数据概览
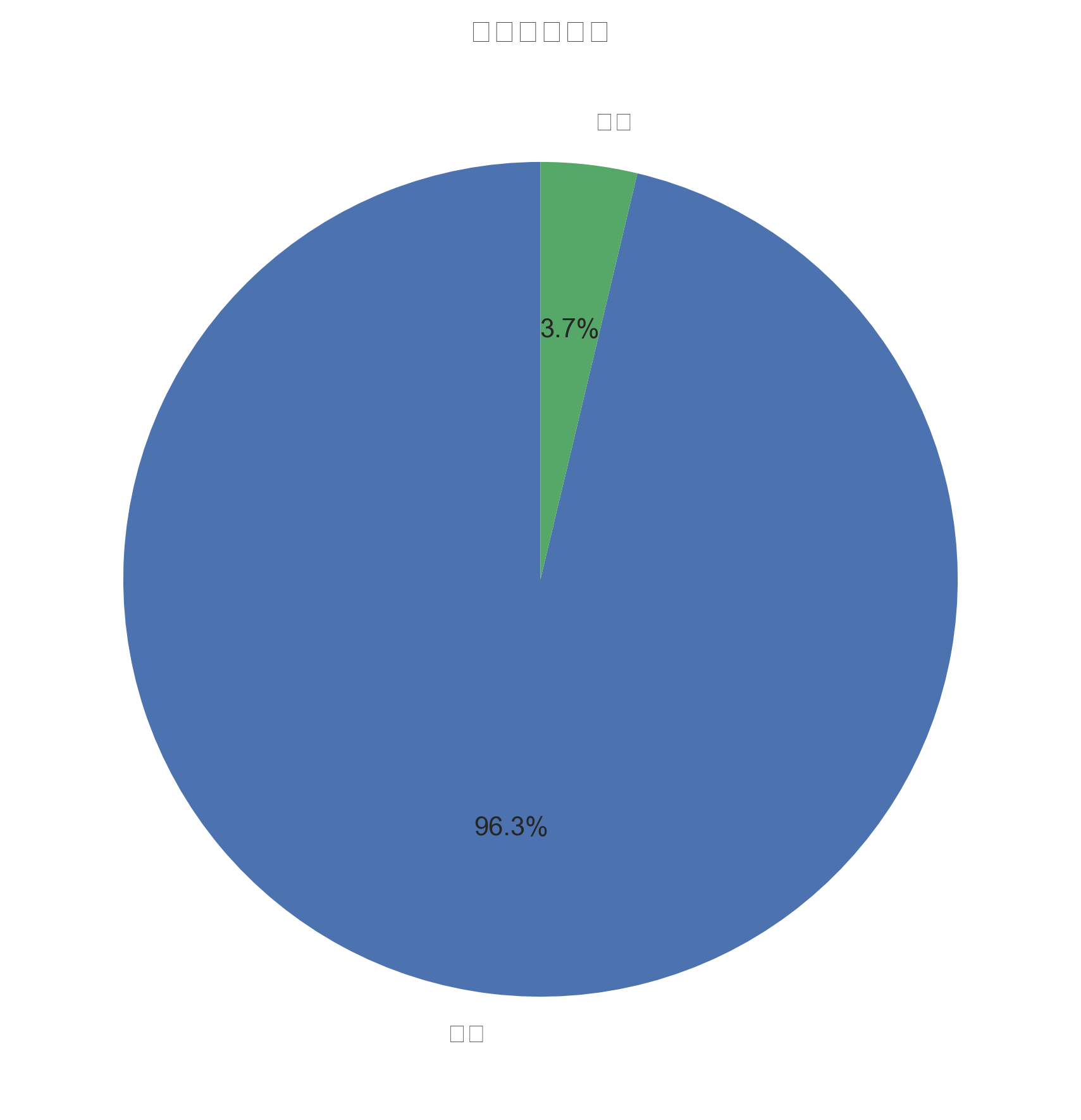
数据洞察: 数据集中违约客户占比3.73%,正常客户占比96.27%,数据分布符合现实情况。
SHAP特征重要性

模型洞察: SHAP分析提供了更精确的特征重要性评估,有助于理解模型决策过程。
SHAP摘要图

模型洞察: SHAP摘要图显示了每个特征如何影响模型输出,红色表示增加风险,蓝色表示降低风险。
年龄分布
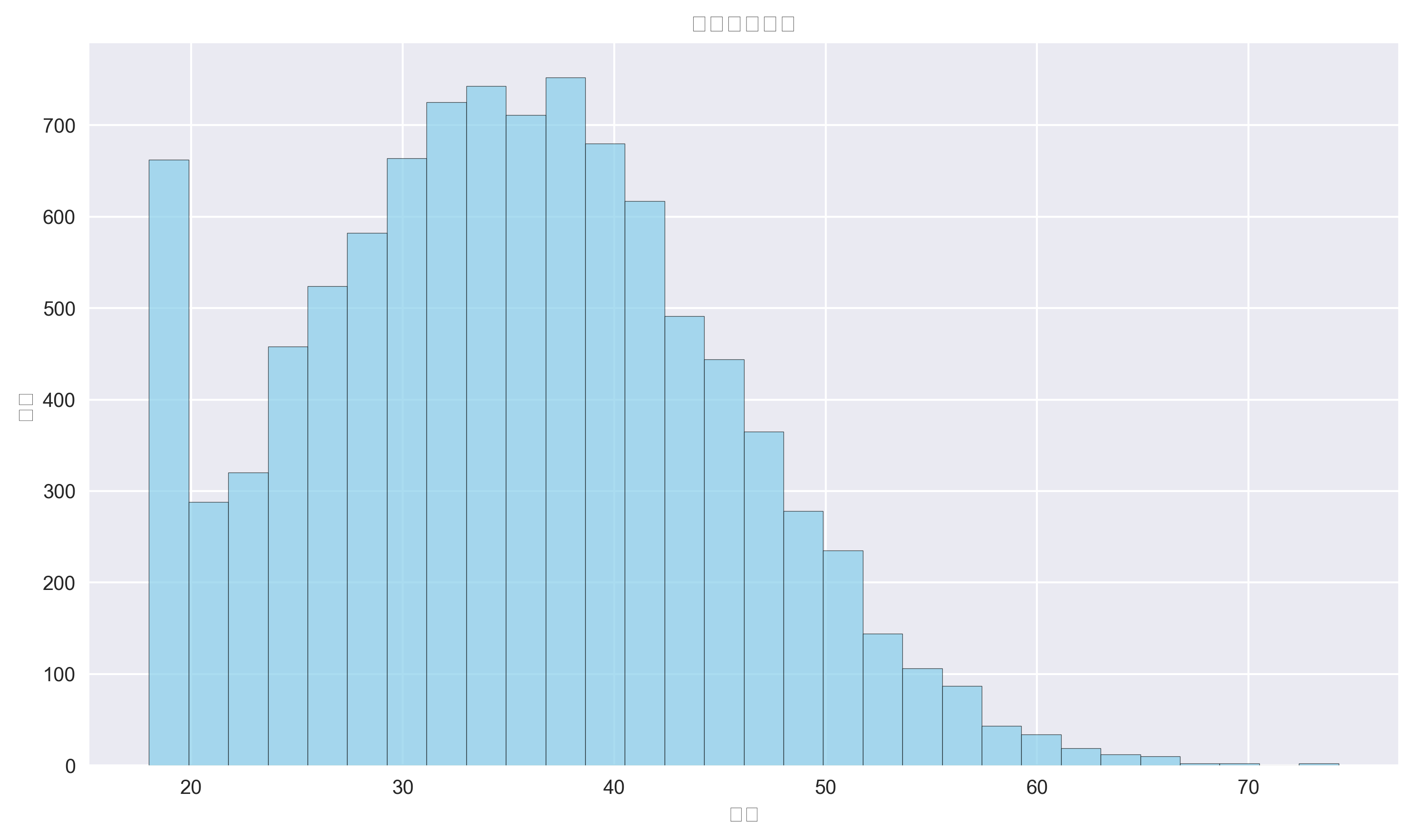
数据洞察: 客户年龄主要分布在25-45岁之间,这是信贷业务的主要目标群体。
收入分布

数据洞察: 客户年收入主要集中在较低水平,符合一般信贷客户群体特征。
信用评分分布

数据洞察: 信用评分分布较为均匀,涵盖了从较差到优秀的各个等级。
违约与年龄关系
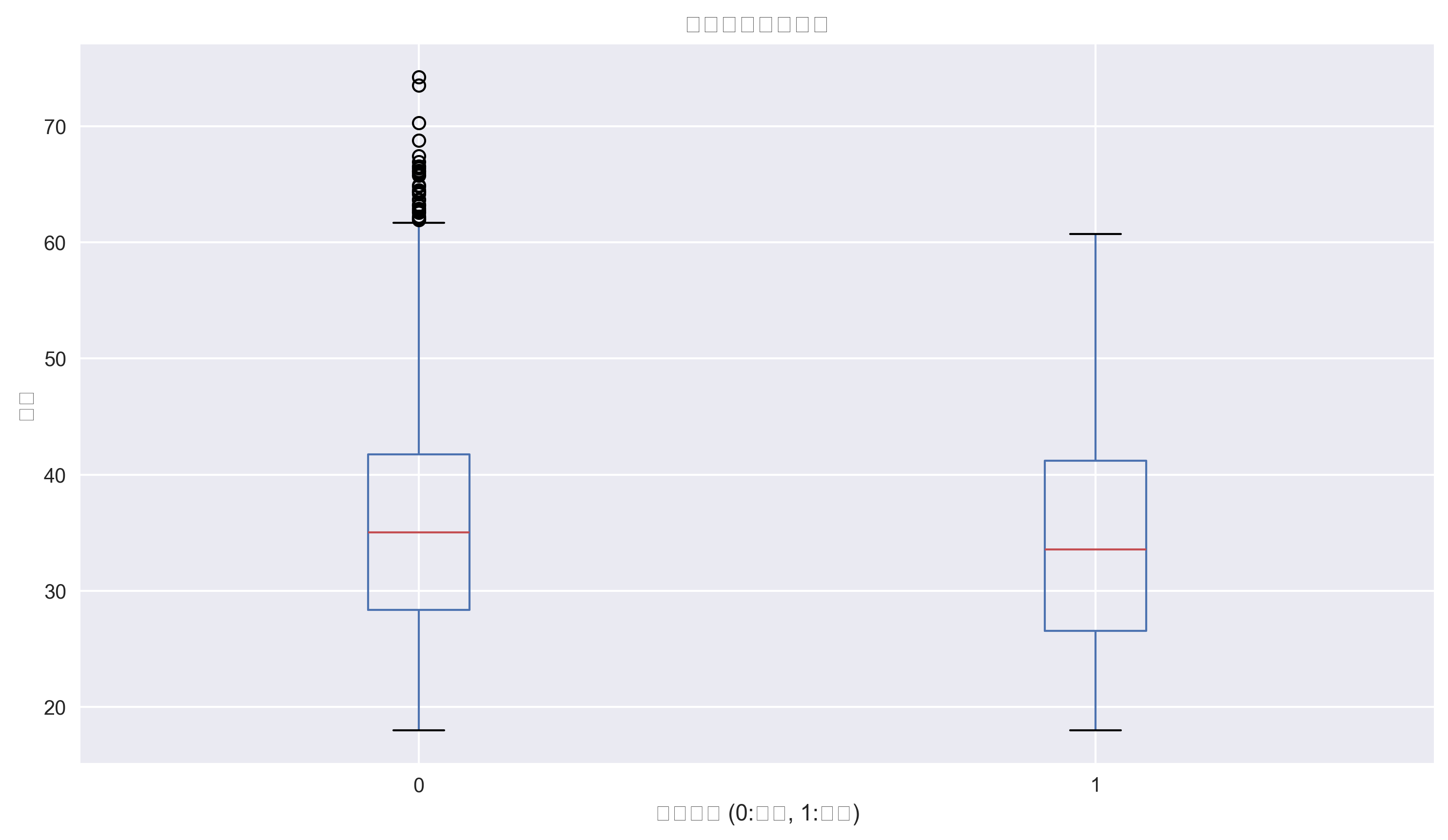
风险洞察: 年龄与违约风险之间没有明显的线性关系,说明需要综合其他特征进行判断。
违约与收入关系

风险洞察: 收入较高的客户违约风险相对较低,但并非绝对,仍需考虑其他因素。
违约与信用评分关系

风险洞察: 信用评分与违约风险呈明显负相关,信用评分越低,违约风险越高。
特征相关性
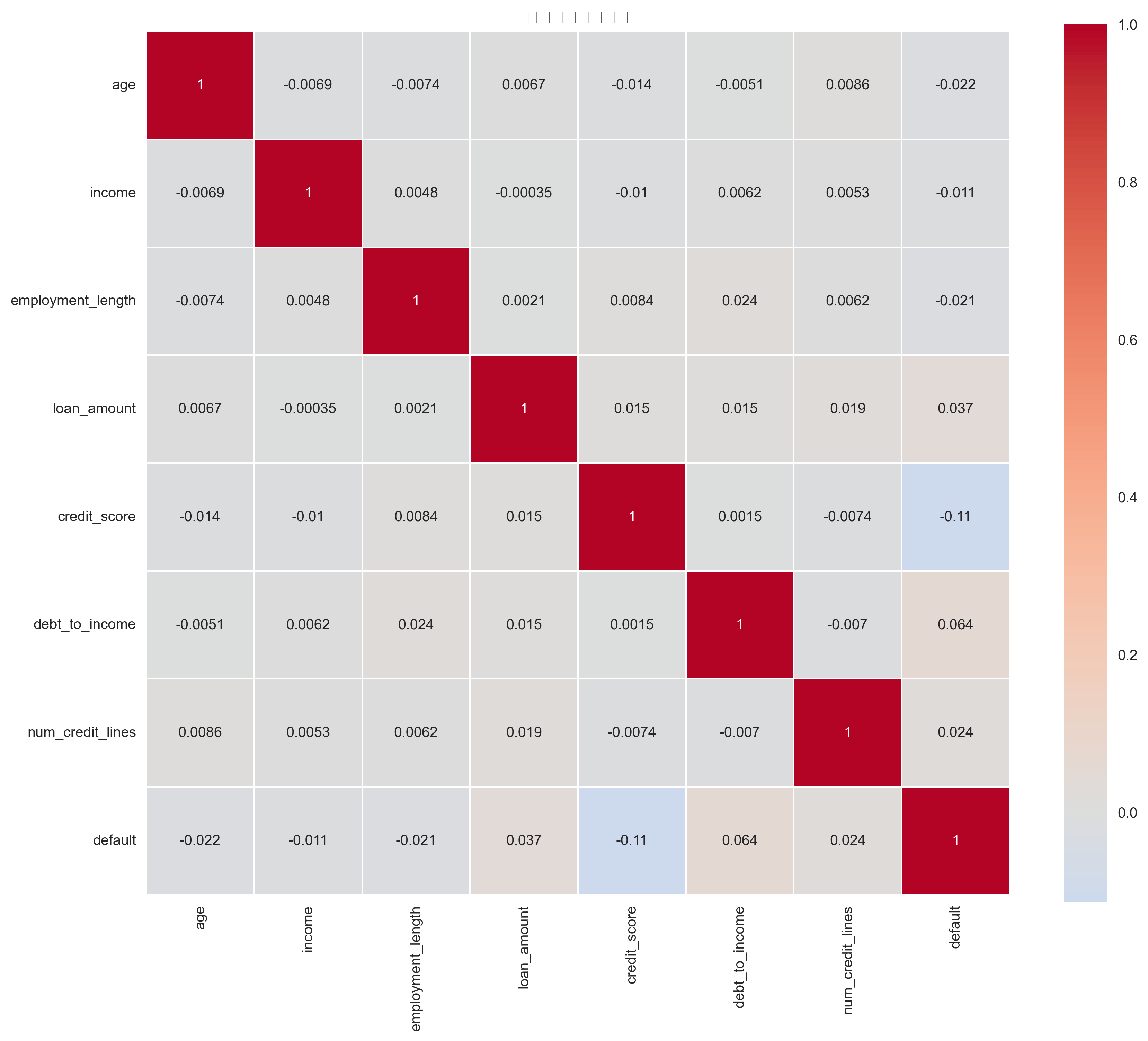
数据洞察: 多数特征之间相关性较低,说明特征具有较好的独立性,有利于模型训练。
教育水平与违约关系
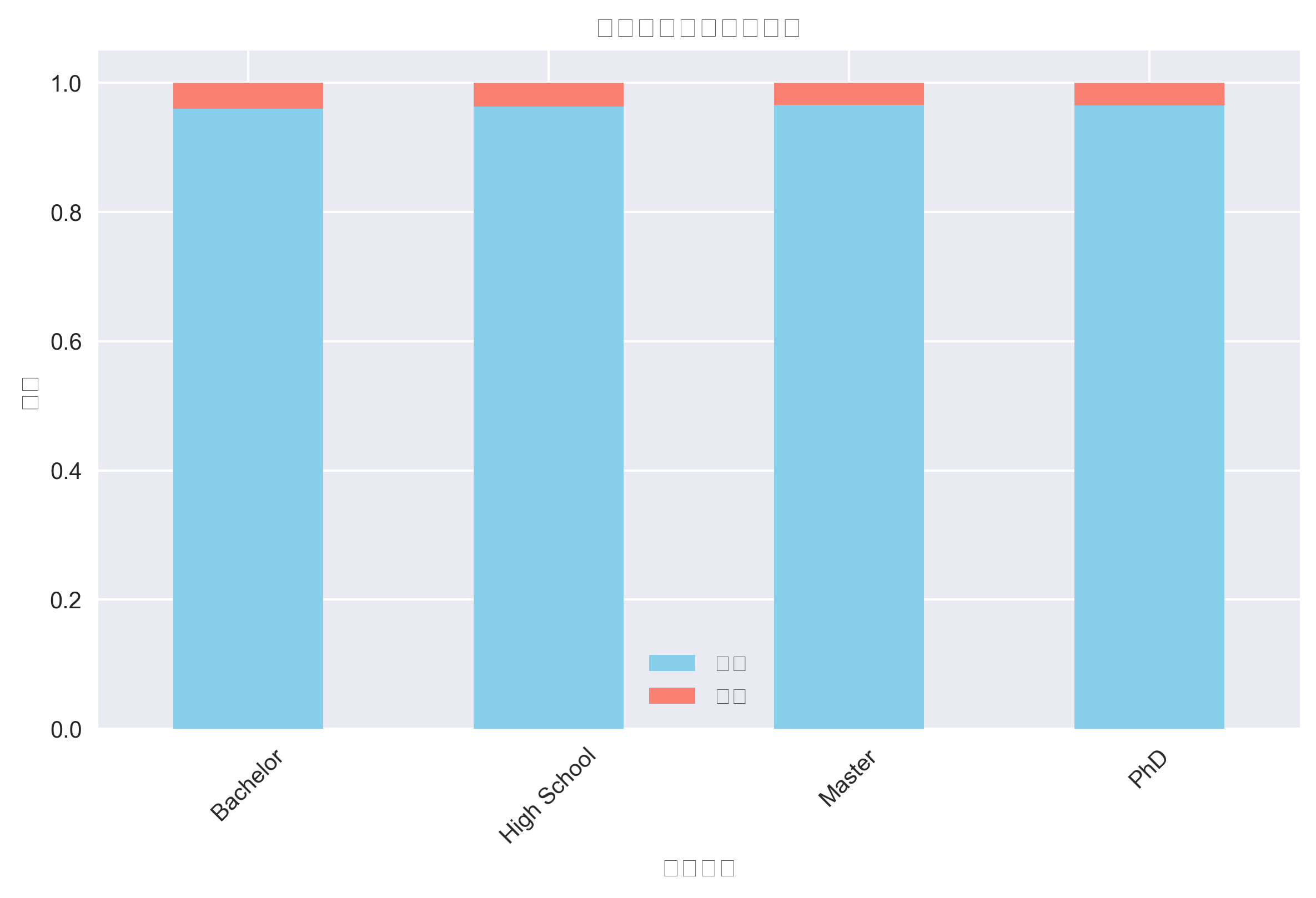
风险洞察: 教育水平较高的客户违约率相对较低,体现了教育对信用的影响。
房产情况与违约关系
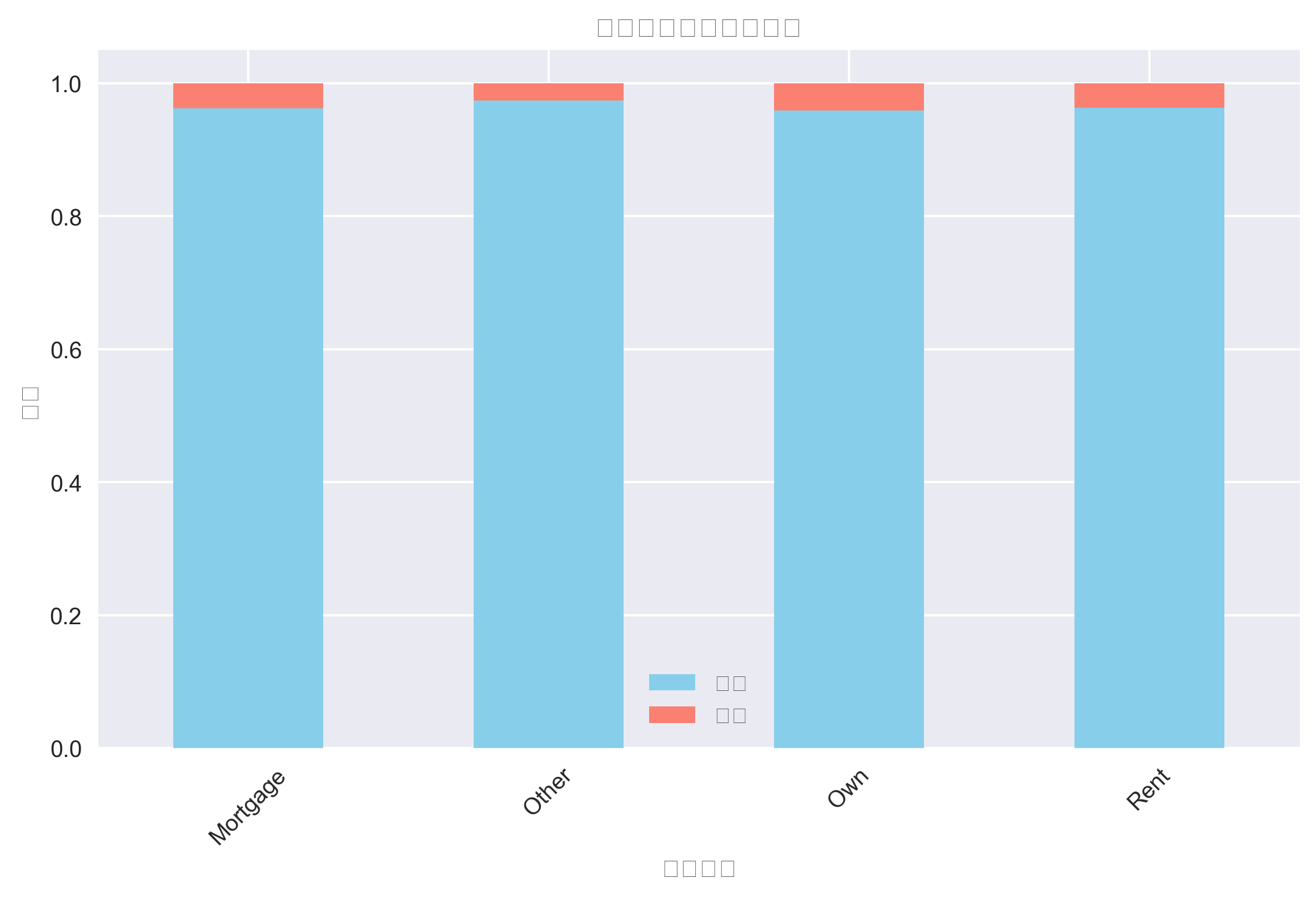
风险洞察: 拥有自有房产的客户违约率最低,租房客户的违约率相对较高。