See our website [@babel/parser](https://babeljs.io/docs/babel-parser) for more information or the [issues](https://github.com/babel/babel/issues?utf8=%E2%9C%93&q=is%3Aissue+label%3A%22pkg%3A%20parser%22+is%3Aopen) associated with this package.
+
+## Install
+
+Using npm:
+
+```sh
+npm install --save-dev @babel/parser
+```
+
+or using yarn:
+
+```sh
+yarn add @babel/parser --dev
+```
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/parser/bin/babel-parser.js b/src/MaxKB-1.5.1/node_modules/@babel/parser/bin/babel-parser.js
new file mode 100644
index 0000000..3aca314
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/parser/bin/babel-parser.js
@@ -0,0 +1,15 @@
+#!/usr/bin/env node
+/* eslint no-var: 0 */
+
+var parser = require("..");
+var fs = require("fs");
+
+var filename = process.argv[2];
+if (!filename) {
+ console.error("no filename specified");
+} else {
+ var file = fs.readFileSync(filename, "utf8");
+ var ast = parser.parse(file);
+
+ console.log(JSON.stringify(ast, null, " "));
+}
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/parser/index.cjs b/src/MaxKB-1.5.1/node_modules/@babel/parser/index.cjs
new file mode 100644
index 0000000..89863a9
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/parser/index.cjs
@@ -0,0 +1,5 @@
+try {
+ module.exports = require("./lib/index.cjs");
+} catch {
+ module.exports = require("./lib/index.js");
+}
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/parser/package.json b/src/MaxKB-1.5.1/node_modules/@babel/parser/package.json
new file mode 100644
index 0000000..0f26557
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/parser/package.json
@@ -0,0 +1,50 @@
+{
+ "name": "@babel/parser",
+ "version": "7.25.8",
+ "description": "A JavaScript parser",
+ "author": "The Babel Team (https://babel.dev/team)",
+ "homepage": "https://babel.dev/docs/en/next/babel-parser",
+ "bugs": "https://github.com/babel/babel/issues?utf8=%E2%9C%93&q=is%3Aissue+label%3A%22pkg%3A+parser+%28babylon%29%22+is%3Aopen",
+ "license": "MIT",
+ "publishConfig": {
+ "access": "public"
+ },
+ "keywords": [
+ "babel",
+ "javascript",
+ "parser",
+ "tc39",
+ "ecmascript",
+ "@babel/parser"
+ ],
+ "repository": {
+ "type": "git",
+ "url": "https://github.com/babel/babel.git",
+ "directory": "packages/babel-parser"
+ },
+ "main": "./lib/index.js",
+ "types": "./typings/babel-parser.d.ts",
+ "files": [
+ "bin",
+ "lib",
+ "typings/babel-parser.d.ts",
+ "index.cjs"
+ ],
+ "engines": {
+ "node": ">=6.0.0"
+ },
+ "# dependencies": "This package doesn't actually have runtime dependencies. @babel/types is only needed for type definitions.",
+ "dependencies": {
+ "@babel/types": "^7.25.8"
+ },
+ "devDependencies": {
+ "@babel/code-frame": "^7.25.7",
+ "@babel/helper-check-duplicate-nodes": "^7.25.7",
+ "@babel/helper-fixtures": "^7.25.7",
+ "@babel/helper-string-parser": "^7.25.7",
+ "@babel/helper-validator-identifier": "^7.25.7",
+ "charcodes": "^0.2.0"
+ },
+ "bin": "./bin/babel-parser.js",
+ "type": "commonjs"
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/parser/typings/babel-parser.d.ts b/src/MaxKB-1.5.1/node_modules/@babel/parser/typings/babel-parser.d.ts
new file mode 100644
index 0000000..0730f96
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/parser/typings/babel-parser.d.ts
@@ -0,0 +1,259 @@
+// This file is auto-generated! Do not modify it directly.
+/* eslint-disable @typescript-eslint/consistent-type-imports, @typescript-eslint/no-redundant-type-constituents */
+import * as _babel_types from '@babel/types';
+
+type BABEL_8_BREAKING = false;
+type IF_BABEL_7 = false extends BABEL_8_BREAKING ? V : never;
+
+type Plugin =
+ | "asyncDoExpressions"
+ | IF_BABEL_7<"asyncGenerators">
+ | IF_BABEL_7<"bigInt">
+ | IF_BABEL_7<"classPrivateMethods">
+ | IF_BABEL_7<"classPrivateProperties">
+ | IF_BABEL_7<"classProperties">
+ | IF_BABEL_7<"classStaticBlock">
+ | IF_BABEL_7<"decimal">
+ | "decorators-legacy"
+ | "deferredImportEvaluation"
+ | "decoratorAutoAccessors"
+ | "destructuringPrivate"
+ | "doExpressions"
+ | IF_BABEL_7<"dynamicImport">
+ | "explicitResourceManagement"
+ | "exportDefaultFrom"
+ | IF_BABEL_7<"exportNamespaceFrom">
+ | "flow"
+ | "flowComments"
+ | "functionBind"
+ | "functionSent"
+ | "importMeta"
+ | "jsx"
+ | IF_BABEL_7<"jsonStrings">
+ | IF_BABEL_7<"logicalAssignment">
+ | IF_BABEL_7<"importAssertions">
+ | IF_BABEL_7<"importReflection">
+ | "moduleBlocks"
+ | IF_BABEL_7<"moduleStringNames">
+ | IF_BABEL_7<"nullishCoalescingOperator">
+ | IF_BABEL_7<"numericSeparator">
+ | IF_BABEL_7<"objectRestSpread">
+ | IF_BABEL_7<"optionalCatchBinding">
+ | IF_BABEL_7<"optionalChaining">
+ | "partialApplication"
+ | "placeholders"
+ | IF_BABEL_7<"privateIn">
+ | IF_BABEL_7<"regexpUnicodeSets">
+ | "sourcePhaseImports"
+ | "throwExpressions"
+ | IF_BABEL_7<"topLevelAwait">
+ | "v8intrinsic"
+ | ParserPluginWithOptions[0];
+
+type ParserPluginWithOptions =
+ | ["decorators", DecoratorsPluginOptions]
+ | ["estree", { classFeatures?: boolean }]
+ | ["importAttributes", { deprecatedAssertSyntax: boolean }]
+ | IF_BABEL_7<["moduleAttributes", { version: "may-2020" }]>
+ | ["optionalChainingAssign", { version: "2023-07" }]
+ | ["pipelineOperator", PipelineOperatorPluginOptions]
+ | ["recordAndTuple", RecordAndTuplePluginOptions]
+ | ["flow", FlowPluginOptions]
+ | ["typescript", TypeScriptPluginOptions];
+
+type PluginConfig = Plugin | ParserPluginWithOptions;
+
+interface DecoratorsPluginOptions {
+ decoratorsBeforeExport?: boolean;
+ allowCallParenthesized?: boolean;
+}
+
+interface PipelineOperatorPluginOptions {
+ proposal: BABEL_8_BREAKING extends false
+ ? "minimal" | "fsharp" | "hack" | "smart"
+ : "fsharp" | "hack";
+ topicToken?: "%" | "#" | "@@" | "^^" | "^";
+}
+
+interface RecordAndTuplePluginOptions {
+ syntaxType: "bar" | "hash";
+}
+
+type FlowPluginOptions = BABEL_8_BREAKING extends true
+ ? {
+ all?: boolean;
+ enums?: boolean;
+ }
+ : {
+ all?: boolean;
+ };
+
+interface TypeScriptPluginOptions {
+ dts?: boolean;
+ disallowAmbiguousJSXLike?: boolean;
+}
+
+// Type definitions for @babel/parser
+// Project: https://github.com/babel/babel/tree/main/packages/babel-parser
+// Definitions by: Troy Gerwien
+// Marvin Hagemeister
+// Avi Vahl
+// TypeScript Version: 2.9
+
+/**
+ * Parse the provided code as an entire ECMAScript program.
+ */
+declare function parse(
+ input: string,
+ options?: ParserOptions
+): ParseResult<_babel_types.File>;
+
+/**
+ * Parse the provided code as a single expression.
+ */
+declare function parseExpression(
+ input: string,
+ options?: ParserOptions
+): ParseResult<_babel_types.Expression>;
+
+interface ParserOptions {
+ /**
+ * By default, import and export declarations can only appear at a program's top level.
+ * Setting this option to true allows them anywhere where a statement is allowed.
+ */
+ allowImportExportEverywhere?: boolean;
+
+ /**
+ * By default, await use is not allowed outside of an async function.
+ * Set this to true to accept such code.
+ */
+ allowAwaitOutsideFunction?: boolean;
+
+ /**
+ * By default, a return statement at the top level raises an error.
+ * Set this to true to accept such code.
+ */
+ allowReturnOutsideFunction?: boolean;
+
+ /**
+ * By default, new.target use is not allowed outside of a function or class.
+ * Set this to true to accept such code.
+ */
+ allowNewTargetOutsideFunction?: boolean;
+
+ allowSuperOutsideMethod?: boolean;
+
+ /**
+ * By default, exported identifiers must refer to a declared variable.
+ * Set this to true to allow export statements to reference undeclared variables.
+ */
+ allowUndeclaredExports?: boolean;
+
+ /**
+ * By default, Babel parser JavaScript code according to Annex B syntax.
+ * Set this to `false` to disable such behavior.
+ */
+ annexB?: boolean;
+
+ /**
+ * By default, Babel attaches comments to adjacent AST nodes.
+ * When this option is set to false, comments are not attached.
+ * It can provide up to 30% performance improvement when the input code has many comments.
+ * @babel/eslint-parser will set it for you.
+ * It is not recommended to use attachComment: false with Babel transform,
+ * as doing so removes all the comments in output code, and renders annotations such as
+ * /* istanbul ignore next *\/ nonfunctional.
+ */
+ attachComment?: boolean;
+
+ /**
+ * By default, Babel always throws an error when it finds some invalid code.
+ * When this option is set to true, it will store the parsing error and
+ * try to continue parsing the invalid input file.
+ */
+ errorRecovery?: boolean;
+
+ /**
+ * Indicate the mode the code should be parsed in.
+ * Can be one of "script", "module", or "unambiguous". Defaults to "script".
+ * "unambiguous" will make @babel/parser attempt to guess, based on the presence
+ * of ES6 import or export statements.
+ * Files with ES6 imports and exports are considered "module" and are otherwise "script".
+ */
+ sourceType?: "script" | "module" | "unambiguous";
+
+ /**
+ * Correlate output AST nodes with their source filename.
+ * Useful when generating code and source maps from the ASTs of multiple input files.
+ */
+ sourceFilename?: string;
+
+ /**
+ * By default, the first line of code parsed is treated as line 1.
+ * You can provide a line number to alternatively start with.
+ * Useful for integration with other source tools.
+ */
+ startLine?: number;
+
+ /**
+ * By default, the parsed code is treated as if it starts from line 1, column 0.
+ * You can provide a column number to alternatively start with.
+ * Useful for integration with other source tools.
+ */
+ startColumn?: number;
+
+ /**
+ * Array containing the plugins that you want to enable.
+ */
+ plugins?: ParserPlugin[];
+
+ /**
+ * Should the parser work in strict mode.
+ * Defaults to true if sourceType === 'module'. Otherwise, false.
+ */
+ strictMode?: boolean;
+
+ /**
+ * Adds a ranges property to each node: [node.start, node.end]
+ */
+ ranges?: boolean;
+
+ /**
+ * Adds all parsed tokens to a tokens property on the File node.
+ */
+ tokens?: boolean;
+
+ /**
+ * By default, the parser adds information about parentheses by setting
+ * `extra.parenthesized` to `true` as needed.
+ * When this option is `true` the parser creates `ParenthesizedExpression`
+ * AST nodes instead of using the `extra` property.
+ */
+ createParenthesizedExpressions?: boolean;
+
+ /**
+ * The default is false in Babel 7 and true in Babel 8
+ * Set this to true to parse it as an `ImportExpression` node.
+ * Otherwise `import(foo)` is parsed as `CallExpression(Import, [Identifier(foo)])`.
+ */
+ createImportExpressions?: boolean;
+}
+
+type ParserPlugin = PluginConfig;
+
+
+declare const tokTypes: {
+ // todo(flow->ts) real token type
+ [name: string]: any;
+};
+
+interface ParseError {
+ code: string;
+ reasonCode: string;
+}
+
+type ParseResult = Result & {
+ errors: ParseError[];
+};
+
+export { DecoratorsPluginOptions, FlowPluginOptions, ParseError, ParseResult, ParserOptions, ParserPlugin, ParserPluginWithOptions, PipelineOperatorPluginOptions, RecordAndTuplePluginOptions, TypeScriptPluginOptions, parse, parseExpression, tokTypes };
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/types/LICENSE b/src/MaxKB-1.5.1/node_modules/@babel/types/LICENSE
new file mode 100644
index 0000000..f31575e
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/types/LICENSE
@@ -0,0 +1,22 @@
+MIT License
+
+Copyright (c) 2014-present Sebastian McKenzie and other contributors
+
+Permission is hereby granted, free of charge, to any person obtaining
+a copy of this software and associated documentation files (the
+"Software"), to deal in the Software without restriction, including
+without limitation the rights to use, copy, modify, merge, publish,
+distribute, sublicense, and/or sell copies of the Software, and to
+permit persons to whom the Software is furnished to do so, subject to
+the following conditions:
+
+The above copyright notice and this permission notice shall be
+included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
+EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
+MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
+NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
+LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
+OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
+WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/types/README.md b/src/MaxKB-1.5.1/node_modules/@babel/types/README.md
new file mode 100644
index 0000000..54c9f81
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/types/README.md
@@ -0,0 +1,19 @@
+# @babel/types
+
+> Babel Types is a Lodash-esque utility library for AST nodes
+
+See our website [@babel/types](https://babeljs.io/docs/babel-types) for more information or the [issues](https://github.com/babel/babel/issues?utf8=%E2%9C%93&q=is%3Aissue+label%3A%22pkg%3A%20types%22+is%3Aopen) associated with this package.
+
+## Install
+
+Using npm:
+
+```sh
+npm install --save-dev @babel/types
+```
+
+or using yarn:
+
+```sh
+yarn add @babel/types --dev
+```
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/types/package.json b/src/MaxKB-1.5.1/node_modules/@babel/types/package.json
new file mode 100644
index 0000000..36440a0
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/types/package.json
@@ -0,0 +1,40 @@
+{
+ "name": "@babel/types",
+ "version": "7.25.8",
+ "description": "Babel Types is a Lodash-esque utility library for AST nodes",
+ "author": "The Babel Team (https://babel.dev/team)",
+ "homepage": "https://babel.dev/docs/en/next/babel-types",
+ "bugs": "https://github.com/babel/babel/issues?utf8=%E2%9C%93&q=is%3Aissue+label%3A%22pkg%3A%20types%22+is%3Aopen",
+ "license": "MIT",
+ "publishConfig": {
+ "access": "public"
+ },
+ "repository": {
+ "type": "git",
+ "url": "https://github.com/babel/babel.git",
+ "directory": "packages/babel-types"
+ },
+ "main": "./lib/index.js",
+ "types": "./lib/index-legacy.d.ts",
+ "typesVersions": {
+ ">=4.1": {
+ "lib/index-legacy.d.ts": [
+ "lib/index.d.ts"
+ ]
+ }
+ },
+ "dependencies": {
+ "@babel/helper-string-parser": "^7.25.7",
+ "@babel/helper-validator-identifier": "^7.25.7",
+ "to-fast-properties": "^2.0.0"
+ },
+ "devDependencies": {
+ "@babel/generator": "^7.25.7",
+ "@babel/parser": "^7.25.8",
+ "glob": "^7.2.0"
+ },
+ "engines": {
+ "node": ">=6.9.0"
+ },
+ "type": "commonjs"
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/types/tsconfig.json b/src/MaxKB-1.5.1/node_modules/@babel/types/tsconfig.json
new file mode 100644
index 0000000..4b338ea
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/types/tsconfig.json
@@ -0,0 +1,20 @@
+/* This file is automatically generated by scripts/generators/tsconfig.js */
+{
+ "extends": [
+ "../../tsconfig.base.json",
+ "../../tsconfig.paths.json"
+ ],
+ "include": [
+ "../../packages/babel-types/src/**/*.ts",
+ "../../lib/globals.d.ts",
+ "../../scripts/repo-utils/*.d.ts"
+ ],
+ "references": [
+ {
+ "path": "../../packages/babel-helper-string-parser"
+ },
+ {
+ "path": "../../packages/babel-helper-validator-identifier"
+ }
+ ]
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@babel/types/tsconfig.tsbuildinfo b/src/MaxKB-1.5.1/node_modules/@babel/types/tsconfig.tsbuildinfo
new file mode 100644
index 0000000..9e979a0
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@babel/types/tsconfig.tsbuildinfo
@@ -0,0 +1 @@
+{"fileNames":["../../node_modules/typescript/lib/lib.es5.d.ts","../../node_modules/typescript/lib/lib.es2015.d.ts","../../node_modules/typescript/lib/lib.es2016.d.ts","../../node_modules/typescript/lib/lib.es2017.d.ts","../../node_modules/typescript/lib/lib.es2018.d.ts","../../node_modules/typescript/lib/lib.es2019.d.ts","../../node_modules/typescript/lib/lib.es2020.d.ts","../../node_modules/typescript/lib/lib.es2021.d.ts","../../node_modules/typescript/lib/lib.es2022.d.ts","../../node_modules/typescript/lib/lib.es2023.d.ts","../../node_modules/typescript/lib/lib.esnext.d.ts","../../node_modules/typescript/lib/lib.es2015.core.d.ts","../../node_modules/typescript/lib/lib.es2015.collection.d.ts","../../node_modules/typescript/lib/lib.es2015.generator.d.ts","../../node_modules/typescript/lib/lib.es2015.iterable.d.ts","../../node_modules/typescript/lib/lib.es2015.promise.d.ts","../../node_modules/typescript/lib/lib.es2015.proxy.d.ts","../../node_modules/typescript/lib/lib.es2015.reflect.d.ts","../../node_modules/typescript/lib/lib.es2015.symbol.d.ts","../../node_modules/typescript/lib/lib.es2015.symbol.wellknown.d.ts","../../node_modules/typescript/lib/lib.es2016.array.include.d.ts","../../node_modules/typescript/lib/lib.es2016.intl.d.ts","../../node_modules/typescript/lib/lib.es2017.date.d.ts","../../node_modules/typescript/lib/lib.es2017.object.d.ts","../../node_modules/typescript/lib/lib.es2017.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2017.string.d.ts","../../node_modules/typescript/lib/lib.es2017.intl.d.ts","../../node_modules/typescript/lib/lib.es2017.typedarrays.d.ts","../../node_modules/typescript/lib/lib.es2018.asyncgenerator.d.ts","../../node_modules/typescript/lib/lib.es2018.asynciterable.d.ts","../../node_modules/typescript/lib/lib.es2018.intl.d.ts","../../node_modules/typescript/lib/lib.es2018.promise.d.ts","../../node_modules/typescript/lib/lib.es2018.regexp.d.ts","../../node_modules/typescript/lib/lib.es2019.array.d.ts","../../node_modules/typescript/lib/lib.es2019.object.d.ts","../../node_modules/typescript/lib/lib.es2019.string.d.ts","../../node_modules/typescript/lib/lib.es2019.symbol.d.ts","../../node_modules/typescript/lib/lib.es2019.intl.d.ts","../../node_modules/typescript/lib/lib.es2020.bigint.d.ts","../../node_modules/typescript/lib/lib.es2020.date.d.ts","../../node_modules/typescript/lib/lib.es2020.promise.d.ts","../../node_modules/typescript/lib/lib.es2020.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2020.string.d.ts","../../node_modules/typescript/lib/lib.es2020.symbol.wellknown.d.ts","../../node_modules/typescript/lib/lib.es2020.intl.d.ts","../../node_modules/typescript/lib/lib.es2020.number.d.ts","../../node_modules/typescript/lib/lib.es2021.promise.d.ts","../../node_modules/typescript/lib/lib.es2021.string.d.ts","../../node_modules/typescript/lib/lib.es2021.weakref.d.ts","../../node_modules/typescript/lib/lib.es2021.intl.d.ts","../../node_modules/typescript/lib/lib.es2022.array.d.ts","../../node_modules/typescript/lib/lib.es2022.error.d.ts","../../node_modules/typescript/lib/lib.es2022.intl.d.ts","../../node_modules/typescript/lib/lib.es2022.object.d.ts","../../node_modules/typescript/lib/lib.es2022.sharedmemory.d.ts","../../node_modules/typescript/lib/lib.es2022.string.d.ts","../../node_modules/typescript/lib/lib.es2022.regexp.d.ts","../../node_modules/typescript/lib/lib.es2023.array.d.ts","../../node_modules/typescript/lib/lib.es2023.collection.d.ts","../../node_modules/typescript/lib/lib.es2023.intl.d.ts","../../node_modules/typescript/lib/lib.esnext.array.d.ts","../../node_modules/typescript/lib/lib.esnext.collection.d.ts","../../node_modules/typescript/lib/lib.esnext.intl.d.ts","../../node_modules/typescript/lib/lib.esnext.disposable.d.ts","../../node_modules/typescript/lib/lib.esnext.string.d.ts","../../node_modules/typescript/lib/lib.esnext.promise.d.ts","../../node_modules/typescript/lib/lib.esnext.decorators.d.ts","../../node_modules/typescript/lib/lib.esnext.object.d.ts","../../node_modules/typescript/lib/lib.esnext.regexp.d.ts","../../node_modules/typescript/lib/lib.esnext.iterator.d.ts","../../node_modules/typescript/lib/lib.decorators.d.ts","../../node_modules/typescript/lib/lib.decorators.legacy.d.ts","./src/utils/shallowEqual.ts","./src/utils/deprecationWarning.ts","./src/validators/generated/index.ts","./src/validators/matchesPattern.ts","./src/validators/buildMatchMemberExpression.ts","./src/validators/react/isReactComponent.ts","./src/validators/react/isCompatTag.ts","../../node_modules/to-fast-properties-BABEL_8_BREAKING-true/index.d.ts","./src/validators/isType.ts","./src/validators/isPlaceholderType.ts","./src/validators/is.ts","../../dts/packages/babel-helper-validator-identifier/src/identifier.d.ts","../../dts/packages/babel-helper-validator-identifier/src/keyword.d.ts","../../dts/packages/babel-helper-validator-identifier/src/index.d.ts","./src/validators/isValidIdentifier.ts","../../dts/packages/babel-helper-string-parser/src/index.d.ts","./src/constants/index.ts","./src/definitions/utils.ts","./src/definitions/core.ts","./src/definitions/flow.ts","./src/definitions/jsx.ts","./src/definitions/placeholders.ts","./src/definitions/misc.ts","./src/definitions/experimental.ts","./src/definitions/typescript.ts","./src/definitions/deprecated-aliases.ts","./src/definitions/index.ts","./src/validators/validate.ts","./src/builders/generated/index.ts","./src/utils/react/cleanJSXElementLiteralChild.ts","./src/builders/react/buildChildren.ts","./src/validators/isNode.ts","./src/asserts/assertNode.ts","./src/asserts/generated/index.ts","./src/builders/flow/createTypeAnnotationBasedOnTypeof.ts","./src/modifications/flow/removeTypeDuplicates.ts","./src/builders/flow/createFlowUnionType.ts","./src/modifications/typescript/removeTypeDuplicates.ts","./src/builders/typescript/createTSUnionType.ts","./src/builders/generated/uppercase.d.ts","./src/builders/productions.ts","./src/clone/cloneNode.ts","./src/clone/clone.ts","./src/clone/cloneDeep.ts","./src/clone/cloneDeepWithoutLoc.ts","./src/clone/cloneWithoutLoc.ts","./src/comments/addComments.ts","./src/comments/addComment.ts","./src/utils/inherit.ts","./src/comments/inheritInnerComments.ts","./src/comments/inheritLeadingComments.ts","./src/comments/inheritTrailingComments.ts","./src/comments/inheritsComments.ts","./src/comments/removeComments.ts","./src/constants/generated/index.ts","./src/converters/toBlock.ts","./src/converters/ensureBlock.ts","./src/converters/toIdentifier.ts","./src/converters/toBindingIdentifierName.ts","./src/converters/toComputedKey.ts","./src/converters/toExpression.ts","./src/traverse/traverseFast.ts","./src/modifications/removeProperties.ts","./src/modifications/removePropertiesDeep.ts","./src/converters/toKeyAlias.ts","./src/converters/toStatement.ts","./src/converters/valueToNode.ts","./src/modifications/appendToMemberExpression.ts","./src/modifications/inherits.ts","./src/modifications/prependToMemberExpression.ts","./src/retrievers/getAssignmentIdentifiers.ts","./src/retrievers/getBindingIdentifiers.ts","./src/retrievers/getOuterBindingIdentifiers.ts","./src/retrievers/getFunctionName.ts","./src/traverse/traverse.ts","./src/validators/isBinding.ts","./src/validators/isLet.ts","./src/validators/isBlockScoped.ts","./src/validators/isImmutable.ts","./src/validators/isNodesEquivalent.ts","./src/validators/isReferenced.ts","./src/validators/isScope.ts","./src/validators/isSpecifierDefault.ts","./src/validators/isValidES3Identifier.ts","./src/validators/isVar.ts","./src/ast-types/generated/index.ts","./src/index.ts","./src/builders/validateNode.ts","./src/converters/gatherSequenceExpressions.ts","./src/converters/toSequenceExpression.ts","../../lib/globals.d.ts","../../node_modules/@types/charcodes/index.d.ts","../../node_modules/@types/color-name/index.d.ts","../../node_modules/@types/convert-source-map/index.d.ts","../../node_modules/@types/debug/index.d.ts","../../node_modules/@types/eslint/helpers.d.ts","../../node_modules/@types/estree/index.d.ts","../../node_modules/@types/json-schema/index.d.ts","../../node_modules/@types/eslint/index.d.ts","../../node_modules/@eslint/core/dist/esm/types.d.ts","../../node_modules/eslint/lib/types/use-at-your-own-risk.d.ts","../../node_modules/eslint/lib/types/index.d.ts","../../node_modules/@types/eslint-scope/index.d.ts","../../node_modules/@types/fs-readdir-recursive/index.d.ts","../../node_modules/@types/gensync/index.d.ts","../../node_modules/@types/node/assert.d.ts","../../node_modules/@types/node/assert/strict.d.ts","../../node_modules/buffer/index.d.ts","../../node_modules/undici-types/header.d.ts","../../node_modules/undici-types/readable.d.ts","../../node_modules/undici-types/file.d.ts","../../node_modules/undici-types/fetch.d.ts","../../node_modules/undici-types/formdata.d.ts","../../node_modules/undici-types/connector.d.ts","../../node_modules/undici-types/client.d.ts","../../node_modules/undici-types/errors.d.ts","../../node_modules/undici-types/dispatcher.d.ts","../../node_modules/undici-types/global-dispatcher.d.ts","../../node_modules/undici-types/global-origin.d.ts","../../node_modules/undici-types/pool-stats.d.ts","../../node_modules/undici-types/pool.d.ts","../../node_modules/undici-types/handlers.d.ts","../../node_modules/undici-types/balanced-pool.d.ts","../../node_modules/undici-types/agent.d.ts","../../node_modules/undici-types/mock-interceptor.d.ts","../../node_modules/undici-types/mock-agent.d.ts","../../node_modules/undici-types/mock-client.d.ts","../../node_modules/undici-types/mock-pool.d.ts","../../node_modules/undici-types/mock-errors.d.ts","../../node_modules/undici-types/proxy-agent.d.ts","../../node_modules/undici-types/env-http-proxy-agent.d.ts","../../node_modules/undici-types/retry-handler.d.ts","../../node_modules/undici-types/retry-agent.d.ts","../../node_modules/undici-types/api.d.ts","../../node_modules/undici-types/interceptors.d.ts","../../node_modules/undici-types/util.d.ts","../../node_modules/undici-types/cookies.d.ts","../../node_modules/undici-types/patch.d.ts","../../node_modules/undici-types/websocket.d.ts","../../node_modules/undici-types/eventsource.d.ts","../../node_modules/undici-types/filereader.d.ts","../../node_modules/undici-types/diagnostics-channel.d.ts","../../node_modules/undici-types/content-type.d.ts","../../node_modules/undici-types/cache.d.ts","../../node_modules/undici-types/index.d.ts","../../node_modules/@types/node/globals.d.ts","../../node_modules/@types/node/async_hooks.d.ts","../../node_modules/@types/node/buffer.d.ts","../../node_modules/@types/node/child_process.d.ts","../../node_modules/@types/node/cluster.d.ts","../../node_modules/@types/node/console.d.ts","../../node_modules/@types/node/constants.d.ts","../../node_modules/@types/node/crypto.d.ts","../../node_modules/@types/node/dgram.d.ts","../../node_modules/@types/node/diagnostics_channel.d.ts","../../node_modules/@types/node/dns.d.ts","../../node_modules/@types/node/dns/promises.d.ts","../../node_modules/@types/node/domain.d.ts","../../node_modules/@types/node/dom-events.d.ts","../../node_modules/@types/node/events.d.ts","../../node_modules/@types/node/fs.d.ts","../../node_modules/@types/node/fs/promises.d.ts","../../node_modules/@types/node/http.d.ts","../../node_modules/@types/node/http2.d.ts","../../node_modules/@types/node/https.d.ts","../../node_modules/@types/node/inspector.d.ts","../../node_modules/@types/node/module.d.ts","../../node_modules/@types/node/net.d.ts","../../node_modules/@types/node/os.d.ts","../../node_modules/@types/node/path.d.ts","../../node_modules/@types/node/perf_hooks.d.ts","../../node_modules/@types/node/process.d.ts","../../node_modules/@types/node/punycode.d.ts","../../node_modules/@types/node/querystring.d.ts","../../node_modules/@types/node/readline.d.ts","../../node_modules/@types/node/readline/promises.d.ts","../../node_modules/@types/node/repl.d.ts","../../node_modules/@types/node/sea.d.ts","../../node_modules/@types/node/sqlite.d.ts","../../node_modules/@types/node/stream.d.ts","../../node_modules/@types/node/stream/promises.d.ts","../../node_modules/@types/node/stream/consumers.d.ts","../../node_modules/@types/node/stream/web.d.ts","../../node_modules/@types/node/string_decoder.d.ts","../../node_modules/@types/node/test.d.ts","../../node_modules/@types/node/timers.d.ts","../../node_modules/@types/node/timers/promises.d.ts","../../node_modules/@types/node/tls.d.ts","../../node_modules/@types/node/trace_events.d.ts","../../node_modules/@types/node/tty.d.ts","../../node_modules/@types/node/url.d.ts","../../node_modules/@types/node/util.d.ts","../../node_modules/@types/node/v8.d.ts","../../node_modules/@types/node/vm.d.ts","../../node_modules/@types/node/wasi.d.ts","../../node_modules/@types/node/worker_threads.d.ts","../../node_modules/@types/node/zlib.d.ts","../../node_modules/@types/node/globals.global.d.ts","../../node_modules/@types/node/index.d.ts","../../node_modules/@types/minimatch/index.d.ts","../../node_modules/@types/glob/index.d.ts","../../node_modules/@types/istanbul-lib-coverage/index.d.ts","../../node_modules/@types/istanbul-lib-report/index.d.ts","../../node_modules/@types/istanbul-reports/index.d.ts","../../node_modules/@types/jest/node_modules/@jest/expect-utils/build/index.d.ts","../../node_modules/@types/jest/node_modules/chalk/index.d.ts","../../node_modules/@sinclair/typebox/typebox.d.ts","../../node_modules/@jest/schemas/build/index.d.ts","../../node_modules/jest-diff/node_modules/pretty-format/build/index.d.ts","../../node_modules/jest-diff/build/index.d.ts","../../node_modules/@types/jest/node_modules/jest-matcher-utils/build/index.d.ts","../../node_modules/@types/jest/node_modules/expect/build/index.d.ts","../../node_modules/@types/jest/node_modules/pretty-format/build/index.d.ts","../../node_modules/@types/jest/index.d.ts","../../node_modules/@types/jsesc/index.d.ts","../../node_modules/@types/json5/index.d.ts","../../node_modules/@types/lru-cache/index.d.ts","../../node_modules/@types/normalize-package-data/index.d.ts","../../node_modules/@types/resolve/index.d.ts","../../node_modules/@types/semver/classes/semver.d.ts","../../node_modules/@types/semver/functions/parse.d.ts","../../node_modules/@types/semver/functions/valid.d.ts","../../node_modules/@types/semver/functions/clean.d.ts","../../node_modules/@types/semver/functions/inc.d.ts","../../node_modules/@types/semver/functions/diff.d.ts","../../node_modules/@types/semver/functions/major.d.ts","../../node_modules/@types/semver/functions/minor.d.ts","../../node_modules/@types/semver/functions/patch.d.ts","../../node_modules/@types/semver/functions/prerelease.d.ts","../../node_modules/@types/semver/functions/compare.d.ts","../../node_modules/@types/semver/functions/rcompare.d.ts","../../node_modules/@types/semver/functions/compare-loose.d.ts","../../node_modules/@types/semver/functions/compare-build.d.ts","../../node_modules/@types/semver/functions/sort.d.ts","../../node_modules/@types/semver/functions/rsort.d.ts","../../node_modules/@types/semver/functions/gt.d.ts","../../node_modules/@types/semver/functions/lt.d.ts","../../node_modules/@types/semver/functions/eq.d.ts","../../node_modules/@types/semver/functions/neq.d.ts","../../node_modules/@types/semver/functions/gte.d.ts","../../node_modules/@types/semver/functions/lte.d.ts","../../node_modules/@types/semver/functions/cmp.d.ts","../../node_modules/@types/semver/functions/coerce.d.ts","../../node_modules/@types/semver/classes/comparator.d.ts","../../node_modules/@types/semver/classes/range.d.ts","../../node_modules/@types/semver/functions/satisfies.d.ts","../../node_modules/@types/semver/ranges/max-satisfying.d.ts","../../node_modules/@types/semver/ranges/min-satisfying.d.ts","../../node_modules/@types/semver/ranges/to-comparators.d.ts","../../node_modules/@types/semver/ranges/min-version.d.ts","../../node_modules/@types/semver/ranges/valid.d.ts","../../node_modules/@types/semver/ranges/outside.d.ts","../../node_modules/@types/semver/ranges/gtr.d.ts","../../node_modules/@types/semver/ranges/ltr.d.ts","../../node_modules/@types/semver/ranges/intersects.d.ts","../../node_modules/@types/semver/ranges/simplify.d.ts","../../node_modules/@types/semver/ranges/subset.d.ts","../../node_modules/@types/semver/internals/identifiers.d.ts","../../node_modules/@types/semver/index.d.ts","../../node_modules/@types/stack-utils/index.d.ts","../../node_modules/@types/v8flags/index.d.ts","../../node_modules/@types/yargs-parser/index.d.ts","../../node_modules/@types/yargs/index.d.ts"],"fileIdsList":[[84,85],[279],[169,174],[168,169,170],[232,233,271,272],[274],[275],[281,284],[219,271,277,283],[278,282],[280],[178],[219],[220,225,255],[221,226,232,233,240,252,263],[221,222,232,240],[223,264],[224,225,233,241],[225,252,260],[226,228,232,240],[219,227],[228,229],[232],[230,232],[219,232],[232,233,234,252,263],[232,233,234,247,252,255],[217,268],[217,228,232,235,240,252,263],[232,233,235,236,240,252,260,263],[235,237,252,260,263],[178,179,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239,240,241,242,243,244,245,246,247,248,249,250,251,252,253,254,255,256,257,258,259,260,261,262,263,264,265,266,267,268,269,270],[232,238],[239,263,268],[228,232,240,252],[241],[242],[219,243],[178,179,219,220,221,222,223,224,225,226,227,228,229,230,232,233,234,235,236,237,238,239,240,241,242,243,244,245,246,247,248,249,250,251,252,253,254,255,256,257,258,259,260,261,262,263,264,265,266,267,268,269],[245],[246],[232,247,248],[247,249,264,266],[220,232,252,253,254,255],[220,252,254],[252,253],[255],[256],[178,252],[232,258,259],[258,259],[225,240,252,260],[261],[240,262],[220,235,246,263],[225,264],[252,265],[239,266],[267],[220,225,232,234,243,252,263,266,268],[252,269],[292,331],[292,316,331],[331],[292],[292,317,331],[292,293,294,295,296,297,298,299,300,301,302,303,304,305,306,307,308,309,310,311,312,313,314,315,316,317,318,319,320,321,322,323,324,325,326,327,328,329,330],[317,331],[334],[169,170,172,173],[174],[281],[189,193,263],[189,252,263],[184],[186,189,260,263],[240,260],[271],[184,271],[186,189,240,263],[181,182,185,188,220,232,252,263],[189,196],[181,187],[189,210,211],[185,189,220,255,263,271],[220,271],[210,220,271],[183,184,271],[189],[183,184,185,186,187,188,189,190,191,193,194,195,196,197,198,199,200,201,202,203,204,205,206,207,208,209,211,212,213,214,215,216],[189,204],[189,196,197],[187,189,197,198],[188],[181,184,189],[189,193,197,198],[193],[187,189,192,263],[181,186,189,196],[220,252],[184,189,210,220,268,271],[104,159],[74,83,159],[101,108,159],[101,159],[74,90,100,159],[101],[75,102,159],[75,101,110,159],[100,159],[114,159],[75,99,159],[119,159],[159],[121,159],[122,123,124,159],[89,159],[99],[128,159],[75,101,113,114,144,159],[130],[75,101,159],[75,159],[86,87],[75,114,136,159],[159,161],[87,101,159],[83,86,87,88,89,90,159],[90],[80,90,91,92,93,94,95,96,97,98],[90,94],[83,90,91],[83,100,159],[73,74,75,76,77,78,79,81,82,83,87,89,99,100,101,103,104,105,106,107,108,109,111,112,113,114,115,116,117,118,119,120,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158],[89,125,159],[134,135,159],[144,159],[99,159],[76,159],[73,74,159],[73,81,82,99,159],[75,149,159],[75,81,159],[75,89,159],[87],[86],[77]],"fileInfos":[{"version":"44e584d4f6444f58791784f1d530875970993129442a847597db702a073ca68c","affectsGlobalScope":true,"impliedFormat":1},{"version":"45b7ab580deca34ae9729e97c13cfd999df04416a79116c3bfb483804f85ded4","impliedFormat":1},{"version":"3facaf05f0c5fc569c5649dd359892c98a85557e3e0c847964caeb67076f4d75","impliedFormat":1},{"version":"9a68c0c07ae2fa71b44384a839b7b8d81662a236d4b9ac30916718f7510b1b2d","impliedFormat":1},{"version":"5e1c4c362065a6b95ff952c0eab010f04dcd2c3494e813b493ecfd4fcb9fc0d8","impliedFormat":1},{"version":"68d73b4a11549f9c0b7d352d10e91e5dca8faa3322bfb77b661839c42b1ddec7","impliedFormat":1},{"version":"5efce4fc3c29ea84e8928f97adec086e3dc876365e0982cc8479a07954a3efd4","impliedFormat":1},{"version":"feecb1be483ed332fad555aff858affd90a48ab19ba7272ee084704eb7167569","impliedFormat":1},{"version":"5514e54f17d6d74ecefedc73c504eadffdeda79c7ea205cf9febead32d45c4bc","impliedFormat":1},{"version":"27bdc30a0e32783366a5abeda841bc22757c1797de8681bbe81fbc735eeb1c10","impliedFormat":1},{"version":"abee51ebffafd50c07d76be5848a34abfe4d791b5745ef1e5648718722fab924","impliedFormat":1},{"version":"6920e1448680767498a0b77c6a00a8e77d14d62c3da8967b171f1ddffa3c18e4","affectsGlobalScope":true,"impliedFormat":1},{"version":"dc2df20b1bcdc8c2d34af4926e2c3ab15ffe1160a63e58b7e09833f616efff44","affectsGlobalScope":true,"impliedFormat":1},{"version":"515d0b7b9bea2e31ea4ec968e9edd2c39d3eebf4a2d5cbd04e88639819ae3b71","affectsGlobalScope":true,"impliedFormat":1},{"version":"45d8ccb3dfd57355eb29749919142d4321a0aa4df6acdfc54e30433d7176600a","affectsGlobalScope":true,"impliedFormat":1},{"version":"0dc1e7ceda9b8b9b455c3a2d67b0412feab00bd2f66656cd8850e8831b08b537","affectsGlobalScope":true,"impliedFormat":1},{"version":"ce691fb9e5c64efb9547083e4a34091bcbe5bdb41027e310ebba8f7d96a98671","affectsGlobalScope":true,"impliedFormat":1},{"version":"8d697a2a929a5fcb38b7a65594020fcef05ec1630804a33748829c5ff53640d0","affectsGlobalScope":true,"impliedFormat":1},{"version":"4ff2a353abf8a80ee399af572debb8faab2d33ad38c4b4474cff7f26e7653b8d","affectsGlobalScope":true,"impliedFormat":1},{"version":"93495ff27b8746f55d19fcbcdbaccc99fd95f19d057aed1bd2c0cafe1335fbf0","affectsGlobalScope":true,"impliedFormat":1},{"version":"6fc23bb8c3965964be8c597310a2878b53a0306edb71d4b5a4dfe760186bcc01","affectsGlobalScope":true,"impliedFormat":1},{"version":"ea011c76963fb15ef1cdd7ce6a6808b46322c527de2077b6cfdf23ae6f5f9ec7","affectsGlobalScope":true,"impliedFormat":1},{"version":"38f0219c9e23c915ef9790ab1d680440d95419ad264816fa15009a8851e79119","affectsGlobalScope":true,"impliedFormat":1},{"version":"69ab18c3b76cd9b1be3d188eaf8bba06112ebbe2f47f6c322b5105a6fbc45a2e","affectsGlobalScope":true,"impliedFormat":1},{"version":"4738f2420687fd85629c9efb470793bb753709c2379e5f85bc1815d875ceadcd","affectsGlobalScope":true,"impliedFormat":1},{"version":"2f11ff796926e0832f9ae148008138ad583bd181899ab7dd768a2666700b1893","affectsGlobalScope":true,"impliedFormat":1},{"version":"4de680d5bb41c17f7f68e0419412ca23c98d5749dcaaea1896172f06435891fc","affectsGlobalScope":true,"impliedFormat":1},{"version":"9fc46429fbe091ac5ad2608c657201eb68b6f1b8341bd6d670047d32ed0a88fa","affectsGlobalScope":true,"impliedFormat":1},{"version":"ac9538681b19688c8eae65811b329d3744af679e0bdfa5d842d0e32524c73e1c","affectsGlobalScope":true,"impliedFormat":1},{"version":"0a969edff4bd52585473d24995c5ef223f6652d6ef46193309b3921d65dd4376","affectsGlobalScope":true,"impliedFormat":1},{"version":"9e9fbd7030c440b33d021da145d3232984c8bb7916f277e8ffd3dc2e3eae2bdb","affectsGlobalScope":true,"impliedFormat":1},{"version":"811ec78f7fefcabbda4bfa93b3eb67d9ae166ef95f9bff989d964061cbf81a0c","affectsGlobalScope":true,"impliedFormat":1},{"version":"717937616a17072082152a2ef351cb51f98802fb4b2fdabd32399843875974ca","affectsGlobalScope":true,"impliedFormat":1},{"version":"d7e7d9b7b50e5f22c915b525acc5a49a7a6584cf8f62d0569e557c5cfc4b2ac2","affectsGlobalScope":true,"impliedFormat":1},{"version":"71c37f4c9543f31dfced6c7840e068c5a5aacb7b89111a4364b1d5276b852557","affectsGlobalScope":true,"impliedFormat":1},{"version":"576711e016cf4f1804676043e6a0a5414252560eb57de9faceee34d79798c850","affectsGlobalScope":true,"impliedFormat":1},{"version":"89c1b1281ba7b8a96efc676b11b264de7a8374c5ea1e6617f11880a13fc56dc6","affectsGlobalScope":true,"impliedFormat":1},{"version":"74f7fa2d027d5b33eb0471c8e82a6c87216223181ec31247c357a3e8e2fddc5b","affectsGlobalScope":true,"impliedFormat":1},{"version":"1a94697425a99354df73d9c8291e2ecd4dddd370aed4023c2d6dee6cccb32666","affectsGlobalScope":true,"impliedFormat":1},{"version":"063600664504610fe3e99b717a1223f8b1900087fab0b4cad1496a114744f8df","affectsGlobalScope":true,"impliedFormat":1},{"version":"934019d7e3c81950f9a8426d093458b65d5aff2c7c1511233c0fd5b941e608ab","affectsGlobalScope":true,"impliedFormat":1},{"version":"bf14a426dbbf1022d11bd08d6b8e709a2e9d246f0c6c1032f3b2edb9a902adbe","affectsGlobalScope":true,"impliedFormat":1},{"version":"e3f9fc0ec0b96a9e642f11eda09c0be83a61c7b336977f8b9fdb1e9788e925fe","affectsGlobalScope":true,"impliedFormat":1},{"version":"59fb2c069260b4ba00b5643b907ef5d5341b167e7d1dbf58dfd895658bda2867","affectsGlobalScope":true,"impliedFormat":1},{"version":"479553e3779be7d4f68e9f40cdb82d038e5ef7592010100410723ceced22a0f7","affectsGlobalScope":true,"impliedFormat":1},{"version":"368af93f74c9c932edd84c58883e736c9e3d53cec1fe24c0b0ff451f529ceab1","affectsGlobalScope":true,"impliedFormat":1},{"version":"af3dd424cf267428f30ccfc376f47a2c0114546b55c44d8c0f1d57d841e28d74","affectsGlobalScope":true,"impliedFormat":1},{"version":"995c005ab91a498455ea8dfb63aa9f83fa2ea793c3d8aa344be4a1678d06d399","affectsGlobalScope":true,"impliedFormat":1},{"version":"d3d7b04b45033f57351c8434f60b6be1ea71a2dfec2d0a0c3c83badbb0e3e693","affectsGlobalScope":true,"impliedFormat":1},{"version":"956d27abdea9652e8368ce029bb1e0b9174e9678a273529f426df4b3d90abd60","affectsGlobalScope":true,"impliedFormat":1},{"version":"4fa6ed14e98aa80b91f61b9805c653ee82af3502dc21c9da5268d3857772ca05","affectsGlobalScope":true,"impliedFormat":1},{"version":"e6633e05da3ff36e6da2ec170d0d03ccf33de50ca4dc6f5aeecb572cedd162fb","affectsGlobalScope":true,"impliedFormat":1},{"version":"15c1c3d7b2e46e0025417ed6d5f03f419e57e6751f87925ca19dc88297053fe6","affectsGlobalScope":true,"impliedFormat":1},{"version":"8444af78980e3b20b49324f4a16ba35024fef3ee069a0eb67616ea6ca821c47a","affectsGlobalScope":true,"impliedFormat":1},{"version":"caccc56c72713969e1cfe5c3d44e5bab151544d9d2b373d7dbe5a1e4166652be","affectsGlobalScope":true,"impliedFormat":1},{"version":"3287d9d085fbd618c3971944b65b4be57859f5415f495b33a6adc994edd2f004","affectsGlobalScope":true,"impliedFormat":1},{"version":"b4b67b1a91182421f5df999988c690f14d813b9850b40acd06ed44691f6727ad","affectsGlobalScope":true,"impliedFormat":1},{"version":"9d540251809289a05349b70ab5f4b7b99f922af66ab3c39ba56a475dcf95d5ff","affectsGlobalScope":true,"impliedFormat":1},{"version":"436aaf437562f276ec2ddbee2f2cdedac7664c1e4c1d2c36839ddd582eeb3d0a","affectsGlobalScope":true,"impliedFormat":1},{"version":"8e3c06ea092138bf9fa5e874a1fdbc9d54805d074bee1de31b99a11e2fec239d","affectsGlobalScope":true,"impliedFormat":1},{"version":"0b11f3ca66aa33124202c80b70cd203219c3d4460cfc165e0707aa9ec710fc53","affectsGlobalScope":true,"impliedFormat":1},{"version":"6a3f5a0129cc80cf439ab71164334d649b47059a4f5afca90282362407d0c87f","affectsGlobalScope":true,"impliedFormat":1},{"version":"811c71eee4aa0ac5f7adf713323a5c41b0cf6c4e17367a34fbce379e12bbf0a4","affectsGlobalScope":true,"impliedFormat":1},{"version":"51ad4c928303041605b4d7ae32e0c1ee387d43a24cd6f1ebf4a2699e1076d4fa","affectsGlobalScope":true,"impliedFormat":1},{"version":"0a6282c8827e4b9a95f4bf4f5c205673ada31b982f50572d27103df8ceb8013c","affectsGlobalScope":true,"impliedFormat":1},{"version":"ac77cb3e8c6d3565793eb90a8373ee8033146315a3dbead3bde8db5eaf5e5ec6","affectsGlobalScope":true,"impliedFormat":1},{"version":"d4b1d2c51d058fc21ec2629fff7a76249dec2e36e12960ea056e3ef89174080f","affectsGlobalScope":true,"impliedFormat":1},{"version":"2fef54945a13095fdb9b84f705f2b5994597640c46afeb2ce78352fab4cb3279","affectsGlobalScope":true,"impliedFormat":1},{"version":"56e4ed5aab5f5920980066a9409bfaf53e6d21d3f8d020c17e4de584d29600ad","affectsGlobalScope":true,"impliedFormat":1},{"version":"61d6a2092f48af66dbfb220e31eea8b10bc02b6932d6e529005fd2d7b3281290","affectsGlobalScope":true,"impliedFormat":1},{"version":"33358442698bb565130f52ba79bfd3d4d484ac85fe33f3cb1759c54d18201393","affectsGlobalScope":true,"impliedFormat":1},{"version":"782dec38049b92d4e85c1585fbea5474a219c6984a35b004963b00beb1aab538","affectsGlobalScope":true,"impliedFormat":1},{"version":"8fcfeade248c2db0d29c967805f6a6d70ddc13a81f867fb2ba1cdfeedba2ad7d","signature":"e1bb914c06cc75205fae8713e349dff14bdfd2d36c784d0d2f2b7b5d37e035e0"},{"version":"4a6273a446ec1a2e1c611d2442d4205297c2b9f34ef7ebcfb3a1c2ff7cd76320","signature":"bfe8f5184c00e9c24f8bb40ec929097b2cafc50cc968bc1604501cb6c4a1440c"},{"version":"c0546f26640bd54a27df096202c4007bb308089dd2392f59da120574a8c9fc58","signature":"243665975c1af5dc7b51b10f52e76d3cb8b7676ccc23a6503977526d94b3cdde"},{"version":"aac28eeaa76e34b6ced7c5b001ed6e80b8b1f8f0816eb592555daf1ec2f4d7bb","signature":"6a7a221f94f9547a86feaa3c2ce81b8556c71ffb12057a43c54fc975bca83cde"},{"version":"3f0a83b294ddd8b8075870cc0cbd7754fedeca16e56bd4cdb7e9313c218c2e65","signature":"e34a316302189537858d6d20d5d77d8f0351ed977da8947a401ad9986cdf147f"},{"version":"afd3d7a25f7ad12ce91561c34ffc674c84ac3249919df4940856c6c6491462ea","signature":"c4fed2ac667845f4fe7863bbd478df921793eada16941b666bcfe161f40caef1"},{"version":"171a63d115fb2e1f18ea8a0a9229809e3441b8024346e8f6eb6f71da2acb0fb5","signature":"b360236d3b226a56126f9f071d68fccd10eba34e4b6831efc39e8a3277380523"},{"version":"d252563303cbd2c3f385c83b550b84b6c5a112da78050ad8922c428d38f63d6b","impliedFormat":1},{"version":"cdae18a2e7912f1ce695077b914ad1c14078e4ca70cdd3ef8c4c3d1caea07f7a","signature":"989f035cd0c3acf51639b2ff4fb3cb8ccce3d7ef0103a1d32ca5e5f1cfd19387"},{"version":"357c8c1eedefe4572a845d2fbf39504afcf63900427de0f25780adaab29023cd","signature":"66612e3b3315adf8702a39830ad8690d6f4293f89193737c604f4b44a51e42ad"},{"version":"8b785e11256e4e78fff7cd69c0e54246cc68d7638efca4866deee66e3a629ca0","signature":"a5e89e63c809c01f8e8175c9d63da68ce734ddf15b7efd98b1eb262d8e4d05ec"},"603a6a23fb575101f92bb7c9d9f70e149b923b0b64b8da3bff10b76dad968f73","a04503349c00a0421942bb14d5e9eea391fa1633d867b13fe5125f7df8355962","e81bb81b21289ef6653935d1dbadedd907b857ada80f9221b260a33e311c9ea1",{"version":"6effa8e58111946b0a830032546674f1254b1e4217d8558460071aff6acc4237","signature":"9ba02d6560cc8cf8063172ba05b5368a24fb236a97c1c852665372be78143592"},"186139eb9963554412f6fb33b35aabee1acdaa644b365de5c38fbd9123bdbe45",{"version":"52050c18a38ecd88e094441b24e00d4c09be722fd4010716dd3482c99b0e3118","signature":"ce8fe0d07c32e6786203b5a3b93468afc6b1fcf57481dc9673e16fb119312c19"},{"version":"c1c438cb3e95a2bfc936bc97ca16d54402e8c82a187a0ef97258e0710df3b012","signature":"c2c806fb1ab5a7003fd76d3fd1a131d10e1ab0974ec0390f251ccda76d326231"},{"version":"8b223e9feacb5897970042c0b79514b89beb2a68e082e10f8d89c43da191ce98","signature":"159b9e1cf7da7202f3a5b0468561ca18d11735f56e3cd9947b5390e68a75cb52"},{"version":"7e8fb0433598bc7e52395270ef6cb44d5fb38ecdb7c5c9edf5ec86e46bb936ff","signature":"8e609bb71c20b858c77f0e9f90bb1319db8477b13f9f965f1a1e18524bf50881"},{"version":"50953664da9490f22364c3d322d48ac62450eb58c6d41ce756233122c8315020","signature":"8e609bb71c20b858c77f0e9f90bb1319db8477b13f9f965f1a1e18524bf50881"},{"version":"bddeccbea54a281dff4c47c0a6fb0044631989d863025fda8438959e439e86ac","signature":"513e4a7dd68f60782a39d5ae4ce6f0a19ccc4c51808b359560ad1f689f0ce93d"},{"version":"c825ca3f05c6e25f236f8e8762b44fbbf66f709b3a8d3ca0e42146ebe1581a9a","signature":"8e609bb71c20b858c77f0e9f90bb1319db8477b13f9f965f1a1e18524bf50881"},{"version":"ed2c8e175ed8002bc7a21b9145596578d6d408bb60e2b3c6fba3f443e39e718d","signature":"8e609bb71c20b858c77f0e9f90bb1319db8477b13f9f965f1a1e18524bf50881"},{"version":"c3b3aa621de26cd75eeed725af6b6e405f82d155d6869014026ea29f4fe280fa","signature":"8e609bb71c20b858c77f0e9f90bb1319db8477b13f9f965f1a1e18524bf50881"},{"version":"1d980ffa590cf05dd111bc619f46a3b22d733f28e53dd43c0ed7c04086a27db0","signature":"519157309e4f7c98b6067933db2a849961eaa0e5dec4a2ce5d2fc92ace85dcfd"},{"version":"8d5646f46ffd5da015100bc01b95cb9bd7865608a2b9f9de49f70574da948299","signature":"c5f8672c8c39b8f9251a57fc2dab217ce20ac4a9d71c0a498b733cb922ff5e4e"},{"version":"9355eb3352186b8c290f79ab7e858b5282f363a23f020250a5c10bbd778878a9","signature":"c2322dd8a6ebf72e6114dea199b58edc03814edebae9c29f5f6b39efde3c94fb"},{"version":"c1026b4a7b1b41a981e5e37af9d4c9b02dd88549e956f5cfc0ca08d77d02667f","signature":"6c659a290add744a16bc6627846d9aa600463c7c1024d7253663ec18aa783628"},{"version":"76e1d2a23e0eff1c239d8135c3df018d086e37731b47712e00c605fb5d223c82","signature":"b1fd1f3a57d18737a7792630d476f230f4eda06a2e3afa85a1725830d912b1cf"},{"version":"a6b289321f7db8293d68955fa596e46dfbcbef03e15612828f6a244e770de6ee","signature":"a73bd08ca8f85d9c1f0307ae7abb246e38cb618f452e15fd3612464e846665b0"},{"version":"226c3a35bba8947d4296e3b1d38dd17d4b16688c580357672a696091479b980a","signature":"4924f889957ee69dfd66643c7e60a5feee526c18b16d10985804c669fe1b6ce4"},{"version":"0d6d17c452ec87c53738e449f61d0642144827b747aa47eada063024e6a114b3","signature":"9b1b103c34f4c56ab0c40c87a85ffd36002295d8fbe17b493509e63a383f5814"},{"version":"edd51847a7bb071792713662c868ef3e68b46db5735d8303dc6c2c22340d1490","signature":"e4a023723ff5cfdc22880b572dd15876d0bc4bb4f2a555d71d226a2578786ad3"},{"version":"be08025002e28149f50ac7814003f38c04bc27532868e7f1e5b308e0772bb7c4","signature":"3aa0ae0c3636319f9bc6e5c2a4bd484f9b2b4e78623b33131056a95fb59c954c"},{"version":"32554cf6a4e226119f09b7f834f7ebb066c78b5c50c04d1bffab36d0b0af7e86","signature":"a73d8151dd40ff705eebd2989e703ba14874574f5fe4f195babe74b6ef93ac59"},{"version":"a029e1c4b13d11618865d30254ff2762481ba33613ec180de6ee6190f75afa86","signature":"dc25e664429b44c379d4d3cf988b2cce06116ae94f5c6f1a0cf73245b4282a93"},{"version":"3c52b0d34d0d2449c0c8266f76c213d038f9d049ef7de02e6db09965588d578b","signature":"f32fa5785766bba7c9c8dd0b2c822abdd6e6df528ac2512786b87103a03628b4"},{"version":"6470630dba76968b44e9fd031270da3f3e39852e9b4af3b63eaa56633120ebdf","signature":"e59daf03ff2d76dee4726e48556aba1d105fd1c7a7a9cbf3e74ec4a1f91a6bea"},"a0fbfc839fefc3d41a12c5a8631e6543135ff18fd516cd06c5a09f84cb81578c",{"version":"33166ad3efe9a4e610e12af338b7a5ea56e0b41b064ed509e40f901ddcc458e6","signature":"9ce376fdbe50ed84260f0dc45cc1f242916f2c0c91da6464df63df0ba2baae7c"},{"version":"b28f5ee81fe3f1793f7150e38f0a77cd338353b0c54ae767eb1093f1a6709063","signature":"c3e41c24eb14414b6995d4bbac99d16ce2e609282c9b53d1333b7b423e0f7d02"},{"version":"0b54bc2b799d87aa1177e909d465f54c6bef360ba83af93005e5ed227d19dab6","signature":"b555d22a622ea0565d08a340e5c19f6f439f40d4451a2f13fe6a33a39b3d761c"},{"version":"764f73212be29948c4fcd78f507088fc7e6defa31e7197c0bb75b6f4347bb1e4","signature":"9f29212a64599c6c5563b78746bf85f709d5437f18dac77502a53af63dadb850"},{"version":"47d2fe1d53745d28b017cf0e222e1d4a4f4227f7dd0a581bd92b113335531e88","signature":"6b714d7db731bb6da813dfa3d88ded4ce0bc9b627464e86315468e1be9adadff"},{"version":"be7e96cd9390cdaef4671d6035bbdaf562ede5e8c0a1276109d8e0bdd6ea6c3d","signature":"5ebd0c7b976b7cbe390e381d27ec9dc5adde1a02cf9ecfb2a7caed7a822a5cae"},{"version":"90ff25e6450736895d78029bff4fbe1ed9e4716ace55d7d68c69629a8b1cee1a","signature":"b8b9aae5a37c0d3dec11813d992b893ed55a080289466ade6c1bc47e3987f53a"},{"version":"c500cb69aa5cf5f562b1494e6094854b4179d1800351d2413da092b6be0abb4f","signature":"4171247c72f90ac86a3cd3cdb0f372214a556aa8b94aa92b28bf6d21dad5f7ee"},{"version":"d60d7a09651839c6bd24d23dd861c6d7bb6db5cef12499d31ec7c70dcd704e82","signature":"a9cb234a7e1c11097b0d897a52a82d54b51545d32863c0e7d026f70309a10eb4"},{"version":"15d3b873cf25203b8d3bde2fdf2290ff0c3bc56fcad31661838f8ddf455a084d","signature":"eb69d4cd5875c471c0dd30988bf8a4816f9b8fab1e71a8c39096e483411faa00"},{"version":"a4b304456b23b28cc0a552fe9a59ccd81b19c92a316071ed6e16b4f52ec77544","signature":"48225779dd7b1b7b384389e325ed6aa271a6745239d8193c2fc161cacbf3dac5"},{"version":"e823b7c5c5284a0915c664ba5116fa0935e1818de3cc34abca01282b017ec8ab","signature":"3f4487628af3e52556d6f33151740876b29a5355b8a5ccf8e56d1b3ae7cbcc0e"},{"version":"f1ef69cbcfb53cde7b93395b8c8e08a27700a153299a2af6eded4ef6f96dcdb1","signature":"c6fd0f9d777f11f972b4decc52beeeae6aad9f2aa949184e8f9984a5c36e4448"},{"version":"769de8be7004cefe640665543efa370ae48b6d6e2010297e2b5b22a8eaf2e939","signature":"2b4ca439136421892cc80ebf6f6ea641a0306e58bd12ed61ae7f20becb2ee15f"},{"version":"0b7052f1b0ffb904374e01198404cac8c4931bfdd7f87e550be5f48b425e9319","signature":"d765a1a0f109522a082c9b8de1f6c0364463e972ece981b0f504fa611187956a"},{"version":"3b4274e19bf0b5551ad7f0190902eaf651a88d213d80e156ee158c8a3d68acd0","signature":"058e39e6fe02e97ddc18b2952a67d0dfb71f1f60f86405480fec569b602f5284"},{"version":"924473fe3db09406d721c813e1d9a9e932ac42de6526cbbf19fcc4b86a5f09d7","signature":"dfa94dabc1567d2b882222947f5c181adc89a3af5b6a2b730b1c3b85d4cfe48f"},{"version":"a030f8b58759c806d7a2ec11a0ae694035182ea7dcb2a93f969dbbe187535118","signature":"9f3f8ff5d06c5d5583e891d3bb98489d58e358e49bda2827f3f7819cdb632ad0"},{"version":"b60bfab426a779fe9bd50b8d19995564654b10b83c592dd00b9a7605bb12f329","signature":"c33fa94c2e88d70a2e98a33474d3cf477d959477236323a748f638b3ca1e2af0"},{"version":"7c676dde7b7864996d974adfa5c57f1ac22d4abd75f60f75c1e18c57ed842763","signature":"8c5dbef5fc0eb113d94132a5ba440d75e33eb85e9497a1f7e3bdb29a3fcd3469"},{"version":"2effc0f6de7a36ef7f347cc9965e0c064d40bd0a4b37e163a07db488809e9667","signature":"0d9808e1f0d2bd4c45462c7e2f20c0cf08b700c6964e7eda5e10d1f6b707deb8"},{"version":"ae29dd93357ed3d406b2ee4c877ce166f55ef9822bebb4f55642a08381bf9073","signature":"3b6aafb284a9943503546844726c7ecea9ae91fc46f1d8e8cbe233f6d8b16a30"},{"version":"88100c31b99360b9a517196944e1a9b509a588be609ddf7498e81ea04c7857f7","signature":"7571f6e856945cea6771a2985e008daff8785c6632f9dc1dc9f24f795f84444d"},{"version":"c690d242a9b796a6632297f61a7030ff914715883601a1f06ce7d06b3a726ca7","signature":"2ff5e66c8448d86302ef11ceeb27cbbd43d3af41aba05c2fc3a48cd0f1d8627f"},{"version":"52b637792df11dd64a7acc6d31ba77ca5ac3b65e2eac6a39f0adf0aa52f49051","signature":"6978b8fc2f45108c4bc2788bd7053f2917d7efa28f74ddf52182dc9ab59d03cf"},{"version":"0814686d7a7474b9c3072198413393be949e3c358587acb6d81fa987faa13bcc","signature":"e127a8fb319d5978d73d966a5a68b85915848f8f96267fff2f0dbe9bc92373e9"},{"version":"d7fff60051446f7a806ad250107f587338e06eb67c9c2e3c49f521eac78131b1","signature":"77adbafe67e2bf42d578d82d2fb994530cce5b9eaa28a2a5b24aca70a008c3d9"},{"version":"0926c32fe1c110a3d7f1d7dc9341c6ced58a237bc894293d144782ca336595e0","signature":"82590ca2dfa968af29be579c534733406fd9c5c4a726213eef9f2308cbb04d23"},{"version":"82b86e1638a2b839335bda260e9f5ff8864c7be8a7ae4749626807eb82f77c09","signature":"e88043fb3ae0a6e33be31d45927494ed42c3263bfb318b024b9dab027f09dc2d"},{"version":"1705c872aaf610b945fe927e224dfd1d186a182c7e65740f1a52ea9ab5178388","signature":"3f7e6d7b1d7155d68b5ec0f8e021f10075c785b29171d1d520d0b9b0dd617aa0"},{"version":"cd13cd446b20bf813d09425b9a1d823c390f34b6b51aa51faf3f522f373dfd5f","signature":"e872f192c494d687561196b8ce88a06d80b2128b0c28b3bd919a7d663c22cc18"},{"version":"4623bcaa845b85cdf21d1594313554a95bec68d1770b4087020cf78868dbdf43","signature":"1a910bff4e17d0f855bd00ef0dadc3ad8e7656499c099d19603f8bb0dbe8853e"},{"version":"54ccf8f7da67b45fb7a69c09d0313c4c6475e918f100fad0088a19f200dc57b3","signature":"23996dceac72973064c9643fff1ca0cf585b642d715c56ed3512703f2b280c5e"},{"version":"185e07f771a4e5d0f485a9ebfe4229375902b76afb86895ee6a204384f668895","signature":"14cba8dd2c615df75bef2f670ec26fbe86157eb03a55ba5dfbe8ad46253c3b5e"},{"version":"e0c730d1cef48b39c0ea78bbece9a770062d40b87f8fbb46dba3b91a39f5e8ae","signature":"95a1a8e1e7777214b2d970c3426819e976abf9120f2824b571e0ae51d1dd465b"},{"version":"bd41bf4f473276c2c3d6ac75a510b82e2a0c171fe6605aa9d6e4aef70b0fc5e2","signature":"466c63574f0654a81f7d760ccb32570f642b6b46e83b6fdc288c2e52bcef287c"},{"version":"ded09790fe023c6a76e3b52f8a37778d89fa0ac82703aa92d294b83a13b10a93","signature":"08cdf95dfc59101c1e7c23865951151455ee7f77f1bf7e257034aae8ba332972"},{"version":"8e6f85f2acce1e4132756c0b3f928a5102abcf9f8bcd6f19f759664cde9fc75c","signature":"c6526b7ad3213f40e40d617f0a150c8a9dcf0e8f868594ef4aa060b994fd11ce"},{"version":"3542d64a563b0efef64ff2553cbeace4e7635d2e9fefa9719ce14b9453b56843","signature":"b5e0565b7ca3ba4c129ed4e1788d4dc1bb30dcdeb14a37df1071c3881507e295"},{"version":"f1e46fa426072281a31a60bb2c50854397f9bc95a8a4efc7cb40824c286b100f","signature":"2c95044092cad1398b593b47290306d73513d163c61e85ebbc39715af4b15578"},{"version":"ea097853cb731b90f8da5b56d5c65dba3d6defcd42c6206753622ec6a51e6ebb","signature":"1d3f6521348f5d591d4da3408457a553274b024c79ecde88054361040967c211"},{"version":"fdf67ae033c8bd49182fef927461ea75acfb741c615820047bcaed083ff3b3f4","signature":"03a629914760ae9bb64a05e72ad0f4e6aeefb1e7c7b6ae3d7836bb46f69ae23e"},{"version":"d757c6a733cf1e7101672c61cd52d3c964fe19a4370bf4e2fa96fde3989ec76f","signature":"95017b0f25bb3cd6782853c14303c20b5099b866ef1491c57fc436add8183f14"},{"version":"ac81e071ce704acdc83cf7155ea62306f105a5d53010308cae52cef8b2eda5af","signature":"9dfbdb5529d2be1c9e77112f7e0e20fba7518865f31501b9aa09c3965ee91f6a"},{"version":"1bce4319db89c0eaebaac319159b604c707fb9f2ae4530c4a9d333263b1168e3","signature":"cafadd60cda0c63471975430893f7c0ac981f268ec719f08f131e41d8404c4db"},{"version":"70b5b41a283a1333677935088c359a16a4254f11c679423aefd7c636e5d6df86","signature":"f3fde2e60bedf94b1972ddb07d65f4d49370a1def38dfe786808a7924650ddaa"},{"version":"e3ea6fd72f892412ee93d86d9a9694c405b36d4fa2856bbcae4a119b8a890ce3","signature":"7b488581d44b9a7bde2131536376fa946cbb3a1b0096427738d5b946a76ca794"},{"version":"d08f6eec80ae543e31b02f603b5ba61b5943971fa452a1c81721e548d925e08d","signature":"e181a4a2b4612772f2fe5a2fc18135d1c1df3f50e6c4884163117c650a495e20"},{"version":"224f6e7ef7c2300442d6b99c77ea4b34458362c08123f711478f6f618a5e3b2f","signature":"b84dbfef60c47b0b4a429d2a07ea7fe1f961eebdb32af9bdd7a66110c013a0b3"},{"version":"eb287c1b37052f20b1f0ddb4688aa6f723f38c013af83cd6f1561e0b477c739e","signature":"968ffdb87c470d380b6ea8db40761a2908278156c836f42c6e0c310b400a580a"},{"version":"f0b6690984c3a44b15740ac24bfb63853617731c0f40c87a956ce537c4b50969","affectsGlobalScope":true},{"version":"b7589677bd27b038f8aae8afeb030e554f1d5ff29dc4f45854e2cb7e5095d59a","impliedFormat":1},{"version":"f0cb4b3ab88193e3e51e9e2622e4c375955003f1f81239d72c5b7a95415dad3e","impliedFormat":1},{"version":"13d94ac3ee5780f99988ae4cce0efd139598ca159553bc0100811eba74fc2351","impliedFormat":1},{"version":"3cf5f191d75bbe7c92f921e5ae12004ac672266e2be2ece69f40b1d6b1b678f9","impliedFormat":1},{"version":"64d4b35c5456adf258d2cf56c341e203a073253f229ef3208fc0d5020253b241","affectsGlobalScope":true,"impliedFormat":1},{"version":"785b9d575b49124ce01b46f5b9402157c7611e6532effa562ac6aebec0074dfc","impliedFormat":1},{"version":"f3d8c757e148ad968f0d98697987db363070abada5f503da3c06aefd9d4248c1","impliedFormat":1},{"version":"0c5a621a8cf10464c2020f05c99a86d8ac6875d9e17038cb8522cc2f604d539f","impliedFormat":1},{"version":"f753fc5954da97c2f399b114fb8e295152d43c0e81d5073e09a7600dd29009b5","impliedFormat":99},{"version":"9d4073b672a0fa8bad4de924b66e6610f2dd2206e3132d1a79f3cc6800d804a0","impliedFormat":1},{"version":"30dc3663389259d8e33ff97f6a233b465cd834da50c78ba2f92c02ff4f7b138b","impliedFormat":1},{"version":"e050a0afcdbb269720a900c85076d18e0c1ab73e580202a2bf6964978181222a","impliedFormat":1},{"version":"1d78c35b7e8ce86a188e3e5528cc5d1edfc85187a85177458d26e17c8b48105f","impliedFormat":1},{"version":"bde8c75c442f701f7c428265ecad3da98023b6152db9ca49552304fd19fdba38","impliedFormat":1},{"version":"e142fda89ed689ea53d6f2c93693898464c7d29a0ae71c6dc8cdfe5a1d76c775","impliedFormat":1},{"version":"7394959e5a741b185456e1ef5d64599c36c60a323207450991e7a42e08911419","impliedFormat":1},{"version":"4967529644e391115ca5592184d4b63980569adf60ee685f968fd59ab1557188","impliedFormat":1},{"version":"5929864ce17fba74232584d90cb721a89b7ad277220627cc97054ba15a98ea8f","impliedFormat":1},{"version":"24bd580b5743dc56402c440dc7f9a4f5d592ad7a419f25414d37a7bfe11e342b","impliedFormat":1},{"version":"25c8056edf4314820382a5fdb4bb7816999acdcb929c8f75e3f39473b87e85bc","impliedFormat":1},{"version":"c464d66b20788266e5353b48dc4aa6bc0dc4a707276df1e7152ab0c9ae21fad8","impliedFormat":1},{"version":"78d0d27c130d35c60b5e5566c9f1e5be77caf39804636bc1a40133919a949f21","impliedFormat":1},{"version":"c6fd2c5a395f2432786c9cb8deb870b9b0e8ff7e22c029954fabdd692bff6195","impliedFormat":1},{"version":"1d6e127068ea8e104a912e42fc0a110e2aa5a66a356a917a163e8cf9a65e4a75","impliedFormat":1},{"version":"5ded6427296cdf3b9542de4471d2aa8d3983671d4cac0f4bf9c637208d1ced43","impliedFormat":1},{"version":"6bdc71028db658243775263e93a7db2fd2abfce3ca569c3cca5aee6ed5eb186d","impliedFormat":1},{"version":"cadc8aced301244057c4e7e73fbcae534b0f5b12a37b150d80e5a45aa4bebcbd","impliedFormat":1},{"version":"385aab901643aa54e1c36f5ef3107913b10d1b5bb8cbcd933d4263b80a0d7f20","impliedFormat":1},{"version":"9670d44354bab9d9982eca21945686b5c24a3f893db73c0dae0fd74217a4c219","impliedFormat":1},{"version":"0b8a9268adaf4da35e7fa830c8981cfa22adbbe5b3f6f5ab91f6658899e657a7","impliedFormat":1},{"version":"11396ed8a44c02ab9798b7dca436009f866e8dae3c9c25e8c1fbc396880bf1bb","impliedFormat":1},{"version":"ba7bc87d01492633cb5a0e5da8a4a42a1c86270e7b3d2dea5d156828a84e4882","impliedFormat":1},{"version":"4893a895ea92c85345017a04ed427cbd6a1710453338df26881a6019432febdd","impliedFormat":1},{"version":"c21dc52e277bcfc75fac0436ccb75c204f9e1b3fa5e12729670910639f27343e","impliedFormat":1},{"version":"13f6f39e12b1518c6650bbb220c8985999020fe0f21d818e28f512b7771d00f9","impliedFormat":1},{"version":"9b5369969f6e7175740bf51223112ff209f94ba43ecd3bb09eefff9fd675624a","impliedFormat":1},{"version":"4fe9e626e7164748e8769bbf74b538e09607f07ed17c2f20af8d680ee49fc1da","impliedFormat":1},{"version":"24515859bc0b836719105bb6cc3d68255042a9f02a6022b3187948b204946bd2","impliedFormat":1},{"version":"ea0148f897b45a76544ae179784c95af1bd6721b8610af9ffa467a518a086a43","impliedFormat":1},{"version":"24c6a117721e606c9984335f71711877293a9651e44f59f3d21c1ea0856f9cc9","impliedFormat":1},{"version":"dd3273ead9fbde62a72949c97dbec2247ea08e0c6952e701a483d74ef92d6a17","impliedFormat":1},{"version":"405822be75ad3e4d162e07439bac80c6bcc6dbae1929e179cf467ec0b9ee4e2e","impliedFormat":1},{"version":"0db18c6e78ea846316c012478888f33c11ffadab9efd1cc8bcc12daded7a60b6","impliedFormat":1},{"version":"4d2b0eb911816f66abe4970898f97a2cfc902bcd743cbfa5017fad79f7ef90d8","impliedFormat":1},{"version":"bd0532fd6556073727d28da0edfd1736417a3f9f394877b6d5ef6ad88fba1d1a","impliedFormat":1},{"version":"89167d696a849fce5ca508032aabfe901c0868f833a8625d5a9c6e861ef935d2","impliedFormat":1},{"version":"e53a3c2a9f624d90f24bf4588aacd223e7bec1b9d0d479b68d2f4a9e6011147f","impliedFormat":1},{"version":"24b8685c62562f5d98615c5a0c1d05f297cf5065f15246edfe99e81ec4c0e011","impliedFormat":1},{"version":"93507c745e8f29090efb99399c3f77bec07db17acd75634249dc92f961573387","impliedFormat":1},{"version":"339dc5265ee5ed92e536a93a04c4ebbc2128f45eeec6ed29f379e0085283542c","impliedFormat":1},{"version":"4732aec92b20fb28c5fe9ad99521fb59974289ed1e45aecb282616202184064f","impliedFormat":1},{"version":"2e85db9e6fd73cfa3d7f28e0ab6b55417ea18931423bd47b409a96e4a169e8e6","impliedFormat":1},{"version":"c46e079fe54c76f95c67fb89081b3e399da2c7d109e7dca8e4b58d83e332e605","impliedFormat":1},{"version":"bf67d53d168abc1298888693338cb82854bdb2e69ef83f8a0092093c2d562107","impliedFormat":1},{"version":"964f307d249df0d7e8eb16d594536c0ac6cc63c8d467edf635d05542821dec8e","affectsGlobalScope":true,"impliedFormat":1},{"version":"db3ec8993b7596a4ef47f309c7b25ee2505b519c13050424d9c34701e5973315","impliedFormat":1},{"version":"6a1ebd564896d530364f67b3257c62555b61d60494a73dfe8893274878c6589d","affectsGlobalScope":true,"impliedFormat":1},{"version":"af49b066a76ce26673fe49d1885cc6b44153f1071ed2d952f2a90fccba1095c9","impliedFormat":1},{"version":"f22fd1dc2df53eaf5ce0ff9e0a3326fc66f880d6a652210d50563ae72625455f","impliedFormat":1},{"version":"3ddbdb519e87a7827c4f0c4007013f3628ca0ebb9e2b018cf31e5b2f61c593f1","affectsGlobalScope":true,"impliedFormat":1},{"version":"a40826e8476694e90da94aa008283a7de50d1dafd37beada623863f1901cb7fb","impliedFormat":1},{"version":"6d498d4fd8036ea02a4edcae10375854a0eb1df0496cf0b9d692577d3c0fd603","affectsGlobalScope":true,"impliedFormat":1},{"version":"24642567d3729bcc545bacb65ee7c0db423400c7f1ef757cab25d05650064f98","impliedFormat":1},{"version":"fd09b892597ab93e7f79745ce725a3aaf6dd005e8db20f0c63a5d10984cba328","impliedFormat":1},{"version":"a3be878ff1e1964ab2dc8e0a3b67087cf838731c7f3d8f603337e7b712fdd558","impliedFormat":1},{"version":"5433f7f77cd1fd53f45bd82445a4e437b2f6a72a32070e907530a4fea56c30c8","impliedFormat":1},{"version":"9be74296ee565af0c12d7071541fdd23260f53c3da7731fb6361f61150a791f6","impliedFormat":1},{"version":"ee1ee365d88c4c6c0c0a5a5701d66ebc27ccd0bcfcfaa482c6e2e7fe7b98edf7","affectsGlobalScope":true,"impliedFormat":1},{"version":"f501a53b94ba382d9ba396a5c486969a3abc68309828fa67f916035f5d37fe2b","affectsGlobalScope":true,"impliedFormat":1},{"version":"aa658b5d765f630c312ac9202d110bbaf2b82d180376457f0a9d57b42629714a","impliedFormat":1},{"version":"312ac7cbd070107766a9886fd27f9faad997ef57d93fdfb4095df2c618ac8162","impliedFormat":1},{"version":"2e9b4e7f9942af902eb85bae6066d04ef1afee51d61554a62d144df3da7dec94","impliedFormat":1},{"version":"672ad3045f329e94002256f8ed460cfd06173a50c92cde41edaadfacffd16808","impliedFormat":1},{"version":"64da4965d1e0559e134d9c1621ae400279a216f87ed00c4cce4f2c7c78021712","impliedFormat":1},{"version":"2205527b976f4f1844adc46a3f0528729fb68cac70027a5fb13c49ca23593797","impliedFormat":1},{"version":"0166fce1204d520fdfd6b5febb3cda3deee438bcbf8ce9ffeb2b1bcde7155346","affectsGlobalScope":true,"impliedFormat":1},{"version":"d8b13eab85b532285031b06a971fa051bf0175d8fff68065a24a6da9c1c986cf","impliedFormat":1},{"version":"50c382ba1827988c59aa9cc9d046e386d55d70f762e9e352e95ee8cb7337cdb8","impliedFormat":1},{"version":"bb9627ab9d078c79bb5623de4ac8e5d08f806ec9b970962dfc83b3211373690d","impliedFormat":1},{"version":"21d7e87f271e72d02f8d167edc902f90b04525edc7918f00f01dd0bd00599f7e","affectsGlobalScope":true,"impliedFormat":1},{"version":"6f6abdaf8764ef01a552a958f45e795b5e79153b87ddad3af5264b86d2681b72","affectsGlobalScope":true,"impliedFormat":1},{"version":"a215554477f7629e3dcbc8cde104bec036b78673650272f5ffdc5a2cee399a0a","impliedFormat":1},{"version":"c3497fc242aabfedcd430b5932412f94f157b5906568e737f6a18cc77b36a954","impliedFormat":1},{"version":"cdc1de3b672f9ef03ff15c443aa1b631edca35b6ae6970a7da6400647ff74d95","impliedFormat":1},{"version":"139ad1dc93a503da85b7a0d5f615bddbae61ad796bc68fedd049150db67a1e26","impliedFormat":1},{"version":"bf01fdd3b93cf633b3f7420718457af19c57ab8cbfea49268df60bae2e84d627","impliedFormat":1},{"version":"15c5e91b5f08be34a78e3d976179bf5b7a9cc28dc0ef1ffebffeb3c7812a2dca","impliedFormat":1},{"version":"5f461d6f5d9ff474f1121cc3fd86aa3cd67476c701f55c306d323c5112201207","impliedFormat":1},{"version":"65b39cc6b610a4a4aecc321f6efb436f10c0509d686124795b4c36a5e915b89e","impliedFormat":1},{"version":"269929a24b2816343a178008ac9ae9248304d92a8ba8e233055e0ed6dbe6ef71","impliedFormat":1},{"version":"93452d394fdd1dc551ec62f5042366f011a00d342d36d50793b3529bfc9bd633","impliedFormat":1},{"version":"83fe38aa2243059ea859325c006da3964ead69b773429fe049ebb0426e75424d","affectsGlobalScope":true,"impliedFormat":1},{"version":"d3edb86744e2c19f2c1503849ac7594a5e06024f2451bacae032390f2e20314a","impliedFormat":1},{"version":"e501cbca25bd54f0bcb89c00f092d3cae227e970b93fd76207287fd8110b123d","affectsGlobalScope":true,"impliedFormat":1},{"version":"8a3e61347b8f80aa5af532094498bceb0c0b257b25a6aa8ab4880fd6ed57c95a","affectsGlobalScope":true,"impliedFormat":1},{"version":"98e00f3613402504bc2a2c9a621800ab48e0a463d1eed062208a4ae98ad8f84c","impliedFormat":1},{"version":"950f6810f7c80e0cffefcf1bcc6ade3485c94394720e334c3c2be3c16b6922fb","impliedFormat":1},{"version":"5475df7cfc493a08483c9d7aa61cc04791aecba9d0a2efc213f23c4006d4d3cd","impliedFormat":1},{"version":"000720870b275764c65e9f28ac97cc9e4d9e4a36942d4750ca8603e416e9c57c","impliedFormat":1},{"version":"54412c70bacb9ed547ed6caae8836f712a83ccf58d94466f3387447ec4e82dc3","affectsGlobalScope":true,"impliedFormat":1},{"version":"e74e7b0baa7a24f073080091427d36a75836d584b9393e6ac2b1daf1647fe65a","affectsGlobalScope":true,"impliedFormat":1},{"version":"4c48e931a72f6971b5add7fdb1136be1d617f124594e94595f7114af749395e0","impliedFormat":1},{"version":"478eb5c32250678a906d91e0529c70243fc4d75477a08f3da408e2615396f558","impliedFormat":1},{"version":"e686a88c9ee004c8ba12ffc9d674ca3192a4c50ed0ca6bd5b2825c289e2b2bfe","impliedFormat":1},{"version":"0d27932df2fbc3728e78b98892540e24084424ce12d3bd32f62a23cf307f411f","affectsGlobalScope":true,"impliedFormat":1},{"version":"4423fb3d6abe6eefb8d7f79eb2df9510824a216ec1c6feee46718c9b18e6d89f","impliedFormat":1},{"version":"ab9b9a36e5284fd8d3bf2f7d5fcbc60052f25f27e4d20954782099282c60d23e","affectsGlobalScope":true,"impliedFormat":1},{"version":"01c47d1c006b3a15b51d89d7764fff7e4fabc4e412b3a61ee5357bd74b822879","impliedFormat":1},{"version":"8841e2aa774b89bd23302dede20663306dc1b9902431ac64b24be8b8d0e3f649","impliedFormat":1},{"version":"fd326577c62145816fe1acc306c734c2396487f76719d3785d4e825b34540b33","impliedFormat":1},{"version":"9e951ec338c4232d611552a1be7b4ecec79a8c2307a893ce39701316fe2374bd","impliedFormat":1},{"version":"70c61ff569aabdf2b36220da6c06caaa27e45cd7acac81a1966ab4ee2eadc4f2","impliedFormat":1},{"version":"905c3e8f7ddaa6c391b60c05b2f4c3931d7127ad717a080359db3df510b7bdab","impliedFormat":1},{"version":"6c1e688f95fcaf53b1e41c0fdadf2c1cfc96fa924eaf7f9fdb60f96deb0a4986","impliedFormat":1},{"version":"0d14fa22c41fdc7277e6f71473b20ebc07f40f00e38875142335d5b63cdfc9d2","impliedFormat":1},{"version":"c085e9aa62d1ae1375794c1fb927a445fa105fed891a7e24edbb1c3300f7384a","impliedFormat":1},{"version":"f315e1e65a1f80992f0509e84e4ae2df15ecd9ef73df975f7c98813b71e4c8da","impliedFormat":1},{"version":"5b9586e9b0b6322e5bfbd2c29bd3b8e21ab9d871f82346cb71020e3d84bae73e","impliedFormat":1},{"version":"3e70a7e67c2cb16f8cd49097360c0309fe9d1e3210ff9222e9dac1f8df9d4fb6","impliedFormat":1},{"version":"ab68d2a3e3e8767c3fba8f80de099a1cfc18c0de79e42cb02ae66e22dfe14a66","impliedFormat":1},{"version":"6d969939c4a63f70f2aa49e88da6f64b655c8e6799612807bef41ccff6ea0da9","impliedFormat":1},{"version":"5b9586e9b0b6322e5bfbd2c29bd3b8e21ab9d871f82346cb71020e3d84bae73e","impliedFormat":1},{"version":"46894b2a21a60f8449ca6b2b7223b7179bba846a61b1434bed77b34b2902c306","affectsGlobalScope":true,"impliedFormat":1},{"version":"84a805c22a49922085dc337ca71ac0b85aad6d4dba6b01cee5bd5776ff54df39","impliedFormat":1},{"version":"96d14f21b7652903852eef49379d04dbda28c16ed36468f8c9fa08f7c14c9538","impliedFormat":1},{"version":"6d727c1f6a7122c04e4f7c164c5e6f460c21ada618856894cdaa6ac25e95f38c","impliedFormat":1},{"version":"22293bd6fa12747929f8dfca3ec1684a3fe08638aa18023dd286ab337e88a592","impliedFormat":1},{"version":"8baa5d0febc68db886c40bf341e5c90dc215a90cd64552e47e8184be6b7e3358","impliedFormat":1},{"version":"cf3d384d082b933d987c4e2fe7bfb8710adfd9dc8155190056ed6695a25a559e","impliedFormat":1},{"version":"9871b7ee672bc16c78833bdab3052615834b08375cb144e4d2cba74473f4a589","impliedFormat":1},{"version":"c863198dae89420f3c552b5a03da6ed6d0acfa3807a64772b895db624b0de707","impliedFormat":1},{"version":"8b03a5e327d7db67112ebbc93b4f744133eda2c1743dbb0a990c61a8007823ef","impliedFormat":1},{"version":"86c73f2ee1752bac8eeeece234fd05dfcf0637a4fbd8032e4f5f43102faa8eec","impliedFormat":1},{"version":"42fad1f540271e35ca37cecda12c4ce2eef27f0f5cf0f8dd761d723c744d3159","impliedFormat":1},{"version":"ff3743a5de32bee10906aff63d1de726f6a7fd6ee2da4b8229054dfa69de2c34","impliedFormat":1},{"version":"83acd370f7f84f203e71ebba33ba61b7f1291ca027d7f9a662c6307d74e4ac22","impliedFormat":1},{"version":"1445cec898f90bdd18b2949b9590b3c012f5b7e1804e6e329fb0fe053946d5ec","impliedFormat":1},{"version":"0e5318ec2275d8da858b541920d9306650ae6ac8012f0e872fe66eb50321a669","impliedFormat":1},{"version":"cf530297c3fb3a92ec9591dd4fa229d58b5981e45fe6702a0bd2bea53a5e59be","impliedFormat":1},{"version":"c1f6f7d08d42148ddfe164d36d7aba91f467dbcb3caa715966ff95f55048b3a4","impliedFormat":1},{"version":"f4e9bf9103191ef3b3612d3ec0044ca4044ca5be27711fe648ada06fad4bcc85","impliedFormat":1},{"version":"0c1ee27b8f6a00097c2d6d91a21ee4d096ab52c1e28350f6362542b55380059a","impliedFormat":1},{"version":"7677d5b0db9e020d3017720f853ba18f415219fb3a9597343b1b1012cfd699f7","impliedFormat":1},{"version":"bc1c6bc119c1784b1a2be6d9c47addec0d83ef0d52c8fbe1f14a51b4dfffc675","impliedFormat":1},{"version":"52cf2ce99c2a23de70225e252e9822a22b4e0adb82643ab0b710858810e00bf1","impliedFormat":1},{"version":"770625067bb27a20b9826255a8d47b6b5b0a2d3dfcbd21f89904c731f671ba77","impliedFormat":1},{"version":"d1ed6765f4d7906a05968fb5cd6d1db8afa14dbe512a4884e8ea5c0f5e142c80","impliedFormat":1},{"version":"799c0f1b07c092626cf1efd71d459997635911bb5f7fc1196efe449bba87e965","impliedFormat":1},{"version":"2a184e4462b9914a30b1b5c41cf80c6d3428f17b20d3afb711fff3f0644001fd","impliedFormat":1},{"version":"9eabde32a3aa5d80de34af2c2206cdc3ee094c6504a8d0c2d6d20c7c179503cc","impliedFormat":1},{"version":"397c8051b6cfcb48aa22656f0faca2553c5f56187262135162ee79d2b2f6c966","impliedFormat":1},{"version":"a8ead142e0c87dcd5dc130eba1f8eeed506b08952d905c47621dc2f583b1bff9","impliedFormat":1},{"version":"a02f10ea5f73130efca046429254a4e3c06b5475baecc8f7b99a0014731be8b3","impliedFormat":1},{"version":"c2576a4083232b0e2d9bd06875dd43d371dee2e090325a9eac0133fd5650c1cb","impliedFormat":1},{"version":"4c9a0564bb317349de6a24eb4efea8bb79898fa72ad63a1809165f5bd42970dd","impliedFormat":1},{"version":"f40ac11d8859092d20f953aae14ba967282c3bb056431a37fced1866ec7a2681","impliedFormat":1},{"version":"cc11e9e79d4746cc59e0e17473a59d6f104692fd0eeea1bdb2e206eabed83b03","impliedFormat":1},{"version":"b444a410d34fb5e98aa5ee2b381362044f4884652e8bc8a11c8fe14bbd85518e","impliedFormat":1},{"version":"c35808c1f5e16d2c571aa65067e3cb95afeff843b259ecfa2fc107a9519b5392","impliedFormat":1},{"version":"14d5dc055143e941c8743c6a21fa459f961cbc3deedf1bfe47b11587ca4b3ef5","impliedFormat":1},{"version":"a3ad4e1fc542751005267d50a6298e6765928c0c3a8dce1572f2ba6ca518661c","impliedFormat":1},{"version":"f237e7c97a3a89f4591afd49ecb3bd8d14f51a1c4adc8fcae3430febedff5eb6","impliedFormat":1},{"version":"3ffdfbec93b7aed71082af62b8c3e0cc71261cc68d796665faa1e91604fbae8f","impliedFormat":1},{"version":"662201f943ed45b1ad600d03a90dffe20841e725203ced8b708c91fcd7f9379a","impliedFormat":1},{"version":"c9ef74c64ed051ea5b958621e7fb853fe3b56e8787c1587aefc6ea988b3c7e79","impliedFormat":1},{"version":"2462ccfac5f3375794b861abaa81da380f1bbd9401de59ffa43119a0b644253d","impliedFormat":1},{"version":"34baf65cfee92f110d6653322e2120c2d368ee64b3c7981dff08ed105c4f19b0","impliedFormat":1},{"version":"7d8ddf0f021c53099e34ee831a06c394d50371816caa98684812f089b4c6b3d4","impliedFormat":1},{"version":"c6c4fea9acc55d5e38ff2b70d57ab0b5cdbd08f8bc5d7a226e322cea128c5b57","impliedFormat":1},{"version":"9ad8802fd8850d22277c08f5653e69e551a2e003a376ce0afb3fe28474b51d65","impliedFormat":1},{"version":"fdfbe321c556c39a2ecf791d537b999591d0849e971dd938d88f460fea0186f6","impliedFormat":1},{"version":"105b9a2234dcb06ae922f2cd8297201136d416503ff7d16c72bfc8791e9895c1","impliedFormat":1}],"root":[[73,79],[81,83],87,[89,163]],"options":{"allowImportingTsExtensions":true,"composite":true,"declaration":true,"declarationDir":"../../dts","declarationMap":true,"emitDeclarationOnly":true,"esModuleInterop":true,"module":200,"noImplicitAny":true,"noImplicitThis":true,"rootDir":"../..","skipLibCheck":true,"strictBindCallApply":true,"target":99},"referencedMap":[[86,1],[280,2],[175,3],[171,4],[273,5],[275,6],[276,7],[286,8],[284,9],[283,10],[285,11],[178,12],[179,12],[219,13],[220,14],[221,15],[222,16],[223,17],[224,18],[225,19],[226,20],[227,21],[228,22],[229,22],[231,23],[230,24],[232,25],[233,26],[234,27],[218,28],[235,29],[236,30],[237,31],[271,32],[238,33],[239,34],[240,35],[241,36],[242,37],[243,38],[244,39],[245,40],[246,41],[247,42],[248,42],[249,43],[252,44],[254,45],[253,46],[255,47],[256,48],[257,49],[258,50],[259,51],[260,52],[261,53],[262,54],[263,55],[264,56],[265,57],[266,58],[267,59],[268,60],[269,61],[316,62],[317,63],[292,64],[295,64],[314,62],[315,62],[305,62],[304,65],[302,62],[297,62],[310,62],[308,62],[312,62],[296,62],[309,62],[313,62],[298,62],[299,62],[311,62],[293,62],[300,62],[301,62],[303,62],[307,62],[318,66],[306,62],[294,62],[331,67],[325,66],[327,68],[326,66],[319,66],[320,66],[322,66],[324,66],[328,68],[329,68],[321,68],[323,68],[335,69],[174,70],[173,71],[282,72],[281,11],[196,73],[206,74],[195,73],[216,75],[187,76],[186,77],[215,78],[209,79],[214,80],[189,81],[203,82],[188,83],[212,84],[184,85],[183,86],[213,87],[185,88],[190,89],[194,89],[217,90],[207,91],[198,92],[199,93],[201,94],[197,95],[200,96],[210,78],[192,97],[193,98],[202,99],[182,100],[205,91],[204,89],[211,101],[105,102],[106,103],[109,104],[107,105],[101,106],[113,107],[103,108],[111,109],[160,110],[115,111],[116,111],[117,111],[114,112],[118,111],[120,113],[119,114],[122,115],[123,115],[124,115],[125,116],[126,117],[127,118],[129,119],[161,120],[131,121],[128,122],[132,122],[133,123],[130,124],[137,125],[162,126],[138,122],[139,127],[91,128],[96,129],[92,129],[99,130],[93,129],[95,131],[94,129],[97,132],[90,133],[159,134],[140,105],[108,123],[141,135],[142,105],[135,117],[136,136],[110,123],[143,114],[144,123],[146,123],[145,137],[147,138],[134,138],[121,114],[102,105],[77,139],[75,140],[83,141],[148,137],[150,142],[151,143],[149,144],[104,138],[152,138],[82,118],[153,114],[154,123],[155,123],[81,138],[156,145],[87,146],[157,144],[76,123],[78,147],[100,138]],"latestChangedDtsFile":"../../dts/packages/babel-types/src/converters/toSequenceExpression.d.ts","version":"5.6.2"}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/LICENSE b/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/LICENSE
new file mode 100644
index 0000000..a331065
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/LICENSE
@@ -0,0 +1,21 @@
+The MIT License
+
+Copyright (c) 2015 Rich Harris
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/README.md b/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/README.md
new file mode 100644
index 0000000..b3e0708
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/README.md
@@ -0,0 +1,264 @@
+# @jridgewell/sourcemap-codec
+
+Encode/decode the `mappings` property of a [sourcemap](https://docs.google.com/document/d/1U1RGAehQwRypUTovF1KRlpiOFze0b-_2gc6fAH0KY0k/edit).
+
+
+## Why?
+
+Sourcemaps are difficult to generate and manipulate, because the `mappings` property – the part that actually links the generated code back to the original source – is encoded using an obscure method called [Variable-length quantity](https://en.wikipedia.org/wiki/Variable-length_quantity). On top of that, each segment in the mapping contains offsets rather than absolute indices, which means that you can't look at a segment in isolation – you have to understand the whole sourcemap.
+
+This package makes the process slightly easier.
+
+
+## Installation
+
+```bash
+npm install @jridgewell/sourcemap-codec
+```
+
+
+## Usage
+
+```js
+import { encode, decode } from '@jridgewell/sourcemap-codec';
+
+var decoded = decode( ';EAEEA,EAAE,EAAC,CAAE;ECQY,UACC' );
+
+assert.deepEqual( decoded, [
+ // the first line (of the generated code) has no mappings,
+ // as shown by the starting semi-colon (which separates lines)
+ [],
+
+ // the second line contains four (comma-separated) segments
+ [
+ // segments are encoded as you'd expect:
+ // [ generatedCodeColumn, sourceIndex, sourceCodeLine, sourceCodeColumn, nameIndex ]
+
+ // i.e. the first segment begins at column 2, and maps back to the second column
+ // of the second line (both zero-based) of the 0th source, and uses the 0th
+ // name in the `map.names` array
+ [ 2, 0, 2, 2, 0 ],
+
+ // the remaining segments are 4-length rather than 5-length,
+ // because they don't map a name
+ [ 4, 0, 2, 4 ],
+ [ 6, 0, 2, 5 ],
+ [ 7, 0, 2, 7 ]
+ ],
+
+ // the final line contains two segments
+ [
+ [ 2, 1, 10, 19 ],
+ [ 12, 1, 11, 20 ]
+ ]
+]);
+
+var encoded = encode( decoded );
+assert.equal( encoded, ';EAEEA,EAAE,EAAC,CAAE;ECQY,UACC' );
+```
+
+## Benchmarks
+
+```
+node v20.10.0
+
+amp.js.map - 45120 segments
+
+Decode Memory Usage:
+local code 5815135 bytes
+@jridgewell/sourcemap-codec 1.4.15 5868160 bytes
+sourcemap-codec 5492584 bytes
+source-map-0.6.1 13569984 bytes
+source-map-0.8.0 6390584 bytes
+chrome dev tools 8011136 bytes
+Smallest memory usage is sourcemap-codec
+
+Decode speed:
+decode: local code x 492 ops/sec ±1.22% (90 runs sampled)
+decode: @jridgewell/sourcemap-codec 1.4.15 x 499 ops/sec ±1.16% (89 runs sampled)
+decode: sourcemap-codec x 376 ops/sec ±1.66% (89 runs sampled)
+decode: source-map-0.6.1 x 34.99 ops/sec ±0.94% (48 runs sampled)
+decode: source-map-0.8.0 x 351 ops/sec ±0.07% (95 runs sampled)
+chrome dev tools x 165 ops/sec ±0.91% (86 runs sampled)
+Fastest is decode: @jridgewell/sourcemap-codec 1.4.15
+
+Encode Memory Usage:
+local code 444248 bytes
+@jridgewell/sourcemap-codec 1.4.15 623024 bytes
+sourcemap-codec 8696280 bytes
+source-map-0.6.1 8745176 bytes
+source-map-0.8.0 8736624 bytes
+Smallest memory usage is local code
+
+Encode speed:
+encode: local code x 796 ops/sec ±0.11% (97 runs sampled)
+encode: @jridgewell/sourcemap-codec 1.4.15 x 795 ops/sec ±0.25% (98 runs sampled)
+encode: sourcemap-codec x 231 ops/sec ±0.83% (86 runs sampled)
+encode: source-map-0.6.1 x 166 ops/sec ±0.57% (86 runs sampled)
+encode: source-map-0.8.0 x 203 ops/sec ±0.45% (88 runs sampled)
+Fastest is encode: local code,encode: @jridgewell/sourcemap-codec 1.4.15
+
+
+***
+
+
+babel.min.js.map - 347793 segments
+
+Decode Memory Usage:
+local code 35424960 bytes
+@jridgewell/sourcemap-codec 1.4.15 35424696 bytes
+sourcemap-codec 36033464 bytes
+source-map-0.6.1 62253704 bytes
+source-map-0.8.0 43843920 bytes
+chrome dev tools 45111400 bytes
+Smallest memory usage is @jridgewell/sourcemap-codec 1.4.15
+
+Decode speed:
+decode: local code x 38.18 ops/sec ±5.44% (52 runs sampled)
+decode: @jridgewell/sourcemap-codec 1.4.15 x 38.36 ops/sec ±5.02% (52 runs sampled)
+decode: sourcemap-codec x 34.05 ops/sec ±4.45% (47 runs sampled)
+decode: source-map-0.6.1 x 4.31 ops/sec ±2.76% (15 runs sampled)
+decode: source-map-0.8.0 x 55.60 ops/sec ±0.13% (73 runs sampled)
+chrome dev tools x 16.94 ops/sec ±3.78% (46 runs sampled)
+Fastest is decode: source-map-0.8.0
+
+Encode Memory Usage:
+local code 2606016 bytes
+@jridgewell/sourcemap-codec 1.4.15 2626440 bytes
+sourcemap-codec 21152576 bytes
+source-map-0.6.1 25023928 bytes
+source-map-0.8.0 25256448 bytes
+Smallest memory usage is local code
+
+Encode speed:
+encode: local code x 127 ops/sec ±0.18% (83 runs sampled)
+encode: @jridgewell/sourcemap-codec 1.4.15 x 128 ops/sec ±0.26% (83 runs sampled)
+encode: sourcemap-codec x 29.31 ops/sec ±2.55% (53 runs sampled)
+encode: source-map-0.6.1 x 18.85 ops/sec ±3.19% (36 runs sampled)
+encode: source-map-0.8.0 x 19.34 ops/sec ±1.97% (36 runs sampled)
+Fastest is encode: @jridgewell/sourcemap-codec 1.4.15
+
+
+***
+
+
+preact.js.map - 1992 segments
+
+Decode Memory Usage:
+local code 261696 bytes
+@jridgewell/sourcemap-codec 1.4.15 244296 bytes
+sourcemap-codec 302816 bytes
+source-map-0.6.1 939176 bytes
+source-map-0.8.0 336 bytes
+chrome dev tools 587368 bytes
+Smallest memory usage is source-map-0.8.0
+
+Decode speed:
+decode: local code x 17,782 ops/sec ±0.32% (97 runs sampled)
+decode: @jridgewell/sourcemap-codec 1.4.15 x 17,863 ops/sec ±0.40% (100 runs sampled)
+decode: sourcemap-codec x 12,453 ops/sec ±0.27% (101 runs sampled)
+decode: source-map-0.6.1 x 1,288 ops/sec ±1.05% (96 runs sampled)
+decode: source-map-0.8.0 x 9,289 ops/sec ±0.27% (101 runs sampled)
+chrome dev tools x 4,769 ops/sec ±0.18% (100 runs sampled)
+Fastest is decode: @jridgewell/sourcemap-codec 1.4.15
+
+Encode Memory Usage:
+local code 262944 bytes
+@jridgewell/sourcemap-codec 1.4.15 25544 bytes
+sourcemap-codec 323048 bytes
+source-map-0.6.1 507808 bytes
+source-map-0.8.0 507480 bytes
+Smallest memory usage is @jridgewell/sourcemap-codec 1.4.15
+
+Encode speed:
+encode: local code x 24,207 ops/sec ±0.79% (95 runs sampled)
+encode: @jridgewell/sourcemap-codec 1.4.15 x 24,288 ops/sec ±0.48% (96 runs sampled)
+encode: sourcemap-codec x 6,761 ops/sec ±0.21% (100 runs sampled)
+encode: source-map-0.6.1 x 5,374 ops/sec ±0.17% (99 runs sampled)
+encode: source-map-0.8.0 x 5,633 ops/sec ±0.32% (99 runs sampled)
+Fastest is encode: @jridgewell/sourcemap-codec 1.4.15,encode: local code
+
+
+***
+
+
+react.js.map - 5726 segments
+
+Decode Memory Usage:
+local code 678816 bytes
+@jridgewell/sourcemap-codec 1.4.15 678816 bytes
+sourcemap-codec 816400 bytes
+source-map-0.6.1 2288864 bytes
+source-map-0.8.0 721360 bytes
+chrome dev tools 1012512 bytes
+Smallest memory usage is local code
+
+Decode speed:
+decode: local code x 6,178 ops/sec ±0.19% (98 runs sampled)
+decode: @jridgewell/sourcemap-codec 1.4.15 x 6,261 ops/sec ±0.22% (100 runs sampled)
+decode: sourcemap-codec x 4,472 ops/sec ±0.90% (99 runs sampled)
+decode: source-map-0.6.1 x 449 ops/sec ±0.31% (95 runs sampled)
+decode: source-map-0.8.0 x 3,219 ops/sec ±0.13% (100 runs sampled)
+chrome dev tools x 1,743 ops/sec ±0.20% (99 runs sampled)
+Fastest is decode: @jridgewell/sourcemap-codec 1.4.15
+
+Encode Memory Usage:
+local code 140960 bytes
+@jridgewell/sourcemap-codec 1.4.15 159808 bytes
+sourcemap-codec 969304 bytes
+source-map-0.6.1 930520 bytes
+source-map-0.8.0 930248 bytes
+Smallest memory usage is local code
+
+Encode speed:
+encode: local code x 8,013 ops/sec ±0.19% (100 runs sampled)
+encode: @jridgewell/sourcemap-codec 1.4.15 x 7,989 ops/sec ±0.20% (101 runs sampled)
+encode: sourcemap-codec x 2,472 ops/sec ±0.21% (99 runs sampled)
+encode: source-map-0.6.1 x 2,200 ops/sec ±0.17% (99 runs sampled)
+encode: source-map-0.8.0 x 2,220 ops/sec ±0.37% (99 runs sampled)
+Fastest is encode: local code
+
+
+***
+
+
+vscode.map - 2141001 segments
+
+Decode Memory Usage:
+local code 198955264 bytes
+@jridgewell/sourcemap-codec 1.4.15 199175352 bytes
+sourcemap-codec 199102688 bytes
+source-map-0.6.1 386323432 bytes
+source-map-0.8.0 244116432 bytes
+chrome dev tools 293734280 bytes
+Smallest memory usage is local code
+
+Decode speed:
+decode: local code x 3.90 ops/sec ±22.21% (15 runs sampled)
+decode: @jridgewell/sourcemap-codec 1.4.15 x 3.95 ops/sec ±23.53% (15 runs sampled)
+decode: sourcemap-codec x 3.82 ops/sec ±17.94% (14 runs sampled)
+decode: source-map-0.6.1 x 0.61 ops/sec ±7.81% (6 runs sampled)
+decode: source-map-0.8.0 x 9.54 ops/sec ±0.28% (28 runs sampled)
+chrome dev tools x 2.18 ops/sec ±10.58% (10 runs sampled)
+Fastest is decode: source-map-0.8.0
+
+Encode Memory Usage:
+local code 13509880 bytes
+@jridgewell/sourcemap-codec 1.4.15 13537648 bytes
+sourcemap-codec 32540104 bytes
+source-map-0.6.1 127531040 bytes
+source-map-0.8.0 127535312 bytes
+Smallest memory usage is local code
+
+Encode speed:
+encode: local code x 20.10 ops/sec ±0.19% (38 runs sampled)
+encode: @jridgewell/sourcemap-codec 1.4.15 x 20.26 ops/sec ±0.32% (38 runs sampled)
+encode: sourcemap-codec x 5.44 ops/sec ±1.64% (18 runs sampled)
+encode: source-map-0.6.1 x 2.30 ops/sec ±4.79% (10 runs sampled)
+encode: source-map-0.8.0 x 2.46 ops/sec ±6.53% (10 runs sampled)
+Fastest is encode: @jridgewell/sourcemap-codec 1.4.15
+```
+
+# License
+
+MIT
diff --git a/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/package.json b/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/package.json
new file mode 100644
index 0000000..7168efc
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@jridgewell/sourcemap-codec/package.json
@@ -0,0 +1,75 @@
+{
+ "name": "@jridgewell/sourcemap-codec",
+ "version": "1.5.0",
+ "description": "Encode/decode sourcemap mappings",
+ "keywords": [
+ "sourcemap",
+ "vlq"
+ ],
+ "main": "dist/sourcemap-codec.umd.js",
+ "module": "dist/sourcemap-codec.mjs",
+ "types": "dist/types/sourcemap-codec.d.ts",
+ "files": [
+ "dist"
+ ],
+ "exports": {
+ ".": [
+ {
+ "types": "./dist/types/sourcemap-codec.d.ts",
+ "browser": "./dist/sourcemap-codec.umd.js",
+ "require": "./dist/sourcemap-codec.umd.js",
+ "import": "./dist/sourcemap-codec.mjs"
+ },
+ "./dist/sourcemap-codec.umd.js"
+ ],
+ "./package.json": "./package.json"
+ },
+ "scripts": {
+ "benchmark": "run-s build:rollup benchmark:*",
+ "benchmark:install": "cd benchmark && npm install",
+ "benchmark:only": "node --expose-gc benchmark/index.js",
+ "build": "run-s -n build:*",
+ "build:rollup": "rollup -c rollup.config.js",
+ "build:ts": "tsc --project tsconfig.build.json",
+ "lint": "run-s -n lint:*",
+ "lint:prettier": "npm run test:lint:prettier -- --write",
+ "lint:ts": "npm run test:lint:ts -- --fix",
+ "prebuild": "rm -rf dist",
+ "prepublishOnly": "npm run preversion",
+ "preversion": "run-s test build",
+ "test": "run-s -n test:lint test:only",
+ "test:debug": "mocha --inspect-brk",
+ "test:lint": "run-s -n test:lint:*",
+ "test:lint:prettier": "prettier --check '{src,test}/**/*.ts'",
+ "test:lint:ts": "eslint '{src,test}/**/*.ts'",
+ "test:only": "mocha",
+ "test:coverage": "c8 mocha",
+ "test:watch": "mocha --watch"
+ },
+ "repository": {
+ "type": "git",
+ "url": "git+https://github.com/jridgewell/sourcemap-codec.git"
+ },
+ "author": "Rich Harris",
+ "license": "MIT",
+ "devDependencies": {
+ "@rollup/plugin-typescript": "8.3.0",
+ "@types/mocha": "10.0.6",
+ "@types/node": "17.0.15",
+ "@typescript-eslint/eslint-plugin": "5.10.0",
+ "@typescript-eslint/parser": "5.10.0",
+ "benchmark": "2.1.4",
+ "c8": "7.11.2",
+ "eslint": "8.7.0",
+ "eslint-config-prettier": "8.3.0",
+ "mocha": "9.2.0",
+ "npm-run-all": "4.1.5",
+ "prettier": "2.5.1",
+ "rollup": "2.64.0",
+ "source-map": "0.6.1",
+ "source-map-js": "1.0.2",
+ "sourcemap-codec": "1.4.8",
+ "tsx": "4.7.1",
+ "typescript": "4.5.4"
+ }
+}
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/LICENSE b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/LICENSE
new file mode 100644
index 0000000..15f1f7e
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/LICENSE
@@ -0,0 +1,21 @@
+The MIT License (MIT)
+
+Copyright (c) 2018-present, Yuxi (Evan) You
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/README.md b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/README.md
new file mode 100644
index 0000000..b43fc55
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/README.md
@@ -0,0 +1 @@
+# @vue/compiler-core
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/index.js b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/index.js
new file mode 100644
index 0000000..d3fc54f
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/index.js
@@ -0,0 +1,7 @@
+'use strict'
+
+if (process.env.NODE_ENV === 'production') {
+ module.exports = require('./dist/compiler-core.cjs.prod.js')
+} else {
+ module.exports = require('./dist/compiler-core.cjs.js')
+}
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/package.json b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/package.json
new file mode 100644
index 0000000..337e7b4
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-core/package.json
@@ -0,0 +1,58 @@
+{
+ "name": "@vue/compiler-core",
+ "version": "3.5.12",
+ "description": "@vue/compiler-core",
+ "main": "index.js",
+ "module": "dist/compiler-core.esm-bundler.js",
+ "types": "dist/compiler-core.d.ts",
+ "files": [
+ "index.js",
+ "dist"
+ ],
+ "exports": {
+ ".": {
+ "types": "./dist/compiler-core.d.ts",
+ "node": {
+ "production": "./dist/compiler-core.cjs.prod.js",
+ "development": "./dist/compiler-core.cjs.js",
+ "default": "./index.js"
+ },
+ "module": "./dist/compiler-core.esm-bundler.js",
+ "import": "./dist/compiler-core.esm-bundler.js",
+ "require": "./index.js"
+ },
+ "./*": "./*"
+ },
+ "buildOptions": {
+ "name": "VueCompilerCore",
+ "compat": true,
+ "formats": [
+ "esm-bundler",
+ "cjs"
+ ]
+ },
+ "repository": {
+ "type": "git",
+ "url": "git+https://github.com/vuejs/core.git",
+ "directory": "packages/compiler-core"
+ },
+ "keywords": [
+ "vue"
+ ],
+ "author": "Evan You",
+ "license": "MIT",
+ "bugs": {
+ "url": "https://github.com/vuejs/core/issues"
+ },
+ "homepage": "https://github.com/vuejs/core/tree/main/packages/compiler-core#readme",
+ "dependencies": {
+ "@babel/parser": "^7.25.3",
+ "entities": "^4.5.0",
+ "estree-walker": "^2.0.2",
+ "source-map-js": "^1.2.0",
+ "@vue/shared": "3.5.12"
+ },
+ "devDependencies": {
+ "@babel/types": "^7.25.2"
+ }
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/LICENSE b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/LICENSE
new file mode 100644
index 0000000..15f1f7e
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/LICENSE
@@ -0,0 +1,21 @@
+The MIT License (MIT)
+
+Copyright (c) 2018-present, Yuxi (Evan) You
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/README.md b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/README.md
new file mode 100644
index 0000000..57748e6
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/README.md
@@ -0,0 +1 @@
+# @vue/compiler-dom
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/index.js b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/index.js
new file mode 100644
index 0000000..b5f7a05
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/index.js
@@ -0,0 +1,7 @@
+'use strict'
+
+if (process.env.NODE_ENV === 'production') {
+ module.exports = require('./dist/compiler-dom.cjs.prod.js')
+} else {
+ module.exports = require('./dist/compiler-dom.cjs.js')
+}
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/package.json b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/package.json
new file mode 100644
index 0000000..940ba7b
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-dom/package.json
@@ -0,0 +1,57 @@
+{
+ "name": "@vue/compiler-dom",
+ "version": "3.5.12",
+ "description": "@vue/compiler-dom",
+ "main": "index.js",
+ "module": "dist/compiler-dom.esm-bundler.js",
+ "types": "dist/compiler-dom.d.ts",
+ "unpkg": "dist/compiler-dom.global.js",
+ "jsdelivr": "dist/compiler-dom.global.js",
+ "files": [
+ "index.js",
+ "dist"
+ ],
+ "exports": {
+ ".": {
+ "types": "./dist/compiler-dom.d.ts",
+ "node": {
+ "production": "./dist/compiler-dom.cjs.prod.js",
+ "development": "./dist/compiler-dom.cjs.js",
+ "default": "./index.js"
+ },
+ "module": "./dist/compiler-dom.esm-bundler.js",
+ "import": "./dist/compiler-dom.esm-bundler.js",
+ "require": "./index.js"
+ },
+ "./*": "./*"
+ },
+ "sideEffects": false,
+ "buildOptions": {
+ "name": "VueCompilerDOM",
+ "compat": true,
+ "formats": [
+ "esm-bundler",
+ "esm-browser",
+ "cjs",
+ "global"
+ ]
+ },
+ "repository": {
+ "type": "git",
+ "url": "git+https://github.com/vuejs/core.git",
+ "directory": "packages/compiler-dom"
+ },
+ "keywords": [
+ "vue"
+ ],
+ "author": "Evan You",
+ "license": "MIT",
+ "bugs": {
+ "url": "https://github.com/vuejs/core/issues"
+ },
+ "homepage": "https://github.com/vuejs/core/tree/main/packages/compiler-dom#readme",
+ "dependencies": {
+ "@vue/shared": "3.5.12",
+ "@vue/compiler-core": "3.5.12"
+ }
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-sfc/LICENSE b/src/MaxKB-1.5.1/node_modules/@vue/compiler-sfc/LICENSE
new file mode 100644
index 0000000..15f1f7e
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-sfc/LICENSE
@@ -0,0 +1,21 @@
+The MIT License (MIT)
+
+Copyright (c) 2018-present, Yuxi (Evan) You
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/src/MaxKB-1.5.1/node_modules/@vue/compiler-sfc/README.md b/src/MaxKB-1.5.1/node_modules/@vue/compiler-sfc/README.md
new file mode 100644
index 0000000..4f8ff3a
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/@vue/compiler-sfc/README.md
@@ -0,0 +1,80 @@
+# @vue/compiler-sfc
+
+> Lower level utilities for compiling Vue Single File Components
+
+**Note: as of 3.2.13+, this package is included as a dependency of the main `vue` package and can be accessed as `vue/compiler-sfc`. This means you no longer need to explicitly install this package and ensure its version match that of `vue`'s. Just use the main `vue/compiler-sfc` deep import instead.**
+
+This package contains lower level utilities that you can use if you are writing a plugin / transform for a bundler or module system that compiles Vue Single File Components (SFCs) into JavaScript. It is used in [vue-loader](https://github.com/vuejs/vue-loader) and [@vitejs/plugin-vue](https://github.com/vitejs/vite-plugin-vue/tree/main/packages/plugin-vue).
+
+## API
+
+The API is intentionally low-level due to the various considerations when integrating Vue SFCs in a build system:
+
+- Separate hot-module replacement (HMR) for script, template and styles
+
+ - template updates should not reset component state
+ - style updates should be performed without component re-render
+
+- Leveraging the tool's plugin system for pre-processor handling. e.g. `
+```
+
+
+
+ displayable. Do not support
+ // the full feature of it.
+ el = parentGroup;
+ }
+ else {
+ // In , elments will not be rendered.
+ // TODO:
+ // do not support elements in yet, until requirement come.
+ // other graphic elements can also be in and referenced by
+ //
+ // multiple times
+ if (!isInDefs) {
+ const parser = nodeParsers[nodeName];
+ if (parser && hasOwn(nodeParsers, nodeName)) {
+
+ el = parser.call(this, xmlNode, parentGroup);
+
+ // Do not support empty string;
+ const nameAttr = xmlNode.getAttribute('name');
+ if (nameAttr) {
+ const newNamed: SVGParserResultNamedItem = {
+ name: nameAttr,
+ namedFrom: null,
+ svgNodeTagLower: nodeName,
+ el: el
+ };
+ named.push(newNamed);
+ if (nodeName === 'g') {
+ namedFromForSub = newNamed;
+ }
+ }
+ else if (namedFrom) {
+ named.push({
+ name: namedFrom.name,
+ namedFrom: namedFrom,
+ svgNodeTagLower: nodeName,
+ el: el
+ });
+ }
+
+ parentGroup.add(el);
+ }
+ }
+
+ // Whether gradients/patterns are declared in or not,
+ // they all work.
+ const parser = paintServerParsers[nodeName];
+ if (parser && hasOwn(paintServerParsers, nodeName)) {
+ const def = parser.call(this, xmlNode);
+ const id = xmlNode.getAttribute('id');
+ if (id) {
+ this._defs[id] = def;
+ }
+ }
+ }
+
+ // If xmlNode is , , , , ,
+ // el will be a group, and traverse the children.
+ if (el && el.isGroup) {
+ let child = xmlNode.firstChild as SVGElement;
+ while (child) {
+ if (child.nodeType === 1) {
+ this._parseNode(child, el as Group, named, namedFromForSub, isInDefs, isInText);
+ }
+ // Is plain text rather than a tagged node.
+ else if (child.nodeType === 3 && isInText) {
+ this._parseText(child, el as Group);
+ }
+ child = child.nextSibling as SVGElement;
+ }
+ }
+
+ }
+
+ private _parseText(xmlNode: SVGElement, parentGroup: Group): TSpan {
+ const text = new TSpan({
+ style: {
+ text: xmlNode.textContent
+ },
+ silent: true,
+ x: this._textX || 0,
+ y: this._textY || 0
+ });
+
+ inheritStyle(parentGroup, text);
+
+ parseAttributes(xmlNode, text, this._defsUsePending, false, false);
+
+ applyTextAlignment(text, parentGroup);
+
+ const textStyle = text.style as TextStyleOptionExtended;
+ const fontSize = textStyle.fontSize;
+ if (fontSize && fontSize < 9) {
+ // PENDING
+ textStyle.fontSize = 9;
+ text.scaleX *= fontSize / 9;
+ text.scaleY *= fontSize / 9;
+ }
+
+ const font = (textStyle.fontSize || textStyle.fontFamily) && [
+ textStyle.fontStyle,
+ textStyle.fontWeight,
+ (textStyle.fontSize || 12) + 'px',
+ // If font properties are defined, `fontFamily` should not be ignored.
+ textStyle.fontFamily || 'sans-serif'
+ ].join(' ');
+ // Make font
+ textStyle.font = font;
+
+ const rect = text.getBoundingRect();
+ this._textX += rect.width;
+
+ parentGroup.add(text);
+
+ return text;
+ }
+
+ static internalField = (function () {
+
+ nodeParsers = {
+ 'g': function (xmlNode, parentGroup) {
+ const g = new Group();
+ inheritStyle(parentGroup, g);
+ parseAttributes(xmlNode, g, this._defsUsePending, false, false);
+
+ return g;
+ },
+ 'rect': function (xmlNode, parentGroup) {
+ const rect = new Rect();
+ inheritStyle(parentGroup, rect);
+ parseAttributes(xmlNode, rect, this._defsUsePending, false, false);
+
+ rect.setShape({
+ x: parseFloat(xmlNode.getAttribute('x') || '0'),
+ y: parseFloat(xmlNode.getAttribute('y') || '0'),
+ width: parseFloat(xmlNode.getAttribute('width') || '0'),
+ height: parseFloat(xmlNode.getAttribute('height') || '0')
+ });
+
+ rect.silent = true;
+
+ return rect;
+ },
+ 'circle': function (xmlNode, parentGroup) {
+ const circle = new Circle();
+ inheritStyle(parentGroup, circle);
+ parseAttributes(xmlNode, circle, this._defsUsePending, false, false);
+
+ circle.setShape({
+ cx: parseFloat(xmlNode.getAttribute('cx') || '0'),
+ cy: parseFloat(xmlNode.getAttribute('cy') || '0'),
+ r: parseFloat(xmlNode.getAttribute('r') || '0')
+ });
+
+ circle.silent = true;
+
+ return circle;
+ },
+ 'line': function (xmlNode, parentGroup) {
+ const line = new Line();
+ inheritStyle(parentGroup, line);
+ parseAttributes(xmlNode, line, this._defsUsePending, false, false);
+
+ line.setShape({
+ x1: parseFloat(xmlNode.getAttribute('x1') || '0'),
+ y1: parseFloat(xmlNode.getAttribute('y1') || '0'),
+ x2: parseFloat(xmlNode.getAttribute('x2') || '0'),
+ y2: parseFloat(xmlNode.getAttribute('y2') || '0')
+ });
+
+ line.silent = true;
+
+ return line;
+ },
+ 'ellipse': function (xmlNode, parentGroup) {
+ const ellipse = new Ellipse();
+ inheritStyle(parentGroup, ellipse);
+ parseAttributes(xmlNode, ellipse, this._defsUsePending, false, false);
+
+ ellipse.setShape({
+ cx: parseFloat(xmlNode.getAttribute('cx') || '0'),
+ cy: parseFloat(xmlNode.getAttribute('cy') || '0'),
+ rx: parseFloat(xmlNode.getAttribute('rx') || '0'),
+ ry: parseFloat(xmlNode.getAttribute('ry') || '0')
+ });
+
+ ellipse.silent = true;
+
+ return ellipse;
+ },
+ 'polygon': function (xmlNode, parentGroup) {
+ const pointsStr = xmlNode.getAttribute('points');
+ let pointsArr;
+ if (pointsStr) {
+ pointsArr = parsePoints(pointsStr);
+ }
+ const polygon = new Polygon({
+ shape: {
+ points: pointsArr || []
+ },
+ silent: true
+ });
+
+ inheritStyle(parentGroup, polygon);
+ parseAttributes(xmlNode, polygon, this._defsUsePending, false, false);
+
+ return polygon;
+ },
+ 'polyline': function (xmlNode, parentGroup) {
+ const pointsStr = xmlNode.getAttribute('points');
+ let pointsArr;
+ if (pointsStr) {
+ pointsArr = parsePoints(pointsStr);
+ }
+ const polyline = new Polyline({
+ shape: {
+ points: pointsArr || []
+ },
+ silent: true
+ });
+
+ inheritStyle(parentGroup, polyline);
+ parseAttributes(xmlNode, polyline, this._defsUsePending, false, false);
+
+ return polyline;
+ },
+ 'image': function (xmlNode, parentGroup) {
+ const img = new ZRImage();
+ inheritStyle(parentGroup, img);
+ parseAttributes(xmlNode, img, this._defsUsePending, false, false);
+
+ img.setStyle({
+ image: xmlNode.getAttribute('xlink:href') || xmlNode.getAttribute('href'),
+ x: +xmlNode.getAttribute('x'),
+ y: +xmlNode.getAttribute('y'),
+ width: +xmlNode.getAttribute('width'),
+ height: +xmlNode.getAttribute('height')
+ });
+ img.silent = true;
+
+ return img;
+ },
+ 'text': function (xmlNode, parentGroup) {
+ const x = xmlNode.getAttribute('x') || '0';
+ const y = xmlNode.getAttribute('y') || '0';
+ const dx = xmlNode.getAttribute('dx') || '0';
+ const dy = xmlNode.getAttribute('dy') || '0';
+
+ this._textX = parseFloat(x) + parseFloat(dx);
+ this._textY = parseFloat(y) + parseFloat(dy);
+
+ const g = new Group();
+ inheritStyle(parentGroup, g);
+ parseAttributes(xmlNode, g, this._defsUsePending, false, true);
+
+ return g;
+ },
+ 'tspan': function (xmlNode, parentGroup) {
+ const x = xmlNode.getAttribute('x');
+ const y = xmlNode.getAttribute('y');
+ if (x != null) {
+ // new offset x
+ this._textX = parseFloat(x);
+ }
+ if (y != null) {
+ // new offset y
+ this._textY = parseFloat(y);
+ }
+ const dx = xmlNode.getAttribute('dx') || '0';
+ const dy = xmlNode.getAttribute('dy') || '0';
+
+ const g = new Group();
+
+ inheritStyle(parentGroup, g);
+ parseAttributes(xmlNode, g, this._defsUsePending, false, true);
+
+ this._textX += parseFloat(dx);
+ this._textY += parseFloat(dy);
+
+ return g;
+ },
+ 'path': function (xmlNode, parentGroup) {
+ // TODO svg fill rule
+ // https://developer.mozilla.org/en-US/docs/Web/SVG/Attribute/fill-rule
+ // path.style.globalCompositeOperation = 'xor';
+ const d = xmlNode.getAttribute('d') || '';
+
+ // Performance sensitive.
+
+ const path = createFromString(d);
+
+ inheritStyle(parentGroup, path);
+ parseAttributes(xmlNode, path, this._defsUsePending, false, false);
+
+ path.silent = true;
+
+ return path;
+ }
+ };
+
+
+ })();
+}
+
+const paintServerParsers: Dictionary<(xmlNode: SVGElement) => any> = {
+
+ 'lineargradient': function (xmlNode: SVGElement) {
+ // TODO:
+ // Support that x1,y1,x2,y2 are not declared lineargradient but in node.
+ const x1 = parseInt(xmlNode.getAttribute('x1') || '0', 10);
+ const y1 = parseInt(xmlNode.getAttribute('y1') || '0', 10);
+ const x2 = parseInt(xmlNode.getAttribute('x2') || '10', 10);
+ const y2 = parseInt(xmlNode.getAttribute('y2') || '0', 10);
+
+ const gradient = new LinearGradient(x1, y1, x2, y2);
+
+ parsePaintServerUnit(xmlNode, gradient);
+
+ parseGradientColorStops(xmlNode, gradient);
+
+ return gradient;
+ },
+
+ 'radialgradient': function (xmlNode) {
+ // TODO:
+ // Support that x1,y1,x2,y2 are not declared radialgradient but in node.
+ // TODO:
+ // Support fx, fy, fr.
+ const cx = parseInt(xmlNode.getAttribute('cx') || '0', 10);
+ const cy = parseInt(xmlNode.getAttribute('cy') || '0', 10);
+ const r = parseInt(xmlNode.getAttribute('r') || '0', 10);
+
+ const gradient = new RadialGradient(cx, cy, r);
+
+ parsePaintServerUnit(xmlNode, gradient);
+
+ parseGradientColorStops(xmlNode, gradient);
+
+ return gradient;
+ }
+
+ // TODO
+ // 'pattern': function (xmlNode: SVGElement) {
+ // }
+};
+
+function parsePaintServerUnit(xmlNode: SVGElement, gradient: Gradient) {
+ const gradientUnits = xmlNode.getAttribute('gradientUnits');
+ if (gradientUnits === 'userSpaceOnUse') {
+ gradient.global = true;
+ }
+}
+
+function parseGradientColorStops(xmlNode: SVGElement, gradient: GradientObject): void {
+
+ let stop = xmlNode.firstChild as SVGStopElement;
+
+ while (stop) {
+ if (stop.nodeType === 1
+ // there might be some other irrelevant tags used by editor.
+ && stop.nodeName.toLocaleLowerCase() === 'stop'
+ ) {
+ const offsetStr = stop.getAttribute('offset');
+ let offset: number;
+ if (offsetStr && offsetStr.indexOf('%') > 0) { // percentage
+ offset = parseInt(offsetStr, 10) / 100;
+ }
+ else if (offsetStr) { // number from 0 to 1
+ offset = parseFloat(offsetStr);
+ }
+ else {
+ offset = 0;
+ }
+
+ // ;
+ parseInlineStyle(stop, styleVals, styleVals);
+ const stopColor = styleVals.stopColor
+ || stop.getAttribute('stop-color')
+ || '#000000';
+
+ gradient.colorStops.push({
+ offset: offset,
+ color: stopColor
+ });
+ }
+ stop = stop.nextSibling as SVGStopElement;
+ }
+}
+
+function inheritStyle(parent: Element, child: Element): void {
+ if (parent && (parent as ElementExtended).__inheritedStyle) {
+ if (!(child as ElementExtended).__inheritedStyle) {
+ (child as ElementExtended).__inheritedStyle = {};
+ }
+ defaults((child as ElementExtended).__inheritedStyle, (parent as ElementExtended).__inheritedStyle);
+ }
+}
+
+function parsePoints(pointsString: string): number[][] {
+ const list = splitNumberSequence(pointsString);
+ const points = [];
+
+ for (let i = 0; i < list.length; i += 2) {
+ const x = parseFloat(list[i]);
+ const y = parseFloat(list[i + 1]);
+ points.push([x, y]);
+ }
+ return points;
+}
+
+function parseAttributes(
+ xmlNode: SVGElement,
+ el: Element,
+ defsUsePending: DefsUsePending,
+ onlyInlineStyle: boolean,
+ isTextGroup: boolean
+): void {
+ const disp = el as DisplayableExtended;
+ const inheritedStyle = disp.__inheritedStyle = disp.__inheritedStyle || {};
+ const selfStyle: SelfStyleByZRKey = {};
+
+ // TODO Shadow
+ if (xmlNode.nodeType === 1) {
+ parseTransformAttribute(xmlNode, el);
+
+ parseInlineStyle(xmlNode, inheritedStyle, selfStyle);
+
+ if (!onlyInlineStyle) {
+ parseAttributeStyle(xmlNode, inheritedStyle, selfStyle);
+ }
+ }
+
+ disp.style = disp.style || {};
+
+ if (inheritedStyle.fill != null) {
+ disp.style.fill = getFillStrokeStyle(disp, 'fill', inheritedStyle.fill, defsUsePending);
+ }
+ if (inheritedStyle.stroke != null) {
+ disp.style.stroke = getFillStrokeStyle(disp, 'stroke', inheritedStyle.stroke, defsUsePending);
+ }
+
+ each([
+ 'lineWidth', 'opacity', 'fillOpacity', 'strokeOpacity', 'miterLimit', 'fontSize'
+ ] as const, function (propName) {
+ if (inheritedStyle[propName] != null) {
+ disp.style[propName] = parseFloat(inheritedStyle[propName]);
+ }
+ });
+
+ each([
+ 'lineDashOffset', 'lineCap', 'lineJoin', 'fontWeight', 'fontFamily', 'fontStyle', 'textAlign'
+ ] as const, function (propName) {
+ if (inheritedStyle[propName] != null) {
+ disp.style[propName] = inheritedStyle[propName];
+ }
+ });
+
+ // Because selfStyle only support textBaseline, so only text group need it.
+ // in other cases selfStyle can be released.
+ if (isTextGroup) {
+ disp.__selfStyle = selfStyle;
+ }
+
+ if (inheritedStyle.lineDash) {
+ disp.style.lineDash = map(splitNumberSequence(inheritedStyle.lineDash), function (str) {
+ return parseFloat(str);
+ });
+ }
+
+ if (inheritedStyle.visibility === 'hidden' || inheritedStyle.visibility === 'collapse') {
+ disp.invisible = true;
+ }
+
+ if (inheritedStyle.display === 'none') {
+ disp.ignore = true;
+ }
+}
+
+function applyTextAlignment(
+ text: TSpan,
+ parentGroup: Group
+): void {
+ const parentSelfStyle = (parentGroup as ElementExtended).__selfStyle;
+ if (parentSelfStyle) {
+ const textBaseline = parentSelfStyle.textBaseline;
+ let zrTextBaseline = textBaseline as CanvasTextBaseline;
+ if (!textBaseline || textBaseline === 'auto') {
+ // FIXME: 'auto' means the value is the dominant-baseline of the script to
+ // which the character belongs - i.e., use the dominant-baseline of the parent.
+ zrTextBaseline = 'alphabetic';
+ }
+ else if (textBaseline === 'baseline') {
+ zrTextBaseline = 'alphabetic';
+ }
+ else if (textBaseline === 'before-edge' || textBaseline === 'text-before-edge') {
+ zrTextBaseline = 'top';
+ }
+ else if (textBaseline === 'after-edge' || textBaseline === 'text-after-edge') {
+ zrTextBaseline = 'bottom';
+ }
+ else if (textBaseline === 'central' || textBaseline === 'mathematical') {
+ zrTextBaseline = 'middle';
+ }
+ text.style.textBaseline = zrTextBaseline;
+ }
+
+ const parentInheritedStyle = (parentGroup as ElementExtended).__inheritedStyle;
+ if (parentInheritedStyle) {
+ // PENDING:
+ // canvas `direction` is an experimental attribute.
+ // so we do not support SVG direction "rtl" for text-anchor yet.
+ const textAlign = parentInheritedStyle.textAlign;
+ let zrTextAlign = textAlign as CanvasTextAlign;
+ if (textAlign) {
+ if (textAlign === 'middle') {
+ zrTextAlign = 'center';
+ }
+ text.style.textAlign = zrTextAlign;
+ }
+ }
+}
+
+// Support `fill:url(#someId)`.
+const urlRegex = /^url\(\s*#(.*?)\)/;
+function getFillStrokeStyle(
+ el: Displayable,
+ method: 'fill' | 'stroke',
+ str: string,
+ defsUsePending: DefsUsePending
+): string {
+ const urlMatch = str && str.match(urlRegex);
+ if (urlMatch) {
+ const url = trim(urlMatch[1]);
+ defsUsePending.push([el, method, url]);
+ return;
+ }
+ // SVG fill and stroke can be 'none'.
+ if (str === 'none') {
+ str = null;
+ }
+ return str;
+}
+
+function applyDefs(
+ defs: DefsMap,
+ defsUsePending: DefsUsePending
+): void {
+ for (let i = 0; i < defsUsePending.length; i++) {
+ const item = defsUsePending[i];
+ item[0].style[item[1]] = defs[item[2]];
+ }
+}
+
+// value can be like:
+// '2e-4', 'l.5.9' (ignore 0), 'M-10-10', 'l-2.43e-1,34.9983',
+// 'l-.5E1,54', '121-23-44-11' (no delimiter)
+// PENDING: here continuous commas are treat as one comma, but the
+// browser SVG parser treats this by printing error.
+const numberReg = /-?([0-9]*\.)?[0-9]+([eE]-?[0-9]+)?/g;
+function splitNumberSequence(rawStr: string): string[] {
+ return rawStr.match(numberReg) || [];
+}
+// Most of the values can be separated by comma and/or white space.
+// const DILIMITER_REG = /[\s,]+/;
+
+
+const transformRegex = /(translate|scale|rotate|skewX|skewY|matrix)\(([\-\s0-9\.eE,]*)\)/g;
+const DEGREE_TO_ANGLE = Math.PI / 180;
+
+function parseTransformAttribute(xmlNode: SVGElement, node: Element): void {
+ let transform = xmlNode.getAttribute('transform');
+ if (transform) {
+ transform = transform.replace(/,/g, ' ');
+ const transformOps: string[] = [];
+ let mt = null;
+ transform.replace(transformRegex, function (str: string, type: string, value: string) {
+ transformOps.push(type, value);
+ return '';
+ });
+
+ for (let i = transformOps.length - 1; i > 0; i -= 2) {
+ const value = transformOps[i];
+ const type = transformOps[i - 1];
+ const valueArr: string[] = splitNumberSequence(value);
+ mt = mt || matrix.create();
+ switch (type) {
+ case 'translate':
+ matrix.translate(mt, mt, [parseFloat(valueArr[0]), parseFloat(valueArr[1] || '0')]);
+ break;
+ case 'scale':
+ matrix.scale(mt, mt, [parseFloat(valueArr[0]), parseFloat(valueArr[1] || valueArr[0])]);
+ break;
+ case 'rotate':
+ // TODO: zrender use different hand in coordinate system.
+ matrix.rotate(mt, mt, -parseFloat(valueArr[0]) * DEGREE_TO_ANGLE, [
+ parseFloat(valueArr[1] || '0'),
+ parseFloat(valueArr[2] || '0')
+ ]);
+ break;
+ case 'skewX':
+ const sx = Math.tan(parseFloat(valueArr[0]) * DEGREE_TO_ANGLE);
+ matrix.mul(mt, [1, 0, sx, 1, 0, 0], mt);
+ break;
+ case 'skewY':
+ const sy = Math.tan(parseFloat(valueArr[0]) * DEGREE_TO_ANGLE);
+ matrix.mul(mt, [1, sy, 0, 1, 0, 0], mt);
+ break;
+ case 'matrix':
+ mt[0] = parseFloat(valueArr[0]);
+ mt[1] = parseFloat(valueArr[1]);
+ mt[2] = parseFloat(valueArr[2]);
+ mt[3] = parseFloat(valueArr[3]);
+ mt[4] = parseFloat(valueArr[4]);
+ mt[5] = parseFloat(valueArr[5]);
+ break;
+ }
+ }
+ node.setLocalTransform(mt);
+ }
+}
+
+// Value may contain space.
+const styleRegex = /([^\s:;]+)\s*:\s*([^:;]+)/g;
+function parseInlineStyle(
+ xmlNode: SVGElement,
+ inheritableStyleResult: Dictionary,
+ selfStyleResult: Dictionary
+): void {
+ const style = xmlNode.getAttribute('style');
+
+ if (!style) {
+ return;
+ }
+
+ styleRegex.lastIndex = 0;
+ let styleRegResult;
+ while ((styleRegResult = styleRegex.exec(style)) != null) {
+ const svgStlAttr = styleRegResult[1];
+
+ const zrInheritableStlAttr = hasOwn(INHERITABLE_STYLE_ATTRIBUTES_MAP, svgStlAttr)
+ ? INHERITABLE_STYLE_ATTRIBUTES_MAP[svgStlAttr as keyof typeof INHERITABLE_STYLE_ATTRIBUTES_MAP]
+ : null;
+ if (zrInheritableStlAttr) {
+ inheritableStyleResult[zrInheritableStlAttr] = styleRegResult[2];
+ }
+
+ const zrSelfStlAttr = hasOwn(SELF_STYLE_ATTRIBUTES_MAP, svgStlAttr)
+ ? SELF_STYLE_ATTRIBUTES_MAP[svgStlAttr as keyof typeof SELF_STYLE_ATTRIBUTES_MAP]
+ : null;
+ if (zrSelfStlAttr) {
+ selfStyleResult[zrSelfStlAttr] = styleRegResult[2];
+ }
+ }
+}
+
+function parseAttributeStyle(
+ xmlNode: SVGElement,
+ inheritableStyleResult: Dictionary,
+ selfStyleResult: Dictionary
+): void {
+ for (let i = 0; i < INHERITABLE_STYLE_ATTRIBUTES_MAP_KEYS.length; i++) {
+ const svgAttrName = INHERITABLE_STYLE_ATTRIBUTES_MAP_KEYS[i];
+ const attrValue = xmlNode.getAttribute(svgAttrName);
+ if (attrValue != null) {
+ inheritableStyleResult[INHERITABLE_STYLE_ATTRIBUTES_MAP[svgAttrName]] = attrValue;
+ }
+ }
+ for (let i = 0; i < SELF_STYLE_ATTRIBUTES_MAP_KEYS.length; i++) {
+ const svgAttrName = SELF_STYLE_ATTRIBUTES_MAP_KEYS[i];
+ const attrValue = xmlNode.getAttribute(svgAttrName);
+ if (attrValue != null) {
+ selfStyleResult[SELF_STYLE_ATTRIBUTES_MAP[svgAttrName]] = attrValue;
+ }
+ }
+}
+
+export function makeViewBoxTransform(viewBoxRect: RectLike, boundingRect: RectLike): {
+ scale: number;
+ x: number;
+ y: number;
+} {
+ const scaleX = boundingRect.width / viewBoxRect.width;
+ const scaleY = boundingRect.height / viewBoxRect.height;
+ const scale = Math.min(scaleX, scaleY);
+ // preserveAspectRatio 'xMidYMid'
+
+ return {
+ scale,
+ x: -(viewBoxRect.x + viewBoxRect.width / 2) * scale + (boundingRect.x + boundingRect.width / 2),
+ y: -(viewBoxRect.y + viewBoxRect.height / 2) * scale + (boundingRect.y + boundingRect.height / 2)
+ };
+}
+
+export function parseSVG(xml: string | Document | SVGElement, opt: SVGParserOption): SVGParserResult {
+ const parser = new SVGParser();
+ return parser.parse(xml, opt);
+}
+
+
+// Also export parseXML to avoid breaking change.
+export {parseXML};
diff --git a/src/MaxKB-1.5.1/node_modules/zrender/src/tool/parseXML.ts b/src/MaxKB-1.5.1/node_modules/zrender/src/tool/parseXML.ts
new file mode 100644
index 0000000..9bbe304
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/zrender/src/tool/parseXML.ts
@@ -0,0 +1,22 @@
+import { isString } from '../core/util';
+
+/**
+ * For big svg string, this method might be time consuming.
+ */
+export function parseXML(svg: Document | string | SVGElement): SVGElement {
+ if (isString(svg)) {
+ const parser = new DOMParser();
+ svg = parser.parseFromString(svg, 'text/xml');
+ }
+ let svgNode: Node = svg;
+ // Document node. If using $.get, doc node may be input.
+ if (svgNode.nodeType === 9) {
+ svgNode = svgNode.firstChild;
+ }
+ // nodeName of is also 'svg'.
+ while (svgNode.nodeName.toLowerCase() !== 'svg' || svgNode.nodeType !== 1) {
+ svgNode = svgNode.nextSibling;
+ }
+
+ return svgNode as SVGElement;
+}
diff --git a/src/MaxKB-1.5.1/node_modules/zrender/src/tool/path.ts b/src/MaxKB-1.5.1/node_modules/zrender/src/tool/path.ts
new file mode 100644
index 0000000..76c4d09
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/zrender/src/tool/path.ts
@@ -0,0 +1,514 @@
+import Path, { PathProps } from '../graphic/Path';
+import PathProxy from '../core/PathProxy';
+import transformPath from './transformPath';
+import { VectorArray } from '../core/vector';
+import { MatrixArray } from '../core/matrix';
+import { extend } from '../core/util';
+
+// command chars
+// const cc = [
+// 'm', 'M', 'l', 'L', 'v', 'V', 'h', 'H', 'z', 'Z',
+// 'c', 'C', 'q', 'Q', 't', 'T', 's', 'S', 'a', 'A'
+// ];
+
+const mathSqrt = Math.sqrt;
+const mathSin = Math.sin;
+const mathCos = Math.cos;
+const PI = Math.PI;
+
+function vMag(v: VectorArray): number {
+ return Math.sqrt(v[0] * v[0] + v[1] * v[1]);
+};
+function vRatio(u: VectorArray, v: VectorArray): number {
+ return (u[0] * v[0] + u[1] * v[1]) / (vMag(u) * vMag(v));
+};
+function vAngle(u: VectorArray, v: VectorArray): number {
+ return (u[0] * v[1] < u[1] * v[0] ? -1 : 1)
+ * Math.acos(vRatio(u, v));
+};
+
+function processArc(
+ x1: number, y1: number, x2: number, y2: number, fa: number, fs: number,
+ rx: number, ry: number, psiDeg: number, cmd: number, path: PathProxy
+) {
+ // https://www.w3.org/TR/SVG11/implnote.html#ArcImplementationNotes
+ const psi = psiDeg * (PI / 180.0);
+ const xp = mathCos(psi) * (x1 - x2) / 2.0
+ + mathSin(psi) * (y1 - y2) / 2.0;
+ const yp = -1 * mathSin(psi) * (x1 - x2) / 2.0
+ + mathCos(psi) * (y1 - y2) / 2.0;
+
+ const lambda = (xp * xp) / (rx * rx) + (yp * yp) / (ry * ry);
+
+ if (lambda > 1) {
+ rx *= mathSqrt(lambda);
+ ry *= mathSqrt(lambda);
+ }
+
+ const f = (fa === fs ? -1 : 1)
+ * mathSqrt((((rx * rx) * (ry * ry))
+ - ((rx * rx) * (yp * yp))
+ - ((ry * ry) * (xp * xp))) / ((rx * rx) * (yp * yp)
+ + (ry * ry) * (xp * xp))
+ ) || 0;
+
+ const cxp = f * rx * yp / ry;
+ const cyp = f * -ry * xp / rx;
+
+ const cx = (x1 + x2) / 2.0
+ + mathCos(psi) * cxp
+ - mathSin(psi) * cyp;
+ const cy = (y1 + y2) / 2.0
+ + mathSin(psi) * cxp
+ + mathCos(psi) * cyp;
+
+ const theta = vAngle([ 1, 0 ], [ (xp - cxp) / rx, (yp - cyp) / ry ]);
+ const u = [ (xp - cxp) / rx, (yp - cyp) / ry ];
+ const v = [ (-1 * xp - cxp) / rx, (-1 * yp - cyp) / ry ];
+ let dTheta = vAngle(u, v);
+
+ if (vRatio(u, v) <= -1) {
+ dTheta = PI;
+ }
+ if (vRatio(u, v) >= 1) {
+ dTheta = 0;
+ }
+
+ if (dTheta < 0) {
+ const n = Math.round(dTheta / PI * 1e6) / 1e6;
+ // Convert to positive
+ dTheta = PI * 2 + (n % 2) * PI;
+ }
+
+ path.addData(cmd, cx, cy, rx, ry, theta, dTheta, psi, fs);
+}
+
+
+const commandReg = /([mlvhzcqtsa])([^mlvhzcqtsa]*)/ig;
+// Consider case:
+// (1) delimiter can be comma or space, where continuous commas
+// or spaces should be seen as one comma.
+// (2) value can be like:
+// '2e-4', 'l.5.9' (ignore 0), 'M-10-10', 'l-2.43e-1,34.9983',
+// 'l-.5E1,54', '121-23-44-11' (no delimiter)
+const numberReg = /-?([0-9]*\.)?[0-9]+([eE]-?[0-9]+)?/g;
+// const valueSplitReg = /[\s,]+/;
+
+function createPathProxyFromString(data: string) {
+ const path = new PathProxy();
+
+ if (!data) {
+ return path;
+ }
+
+ // const data = data.replace(/-/g, ' -')
+ // .replace(/ /g, ' ')
+ // .replace(/ /g, ',')
+ // .replace(/,,/g, ',');
+
+ // const n;
+ // create pipes so that we can split the data
+ // for (n = 0; n < cc.length; n++) {
+ // cs = cs.replace(new RegExp(cc[n], 'g'), '|' + cc[n]);
+ // }
+
+ // data = data.replace(/-/g, ',-');
+
+ // create array
+ // const arr = cs.split('|');
+ // init context point
+ let cpx = 0;
+ let cpy = 0;
+ let subpathX = cpx;
+ let subpathY = cpy;
+ let prevCmd;
+
+ const CMD = PathProxy.CMD;
+
+ // commandReg.lastIndex = 0;
+ // const cmdResult;
+ // while ((cmdResult = commandReg.exec(data)) != null) {
+ // const cmdStr = cmdResult[1];
+ // const cmdContent = cmdResult[2];
+
+ const cmdList = data.match(commandReg);
+ if (!cmdList) {
+ // Invalid svg path.
+ return path;
+ }
+
+ for (let l = 0; l < cmdList.length; l++) {
+ const cmdText = cmdList[l];
+ let cmdStr = cmdText.charAt(0);
+
+ let cmd;
+
+ // String#split is faster a little bit than String#replace or RegExp#exec.
+ // const p = cmdContent.split(valueSplitReg);
+ // const pLen = 0;
+ // for (let i = 0; i < p.length; i++) {
+ // // '' and other invalid str => NaN
+ // const val = parseFloat(p[i]);
+ // !isNaN(val) && (p[pLen++] = val);
+ // }
+
+
+ // Following code will convert string to number. So convert type to number here
+ const p = cmdText.match(numberReg) as any[] as number[] || [];
+ const pLen = p.length;
+ for (let i = 0; i < pLen; i++) {
+ p[i] = parseFloat(p[i] as any as string);
+ }
+
+ let off = 0;
+ while (off < pLen) {
+ let ctlPtx;
+ let ctlPty;
+
+ let rx;
+ let ry;
+ let psi;
+ let fa;
+ let fs;
+
+ let x1 = cpx;
+ let y1 = cpy;
+
+ let len: number;
+ let pathData: number[] | Float32Array;
+ // convert l, H, h, V, and v to L
+ switch (cmdStr) {
+ case 'l':
+ cpx += p[off++];
+ cpy += p[off++];
+ cmd = CMD.L;
+ path.addData(cmd, cpx, cpy);
+ break;
+ case 'L':
+ cpx = p[off++];
+ cpy = p[off++];
+ cmd = CMD.L;
+ path.addData(cmd, cpx, cpy);
+ break;
+ case 'm':
+ cpx += p[off++];
+ cpy += p[off++];
+ cmd = CMD.M;
+ path.addData(cmd, cpx, cpy);
+ subpathX = cpx;
+ subpathY = cpy;
+ cmdStr = 'l';
+ break;
+ case 'M':
+ cpx = p[off++];
+ cpy = p[off++];
+ cmd = CMD.M;
+ path.addData(cmd, cpx, cpy);
+ subpathX = cpx;
+ subpathY = cpy;
+ cmdStr = 'L';
+ break;
+ case 'h':
+ cpx += p[off++];
+ cmd = CMD.L;
+ path.addData(cmd, cpx, cpy);
+ break;
+ case 'H':
+ cpx = p[off++];
+ cmd = CMD.L;
+ path.addData(cmd, cpx, cpy);
+ break;
+ case 'v':
+ cpy += p[off++];
+ cmd = CMD.L;
+ path.addData(cmd, cpx, cpy);
+ break;
+ case 'V':
+ cpy = p[off++];
+ cmd = CMD.L;
+ path.addData(cmd, cpx, cpy);
+ break;
+ case 'C':
+ cmd = CMD.C;
+ path.addData(
+ cmd, p[off++], p[off++], p[off++], p[off++], p[off++], p[off++]
+ );
+ cpx = p[off - 2];
+ cpy = p[off - 1];
+ break;
+ case 'c':
+ cmd = CMD.C;
+ path.addData(
+ cmd,
+ p[off++] + cpx, p[off++] + cpy,
+ p[off++] + cpx, p[off++] + cpy,
+ p[off++] + cpx, p[off++] + cpy
+ );
+ cpx += p[off - 2];
+ cpy += p[off - 1];
+ break;
+ case 'S':
+ ctlPtx = cpx;
+ ctlPty = cpy;
+ len = path.len();
+ pathData = path.data;
+ if (prevCmd === CMD.C) {
+ ctlPtx += cpx - pathData[len - 4];
+ ctlPty += cpy - pathData[len - 3];
+ }
+ cmd = CMD.C;
+ x1 = p[off++];
+ y1 = p[off++];
+ cpx = p[off++];
+ cpy = p[off++];
+ path.addData(cmd, ctlPtx, ctlPty, x1, y1, cpx, cpy);
+ break;
+ case 's':
+ ctlPtx = cpx;
+ ctlPty = cpy;
+ len = path.len();
+ pathData = path.data;
+ if (prevCmd === CMD.C) {
+ ctlPtx += cpx - pathData[len - 4];
+ ctlPty += cpy - pathData[len - 3];
+ }
+ cmd = CMD.C;
+ x1 = cpx + p[off++];
+ y1 = cpy + p[off++];
+ cpx += p[off++];
+ cpy += p[off++];
+ path.addData(cmd, ctlPtx, ctlPty, x1, y1, cpx, cpy);
+ break;
+ case 'Q':
+ x1 = p[off++];
+ y1 = p[off++];
+ cpx = p[off++];
+ cpy = p[off++];
+ cmd = CMD.Q;
+ path.addData(cmd, x1, y1, cpx, cpy);
+ break;
+ case 'q':
+ x1 = p[off++] + cpx;
+ y1 = p[off++] + cpy;
+ cpx += p[off++];
+ cpy += p[off++];
+ cmd = CMD.Q;
+ path.addData(cmd, x1, y1, cpx, cpy);
+ break;
+ case 'T':
+ ctlPtx = cpx;
+ ctlPty = cpy;
+ len = path.len();
+ pathData = path.data;
+ if (prevCmd === CMD.Q) {
+ ctlPtx += cpx - pathData[len - 4];
+ ctlPty += cpy - pathData[len - 3];
+ }
+ cpx = p[off++];
+ cpy = p[off++];
+ cmd = CMD.Q;
+ path.addData(cmd, ctlPtx, ctlPty, cpx, cpy);
+ break;
+ case 't':
+ ctlPtx = cpx;
+ ctlPty = cpy;
+ len = path.len();
+ pathData = path.data;
+ if (prevCmd === CMD.Q) {
+ ctlPtx += cpx - pathData[len - 4];
+ ctlPty += cpy - pathData[len - 3];
+ }
+ cpx += p[off++];
+ cpy += p[off++];
+ cmd = CMD.Q;
+ path.addData(cmd, ctlPtx, ctlPty, cpx, cpy);
+ break;
+ case 'A':
+ rx = p[off++];
+ ry = p[off++];
+ psi = p[off++];
+ fa = p[off++];
+ fs = p[off++];
+
+ x1 = cpx, y1 = cpy;
+ cpx = p[off++];
+ cpy = p[off++];
+ cmd = CMD.A;
+ processArc(
+ x1, y1, cpx, cpy, fa, fs, rx, ry, psi, cmd, path
+ );
+ break;
+ case 'a':
+ rx = p[off++];
+ ry = p[off++];
+ psi = p[off++];
+ fa = p[off++];
+ fs = p[off++];
+
+ x1 = cpx, y1 = cpy;
+ cpx += p[off++];
+ cpy += p[off++];
+ cmd = CMD.A;
+ processArc(
+ x1, y1, cpx, cpy, fa, fs, rx, ry, psi, cmd, path
+ );
+ break;
+ }
+ }
+
+ if (cmdStr === 'z' || cmdStr === 'Z') {
+ cmd = CMD.Z;
+ path.addData(cmd);
+ // z may be in the middle of the path.
+ cpx = subpathX;
+ cpy = subpathY;
+ }
+
+ prevCmd = cmd;
+ }
+
+ path.toStatic();
+
+ return path;
+}
+
+type SVGPathOption = Omit
+interface InnerSVGPathOption extends PathProps {
+ applyTransform?: (m: MatrixArray) => void
+}
+class SVGPath extends Path {
+ applyTransform(m: MatrixArray) {}
+}
+
+function isPathProxy(path: PathProxy | CanvasRenderingContext2D): path is PathProxy {
+ return (path as PathProxy).setData != null;
+}
+// TODO Optimize double memory cost problem
+function createPathOptions(str: string, opts: SVGPathOption): InnerSVGPathOption {
+ const pathProxy = createPathProxyFromString(str);
+ const innerOpts: InnerSVGPathOption = extend({}, opts);
+ innerOpts.buildPath = function (path: PathProxy | CanvasRenderingContext2D) {
+ if (isPathProxy(path)) {
+ path.setData(pathProxy.data);
+ // Svg and vml renderer don't have context
+ const ctx = path.getContext();
+ if (ctx) {
+ path.rebuildPath(ctx, 1);
+ }
+ }
+ else {
+ const ctx = path;
+ pathProxy.rebuildPath(ctx, 1);
+ }
+ };
+
+ innerOpts.applyTransform = function (this: SVGPath, m: MatrixArray) {
+ transformPath(pathProxy, m);
+ this.dirtyShape();
+ };
+
+ return innerOpts;
+}
+
+/**
+ * Create a Path object from path string data
+ * http://www.w3.org/TR/SVG/paths.html#PathData
+ * @param opts Other options
+ */
+export function createFromString(str: string, opts?: SVGPathOption): SVGPath {
+ // PENDING
+ return new SVGPath(createPathOptions(str, opts));
+}
+
+/**
+ * Create a Path class from path string data
+ * @param str
+ * @param opts Other options
+ */
+export function extendFromString(str: string, defaultOpts?: SVGPathOption): typeof SVGPath {
+ const innerOpts = createPathOptions(str, defaultOpts);
+ class Sub extends SVGPath {
+ constructor(opts: InnerSVGPathOption) {
+ super(opts);
+ this.applyTransform = innerOpts.applyTransform;
+ this.buildPath = innerOpts.buildPath;
+ }
+ }
+ return Sub;
+}
+
+/**
+ * Merge multiple paths
+ */
+// TODO Apply transform
+// TODO stroke dash
+// TODO Optimize double memory cost problem
+export function mergePath(pathEls: Path[], opts: PathProps) {
+ const pathList: PathProxy[] = [];
+ const len = pathEls.length;
+ for (let i = 0; i < len; i++) {
+ const pathEl = pathEls[i];
+ pathList.push(pathEl.getUpdatedPathProxy(true));
+ }
+
+ const pathBundle = new Path(opts);
+ // Need path proxy.
+ pathBundle.createPathProxy();
+ pathBundle.buildPath = function (path: PathProxy | CanvasRenderingContext2D) {
+ if (isPathProxy(path)) {
+ path.appendPath(pathList);
+ // Svg and vml renderer don't have context
+ const ctx = path.getContext();
+ if (ctx) {
+ // Path bundle not support percent draw.
+ path.rebuildPath(ctx, 1);
+ }
+ }
+ };
+
+ return pathBundle;
+}
+
+/**
+ * Clone a path.
+ */
+export function clonePath(sourcePath: Path, opts?: {
+ /**
+ * If bake global transform to path.
+ */
+ bakeTransform?: boolean
+ /**
+ * Convert global transform to local.
+ */
+ toLocal?: boolean
+}) {
+ opts = opts || {};
+ const path = new Path();
+ if (sourcePath.shape) {
+ path.setShape(sourcePath.shape);
+ }
+ path.setStyle(sourcePath.style);
+
+ if (opts.bakeTransform) {
+ transformPath(path.path, sourcePath.getComputedTransform());
+ }
+ else {
+ // TODO Copy getLocalTransform, updateTransform since they can be changed.
+ if (opts.toLocal) {
+ path.setLocalTransform(sourcePath.getComputedTransform());
+ }
+ else {
+ path.copyTransform(sourcePath);
+ }
+ }
+
+ // These methods may be overridden
+ path.buildPath = sourcePath.buildPath;
+ (path as SVGPath).applyTransform = (path as SVGPath).applyTransform;
+
+ path.z = sourcePath.z;
+ path.z2 = sourcePath.z2;
+ path.zlevel = sourcePath.zlevel;
+
+ return path;
+}
diff --git a/src/MaxKB-1.5.1/node_modules/zrender/src/tool/transformPath.ts b/src/MaxKB-1.5.1/node_modules/zrender/src/tool/transformPath.ts
new file mode 100644
index 0000000..e6ff2f4
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/zrender/src/tool/transformPath.ts
@@ -0,0 +1,103 @@
+import PathProxy from '../core/PathProxy';
+import {applyTransform as v2ApplyTransform, VectorArray} from '../core/vector';
+import { MatrixArray } from '../core/matrix';
+
+const CMD = PathProxy.CMD;
+
+const points: VectorArray[] = [[], [], []];
+const mathSqrt = Math.sqrt;
+const mathAtan2 = Math.atan2;
+
+export default function transformPath(path: PathProxy, m: MatrixArray) {
+ if (!m) {
+ return;
+ }
+
+ let data = path.data;
+ const len = path.len();
+ let cmd;
+ let nPoint: number;
+ let i: number;
+ let j: number;
+ let k: number;
+ let p: VectorArray;
+
+ const M = CMD.M;
+ const C = CMD.C;
+ const L = CMD.L;
+ const R = CMD.R;
+ const A = CMD.A;
+ const Q = CMD.Q;
+
+ for (i = 0, j = 0; i < len;) {
+ cmd = data[i++];
+ j = i;
+ nPoint = 0;
+
+ switch (cmd) {
+ case M:
+ nPoint = 1;
+ break;
+ case L:
+ nPoint = 1;
+ break;
+ case C:
+ nPoint = 3;
+ break;
+ case Q:
+ nPoint = 2;
+ break;
+ case A:
+ const x = m[4];
+ const y = m[5];
+ const sx = mathSqrt(m[0] * m[0] + m[1] * m[1]);
+ const sy = mathSqrt(m[2] * m[2] + m[3] * m[3]);
+ const angle = mathAtan2(-m[1] / sy, m[0] / sx);
+ // cx
+ data[i] *= sx;
+ data[i++] += x;
+ // cy
+ data[i] *= sy;
+ data[i++] += y;
+ // Scale rx and ry
+ // FIXME Assume psi is 0 here
+ data[i++] *= sx;
+ data[i++] *= sy;
+
+ // Start angle
+ data[i++] += angle;
+ // end angle
+ data[i++] += angle;
+ // FIXME psi
+ i += 2;
+ j = i;
+ break;
+ case R:
+ // x0, y0
+ p[0] = data[i++];
+ p[1] = data[i++];
+ v2ApplyTransform(p, p, m);
+ data[j++] = p[0];
+ data[j++] = p[1];
+ // x1, y1
+ p[0] += data[i++];
+ p[1] += data[i++];
+ v2ApplyTransform(p, p, m);
+ data[j++] = p[0];
+ data[j++] = p[1];
+ }
+
+ for (k = 0; k < nPoint; k++) {
+ let p = points[k];
+ p[0] = data[i++];
+ p[1] = data[i++];
+
+ v2ApplyTransform(p, p, m);
+ // Write back
+ data[j++] = p[0];
+ data[j++] = p[1];
+ }
+ }
+
+ path.increaseVersion();
+}
diff --git a/src/MaxKB-1.5.1/node_modules/zrender/src/zrender.ts b/src/MaxKB-1.5.1/node_modules/zrender/src/zrender.ts
new file mode 100644
index 0000000..4a460df
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/zrender/src/zrender.ts
@@ -0,0 +1,562 @@
+/*!
+* ZRender, a high performance 2d drawing library.
+*
+* Copyright (c) 2013, Baidu Inc.
+* All rights reserved.
+*
+* LICENSE
+* https://github.com/ecomfe/zrender/blob/master/LICENSE.txt
+*/
+
+import env from './core/env';
+import * as zrUtil from './core/util';
+import Handler from './Handler';
+import Storage from './Storage';
+import {PainterBase} from './PainterBase';
+import Animation, {getTime} from './animation/Animation';
+import HandlerProxy from './dom/HandlerProxy';
+import Element, { ElementEventCallback } from './Element';
+import { Dictionary, ElementEventName, RenderedEvent, WithThisType } from './core/types';
+import { LayerConfig } from './canvas/Layer';
+import { GradientObject } from './graphic/Gradient';
+import { PatternObject } from './graphic/Pattern';
+import { EventCallback } from './core/Eventful';
+import Displayable from './graphic/Displayable';
+import { lum } from './tool/color';
+import { DARK_MODE_THRESHOLD } from './config';
+import Group from './graphic/Group';
+
+
+type PainterBaseCtor = {
+ new(dom: HTMLElement, storage: Storage, ...args: any[]): PainterBase
+}
+
+const painterCtors: Dictionary = {};
+
+let instances: { [key: number]: ZRender } = {};
+
+function delInstance(id: number) {
+ delete instances[id];
+}
+
+function isDarkMode(backgroundColor: string | GradientObject | PatternObject): boolean {
+ if (!backgroundColor) {
+ return false;
+ }
+ if (typeof backgroundColor === 'string') {
+ return lum(backgroundColor, 1) < DARK_MODE_THRESHOLD;
+ }
+ else if ((backgroundColor as GradientObject).colorStops) {
+ const colorStops = (backgroundColor as GradientObject).colorStops;
+ let totalLum = 0;
+ const len = colorStops.length;
+ // Simply do the math of average the color. Not consider the offset
+ for (let i = 0; i < len; i++) {
+ totalLum += lum(colorStops[i].color, 1);
+ }
+ totalLum /= len;
+
+ return totalLum < DARK_MODE_THRESHOLD;
+ }
+ // Can't determine
+ return false;
+}
+
+class ZRender {
+ /**
+ * Not necessary if using SSR painter like svg-ssr
+ */
+ dom?: HTMLElement
+
+ id: number
+
+ storage: Storage
+ painter: PainterBase
+ handler: Handler
+ animation: Animation
+
+ private _sleepAfterStill = 10;
+
+ private _stillFrameAccum = 0;
+
+ private _needsRefresh = true
+ private _needsRefreshHover = true
+ private _disposed: boolean;
+ /**
+ * If theme is dark mode. It will determine the color strategy for labels.
+ */
+ private _darkMode = false;
+
+ private _backgroundColor: string | GradientObject | PatternObject;
+
+ constructor(id: number, dom?: HTMLElement, opts?: ZRenderInitOpt) {
+ opts = opts || {};
+
+ /**
+ * @type {HTMLDomElement}
+ */
+ this.dom = dom;
+
+ this.id = id;
+
+ const storage = new Storage();
+
+ let rendererType = opts.renderer || 'canvas';
+
+ if (!painterCtors[rendererType]) {
+ // Use the first registered renderer.
+ rendererType = zrUtil.keys(painterCtors)[0];
+ }
+ if (process.env.NODE_ENV !== 'production') {
+ if (!painterCtors[rendererType]) {
+ throw new Error(`Renderer '${rendererType}' is not imported. Please import it first.`);
+ }
+ }
+
+ opts.useDirtyRect = opts.useDirtyRect == null
+ ? false
+ : opts.useDirtyRect;
+
+ const painter = new painterCtors[rendererType](dom, storage, opts, id);
+ const ssrMode = opts.ssr || painter.ssrOnly;
+
+ this.storage = storage;
+ this.painter = painter;
+
+ const handlerProxy = (!env.node && !env.worker && !ssrMode)
+ ? new HandlerProxy(painter.getViewportRoot(), painter.root)
+ : null;
+
+ const useCoarsePointer = opts.useCoarsePointer;
+ const usePointerSize = (useCoarsePointer == null || useCoarsePointer === 'auto')
+ ? env.touchEventsSupported
+ : !!useCoarsePointer;
+ const defaultPointerSize = 44;
+ let pointerSize;
+ if (usePointerSize) {
+ pointerSize = zrUtil.retrieve2(opts.pointerSize, defaultPointerSize);
+ }
+
+ this.handler = new Handler(storage, painter, handlerProxy, painter.root, pointerSize);
+
+ this.animation = new Animation({
+ stage: {
+ update: ssrMode ? null : () => this._flush(true)
+ }
+ });
+
+ if (!ssrMode) {
+ this.animation.start();
+ }
+ }
+
+ /**
+ * 添加元素
+ */
+ add(el: Element) {
+ if (this._disposed || !el) {
+ return;
+ }
+ this.storage.addRoot(el);
+ el.addSelfToZr(this);
+ this.refresh();
+ }
+
+ /**
+ * 删除元素
+ */
+ remove(el: Element) {
+ if (this._disposed || !el) {
+ return;
+ }
+ this.storage.delRoot(el);
+ el.removeSelfFromZr(this);
+ this.refresh();
+ }
+
+ /**
+ * Change configuration of layer
+ */
+ configLayer(zLevel: number, config: LayerConfig) {
+ if (this._disposed) {
+ return;
+ }
+ if (this.painter.configLayer) {
+ this.painter.configLayer(zLevel, config);
+ }
+ this.refresh();
+ }
+
+ /**
+ * Set background color
+ */
+ setBackgroundColor(backgroundColor: string | GradientObject | PatternObject) {
+ if (this._disposed) {
+ return;
+ }
+ if (this.painter.setBackgroundColor) {
+ this.painter.setBackgroundColor(backgroundColor);
+ }
+ this.refresh();
+ this._backgroundColor = backgroundColor;
+ this._darkMode = isDarkMode(backgroundColor);
+ }
+
+ getBackgroundColor() {
+ return this._backgroundColor;
+ }
+
+ /**
+ * Force to set dark mode
+ */
+ setDarkMode(darkMode: boolean) {
+ this._darkMode = darkMode;
+ }
+
+ isDarkMode() {
+ return this._darkMode;
+ }
+
+ /**
+ * Repaint the canvas immediately
+ */
+ refreshImmediately(fromInside?: boolean) {
+ if (this._disposed) {
+ return;
+ }
+ // const start = new Date();
+ if (!fromInside) {
+ // Update animation if refreshImmediately is invoked from outside.
+ // Not trigger stage update to call flush again. Which may refresh twice
+ this.animation.update(true);
+ }
+
+ // Clear needsRefresh ahead to avoid something wrong happens in refresh
+ // Or it will cause zrender refreshes again and again.
+ this._needsRefresh = false;
+ this.painter.refresh();
+ // Avoid trigger zr.refresh in Element#beforeUpdate hook
+ this._needsRefresh = false;
+ }
+
+ /**
+ * Mark and repaint the canvas in the next frame of browser
+ */
+ refresh() {
+ if (this._disposed) {
+ return;
+ }
+ this._needsRefresh = true;
+ // Active the animation again.
+ this.animation.start();
+ }
+
+ /**
+ * Perform all refresh
+ */
+ flush() {
+ if (this._disposed) {
+ return;
+ }
+ this._flush(false);
+ }
+
+ private _flush(fromInside?: boolean) {
+ let triggerRendered;
+
+ const start = getTime();
+ if (this._needsRefresh) {
+ triggerRendered = true;
+ this.refreshImmediately(fromInside);
+ }
+
+ if (this._needsRefreshHover) {
+ triggerRendered = true;
+ this.refreshHoverImmediately();
+ }
+ const end = getTime();
+
+ if (triggerRendered) {
+ this._stillFrameAccum = 0;
+ this.trigger('rendered', {
+ elapsedTime: end - start
+ } as RenderedEvent);
+ }
+ else if (this._sleepAfterStill > 0) {
+ this._stillFrameAccum++;
+ // Stop the animation after still for 10 frames.
+ if (this._stillFrameAccum > this._sleepAfterStill) {
+ this.animation.stop();
+ }
+ }
+ }
+
+ /**
+ * Set sleep after still for frames.
+ * Disable auto sleep when it's 0.
+ */
+ setSleepAfterStill(stillFramesCount: number) {
+ this._sleepAfterStill = stillFramesCount;
+ }
+
+ /**
+ * Wake up animation loop. But not render.
+ */
+ wakeUp() {
+ if (this._disposed) {
+ return;
+ }
+ this.animation.start();
+ // Reset the frame count.
+ this._stillFrameAccum = 0;
+ }
+
+ /**
+ * Refresh hover in next frame
+ */
+ refreshHover() {
+ this._needsRefreshHover = true;
+ }
+
+ /**
+ * Refresh hover immediately
+ */
+ refreshHoverImmediately() {
+ if (this._disposed) {
+ return;
+ }
+ this._needsRefreshHover = false;
+ if (this.painter.refreshHover && this.painter.getType() === 'canvas') {
+ this.painter.refreshHover();
+ }
+ }
+
+ /**
+ * Resize the canvas.
+ * Should be invoked when container size is changed
+ */
+ resize(opts?: {
+ width?: number| string
+ height?: number | string
+ }) {
+ if (this._disposed) {
+ return;
+ }
+ opts = opts || {};
+ this.painter.resize(opts.width, opts.height);
+ this.handler.resize();
+ }
+
+ /**
+ * Stop and clear all animation immediately
+ */
+ clearAnimation() {
+ if (this._disposed) {
+ return;
+ }
+ this.animation.clear();
+ }
+
+ /**
+ * Get container width
+ */
+ getWidth(): number | undefined {
+ if (this._disposed) {
+ return;
+ }
+ return this.painter.getWidth();
+ }
+
+ /**
+ * Get container height
+ */
+ getHeight(): number | undefined {
+ if (this._disposed) {
+ return;
+ }
+ return this.painter.getHeight();
+ }
+
+ /**
+ * Set default cursor
+ * @param cursorStyle='default' 例如 crosshair
+ */
+ setCursorStyle(cursorStyle: string) {
+ if (this._disposed) {
+ return;
+ }
+ this.handler.setCursorStyle(cursorStyle);
+ }
+
+ /**
+ * Find hovered element
+ * @param x
+ * @param y
+ * @return {target, topTarget}
+ */
+ findHover(x: number, y: number): {
+ target: Displayable
+ topTarget: Displayable
+ } | undefined {
+ if (this._disposed) {
+ return;
+ }
+ return this.handler.findHover(x, y);
+ }
+
+ on(eventName: ElementEventName, eventHandler: ElementEventCallback, context?: Ctx): this
+ // eslint-disable-next-line max-len
+ on(eventName: string, eventHandler: WithThisType, unknown extends Ctx ? ZRenderType : Ctx>, context?: Ctx): this
+ // eslint-disable-next-line max-len
+ on(eventName: string, eventHandler: (...args: any) => any, context?: Ctx): this {
+ if (!this._disposed) {
+ this.handler.on(eventName, eventHandler, context);
+ }
+ return this;
+ }
+
+ /**
+ * Unbind event
+ * @param eventName Event name
+ * @param eventHandler Handler function
+ */
+ // eslint-disable-next-line max-len
+ off(eventName?: string, eventHandler?: EventCallback) {
+ if (this._disposed) {
+ return;
+ }
+ this.handler.off(eventName, eventHandler);
+ }
+
+ /**
+ * Trigger event manually
+ *
+ * @param eventName Event name
+ * @param event Event object
+ */
+ trigger(eventName: string, event?: unknown) {
+ if (this._disposed) {
+ return;
+ }
+ this.handler.trigger(eventName, event);
+ }
+
+
+ /**
+ * Clear all objects and the canvas.
+ */
+ clear() {
+ if (this._disposed) {
+ return;
+ }
+ const roots = this.storage.getRoots();
+ for (let i = 0; i < roots.length; i++) {
+ if (roots[i] instanceof Group) {
+ roots[i].removeSelfFromZr(this);
+ }
+ }
+ this.storage.delAllRoots();
+ this.painter.clear();
+ }
+
+ /**
+ * Dispose self.
+ */
+ dispose() {
+ if (this._disposed) {
+ return;
+ }
+
+ this.animation.stop();
+
+ this.clear();
+ this.storage.dispose();
+ this.painter.dispose();
+ this.handler.dispose();
+
+ this.animation =
+ this.storage =
+ this.painter =
+ this.handler = null;
+
+ this._disposed = true;
+
+ delInstance(this.id);
+ }
+}
+
+
+export interface ZRenderInitOpt {
+ renderer?: string // 'canvas' or 'svg
+ devicePixelRatio?: number
+ width?: number | string // 10, 10px, 'auto'
+ height?: number | string
+ useDirtyRect?: boolean
+ useCoarsePointer?: 'auto' | boolean
+ pointerSize?: number
+ ssr?: boolean // If enable ssr mode.
+}
+
+/**
+ * Initializing a zrender instance
+ *
+ * @param dom Not necessary if using SSR painter like svg-ssr
+ */
+export function init(dom?: HTMLElement | null, opts?: ZRenderInitOpt) {
+ const zr = new ZRender(zrUtil.guid(), dom, opts);
+ instances[zr.id] = zr;
+ return zr;
+}
+
+/**
+ * Dispose zrender instance
+ */
+export function dispose(zr: ZRender) {
+ zr.dispose();
+}
+
+/**
+ * Dispose all zrender instances
+ */
+export function disposeAll() {
+ for (let key in instances) {
+ if (instances.hasOwnProperty(key)) {
+ instances[key].dispose();
+ }
+ }
+ instances = {};
+}
+
+/**
+ * Get zrender instance by id
+ */
+export function getInstance(id: number): ZRender {
+ return instances[id];
+}
+
+export function registerPainter(name: string, Ctor: PainterBaseCtor) {
+ painterCtors[name] = Ctor;
+}
+
+export type ElementSSRData = zrUtil.HashMap;
+export type ElementSSRDataGetter = (el: Element) => zrUtil.HashMap;
+
+let ssrDataGetter: ElementSSRDataGetter;
+
+export function getElementSSRData(el: Element): ElementSSRData {
+ if (typeof ssrDataGetter === 'function') {
+ return ssrDataGetter(el);
+ }
+}
+
+export function registerSSRDataGetter(getter: ElementSSRDataGetter) {
+ ssrDataGetter = getter;
+}
+
+/**
+ * @type {string}
+ */
+export const version = '5.6.0';
+
+
+export interface ZRenderType extends ZRender {};
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/node_modules/zrender/tsconfig.json b/src/MaxKB-1.5.1/node_modules/zrender/tsconfig.json
new file mode 100644
index 0000000..a09b6de
--- /dev/null
+++ b/src/MaxKB-1.5.1/node_modules/zrender/tsconfig.json
@@ -0,0 +1,29 @@
+{
+ "compilerOptions": {
+ "target": "ES3",
+ "noImplicitAny": true,
+ "strictBindCallApply": true,
+ "removeComments": true,
+ "sourceMap": false,
+
+ "noImplicitThis": true,
+
+ // https://github.com/ezolenko/rollup-plugin-typescript2/issues/12#issuecomment-536173372
+ "moduleResolution": "Node",
+
+ "declaration": true,
+ "declarationMap": false,
+
+ // Compile to lib
+ "rootDir": "src",
+
+ "importHelpers": true,
+
+ "pretty": true
+ },
+ "include": [
+ "src/**/*.ts"
+ ],
+ "exclude": [
+ ]
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/one.html b/src/MaxKB-1.5.1/one.html
new file mode 100644
index 0000000..fb72683
--- /dev/null
+++ b/src/MaxKB-1.5.1/one.html
@@ -0,0 +1,40 @@
+
+
+
+
+ 第一个 ECharts 实例
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/package-lock.json b/src/MaxKB-1.5.1/package-lock.json
new file mode 100644
index 0000000..8514508
--- /dev/null
+++ b/src/MaxKB-1.5.1/package-lock.json
@@ -0,0 +1,484 @@
+{
+ "name": "MaxKB-1.5.1",
+ "lockfileVersion": 3,
+ "requires": true,
+ "packages": {
+ "": {
+ "dependencies": {
+ "axios": "^1.7.7",
+ "echarts": "^5.5.1",
+ "vue-echarts": "^7.0.3"
+ }
+ },
+ "node_modules/@babel/helper-string-parser": {
+ "version": "7.25.7",
+ "resolved": "https://registry.npmmirror.com/@babel/helper-string-parser/-/helper-string-parser-7.25.7.tgz",
+ "integrity": "sha512-CbkjYdsJNHFk8uqpEkpCvRs3YRp9tY6FmFY7wLMSYuGYkrdUi7r2lc4/wqsvlHoMznX3WJ9IP8giGPq68T/Y6g==",
+ "license": "MIT",
+ "peer": true,
+ "engines": {
+ "node": ">=6.9.0"
+ }
+ },
+ "node_modules/@babel/helper-validator-identifier": {
+ "version": "7.25.7",
+ "resolved": "https://registry.npmmirror.com/@babel/helper-validator-identifier/-/helper-validator-identifier-7.25.7.tgz",
+ "integrity": "sha512-AM6TzwYqGChO45oiuPqwL2t20/HdMC1rTPAesnBCgPCSF1x3oN9MVUwQV2iyz4xqWrctwK5RNC8LV22kaQCNYg==",
+ "license": "MIT",
+ "peer": true,
+ "engines": {
+ "node": ">=6.9.0"
+ }
+ },
+ "node_modules/@babel/parser": {
+ "version": "7.25.8",
+ "resolved": "https://registry.npmmirror.com/@babel/parser/-/parser-7.25.8.tgz",
+ "integrity": "sha512-HcttkxzdPucv3nNFmfOOMfFf64KgdJVqm1KaCm25dPGMLElo9nsLvXeJECQg8UzPuBGLyTSA0ZzqCtDSzKTEoQ==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/types": "^7.25.8"
+ },
+ "bin": {
+ "parser": "bin/babel-parser.js"
+ },
+ "engines": {
+ "node": ">=6.0.0"
+ }
+ },
+ "node_modules/@babel/types": {
+ "version": "7.25.8",
+ "resolved": "https://registry.npmmirror.com/@babel/types/-/types-7.25.8.tgz",
+ "integrity": "sha512-JWtuCu8VQsMladxVz/P4HzHUGCAwpuqacmowgXFs5XjxIgKuNjnLokQzuVjlTvIzODaDmpjT3oxcC48vyk9EWg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/helper-string-parser": "^7.25.7",
+ "@babel/helper-validator-identifier": "^7.25.7",
+ "to-fast-properties": "^2.0.0"
+ },
+ "engines": {
+ "node": ">=6.9.0"
+ }
+ },
+ "node_modules/@jridgewell/sourcemap-codec": {
+ "version": "1.5.0",
+ "resolved": "https://registry.npmmirror.com/@jridgewell/sourcemap-codec/-/sourcemap-codec-1.5.0.tgz",
+ "integrity": "sha512-gv3ZRaISU3fjPAgNsriBRqGWQL6quFx04YMPW/zD8XMLsU32mhCCbfbO6KZFLjvYpCZ8zyDEgqsgf+PwPaM7GQ==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/@vue/compiler-core": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-core/-/compiler-core-3.5.12.tgz",
+ "integrity": "sha512-ISyBTRMmMYagUxhcpyEH0hpXRd/KqDU4ymofPgl2XAkY9ZhQ+h0ovEZJIiPop13UmR/54oA2cgMDjgroRelaEw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/parser": "^7.25.3",
+ "@vue/shared": "3.5.12",
+ "entities": "^4.5.0",
+ "estree-walker": "^2.0.2",
+ "source-map-js": "^1.2.0"
+ }
+ },
+ "node_modules/@vue/compiler-dom": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-dom/-/compiler-dom-3.5.12.tgz",
+ "integrity": "sha512-9G6PbJ03uwxLHKQ3P42cMTi85lDRvGLB2rSGOiQqtXELat6uI4n8cNz9yjfVHRPIu+MsK6TE418Giruvgptckg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-core": "3.5.12",
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/compiler-sfc": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-sfc/-/compiler-sfc-3.5.12.tgz",
+ "integrity": "sha512-2k973OGo2JuAa5+ZlekuQJtitI5CgLMOwgl94BzMCsKZCX/xiqzJYzapl4opFogKHqwJk34vfsaKpfEhd1k5nw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@babel/parser": "^7.25.3",
+ "@vue/compiler-core": "3.5.12",
+ "@vue/compiler-dom": "3.5.12",
+ "@vue/compiler-ssr": "3.5.12",
+ "@vue/shared": "3.5.12",
+ "estree-walker": "^2.0.2",
+ "magic-string": "^0.30.11",
+ "postcss": "^8.4.47",
+ "source-map-js": "^1.2.0"
+ }
+ },
+ "node_modules/@vue/compiler-ssr": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/compiler-ssr/-/compiler-ssr-3.5.12.tgz",
+ "integrity": "sha512-eLwc7v6bfGBSM7wZOGPmRavSWzNFF6+PdRhE+VFJhNCgHiF8AM7ccoqcv5kBXA2eWUfigD7byekvf/JsOfKvPA==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-dom": "3.5.12",
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/reactivity": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/reactivity/-/reactivity-3.5.12.tgz",
+ "integrity": "sha512-UzaN3Da7xnJXdz4Okb/BGbAaomRHc3RdoWqTzlvd9+WBR5m3J39J1fGcHes7U3za0ruYn/iYy/a1euhMEHvTAg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/runtime-core": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/runtime-core/-/runtime-core-3.5.12.tgz",
+ "integrity": "sha512-hrMUYV6tpocr3TL3Ad8DqxOdpDe4zuQY4HPY3X/VRh+L2myQO8MFXPAMarIOSGNu0bFAjh1yBkMPXZBqCk62Uw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/reactivity": "3.5.12",
+ "@vue/shared": "3.5.12"
+ }
+ },
+ "node_modules/@vue/runtime-dom": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/runtime-dom/-/runtime-dom-3.5.12.tgz",
+ "integrity": "sha512-q8VFxR9A2MRfBr6/55Q3umyoN7ya836FzRXajPB6/Vvuv0zOPL+qltd9rIMzG/DbRLAIlREmnLsplEF/kotXKA==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/reactivity": "3.5.12",
+ "@vue/runtime-core": "3.5.12",
+ "@vue/shared": "3.5.12",
+ "csstype": "^3.1.3"
+ }
+ },
+ "node_modules/@vue/server-renderer": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/server-renderer/-/server-renderer-3.5.12.tgz",
+ "integrity": "sha512-I3QoeDDeEPZm8yR28JtY+rk880Oqmj43hreIBVTicisFTx/Dl7JpG72g/X7YF8hnQD3IFhkky5i2bPonwrTVPg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-ssr": "3.5.12",
+ "@vue/shared": "3.5.12"
+ },
+ "peerDependencies": {
+ "vue": "3.5.12"
+ }
+ },
+ "node_modules/@vue/shared": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/@vue/shared/-/shared-3.5.12.tgz",
+ "integrity": "sha512-L2RPSAwUFbgZH20etwrXyVyCBu9OxRSi8T/38QsvnkJyvq2LufW2lDCOzm7t/U9C1mkhJGWYfCuFBCmIuNivrg==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/asynckit": {
+ "version": "0.4.0",
+ "resolved": "https://registry.npmmirror.com/asynckit/-/asynckit-0.4.0.tgz",
+ "integrity": "sha512-Oei9OH4tRh0YqU3GxhX79dM/mwVgvbZJaSNaRk+bshkj0S5cfHcgYakreBjrHwatXKbz+IoIdYLxrKim2MjW0Q==",
+ "license": "MIT"
+ },
+ "node_modules/axios": {
+ "version": "1.7.7",
+ "resolved": "https://registry.npmmirror.com/axios/-/axios-1.7.7.tgz",
+ "integrity": "sha512-S4kL7XrjgBmvdGut0sN3yJxqYzrDOnivkBiN0OFs6hLiUam3UPvswUo0kqGyhqUZGEOytHyumEdXsAkgCOUf3Q==",
+ "license": "MIT",
+ "dependencies": {
+ "follow-redirects": "^1.15.6",
+ "form-data": "^4.0.0",
+ "proxy-from-env": "^1.1.0"
+ }
+ },
+ "node_modules/combined-stream": {
+ "version": "1.0.8",
+ "resolved": "https://registry.npmmirror.com/combined-stream/-/combined-stream-1.0.8.tgz",
+ "integrity": "sha512-FQN4MRfuJeHf7cBbBMJFXhKSDq+2kAArBlmRBvcvFE5BB1HZKXtSFASDhdlz9zOYwxh8lDdnvmMOe/+5cdoEdg==",
+ "license": "MIT",
+ "dependencies": {
+ "delayed-stream": "~1.0.0"
+ },
+ "engines": {
+ "node": ">= 0.8"
+ }
+ },
+ "node_modules/csstype": {
+ "version": "3.1.3",
+ "resolved": "https://registry.npmmirror.com/csstype/-/csstype-3.1.3.tgz",
+ "integrity": "sha512-M1uQkMl8rQK/szD0LNhtqxIPLpimGm8sOBwU7lLnCpSbTyY3yeU1Vc7l4KT5zT4s/yOxHH5O7tIuuLOCnLADRw==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/delayed-stream": {
+ "version": "1.0.0",
+ "resolved": "https://registry.npmmirror.com/delayed-stream/-/delayed-stream-1.0.0.tgz",
+ "integrity": "sha512-ZySD7Nf91aLB0RxL4KGrKHBXl7Eds1DAmEdcoVawXnLD7SDhpNgtuII2aAkg7a7QS41jxPSZ17p4VdGnMHk3MQ==",
+ "license": "MIT",
+ "engines": {
+ "node": ">=0.4.0"
+ }
+ },
+ "node_modules/echarts": {
+ "version": "5.5.1",
+ "resolved": "https://registry.npmmirror.com/echarts/-/echarts-5.5.1.tgz",
+ "integrity": "sha512-Fce8upazaAXUVUVsjgV6mBnGuqgO+JNDlcgF79Dksy4+wgGpQB2lmYoO4TSweFg/mZITdpGHomw/cNBJZj1icA==",
+ "license": "Apache-2.0",
+ "dependencies": {
+ "tslib": "2.3.0",
+ "zrender": "5.6.0"
+ }
+ },
+ "node_modules/entities": {
+ "version": "4.5.0",
+ "resolved": "https://registry.npmmirror.com/entities/-/entities-4.5.0.tgz",
+ "integrity": "sha512-V0hjH4dGPh9Ao5p0MoRY6BVqtwCjhz6vI5LT8AJ55H+4g9/4vbHx1I54fS0XuclLhDHArPQCiMjDxjaL8fPxhw==",
+ "license": "BSD-2-Clause",
+ "peer": true,
+ "engines": {
+ "node": ">=0.12"
+ },
+ "funding": {
+ "url": "https://github.com/fb55/entities?sponsor=1"
+ }
+ },
+ "node_modules/estree-walker": {
+ "version": "2.0.2",
+ "resolved": "https://registry.npmmirror.com/estree-walker/-/estree-walker-2.0.2.tgz",
+ "integrity": "sha512-Rfkk/Mp/DL7JVje3u18FxFujQlTNR2q6QfMSMB7AvCBx91NGj/ba3kCfza0f6dVDbw7YlRf/nDrn7pQrCCyQ/w==",
+ "license": "MIT",
+ "peer": true
+ },
+ "node_modules/follow-redirects": {
+ "version": "1.15.9",
+ "resolved": "https://registry.npmmirror.com/follow-redirects/-/follow-redirects-1.15.9.tgz",
+ "integrity": "sha512-gew4GsXizNgdoRyqmyfMHyAmXsZDk6mHkSxZFCzW9gwlbtOW44CDtYavM+y+72qD/Vq2l550kMF52DT8fOLJqQ==",
+ "funding": [
+ {
+ "type": "individual",
+ "url": "https://github.com/sponsors/RubenVerborgh"
+ }
+ ],
+ "license": "MIT",
+ "engines": {
+ "node": ">=4.0"
+ },
+ "peerDependenciesMeta": {
+ "debug": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/form-data": {
+ "version": "4.0.1",
+ "resolved": "https://registry.npmmirror.com/form-data/-/form-data-4.0.1.tgz",
+ "integrity": "sha512-tzN8e4TX8+kkxGPK8D5u0FNmjPUjw3lwC9lSLxxoB/+GtsJG91CO8bSWy73APlgAZzZbXEYZJuxjkHH2w+Ezhw==",
+ "license": "MIT",
+ "dependencies": {
+ "asynckit": "^0.4.0",
+ "combined-stream": "^1.0.8",
+ "mime-types": "^2.1.12"
+ },
+ "engines": {
+ "node": ">= 6"
+ }
+ },
+ "node_modules/magic-string": {
+ "version": "0.30.12",
+ "resolved": "https://registry.npmmirror.com/magic-string/-/magic-string-0.30.12.tgz",
+ "integrity": "sha512-Ea8I3sQMVXr8JhN4z+H/d8zwo+tYDgHE9+5G4Wnrwhs0gaK9fXTKx0Tw5Xwsd/bCPTTZNRAdpyzvoeORe9LYpw==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@jridgewell/sourcemap-codec": "^1.5.0"
+ }
+ },
+ "node_modules/mime-db": {
+ "version": "1.52.0",
+ "resolved": "https://registry.npmmirror.com/mime-db/-/mime-db-1.52.0.tgz",
+ "integrity": "sha512-sPU4uV7dYlvtWJxwwxHD0PuihVNiE7TyAbQ5SWxDCB9mUYvOgroQOwYQQOKPJ8CIbE+1ETVlOoK1UC2nU3gYvg==",
+ "license": "MIT",
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
+ "node_modules/mime-types": {
+ "version": "2.1.35",
+ "resolved": "https://registry.npmmirror.com/mime-types/-/mime-types-2.1.35.tgz",
+ "integrity": "sha512-ZDY+bPm5zTTF+YpCrAU9nK0UgICYPT0QtT1NZWFv4s++TNkcgVaT0g6+4R2uI4MjQjzysHB1zxuWL50hzaeXiw==",
+ "license": "MIT",
+ "dependencies": {
+ "mime-db": "1.52.0"
+ },
+ "engines": {
+ "node": ">= 0.6"
+ }
+ },
+ "node_modules/nanoid": {
+ "version": "3.3.7",
+ "resolved": "https://registry.npmmirror.com/nanoid/-/nanoid-3.3.7.tgz",
+ "integrity": "sha512-eSRppjcPIatRIMC1U6UngP8XFcz8MQWGQdt1MTBQ7NaAmvXDfvNxbvWV3x2y6CdEUciCSsDHDQZbhYaB8QEo2g==",
+ "funding": [
+ {
+ "type": "github",
+ "url": "https://github.com/sponsors/ai"
+ }
+ ],
+ "license": "MIT",
+ "peer": true,
+ "bin": {
+ "nanoid": "bin/nanoid.cjs"
+ },
+ "engines": {
+ "node": "^10 || ^12 || ^13.7 || ^14 || >=15.0.1"
+ }
+ },
+ "node_modules/picocolors": {
+ "version": "1.1.0",
+ "resolved": "https://registry.npmmirror.com/picocolors/-/picocolors-1.1.0.tgz",
+ "integrity": "sha512-TQ92mBOW0l3LeMeyLV6mzy/kWr8lkd/hp3mTg7wYK7zJhuBStmGMBG0BdeDZS/dZx1IukaX6Bk11zcln25o1Aw==",
+ "license": "ISC",
+ "peer": true
+ },
+ "node_modules/postcss": {
+ "version": "8.4.47",
+ "resolved": "https://registry.npmmirror.com/postcss/-/postcss-8.4.47.tgz",
+ "integrity": "sha512-56rxCq7G/XfB4EkXq9Egn5GCqugWvDFjafDOThIdMBsI15iqPqR5r15TfSr1YPYeEI19YeaXMCbY6u88Y76GLQ==",
+ "funding": [
+ {
+ "type": "opencollective",
+ "url": "https://opencollective.com/postcss/"
+ },
+ {
+ "type": "tidelift",
+ "url": "https://tidelift.com/funding/github/npm/postcss"
+ },
+ {
+ "type": "github",
+ "url": "https://github.com/sponsors/ai"
+ }
+ ],
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "nanoid": "^3.3.7",
+ "picocolors": "^1.1.0",
+ "source-map-js": "^1.2.1"
+ },
+ "engines": {
+ "node": "^10 || ^12 || >=14"
+ }
+ },
+ "node_modules/proxy-from-env": {
+ "version": "1.1.0",
+ "resolved": "https://registry.npmmirror.com/proxy-from-env/-/proxy-from-env-1.1.0.tgz",
+ "integrity": "sha512-D+zkORCbA9f1tdWRK0RaCR3GPv50cMxcrz4X8k5LTSUD1Dkw47mKJEZQNunItRTkWwgtaUSo1RVFRIG9ZXiFYg==",
+ "license": "MIT"
+ },
+ "node_modules/source-map-js": {
+ "version": "1.2.1",
+ "resolved": "https://registry.npmmirror.com/source-map-js/-/source-map-js-1.2.1.tgz",
+ "integrity": "sha512-UXWMKhLOwVKb728IUtQPXxfYU+usdybtUrK/8uGE8CQMvrhOpwvzDBwj0QhSL7MQc7vIsISBG8VQ8+IDQxpfQA==",
+ "license": "BSD-3-Clause",
+ "peer": true,
+ "engines": {
+ "node": ">=0.10.0"
+ }
+ },
+ "node_modules/to-fast-properties": {
+ "version": "2.0.0",
+ "resolved": "https://registry.npmmirror.com/to-fast-properties/-/to-fast-properties-2.0.0.tgz",
+ "integrity": "sha512-/OaKK0xYrs3DmxRYqL/yDc+FxFUVYhDlXMhRmv3z915w2HF1tnN1omB354j8VUGO/hbRzyD6Y3sA7v7GS/ceog==",
+ "license": "MIT",
+ "peer": true,
+ "engines": {
+ "node": ">=4"
+ }
+ },
+ "node_modules/tslib": {
+ "version": "2.3.0",
+ "resolved": "https://registry.npmmirror.com/tslib/-/tslib-2.3.0.tgz",
+ "integrity": "sha512-N82ooyxVNm6h1riLCoyS9e3fuJ3AMG2zIZs2Gd1ATcSFjSA23Q0fzjjZeh0jbJvWVDZ0cJT8yaNNaaXHzueNjg==",
+ "license": "0BSD"
+ },
+ "node_modules/vue": {
+ "version": "3.5.12",
+ "resolved": "https://registry.npmmirror.com/vue/-/vue-3.5.12.tgz",
+ "integrity": "sha512-CLVZtXtn2ItBIi/zHZ0Sg1Xkb7+PU32bJJ8Bmy7ts3jxXTcbfsEfBivFYYWz1Hur+lalqGAh65Coin0r+HRUfg==",
+ "license": "MIT",
+ "peer": true,
+ "dependencies": {
+ "@vue/compiler-dom": "3.5.12",
+ "@vue/compiler-sfc": "3.5.12",
+ "@vue/runtime-dom": "3.5.12",
+ "@vue/server-renderer": "3.5.12",
+ "@vue/shared": "3.5.12"
+ },
+ "peerDependencies": {
+ "typescript": "*"
+ },
+ "peerDependenciesMeta": {
+ "typescript": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/vue-demi": {
+ "version": "0.13.11",
+ "resolved": "https://registry.npmmirror.com/vue-demi/-/vue-demi-0.13.11.tgz",
+ "integrity": "sha512-IR8HoEEGM65YY3ZJYAjMlKygDQn25D5ajNFNoKh9RSDMQtlzCxtfQjdQgv9jjK+m3377SsJXY8ysq8kLCZL25A==",
+ "hasInstallScript": true,
+ "license": "MIT",
+ "bin": {
+ "vue-demi-fix": "bin/vue-demi-fix.js",
+ "vue-demi-switch": "bin/vue-demi-switch.js"
+ },
+ "engines": {
+ "node": ">=12"
+ },
+ "funding": {
+ "url": "https://github.com/sponsors/antfu"
+ },
+ "peerDependencies": {
+ "@vue/composition-api": "^1.0.0-rc.1",
+ "vue": "^3.0.0-0 || ^2.6.0"
+ },
+ "peerDependenciesMeta": {
+ "@vue/composition-api": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/vue-echarts": {
+ "version": "7.0.3",
+ "resolved": "https://registry.npmmirror.com/vue-echarts/-/vue-echarts-7.0.3.tgz",
+ "integrity": "sha512-/jSxNwOsw5+dYAUcwSfkLwKPuzTQ0Cepz1LxCOpj2QcHrrmUa/Ql0eQqMmc1rTPQVrh2JQ29n2dhq75ZcHvRDw==",
+ "license": "MIT",
+ "dependencies": {
+ "vue-demi": "^0.13.11"
+ },
+ "peerDependencies": {
+ "@vue/runtime-core": "^3.0.0",
+ "echarts": "^5.5.1",
+ "vue": "^2.7.0 || ^3.1.1"
+ },
+ "peerDependenciesMeta": {
+ "@vue/runtime-core": {
+ "optional": true
+ }
+ }
+ },
+ "node_modules/zrender": {
+ "version": "5.6.0",
+ "resolved": "https://registry.npmmirror.com/zrender/-/zrender-5.6.0.tgz",
+ "integrity": "sha512-uzgraf4njmmHAbEUxMJ8Oxg+P3fT04O+9p7gY+wJRVxo8Ge+KmYv0WJev945EH4wFuc4OY2NLXz46FZrWS9xJg==",
+ "license": "BSD-3-Clause",
+ "dependencies": {
+ "tslib": "2.3.0"
+ }
+ }
+ }
+}
diff --git a/src/MaxKB-1.5.1/package.json b/src/MaxKB-1.5.1/package.json
new file mode 100644
index 0000000..f02e0f9
--- /dev/null
+++ b/src/MaxKB-1.5.1/package.json
@@ -0,0 +1,7 @@
+{
+ "dependencies": {
+ "axios": "^1.7.7",
+ "echarts": "^5.5.1",
+ "vue-echarts": "^7.0.3"
+ }
+}
diff --git a/src/MaxKB-1.5.1/pyproject.toml b/src/MaxKB-1.5.1/pyproject.toml
new file mode 100644
index 0000000..d37963c
--- /dev/null
+++ b/src/MaxKB-1.5.1/pyproject.toml
@@ -0,0 +1,70 @@
+[tool.poetry]
+name = "maxkb"
+version = "0.1.0"
+description = "智能知识库"
+authors = ["shaohuzhang1 "]
+readme = "README.md"
+
+[tool.poetry.dependencies]
+python = ">=3.11,<3.12"
+django = "4.2.15"
+djangorestframework = "^3.15.2"
+drf-yasg = "1.21.7"
+django-filter = "23.2"
+langchain = "0.2.3"
+langchain_community = "0.2.4"
+langchain-huggingface = "^0.0.3"
+psycopg2-binary = "2.9.7"
+jieba = "^0.42.1"
+diskcache = "^5.6.3"
+pillow = "^10.2.0"
+filetype = "^1.2.0"
+torch = "2.2.1"
+sentence-transformers = "^2.2.2"
+openai = "^1.13.3"
+tiktoken = "^0.7.0"
+qianfan = "^0.3.6.1"
+pycryptodome = "^3.19.0"
+beautifulsoup4 = "^4.12.2"
+html2text = "^2024.2.26"
+langchain-openai = "^0.1.8"
+django-ipware = "^6.0.4"
+django-apscheduler = "^0.6.2"
+pymupdf = "1.24.9"
+pypdf = "4.3.1"
+rapidocr-onnxruntime = "1.3.24"
+opencv-python-headless = "^4.10.0"
+python-docx = "^1.1.0"
+xlwt = "^1.3.0"
+dashscope = "^1.17.0"
+zhipuai = "^2.0.1"
+httpx = "^0.27.0"
+httpx-sse = "^0.4.0"
+websocket-client = "^1.7.0"
+langchain-google-genai = "^1.0.3"
+openpyxl = "^3.1.2"
+xlrd = "^2.0.1"
+gunicorn = "^22.0.0"
+python-daemon = "3.0.1"
+gevent = "^24.2.1"
+restrictedpython = "^7.2"
+cgroups = "^0.1.0"
+wasm-exec = "^0.1.9"
+
+boto3 = "^1.34.151"
+langchain-aws = "^0.1.13"
+tencentcloud-sdk-python = "^3.0.1205"
+xinference-client = "^0.14.0.post1"
+psutil = "^6.0.0"
+celery = { extras = ["sqlalchemy"], version = "^5.4.0" }
+eventlet = "^0.36.1"
+django-celery-beat = "^2.6.0"
+celery-once = "^3.0.1"
+[build-system]
+requires = ["poetry-core"]
+build-backend = "poetry.core.masonry.api"
+
+[[tool.poetry.source]]
+name = "pytorch"
+url = "https://download.pytorch.org/whl/cpu"
+priority = "explicit"
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/start_program.bat b/src/MaxKB-1.5.1/start_program.bat
new file mode 100644
index 0000000..0473e6f
--- /dev/null
+++ b/src/MaxKB-1.5.1/start_program.bat
@@ -0,0 +1,13 @@
+@echo off
+
+rem
+start "Dev" cmd /k ".\venv\Scripts\activate & python main.py dev"
+
+rem
+start "Terminal" cmd /k "cd ui & npm run dev"
+
+rem
+start "Celery" cmd /k ".\venv\Scripts\activate & python main.py dev celery"
+
+rem
+start "Local_Model" cmd /k ".\venv\Scripts\activate & python main.py dev local_model"
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/ui/.eslintrc.cjs b/src/MaxKB-1.5.1/ui/.eslintrc.cjs
new file mode 100644
index 0000000..d6c3088
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/.eslintrc.cjs
@@ -0,0 +1,21 @@
+/* eslint-env node */
+require('@rushstack/eslint-patch/modern-module-resolution')
+
+module.exports = {
+ root: true,
+ 'extends': [
+ 'plugin:vue/vue3-essential',
+ 'eslint:recommended',
+ '@vue/eslint-config-typescript',
+ '@vue/eslint-config-prettier/skip-formatting'
+ ],
+ parserOptions: {
+ ecmaVersion: 'latest'
+ },
+ rules: {
+ // 添加组件命名忽略规则
+ "vue/multi-word-component-names": ["error",{
+ "ignores": ["index","main"]//需要忽略的组件名
+ }]
+ }
+}
diff --git a/src/MaxKB-1.5.1/ui/.gitignore b/src/MaxKB-1.5.1/ui/.gitignore
new file mode 100644
index 0000000..38adffa
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/.gitignore
@@ -0,0 +1,28 @@
+# Logs
+logs
+*.log
+npm-debug.log*
+yarn-debug.log*
+yarn-error.log*
+pnpm-debug.log*
+lerna-debug.log*
+
+node_modules
+.DS_Store
+dist
+dist-ssr
+coverage
+*.local
+
+/cypress/videos/
+/cypress/screenshots/
+
+# Editor directories and files
+.vscode/*
+!.vscode/extensions.json
+.idea
+*.suo
+*.ntvs*
+*.njsproj
+*.sln
+*.sw?
diff --git a/src/MaxKB-1.5.1/ui/.prettierrc.json b/src/MaxKB-1.5.1/ui/.prettierrc.json
new file mode 100644
index 0000000..66e2335
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/.prettierrc.json
@@ -0,0 +1,8 @@
+{
+ "$schema": "https://json.schemastore.org/prettierrc",
+ "semi": false,
+ "tabWidth": 2,
+ "singleQuote": true,
+ "printWidth": 100,
+ "trailingComma": "none"
+}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/ui/README.md b/src/MaxKB-1.5.1/ui/README.md
new file mode 100644
index 0000000..12c6c8c
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/README.md
@@ -0,0 +1,52 @@
+# web
+
+This template should help get you started developing with Vue 3 in Vite.
+
+## Recommended IDE Setup
+
+[VSCode](https://code.visualstudio.com/) + [Volar](https://marketplace.visualstudio.com/items?itemName=Vue.volar) (and disable Vetur) + [TypeScript Vue Plugin (Volar)](https://marketplace.visualstudio.com/items?itemName=Vue.vscode-typescript-vue-plugin).
+
+## Type Support for `.vue` Imports in TS
+
+TypeScript cannot handle type information for `.vue` imports by default, so we replace the `tsc` CLI with `vue-tsc` for type checking. In editors, we need [TypeScript Vue Plugin (Volar)](https://marketplace.visualstudio.com/items?itemName=Vue.vscode-typescript-vue-plugin) to make the TypeScript language service aware of `.vue` types.
+
+If the standalone TypeScript plugin doesn't feel fast enough to you, Volar has also implemented a [Take Over Mode](https://github.com/johnsoncodehk/volar/discussions/471#discussioncomment-1361669) that is more performant. You can enable it by the following steps:
+
+1. Disable the built-in TypeScript Extension
+ 1) Run `Extensions: Show Built-in Extensions` from VSCode's command palette
+ 2) Find `TypeScript and JavaScript Language Features`, right click and select `Disable (Workspace)`
+2. Reload the VSCode window by running `Developer: Reload Window` from the command palette.
+
+## Customize configuration
+
+See [Vite Configuration Reference](https://vitejs.dev/config/).
+
+## Project Setup
+
+```sh
+npm install
+```
+
+### Compile and Hot-Reload for Development
+
+```sh
+npm run dev
+```
+
+### Type-Check, Compile and Minify for Production
+
+```sh
+npm run build
+```
+
+### Run Unit Tests with [Vitest](https://vitest.dev/)
+
+```sh
+npm run test:unit
+```
+
+### Lint with [ESLint](https://eslint.org/)
+
+```sh
+npm run lint
+```
diff --git a/src/MaxKB-1.5.1/ui/env.d.ts b/src/MaxKB-1.5.1/ui/env.d.ts
new file mode 100644
index 0000000..52f5452
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/env.d.ts
@@ -0,0 +1,14 @@
+/// = Record;
diff --git a/src/MaxKB-1.5.1/ui/index.html b/src/MaxKB-1.5.1/ui/index.html
new file mode 100644
index 0000000..09bec9a
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/index.html
@@ -0,0 +1,18 @@
+
+
+
+
+
+
+ %VITE_APP_TITLE%
+
+
+
+
+
+
diff --git a/src/MaxKB-1.5.1/ui/package.json b/src/MaxKB-1.5.1/ui/package.json
new file mode 100644
index 0000000..0a3635c
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/package.json
@@ -0,0 +1,72 @@
+{
+ "name": "web",
+ "version": "v1.0.0",
+ "private": true,
+ "scripts": {
+ "dev": "vite",
+ "build": "run-p type-check build-only",
+ "preview": "vite preview",
+ "test:unit": "vitest",
+ "build-only": "vite build",
+ "type-check": "vue-tsc --noEmit -p tsconfig.vitest.json --composite false",
+ "lint": "eslint . --ext .vue,.js,.jsx,.cjs,.mjs,.ts,.tsx,.cts,.mts --fix --ignore-path .gitignore",
+ "format": "prettier --write src/"
+ },
+ "dependencies": {
+ "@ctrl/tinycolor": "^4.1.0",
+ "@logicflow/core": "^1.2.27",
+ "@logicflow/extension": "^1.2.27",
+ "@vueuse/core": "^10.9.0",
+ "axios": "^0.28.0",
+ "codemirror": "^6.0.1",
+ "cropperjs": "^1.6.2",
+ "echarts": "^5.5.0",
+ "element-plus": "^2.5.6",
+ "file-saver": "^2.0.5",
+ "highlight.js": "^11.9.0",
+ "install": "^0.13.0",
+ "katex": "^0.16.10",
+ "lodash": "^4.17.21",
+ "marked": "^12.0.2",
+ "md-editor-v3": "^4.16.7",
+ "medium-zoom": "^1.1.0",
+ "mermaid": "^10.9.0",
+ "mitt": "^3.0.0",
+ "moment": "^2.30.1",
+ "npm": "^10.2.4",
+ "nprogress": "^0.2.0",
+ "pinia": "^2.1.6",
+ "pinyin-pro": "^3.18.2",
+ "screenfull": "^6.0.2",
+ "use-element-plus-theme": "^0.0.5",
+ "vue": "^3.3.4",
+ "vue-clipboard3": "^2.0.0",
+ "vue-codemirror": "^6.1.1",
+ "vue-i18n": "^9.13.1",
+ "vue-router": "^4.2.4"
+ },
+ "devDependencies": {
+ "@rushstack/eslint-patch": "^1.3.2",
+ "@tsconfig/node18": "^18.2.0",
+ "@types/file-saver": "^2.0.7",
+ "@types/jsdom": "^21.1.1",
+ "@types/node": "^18.17.5",
+ "@types/nprogress": "^0.2.0",
+ "@vitejs/plugin-vue": "^4.3.1",
+ "@vue/eslint-config-prettier": "^8.0.0",
+ "@vue/eslint-config-typescript": "^11.0.3",
+ "@vue/test-utils": "^2.4.1",
+ "@vue/tsconfig": "^0.4.0",
+ "eslint": "^8.46.0",
+ "eslint-plugin-vue": "^9.16.1",
+ "jsdom": "^22.1.0",
+ "npm-run-all": "^4.1.5",
+ "prettier": "^3.0.0",
+ "sass": "^1.66.1",
+ "typescript": "~5.1.6",
+ "unplugin-vue-define-options": "^1.3.18",
+ "vite": "^4.4.9",
+ "vitest": "^0.34.2",
+ "vue-tsc": "^1.8.8"
+ }
+}
diff --git a/src/MaxKB-1.5.1/ui/public/favicon.ico b/src/MaxKB-1.5.1/ui/public/favicon.ico
new file mode 100644
index 0000000..7d9781e
Binary files /dev/null and b/src/MaxKB-1.5.1/ui/public/favicon.ico differ
diff --git a/src/MaxKB-1.5.1/ui/src/App.vue b/src/MaxKB-1.5.1/ui/src/App.vue
new file mode 100644
index 0000000..8664306
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/src/App.vue
@@ -0,0 +1,7 @@
+
+
+
+ ) => Promise> = (
+ application_id,
+ loading
+) => {
+ return get(`${prefix}/${application_id}/api_key`, undefined, loading)
+}
+
+/**
+ * 新增API_KEY
+ * @param 参数 application_id
+ */
+const postAPIKey: (application_id: string, loading?: Ref) => Promise> = (
+ application_id,
+ loading
+) => {
+ return post(`${prefix}/${application_id}/api_key`, {}, undefined, loading)
+}
+
+/**
+ * 删除API_KEY
+ * @param 参数 application_id api_key_id
+ */
+const delAPIKey: (
+ application_id: String,
+ api_key_id: String,
+ loading?: Ref
+) => Promise> = (application_id, api_key_id, loading) => {
+ return del(`${prefix}/${application_id}/api_key/${api_key_id}`, undefined, undefined, loading)
+}
+
+/**
+ * 修改API_KEY
+ * @param 参数 application_id,api_key_id
+ * data {
+ * is_active: boolean
+ * }
+ */
+const putAPIKey: (
+ application_id: string,
+ api_key_id: String,
+ data: any,
+ loading?: Ref
+) => Promise> = (application_id, api_key_id, data, loading) => {
+ return put(`${prefix}/${application_id}/api_key/${api_key_id}`, data, undefined, loading)
+}
+
+/**
+ * 统计
+ * @param 参数 application_id, data
+ */
+const getStatistics: (
+ application_id: string,
+ data: any,
+ loading?: Ref
+) => Promise> = (application_id, data, loading) => {
+ return get(`${prefix}/${application_id}/statistics/chat_record_aggregate_trend`, data, loading)
+}
+
+/**
+ * 修改应用icon
+ * @param 参数 application_id
+ * data: file
+ */
+const putAppIcon: (
+ application_id: string,
+ data: any,
+ loading?: Ref
+) => Promise> = (application_id, data, loading) => {
+ return put(`${prefix}/${application_id}/edit_icon`, data, undefined, loading)
+}
+
+export default {
+ getAPIKey,
+ postAPIKey,
+ delAPIKey,
+ putAPIKey,
+ getStatistics,
+ putAppIcon
+}
diff --git a/src/MaxKB-1.5.1/ui/src/api/application-xpack.ts b/src/MaxKB-1.5.1/ui/src/api/application-xpack.ts
new file mode 100644
index 0000000..f71c08a
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/src/api/application-xpack.ts
@@ -0,0 +1,53 @@
+import { Result } from '@/request/Result'
+import { get, put } from '@/request/index'
+import { type Ref } from 'vue'
+
+const prefix = '/application'
+
+/**
+ * 替换社区版-获取AccessToken
+ * @param 参数 application_id
+ */
+const getAccessToken: (application_id: string, loading?: Ref) => Promise> = (
+ application_id,
+ loading
+) => {
+ return get(`${prefix}/${application_id}/setting`, undefined, loading)
+}
+
+/**
+ * 替换社区版-修改AccessToken
+ * @param 参数 application_id
+ * data {
+ * "show_source": boolean,
+ * "show_history": boolean,
+ * "draggable": boolean,
+ * "show_guide": boolean,
+ * "avatar": file,
+ * "float_icon": file,
+ * }
+ */
+const putAccessToken: (
+ application_id: string,
+ data: any,
+ loading?: Ref
+) => Promise> = (application_id, data, loading) => {
+ return put(`${prefix}/${application_id}/setting`, data, undefined, loading)
+}
+
+/**
+ * 对话获取应用相关信息
+ * @param 参数
+ {
+ "access_token": "string"
+}
+ */
+const getAppXpackProfile: (loading?: Ref) => Promise = (loading) => {
+ return get(`${prefix}/xpack/profile`, undefined, loading)
+}
+
+export default {
+ getAccessToken,
+ putAccessToken,
+ getAppXpackProfile
+}
diff --git a/src/MaxKB-1.5.1/ui/src/api/application.ts b/src/MaxKB-1.5.1/ui/src/api/application.ts
new file mode 100644
index 0000000..76c20f3
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/src/api/application.ts
@@ -0,0 +1,314 @@
+import { Result } from '@/request/Result'
+import { get, post, postStream, del, put } from '@/request/index'
+import type { pageRequest } from '@/api/type/common'
+import type { ApplicationFormType } from '@/api/type/application'
+import { type Ref } from 'vue'
+import type { FormField } from '@/components/dynamics-form/type'
+const prefix = '/application'
+
+/**
+ * 获取全部应用
+ * @param 参数
+ */
+const getAllAppilcation: () => Promise> = () => {
+ return get(`${prefix}`)
+}
+
+/**
+ * 获取分页应用
+ * page {
+ "current_page": "string",
+ "page_size": "string",
+ }
+ * param {
+ "name": "string",
+ }
+ */
+const getApplication: (
+ page: pageRequest,
+ param: any,
+ loading?: Ref
+) => Promise> = (page, param, loading) => {
+ return get(`${prefix}/${page.current_page}/${page.page_size}`, param, loading)
+}
+
+/**
+ * 创建应用
+ * @param 参数
+ */
+const postApplication: (
+ data: ApplicationFormType,
+ loading?: Ref
+) => Promise> = (data, loading) => {
+ return post(`${prefix}`, data, undefined, loading)
+}
+
+/**
+ * 修改应用
+ * @param 参数
+ */
+const putApplication: (
+ application_id: String,
+ data: ApplicationFormType,
+ loading?: Ref
+) => Promise> = (application_id, data, loading) => {
+ return put(`${prefix}/${application_id}`, data, undefined, loading)
+}
+
+/**
+ * 删除应用
+ * @param 参数 application_id
+ */
+const delApplication: (
+ application_id: String,
+ loading?: Ref
+) => Promise> = (application_id, loading) => {
+ return del(`${prefix}/${application_id}`, undefined, {}, loading)
+}
+
+/**
+ * 应用详情
+ * @param 参数 application_id
+ */
+const getApplicationDetail: (
+ application_id: string,
+ loading?: Ref
+) => Promise> = (application_id, loading) => {
+ return get(`${prefix}/${application_id}`, undefined, loading)
+}
+
+/**
+ * 获得当前应用可使用的知识库
+ * @param 参数 application_id
+ */
+const getApplicationDataset: (
+ application_id: string,
+ loading?: Ref
+) => Promise> = (application_id, loading) => {
+ return get(`${prefix}/${application_id}/list_dataset`, undefined, loading)
+}
+
+/**
+ * 获取AccessToken
+ * @param 参数 application_id
+ */
+const getAccessToken: (application_id: string, loading?: Ref) => Promise> = (
+ application_id,
+ loading
+) => {
+ return get(`${prefix}/${application_id}/access_token`, undefined, loading)
+}
+
+/**
+ * 修改AccessToken
+ * @param 参数 application_id
+ * data {
+ * "is_active": true
+ * }
+ */
+const putAccessToken: (
+ application_id: string,
+ data: any,
+ loading?: Ref
+) => Promise> = (application_id, data, loading) => {
+ return put(`${prefix}/${application_id}/access_token`, data, undefined, loading)
+}
+
+/**
+ * 应用认证
+ * @param 参数
+ {
+ "access_token": "string"
+ }
+ */
+const postAppAuthentication: (access_token: string, loading?: Ref) => Promise = (
+ access_token,
+ loading
+) => {
+ return post(`${prefix}/authentication`, { access_token }, undefined, loading)
+}
+
+/**
+ * 对话获取应用相关信息
+ * @param 参数
+ {
+ "access_token": "string"
+ }
+ */
+const getAppProfile: (loading?: Ref) => Promise = (loading) => {
+ return get(`${prefix}/profile`, undefined, loading)
+}
+
+/**
+ * 获得临时回话Id
+ * @param 参数
+
+ }
+ */
+const postChatOpen: (data: ApplicationFormType) => Promise> = (data) => {
+ return post(`${prefix}/chat/open`, data)
+}
+
+/**
+ * 获得工作流临时回话Id
+ * @param 参数
+
+ }
+ */
+const postWorkflowChatOpen: (data: ApplicationFormType) => Promise> = (data) => {
+ return post(`${prefix}/chat_workflow/open`, data)
+}
+
+/**
+ * 正式回话Id
+ * @param 参数
+ * {
+ "model_id": "string",
+ "multiple_rounds_dialogue": true,
+ "dataset_id_list": [
+ "string"
+ ]
+ }
+ */
+const getChatOpen: (application_id: String) => Promise> = (application_id) => {
+ return get(`${prefix}/${application_id}/chat/open`)
+}
+/**
+ * 对话
+ * @param 参数
+ * chat_id: string
+ * data
+ */
+const postChatMessage: (chat_id: string, data: any) => Promise = (chat_id, data) => {
+ return postStream(`/api${prefix}/chat_message/${chat_id}`, data)
+}
+
+/**
+ * 点赞、点踩
+ * @param 参数
+ * application_id : string; chat_id : string; chat_record_id : string
+ * {
+ "vote_status": "string", // -1 0 1
+ }
+ */
+const putChatVote: (
+ application_id: string,
+ chat_id: string,
+ chat_record_id: string,
+ vote_status: string,
+ loading?: Ref
+) => Promise = (application_id, chat_id, chat_record_id, vote_status, loading) => {
+ return put(
+ `${prefix}/${application_id}/chat/${chat_id}/chat_record/${chat_record_id}/vote`,
+ {
+ vote_status
+ },
+ undefined,
+ loading
+ )
+}
+
+/**
+ * 命中测试列表
+ * @param application_id
+ * @param loading
+ * @query { query_text: string, top_number: number, similarity: number }
+ * @returns
+ */
+const getApplicationHitTest: (
+ application_id: string,
+ data: any,
+ loading?: Ref
+) => Promise>> = (application_id, data, loading) => {
+ return get(`${prefix}/${application_id}/hit_test`, data, loading)
+}
+
+/**
+ * 获取当前用户可使用的模型列表
+ * @param application_id
+ * @param loading
+ * @query { query_text: string, top_number: number, similarity: number }
+ * @returns
+ */
+const getApplicationModel: (
+ application_id: string,
+ loading?: Ref
+) => Promise>> = (application_id, loading) => {
+ return get(`${prefix}/${application_id}/model`, loading)
+}
+
+/**
+ * 发布应用
+ * @param 参数
+ */
+const putPublishApplication: (
+ application_id: String,
+ data: ApplicationFormType,
+ loading?: Ref
+) => Promise> = (application_id, data, loading) => {
+ return put(`${prefix}/${application_id}/publish`, data, undefined, loading)
+}
+/**
+ * 获取应用所属的函数库列表
+ * @param application_id 应用id
+ * @param loading
+ * @returns
+ */
+const listFunctionLib: (application_id: String, loading?: Ref) => Promise> = (
+ application_id,
+ loading
+) => {
+ return get(`${prefix}/${application_id}/function_lib`, undefined, loading)
+}
+/**
+ * 获取应用所属的函数库
+ * @param application_id
+ * @param function_lib_id
+ * @param loading
+ * @returns
+ */
+const getFunctionLib: (
+ application_id: String,
+ function_lib_id: String,
+ loading?: Ref
+) => Promise> = (application_id, function_lib_id, loading) => {
+ return get(`${prefix}/${application_id}/function_lib/${function_lib_id}`, undefined, loading)
+}
+/**
+ * 获取模型参数表单
+ * @param application_id 应用id
+ * @param model_id 模型id
+ * @param loading
+ * @returns
+ */
+const getModelParamsForm: (
+ application_id: String,
+ model_id: String,
+ loading?: Ref
+) => Promise>> = (application_id, model_id, loading) => {
+ return get(`${prefix}/${application_id}/model_params_form/${model_id}`, undefined, loading)
+}
+export default {
+ getAllAppilcation,
+ getApplication,
+ postApplication,
+ putApplication,
+ postChatOpen,
+ getChatOpen,
+ postChatMessage,
+ delApplication,
+ getApplicationDetail,
+ getApplicationDataset,
+ getAccessToken,
+ putAccessToken,
+ postAppAuthentication,
+ getAppProfile,
+ putChatVote,
+ getApplicationHitTest,
+ getApplicationModel,
+ putPublishApplication,
+ postWorkflowChatOpen,
+ listFunctionLib,
+ getFunctionLib,
+ getModelParamsForm
+}
diff --git a/src/MaxKB-1.5.1/ui/src/api/auth-setting.ts b/src/MaxKB-1.5.1/ui/src/api/auth-setting.ts
new file mode 100644
index 0000000..e1d239b
--- /dev/null
+++ b/src/MaxKB-1.5.1/ui/src/api/auth-setting.ts
@@ -0,0 +1,39 @@
+import {Result} from '@/request/Result'
+import {get, post, del, put} from '@/request/index'
+import type {pageRequest} from '@/api/type/common'
+import {type Ref} from 'vue'
+
+const prefix = '/auth'
+/**
+ * 获取认证设置
+ */
+const getAuthSetting: (auth_type: string, loading?: Ref) => Promise> = (auth_type, loading) => {
+ return get(`${prefix}/${auth_type}/detail`, undefined, loading)
+}
+
+/**
+ * 邮箱测试
+ */
+const postAuthSetting: (data: any, loading?: Ref
+
+
+`
+}
+/**
+ * 初始化引导
+ * @param {*} root
+ */
+const initGuide=(root)=>{
+ root.insertAdjacentHTML("beforeend",guideHtml)
+ const button=root.querySelector(".maxkb-button")
+ const close_icon=root.querySelector('.maxkb-close')
+ const close_func=()=>{
+ root.removeChild(root.querySelector('.maxkb-tips'))
+ root.removeChild(root.querySelector('.maxkb-mask'))
+ localStorage.setItem('maxkbMaskTip',true)
+ }
+ button.onclick=close_func
+ close_icon.onclick=close_func
+}
+const initChat=(root)=>{
+ // 添加对话icon
+ root.insertAdjacentHTML("beforeend",chatButtonHtml)
+ // 添加对话框
+ root.insertAdjacentHTML('beforeend',getChatContainerHtml('{{protocol}}','{{host}}','{{token}}'))
+ // 按钮元素
+ const chat_button=root.querySelector('.maxkb-chat-button')
+ // 对话框元素
+ const chat_container=root.querySelector('#maxkb-chat-container')
+
+ const viewport=root.querySelector('.maxkb-openviewport')
+ const closeviewport=root.querySelector('.maxkb-closeviewport')
+ const close_func=()=>{
+ chat_container.style['display']=chat_container.style['display']=='block'?'none':'block'
+ chat_button.style['display']=chat_container.style['display']=='block'?'none':'block'
+ }
+ close_icon=chat_container.querySelector('.maxkb-chat-close')
+ chat_button.onclick = close_func
+ close_icon.onclick=close_func
+ const viewport_func=()=>{
+ if(chat_container.classList.contains('maxkb-enlarge')){
+ chat_container.classList.remove("maxkb-enlarge");
+ viewport.classList.remove('maxkb-viewportnone')
+ closeviewport.classList.add('maxkb-viewportnone')
+ }else{
+ chat_container.classList.add("maxkb-enlarge");
+ viewport.classList.add('maxkb-viewportnone')
+ closeviewport.classList.remove('maxkb-viewportnone')
+ }
+ }
+ const drag=(e)=>{
+ if (['touchmove','touchstart'].includes(e.type)) {
+ chat_button.style.top=(e.touches[0].clientY-25)+'px'
+ chat_button.style.left=(e.touches[0].clientX-25)+'px'
+ } else {
+ chat_button.style.top=(e.y-25)+'px'
+ chat_button.style.left=(e.x-25)+'px'
+ }
+ }
+ if({{is_draggable}}){
+ chat_button.addEventListener("drag",drag)
+ chat_button.addEventListener("dragover",(e)=>{
+ e.preventDefault()
+ })
+ chat_button.addEventListener("dragend",drag)
+ chat_button.addEventListener("touchstart",drag)
+ chat_button.addEventListener("touchmove",drag)
+ }
+ viewport.onclick=viewport_func
+ closeviewport.onclick=viewport_func
+}
+/**
+ * 第一次进来的引导提示
+ */
+function initMaxkb(){
+ const maxkb=document.createElement('div')
+ const root=document.createElement('div')
+ root.id="maxkb"
+ initMaxkbStyle(maxkb)
+ maxkb.appendChild(root)
+ document.body.appendChild(maxkb)
+ const maxkbMaskTip=localStorage.getItem('maxkbMaskTip')
+ if(maxkbMaskTip==null && {{show_guide}}){
+ initGuide(root)
+ }
+ initChat(root)
+}
+
+
+// 初始化全局样式
+function initMaxkbStyle(root){
+ style=document.createElement('style')
+ style.type='text/css'
+ style.innerText= `
+ /* 放大 */
+ #maxkb .maxkb-enlarge {
+ width: 50%!important;
+ height: 100%!important;
+ bottom: 0!important;
+ right: 0 !important;
+ }
+ @media only screen and (max-width: 768px){
+ #maxkb .maxkb-enlarge {
+ width: 100%!important;
+ height: 100%!important;
+ right: 0 !important;
+ bottom: 0!important;
+ }
+ }
+
+ /* 引导 */
+
+ #maxkb .maxkb-mask {
+ position: fixed;
+ z-index: 999;
+ background-color: transparent;
+ height: 100%;
+ width: 100%;
+ top: 0;
+ left: 0;
+ }
+ #maxkb .maxkb-mask .maxkb-content {
+ width: 50px;
+ height: 50px;
+ box-shadow: 1px 1px 1px 2000px rgba(0,0,0,.6);
+ position: absolute;
+ right: 0;
+ bottom: 30px;
+ z-index: 1000;
+ }
+ #maxkb .maxkb-tips {
+ position: fixed;
+ bottom: 30px;
+ right: 66px;
+ padding: 22px 24px 24px;
+ border-radius: 6px;
+ color: #ffffff;
+ font-size: 14px;
+ background: #3370FF;
+ z-index: 1000;
+ }
+ #maxkb .maxkb-tips .maxkb-arrow {
+ position: absolute;
+ background: #3370FF;
+ width: 10px;
+ height: 10px;
+ pointer-events: none;
+ transform: rotate(45deg);
+ box-sizing: border-box;
+ /* left */
+ right: -5px;
+ bottom: 33px;
+ border-left-color: transparent;
+ border-bottom-color: transparent
+ }
+ #maxkb .maxkb-tips .maxkb-title {
+ font-size: 20px;
+ font-weight: 500;
+ margin-bottom: 8px;
+ }
+ #maxkb .maxkb-tips .maxkb-button {
+ text-align: right;
+ margin-top: 24px;
+ }
+ #maxkb .maxkb-tips .maxkb-button button {
+ border-radius: 4px;
+ background: #FFF;
+ padding: 3px 12px;
+ color: #3370FF;
+ cursor: pointer;
+ outline: none;
+ border: none;
+ }
+ #maxkb .maxkb-tips .maxkb-button button::after{
+ border: none;
+ }
+ #maxkb .maxkb-tips .maxkb-close {
+ position: absolute;
+ right: 20px;
+ top: 20px;
+ cursor: pointer;
+
+ }
+ #maxkb-chat-container {
+ width: 420px;
+ height: 600px;
+ display:none;
+ }
+ @media only screen and (max-width: 768px) {
+ #maxkb-chat-container {
+ width: 100%;
+ height: 70%;
+ right: 0 !important;
+ }
+ }
+
+ #maxkb .maxkb-chat-button{
+ position: fixed;
+ bottom: 30px;
+ right: 0;
+ cursor: pointer;
+ height:50px;
+ width:50px;
+ }
+ #maxkb #maxkb-chat-container{
+ z-index:10000;position: relative;
+ border-radius: 8px;
+ border: 1px solid #ffffff;
+ background: linear-gradient(188deg, rgba(235, 241, 255, 0.20) 39.6%, rgba(231, 249, 255, 0.20) 94.3%), #EFF0F1;
+ box-shadow: 0px 4px 8px 0px rgba(31, 35, 41, 0.10);
+ position: fixed;bottom: 16px;right: 16px;overflow: hidden;
+ }
+
+ #maxkb #maxkb-chat-container .maxkb-operate{
+ top: 18px;
+ right: 15px;
+ position: absolute;
+ display: flex;
+ align-items: center;
+ }
+ #maxkb #maxkb-chat-container .maxkb-operate .maxkb-chat-close{
+ margin-left:15px;
+ cursor: pointer;
+ }
+ #maxkb #maxkb-chat-container .maxkb-operate .maxkb-openviewport{
+
+ cursor: pointer;
+ }
+ #maxkb #maxkb-chat-container .maxkb-operate .maxkb-closeviewport{
+
+ cursor: pointer;
+ }
+ #maxkb #maxkb-chat-container .maxkb-viewportnone{
+ display:none;
+ }
+ #maxkb #maxkb-chat-container #maxkb-chat{
+ height:100%;
+ width:100%;
+ border: none;
+}
+ #maxkb #maxkb-chat-container {
+ animation: appear .4s ease-in-out;
+ }
+ @keyframes appear {
+ from {
+ height: 0;;
+ }
+
+ to {
+ height: 600px;
+ }
+ }`
+ root.appendChild(style)
+}
+
+function embedChatbot() {
+ white_list_str='{{white_list_str}}'
+ white_list=white_list_str.split(',')
+
+ if ({{is_auth}}&&({{white_active}}?white_list.includes(window.location.origin):true)) {
+ // 初始化maxkb智能小助手
+ initMaxkb()
+ } else console.error('invalid parameter')
+}
+window.onload = embedChatbot
diff --git a/src/MaxKB-1.5.1/apps/application/tests.py b/src/MaxKB-1.5.1/apps/application/tests.py
new file mode 100644
index 0000000..7ce503c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/application/tests.py
@@ -0,0 +1,3 @@
+from django.test import TestCase
+
+# Create your tests here.
diff --git a/src/MaxKB-1.5.1/apps/application/urls.py b/src/MaxKB-1.5.1/apps/application/urls.py
new file mode 100644
index 0000000..d54b1ee
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/application/urls.py
@@ -0,0 +1,68 @@
+from django.urls import path
+
+from . import views
+
+app_name = "application"
+urlpatterns = [
+ path('application', views.Application.as_view(), name="application"),
+ path('application/profile', views.Application.Profile.as_view(), name='application/profile'),
+ path('application/embed', views.Application.Embed.as_view()),
+ path('application/authentication', views.Application.Authentication.as_view()),
+ path('application/
+
+
+
+
+
+
+
diff --git a/src/MaxKB-1.5.1/apps/common/util/cache_util.py b/src/MaxKB-1.5.1/apps/common/util/cache_util.py
new file mode 100644
index 0000000..a206b56
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/cache_util.py
@@ -0,0 +1,66 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: cache_util.py
+ @date:2024/7/24 19:23
+ @desc:
+"""
+from django.core.cache import cache
+
+
+def get_data_by_default_cache(key: str, get_data, cache_instance=cache, version=None, kwargs=None):
+ """
+ 获取数据, 先从缓存中获取,如果获取不到再调用get_data 获取数据
+ @param kwargs: get_data所需参数
+ @param key: key
+ @param get_data: 获取数据函数
+ @param cache_instance: cache实例
+ @param version: 版本用于隔离
+ @return:
+ """
+ if kwargs is None:
+ kwargs = {}
+ if cache_instance.has_key(key, version=version):
+ return cache_instance.get(key, version=version)
+ data = get_data(**kwargs)
+ cache_instance.add(key, data, version=version)
+ return data
+
+
+def set_data_by_default_cache(key: str, get_data, cache_instance=cache, version=None):
+ data = get_data()
+ cache_instance.set(key, data, version=version)
+ return data
+
+
+def get_cache(cache_key, use_get_data: any = True, cache_instance=cache, version=None):
+ def inner(get_data):
+ def run(*args, **kwargs):
+ key = cache_key(*args, **kwargs) if callable(cache_key) else cache_key
+ is_use_get_data = use_get_data(*args, **kwargs) if callable(use_get_data) else use_get_data
+ if is_use_get_data:
+ if cache_instance.has_key(key, version=version):
+ return cache_instance.get(key, version=version)
+ data = get_data(*args, **kwargs)
+ cache_instance.add(key, data, version=version)
+ return data
+ data = get_data(*args, **kwargs)
+ cache_instance.set(key, data, version=version)
+ return data
+
+ return run
+
+ return inner
+
+
+def del_cache(cache_key, cache_instance=cache, version=None):
+ def inner(func):
+ def run(*args, **kwargs):
+ key = cache_key(*args, **kwargs) if callable(cache_key) else cache_key
+ func(*args, **kwargs)
+ cache_instance.delete(key, version=version)
+
+ return run
+
+ return inner
diff --git a/src/MaxKB-1.5.1/apps/common/util/common.py b/src/MaxKB-1.5.1/apps/common/util/common.py
new file mode 100644
index 0000000..9a3ca0c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/common.py
@@ -0,0 +1,89 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: common.py
+ @date:2023/10/16 16:42
+ @desc:
+"""
+import importlib
+from functools import reduce
+from typing import Dict, List
+
+from django.conf import settings
+from django.db.models import QuerySet
+
+from ..exception.app_exception import AppApiException
+
+
+def sub_array(array: List, item_num=10):
+ result = []
+ temp = []
+ for item in array:
+ temp.append(item)
+ if len(temp) >= item_num:
+ result.append(temp)
+ temp = []
+ if len(temp) > 0:
+ result.append(temp)
+ return result
+
+
+def query_params_to_single_dict(query_params: Dict):
+ return reduce(lambda x, y: {**x, **y}, list(
+ filter(lambda item: item is not None, [({key: value} if value is not None and len(value) > 0 else None) for
+ key, value in
+ query_params.items()])), {})
+
+
+def get_exec_method(clazz_: str, method_: str):
+ """
+ 根据 class 和method函数 获取执行函数
+ :param clazz_: class 字符串
+ :param method_: 执行函数
+ :return: 执行函数
+ """
+ clazz_split = clazz_.split('.')
+ clazz_name = clazz_split[-1]
+ package = ".".join([clazz_split[index] for index in range(len(clazz_split) - 1)])
+ package_model = importlib.import_module(package)
+ return getattr(getattr(package_model, clazz_name), method_)
+
+
+def flat_map(array: List[List]):
+ """
+ 将二位数组转为一维数组
+ :param array: 二维数组
+ :return: 一维数组
+ """
+ result = []
+ for e in array:
+ result += e
+ return result
+
+
+def post(post_function):
+ def inner(func):
+ def run(*args, **kwargs):
+ result = func(*args, **kwargs)
+ return post_function(*result)
+
+ return run
+
+ return inner
+
+
+def valid_license(model=None, count=None, message=None):
+ def inner(func):
+ def run(*args, **kwargs):
+ if (not (settings.XPACK_LICENSE_IS_VALID if hasattr(settings,
+ 'XPACK_LICENSE_IS_VALID') else None)
+ and QuerySet(
+ model).count() >= count):
+ error = message or f'超出限制{count},请联系我们(https://fit2cloud.com/)。'
+ raise AppApiException(400, error)
+ return func(*args, **kwargs)
+
+ return run
+
+ return inner
diff --git a/src/MaxKB-1.5.1/apps/common/util/field_message.py b/src/MaxKB-1.5.1/apps/common/util/field_message.py
new file mode 100644
index 0000000..3d39454
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/field_message.py
@@ -0,0 +1,116 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: field_message.py
+ @date:2024/3/1 14:30
+ @desc:
+"""
+from django.utils.translation import gettext_lazy
+
+
+class ErrMessage:
+ @staticmethod
+ def char(field: str):
+ return {
+ 'invalid': gettext_lazy("【%s】不是有效的字符串。" % field),
+ 'blank': gettext_lazy("【%s】此字段不能为空字符串。" % field),
+ 'max_length': gettext_lazy("【%s】请确保此字段的字符数不超过 {max_length} 个。" % field),
+ 'min_length': gettext_lazy("【%s】请确保此字段至少包含 {min_length} 个字符。" % field),
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field)
+ }
+
+ @staticmethod
+ def uuid(field: str):
+ return {'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ 'invalid': gettext_lazy("【%s】必须是有效的UUID。" % field),
+ }
+
+ @staticmethod
+ def integer(field: str):
+ return {'invalid': gettext_lazy('【%s】必须是有效的integer。' % field),
+ 'max_value': gettext_lazy('【%s】请确保此值小于或等于 {max_value} 。' % field),
+ 'min_value': gettext_lazy('【%s】请确保此值大于或等于 {min_value} 。' % field),
+ 'max_string_length': gettext_lazy('【%s】字符串值太大。') % field,
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ }
+
+ @staticmethod
+ def list(field: str):
+ return {'not_a_list': gettext_lazy('【%s】应为列表,但得到的类型为 "{input_type}".' % field),
+ 'empty': gettext_lazy('【%s】此列表不能为空。' % field),
+ 'min_length': gettext_lazy('【%s】请确保此字段至少包含 {min_length} 个元素。' % field),
+ 'max_length': gettext_lazy('【%s】请确保此字段的元素不超过 {max_length} 个。' % field),
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ }
+
+ @staticmethod
+ def boolean(field: str):
+ return {'invalid': gettext_lazy('【%s】必须是有效的布尔值。' % field),
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field)}
+
+ @staticmethod
+ def dict(field: str):
+ return {'not_a_dict': gettext_lazy('【%s】应为字典,但得到的类型为 "{input_type}' % field),
+ 'empty': gettext_lazy('【%s】能是空的。' % field),
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ }
+
+ @staticmethod
+ def float(field: str):
+ return {'invalid': gettext_lazy('【%s】需要一个有效的数字。' % field),
+ 'max_value': gettext_lazy('【%s】请确保此值小于或等于 {max_value}。' % field),
+ 'min_value': gettext_lazy('【%s】请确保此值大于或等于 {min_value}。' % field),
+ 'max_string_length': gettext_lazy('【%s】字符串值太大。' % field),
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ }
+
+ @staticmethod
+ def json(field: str):
+ return {
+ 'invalid': gettext_lazy('【%s】值必须是有效的JSON。' % field),
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ }
+
+ @staticmethod
+ def base(field: str):
+ return {
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ }
+
+ @staticmethod
+ def date(field: str):
+ return {
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ 'invalid': gettext_lazy('【%s】日期格式错误。请改用以下格式之一: {format}。'),
+ 'datetime': gettext_lazy('【%s】应为日期,但得到的是日期时间。')
+ }
+
+ @staticmethod
+ def image(field: str):
+ return {
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'null': gettext_lazy('【%s】此字段不能为null。' % field),
+ 'invalid_image': gettext_lazy('【%s】上载有效的图像。您上载的文件不是图像或图像已损坏。' % field),
+ 'max_length': gettext_lazy('请确保此文件名最多包含 {max_length} 个字符(长度为 {length})。')
+ }
+
+ @staticmethod
+ def file(field: str):
+ return {
+ 'required': gettext_lazy('【%s】此字段必填。' % field),
+ 'empty': gettext_lazy('【%s】提交的文件为空。' % field),
+ 'invalid': gettext_lazy('【%s】提交的数据不是文件。请检查表单上的编码类型。' % field),
+ 'no_name': gettext_lazy('【%s】无法确定任何文件名。' % field),
+ 'max_length': gettext_lazy('请确保此文件名最多包含 {max_length} 个字符(长度为 {length})。')
+ }
diff --git a/src/MaxKB-1.5.1/apps/common/util/file_util.py b/src/MaxKB-1.5.1/apps/common/util/file_util.py
new file mode 100644
index 0000000..447b007
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/file_util.py
@@ -0,0 +1,14 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: file_util.py
+ @date:2023/9/25 21:06
+ @desc:
+"""
+
+
+def get_file_content(path):
+ with open(path, "r", encoding='utf-8') as file:
+ content = file.read()
+ return content
diff --git a/src/MaxKB-1.5.1/apps/common/util/fork.py b/src/MaxKB-1.5.1/apps/common/util/fork.py
new file mode 100644
index 0000000..ee30f69
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/fork.py
@@ -0,0 +1,175 @@
+import copy
+import logging
+import re
+import traceback
+from functools import reduce
+from typing import List, Set
+from urllib.parse import urljoin, urlparse, ParseResult, urlsplit, urlunparse
+
+import html2text as ht
+import requests
+from bs4 import BeautifulSoup
+
+requests.packages.urllib3.disable_warnings()
+
+
+class ChildLink:
+ def __init__(self, url, tag):
+ self.url = url
+ self.tag = copy.deepcopy(tag)
+
+
+class ForkManage:
+ def __init__(self, base_url: str, selector_list: List[str]):
+ self.base_url = base_url
+ self.selector_list = selector_list
+
+ def fork(self, level: int, exclude_link_url: Set[str], fork_handler):
+ self.fork_child(ChildLink(self.base_url, None), self.selector_list, level, exclude_link_url, fork_handler)
+
+ @staticmethod
+ def fork_child(child_link: ChildLink, selector_list: List[str], level: int, exclude_link_url: Set[str],
+ fork_handler):
+ if level < 0:
+ return
+ else:
+ child_link.url = remove_fragment(child_link.url)
+ child_url = child_link.url[:-1] if child_link.url.endswith('/') else child_link.url
+ if not exclude_link_url.__contains__(child_url):
+ exclude_link_url.add(child_url)
+ response = Fork(child_link.url, selector_list).fork()
+ fork_handler(child_link, response)
+ for child_link in response.child_link_list:
+ child_url = child_link.url[:-1] if child_link.url.endswith('/') else child_link.url
+ if not exclude_link_url.__contains__(child_url):
+ ForkManage.fork_child(child_link, selector_list, level - 1, exclude_link_url, fork_handler)
+
+
+def remove_fragment(url: str) -> str:
+ parsed_url = urlparse(url)
+ modified_url = ParseResult(scheme=parsed_url.scheme, netloc=parsed_url.netloc, path=parsed_url.path,
+ params=parsed_url.params, query=parsed_url.query, fragment=None)
+ return urlunparse(modified_url)
+
+
+class Fork:
+ class Response:
+ def __init__(self, content: str, child_link_list: List[ChildLink], status, message: str):
+ self.content = content
+ self.child_link_list = child_link_list
+ self.status = status
+ self.message = message
+
+ @staticmethod
+ def success(html_content: str, child_link_list: List[ChildLink]):
+ return Fork.Response(html_content, child_link_list, 200, '')
+
+ @staticmethod
+ def error(message: str):
+ return Fork.Response('', [], 500, message)
+
+ def __init__(self, base_fork_url: str, selector_list: List[str]):
+ base_fork_url = remove_fragment(base_fork_url)
+ self.base_fork_url = urljoin(base_fork_url if base_fork_url.endswith("/") else base_fork_url + '/', '.')
+ parsed = urlsplit(base_fork_url)
+ query = parsed.query
+ self.base_fork_url = self.base_fork_url[:-1]
+ if query is not None and len(query) > 0:
+ self.base_fork_url = self.base_fork_url + '?' + query
+ self.selector_list = [selector for selector in selector_list if selector is not None and len(selector) > 0]
+ self.urlparse = urlparse(self.base_fork_url)
+ self.base_url = ParseResult(scheme=self.urlparse.scheme, netloc=self.urlparse.netloc, path='', params='',
+ query='',
+ fragment='').geturl()
+
+ def get_child_link_list(self, bf: BeautifulSoup):
+ pattern = "^((?!(http:|https:|tel:/|#|mailto:|javascript:))|" + self.base_fork_url + "|/).*"
+ link_list = bf.find_all(name='a', href=re.compile(pattern))
+ result = [ChildLink(link.get('href'), link) if link.get('href').startswith(self.base_url) else ChildLink(
+ self.base_url + link.get('href'), link) for link in link_list]
+ result = [row for row in result if row.url.startswith(self.base_fork_url)]
+ return result
+
+ def get_content_html(self, bf: BeautifulSoup):
+ if self.selector_list is None or len(self.selector_list) == 0:
+ return str(bf)
+ params = reduce(lambda x, y: {**x, **y},
+ [{'class_': selector.replace('.', '')} if selector.startswith('.') else
+ {'id': selector.replace("#", "")} if selector.startswith("#") else {'name': selector} for
+ selector in
+ self.selector_list], {})
+ f = bf.find_all(**params)
+ return "\n".join([str(row) for row in f])
+
+ @staticmethod
+ def reset_url(tag, field, base_fork_url):
+ field_value: str = tag[field]
+ if field_value.startswith("/"):
+ result = urlparse(base_fork_url)
+ result_url = ParseResult(scheme=result.scheme, netloc=result.netloc, path=field_value, params='', query='',
+ fragment='').geturl()
+ else:
+ result_url = urljoin(
+ base_fork_url + '/' + (field_value if field_value.endswith('/') else field_value + '/'),
+ ".")
+ result_url = result_url[:-1] if result_url.endswith('/') else result_url
+ tag[field] = result_url
+
+ def reset_beautiful_soup(self, bf: BeautifulSoup):
+ reset_config_list = [
+ {
+ 'field': 'href',
+ },
+ {
+ 'field': 'src',
+ }
+ ]
+ for reset_config in reset_config_list:
+ field = reset_config.get('field')
+ tag_list = bf.find_all(**{field: re.compile('^(?!(http:|https:|tel:/|#|mailto:|javascript:)).*')})
+ for tag in tag_list:
+ self.reset_url(tag, field, self.base_fork_url)
+ return bf
+
+ @staticmethod
+ def get_beautiful_soup(response):
+ encoding = response.encoding if response.encoding is not None and response.encoding != 'ISO-8859-1' else response.apparent_encoding
+ html_content = response.content.decode(encoding)
+ beautiful_soup = BeautifulSoup(html_content, "html.parser")
+ meta_list = beautiful_soup.find_all('meta')
+ charset_list = [meta.attrs.get('charset') for meta in meta_list if
+ meta.attrs is not None and 'charset' in meta.attrs]
+ if len(charset_list) > 0:
+ charset = charset_list[0]
+ if charset != encoding:
+ html_content = response.content.decode(charset)
+ return BeautifulSoup(html_content, "html.parser")
+ return beautiful_soup
+
+ def fork(self):
+ try:
+
+ headers = {
+ 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
+ }
+
+ logging.getLogger("max_kb").info(f'fork:{self.base_fork_url}')
+ response = requests.get(self.base_fork_url, verify=False, headers=headers)
+ if response.status_code != 200:
+ logging.getLogger("max_kb").error(f"url: {self.base_fork_url} code:{response.status_code}")
+ return Fork.Response.error(f"url: {self.base_fork_url} code:{response.status_code}")
+ bf = self.get_beautiful_soup(response)
+ except Exception as e:
+ logging.getLogger("max_kb_error").error(f'{str(e)}:{traceback.format_exc()}')
+ return Fork.Response.error(str(e))
+ bf = self.reset_beautiful_soup(bf)
+ link_list = self.get_child_link_list(bf)
+ content = self.get_content_html(bf)
+ r = ht.html2text(content)
+ return Fork.Response.success(r, link_list)
+
+
+def handler(base_url, response: Fork.Response):
+ print(base_url.url, base_url.tag.text if base_url.tag else None, response.content)
+
+# ForkManage('https://bbs.fit2cloud.com/c/de/6', ['.md-content']).fork(3, set(), handler)
diff --git a/src/MaxKB-1.5.1/apps/common/util/function_code.py b/src/MaxKB-1.5.1/apps/common/util/function_code.py
new file mode 100644
index 0000000..31ab0ce
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/function_code.py
@@ -0,0 +1,94 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: function_code.py
+ @date:2024/8/7 16:11
+ @desc:
+"""
+import os
+import subprocess
+import sys
+import uuid
+from textwrap import dedent
+
+from diskcache import Cache
+
+from smartdoc.const import BASE_DIR
+from smartdoc.const import PROJECT_DIR
+
+python_directory = sys.executable
+
+
+class FunctionExecutor:
+ def __init__(self, sandbox=False):
+ self.sandbox = sandbox
+ if sandbox:
+ self.sandbox_path = '/opt/maxkb/app/sandbox'
+ self.user = 'sandbox'
+ else:
+ self.sandbox_path = os.path.join(PROJECT_DIR, 'data', 'sandbox')
+ self.user = None
+ self._createdir()
+ if self.sandbox:
+ os.system(f"chown -R {self.user}:{self.user} {self.sandbox_path}")
+
+ def _createdir(self):
+ old_mask = os.umask(0o077)
+ try:
+ os.makedirs(self.sandbox_path, 0o700, exist_ok=True)
+ finally:
+ os.umask(old_mask)
+
+ def exec_code(self, code_str, keywords):
+ _id = str(uuid.uuid1())
+ success = '{"code":200,"msg":"成功","data":exec_result}'
+ err = '{"code":500,"msg":str(e),"data":None}'
+ path = r'' + self.sandbox_path + ''
+ _exec_code = f"""
+try:
+ locals_v={'{}'}
+ keywords={keywords}
+ globals_v=globals()
+ exec({dedent(code_str)!a}, globals_v, locals_v)
+ f_name, f = locals_v.popitem()
+ for local in locals_v:
+ globals_v[local] = locals_v[local]
+ exec_result=f(**keywords)
+ from diskcache import Cache
+ cache = Cache({path!a})
+ cache.set({_id!a},{success})
+except Exception as e:
+ from diskcache import Cache
+ cache = Cache({path!a})
+ cache.set({_id!a},{err})
+"""
+ if self.sandbox:
+ subprocess_result = self._exec_sandbox(_exec_code, _id)
+ else:
+ subprocess_result = self._exec(_exec_code)
+ if subprocess_result.returncode == 1:
+ raise Exception(subprocess_result.stderr)
+ cache = Cache(self.sandbox_path)
+ result = cache.get(_id)
+ cache.delete(_id)
+ if result.get('code') == 200:
+ return result.get('data')
+ raise Exception(result.get('msg'))
+
+ def _exec_sandbox(self, _code, _id):
+ exec_python_file = f'{self.sandbox_path}/{_id}.py'
+ with open(exec_python_file, 'w') as file:
+ file.write(_code)
+ os.system(f"chown {self.user}:{self.user} {exec_python_file}")
+ kwargs = {'cwd': BASE_DIR}
+ subprocess_result = subprocess.run(
+ ['su', '-c', python_directory + ' ' + exec_python_file, self.user],
+ text=True,
+ capture_output=True, **kwargs)
+ os.remove(exec_python_file)
+ return subprocess_result
+
+ @staticmethod
+ def _exec(_code):
+ return subprocess.run([python_directory, '-c', _code], text=True, capture_output=True)
diff --git a/src/MaxKB-1.5.1/apps/common/util/lock.py b/src/MaxKB-1.5.1/apps/common/util/lock.py
new file mode 100644
index 0000000..4276f1c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/lock.py
@@ -0,0 +1,53 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: lock.py
+ @date:2023/9/11 11:45
+ @desc:
+"""
+from datetime import timedelta
+
+from django.core.cache import caches
+
+memory_cache = caches['default']
+
+
+def try_lock(key: str, timeout=None):
+ """
+ 获取锁
+ :param key: 获取锁 key
+ :param timeout 超时时间
+ :return: 是否获取到锁
+ """
+ return memory_cache.add(key, 'lock', timeout=timedelta(hours=1).total_seconds() if timeout is not None else timeout)
+
+
+def un_lock(key: str):
+ """
+ 解锁
+ :param key: 解锁 key
+ :return: 是否解锁成功
+ """
+ return memory_cache.delete(key)
+
+
+def lock(lock_key):
+ """
+ 给一个函数上锁
+ :param lock_key: 上锁key 字符串|函数 函数返回值为字符串
+ :return: 装饰器函数 当前装饰器主要限制一个key只能一个线程去调用 相同key只能阻塞等待上一个任务执行完毕 不同key不需要等待
+ """
+
+ def inner(func):
+ def run(*args, **kwargs):
+ key = lock_key(*args, **kwargs) if callable(lock_key) else lock_key
+ try:
+ if try_lock(key=key):
+ return func(*args, **kwargs)
+ finally:
+ un_lock(key=key)
+
+ return run
+
+ return inner
diff --git a/src/MaxKB-1.5.1/apps/common/util/rsa_util.py b/src/MaxKB-1.5.1/apps/common/util/rsa_util.py
new file mode 100644
index 0000000..0030186
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/rsa_util.py
@@ -0,0 +1,140 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: rsa_util.py
+ @date:2023/11/3 11:13
+ @desc:
+"""
+import base64
+import threading
+
+from Crypto.Cipher import PKCS1_v1_5 as PKCS1_cipher
+from Crypto.PublicKey import RSA
+from django.core import cache
+from django.db.models import QuerySet
+
+from setting.models import SystemSetting, SettingType
+
+lock = threading.Lock()
+rsa_cache = cache.caches['default']
+cache_key = "rsa_key"
+# 对密钥加密的密码
+secret_code = "mac_kb_password"
+
+
+def generate():
+ """
+ 生成 私钥秘钥对
+ :return:{key:'公钥',value:'私钥'}
+ """
+ # 生成一个 2048 位的密钥
+ key = RSA.generate(2048)
+
+ # 获取私钥
+ encrypted_key = key.export_key(passphrase=secret_code, pkcs=8,
+ protection="scryptAndAES128-CBC")
+ return {'key': key.publickey().export_key(), 'value': encrypted_key}
+
+
+def get_key_pair():
+ rsa_value = rsa_cache.get(cache_key)
+ if rsa_value is None:
+ lock.acquire()
+ rsa_value = rsa_cache.get(cache_key)
+ if rsa_value is not None:
+ return rsa_value
+ try:
+ rsa_value = get_key_pair_by_sql()
+ rsa_cache.set(cache_key, rsa_value)
+ finally:
+ lock.release()
+ return rsa_value
+
+
+def get_key_pair_by_sql():
+ system_setting = QuerySet(SystemSetting).filter(type=SettingType.RSA.value).first()
+ if system_setting is None:
+ kv = generate()
+ system_setting = SystemSetting(type=SettingType.RSA.value,
+ meta={'key': kv.get('key').decode(), 'value': kv.get('value').decode()})
+ system_setting.save()
+ return system_setting.meta
+
+
+def encrypt(msg, public_key: str | None = None):
+ """
+ 加密
+ :param msg: 加密数据
+ :param public_key: 公钥
+ :return: 加密后的数据
+ """
+ if public_key is None:
+ public_key = get_key_pair().get('key')
+ cipher = PKCS1_cipher.new(RSA.importKey(public_key))
+ encrypt_msg = cipher.encrypt(msg.encode("utf-8"))
+ return base64.b64encode(encrypt_msg).decode()
+
+
+def decrypt(msg, pri_key: str | None = None):
+ """
+ 解密
+ :param msg: 需要解密的数据
+ :param pri_key: 私钥
+ :return: 解密后数据
+ """
+ if pri_key is None:
+ pri_key = get_key_pair().get('value')
+ cipher = PKCS1_cipher.new(RSA.importKey(pri_key, passphrase=secret_code))
+ decrypt_data = cipher.decrypt(base64.b64decode(msg), 0)
+ return decrypt_data.decode("utf-8")
+
+
+def rsa_long_encrypt(message, public_key: str | None = None, length=200):
+ """
+ 超长文本加密
+
+ :param message: 需要加密的字符串
+ :param public_key 公钥
+ :param length: 1024bit的证书用100, 2048bit的证书用 200
+ :return: 加密后的数据
+ """
+ # 读取公钥
+ if public_key is None:
+ public_key = get_key_pair().get('key')
+ cipher = PKCS1_cipher.new(RSA.importKey(extern_key=public_key,
+ passphrase=secret_code))
+ # 处理:Plaintext is too long. 分段加密
+ if len(message) <= length:
+ # 对编码的数据进行加密,并通过base64进行编码
+ result = base64.b64encode(cipher.encrypt(message.encode('utf-8')))
+ else:
+ rsa_text = []
+ # 对编码后的数据进行切片,原因:加密长度不能过长
+ for i in range(0, len(message), length):
+ cont = message[i:i + length]
+ # 对切片后的数据进行加密,并新增到text后面
+ rsa_text.append(cipher.encrypt(cont.encode('utf-8')))
+ # 加密完进行拼接
+ cipher_text = b''.join(rsa_text)
+ # base64进行编码
+ result = base64.b64encode(cipher_text)
+ return result.decode()
+
+
+def rsa_long_decrypt(message, pri_key: str | None = None, length=256):
+ """
+ 超长文本解密,默认不加密
+ :param message: 需要解密的数据
+ :param pri_key: 秘钥
+ :param length : 1024bit的证书用128,2048bit证书用256位
+ :return: 解密后的数据
+ """
+ if pri_key is None:
+ pri_key = get_key_pair().get('value')
+ cipher = PKCS1_cipher.new(RSA.importKey(pri_key, passphrase=secret_code))
+ base64_de = base64.b64decode(message)
+ res = []
+ for i in range(0, len(base64_de), length):
+ res.append(cipher.decrypt(base64_de[i:i + length], 0))
+ return b"".join(res).decode()
diff --git a/src/MaxKB-1.5.1/apps/common/util/split_model.py b/src/MaxKB-1.5.1/apps/common/util/split_model.py
new file mode 100644
index 0000000..0e7bcd5
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/common/util/split_model.py
@@ -0,0 +1,413 @@
+# coding=utf-8
+"""
+ @project: qabot
+ @Author:虎
+ @file: split_model.py
+ @date:2023/9/1 15:12
+ @desc:
+"""
+import re
+from functools import reduce
+from typing import List, Dict
+
+import jieba
+
+
+def get_level_block(text, level_content_list, level_content_index, cursor):
+ """
+ 从文本中获取块数据
+ :param text: 文本
+ :param level_content_list: 拆分的title数组
+ :param level_content_index: 指定的下标
+ :param cursor: 开始的下标位置
+ :return: 拆分后的文本数据
+ """
+ start_content: str = level_content_list[level_content_index].get('content')
+ next_content = level_content_list[level_content_index + 1].get("content") if level_content_index + 1 < len(
+ level_content_list) else None
+ start_index = text.index(start_content, cursor)
+ end_index = text.index(next_content, start_index + 1) if next_content is not None else len(text)
+ return text[start_index + len(start_content):end_index], end_index
+
+
+def to_tree_obj(content, state='title'):
+ """
+ 转换为树形对象
+ :param content: 文本数据
+ :param state: 状态: title block
+ :return: 转换后的数据
+ """
+ return {'content': content, 'state': state}
+
+
+def remove_special_symbol(str_source: str):
+ """
+ 删除特殊字符
+ :param str_source: 需要删除的文本数据
+ :return: 删除后的数据
+ """
+ return str_source
+
+
+def filter_special_symbol(content: dict):
+ """
+ 过滤文本中的特殊字符
+ :param content: 需要过滤的对象
+ :return: 过滤后返回
+ """
+ content['content'] = remove_special_symbol(content['content'])
+ return content
+
+
+def flat(tree_data_list: List[dict], parent_chain: List[dict], result: List[dict]):
+ """
+ 扁平化树形结构数据
+ :param tree_data_list: 树形接口数据
+ :param parent_chain: 父级数据 传[] 用于递归存储数据
+ :param result: 响应数据 传[] 用于递归存放数据
+ :return: result 扁平化后的数据
+ """
+ if parent_chain is None:
+ parent_chain = []
+ if result is None:
+ result = []
+ for tree_data in tree_data_list:
+ p = parent_chain.copy()
+ p.append(tree_data)
+ result.append(to_flat_obj(parent_chain, content=tree_data["content"], state=tree_data["state"]))
+ children = tree_data.get('children')
+ if children is not None and len(children) > 0:
+ flat(children, p, result)
+ return result
+
+
+def to_paragraph(obj: dict):
+ """
+ 转换为段落
+ :param obj: 需要转换的对象
+ :return: 段落对象
+ """
+ content = obj['content']
+ return {"keywords": get_keyword(content),
+ 'parent_chain': list(map(lambda p: p['content'], obj['parent_chain'])),
+ 'content': ",".join(list(map(lambda p: p['content'], obj['parent_chain']))) + content}
+
+
+def get_keyword(content: str):
+ """
+ 获取content中的关键词
+ :param content: 文本
+ :return: 关键词数组
+ """
+ stopwords = [':', '“', '!', '”', '\n', '\\s']
+ cutworms = jieba.lcut(content)
+ return list(set(list(filter(lambda k: (k not in stopwords) | len(k) > 1, cutworms))))
+
+
+def titles_to_paragraph(list_title: List[dict]):
+ """
+ 将同一父级的title转换为块段落
+ :param list_title: 同父级title
+ :return: 块段落
+ """
+ if len(list_title) > 0:
+ content = "\n,".join(
+ list(map(lambda d: d['content'].strip("\r\n").strip("\n").strip("\\s"), list_title)))
+
+ return {'keywords': '',
+ 'parent_chain': list(
+ map(lambda p: p['content'].strip("\r\n").strip("\n").strip("\\s"), list_title[0]['parent_chain'])),
+ 'content': ",".join(list(
+ map(lambda p: p['content'].strip("\r\n").strip("\n").strip("\\s"),
+ list_title[0]['parent_chain']))) + content}
+ return None
+
+
+def parse_group_key(level_list: List[dict]):
+ """
+ 将同级别同父级的title生成段落,加上本身的段落数据形成新的数据
+ :param level_list: title n 级数据
+ :return: 根据title生成的数据 + 段落数据
+ """
+ result = []
+ group_data = group_by(list(filter(lambda f: f['state'] == 'title' and len(f['parent_chain']) > 0, level_list)),
+ key=lambda d: ",".join(list(map(lambda p: p['content'], d['parent_chain']))))
+ result += list(map(lambda group_data_key: titles_to_paragraph(group_data[group_data_key]), group_data))
+ result += list(map(to_paragraph, list(filter(lambda f: f['state'] == 'block', level_list))))
+ return result
+
+
+def to_block_paragraph(tree_data_list: List[dict]):
+ """
+ 转换为块段落对象
+ :param tree_data_list: 树数据
+ :return: 块段落
+ """
+ flat_list = flat(tree_data_list, [], [])
+ level_group_dict: dict = group_by(flat_list, key=lambda f: f['level'])
+ return list(map(lambda level: parse_group_key(level_group_dict[level]), level_group_dict))
+
+
+def parse_title_level(text, content_level_pattern: List, index):
+ if index >= len(content_level_pattern):
+ return []
+ result = parse_level(text, content_level_pattern[index])
+ if len(result) == 0 and len(content_level_pattern) > index:
+ return parse_title_level(text, content_level_pattern, index + 1)
+ return result
+
+
+def parse_level(text, pattern: str):
+ """
+ 获取正则匹配到的文本
+ :param text: 需要匹配的文本
+ :param pattern: 正则
+ :return: 符合正则的文本
+ """
+ level_content_list = list(map(to_tree_obj, [r[0:255] for r in re_findall(pattern, text) if r is not None]))
+ return list(map(filter_special_symbol, level_content_list))
+
+
+def re_findall(pattern, text):
+ result = re.findall(pattern, text, flags=0)
+ return list(filter(lambda r: r is not None and len(r) > 0, reduce(lambda x, y: [*x, *y], list(
+ map(lambda row: [*(row if isinstance(row, tuple) else [row])], result)),
+ [])))
+
+
+def to_flat_obj(parent_chain: List[dict], content: str, state: str):
+ """
+ 将树形属性转换为扁平对象
+ :param parent_chain:
+ :param content:
+ :param state:
+ :return:
+ """
+ return {'parent_chain': parent_chain, 'level': len(parent_chain), "content": content, 'state': state}
+
+
+def flat_map(array: List[List]):
+ """
+ 将二位数组转为一维数组
+ :param array: 二维数组
+ :return: 一维数组
+ """
+ result = []
+ for e in array:
+ result += e
+ return result
+
+
+def group_by(list_source: List, key):
+ """
+ 將數組分組
+ :param list_source: 需要分組的數組
+ :param key: 分組函數
+ :return: key->[]
+ """
+ result = {}
+ for e in list_source:
+ k = key(e)
+ array = result.get(k) if k in result else []
+ array.append(e)
+ result[k] = array
+ return result
+
+
+def result_tree_to_paragraph(result_tree: List[dict], result, parent_chain, with_filter: bool):
+ """
+ 转换为分段对象
+ :param result_tree: 解析文本的树
+ :param result: 传[] 用于递归
+ :param parent_chain: 传[] 用户递归存储数据
+ :param with_filter: 是否过滤block
+ :return: List[{'problem':'xx','content':'xx'}]
+ """
+ for item in result_tree:
+ if item.get('state') == 'block':
+ result.append({'title': " ".join(parent_chain),
+ 'content': filter_special_char(item.get("content")) if with_filter else item.get("content")})
+ children = item.get("children")
+ if children is not None and len(children) > 0:
+ result_tree_to_paragraph(children, result,
+ [*parent_chain, remove_special_symbol(item.get('content'))], with_filter)
+ return result
+
+
+def post_handler_paragraph(content: str, limit: int):
+ """
+ 根据文本的最大字符分段
+ :param content: 需要分段的文本字段
+ :param limit: 最大分段字符
+ :return: 分段后数据
+ """
+ result = []
+ temp_char, start = '', 0
+ while (pos := content.find("\n", start)) != -1:
+ split, start = content[start:pos + 1], pos + 1
+ if len(temp_char + split) > limit:
+ if len(temp_char) > 4096:
+ pass
+ result.append(temp_char)
+ temp_char = ''
+ temp_char = temp_char + split
+ temp_char = temp_char + content[start:]
+ if len(temp_char) > 0:
+ if len(temp_char) > 4096:
+ pass
+ result.append(temp_char)
+
+ pattern = "[\\S\\s]{1," + str(limit) + '}'
+ # 如果\n 单段超过限制,则继续拆分
+ return reduce(lambda x, y: [*x, *y], map(lambda row: re.findall(pattern, row), result), [])
+
+
+replace_map = {
+ re.compile('\n+'): '\n',
+ re.compile(' +'): ' ',
+ re.compile('#+'): "",
+ re.compile("\t+"): ''
+}
+
+
+def filter_special_char(content: str):
+ """
+ 过滤特殊字段
+ :param content: 文本
+ :return: 过滤后字段
+ """
+ items = replace_map.items()
+ for key, value in items:
+ content = re.sub(key, value, content)
+ return content
+
+
+class SplitModel:
+
+ def __init__(self, content_level_pattern, with_filter=True, limit=100000):
+ self.content_level_pattern = content_level_pattern
+ self.with_filter = with_filter
+ if limit is None or limit > 100000:
+ limit = 100000
+ if limit < 50:
+ limit = 50
+ self.limit = limit
+
+ def parse_to_tree(self, text: str, index=0):
+ """
+ 解析文本
+ :param text: 需要解析的文本
+ :param index: 从那个正则开始解析
+ :return: 解析后的树形结果数据
+ """
+ level_content_list = parse_title_level(text, self.content_level_pattern, index)
+ if len(level_content_list) == 0:
+ return [to_tree_obj(row, 'block') for row in post_handler_paragraph(text, limit=self.limit)]
+ if index == 0 and text.lstrip().index(level_content_list[0]["content"].lstrip()) != 0:
+ level_content_list.insert(0, to_tree_obj(""))
+
+ cursor = 0
+ level_title_content_list = [item for item in level_content_list if item.get('state') == 'title']
+ for i in range(len(level_title_content_list)):
+ start_content: str = level_title_content_list[i].get('content')
+ if cursor < text.index(start_content, cursor):
+ for row in post_handler_paragraph(text[cursor: text.index(start_content, cursor)], limit=self.limit):
+ level_content_list.insert(0, to_tree_obj(row, 'block'))
+
+ block, cursor = get_level_block(text, level_title_content_list, i, cursor)
+ if len(block) == 0:
+ continue
+ children = self.parse_to_tree(text=block, index=index + 1)
+ level_title_content_list[i]['children'] = children
+ first_child_idx_in_block = block.lstrip().index(children[0]["content"].lstrip())
+ if first_child_idx_in_block != 0:
+ inner_children = self.parse_to_tree(block[:first_child_idx_in_block], index + 1)
+ level_title_content_list[i]['children'].extend(inner_children)
+ return level_content_list
+
+ def parse(self, text: str):
+ """
+ 解析文本
+ :param text: 文本数据
+ :return: 解析后数据 {content:段落数据,keywords:[‘段落关键词’],parent_chain:['段落父级链路']}
+ """
+ text = text.replace('\r\n', '\n')
+ text = text.replace('\r', '\n')
+ text = text.replace("\0", '')
+ result_tree = self.parse_to_tree(text, 0)
+ result = result_tree_to_paragraph(result_tree, [], [], self.with_filter)
+ for e in result:
+ if len(e['content']) > 4096:
+ pass
+ return [item for item in [self.post_reset_paragraph(row) for row in result] if
+ 'content' in item and len(item.get('content').strip()) > 0]
+
+ def post_reset_paragraph(self, paragraph: Dict):
+ result = self.filter_title_special_characters(paragraph)
+ result = self.sub_title(result)
+ result = self.content_is_null(result)
+ return result
+
+ @staticmethod
+ def sub_title(paragraph: Dict):
+ if 'title' in paragraph:
+ title = paragraph.get('title')
+ if len(title) > 255:
+ return {**paragraph, 'title': title[0:255], 'content': title[255:len(title)] + paragraph.get('content')}
+ return paragraph
+
+ @staticmethod
+ def content_is_null(paragraph: Dict):
+ if 'title' in paragraph:
+ title = paragraph.get('title')
+ content = paragraph.get('content')
+ if (content is None or len(content.strip()) == 0) and (title is not None and len(title) > 0):
+ return {'title': '', 'content': title}
+ return paragraph
+
+ @staticmethod
+ def filter_title_special_characters(paragraph: Dict):
+ title = paragraph.get('title') if 'title' in paragraph else ''
+ for title_special_characters in title_special_characters_list:
+ title = title.replace(title_special_characters, '')
+ return {**paragraph,
+ 'title': title}
+
+
+title_special_characters_list = ['#', '\n', '\r', '\\s']
+
+default_split_pattern = {
+ 'md': [re.compile('(?<=^)# .*|(?<=\\n)# .*'),
+ re.compile('(?<=\\n)(?!@#¥%……&*()!@#$%^&*(): ;,/"./'
+
+jieba_remove_flag_list = ['x', 'w']
+
+
+def get_word_list(text: str):
+ result = []
+ for pattern in word_pattern_list:
+ word_list = re.findall(pattern, text)
+ for child_list in word_list:
+ for word in child_list if isinstance(child_list, tuple) else [child_list]:
+ # 不能有: 所以再使用: 进行分割
+ if word.__contains__(':'):
+ item_list = word.split(":")
+ for w in item_list:
+ result.append(w)
+ else:
+ result.append(word)
+ return result
+
+
+def replace_word(word_dict, text: str):
+ for key in word_dict:
+ pattern = '(?= 0])
+
+
+def to_query(text: str):
+ # 获取不分词的数据
+ word_list = get_word_list(text)
+ # 获取关键词关系
+ word_dict = to_word_dict(word_list, text)
+ # 替换字符串
+ text = replace_word(word_dict, text)
+ extract_tags = analyse.extract_tags(text, topK=5, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v', 'eng'))
+ result = " ".join([get_key_by_word_dict(word, word_dict) for word, score in extract_tags if
+ not remove_chars.__contains__(word)])
+ # 删除词库
+ for word in word_list:
+ jieba.del_word(word)
+ return result
diff --git a/src/MaxKB-1.5.1/apps/dataset/__init__.py b/src/MaxKB-1.5.1/apps/dataset/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/dataset/apps.py b/src/MaxKB-1.5.1/apps/dataset/apps.py
new file mode 100644
index 0000000..166bedb
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/apps.py
@@ -0,0 +1,6 @@
+from django.apps import AppConfig
+
+
+class DatasetConfig(AppConfig):
+ default_auto_field = 'django.db.models.BigAutoField'
+ name = 'dataset'
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0001_initial.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0001_initial.py
new file mode 100644
index 0000000..e19fc6b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0001_initial.py
@@ -0,0 +1,98 @@
+# Generated by Django 4.1.10 on 2024-03-18 16:02
+
+from django.db import migrations, models
+import django.db.models.deletion
+import uuid
+
+
+class Migration(migrations.Migration):
+
+ initial = True
+
+ dependencies = [
+ ('users', '0001_initial'),
+ ]
+
+ operations = [
+ migrations.CreateModel(
+ name='DataSet',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('name', models.CharField(max_length=150, verbose_name='数据集名称')),
+ ('desc', models.CharField(max_length=256, verbose_name='数据库描述')),
+ ('type', models.CharField(choices=[('0', '通用类型'), ('1', 'web站点类型')], default='0', max_length=1, verbose_name='类型')),
+ ('meta', models.JSONField(default=dict, verbose_name='元数据')),
+ ('user', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='users.user', verbose_name='所属用户')),
+ ],
+ options={
+ 'db_table': 'dataset',
+ },
+ ),
+ migrations.CreateModel(
+ name='Document',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('name', models.CharField(max_length=150, verbose_name='文档名称')),
+ ('char_length', models.IntegerField(verbose_name='文档字符数 冗余字段')),
+ ('status', models.CharField(choices=[('0', '导入中'), ('1', '已完成'), ('2', '导入失败')], default='0', max_length=1, verbose_name='状态')),
+ ('is_active', models.BooleanField(default=True)),
+ ('type', models.CharField(choices=[('0', '通用类型'), ('1', 'web站点类型')], default='0', max_length=1, verbose_name='类型')),
+ ('meta', models.JSONField(default=dict, verbose_name='元数据')),
+ ('dataset', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.dataset')),
+ ],
+ options={
+ 'db_table': 'document',
+ },
+ ),
+ migrations.CreateModel(
+ name='Paragraph',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('content', models.CharField(max_length=4096, verbose_name='段落内容')),
+ ('title', models.CharField(default='', max_length=256, verbose_name='标题')),
+ ('status', models.CharField(choices=[('0', '导入中'), ('1', '已完成'), ('2', '导入失败')], default='0', max_length=1, verbose_name='状态')),
+ ('hit_num', models.IntegerField(default=0, verbose_name='命中次数')),
+ ('is_active', models.BooleanField(default=True)),
+ ('dataset', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.dataset')),
+ ('document', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.document')),
+ ],
+ options={
+ 'db_table': 'paragraph',
+ },
+ ),
+ migrations.CreateModel(
+ name='Problem',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('content', models.CharField(max_length=256, verbose_name='问题内容')),
+ ('hit_num', models.IntegerField(default=0, verbose_name='命中次数')),
+ ('dataset', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.dataset')),
+ ],
+ options={
+ 'db_table': 'problem',
+ },
+ ),
+ migrations.CreateModel(
+ name='ProblemParagraphMapping',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('dataset', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.dataset')),
+ ('document', models.ForeignKey(on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.document')),
+ ('paragraph', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.paragraph')),
+ ('problem', models.ForeignKey(db_constraint=False, on_delete=django.db.models.deletion.DO_NOTHING, to='dataset.problem')),
+ ],
+ options={
+ 'db_table': 'problem_paragraph_mapping',
+ },
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0002_image.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0002_image.py
new file mode 100644
index 0000000..a5fb59e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0002_image.py
@@ -0,0 +1,27 @@
+# Generated by Django 4.1.13 on 2024-04-22 19:31
+
+from django.db import migrations, models
+import uuid
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('dataset', '0001_initial'),
+ ]
+
+ operations = [
+ migrations.CreateModel(
+ name='Image',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False, verbose_name='主键id')),
+ ('image', models.BinaryField(verbose_name='图片数据')),
+ ('image_name', models.CharField(default='', max_length=256, verbose_name='图片名称')),
+ ],
+ options={
+ 'db_table': 'image',
+ },
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0003_document_hit_handling_method.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0003_document_hit_handling_method.py
new file mode 100644
index 0000000..e1746d6
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0003_document_hit_handling_method.py
@@ -0,0 +1,18 @@
+# Generated by Django 4.1.13 on 2024-04-24 15:36
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('dataset', '0002_image'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='document',
+ name='hit_handling_method',
+ field=models.CharField(choices=[('optimization', '模型优化'), ('directly_return', '直接返回')], default='optimization', max_length=20, verbose_name='命中处理方式'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0004_document_directly_return_similarity.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0004_document_directly_return_similarity.py
new file mode 100644
index 0000000..cddf38c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0004_document_directly_return_similarity.py
@@ -0,0 +1,18 @@
+# Generated by Django 4.1.13 on 2024-05-08 16:43
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('dataset', '0003_document_hit_handling_method'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='document',
+ name='directly_return_similarity',
+ field=models.FloatField(default=0.9, verbose_name='直接回答相似度'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0005_file.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0005_file.py
new file mode 100644
index 0000000..3c74fc8
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0005_file.py
@@ -0,0 +1,30 @@
+# Generated by Django 4.2.13 on 2024-07-05 18:59
+
+from django.db import migrations, models
+import uuid
+
+from smartdoc.const import CONFIG
+
+
+class Migration(migrations.Migration):
+ dependencies = [
+ ('dataset', '0004_document_directly_return_similarity'),
+ ]
+
+ operations = [
+ migrations.RunSQL(f"grant execute on function lo_from_bytea to {CONFIG.get('DB_USER')}"),
+ migrations.CreateModel(
+ name='File',
+ fields=[
+ ('create_time', models.DateTimeField(auto_now_add=True, verbose_name='创建时间')),
+ ('update_time', models.DateTimeField(auto_now=True, verbose_name='修改时间')),
+ ('id', models.UUIDField(default=uuid.uuid1, editable=False, primary_key=True, serialize=False,
+ verbose_name='主键id')),
+ ('file_name', models.CharField(default='', max_length=256, verbose_name='文件名称')),
+ ('loid', models.IntegerField(verbose_name='loid')),
+ ],
+ options={
+ 'db_table': 'file',
+ },
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0006_dataset_embedding_mode.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0006_dataset_embedding_mode.py
new file mode 100644
index 0000000..2248d8e
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0006_dataset_embedding_mode.py
@@ -0,0 +1,21 @@
+# Generated by Django 4.2.13 on 2024-07-17 13:56
+
+import dataset.models.data_set
+from django.db import migrations, models
+import django.db.models.deletion
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('setting', '0005_model_permission_type'),
+ ('dataset', '0005_file'),
+ ]
+
+ operations = [
+ migrations.AddField(
+ model_name='dataset',
+ name='embedding_mode',
+ field=models.ForeignKey(default=dataset.models.data_set.default_model, on_delete=django.db.models.deletion.DO_NOTHING, to='setting.model', verbose_name='向量模型'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0007_alter_paragraph_content.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0007_alter_paragraph_content.py
new file mode 100644
index 0000000..ab654b1
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0007_alter_paragraph_content.py
@@ -0,0 +1,18 @@
+# Generated by Django 4.2.14 on 2024-07-24 14:35
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('dataset', '0006_dataset_embedding_mode'),
+ ]
+
+ operations = [
+ migrations.AlterField(
+ model_name='paragraph',
+ name='content',
+ field=models.CharField(max_length=102400, verbose_name='段落内容'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/0008_alter_document_status_alter_paragraph_status.py b/src/MaxKB-1.5.1/apps/dataset/migrations/0008_alter_document_status_alter_paragraph_status.py
new file mode 100644
index 0000000..3380d7b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/migrations/0008_alter_document_status_alter_paragraph_status.py
@@ -0,0 +1,23 @@
+# Generated by Django 4.2.14 on 2024-07-29 15:37
+
+from django.db import migrations, models
+
+
+class Migration(migrations.Migration):
+
+ dependencies = [
+ ('dataset', '0007_alter_paragraph_content'),
+ ]
+
+ operations = [
+ migrations.AlterField(
+ model_name='document',
+ name='status',
+ field=models.CharField(choices=[('0', '导入中'), ('1', '已完成'), ('2', '导入失败'), ('3', '排队中')], default='3', max_length=1, verbose_name='状态'),
+ ),
+ migrations.AlterField(
+ model_name='paragraph',
+ name='status',
+ field=models.CharField(choices=[('0', '导入中'), ('1', '已完成'), ('2', '导入失败'), ('3', '排队中')], default='0', max_length=1, verbose_name='状态'),
+ ),
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/migrations/__init__.py b/src/MaxKB-1.5.1/apps/dataset/migrations/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/MaxKB-1.5.1/apps/dataset/serializers/common_serializers.py b/src/MaxKB-1.5.1/apps/dataset/serializers/common_serializers.py
new file mode 100644
index 0000000..8f08a26
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/serializers/common_serializers.py
@@ -0,0 +1,167 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: common_serializers.py
+ @date:2023/11/17 11:00
+ @desc:
+"""
+import os
+import uuid
+from typing import List
+
+from django.db.models import QuerySet
+from drf_yasg import openapi
+from rest_framework import serializers
+
+from common.config.embedding_config import ModelManage
+from common.db.search import native_search
+from common.db.sql_execute import update_execute
+from common.exception.app_exception import AppApiException
+from common.mixins.api_mixin import ApiMixin
+from common.util.field_message import ErrMessage
+from common.util.file_util import get_file_content
+from common.util.fork import Fork
+from dataset.models import Paragraph, Problem, ProblemParagraphMapping, DataSet
+from setting.models_provider import get_model
+from smartdoc.conf import PROJECT_DIR
+
+
+def update_document_char_length(document_id: str):
+ update_execute(get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'update_document_char_length.sql')),
+ (document_id, document_id))
+
+
+def list_paragraph(paragraph_list: List[str]):
+ if paragraph_list is None or len(paragraph_list) == 0:
+ return []
+ return native_search(QuerySet(Paragraph).filter(id__in=paragraph_list), get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_paragraph.sql')))
+
+
+class MetaSerializer(serializers.Serializer):
+ class WebMeta(serializers.Serializer):
+ source_url = serializers.CharField(required=True, error_messages=ErrMessage.char("文档地址"))
+ selector = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("选择器"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ source_url = self.data.get('source_url')
+ response = Fork(source_url, []).fork()
+ if response.status == 500:
+ raise AppApiException(500, f"url错误,无法解析【{source_url}】")
+
+ class BaseMeta(serializers.Serializer):
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+
+
+class BatchSerializer(ApiMixin, serializers.Serializer):
+ id_list = serializers.ListField(required=True, child=serializers.UUIDField(required=True),
+ error_messages=ErrMessage.char("id列表"))
+
+ def is_valid(self, *, model=None, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if model is not None:
+ id_list = self.data.get('id_list')
+ model_list = QuerySet(model).filter(id__in=id_list)
+ if len(model_list) != len(id_list):
+ model_id_list = [str(m.id) for m in model_list]
+ error_id_list = list(filter(lambda row_id: not model_id_list.__contains__(row_id), id_list))
+ raise AppApiException(500, f"id不正确:{error_id_list}")
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'id_list': openapi.Schema(type=openapi.TYPE_ARRAY, items=openapi.Schema(type=openapi.TYPE_STRING),
+ title="主键id列表",
+ description="主键id列表")
+ }
+ )
+
+
+class ProblemParagraphObject:
+ def __init__(self, dataset_id: str, document_id: str, paragraph_id: str, problem_content: str):
+ self.dataset_id = dataset_id
+ self.document_id = document_id
+ self.paragraph_id = paragraph_id
+ self.problem_content = problem_content
+
+
+def or_get(exists_problem_list, content, dataset_id, document_id, paragraph_id, problem_content_dict):
+ if content in problem_content_dict:
+ return problem_content_dict.get(content)[0], document_id, paragraph_id
+ exists = [row for row in exists_problem_list if row.content == content]
+ if len(exists) > 0:
+ problem_content_dict[content] = exists[0], False
+ return exists[0], document_id, paragraph_id
+ else:
+ problem = Problem(id=uuid.uuid1(), content=content, dataset_id=dataset_id)
+ problem_content_dict[content] = problem, True
+ return problem, document_id, paragraph_id
+
+
+class ProblemParagraphManage:
+ def __init__(self, problemParagraphObjectList: [ProblemParagraphObject], dataset_id):
+ self.dataset_id = dataset_id
+ self.problemParagraphObjectList = problemParagraphObjectList
+
+ def to_problem_model_list(self):
+ problem_list = [item.problem_content for item in self.problemParagraphObjectList]
+ exists_problem_list = []
+ if len(self.problemParagraphObjectList) > 0:
+ # 查询到已存在的问题列表
+ exists_problem_list = QuerySet(Problem).filter(dataset_id=self.dataset_id,
+ content__in=problem_list).all()
+ problem_content_dict = {}
+ problem_model_list = [
+ or_get(exists_problem_list, problemParagraphObject.problem_content, problemParagraphObject.dataset_id,
+ problemParagraphObject.document_id, problemParagraphObject.paragraph_id, problem_content_dict) for
+ problemParagraphObject in self.problemParagraphObjectList]
+
+ problem_paragraph_mapping_list = [
+ ProblemParagraphMapping(id=uuid.uuid1(), document_id=document_id, problem_id=problem_model.id,
+ paragraph_id=paragraph_id,
+ dataset_id=self.dataset_id) for
+ problem_model, document_id, paragraph_id in problem_model_list]
+
+ result = [problem_model for problem_model, is_create in problem_content_dict.values() if
+ is_create], problem_paragraph_mapping_list
+ return result
+
+
+def get_embedding_model_by_dataset_id_list(dataset_id_list: List):
+ dataset_list = QuerySet(DataSet).filter(id__in=dataset_id_list)
+ if len(set([dataset.embedding_mode_id for dataset in dataset_list])) > 1:
+ raise Exception("知识库未向量模型不一致")
+ if len(dataset_list) == 0:
+ raise Exception("知识库设置错误,请重新设置知识库")
+ return ModelManage.get_model(str(dataset_list[0].embedding_mode_id),
+ lambda _id: get_model(dataset_list[0].embedding_mode))
+
+
+def get_embedding_model_by_dataset_id(dataset_id: str):
+ dataset = QuerySet(DataSet).select_related('embedding_mode').filter(id=dataset_id).first()
+ return ModelManage.get_model(str(dataset.embedding_mode_id), lambda _id: get_model(dataset.embedding_mode))
+
+
+def get_embedding_model_by_dataset(dataset):
+ return ModelManage.get_model(str(dataset.embedding_mode_id), lambda _id: get_model(dataset.embedding_mode))
+
+
+def get_embedding_model_id_by_dataset_id(dataset_id):
+ dataset = QuerySet(DataSet).select_related('embedding_mode').filter(id=dataset_id).first()
+ return str(dataset.embedding_mode_id)
+
+
+def get_embedding_model_id_by_dataset_id_list(dataset_id_list: List):
+ dataset_list = QuerySet(DataSet).filter(id__in=dataset_id_list)
+ if len(set([dataset.embedding_mode_id for dataset in dataset_list])) > 1:
+ raise Exception("知识库未向量模型不一致")
+ if len(dataset_list) == 0:
+ raise Exception("知识库设置错误,请重新设置知识库")
+ return str(dataset_list[0].embedding_mode_id)
diff --git a/src/MaxKB-1.5.1/apps/dataset/serializers/dataset_serializers.py b/src/MaxKB-1.5.1/apps/dataset/serializers/dataset_serializers.py
new file mode 100644
index 0000000..2fdfd9b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/serializers/dataset_serializers.py
@@ -0,0 +1,869 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: dataset_serializers.py
+ @date:2023/9/21 16:14
+ @desc:
+"""
+import logging
+import os.path
+import re
+import traceback
+import uuid
+from functools import reduce
+from typing import Dict, List
+from urllib.parse import urlparse
+
+from django.contrib.postgres.fields import ArrayField
+from django.core import validators
+from django.db import transaction, models
+from django.db.models import QuerySet
+from django.http import HttpResponse
+from drf_yasg import openapi
+from rest_framework import serializers
+
+from application.models import ApplicationDatasetMapping
+from common.config.embedding_config import VectorStore
+from common.db.search import get_dynamics_model, native_page_search, native_search
+from common.db.sql_execute import select_list
+from common.exception.app_exception import AppApiException
+from common.mixins.api_mixin import ApiMixin
+from common.util.common import post, flat_map, valid_license
+from common.util.field_message import ErrMessage
+from common.util.file_util import get_file_content
+from common.util.fork import ChildLink, Fork
+from common.util.split_model import get_split_model
+from dataset.models.data_set import DataSet, Document, Paragraph, Problem, Type, ProblemParagraphMapping, Status
+from dataset.serializers.common_serializers import list_paragraph, MetaSerializer, ProblemParagraphManage, \
+ get_embedding_model_by_dataset_id, get_embedding_model_id_by_dataset_id
+from dataset.serializers.document_serializers import DocumentSerializers, DocumentInstanceSerializer
+from dataset.task import sync_web_dataset
+from embedding.models import SearchMode
+from embedding.task import embedding_by_dataset, delete_embedding_by_dataset
+from setting.models import AuthOperate
+from smartdoc.conf import PROJECT_DIR
+
+"""
+# __exact 精确等于 like ‘aaa’
+# __iexact 精确等于 忽略大小写 ilike 'aaa'
+# __contains 包含like '%aaa%'
+# __icontains 包含 忽略大小写 ilike ‘%aaa%’,但是对于sqlite来说,contains的作用效果等同于icontains。
+# __gt 大于
+# __gte 大于等于
+# __lt 小于
+# __lte 小于等于
+# __in 存在于一个list范围内
+# __startswith 以…开头
+# __istartswith 以…开头 忽略大小写
+# __endswith 以…结尾
+# __iendswith 以…结尾,忽略大小写
+# __range 在…范围内
+# __year 日期字段的年份
+# __month 日期字段的月份
+# __day 日期字段的日
+# __isnull=True/False
+"""
+
+
+class DataSetSerializers(serializers.ModelSerializer):
+ class Meta:
+ model = DataSet
+ fields = ['id', 'name', 'desc', 'meta', 'create_time', 'update_time']
+
+ class Application(ApiMixin, serializers.Serializer):
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char("用户id"))
+
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char("数据集id"))
+
+ @staticmethod
+ def get_request_params_api():
+ return [
+ openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id')
+ ]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'name', 'desc', 'model_id', 'multiple_rounds_dialogue', 'user_id', 'status',
+ 'create_time',
+ 'update_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="", description="主键id"),
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="应用名称", description="应用名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="应用描述", description="应用描述"),
+ 'model_id': openapi.Schema(type=openapi.TYPE_STRING, title="模型id", description="模型id"),
+ "multiple_rounds_dialogue": openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否开启多轮对话",
+ description="是否开启多轮对话"),
+ 'prologue': openapi.Schema(type=openapi.TYPE_STRING, title="开场白", description="开场白"),
+ 'example': openapi.Schema(type=openapi.TYPE_ARRAY, items=openapi.Schema(type=openapi.TYPE_STRING),
+ title="示例列表", description="示例列表"),
+ 'user_id': openapi.Schema(type=openapi.TYPE_STRING, title="所属用户", description="所属用户"),
+
+ 'status': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否发布", description='是否发布'),
+
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间", description='创建时间'),
+
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间", description='修改时间')
+ }
+ )
+
+ class Query(ApiMixin, serializers.Serializer):
+ """
+ 查询对象
+ """
+ name = serializers.CharField(required=False,
+ error_messages=ErrMessage.char("知识库名称"),
+ max_length=64,
+ min_length=1)
+
+ desc = serializers.CharField(required=False,
+ error_messages=ErrMessage.char("知识库描述"),
+ max_length=256,
+ min_length=1,
+ )
+
+ user_id = serializers.CharField(required=True)
+
+ def get_query_set(self):
+ user_id = self.data.get("user_id")
+ query_set_dict = {}
+ query_set = QuerySet(model=get_dynamics_model(
+ {'temp.name': models.CharField(), 'temp.desc': models.CharField(),
+ "document_temp.char_length": models.IntegerField(), 'temp.create_time': models.DateTimeField()}))
+ if "desc" in self.data and self.data.get('desc') is not None:
+ query_set = query_set.filter(**{'temp.desc__icontains': self.data.get("desc")})
+ if "name" in self.data and self.data.get('name') is not None:
+ query_set = query_set.filter(**{'temp.name__icontains': self.data.get("name")})
+ query_set = query_set.order_by("-temp.create_time")
+ query_set_dict['default_sql'] = query_set
+
+ query_set_dict['dataset_custom_sql'] = QuerySet(model=get_dynamics_model(
+ {'dataset.user_id': models.CharField(),
+ })).filter(
+ **{'dataset.user_id': user_id}
+ )
+
+ query_set_dict['team_member_permission_custom_sql'] = QuerySet(model=get_dynamics_model(
+ {'user_id': models.CharField(),
+ 'team_member_permission.auth_target_type': models.CharField(),
+ 'team_member_permission.operate': ArrayField(verbose_name="权限操作列表",
+ base_field=models.CharField(max_length=256,
+ blank=True,
+ choices=AuthOperate.choices,
+ default=AuthOperate.USE)
+ )})).filter(
+ **{'user_id': user_id, 'team_member_permission.operate__contains': ['USE'],
+ 'team_member_permission.auth_target_type': 'DATASET'})
+
+ return query_set_dict
+
+ def page(self, current_page: int, page_size: int):
+ return native_page_search(current_page, page_size, self.get_query_set(), select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_dataset.sql')),
+ post_records_handler=lambda r: r)
+
+ def list(self):
+ return native_search(self.get_query_set(), select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_dataset.sql')))
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='name',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='知识库名称'),
+ openapi.Parameter(name='desc',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='知识库描述')
+ ]
+
+ @staticmethod
+ def get_response_body_api():
+ return DataSetSerializers.Operate.get_response_body_api()
+
+ class Create(ApiMixin, serializers.Serializer):
+ user_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char("用户id"), )
+
+ class CreateBaseSerializers(ApiMixin, serializers.Serializer):
+ """
+ 创建通用数据集序列化对象
+ """
+ name = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("知识库名称"),
+ max_length=64,
+ min_length=1)
+
+ desc = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("知识库描述"),
+ max_length=256,
+ min_length=1)
+
+ embedding_mode_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("向量模型"))
+
+ documents = DocumentInstanceSerializer(required=False, many=True)
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ return True
+
+ class CreateQASerializers(serializers.Serializer):
+ """
+ 创建web站点序列化对象
+ """
+ name = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("知识库名称"),
+ max_length=64,
+ min_length=1)
+
+ desc = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("知识库描述"),
+ max_length=256,
+ min_length=1)
+
+ embedding_mode_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("向量模型"))
+
+ file_list = serializers.ListSerializer(required=True,
+ error_messages=ErrMessage.list("文件列表"),
+ child=serializers.FileField(required=True,
+ error_messages=ErrMessage.file("文件")))
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='file',
+ in_=openapi.IN_FORM,
+ type=openapi.TYPE_ARRAY,
+ items=openapi.Items(type=openapi.TYPE_FILE),
+ required=True,
+ description='上传文件'),
+ openapi.Parameter(name='name',
+ in_=openapi.IN_FORM,
+ required=True,
+ type=openapi.TYPE_STRING, title="知识库名称", description="知识库名称"),
+ openapi.Parameter(name='desc',
+ in_=openapi.IN_FORM,
+ required=True,
+ type=openapi.TYPE_STRING, title="知识库描述", description="知识库描述"),
+ ]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'name', 'desc', 'user_id', 'char_length', 'document_count',
+ 'update_time', 'create_time', 'document_list'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="名称",
+ description="名称", default="测试知识库"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="描述",
+ description="描述", default="测试知识库描述"),
+ 'user_id': openapi.Schema(type=openapi.TYPE_STRING, title="所属用户id",
+ description="所属用户id", default="user_xxxx"),
+ 'char_length': openapi.Schema(type=openapi.TYPE_STRING, title="字符数",
+ description="字符数", default=10),
+ 'document_count': openapi.Schema(type=openapi.TYPE_STRING, title="文档数量",
+ description="文档数量", default=1),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ ),
+ 'document_list': openapi.Schema(type=openapi.TYPE_ARRAY, title="文档列表",
+ description="文档列表",
+ items=DocumentSerializers.Operate.get_response_body_api())
+ }
+ )
+
+ class CreateWebSerializers(serializers.Serializer):
+ """
+ 创建web站点序列化对象
+ """
+ name = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("知识库名称"),
+ max_length=64,
+ min_length=1)
+
+ desc = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("知识库描述"),
+ max_length=256,
+ min_length=1)
+ source_url = serializers.CharField(required=True, error_messages=ErrMessage.char("Web 根地址"), )
+
+ embedding_mode_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("向量模型"))
+
+ selector = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char("选择器"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ source_url = self.data.get('source_url')
+ response = Fork(source_url, []).fork()
+ if response.status == 500:
+ raise AppApiException(500, f"url错误,无法解析【{source_url}】")
+ return True
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'name', 'desc', 'user_id', 'char_length', 'document_count',
+ 'update_time', 'create_time', 'document_list'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="名称",
+ description="名称", default="测试知识库"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="描述",
+ description="描述", default="测试知识库描述"),
+ 'user_id': openapi.Schema(type=openapi.TYPE_STRING, title="所属用户id",
+ description="所属用户id", default="user_xxxx"),
+ 'char_length': openapi.Schema(type=openapi.TYPE_STRING, title="字符数",
+ description="字符数", default=10),
+ 'document_count': openapi.Schema(type=openapi.TYPE_STRING, title="文档数量",
+ description="文档数量", default=1),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ ),
+ 'document_list': openapi.Schema(type=openapi.TYPE_ARRAY, title="文档列表",
+ description="文档列表",
+ items=DocumentSerializers.Operate.get_response_body_api())
+ }
+ )
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['name', 'desc', 'url'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="知识库名称", description="知识库名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="知识库描述", description="知识库描述"),
+ 'embedding_mode_id': openapi.Schema(type=openapi.TYPE_STRING, title="向量模型id",
+ description="向量模型id"),
+ 'source_url': openapi.Schema(type=openapi.TYPE_STRING, title="web站点url",
+ description="web站点url"),
+ 'selector': openapi.Schema(type=openapi.TYPE_STRING, title="选择器", description="选择器")
+ }
+ )
+
+ @staticmethod
+ def post_embedding_dataset(document_list, dataset_id):
+ model_id = get_embedding_model_id_by_dataset_id(dataset_id)
+ # 发送向量化事件
+ embedding_by_dataset.delay(dataset_id, model_id)
+ return document_list
+
+ def save_qa(self, instance: Dict, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ self.CreateQASerializers(data=instance).is_valid()
+ file_list = instance.get('file_list')
+ document_list = flat_map([DocumentSerializers.Create.parse_qa_file(file) for file in file_list])
+ dataset_instance = {'name': instance.get('name'), 'desc': instance.get('desc'), 'documents': document_list,
+ 'embedding_mode_id': instance.get('embedding_mode_id')}
+ return self.save(dataset_instance, with_valid=True)
+
+ @valid_license(model=DataSet, count=50,
+ message='社区版最多支持 50 个知识库,如需拥有更多知识库,请联系我们(https://fit2cloud.com/)。')
+ @post(post_function=post_embedding_dataset)
+ @transaction.atomic
+ def save(self, instance: Dict, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ self.CreateBaseSerializers(data=instance).is_valid()
+ dataset_id = uuid.uuid1()
+ user_id = self.data.get('user_id')
+ if QuerySet(DataSet).filter(user_id=user_id, name=instance.get('name')).exists():
+ raise AppApiException(500, "知识库名称重复!")
+ dataset = DataSet(
+ **{'id': dataset_id, 'name': instance.get("name"), 'desc': instance.get('desc'), 'user_id': user_id,
+ 'embedding_mode_id': instance.get('embedding_mode_id')})
+
+ document_model_list = []
+ paragraph_model_list = []
+ problem_paragraph_object_list = []
+ # 插入文档
+ for document in instance.get('documents') if 'documents' in instance else []:
+ document_paragraph_dict_model = DocumentSerializers.Create.get_document_paragraph_model(dataset_id,
+ document)
+ document_model_list.append(document_paragraph_dict_model.get('document'))
+ for paragraph in document_paragraph_dict_model.get('paragraph_model_list'):
+ paragraph_model_list.append(paragraph)
+ for problem_paragraph_object in document_paragraph_dict_model.get('problem_paragraph_object_list'):
+ problem_paragraph_object_list.append(problem_paragraph_object)
+
+ problem_model_list, problem_paragraph_mapping_list = (ProblemParagraphManage(problem_paragraph_object_list,
+ dataset_id)
+ .to_problem_model_list())
+ # 插入知识库
+ dataset.save()
+ # 插入文档
+ QuerySet(Document).bulk_create(document_model_list) if len(document_model_list) > 0 else None
+ # 批量插入段落
+ QuerySet(Paragraph).bulk_create(paragraph_model_list) if len(paragraph_model_list) > 0 else None
+ # 批量插入问题
+ QuerySet(Problem).bulk_create(problem_model_list) if len(problem_model_list) > 0 else None
+ # 批量插入关联问题
+ QuerySet(ProblemParagraphMapping).bulk_create(problem_paragraph_mapping_list) if len(
+ problem_paragraph_mapping_list) > 0 else None
+
+ # 响应数据
+ return {**DataSetSerializers(dataset).data,
+ 'document_list': DocumentSerializers.Query(data={'dataset_id': dataset_id}).list(
+ with_valid=True)}, dataset_id
+
+ @staticmethod
+ def get_last_url_path(url):
+ parsed_url = urlparse(url)
+ if parsed_url.path is None or len(parsed_url.path) == 0:
+ return url
+ else:
+ return parsed_url.path.split("/")[-1]
+
+ def save_web(self, instance: Dict, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ self.CreateWebSerializers(data=instance).is_valid(raise_exception=True)
+ user_id = self.data.get('user_id')
+ if QuerySet(DataSet).filter(user_id=user_id, name=instance.get('name')).exists():
+ raise AppApiException(500, "知识库名称重复!")
+ dataset_id = uuid.uuid1()
+ dataset = DataSet(
+ **{'id': dataset_id, 'name': instance.get("name"), 'desc': instance.get('desc'), 'user_id': user_id,
+ 'type': Type.web,
+ 'embedding_mode_id': instance.get('embedding_mode_id'),
+ 'meta': {'source_url': instance.get('source_url'), 'selector': instance.get('selector'),
+ 'embedding_mode_id': instance.get('embedding_mode_id')}})
+ dataset.save()
+ sync_web_dataset.delay(str(dataset_id), instance.get('source_url'), instance.get('selector'))
+ return {**DataSetSerializers(dataset).data,
+ 'document_list': []}
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'name', 'desc', 'user_id', 'char_length', 'document_count',
+ 'update_time', 'create_time', 'document_list'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="名称",
+ description="名称", default="测试知识库"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="描述",
+ description="描述", default="测试知识库描述"),
+ 'user_id': openapi.Schema(type=openapi.TYPE_STRING, title="所属用户id",
+ description="所属用户id", default="user_xxxx"),
+ 'char_length': openapi.Schema(type=openapi.TYPE_STRING, title="字符数",
+ description="字符数", default=10),
+ 'document_count': openapi.Schema(type=openapi.TYPE_STRING, title="文档数量",
+ description="文档数量", default=1),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ ),
+ 'document_list': openapi.Schema(type=openapi.TYPE_ARRAY, title="文档列表",
+ description="文档列表",
+ items=DocumentSerializers.Operate.get_response_body_api())
+ }
+ )
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['name', 'desc'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="知识库名称", description="知识库名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="知识库描述", description="知识库描述"),
+ 'embedding_mode_id': openapi.Schema(type=openapi.TYPE_STRING, title='向量模型',
+ description='向量模型'),
+ 'documents': openapi.Schema(type=openapi.TYPE_ARRAY, title="文档数据", description="文档数据",
+ items=DocumentSerializers().Create.get_request_body_api()
+ )
+ }
+ )
+
+ class Edit(serializers.Serializer):
+ name = serializers.CharField(required=False, max_length=64, min_length=1,
+ error_messages=ErrMessage.char("知识库名称"))
+ desc = serializers.CharField(required=False, max_length=256, min_length=1,
+ error_messages=ErrMessage.char("知识库描述"))
+ meta = serializers.DictField(required=False)
+ application_id_list = serializers.ListSerializer(required=False, child=serializers.UUIDField(required=True,
+ error_messages=ErrMessage.char(
+ "应用id")),
+ error_messages=ErrMessage.char("应用列表"))
+
+ @staticmethod
+ def get_dataset_meta_valid_map():
+ dataset_meta_valid_map = {
+ Type.base: MetaSerializer.BaseMeta,
+ Type.web: MetaSerializer.WebMeta
+ }
+ return dataset_meta_valid_map
+
+ def is_valid(self, *, dataset: DataSet = None):
+ super().is_valid(raise_exception=True)
+ if 'meta' in self.data and self.data.get('meta') is not None:
+ dataset_meta_valid_map = self.get_dataset_meta_valid_map()
+ valid_class = dataset_meta_valid_map.get(dataset.type)
+ valid_class(data=self.data.get('meta')).is_valid(raise_exception=True)
+
+ class HitTest(ApiMixin, serializers.Serializer):
+ id = serializers.CharField(required=True, error_messages=ErrMessage.char("id"))
+ user_id = serializers.UUIDField(required=False, error_messages=ErrMessage.char("用户id"))
+ query_text = serializers.CharField(required=True, error_messages=ErrMessage.char("查询文本"))
+ top_number = serializers.IntegerField(required=True, max_value=100, min_value=1,
+ error_messages=ErrMessage.char("响应Top"))
+ similarity = serializers.FloatField(required=True, max_value=2, min_value=0,
+ error_messages=ErrMessage.char("相似度"))
+ search_mode = serializers.CharField(required=True, validators=[
+ validators.RegexValidator(regex=re.compile("^embedding|keywords|blend$"),
+ message="类型只支持register|reset_password", code=500)
+ ], error_messages=ErrMessage.char("检索模式"))
+
+ def is_valid(self, *, raise_exception=True):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(DataSet).filter(id=self.data.get("id")).exists():
+ raise AppApiException(300, "id不存在")
+
+ def hit_test(self):
+ self.is_valid()
+ vector = VectorStore.get_embedding_vector()
+ exclude_document_id_list = [str(document.id) for document in
+ QuerySet(Document).filter(
+ dataset_id=self.data.get('id'),
+ is_active=False)]
+ model = get_embedding_model_by_dataset_id(self.data.get('id'))
+ # 向量库检索
+ hit_list = vector.hit_test(self.data.get('query_text'), [self.data.get('id')], exclude_document_id_list,
+ self.data.get('top_number'),
+ self.data.get('similarity'),
+ SearchMode(self.data.get('search_mode')),
+ model)
+ hit_dict = reduce(lambda x, y: {**x, **y}, [{hit.get('paragraph_id'): hit} for hit in hit_list], {})
+ p_list = list_paragraph([h.get('paragraph_id') for h in hit_list])
+ return [{**p, 'similarity': hit_dict.get(p.get('id')).get('similarity'),
+ 'comprehensive_score': hit_dict.get(p.get('id')).get('comprehensive_score')} for p in p_list]
+
+ class SyncWeb(ApiMixin, serializers.Serializer):
+ id = serializers.CharField(required=True, error_messages=ErrMessage.char(
+ "知识库id"))
+ user_id = serializers.UUIDField(required=False, error_messages=ErrMessage.char(
+ "用户id"))
+ sync_type = serializers.CharField(required=True, error_messages=ErrMessage.char(
+ "同步类型"), validators=[
+ validators.RegexValidator(regex=re.compile("^replace|complete$"),
+ message="同步类型只支持:replace|complete", code=500)
+ ])
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ first = QuerySet(DataSet).filter(id=self.data.get("id")).first()
+ if first is None:
+ raise AppApiException(300, "id不存在")
+ if first.type != Type.web:
+ raise AppApiException(500, "只有web站点类型才支持同步")
+
+ def sync(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ sync_type = self.data.get('sync_type')
+ dataset_id = self.data.get('id')
+ dataset = QuerySet(DataSet).get(id=dataset_id)
+ self.__getattribute__(sync_type + '_sync')(dataset)
+ return True
+
+ @staticmethod
+ def get_sync_handler(dataset):
+ def handler(child_link: ChildLink, response: Fork.Response):
+ if response.status == 200:
+ try:
+ document_name = child_link.tag.text if child_link.tag is not None and len(
+ child_link.tag.text.strip()) > 0 else child_link.url
+ paragraphs = get_split_model('web.md').parse(response.content)
+ first = QuerySet(Document).filter(meta__source_url=child_link.url, dataset=dataset).first()
+ if first is not None:
+ # 如果存在,使用文档同步
+ DocumentSerializers.Sync(data={'document_id': first.id}).sync()
+ else:
+ # 插入
+ DocumentSerializers.Create(data={'dataset_id': dataset.id}).save(
+ {'name': document_name, 'paragraphs': paragraphs,
+ 'meta': {'source_url': child_link.url, 'selector': dataset.meta.get('selector')},
+ 'type': Type.web}, with_valid=True)
+ except Exception as e:
+ logging.getLogger("max_kb_error").error(f'{str(e)}:{traceback.format_exc()}')
+
+ return handler
+
+ def replace_sync(self, dataset):
+ """
+ 替换同步
+ :return:
+ """
+ url = dataset.meta.get('source_url')
+ selector = dataset.meta.get('selector') if 'selector' in dataset.meta else None
+ sync_web_dataset.delay(str(dataset.id), url, selector)
+
+ def complete_sync(self, dataset):
+ """
+ 完整同步 删掉当前数据集下所有的文档,再进行同步
+ :return:
+ """
+ # 删除关联问题
+ QuerySet(ProblemParagraphMapping).filter(dataset=dataset).delete()
+ # 删除文档
+ QuerySet(Document).filter(dataset=dataset).delete()
+ # 删除段落
+ QuerySet(Paragraph).filter(dataset=dataset).delete()
+ # 删除向量
+ delete_embedding_by_dataset(self.data.get('id'))
+ # 同步
+ self.replace_sync(dataset)
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='sync_type',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='同步类型->replace:替换同步,complete:完整同步')
+ ]
+
+ class Operate(ApiMixin, serializers.Serializer):
+ id = serializers.CharField(required=True, error_messages=ErrMessage.char(
+ "知识库id"))
+ user_id = serializers.UUIDField(required=False, error_messages=ErrMessage.char(
+ "用户id"))
+
+ def is_valid(self, *, raise_exception=True):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(DataSet).filter(id=self.data.get("id")).exists():
+ raise AppApiException(300, "id不存在")
+
+ def export_excel(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ document_list = QuerySet(Document).filter(dataset_id=self.data.get('id'))
+ paragraph_list = native_search(QuerySet(Paragraph).filter(dataset_id=self.data.get("id")), get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_paragraph_document_name.sql')))
+ problem_mapping_list = native_search(
+ QuerySet(ProblemParagraphMapping).filter(dataset_id=self.data.get("id")), get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_problem_mapping.sql')),
+ with_table_name=True)
+ data_dict, document_dict = DocumentSerializers.Operate.merge_problem(paragraph_list, problem_mapping_list,
+ document_list)
+ workbook = DocumentSerializers.Operate.get_workbook(data_dict, document_dict)
+ response = HttpResponse(content_type='application/vnd.ms-excel')
+ response['Content-Disposition'] = 'attachment; filename="dataset.xls"'
+ workbook.save(response)
+ return response
+
+ @staticmethod
+ def merge_problem(paragraph_list: List[Dict], problem_mapping_list: List[Dict]):
+ result = {}
+ document_dict = {}
+
+ for paragraph in paragraph_list:
+ problem_list = [problem_mapping.get('content') for problem_mapping in problem_mapping_list if
+ problem_mapping.get('paragraph_id') == paragraph.get('id')]
+ document_sheet = result.get(paragraph.get('document_id'))
+ d = document_dict.get(paragraph.get('document_name'))
+ if d is None:
+ document_dict[paragraph.get('document_name')] = {paragraph.get('document_id')}
+ else:
+ d.add(paragraph.get('document_id'))
+
+ if document_sheet is None:
+ result[paragraph.get('document_id')] = [[paragraph.get('title'), paragraph.get('content'),
+ '\n'.join(problem_list)]]
+ else:
+ document_sheet.append([paragraph.get('title'), paragraph.get('content'), '\n'.join(problem_list)])
+ result_document_dict = {}
+ for d_name in document_dict:
+ for index, d_id in enumerate(document_dict.get(d_name)):
+ result_document_dict[d_id] = d_name if index == 0 else d_name + str(index)
+ return result, result_document_dict
+
+ @transaction.atomic
+ def delete(self):
+ self.is_valid()
+ dataset = QuerySet(DataSet).get(id=self.data.get("id"))
+ QuerySet(Document).filter(dataset=dataset).delete()
+ QuerySet(ProblemParagraphMapping).filter(dataset=dataset).delete()
+ QuerySet(Paragraph).filter(dataset=dataset).delete()
+ QuerySet(Problem).filter(dataset=dataset).delete()
+ dataset.delete()
+ delete_embedding_by_dataset(self.data.get('id'))
+ return True
+
+ def re_embedding(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+
+ QuerySet(Document).filter(dataset_id=self.data.get('id')).update(**{'status': Status.queue_up})
+ QuerySet(Paragraph).filter(dataset_id=self.data.get('id')).update(**{'status': Status.queue_up})
+ embedding_model_id = get_embedding_model_id_by_dataset_id(self.data.get('id'))
+ embedding_by_dataset.delay(self.data.get('id'), embedding_model_id)
+
+ def list_application(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ dataset = QuerySet(DataSet).get(id=self.data.get("id"))
+ return select_list(get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_dataset_application.sql')),
+ [self.data.get('user_id') if self.data.get('user_id') == str(dataset.user_id) else None,
+ dataset.user_id, self.data.get('user_id')])
+
+ def one(self, user_id, with_valid=True):
+ if with_valid:
+ self.is_valid()
+ query_set_dict = {'default_sql': QuerySet(model=get_dynamics_model(
+ {'temp.id': models.UUIDField()})).filter(**{'temp.id': self.data.get("id")}),
+ 'dataset_custom_sql': QuerySet(model=get_dynamics_model(
+ {'dataset.user_id': models.CharField()})).filter(
+ **{'dataset.user_id': user_id}
+ ), 'team_member_permission_custom_sql': QuerySet(
+ model=get_dynamics_model({'user_id': models.CharField(),
+ 'team_member_permission.operate': ArrayField(
+ verbose_name="权限操作列表",
+ base_field=models.CharField(max_length=256,
+ blank=True,
+ choices=AuthOperate.choices,
+ default=AuthOperate.USE)
+ )})).filter(
+ **{'user_id': user_id, 'team_member_permission.operate__contains': ['USE']})}
+ all_application_list = [str(adm.get('id')) for adm in self.list_application(with_valid=False)]
+ return {**native_search(query_set_dict, select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_dataset.sql')), with_search_one=True),
+ 'application_id_list': list(
+ filter(lambda application_id: all_application_list.__contains__(application_id),
+ [str(application_dataset_mapping.application_id) for
+ application_dataset_mapping in
+ QuerySet(ApplicationDatasetMapping).filter(
+ dataset_id=self.data.get('id'))]))}
+
+ @transaction.atomic
+ def edit(self, dataset: Dict, user_id: str):
+ """
+ 修改知识库
+ :param user_id: 用户id
+ :param dataset: Dict name desc
+ :return:
+ """
+ self.is_valid()
+ if QuerySet(DataSet).filter(user_id=user_id, name=dataset.get('name')).exclude(
+ id=self.data.get('id')).exists():
+ raise AppApiException(500, "知识库名称重复!")
+ _dataset = QuerySet(DataSet).get(id=self.data.get("id"))
+ DataSetSerializers.Edit(data=dataset).is_valid(dataset=_dataset)
+ if 'embedding_mode_id' in dataset:
+ _dataset.embedding_mode_id = dataset.get('embedding_mode_id')
+ if "name" in dataset:
+ _dataset.name = dataset.get("name")
+ if 'desc' in dataset:
+ _dataset.desc = dataset.get("desc")
+ if 'meta' in dataset:
+ _dataset.meta = dataset.get('meta')
+ if 'application_id_list' in dataset and dataset.get('application_id_list') is not None:
+ application_id_list = dataset.get('application_id_list')
+ # 当前用户可修改关联的知识库列表
+ application_dataset_id_list = [str(dataset_dict.get('id')) for dataset_dict in
+ self.list_application(with_valid=False)]
+ for dataset_id in application_id_list:
+ if not application_dataset_id_list.__contains__(dataset_id):
+ raise AppApiException(500, f"未知的应用id${dataset_id},无法关联")
+
+ # 删除已经关联的id
+ QuerySet(ApplicationDatasetMapping).filter(application_id__in=application_dataset_id_list,
+ dataset_id=self.data.get("id")).delete()
+ # 插入
+ QuerySet(ApplicationDatasetMapping).bulk_create(
+ [ApplicationDatasetMapping(application_id=application_id, dataset_id=self.data.get('id')) for
+ application_id in
+ application_id_list]) if len(application_id_list) > 0 else None
+ [ApplicationDatasetMapping(application_id=application_id, dataset_id=self.data.get('id')) for
+ application_id in application_id_list]
+
+ _dataset.save()
+ return self.one(with_valid=False, user_id=user_id)
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['name', 'desc'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="知识库名称", description="知识库名称"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="知识库描述", description="知识库描述"),
+ 'meta': openapi.Schema(type=openapi.TYPE_OBJECT, title="知识库元数据",
+ description="知识库元数据->web:{source_url:xxx,selector:'xxx'},base:{}"),
+ 'application_id_list': openapi.Schema(type=openapi.TYPE_ARRAY, title="应用id列表",
+ description="应用id列表",
+ items=openapi.Schema(type=openapi.TYPE_STRING))
+ }
+ )
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'name', 'desc', 'user_id', 'char_length', 'document_count',
+ 'update_time', 'create_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="名称",
+ description="名称", default="测试知识库"),
+ 'desc': openapi.Schema(type=openapi.TYPE_STRING, title="描述",
+ description="描述", default="测试知识库描述"),
+ 'user_id': openapi.Schema(type=openapi.TYPE_STRING, title="所属用户id",
+ description="所属用户id", default="user_xxxx"),
+ 'char_length': openapi.Schema(type=openapi.TYPE_STRING, title="字符数",
+ description="字符数", default=10),
+ 'document_count': openapi.Schema(type=openapi.TYPE_STRING, title="文档数量",
+ description="文档数量", default=1),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ )
+ }
+ )
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id')
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/serializers/document_serializers.py b/src/MaxKB-1.5.1/apps/dataset/serializers/document_serializers.py
new file mode 100644
index 0000000..43d4014
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/serializers/document_serializers.py
@@ -0,0 +1,919 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: document_serializers.py
+ @date:2023/9/22 13:43
+ @desc:
+"""
+import logging
+import os
+import re
+import traceback
+import uuid
+from functools import reduce
+from typing import List, Dict
+
+import xlwt
+from celery_once import AlreadyQueued
+from django.core import validators
+from django.db import transaction
+from django.db.models import QuerySet
+from django.http import HttpResponse
+from drf_yasg import openapi
+from rest_framework import serializers
+from xlwt import Utils
+
+from common.db.search import native_search, native_page_search
+from common.event.common import work_thread_pool
+from common.exception.app_exception import AppApiException
+from common.handle.impl.doc_split_handle import DocSplitHandle
+from common.handle.impl.html_split_handle import HTMLSplitHandle
+from common.handle.impl.pdf_split_handle import PdfSplitHandle
+from common.handle.impl.qa.csv_parse_qa_handle import CsvParseQAHandle
+from common.handle.impl.qa.xls_parse_qa_handle import XlsParseQAHandle
+from common.handle.impl.qa.xlsx_parse_qa_handle import XlsxParseQAHandle
+from common.handle.impl.text_split_handle import TextSplitHandle
+from common.mixins.api_mixin import ApiMixin
+from common.util.common import post, flat_map
+from common.util.field_message import ErrMessage
+from common.util.file_util import get_file_content
+from common.util.fork import Fork
+from common.util.split_model import get_split_model
+from dataset.models.data_set import DataSet, Document, Paragraph, Problem, Type, Status, ProblemParagraphMapping, Image
+from dataset.serializers.common_serializers import BatchSerializer, MetaSerializer, ProblemParagraphManage, \
+ get_embedding_model_id_by_dataset_id
+from dataset.serializers.paragraph_serializers import ParagraphSerializers, ParagraphInstanceSerializer
+from dataset.task import sync_web_document
+from embedding.task.embedding import embedding_by_document, delete_embedding_by_document_list, \
+ delete_embedding_by_document, update_embedding_dataset_id, delete_embedding_by_paragraph_ids, \
+ embedding_by_document_list
+from smartdoc.conf import PROJECT_DIR
+
+parse_qa_handle_list = [XlsParseQAHandle(), CsvParseQAHandle(), XlsxParseQAHandle()]
+
+
+class FileBufferHandle:
+ buffer = None
+
+ def get_buffer(self, file):
+ if self.buffer is None:
+ self.buffer = file.read()
+ return self.buffer
+
+
+class DocumentEditInstanceSerializer(ApiMixin, serializers.Serializer):
+ meta = serializers.DictField(required=False)
+ name = serializers.CharField(required=False, max_length=128, min_length=1,
+ error_messages=ErrMessage.char(
+ "文档名称"))
+ hit_handling_method = serializers.CharField(required=False, validators=[
+ validators.RegexValidator(regex=re.compile("^optimization|directly_return$"),
+ message="类型只支持optimization|directly_return",
+ code=500)
+ ], error_messages=ErrMessage.char("命中处理方式"))
+
+ directly_return_similarity = serializers.FloatField(required=False,
+ max_value=2,
+ min_value=0,
+ error_messages=ErrMessage.float(
+ "直接返回分数"))
+
+ is_active = serializers.BooleanField(required=False, error_messages=ErrMessage.boolean(
+ "文档是否可用"))
+
+ @staticmethod
+ def get_meta_valid_map():
+ dataset_meta_valid_map = {
+ Type.base: MetaSerializer.BaseMeta,
+ Type.web: MetaSerializer.WebMeta
+ }
+ return dataset_meta_valid_map
+
+ def is_valid(self, *, document: Document = None):
+ super().is_valid(raise_exception=True)
+ if 'meta' in self.data and self.data.get('meta') is not None:
+ dataset_meta_valid_map = self.get_meta_valid_map()
+ valid_class = dataset_meta_valid_map.get(document.type)
+ valid_class(data=self.data.get('meta')).is_valid(raise_exception=True)
+
+
+class DocumentWebInstanceSerializer(ApiMixin, serializers.Serializer):
+ source_url_list = serializers.ListField(required=True,
+ child=serializers.CharField(required=True, error_messages=ErrMessage.char(
+ "文档地址")),
+ error_messages=ErrMessage.char(
+ "文档地址列表"))
+ selector = serializers.CharField(required=False, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char(
+ "选择器"))
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='file',
+ in_=openapi.IN_FORM,
+ type=openapi.TYPE_ARRAY,
+ items=openapi.Items(type=openapi.TYPE_FILE),
+ required=True,
+ description='上传文件'),
+ openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ ]
+
+
+class DocumentInstanceSerializer(ApiMixin, serializers.Serializer):
+ name = serializers.CharField(required=True,
+ error_messages=ErrMessage.char("文档名称"),
+ max_length=128,
+ min_length=1)
+
+ paragraphs = ParagraphInstanceSerializer(required=False, many=True, allow_null=True)
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['name', 'paragraphs'],
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="文档名称", description="文档名称"),
+ 'paragraphs': openapi.Schema(type=openapi.TYPE_ARRAY, title="段落列表", description="段落列表",
+ items=ParagraphSerializers.Create.get_request_body_api())
+ }
+ )
+
+
+class DocumentInstanceQASerializer(ApiMixin, serializers.Serializer):
+ file_list = serializers.ListSerializer(required=True,
+ error_messages=ErrMessage.list("文件列表"),
+ child=serializers.FileField(required=True,
+ error_messages=ErrMessage.file("文件")))
+
+
+class DocumentSerializers(ApiMixin, serializers.Serializer):
+ class Export(ApiMixin, serializers.Serializer):
+ type = serializers.CharField(required=True, validators=[
+ validators.RegexValidator(regex=re.compile("^csv|excel$"),
+ message="模版类型只支持excel|csv",
+ code=500)
+ ], error_messages=ErrMessage.char("模版类型"))
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='type',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='导出模板类型csv|excel'),
+
+ ]
+
+ def export(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+
+ if self.data.get('type') == 'csv':
+ file = open(os.path.join(PROJECT_DIR, "apps", "dataset", 'template', 'csv_template.csv'), "rb")
+ content = file.read()
+ file.close()
+ return HttpResponse(content, status=200, headers={'Content-Type': 'text/cxv',
+ 'Content-Disposition': 'attachment; filename="csv_template.csv"'})
+ elif self.data.get('type') == 'excel':
+ file = open(os.path.join(PROJECT_DIR, "apps", "dataset", 'template', 'excel_template.xlsx'), "rb")
+ content = file.read()
+ file.close()
+ return HttpResponse(content, status=200, headers={'Content-Type': 'application/vnd.ms-excel',
+ 'Content-Disposition': 'attachment; filename="excel_template.xlsx"'})
+
+ class Migrate(ApiMixin, serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True,
+ error_messages=ErrMessage.char(
+ "知识库id"))
+ target_dataset_id = serializers.UUIDField(required=True,
+ error_messages=ErrMessage.char(
+ "目标知识库id"))
+ document_id_list = serializers.ListField(required=True, error_messages=ErrMessage.char("文档列表"),
+ child=serializers.UUIDField(required=True,
+ error_messages=ErrMessage.uuid("文档id")))
+
+ @transaction.atomic
+ def migrate(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ dataset_id = self.data.get('dataset_id')
+ target_dataset_id = self.data.get('target_dataset_id')
+ dataset = QuerySet(DataSet).filter(id=dataset_id).first()
+ target_dataset = QuerySet(DataSet).filter(id=target_dataset_id).first()
+ document_id_list = self.data.get('document_id_list')
+ document_list = QuerySet(Document).filter(dataset_id=dataset_id, id__in=document_id_list)
+ paragraph_list = QuerySet(Paragraph).filter(dataset_id=dataset_id, document_id__in=document_id_list)
+
+ problem_paragraph_mapping_list = QuerySet(ProblemParagraphMapping).filter(paragraph__in=paragraph_list)
+ problem_list = QuerySet(Problem).filter(
+ id__in=[problem_paragraph_mapping.problem_id for problem_paragraph_mapping in
+ problem_paragraph_mapping_list])
+ target_problem_list = list(
+ QuerySet(Problem).filter(content__in=[problem.content for problem in problem_list],
+ dataset_id=target_dataset_id))
+ target_handle_problem_list = [
+ self.get_target_dataset_problem(target_dataset_id, problem_paragraph_mapping,
+ problem_list, target_problem_list) for
+ problem_paragraph_mapping
+ in
+ problem_paragraph_mapping_list]
+
+ create_problem_list = [problem for problem, is_create in target_handle_problem_list if
+ is_create is not None and is_create]
+ # 插入问题
+ QuerySet(Problem).bulk_create(create_problem_list)
+ # 修改mapping
+ QuerySet(ProblemParagraphMapping).bulk_update(problem_paragraph_mapping_list, ['problem_id', 'dataset_id'])
+ # 修改文档
+ if dataset.type == Type.base.value and target_dataset.type == Type.web.value:
+ document_list.update(dataset_id=target_dataset_id, type=Type.web,
+ meta={'source_url': '', 'selector': ''})
+ elif target_dataset.type == Type.base.value and dataset.type == Type.web.value:
+ document_list.update(dataset_id=target_dataset_id, type=Type.base,
+ meta={})
+ else:
+ document_list.update(dataset_id=target_dataset_id)
+ model_id = None
+ if dataset.embedding_mode_id != target_dataset.embedding_mode_id:
+ model_id = get_embedding_model_id_by_dataset_id(target_dataset_id)
+
+ pid_list = [paragraph.id for paragraph in paragraph_list]
+ # 修改段落信息
+ paragraph_list.update(dataset_id=target_dataset_id)
+ # 修改向量信息
+ if model_id:
+ delete_embedding_by_paragraph_ids(pid_list)
+ QuerySet(Document).filter(id__in=document_id_list).update(status=Status.queue_up)
+ embedding_by_document_list.delay(document_id_list, model_id)
+ else:
+ update_embedding_dataset_id(pid_list, target_dataset_id)
+
+ @staticmethod
+ def get_target_dataset_problem(target_dataset_id: str,
+ problem_paragraph_mapping,
+ source_problem_list,
+ target_problem_list):
+ source_problem_list = [source_problem for source_problem in source_problem_list if
+ source_problem.id == problem_paragraph_mapping.problem_id]
+ problem_paragraph_mapping.dataset_id = target_dataset_id
+ if len(source_problem_list) > 0:
+ problem_content = source_problem_list[-1].content
+ problem_list = [problem for problem in target_problem_list if problem.content == problem_content]
+ if len(problem_list) > 0:
+ problem = problem_list[-1]
+ problem_paragraph_mapping.problem_id = problem.id
+ return problem, False
+ else:
+ problem = Problem(id=uuid.uuid1(), dataset_id=target_dataset_id, content=problem_content)
+ target_problem_list.append(problem)
+ problem_paragraph_mapping.problem_id = problem.id
+ return problem, True
+ return None
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='target_dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='目标知识库id')
+ ]
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_ARRAY,
+ items=openapi.Schema(type=openapi.TYPE_STRING),
+ title='文档id列表',
+ description="文档id列表"
+ )
+
+ class Query(ApiMixin, serializers.Serializer):
+ # 知识库id
+ dataset_id = serializers.UUIDField(required=True,
+ error_messages=ErrMessage.char(
+ "知识库id"))
+
+ name = serializers.CharField(required=False, max_length=128,
+ min_length=1,
+ error_messages=ErrMessage.char(
+ "文档名称"))
+ hit_handling_method = serializers.CharField(required=False, error_messages=ErrMessage.char("命中处理方式"))
+
+ def get_query_set(self):
+ query_set = QuerySet(model=Document)
+ query_set = query_set.filter(**{'dataset_id': self.data.get("dataset_id")})
+ if 'name' in self.data and self.data.get('name') is not None:
+ query_set = query_set.filter(**{'name__icontains': self.data.get('name')})
+ if 'hit_handling_method' in self.data and self.data.get('hit_handling_method') is not None:
+ query_set = query_set.filter(**{'hit_handling_method': self.data.get('hit_handling_method')})
+ query_set = query_set.order_by('-create_time')
+ return query_set
+
+ def list(self, with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ query_set = self.get_query_set()
+ return native_search(query_set, select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_document.sql')))
+
+ def page(self, current_page, page_size):
+ query_set = self.get_query_set()
+ return native_page_search(current_page, page_size, query_set, select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_document.sql')))
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='name',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='文档名称'),
+ openapi.Parameter(name='hit_handling_method', in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='文档命中处理方式')]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(type=openapi.TYPE_ARRAY,
+ title="文档列表", description="文档列表",
+ items=DocumentSerializers.Operate.get_response_body_api())
+
+ class Sync(ApiMixin, serializers.Serializer):
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "文档id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ document_id = self.data.get('document_id')
+ first = QuerySet(Document).filter(id=document_id).first()
+ if first is None:
+ raise AppApiException(500, "文档id不存在")
+ if first.type != Type.web:
+ raise AppApiException(500, "只有web站点类型才支持同步")
+
+ def sync(self, with_valid=True, with_embedding=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ document_id = self.data.get('document_id')
+ document = QuerySet(Document).filter(id=document_id).first()
+ if document.type != Type.web:
+ return True
+ try:
+ document.status = Status.queue_up
+ document.save()
+ source_url = document.meta.get('source_url')
+ selector_list = document.meta.get('selector').split(
+ " ") if 'selector' in document.meta and document.meta.get('selector') is not None else []
+ result = Fork(source_url, selector_list).fork()
+ if result.status == 200:
+ # 删除段落
+ QuerySet(model=Paragraph).filter(document_id=document_id).delete()
+ # 删除问题
+ QuerySet(model=ProblemParagraphMapping).filter(document_id=document_id).delete()
+ # 删除向量库
+ delete_embedding_by_document(document_id)
+ paragraphs = get_split_model('web.md').parse(result.content)
+ document.char_length = reduce(lambda x, y: x + y,
+ [len(p.get('content')) for p in paragraphs],
+ 0)
+ document.save()
+ document_paragraph_model = DocumentSerializers.Create.get_paragraph_model(document, paragraphs)
+
+ paragraph_model_list = document_paragraph_model.get('paragraph_model_list')
+ problem_paragraph_object_list = document_paragraph_model.get('problem_paragraph_object_list')
+ problem_model_list, problem_paragraph_mapping_list = ProblemParagraphManage(
+ problem_paragraph_object_list, document.dataset_id).to_problem_model_list()
+ # 批量插入段落
+ QuerySet(Paragraph).bulk_create(paragraph_model_list) if len(paragraph_model_list) > 0 else None
+ # 批量插入问题
+ QuerySet(Problem).bulk_create(problem_model_list) if len(problem_model_list) > 0 else None
+ # 插入关联问题
+ QuerySet(ProblemParagraphMapping).bulk_create(problem_paragraph_mapping_list) if len(
+ problem_paragraph_mapping_list) > 0 else None
+ # 向量化
+ if with_embedding:
+ embedding_model_id = get_embedding_model_id_by_dataset_id(document.dataset_id)
+ embedding_by_document.delay(document_id, embedding_model_id)
+ else:
+ document.status = Status.error
+ document.save()
+ except Exception as e:
+ logging.getLogger("max_kb_error").error(f'{str(e)}:{traceback.format_exc()}')
+ document.status = Status.error
+ document.save()
+ return True
+
+ class Operate(ApiMixin, serializers.Serializer):
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "文档id"))
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char("数据集id"))
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='document_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='文档id')
+ ]
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ document_id = self.data.get('document_id')
+ if not QuerySet(Document).filter(id=document_id).exists():
+ raise AppApiException(500, "文档id不存在")
+
+ def export(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ document = QuerySet(Document).filter(id=self.data.get("document_id")).first()
+ paragraph_list = native_search(QuerySet(Paragraph).filter(document_id=self.data.get("document_id")),
+ get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql',
+ 'list_paragraph_document_name.sql')))
+ problem_mapping_list = native_search(
+ QuerySet(ProblemParagraphMapping).filter(document_id=self.data.get("document_id")), get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_problem_mapping.sql')),
+ with_table_name=True)
+ data_dict, document_dict = self.merge_problem(paragraph_list, problem_mapping_list, [document])
+ workbook = self.get_workbook(data_dict, document_dict)
+ response = HttpResponse(content_type='application/vnd.ms-excel')
+ response['Content-Disposition'] = f'attachment; filename="data.xls"'
+ workbook.save(response)
+ return response
+
+ @staticmethod
+ def get_workbook(data_dict, document_dict):
+ # 创建工作簿对象
+ workbook = xlwt.Workbook(encoding='utf-8')
+ for sheet_id in data_dict:
+ # 添加工作表
+ worksheet = workbook.add_sheet(document_dict.get(sheet_id))
+ data = [
+ ['分段标题(选填)', '分段内容(必填,问题答案,最长不超过4096个字符)', '问题(选填,单元格内一行一个)'],
+ *data_dict.get(sheet_id)
+ ]
+ # 写入数据到工作表
+ for row_idx, row in enumerate(data):
+ for col_idx, col in enumerate(row):
+ worksheet.write(row_idx, col_idx, col)
+ # 创建HttpResponse对象返回Excel文件
+ return workbook
+
+ @staticmethod
+ def merge_problem(paragraph_list: List[Dict], problem_mapping_list: List[Dict], document_list):
+ result = {}
+ document_dict = {}
+
+ for paragraph in paragraph_list:
+ problem_list = [problem_mapping.get('content') for problem_mapping in problem_mapping_list if
+ problem_mapping.get('paragraph_id') == paragraph.get('id')]
+ document_sheet = result.get(paragraph.get('document_id'))
+ document_name = DocumentSerializers.Operate.reset_document_name(paragraph.get('document_name'))
+ d = document_dict.get(document_name)
+ if d is None:
+ document_dict[document_name] = {paragraph.get('document_id')}
+ else:
+ d.add(paragraph.get('document_id'))
+
+ if document_sheet is None:
+ result[paragraph.get('document_id')] = [[paragraph.get('title'), paragraph.get('content'),
+ '\n'.join(problem_list)]]
+ else:
+ document_sheet.append([paragraph.get('title'), paragraph.get('content'), '\n'.join(problem_list)])
+ for document in document_list:
+ if document.id not in result:
+ document_name = DocumentSerializers.Operate.reset_document_name(document.name)
+ result[document.id] = [[]]
+ d = document_dict.get(document_name)
+ if d is None:
+ document_dict[document_name] = {document.id}
+ else:
+ d.add(document.id)
+ result_document_dict = {}
+ for d_name in document_dict:
+ for index, d_id in enumerate(document_dict.get(d_name)):
+ result_document_dict[d_id] = d_name if index == 0 else d_name + str(index)
+ return result, result_document_dict
+
+ @staticmethod
+ def reset_document_name(document_name):
+ if document_name is None or not Utils.valid_sheet_name(document_name):
+ return "Sheet"
+ return document_name.strip()
+
+ def one(self, with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ query_set = QuerySet(model=Document)
+ query_set = query_set.filter(**{'id': self.data.get("document_id")})
+ return native_search(query_set, select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_document.sql')), with_search_one=True)
+
+ def edit(self, instance: Dict, with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ _document = QuerySet(Document).get(id=self.data.get("document_id"))
+ if with_valid:
+ DocumentEditInstanceSerializer(data=instance).is_valid(document=_document)
+ update_keys = ['name', 'is_active', 'hit_handling_method', 'directly_return_similarity', 'meta']
+ for update_key in update_keys:
+ if update_key in instance and instance.get(update_key) is not None:
+ _document.__setattr__(update_key, instance.get(update_key))
+ _document.save()
+ return self.one()
+
+ def refresh(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ document_id = self.data.get("document_id")
+ QuerySet(Document).filter(id=document_id).update(**{'status': Status.queue_up})
+ QuerySet(Paragraph).filter(document_id=document_id).update(**{'status': Status.queue_up})
+ embedding_model_id = get_embedding_model_id_by_dataset_id(dataset_id=self.data.get('dataset_id'))
+ try:
+ embedding_by_document.delay(document_id, embedding_model_id)
+ except AlreadyQueued as e:
+ raise AppApiException(500, "任务正在执行中,请勿重复下发")
+
+ @transaction.atomic
+ def delete(self):
+ document_id = self.data.get("document_id")
+ QuerySet(model=Document).filter(id=document_id).delete()
+ # 删除段落
+ QuerySet(model=Paragraph).filter(document_id=document_id).delete()
+ # 删除问题
+ QuerySet(model=ProblemParagraphMapping).filter(document_id=document_id).delete()
+ # 删除向量库
+ delete_embedding_by_document(document_id)
+ return True
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'name', 'char_length', 'user_id', 'paragraph_count', 'is_active'
+ 'update_time', 'create_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="名称",
+ description="名称", default="测试知识库"),
+ 'char_length': openapi.Schema(type=openapi.TYPE_INTEGER, title="字符数",
+ description="字符数", default=10),
+ 'user_id': openapi.Schema(type=openapi.TYPE_STRING, title="用户id", description="用户id"),
+ 'paragraph_count': openapi.Schema(type=openapi.TYPE_INTEGER, title="文档数量",
+ description="文档数量", default=1),
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否可用",
+ description="是否可用", default=True),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ )
+ }
+ )
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'name': openapi.Schema(type=openapi.TYPE_STRING, title="文档名称", description="文档名称"),
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否可用", description="是否可用"),
+ 'hit_handling_method': openapi.Schema(type=openapi.TYPE_STRING, title="命中处理方式",
+ description="ai优化:optimization,直接返回:directly_return"),
+ 'directly_return_similarity': openapi.Schema(type=openapi.TYPE_NUMBER, title="直接返回分数",
+ default=0.9),
+ 'meta': openapi.Schema(type=openapi.TYPE_OBJECT, title="文档元数据",
+ description="文档元数据->web:{source_url:xxx,selector:'xxx'},base:{}"),
+ }
+ )
+
+ class Create(ApiMixin, serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "文档id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(DataSet).filter(id=self.data.get('dataset_id')).exists():
+ raise AppApiException(10000, "知识库id不存在")
+ return True
+
+ @staticmethod
+ def post_embedding(result, document_id, dataset_id):
+ model_id = get_embedding_model_id_by_dataset_id(dataset_id)
+ embedding_by_document.delay(document_id, model_id)
+ return result
+
+ @staticmethod
+ def parse_qa_file(file):
+ get_buffer = FileBufferHandle().get_buffer
+ for parse_qa_handle in parse_qa_handle_list:
+ if parse_qa_handle.support(file, get_buffer):
+ return parse_qa_handle.handle(file, get_buffer)
+ raise AppApiException(500, '不支持的文件格式')
+
+ def save_qa(self, instance: Dict, with_valid=True):
+ if with_valid:
+ DocumentInstanceQASerializer(data=instance).is_valid(raise_exception=True)
+ self.is_valid(raise_exception=True)
+ file_list = instance.get('file_list')
+ document_list = flat_map([self.parse_qa_file(file) for file in file_list])
+ return DocumentSerializers.Batch(data={'dataset_id': self.data.get('dataset_id')}).batch_save(document_list)
+
+ @post(post_function=post_embedding)
+ @transaction.atomic
+ def save(self, instance: Dict, with_valid=False, **kwargs):
+ if with_valid:
+ DocumentInstanceSerializer(data=instance).is_valid(raise_exception=True)
+ self.is_valid(raise_exception=True)
+ dataset_id = self.data.get('dataset_id')
+ document_paragraph_model = self.get_document_paragraph_model(dataset_id, instance)
+
+ document_model = document_paragraph_model.get('document')
+ paragraph_model_list = document_paragraph_model.get('paragraph_model_list')
+ problem_paragraph_object_list = document_paragraph_model.get('problem_paragraph_object_list')
+ problem_model_list, problem_paragraph_mapping_list = (ProblemParagraphManage(problem_paragraph_object_list,
+ dataset_id)
+ .to_problem_model_list())
+ # 插入文档
+ document_model.save()
+ # 批量插入段落
+ QuerySet(Paragraph).bulk_create(paragraph_model_list) if len(paragraph_model_list) > 0 else None
+ # 批量插入问题
+ QuerySet(Problem).bulk_create(problem_model_list) if len(problem_model_list) > 0 else None
+ # 批量插入关联问题
+ QuerySet(ProblemParagraphMapping).bulk_create(problem_paragraph_mapping_list) if len(
+ problem_paragraph_mapping_list) > 0 else None
+ document_id = str(document_model.id)
+ return DocumentSerializers.Operate(
+ data={'dataset_id': dataset_id, 'document_id': document_id}).one(
+ with_valid=True), document_id, dataset_id
+
+ def save_web(self, instance: Dict, with_valid=True):
+ if with_valid:
+ DocumentWebInstanceSerializer(data=instance).is_valid(raise_exception=True)
+ self.is_valid(raise_exception=True)
+ dataset_id = self.data.get('dataset_id')
+ source_url_list = instance.get('source_url_list')
+ selector = instance.get('selector')
+ sync_web_document.delay(dataset_id, source_url_list, selector)
+
+ @staticmethod
+ def get_paragraph_model(document_model, paragraph_list: List):
+ dataset_id = document_model.dataset_id
+ paragraph_model_dict_list = [ParagraphSerializers.Create(
+ data={'dataset_id': dataset_id, 'document_id': str(document_model.id)}).get_paragraph_problem_model(
+ dataset_id, document_model.id, paragraph) for paragraph in paragraph_list]
+
+ paragraph_model_list = []
+ problem_paragraph_object_list = []
+ for paragraphs in paragraph_model_dict_list:
+ paragraph = paragraphs.get('paragraph')
+ for problem_model in paragraphs.get('problem_paragraph_object_list'):
+ problem_paragraph_object_list.append(problem_model)
+ paragraph_model_list.append(paragraph)
+
+ return {'document': document_model, 'paragraph_model_list': paragraph_model_list,
+ 'problem_paragraph_object_list': problem_paragraph_object_list}
+
+ @staticmethod
+ def get_document_paragraph_model(dataset_id, instance: Dict):
+ document_model = Document(
+ **{'dataset_id': dataset_id,
+ 'id': uuid.uuid1(),
+ 'name': instance.get('name'),
+ 'char_length': reduce(lambda x, y: x + y,
+ [len(p.get('content')) for p in instance.get('paragraphs', [])],
+ 0),
+ 'meta': instance.get('meta') if instance.get('meta') is not None else {},
+ 'type': instance.get('type') if instance.get('type') is not None else Type.base})
+
+ return DocumentSerializers.Create.get_paragraph_model(document_model,
+ instance.get('paragraphs') if
+ 'paragraphs' in instance else [])
+
+ @staticmethod
+ def get_request_body_api():
+ return DocumentInstanceSerializer.get_request_body_api()
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id')
+ ]
+
+ class Split(ApiMixin, serializers.Serializer):
+ file = serializers.ListField(required=True, error_messages=ErrMessage.list(
+ "文件列表"))
+
+ limit = serializers.IntegerField(required=False, error_messages=ErrMessage.integer(
+ "分段长度"))
+
+ patterns = serializers.ListField(required=False,
+ child=serializers.CharField(required=True, error_messages=ErrMessage.char(
+ "分段标识")),
+ error_messages=ErrMessage.uuid(
+ "分段标识列表"))
+
+ with_filter = serializers.BooleanField(required=False, error_messages=ErrMessage.boolean(
+ "自动清洗"))
+
+ def is_valid(self, *, raise_exception=True):
+ super().is_valid(raise_exception=True)
+ files = self.data.get('file')
+ for f in files:
+ if f.size > 1024 * 1024 * 100:
+ raise AppApiException(500, "上传文件最大不能超过100MB")
+
+ @staticmethod
+ def get_request_params_api():
+ return [
+ openapi.Parameter(name='file',
+ in_=openapi.IN_FORM,
+ type=openapi.TYPE_ARRAY,
+ items=openapi.Items(type=openapi.TYPE_FILE),
+ required=True,
+ description='上传文件'),
+ openapi.Parameter(name='limit',
+ in_=openapi.IN_FORM,
+ required=False,
+ type=openapi.TYPE_INTEGER, title="分段长度", description="分段长度"),
+ openapi.Parameter(name='patterns',
+ in_=openapi.IN_FORM,
+ required=False,
+ type=openapi.TYPE_ARRAY, items=openapi.Items(type=openapi.TYPE_STRING),
+ title="分段正则列表", description="分段正则列表"),
+ openapi.Parameter(name='with_filter',
+ in_=openapi.IN_FORM,
+ required=False,
+ type=openapi.TYPE_BOOLEAN, title="是否清除特殊字符", description="是否清除特殊字符"),
+ ]
+
+ def parse(self):
+ file_list = self.data.get("file")
+ return list(
+ map(lambda f: file_to_paragraph(f, self.data.get("patterns", None), self.data.get("with_filter", None),
+ self.data.get("limit", 4096)), file_list))
+
+ class SplitPattern(ApiMixin, serializers.Serializer):
+ @staticmethod
+ def list():
+ return [{'key': "#", 'value': '(?<=^)# .*|(?<=\\n)# .*'},
+ {'key': '##', 'value': '(?<=\\n)(? 0 else None
+ # 批量插入段落
+ QuerySet(Paragraph).bulk_create(paragraph_model_list) if len(paragraph_model_list) > 0 else None
+ # 批量插入问题
+ QuerySet(Problem).bulk_create(problem_model_list) if len(problem_model_list) > 0 else None
+ # 批量插入关联问题
+ QuerySet(ProblemParagraphMapping).bulk_create(problem_paragraph_mapping_list) if len(
+ problem_paragraph_mapping_list) > 0 else None
+ # 查询文档
+ query_set = QuerySet(model=Document)
+ if len(document_model_list) == 0:
+ return [],
+ query_set = query_set.filter(**{'id__in': [d.id for d in document_model_list]})
+ return native_search(query_set, select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_document.sql')),
+ with_search_one=False), dataset_id
+
+ @staticmethod
+ def _batch_sync(document_id_list: List[str]):
+ for document_id in document_id_list:
+ DocumentSerializers.Sync(data={'document_id': document_id}).sync()
+
+ def batch_sync(self, instance: Dict, with_valid=True):
+ if with_valid:
+ BatchSerializer(data=instance).is_valid(model=Document, raise_exception=True)
+ self.is_valid(raise_exception=True)
+ # 异步同步
+ work_thread_pool.submit(self._batch_sync,
+ instance.get('id_list'))
+ return True
+
+ @transaction.atomic
+ def batch_delete(self, instance: Dict, with_valid=True):
+ if with_valid:
+ BatchSerializer(data=instance).is_valid(model=Document, raise_exception=True)
+ self.is_valid(raise_exception=True)
+ document_id_list = instance.get("id_list")
+ QuerySet(Document).filter(id__in=document_id_list).delete()
+ QuerySet(Paragraph).filter(document_id__in=document_id_list).delete()
+ QuerySet(ProblemParagraphMapping).filter(document_id__in=document_id_list).delete()
+ # 删除向量库
+ delete_embedding_by_document_list(document_id_list)
+ return True
+
+ def batch_edit_hit_handling(self, instance: Dict, with_valid=True):
+ if with_valid:
+ BatchSerializer(data=instance).is_valid(model=Document, raise_exception=True)
+ hit_handling_method = instance.get('hit_handling_method')
+ if hit_handling_method is None:
+ raise AppApiException(500, '命中处理方式必填')
+ if hit_handling_method != 'optimization' and hit_handling_method != 'directly_return':
+ raise AppApiException(500, '命中处理方式必须为directly_return|optimization')
+ self.is_valid(raise_exception=True)
+ document_id_list = instance.get("id_list")
+ hit_handling_method = instance.get('hit_handling_method')
+ directly_return_similarity = instance.get('directly_return_similarity')
+ update_dict = {'hit_handling_method': hit_handling_method}
+ if directly_return_similarity is not None:
+ update_dict['directly_return_similarity'] = directly_return_similarity
+ QuerySet(Document).filter(id__in=document_id_list).update(**update_dict)
+
+
+class FileBufferHandle:
+ buffer = None
+
+ def get_buffer(self, file):
+ if self.buffer is None:
+ self.buffer = file.read()
+ return self.buffer
+
+
+default_split_handle = TextSplitHandle()
+split_handles = [HTMLSplitHandle(), DocSplitHandle(), PdfSplitHandle(), default_split_handle]
+
+
+def save_image(image_list):
+ QuerySet(Image).bulk_create(image_list)
+
+
+def file_to_paragraph(file, pattern_list: List, with_filter: bool, limit: int):
+ get_buffer = FileBufferHandle().get_buffer
+ for split_handle in split_handles:
+ if split_handle.support(file, get_buffer):
+ return split_handle.handle(file, pattern_list, with_filter, limit, get_buffer, save_image)
+ return default_split_handle.handle(file, pattern_list, with_filter, limit, get_buffer, save_image)
diff --git a/src/MaxKB-1.5.1/apps/dataset/serializers/file_serializers.py b/src/MaxKB-1.5.1/apps/dataset/serializers/file_serializers.py
new file mode 100644
index 0000000..894f149
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/serializers/file_serializers.py
@@ -0,0 +1,79 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: image_serializers.py
+ @date:2024/4/22 16:36
+ @desc:
+"""
+import uuid
+
+from django.db.models import QuerySet
+from django.http import HttpResponse
+from rest_framework import serializers
+
+from common.exception.app_exception import NotFound404
+from common.field.common import UploadedFileField
+from common.util.field_message import ErrMessage
+from dataset.models import File
+
+mime_types = {"html": "text/html", "htm": "text/html", "shtml": "text/html", "css": "text/css", "xml": "text/xml",
+ "gif": "image/gif", "jpeg": "image/jpeg", "jpg": "image/jpeg", "js": "application/javascript",
+ "atom": "application/atom+xml", "rss": "application/rss+xml", "mml": "text/mathml", "txt": "text/plain",
+ "jad": "text/vnd.sun.j2me.app-descriptor", "wml": "text/vnd.wap.wml", "htc": "text/x-component",
+ "avif": "image/avif", "png": "image/png", "svg": "image/svg+xml", "svgz": "image/svg+xml",
+ "tif": "image/tiff", "tiff": "image/tiff", "wbmp": "image/vnd.wap.wbmp", "webp": "image/webp",
+ "ico": "image/x-icon", "jng": "image/x-jng", "bmp": "image/x-ms-bmp", "woff": "font/woff",
+ "woff2": "font/woff2", "jar": "application/java-archive", "war": "application/java-archive",
+ "ear": "application/java-archive", "json": "application/json", "hqx": "application/mac-binhex40",
+ "doc": "application/msword", "pdf": "application/pdf", "ps": "application/postscript",
+ "eps": "application/postscript", "ai": "application/postscript", "rtf": "application/rtf",
+ "m3u8": "application/vnd.apple.mpegurl", "kml": "application/vnd.google-earth.kml+xml",
+ "kmz": "application/vnd.google-earth.kmz", "xls": "application/vnd.ms-excel",
+ "eot": "application/vnd.ms-fontobject", "ppt": "application/vnd.ms-powerpoint",
+ "odg": "application/vnd.oasis.opendocument.graphics",
+ "odp": "application/vnd.oasis.opendocument.presentation",
+ "ods": "application/vnd.oasis.opendocument.spreadsheet", "odt": "application/vnd.oasis.opendocument.text",
+ "wmlc": "application/vnd.wap.wmlc", "wasm": "application/wasm", "7z": "application/x-7z-compressed",
+ "cco": "application/x-cocoa", "jardiff": "application/x-java-archive-diff",
+ "jnlp": "application/x-java-jnlp-file", "run": "application/x-makeself", "pl": "application/x-perl",
+ "pm": "application/x-perl", "prc": "application/x-pilot", "pdb": "application/x-pilot",
+ "rar": "application/x-rar-compressed", "rpm": "application/x-redhat-package-manager",
+ "sea": "application/x-sea", "swf": "application/x-shockwave-flash", "sit": "application/x-stuffit",
+ "tcl": "application/x-tcl", "tk": "application/x-tcl", "der": "application/x-x509-ca-cert",
+ "pem": "application/x-x509-ca-cert", "crt": "application/x-x509-ca-cert",
+ "xpi": "application/x-xpinstall", "xhtml": "application/xhtml+xml", "xspf": "application/xspf+xml",
+ "zip": "application/zip", "bin": "application/octet-stream", "exe": "application/octet-stream",
+ "dll": "application/octet-stream", "deb": "application/octet-stream", "dmg": "application/octet-stream",
+ "iso": "application/octet-stream", "img": "application/octet-stream", "msi": "application/octet-stream",
+ "msp": "application/octet-stream", "msm": "application/octet-stream", "mid": "audio/midi",
+ "midi": "audio/midi", "kar": "audio/midi", "mp3": "audio/mpeg", "ogg": "audio/ogg", "m4a": "audio/x-m4a",
+ "ra": "audio/x-realaudio", "3gpp": "video/3gpp", "3gp": "video/3gpp", "ts": "video/mp2t",
+ "mp4": "video/mp4", "mpeg": "video/mpeg", "mpg": "video/mpeg", "mov": "video/quicktime",
+ "webm": "video/webm", "flv": "video/x-flv", "m4v": "video/x-m4v", "mng": "video/x-mng",
+ "asx": "video/x-ms-asf", "asf": "video/x-ms-asf", "wmv": "video/x-ms-wmv", "avi": "video/x-msvideo"}
+
+
+class FileSerializer(serializers.Serializer):
+ file = UploadedFileField(required=True, error_messages=ErrMessage.image("文件"))
+
+ def upload(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ file_id = uuid.uuid1()
+ file = File(id=file_id, file_name=self.data.get('file').name)
+ file.save(self.data.get('file').read())
+ return f'/api/file/{file_id}'
+
+ class Operate(serializers.Serializer):
+ id = serializers.UUIDField(required=True)
+
+ def get(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ file_id = self.data.get('id')
+ file = QuerySet(File).filter(id=file_id).first()
+ if file is None:
+ raise NotFound404(404, "不存在的文件")
+ return HttpResponse(file.get_byte(), status=200,
+ headers={'Content-Type': mime_types.get(file.file_name.split(".")[-1], 'text/plain')})
diff --git a/src/MaxKB-1.5.1/apps/dataset/serializers/image_serializers.py b/src/MaxKB-1.5.1/apps/dataset/serializers/image_serializers.py
new file mode 100644
index 0000000..694b6de
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/serializers/image_serializers.py
@@ -0,0 +1,44 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: image_serializers.py
+ @date:2024/4/22 16:36
+ @desc:
+"""
+import uuid
+
+from django.db.models import QuerySet
+from django.http import HttpResponse
+from rest_framework import serializers
+
+from common.exception.app_exception import NotFound404
+from common.field.common import UploadedImageField
+from common.util.field_message import ErrMessage
+from dataset.models import Image
+
+
+class ImageSerializer(serializers.Serializer):
+ image = UploadedImageField(required=True, error_messages=ErrMessage.image("图片"))
+
+ def upload(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ image_id = uuid.uuid1()
+ image = Image(id=image_id, image=self.data.get('image').read(), image_name=self.data.get('image').name)
+ image.save()
+ return f'/api/image/{image_id}'
+
+ class Operate(serializers.Serializer):
+ id = serializers.UUIDField(required=True)
+
+ def get(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ image_id = self.data.get('id')
+ image = QuerySet(Image).filter(id=image_id).first()
+ if image is None:
+ raise NotFound404(404, "不存在的图片")
+ if image.image_name.endswith('.svg'):
+ return HttpResponse(image.image, status=200, headers={'Content-Type': 'image/svg+xml'})
+ return HttpResponse(image.image, status=200, headers={'Content-Type': 'image/png'})
diff --git a/src/MaxKB-1.5.1/apps/dataset/serializers/paragraph_serializers.py b/src/MaxKB-1.5.1/apps/dataset/serializers/paragraph_serializers.py
new file mode 100644
index 0000000..84423dd
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/serializers/paragraph_serializers.py
@@ -0,0 +1,721 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: paragraph_serializers.py
+ @date:2023/10/16 15:51
+ @desc:
+"""
+import uuid
+from typing import Dict
+
+from django.db import transaction
+from django.db.models import QuerySet
+from drf_yasg import openapi
+from rest_framework import serializers
+
+from common.db.search import page_search
+from common.exception.app_exception import AppApiException
+from common.mixins.api_mixin import ApiMixin
+from common.util.common import post
+from common.util.field_message import ErrMessage
+from dataset.models import Paragraph, Problem, Document, ProblemParagraphMapping, DataSet
+from dataset.serializers.common_serializers import update_document_char_length, BatchSerializer, ProblemParagraphObject, \
+ ProblemParagraphManage, get_embedding_model_id_by_dataset_id
+from dataset.serializers.problem_serializers import ProblemInstanceSerializer, ProblemSerializer, ProblemSerializers
+from embedding.models import SourceType
+from embedding.task.embedding import embedding_by_problem as embedding_by_problem_task, embedding_by_problem, \
+ delete_embedding_by_source, enable_embedding_by_paragraph, disable_embedding_by_paragraph, embedding_by_paragraph, \
+ delete_embedding_by_paragraph, delete_embedding_by_paragraph_ids, update_embedding_document_id
+
+
+class ParagraphSerializer(serializers.ModelSerializer):
+ class Meta:
+ model = Paragraph
+ fields = ['id', 'content', 'is_active', 'document_id', 'title',
+ 'create_time', 'update_time']
+
+
+class ParagraphInstanceSerializer(ApiMixin, serializers.Serializer):
+ """
+ 段落实例对象
+ """
+ content = serializers.CharField(required=True, error_messages=ErrMessage.char("段落内容"),
+ max_length=102400,
+ min_length=1,
+ allow_null=True, allow_blank=True)
+
+ title = serializers.CharField(required=False, max_length=256, error_messages=ErrMessage.char("段落标题"),
+ allow_null=True, allow_blank=True)
+
+ problem_list = ProblemInstanceSerializer(required=False, many=True)
+
+ is_active = serializers.BooleanField(required=False, error_messages=ErrMessage.char("段落是否可用"))
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['content'],
+ properties={
+ 'content': openapi.Schema(type=openapi.TYPE_STRING, max_length=4096, title="分段内容",
+ description="分段内容"),
+
+ 'title': openapi.Schema(type=openapi.TYPE_STRING, max_length=256, title="分段标题",
+ description="分段标题"),
+
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否可用", description="是否可用"),
+
+ 'problem_list': openapi.Schema(type=openapi.TYPE_ARRAY, title='问题列表',
+ description="问题列表",
+ items=ProblemInstanceSerializer.get_request_body_api())
+ }
+ )
+
+
+class EditParagraphSerializers(serializers.Serializer):
+ title = serializers.CharField(required=False, max_length=256, error_messages=ErrMessage.char(
+ "分段标题"), allow_null=True, allow_blank=True)
+ content = serializers.CharField(required=False, max_length=102400, allow_null=True, allow_blank=True,
+ error_messages=ErrMessage.char(
+ "分段内容"))
+ problem_list = ProblemInstanceSerializer(required=False, many=True)
+
+
+class ParagraphSerializers(ApiMixin, serializers.Serializer):
+ title = serializers.CharField(required=False, max_length=256, error_messages=ErrMessage.char(
+ "分段标题"), allow_null=True, allow_blank=True)
+ content = serializers.CharField(required=True, max_length=102400, error_messages=ErrMessage.char(
+ "分段内容"))
+
+ class Problem(ApiMixin, serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("文档id"))
+
+ paragraph_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("段落id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(Paragraph).filter(id=self.data.get('paragraph_id')).exists():
+ raise AppApiException(500, "段落id不存在")
+
+ def list(self, with_valid=False):
+ """
+ 获取问题列表
+ :param with_valid: 是否校验
+ :return: 问题列表
+ """
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ problem_paragraph_mapping = QuerySet(ProblemParagraphMapping).filter(dataset_id=self.data.get("dataset_id"),
+ paragraph_id=self.data.get(
+ 'paragraph_id'))
+ return [ProblemSerializer(row).data for row in
+ QuerySet(Problem).filter(id__in=[row.problem_id for row in problem_paragraph_mapping])]
+
+ @transaction.atomic
+ def save(self, instance: Dict, with_valid=True, with_embedding=True, embedding_by_problem=None):
+ if with_valid:
+ self.is_valid()
+ ProblemInstanceSerializer(data=instance).is_valid(raise_exception=True)
+ problem = QuerySet(Problem).filter(dataset_id=self.data.get('dataset_id'),
+ content=instance.get('content')).first()
+ if problem is None:
+ problem = Problem(id=uuid.uuid1(), dataset_id=self.data.get('dataset_id'),
+ content=instance.get('content'))
+ problem.save()
+ if QuerySet(ProblemParagraphMapping).filter(dataset_id=self.data.get('dataset_id'), problem_id=problem.id,
+ paragraph_id=self.data.get('paragraph_id')).exists():
+ raise AppApiException(500, "已经关联,请勿重复关联")
+ problem_paragraph_mapping = ProblemParagraphMapping(id=uuid.uuid1(),
+ problem_id=problem.id,
+ document_id=self.data.get('document_id'),
+ paragraph_id=self.data.get('paragraph_id'),
+ dataset_id=self.data.get('dataset_id'))
+ problem_paragraph_mapping.save()
+ model_id = get_embedding_model_id_by_dataset_id(self.data.get('dataset_id'))
+ if with_embedding:
+ embedding_by_problem_task({'text': problem.content,
+ 'is_active': True,
+ 'source_type': SourceType.PROBLEM,
+ 'source_id': problem_paragraph_mapping.id,
+ 'document_id': self.data.get('document_id'),
+ 'paragraph_id': self.data.get('paragraph_id'),
+ 'dataset_id': self.data.get('dataset_id'),
+ }, model_id)
+
+ return ProblemSerializers.Operate(
+ data={'dataset_id': self.data.get('dataset_id'),
+ 'problem_id': problem.id}).one(with_valid=True)
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='document_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='文档id'),
+ openapi.Parameter(name='paragraph_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='段落id')]
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ required=["content"],
+ properties={
+ 'content': openapi.Schema(
+ type=openapi.TYPE_STRING, title="内容")
+ })
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'content', 'hit_num', 'dataset_id', 'create_time', 'update_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'content': openapi.Schema(type=openapi.TYPE_STRING, title="问题内容",
+ description="问题内容", default='问题内容'),
+ 'hit_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="命中数量", description="命中数量",
+ default=1),
+ 'dataset_id': openapi.Schema(type=openapi.TYPE_STRING, title="知识库id",
+ description="知识库id", default='xxx'),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ )
+ }
+ )
+
+ class Association(ApiMixin, serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+
+ problem_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("问题id"))
+
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("文档id"))
+
+ paragraph_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("段落id"))
+
+ def is_valid(self, *, raise_exception=True):
+ super().is_valid(raise_exception=True)
+ dataset_id = self.data.get('dataset_id')
+ paragraph_id = self.data.get('paragraph_id')
+ problem_id = self.data.get("problem_id")
+ if not QuerySet(Paragraph).filter(dataset_id=dataset_id, id=paragraph_id).exists():
+ raise AppApiException(500, "段落不存在")
+ if not QuerySet(Problem).filter(dataset_id=dataset_id, id=problem_id).exists():
+ raise AppApiException(500, "问题不存在")
+
+ def association(self, with_valid=True, with_embedding=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ problem = QuerySet(Problem).filter(id=self.data.get("problem_id")).first()
+ problem_paragraph_mapping = ProblemParagraphMapping(id=uuid.uuid1(),
+ document_id=self.data.get('document_id'),
+ paragraph_id=self.data.get('paragraph_id'),
+ dataset_id=self.data.get('dataset_id'),
+ problem_id=problem.id)
+ problem_paragraph_mapping.save()
+ if with_embedding:
+ model_id = get_embedding_model_id_by_dataset_id(self.data.get('dataset_id'))
+ embedding_by_problem({'text': problem.content,
+ 'is_active': True,
+ 'source_type': SourceType.PROBLEM,
+ 'source_id': problem_paragraph_mapping.id,
+ 'document_id': self.data.get('document_id'),
+ 'paragraph_id': self.data.get('paragraph_id'),
+ 'dataset_id': self.data.get('dataset_id'),
+ }, model_id)
+
+ def un_association(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ problem_paragraph_mapping = QuerySet(ProblemParagraphMapping).filter(
+ paragraph_id=self.data.get('paragraph_id'),
+ dataset_id=self.data.get('dataset_id'),
+ problem_id=self.data.get(
+ 'problem_id')).first()
+ problem_paragraph_mapping_id = problem_paragraph_mapping.id
+ problem_paragraph_mapping.delete()
+ delete_embedding_by_source(problem_paragraph_mapping_id)
+ return True
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='document_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='文档id')
+ , openapi.Parameter(name='paragraph_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='段落id'),
+ openapi.Parameter(name='problem_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='问题id')
+ ]
+
+ class Batch(serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("文档id"))
+
+ @transaction.atomic
+ def batch_delete(self, instance: Dict, with_valid=True):
+ if with_valid:
+ BatchSerializer(data=instance).is_valid(model=Paragraph, raise_exception=True)
+ self.is_valid(raise_exception=True)
+ paragraph_id_list = instance.get("id_list")
+ QuerySet(Paragraph).filter(id__in=paragraph_id_list).delete()
+ QuerySet(ProblemParagraphMapping).filter(paragraph_id__in=paragraph_id_list).delete()
+ update_document_char_length(self.data.get('document_id'))
+ # 删除向量库
+ delete_embedding_by_paragraph_ids(paragraph_id_list)
+ return True
+
+ class Migrate(ApiMixin, serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("文档id"))
+ target_dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("目标知识库id"))
+ target_document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("目标文档id"))
+ paragraph_id_list = serializers.ListField(required=True, error_messages=ErrMessage.char("段落列表"),
+ child=serializers.UUIDField(required=True,
+ error_messages=ErrMessage.uuid("段落id")))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ document_list = QuerySet(Document).filter(
+ id__in=[self.data.get('document_id'), self.data.get('target_document_id')])
+ document_id = self.data.get('document_id')
+ target_document_id = self.data.get('target_document_id')
+ if document_id == target_document_id:
+ raise AppApiException(5000, "需要迁移的文档和目标文档一致")
+ if len([document for document in document_list if str(document.id) == self.data.get('document_id')]) < 1:
+ raise AppApiException(5000, f"文档id不存在【{self.data.get('document_id')}】")
+ if len([document for document in document_list if
+ str(document.id) == self.data.get('target_document_id')]) < 1:
+ raise AppApiException(5000, f"目标文档id不存在【{self.data.get('target_document_id')}】")
+
+ @transaction.atomic
+ def migrate(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ dataset_id = self.data.get('dataset_id')
+ target_dataset_id = self.data.get('target_dataset_id')
+ document_id = self.data.get('document_id')
+ target_document_id = self.data.get('target_document_id')
+ paragraph_id_list = self.data.get('paragraph_id_list')
+ paragraph_list = QuerySet(Paragraph).filter(dataset_id=dataset_id, document_id=document_id,
+ id__in=paragraph_id_list)
+ problem_paragraph_mapping_list = QuerySet(ProblemParagraphMapping).filter(paragraph__in=paragraph_list)
+ # 同数据集迁移
+ if target_dataset_id == dataset_id:
+ if len(problem_paragraph_mapping_list):
+ problem_paragraph_mapping_list = [
+ self.update_problem_paragraph_mapping(target_document_id,
+ problem_paragraph_mapping) for problem_paragraph_mapping
+ in
+ problem_paragraph_mapping_list]
+ # 修改mapping
+ QuerySet(ProblemParagraphMapping).bulk_update(problem_paragraph_mapping_list,
+ ['document_id'])
+ update_embedding_document_id([paragraph.id for paragraph in paragraph_list],
+ target_document_id, target_dataset_id, None)
+ # 修改段落信息
+ paragraph_list.update(document_id=target_document_id)
+ # 不同数据集迁移
+ else:
+ problem_list = QuerySet(Problem).filter(
+ id__in=[problem_paragraph_mapping.problem_id for problem_paragraph_mapping in
+ problem_paragraph_mapping_list])
+ # 目标数据集问题
+ target_problem_list = list(
+ QuerySet(Problem).filter(content__in=[problem.content for problem in problem_list],
+ dataset_id=target_dataset_id))
+
+ target_handle_problem_list = [
+ self.get_target_dataset_problem(target_dataset_id, target_document_id, problem_paragraph_mapping,
+ problem_list, target_problem_list) for
+ problem_paragraph_mapping
+ in
+ problem_paragraph_mapping_list]
+
+ create_problem_list = [problem for problem, is_create in target_handle_problem_list if
+ is_create is not None and is_create]
+ # 插入问题
+ QuerySet(Problem).bulk_create(create_problem_list)
+ # 修改mapping
+ QuerySet(ProblemParagraphMapping).bulk_update(problem_paragraph_mapping_list,
+ ['problem_id', 'dataset_id', 'document_id'])
+ target_dataset = QuerySet(DataSet).filter(id=target_dataset_id).first()
+ dataset = QuerySet(DataSet).filter(id=dataset_id).first()
+ embedding_model_id = None
+ if target_dataset.embedding_mode_id != dataset.embedding_mode_id:
+ embedding_model_id = str(target_dataset.embedding_mode_id)
+ pid_list = [paragraph.id for paragraph in paragraph_list]
+ # 修改段落信息
+ paragraph_list.update(dataset_id=target_dataset_id, document_id=target_document_id)
+ # 修改向量段落信息
+ update_embedding_document_id(pid_list, target_document_id, target_dataset_id, embedding_model_id)
+
+ update_document_char_length(document_id)
+ update_document_char_length(target_document_id)
+
+ @staticmethod
+ def update_problem_paragraph_mapping(target_document_id: str, problem_paragraph_mapping):
+ problem_paragraph_mapping.document_id = target_document_id
+ return problem_paragraph_mapping
+
+ @staticmethod
+ def get_target_dataset_problem(target_dataset_id: str,
+ target_document_id: str,
+ problem_paragraph_mapping,
+ source_problem_list,
+ target_problem_list):
+ source_problem_list = [source_problem for source_problem in source_problem_list if
+ source_problem.id == problem_paragraph_mapping.problem_id]
+ problem_paragraph_mapping.dataset_id = target_dataset_id
+ problem_paragraph_mapping.document_id = target_document_id
+ if len(source_problem_list) > 0:
+ problem_content = source_problem_list[-1].content
+ problem_list = [problem for problem in target_problem_list if problem.content == problem_content]
+ if len(problem_list) > 0:
+ problem = problem_list[-1]
+ problem_paragraph_mapping.problem_id = problem.id
+ return problem, False
+ else:
+ problem = Problem(id=uuid.uuid1(), dataset_id=target_dataset_id, content=problem_content)
+ target_problem_list.append(problem)
+ problem_paragraph_mapping.problem_id = problem.id
+ return problem, True
+ return None
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='文档id'),
+ openapi.Parameter(name='document_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='文档id'),
+ openapi.Parameter(name='target_dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='目标知识库id'),
+ openapi.Parameter(name='target_document_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='目标知识库id')
+ ]
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_ARRAY,
+ items=openapi.Schema(type=openapi.TYPE_STRING),
+ title='段落id列表',
+ description="段落id列表"
+ )
+
+ class Operate(ApiMixin, serializers.Serializer):
+ # 段落id
+ paragraph_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "段落id"))
+ # 知识库id
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "知识库id"))
+ # 文档id
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "文档id"))
+
+ def is_valid(self, *, raise_exception=True):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(Paragraph).filter(id=self.data.get('paragraph_id')).exists():
+ raise AppApiException(500, "段落id不存在")
+
+ @staticmethod
+ def post_embedding(paragraph, instance, dataset_id):
+ if 'is_active' in instance and instance.get('is_active') is not None:
+ (enable_embedding_by_paragraph if instance.get(
+ 'is_active') else disable_embedding_by_paragraph)(paragraph.get('id'))
+
+ else:
+ model_id = get_embedding_model_id_by_dataset_id(dataset_id)
+ embedding_by_paragraph(paragraph.get('id'), model_id)
+ return paragraph
+
+ @post(post_embedding)
+ @transaction.atomic
+ def edit(self, instance: Dict):
+ self.is_valid()
+ EditParagraphSerializers(data=instance).is_valid(raise_exception=True)
+ _paragraph = QuerySet(Paragraph).get(id=self.data.get("paragraph_id"))
+ update_keys = ['title', 'content', 'is_active']
+ for update_key in update_keys:
+ if update_key in instance and instance.get(update_key) is not None:
+ _paragraph.__setattr__(update_key, instance.get(update_key))
+
+ if 'problem_list' in instance:
+ update_problem_list = list(
+ filter(lambda row: 'id' in row and row.get('id') is not None, instance.get('problem_list')))
+
+ create_problem_list = list(filter(lambda row: row.get('id') is None, instance.get('problem_list')))
+
+ # 问题集合
+ problem_list = QuerySet(Problem).filter(paragraph_id=self.data.get("paragraph_id"))
+
+ # 校验前端 携带过来的id
+ for update_problem in update_problem_list:
+ if not set([str(row.id) for row in problem_list]).__contains__(update_problem.get('id')):
+ raise AppApiException(500, update_problem.get('id') + '问题id不存在')
+ # 对比需要删除的问题
+ delete_problem_list = list(filter(
+ lambda row: not [str(update_row.get('id')) for update_row in update_problem_list].__contains__(
+ str(row.id)), problem_list)) if len(update_problem_list) > 0 else []
+ # 删除问题
+ QuerySet(Problem).filter(id__in=[row.id for row in delete_problem_list]).delete() if len(
+ delete_problem_list) > 0 else None
+ # 插入新的问题
+ QuerySet(Problem).bulk_create(
+ [Problem(id=uuid.uuid1(), content=p.get('content'), paragraph_id=self.data.get('paragraph_id'),
+ dataset_id=self.data.get('dataset_id'), document_id=self.data.get('document_id')) for
+ p in create_problem_list]) if len(create_problem_list) else None
+
+ # 修改问题集合
+ QuerySet(Problem).bulk_update(
+ [Problem(id=row.get('id'), content=row.get('content')) for row in update_problem_list],
+ ['content']) if len(
+ update_problem_list) > 0 else None
+
+ _paragraph.save()
+ update_document_char_length(self.data.get('document_id'))
+ return self.one(), instance, self.data.get('dataset_id')
+
+ def get_problem_list(self):
+ ProblemParagraphMapping(ProblemParagraphMapping)
+ problem_paragraph_mapping = QuerySet(ProblemParagraphMapping).filter(
+ paragraph_id=self.data.get("paragraph_id"))
+ if len(problem_paragraph_mapping) > 0:
+ return [ProblemSerializer(problem).data for problem in
+ QuerySet(Problem).filter(id__in=[ppm.problem_id for ppm in problem_paragraph_mapping])]
+ return []
+
+ def one(self, with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ return {**ParagraphSerializer(QuerySet(model=Paragraph).get(id=self.data.get('paragraph_id'))).data,
+ 'problem_list': self.get_problem_list()}
+
+ def delete(self, with_valid=False):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ paragraph_id = self.data.get('paragraph_id')
+ QuerySet(Paragraph).filter(id=paragraph_id).delete()
+ QuerySet(ProblemParagraphMapping).filter(paragraph_id=paragraph_id).delete()
+ update_document_char_length(self.data.get('document_id'))
+ delete_embedding_by_paragraph(paragraph_id)
+
+ @staticmethod
+ def get_request_body_api():
+ return ParagraphInstanceSerializer.get_request_body_api()
+
+ @staticmethod
+ def get_response_body_api():
+ return ParagraphInstanceSerializer.get_request_body_api()
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(type=openapi.TYPE_STRING, in_=openapi.IN_PATH, name='paragraph_id',
+ description="段落id")]
+
+ class Create(ApiMixin, serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "知识库id"))
+
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "文档id"))
+
+ def is_valid(self, *, raise_exception=False):
+ super().is_valid(raise_exception=True)
+ if not QuerySet(Document).filter(id=self.data.get('document_id'),
+ dataset_id=self.data.get('dataset_id')).exists():
+ raise AppApiException(500, "文档id不正确")
+
+ def save(self, instance: Dict, with_valid=True, with_embedding=True):
+ if with_valid:
+ ParagraphSerializers(data=instance).is_valid(raise_exception=True)
+ self.is_valid()
+ dataset_id = self.data.get("dataset_id")
+ document_id = self.data.get('document_id')
+ paragraph_problem_model = self.get_paragraph_problem_model(dataset_id, document_id, instance)
+ paragraph = paragraph_problem_model.get('paragraph')
+ problem_paragraph_object_list = paragraph_problem_model.get('problem_paragraph_object_list')
+ problem_model_list, problem_paragraph_mapping_list = (ProblemParagraphManage(problem_paragraph_object_list,
+ dataset_id).
+ to_problem_model_list())
+ # 插入段落
+ paragraph_problem_model.get('paragraph').save()
+ # 插入問題
+ QuerySet(Problem).bulk_create(problem_model_list) if len(problem_model_list) > 0 else None
+ # 插入问题关联关系
+ QuerySet(ProblemParagraphMapping).bulk_create(problem_paragraph_mapping_list) if len(
+ problem_paragraph_mapping_list) > 0 else None
+ # 修改长度
+ update_document_char_length(document_id)
+ if with_embedding:
+ model_id = get_embedding_model_id_by_dataset_id(dataset_id)
+ embedding_by_paragraph(str(paragraph.id), model_id)
+ return ParagraphSerializers.Operate(
+ data={'paragraph_id': str(paragraph.id), 'dataset_id': dataset_id, 'document_id': document_id}).one(
+ with_valid=True)
+
+ @staticmethod
+ def get_paragraph_problem_model(dataset_id: str, document_id: str, instance: Dict):
+ paragraph = Paragraph(id=uuid.uuid1(),
+ document_id=document_id,
+ content=instance.get("content"),
+ dataset_id=dataset_id,
+ title=instance.get("title") if 'title' in instance else '')
+ problem_paragraph_object_list = [
+ ProblemParagraphObject(dataset_id, document_id, paragraph.id, problem.get('content')) for problem in
+ (instance.get('problem_list') if 'problem_list' in instance else [])]
+
+ return {'paragraph': paragraph,
+ 'problem_paragraph_object_list': problem_paragraph_object_list}
+
+ @staticmethod
+ def or_get(exists_problem_list, content, dataset_id):
+ exists = [row for row in exists_problem_list if row.content == content]
+ if len(exists) > 0:
+ return exists[0]
+ else:
+ return Problem(id=uuid.uuid1(), content=content, dataset_id=dataset_id)
+
+ @staticmethod
+ def get_request_body_api():
+ return ParagraphInstanceSerializer.get_request_body_api()
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='document_id', in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description="文档id")
+ ]
+
+ class Query(ApiMixin, serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "知识库id"))
+
+ document_id = serializers.UUIDField(required=True, error_messages=ErrMessage.char(
+ "文档id"))
+
+ title = serializers.CharField(required=False, error_messages=ErrMessage.char(
+ "段落标题"))
+
+ content = serializers.CharField(required=False)
+
+ def get_query_set(self):
+ query_set = QuerySet(model=Paragraph)
+ query_set = query_set.filter(
+ **{'dataset_id': self.data.get('dataset_id'), 'document_id': self.data.get("document_id")})
+ if 'title' in self.data:
+ query_set = query_set.filter(
+ **{'title__icontains': self.data.get('title')})
+ if 'content' in self.data:
+ query_set = query_set.filter(**{'content__icontains': self.data.get('content')})
+ return query_set
+
+ def list(self):
+ return list(map(lambda row: ParagraphSerializer(row).data, self.get_query_set()))
+
+ def page(self, current_page, page_size):
+ query_set = self.get_query_set()
+ return page_search(current_page, page_size, query_set, lambda row: ParagraphSerializer(row).data)
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='document_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='文档id'),
+ openapi.Parameter(name='title',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='标题'),
+ openapi.Parameter(name='content',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='内容')
+ ]
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'content', 'hit_num', 'star_num', 'trample_num', 'is_active', 'dataset_id',
+ 'document_id', 'title',
+ 'create_time', 'update_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'content': openapi.Schema(type=openapi.TYPE_STRING, title="段落内容",
+ description="段落内容", default='段落内容'),
+ 'title': openapi.Schema(type=openapi.TYPE_STRING, title="标题",
+ description="标题", default="xxx的描述"),
+ 'hit_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="命中数量", description="命中数量",
+ default=1),
+ 'star_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="点赞数量",
+ description="点赞数量", default=1),
+ 'trample_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="点踩数量",
+ description="点踩数", default=1),
+ 'dataset_id': openapi.Schema(type=openapi.TYPE_STRING, title="知识库id",
+ description="知识库id", default='xxx'),
+ 'document_id': openapi.Schema(type=openapi.TYPE_STRING, title="文档id",
+ description="文档id", default='xxx'),
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否可用",
+ description="是否可用", default=True),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ )
+ }
+ )
diff --git a/src/MaxKB-1.5.1/apps/dataset/serializers/problem_serializers.py b/src/MaxKB-1.5.1/apps/dataset/serializers/problem_serializers.py
new file mode 100644
index 0000000..65fb44d
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/serializers/problem_serializers.py
@@ -0,0 +1,165 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: problem_serializers.py
+ @date:2023/10/23 13:55
+ @desc:
+"""
+import os
+import uuid
+from typing import Dict, List
+
+from django.db import transaction
+from django.db.models import QuerySet
+from drf_yasg import openapi
+from rest_framework import serializers
+
+from common.db.search import native_search, native_page_search
+from common.mixins.api_mixin import ApiMixin
+from common.util.field_message import ErrMessage
+from common.util.file_util import get_file_content
+from dataset.models import Problem, Paragraph, ProblemParagraphMapping, DataSet
+from dataset.serializers.common_serializers import get_embedding_model_id_by_dataset_id
+from embedding.task import delete_embedding_by_source_ids, update_problem_embedding
+from smartdoc.conf import PROJECT_DIR
+
+
+class ProblemSerializer(serializers.ModelSerializer):
+ class Meta:
+ model = Problem
+ fields = ['id', 'content', 'dataset_id',
+ 'create_time', 'update_time']
+
+
+class ProblemInstanceSerializer(ApiMixin, serializers.Serializer):
+ id = serializers.CharField(required=False, error_messages=ErrMessage.char("问题id"))
+
+ content = serializers.CharField(required=True, max_length=256, error_messages=ErrMessage.char("问题内容"))
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_OBJECT,
+ required=["content"],
+ properties={
+ 'id': openapi.Schema(
+ type=openapi.TYPE_STRING,
+ title="问题id,修改的时候传递,创建的时候不传"),
+ 'content': openapi.Schema(
+ type=openapi.TYPE_STRING, title="内容")
+ })
+
+
+class ProblemSerializers(ApiMixin, serializers.Serializer):
+ class Create(serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+ problem_list = serializers.ListField(required=True, error_messages=ErrMessage.list("问题列表"),
+ child=serializers.CharField(required=True,
+ error_messages=ErrMessage.char("问题")))
+
+ def batch(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ problem_list = self.data.get('problem_list')
+ problem_list = list(set(problem_list))
+ dataset_id = self.data.get('dataset_id')
+ exists_problem_content_list = [problem.content for problem in
+ QuerySet(Problem).filter(dataset_id=dataset_id,
+ content__in=problem_list)]
+ problem_instance_list = [Problem(id=uuid.uuid1(), dataset_id=dataset_id, content=problem_content) for
+ problem_content in
+ problem_list if
+ (not exists_problem_content_list.__contains__(problem_content) if
+ len(exists_problem_content_list) > 0 else True)]
+
+ QuerySet(Problem).bulk_create(problem_instance_list) if len(problem_instance_list) > 0 else None
+ return [ProblemSerializer(problem_instance).data for problem_instance in problem_instance_list]
+
+ class Query(serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+ content = serializers.CharField(required=False, error_messages=ErrMessage.char("问题"))
+
+ def get_query_set(self):
+ query_set = QuerySet(model=Problem)
+ query_set = query_set.filter(
+ **{'dataset_id': self.data.get('dataset_id')})
+ if 'content' in self.data:
+ query_set = query_set.filter(**{'content__icontains': self.data.get('content')})
+ query_set = query_set.order_by("-create_time")
+ return query_set
+
+ def list(self):
+ query_set = self.get_query_set()
+ return native_search(query_set, select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_problem.sql')))
+
+ def page(self, current_page, page_size):
+ query_set = self.get_query_set()
+ return native_page_search(current_page, page_size, query_set, select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_problem.sql')))
+
+ class BatchOperate(serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+
+ def delete(self, problem_id_list: List, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ dataset_id = self.data.get('dataset_id')
+ problem_paragraph_mapping_list = QuerySet(ProblemParagraphMapping).filter(
+ dataset_id=dataset_id,
+ problem_id__in=problem_id_list)
+ source_ids = [row.id for row in problem_paragraph_mapping_list]
+ problem_paragraph_mapping_list.delete()
+ QuerySet(Problem).filter(id__in=problem_id_list).delete()
+ delete_embedding_by_source_ids(source_ids)
+ return True
+
+ class Operate(serializers.Serializer):
+ dataset_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("知识库id"))
+
+ problem_id = serializers.UUIDField(required=True, error_messages=ErrMessage.uuid("问题id"))
+
+ def list_paragraph(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ problem_paragraph_mapping = QuerySet(ProblemParagraphMapping).filter(dataset_id=self.data.get("dataset_id"),
+ problem_id=self.data.get("problem_id"))
+ if problem_paragraph_mapping is None or len(problem_paragraph_mapping) == 0:
+ return []
+ return native_search(
+ QuerySet(Paragraph).filter(id__in=[row.paragraph_id for row in problem_paragraph_mapping]),
+ select_string=get_file_content(
+ os.path.join(PROJECT_DIR, "apps", "dataset", 'sql', 'list_paragraph.sql')))
+
+ def one(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ return ProblemInstanceSerializer(QuerySet(Problem).get(**{'id': self.data.get('problem_id')})).data
+
+ @transaction.atomic
+ def delete(self, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ problem_paragraph_mapping_list = QuerySet(ProblemParagraphMapping).filter(
+ dataset_id=self.data.get('dataset_id'),
+ problem_id=self.data.get('problem_id'))
+ source_ids = [row.id for row in problem_paragraph_mapping_list]
+ problem_paragraph_mapping_list.delete()
+ QuerySet(Problem).filter(id=self.data.get('problem_id')).delete()
+ delete_embedding_by_source_ids(source_ids)
+ return True
+
+ @transaction.atomic
+ def edit(self, instance: Dict, with_valid=True):
+ if with_valid:
+ self.is_valid(raise_exception=True)
+ problem_id = self.data.get('problem_id')
+ dataset_id = self.data.get('dataset_id')
+ content = instance.get('content')
+ problem = QuerySet(Problem).filter(id=problem_id,
+ dataset_id=dataset_id).first()
+ QuerySet(DataSet).filter(id=dataset_id)
+ problem.content = content
+ problem.save()
+ model_id = get_embedding_model_id_by_dataset_id(dataset_id)
+ update_problem_embedding(problem_id, content, model_id)
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/list_dataset.sql b/src/MaxKB-1.5.1/apps/dataset/sql/list_dataset.sql
new file mode 100644
index 0000000..8f62034
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/list_dataset.sql
@@ -0,0 +1,35 @@
+SELECT
+ *,
+ to_json(meta) as meta
+FROM
+ (
+ SELECT
+ "temp_dataset".*,
+ "document_temp"."char_length",
+ CASE
+ WHEN
+ "app_dataset_temp"."count" IS NULL THEN 0 ELSE "app_dataset_temp"."count" END AS application_mapping_count,
+ "document_temp".document_count FROM (
+ SELECT dataset.*
+ FROM
+ dataset dataset
+ ${dataset_custom_sql}
+ UNION
+ SELECT
+ *
+ FROM
+ dataset
+ WHERE
+ dataset."id" IN (
+ SELECT
+ team_member_permission.target
+ FROM
+ team_member team_member
+ LEFT JOIN team_member_permission team_member_permission ON team_member_permission.member_id = team_member."id"
+ ${team_member_permission_custom_sql}
+ )
+ ) temp_dataset
+ LEFT JOIN ( SELECT "count" ( "id" ) AS document_count, "sum" ( "char_length" ) "char_length", dataset_id FROM "document" GROUP BY dataset_id ) "document_temp" ON temp_dataset."id" = "document_temp".dataset_id
+ LEFT JOIN (SELECT "count"("id"),dataset_id FROM application_dataset_mapping GROUP BY dataset_id) app_dataset_temp ON temp_dataset."id" = "app_dataset_temp".dataset_id
+ ) temp
+ ${default_sql}
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/list_dataset_application.sql b/src/MaxKB-1.5.1/apps/dataset/sql/list_dataset_application.sql
new file mode 100644
index 0000000..9da36a3
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/list_dataset_application.sql
@@ -0,0 +1,20 @@
+SELECT
+ *
+FROM
+ application
+WHERE
+ user_id = %s UNION
+SELECT
+ *
+FROM
+ application
+WHERE
+ "id" IN (
+ SELECT
+ team_member_permission.target
+ FROM
+ team_member team_member
+ LEFT JOIN team_member_permission team_member_permission ON team_member_permission.member_id = team_member."id"
+ WHERE
+ ( "team_member_permission"."auth_target_type" = 'APPLICATION' AND "team_member_permission"."operate"::text[] @> ARRAY['USE'] AND team_member.team_id = %s AND team_member.user_id =%s )
+ )
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/list_document.sql b/src/MaxKB-1.5.1/apps/dataset/sql/list_document.sql
new file mode 100644
index 0000000..818d783
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/list_document.sql
@@ -0,0 +1,6 @@
+SELECT
+ "document".* ,
+ to_json("document"."meta") as meta,
+ (SELECT "count"("id") FROM "paragraph" WHERE document_id="document"."id") as "paragraph_count"
+FROM
+ "document" "document"
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/list_paragraph.sql b/src/MaxKB-1.5.1/apps/dataset/sql/list_paragraph.sql
new file mode 100644
index 0000000..2256f3f
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/list_paragraph.sql
@@ -0,0 +1,6 @@
+SELECT
+ (SELECT "name" FROM "document" WHERE "id"=document_id) as document_name,
+ (SELECT "name" FROM "dataset" WHERE "id"=dataset_id) as dataset_name,
+ *
+FROM
+ "paragraph"
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/list_paragraph_document_name.sql b/src/MaxKB-1.5.1/apps/dataset/sql/list_paragraph_document_name.sql
new file mode 100644
index 0000000..a95209b
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/list_paragraph_document_name.sql
@@ -0,0 +1,5 @@
+SELECT
+ (SELECT "name" FROM "document" WHERE "id"=document_id) as document_name,
+ *
+FROM
+ "paragraph"
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/list_problem.sql b/src/MaxKB-1.5.1/apps/dataset/sql/list_problem.sql
new file mode 100644
index 0000000..affb513
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/list_problem.sql
@@ -0,0 +1,5 @@
+SELECT
+ problem.*,
+ (SELECT "count"("id") FROM "problem_paragraph_mapping" WHERE problem_id="problem"."id") as "paragraph_count"
+ FROM
+ problem problem
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/list_problem_mapping.sql b/src/MaxKB-1.5.1/apps/dataset/sql/list_problem_mapping.sql
new file mode 100644
index 0000000..8c8ac3c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/list_problem_mapping.sql
@@ -0,0 +1,2 @@
+SELECT "problem"."content",problem_paragraph_mapping.paragraph_id FROM problem problem
+LEFT JOIN problem_paragraph_mapping problem_paragraph_mapping ON problem_paragraph_mapping.problem_id=problem."id"
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/dataset/sql/update_document_char_length.sql b/src/MaxKB-1.5.1/apps/dataset/sql/update_document_char_length.sql
new file mode 100644
index 0000000..4a4060c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/sql/update_document_char_length.sql
@@ -0,0 +1,7 @@
+UPDATE "document"
+SET "char_length" = ( SELECT CASE WHEN
+ "sum" ( "char_length" ( "content" ) ) IS NULL THEN
+ 0 ELSE "sum" ( "char_length" ( "content" ) )
+ END FROM paragraph WHERE "document_id" = %s )
+WHERE
+ "id" = %s
\ No newline at end of file
diff --git a/src/MaxKB-1.5.1/apps/dataset/swagger_api/document_api.py b/src/MaxKB-1.5.1/apps/dataset/swagger_api/document_api.py
new file mode 100644
index 0000000..637a7e5
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/swagger_api/document_api.py
@@ -0,0 +1,28 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: document_api.py
+ @date:2024/4/28 13:56
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class DocumentApi(ApiMixin):
+ class BatchEditHitHandlingApi(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ properties={
+ 'id_list': openapi.Schema(type=openapi.TYPE_ARRAY, items=openapi.Schema(type=openapi.TYPE_STRING),
+ title="主键id列表",
+ description="主键id列表"),
+ 'hit_handling_method': openapi.Schema(type=openapi.TYPE_STRING, title="命中处理方式",
+ description="directly_return|optimization"),
+ 'directly_return_similarity': openapi.Schema(type=openapi.TYPE_NUMBER, title="直接返回相似度")
+ }
+ )
diff --git a/src/MaxKB-1.5.1/apps/dataset/swagger_api/image_api.py b/src/MaxKB-1.5.1/apps/dataset/swagger_api/image_api.py
new file mode 100644
index 0000000..f69b947
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/swagger_api/image_api.py
@@ -0,0 +1,22 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: image_api.py
+ @date:2024/4/23 11:23
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class ImageApi(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='file',
+ in_=openapi.IN_FORM,
+ type=openapi.TYPE_FILE,
+ required=True,
+ description='上传图片文件')
+ ]
diff --git a/src/MaxKB-1.5.1/apps/dataset/swagger_api/problem_api.py b/src/MaxKB-1.5.1/apps/dataset/swagger_api/problem_api.py
new file mode 100644
index 0000000..a7397aa
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/swagger_api/problem_api.py
@@ -0,0 +1,146 @@
+# coding=utf-8
+"""
+ @project: maxkb
+ @Author:虎
+ @file: problem_api.py
+ @date:2024/3/11 10:49
+ @desc:
+"""
+from drf_yasg import openapi
+
+from common.mixins.api_mixin import ApiMixin
+
+
+class ProblemApi(ApiMixin):
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['id', 'content', 'hit_num', 'dataset_id', 'create_time', 'update_time'],
+ properties={
+ 'id': openapi.Schema(type=openapi.TYPE_STRING, title="id",
+ description="id", default="xx"),
+ 'content': openapi.Schema(type=openapi.TYPE_STRING, title="问题内容",
+ description="问题内容", default='问题内容'),
+ 'hit_num': openapi.Schema(type=openapi.TYPE_INTEGER, title="命中数量", description="命中数量",
+ default=1),
+ 'dataset_id': openapi.Schema(type=openapi.TYPE_STRING, title="知识库id",
+ description="知识库id", default='xxx'),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ )
+ }
+ )
+
+ class BatchOperate(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ ]
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ title="问题id列表",
+ description="问题id列表",
+ type=openapi.TYPE_ARRAY,
+ items=openapi.Schema(type=openapi.TYPE_STRING)
+ )
+
+ class Operate(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='problem_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='问题id')]
+
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['content'],
+ properties={
+ 'content': openapi.Schema(type=openapi.TYPE_STRING, title="问题内容",
+ description="问题内容"),
+
+ }
+ )
+
+ class Paragraph(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return ProblemApi.Operate.get_request_params_api()
+
+ @staticmethod
+ def get_response_body_api():
+ return openapi.Schema(
+ type=openapi.TYPE_OBJECT,
+ required=['content'],
+ properties={
+ 'content': openapi.Schema(type=openapi.TYPE_STRING, max_length=4096, title="分段内容",
+ description="分段内容"),
+ 'title': openapi.Schema(type=openapi.TYPE_STRING, max_length=256, title="分段标题",
+ description="分段标题"),
+ 'is_active': openapi.Schema(type=openapi.TYPE_BOOLEAN, title="是否可用", description="是否可用"),
+ 'hit_num': openapi.Schema(type=openapi.TYPE_NUMBER, title="命中次数", description="命中次数"),
+ 'update_time': openapi.Schema(type=openapi.TYPE_STRING, title="修改时间",
+ description="修改时间",
+ default="1970-01-01 00:00:00"),
+ 'create_time': openapi.Schema(type=openapi.TYPE_STRING, title="创建时间",
+ description="创建时间",
+ default="1970-01-01 00:00:00"
+ ),
+ }
+ )
+
+ class Query(ApiMixin):
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id'),
+ openapi.Parameter(name='content',
+ in_=openapi.IN_QUERY,
+ type=openapi.TYPE_STRING,
+ required=False,
+ description='问题')]
+
+ class BatchCreate(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_ARRAY,
+ items=ProblemApi.Create.get_request_body_api())
+
+ @staticmethod
+ def get_request_params_api():
+ return ProblemApi.Create.get_request_params_api()
+
+ class Create(ApiMixin):
+ @staticmethod
+ def get_request_body_api():
+ return openapi.Schema(type=openapi.TYPE_STRING, description="问题文本")
+
+ @staticmethod
+ def get_request_params_api():
+ return [openapi.Parameter(name='dataset_id',
+ in_=openapi.IN_PATH,
+ type=openapi.TYPE_STRING,
+ required=True,
+ description='知识库id')]
diff --git a/src/MaxKB-1.5.1/apps/dataset/task/__init__.py b/src/MaxKB-1.5.1/apps/dataset/task/__init__.py
new file mode 100644
index 0000000..de3f965
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/task/__init__.py
@@ -0,0 +1,9 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: __init__.py
+ @date:2024/8/21 9:57
+ @desc:
+"""
+from .sync import *
diff --git a/src/MaxKB-1.5.1/apps/dataset/task/sync.py b/src/MaxKB-1.5.1/apps/dataset/task/sync.py
new file mode 100644
index 0000000..ee4c034
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/task/sync.py
@@ -0,0 +1,42 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: sync.py
+ @date:2024/8/20 21:37
+ @desc:
+"""
+
+import logging
+import traceback
+from typing import List
+
+from celery_once import QueueOnce
+
+from common.util.fork import ForkManage, Fork
+from dataset.task.tools import get_save_handler, get_sync_web_document_handler
+
+from ops import celery_app
+
+max_kb_error = logging.getLogger("max_kb_error")
+max_kb = logging.getLogger("max_kb")
+
+
+@celery_app.task(base=QueueOnce, once={'keys': ['dataset_id']}, name='celery:sync_web_dataset')
+def sync_web_dataset(dataset_id: str, url: str, selector: str):
+ try:
+ max_kb.info(f"开始--->开始同步web知识库:{dataset_id}")
+ ForkManage(url, selector.split(" ") if selector is not None else []).fork(2, set(),
+ get_save_handler(dataset_id,
+ selector))
+ max_kb.info(f"结束--->结束同步web知识库:{dataset_id}")
+ except Exception as e:
+ max_kb_error.error(f'同步web知识库:{dataset_id}出现错误{str(e)}{traceback.format_exc()}')
+
+
+@celery_app.task(name='celery:sync_web_document')
+def sync_web_document(dataset_id, source_url_list: List[str], selector: str):
+ handler = get_sync_web_document_handler(dataset_id)
+ for source_url in source_url_list:
+ result = Fork(base_fork_url=source_url, selector_list=selector.split(' ')).fork()
+ handler(source_url, selector, result)
diff --git a/src/MaxKB-1.5.1/apps/dataset/task/tools.py b/src/MaxKB-1.5.1/apps/dataset/task/tools.py
new file mode 100644
index 0000000..5eb4408
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/task/tools.py
@@ -0,0 +1,62 @@
+# coding=utf-8
+"""
+ @project: MaxKB
+ @Author:虎
+ @file: tools.py
+ @date:2024/8/20 21:48
+ @desc:
+"""
+
+import logging
+import traceback
+
+from common.util.fork import ChildLink, Fork
+from common.util.split_model import get_split_model
+from dataset.models import Type, Document, Status
+
+max_kb_error = logging.getLogger("max_kb_error")
+max_kb = logging.getLogger("max_kb")
+
+
+def get_save_handler(dataset_id, selector):
+ from dataset.serializers.document_serializers import DocumentSerializers
+
+ def handler(child_link: ChildLink, response: Fork.Response):
+ if response.status == 200:
+ try:
+ document_name = child_link.tag.text if child_link.tag is not None and len(
+ child_link.tag.text.strip()) > 0 else child_link.url
+ paragraphs = get_split_model('web.md').parse(response.content)
+ DocumentSerializers.Create(data={'dataset_id': dataset_id}).save(
+ {'name': document_name, 'paragraphs': paragraphs,
+ 'meta': {'source_url': child_link.url, 'selector': selector},
+ 'type': Type.web}, with_valid=True)
+ except Exception as e:
+ logging.getLogger("max_kb_error").error(f'{str(e)}:{traceback.format_exc()}')
+
+ return handler
+
+
+def get_sync_web_document_handler(dataset_id):
+ from dataset.serializers.document_serializers import DocumentSerializers
+
+ def handler(source_url: str, selector, response: Fork.Response):
+ if response.status == 200:
+ try:
+ paragraphs = get_split_model('web.md').parse(response.content)
+ # 插入
+ DocumentSerializers.Create(data={'dataset_id': dataset_id}).save(
+ {'name': source_url[0:128], 'paragraphs': paragraphs,
+ 'meta': {'source_url': source_url, 'selector': selector},
+ 'type': Type.web}, with_valid=True)
+ except Exception as e:
+ logging.getLogger("max_kb_error").error(f'{str(e)}:{traceback.format_exc()}')
+ else:
+ Document(name=source_url[0:128],
+ dataset_id=dataset_id,
+ meta={'source_url': source_url, 'selector': selector},
+ type=Type.web,
+ char_length=0,
+ status=Status.error).save()
+
+ return handler
diff --git a/src/MaxKB-1.5.1/apps/dataset/template/csv_template.csv b/src/MaxKB-1.5.1/apps/dataset/template/csv_template.csv
new file mode 100644
index 0000000..b306a9c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/template/csv_template.csv
@@ -0,0 +1,8 @@
+分段标题(选填),分段内容(必填,问题答案,最长不超过4096个字符)),问题(选填,单元格内一行一个)
+MaxKB产品介绍,"MaxKB 是一款基于 LLM 大语言模型的知识库问答系统。MaxKB = Max Knowledge Base,旨在成为企业的最强大脑。
+开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化,智能问答交互体验好;
+无缝嵌入:支持零编码快速嵌入到第三方业务系统;
+多模型支持:支持对接主流的大模型,包括 Ollama 本地私有大模型(如 Llama 2、Llama 3、qwen)、通义千问、OpenAI、Azure OpenAI、Kimi、智谱 AI、讯飞星火和百度千帆大模型等。","MaxKB是什么?
+MaxKB产品介绍
+MaxKB支持的大语言模型
+MaxKB优势"
diff --git a/src/MaxKB-1.5.1/apps/dataset/template/excel_template.xlsx b/src/MaxKB-1.5.1/apps/dataset/template/excel_template.xlsx
new file mode 100644
index 0000000..6517b15
Binary files /dev/null and b/src/MaxKB-1.5.1/apps/dataset/template/excel_template.xlsx differ
diff --git a/src/MaxKB-1.5.1/apps/dataset/tests.py b/src/MaxKB-1.5.1/apps/dataset/tests.py
new file mode 100644
index 0000000..7ce503c
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/tests.py
@@ -0,0 +1,3 @@
+from django.test import TestCase
+
+# Create your tests here.
diff --git a/src/MaxKB-1.5.1/apps/dataset/urls.py b/src/MaxKB-1.5.1/apps/dataset/urls.py
new file mode 100644
index 0000000..8162a13
--- /dev/null
+++ b/src/MaxKB-1.5.1/apps/dataset/urls.py
@@ -0,0 +1,61 @@
+from django.urls import path
+
+from . import views
+
+app_name = "dataset"
+urlpatterns = [
+ path('dataset', views.Dataset.as_view(), name="dataset"),
+ path('dataset/web', views.Dataset.CreateWebDataset.as_view()),
+ path('dataset/qa', views.Dataset.CreateQADataset.as_view()),
+ path('dataset/|
+
+ MaxKB 智能知识库
+
+ |
+
|---|
|
+
+
+ + + + 尊敬的用户: + ++ ++ ${code} 为您的动态验证码,请于30分钟内填写,为保障帐户安全,请勿向任何人提供此验证码。 + ++ +
+
+
+
+ 飞致云 - MaxKB 项目组 ++
+ 此为系统邮件,请勿回复 |
+
{/* foo */}
+```
+
+Use fromCodePoint to convert high value unicode entities ([#243](https://github.com/babel/babylon/pull/243)) (Ryan Duffy)
+
+When high value unicode entities (e.g. 💩) were used in the input source code they are now correctly encoded in the resulting AST.
+
+Rename folder to avoid Windows-illegal characters ([#281](https://github.com/babel/babylon/pull/281)) (Ryan Plant)
+
+Allow this.state.clone() when parsing decorators ([#262](https://github.com/babel/babylon/pull/262)) (Alex Rattray)
+
+### :house: Internal
+
+User external-helpers ([#254](https://github.com/babel/babylon/pull/254)) (Daniel Tschinder)
+
+Add watch script for dev ([#234](https://github.com/babel/babylon/pull/234)) (Kai Cataldo)
+
+Freeze current plugins list for "*" option, and remove from README.md ([#245](https://github.com/babel/babylon/pull/245)) (Andrew Levine)
+
+Prepare tests for multiple fixture runners. ([#240](https://github.com/babel/babylon/pull/240)) (Daniel Tschinder)
+
+Add some test coverage for decorators stage-0 plugin ([#250](https://github.com/babel/babylon/pull/250)) (Andrew Levine)
+
+Refactor tokenizer types file ([#263](https://github.com/babel/babylon/pull/263)) (Sven SAULEAU)
+
+Update eslint-config-babel to the latest version 🚀 ([#273](https://github.com/babel/babylon/pull/273)) (greenkeeper[bot])
+
+chore(package): update rollup to version 0.41.0 ([#272](https://github.com/babel/babylon/pull/272)) (greenkeeper[bot])
+
+chore(package): update flow-bin to version 0.37.0 ([#255](https://github.com/babel/babylon/pull/255)) (greenkeeper[bot])
+
+## 6.14.1 (2016-11-17)
+
+### :bug: Bug Fix
+
+Allow `"plugins": ["*"]` ([#229](https://github.com/babel/babylon/pull/229)) (Daniel Tschinder)
+
+```js
+{
+ "plugins": ["*"]
+}
+```
+
+Will include all parser plugins instead of specifying each one individually. Useful for tools like babel-eslint, jscodeshift, and ast-explorer.
+
+## 6.14.0 (2016-11-16)
+
+### :eyeglasses: Spec Compliance
+
+Throw error for reserved words `enum` and `await` ([#195](https://github.com/babel/babylon/pull/195)) (Kai Cataldo)
+
+[11.6.2.2 Future Reserved Words](http://www.ecma-international.org/ecma-262/6.0/#sec-future-reserved-words)
+
+Babylon will throw for more reserved words such as `enum` or `await` (in strict mode).
+
+```
+class enum {} // throws
+class await {} // throws in strict mode (module)
+```
+
+Optional names for function types and object type indexers ([#197](https://github.com/babel/babylon/pull/197)) (Gabe Levi)
+
+So where you used to have to write
+
+```js
+type A = (x: string, y: boolean) => number;
+type B = (z: string) => number;
+type C = { [key: string]: number };
+```
+
+you can now write (with flow 0.34.0)
+
+```js
+type A = (string, boolean) => number;
+type B = string => number;
+type C = { [string]: number };
+```
+
+Parse flow nested array type annotations like `number[][]` ([#219](https://github.com/babel/babylon/pull/219)) (Bernhard Häussner)
+
+Supports these form now of specifying array types:
+
+```js
+var a: number[][][][];
+var b: string[][];
+```
+
+### :bug: Bug Fix
+
+Correctly eat semicolon at the end of `DelcareModuleExports` ([#223](https://github.com/babel/babylon/pull/223)) (Daniel Tschinder)
+
+```
+declare module "foo" { declare module.exports: number }
+declare module "foo" { declare module.exports: number; } // also allowed now
+```
+
+### :house: Internal
+
+ * Count Babel tests towards Babylon code coverage ([#182](https://github.com/babel/babylon/pull/182)) (Moti Zilberman)
+ * Fix strange line endings ([#214](https://github.com/babel/babylon/pull/214)) (Thomas Grainger)
+ * Add node 7 (Daniel Tschinder)
+ * chore(package): update flow-bin to version 0.34.0 ([#204](https://github.com/babel/babylon/pull/204)) (Greenkeeper)
+
+## v6.13.1 (2016-10-26)
+
+### :nail_care: Polish
+
+- Use rollup for bundling to speed up startup time ([#190](https://github.com/babel/babylon/pull/190)) ([@drewml](https://github.com/DrewML))
+
+```js
+const babylon = require('babylon');
+const ast = babylon.parse('var foo = "lol";');
+```
+
+With that test case, there was a ~95ms savings by removing the need for node to build/traverse the dependency graph.
+
+**Without bundling**
+
+
+**With bundling**
+
+
+- add clean command [skip ci] ([#201](https://github.com/babel/babylon/pull/201)) (Henry Zhu)
+- add ForAwaitStatement (async generator already added) [skip ci] ([#196](https://github.com/babel/babylon/pull/196)) (Henry Zhu)
+
+## v6.13.0 (2016-10-21)
+
+### :eyeglasses: Spec Compliance
+
+Property variance type annotations for Flow plugin ([#161](https://github.com/babel/babylon/pull/161)) (Sam Goldman)
+
+> See https://flowtype.org/docs/variance.html for more information
+
+```js
+type T = { +p: T };
+interface T { -p: T };
+declare class T { +[k:K]: V };
+class T { -[k:K]: V };
+class C2 { +p: T = e };
+```
+
+Raise error on duplicate definition of __proto__ ([#183](https://github.com/babel/babylon/pull/183)) (Moti Zilberman)
+
+```js
+({ __proto__: 1, __proto__: 2 }) // Throws an error now
+```
+
+### :bug: Bug Fix
+
+Flow: Allow class properties to be named `static` ([#184](https://github.com/babel/babylon/pull/184)) (Moti Zilberman)
+
+```js
+declare class A {
+ static: T;
+}
+```
+
+Allow "async" as identifier for object literal property shorthand ([#187](https://github.com/babel/babylon/pull/187)) (Andrew Levine)
+
+```js
+var foo = { async, bar };
+```
+
+### :nail_care: Polish
+
+Fix flowtype and add inType to state ([#189](https://github.com/babel/babylon/pull/189)) (Daniel Tschinder)
+
+> This improves the performance slightly (because of hidden classes)
+
+### :house: Internal
+
+Fix .gitattributes line ending setting ([#191](https://github.com/babel/babylon/pull/191)) (Moti Zilberman)
+
+Increase test coverage ([#175](https://github.com/babel/babylon/pull/175) (Moti Zilberman)
+
+Readd missin .eslinignore for IDEs (Daniel Tschinder)
+
+Error on missing expected.json fixture in CI ([#188](https://github.com/babel/babylon/pull/188)) (Moti Zilberman)
+
+Add .gitattributes and .editorconfig for LF line endings ([#179](https://github.com/babel/babylon/pull/179)) (Moti Zilberman)
+
+Fixes two tests that are failing after the merge of #172 ([#177](https://github.com/babel/babylon/pull/177)) (Moti Zilberman)
+
+## v6.12.0 (2016-10-14)
+
+### :eyeglasses: Spec Compliance
+
+Implement import() syntax ([#163](https://github.com/babel/babylon/pull/163)) (Jordan Gensler)
+
+#### Dynamic Import
+
+- Proposal Repo: https://github.com/domenic/proposal-dynamic-import
+- Championed by [@domenic](https://github.com/domenic)
+- stage-2
+- [sept-28 tc39 notes](https://github.com/rwaldron/tc39-notes/blob/master/es7/2016-09/sept-28.md#113a-import)
+
+> This repository contains a proposal for adding a "function-like" import() module loading syntactic form to JavaScript
+
+```js
+import(`./section-modules/${link.dataset.entryModule}.js`)
+.then(module => {
+ module.loadPageInto(main);
+})
+```
+
+Add EmptyTypeAnnotation ([#171](https://github.com/babel/babylon/pull/171)) (Sam Goldman)
+
+#### EmptyTypeAnnotation
+
+Just wasn't covered before.
+
+```js
+type T = empty;
+```
+
+### :bug: Bug Fix
+
+Fix crash when exporting with destructuring and sparse array ([#170](https://github.com/babel/babylon/pull/170)) (Jeroen Engels)
+
+```js
+// was failing due to sparse array
+export const { foo: [ ,, qux7 ] } = bar;
+```
+
+Allow keyword in Flow object declaration property names with type parameters ([#146](https://github.com/babel/babylon/pull/146)) (Dan Harper)
+
+```js
+declare class X {
+ foobar
+ {...todos.map(todo => )}
+
+```
+
+- Add support for declare module.exports ([#72](https://github.com/babel/babylon/pull/72)) @danez
+
+```js
+declare module "foo" {
+ declare module.exports: {}
+}
+```
+
+### New Features
+
+- If supplied, attach filename property to comment node loc. ([#80](https://github.com/babel/babylon/pull/80)) @divmain
+- Add identifier name to node loc field ([#90](https://github.com/babel/babylon/pull/90)) @kittens
+
+### Bug Fixes
+
+- Fix exponential operator to behave according to spec ([#75](https://github.com/babel/babylon/pull/75)) @danez
+- Fix lookahead to not add comments to arrays which are not cloned ([#76](https://github.com/babel/babylon/pull/76)) @danez
+- Fix accidental fall-through in Flow type parsing. ([#82](https://github.com/babel/babylon/pull/82)) @xiemaisi
+- Only allow declares inside declare module ([#73](https://github.com/babel/babylon/pull/73)) @danez
+- Small fix for parsing type parameter declarations ([#83](https://github.com/babel/babylon/pull/83)) @gabelevi
+- Fix arrow param locations with flow types ([#57](https://github.com/babel/babylon/pull/57)) @danez
+- Fixes SyntaxError position with flow optional type ([#65](https://github.com/babel/babylon/pull/65)) @danez
+
+### Internal
+
+- Add codecoverage to tests @danez
+- Fix tests to not save expected output if we expect the test to fail @danez
+- Make a shallow clone of babel for testing @danez
+- chore(package): update cross-env to version 2.0.0 ([#77](https://github.com/babel/babylon/pull/77)) @greenkeeperio-bot
+- chore(package): update ava to version 0.16.0 ([#86](https://github.com/babel/babylon/pull/86)) @greenkeeperio-bot
+- chore(package): update babel-plugin-istanbul to version 2.0.0 ([#89](https://github.com/babel/babylon/pull/89)) @greenkeeperio-bot
+- chore(package): update nyc to version 8.0.0 ([#88](https://github.com/babel/babylon/pull/88)) @greenkeeperio-bot
+
+## 6.8.4 (2016-07-06)
+
+### Bug Fixes
+
+- Fix the location of params, when flow and default value used ([#68](https://github.com/babel/babylon/pull/68)) @danez
+
+## 6.8.3 (2016-07-02)
+
+### Bug Fixes
+
+- Fix performance regression introduced in 6.8.2 with conditionals ([#63](https://github.com/babel/babylon/pull/63)) @danez
+
+## 6.8.2 (2016-06-24)
+
+### Bug Fixes
+
+- Fix parse error with yielding jsx elements in generators `function* it() { yield ; }` ([#31](https://github.com/babel/babylon/pull/31)) @eldereal
+- When cloning nodes do not clone its comments ([#24](https://github.com/babel/babylon/pull/24)) @danez
+- Fix parse errors when using arrow functions with an spread element and return type `(...props): void => {}` ([#10](https://github.com/babel/babylon/pull/10)) @danez
+- Fix leading comments added from previous node ([#23](https://github.com/babel/babylon/pull/23)) @danez
+- Fix parse errors with flow's optional arguments `(arg?) => {}` ([#19](https://github.com/babel/babylon/pull/19)) @danez
+- Support negative numeric type literals @kittens
+- Remove line terminator restriction after await keyword @kittens
+- Remove grouped type arrow restriction as it seems flow no longer has it @kittens
+- Fix parse error with generic methods that have the name `get` or `set` `class foo { get() {} }` ([#55](https://github.com/babel/babylon/pull/55)) @vkurchatkin
+- Fix parse error with arrow functions that have flow type parameter declarations `
+
+
+> [!IMPORTANT]
+> We encourage manually importing components and charts from ECharts for smaller bundle size. We've built an [import code generator](https://vue-echarts.dev/#codegen) to help you with that. You can just paste in your `option` code and we'll generate the precise import code for you.
+>
+> 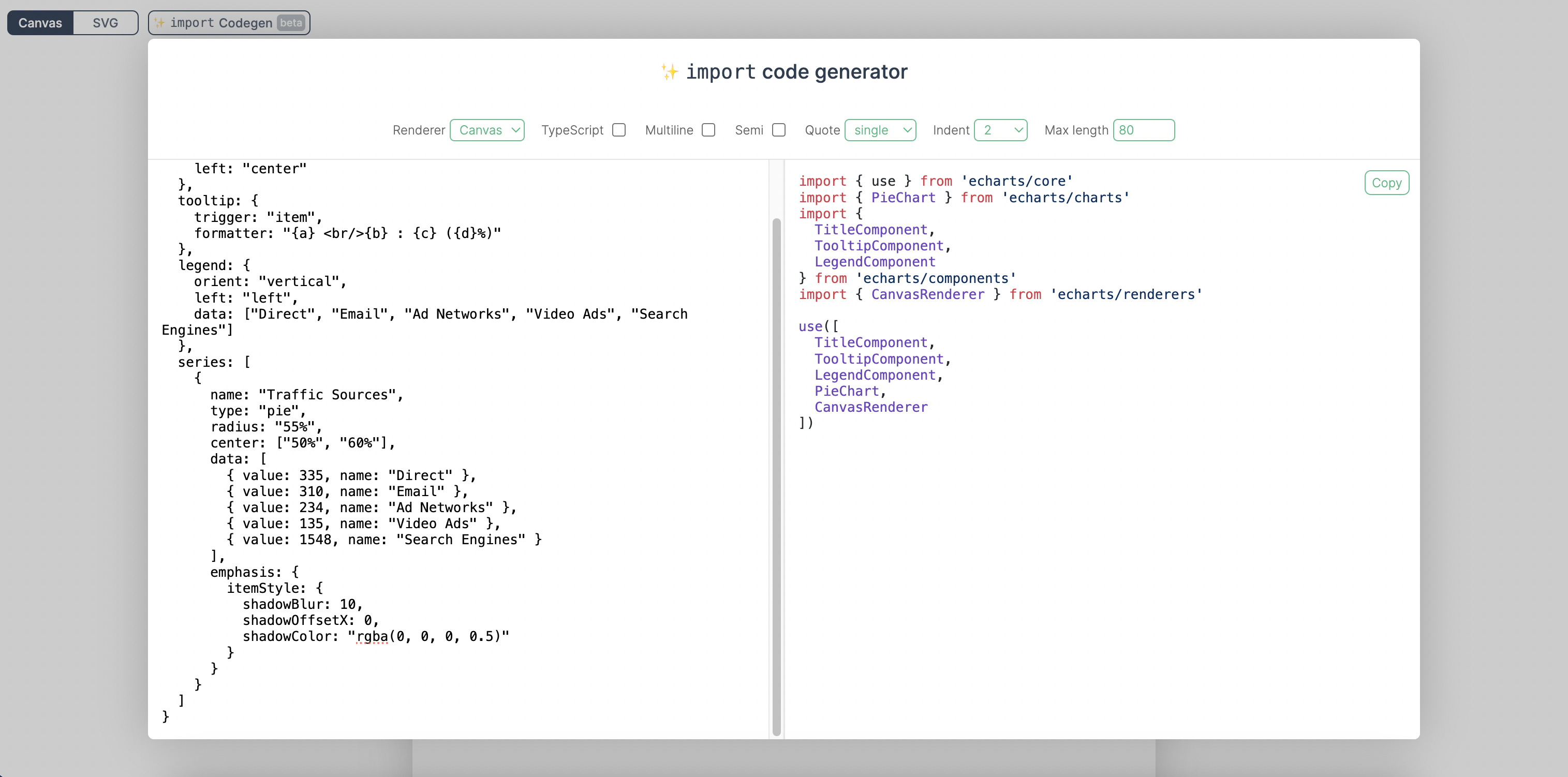
+>
+> [Try it →](https://vue-echarts.dev/#codegen)
+
+But if you really want to import the whole ECharts bundle without having to import modules manually, just add this in your code:
+
+```js
+import "echarts";
+```
+
+### CDN
+
+Drop `
+
+
+```
+
+
+```js
+const app = Vue.createApp(...)
+
+// register globally (or you can do it locally)
+app.component('v-chart', VueECharts)
+```
+
+
+
+Vue 2 Demo →
+ +```vue + +
+
+
+See more examples [here](https://github.com/ecomfe/vue-echarts/tree/main/src/demo).
+
+### Props
+
+- `init-options: object`
+
+ Optional chart init configurations. See `echarts.init`'s `opts` parameter [here →](https://echarts.apache.org/en/api.html#echarts.init)
+
+ Injection key: `INIT_OPTIONS_KEY`.
+
+- `theme: string | object`
+
+ Theme to be applied. See `echarts.init`'s `theme` parameter [here →](https://echarts.apache.org/en/api.html#echarts.init)
+
+ Injection key: `THEME_KEY`.
+
+- `option: object`
+
+ ECharts' universal interface. Modifying this prop will trigger ECharts' `setOption` method. Read more [here →](https://echarts.apache.org/en/option.html)
+
+ > 💡 When `update-options` is not specified, `notMerge: false` will be specified by default when the `setOption` method is called if the `option` object is modified directly and the reference remains unchanged; otherwise, if a new reference is bound to `option`, ` notMerge: true` will be specified.
+
+- `update-options: object`
+
+ Options for updating chart option. See `echartsInstance.setOption`'s `opts` parameter [here →](https://echarts.apache.org/en/api.html#echartsInstance.setOption)
+
+ Injection key: `UPDATE_OPTIONS_KEY`.
+
+- `group: string`
+
+ Group name to be used in chart [connection](https://echarts.apache.org/en/api.html#echarts.connect). See `echartsInstance.group` [here →](https://echarts.apache.org/en/api.html#echartsInstance.group)
+
+- `autoresize: boolean | { throttle?: number, onResize?: () => void }` (default: `false`)
+
+ Whether the chart should be resized automatically whenever its root is resized. Use the options object to specify a custom throttle delay (in milliseconds) and/or an extra resize callback function.
+
+- `loading: boolean` (default: `false`)
+
+ Whether the chart is in loading state.
+
+- `loading-options: object`
+
+ Configuration item of loading animation. See `echartsInstance.showLoading`'s `opts` parameter [here →](https://echarts.apache.org/en/api.html#echartsInstance.showLoading)
+
+ Injection key: `LOADING_OPTIONS_KEY`.
+
+- `manual-update: boolean` (default: `false`)
+
+ For performance critical scenarios (having a large dataset) we'd better bypass Vue's reactivity system for `option` prop. By specifying `manual-update` prop with `true` and not providing `option` prop, the dataset won't be watched any more. After doing so, you need to retrieve the component instance with `ref` and manually call `setOption` method to update the chart.
+
+### Events
+
+You can bind events with Vue's `v-on` directive.
+
+```vue
+
+ Vue 2 Demo →
+ + +```html + + + +``` + + +```js +// register globally (or you can do it locally) +Vue.component("v-chart", VueECharts); +``` + +
+
+
+Vue 3
+ +```js +import { THEME_KEY } from 'vue-echarts' +import { provide } from 'vue' + +// composition API +provide(THEME_KEY, 'dark') + +// options API +{ + provide: { + [THEME_KEY]: 'dark' + } +} +``` + +
+
+
+### Methods
+
+- `setOption` [→](https://echarts.apache.org/en/api.html#echartsInstance.setOption)
+- `getWidth` [→](https://echarts.apache.org/en/api.html#echartsInstance.getWidth)
+- `getHeight` [→](https://echarts.apache.org/en/api.html#echartsInstance.getHeight)
+- `getDom` [→](https://echarts.apache.org/en/api.html#echartsInstance.getDom)
+- `getOption` [→](https://echarts.apache.org/en/api.html#echartsInstance.getOption)
+- `resize` [→](https://echarts.apache.org/en/api.html#echartsInstance.resize)
+- `dispatchAction` [→](https://echarts.apache.org/en/api.html#echartsInstance.dispatchAction)
+- `convertToPixel` [→](https://echarts.apache.org/en/api.html#echartsInstance.convertToPixel)
+- `convertFromPixel` [→](https://echarts.apache.org/en/api.html#echartsInstance.convertFromPixel)
+- `containPixel` [→](https://echarts.apache.org/en/api.html#echartsInstance.containPixel)
+- `showLoading` [→](https://echarts.apache.org/en/api.html#echartsInstance.showLoading)
+- `hideLoading` [→](https://echarts.apache.org/en/api.html#echartsInstance.hideLoading)
+- `getDataURL` [→](https://echarts.apache.org/en/api.html#echartsInstance.getDataURL)
+- `getConnectedDataURL` [→](https://echarts.apache.org/en/api.html#echartsInstance.getConnectedDataURL)
+- `clear` [→](https://echarts.apache.org/en/api.html#echartsInstance.clear)
+- `dispose` [→](https://echarts.apache.org/en/api.html#echartsInstance.dispose)
+
+### Static Methods
+
+Static methods can be accessed from [`echarts` itself](https://echarts.apache.org/en/api.html#echarts).
+
+## CSP: `style-src` or `style-src-elem`
+
+If you are applying a CSP to prevent inline `
+```
+
+
+
+Vue 2
+ +```js +import { THEME_KEY } from 'vue-echarts' + +// in component options +{ + provide: { + [THEME_KEY]: 'dark' + } +} +``` + +> **Note** +> +> You need to provide an object for Vue 2 if you want to change it dynamically. +> +> ```js +> // in component options +> { +> data () { +> return { +> theme: { value: 'dark' } +> } +> }, +> provide () { +> return { +> [THEME_KEY]: this.theme +> } +> } +> } +> ``` + +
+
+
+> [!IMPORTANT]
+> 我们鼓励手动从 ECharts 中引入组件和图表,以减小打包体积。我们已经为此构建了一个[导入代码生成器](https://vue-echarts.dev/#codegen)。你只需要把`option` 代码粘贴进去,就可以得到精确的导入代码。
+>
+> 
+>
+> [试一试 →](https://vue-echarts.dev/#codegen)
+
+但如果你实在需要全量引入 ECharts 从而无需手动引入模块,只需要在代码中添加:
+
+```js
+import "echarts";
+```
+
+### CDN
+
+用如下方式在 HTML 中插入 `
+
+
+```
+
+
+```js
+const app = Vue.createApp(...)
+
+// 全局注册组件(也可以使用局部注册)
+app.component('v-chart', VueECharts)
+```
+
+
+
+Vue 2 Demo →
+ +```vue + +
+
+
+可以在[这里](https://github.com/ecomfe/vue-echarts/tree/main/src/demo)查看更多例子。
+
+### Prop
+
+- `init-options: object`
+
+ 初始化附加参数。请参考 `echarts.init` 的 `opts` 参数。[前往 →](https://echarts.apache.org/zh/api.html#echarts.init)
+
+ Inject 键名:`INIT_OPTIONS_KEY`。
+
+- `theme: string | object`
+
+ 要应用的主题。请参考 `echarts.init` 的 `theme` 参数。[前往 →](https://echarts.apache.org/zh/api.html#echarts.init)
+
+ Inject 键名:`THEME_KEY`。
+
+- `option: object`
+
+ ECharts 的万能接口。修改这个 prop 会触发 ECharts 实例的 `setOption` 方法。查看[详情 →](https://echarts.apache.org/zh/option.html)
+
+ > 💡 在没有指定 `update-options` 时,如果直接修改 `option` 对象而引用保持不变,`setOption` 方法调用时将默认指定 `notMerge: false`;否则,如果为 `option` 绑定一个新的引用,将指定 `notMerge: true`。
+
+- `update-options: object`
+
+ 图表更新的配置项。请参考 `echartsInstance.setOption` 的 `opts` 参数。[前往 →](https://echarts.apache.org/zh/api.html#echartsInstance.setOption)
+
+ Inject 键名:`UPDATE_OPTIONS_KEY`。
+
+- `group: string`
+
+ 图表的分组,用于[联动](https://echarts.apache.org/zh/api.html#echarts.connect)。请参考 `echartsInstance.group`。[前往 →](https://echarts.apache.org/zh/api.html#echartsInstance.group)
+
+- `autoresize: boolean | { throttle?: number, onResize?: () => void }`(默认值`false`)
+
+ 图表在组件根元素尺寸变化时是否需要自动进行重绘。也可以传入一个选项对象来指定自定义的节流延迟和尺寸变化时的额外回调函数。
+
+- `loading: boolean`(默认值:`false`)
+
+ 图表是否处于加载状态。
+
+- `loading-options: object`
+
+ 加载动画配置项。请参考 `echartsInstance.showLoading` 的 `opts` 参数。[前往 →](https://echarts.apache.org/zh/api.html#echartsInstance.showLoading)
+
+ Inject 键名:`LOADING_OPTIONS_KEY`。
+
+- `manual-update: boolean`(默认值`false`)
+
+ 在性能敏感(数据量很大)的场景下,我们最好对于 `option` prop 绕过 Vue 的响应式系统。当将 `manual-update` prop 指定为 `true` 且不传入 `option` prop 时,数据将不会被监听。然后,需要用 `ref` 获取组件实例以后手动调用 `setOption` 方法来更新图表。
+
+### 事件
+
+可以使用 Vue 的 `v-on` 指令绑定事件。
+
+```vue
+
+ Vue 2 Demo →
+ + +```html + + + +``` + + +```js +// 全局注册组件(也可以使用局部注册) +Vue.component("v-chart", VueECharts); +``` + +
+
+
+Vue 3
+ +```js +import { THEME_KEY } from 'vue-echarts' +import { provide } from 'vue' + +// 组合式 API +provide(THEME_KEY, 'dark') + +// 选项式 API +{ + provide: { + [THEME_KEY]: 'dark' + } +} +``` + +
+
+
+### 方法
+
+- `setOption` [→](https://echarts.apache.org/zh/api.html#echartsInstance.setOption)
+- `getWidth` [→](https://echarts.apache.org/zh/api.html#echartsInstance.getWidth)
+- `getHeight` [→](https://echarts.apache.org/zh/api.html#echartsInstance.getHeight)
+- `getDom` [→](https://echarts.apache.org/zh/api.html#echartsInstance.getDom)
+- `getOption` [→](https://echarts.apache.org/zh/api.html#echartsInstance.getOption)
+- `resize` [→](https://echarts.apache.org/zh/api.html#echartsInstance.resize)
+- `dispatchAction` [→](https://echarts.apache.org/zh/api.html#echartsInstance.dispatchAction)
+- `convertToPixel` [→](https://echarts.apache.org/zh/api.html#echartsInstance.convertToPixel)
+- `convertFromPixel` [→](https://echarts.apache.org/zh/api.html#echartsInstance.convertFromPixel)
+- `containPixel` [→](https://echarts.apache.org/zh/api.html#echartsInstance.containPixel)
+- `showLoading` [→](https://echarts.apache.org/zh/api.html#echartsInstance.showLoading)
+- `hideLoading` [→](https://echarts.apache.org/zh/api.html#echartsInstance.hideLoading)
+- `getDataURL` [→](https://echarts.apache.org/zh/api.html#echartsInstance.getDataURL)
+- `getConnectedDataURL` [→](https://echarts.apache.org/zh/api.html#echartsInstance.getConnectedDataURL)
+- `clear` [→](https://echarts.apache.org/zh/api.html#echartsInstance.clear)
+- `dispose` [→](https://echarts.apache.org/zh/api.html#echartsInstance.dispose)
+
+### 静态方法
+
+静态方法请直接通过 [`echarts` 本身](https://echarts.apache.org/zh/api.html#echarts)进行调用。
+
+
+
+## CSP: `style-src` 或 `style-src-elem`
+
+如果你正在应用 CSP 来防止内联 ` in svg, where nodeName is 'style',
+ // CSS classes is defined globally wherever the style tags are declared.
+
+ let el;
+ let namedFromForSub = namedFrom;
+
+ if (nodeName === 'defs') {
+ isInDefs = true;
+ }
+ if (nodeName === 'text') {
+ isInText = true;
+ }
+
+ if (nodeName === 'defs' || nodeName === 'switch') {
+ // Just make