Document not found (404)
-This URL is invalid, sorry. Please use the navigation bar or search to continue.
- - -This URL is invalid, sorry. Please use the navigation bar or search to continue.
- - - -
-每个同学可能都遇到过以下疑惑:
-而 Rusty Book 就是帮助大家解决这些问题的。
-在 Rust 元宇宙,夸奖别人的最高境界就是 rusty: 今天你"锈"了吗? 你的 Rust 代码好锈啊!
而本书,就是精选了各种开源库和代码片段,帮助大家打造优"锈"的 Rust 项目。
-以往,想要锈起来,你需要做到以下两步:
-为项目挑选 Awesome 依赖库 -但是目前已有的 awesome-rust项目有非常大的问题:里面鱼龙混杂,因为它的目的是列出所有项目,但对用户而言,更想看到的是可以在生产中使用的、稳定更新的优秀项目。
-在 Cookbook 中查询实用的代码片段,直接复制到项目中 -对于开发者而言,Cookbook 非常实用,几乎每一门编程语言都是如此。原因无他:聪明的开发者大部分时间不是在复制粘贴就是在复制粘贴的路上。而 CookBook 恰恰为各种实用场景提供了可供直接复制粘贴的代码,例如网络协议、数据库和文件操作、随机数生成、命令行解析等。
-但目前的 Rust Cookbook 更新非常不活跃,里面缺少了大量实用库,还有一些过时的老库。
-鉴于以上痛点,我们决定打造一本真正的锈书:一本足够"锈"但是又不会锈的书。
-这本书其实就是 Awesome Rust + Rust Cookbook 的结合体,但是我们不是简单粗暴的对内容进行了合并,而是从深层次将两者进行了融合,希望大家能喜欢。
-本书适合所有程度的 Rust 开发者使用:
-毕竟咱不是在面试造飞机,谁脑袋中能记住文件操作的各种细节,对不?
- - -rust-algorithms收集了一些经典的算法和数据结构,更强调算法实现的美观性,因此该库更适用于教学目的,请不要把它当成一个实用算法库在生产环境使用。
-TheAlgorithms/Rust项目所属的组织使用各种语言实现了多种算法,但是仅适用于演示的目的。
-rustgym 实现了相当多的 leetcode 和 Avent of Code 题解。
-raft-rs 是由 Tikv 提供的 Raft 分布式算法实现。Raft是一个强一致性的分布式算法,比 Paxos 协议更简单、更好理解
-Rust Crypto提供了一些常用的密码学算法实现,更新较为活跃。
-rust-bio 有常用的生物信息学所需的算法和数据结构。
- - -以下代码将解压缩( GzDecoder )当前目录中的 archive.tar.gz ,并将所有文件抽取出( Archive::unpack )来后当入到当前目录中。
-use std::fs::File; -use flate2::read::GzDecoder; -use tar::Archive; - -fn main() -> Result<(), std::io::Error> { - let path = "archive.tar.gz"; - - let tar_gz = File::open(path)?; - let tar = GzDecoder::new(tar_gz); - let mut archive = Archive::new(tar); - archive.unpack(".")?; - - Ok(()) -} -
以下代码将 /var/log 目录压缩成 archive.tar.gz:
/var/log 目录下的所有内容添加到压缩文件中,该文件在 backup/logs 目录下。archive.tar.gz 之前对数据进行压缩。-use std::fs::File; -use flate2::Compression; -use flate2::write::GzEncoder; - -fn main() -> Result<(), std::io::Error> { - let tar_gz = File::create("archive.tar.gz")?; - let enc = GzEncoder::new(tar_gz, Compression::default()); - let mut tar = tar::Builder::new(enc); - tar.append_dir_all("backup/logs", "/var/log")?; - Ok(()) -} -
遍历目录中的文件 Archive::entries,若解压前的文件名包含 bundle/logs 前缀,需要将前缀从文件名移除( Path::strip_prefix )后,再解压。
- - -use std::fs::File; -use std::path::PathBuf; -use flate2::read::GzDecoder; -use tar::Archive; - -fn main() -> Result<()> { - let file = File::open("archive.tar.gz")?; - let mut archive = Archive::new(GzDecoder::new(file)); - let prefix = "bundle/logs"; - - println!("Extracted the following files:"); - archive - .entries()? // 获取压缩档案中的文件条目列表 - .filter_map(|e| e.ok()) - // 对每个文件条目进行 map 处理 - .map(|mut entry| -> Result<PathBuf> { - // 将文件路径名中的前缀移除,获取一个新的路径名 - let path = entry.path()?.strip_prefix(prefix)?.to_owned(); - // 将内容解压到新的路径名中 - entry.unpack(&path)?; - Ok(path) - }) - .filter_map(|e| e.ok()) - .for_each(|x| println!("> {}", x.display())); - - Ok(()) -} -
ring::pbkdf2 可以对一个加盐密码进行哈希。
-- - --use data_encoding::HEXUPPER; -use ring::error::Unspecified; -use ring::rand::SecureRandom; -use ring::{digest, pbkdf2, rand}; -use std::num::NonZeroU32; - -fn main() -> Result<(), Unspecified> { - const CREDENTIAL_LEN: usize = digest::SHA512_OUTPUT_LEN; - let n_iter = NonZeroU32::new(100_000).unwrap(); - let rng = rand::SystemRandom::new(); - - let mut salt = [0u8; CREDENTIAL_LEN]; - // 生成 salt: 将安全生成的随机数填入到字节数组中 - rng.fill(&mut salt)?; - - let password = "Guess Me If You Can!"; - let mut pbkdf2_hash = [0u8; CREDENTIAL_LEN]; - pbkdf2::derive( - pbkdf2::PBKDF2_HMAC_SHA512, - n_iter, - &salt, - password.as_bytes(), - &mut pbkdf2_hash, - ); - println!("Salt: {}", HEXUPPER.encode(&salt)); - println!("PBKDF2 hash: {}", HEXUPPER.encode(&pbkdf2_hash)); - - // `verify` 检查哈希是否正确 - let should_`succeed = pbkdf2::verify( - pbkdf2::PBKDF2_HMAC_SHA512, - n_iter, - &salt, - password.as_bytes(), - &pbkdf2_hash, - ); - let wrong_password = "Definitely not the correct password"; - let should_fail = pbkdf2::verify( - pbkdf2::PBKDF2_HMAC_SHA512, - n_iter, - &salt, - wrong_password.as_bytes(), - &pbkdf2_hash, - ); - - assert!(should_succeed.is_ok()); - assert!(!should_fail.is_ok()); - - Ok(()) -} -
写入一些数据到文件中,然后使用 digest::Context 来计算文件内容的 SHA-256 摘要 digest::Digest。
--use error_chain::error_chain; -use data_encoding::HEXUPPER; -use ring::digest::{Context, Digest, SHA256}; -use std::fs::File; -use std::io::{BufReader, Read, Write}; - -error_chain! { - foreign_links { - Io(std::io::Error); - Decode(data_encoding::DecodeError); - } -} - -fn sha256_digest<R: Read>(mut reader: R) -> Result<Digest> { - let mut context = Context::new(&SHA256); - let mut buffer = [0; 1024]; - - loop { - let count = reader.read(&mut buffer)?; - if count == 0 { - break; - } - context.update(&buffer[..count]); - } - - Ok(context.finish()) -} - -fn main() -> Result<()> { - let path = "file.txt"; - - let mut output = File::create(path)?; - write!(output, "We will generate a digest of this text")?; - - let input = File::open(path)?; - let reader = BufReader::new(input); - let digest = sha256_digest(reader)?; - - println!("SHA-256 digest is {}", HEXUPPER.encode(digest.as_ref())); - - Ok(()) -} -
使用 ring::hmac 创建一个字符串签名并检查该签名的正确性。
-- - -use ring::{hmac, rand}; -use ring::rand::SecureRandom; -use ring::error::Unspecified; - -fn main() -> Result<(), Unspecified> { - let mut key_value = [0u8; 48]; - let rng = rand::SystemRandom::new(); - rng.fill(&mut key_value)?; - let key = hmac::Key::new(hmac::HMAC_SHA256, &key_value); - - let message = "Legitimate and important message."; - let signature = hmac::sign(&key, message.as_bytes()); - hmac::verify(&key, message.as_bytes(), signature.as_ref())?; - - Ok(()) -} -
num::complex::Complex 可以帮助我们创建复数,其中实部和虚部必须是一样的类型。
--fn main() { - let complex_integer = num::complex::Complex::new(10, 20); - let complex_float = num::complex::Complex::new(10.1, 20.1); - - println!("Complex integer: {}", complex_integer); - println!("Complex float: {}", complex_float); -} -
复数计算和 Rust 基本类型的计算并无区别。
--fn main() { - let complex_num1 = num::complex::Complex::new(10.0, 20.0); // Must use floats - let complex_num2 = num::complex::Complex::new(3.1, -4.2); - - let sum = complex_num1 + complex_num2; - - println!("Sum: {}", sum); -} -
在 num::complex::Complex 中定义了一些内置的数学函数,可用于对复数进行数学运算。
-- - -use std::f64::consts::PI; -use num::complex::Complex; - -fn main() { - let x = Complex::new(0.0, 2.0*PI); - - println!("e^(2i * pi) = {}", x.exp()); // =~1 -} -
使用 ndarray::arr2 可以创建二阶矩阵,并计算它们的和。
--use ndarray::arr2; - -fn main() { - let a = arr2(&[[1, 2, 3], - [4, 5, 6]]); - - let b = arr2(&[[6, 5, 4], - [3, 2, 1]]); - - // 借用 a 和 b,求和后生成新的矩阵 sum - let sum = &a + &b; - - println!("{}", a); - println!("+"); - println!("{}", b); - println!("="); - println!("{}", sum); -} -
ndarray::ArrayBase::dot 可以用于计算矩阵乘法。
--use ndarray::arr2; - -fn main() { - let a = arr2(&[[1, 2, 3], - [4, 5, 6]]); - - let b = arr2(&[[6, 3], - [5, 2], - [4, 1]]); - - println!("{}", a.dot(&b)); -} -
在 ndarry中,1 阶数组根据上下文既可以作为行向量也可以作为列向量。如果对你来说,这个行或列的方向很重要,可以考虑使用一行或一列的 2 阶数组来表示。
在下面例子中,由于 1 阶数组处于乘号的右边位置,因此 dot 会把它当成列向量来处理。
-use ndarray::{arr1, arr2, Array1}; - -fn main() { - let scalar = 4; - - let vector = arr1(&[1, 2, 3]); - - let matrix = arr2(&[[4, 5, 6], - [7, 8, 9]]); - - let new_vector: Array1<_> = scalar * vector; - println!("{}", new_vector); - - let new_matrix = matrix.dot(&new_vector); - println!("{}", new_matrix); -} -
浮点数通常是不精确的,因此比较浮点数不是一件简单的事。approx 提供的 assert_abs_diff_eq! 宏提供了方便的按元素比较的方式。为了使用 approx ,你需要在 ndarray 的依赖中开启相应的 feature:例如,在 Cargo.toml 中修改 ndarray 的依赖引入为 ndarray = { version = "0.13", features = ["approx"] }。
-use approx::assert_abs_diff_eq; -use ndarray::Array; - -fn main() { - let a = Array::from(vec![1., 2., 3., 4., 5.]); - let b = Array::from(vec![5., 4., 3., 2., 1.]); - let mut c = Array::from(vec![1., 2., 3., 4., 5.]); - let mut d = Array::from(vec![5., 4., 3., 2., 1.]); - - // 消耗 a 和 b 的所有权 - let z = a + b; - // 借用 c 和 d - let w = &c + &d; - - assert_abs_diff_eq!(z, Array::from(vec![6., 6., 6., 6., 6.])); - - println!("c = {}", c); - c[0] = 10.; - d[1] = 10.; - - assert_abs_diff_eq!(w, Array::from(vec![6., 6., 6., 6., 6.])); - -} -
需要注意的是 Array 和 ArrayView 都是 ArrayBase 的别名。因此一个更通用的参数应该是 &ArrayBase<S, Ix1> where S: Data,特别是在你提供一个公共 API 给其它用户时,但由于咱们是内部使用,因此更精准的 ArrayView1<f64> 会更适合。
-use ndarray::{array, Array1, ArrayView1}; - -fn l1_norm(x: ArrayView1<f64>) -> f64 { - x.fold(0., |acc, elem| acc + elem.abs()) -} - -fn l2_norm(x: ArrayView1<f64>) -> f64 { - x.dot(&x).sqrt() -} - -fn normalize(mut x: Array1<f64>) -> Array1<f64> { - let norm = l2_norm(x.view()); - x.mapv_inplace(|e| e/norm); - x -} - -fn main() { - let x = array![1., 2., 3., 4., 5.]; - println!("||x||_2 = {}", l2_norm(x.view())); - println!("||x||_1 = {}", l1_norm(x.view())); - println!("Normalizing x yields {:?}", normalize(x)); -} -
例子中使用 nalgebra::Matrix3 创建一个 3x3 的矩阵,然后尝试对其进行逆变换,获取一个逆矩阵。
--use nalgebra::Matrix3; - -fn main() { - let m1 = Matrix3::new(2.0, 1.0, 1.0, 3.0, 2.0, 1.0, 2.0, 1.0, 2.0); - println!("m1 = {}", m1); - match m1.try_inverse() { - Some(inv) => { - println!("The inverse of m1 is: {}", inv); - } - None => { - println!("m1 is not invertible!"); - } - } -} -
下面将展示如何将矩阵序列化为 JSON ,然后再反序列化为原矩阵。
-- - -extern crate nalgebra; -extern crate serde_json; - -use nalgebra::DMatrix; - -fn main() -> Result<(), std::io::Error> { - let row_slice: Vec<i32> = (1..5001).collect(); - let matrix = DMatrix::from_row_slice(50, 100, &row_slice); - - // 序列化矩阵 - let serialized_matrix = serde_json::to_string(&matrix)?; - - // 反序列化 - let deserialized_matrix: DMatrix<i32> = serde_json::from_str(&serialized_matrix)?; - - // 验证反序列化后的矩阵跟原始矩阵相等 - assert!(deserialized_matrix == matrix); - - Ok(()) -} -
使用 BitInt 可以对超过 128bit 的整数进行计算。
-- - -use num::bigint::{BigInt, ToBigInt}; - -fn factorial(x: i32) -> BigInt { - if let Some(mut factorial) = 1.to_bigint() { - for i in 1..=x { - factorial = factorial * i; - } - factorial - } - else { - panic!("Failed to calculate factorial!"); - } -} - -fn main() { - println!("{}! equals {}", 100, factorial(100)); -} -
下面的一些例子为 Rust 数组中的数据计算它们的中心趋势。
-首先计算的是平均值。
--fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let sum = data.iter().sum::<i32>() as f32; - let count = data.len(); - - let mean = match count { - positive if positive > 0 => Some(sum / count as f32), - _ => None - }; - - println!("Mean of the data is {:?}", mean); -} -
下面使用快速选择算法来计算中位数。该算法只会对可能包含中位数的数据分区进行排序,从而避免了对所有数据进行全排序。
--use std::cmp::Ordering; - -fn partition(data: &[i32]) -> Option<(Vec<i32>, i32, Vec<i32>)> { - match data.len() { - 0 => None, - _ => { - let (pivot_slice, tail) = data.split_at(1); - let pivot = pivot_slice[0]; - let (left, right) = tail.iter() - .fold((vec![], vec![]), |mut splits, next| { - { - let (ref mut left, ref mut right) = &mut splits; - if next < &pivot { - left.push(*next); - } else { - right.push(*next); - } - } - splits - }); - - Some((left, pivot, right)) - } - } -} - -fn select(data: &[i32], k: usize) -> Option<i32> { - let part = partition(data); - - match part { - None => None, - Some((left, pivot, right)) => { - let pivot_idx = left.len(); - - match pivot_idx.cmp(&k) { - Ordering::Equal => Some(pivot), - Ordering::Greater => select(&left, k), - Ordering::Less => select(&right, k - (pivot_idx + 1)), - } - }, - } -} - -fn median(data: &[i32]) -> Option<f32> { - let size = data.len(); - - match size { - even if even % 2 == 0 => { - let fst_med = select(data, (even / 2) - 1); - let snd_med = select(data, even / 2); - - match (fst_med, snd_med) { - (Some(fst), Some(snd)) => Some((fst + snd) as f32 / 2.0), - _ => None - } - }, - odd => select(data, odd / 2).map(|x| x as f32) - } -} - -fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let part = partition(&data); - println!("Partition is {:?}", part); - - let sel = select(&data, 5); - println!("Selection at ordered index {} is {:?}", 5, sel); - - let med = median(&data); - println!("Median is {:?}", med); -} -
下面使用了 HashMap 对不同数字出现的次数进行了分别统计。
-use std::collections::HashMap; - -fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let frequencies = data.iter().fold(HashMap::new(), |mut freqs, value| { - *freqs.entry(value).or_insert(0) += 1; - freqs - }); - - let mode = frequencies - .into_iter() - .max_by_key(|&(_, count)| count) - .map(|(value, _)| *value); - - println!("Mode of the data is {:?}", mode); -} -
下面一起来看看该如何计算一组测量值的标准偏差和 z-score。
-- - -fn mean(data: &[i32]) -> Option<f32> { - let sum = data.iter().sum::<i32>() as f32; - let count = data.len(); - - match count { - positive if positive > 0 => Some(sum / count as f32), - _ => None, - } -} - -fn std_deviation(data: &[i32]) -> Option<f32> { - match (mean(data), data.len()) { - (Some(data_mean), count) if count > 0 => { - let variance = data.iter().map(|value| { - let diff = data_mean - (*value as f32); - - diff * diff - }).sum::<f32>() / count as f32; - - Some(variance.sqrt()) - }, - _ => None - } -} - -fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let data_mean = mean(&data); - println!("Mean is {:?}", data_mean); - - let data_std_deviation = std_deviation(&data); - println!("Standard deviation is {:?}", data_std_deviation); - - let zscore = match (data_mean, data_std_deviation) { - (Some(mean), Some(std_deviation)) => { - let diff = data[4] as f32 - mean; - - Some(diff / std_deviation) - }, - _ => None - }; - println!("Z-score of data at index 4 (with value {}) is {:?}", data[4], zscore); -} -
计算角为 2 弧度、对边长度为 80 的直角三角形的斜边长度。
--fn main() { - let angle: f64 = 2.0; - let side_length = 80.0; - - let hypotenuse = side_length / angle.sin(); - - println!("Hypotenuse: {}", hypotenuse); -} -
-fn main() { - let x: f64 = 6.0; - - let a = x.tan(); - let b = x.sin() / x.cos(); - - assert_eq!(a, b); -} -
下面的代码使用 Haversine 公式 计算地球上两点之间的公里数。
-- - -fn main() { - let earth_radius_kilometer = 6371.0_f64; - let (paris_latitude_degrees, paris_longitude_degrees) = (48.85341_f64, -2.34880_f64); - let (london_latitude_degrees, london_longitude_degrees) = (51.50853_f64, -0.12574_f64); - - let paris_latitude = paris_latitude_degrees.to_radians(); - let london_latitude = london_latitude_degrees.to_radians(); - - let delta_latitude = (paris_latitude_degrees - london_latitude_degrees).to_radians(); - let delta_longitude = (paris_longitude_degrees - london_longitude_degrees).to_radians(); - - let central_angle_inner = (delta_latitude / 2.0).sin().powi(2) - + paris_latitude.cos() * london_latitude.cos() * (delta_longitude / 2.0).sin().powi(2); - let central_angle = 2.0 * central_angle_inner.sqrt().asin(); - - let distance = earth_radius_kilometer * central_angle; - - println!( - "Distance between Paris and London on the surface of Earth is {:.1} kilometers", - distance - ); -} -
使用 rand::thread_rng 可以获取一个随机数生成器 rand::Rng ,该生成器需要在每个线程都初始化一个。
-整数的随机分布范围等于类型的取值范围,但是浮点数只分布在 [0, 1) 区间内。
-use rand::Rng; - -fn main() { - let mut rng = rand::thread_rng(); - - let n1: u8 = rng.gen(); - let n2: u16 = rng.gen(); - println!("Random u8: {}", n1); - println!("Random u16: {}", n2); - println!("Random u32: {}", rng.gen::<u32>()); - println!("Random i32: {}", rng.gen::<i32>()); - println!("Random float: {}", rng.gen::<f64>()); -} -
使用 Rng::gen_range 生成 [0, 10) 区间内的随机数( 右开区间,不包括 10 )。
-use rand::Rng; - -fn main() { - let mut rng = rand::thread_rng(); - println!("Integer: {}", rng.gen_range(0..10)); - println!("Float: {}", rng.gen_range(0.0..10.0)); -} -
Uniform 可以用于生成均匀分布的随机数。当需要在同一个范围内重复生成随机数时,该方法虽然和之前的方法效果一样,但会更快一些。
--use rand::distributions::{Distribution, Uniform}; - -fn main() { - let mut rng = rand::thread_rng(); - let die = Uniform::from(1..7); - - loop { - let throw = die.sample(&mut rng); - println!("Roll the die: {}", throw); - if throw == 6 { - break; - } - } -} -
默认情况下,rand 包使用均匀分布来生成随机数,而 rand_distr 包提供了其它类型的分布方式。
首先,你需要获取想要使用的分布的实例,然后在 rand::Rng 的帮助下使用 Distribution::sample 对该实例进行取样。
-如果想要查询可用的分布列表,可以访问这里,下面的示例中我们将使用 Normal 分布:
--use rand_distr::{Distribution, Normal, NormalError}; -use rand::thread_rng; - -fn main() -> Result<(), NormalError> { - let mut rng = thread_rng(); - let normal = Normal::new(2.0, 3.0)?; - let v = normal.sample(&mut rng); - println!("{} is from a N(2, 9) distribution", v); - Ok(()) -} -
使用 Distribution 特征包裹我们的自定义类型,并为 Standard 实现该特征,可以为自定义类型的指定字段生成随机数。
--use rand::Rng; -use rand::distributions::{Distribution, Standard}; - -#[derive(Debug)] -struct Point { - x: i32, - y: i32, -} - -impl Distribution<Point> for Standard { - fn sample<R: Rng + ?Sized>(&self, rng: &mut R) -> Point { - let (rand_x, rand_y) = rng.gen(); - Point { - x: rand_x, - y: rand_y, - } - } -} - -fn main() { - let mut rng = rand::thread_rng(); - - // 生成一个随机的 Point - let rand_point: Point = rng.gen(); - println!("Random Point: {:?}", rand_point); - - // 通过类型暗示( hint )生成一个随机的元组 - let rand_tuple = rng.gen::<(i32, bool, f64)>(); - println!("Random tuple: {:?}", rand_tuple); -} -
通过 Alphanumeric 采样来生成随机的 ASCII 字符串,包含从 A-Z, a-z, 0-9 的字符。
-use rand::{thread_rng, Rng}; -use rand::distributions::Alphanumeric; - -fn main() { - let rand_string: String = thread_rng() - .sample_iter(&Alphanumeric) - .take(30) - .map(char::from) - .collect(); - - println!("{}", rand_string); -} -
通过 gen_string 生成随机的 ASCII 字符串,包含用户指定的字符。
-- - -fn main() { - use rand::Rng; - const CHARSET: &[u8] = b"ABCDEFGHIJKLMNOPQRSTUVWXYZ\ - abcdefghijklmnopqrstuvwxyz\ - 0123456789)(*&^%$#@!~"; - const PASSWORD_LEN: usize = 30; - let mut rng = rand::thread_rng(); - - let password: String = (0..PASSWORD_LEN) - .map(|_| { - let idx = rng.gen_range(0..CHARSET.len()); - CHARSET[idx] as char - }) - .collect(); - - println!("{:?}", password); -} -
以下示例使用 Vec::sort 来排序,如果大家希望获得更高的性能,可以使用 Vec::sort_unstable,但是该方法无法保留相等元素的顺序。
--fn main() { - let mut vec = vec![1, 5, 10, 2, 15]; - - vec.sort(); - - assert_eq!(vec, vec![1, 2, 5, 10, 15]); -} -
浮点数数组可以使用 Vec::sort_by 和 PartialOrd::partial_cmp 进行排序。
--fn main() { - let mut vec = vec![1.1, 1.15, 5.5, 1.123, 2.0]; - - vec.sort_by(|a, b| a.partial_cmp(b).unwrap()); - - assert_eq!(vec, vec![1.1, 1.123, 1.15, 2.0, 5.5]); -} -
以下示例中的结构体 Person 将实现基于字段 name 和 age 的自然排序。为了让 Person 变为可排序的,我们需要为其派生 Eq、PartialEq、Ord、PartialOrd 特征,关于这几个特征的详情,请见这里。
当然,还可以使用 vec:sort_by 方法配合一个自定义比较函数,只按照 age 的维度对 Person 数组排序。
- - -#[derive(Debug, Eq, Ord, PartialEq, PartialOrd)] -struct Person { - name: String, - age: u32 -} - -impl Person { - pub fn new(name: String, age: u32) -> Self { - Person { - name, - age - } - } -} - -fn main() { - let mut people = vec![ - Person::new("Zoe".to_string(), 25), - Person::new("Al".to_string(), 60), - Person::new("John".to_string(), 1), - ]; - - // 通过派生后的自然顺序(Name and age)排序 - people.sort(); - - assert_eq!( - people, - vec![ - Person::new("Al".to_string(), 60), - Person::new("John".to_string(), 1), - Person::new("Zoe".to_string(), 25), - ]); - - // 只通过 age 排序 - people.sort_by(|a, b| b.age.cmp(&a.age)); - - assert_eq!( - people, - vec![ - Person::new("Al".to_string(), 60), - Person::new("Zoe".to_string(), 25), - Person::new("John".to_string(), 1), - ]); - -} -
ansi_term 包可以帮我们控制终端上的输出样式,例如使用颜色文字、控制输出格式等,当然,前提是在 ANSI 终端上。
-ansi_term 中有两个主要数据结构:ANSIString 和 Style。
Style 用于控制样式:颜色、加粗、闪烁等,而前者是一个带有样式的字符串。
-use ansi_term::Colour; - -fn main() { - println!("This is {} in color, {} in color and {} in color", - Colour::Red.paint("red"), - Colour::Blue.paint("blue"), - Colour::Green.paint("green")); -} -
比颜色复杂的样式构建需要使用 Style 结构体:
-use ansi_term::Style; - -fn main() { - println!("{} and this is not", - Style::new().bold().paint("This is Bold")); -} -
Colour 实现了很多跟 Style 类似的函数,因此可以实现链式调用。
- - -use ansi_term::Colour; -use ansi_term::Style; - -fn main(){ - println!("{}, {} and {}", - Colour::Yellow.paint("This is colored"), - Style::new().bold().paint("this is bold"), - // Colour 也可以使用 bold 方法进行加粗 - Colour::Yellow.bold().paint("this is bold and colored")); -} -
对于每一个程序员而言,命令行工具都非常关键。你对他越熟悉,在使用计算机、处理工作流程等越是高效。
-下面我们收集了一些优秀的Rust所写的命令行工具,它们相比目前已有的其它语言的实现,可以提供更加现代化的代码实现、更加高效的性能以及更好的可用性。
-| 新工具 | 替代的目标或功能描述 |
|---|---|
| bat | cat |
| exa | ls |
| lsd | ls |
| fd | find |
| procs | ps |
| sd | sed |
| dust | du |
| starship | 现代化的命令行提示 |
| ripgrep | grep |
| tokei | 代码统计工具 |
| hyperfine | 命令行benchmark工具 |
| bottom | top |
| teeldear | tldr |
| grex | 根据文本示例生成正则 |
| bandwitch | 显示进程、连接网络使用情况 |
| zoxide | cd |
| delta | git可视化 |
| nushell | 全新的现代化shell |
| mcfly | 替代ctrl + R命令搜索 |
| fselect | 使用SQL语法查找文件 |
| pueue | 命令行任务管理工具 |
| watchexec | 监视目录文件变动并执行命令 |
| dura | 更加安全的使用git |
| alacritty | 强大的基于OpenGL的终端 |
| broot | 可视化访问目录树 |
bat克隆了**cat**的功能并提供了语法高亮和Git集成,它支持Windows,MacOS和Linux`。同时,它默认提供了多种文件后缀的语法高亮。
 -
-exa是ls命令的现代化实现,后者是目前Unix/Linux系统的默认命令,用于列出当前目录中的内容。
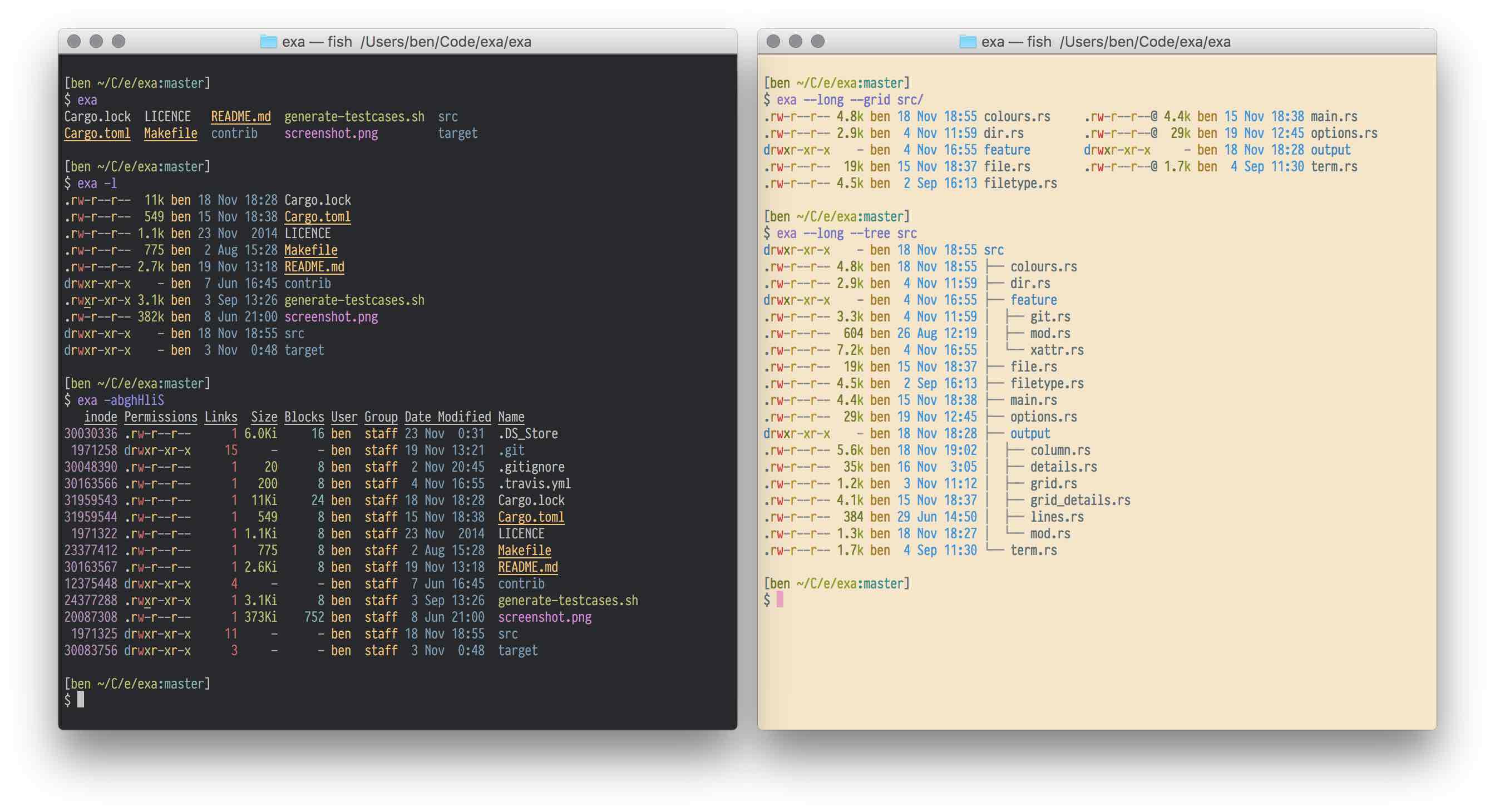 -
-lsd 也是 ls 的新实现,同时增加了很多特性,例如:颜色标注、icons、树形查看、更多的格式化选项等。
 -
-fd 是一个更快、对用户更友好的find实现,后者是 Unix/Linux 内置的文件目录搜索工具。之所以说它用户友好,一方面是 API 非常清晰明了,其次是它对最常用的场景提供了有意义的默认值:例如,想要通过名称搜索文件:
fd: fd PATTERNfind: find -iname 'PATTERN'同时 fd 性能非常非常高,还提供了非常多的搜索选项,例如允许用户通过 .gitignore 文件忽略隐藏的目录、文件等。
 -
-procs 是 ps 的默认实现,后者是 Unix/Linux 的内置命令,用于获取进程( process )的信息。proc 提供了更便利、可读性更好的格式化输出。
 -
-sd 是 sed 命令的现代化实现,后者是 Unix/Linux 中内置的工具,用于分析和转换文本。
sd 拥有更简单的使用方式,而且支持方便的正则表达式语法,sd 拥有闪电般的性能,比 sed 快 2x-11x 倍。
以下是其中一个性能测试结果:
-对1.5G大小的 JSON 文本进行简单替换
-hyperfine -w 3 'sed -E "s/\"/\'/g" *.json >/dev/null' 'sd "\"" "\'" *.json >/dev/null' --export-markdown out.md
| Command | Mean [s] | Min…Max [s] |
|---|---|---|
sed -E "s/\"/'/g" *.json >/dev/null | 2.338 ± 0.008 | 2.332…2.358 |
sed "s/\"/'/g" *.json >/dev/null | 2.365 ± 0.009 | 2.351…2.378 |
sd "\"" "'" *.json >/dev/null | 0.997 ± 0.006 | 0.987…1.007 |
结果: ~2.35 times faster
-dust 是一个更符合使用习惯的du,后者是 Unix/Linux 内置的命令行工具,用于显示硬盘使用情况的统计。
 -
-starship 是一个命令行提示,支持任何 shell ,包括 zsh ,简单易用、非常快且拥有极高的可配置性, 同时支持智能提示。
 -
-ripgrep 是一个性能极高的现代化 grep 实现,后者是 Unix/Linux 下的内置文件搜索工具。该项目是 Rust 的明星项目,一个是因为性能极其的高,另一个就是源代码质量很高,值得学习, 同时 Vscode 使用它作为内置的搜索引擎。
从功能来说,除了全面支持 grep 的功能外,repgre 支持使用正则递归搜索指定的文件目录,默认使用 .gitignore 对指定的文件进行忽略。
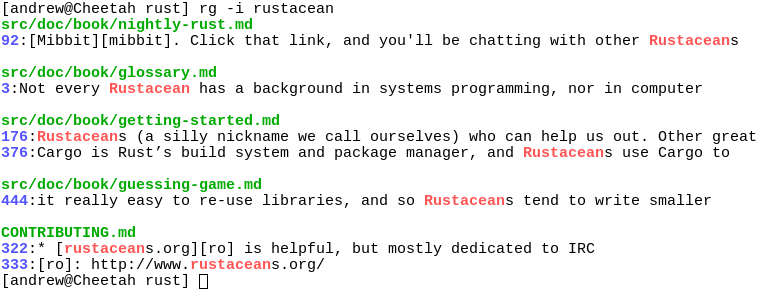 -
-tokei 可以分门别类的统计目录内的代码行数,速度非常快!
- -
-hyperfine 是命令行benchmark工具,它支持在多次运行中提供静态的分析,同时支持任何的 shell 命令,准确的 benchmark 进度和当前预估等等高级特性。
 -
-bottom 是一个现代化实现的 top,可以跨平台、图形化的显示进程/系统的当前信息。
 -
-tealdear 是一个更快实现的tldr, 一个用于显示 man pages 的命令行程序,简单易用、基于例子和社区驱动是主要特性。
 -
-bandwhich 是一个客户端实用工具,用于显示当前进程、连接、远程 IP( hostname ) 的网络信息。
-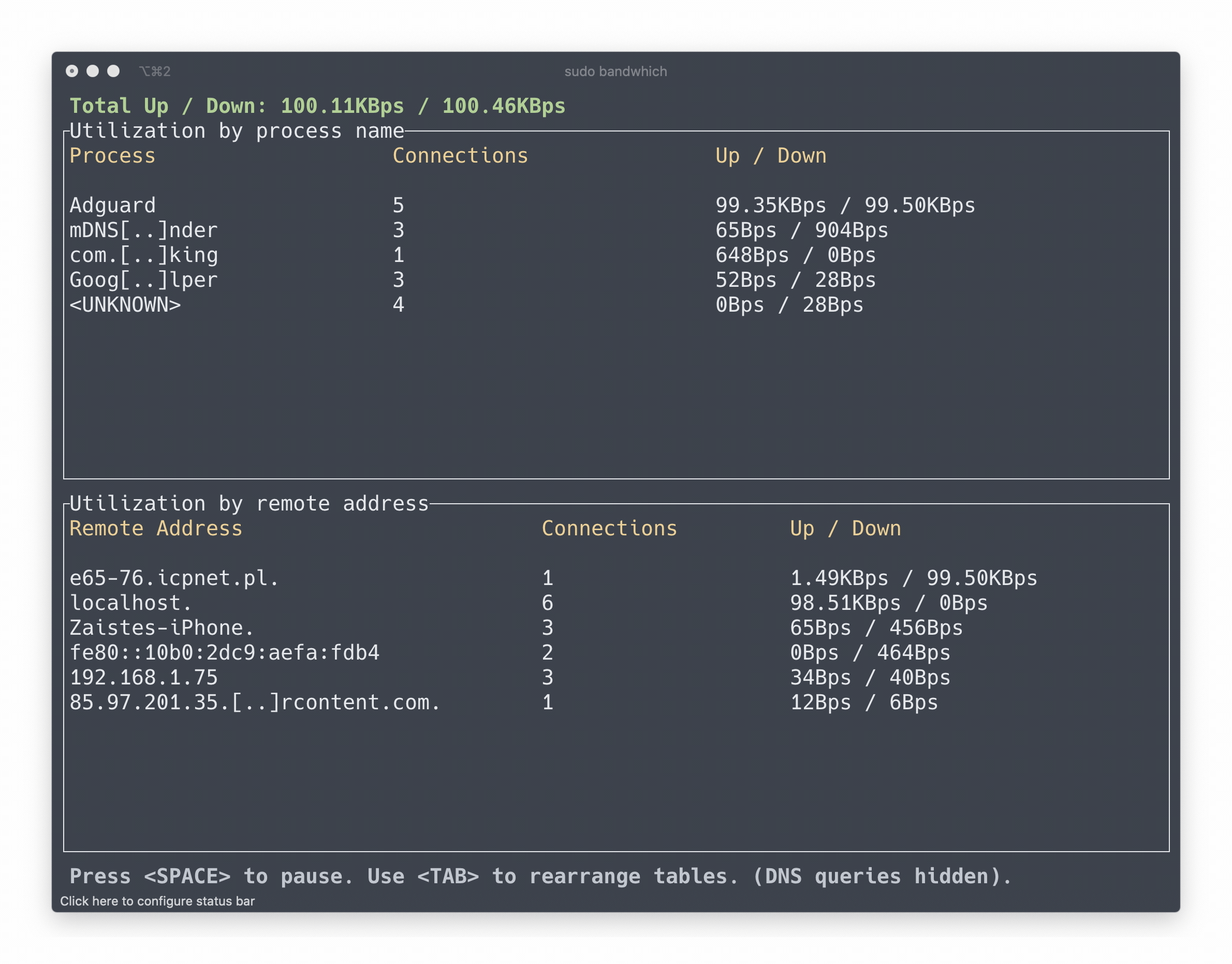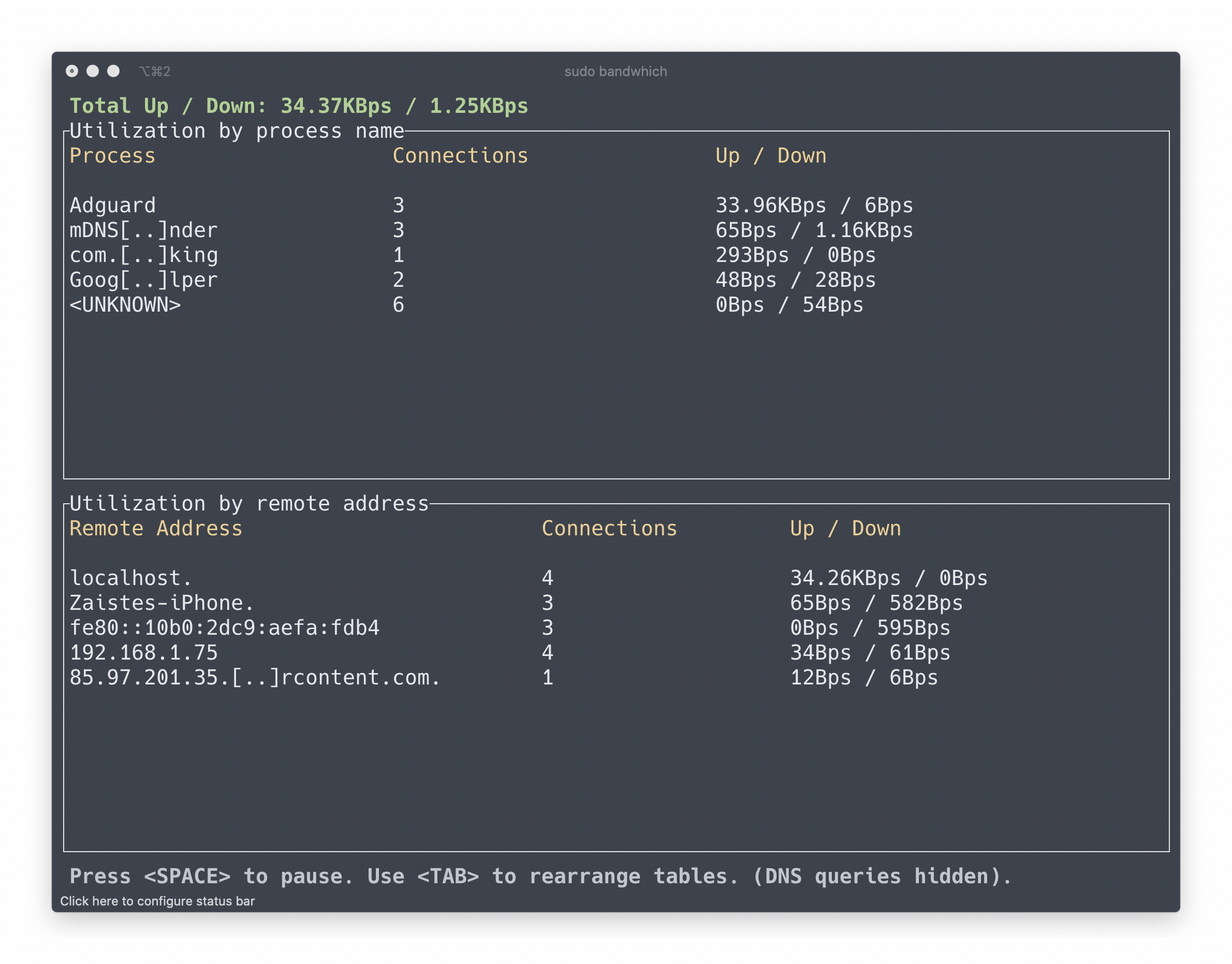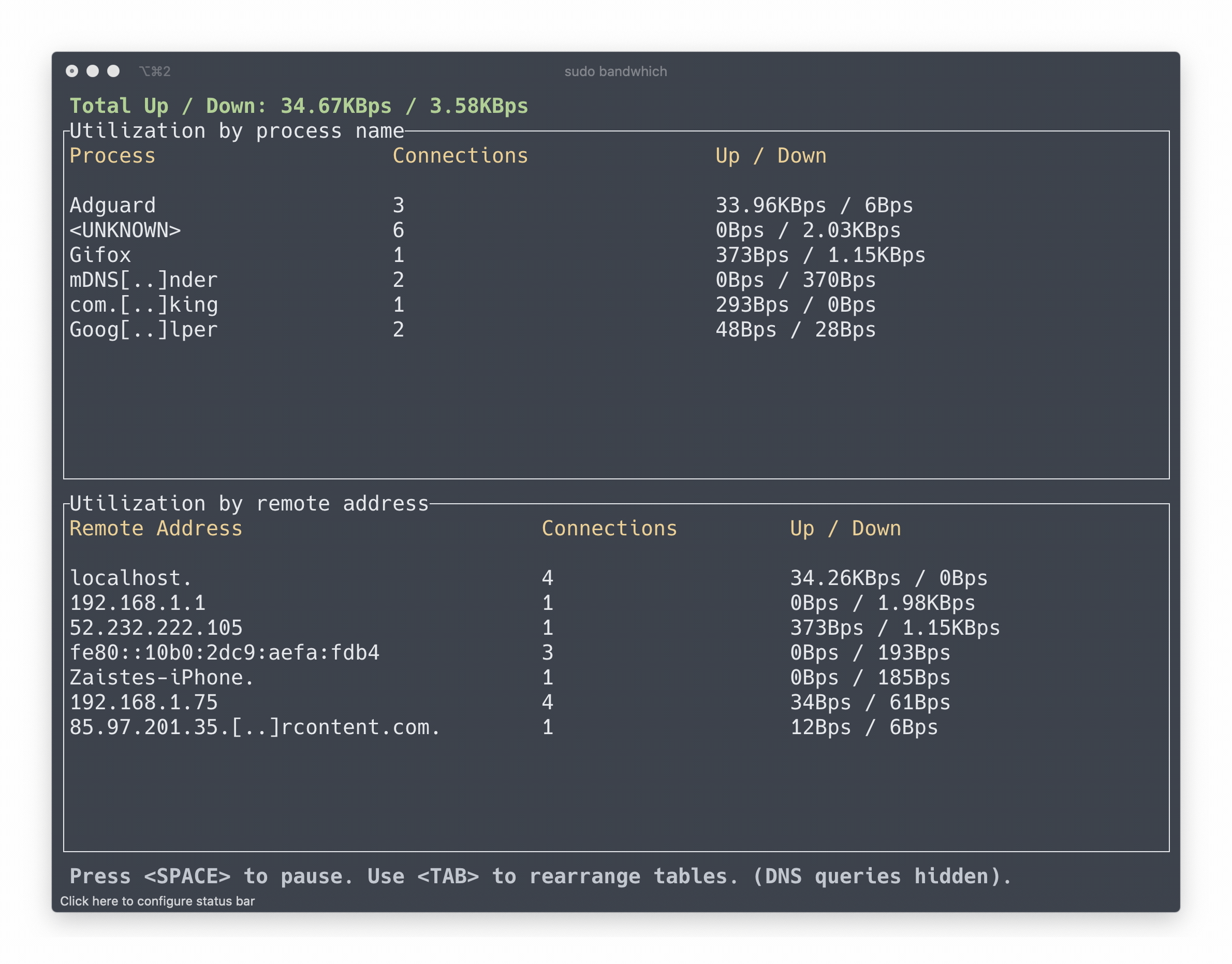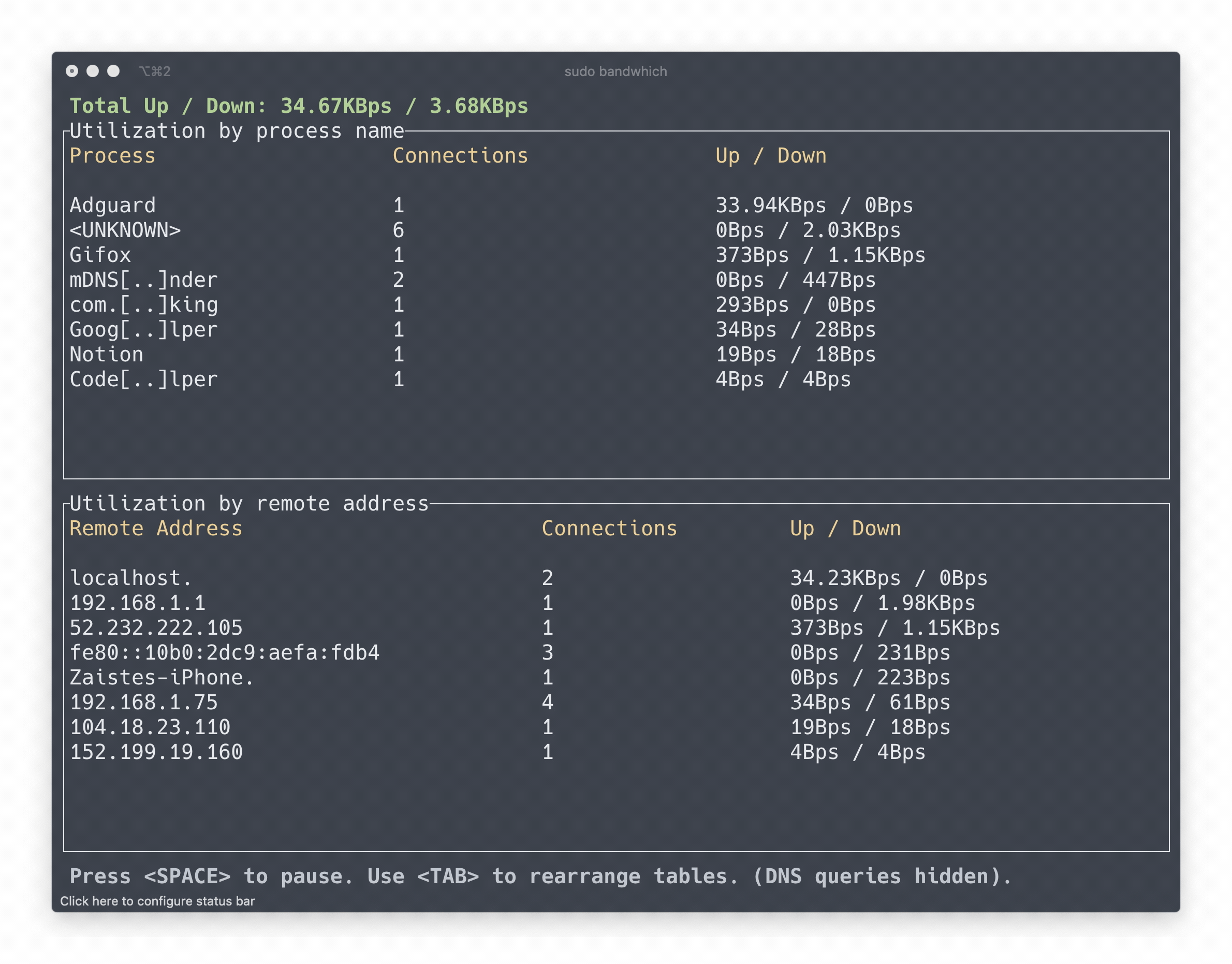 -
-grex 既是一个命令行工具又是一个库,可以根据用户提供的文本示例生成对应的正则表达式,非常强大。
- -
-zoxide 是一个智能化的 cd 命令,它甚至会记忆你常用的目录。
 -
-delta 是一个 git 分页展示工具,支持语法高亮、代码比对、输出 grep 等。
 -
-nushell 是一个全新的 shell ,使用 Rust 实现。它的目标是创建一个现代化的 shell :虽然依然基于 Unix 的哲学,但是更适合现在的时代。例如,你可以使用 SQL 语法来选择你想要的内容!
 -
-mcfly 会替换默认的 ctrl-R,用于在终端中搜索历史命令, 它提供了智能提示功能,并且会根据当前目录中最近执行过的上下文命令进行提示。mcfly 甚至使用了一个小型的神经网络用于智能提示!
 -
-fselect 允许使用 SQL 语法来查找系统中的文件。它支持复杂查询、聚合查询、.gitignore 忽略文件、通过宽度高度搜索图片、通过 hash 搜索文件、文件属性查询等等,相当强大!
-# 复杂查询
-fselect "name from /tmp where (name = *.tmp and size = 0) or (name = *.cfg and size > 1000000)"
-
-# 聚合函数
-fselect "MIN(size), MAX(size), AVG(size), SUM(size), COUNT(*) from /home/user/Downloads"
-
-# 格式化函数
-fselect "LOWER(name), UPPER(name), LENGTH(name), YEAR(modified) from /home/user/Downloads"
-pueue 是一个命令行任务管理工具,它可以管理你的长时间运行的命令,支持顺序或并行执行。简单来说,它可以管理一个命令队列。
- -
-watchexec 可以监视指定的目录、文件的改动,并执行你预设的命令,支持多种配置项和操作系统。
-# 监视当前目录/子目录中的所有js、css、html文件,一旦发生改变,运行`npm run build`命令
-$ watchexec -e js,css,html npm run build
-
-# 当前目录/子目录下任何python文件发生改变时,重启`python server.py`
-$ watchexec -r -e py -- python server.py
-dura 运行在后台,监视你的 git 目录,提交你未提交的更改但是并不会影响 HEAD、当前的分支和 git 索引(staged文件)。
如果你曾经遇到过**"完蛋, 我这几天的工作内容丢了"**的情况,那么就可以尝试下 dura,checkout dura brach,然后代码就可以顺利恢复了:)
恢复代码
-dura 分支来恢复$ echo "dura/$(git rev-parse HEAD)"
-# Or, if you don't trust dura yet, `git stash`
-$ git reset HEAD --hard
-# get the changes into your working directory
-$ git checkout $THE_HASH
-# last few commands reset HEAD back to master but with changes uncommitted
-$ git checkout -b temp-branch
-$ git reset master
-$ git checkout master
-$ git branch -D temp-branch
-alacritty 是一个跨平台、基于OpenGL的终端,性能极高的同时还支持丰富的自定义和可扩展性,可以说是非常优秀的现代化终端。
-目前已经是 beta 阶段,可以作为日常工具来使用。
 -
-broot 允许你可视化的去访问一个目录结构。
 -
-
-
- 下面的程序给出了使用 clap 来解析命令行参数的样式结构,如果大家想了解更多,在 clap 文档中还给出了另外两种初始化一个应用的方式。
在下面的构建中,value_of 将获取通过 with_name 解析出的值。short 和 long 用于设置用户输入的长短命令格式,例如短命令 -f 和长命令 --file。
-use clap::{Arg, App}; - -fn main() { - let matches = App::new("My Test Program") - .version("0.1.0") - .author("Hackerman Jones <hckrmnjones@hack.gov>") - .about("Teaches argument parsing") - .arg(Arg::with_name("file") - .short("f") - .long("file") - .takes_value(true) - .help("A cool file")) - .arg(Arg::with_name("num") - .short("n") - .long("number") - .takes_value(true) - .help("Five less than your favorite number")) - .get_matches(); - - let myfile = matches.value_of("file").unwrap_or("input.txt"); - println!("The file passed is: {}", myfile); - - let num_str = matches.value_of("num"); - match num_str { - None => println!("No idea what your favorite number is."), - Some(s) => { - match s.parse::<i32>() { - Ok(n) => println!("Your favorite number must be {}.", n + 5), - Err(_) => println!("That's not a number! {}", s), - } - } - } -} -
clap 针对上面提供的构建样式,会自动帮我们生成相应的使用方式说明。例如,上面代码生成的使用说明如下:
My Test Program 0.1.0
-Hackerman Jones <hckrmnjones@hack.gov>
-Teaches argument parsing
-
-USAGE:
- testing [OPTIONS]
-
-FLAGS:
- -h, --help Prints help information
- -V, --version Prints version information
-
-OPTIONS:
- -f, --file <file> A cool file
- -n, --number <num> Five less than your favorite number
-最后,再使用一些参数来运行下我们的代码:
-$ cargo run -- -f myfile.txt -n 251
-The file passed is: myfile.txt
-Your favorite number must be 256.
-@todo
- - -rayon 提供了一个 par_iter_mut 方法用于并行化迭代一个数据集合。
--use rayon::prelude::*; - -fn main() { - let mut arr = [0, 7, 9, 11]; - arr.par_iter_mut().for_each(|p| *p -= 1); - println!("{:?}", arr); -} -
rayon::any 和 rayon::all 类似于 std::any / std::all ,但是是并行版本的。
-rayon::any 并行检查迭代器中是否有任何元素满足给定的条件,一旦发现符合条件的元素,就立即返回rayon::all 并行检查迭代器中的所有元素是否满足给定的条件,一旦发现不满足条件的元素,就立即返回-use rayon::prelude::*; - -fn main() { - let mut vec = vec![2, 4, 6, 8]; - - assert!(!vec.par_iter().any(|n| (*n % 2) != 0)); - assert!(vec.par_iter().all(|n| (*n % 2) == 0)); - assert!(!vec.par_iter().any(|n| *n > 8 )); - assert!(vec.par_iter().all(|n| *n <= 8 )); - - vec.push(9); - - assert!(vec.par_iter().any(|n| (*n % 2) != 0)); - assert!(!vec.par_iter().all(|n| (*n % 2) == 0)); - assert!(vec.par_iter().any(|n| *n > 8 )); - assert!(!vec.par_iter().all(|n| *n <= 8 )); -} -
下面例子使用 par_iter 和 rayon::find_any 来并行搜索一个数组,直到找到任意一个满足条件的元素。
-如果有多个元素满足条件,rayon 会返回第一个找到的元素,注意:第一个找到的元素未必是数组中的顺序最靠前的那个。
-use rayon::prelude::*; - -fn main() { - let v = vec![6, 2, 1, 9, 3, 8, 11]; - - // 这里使用了 `&&x` 的形式,大家可以在以下链接阅读更多 https://doc.rust-lang.org/std/iter/trait.Iterator.html#method.find - let f1 = v.par_iter().find_any(|&&x| x == 9); - let f2 = v.par_iter().find_any(|&&x| x % 2 == 0 && x > 6); - let f3 = v.par_iter().find_any(|&&x| x > 8); - - assert_eq!(f1, Some(&9)); - assert_eq!(f2, Some(&8)); - assert!(f3 > Some(&8)); -} -
下面的例子将对字符串数组进行并行排序。
-par_sort_unstable 方法的排序性能往往要比稳定的排序算法更高。
--use rand::{Rng, thread_rng}; -use rand::distributions::Alphanumeric; -use rayon::prelude::*; - -fn main() { - let mut vec = vec![String::new(); 100_000]; - // 并行生成数组中的字符串 - vec.par_iter_mut().for_each(|p| { - let mut rng = thread_rng(); - *p = (0..5).map(|_| rng.sample(&Alphanumeric)).collect() - }); - - // - vec.par_sort_unstable(); -} -
下面例子使用 rayon::filter, rayon::map, 和 rayon::reduce 来超过 30 岁的 Person 的平均年龄。
rayon::filter 返回集合中所有满足给定条件的元素rayon::map 对集合中的每一个元素执行一个操作,创建并返回新的迭代器,类似于迭代器适配器rayon::reduce 则迭代器的元素进行不停的聚合运算,直到获取一个最终结果,这个结果跟例子中 rayon::sum 获取的结果是相同的-use rayon::prelude::*; - -struct Person { - age: u32, -} - -fn main() { - let v: Vec<Person> = vec![ - Person { age: 23 }, - Person { age: 19 }, - Person { age: 42 }, - Person { age: 17 }, - Person { age: 17 }, - Person { age: 31 }, - Person { age: 30 }, - ]; - - let num_over_30 = v.par_iter().filter(|&x| x.age > 30).count() as f32; - let sum_over_30 = v.par_iter() - .map(|x| x.age) - .filter(|&x| x > 30) - .reduce(|| 0, |x, y| x + y); - - let alt_sum_30: u32 = v.par_iter() - .map(|x| x.age) - .filter(|&x| x > 30) - .sum(); - - let avg_over_30 = sum_over_30 as f32 / num_over_30; - let alt_avg_over_30 = alt_sum_30 as f32/ num_over_30; - - assert!((avg_over_30 - alt_avg_over_30).abs() < std::f32::EPSILON); - println!("The average age of people older than 30 is {}", avg_over_30); -} -
下面例子将为目录中的所有图片并行生成缩略图,然后将结果存到新的目录 thumbnails 中。
glob::glob_with 可以找出当前目录下的所有 .jpg 文件,rayon 通过 DynamicImage::resize 来并行调整图片的大小。
- - -use error_chain::error_chain; - -use std::path::Path; -use std::fs::create_dir_all; - -use error_chain::ChainedError; -use glob::{glob_with, MatchOptions}; -use image::{FilterType, ImageError}; -use rayon::prelude::*; - -error_chain! { - foreign_links { - Image(ImageError); - Io(std::io::Error); - Glob(glob::PatternError); - } -} - -fn main() -> Result<()> { - let options: MatchOptions = Default::default(); - // 找到当前目录中的所有 `jpg` 文件 - let files: Vec<_> = glob_with("*.jpg", options)? - .filter_map(|x| x.ok()) - .collect(); - - if files.len() == 0 { - error_chain::bail!("No .jpg files found in current directory"); - } - - let thumb_dir = "thumbnails"; - create_dir_all(thumb_dir)?; - - println!("Saving {} thumbnails into '{}'...", files.len(), thumb_dir); - - let image_failures: Vec<_> = files - .par_iter() - .map(|path| { - make_thumbnail(path, thumb_dir, 300) - .map_err(|e| e.chain_err(|| path.display().to_string())) - }) - .filter_map(|x| x.err()) - .collect(); - - image_failures.iter().for_each(|x| println!("{}", x.display_chain())); - - println!("{} thumbnails saved successfully", files.len() - image_failures.len()); - Ok(()) -} - -fn make_thumbnail<PA, PB>(original: PA, thumb_dir: PB, longest_edge: u32) -> Result<()> -where - PA: AsRef<Path>, - PB: AsRef<Path>, -{ - let img = image::open(original.as_ref())?; - let file_path = thumb_dir.as_ref().join(original); - - Ok(img.resize(longest_edge, longest_edge, FilterType::Nearest) - .save(file_path)?) -} -
下面例子用到了 crossbeam 包,它提供了非常实用的、用于并发和并行编程的数据结构和函数。
-Scope::spawn 会生成一个被限定了作用域的线程,该线程最大的特点就是:它会在传给 crossbeam::scope 的闭包函数返回前先行结束。得益于这个特点,子线程的创建使用就像是本地闭包函数调用,因此生成的线程内部可以使用外部环境中的变量!
--fn main() { - let arr = &[1, 25, -4, 10]; - let max = find_max(arr); - assert_eq!(max, Some(25)); -} - -// 将数组分成两个部分,并使用新的线程对它们进行处理 -fn find_max(arr: &[i32]) -> Option<i32> { - const THRESHOLD: usize = 2; - - if arr.len() <= THRESHOLD { - return arr.iter().cloned().max(); - } - - let mid = arr.len() / 2; - let (left, right) = arr.split_at(mid); - - crossbeam::scope(|s| { - let thread_l = s.spawn(|_| find_max(left)); - let thread_r = s.spawn(|_| find_max(right)); - - let max_l = thread_l.join().unwrap()?; - let max_r = thread_r.join().unwrap()?; - - Some(max_l.max(max_r)) - }).unwrap() -} -
下面我们使用 crossbeam 和 crossbeam-channel 来创建一个并行流水线:流水线的两端分别是数据源和数据下沉( sink ),在流水线中间,有两个工作线程会从源头接收数据,对数据进行并行处理,最后将数据下沉。
-rcv2 处于阻塞读取状态,无比被关闭,因此我们必须要关闭所有发送者: drop(snd1); drop(snd2) ,这样 channel 关闭后,主线程的 rcv2 才能从阻塞状态退出,最后整个程序结束。大家还是迷惑的话,可以看看这篇文章。-extern crate crossbeam; -extern crate crossbeam_channel; - -use std::thread; -use std::time::Duration; -use crossbeam_channel::bounded; - -fn main() { - let (snd1, rcv1) = bounded(1); - let (snd2, rcv2) = bounded(1); - let n_msgs = 4; - let n_workers = 2; - - crossbeam::scope(|s| { - // 生产者线程 - s.spawn(|_| { - for i in 0..n_msgs { - snd1.send(i).unwrap(); - println!("Source sent {}", i); - } - - // 关闭其中一个发送者 snd1 - // 该关闭操作对于结束最后的循环是必须的 - drop(snd1); - }); - - // 通过两个线程并行处理 - for _ in 0..n_workers { - // 从数据源接收数据,然后发送到下沉端 - let (sendr, recvr) = (snd2.clone(), rcv1.clone()); - // 生成单独的工作线程 - s.spawn(move |_| { - thread::sleep(Duration::from_millis(500)); - // 等待通道的关闭 - for msg in recvr.iter() { - println!("Worker {:?} received {}.", - thread::current().id(), msg); - sendr.send(msg * 2).unwrap(); - } - }); - } - // 关闭通道,如果不关闭,下沉端将永远无法结束循环 - drop(snd2); - - // 下沉端 - for msg in rcv2.iter() { - println!("Sink received {}", msg); - } - }).unwrap(); -} -
下面我们来看看 crossbeam-channel 的单生产者单消费者( SPSC ) 使用场景。
--use std::{thread, time}; -use crossbeam_channel::unbounded; - -fn main() { - // unbounded 意味着 channel 可以存储任意多的消息 - let (snd, rcv) = unbounded(); - let n_msgs = 5; - crossbeam::scope(|s| { - s.spawn(|_| { - for i in 0..n_msgs { - snd.send(i).unwrap(); - thread::sleep(time::Duration::from_millis(100)); - } - }); - }).unwrap(); - for _ in 0..n_msgs { - let msg = rcv.recv().unwrap(); - println!("Received {}", msg); - } -} -
lazy_static 会创建一个全局的静态引用( static ref ),该引用使用了 Mutex 以支持可变性,因此我们可以在代码中对其进行修改。Mutex 能保证该全局状态同时只能被一个线程所访问。
-use error_chain::error_chain; -use lazy_static::lazy_static; -use std::sync::Mutex; - -error_chain!{ } - -lazy_static! { - static ref FRUIT: Mutex<Vec<String>> = Mutex::new(Vec::new()); -} - -fn insert(fruit: &str) -> Result<()> { - let mut db = FRUIT.lock().map_err(|_| "Failed to acquire MutexGuard")?; - db.push(fruit.to_string()); - Ok(()) -} - -fn main() -> Result<()> { - insert("apple")?; - insert("orange")?; - insert("peach")?; - { - let db = FRUIT.lock().map_err(|_| "Failed to acquire MutexGuard")?; - - db.iter().enumerate().for_each(|(i, item)| println!("{}: {}", i, item)); - } - insert("grape")?; - Ok(()) -} -
下面的示例将为当前目录中的每一个 .iso 文件都计算一个 SHA256 sum。其中线程池中会初始化和 CPU 核心数一致的线程数,其中核心数是通过 num_cpus::get 函数获取。
-Walkdir::new 可以遍历当前的目录,然后调用 execute 来执行读操作和 SHA256 哈希计算。
--use walkdir::WalkDir; -use std::fs::File; -use std::io::{BufReader, Read, Error}; -use std::path::Path; -use threadpool::ThreadPool; -use std::sync::mpsc::channel; -use ring::digest::{Context, Digest, SHA256}; - -// Verify the iso extension -fn is_iso(entry: &Path) -> bool { - match entry.extension() { - Some(e) if e.to_string_lossy().to_lowercase() == "iso" => true, - _ => false, - } -} - -fn compute_digest<P: AsRef<Path>>(filepath: P) -> Result<(Digest, P), Error> { - let mut buf_reader = BufReader::new(File::open(&filepath)?); - let mut context = Context::new(&SHA256); - let mut buffer = [0; 1024]; - - loop { - let count = buf_reader.read(&mut buffer)?; - if count == 0 { - break; - } - context.update(&buffer[..count]); - } - - Ok((context.finish(), filepath)) -} - -fn main() -> Result<(), Error> { - let pool = ThreadPool::new(num_cpus::get()); - - let (tx, rx) = channel(); - - for entry in WalkDir::new("/home/user/Downloads") - .follow_links(true) - .into_iter() - .filter_map(|e| e.ok()) - .filter(|e| !e.path().is_dir() && is_iso(e.path())) { - let path = entry.path().to_owned(); - let tx = tx.clone(); - pool.execute(move || { - let digest = compute_digest(path); - tx.send(digest).expect("Could not send data!"); - }); - } - - drop(tx); - for t in rx.iter() { - let (sha, path) = t?; - println!("{:?} {:?}", sha, path); - } - Ok(()) -} -
下面例子中将基于 Julia Set 来绘制一个分形图片,其中使用到了线程池来做分布式计算。
- -
-- - -use error_chain::error_chain; -use std::sync::mpsc::{channel, RecvError}; -use threadpool::ThreadPool; -use num::complex::Complex; -use image::{ImageBuffer, Pixel, Rgb}; - - -error_chain! { - foreign_links { - MpscRecv(RecvError); - Io(std::io::Error); - } -} - -// Function converting intensity values to RGB -// Based on http://www.efg2.com/Lab/ScienceAndEngineering/Spectra.htm -fn wavelength_to_rgb(wavelength: u32) -> Rgb<u8> { - let wave = wavelength as f32; - - let (r, g, b) = match wavelength { - 380..=439 => ((440. - wave) / (440. - 380.), 0.0, 1.0), - 440..=489 => (0.0, (wave - 440.) / (490. - 440.), 1.0), - 490..=509 => (0.0, 1.0, (510. - wave) / (510. - 490.)), - 510..=579 => ((wave - 510.) / (580. - 510.), 1.0, 0.0), - 580..=644 => (1.0, (645. - wave) / (645. - 580.), 0.0), - 645..=780 => (1.0, 0.0, 0.0), - _ => (0.0, 0.0, 0.0), - }; - - let factor = match wavelength { - 380..=419 => 0.3 + 0.7 * (wave - 380.) / (420. - 380.), - 701..=780 => 0.3 + 0.7 * (780. - wave) / (780. - 700.), - _ => 1.0, - }; - - let (r, g, b) = (normalize(r, factor), normalize(g, factor), normalize(b, factor)); - Rgb::from_channels(r, g, b, 0) -} - -// Maps Julia set distance estimation to intensity values -fn julia(c: Complex<f32>, x: u32, y: u32, width: u32, height: u32, max_iter: u32) -> u32 { - let width = width as f32; - let height = height as f32; - - let mut z = Complex { - // scale and translate the point to image coordinates - re: 3.0 * (x as f32 - 0.5 * width) / width, - im: 2.0 * (y as f32 - 0.5 * height) / height, - }; - - let mut i = 0; - for t in 0..max_iter { - if z.norm() >= 2.0 { - break; - } - z = z * z + c; - i = t; - } - i -} - -// Normalizes color intensity values within RGB range -fn normalize(color: f32, factor: f32) -> u8 { - ((color * factor).powf(0.8) * 255.) as u8 -} - -fn main() -> Result<()> { - let (width, height) = (1920, 1080); - // 为指定宽高的输出图片分配内存 - let mut img = ImageBuffer::new(width, height); - let iterations = 300; - - let c = Complex::new(-0.8, 0.156); - - let pool = ThreadPool::new(num_cpus::get()); - let (tx, rx) = channel(); - - for y in 0..height { - let tx = tx.clone(); - // execute 将每个像素作为单独的作业接收 - pool.execute(move || for x in 0..width { - let i = julia(c, x, y, width, height, iterations); - let pixel = wavelength_to_rgb(380 + i * 400 / iterations); - tx.send((x, y, pixel)).expect("Could not send data!"); - }); - } - - for _ in 0..(width * height) { - let (x, y, pixel) = rx.recv()?; - // 使用数据来设置像素的颜色 - img.put_pixel(x, y, pixel); - } - - // 输出图片内容到指定文件中 - let _ = img.save("output.png")?; - Ok(()) -} -
HTTP客户端
-reqwest是目前使用最多的HTTP库 Web框架
-axum > Rocket > actix-web。 不过如果你不需要多么完善的web功能,只需要一个性能极高的http库,那么actix-web是非常好的选择,它的性能非常非常非常高!logback和log4j实现的日志库, 可配置性较强slog自己也推荐使用tracing。OpenTelemetry是现在非常火的可观测性解决方案,提供了协议、API、SDK等核心工具,用于收集监控数据,最后将这些metrics/logs/traces数据写入到prometheus, jaeger等监控平台中。最主要是,它后台很硬,后面有各大公司作为背书,未来非常看好!性能对比
-通用
-PostgreSQL, MySQL, SQLite,和 MSSQL.ORM
-Mysql、Postgre、SqlLiteMysql
-Postgre
-Sqlite
- -Redis
-Canssandra
-MongoDB
-tungstenite-rs库和tokio实现tonic放在第一位,主要是因为它是纯Rust实现,同时社区也更为活跃,但是并不代表它比tikv的更好!cloudflare提供的QUIC实现,据说在公司内部重度使用,有了大规模生产级别的验证,非常值得信任,同时该库还实现了HTTP/3actix-web的开发tokio,稳定可靠,功能丰富,控制粒度细;自己的学习项目或者没有那么严肃的开源项目,我推荐async-std,简单好用,值得学习;当你确切知道需要Actor网络模型时,就用actixElasticSearch客户端
-Rust搜索引擎
-lucene,如果你不需要分布式,那么引入tantivy作为自己本地Rust服务的一个搜索,是相当不错的选择,该库作者一直很活跃,而且最近还创立了搜索引擎公司,感觉大有作为. 该库的优点在于纯Rust实现,性能高(lucene的2-3倍),资源占用低(对比java自然不是一个数量级),社区活跃。Rust搜索平台
-MeiliSearch目标是为终端用户提供边输入边提示的即刻搜索功能,因此是一个轻量级搜索平台,不适用于数据量大时的搜索目的。总之,如果你需要在网页端或者APP为用户提供一个搜索条,然后支持输入容错、前缀搜索时,就可以使用它。perf不同,flame库允许你自己定义想要测试的代码片段,只需要在代码前后加上相应的指令即可,非常好用crossbeam主仓库中parking_lot高一点,最近没怎么更新serde使用serde使用,文档较为详细serde编解码YAML格式的数据WASM、Desktop、TUI 等应用开发,文档较为详细我们通过 postgres 来操作数据库。下面的例子有一个前提:数据库 library 已经存在,其中用户名和密码都是 postgres。
-use postgres::{Client, NoTls, Error}; - -fn main() -> Result<(), Error> { - // 连接到数据库 library - let mut client = Client::connect("postgresql://postgres:postgres@localhost/library", NoTls)?; - - client.batch_execute(" - CREATE TABLE IF NOT EXISTS author ( - id SERIAL PRIMARY KEY, - name VARCHAR NOT NULL, - country VARCHAR NOT NULL - ) - ")?; - - client.batch_execute(" - CREATE TABLE IF NOT EXISTS book ( - id SERIAL PRIMARY KEY, - title VARCHAR NOT NULL, - author_id INTEGER NOT NULL REFERENCES author - ) - ")?; - - Ok(()) - -} -
-use postgres::{Client, NoTls, Error}; -use std::collections::HashMap; - -struct Author { - _id: i32, - name: String, - country: String -} - -fn main() -> Result<(), Error> { - let mut client = Client::connect("postgresql://postgres:postgres@localhost/library", - NoTls)?; - - let mut authors = HashMap::new(); - authors.insert(String::from("Chinua Achebe"), "Nigeria"); - authors.insert(String::from("Rabindranath Tagore"), "India"); - authors.insert(String::from("Anita Nair"), "India"); - - for (key, value) in &authors { - let author = Author { - _id: 0, - name: key.to_string(), - country: value.to_string() - }; - - // 插入数据 - client.execute( - "INSERT INTO author (name, country) VALUES ($1, $2)", - &[&author.name, &author.country], - )?; - } - - // 查询数据 - for row in client.query("SELECT id, name, country FROM author", &[])? { - let author = Author { - _id: row.get(0), - name: row.get(1), - country: row.get(2), - }; - println!("Author {} is from {}", author.name, author.country); - } - - Ok(()) - -} -
下面代码将使用降序的方式列出 Museum of Modern Art 数据库中的前 7999 名艺术家的国籍分布.
-- - -use postgres::{Client, Error, NoTls}; - -struct Nation { - nationality: String, - count: i64, -} - -fn main() -> Result<(), Error> { - let mut client = Client::connect( - "postgresql://postgres:postgres@127.0.0.1/moma", - NoTls, - )?; - - for row in client.query - ("SELECT nationality, COUNT(nationality) AS count - FROM artists GROUP BY nationality ORDER BY count DESC", &[])? { - - let (nationality, count) : (Option<String>, Option<i64>) - = (row.get (0), row.get (1)); - - if nationality.is_some () && count.is_some () { - - let nation = Nation{ - nationality: nationality.unwrap(), - count: count.unwrap(), - }; - println!("{} {}", nation.nationality, nation.count); - - } - } - - Ok(()) -} -
使用 rusqlite 可以创建 SQLite 数据库,Connection::open 会尝试打开一个数据库,若不存在,则创建新的数据库。
--这里创建的
-cats.db数据库将被后面的例子所使用
-use rusqlite::{Connection, Result}; -use rusqlite::NO_PARAMS; - -fn main() -> Result<()> { - let conn = Connection::open("cats.db")?; - - conn.execute( - "create table if not exists cat_colors ( - id integer primary key, - name text not null unique - )", - NO_PARAMS, - )?; - conn.execute( - "create table if not exists cats ( - id integer primary key, - name text not null, - color_id integer not null references cat_colors(id) - )", - NO_PARAMS, - )?; - - Ok(()) -} -
--use rusqlite::NO_PARAMS; -use rusqlite::{Connection, Result}; -use std::collections::HashMap; - -#[derive(Debug)] -struct Cat { - name: String, - color: String, -} - -fn main() -> Result<()> { - // 打开第一个例子所创建的数据库 - let conn = Connection::open("cats.db")?; - - let mut cat_colors = HashMap::new(); - cat_colors.insert(String::from("Blue"), vec!["Tigger", "Sammy"]); - cat_colors.insert(String::from("Black"), vec!["Oreo", "Biscuit"]); - - for (color, catnames) in &cat_colors { - // 插入一条数据行 - conn.execute( - "INSERT INTO cat_colors (name) values (?1)", - &[&color.to_string()], - )?; - // 获取最近插入数据行的 id - let last_id: String = conn.last_insert_rowid().to_string(); - - for cat in catnames { - conn.execute( - "INSERT INTO cats (name, color_id) values (?1, ?2)", - &[&cat.to_string(), &last_id], - )?; - } - } - let mut stmt = conn.prepare( - "SELECT c.name, cc.name from cats c - INNER JOIN cat_colors cc - ON cc.id = c.color_id;", - )?; - - let cats = stmt.query_map(NO_PARAMS, |row| { - Ok(Cat { - name: row.get(0)?, - color: row.get(1)?, - }) - })?; - - for cat in cats { - println!("Found cat {:?}", cat); - } - - Ok(()) -} -
使用 Connection::transaction 可以开始新的事务,若没有对事务进行显式地提交 Transaction::commit,则会进行回滚。
-下面的例子中,rolled_back_tx 插入了重复的颜色名称,会发生回滚。
- - -use rusqlite::{Connection, Result, NO_PARAMS}; - -fn main() -> Result<()> { - // 打开第一个例子所创建的数据库 - let mut conn = Connection::open("cats.db")?; - - successful_tx(&mut conn)?; - - let res = rolled_back_tx(&mut conn); - assert!(res.is_err()); - - Ok(()) -} - -fn successful_tx(conn: &mut Connection) -> Result<()> { - let tx = conn.transaction()?; - - tx.execute("delete from cat_colors", NO_PARAMS)?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"lavender"])?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"blue"])?; - - tx.commit() -} - -fn rolled_back_tx(conn: &mut Connection) -> Result<()> { - let tx = conn.transaction()?; - - tx.execute("delete from cat_colors", NO_PARAMS)?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"lavender"])?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"blue"])?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"lavender"])?; - - tx.commit() -} -
使用 bitflags! 宏可以帮助我们创建安全的位字段类型 MyFlags,然后为其实现基本的 clear 操作。以下代码展示了基本的位操作和格式化:
- - -use bitflags::bitflags; -use std::fmt; - -bitflags! { - struct MyFlags: u32 { - const FLAG_A = 0b00000001; - const FLAG_B = 0b00000010; - const FLAG_C = 0b00000100; - const FLAG_ABC = Self::FLAG_A.bits - | Self::FLAG_B.bits - | Self::FLAG_C.bits; - } -} - -impl MyFlags { - pub fn clear(&mut self) -> &mut MyFlags { - self.bits = 0; - self - } -} - -impl fmt::Display for MyFlags { - fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { - write!(f, "{:032b}", self.bits) - } -} - -fn main() { - let e1 = MyFlags::FLAG_A | MyFlags::FLAG_C; - let e2 = MyFlags::FLAG_B | MyFlags::FLAG_C; - assert_eq!((e1 | e2), MyFlags::FLAG_ABC); - assert_eq!((e1 & e2), MyFlags::FLAG_C); - assert_eq!((e1 - e2), MyFlags::FLAG_A); - assert_eq!(!e2, MyFlags::FLAG_A); - - let mut flags = MyFlags::FLAG_ABC; - assert_eq!(format!("{}", flags), "00000000000000000000000000000111"); - assert_eq!(format!("{}", flags.clear()), "00000000000000000000000000000000"); - assert_eq!(format!("{:?}", MyFlags::FLAG_B), "FLAG_B"); - assert_eq!(format!("{:?}", MyFlags::FLAG_A | MyFlags::FLAG_B), "FLAG_A | FLAG_B"); -} -
测量从 time::Instant::now 开始所经过的时间 time::Instant::elapsed.
--use std::time::{Duration, Instant}; - -fn main() { - let start = Instant::now(); - expensive_function(); - let duration = start.elapsed(); - - println!("Time elapsed in expensive_function() is: {:?}", duration); -} -
使用 DateTime::checked_add_signed 计算和显示从现在开始两周后的日期和时间,然后再计算一天前的日期 DateTime::checked_sub_signed。
-DateTime::format 所支持的转义序列可以在 chrono::format::strftime 找到.
--use chrono::{DateTime, Duration, Utc}; - -fn day_earlier(date_time: DateTime<Utc>) -> Option<DateTime<Utc>> { - date_time.checked_sub_signed(Duration::days(1)) -} - -fn main() { - let now = Utc::now(); - println!("{}", now); - - let almost_three_weeks_from_now = now.checked_add_signed(Duration::weeks(2)) - .and_then(|in_2weeks| in_2weeks.checked_add_signed(Duration::weeks(1))) - .and_then(day_earlier); - - match almost_three_weeks_from_now { - Some(x) => println!("{}", x), - None => eprintln!("Almost three weeks from now overflows!"), - } - - match now.checked_add_signed(Duration::max_value()) { - Some(x) => println!("{}", x), - None => eprintln!("We can't use chrono to tell the time for the Solar System to complete more than one full orbit around the galactic center."), - } -} -
使用 offset::Local::now 获取本地时间并进行显示,接着,使用 DateTime::from_utc 将它转换成 UTC 标准时间。最后,再使用 offset::FixedOffset 将 UTC 时间转换成 UTC+8 和 UTC-2 的时间。
-- - -use chrono::{DateTime, FixedOffset, Local, Utc}; - -fn main() { - let local_time = Local::now(); - let utc_time = DateTime::<Utc>::from_utc(local_time.naive_utc(), Utc); - let china_timezone = FixedOffset::east(8 * 3600); - let rio_timezone = FixedOffset::west(2 * 3600); - println!("Local time now is {}", local_time); - println!("UTC time now is {}", utc_time); - println!( - "Time in Hong Kong now is {}", - utc_time.with_timezone(&china_timezone) - ); - println!("Time in Rio de Janeiro now is {}", utc_time.with_timezone(&rio_timezone)); -} -
通过 DateTime 获取当前的 UTC 时间:
- --use chrono::{Datelike, Timelike, Utc}; - -fn main() { - let now = Utc::now(); - - let (is_pm, hour) = now.hour12(); - println!( - "The current UTC time is {:02}:{:02}:{:02} {}", - hour, - now.minute(), - now.second(), - if is_pm { "PM" } else { "AM" } - ); - println!( - "And there have been {} seconds since midnight", - now.num_seconds_from_midnight() - ); - - let (is_common_era, year) = now.year_ce(); - println!( - "The current UTC date is {}-{:02}-{:02} {:?} ({})", - year, - now.month(), - now.day(), - now.weekday(), - if is_common_era { "CE" } else { "BCE" } - ); - println!( - "And the Common Era began {} days ago", - now.num_days_from_ce() - ); -} -
-use chrono::{NaiveDate, NaiveDateTime}; - -fn main() { - // 生成一个具体的日期时间 - let date_time: NaiveDateTime = NaiveDate::from_ymd(2017, 11, 12).and_hms(17, 33, 44); - println!( - "Number of seconds between 1970-01-01 00:00:00 and {} is {}.", - // 打印日期和日期对应的时间戳 - date_time, date_time.timestamp()); - - // 计算从 1970 1月1日 0:00:00 UTC 开始,10亿秒后是什么日期时间 - let date_time_after_a_billion_seconds = NaiveDateTime::from_timestamp(1_000_000_000, 0); - println!( - "Date after a billion seconds since 1970-01-01 00:00:00 was {}.", - date_time_after_a_billion_seconds); -} -
通过 Utc::now 可以获取当前的 UTC 时间。
--use chrono::{DateTime, Utc}; - -fn main() { - let now: DateTime<Utc> = Utc::now(); - - println!("UTC now is: {}", now); - // 使用 RFC 2822 格式显示当前时间 - println!("UTC now in RFC 2822 is: {}", now.to_rfc2822()); - // 使用 RFC 3339 格式显示当前时间 - println!("UTC now in RFC 3339 is: {}", now.to_rfc3339()); - // 使用自定义格式显示当前时间 - println!("UTC now in a custom format is: {}", now.format("%a %b %e %T %Y")); -} -
我们可以将多种格式的日期时间字符串转换成 DateTime 结构体。DateTime::parse_from_str 使用的转义序列可以在 chrono::format::strftime 找到.
-只有当能唯一的标识出日期和时间时,才能创建 DateTime。如果要在没有时区的情况下解析日期或时间,你需要使用 NativeDate 等函数。
- - -use chrono::{DateTime, NaiveDate, NaiveDateTime, NaiveTime}; -use chrono::format::ParseError; - - -fn main() -> Result<(), ParseError> { - let rfc2822 = DateTime::parse_from_rfc2822("Tue, 1 Jul 2003 10:52:37 +0200")?; - println!("{}", rfc2822); - - let rfc3339 = DateTime::parse_from_rfc3339("1996-12-19T16:39:57-08:00")?; - println!("{}", rfc3339); - - let custom = DateTime::parse_from_str("5.8.1994 8:00 am +0000", "%d.%m.%Y %H:%M %P %z")?; - println!("{}", custom); - - let time_only = NaiveTime::parse_from_str("23:56:04", "%H:%M:%S")?; - println!("{}", time_only); - - let date_only = NaiveDate::parse_from_str("2015-09-05", "%Y-%m-%d")?; - println!("{}", date_only); - - let no_timezone = NaiveDateTime::parse_from_str("2015-09-05 23:56:04", "%Y-%m-%d %H:%M:%S")?; - println!("{}", no_timezone); - - Ok(()) -} -
本章节的内容是关于构建工具的,如果大家没有听说过 build.rs 文件,强烈建议先看看这里了解下何为构建工具。
cc 包能帮助我们更好地跟 C/C++/汇编进行交互:它提供了简单的 API 可以将外部的库编译成静态库( .a ),然后通过 rustc 进行静态链接。
下面的例子中,我们将在 Rust 代码中使用 C 的代码: src/hello.c。在开始编译 Rust 的项目代码前,build.rs 构建脚本将先被执行。通过 cc 包,一个静态的库可以被生成( libhello.a ),然后该库将被 Rust的代码所使用:通过 extern 声明外部函数签名的方式来使用。
由于例子中的 C 代码很简单,因此只需要将一个文件传递给 cc::Build。如果大家需要更复杂的构建,cc::Build 还提供了通过 include 来包含路径的方式,以及额外的编译标志( flags )。
Cargo.toml
-[package]
-...
-build = "build.rs"
-
-[build-dependencies]
-cc = "1"
-
-[dependencies]
-error-chain = "0.11"
-build.rs
--fn main() { - cc::Build::new() - .file("src/hello.c") - .compile("hello"); // outputs `libhello.a` -} -
src/hello.c
-#include <stdio.h>
-
-
-void hello() {
- printf("Hello from C!\n");
-}
-
-void greet(const char* name) {
- printf("Hello, %s!\n", name);
-}
-src/main.rs
--use error_chain::error_chain; -use std::ffi::CString; -use std::os::raw::c_char; - -error_chain! { - foreign_links { - NulError(::std::ffi::NulError); - Io(::std::io::Error); - } -} -fn prompt(s: &str) -> Result<String> { - use std::io::Write; - print!("{}", s); - std::io::stdout().flush()?; - let mut input = String::new(); - std::io::stdin().read_line(&mut input)?; - Ok(input.trim().to_string()) -} - -extern { - fn hello(); - fn greet(name: *const c_char); -} - -fn main() -> Result<()> { - unsafe { hello() } - let name = prompt("What's your name? ")?; - let c_name = CString::new(name)?; - unsafe { greet(c_name.as_ptr()) } - Ok(()) -} -
链接到 C++ 库跟之前的方式非常相似。主要的区别在于链接到 C++ 库时,你需要通过构建方法 cpp(true) 来指定一个 C++ 编译器,然后在 C++ 的代码顶部添加 extern "C" 来阻止 C++ 编译器对库名进行名称重整( name mangling )。
Cargo.toml
-[package]
-...
-build = "build.rs"
-
-[build-dependencies]
-cc = "1"
-build.rs
--fn main() { - cc::Build::new() - .cpp(true) - .file("src/foo.cpp") - .compile("foo"); -} -
src/foo.cpp
-extern "C" {
- int multiply(int x, int y);
-}
-
-int multiply(int x, int y) {
- return x*y;
-}
-src/main.rs
--extern { - fn multiply(x : i32, y : i32) -> i32; -} - -fn main(){ - unsafe { - println!("{}", multiply(5,7)); - } -} -
cc::Build::define 可以让我们使用自定义的 define 来构建 C 库。
-以下示例在构建脚本 build.rs 中动态定义了一个 define,然后在运行时打印出 Welcome to foo - version 1.0.2。Cargo 会设置一些环境变量,它们对于自定义的 define 会有所帮助。
Cargo.toml
-[package]
-...
-version = "1.0.2"
-build = "build.rs"
-
-[build-dependencies]
-cc = "1"
-build.rs
--fn main() { - cc::Build::new() - .define("APP_NAME", "\"foo\"") - .define("VERSION", format!("\"{}\"", env!("CARGO_PKG_VERSION")).as_str()) - .define("WELCOME", None) - .file("src/foo.c") - .compile("foo"); -} -
src/foo.c
-#include <stdio.h>
-
-void print_app_info() {
-#ifdef WELCOME
- printf("Welcome to ");
-#endif
- printf("%s - version %s\n", APP_NAME, VERSION);
-}
-src/main.rs
-- - -extern { - fn print_app_info(); -} - -fn main(){ - unsafe { - print_app_info(); - } -} -
下面代码创建了模块 foo 和嵌套模块 foo::bar,并通过 RUST_LOG 环境变量对各自的日志级别进行了控制。
-mod foo { - mod bar { - pub fn run() { - log::warn!("[bar] warn"); - log::info!("[bar] info"); - log::debug!("[bar] debug"); - } - } - - pub fn run() { - log::warn!("[foo] warn"); - log::info!("[foo] info"); - log::debug!("[foo] debug"); - bar::run(); - } -} - -fn main() { - env_logger::init(); - log::warn!("[root] warn"); - log::info!("[root] info"); - log::debug!("[root] debug"); - foo::run(); -} -
要让环境变量生效,首先需要通过 env_logger::init() 开启相关的支持。然后通过以下命令来运行程序:
RUST_LOG="warn,test::foo=info,test::foo::bar=debug" ./test
-此时的默认日志级别被设置为 warn,但我们还将 foo 模块级别设置为 info, foo::bar 模块日志级别设置为 debug。
WARN:test: [root] warn
-WARN:test::foo: [foo] warn
-INFO:test::foo: [foo] info
-WARN:test::foo::bar: [bar] warn
-INFO:test::foo::bar: [bar] info
-DEBUG:test::foo::bar: [bar] debug
-Builder 将对日志进行配置,以下代码使用 MY_APP_LOG 来替代 RUST_LOG 环境变量:
-use std::env; -use env_logger::Builder; - -fn main() { - Builder::new() - .parse(&env::var("MY_APP_LOG").unwrap_or_default()) - .init(); - - log::info!("informational message"); - log::warn!("warning message"); - log::error!("this is an error {}", "message"); -} -
-use std::io::Write; -use chrono::Local; -use env_logger::Builder; -use log::LevelFilter; - -fn main() { - Builder::new() - .format(|buf, record| { - writeln!(buf, - "{} [{}] - {}", - Local::now().format("%Y-%m-%dT%H:%M:%S"), - record.level(), - record.args() - ) - }) - .filter(None, LevelFilter::Info) - .init(); - - log::warn!("warn"); - log::info!("info"); - log::debug!("debug"); -} -
以下是 stderr 的输出:
2022-03-22T21:57:06 [WARN] - warn
-2022-03-22T21:57:06 [INFO] - info
-log4rs 可以帮我们将日志输出指定的位置,它可以使用外部 YAML 文件或 builder 的方式进行配置。
- - -use error_chain::error_chain; - -use log::LevelFilter; -use log4rs::append::file::FileAppender; -use log4rs::encode::pattern::PatternEncoder; -use log4rs::config::{Appender, Config, Root}; - -error_chain! { - foreign_links { - Io(std::io::Error); - LogConfig(log4rs::config::Errors); - SetLogger(log::SetLoggerError); - } -} - -fn main() -> Result<()> { - // 创建日志配置,并指定输出的位置 - let logfile = FileAppender::builder() - // 编码模式的详情参见: https://docs.rs/log4rs/1.0.0/log4rs/encode/pattern/index.html - .encoder(Box::new(PatternEncoder::new("{l} - {m}\n"))) - .build("log/output.log")?; - - let config = Config::builder() - .appender(Appender::builder().build("logfile", Box::new(logfile))) - .build(Root::builder() - .appender("logfile") - .build(LevelFilter::Info))?; - - log4rs::init_config(config)?; - - log::info!("Hello, world!"); - - Ok(()) -} - -
log 提供了日志相关的实用工具。
-env_logger 通过环境变量来配置日志。log::debug! 使用起来跟 std::fmt 中的格式化字符串很像。
-fn execute_query(query: &str) { - log::debug!("Executing query: {}", query); -} - -fn main() { - env_logger::init(); - - execute_query("DROP TABLE students"); -} -
如果大家运行代码,会发现没有任何日志输出,原因是默认的日志级别是 error,因此我们需要通过 RUST_LOG 环境变量来设置下新的日志级别:
$ RUST_LOG=debug cargo run
-然后你将成功看到以下输出:
-DEBUG:main: Executing query: DROP TABLE students
-下面我们通过 log::error! 将错误日志输出到标准错误 stderr。
-fn execute_query(_query: &str) -> Result<(), &'static str> { - Err("I'm afraid I can't do that") -} - -fn main() { - env_logger::init(); - - let response = execute_query("DROP TABLE students"); - if let Err(err) = response { - log::error!("Failed to execute query: {}", err); - } -} -
默认的错误会输出到标准错误输出 stderr,下面我们通过自定的配置来让错误输出到标准输出 stdout。
-use env_logger::{Builder, Target}; - -fn main() { - Builder::new() - .target(Target::Stdout) - .init(); - - log::error!("This error has been printed to Stdout"); -} -
下面的代码将实现一个自定义 logger ConsoleLogger,输出到标准输出 stdout。为了使用日志宏,ConsoleLogger 需要实现 log::Log 特征,然后使用 log::set_logger 来安装使用。
-use log::{Record, Level, Metadata, LevelFilter, SetLoggerError}; - -static CONSOLE_LOGGER: ConsoleLogger = ConsoleLogger; - -struct ConsoleLogger; - -impl log::Log for ConsoleLogger { - fn enabled(&self, metadata: &Metadata) -> bool { - metadata.level() <= Level::Info - } - - fn log(&self, record: &Record) { - if self.enabled(record.metadata()) { - println!("Rust says: {} - {}", record.level(), record.args()); - } - } - - fn flush(&self) {} -} - -fn main() -> Result<(), SetLoggerError> { - log::set_logger(&CONSOLE_LOGGER)?; - log::set_max_level(LevelFilter::Info); - - log::info!("hello log"); - log::warn!("warning"); - log::error!("oops"); - Ok(()) -} -
下面的代码将使用 syslog 包将日志输出到 Unix Syslog.
--#[cfg(target_os = "linux")] -#[cfg(target_os = "linux")] -use syslog::{Facility, Error}; - -#[cfg(target_os = "linux")] -fn main() -> Result<(), Error> { - // 初始化 logger - syslog::init(Facility::LOG_USER, - log::LevelFilter::Debug, - // 可选的应用名称 - Some("My app name"))?; - log::debug!("this is a debug {}", "message"); - log::error!("this is an error!"); - Ok(()) -} - -#[cfg(not(target_os = "linux"))] -fn main() { - println!("So far, only Linux systems are supported."); -} -
@todo
- - -下面例子使用 Version::parse 将一个字符串转换成 semver::Version 版本号,然后将它的 patch, minor, major 版本号都增加 1。
-注意,为了符合语义化版本的说明,增加 minor 版本时,patch 版本会被重设为 0,当增加 major 版本时,minor 和 patch 都将被重设为 0。
-use semver::{Version, SemVerError}; - -fn main() -> Result<(), SemVerError> { - let mut parsed_version = Version::parse("0.2.6")?; - - assert_eq!( - parsed_version, - Version { - major: 0, - minor: 2, - patch: 6, - pre: vec![], - build: vec![], - } - ); - - parsed_version.increment_patch(); - assert_eq!(parsed_version.to_string(), "0.2.7"); - println!("New patch release: v{}", parsed_version); - - parsed_version.increment_minor(); - assert_eq!(parsed_version.to_string(), "0.3.0"); - println!("New minor release: v{}", parsed_version); - - parsed_version.increment_major(); - assert_eq!(parsed_version.to_string(), "1.0.0"); - println!("New major release: v{}", parsed_version); - - Ok(()) -} -
这里的版本号字符串还将包含 SemVer 中定义的预发布和构建元信息。
值得注意的是,为了符合 SemVer 的规则,构建元信息虽然会被解析,但是在做版本号比较时,该信息会被忽略。换而言之,即使两个版本号的构建字符串不同,它们的版本号依然可能相同。
-use semver::{Identifier, Version, SemVerError}; - -fn main() -> Result<(), SemVerError> { - let version_str = "1.0.49-125+g72ee7853"; - let parsed_version = Version::parse(version_str)?; - - assert_eq!( - parsed_version, - Version { - major: 1, - minor: 0, - patch: 49, - pre: vec![Identifier::Numeric(125)], - build: vec![], - } - ); - assert_eq!( - parsed_version.build, - vec![Identifier::AlphaNumeric(String::from("g72ee7853"))] - ); - - let serialized_version = parsed_version.to_string(); - assert_eq!(&serialized_version, version_str); - - Ok(()) -} -
下面例子给出两个版本号,然后通过 is_prerelease 判断哪个是预发布的版本号。
--use semver::{Version, SemVerError}; - -fn main() -> Result<(), SemVerError> { - let version_1 = Version::parse("1.0.0-alpha")?; - let version_2 = Version::parse("1.0.0")?; - - assert!(version_1.is_prerelease()); - assert!(!version_2.is_prerelease()); - - Ok(()) -} -
下面例子给出了一个版本号列表,我们需要找到其中最新的版本。
--use error_chain::error_chain; - -use semver::{Version, VersionReq}; - -error_chain! { - foreign_links { - SemVer(semver::SemVerError); - SemVerReq(semver::ReqParseError); - } -3} - -fn find_max_matching_version<'a, I>(version_req_str: &str, iterable: I) -> Result<Option<Version>> -where - I: IntoIterator<Item = &'a str>, -{ - let vreq = VersionReq::parse(version_req_str)?; - - Ok( - iterable - .into_iter() - .filter_map(|s| Version::parse(s).ok()) - .filter(|s| vreq.matches(s)) - .max(), - ) -} - -fn main() -> Result<()> { - assert_eq!( - find_max_matching_version("<= 1.0.0", vec!["0.9.0", "1.0.0", "1.0.1"])?, - Some(Version::parse("1.0.0")?) - ); - - assert_eq!( - find_max_matching_version( - ">1.2.3-alpha.3", - vec![ - "1.2.3-alpha.3", - "1.2.3-alpha.4", - "1.2.3-alpha.10", - "1.2.3-beta.4", - "3.4.5-alpha.9", - ] - )?, - Some(Version::parse("1.2.3-beta.4")?) - ); - - Ok(()) -} -
下面将通过 Command 来执行系统命令 git --version,并对该系统命令返回的 git 版本号进行解析。
- - -use error_chain::error_chain; - -use std::process::Command; -use semver::{Version, VersionReq}; - -error_chain! { - foreign_links { - Io(std::io::Error); - Utf8(std::string::FromUtf8Error); - SemVer(semver::SemVerError); - SemVerReq(semver::ReqParseError); - } -} - -fn main() -> Result<()> { - let version_constraint = "> 1.12.0"; - let version_test = VersionReq::parse(version_constraint)?; - let output = Command::new("git").arg("--version").output()?; - - if !output.status.success() { - error_chain::bail!("Command executed with failing error code"); - } - - let stdout = String::from_utf8(output.stdout)?; - let version = stdout.split(" ").last().ok_or_else(|| { - "Invalid command output" - })?; - let parsed_version = Version::parse(version)?; - - if !version_test.matches(&parsed_version) { - error_chain::bail!("Command version lower than minimum supported version (found {}, need {})", - parsed_version, version_constraint); - } - - Ok(()) -} -
Javascript是目前全世界使用最广的语言(TIOBE排行榜比较迷,JS并没有排在第一位,我个人并不认同它的排名)。在过去这么多年中,围绕着Javascript已经建立了庞大的基础设施生态:例如使用webpack来将多个js文件打包成一个;使用Babel允许你用现代化的js语法编写兼容旧浏览器的代码;使用Eslint帮助开发找出代码中潜在的问题,类似cargo clippy。
以上的种种都在帮助js成为更好的语言和工具,它们是Web应用程序得以顺利、高效的开发和运行的基石。这些工具往往使用Javascript语言编写,一般来说,是没有问题的,但是在某些时候,可能会存在性能上的瓶颈或者安全隐患,因此阴差阳错、机缘巧合下,Rust成为了一个搅局者。
首先出场的自然是咖位最重的之一,可以说正是因为deno和swc的横空出世,才让一堆观望的大神对于Rust实现Javascript基建有了更强的信心。
deno是node半逆转后的字序,从此可以看出deno是Node.js的替代,它的目标是为Typescript/Javascript提供一个更现代化、更安全、更强大 的运行时,同时内置了很多强大的工具,可以用于打包、编译成可执行文件、文档、测试、lint等。
值得一提的是,deno的不少工具都使用了swc进行建造,包括代码审查、格式化、文档生成等。
通过包引入的方式来对比下deno和node,大家可以自己品味下。
// node
-const koa = require("koa" );
-cost logger = require("@adesso/logger")
-
-// deno
-import { Application } from "https://deno.land/x/oak/mod.ts";
-import { Logger } from "https://adesso.de/lib/logger.ts"
-swc是Typescript/Javascript编译器,它可以用来编译、压缩和打包JS,同时支持使用插件进行扩展,例如做代码变换等。
swc目前正在被一些知名项目所使用,包括Next.js,Parcel和Deno,还有些著名的公司也在使用它,例如Vercel、字节跳动、腾讯等。
它的性能非常非常高,官方号称,在单线程下比Babel快20倍,在4核心下比Babel快70倍!
几个使用案例:
- - -
-官方还提供了一个在线运行的demo,功能齐全,可以试试。
-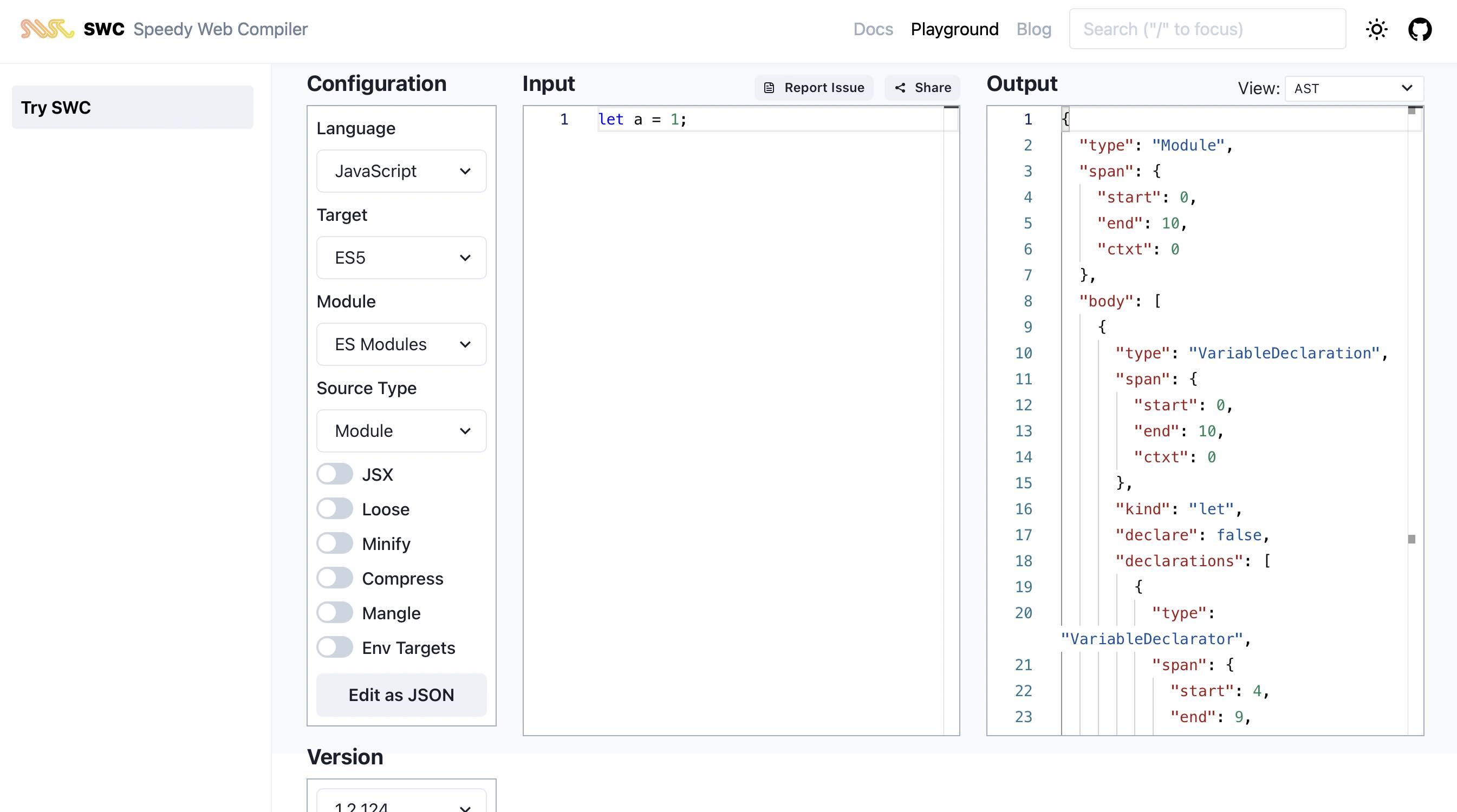 -
-Rome可以用来对JavaScript、TypeScript、HTML、JSON、Markdown 和 CSS 进行lint、编译、打包等功能,它的目标是替代Babel、ESLint、webpack、Prettier、Jest等。
一开始Rome是使用Typescript开发,目前正在用Rust进行重写。有趣的是: Rome的作者也是Babel的作者, 后者还是他在学习编译原理时做的。
fnm是一个简单易用、高性能的Node版本管理工具,还支持.nvmrc文件(nvm的node版本描述文件)
 -
-boa是一个高性能的javascript词法分析器,解析器和解释器,目前还是实验性质的。
 -
-napi可以用于构建基于Node API的Nodejs插件,目前由nextjs主导开发。
volt是一个现代化的、高性能、安全可靠的Javascript包管理工具。目前该库正处于活跃开发阶段,只供学习使用。
 -
-neon可以用于写安全、高性能的原生Nodejs模块。
--#![allow(unused)] -fn main() { -fn make_an_array(mut cx: FunctionContext) -> JsResult<JsArray> { - // 创建一些值: - let n = cx.number(9000); - let s = cx.string("hello"); - let b = cx.boolean(true); - - // 创建一个新数组: - let array: Handle<JsArray> = cx.empty_array(); - - // 将值推入数组中 - array.set(&mut cx, 0, n)?; - array.set(&mut cx, 1, s)?; - array.set(&mut cx, 2, b)?; - - // 返回数组 - Ok(array) -} - -register_module!(mut cx, { - cx.export_function("makeAnArray", make_an_array) -}) -} -
resvg-js是一个高性能svg渲染库,使用Rust + Typescript实现。下面的图片通过svg实现(羞~~~):
 -
-deno_lint, 由deno团队出品的lint工具,支持Javascript/Typescript,支持Deno也支持Node。
优点之一就是极致的快:
-[
- {
- "name": "deno_lint",
- "totalMs": 105.3750100000002,
- "runsCount": 5,
- "measuredRunsAvgMs": 21.07500200000004,
- "measuredRunsMs": [
- 24.79783199999997,
- 19.563640000000078,
- 20.759051999999883,
- ]
- },
- {
- "name": "eslint",
- "totalMs": 11845.073306000002,
- "runsCount": 5,
- "measuredRunsAvgMs": 2369.0146612000003,
- "measuredRunsMs": [
- 2686.1039550000005,
- 2281.501061,
- 2298.6185210000003,
- ]
- }
-]
-rslint是一个高性能、可定制性强、简单易用的Javascript/Typescript lint分析工具。
$ echo "let a = foo.hasOwnProperty('bar');" > foo.js
-$ rslint ./foo.js
-error[no-prototype-builtins]: do not access the object property `hasOwnProperty` directly from `foo`
- ┌─ ./foo.js:1:9
- │
-1 │ let a = foo.hasOwnProperty('bar');
- │ ^^^^^^^^^^^^^^^^^^^^^^^^^
- │
-help: get the function from the prototype of `Object` and call it
- │
-1 │ let a = Object.prototype.hasOwnProperty.call(foo, 'bar');
- │ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
- │
- ╧ note: the method may be shadowed and cause random bugs and denial of service vulnerabilities
-
-Outcome: 1 fail, 0 warn, 0 success
-
-help: for more information about the errors try the explain command: `rslint explain <rules>`
-rusty_v8是v8的Rust语言绑定,底层封装了c++ API。
wasm(web assembly)是一种低级语言,它运行在浏览器中,可以和javascript相互调用,几乎所有浏览器都支持, 而且目前有多种高级语言都可以直接编译成wasm,更是大大增强了它的地位。
目前来说Rust可以编译成wasm,虽然还不够完美,但是它正在以肉眼可见的速度快速发展中。因此同时使用Rust和Javascript成为了一种可能:将Rust编译成wasm,再跟js进行交互,两者共生共存,各自解决擅长的场景(wasm性能高,js开发速度快)。
yew是一个正在活跃开发的Rust/Wasm框架,用于构建Web客户端应用。
 -
-[gloo]是一个模块化的工具,使用Rust/WASM构建快速、可靠的Web应用。
--#![allow(unused)] -fn main() { -use gloo::{events::EventListener, timers::callback::Timeout}; -use wasm_bindgen::prelude::*; - -pub struct DelayedHelloButton { - button: web_sys::Element, - on_click: events::EventListener, -} - -impl DelayedHelloButton { - pub fn new(document: &web_sys::Document) -> Result<DelayedHelloButton, JsValue> { - // 创建 `<button>` 元素. - let button = document.create_element("button")?; - - // 监听button上的`click`事件 - let button2 = button.clone(); - let on_click = EventListener::new(&button, "click", move |_event| { - // 一秒后,更新button中的文本 - let button3 = button2.clone(); - Timeout::new(1_000, move || { - button3.set_text_content(Some("Hello from one second ago!")); - }) - .forget(); - }); - - Ok(DelayedHelloButton { button, on_click }) - } -} -} -
wasm-bindgen可以让WASM模块和Javascript模块进行更好的交互。
--#![allow(unused)] -fn main() { -use wasm_bindgen::prelude::*; - -// 从Web导入 `window.alert` 函数 -#[wasm_bindgen] -extern "C" { - fn alert(s: &str); -} - -// 从Rust导出一个`greet`函数到Javascript,该函数会`alert`一条欢迎信息 -#[wasm_bindgen] -pub fn greet(name: &str) { - alert(&format!("Hello, {}!", name)); -} -} -
wasm-pack是一站式的解决方案,用于构建和使用Rust生成的WASM,支持在浏览器中或后台的Node.js中与Javascript进行交互。
 -
-wasmer是业界领先的WASM运行时,支持WASI和Emscripten。
$ wasmer qjs.wasm
-QuickJS - Type "\h" for help
-qjs > const i = 1 + 2;
-qjs > console.log("hello " + i);
-hello 3
-wasmtime是一个为WASM设计的JIT风格的独立运行时。
-fn main() { - println!("Hello, world!"); -} -
$ rustup target add wasm32-wasi
-$ rustc hello.rs --target wasm32-wasi
-$ wasmtime hello.wasm
-Hello, world!
-trunk是一个WASM构建、打包、Web发布工具。
photon是高性能的、跨平台的图片处理库,使用Rust开发,编译成WASM运行,为你的Web应用和Node.js应用提供无与伦比的图片处理速度,当然,它既然使用Rust开发,也可以作为一个库被你的后台程序所使用。
 -
-tinysearch是一个搜索工具,用于静态网站中的内容搜索,使用Rust和WASM构建。优点是体积小(适用于浏览器)、性能高、全文索引。
 -
-wasm-pdf通过Javascript和WASM来生成PDF,可以直接在浏览器中使用。
makepad是一个充满创意的Rust开发平台,支持编译成wasm,并使用webGL进行渲染。
 -
-wasm-book是一本讲述Rust和wasm的书,篇幅不算长,但是值得学习,还包含了几个很酷的例子。
wasm-learning是一个英文教程,用于学习Rust, wasm和Node.js,你可以学会如何使用Rust来为Nodejs构建函数,可以同时利用Rust的性能、wasm的安全性和可移植性、js的易用性。
rust-js-snake-game是一个用rust + js + wasm构建的贪食蛇游戏。
我们可以将标准的 CSV 记录值读取到 csv::StringRecord 中,但是该数据结构期待合法的 UTF8 数据行,你还可以使用 csv::ByteRecord 来读取非 UTF8 数据。
--use csv::Error; - -fn main() -> Result<(), Error> { - let csv = "year,make,model,description - 1948,Porsche,356,Luxury sports car - 1967,Ford,Mustang fastback 1967,American car"; - - let mut reader = csv::Reader::from_reader(csv.as_bytes()); - for record in reader.records() { - let record = record?; - println!( - "In {}, {} built the {} model. It is a {}.", - &record[0], - &record[1], - &record[2], - &record[3] - ); - } - - Ok(()) -} -
还可以使用 serde 将数据反序列化成一个强类型的结构体。
-use serde::Deserialize; -#[derive(Deserialize)] -struct Record { - year: u16, - make: String, - model: String, - description: String, -} - -fn main() -> Result<(), csv::Error> { - let csv = "year,make,model,description -1948,Porsche,356,Luxury sports car -1967,Ford,Mustang fastback 1967,American car"; - - let mut reader = csv::Reader::from_reader(csv.as_bytes()); - - for record in reader.deserialize() { - let record: Record = record?; - println!( - "In {}, {} built the {} model. It is a {}.", - record.year, - record.make, - record.model, - record.description - ); - } - - Ok(()) -} -
下面的例子将读取使用了 tab 作为分隔符的 CSV 记录。
-use csv::Error; -use serde::Deserialize; -#[derive(Debug, Deserialize)] -struct Record { - name: String, - place: String, - #[serde(deserialize_with = "csv::invalid_option")] - id: Option<u64>, -} - -use csv::ReaderBuilder; - -fn main() -> Result<(), Error> { - let data = "name\tplace\tid - Mark\tMelbourne\t46 - Ashley\tZurich\t92"; - - let mut reader = ReaderBuilder::new().delimiter(b'\t').from_reader(data.as_bytes()); - for result in reader.deserialize::<Record>() { - println!("{:?}", result?); - } - - Ok(()) -} -
-use error_chain::error_chain; - -use std::io; - -error_chain!{ - foreign_links { - Io(std::io::Error); - CsvError(csv::Error); - } -} - -fn main() -> Result<()> { - let query = "CA"; - let data = "\ -City,State,Population,Latitude,Longitude -Kenai,AK,7610,60.5544444,-151.2583333 -Oakman,AL,,33.7133333,-87.3886111 -Sandfort,AL,,32.3380556,-85.2233333 -West Hollywood,CA,37031,34.0900000,-118.3608333"; - - let mut rdr = csv::ReaderBuilder::new().from_reader(data.as_bytes()); - let mut wtr = csv::Writer::from_writer(io::stdout()); - - wtr.write_record(rdr.headers()?)?; - - for result in rdr.records() { - let record = result?; - if record.iter().any(|field| field == query) { - wtr.write_record(&record)?; - } - } - - wtr.flush()?; - Ok(()) -} -
下面例子展示了如何将 Rust 类型序列化为 CSV。
--use std::io; - -fn main() -> Result<()> { - let mut wtr = csv::Writer::from_writer(io::stdout()); - - wtr.write_record(&["Name", "Place", "ID"])?; - - wtr.serialize(("Mark", "Sydney", 87))?; - wtr.serialize(("Ashley", "Dublin", 32))?; - wtr.serialize(("Akshat", "Delhi", 11))?; - - wtr.flush()?; - Ok(()) -} -
下面例子将自定义数据结构通过 serde 序列化 CSV。
-use error_chain::error_chain; -use serde::Serialize; -use std::io; - -error_chain! { - foreign_links { - IOError(std::io::Error); - CSVError(csv::Error); - } -} - -#[derive(Serialize)] -struct Record<'a> { - name: &'a str, - place: &'a str, - id: u64, -} - -fn main() -> Result<()> { - let mut wtr = csv::Writer::from_writer(io::stdout()); - - let rec1 = Record { name: "Mark", place: "Melbourne", id: 56}; - let rec2 = Record { name: "Ashley", place: "Sydney", id: 64}; - let rec3 = Record { name: "Akshat", place: "Delhi", id: 98}; - - wtr.serialize(rec1)?; - wtr.serialize(rec2)?; - wtr.serialize(rec3)?; - - wtr.flush()?; - - Ok(()) -} -
下面代码将包含有颜色名和十六进制颜色的 CSV 文件转换为包含颜色名和 rgb 颜色。这里使用 csv 包对 CSV 文件进行读写,然后用 serde 进行序列化和反序列化。
- - -use error_chain::error_chain; -use csv::{Reader, Writer}; -use serde::{de, Deserialize, Deserializer}; -use std::str::FromStr; - -error_chain! { - foreign_links { - CsvError(csv::Error); - ParseInt(std::num::ParseIntError); - CsvInnerError(csv::IntoInnerError<Writer<Vec<u8>>>); - IO(std::fmt::Error); - UTF8(std::string::FromUtf8Error); - } -} - -#[derive(Debug)] -struct HexColor { - red: u8, - green: u8, - blue: u8, -} - -#[derive(Debug, Deserialize)] -struct Row { - color_name: String, - color: HexColor, -} - -impl FromStr for HexColor { - type Err = Error; - - fn from_str(hex_color: &str) -> std::result::Result<Self, Self::Err> { - let trimmed = hex_color.trim_matches('#'); - if trimmed.len() != 6 { - Err("Invalid length of hex string".into()) - } else { - Ok(HexColor { - red: u8::from_str_radix(&trimmed[..2], 16)?, - green: u8::from_str_radix(&trimmed[2..4], 16)?, - blue: u8::from_str_radix(&trimmed[4..6], 16)?, - }) - } - } -} - -impl<'de> Deserialize<'de> for HexColor { - fn deserialize<D>(deserializer: D) -> std::result::Result<Self, D::Error> - where - D: Deserializer<'de>, - { - let s = String::deserialize(deserializer)?; - FromStr::from_str(&s).map_err(de::Error::custom) - } -} - -fn main() -> Result<()> { - let data = "color_name,color -red,#ff0000 -green,#00ff00 -blue,#0000FF -periwinkle,#ccccff -magenta,#ff00ff" - .to_owned(); - let mut out = Writer::from_writer(vec![]); - let mut reader = Reader::from_reader(data.as_bytes()); - for result in reader.deserialize::<Row>() { - let res = result?; - out.serialize(( - res.color_name, - res.color.red, - res.color.green, - res.color.blue, - ))?; - } - let written = String::from_utf8(out.into_inner()?)?; - assert_eq!(Some("magenta,255,0,255"), written.lines().last()); - println!("{}", written); - Ok(()) -} -
百分号编码又称 URL 编码。
-percent-encoding 包提供了两个函数:utf8_percent_encode 函数用于编码、percent_decode 用于解码。
-use percent_encoding::{utf8_percent_encode, percent_decode, AsciiSet, CONTROLS}; -use std::str::Utf8Error; - -/// https://url.spec.whatwg.org/#fragment-percent-encode-set -const FRAGMENT: &AsciiSet = &CONTROLS.add(b' ').add(b'"').add(b'<').add(b'>').add(b'`'); - -fn main() -> Result<(), Utf8Error> { - let input = "confident, productive systems programming"; - - let iter = utf8_percent_encode(input, FRAGMENT); - // 将元素类型为 &str 的迭代器收集为 String 类型 - let encoded: String = iter.collect(); - assert_eq!(encoded, "confident,%20productive%20systems%20programming"); - - let iter = percent_decode(encoded.as_bytes()); - let decoded = iter.decode_utf8()?; - assert_eq!(decoded, "confident, productive systems programming"); - - Ok(()) -} -
该编码集定义了哪些字符( 特别是非 ASCII 和控制字符 )需要被百分比编码。具体的选择取决于上下文,例如 url 会对 URL 路径中的 ? 进行编码,但是在路径后的查询字符串中,并不会进行编码。
使用 form_urlencoded::byte_serialize 函数将一个字符串编码成 application/x-www-form-urlencoded 格式,然后再使用 form_urlencoded::parse 对其进行解码。
--use url::form_urlencoded::{byte_serialize, parse}; - -fn main() { - let urlencoded: String = byte_serialize("What is ❤?".as_bytes()).collect(); - assert_eq!(urlencoded, "What+is+%E2%9D%A4%3F"); - println!("urlencoded:'{}'", urlencoded); - - let decoded: String = parse(urlencoded.as_bytes()) - .map(|(key, val)| [key, val].concat()) - .collect(); - assert_eq!(decoded, "What is ❤?"); - println!("decoded:'{}'", decoded); -} -
data_encoding 可以将一个字符串编码成十六进制字符串,反之亦然。
-下面的例子将 &[u8] 转换成十六进制等效形式,然后与期待的值进行比较。
-use data_encoding::{HEXUPPER, DecodeError}; - -fn main() -> Result<(), DecodeError> { - let original = b"The quick brown fox jumps over the lazy dog."; - let expected = "54686520717569636B2062726F776E20666F78206A756D7073206F76\ - 657220746865206C617A7920646F672E"; - - let encoded = HEXUPPER.encode(original); - assert_eq!(encoded, expected); - - let decoded = HEXUPPER.decode(&encoded.into_bytes())?; - assert_eq!(&decoded[..], &original[..]); - - Ok(()) -} -
base64 可以把一个字节切片编码成 base64 String。
- - -use error_chain::error_chain; - -use std::str; -use base64::{encode, decode}; - -error_chain! { - foreign_links { - Base64(base64::DecodeError); - Utf8Error(str::Utf8Error); - } -} - -fn main() -> Result<()> { - // 将 `&str` 转换成 `&[u8; N]` - let hello = b"hello rustaceans"; - let encoded = encode(hello); - let decoded = decode(&encoded)?; - - println!("origin: {}", str::from_utf8(hello)?); - println!("base64 encoded: {}", encoded); - println!("back to origin: {}", str::from_utf8(&decoded)?); - - Ok(()) -} -
serde_json 是一个高性能的 JSON 包,它支持我们在不声明结构体的情况下,去解析 JSON。
--use serde_json::json; -use serde_json::{Value, Error}; - -fn main() -> Result<(), Error> { - let j = r#"{ - "userid": 103609, - "verified": true, - "access_privileges": [ - "user", - "admin" - ] - }"#; - - let parsed: Value = serde_json::from_str(j)?; - - let expected = json!({ - "userid": 103609, - "verified": true, - "access_privileges": [ - "user", - "admin" - ] - }); - - assert_eq!(parsed, expected); - - Ok(()) -} -
toml 包可以将 TOML 文件的内容解析为一个 toml::Value 值,该值能代表任何合法的 TOML 数据。
-use toml::{Value, de::Error}; - -fn main() -> Result<(), Error> { - let toml_content = r#" - [package] - name = "your_package" - version = "0.1.0" - authors = ["You! <you@example.org>"] - - [dependencies] - serde = "1.0" - "#; - - let package_info: Value = toml::from_str(toml_content)?; - - assert_eq!(package_info["dependencies"]["serde"].as_str(), Some("1.0")); - assert_eq!(package_info["package"]["name"].as_str(), - Some("your_package")); - - Ok(()) -} -
还可以配合 serde 将 TOML 解析到我们自定义的结构体中:
--use serde::Deserialize; - -use toml::de::Error; -use std::collections::HashMap; - -#[derive(Deserialize)] -struct Config { - package: Package, - dependencies: HashMap<String, String>, -} - -#[derive(Deserialize)] -struct Package { - name: String, - version: String, - authors: Vec<String>, -} - -fn main() -> Result<(), Error> { - let toml_content = r#" - [package] - name = "your_package" - version = "0.1.0" - authors = ["You! <you@example.org>"] - - [dependencies] - serde = "1.0" - "#; - - let package_info: Config = toml::from_str(toml_content)?; - - assert_eq!(package_info.package.name, "your_package"); - assert_eq!(package_info.package.version, "0.1.0"); - assert_eq!(package_info.package.authors, vec!["You! <you@example.org>"]); - assert_eq!(package_info.dependencies["serde"], "1.0"); - - Ok(()) -} -
byteorder 在自行接收或发送网络字节流时会非常有用( 除非性能要求高,否则还是建议使用 JSON 等数据协议,不要自己做字节流解析 )。
-- - --use byteorder::{LittleEndian, ReadBytesExt, WriteBytesExt}; -use std::io::Error; - -#[derive(Default, PartialEq, Debug)] -struct Payload { - kind: u8, - value: u16, -} - -fn main() -> Result<(), Error> { - let original_payload = Payload::default(); - let encoded_bytes = encode(&original_payload)?; - let decoded_payload = decode(&encoded_bytes)?; - assert_eq!(original_payload, decoded_payload); - Ok(()) -} - -fn encode(payload: &Payload) -> Result<Vec<u8>, Error> { - let mut bytes = vec![]; - bytes.write_u8(payload.kind)?; - bytes.write_u16::<LittleEndian>(payload.value)?; - Ok(bytes) -} - -fn decode(mut bytes: &[u8]) -> Result<Payload, Error> { - let payload = Payload { - kind: bytes.read_u8()?, - value: bytes.read_u16::<LittleEndian>()?, - }; - Ok(payload) -} -
通过遍历读取目录中文件的 Metadata::modified 属性,来获取目标文件名列表。
--use error_chain::error_chain; - -use std::{env, fs}; - -error_chain! { - foreign_links { - Io(std::io::Error); - SystemTimeError(std::time::SystemTimeError); - } -} - -fn main() -> Result<()> { - let current_dir = env::current_dir()?; - println!( - "Entries modified in the last 24 hours in {:?}:", - current_dir - ); - - for entry in fs::read_dir(current_dir)? { - let entry = entry?; - let path = entry.path(); - - let metadata = fs::metadata(&path)?; - let last_modified = metadata.modified()?.elapsed()?.as_secs(); - - if last_modified < 24 * 3600 && metadata.is_file() { - println!( - "Last modified: {:?} seconds, is read only: {:?}, size: {:?} bytes, filename: {:?}", - last_modified, - metadata.permissions().readonly(), - metadata.len(), - path.file_name().ok_or("No filename")? - ); - } - } - - Ok(()) -} -
使用 same_file::is_same_file 可以检查给定路径的 loops,loop 可以通过以下方式创建:
-mkdir -p /tmp/foo/bar/baz
-ln -s /tmp/foo/ /tmp/foo/bar/baz/qux
--use std::io; -use std::path::{Path, PathBuf}; -use same_file::is_same_file; - -fn contains_loop<P: AsRef<Path>>(path: P) -> io::Result<Option<(PathBuf, PathBuf)>> { - let path = path.as_ref(); - let mut path_buf = path.to_path_buf(); - while path_buf.pop() { - if is_same_file(&path_buf, path)? { - return Ok(Some((path_buf, path.to_path_buf()))); - } else if let Some(looped_paths) = contains_loop(&path_buf)? { - return Ok(Some(looped_paths)); - } - } - return Ok(None); -} - -fn main() { - assert_eq!( - contains_loop("/tmp/foo/bar/baz/qux/bar/baz").unwrap(), - Some(( - PathBuf::from("/tmp/foo"), - PathBuf::from("/tmp/foo/bar/baz/qux") - )) - ); -} -
walkdir 可以帮助我们遍历指定的目录。
--use std::collections::HashMap; -use walkdir::WalkDir; - -fn main() { - let mut filenames = HashMap::new(); - - // 遍历当前目录 - for entry in WalkDir::new(".") - .into_iter() - .filter_map(Result::ok) - .filter(|e| !e.file_type().is_dir()) { - let f_name = String::from(entry.file_name().to_string_lossy()); - let counter = filenames.entry(f_name.clone()).or_insert(0); - *counter += 1; - - if *counter == 2 { - println!("{}", f_name); - } - } -} -
下面的代码通过 walkdir 来查找当前目录中最近一天内发生过修改的所有文件。
-follow_links 为 true 时,那软链接会被当成正常的文件或目录一样对待,也就是说软链接指向的文件或目录也会被访问和检查。若软链接指向的目标不存在或它是一个 loops,就会导致错误的发生。
-use error_chain::error_chain; - -use walkdir::WalkDir; - -error_chain! { - foreign_links { - WalkDir(walkdir::Error); - Io(std::io::Error); - SystemTime(std::time::SystemTimeError); - } -} - -fn main() -> Result<()> { - for entry in WalkDir::new(".") - .follow_links(true) - .into_iter() - .filter_map(|e| e.ok()) { - let f_name = entry.file_name().to_string_lossy(); - let sec = entry.metadata()?.modified()?; - - if f_name.ends_with(".json") && sec.elapsed()?.as_secs() < 86400 { - println!("{}", f_name); - } - } - - Ok(()) -} -
下面例子使用 walkdir 来遍历一个目录,同时跳过隐藏文件 is_not_hidden。
-use walkdir::{DirEntry, WalkDir}; - -fn is_not_hidden(entry: &DirEntry) -> bool { - entry - .file_name() - .to_str() - .map(|s| entry.depth() == 0 || !s.starts_with(".")) - .unwrap_or(false) -} - -fn main() { - WalkDir::new(".") - .into_iter() - .filter_entry(|e| is_not_hidden(e)) - .filter_map(|v| v.ok()) - .for_each(|x| println!("{}", x.path().display())); -} -
递归访问的深度可以使用 WalkDir::min_depth 和 WalkDir::max_depth 来控制。
--use walkdir::WalkDir; - -fn main() { - let total_size = WalkDir::new(".") - .min_depth(1) - .max_depth(3) - .into_iter() - .filter_map(|entry| entry.ok()) - .filter_map(|entry| entry.metadata().ok()) - .filter(|metadata| metadata.is_file()) - .fold(0, |acc, m| acc + m.len()); - - println!("Total size: {} bytes.", total_size); -} -
例子中使用了 glob 包,其中的 ** 代表当前目录及其所有子目录,例如,/media/**/*.png 代表在 media 和它的所有子目录下查找 png 文件.
-use error_chain::error_chain; - -use glob::glob; - -error_chain! { - foreign_links { - Glob(glob::GlobError); - Pattern(glob::PatternError); - } -} - -fn main() -> Result<()> { - for entry in glob("**/*.png")? { - println!("{}", entry?.display()); - } - - Ok(()) -} -
glob_with 函数可以按照给定的正则表达式进行查找,同时还能使用选项来控制一些匹配设置。
-- - -use error_chain::error_chain; -use glob::{glob_with, MatchOptions}; - -error_chain! { - foreign_links { - Glob(glob::GlobError); - Pattern(glob::PatternError); - } -} - -fn main() -> Result<()> { - let options = MatchOptions { - case_sensitive: false, - ..Default::default() - }; - - for entry in glob_with("/media/img_[0-9]*.png", options)? { - println!("{}", entry?.display()); - } - - Ok(()) -} -
-use std::fs::File; -use std::io::{Write, BufReader, BufRead, Error}; - -fn main() -> Result<(), Error> { - let path = "lines.txt"; - - // 创建文件 - let mut output = File::create(path)?; - // 写入三行内容 - write!(output, "Rust\n💖\nFun")?; - - let input = File::open(path)?; - let buffered = BufReader::new(input); - - // 迭代文件中的每一行内容,line 是字符串 - for line in buffered.lines() { - println!("{}", line?); - } - - Ok(()) -} -
same_file 可以帮我们识别两个文件是否是相同的。
--use same_file::Handle; -use std::fs::File; -use std::io::{BufRead, BufReader, Error, ErrorKind}; -use std::path::Path; - -fn main() -> Result<(), Error> { - let path_to_read = Path::new("new.txt"); - - // 从标准输出上获取待写入的文件名 - let stdout_handle = Handle::stdout()?; - // 将待写入的文件名跟待读取的文件名进行比较 - let handle = Handle::from_path(path_to_read)?; - - if stdout_handle == handle { - return Err(Error::new( - ErrorKind::Other, - "You are reading and writing to the same file", - )); - } else { - let file = File::open(&path_to_read)?; - let file = BufReader::new(file); - for (num, line) in file.lines().enumerate() { - println!("{} : {}", num, line?.to_uppercase()); - } - } - - Ok(()) -} -
以下代码会报错,因为待写入的文件名也是 new.txt,跟待读取的文件名相同
-cargo run >> ./new.txt
-memmap 能创建一个文件的内存映射( memory map ),然后模拟一些非顺序读。
-使用内存映射,意味着你将相关的索引加载到内存中,而不是通过 seek 的方式去访问文件。
-Mmap::map 函数会假定待映射的文件不会同时被其它进程修改。
-- - -use memmap::Mmap; -use std::fs::File; -use std::io::{Write, Error}; - -fn main() -> Result<(), Error> { - write!(File::create("content.txt")?, "My hovercraft is full of eels!")?; - - let file = File::open("content.txt")?; - let map = unsafe { Mmap::map(&file)? }; - - let random_indexes = [0, 1, 2, 19, 22, 10, 11, 29]; - assert_eq!(&map[3..13], b"hovercraft"); - let random_bytes: Vec<u8> = random_indexes.iter() - .map(|&idx| map[idx]) - .collect(); - assert_eq!(&random_bytes[..], b"My loaf!"); - Ok(()) -} -
我在这里大胆预言:Rust未来会成为和C++同级别的游戏开发语言,特别是在游戏引擎方面,会大放异彩。
bevy是一个数据驱动的游戏引擎,支持2D和3D图形开发,优点是社区活跃、更新快、模块化设计优秀、性能高,缺点是还处于快速开发中,并不适合生产使用。
-同时bevy的文档齐全,官方示例很多,非常适合学习和使用。
 -
-fyrox是一个2D和3D游戏图形化引擎,功能丰富,生产可用(官方宣称)。
该项目前身是rg3d,但是被收购后,更名为fyrox,潜力应该是相当好的,下面截图来源于基于该引擎开发的游戏StationIapetus。
 -
-ggez是一个轻量级的2D游戏图形引擎,它的目标是让游戏开发尽量的简单,因此它的功能并不是很强大,例如如果你想要强大且真实的物理引擎,它可能无能为力,但你可以选择在它的基础上构建自己的更高级的引擎。
 -
-oxygengine是一个2D HTML5游戏引擎,支持编译成WASM在浏览器中运行。
 -
-macroquad是一个2D游戏引擎,特点是简单易用,例如它试图让使用者不会遇到Rust生命周期的难题。
godot-rust是大名鼎鼎的godot引擎的Rust绑定,godot是c++开发的游戏2D/3D引擎,但是对Rust语言提供了很好的支持。
 -
-piston是前两年较火的模块化的游戏引擎,但是最近半年开发速度缓慢,我调查了一番,但不清楚发生了什么。
-Amethyst, 前几年较火的Rust游戏引擎,但是最近开发已经停滞,经过我调查,是因为作者团队转型Rust游戏开发知识分享,因此项目被放弃。
-wgpu是一个纯Rust实现的图形化API库,具有安全、可移植等优点,如果你使用基于wgpu构建的库,那该库可以很多平台上运行:Linux, windows, MacOS, Android和IOS。
它可以原生的运行在Vulkan, Metal等主流平台上,且可以使用wasm的方式运行在WebGPU上,同时API兼容WebGPU标准。
总之,如果你要使用WebGPU, 选它就对了。
rust-gpu的目标是让Rust成为GPU编程的第一梯队语言,由大名鼎鼎的Embark公司开发,后台较硬。
如果需要通用的GPU编程,选它就对了。
kajiya是一个实时的、全局光照渲染系统,由Embark公司开发,该公司在秘密研究急于Rust的游戏引擎,据说准备应用在新游戏上,有朝一日它可能会是推动Rust游戏引擎爆发式发展的功臣。
kajiya应用了非常先进的论文和设计理念,因此非常值得有志于游戏引擎开发的同学学习。但目前还不适用于生产级使用,具体见这里。
 -
-lyon可以使用GPU进行向量路径渲染,例如高效渲染复杂的svg等。
ash是一个轻量级的Vulkan绑定。
 -
-vulkano是一个安全、特性丰富的Vulkan绑定。
rend3是一个简单易用、可定制性强、高效的3D渲染库,基于wgpu开发。
 -
-rafx是一个多后端渲染器,目标是性能、扩展性和生产力。
- -
-gfx是一个底层的图形库,目前已经不怎么活跃,主要原因是:它的核心组件gfx-hal最开始的目标是为wgpu提供功能,但是后面wgpu实现了自己的wgpu-hal,因此gfx-hal目前仅处于维护状态。
luminance是一个类型安全、无状态的图形框架,目标是让图形渲染变得简单和优雅,最开始是通过Haskell语言实现,然后在2016年移植到Rust上。
它很简单,功能也不够强大,如果你没有OpenGL、Vulkan的经验,可以使用它做一些简单的图形渲染项目试试。
miniquad是一个安全和跨平台的图形渲染库,它提供了较为底层的API,如果需要抽象层次更高的API,可以使用之前提到的macroquad,后者是基于miniquad封装实现。
 -
-glow提供了各种GL绑定(OpenGL, WebGL), 提供了一定的抽象,避免你写平台相关的特定代码实现。
macroquad,并且可以参考用它开发的两个游戏: fish fight和zemerothfyrox(rg3d)godot引擎提供的Rust绑定:godot-rustbevy,它拥有最好的ECS实现和最先进的设计理念(可能)我们在上面提到的很多系统都使用了ECS和DOD,因此这两者对于游戏开发是极其重要的,下面是一些相关的英文资料(部分需要翻墙),可以帮助大家理解相关概念。
我们精心挑选了一些用Rust写得优秀游戏,希望大家喜欢:)
-| 游戏名 | 描述 |
|---|---|
| veloren | 多人在线3D PRG游戏 |
| citybound | 多人在线城市模拟游戏 |
| sandspiel | 创意游戏-落沙世界 |
| fish fight | 多人2D射击策略游戏 |
| doukutsu | Cave Story重制版 |
| rusted ruins | 开发世界、像素游戏 |
| sulis | 回合制策略游戏 |
| zemeroth | 2D棋盘策略游戏 |
| mk48 | 2D多人在线海战游戏 |
| theta wave | 2D太空射击游戏 |
| rust doom | 模仿Doom的射击游戏 |
Veloren是一款多人在线3D RPG游戏,该游戏借鉴了Cube World、Minecraft(我的世界)和Dwarf fortress。
目前游戏开发非常活跃,也是Rust目前游戏中最有前景的之一,值得看好,当前已经可以玩,你可以通过官方地址在线试玩。
- -
-citybound是一个多人在线模拟游戏,使用Rust + WASM + JS开发。
- -
-sandspiel是一款很有创意、很艺术的游戏,通过天上落下的沙子来构建美丽的沙世界。该游戏使用Rust + wasm + webgl + js(胶水,用来粘合前几个)构建。
-你可以在线试玩,尝试构建自己的沙世界。
- -
-Fish Fight是一款2D射击策略游戏,支持最多4人一起玩,可以通过在线的方式或共享屏幕的方式玩,总之这是一款相当不错的游戏,官网做得也很酷。
- -
-doukutsu是2004年发行的视频游戏Cave Story的重制版,使用Rust开发。
-
rusted-ruins是一个开放世界2D像素游戏,用户可以在里面探索各种野外和废墟。
-目前游戏还处于较为早期阶段,但是开发活跃。
-
-
sulis是一款回合制策略游戏,包含了一个从零开发的引擎,目前游戏已经具备相当高的可玩性,你还可以选择不同的势力,感兴趣的同学可以一试。
- -
-zemeroth是一个2D棋盘策略游戏,通过Rust + WASM实现。
-你可以通过在线网址,使用WASM来体验这个游戏。
-
-
mk48是一个2D海战游戏,支持多人在线和和多语言(包括中文),你可以通过官方网址在线试玩: https://mk48.io。
-Theta Wave是一款2D太空射击游戏,基于Amethyst引擎开发。
在游戏中,你扮演的是保卫目标的飞船,游戏的目标是通过摧毁敌人来存活,还可以收集货币用于购买对你的生存有帮助的物品,并击败最终BOSS取得胜利。
-Rust doom是一款模仿Doom 1&2的简单射击游戏,需要注意,它并不是一个Doom移植版。
-每个同学可能都遇到过以下疑惑:
-而 Rusty Book 就是帮助大家解决这些问题的。
-在 Rust 元宇宙,夸奖别人的最高境界就是 rusty: 今天你"锈"了吗? 你的 Rust 代码好锈啊!
而本书,就是精选了各种开源库和代码片段,帮助大家打造优"锈"的 Rust 项目。
-以往,想要锈起来,你需要做到以下两步:
-为项目挑选 Awesome 依赖库 -但是目前已有的 awesome-rust项目有非常大的问题:里面鱼龙混杂,因为它的目的是列出所有项目,但对用户而言,更想看到的是可以在生产中使用的、稳定更新的优秀项目。
-在 Cookbook 中查询实用的代码片段,直接复制到项目中 -对于开发者而言,Cookbook 非常实用,几乎每一门编程语言都是如此。原因无他:聪明的开发者大部分时间不是在复制粘贴就是在复制粘贴的路上。而 CookBook 恰恰为各种实用场景提供了可供直接复制粘贴的代码,例如网络协议、数据库和文件操作、随机数生成、命令行解析等。
-但目前的 Rust Cookbook 更新非常不活跃,里面缺少了大量实用库,还有一些过时的老库。
-鉴于以上痛点,我们决定打造一本真正的锈书:一本足够"锈"但是又不会锈的书。
-这本书其实就是 Awesome Rust + Rust Cookbook 的结合体,但是我们不是简单粗暴的对内容进行了合并,而是从深层次将两者进行了融合,希望大家能喜欢。
-本书适合所有程度的 Rust 开发者使用:
-毕竟咱不是在面试造飞机,谁脑袋中能记住文件操作的各种细节,对不?
- - -下面的例子,我们将使用 lazy_static 声明一个在运行期初始化( 懒求值 )的 Hashmap,它会被求值一次,然后保存在一个全局的 static 引用之后。
- - -use lazy_static::lazy_static; -use std::collections::HashMap; - -lazy_static! { - static ref PRIVILEGES: HashMap<&'static str, Vec<&'static str>> = { - let mut map = HashMap::new(); - map.insert("James", vec!["user", "admin"]); - map.insert("Jim", vec!["user"]); - map - }; -} - -fn show_access(name: &str) { - let access = PRIVILEGES.get(name); - println!("{}: {:?}", name, access); -} - -fn main() { - let access = PRIVILEGES.get("James"); - println!("James: {:?}", access); - - show_access("Jim"); -} -
操作系统范畴很大,本章节中精选的内容聚焦在用Rust实现的操作系统以及用Rust写操作系统的教程。
-| 系统 | 描述 |
|---|---|
| redox | Unix风格的微内核OS |
| tock | 嵌入式操作系统 |
| theseus | 独特设计的OS |
| writing os in rust | 使用Rust开发简单的操作系统 |
| rust-raspberrypi-OS-tutorials | Rust嵌入式系统开发教程 |
| rcore-os | 清华大学提供的rcore操作系统教程 |
| edu-os | 亚琛工业大学操作系统课程的配套项目 |
redox 是一个 Unix 风格的微内核操作系统,使用 Rust 实现。redox 的目标是安全、快速、免费、可用,它在内核设计上借鉴了很多优秀的内核,例如:SeL4, MINIX, Plan 9和BSD。
但 redox 不仅仅是一个内核,它还是一个功能齐全的操作系统,提供了操作系统该有的功能,例如:内存分配器、文件系统、显示管理、核心工具等等。你可以大概认为它是一个 GNU 或 BSD 生态,但是是通过一门现代化、内存安全的语言实现的。
--不过据我仔细观察,redox目前的开发进度不是很活跃,不知道发生了什么,未来若有新的发现会在这里进行更新 - Sunface
-
 -
- -
-tock 是一个嵌入式操作系统,设计用于在低内存和低功耗的微控制器上运行多个并发的、相互不信任的应用程序,例如它可在 Cortex-M 和 RISC-V 平台上运行。
Tock 使用两个核心机制保护操作系统中不同组件的安全运行:
具体可通过这本书了解: The Tock Book.
- -
-Theseus 是从零开始构建的操作系统,完全使用Rust进行开发。它使用了新的操作系统结构、更好的状态管理,以及利用语言内设计原则将操作系统的职责(如资源管理)转移到编译器中。
-该OS目前尚处于早期阶段,但是看上去作者很有信心未来可以落地,如果想要了解,可以通过官方提供的在线书籍进行学习。
-Writing an OS in Rust 是非常有名的博客系列,专门讲解如何使用Rust来写一个简单的操作系统,配套源码在这里,目前已经发布了第二版。
-以下是async/await的目录截图:
-
rust-raspberrypi-OS-tutorials 教大家如何用Rust开发一个嵌入式操作系统,可以运行在树莓派上。这个教程讲得很细,号称手把手教学,而且是从零实现,因此很值得学习。
- -
- -
-rcore-os 是由清华大学开发的操作系统,用 Rus t实现, 与 linux 相兼容,主要目的目前还是用于教学,因为还有相关的配套教程,非常值得学习。目前支持的功能不完全列表如下:linux 兼容的 syscall 接口、网络协议栈、简单的文件系统、信号系统、异步IO、内核模块化。
以下是在树莓派上运行的图:
-
edu-os 是 Unix 风格的操作系统,用于教学目的,它是亚琛工业大学(RWTH Aachen University)操作系统课程的配套大项目,但是我并没有找到对应的课程资料,根据作者的描述,上面部分的Writing an OS in Rust对他有很大的启发。
 -
-
-
- 下面的代码将调用操作系统中的 git log --oneline 命令,然后使用 regex 对它输出到 stdout 上的调用结果进行解析,以获取哈希值和最后 5 条提交信息( commit )。
-use error_chain::error_chain; - -use std::process::Command; -use regex::Regex; - -error_chain!{ - foreign_links { - Io(std::io::Error); - Regex(regex::Error); - Utf8(std::string::FromUtf8Error); - } -} - -#[derive(PartialEq, Default, Clone, Debug)] -struct Commit { - hash: String, - message: String, -} - -fn main() -> Result<()> { - let output = Command::new("git").arg("log").arg("--oneline").output()?; - - if !output.status.success() { - error_chain::bail!("Command executed with failing error code"); - } - - let pattern = Regex::new(r"(?x) - ([0-9a-fA-F]+) # commit hash - (.*) # The commit message")?; - - String::from_utf8(output.stdout)? - .lines() - .filter_map(|line| pattern.captures(line)) - .map(|cap| { - Commit { - hash: cap[1].to_string(), - message: cap[2].trim().to_string(), - } - }) - .take(5) - .for_each(|x| println!("{:?}", x)); - - Ok(()) -} -
-use error_chain::error_chain; - -use std::collections::HashSet; -use std::io::Write; -use std::process::{Command, Stdio}; - -error_chain!{ - errors { CmdError } - foreign_links { - Io(std::io::Error); - Utf8(std::string::FromUtf8Error); - } -} - -fn main() -> Result<()> { - let mut child = Command::new("python").stdin(Stdio::piped()) - .stderr(Stdio::piped()) - .stdout(Stdio::piped()) - .spawn()?; - - child.stdin - .as_mut() - .ok_or("Child process stdin has not been captured!")? - .write_all(b"import this; copyright(); credits(); exit()")?; - - let output = child.wait_with_output()?; - - if output.status.success() { - let raw_output = String::from_utf8(output.stdout)?; - let words = raw_output.split_whitespace() - .map(|s| s.to_lowercase()) - .collect::<HashSet<_>>(); - println!("Found {} unique words:", words.len()); - println!("{:#?}", words); - Ok(()) - } else { - let err = String::from_utf8(output.stderr)?; - error_chain::bail!("External command failed:\n {}", err) - } -} -
下面的例子将显示当前目录中大小排名前十的文件和子目录,效果等效于命令 du -ah . | sort -hr | head -n 10。
Command 命令代表一个进程,其中父进程通过 Stdio::piped 来捕获子进程的输出。
-use error_chain::error_chain; - -use std::process::{Command, Stdio}; - -error_chain! { - foreign_links { - Io(std::io::Error); - Utf8(std::string::FromUtf8Error); - } -} - -fn main() -> Result<()> { - let directory = std::env::current_dir()?; - let mut du_output_child = Command::new("du") - .arg("-ah") - .arg(&directory) - .stdout(Stdio::piped()) - .spawn()?; - - if let Some(du_output) = du_output_child.stdout.take() { - let mut sort_output_child = Command::new("sort") - .arg("-hr") - .stdin(du_output) - .stdout(Stdio::piped()) - .spawn()?; - - du_output_child.wait()?; - - if let Some(sort_output) = sort_output_child.stdout.take() { - let head_output_child = Command::new("head") - .args(&["-n", "10"]) - .stdin(sort_output) - .stdout(Stdio::piped()) - .spawn()?; - - let head_stdout = head_output_child.wait_with_output()?; - - sort_output_child.wait()?; - - println!( - "Top 10 biggest files and directories in '{}':\n{}", - directory.display(), - String::from_utf8(head_stdout.stdout).unwrap() - ); - } - } - - Ok(()) -} -
下面的例子将生成一个子进程,然后将它的标准输出和标准错误输出都输出到同一个文件中。最终的效果跟 Unix 命令 ls . oops >out.txt 2>&1 相同。
File::try_clone 会克隆一份文件句柄的引用,然后保证这两个句柄在写的时候会使用相同的游标位置。
--use std::fs::File; -use std::io::Error; -use std::process::{Command, Stdio}; - -fn main() -> Result<(), Error> { - let outputs = File::create("out.txt")?; - let errors = outputs.try_clone()?; - - Command::new("ls") - .args(&[".", "oops"]) - .stdout(Stdio::from(outputs)) - .stderr(Stdio::from(errors)) - .spawn()? - .wait_with_output()?; - - Ok(()) -} -
下面的代码会创建一个管道,然后当 BufReader 更新时,就持续从 stdout 中读取数据。最终效果等同于 Unix 命令 journalctl | grep usb。
-use std::process::{Command, Stdio}; -use std::io::{BufRead, BufReader, Error, ErrorKind}; - -fn main() -> Result<(), Error> { - let stdout = Command::new("journalctl") - .stdout(Stdio::piped()) - .spawn()? - .stdout - .ok_or_else(|| Error::new(ErrorKind::Other,"Could not capture standard output."))?; - - let reader = BufReader::new(stdout); - - reader - .lines() - .filter_map(|line| line.ok()) - .filter(|line| line.find("usb").is_some()) - .for_each(|line| println!("{}", line)); - - Ok(()) -} -
使用 std::env::var 可以读取系统中的环境变量。
-- - -use std::env; -use std::fs; -use std::io::Error; - -fn main() -> Result<(), Error> { - // 读取环境变量 `CONFIG` 的值并写入到 `config_path` 中。 - // 若 `CONFIG` 环境变量没有设置,则使用一个默认的值 "/etc/myapp/config" - let config_path = env::var("CONFIG") - .unwrap_or("/etc/myapp/config".to_string()); - - let config: String = fs::read_to_string(config_path)?; - println!("Config: {}", config); - - Ok(()) -} -
num_cpus 可以用于获取逻辑和物理的 CPU 核心数,下面的例子是获取逻辑核心数。
-- - -fn main() { - println!("Number of logical cores is {}", num_cpus::get()); -} -
-每个同学可能都遇到过以下疑惑:
-而 Rusty Book 就是帮助大家解决这些问题的。
-在 Rust 元宇宙,夸奖别人的最高境界就是 rusty: 今天你"锈"了吗? 你的 Rust 代码好锈啊!
而本书,就是精选了各种开源库和代码片段,帮助大家打造优"锈"的 Rust 项目。
-以往,想要锈起来,你需要做到以下两步:
-为项目挑选 Awesome 依赖库 -但是目前已有的 awesome-rust项目有非常大的问题:里面鱼龙混杂,因为它的目的是列出所有项目,但对用户而言,更想看到的是可以在生产中使用的、稳定更新的优秀项目。
-在 Cookbook 中查询实用的代码片段,直接复制到项目中 -对于开发者而言,Cookbook 非常实用,几乎每一门编程语言都是如此。原因无他:聪明的开发者大部分时间不是在复制粘贴就是在复制粘贴的路上。而 CookBook 恰恰为各种实用场景提供了可供直接复制粘贴的代码,例如网络协议、数据库和文件操作、随机数生成、命令行解析等。
-但目前的 Rust Cookbook 更新非常不活跃,里面缺少了大量实用库,还有一些过时的老库。
-鉴于以上痛点,我们决定打造一本真正的锈书:一本足够"锈"但是又不会锈的书。
-这本书其实就是 Awesome Rust + Rust Cookbook 的结合体,但是我们不是简单粗暴的对内容进行了合并,而是从深层次将两者进行了融合,希望大家能喜欢。
-本书适合所有程度的 Rust 开发者使用:
-毕竟咱不是在面试造飞机,谁脑袋中能记住文件操作的各种细节,对不?
-HTTP客户端
-reqwest是目前使用最多的HTTP库 Web框架
-axum > Rocket > actix-web。 不过如果你不需要多么完善的web功能,只需要一个性能极高的http库,那么actix-web是非常好的选择,它的性能非常非常非常高!logback和log4j实现的日志库, 可配置性较强slog自己也推荐使用tracing。OpenTelemetry是现在非常火的可观测性解决方案,提供了协议、API、SDK等核心工具,用于收集监控数据,最后将这些metrics/logs/traces数据写入到prometheus, jaeger等监控平台中。最主要是,它后台很硬,后面有各大公司作为背书,未来非常看好!性能对比
-通用
-PostgreSQL, MySQL, SQLite,和 MSSQL.ORM
-Mysql、Postgre、SqlLiteMysql
-Postgre
-Sqlite
- -Redis
-Canssandra
-MongoDB
-tungstenite-rs库和tokio实现tonic放在第一位,主要是因为它是纯Rust实现,同时社区也更为活跃,但是并不代表它比tikv的更好!cloudflare提供的QUIC实现,据说在公司内部重度使用,有了大规模生产级别的验证,非常值得信任,同时该库还实现了HTTP/3actix-web的开发tokio,稳定可靠,功能丰富,控制粒度细;自己的学习项目或者没有那么严肃的开源项目,我推荐async-std,简单好用,值得学习;当你确切知道需要Actor网络模型时,就用actixElasticSearch客户端
-Rust搜索引擎
-lucene,如果你不需要分布式,那么引入tantivy作为自己本地Rust服务的一个搜索,是相当不错的选择,该库作者一直很活跃,而且最近还创立了搜索引擎公司,感觉大有作为. 该库的优点在于纯Rust实现,性能高(lucene的2-3倍),资源占用低(对比java自然不是一个数量级),社区活跃。Rust搜索平台
-MeiliSearch目标是为终端用户提供边输入边提示的即刻搜索功能,因此是一个轻量级搜索平台,不适用于数据量大时的搜索目的。总之,如果你需要在网页端或者APP为用户提供一个搜索条,然后支持输入容错、前缀搜索时,就可以使用它。perf不同,flame库允许你自己定义想要测试的代码片段,只需要在代码前后加上相应的指令即可,非常好用crossbeam主仓库中parking_lot高一点,最近没怎么更新serde使用serde使用,文档较为详细serde编解码YAML格式的数据WASM、Desktop、TUI 等应用开发,文档较为详细--滚滚长江东逝水,浪花淘尽英雄,是非成败转头空 - 临江仙·滚滚长江东逝水
-
经过大浪淘沙留下来的才是真金白银,对于开源项目也是如此。对于明星项目,本文不仅仅以star数的多少作为评判维度,还会结合项目规模、影响力、活跃度、社区活跃度等多个方面进行评定,希望大家能喜欢。
需要注意,本文列出的几乎都是平台级项目,因此并不是star多,就能名列其中,例如很多star很多的工具、Rust库、书籍都没有列入,如果大家想要看更多的子类项目,请访问对应的文件进行查看。
首先出场的自然是咖位最重的之一,可以说正是因为deno和swc的横空出世,才让一堆观望的大神对于Rust实现Javascript基建有了更强的信心。
deno是node半逆转后的字序,从此可以看出deno是Node.js的替代,它的目标是为Typescript/Javascript提供一个更现代化、更安全、更强大 的运行时,同时内置了很多强大的工具,可以用于打包、编译成可执行文件、文档、测试、lint等。
alacritty是一个跨平台、基于OpenGL的终端,性能极高的同时还支持丰富的自定义和可扩展性,可以说是非常优秀的现代化终端。
-目前已经是beta阶段,可以作为日常工具来使用。
-starship是一个命令行提示,支持任何shell,包括zsh,简单易用、非常快且拥有极高的可配置性, 同时支持智能提示。
-MeiliSearch是一个搜索平台,但是跟ElasticSearch不同,MeiliSearch并不是通用目的的,它的目标是为终端用户提供边输入边提示的即刻搜索功能,因此是一个轻量级搜索平台,不适用于数据量大时的搜索目的。
总之,如果你需要在网页端或者APP为用户提供一个搜索条,然后支持输入容错、前缀搜索时,就可以使用它。
-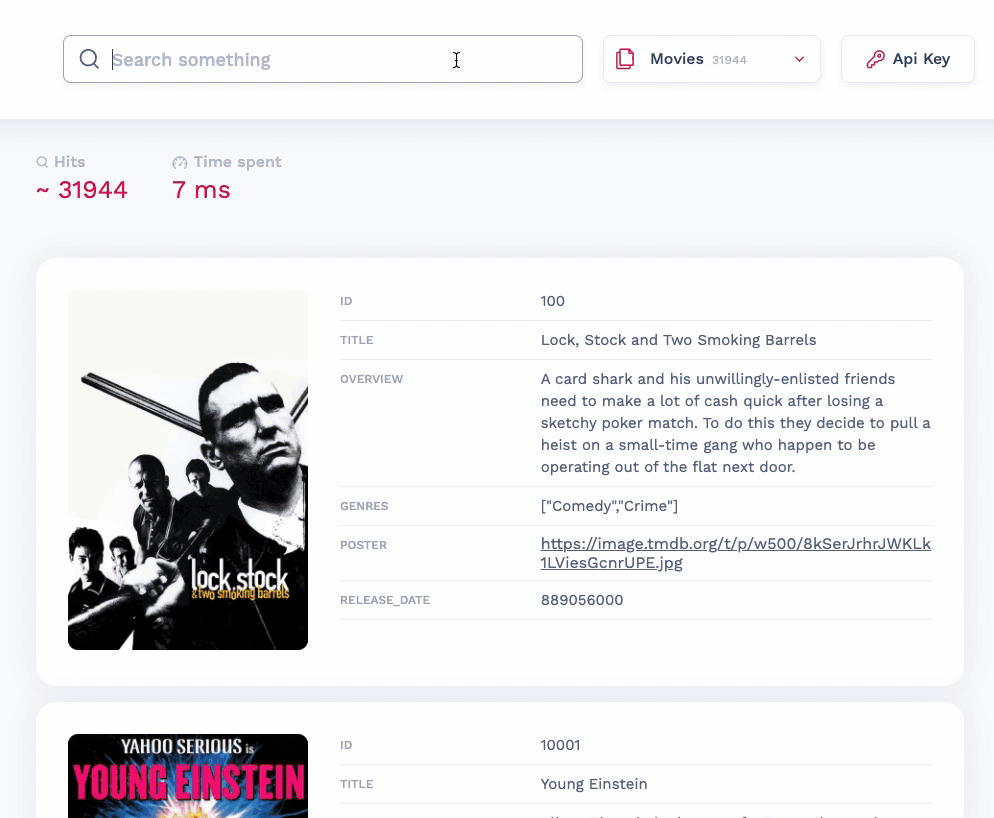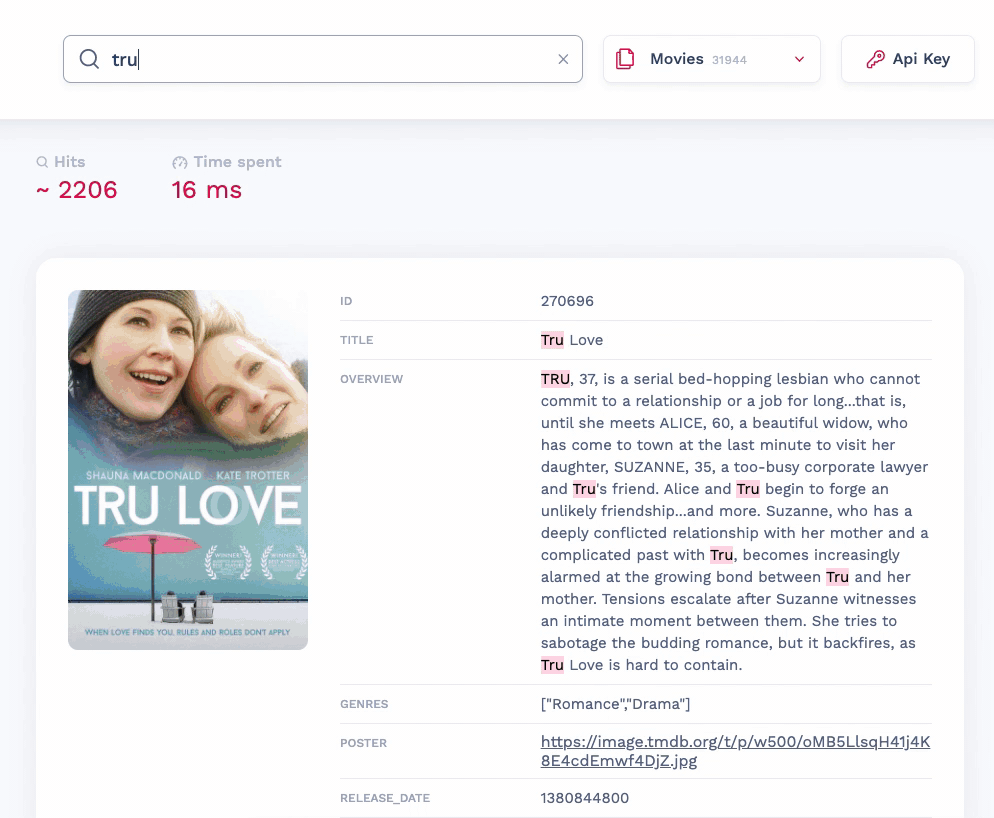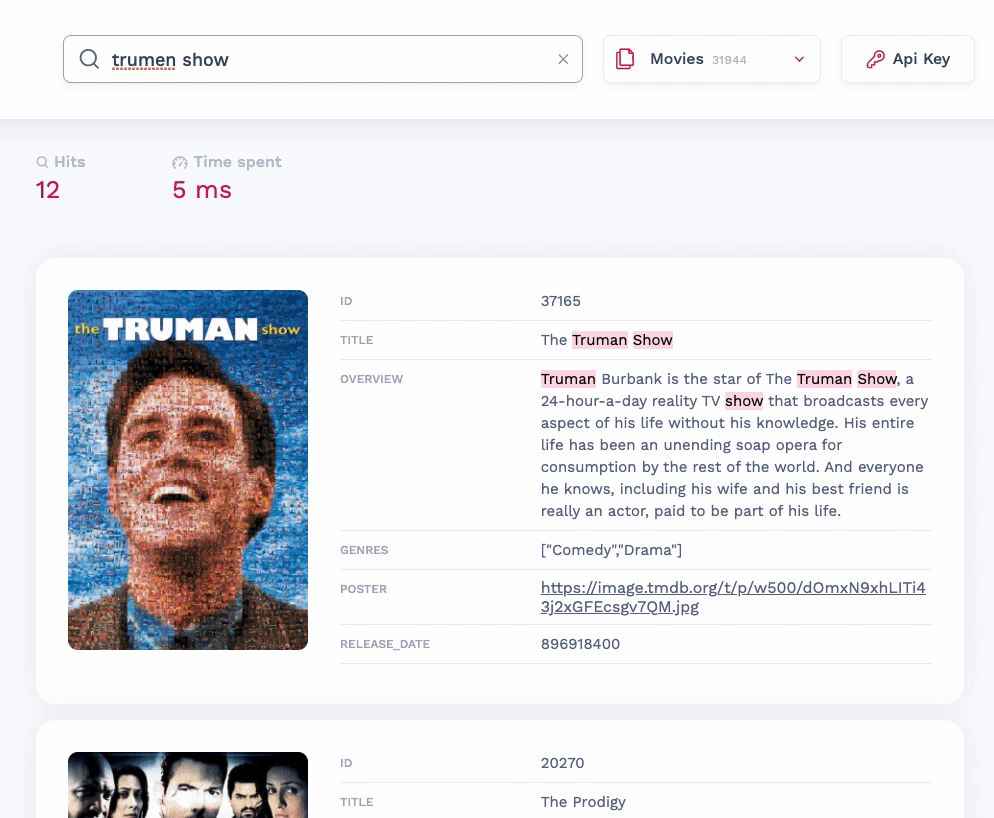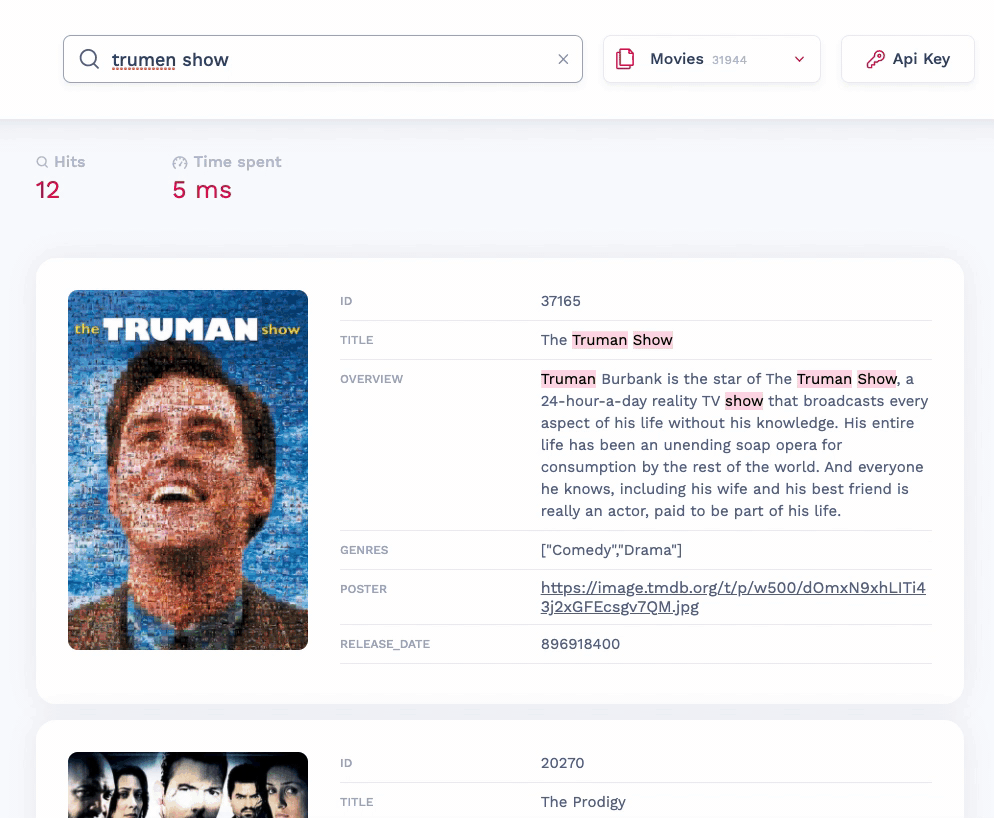 -
-swc是Typescript/Javascript编译器,它可以用来编译、压缩和打包JS,同时支持使用插件进行扩展,例如做代码变换等。
swc目前正在被一些知名项目所使用,包括Next.js,Parcel和Deno,还有些著名的公司也在使用它,例如Vercel、字节跳动、腾讯等。
它的性能非常非常高,官方号称,在单线程下比Babel快20倍,在4核心下比Babel快70倍!
几个使用案例:
- -
-tauri可以用来更小、更快、更安全的桌面应用,它想要替代的是electro.js。
下面是援引自官网的性能对比图:
- -
- -
-yew是一个正在活跃开发的Rust/Wasm框架,用于构建Web应用。
-firecracker是一个安全、高性能的无服务计算虚拟机(FaaS),支持多租户、资源隔离等高级特性,由Amazon公司开发,为AWS部分云计算服务提供了强力有的支持。BTW,亚马逊Amazon公司对于Rust语言的喜爱是众所周知的,几乎已经成了Rust的形象大使之一了:)
nushell是一个全新的shell,使用Rust实现。它的目标是创建一个现代化的shell:虽然依然基于Unix的哲学,但是更适合现在的时代。例如,你可以使用SQL语法来选择你想要的内容!
-tokio的名声可以说是如雷贯耳,如果学过Rust但是没有听说过它,那我觉得可能要回炉重造下:)
tokio是一个异步IO的运行时,提供了I/O、网络、调度、定时器等等异步编程所必须的功能和工具,性能和功能都异常强大。
AppFlowy是Notion的开源实现,使用Rust和Flutter进行开发,用于用户文档和数据的管理,支持丰富的自定义特性。
 -
-bevy是一个数据驱动的游戏引擎,支持2D和3D图形开发,优点是社区活跃、更新快、模块化设计优秀、性能高,缺点是还处于快速开发中,并不适合生产使用。
-同时bevy的文档齐全,官方示例很多,非常适合学习和使用。
-actix-web是全世界最快的web框架之一,甚至可以把之一去掉,因为排在它前面的看上去像是一个专为跑分而生的轻量级框架,而actix-web可是功能相当多的!
下面给出actix和Go语言Gin框架的性能对比:
 -
-iced是一个跨平台GUI库,具有简单易用、模块化设计、响应式布局等优点。
 -
-cube.js是一个数据分析API平台,可以用于构建内部的BI或为现有的应用增加客户数据统计等功能,使用Rust和Typescript构建。
 -
-wasmer是业界领先的WASM运行时,支持WASI和Emscripten。
$ wasmer qjs.wasm
-QuickJS - Type "\h" for help
-qjs > const i = 1 + 2;
-qjs > console.log("hello " + i);
-hello 3
-tikv相信大家都已知道,tidb的底层存储服务,国人之光项目,在数据之外,还做了大量的技术知识普及工作,值得敬佩!
tikv是分布式KV数据库,支持分布式事务。
 -
-ruffle是用Rust写的Flash Player模拟器,同时支持桌面端和Web端,其中后者通过WASM提供支持。
rustdesk是国内团队开发的一款远程桌面软件。
 -
-[RustPython]是使用Rust实现的Python解释器, 支持Python3(CPython >= 3.9.0)。
大家可以通过官方提供的在线网址进行尝试。
-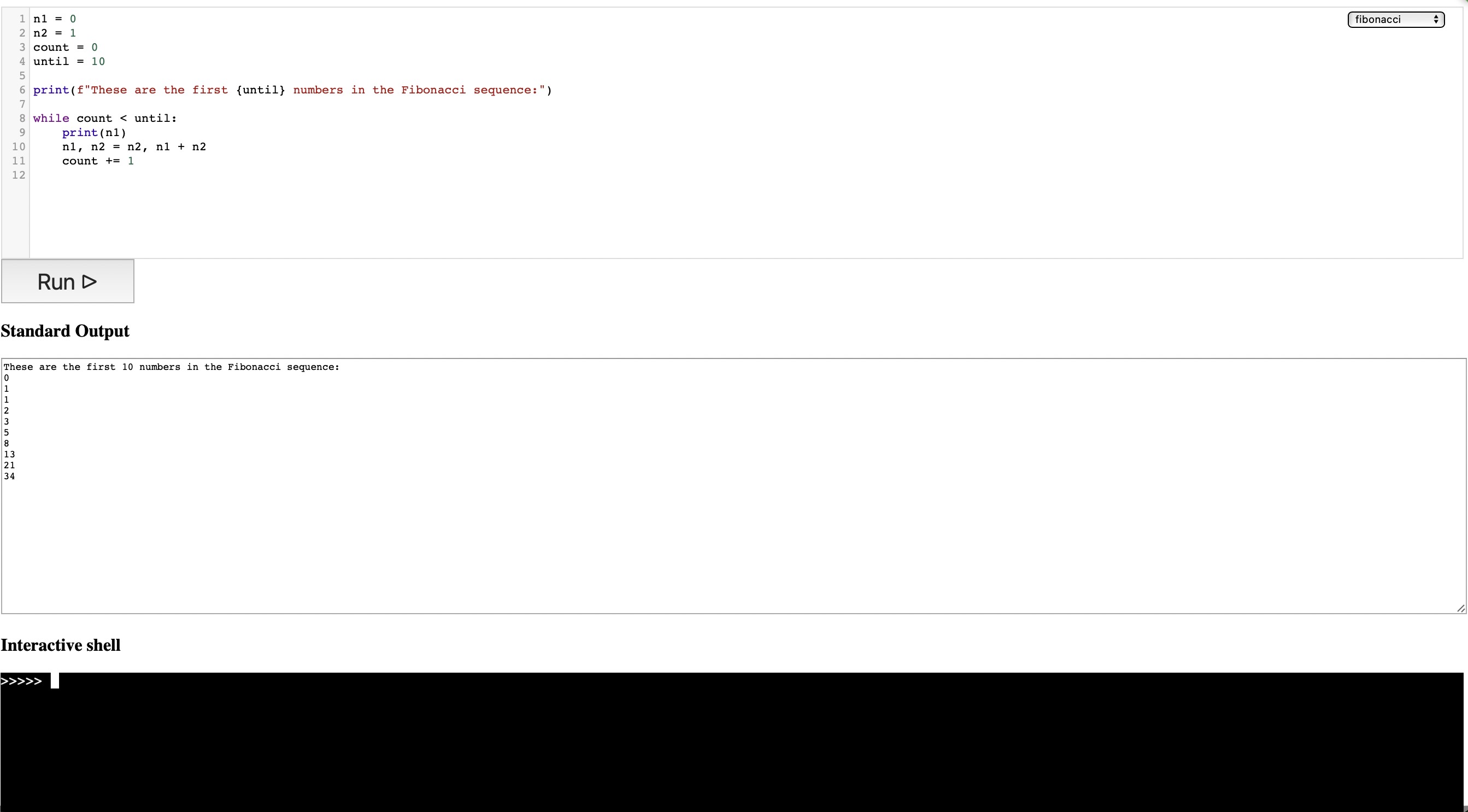 -
-vector是一个性能很高的数据采集agent,采集本地的日志、监控等数据,发送到远程的kafka、jaeger等数据下沉端,它最大的优点就是能从多种数据源(包括Opentelemetry)收集数据,然后推送到多个数据处理或者存储等下沉端。
 -
-mdbbok可以基于markdown文件自动创建在线电子书,非常简单好用,目前的问题就是缺乏章节内部的目录跳转和中文搜索。
 -
-zola是一个静态网站生成器,类似hugo。
 -
-gitui是一个奇快无比的Git终端UI,无需浏览器即可使用。
 -
-solana是知名的区块链平台,快速、安全、去中心化,还自带应用市场。
ripgrep是一个性能极高的现代化grep实现,后者是Unix/Linux下的内置文件搜索工具。该项目是Rust的明星项目,一个是因为性能极其的高,另一个就是源代码质量很高,值得学习, 同时Vscode使用它作为内置的搜索引擎。
从功能来说,除了全面支持grep的功能外,repgre支持使用正则递归搜索指定的文件目录,默认使用.gitignore对指定的文件进行忽略。
-citybound是一个多人在线模拟游戏,使用Rust + WASM + JS开发。
-bottlerocket是一个基于Linux的操作系统,它的目标是为容器提供宿主环境。
lemmy是一个reddit克隆,可以通过连接聚合的方式来构建社区,支持桌面和移动端。
 -
-tantivy是Rust实现的本地搜索库,功能对标lucene,如果你不需要分布式,那么引入tantivy作为自己本地Rust服务的一个搜索,是相当不错的选择,该库作者一直很活跃,而且最近还创立了搜索引擎公司,感觉大有作为. 该库的优点在于纯Rust实现,性能高(lucene的2-3倍),资源占用低(对比java自然不是一个数量级),社区活跃。
sled是本地嵌入式的数据库。
--#![allow(unused)] -fn main() { -let tree = sled::open("/tmp/welcome-to-sled")?; - -// insert and get, similar to std's BTreeMap -let old_value = tree.insert("key", "value")?; - -assert_eq!( - tree.get(&"key")?, - Some(sled::IVec::from("value")), -); - -// range queries -for kv_result in tree.range("key_1".."key_9") {} - -// deletion -let old_value = tree.remove(&"key")?; - -// atomic compare and swap -tree.compare_and_swap( - "key", - Some("current_value"), - Some("new_value"), -)?; - -// block until all operations are stable on disk -// (flush_async also available to get a Future) -tree.flush()?; -} -
Redox是一个Unix风格的微内核操作系统,使用Rust实现。redox的目标是安全、快速、免费、可用,它在内核设计上借鉴了很多优秀的内核,例如:SeL4, MINIX, Plan 9和BSD。
但redox不仅仅是一个内核,它还是一个功能齐全的操作系统,提供了操作系统该有的功能,例如:内存分配器、文件系统、显示管理、核心工具等等。你可以大概认为它是一个GNU或BSD生态,但是是通过一门现代化、内存安全的语言实现的。
--不过据我仔细观察,redox目前的开发进度不是很活跃,不知道发生了什么,未来若有新的发现会在这里进行更新 - Sunface
-
-
-youki是一个容器运行时,实现了OCI标准,性能非常好的同时具备非常高的安全性, 目前来说,它的性能跟crun差不多,比runc快50%以上。
sixtyfps是一个GUI工具集,同时适用于嵌入式系统、桌面系统、移动端、浏览器(WASM),支持使用多种语言进行开发,背后有商业公司的支持,未来前景看好。
 -
-wasmtime是一个为WASM设计的JIT风格的独立运行时,支持WASI。
-fn main() { - println!("Hello, world!"); -} -
$ rustup target add wasm32-wasi
-$ rustc hello.rs --target wasm32-wasi
-$ wasmtime hello.wasm
-Hello, w
-polkadot是知名的区块链平台,它是从Substrate抽离出来,后者是下一代区块链开发框架。
lapce是一款性能极高、功能强大、基于wgpu渲染的代码编辑器,基于Xi-Editor开发,后者Xi-Editor曾经也红极一时,可惜不再维护了,但是依然非常适合做一个编辑器内核。
 -
-rust-gpu的目标是让Rust成为GPU编程的第一梯队语言,由大名鼎鼎的Embark公司开发,后台较硬。
如果需要通用的GPU编程,选它就对了。
Javascript是目前全世界使用最广的语言(TIOBE排行榜比较迷,JS并没有排在第一位,我个人并不认同它的排名)。在过去这么多年中,围绕着Javascript已经建立了庞大的基础设施生态:例如使用webpack来将多个js文件打包成一个;使用Babel允许你用现代化的js语法编写兼容旧浏览器的代码;使用Eslint帮助开发找出代码中潜在的问题,类似cargo clippy。
以上的种种都在帮助js成为更好的语言和工具,它们是Web应用程序得以顺利、高效的开发和运行的基石。这些工具往往使用Javascript语言编写,一般来说,是没有问题的,但是在某些时候,可能会存在性能上的瓶颈或者安全隐患,因此阴差阳错、机缘巧合下,Rust成为了一个搅局者。
首先出场的自然是咖位最重的之一,可以说正是因为deno和swc的横空出世,才让一堆观望的大神对于Rust实现Javascript基建有了更强的信心。
deno是node半逆转后的字序,从此可以看出deno是Node.js的替代,它的目标是为Typescript/Javascript提供一个更现代化、更安全、更强大 的运行时,同时内置了很多强大的工具,可以用于打包、编译成可执行文件、文档、测试、lint等。
值得一提的是,deno的不少工具都使用了swc进行建造,包括代码审查、格式化、文档生成等。
通过包引入的方式来对比下deno和node,大家可以自己品味下。
// node
-const koa = require("koa" );
-cost logger = require("@adesso/logger")
-
-// deno
-import { Application } from "https://deno.land/x/oak/mod.ts";
-import { Logger } from "https://adesso.de/lib/logger.ts"
-swc是Typescript/Javascript编译器,它可以用来编译、压缩和打包JS,同时支持使用插件进行扩展,例如做代码变换等。
swc目前正在被一些知名项目所使用,包括Next.js,Parcel和Deno,还有些著名的公司也在使用它,例如Vercel、字节跳动、腾讯等。
它的性能非常非常高,官方号称,在单线程下比Babel快20倍,在4核心下比Babel快70倍!
几个使用案例:
- -
-官方还提供了一个在线运行的demo,功能齐全,可以试试。
-
-Rome可以用来对JavaScript、TypeScript、HTML、JSON、Markdown 和 CSS 进行lint、编译、打包等功能,它的目标是替代Babel、ESLint、webpack、Prettier、Jest等。
一开始Rome是使用Typescript开发,目前正在用Rust进行重写。有趣的是: Rome的作者也是Babel的作者, 后者还是他在学习编译原理时做的。
fnm是一个简单易用、高性能的Node版本管理工具,还支持.nvmrc文件(nvm的node版本描述文件)
-boa是一个高性能的javascript词法分析器,解析器和解释器,目前还是实验性质的。
-napi可以用于构建基于Node API的Nodejs插件,目前由nextjs主导开发。
volt是一个现代化的、高性能、安全可靠的Javascript包管理工具。目前该库正处于活跃开发阶段,只供学习使用。
-neon可以用于写安全、高性能的原生Nodejs模块。
--#![allow(unused)] -fn main() { -fn make_an_array(mut cx: FunctionContext) -> JsResult<JsArray> { - // 创建一些值: - let n = cx.number(9000); - let s = cx.string("hello"); - let b = cx.boolean(true); - - // 创建一个新数组: - let array: Handle<JsArray> = cx.empty_array(); - - // 将值推入数组中 - array.set(&mut cx, 0, n)?; - array.set(&mut cx, 1, s)?; - array.set(&mut cx, 2, b)?; - - // 返回数组 - Ok(array) -} - -register_module!(mut cx, { - cx.export_function("makeAnArray", make_an_array) -}) -} -
resvg-js是一个高性能svg渲染库,使用Rust + Typescript实现。下面的图片通过svg实现(羞~~~):
-deno_lint, 由deno团队出品的lint工具,支持Javascript/Typescript,支持Deno也支持Node。
优点之一就是极致的快:
-[
- {
- "name": "deno_lint",
- "totalMs": 105.3750100000002,
- "runsCount": 5,
- "measuredRunsAvgMs": 21.07500200000004,
- "measuredRunsMs": [
- 24.79783199999997,
- 19.563640000000078,
- 20.759051999999883,
- ]
- },
- {
- "name": "eslint",
- "totalMs": 11845.073306000002,
- "runsCount": 5,
- "measuredRunsAvgMs": 2369.0146612000003,
- "measuredRunsMs": [
- 2686.1039550000005,
- 2281.501061,
- 2298.6185210000003,
- ]
- }
-]
-rslint是一个高性能、可定制性强、简单易用的Javascript/Typescript lint分析工具。
$ echo "let a = foo.hasOwnProperty('bar');" > foo.js
-$ rslint ./foo.js
-error[no-prototype-builtins]: do not access the object property `hasOwnProperty` directly from `foo`
- ┌─ ./foo.js:1:9
- │
-1 │ let a = foo.hasOwnProperty('bar');
- │ ^^^^^^^^^^^^^^^^^^^^^^^^^
- │
-help: get the function from the prototype of `Object` and call it
- │
-1 │ let a = Object.prototype.hasOwnProperty.call(foo, 'bar');
- │ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
- │
- ╧ note: the method may be shadowed and cause random bugs and denial of service vulnerabilities
-
-Outcome: 1 fail, 0 warn, 0 success
-
-help: for more information about the errors try the explain command: `rslint explain <rules>`
-rusty_v8是v8的Rust语言绑定,底层封装了c++ API。
wasm(web assembly)是一种低级语言,它运行在浏览器中,可以和javascript相互调用,几乎所有浏览器都支持, 而且目前有多种高级语言都可以直接编译成wasm,更是大大增强了它的地位。
目前来说Rust可以编译成wasm,虽然还不够完美,但是它正在以肉眼可见的速度快速发展中。因此同时使用Rust和Javascript成为了一种可能:将Rust编译成wasm,再跟js进行交互,两者共生共存,各自解决擅长的场景(wasm性能高,js开发速度快)。
yew是一个正在活跃开发的Rust/Wasm框架,用于构建Web客户端应用。
-[gloo]是一个模块化的工具,使用Rust/WASM构建快速、可靠的Web应用。
--#![allow(unused)] -fn main() { -use gloo::{events::EventListener, timers::callback::Timeout}; -use wasm_bindgen::prelude::*; - -pub struct DelayedHelloButton { - button: web_sys::Element, - on_click: events::EventListener, -} - -impl DelayedHelloButton { - pub fn new(document: &web_sys::Document) -> Result<DelayedHelloButton, JsValue> { - // 创建 `<button>` 元素. - let button = document.create_element("button")?; - - // 监听button上的`click`事件 - let button2 = button.clone(); - let on_click = EventListener::new(&button, "click", move |_event| { - // 一秒后,更新button中的文本 - let button3 = button2.clone(); - Timeout::new(1_000, move || { - button3.set_text_content(Some("Hello from one second ago!")); - }) - .forget(); - }); - - Ok(DelayedHelloButton { button, on_click }) - } -} -} -
wasm-bindgen可以让WASM模块和Javascript模块进行更好的交互。
--#![allow(unused)] -fn main() { -use wasm_bindgen::prelude::*; - -// 从Web导入 `window.alert` 函数 -#[wasm_bindgen] -extern "C" { - fn alert(s: &str); -} - -// 从Rust导出一个`greet`函数到Javascript,该函数会`alert`一条欢迎信息 -#[wasm_bindgen] -pub fn greet(name: &str) { - alert(&format!("Hello, {}!", name)); -} -} -
wasm-pack是一站式的解决方案,用于构建和使用Rust生成的WASM,支持在浏览器中或后台的Node.js中与Javascript进行交互。
-wasmer是业界领先的WASM运行时,支持WASI和Emscripten。
$ wasmer qjs.wasm
-QuickJS - Type "\h" for help
-qjs > const i = 1 + 2;
-qjs > console.log("hello " + i);
-hello 3
-wasmtime是一个为WASM设计的JIT风格的独立运行时。
-fn main() { - println!("Hello, world!"); -} -
$ rustup target add wasm32-wasi
-$ rustc hello.rs --target wasm32-wasi
-$ wasmtime hello.wasm
-Hello, world!
-trunk是一个WASM构建、打包、Web发布工具。
photon是高性能的、跨平台的图片处理库,使用Rust开发,编译成WASM运行,为你的Web应用和Node.js应用提供无与伦比的图片处理速度,当然,它既然使用Rust开发,也可以作为一个库被你的后台程序所使用。
-tinysearch是一个搜索工具,用于静态网站中的内容搜索,使用Rust和WASM构建。优点是体积小(适用于浏览器)、性能高、全文索引。
-wasm-pdf通过Javascript和WASM来生成PDF,可以直接在浏览器中使用。
makepad是一个充满创意的Rust开发平台,支持编译成wasm,并使用webGL进行渲染。
-wasm-book是一本讲述Rust和wasm的书,篇幅不算长,但是值得学习,还包含了几个很酷的例子。
wasm-learning是一个英文教程,用于学习Rust, wasm和Node.js,你可以学会如何使用Rust来为Nodejs构建函数,可以同时利用Rust的性能、wasm的安全性和可移植性、js的易用性。
rust-js-snake-game是一个用rust + js + wasm构建的贪食蛇游戏。
我们精心挑选了一些用Rust写得优秀游戏,希望大家喜欢:)
-| 游戏名 | 描述 |
|---|---|
| veloren | 多人在线3D PRG游戏 |
| citybound | 多人在线城市模拟游戏 |
| sandspiel | 创意游戏-落沙世界 |
| fish fight | 多人2D射击策略游戏 |
| doukutsu | Cave Story重制版 |
| rusted ruins | 开发世界、像素游戏 |
| sulis | 回合制策略游戏 |
| zemeroth | 2D棋盘策略游戏 |
| mk48 | 2D多人在线海战游戏 |
| theta wave | 2D太空射击游戏 |
| rust doom | 模仿Doom的射击游戏 |
Veloren是一款多人在线3D RPG游戏,该游戏借鉴了Cube World、Minecraft(我的世界)和Dwarf fortress。
目前游戏开发非常活跃,也是Rust目前游戏中最有前景的之一,值得看好,当前已经可以玩,你可以通过官方地址在线试玩。
-
-citybound是一个多人在线模拟游戏,使用Rust + WASM + JS开发。
-
-sandspiel是一款很有创意、很艺术的游戏,通过天上落下的沙子来构建美丽的沙世界。该游戏使用Rust + wasm + webgl + js(胶水,用来粘合前几个)构建。
-你可以在线试玩,尝试构建自己的沙世界。
-
-Fish Fight是一款2D射击策略游戏,支持最多4人一起玩,可以通过在线的方式或共享屏幕的方式玩,总之这是一款相当不错的游戏,官网做得也很酷。
-
-doukutsu是2004年发行的视频游戏Cave Story的重制版,使用Rust开发。
-
rusted-ruins是一个开放世界2D像素游戏,用户可以在里面探索各种野外和废墟。
-目前游戏还处于较为早期阶段,但是开发活跃。
-
-
sulis是一款回合制策略游戏,包含了一个从零开发的引擎,目前游戏已经具备相当高的可玩性,你还可以选择不同的势力,感兴趣的同学可以一试。
-
-zemeroth是一个2D棋盘策略游戏,通过Rust + WASM实现。
-你可以通过在线网址,使用WASM来体验这个游戏。
-
-
mk48是一个2D海战游戏,支持多人在线和和多语言(包括中文),你可以通过官方网址在线试玩: https://mk48.io。
-Theta Wave是一款2D太空射击游戏,基于Amethyst引擎开发。
在游戏中,你扮演的是保卫目标的飞船,游戏的目标是通过摧毁敌人来存活,还可以收集货币用于购买对你的生存有帮助的物品,并击败最终BOSS取得胜利。
-Rust doom是一款模仿Doom 1&2的简单射击游戏,需要注意,它并不是一个Doom移植版。
我在这里大胆预言:Rust未来会成为和C++同级别的游戏开发语言,特别是在游戏引擎方面,会大放异彩。
bevy是一个数据驱动的游戏引擎,支持2D和3D图形开发,优点是社区活跃、更新快、模块化设计优秀、性能高,缺点是还处于快速开发中,并不适合生产使用。
-同时bevy的文档齐全,官方示例很多,非常适合学习和使用。
-fyrox是一个2D和3D游戏图形化引擎,功能丰富,生产可用(官方宣称)。
该项目前身是rg3d,但是被收购后,更名为fyrox,潜力应该是相当好的,下面截图来源于基于该引擎开发的游戏StationIapetus。
-ggez是一个轻量级的2D游戏图形引擎,它的目标是让游戏开发尽量的简单,因此它的功能并不是很强大,例如如果你想要强大且真实的物理引擎,它可能无能为力,但你可以选择在它的基础上构建自己的更高级的引擎。
-oxygengine是一个2D HTML5游戏引擎,支持编译成WASM在浏览器中运行。
-macroquad是一个2D游戏引擎,特点是简单易用,例如它试图让使用者不会遇到Rust生命周期的难题。
godot-rust是大名鼎鼎的godot引擎的Rust绑定,godot是c++开发的游戏2D/3D引擎,但是对Rust语言提供了很好的支持。
-piston是前两年较火的模块化的游戏引擎,但是最近半年开发速度缓慢,我调查了一番,但不清楚发生了什么。
-Amethyst, 前几年较火的Rust游戏引擎,但是最近开发已经停滞,经过我调查,是因为作者团队转型Rust游戏开发知识分享,因此项目被放弃。
-wgpu是一个纯Rust实现的图形化API库,具有安全、可移植等优点,如果你使用基于wgpu构建的库,那该库可以很多平台上运行:Linux, windows, MacOS, Android和IOS。
它可以原生的运行在Vulkan, Metal等主流平台上,且可以使用wasm的方式运行在WebGPU上,同时API兼容WebGPU标准。
总之,如果你要使用WebGPU, 选它就对了。
rust-gpu的目标是让Rust成为GPU编程的第一梯队语言,由大名鼎鼎的Embark公司开发,后台较硬。
如果需要通用的GPU编程,选它就对了。
kajiya是一个实时的、全局光照渲染系统,由Embark公司开发,该公司在秘密研究急于Rust的游戏引擎,据说准备应用在新游戏上,有朝一日它可能会是推动Rust游戏引擎爆发式发展的功臣。
kajiya应用了非常先进的论文和设计理念,因此非常值得有志于游戏引擎开发的同学学习。但目前还不适用于生产级使用,具体见这里。
-lyon可以使用GPU进行向量路径渲染,例如高效渲染复杂的svg等。
ash是一个轻量级的Vulkan绑定。
-vulkano是一个安全、特性丰富的Vulkan绑定。
rend3是一个简单易用、可定制性强、高效的3D渲染库,基于wgpu开发。
-rafx是一个多后端渲染器,目标是性能、扩展性和生产力。
-
-gfx是一个底层的图形库,目前已经不怎么活跃,主要原因是:它的核心组件gfx-hal最开始的目标是为wgpu提供功能,但是后面wgpu实现了自己的wgpu-hal,因此gfx-hal目前仅处于维护状态。
luminance是一个类型安全、无状态的图形框架,目标是让图形渲染变得简单和优雅,最开始是通过Haskell语言实现,然后在2016年移植到Rust上。
它很简单,功能也不够强大,如果你没有OpenGL、Vulkan的经验,可以使用它做一些简单的图形渲染项目试试。
miniquad是一个安全和跨平台的图形渲染库,它提供了较为底层的API,如果需要抽象层次更高的API,可以使用之前提到的macroquad,后者是基于miniquad封装实现。
-glow提供了各种GL绑定(OpenGL, WebGL), 提供了一定的抽象,避免你写平台相关的特定代码实现。
macroquad,并且可以参考用它开发的两个游戏: fish fight和zemerothfyrox(rg3d)godot引擎提供的Rust绑定:godot-rustbevy,它拥有最好的ECS实现和最先进的设计理念(可能)我们在上面提到的很多系统都使用了ECS和DOD,因此这两者对于游戏开发是极其重要的,下面是一些相关的英文资料(部分需要翻墙),可以帮助大家理解相关概念。
rust-algorithms收集了一些经典的算法和数据结构,更强调算法实现的美观性,因此该库更适用于教学目的,请不要把它当成一个实用算法库在生产环境使用。
-TheAlgorithms/Rust项目所属的组织使用各种语言实现了多种算法,但是仅适用于演示的目的。
-rustgym 实现了相当多的 leetcode 和 Avent of Code 题解。
-raft-rs 是由 Tikv 提供的 Raft 分布式算法实现。Raft是一个强一致性的分布式算法,比 Paxos 协议更简单、更好理解
-Rust Crypto提供了一些常用的密码学算法实现,更新较为活跃。
-rust-bio 有常用的生物信息学所需的算法和数据结构。
-使用 rand::thread_rng 可以获取一个随机数生成器 rand::Rng ,该生成器需要在每个线程都初始化一个。
-整数的随机分布范围等于类型的取值范围,但是浮点数只分布在 [0, 1) 区间内。
-use rand::Rng; - -fn main() { - let mut rng = rand::thread_rng(); - - let n1: u8 = rng.gen(); - let n2: u16 = rng.gen(); - println!("Random u8: {}", n1); - println!("Random u16: {}", n2); - println!("Random u32: {}", rng.gen::<u32>()); - println!("Random i32: {}", rng.gen::<i32>()); - println!("Random float: {}", rng.gen::<f64>()); -} -
使用 Rng::gen_range 生成 [0, 10) 区间内的随机数( 右开区间,不包括 10 )。
-use rand::Rng; - -fn main() { - let mut rng = rand::thread_rng(); - println!("Integer: {}", rng.gen_range(0..10)); - println!("Float: {}", rng.gen_range(0.0..10.0)); -} -
Uniform 可以用于生成均匀分布的随机数。当需要在同一个范围内重复生成随机数时,该方法虽然和之前的方法效果一样,但会更快一些。
--use rand::distributions::{Distribution, Uniform}; - -fn main() { - let mut rng = rand::thread_rng(); - let die = Uniform::from(1..7); - - loop { - let throw = die.sample(&mut rng); - println!("Roll the die: {}", throw); - if throw == 6 { - break; - } - } -} -
默认情况下,rand 包使用均匀分布来生成随机数,而 rand_distr 包提供了其它类型的分布方式。
首先,你需要获取想要使用的分布的实例,然后在 rand::Rng 的帮助下使用 Distribution::sample 对该实例进行取样。
-如果想要查询可用的分布列表,可以访问这里,下面的示例中我们将使用 Normal 分布:
--use rand_distr::{Distribution, Normal, NormalError}; -use rand::thread_rng; - -fn main() -> Result<(), NormalError> { - let mut rng = thread_rng(); - let normal = Normal::new(2.0, 3.0)?; - let v = normal.sample(&mut rng); - println!("{} is from a N(2, 9) distribution", v); - Ok(()) -} -
使用 Distribution 特征包裹我们的自定义类型,并为 Standard 实现该特征,可以为自定义类型的指定字段生成随机数。
--use rand::Rng; -use rand::distributions::{Distribution, Standard}; - -#[derive(Debug)] -struct Point { - x: i32, - y: i32, -} - -impl Distribution<Point> for Standard { - fn sample<R: Rng + ?Sized>(&self, rng: &mut R) -> Point { - let (rand_x, rand_y) = rng.gen(); - Point { - x: rand_x, - y: rand_y, - } - } -} - -fn main() { - let mut rng = rand::thread_rng(); - - // 生成一个随机的 Point - let rand_point: Point = rng.gen(); - println!("Random Point: {:?}", rand_point); - - // 通过类型暗示( hint )生成一个随机的元组 - let rand_tuple = rng.gen::<(i32, bool, f64)>(); - println!("Random tuple: {:?}", rand_tuple); -} -
通过 Alphanumeric 采样来生成随机的 ASCII 字符串,包含从 A-Z, a-z, 0-9 的字符。
-use rand::{thread_rng, Rng}; -use rand::distributions::Alphanumeric; - -fn main() { - let rand_string: String = thread_rng() - .sample_iter(&Alphanumeric) - .take(30) - .map(char::from) - .collect(); - - println!("{}", rand_string); -} -
通过 gen_string 生成随机的 ASCII 字符串,包含用户指定的字符。
--fn main() { - use rand::Rng; - const CHARSET: &[u8] = b"ABCDEFGHIJKLMNOPQRSTUVWXYZ\ - abcdefghijklmnopqrstuvwxyz\ - 0123456789)(*&^%$#@!~"; - const PASSWORD_LEN: usize = 30; - let mut rng = rand::thread_rng(); - - let password: String = (0..PASSWORD_LEN) - .map(|_| { - let idx = rng.gen_range(0..CHARSET.len()); - CHARSET[idx] as char - }) - .collect(); - - println!("{:?}", password); -} -
以下示例使用 Vec::sort 来排序,如果大家希望获得更高的性能,可以使用 Vec::sort_unstable,但是该方法无法保留相等元素的顺序。
--fn main() { - let mut vec = vec![1, 5, 10, 2, 15]; - - vec.sort(); - - assert_eq!(vec, vec![1, 2, 5, 10, 15]); -} -
浮点数数组可以使用 Vec::sort_by 和 PartialOrd::partial_cmp 进行排序。
--fn main() { - let mut vec = vec![1.1, 1.15, 5.5, 1.123, 2.0]; - - vec.sort_by(|a, b| a.partial_cmp(b).unwrap()); - - assert_eq!(vec, vec![1.1, 1.123, 1.15, 2.0, 5.5]); -} -
以下示例中的结构体 Person 将实现基于字段 name 和 age 的自然排序。为了让 Person 变为可排序的,我们需要为其派生 Eq、PartialEq、Ord、PartialOrd 特征,关于这几个特征的详情,请见这里。
当然,还可以使用 vec:sort_by 方法配合一个自定义比较函数,只按照 age 的维度对 Person 数组排序。
-#[derive(Debug, Eq, Ord, PartialEq, PartialOrd)] -struct Person { - name: String, - age: u32 -} - -impl Person { - pub fn new(name: String, age: u32) -> Self { - Person { - name, - age - } - } -} - -fn main() { - let mut people = vec![ - Person::new("Zoe".to_string(), 25), - Person::new("Al".to_string(), 60), - Person::new("John".to_string(), 1), - ]; - - // 通过派生后的自然顺序(Name and age)排序 - people.sort(); - - assert_eq!( - people, - vec![ - Person::new("Al".to_string(), 60), - Person::new("John".to_string(), 1), - Person::new("Zoe".to_string(), 25), - ]); - - // 只通过 age 排序 - people.sort_by(|a, b| b.age.cmp(&a.age)); - - assert_eq!( - people, - vec![ - Person::new("Al".to_string(), 60), - Person::new("Zoe".to_string(), 25), - Person::new("John".to_string(), 1), - ]); - -} -
以下代码将解压缩( GzDecoder )当前目录中的 archive.tar.gz ,并将所有文件抽取出( Archive::unpack )来后当入到当前目录中。
-use std::fs::File; -use flate2::read::GzDecoder; -use tar::Archive; - -fn main() -> Result<(), std::io::Error> { - let path = "archive.tar.gz"; - - let tar_gz = File::open(path)?; - let tar = GzDecoder::new(tar_gz); - let mut archive = Archive::new(tar); - archive.unpack(".")?; - - Ok(()) -} -
以下代码将 /var/log 目录压缩成 archive.tar.gz:
/var/log 目录下的所有内容添加到压缩文件中,该文件在 backup/logs 目录下。archive.tar.gz 之前对数据进行压缩。-use std::fs::File; -use flate2::Compression; -use flate2::write::GzEncoder; - -fn main() -> Result<(), std::io::Error> { - let tar_gz = File::create("archive.tar.gz")?; - let enc = GzEncoder::new(tar_gz, Compression::default()); - let mut tar = tar::Builder::new(enc); - tar.append_dir_all("backup/logs", "/var/log")?; - Ok(()) -} -
遍历目录中的文件 Archive::entries,若解压前的文件名包含 bundle/logs 前缀,需要将前缀从文件名移除( Path::strip_prefix )后,再解压。
-use std::fs::File; -use std::path::PathBuf; -use flate2::read::GzDecoder; -use tar::Archive; - -fn main() -> Result<()> { - let file = File::open("archive.tar.gz")?; - let mut archive = Archive::new(GzDecoder::new(file)); - let prefix = "bundle/logs"; - - println!("Extracted the following files:"); - archive - .entries()? // 获取压缩档案中的文件条目列表 - .filter_map(|e| e.ok()) - // 对每个文件条目进行 map 处理 - .map(|mut entry| -> Result<PathBuf> { - // 将文件路径名中的前缀移除,获取一个新的路径名 - let path = entry.path()?.strip_prefix(prefix)?.to_owned(); - // 将内容解压到新的路径名中 - entry.unpack(&path)?; - Ok(path) - }) - .filter_map(|e| e.ok()) - .for_each(|x| println!("> {}", x.display())); - - Ok(()) -} -
写入一些数据到文件中,然后使用 digest::Context 来计算文件内容的 SHA-256 摘要 digest::Digest。
--use error_chain::error_chain; -use data_encoding::HEXUPPER; -use ring::digest::{Context, Digest, SHA256}; -use std::fs::File; -use std::io::{BufReader, Read, Write}; - -error_chain! { - foreign_links { - Io(std::io::Error); - Decode(data_encoding::DecodeError); - } -} - -fn sha256_digest<R: Read>(mut reader: R) -> Result<Digest> { - let mut context = Context::new(&SHA256); - let mut buffer = [0; 1024]; - - loop { - let count = reader.read(&mut buffer)?; - if count == 0 { - break; - } - context.update(&buffer[..count]); - } - - Ok(context.finish()) -} - -fn main() -> Result<()> { - let path = "file.txt"; - - let mut output = File::create(path)?; - write!(output, "We will generate a digest of this text")?; - - let input = File::open(path)?; - let reader = BufReader::new(input); - let digest = sha256_digest(reader)?; - - println!("SHA-256 digest is {}", HEXUPPER.encode(digest.as_ref())); - - Ok(()) -} -
使用 ring::hmac 创建一个字符串签名并检查该签名的正确性。
--use ring::{hmac, rand}; -use ring::rand::SecureRandom; -use ring::error::Unspecified; - -fn main() -> Result<(), Unspecified> { - let mut key_value = [0u8; 48]; - let rng = rand::SystemRandom::new(); - rng.fill(&mut key_value)?; - let key = hmac::Key::new(hmac::HMAC_SHA256, &key_value); - - let message = "Legitimate and important message."; - let signature = hmac::sign(&key, message.as_bytes()); - hmac::verify(&key, message.as_bytes(), signature.as_ref())?; - - Ok(()) -} -
ring::pbkdf2 可以对一个加盐密码进行哈希。
---use data_encoding::HEXUPPER; -use ring::error::Unspecified; -use ring::rand::SecureRandom; -use ring::{digest, pbkdf2, rand}; -use std::num::NonZeroU32; - -fn main() -> Result<(), Unspecified> { - const CREDENTIAL_LEN: usize = digest::SHA512_OUTPUT_LEN; - let n_iter = NonZeroU32::new(100_000).unwrap(); - let rng = rand::SystemRandom::new(); - - let mut salt = [0u8; CREDENTIAL_LEN]; - // 生成 salt: 将安全生成的随机数填入到字节数组中 - rng.fill(&mut salt)?; - - let password = "Guess Me If You Can!"; - let mut pbkdf2_hash = [0u8; CREDENTIAL_LEN]; - pbkdf2::derive( - pbkdf2::PBKDF2_HMAC_SHA512, - n_iter, - &salt, - password.as_bytes(), - &mut pbkdf2_hash, - ); - println!("Salt: {}", HEXUPPER.encode(&salt)); - println!("PBKDF2 hash: {}", HEXUPPER.encode(&pbkdf2_hash)); - - // `verify` 检查哈希是否正确 - let should_`succeed = pbkdf2::verify( - pbkdf2::PBKDF2_HMAC_SHA512, - n_iter, - &salt, - password.as_bytes(), - &pbkdf2_hash, - ); - let wrong_password = "Definitely not the correct password"; - let should_fail = pbkdf2::verify( - pbkdf2::PBKDF2_HMAC_SHA512, - n_iter, - &salt, - wrong_password.as_bytes(), - &pbkdf2_hash, - ); - - assert!(should_succeed.is_ok()); - assert!(!should_fail.is_ok()); - - Ok(()) -} -
使用 ndarray::arr2 可以创建二阶矩阵,并计算它们的和。
--use ndarray::arr2; - -fn main() { - let a = arr2(&[[1, 2, 3], - [4, 5, 6]]); - - let b = arr2(&[[6, 5, 4], - [3, 2, 1]]); - - // 借用 a 和 b,求和后生成新的矩阵 sum - let sum = &a + &b; - - println!("{}", a); - println!("+"); - println!("{}", b); - println!("="); - println!("{}", sum); -} -
ndarray::ArrayBase::dot 可以用于计算矩阵乘法。
--use ndarray::arr2; - -fn main() { - let a = arr2(&[[1, 2, 3], - [4, 5, 6]]); - - let b = arr2(&[[6, 3], - [5, 2], - [4, 1]]); - - println!("{}", a.dot(&b)); -} -
在 ndarry中,1 阶数组根据上下文既可以作为行向量也可以作为列向量。如果对你来说,这个行或列的方向很重要,可以考虑使用一行或一列的 2 阶数组来表示。
在下面例子中,由于 1 阶数组处于乘号的右边位置,因此 dot 会把它当成列向量来处理。
-use ndarray::{arr1, arr2, Array1}; - -fn main() { - let scalar = 4; - - let vector = arr1(&[1, 2, 3]); - - let matrix = arr2(&[[4, 5, 6], - [7, 8, 9]]); - - let new_vector: Array1<_> = scalar * vector; - println!("{}", new_vector); - - let new_matrix = matrix.dot(&new_vector); - println!("{}", new_matrix); -} -
浮点数通常是不精确的,因此比较浮点数不是一件简单的事。approx 提供的 assert_abs_diff_eq! 宏提供了方便的按元素比较的方式。为了使用 approx ,你需要在 ndarray 的依赖中开启相应的 feature:例如,在 Cargo.toml 中修改 ndarray 的依赖引入为 ndarray = { version = "0.13", features = ["approx"] }。
-use approx::assert_abs_diff_eq; -use ndarray::Array; - -fn main() { - let a = Array::from(vec![1., 2., 3., 4., 5.]); - let b = Array::from(vec![5., 4., 3., 2., 1.]); - let mut c = Array::from(vec![1., 2., 3., 4., 5.]); - let mut d = Array::from(vec![5., 4., 3., 2., 1.]); - - // 消耗 a 和 b 的所有权 - let z = a + b; - // 借用 c 和 d - let w = &c + &d; - - assert_abs_diff_eq!(z, Array::from(vec![6., 6., 6., 6., 6.])); - - println!("c = {}", c); - c[0] = 10.; - d[1] = 10.; - - assert_abs_diff_eq!(w, Array::from(vec![6., 6., 6., 6., 6.])); - -} -
需要注意的是 Array 和 ArrayView 都是 ArrayBase 的别名。因此一个更通用的参数应该是 &ArrayBase<S, Ix1> where S: Data,特别是在你提供一个公共 API 给其它用户时,但由于咱们是内部使用,因此更精准的 ArrayView1<f64> 会更适合。
-use ndarray::{array, Array1, ArrayView1}; - -fn l1_norm(x: ArrayView1<f64>) -> f64 { - x.fold(0., |acc, elem| acc + elem.abs()) -} - -fn l2_norm(x: ArrayView1<f64>) -> f64 { - x.dot(&x).sqrt() -} - -fn normalize(mut x: Array1<f64>) -> Array1<f64> { - let norm = l2_norm(x.view()); - x.mapv_inplace(|e| e/norm); - x -} - -fn main() { - let x = array![1., 2., 3., 4., 5.]; - println!("||x||_2 = {}", l2_norm(x.view())); - println!("||x||_1 = {}", l1_norm(x.view())); - println!("Normalizing x yields {:?}", normalize(x)); -} -
例子中使用 nalgebra::Matrix3 创建一个 3x3 的矩阵,然后尝试对其进行逆变换,获取一个逆矩阵。
--use nalgebra::Matrix3; - -fn main() { - let m1 = Matrix3::new(2.0, 1.0, 1.0, 3.0, 2.0, 1.0, 2.0, 1.0, 2.0); - println!("m1 = {}", m1); - match m1.try_inverse() { - Some(inv) => { - println!("The inverse of m1 is: {}", inv); - } - None => { - println!("m1 is not invertible!"); - } - } -} -
下面将展示如何将矩阵序列化为 JSON ,然后再反序列化为原矩阵。
--extern crate nalgebra; -extern crate serde_json; - -use nalgebra::DMatrix; - -fn main() -> Result<(), std::io::Error> { - let row_slice: Vec<i32> = (1..5001).collect(); - let matrix = DMatrix::from_row_slice(50, 100, &row_slice); - - // 序列化矩阵 - let serialized_matrix = serde_json::to_string(&matrix)?; - - // 反序列化 - let deserialized_matrix: DMatrix<i32> = serde_json::from_str(&serialized_matrix)?; - - // 验证反序列化后的矩阵跟原始矩阵相等 - assert!(deserialized_matrix == matrix); - - Ok(()) -} -
计算角为 2 弧度、对边长度为 80 的直角三角形的斜边长度。
--fn main() { - let angle: f64 = 2.0; - let side_length = 80.0; - - let hypotenuse = side_length / angle.sin(); - - println!("Hypotenuse: {}", hypotenuse); -} -
-fn main() { - let x: f64 = 6.0; - - let a = x.tan(); - let b = x.sin() / x.cos(); - - assert_eq!(a, b); -} -
下面的代码使用 Haversine 公式 计算地球上两点之间的公里数。
--fn main() { - let earth_radius_kilometer = 6371.0_f64; - let (paris_latitude_degrees, paris_longitude_degrees) = (48.85341_f64, -2.34880_f64); - let (london_latitude_degrees, london_longitude_degrees) = (51.50853_f64, -0.12574_f64); - - let paris_latitude = paris_latitude_degrees.to_radians(); - let london_latitude = london_latitude_degrees.to_radians(); - - let delta_latitude = (paris_latitude_degrees - london_latitude_degrees).to_radians(); - let delta_longitude = (paris_longitude_degrees - london_longitude_degrees).to_radians(); - - let central_angle_inner = (delta_latitude / 2.0).sin().powi(2) - + paris_latitude.cos() * london_latitude.cos() * (delta_longitude / 2.0).sin().powi(2); - let central_angle = 2.0 * central_angle_inner.sqrt().asin(); - - let distance = earth_radius_kilometer * central_angle; - - println!( - "Distance between Paris and London on the surface of Earth is {:.1} kilometers", - distance - ); -} -
num::complex::Complex 可以帮助我们创建复数,其中实部和虚部必须是一样的类型。
--fn main() { - let complex_integer = num::complex::Complex::new(10, 20); - let complex_float = num::complex::Complex::new(10.1, 20.1); - - println!("Complex integer: {}", complex_integer); - println!("Complex float: {}", complex_float); -} -
复数计算和 Rust 基本类型的计算并无区别。
--fn main() { - let complex_num1 = num::complex::Complex::new(10.0, 20.0); // Must use floats - let complex_num2 = num::complex::Complex::new(3.1, -4.2); - - let sum = complex_num1 + complex_num2; - - println!("Sum: {}", sum); -} -
在 num::complex::Complex 中定义了一些内置的数学函数,可用于对复数进行数学运算。
--use std::f64::consts::PI; -use num::complex::Complex; - -fn main() { - let x = Complex::new(0.0, 2.0*PI); - - println!("e^(2i * pi) = {}", x.exp()); // =~1 -} -
下面的一些例子为 Rust 数组中的数据计算它们的中心趋势。
-首先计算的是平均值。
--fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let sum = data.iter().sum::<i32>() as f32; - let count = data.len(); - - let mean = match count { - positive if positive > 0 => Some(sum / count as f32), - _ => None - }; - - println!("Mean of the data is {:?}", mean); -} -
下面使用快速选择算法来计算中位数。该算法只会对可能包含中位数的数据分区进行排序,从而避免了对所有数据进行全排序。
--use std::cmp::Ordering; - -fn partition(data: &[i32]) -> Option<(Vec<i32>, i32, Vec<i32>)> { - match data.len() { - 0 => None, - _ => { - let (pivot_slice, tail) = data.split_at(1); - let pivot = pivot_slice[0]; - let (left, right) = tail.iter() - .fold((vec![], vec![]), |mut splits, next| { - { - let (ref mut left, ref mut right) = &mut splits; - if next < &pivot { - left.push(*next); - } else { - right.push(*next); - } - } - splits - }); - - Some((left, pivot, right)) - } - } -} - -fn select(data: &[i32], k: usize) -> Option<i32> { - let part = partition(data); - - match part { - None => None, - Some((left, pivot, right)) => { - let pivot_idx = left.len(); - - match pivot_idx.cmp(&k) { - Ordering::Equal => Some(pivot), - Ordering::Greater => select(&left, k), - Ordering::Less => select(&right, k - (pivot_idx + 1)), - } - }, - } -} - -fn median(data: &[i32]) -> Option<f32> { - let size = data.len(); - - match size { - even if even % 2 == 0 => { - let fst_med = select(data, (even / 2) - 1); - let snd_med = select(data, even / 2); - - match (fst_med, snd_med) { - (Some(fst), Some(snd)) => Some((fst + snd) as f32 / 2.0), - _ => None - } - }, - odd => select(data, odd / 2).map(|x| x as f32) - } -} - -fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let part = partition(&data); - println!("Partition is {:?}", part); - - let sel = select(&data, 5); - println!("Selection at ordered index {} is {:?}", 5, sel); - - let med = median(&data); - println!("Median is {:?}", med); -} -
下面使用了 HashMap 对不同数字出现的次数进行了分别统计。
-use std::collections::HashMap; - -fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let frequencies = data.iter().fold(HashMap::new(), |mut freqs, value| { - *freqs.entry(value).or_insert(0) += 1; - freqs - }); - - let mode = frequencies - .into_iter() - .max_by_key(|&(_, count)| count) - .map(|(value, _)| *value); - - println!("Mode of the data is {:?}", mode); -} -
下面一起来看看该如何计算一组测量值的标准偏差和 z-score。
--fn mean(data: &[i32]) -> Option<f32> { - let sum = data.iter().sum::<i32>() as f32; - let count = data.len(); - - match count { - positive if positive > 0 => Some(sum / count as f32), - _ => None, - } -} - -fn std_deviation(data: &[i32]) -> Option<f32> { - match (mean(data), data.len()) { - (Some(data_mean), count) if count > 0 => { - let variance = data.iter().map(|value| { - let diff = data_mean - (*value as f32); - - diff * diff - }).sum::<f32>() / count as f32; - - Some(variance.sqrt()) - }, - _ => None - } -} - -fn main() { - let data = [3, 1, 6, 1, 5, 8, 1, 8, 10, 11]; - - let data_mean = mean(&data); - println!("Mean is {:?}", data_mean); - - let data_std_deviation = std_deviation(&data); - println!("Standard deviation is {:?}", data_std_deviation); - - let zscore = match (data_mean, data_std_deviation) { - (Some(mean), Some(std_deviation)) => { - let diff = data[4] as f32 - mean; - - Some(diff / std_deviation) - }, - _ => None - }; - println!("Z-score of data at index 4 (with value {}) is {:?}", data[4], zscore); -} -
使用 BitInt 可以对超过 128bit 的整数进行计算。
--use num::bigint::{BigInt, ToBigInt}; - -fn factorial(x: i32) -> BigInt { - if let Some(mut factorial) = 1.to_bigint() { - for i in 1..=x { - factorial = factorial * i; - } - factorial - } - else { - panic!("Failed to calculate factorial!"); - } -} - -fn main() { - println!("{}! equals {}", 100, factorial(100)); -} -
使用 bitflags! 宏可以帮助我们创建安全的位字段类型 MyFlags,然后为其实现基本的 clear 操作。以下代码展示了基本的位操作和格式化:
-use bitflags::bitflags; -use std::fmt; - -bitflags! { - struct MyFlags: u32 { - const FLAG_A = 0b00000001; - const FLAG_B = 0b00000010; - const FLAG_C = 0b00000100; - const FLAG_ABC = Self::FLAG_A.bits - | Self::FLAG_B.bits - | Self::FLAG_C.bits; - } -} - -impl MyFlags { - pub fn clear(&mut self) -> &mut MyFlags { - self.bits = 0; - self - } -} - -impl fmt::Display for MyFlags { - fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { - write!(f, "{:032b}", self.bits) - } -} - -fn main() { - let e1 = MyFlags::FLAG_A | MyFlags::FLAG_C; - let e2 = MyFlags::FLAG_B | MyFlags::FLAG_C; - assert_eq!((e1 | e2), MyFlags::FLAG_ABC); - assert_eq!((e1 & e2), MyFlags::FLAG_C); - assert_eq!((e1 - e2), MyFlags::FLAG_A); - assert_eq!(!e2, MyFlags::FLAG_A); - - let mut flags = MyFlags::FLAG_ABC; - assert_eq!(format!("{}", flags), "00000000000000000000000000000111"); - assert_eq!(format!("{}", flags.clear()), "00000000000000000000000000000000"); - assert_eq!(format!("{:?}", MyFlags::FLAG_B), "FLAG_B"); - assert_eq!(format!("{:?}", MyFlags::FLAG_A | MyFlags::FLAG_B), "FLAG_A | FLAG_B"); -} -
对于每一个程序员而言,命令行工具都非常关键。你对他越熟悉,在使用计算机、处理工作流程等越是高效。
-下面我们收集了一些优秀的Rust所写的命令行工具,它们相比目前已有的其它语言的实现,可以提供更加现代化的代码实现、更加高效的性能以及更好的可用性。
-| 新工具 | 替代的目标或功能描述 |
|---|---|
| bat | cat |
| exa | ls |
| lsd | ls |
| fd | find |
| procs | ps |
| sd | sed |
| dust | du |
| starship | 现代化的命令行提示 |
| ripgrep | grep |
| tokei | 代码统计工具 |
| hyperfine | 命令行benchmark工具 |
| bottom | top |
| teeldear | tldr |
| grex | 根据文本示例生成正则 |
| bandwitch | 显示进程、连接网络使用情况 |
| zoxide | cd |
| delta | git可视化 |
| nushell | 全新的现代化shell |
| mcfly | 替代ctrl + R命令搜索 |
| fselect | 使用SQL语法查找文件 |
| pueue | 命令行任务管理工具 |
| watchexec | 监视目录文件变动并执行命令 |
| dura | 更加安全的使用git |
| alacritty | 强大的基于OpenGL的终端 |
| broot | 可视化访问目录树 |
bat克隆了**cat**的功能并提供了语法高亮和Git集成,它支持Windows,MacOS和Linux`。同时,它默认提供了多种文件后缀的语法高亮。
-exa是ls命令的现代化实现,后者是目前Unix/Linux系统的默认命令,用于列出当前目录中的内容。
-lsd 也是 ls 的新实现,同时增加了很多特性,例如:颜色标注、icons、树形查看、更多的格式化选项等。
-fd 是一个更快、对用户更友好的find实现,后者是 Unix/Linux 内置的文件目录搜索工具。之所以说它用户友好,一方面是 API 非常清晰明了,其次是它对最常用的场景提供了有意义的默认值:例如,想要通过名称搜索文件:
fd: fd PATTERNfind: find -iname 'PATTERN'同时 fd 性能非常非常高,还提供了非常多的搜索选项,例如允许用户通过 .gitignore 文件忽略隐藏的目录、文件等。
-procs 是 ps 的默认实现,后者是 Unix/Linux 的内置命令,用于获取进程( process )的信息。proc 提供了更便利、可读性更好的格式化输出。
-sd 是 sed 命令的现代化实现,后者是 Unix/Linux 中内置的工具,用于分析和转换文本。
sd 拥有更简单的使用方式,而且支持方便的正则表达式语法,sd 拥有闪电般的性能,比 sed 快 2x-11x 倍。
以下是其中一个性能测试结果:
-对1.5G大小的 JSON 文本进行简单替换
-hyperfine -w 3 'sed -E "s/\"/\'/g" *.json >/dev/null' 'sd "\"" "\'" *.json >/dev/null' --export-markdown out.md
| Command | Mean [s] | Min…Max [s] |
|---|---|---|
sed -E "s/\"/'/g" *.json >/dev/null | 2.338 ± 0.008 | 2.332…2.358 |
sed "s/\"/'/g" *.json >/dev/null | 2.365 ± 0.009 | 2.351…2.378 |
sd "\"" "'" *.json >/dev/null | 0.997 ± 0.006 | 0.987…1.007 |
结果: ~2.35 times faster
-dust 是一个更符合使用习惯的du,后者是 Unix/Linux 内置的命令行工具,用于显示硬盘使用情况的统计。
-starship 是一个命令行提示,支持任何 shell ,包括 zsh ,简单易用、非常快且拥有极高的可配置性, 同时支持智能提示。
-ripgrep 是一个性能极高的现代化 grep 实现,后者是 Unix/Linux 下的内置文件搜索工具。该项目是 Rust 的明星项目,一个是因为性能极其的高,另一个就是源代码质量很高,值得学习, 同时 Vscode 使用它作为内置的搜索引擎。
从功能来说,除了全面支持 grep 的功能外,repgre 支持使用正则递归搜索指定的文件目录,默认使用 .gitignore 对指定的文件进行忽略。
-tokei 可以分门别类的统计目录内的代码行数,速度非常快!
-
-hyperfine 是命令行benchmark工具,它支持在多次运行中提供静态的分析,同时支持任何的 shell 命令,准确的 benchmark 进度和当前预估等等高级特性。
-bottom 是一个现代化实现的 top,可以跨平台、图形化的显示进程/系统的当前信息。
-tealdear 是一个更快实现的tldr, 一个用于显示 man pages 的命令行程序,简单易用、基于例子和社区驱动是主要特性。
-bandwhich 是一个客户端实用工具,用于显示当前进程、连接、远程 IP( hostname ) 的网络信息。
-
-grex 既是一个命令行工具又是一个库,可以根据用户提供的文本示例生成对应的正则表达式,非常强大。
-
-zoxide 是一个智能化的 cd 命令,它甚至会记忆你常用的目录。
-delta 是一个 git 分页展示工具,支持语法高亮、代码比对、输出 grep 等。
-nushell 是一个全新的 shell ,使用 Rust 实现。它的目标是创建一个现代化的 shell :虽然依然基于 Unix 的哲学,但是更适合现在的时代。例如,你可以使用 SQL 语法来选择你想要的内容!
-mcfly 会替换默认的 ctrl-R,用于在终端中搜索历史命令, 它提供了智能提示功能,并且会根据当前目录中最近执行过的上下文命令进行提示。mcfly 甚至使用了一个小型的神经网络用于智能提示!
-fselect 允许使用 SQL 语法来查找系统中的文件。它支持复杂查询、聚合查询、.gitignore 忽略文件、通过宽度高度搜索图片、通过 hash 搜索文件、文件属性查询等等,相当强大!
-# 复杂查询
-fselect "name from /tmp where (name = *.tmp and size = 0) or (name = *.cfg and size > 1000000)"
-
-# 聚合函数
-fselect "MIN(size), MAX(size), AVG(size), SUM(size), COUNT(*) from /home/user/Downloads"
-
-# 格式化函数
-fselect "LOWER(name), UPPER(name), LENGTH(name), YEAR(modified) from /home/user/Downloads"
-pueue 是一个命令行任务管理工具,它可以管理你的长时间运行的命令,支持顺序或并行执行。简单来说,它可以管理一个命令队列。
-
-watchexec 可以监视指定的目录、文件的改动,并执行你预设的命令,支持多种配置项和操作系统。
-# 监视当前目录/子目录中的所有js、css、html文件,一旦发生改变,运行`npm run build`命令
-$ watchexec -e js,css,html npm run build
-
-# 当前目录/子目录下任何python文件发生改变时,重启`python server.py`
-$ watchexec -r -e py -- python server.py
-dura 运行在后台,监视你的 git 目录,提交你未提交的更改但是并不会影响 HEAD、当前的分支和 git 索引(staged文件)。
如果你曾经遇到过**"完蛋, 我这几天的工作内容丢了"**的情况,那么就可以尝试下 dura,checkout dura brach,然后代码就可以顺利恢复了:)
恢复代码
-dura 分支来恢复$ echo "dura/$(git rev-parse HEAD)"
-# Or, if you don't trust dura yet, `git stash`
-$ git reset HEAD --hard
-# get the changes into your working directory
-$ git checkout $THE_HASH
-# last few commands reset HEAD back to master but with changes uncommitted
-$ git checkout -b temp-branch
-$ git reset master
-$ git checkout master
-$ git branch -D temp-branch
-alacritty 是一个跨平台、基于OpenGL的终端,性能极高的同时还支持丰富的自定义和可扩展性,可以说是非常优秀的现代化终端。
-目前已经是 beta 阶段,可以作为日常工具来使用。
-broot 允许你可视化的去访问一个目录结构。
下面的程序给出了使用 clap 来解析命令行参数的样式结构,如果大家想了解更多,在 clap 文档中还给出了另外两种初始化一个应用的方式。
在下面的构建中,value_of 将获取通过 with_name 解析出的值。short 和 long 用于设置用户输入的长短命令格式,例如短命令 -f 和长命令 --file。
-use clap::{Arg, App}; - -fn main() { - let matches = App::new("My Test Program") - .version("0.1.0") - .author("Hackerman Jones <hckrmnjones@hack.gov>") - .about("Teaches argument parsing") - .arg(Arg::with_name("file") - .short("f") - .long("file") - .takes_value(true) - .help("A cool file")) - .arg(Arg::with_name("num") - .short("n") - .long("number") - .takes_value(true) - .help("Five less than your favorite number")) - .get_matches(); - - let myfile = matches.value_of("file").unwrap_or("input.txt"); - println!("The file passed is: {}", myfile); - - let num_str = matches.value_of("num"); - match num_str { - None => println!("No idea what your favorite number is."), - Some(s) => { - match s.parse::<i32>() { - Ok(n) => println!("Your favorite number must be {}.", n + 5), - Err(_) => println!("That's not a number! {}", s), - } - } - } -} -
clap 针对上面提供的构建样式,会自动帮我们生成相应的使用方式说明。例如,上面代码生成的使用说明如下:
My Test Program 0.1.0
-Hackerman Jones <hckrmnjones@hack.gov>
-Teaches argument parsing
-
-USAGE:
- testing [OPTIONS]
-
-FLAGS:
- -h, --help Prints help information
- -V, --version Prints version information
-
-OPTIONS:
- -f, --file <file> A cool file
- -n, --number <num> Five less than your favorite number
-最后,再使用一些参数来运行下我们的代码:
-$ cargo run -- -f myfile.txt -n 251
-The file passed is: myfile.txt
-Your favorite number must be 256.
-@todo
-ansi_term 包可以帮我们控制终端上的输出样式,例如使用颜色文字、控制输出格式等,当然,前提是在 ANSI 终端上。
-ansi_term 中有两个主要数据结构:ANSIString 和 Style。
Style 用于控制样式:颜色、加粗、闪烁等,而前者是一个带有样式的字符串。
-use ansi_term::Colour; - -fn main() { - println!("This is {} in color, {} in color and {} in color", - Colour::Red.paint("red"), - Colour::Blue.paint("blue"), - Colour::Green.paint("green")); -} -
比颜色复杂的样式构建需要使用 Style 结构体:
-use ansi_term::Style; - -fn main() { - println!("{} and this is not", - Style::new().bold().paint("This is Bold")); -} -
Colour 实现了很多跟 Style 类似的函数,因此可以实现链式调用。
-use ansi_term::Colour; -use ansi_term::Style; - -fn main(){ - println!("{}, {} and {}", - Colour::Yellow.paint("This is colored"), - Style::new().bold().paint("this is bold"), - // Colour 也可以使用 bold 方法进行加粗 - Colour::Yellow.bold().paint("this is bold and colored")); -} -
操作系统范畴很大,本章节中精选的内容聚焦在用Rust实现的操作系统以及用Rust写操作系统的教程。
-| 系统 | 描述 |
|---|---|
| redox | Unix风格的微内核OS |
| tock | 嵌入式操作系统 |
| theseus | 独特设计的OS |
| writing os in rust | 使用Rust开发简单的操作系统 |
| rust-raspberrypi-OS-tutorials | Rust嵌入式系统开发教程 |
| rcore-os | 清华大学提供的rcore操作系统教程 |
| edu-os | 亚琛工业大学操作系统课程的配套项目 |
redox 是一个 Unix 风格的微内核操作系统,使用 Rust 实现。redox 的目标是安全、快速、免费、可用,它在内核设计上借鉴了很多优秀的内核,例如:SeL4, MINIX, Plan 9和BSD。
但 redox 不仅仅是一个内核,它还是一个功能齐全的操作系统,提供了操作系统该有的功能,例如:内存分配器、文件系统、显示管理、核心工具等等。你可以大概认为它是一个 GNU 或 BSD 生态,但是是通过一门现代化、内存安全的语言实现的。
--不过据我仔细观察,redox目前的开发进度不是很活跃,不知道发生了什么,未来若有新的发现会在这里进行更新 - Sunface
-
-
-tock 是一个嵌入式操作系统,设计用于在低内存和低功耗的微控制器上运行多个并发的、相互不信任的应用程序,例如它可在 Cortex-M 和 RISC-V 平台上运行。
Tock 使用两个核心机制保护操作系统中不同组件的安全运行:
具体可通过这本书了解: The Tock Book.
-
-Theseus 是从零开始构建的操作系统,完全使用Rust进行开发。它使用了新的操作系统结构、更好的状态管理,以及利用语言内设计原则将操作系统的职责(如资源管理)转移到编译器中。
-该OS目前尚处于早期阶段,但是看上去作者很有信心未来可以落地,如果想要了解,可以通过官方提供的在线书籍进行学习。
-Writing an OS in Rust 是非常有名的博客系列,专门讲解如何使用Rust来写一个简单的操作系统,配套源码在这里,目前已经发布了第二版。
-以下是async/await的目录截图:
-
rust-raspberrypi-OS-tutorials 教大家如何用Rust开发一个嵌入式操作系统,可以运行在树莓派上。这个教程讲得很细,号称手把手教学,而且是从零实现,因此很值得学习。
-
-
-rcore-os 是由清华大学开发的操作系统,用 Rus t实现, 与 linux 相兼容,主要目的目前还是用于教学,因为还有相关的配套教程,非常值得学习。目前支持的功能不完全列表如下:linux 兼容的 syscall 接口、网络协议栈、简单的文件系统、信号系统、异步IO、内核模块化。
以下是在树莓派上运行的图:
-
edu-os 是 Unix 风格的操作系统,用于教学目的,它是亚琛工业大学(RWTH Aachen University)操作系统课程的配套大项目,但是我并没有找到对应的课程资料,根据作者的描述,上面部分的Writing an OS in Rust对他有很大的启发。
num_cpus 可以用于获取逻辑和物理的 CPU 核心数,下面的例子是获取逻辑核心数。
--fn main() { - println!("Number of logical cores is {}", num_cpus::get()); -} -
下面的代码将调用操作系统中的 git log --oneline 命令,然后使用 regex 对它输出到 stdout 上的调用结果进行解析,以获取哈希值和最后 5 条提交信息( commit )。
-use error_chain::error_chain; - -use std::process::Command; -use regex::Regex; - -error_chain!{ - foreign_links { - Io(std::io::Error); - Regex(regex::Error); - Utf8(std::string::FromUtf8Error); - } -} - -#[derive(PartialEq, Default, Clone, Debug)] -struct Commit { - hash: String, - message: String, -} - -fn main() -> Result<()> { - let output = Command::new("git").arg("log").arg("--oneline").output()?; - - if !output.status.success() { - error_chain::bail!("Command executed with failing error code"); - } - - let pattern = Regex::new(r"(?x) - ([0-9a-fA-F]+) # commit hash - (.*) # The commit message")?; - - String::from_utf8(output.stdout)? - .lines() - .filter_map(|line| pattern.captures(line)) - .map(|cap| { - Commit { - hash: cap[1].to_string(), - message: cap[2].trim().to_string(), - } - }) - .take(5) - .for_each(|x| println!("{:?}", x)); - - Ok(()) -} -
-use error_chain::error_chain; - -use std::collections::HashSet; -use std::io::Write; -use std::process::{Command, Stdio}; - -error_chain!{ - errors { CmdError } - foreign_links { - Io(std::io::Error); - Utf8(std::string::FromUtf8Error); - } -} - -fn main() -> Result<()> { - let mut child = Command::new("python").stdin(Stdio::piped()) - .stderr(Stdio::piped()) - .stdout(Stdio::piped()) - .spawn()?; - - child.stdin - .as_mut() - .ok_or("Child process stdin has not been captured!")? - .write_all(b"import this; copyright(); credits(); exit()")?; - - let output = child.wait_with_output()?; - - if output.status.success() { - let raw_output = String::from_utf8(output.stdout)?; - let words = raw_output.split_whitespace() - .map(|s| s.to_lowercase()) - .collect::<HashSet<_>>(); - println!("Found {} unique words:", words.len()); - println!("{:#?}", words); - Ok(()) - } else { - let err = String::from_utf8(output.stderr)?; - error_chain::bail!("External command failed:\n {}", err) - } -} -
下面的例子将显示当前目录中大小排名前十的文件和子目录,效果等效于命令 du -ah . | sort -hr | head -n 10。
Command 命令代表一个进程,其中父进程通过 Stdio::piped 来捕获子进程的输出。
-use error_chain::error_chain; - -use std::process::{Command, Stdio}; - -error_chain! { - foreign_links { - Io(std::io::Error); - Utf8(std::string::FromUtf8Error); - } -} - -fn main() -> Result<()> { - let directory = std::env::current_dir()?; - let mut du_output_child = Command::new("du") - .arg("-ah") - .arg(&directory) - .stdout(Stdio::piped()) - .spawn()?; - - if let Some(du_output) = du_output_child.stdout.take() { - let mut sort_output_child = Command::new("sort") - .arg("-hr") - .stdin(du_output) - .stdout(Stdio::piped()) - .spawn()?; - - du_output_child.wait()?; - - if let Some(sort_output) = sort_output_child.stdout.take() { - let head_output_child = Command::new("head") - .args(&["-n", "10"]) - .stdin(sort_output) - .stdout(Stdio::piped()) - .spawn()?; - - let head_stdout = head_output_child.wait_with_output()?; - - sort_output_child.wait()?; - - println!( - "Top 10 biggest files and directories in '{}':\n{}", - directory.display(), - String::from_utf8(head_stdout.stdout).unwrap() - ); - } - } - - Ok(()) -} -
下面的例子将生成一个子进程,然后将它的标准输出和标准错误输出都输出到同一个文件中。最终的效果跟 Unix 命令 ls . oops >out.txt 2>&1 相同。
File::try_clone 会克隆一份文件句柄的引用,然后保证这两个句柄在写的时候会使用相同的游标位置。
--use std::fs::File; -use std::io::Error; -use std::process::{Command, Stdio}; - -fn main() -> Result<(), Error> { - let outputs = File::create("out.txt")?; - let errors = outputs.try_clone()?; - - Command::new("ls") - .args(&[".", "oops"]) - .stdout(Stdio::from(outputs)) - .stderr(Stdio::from(errors)) - .spawn()? - .wait_with_output()?; - - Ok(()) -} -
下面的代码会创建一个管道,然后当 BufReader 更新时,就持续从 stdout 中读取数据。最终效果等同于 Unix 命令 journalctl | grep usb。
-use std::process::{Command, Stdio}; -use std::io::{BufRead, BufReader, Error, ErrorKind}; - -fn main() -> Result<(), Error> { - let stdout = Command::new("journalctl") - .stdout(Stdio::piped()) - .spawn()? - .stdout - .ok_or_else(|| Error::new(ErrorKind::Other,"Could not capture standard output."))?; - - let reader = BufReader::new(stdout); - - reader - .lines() - .filter_map(|line| line.ok()) - .filter(|line| line.find("usb").is_some()) - .for_each(|line| println!("{}", line)); - - Ok(()) -} -
使用 std::env::var 可以读取系统中的环境变量。
--use std::env; -use std::fs; -use std::io::Error; - -fn main() -> Result<(), Error> { - // 读取环境变量 `CONFIG` 的值并写入到 `config_path` 中。 - // 若 `CONFIG` 环境变量没有设置,则使用一个默认的值 "/etc/myapp/config" - let config_path = env::var("CONFIG") - .unwrap_or("/etc/myapp/config".to_string()); - - let config: String = fs::read_to_string(config_path)?; - println!("Config: {}", config); - - Ok(()) -} -
下面例子用到了 crossbeam 包,它提供了非常实用的、用于并发和并行编程的数据结构和函数。
-Scope::spawn 会生成一个被限定了作用域的线程,该线程最大的特点就是:它会在传给 crossbeam::scope 的闭包函数返回前先行结束。得益于这个特点,子线程的创建使用就像是本地闭包函数调用,因此生成的线程内部可以使用外部环境中的变量!
--fn main() { - let arr = &[1, 25, -4, 10]; - let max = find_max(arr); - assert_eq!(max, Some(25)); -} - -// 将数组分成两个部分,并使用新的线程对它们进行处理 -fn find_max(arr: &[i32]) -> Option<i32> { - const THRESHOLD: usize = 2; - - if arr.len() <= THRESHOLD { - return arr.iter().cloned().max(); - } - - let mid = arr.len() / 2; - let (left, right) = arr.split_at(mid); - - crossbeam::scope(|s| { - let thread_l = s.spawn(|_| find_max(left)); - let thread_r = s.spawn(|_| find_max(right)); - - let max_l = thread_l.join().unwrap()?; - let max_r = thread_r.join().unwrap()?; - - Some(max_l.max(max_r)) - }).unwrap() -} -
下面我们使用 crossbeam 和 crossbeam-channel 来创建一个并行流水线:流水线的两端分别是数据源和数据下沉( sink ),在流水线中间,有两个工作线程会从源头接收数据,对数据进行并行处理,最后将数据下沉。
-rcv2 处于阻塞读取状态,无比被关闭,因此我们必须要关闭所有发送者: drop(snd1); drop(snd2) ,这样 channel 关闭后,主线程的 rcv2 才能从阻塞状态退出,最后整个程序结束。大家还是迷惑的话,可以看看这篇文章。-extern crate crossbeam; -extern crate crossbeam_channel; - -use std::thread; -use std::time::Duration; -use crossbeam_channel::bounded; - -fn main() { - let (snd1, rcv1) = bounded(1); - let (snd2, rcv2) = bounded(1); - let n_msgs = 4; - let n_workers = 2; - - crossbeam::scope(|s| { - // 生产者线程 - s.spawn(|_| { - for i in 0..n_msgs { - snd1.send(i).unwrap(); - println!("Source sent {}", i); - } - - // 关闭其中一个发送者 snd1 - // 该关闭操作对于结束最后的循环是必须的 - drop(snd1); - }); - - // 通过两个线程并行处理 - for _ in 0..n_workers { - // 从数据源接收数据,然后发送到下沉端 - let (sendr, recvr) = (snd2.clone(), rcv1.clone()); - // 生成单独的工作线程 - s.spawn(move |_| { - thread::sleep(Duration::from_millis(500)); - // 等待通道的关闭 - for msg in recvr.iter() { - println!("Worker {:?} received {}.", - thread::current().id(), msg); - sendr.send(msg * 2).unwrap(); - } - }); - } - // 关闭通道,如果不关闭,下沉端将永远无法结束循环 - drop(snd2); - - // 下沉端 - for msg in rcv2.iter() { - println!("Sink received {}", msg); - } - }).unwrap(); -} -
下面我们来看看 crossbeam-channel 的单生产者单消费者( SPSC ) 使用场景。
--use std::{thread, time}; -use crossbeam_channel::unbounded; - -fn main() { - // unbounded 意味着 channel 可以存储任意多的消息 - let (snd, rcv) = unbounded(); - let n_msgs = 5; - crossbeam::scope(|s| { - s.spawn(|_| { - for i in 0..n_msgs { - snd.send(i).unwrap(); - thread::sleep(time::Duration::from_millis(100)); - } - }); - }).unwrap(); - for _ in 0..n_msgs { - let msg = rcv.recv().unwrap(); - println!("Received {}", msg); - } -} -
lazy_static 会创建一个全局的静态引用( static ref ),该引用使用了 Mutex 以支持可变性,因此我们可以在代码中对其进行修改。Mutex 能保证该全局状态同时只能被一个线程所访问。
-use error_chain::error_chain; -use lazy_static::lazy_static; -use std::sync::Mutex; - -error_chain!{ } - -lazy_static! { - static ref FRUIT: Mutex<Vec<String>> = Mutex::new(Vec::new()); -} - -fn insert(fruit: &str) -> Result<()> { - let mut db = FRUIT.lock().map_err(|_| "Failed to acquire MutexGuard")?; - db.push(fruit.to_string()); - Ok(()) -} - -fn main() -> Result<()> { - insert("apple")?; - insert("orange")?; - insert("peach")?; - { - let db = FRUIT.lock().map_err(|_| "Failed to acquire MutexGuard")?; - - db.iter().enumerate().for_each(|(i, item)| println!("{}: {}", i, item)); - } - insert("grape")?; - Ok(()) -} -
下面的示例将为当前目录中的每一个 .iso 文件都计算一个 SHA256 sum。其中线程池中会初始化和 CPU 核心数一致的线程数,其中核心数是通过 num_cpus::get 函数获取。
-Walkdir::new 可以遍历当前的目录,然后调用 execute 来执行读操作和 SHA256 哈希计算。
--use walkdir::WalkDir; -use std::fs::File; -use std::io::{BufReader, Read, Error}; -use std::path::Path; -use threadpool::ThreadPool; -use std::sync::mpsc::channel; -use ring::digest::{Context, Digest, SHA256}; - -// Verify the iso extension -fn is_iso(entry: &Path) -> bool { - match entry.extension() { - Some(e) if e.to_string_lossy().to_lowercase() == "iso" => true, - _ => false, - } -} - -fn compute_digest<P: AsRef<Path>>(filepath: P) -> Result<(Digest, P), Error> { - let mut buf_reader = BufReader::new(File::open(&filepath)?); - let mut context = Context::new(&SHA256); - let mut buffer = [0; 1024]; - - loop { - let count = buf_reader.read(&mut buffer)?; - if count == 0 { - break; - } - context.update(&buffer[..count]); - } - - Ok((context.finish(), filepath)) -} - -fn main() -> Result<(), Error> { - let pool = ThreadPool::new(num_cpus::get()); - - let (tx, rx) = channel(); - - for entry in WalkDir::new("/home/user/Downloads") - .follow_links(true) - .into_iter() - .filter_map(|e| e.ok()) - .filter(|e| !e.path().is_dir() && is_iso(e.path())) { - let path = entry.path().to_owned(); - let tx = tx.clone(); - pool.execute(move || { - let digest = compute_digest(path); - tx.send(digest).expect("Could not send data!"); - }); - } - - drop(tx); - for t in rx.iter() { - let (sha, path) = t?; - println!("{:?} {:?}", sha, path); - } - Ok(()) -} -
下面例子中将基于 Julia Set 来绘制一个分形图片,其中使用到了线程池来做分布式计算。
-
--use error_chain::error_chain; -use std::sync::mpsc::{channel, RecvError}; -use threadpool::ThreadPool; -use num::complex::Complex; -use image::{ImageBuffer, Pixel, Rgb}; - - -error_chain! { - foreign_links { - MpscRecv(RecvError); - Io(std::io::Error); - } -} - -// Function converting intensity values to RGB -// Based on http://www.efg2.com/Lab/ScienceAndEngineering/Spectra.htm -fn wavelength_to_rgb(wavelength: u32) -> Rgb<u8> { - let wave = wavelength as f32; - - let (r, g, b) = match wavelength { - 380..=439 => ((440. - wave) / (440. - 380.), 0.0, 1.0), - 440..=489 => (0.0, (wave - 440.) / (490. - 440.), 1.0), - 490..=509 => (0.0, 1.0, (510. - wave) / (510. - 490.)), - 510..=579 => ((wave - 510.) / (580. - 510.), 1.0, 0.0), - 580..=644 => (1.0, (645. - wave) / (645. - 580.), 0.0), - 645..=780 => (1.0, 0.0, 0.0), - _ => (0.0, 0.0, 0.0), - }; - - let factor = match wavelength { - 380..=419 => 0.3 + 0.7 * (wave - 380.) / (420. - 380.), - 701..=780 => 0.3 + 0.7 * (780. - wave) / (780. - 700.), - _ => 1.0, - }; - - let (r, g, b) = (normalize(r, factor), normalize(g, factor), normalize(b, factor)); - Rgb::from_channels(r, g, b, 0) -} - -// Maps Julia set distance estimation to intensity values -fn julia(c: Complex<f32>, x: u32, y: u32, width: u32, height: u32, max_iter: u32) -> u32 { - let width = width as f32; - let height = height as f32; - - let mut z = Complex { - // scale and translate the point to image coordinates - re: 3.0 * (x as f32 - 0.5 * width) / width, - im: 2.0 * (y as f32 - 0.5 * height) / height, - }; - - let mut i = 0; - for t in 0..max_iter { - if z.norm() >= 2.0 { - break; - } - z = z * z + c; - i = t; - } - i -} - -// Normalizes color intensity values within RGB range -fn normalize(color: f32, factor: f32) -> u8 { - ((color * factor).powf(0.8) * 255.) as u8 -} - -fn main() -> Result<()> { - let (width, height) = (1920, 1080); - // 为指定宽高的输出图片分配内存 - let mut img = ImageBuffer::new(width, height); - let iterations = 300; - - let c = Complex::new(-0.8, 0.156); - - let pool = ThreadPool::new(num_cpus::get()); - let (tx, rx) = channel(); - - for y in 0..height { - let tx = tx.clone(); - // execute 将每个像素作为单独的作业接收 - pool.execute(move || for x in 0..width { - let i = julia(c, x, y, width, height, iterations); - let pixel = wavelength_to_rgb(380 + i * 400 / iterations); - tx.send((x, y, pixel)).expect("Could not send data!"); - }); - } - - for _ in 0..(width * height) { - let (x, y, pixel) = rx.recv()?; - // 使用数据来设置像素的颜色 - img.put_pixel(x, y, pixel); - } - - // 输出图片内容到指定文件中 - let _ = img.save("output.png")?; - Ok(()) -} -
rayon 提供了一个 par_iter_mut 方法用于并行化迭代一个数据集合。
--use rayon::prelude::*; - -fn main() { - let mut arr = [0, 7, 9, 11]; - arr.par_iter_mut().for_each(|p| *p -= 1); - println!("{:?}", arr); -} -
rayon::any 和 rayon::all 类似于 std::any / std::all ,但是是并行版本的。
-rayon::any 并行检查迭代器中是否有任何元素满足给定的条件,一旦发现符合条件的元素,就立即返回rayon::all 并行检查迭代器中的所有元素是否满足给定的条件,一旦发现不满足条件的元素,就立即返回-use rayon::prelude::*; - -fn main() { - let mut vec = vec![2, 4, 6, 8]; - - assert!(!vec.par_iter().any(|n| (*n % 2) != 0)); - assert!(vec.par_iter().all(|n| (*n % 2) == 0)); - assert!(!vec.par_iter().any(|n| *n > 8 )); - assert!(vec.par_iter().all(|n| *n <= 8 )); - - vec.push(9); - - assert!(vec.par_iter().any(|n| (*n % 2) != 0)); - assert!(!vec.par_iter().all(|n| (*n % 2) == 0)); - assert!(vec.par_iter().any(|n| *n > 8 )); - assert!(!vec.par_iter().all(|n| *n <= 8 )); -} -
下面例子使用 par_iter 和 rayon::find_any 来并行搜索一个数组,直到找到任意一个满足条件的元素。
-如果有多个元素满足条件,rayon 会返回第一个找到的元素,注意:第一个找到的元素未必是数组中的顺序最靠前的那个。
-use rayon::prelude::*; - -fn main() { - let v = vec![6, 2, 1, 9, 3, 8, 11]; - - // 这里使用了 `&&x` 的形式,大家可以在以下链接阅读更多 https://doc.rust-lang.org/std/iter/trait.Iterator.html#method.find - let f1 = v.par_iter().find_any(|&&x| x == 9); - let f2 = v.par_iter().find_any(|&&x| x % 2 == 0 && x > 6); - let f3 = v.par_iter().find_any(|&&x| x > 8); - - assert_eq!(f1, Some(&9)); - assert_eq!(f2, Some(&8)); - assert!(f3 > Some(&8)); -} -
下面的例子将对字符串数组进行并行排序。
-par_sort_unstable 方法的排序性能往往要比稳定的排序算法更高。
--use rand::{Rng, thread_rng}; -use rand::distributions::Alphanumeric; -use rayon::prelude::*; - -fn main() { - let mut vec = vec![String::new(); 100_000]; - // 并行生成数组中的字符串 - vec.par_iter_mut().for_each(|p| { - let mut rng = thread_rng(); - *p = (0..5).map(|_| rng.sample(&Alphanumeric)).collect() - }); - - // - vec.par_sort_unstable(); -} -
下面例子使用 rayon::filter, rayon::map, 和 rayon::reduce 来超过 30 岁的 Person 的平均年龄。
rayon::filter 返回集合中所有满足给定条件的元素rayon::map 对集合中的每一个元素执行一个操作,创建并返回新的迭代器,类似于迭代器适配器rayon::reduce 则迭代器的元素进行不停的聚合运算,直到获取一个最终结果,这个结果跟例子中 rayon::sum 获取的结果是相同的-use rayon::prelude::*; - -struct Person { - age: u32, -} - -fn main() { - let v: Vec<Person> = vec![ - Person { age: 23 }, - Person { age: 19 }, - Person { age: 42 }, - Person { age: 17 }, - Person { age: 17 }, - Person { age: 31 }, - Person { age: 30 }, - ]; - - let num_over_30 = v.par_iter().filter(|&x| x.age > 30).count() as f32; - let sum_over_30 = v.par_iter() - .map(|x| x.age) - .filter(|&x| x > 30) - .reduce(|| 0, |x, y| x + y); - - let alt_sum_30: u32 = v.par_iter() - .map(|x| x.age) - .filter(|&x| x > 30) - .sum(); - - let avg_over_30 = sum_over_30 as f32 / num_over_30; - let alt_avg_over_30 = alt_sum_30 as f32/ num_over_30; - - assert!((avg_over_30 - alt_avg_over_30).abs() < std::f32::EPSILON); - println!("The average age of people older than 30 is {}", avg_over_30); -} -
下面例子将为目录中的所有图片并行生成缩略图,然后将结果存到新的目录 thumbnails 中。
glob::glob_with 可以找出当前目录下的所有 .jpg 文件,rayon 通过 DynamicImage::resize 来并行调整图片的大小。
-use error_chain::error_chain; - -use std::path::Path; -use std::fs::create_dir_all; - -use error_chain::ChainedError; -use glob::{glob_with, MatchOptions}; -use image::{FilterType, ImageError}; -use rayon::prelude::*; - -error_chain! { - foreign_links { - Image(ImageError); - Io(std::io::Error); - Glob(glob::PatternError); - } -} - -fn main() -> Result<()> { - let options: MatchOptions = Default::default(); - // 找到当前目录中的所有 `jpg` 文件 - let files: Vec<_> = glob_with("*.jpg", options)? - .filter_map(|x| x.ok()) - .collect(); - - if files.len() == 0 { - error_chain::bail!("No .jpg files found in current directory"); - } - - let thumb_dir = "thumbnails"; - create_dir_all(thumb_dir)?; - - println!("Saving {} thumbnails into '{}'...", files.len(), thumb_dir); - - let image_failures: Vec<_> = files - .par_iter() - .map(|path| { - make_thumbnail(path, thumb_dir, 300) - .map_err(|e| e.chain_err(|| path.display().to_string())) - }) - .filter_map(|x| x.err()) - .collect(); - - image_failures.iter().for_each(|x| println!("{}", x.display_chain())); - - println!("{} thumbnails saved successfully", files.len() - image_failures.len()); - Ok(()) -} - -fn make_thumbnail<PA, PB>(original: PA, thumb_dir: PB, longest_edge: u32) -> Result<()> -where - PA: AsRef<Path>, - PB: AsRef<Path>, -{ - let img = image::open(original.as_ref())?; - let file_path = thumb_dir.as_ref().join(original); - - Ok(img.resize(longest_edge, longest_edge, FilterType::Nearest) - .save(file_path)?) -} -
使用 rusqlite 可以创建 SQLite 数据库,Connection::open 会尝试打开一个数据库,若不存在,则创建新的数据库。
--这里创建的
-cats.db数据库将被后面的例子所使用
-use rusqlite::{Connection, Result}; -use rusqlite::NO_PARAMS; - -fn main() -> Result<()> { - let conn = Connection::open("cats.db")?; - - conn.execute( - "create table if not exists cat_colors ( - id integer primary key, - name text not null unique - )", - NO_PARAMS, - )?; - conn.execute( - "create table if not exists cats ( - id integer primary key, - name text not null, - color_id integer not null references cat_colors(id) - )", - NO_PARAMS, - )?; - - Ok(()) -} -
--use rusqlite::NO_PARAMS; -use rusqlite::{Connection, Result}; -use std::collections::HashMap; - -#[derive(Debug)] -struct Cat { - name: String, - color: String, -} - -fn main() -> Result<()> { - // 打开第一个例子所创建的数据库 - let conn = Connection::open("cats.db")?; - - let mut cat_colors = HashMap::new(); - cat_colors.insert(String::from("Blue"), vec!["Tigger", "Sammy"]); - cat_colors.insert(String::from("Black"), vec!["Oreo", "Biscuit"]); - - for (color, catnames) in &cat_colors { - // 插入一条数据行 - conn.execute( - "INSERT INTO cat_colors (name) values (?1)", - &[&color.to_string()], - )?; - // 获取最近插入数据行的 id - let last_id: String = conn.last_insert_rowid().to_string(); - - for cat in catnames { - conn.execute( - "INSERT INTO cats (name, color_id) values (?1, ?2)", - &[&cat.to_string(), &last_id], - )?; - } - } - let mut stmt = conn.prepare( - "SELECT c.name, cc.name from cats c - INNER JOIN cat_colors cc - ON cc.id = c.color_id;", - )?; - - let cats = stmt.query_map(NO_PARAMS, |row| { - Ok(Cat { - name: row.get(0)?, - color: row.get(1)?, - }) - })?; - - for cat in cats { - println!("Found cat {:?}", cat); - } - - Ok(()) -} -
使用 Connection::transaction 可以开始新的事务,若没有对事务进行显式地提交 Transaction::commit,则会进行回滚。
-下面的例子中,rolled_back_tx 插入了重复的颜色名称,会发生回滚。
-use rusqlite::{Connection, Result, NO_PARAMS}; - -fn main() -> Result<()> { - // 打开第一个例子所创建的数据库 - let mut conn = Connection::open("cats.db")?; - - successful_tx(&mut conn)?; - - let res = rolled_back_tx(&mut conn); - assert!(res.is_err()); - - Ok(()) -} - -fn successful_tx(conn: &mut Connection) -> Result<()> { - let tx = conn.transaction()?; - - tx.execute("delete from cat_colors", NO_PARAMS)?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"lavender"])?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"blue"])?; - - tx.commit() -} - -fn rolled_back_tx(conn: &mut Connection) -> Result<()> { - let tx = conn.transaction()?; - - tx.execute("delete from cat_colors", NO_PARAMS)?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"lavender"])?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"blue"])?; - tx.execute("insert into cat_colors (name) values (?1)", &[&"lavender"])?; - - tx.commit() -} -
我们通过 postgres 来操作数据库。下面的例子有一个前提:数据库 library 已经存在,其中用户名和密码都是 postgres。
-use postgres::{Client, NoTls, Error}; - -fn main() -> Result<(), Error> { - // 连接到数据库 library - let mut client = Client::connect("postgresql://postgres:postgres@localhost/library", NoTls)?; - - client.batch_execute(" - CREATE TABLE IF NOT EXISTS author ( - id SERIAL PRIMARY KEY, - name VARCHAR NOT NULL, - country VARCHAR NOT NULL - ) - ")?; - - client.batch_execute(" - CREATE TABLE IF NOT EXISTS book ( - id SERIAL PRIMARY KEY, - title VARCHAR NOT NULL, - author_id INTEGER NOT NULL REFERENCES author - ) - ")?; - - Ok(()) - -} -
-use postgres::{Client, NoTls, Error}; -use std::collections::HashMap; - -struct Author { - _id: i32, - name: String, - country: String -} - -fn main() -> Result<(), Error> { - let mut client = Client::connect("postgresql://postgres:postgres@localhost/library", - NoTls)?; - - let mut authors = HashMap::new(); - authors.insert(String::from("Chinua Achebe"), "Nigeria"); - authors.insert(String::from("Rabindranath Tagore"), "India"); - authors.insert(String::from("Anita Nair"), "India"); - - for (key, value) in &authors { - let author = Author { - _id: 0, - name: key.to_string(), - country: value.to_string() - }; - - // 插入数据 - client.execute( - "INSERT INTO author (name, country) VALUES ($1, $2)", - &[&author.name, &author.country], - )?; - } - - // 查询数据 - for row in client.query("SELECT id, name, country FROM author", &[])? { - let author = Author { - _id: row.get(0), - name: row.get(1), - country: row.get(2), - }; - println!("Author {} is from {}", author.name, author.country); - } - - Ok(()) - -} -
下面代码将使用降序的方式列出 Museum of Modern Art 数据库中的前 7999 名艺术家的国籍分布.
--use postgres::{Client, Error, NoTls}; - -struct Nation { - nationality: String, - count: i64, -} - -fn main() -> Result<(), Error> { - let mut client = Client::connect( - "postgresql://postgres:postgres@127.0.0.1/moma", - NoTls, - )?; - - for row in client.query - ("SELECT nationality, COUNT(nationality) AS count - FROM artists GROUP BY nationality ORDER BY count DESC", &[])? { - - let (nationality, count) : (Option<String>, Option<i64>) - = (row.get (0), row.get (1)); - - if nationality.is_some () && count.is_some () { - - let nation = Nation{ - nationality: nationality.unwrap(), - count: count.unwrap(), - }; - println!("{} {}", nation.nationality, nation.count); - - } - } - - Ok(()) -} -
测量从 time::Instant::now 开始所经过的时间 time::Instant::elapsed.
--use std::time::{Duration, Instant}; - -fn main() { - let start = Instant::now(); - expensive_function(); - let duration = start.elapsed(); - - println!("Time elapsed in expensive_function() is: {:?}", duration); -} -
使用 DateTime::checked_add_signed 计算和显示从现在开始两周后的日期和时间,然后再计算一天前的日期 DateTime::checked_sub_signed。
-DateTime::format 所支持的转义序列可以在 chrono::format::strftime 找到.
--use chrono::{DateTime, Duration, Utc}; - -fn day_earlier(date_time: DateTime<Utc>) -> Option<DateTime<Utc>> { - date_time.checked_sub_signed(Duration::days(1)) -} - -fn main() { - let now = Utc::now(); - println!("{}", now); - - let almost_three_weeks_from_now = now.checked_add_signed(Duration::weeks(2)) - .and_then(|in_2weeks| in_2weeks.checked_add_signed(Duration::weeks(1))) - .and_then(day_earlier); - - match almost_three_weeks_from_now { - Some(x) => println!("{}", x), - None => eprintln!("Almost three weeks from now overflows!"), - } - - match now.checked_add_signed(Duration::max_value()) { - Some(x) => println!("{}", x), - None => eprintln!("We can't use chrono to tell the time for the Solar System to complete more than one full orbit around the galactic center."), - } -} -
使用 offset::Local::now 获取本地时间并进行显示,接着,使用 DateTime::from_utc 将它转换成 UTC 标准时间。最后,再使用 offset::FixedOffset 将 UTC 时间转换成 UTC+8 和 UTC-2 的时间。
--use chrono::{DateTime, FixedOffset, Local, Utc}; - -fn main() { - let local_time = Local::now(); - let utc_time = DateTime::<Utc>::from_utc(local_time.naive_utc(), Utc); - let china_timezone = FixedOffset::east(8 * 3600); - let rio_timezone = FixedOffset::west(2 * 3600); - println!("Local time now is {}", local_time); - println!("UTC time now is {}", utc_time); - println!( - "Time in Hong Kong now is {}", - utc_time.with_timezone(&china_timezone) - ); - println!("Time in Rio de Janeiro now is {}", utc_time.with_timezone(&rio_timezone)); -} -
通过 DateTime 获取当前的 UTC 时间:
- --use chrono::{Datelike, Timelike, Utc}; - -fn main() { - let now = Utc::now(); - - let (is_pm, hour) = now.hour12(); - println!( - "The current UTC time is {:02}:{:02}:{:02} {}", - hour, - now.minute(), - now.second(), - if is_pm { "PM" } else { "AM" } - ); - println!( - "And there have been {} seconds since midnight", - now.num_seconds_from_midnight() - ); - - let (is_common_era, year) = now.year_ce(); - println!( - "The current UTC date is {}-{:02}-{:02} {:?} ({})", - year, - now.month(), - now.day(), - now.weekday(), - if is_common_era { "CE" } else { "BCE" } - ); - println!( - "And the Common Era began {} days ago", - now.num_days_from_ce() - ); -} -
-use chrono::{NaiveDate, NaiveDateTime}; - -fn main() { - // 生成一个具体的日期时间 - let date_time: NaiveDateTime = NaiveDate::from_ymd(2017, 11, 12).and_hms(17, 33, 44); - println!( - "Number of seconds between 1970-01-01 00:00:00 and {} is {}.", - // 打印日期和日期对应的时间戳 - date_time, date_time.timestamp()); - - // 计算从 1970 1月1日 0:00:00 UTC 开始,10亿秒后是什么日期时间 - let date_time_after_a_billion_seconds = NaiveDateTime::from_timestamp(1_000_000_000, 0); - println!( - "Date after a billion seconds since 1970-01-01 00:00:00 was {}.", - date_time_after_a_billion_seconds); -} -
通过 Utc::now 可以获取当前的 UTC 时间。
--use chrono::{DateTime, Utc}; - -fn main() { - let now: DateTime<Utc> = Utc::now(); - - println!("UTC now is: {}", now); - // 使用 RFC 2822 格式显示当前时间 - println!("UTC now in RFC 2822 is: {}", now.to_rfc2822()); - // 使用 RFC 3339 格式显示当前时间 - println!("UTC now in RFC 3339 is: {}", now.to_rfc3339()); - // 使用自定义格式显示当前时间 - println!("UTC now in a custom format is: {}", now.format("%a %b %e %T %Y")); -} -
我们可以将多种格式的日期时间字符串转换成 DateTime 结构体。DateTime::parse_from_str 使用的转义序列可以在 chrono::format::strftime 找到.
-只有当能唯一的标识出日期和时间时,才能创建 DateTime。如果要在没有时区的情况下解析日期或时间,你需要使用 NativeDate 等函数。
-use chrono::{DateTime, NaiveDate, NaiveDateTime, NaiveTime}; -use chrono::format::ParseError; - - -fn main() -> Result<(), ParseError> { - let rfc2822 = DateTime::parse_from_rfc2822("Tue, 1 Jul 2003 10:52:37 +0200")?; - println!("{}", rfc2822); - - let rfc3339 = DateTime::parse_from_rfc3339("1996-12-19T16:39:57-08:00")?; - println!("{}", rfc3339); - - let custom = DateTime::parse_from_str("5.8.1994 8:00 am +0000", "%d.%m.%Y %H:%M %P %z")?; - println!("{}", custom); - - let time_only = NaiveTime::parse_from_str("23:56:04", "%H:%M:%S")?; - println!("{}", time_only); - - let date_only = NaiveDate::parse_from_str("2015-09-05", "%Y-%m-%d")?; - println!("{}", date_only); - - let no_timezone = NaiveDateTime::parse_from_str("2015-09-05 23:56:04", "%Y-%m-%d %H:%M:%S")?; - println!("{}", no_timezone); - - Ok(()) -} -
log 提供了日志相关的实用工具。
-env_logger 通过环境变量来配置日志。log::debug! 使用起来跟 std::fmt 中的格式化字符串很像。
-fn execute_query(query: &str) { - log::debug!("Executing query: {}", query); -} - -fn main() { - env_logger::init(); - - execute_query("DROP TABLE students"); -} -
如果大家运行代码,会发现没有任何日志输出,原因是默认的日志级别是 error,因此我们需要通过 RUST_LOG 环境变量来设置下新的日志级别:
$ RUST_LOG=debug cargo run
-然后你将成功看到以下输出:
-DEBUG:main: Executing query: DROP TABLE students
-下面我们通过 log::error! 将错误日志输出到标准错误 stderr。
-fn execute_query(_query: &str) -> Result<(), &'static str> { - Err("I'm afraid I can't do that") -} - -fn main() { - env_logger::init(); - - let response = execute_query("DROP TABLE students"); - if let Err(err) = response { - log::error!("Failed to execute query: {}", err); - } -} -
默认的错误会输出到标准错误输出 stderr,下面我们通过自定的配置来让错误输出到标准输出 stdout。
-use env_logger::{Builder, Target}; - -fn main() { - Builder::new() - .target(Target::Stdout) - .init(); - - log::error!("This error has been printed to Stdout"); -} -
下面的代码将实现一个自定义 logger ConsoleLogger,输出到标准输出 stdout。为了使用日志宏,ConsoleLogger 需要实现 log::Log 特征,然后使用 log::set_logger 来安装使用。
-use log::{Record, Level, Metadata, LevelFilter, SetLoggerError}; - -static CONSOLE_LOGGER: ConsoleLogger = ConsoleLogger; - -struct ConsoleLogger; - -impl log::Log for ConsoleLogger { - fn enabled(&self, metadata: &Metadata) -> bool { - metadata.level() <= Level::Info - } - - fn log(&self, record: &Record) { - if self.enabled(record.metadata()) { - println!("Rust says: {} - {}", record.level(), record.args()); - } - } - - fn flush(&self) {} -} - -fn main() -> Result<(), SetLoggerError> { - log::set_logger(&CONSOLE_LOGGER)?; - log::set_max_level(LevelFilter::Info); - - log::info!("hello log"); - log::warn!("warning"); - log::error!("oops"); - Ok(()) -} -
下面的代码将使用 syslog 包将日志输出到 Unix Syslog.
--#[cfg(target_os = "linux")] -#[cfg(target_os = "linux")] -use syslog::{Facility, Error}; - -#[cfg(target_os = "linux")] -fn main() -> Result<(), Error> { - // 初始化 logger - syslog::init(Facility::LOG_USER, - log::LevelFilter::Debug, - // 可选的应用名称 - Some("My app name"))?; - log::debug!("this is a debug {}", "message"); - log::error!("this is an error!"); - Ok(()) -} - -#[cfg(not(target_os = "linux"))] -fn main() { - println!("So far, only Linux systems are supported."); -} -
@todo
-下面代码创建了模块 foo 和嵌套模块 foo::bar,并通过 RUST_LOG 环境变量对各自的日志级别进行了控制。
-mod foo { - mod bar { - pub fn run() { - log::warn!("[bar] warn"); - log::info!("[bar] info"); - log::debug!("[bar] debug"); - } - } - - pub fn run() { - log::warn!("[foo] warn"); - log::info!("[foo] info"); - log::debug!("[foo] debug"); - bar::run(); - } -} - -fn main() { - env_logger::init(); - log::warn!("[root] warn"); - log::info!("[root] info"); - log::debug!("[root] debug"); - foo::run(); -} -
要让环境变量生效,首先需要通过 env_logger::init() 开启相关的支持。然后通过以下命令来运行程序:
RUST_LOG="warn,test::foo=info,test::foo::bar=debug" ./test
-此时的默认日志级别被设置为 warn,但我们还将 foo 模块级别设置为 info, foo::bar 模块日志级别设置为 debug。
WARN:test: [root] warn
-WARN:test::foo: [foo] warn
-INFO:test::foo: [foo] info
-WARN:test::foo::bar: [bar] warn
-INFO:test::foo::bar: [bar] info
-DEBUG:test::foo::bar: [bar] debug
-Builder 将对日志进行配置,以下代码使用 MY_APP_LOG 来替代 RUST_LOG 环境变量:
-use std::env; -use env_logger::Builder; - -fn main() { - Builder::new() - .parse(&env::var("MY_APP_LOG").unwrap_or_default()) - .init(); - - log::info!("informational message"); - log::warn!("warning message"); - log::error!("this is an error {}", "message"); -} -
-use std::io::Write; -use chrono::Local; -use env_logger::Builder; -use log::LevelFilter; - -fn main() { - Builder::new() - .format(|buf, record| { - writeln!(buf, - "{} [{}] - {}", - Local::now().format("%Y-%m-%dT%H:%M:%S"), - record.level(), - record.args() - ) - }) - .filter(None, LevelFilter::Info) - .init(); - - log::warn!("warn"); - log::info!("info"); - log::debug!("debug"); -} -
以下是 stderr 的输出:
2022-03-22T21:57:06 [WARN] - warn
-2022-03-22T21:57:06 [INFO] - info
-log4rs 可以帮我们将日志输出指定的位置,它可以使用外部 YAML 文件或 builder 的方式进行配置。
-use error_chain::error_chain; - -use log::LevelFilter; -use log4rs::append::file::FileAppender; -use log4rs::encode::pattern::PatternEncoder; -use log4rs::config::{Appender, Config, Root}; - -error_chain! { - foreign_links { - Io(std::io::Error); - LogConfig(log4rs::config::Errors); - SetLogger(log::SetLoggerError); - } -} - -fn main() -> Result<()> { - // 创建日志配置,并指定输出的位置 - let logfile = FileAppender::builder() - // 编码模式的详情参见: https://docs.rs/log4rs/1.0.0/log4rs/encode/pattern/index.html - .encoder(Box::new(PatternEncoder::new("{l} - {m}\n"))) - .build("log/output.log")?; - - let config = Config::builder() - .appender(Appender::builder().build("logfile", Box::new(logfile))) - .build(Root::builder() - .appender("logfile") - .build(LevelFilter::Info))?; - - log4rs::init_config(config)?; - - log::info!("Hello, world!"); - - Ok(()) -} - -
下面例子使用 Version::parse 将一个字符串转换成 semver::Version 版本号,然后将它的 patch, minor, major 版本号都增加 1。
-注意,为了符合语义化版本的说明,增加 minor 版本时,patch 版本会被重设为 0,当增加 major 版本时,minor 和 patch 都将被重设为 0。
-use semver::{Version, SemVerError}; - -fn main() -> Result<(), SemVerError> { - let mut parsed_version = Version::parse("0.2.6")?; - - assert_eq!( - parsed_version, - Version { - major: 0, - minor: 2, - patch: 6, - pre: vec![], - build: vec![], - } - ); - - parsed_version.increment_patch(); - assert_eq!(parsed_version.to_string(), "0.2.7"); - println!("New patch release: v{}", parsed_version); - - parsed_version.increment_minor(); - assert_eq!(parsed_version.to_string(), "0.3.0"); - println!("New minor release: v{}", parsed_version); - - parsed_version.increment_major(); - assert_eq!(parsed_version.to_string(), "1.0.0"); - println!("New major release: v{}", parsed_version); - - Ok(()) -} -
这里的版本号字符串还将包含 SemVer 中定义的预发布和构建元信息。
值得注意的是,为了符合 SemVer 的规则,构建元信息虽然会被解析,但是在做版本号比较时,该信息会被忽略。换而言之,即使两个版本号的构建字符串不同,它们的版本号依然可能相同。
-use semver::{Identifier, Version, SemVerError}; - -fn main() -> Result<(), SemVerError> { - let version_str = "1.0.49-125+g72ee7853"; - let parsed_version = Version::parse(version_str)?; - - assert_eq!( - parsed_version, - Version { - major: 1, - minor: 0, - patch: 49, - pre: vec![Identifier::Numeric(125)], - build: vec![], - } - ); - assert_eq!( - parsed_version.build, - vec![Identifier::AlphaNumeric(String::from("g72ee7853"))] - ); - - let serialized_version = parsed_version.to_string(); - assert_eq!(&serialized_version, version_str); - - Ok(()) -} -
下面例子给出两个版本号,然后通过 is_prerelease 判断哪个是预发布的版本号。
--use semver::{Version, SemVerError}; - -fn main() -> Result<(), SemVerError> { - let version_1 = Version::parse("1.0.0-alpha")?; - let version_2 = Version::parse("1.0.0")?; - - assert!(version_1.is_prerelease()); - assert!(!version_2.is_prerelease()); - - Ok(()) -} -
下面例子给出了一个版本号列表,我们需要找到其中最新的版本。
--use error_chain::error_chain; - -use semver::{Version, VersionReq}; - -error_chain! { - foreign_links { - SemVer(semver::SemVerError); - SemVerReq(semver::ReqParseError); - } -3} - -fn find_max_matching_version<'a, I>(version_req_str: &str, iterable: I) -> Result<Option<Version>> -where - I: IntoIterator<Item = &'a str>, -{ - let vreq = VersionReq::parse(version_req_str)?; - - Ok( - iterable - .into_iter() - .filter_map(|s| Version::parse(s).ok()) - .filter(|s| vreq.matches(s)) - .max(), - ) -} - -fn main() -> Result<()> { - assert_eq!( - find_max_matching_version("<= 1.0.0", vec!["0.9.0", "1.0.0", "1.0.1"])?, - Some(Version::parse("1.0.0")?) - ); - - assert_eq!( - find_max_matching_version( - ">1.2.3-alpha.3", - vec![ - "1.2.3-alpha.3", - "1.2.3-alpha.4", - "1.2.3-alpha.10", - "1.2.3-beta.4", - "3.4.5-alpha.9", - ] - )?, - Some(Version::parse("1.2.3-beta.4")?) - ); - - Ok(()) -} -
下面将通过 Command 来执行系统命令 git --version,并对该系统命令返回的 git 版本号进行解析。
-use error_chain::error_chain; - -use std::process::Command; -use semver::{Version, VersionReq}; - -error_chain! { - foreign_links { - Io(std::io::Error); - Utf8(std::string::FromUtf8Error); - SemVer(semver::SemVerError); - SemVerReq(semver::ReqParseError); - } -} - -fn main() -> Result<()> { - let version_constraint = "> 1.12.0"; - let version_test = VersionReq::parse(version_constraint)?; - let output = Command::new("git").arg("--version").output()?; - - if !output.status.success() { - error_chain::bail!("Command executed with failing error code"); - } - - let stdout = String::from_utf8(output.stdout)?; - let version = stdout.split(" ").last().ok_or_else(|| { - "Invalid command output" - })?; - let parsed_version = Version::parse(version)?; - - if !version_test.matches(&parsed_version) { - error_chain::bail!("Command version lower than minimum supported version (found {}, need {})", - parsed_version, version_constraint); - } - - Ok(()) -} -
本章节的内容是关于构建工具的,如果大家没有听说过 build.rs 文件,强烈建议先看看这里了解下何为构建工具。
cc 包能帮助我们更好地跟 C/C++/汇编进行交互:它提供了简单的 API 可以将外部的库编译成静态库( .a ),然后通过 rustc 进行静态链接。
下面的例子中,我们将在 Rust 代码中使用 C 的代码: src/hello.c。在开始编译 Rust 的项目代码前,build.rs 构建脚本将先被执行。通过 cc 包,一个静态的库可以被生成( libhello.a ),然后该库将被 Rust的代码所使用:通过 extern 声明外部函数签名的方式来使用。
由于例子中的 C 代码很简单,因此只需要将一个文件传递给 cc::Build。如果大家需要更复杂的构建,cc::Build 还提供了通过 include 来包含路径的方式,以及额外的编译标志( flags )。
Cargo.toml
-[package]
-...
-build = "build.rs"
-
-[build-dependencies]
-cc = "1"
-
-[dependencies]
-error-chain = "0.11"
-build.rs
--fn main() { - cc::Build::new() - .file("src/hello.c") - .compile("hello"); // outputs `libhello.a` -} -
src/hello.c
-#include <stdio.h>
-
-
-void hello() {
- printf("Hello from C!\n");
-}
-
-void greet(const char* name) {
- printf("Hello, %s!\n", name);
-}
-src/main.rs
--use error_chain::error_chain; -use std::ffi::CString; -use std::os::raw::c_char; - -error_chain! { - foreign_links { - NulError(::std::ffi::NulError); - Io(::std::io::Error); - } -} -fn prompt(s: &str) -> Result<String> { - use std::io::Write; - print!("{}", s); - std::io::stdout().flush()?; - let mut input = String::new(); - std::io::stdin().read_line(&mut input)?; - Ok(input.trim().to_string()) -} - -extern { - fn hello(); - fn greet(name: *const c_char); -} - -fn main() -> Result<()> { - unsafe { hello() } - let name = prompt("What's your name? ")?; - let c_name = CString::new(name)?; - unsafe { greet(c_name.as_ptr()) } - Ok(()) -} -
链接到 C++ 库跟之前的方式非常相似。主要的区别在于链接到 C++ 库时,你需要通过构建方法 cpp(true) 来指定一个 C++ 编译器,然后在 C++ 的代码顶部添加 extern "C" 来阻止 C++ 编译器对库名进行名称重整( name mangling )。
Cargo.toml
-[package]
-...
-build = "build.rs"
-
-[build-dependencies]
-cc = "1"
-build.rs
--fn main() { - cc::Build::new() - .cpp(true) - .file("src/foo.cpp") - .compile("foo"); -} -
src/foo.cpp
-extern "C" {
- int multiply(int x, int y);
-}
-
-int multiply(int x, int y) {
- return x*y;
-}
-src/main.rs
--extern { - fn multiply(x : i32, y : i32) -> i32; -} - -fn main(){ - unsafe { - println!("{}", multiply(5,7)); - } -} -
cc::Build::define 可以让我们使用自定义的 define 来构建 C 库。
-以下示例在构建脚本 build.rs 中动态定义了一个 define,然后在运行时打印出 Welcome to foo - version 1.0.2。Cargo 会设置一些环境变量,它们对于自定义的 define 会有所帮助。
Cargo.toml
-[package]
-...
-version = "1.0.2"
-build = "build.rs"
-
-[build-dependencies]
-cc = "1"
-build.rs
--fn main() { - cc::Build::new() - .define("APP_NAME", "\"foo\"") - .define("VERSION", format!("\"{}\"", env!("CARGO_PKG_VERSION")).as_str()) - .define("WELCOME", None) - .file("src/foo.c") - .compile("foo"); -} -
src/foo.c
-#include <stdio.h>
-
-void print_app_info() {
-#ifdef WELCOME
- printf("Welcome to ");
-#endif
- printf("%s - version %s\n", APP_NAME, VERSION);
-}
-src/main.rs
--extern { - fn print_app_info(); -} - -fn main(){ - unsafe { - print_app_info(); - } -} -
百分号编码又称 URL 编码。
-percent-encoding 包提供了两个函数:utf8_percent_encode 函数用于编码、percent_decode 用于解码。
-use percent_encoding::{utf8_percent_encode, percent_decode, AsciiSet, CONTROLS}; -use std::str::Utf8Error; - -/// https://url.spec.whatwg.org/#fragment-percent-encode-set -const FRAGMENT: &AsciiSet = &CONTROLS.add(b' ').add(b'"').add(b'<').add(b'>').add(b'`'); - -fn main() -> Result<(), Utf8Error> { - let input = "confident, productive systems programming"; - - let iter = utf8_percent_encode(input, FRAGMENT); - // 将元素类型为 &str 的迭代器收集为 String 类型 - let encoded: String = iter.collect(); - assert_eq!(encoded, "confident,%20productive%20systems%20programming"); - - let iter = percent_decode(encoded.as_bytes()); - let decoded = iter.decode_utf8()?; - assert_eq!(decoded, "confident, productive systems programming"); - - Ok(()) -} -
该编码集定义了哪些字符( 特别是非 ASCII 和控制字符 )需要被百分比编码。具体的选择取决于上下文,例如 url 会对 URL 路径中的 ? 进行编码,但是在路径后的查询字符串中,并不会进行编码。
使用 form_urlencoded::byte_serialize 函数将一个字符串编码成 application/x-www-form-urlencoded 格式,然后再使用 form_urlencoded::parse 对其进行解码。
--use url::form_urlencoded::{byte_serialize, parse}; - -fn main() { - let urlencoded: String = byte_serialize("What is ❤?".as_bytes()).collect(); - assert_eq!(urlencoded, "What+is+%E2%9D%A4%3F"); - println!("urlencoded:'{}'", urlencoded); - - let decoded: String = parse(urlencoded.as_bytes()) - .map(|(key, val)| [key, val].concat()) - .collect(); - assert_eq!(decoded, "What is ❤?"); - println!("decoded:'{}'", decoded); -} -
data_encoding 可以将一个字符串编码成十六进制字符串,反之亦然。
-下面的例子将 &[u8] 转换成十六进制等效形式,然后与期待的值进行比较。
-use data_encoding::{HEXUPPER, DecodeError}; - -fn main() -> Result<(), DecodeError> { - let original = b"The quick brown fox jumps over the lazy dog."; - let expected = "54686520717569636B2062726F776E20666F78206A756D7073206F76\ - 657220746865206C617A7920646F672E"; - - let encoded = HEXUPPER.encode(original); - assert_eq!(encoded, expected); - - let decoded = HEXUPPER.decode(&encoded.into_bytes())?; - assert_eq!(&decoded[..], &original[..]); - - Ok(()) -} -
base64 可以把一个字节切片编码成 base64 String。
-use error_chain::error_chain; - -use std::str; -use base64::{encode, decode}; - -error_chain! { - foreign_links { - Base64(base64::DecodeError); - Utf8Error(str::Utf8Error); - } -} - -fn main() -> Result<()> { - // 将 `&str` 转换成 `&[u8; N]` - let hello = b"hello rustaceans"; - let encoded = encode(hello); - let decoded = decode(&encoded)?; - - println!("origin: {}", str::from_utf8(hello)?); - println!("base64 encoded: {}", encoded); - println!("back to origin: {}", str::from_utf8(&decoded)?); - - Ok(()) -} -
我们可以将标准的 CSV 记录值读取到 csv::StringRecord 中,但是该数据结构期待合法的 UTF8 数据行,你还可以使用 csv::ByteRecord 来读取非 UTF8 数据。
--use csv::Error; - -fn main() -> Result<(), Error> { - let csv = "year,make,model,description - 1948,Porsche,356,Luxury sports car - 1967,Ford,Mustang fastback 1967,American car"; - - let mut reader = csv::Reader::from_reader(csv.as_bytes()); - for record in reader.records() { - let record = record?; - println!( - "In {}, {} built the {} model. It is a {}.", - &record[0], - &record[1], - &record[2], - &record[3] - ); - } - - Ok(()) -} -
还可以使用 serde 将数据反序列化成一个强类型的结构体。
-use serde::Deserialize; -#[derive(Deserialize)] -struct Record { - year: u16, - make: String, - model: String, - description: String, -} - -fn main() -> Result<(), csv::Error> { - let csv = "year,make,model,description -1948,Porsche,356,Luxury sports car -1967,Ford,Mustang fastback 1967,American car"; - - let mut reader = csv::Reader::from_reader(csv.as_bytes()); - - for record in reader.deserialize() { - let record: Record = record?; - println!( - "In {}, {} built the {} model. It is a {}.", - record.year, - record.make, - record.model, - record.description - ); - } - - Ok(()) -} -
下面的例子将读取使用了 tab 作为分隔符的 CSV 记录。
-use csv::Error; -use serde::Deserialize; -#[derive(Debug, Deserialize)] -struct Record { - name: String, - place: String, - #[serde(deserialize_with = "csv::invalid_option")] - id: Option<u64>, -} - -use csv::ReaderBuilder; - -fn main() -> Result<(), Error> { - let data = "name\tplace\tid - Mark\tMelbourne\t46 - Ashley\tZurich\t92"; - - let mut reader = ReaderBuilder::new().delimiter(b'\t').from_reader(data.as_bytes()); - for result in reader.deserialize::<Record>() { - println!("{:?}", result?); - } - - Ok(()) -} -
-use error_chain::error_chain; - -use std::io; - -error_chain!{ - foreign_links { - Io(std::io::Error); - CsvError(csv::Error); - } -} - -fn main() -> Result<()> { - let query = "CA"; - let data = "\ -City,State,Population,Latitude,Longitude -Kenai,AK,7610,60.5544444,-151.2583333 -Oakman,AL,,33.7133333,-87.3886111 -Sandfort,AL,,32.3380556,-85.2233333 -West Hollywood,CA,37031,34.0900000,-118.3608333"; - - let mut rdr = csv::ReaderBuilder::new().from_reader(data.as_bytes()); - let mut wtr = csv::Writer::from_writer(io::stdout()); - - wtr.write_record(rdr.headers()?)?; - - for result in rdr.records() { - let record = result?; - if record.iter().any(|field| field == query) { - wtr.write_record(&record)?; - } - } - - wtr.flush()?; - Ok(()) -} -
下面例子展示了如何将 Rust 类型序列化为 CSV。
--use std::io; - -fn main() -> Result<()> { - let mut wtr = csv::Writer::from_writer(io::stdout()); - - wtr.write_record(&["Name", "Place", "ID"])?; - - wtr.serialize(("Mark", "Sydney", 87))?; - wtr.serialize(("Ashley", "Dublin", 32))?; - wtr.serialize(("Akshat", "Delhi", 11))?; - - wtr.flush()?; - Ok(()) -} -
下面例子将自定义数据结构通过 serde 序列化 CSV。
-use error_chain::error_chain; -use serde::Serialize; -use std::io; - -error_chain! { - foreign_links { - IOError(std::io::Error); - CSVError(csv::Error); - } -} - -#[derive(Serialize)] -struct Record<'a> { - name: &'a str, - place: &'a str, - id: u64, -} - -fn main() -> Result<()> { - let mut wtr = csv::Writer::from_writer(io::stdout()); - - let rec1 = Record { name: "Mark", place: "Melbourne", id: 56}; - let rec2 = Record { name: "Ashley", place: "Sydney", id: 64}; - let rec3 = Record { name: "Akshat", place: "Delhi", id: 98}; - - wtr.serialize(rec1)?; - wtr.serialize(rec2)?; - wtr.serialize(rec3)?; - - wtr.flush()?; - - Ok(()) -} -
下面代码将包含有颜色名和十六进制颜色的 CSV 文件转换为包含颜色名和 rgb 颜色。这里使用 csv 包对 CSV 文件进行读写,然后用 serde 进行序列化和反序列化。
-use error_chain::error_chain; -use csv::{Reader, Writer}; -use serde::{de, Deserialize, Deserializer}; -use std::str::FromStr; - -error_chain! { - foreign_links { - CsvError(csv::Error); - ParseInt(std::num::ParseIntError); - CsvInnerError(csv::IntoInnerError<Writer<Vec<u8>>>); - IO(std::fmt::Error); - UTF8(std::string::FromUtf8Error); - } -} - -#[derive(Debug)] -struct HexColor { - red: u8, - green: u8, - blue: u8, -} - -#[derive(Debug, Deserialize)] -struct Row { - color_name: String, - color: HexColor, -} - -impl FromStr for HexColor { - type Err = Error; - - fn from_str(hex_color: &str) -> std::result::Result<Self, Self::Err> { - let trimmed = hex_color.trim_matches('#'); - if trimmed.len() != 6 { - Err("Invalid length of hex string".into()) - } else { - Ok(HexColor { - red: u8::from_str_radix(&trimmed[..2], 16)?, - green: u8::from_str_radix(&trimmed[2..4], 16)?, - blue: u8::from_str_radix(&trimmed[4..6], 16)?, - }) - } - } -} - -impl<'de> Deserialize<'de> for HexColor { - fn deserialize<D>(deserializer: D) -> std::result::Result<Self, D::Error> - where - D: Deserializer<'de>, - { - let s = String::deserialize(deserializer)?; - FromStr::from_str(&s).map_err(de::Error::custom) - } -} - -fn main() -> Result<()> { - let data = "color_name,color -red,#ff0000 -green,#00ff00 -blue,#0000FF -periwinkle,#ccccff -magenta,#ff00ff" - .to_owned(); - let mut out = Writer::from_writer(vec![]); - let mut reader = Reader::from_reader(data.as_bytes()); - for result in reader.deserialize::<Row>() { - let res = result?; - out.serialize(( - res.color_name, - res.color.red, - res.color.green, - res.color.blue, - ))?; - } - let written = String::from_utf8(out.into_inner()?)?; - assert_eq!(Some("magenta,255,0,255"), written.lines().last()); - println!("{}", written); - Ok(()) -} -
serde_json 是一个高性能的 JSON 包,它支持我们在不声明结构体的情况下,去解析 JSON。
--use serde_json::json; -use serde_json::{Value, Error}; - -fn main() -> Result<(), Error> { - let j = r#"{ - "userid": 103609, - "verified": true, - "access_privileges": [ - "user", - "admin" - ] - }"#; - - let parsed: Value = serde_json::from_str(j)?; - - let expected = json!({ - "userid": 103609, - "verified": true, - "access_privileges": [ - "user", - "admin" - ] - }); - - assert_eq!(parsed, expected); - - Ok(()) -} -
toml 包可以将 TOML 文件的内容解析为一个 toml::Value 值,该值能代表任何合法的 TOML 数据。
-use toml::{Value, de::Error}; - -fn main() -> Result<(), Error> { - let toml_content = r#" - [package] - name = "your_package" - version = "0.1.0" - authors = ["You! <you@example.org>"] - - [dependencies] - serde = "1.0" - "#; - - let package_info: Value = toml::from_str(toml_content)?; - - assert_eq!(package_info["dependencies"]["serde"].as_str(), Some("1.0")); - assert_eq!(package_info["package"]["name"].as_str(), - Some("your_package")); - - Ok(()) -} -
还可以配合 serde 将 TOML 解析到我们自定义的结构体中:
--use serde::Deserialize; - -use toml::de::Error; -use std::collections::HashMap; - -#[derive(Deserialize)] -struct Config { - package: Package, - dependencies: HashMap<String, String>, -} - -#[derive(Deserialize)] -struct Package { - name: String, - version: String, - authors: Vec<String>, -} - -fn main() -> Result<(), Error> { - let toml_content = r#" - [package] - name = "your_package" - version = "0.1.0" - authors = ["You! <you@example.org>"] - - [dependencies] - serde = "1.0" - "#; - - let package_info: Config = toml::from_str(toml_content)?; - - assert_eq!(package_info.package.name, "your_package"); - assert_eq!(package_info.package.version, "0.1.0"); - assert_eq!(package_info.package.authors, vec!["You! <you@example.org>"]); - assert_eq!(package_info.dependencies["serde"], "1.0"); - - Ok(()) -} -
byteorder 在自行接收或发送网络字节流时会非常有用( 除非性能要求高,否则还是建议使用 JSON 等数据协议,不要自己做字节流解析 )。
---use byteorder::{LittleEndian, ReadBytesExt, WriteBytesExt}; -use std::io::Error; - -#[derive(Default, PartialEq, Debug)] -struct Payload { - kind: u8, - value: u16, -} - -fn main() -> Result<(), Error> { - let original_payload = Payload::default(); - let encoded_bytes = encode(&original_payload)?; - let decoded_payload = decode(&encoded_bytes)?; - assert_eq!(original_payload, decoded_payload); - Ok(()) -} - -fn encode(payload: &Payload) -> Result<Vec<u8>, Error> { - let mut bytes = vec![]; - bytes.write_u8(payload.kind)?; - bytes.write_u16::<LittleEndian>(payload.value)?; - Ok(bytes) -} - -fn decode(mut bytes: &[u8]) -> Result<Payload, Error> { - let payload = Payload { - kind: bytes.read_u8()?, - value: bytes.read_u16::<LittleEndian>()?, - }; - Ok(payload) -} -
-use std::fs::File; -use std::io::{Write, BufReader, BufRead, Error}; - -fn main() -> Result<(), Error> { - let path = "lines.txt"; - - // 创建文件 - let mut output = File::create(path)?; - // 写入三行内容 - write!(output, "Rust\n💖\nFun")?; - - let input = File::open(path)?; - let buffered = BufReader::new(input); - - // 迭代文件中的每一行内容,line 是字符串 - for line in buffered.lines() { - println!("{}", line?); - } - - Ok(()) -} -
same_file 可以帮我们识别两个文件是否是相同的。
--use same_file::Handle; -use std::fs::File; -use std::io::{BufRead, BufReader, Error, ErrorKind}; -use std::path::Path; - -fn main() -> Result<(), Error> { - let path_to_read = Path::new("new.txt"); - - // 从标准输出上获取待写入的文件名 - let stdout_handle = Handle::stdout()?; - // 将待写入的文件名跟待读取的文件名进行比较 - let handle = Handle::from_path(path_to_read)?; - - if stdout_handle == handle { - return Err(Error::new( - ErrorKind::Other, - "You are reading and writing to the same file", - )); - } else { - let file = File::open(&path_to_read)?; - let file = BufReader::new(file); - for (num, line) in file.lines().enumerate() { - println!("{} : {}", num, line?.to_uppercase()); - } - } - - Ok(()) -} -
以下代码会报错,因为待写入的文件名也是 new.txt,跟待读取的文件名相同
-cargo run >> ./new.txt
-memmap 能创建一个文件的内存映射( memory map ),然后模拟一些非顺序读。
-使用内存映射,意味着你将相关的索引加载到内存中,而不是通过 seek 的方式去访问文件。
-Mmap::map 函数会假定待映射的文件不会同时被其它进程修改。
--use memmap::Mmap; -use std::fs::File; -use std::io::{Write, Error}; - -fn main() -> Result<(), Error> { - write!(File::create("content.txt")?, "My hovercraft is full of eels!")?; - - let file = File::open("content.txt")?; - let map = unsafe { Mmap::map(&file)? }; - - let random_indexes = [0, 1, 2, 19, 22, 10, 11, 29]; - assert_eq!(&map[3..13], b"hovercraft"); - let random_bytes: Vec<u8> = random_indexes.iter() - .map(|&idx| map[idx]) - .collect(); - assert_eq!(&random_bytes[..], b"My loaf!"); - Ok(()) -} -
通过遍历读取目录中文件的 Metadata::modified 属性,来获取目标文件名列表。
--use error_chain::error_chain; - -use std::{env, fs}; - -error_chain! { - foreign_links { - Io(std::io::Error); - SystemTimeError(std::time::SystemTimeError); - } -} - -fn main() -> Result<()> { - let current_dir = env::current_dir()?; - println!( - "Entries modified in the last 24 hours in {:?}:", - current_dir - ); - - for entry in fs::read_dir(current_dir)? { - let entry = entry?; - let path = entry.path(); - - let metadata = fs::metadata(&path)?; - let last_modified = metadata.modified()?.elapsed()?.as_secs(); - - if last_modified < 24 * 3600 && metadata.is_file() { - println!( - "Last modified: {:?} seconds, is read only: {:?}, size: {:?} bytes, filename: {:?}", - last_modified, - metadata.permissions().readonly(), - metadata.len(), - path.file_name().ok_or("No filename")? - ); - } - } - - Ok(()) -} -
使用 same_file::is_same_file 可以检查给定路径的 loops,loop 可以通过以下方式创建:
-mkdir -p /tmp/foo/bar/baz
-ln -s /tmp/foo/ /tmp/foo/bar/baz/qux
--use std::io; -use std::path::{Path, PathBuf}; -use same_file::is_same_file; - -fn contains_loop<P: AsRef<Path>>(path: P) -> io::Result<Option<(PathBuf, PathBuf)>> { - let path = path.as_ref(); - let mut path_buf = path.to_path_buf(); - while path_buf.pop() { - if is_same_file(&path_buf, path)? { - return Ok(Some((path_buf, path.to_path_buf()))); - } else if let Some(looped_paths) = contains_loop(&path_buf)? { - return Ok(Some(looped_paths)); - } - } - return Ok(None); -} - -fn main() { - assert_eq!( - contains_loop("/tmp/foo/bar/baz/qux/bar/baz").unwrap(), - Some(( - PathBuf::from("/tmp/foo"), - PathBuf::from("/tmp/foo/bar/baz/qux") - )) - ); -} -
walkdir 可以帮助我们遍历指定的目录。
--use std::collections::HashMap; -use walkdir::WalkDir; - -fn main() { - let mut filenames = HashMap::new(); - - // 遍历当前目录 - for entry in WalkDir::new(".") - .into_iter() - .filter_map(Result::ok) - .filter(|e| !e.file_type().is_dir()) { - let f_name = String::from(entry.file_name().to_string_lossy()); - let counter = filenames.entry(f_name.clone()).or_insert(0); - *counter += 1; - - if *counter == 2 { - println!("{}", f_name); - } - } -} -
下面的代码通过 walkdir 来查找当前目录中最近一天内发生过修改的所有文件。
-follow_links 为 true 时,那软链接会被当成正常的文件或目录一样对待,也就是说软链接指向的文件或目录也会被访问和检查。若软链接指向的目标不存在或它是一个 loops,就会导致错误的发生。
-use error_chain::error_chain; - -use walkdir::WalkDir; - -error_chain! { - foreign_links { - WalkDir(walkdir::Error); - Io(std::io::Error); - SystemTime(std::time::SystemTimeError); - } -} - -fn main() -> Result<()> { - for entry in WalkDir::new(".") - .follow_links(true) - .into_iter() - .filter_map(|e| e.ok()) { - let f_name = entry.file_name().to_string_lossy(); - let sec = entry.metadata()?.modified()?; - - if f_name.ends_with(".json") && sec.elapsed()?.as_secs() < 86400 { - println!("{}", f_name); - } - } - - Ok(()) -} -
下面例子使用 walkdir 来遍历一个目录,同时跳过隐藏文件 is_not_hidden。
-use walkdir::{DirEntry, WalkDir}; - -fn is_not_hidden(entry: &DirEntry) -> bool { - entry - .file_name() - .to_str() - .map(|s| entry.depth() == 0 || !s.starts_with(".")) - .unwrap_or(false) -} - -fn main() { - WalkDir::new(".") - .into_iter() - .filter_entry(|e| is_not_hidden(e)) - .filter_map(|v| v.ok()) - .for_each(|x| println!("{}", x.path().display())); -} -
递归访问的深度可以使用 WalkDir::min_depth 和 WalkDir::max_depth 来控制。
--use walkdir::WalkDir; - -fn main() { - let total_size = WalkDir::new(".") - .min_depth(1) - .max_depth(3) - .into_iter() - .filter_map(|entry| entry.ok()) - .filter_map(|entry| entry.metadata().ok()) - .filter(|metadata| metadata.is_file()) - .fold(0, |acc, m| acc + m.len()); - - println!("Total size: {} bytes.", total_size); -} -
例子中使用了 glob 包,其中的 ** 代表当前目录及其所有子目录,例如,/media/**/*.png 代表在 media 和它的所有子目录下查找 png 文件.
-use error_chain::error_chain; - -use glob::glob; - -error_chain! { - foreign_links { - Glob(glob::GlobError); - Pattern(glob::PatternError); - } -} - -fn main() -> Result<()> { - for entry in glob("**/*.png")? { - println!("{}", entry?.display()); - } - - Ok(()) -} -
glob_with 函数可以按照给定的正则表达式进行查找,同时还能使用选项来控制一些匹配设置。
--use error_chain::error_chain; -use glob::{glob_with, MatchOptions}; - -error_chain! { - foreign_links { - Glob(glob::GlobError); - Pattern(glob::PatternError); - } -} - -fn main() -> Result<()> { - let options = MatchOptions { - case_sensitive: false, - ..Default::default() - }; - - for entry in glob_with("/media/img_[0-9]*.png", options)? { - println!("{}", entry?.display()); - } - - Ok(()) -} -
下面的例子,我们将使用 lazy_static 声明一个在运行期初始化( 懒求值 )的 Hashmap,它会被求值一次,然后保存在一个全局的 static 引用之后。
-use lazy_static::lazy_static; -use std::collections::HashMap; - -lazy_static! { - static ref PRIVILEGES: HashMap<&'static str, Vec<&'static str>> = { - let mut map = HashMap::new(); - map.insert("James", vec!["user", "admin"]); - map.insert("Jim", vec!["user"]); - map - }; -} - -fn show_access(name: &str) { - let access = PRIVILEGES.get(name); - println!("{}: {:?}", name, access); -} - -fn main() { - let access = PRIVILEGES.get("James"); - println!("James: {:?}", access); - - show_access("Jim"); -} -
以下代码会监听指定的 TCP 端口,并接收一条外部进入的 TCP 连接,然后将读取到的一条信息输出到标准输出( println! )。
-use std::net::{SocketAddrV4, Ipv4Addr, TcpListener}; -use std::io::{Read, Error}; - -fn main() -> Result<(), Error> { - let loopback = Ipv4Addr::new(127, 0, 0, 1); - let socket = SocketAddrV4::new(loopback, 0); - let listener = TcpListener::bind(socket)?; - let port = listener.local_addr()?; - println!("Listening on {}, access this port to end the program", port); - let (mut tcp_stream, addr) = listener.accept()?; //block until requested - println!("Connection received! {:?} is sending data.", addr); - let mut input = String::new(); - let _ = tcp_stream.read_to_string(&mut input)?; - println!("{:?} says {}", addr, input); - Ok(()) -} -
@todo
-下面代码使用 regex 包来验证邮件格式的正确性,然后提取出 @ 符号前的所有内容。
-use lazy_static::lazy_static; - -use regex::Regex; - -fn extract_login(input: &str) -> Option<&str> { - lazy_static! { - static ref RE: Regex = Regex::new(r"(?x) - ^(?P<login>[^@\s]+)@ - ([[:word:]]+\.)* - [[:word:]]+$ - ").unwrap(); - } - RE.captures(input).and_then(|cap| { - cap.name("login").map(|login| login.as_str()) - }) -} - -fn main() { - assert_eq!(extract_login(r"I❤email@example.com"), Some(r"I❤email")); - assert_eq!( - extract_login(r"sdf+sdsfsd.as.sdsd@jhkk.d.rl"), - Some(r"sdf+sdsfsd.as.sdsd") - ); - assert_eq!(extract_login(r"More@Than@One@at.com"), None); - assert_eq!(extract_login(r"Not an email@email"), None); -} -
例子对标签进行提取、排序和去重。需要注意,下面的标签仅仅是拉丁字母的,如果你要支持更多的字母,可以参考下 Twitter 的正则语法,友情提示,复杂的多!
--use lazy_static::lazy_static; - -use regex::Regex; -use std::collections::HashSet; - -fn extract_hashtags(text: &str) -> HashSet<&str> { - lazy_static! { - static ref HASHTAG_REGEX : Regex = Regex::new( - r"\#[a-zA-Z][0-9a-zA-Z_]*" - ).unwrap(); - } - HASHTAG_REGEX.find_iter(text).map(|mat| mat.as_str()).collect() -} - -fn main() { - let tweet = "Hey #world, I just got my new #dog, say hello to Till. #dog #forever #2 #_ "; - let tags = extract_hashtags(tweet); - assert!(tags.contains("#dog") && tags.contains("#forever") && tags.contains("#world")); - assert_eq!(tags.len(), 3); -} -
[Regex::captures_iter] 可以对字符串型文本进行处理,以获取文本中的多个手机号。下面的例子适用于美国的号码。
--use error_chain::error_chain; - -use regex::Regex; -use std::fmt; - -error_chain!{ - foreign_links { - Regex(regex::Error); - Io(std::io::Error); - } -} - -struct PhoneNumber<'a> { - area: &'a str, - exchange: &'a str, - subscriber: &'a str, -} - -impl<'a> fmt::Display for PhoneNumber<'a> { - fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { - write!(f, "1 ({}) {}-{}", self.area, self.exchange, self.subscriber) - } -} - -fn main() -> Result<()> { - let phone_text = " - +1 505 881 9292 (v) +1 505 778 2212 (c) +1 505 881 9297 (f) - (202) 991 9534 - Alex 5553920011 - 1 (800) 233-2010 - 1.299.339.1020"; - - let re = Regex::new( - r#"(?x) - (?:\+?1)? # Country Code Optional - [\s\.]? - (([2-9]\d{2})|\(([2-9]\d{2})\)) # Area Code - [\s\.\-]? - ([2-9]\d{2}) # Exchange Code - [\s\.\-]? - (\d{4}) # Subscriber Number"#, - )?; - - let phone_numbers = re.captures_iter(phone_text).filter_map(|cap| { - let groups = (cap.get(2).or(cap.get(3)), cap.get(4), cap.get(5)); - match groups { - (Some(area), Some(ext), Some(sub)) => Some(PhoneNumber { - area: area.as_str(), - exchange: ext.as_str(), - subscriber: sub.as_str(), - }), - _ => None, - } - }); - - assert_eq!( - phone_numbers.map(|m| m.to_string()).collect::<Vec<_>>(), - vec![ - "1 (505) 881-9292", - "1 (505) 778-2212", - "1 (505) 881-9297", - "1 (202) 991-9534", - "1 (555) 392-0011", - "1 (800) 233-2010", - "1 (299) 339-1020", - ] - ); - - Ok(()) -} -
例子的目标是过滤出包含 "version X.X.X"、以 443 结尾的 IP 地址和特别的警告的日志行。
-值得注意的是,由于在正则中反斜杠非常常见,因此使用 r#"" 形式的原生字符串对于开发者和使用者都更加友好。
-use error_chain::error_chain; - -use std::fs::File; -use std::io::{BufReader, BufRead}; -use regex::RegexSetBuilder; - -error_chain! { - foreign_links { - Io(std::io::Error); - Regex(regex::Error); - } -} - -fn main() -> Result<()> { - let log_path = "application.log"; - let buffered = BufReader::new(File::open(log_path)?); - - let set = RegexSetBuilder::new(&[ - r#"version "\d\.\d\.\d""#, - r#"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}:443"#, - r#"warning.*timeout expired"#, - ]).case_insensitive(true) - .build()?; - - buffered - .lines() - .filter_map(|line| line.ok()) - .filter(|line| set.is_match(line.as_str())) - .for_each(|x| println!("{}", x)); - - Ok(()) -} -
下面代码将标准的 ISO 8601 YYYY-MM-DD 日期模式替换成带有斜杠的美式英语日期。例如 2013-01-15 -> 01/15/2013。
-use lazy_static::lazy_static; - -use std::borrow::Cow; -use regex::Regex; - -fn reformat_dates(before: &str) -> Cow<str> { - lazy_static! { - static ref ISO8601_DATE_REGEX : Regex = Regex::new( - r"(?P<y>\d{4})-(?P<m>\d{2})-(?P<d>\d{2})" - ).unwrap(); - } - ISO8601_DATE_REGEX.replace_all(before, "$m/$d/$y") -} - -fn main() { - let before = "2012-03-14, 2013-01-15 and 2014-07-05"; - let after = reformat_dates(before); - assert_eq!(after, "03/14/2012, 01/15/2013 and 07/05/2014"); -} -
unicode-segmentation 包的 UnicodeSegmentation::graphemes 函数可以将 UTF-8 字符串收集成一个 Unicode 字符组成的数组。这样我们就可以通过索引的方式来访问对应的字符了。
--use unicode_segmentation::UnicodeSegmentation; - -fn main() { - let name = "José Guimarães\r\n"; - let graphemes = UnicodeSegmentation::graphemes(name, true) - .collect::<Vec<&str>>(); - assert_eq!(graphemes[3], "é"); -} -
为我们的 RGB 结构体实现 FromStr 特征后,就可以将一个十六进制的颜色表示字符串转换成 RGB 结构体。
-use std::str::FromStr; - -#[derive(Debug, PartialEq)] -struct RGB { - r: u8, - g: u8, - b: u8, -} - -impl FromStr for RGB { - type Err = std::num::ParseIntError; - - - // 将十六进制的颜色码解析为 `RGB` 的实例 - fn from_str(hex_code: &str) -> Result<Self, Self::Err> { - - // u8::from_str_radix(src: &str, radix: u32) 将一个字符串切片按照指定的基数转换为 u8 类型 - let r: u8 = u8::from_str_radix(&hex_code[1..3], 16)?; - let g: u8 = u8::from_str_radix(&hex_code[3..5], 16)?; - let b: u8 = u8::from_str_radix(&hex_code[5..7], 16)?; - - Ok(RGB { r, g, b }) - } -} - -fn main() { - let code: &str = &r"#fa7268"; - match RGB::from_str(code) { - Ok(rgb) => { - println!( - r"The RGB color code is: R: {} G: {} B: {}", - rgb.r, rgb.g, rgb.b - ); - } - Err(_) => { - println!("{} is not a valid color hex code!", code); - } - } - - // 测试 from_str 是否按照预期工作 - assert_eq!( - RGB::from_str(&r"#fa7268").unwrap(), - RGB { - r: 250, - g: 114, - b: 104 - } - ); -} -
@todo
- - -以下代码会监听指定的 TCP 端口,并接收一条外部进入的 TCP 连接,然后将读取到的一条信息输出到标准输出( println! )。
-use std::net::{SocketAddrV4, Ipv4Addr, TcpListener}; -use std::io::{Read, Error}; - -fn main() -> Result<(), Error> { - let loopback = Ipv4Addr::new(127, 0, 0, 1); - let socket = SocketAddrV4::new(loopback, 0); - let listener = TcpListener::bind(socket)?; - let port = listener.local_addr()?; - println!("Listening on {}, access this port to end the program", port); - let (mut tcp_stream, addr) = listener.accept()?; //block until requested - println!("Connection received! {:?} is sending data.", addr); - let mut input = String::new(); - let _ = tcp_stream.read_to_string(&mut input)?; - println!("{:?} says {}", addr, input); - Ok(()) -} -
@todo
- - -