+
+  +
+
+
+  +
+  +
+  +
+
+ +
+  +
+  +
+
+
+
+ +
+ +
+ YOLOv5🚀是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的公开研究,其中包含了在数千小时的研究和开发中所获得的经验和最佳实践。 +
+ + +
+
+
+
+
+ + YOLOv5🚀是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的公开研究,其中包含了在数千小时的研究和开发中所获得的经验和最佳实践。 +
+ + + +
+
+
+ +
+ +
+
+##
+
+
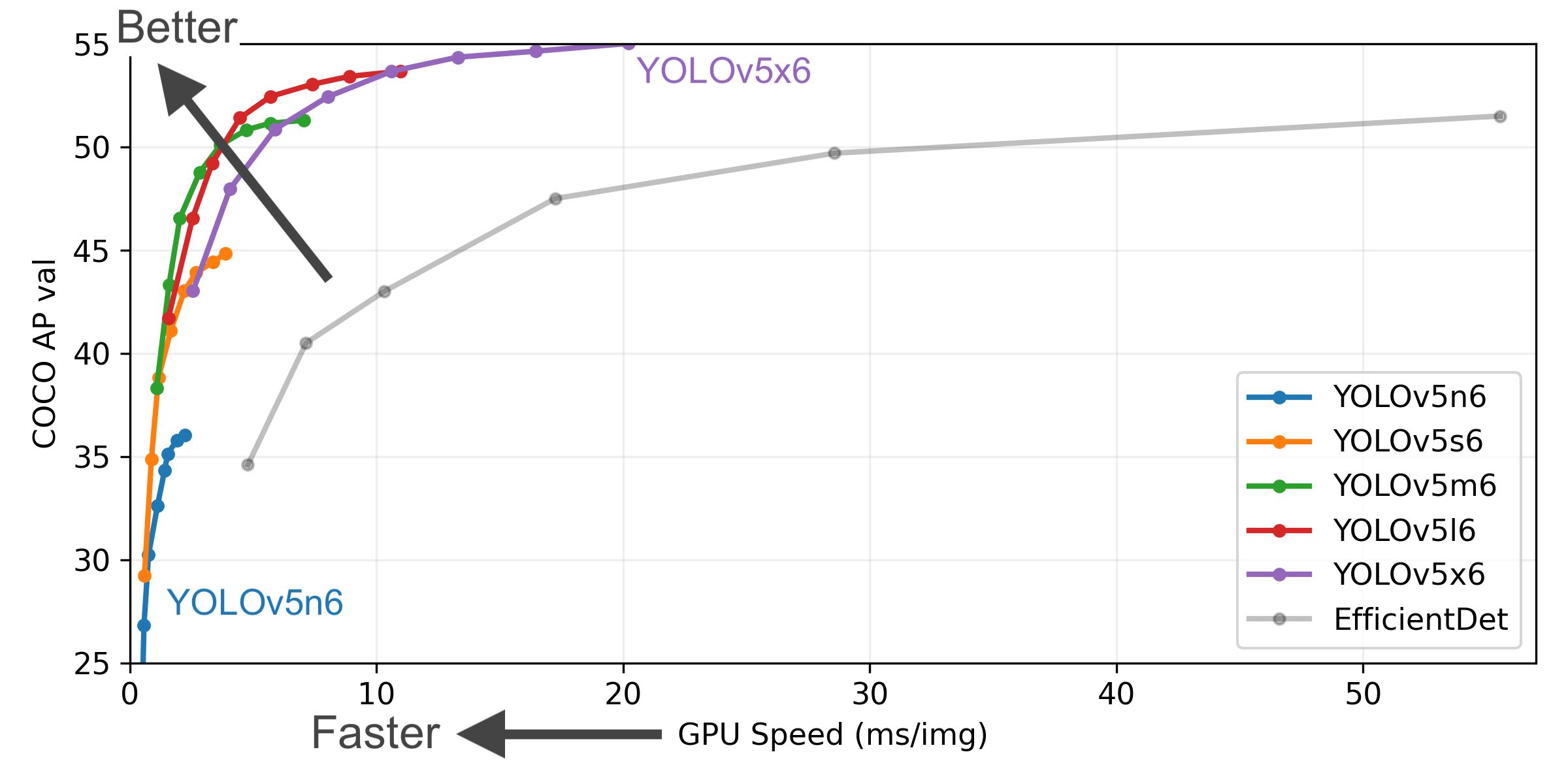
+## 
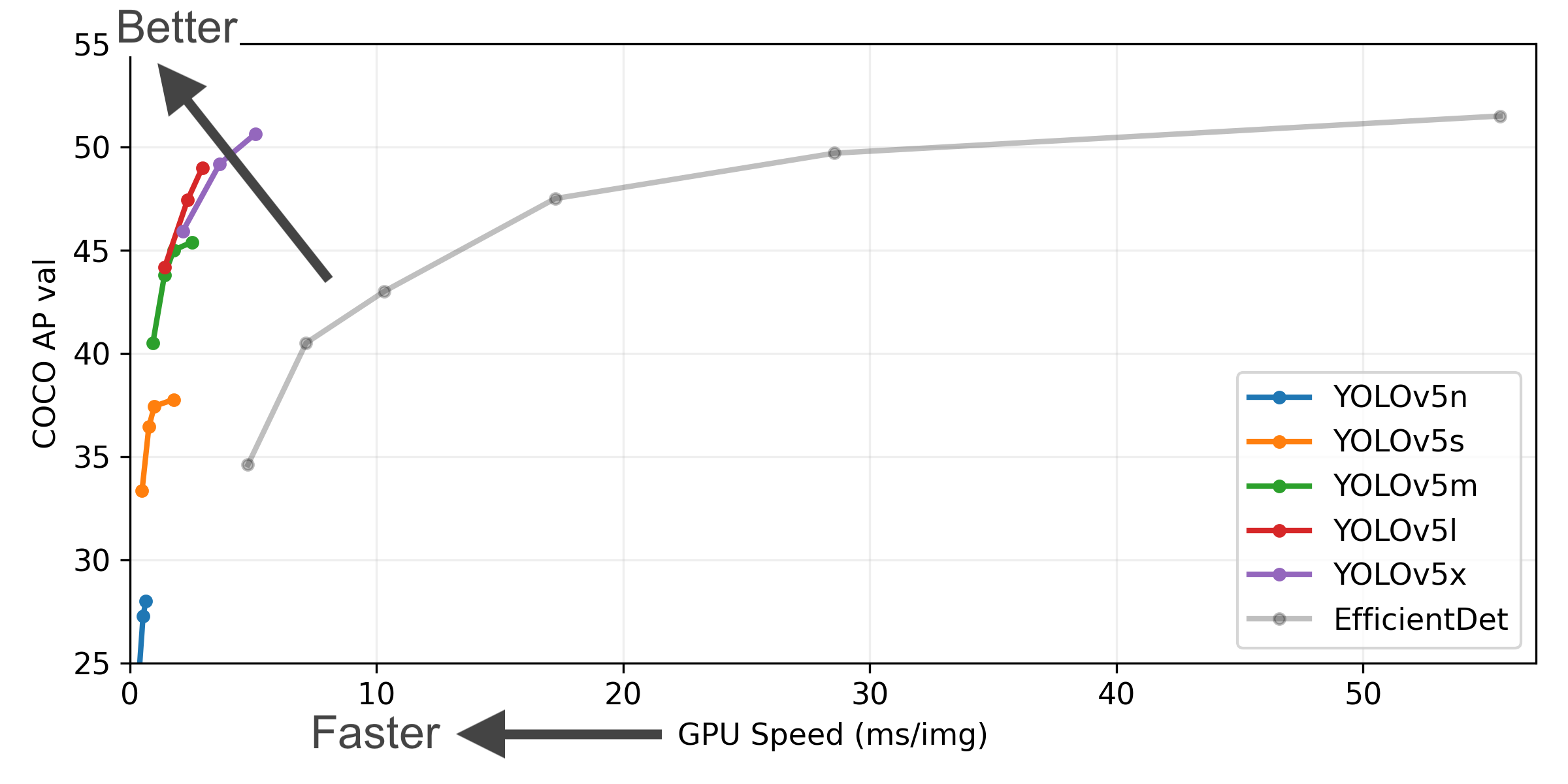
 +
+##
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+ - **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+ ## Status
+
+
+
+##
+ - **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+ - **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+ - **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+ ## Status
+
+ 
 +
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+
+
+## About ClearML
+
+[ClearML](https://cutt.ly/yolov5-tutorial-clearml) is an [open-source](https://github.com/allegroai/clearml) toolbox designed to save you time ⏱️.
+
+🔨 Track every YOLOv5 training run in the experiment manager
+
+🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+
+🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
+
+🔬 Get the very best mAP using ClearML Hyperparameter Optimization
+
+🔭 Turn your newly trained YOLOv5 model into an API with just a few commands using ClearML Serving
+
+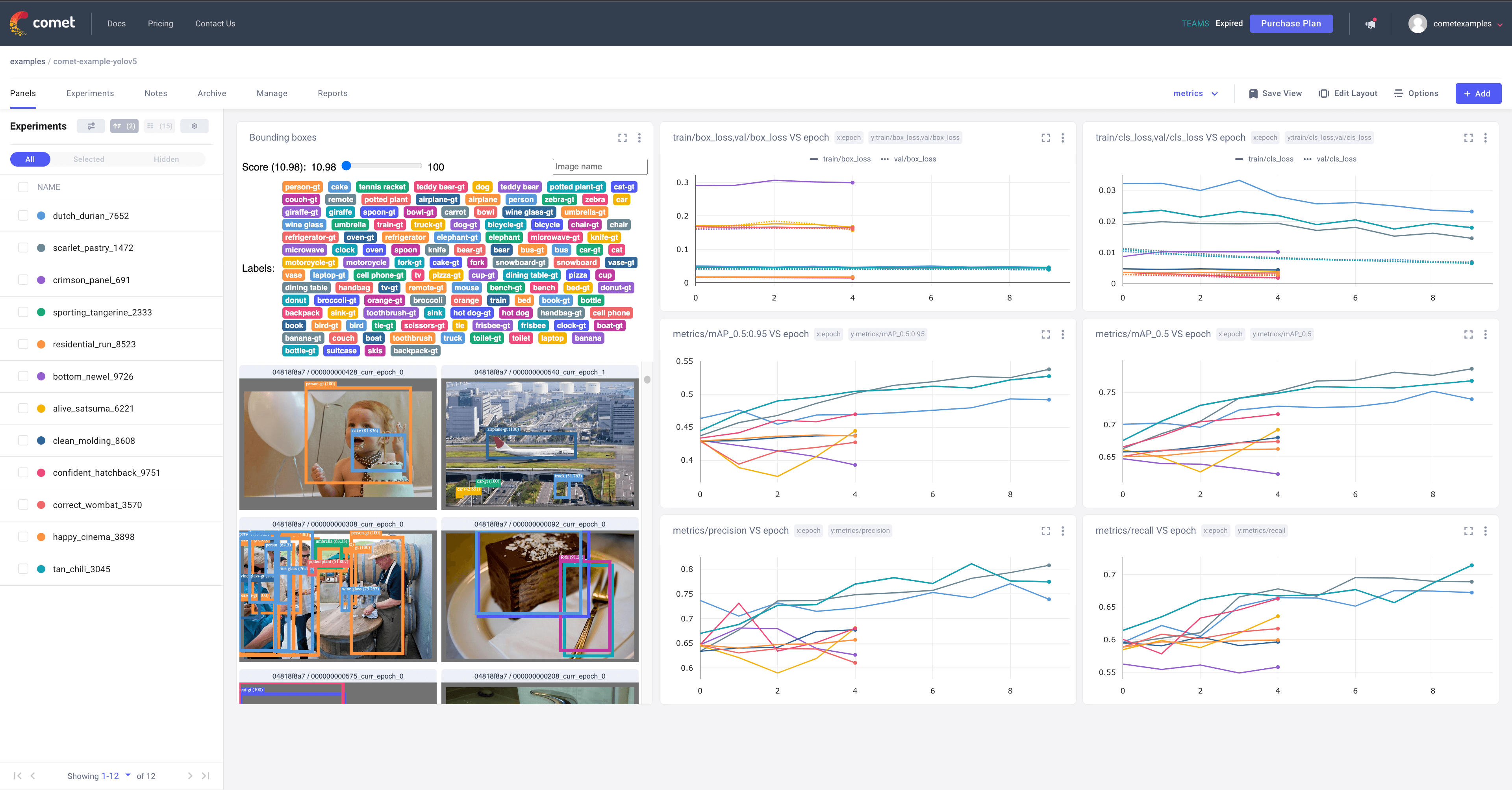 +
+# Try out an Example!
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME=
+
+# Try out an Example!
+Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
+
+Or better yet, try it out yourself in this Colab Notebook
+
+[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
+
+# Log automatically
+
+By default, Comet will log the following items
+
+## Metrics
+- Box Loss, Object Loss, Classification Loss for the training and validation data
+- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
+- Precision and Recall for the validation data
+
+## Parameters
+
+- Model Hyperparameters
+- All parameters passed through the command line options
+
+## Visualizations
+
+- Confusion Matrix of the model predictions on the validation data
+- Plots for the PR and F1 curves across all classes
+- Correlogram of the Class Labels
+
+# Configure Comet Logging
+
+Comet can be configured to log additional data either through command line flags passed to the training script
+or through environment variables.
+
+```shell
+export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
+export COMET_MODEL_NAME= +
+You can preview the data directly in the Comet UI.
+
+
+You can preview the data directly in the Comet UI.
+ +
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+
+
+Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
+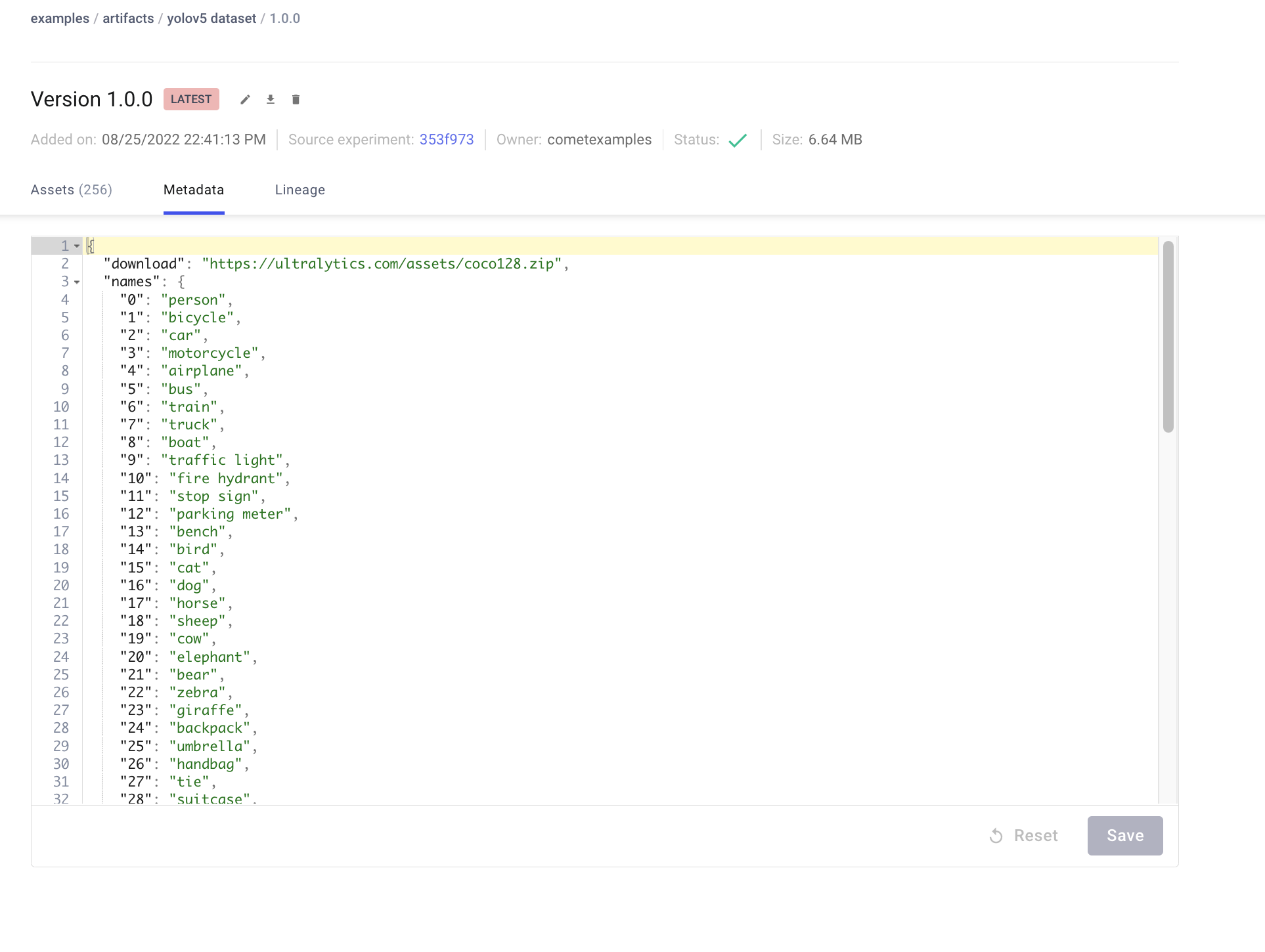 +
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet://
+
+### Using a saved Artifact
+
+If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
+
+```
+# contents of artifact.yaml file
+path: "comet:// +
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet://
+
+## Resuming a Training Run
+
+If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
+
+The Run Path has the following format `comet://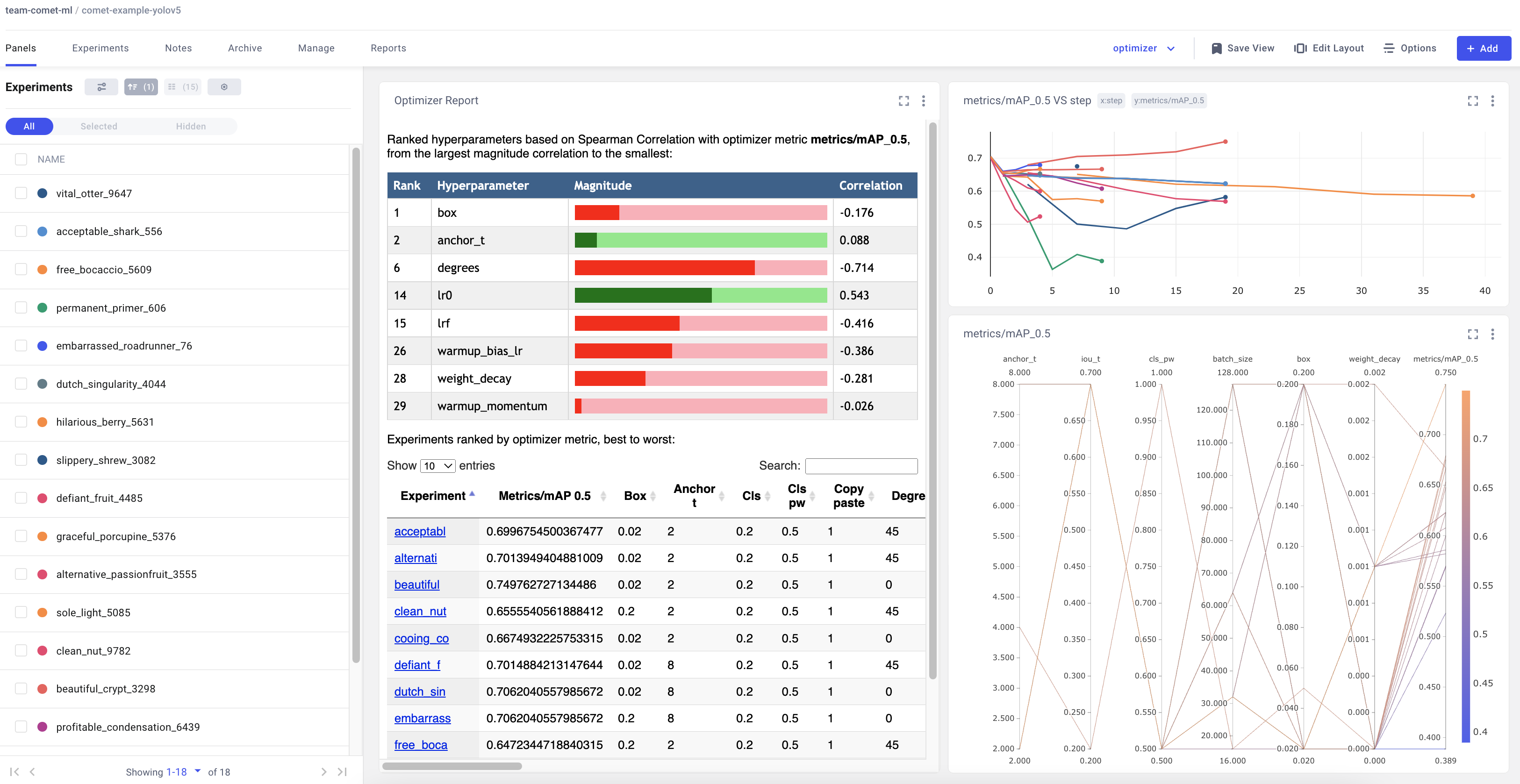 diff --git a/src/FireDetect/utils/loggers/comet/__init__.py b/src/FireDetect/utils/loggers/comet/__init__.py
new file mode 100644
index 0000000..b0318f8
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/__init__.py
@@ -0,0 +1,508 @@
+import glob
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+try:
+ import comet_ml
+
+ # Project Configuration
+ config = comet_ml.config.get_config()
+ COMET_PROJECT_NAME = config.get_string(os.getenv("COMET_PROJECT_NAME"), "comet.project_name", default="yolov5")
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+ COMET_PROJECT_NAME = None
+
+import PIL
+import torch
+import torchvision.transforms as T
+import yaml
+
+from utils.dataloaders import img2label_paths
+from utils.general import check_dataset, scale_boxes, xywh2xyxy
+from utils.metrics import box_iou
+
+COMET_PREFIX = "comet://"
+
+COMET_MODE = os.getenv("COMET_MODE", "online")
+
+# Model Saving Settings
+COMET_MODEL_NAME = os.getenv("COMET_MODEL_NAME", "yolov5")
+
+# Dataset Artifact Settings
+COMET_UPLOAD_DATASET = os.getenv("COMET_UPLOAD_DATASET", "false").lower() == "true"
+
+# Evaluation Settings
+COMET_LOG_CONFUSION_MATRIX = os.getenv("COMET_LOG_CONFUSION_MATRIX", "true").lower() == "true"
+COMET_LOG_PREDICTIONS = os.getenv("COMET_LOG_PREDICTIONS", "true").lower() == "true"
+COMET_MAX_IMAGE_UPLOADS = int(os.getenv("COMET_MAX_IMAGE_UPLOADS", 100))
+
+# Confusion Matrix Settings
+CONF_THRES = float(os.getenv("CONF_THRES", 0.001))
+IOU_THRES = float(os.getenv("IOU_THRES", 0.6))
+
+# Batch Logging Settings
+COMET_LOG_BATCH_METRICS = os.getenv("COMET_LOG_BATCH_METRICS", "false").lower() == "true"
+COMET_BATCH_LOGGING_INTERVAL = os.getenv("COMET_BATCH_LOGGING_INTERVAL", 1)
+COMET_PREDICTION_LOGGING_INTERVAL = os.getenv("COMET_PREDICTION_LOGGING_INTERVAL", 1)
+COMET_LOG_PER_CLASS_METRICS = os.getenv("COMET_LOG_PER_CLASS_METRICS", "false").lower() == "true"
+
+RANK = int(os.getenv("RANK", -1))
+
+to_pil = T.ToPILImage()
+
+
+class CometLogger:
+ """Log metrics, parameters, source code, models and much more
+ with Comet
+ """
+
+ def __init__(self, opt, hyp, run_id=None, job_type="Training", **experiment_kwargs) -> None:
+ self.job_type = job_type
+ self.opt = opt
+ self.hyp = hyp
+
+ # Comet Flags
+ self.comet_mode = COMET_MODE
+
+ self.save_model = opt.save_period > -1
+ self.model_name = COMET_MODEL_NAME
+
+ # Batch Logging Settings
+ self.log_batch_metrics = COMET_LOG_BATCH_METRICS
+ self.comet_log_batch_interval = COMET_BATCH_LOGGING_INTERVAL
+
+ # Dataset Artifact Settings
+ self.upload_dataset = self.opt.upload_dataset if self.opt.upload_dataset else COMET_UPLOAD_DATASET
+ self.resume = self.opt.resume
+
+ # Default parameters to pass to Experiment objects
+ self.default_experiment_kwargs = {
+ "log_code": False,
+ "log_env_gpu": True,
+ "log_env_cpu": True,
+ "project_name": COMET_PROJECT_NAME,}
+ self.default_experiment_kwargs.update(experiment_kwargs)
+ self.experiment = self._get_experiment(self.comet_mode, run_id)
+
+ self.data_dict = self.check_dataset(self.opt.data)
+ self.class_names = self.data_dict["names"]
+ self.num_classes = self.data_dict["nc"]
+
+ self.logged_images_count = 0
+ self.max_images = COMET_MAX_IMAGE_UPLOADS
+
+ if run_id is None:
+ self.experiment.log_other("Created from", "YOLOv5")
+ if not isinstance(self.experiment, comet_ml.OfflineExperiment):
+ workspace, project_name, experiment_id = self.experiment.url.split("/")[-3:]
+ self.experiment.log_other(
+ "Run Path",
+ f"{workspace}/{project_name}/{experiment_id}",
+ )
+ self.log_parameters(vars(opt))
+ self.log_parameters(self.opt.hyp)
+ self.log_asset_data(
+ self.opt.hyp,
+ name="hyperparameters.json",
+ metadata={"type": "hyp-config-file"},
+ )
+ self.log_asset(
+ f"{self.opt.save_dir}/opt.yaml",
+ metadata={"type": "opt-config-file"},
+ )
+
+ self.comet_log_confusion_matrix = COMET_LOG_CONFUSION_MATRIX
+
+ if hasattr(self.opt, "conf_thres"):
+ self.conf_thres = self.opt.conf_thres
+ else:
+ self.conf_thres = CONF_THRES
+ if hasattr(self.opt, "iou_thres"):
+ self.iou_thres = self.opt.iou_thres
+ else:
+ self.iou_thres = IOU_THRES
+
+ self.log_parameters({"val_iou_threshold": self.iou_thres, "val_conf_threshold": self.conf_thres})
+
+ self.comet_log_predictions = COMET_LOG_PREDICTIONS
+ if self.opt.bbox_interval == -1:
+ self.comet_log_prediction_interval = 1 if self.opt.epochs < 10 else self.opt.epochs // 10
+ else:
+ self.comet_log_prediction_interval = self.opt.bbox_interval
+
+ if self.comet_log_predictions:
+ self.metadata_dict = {}
+ self.logged_image_names = []
+
+ self.comet_log_per_class_metrics = COMET_LOG_PER_CLASS_METRICS
+
+ self.experiment.log_others({
+ "comet_mode": COMET_MODE,
+ "comet_max_image_uploads": COMET_MAX_IMAGE_UPLOADS,
+ "comet_log_per_class_metrics": COMET_LOG_PER_CLASS_METRICS,
+ "comet_log_batch_metrics": COMET_LOG_BATCH_METRICS,
+ "comet_log_confusion_matrix": COMET_LOG_CONFUSION_MATRIX,
+ "comet_model_name": COMET_MODEL_NAME,})
+
+ # Check if running the Experiment with the Comet Optimizer
+ if hasattr(self.opt, "comet_optimizer_id"):
+ self.experiment.log_other("optimizer_id", self.opt.comet_optimizer_id)
+ self.experiment.log_other("optimizer_objective", self.opt.comet_optimizer_objective)
+ self.experiment.log_other("optimizer_metric", self.opt.comet_optimizer_metric)
+ self.experiment.log_other("optimizer_parameters", json.dumps(self.hyp))
+
+ def _get_experiment(self, mode, experiment_id=None):
+ if mode == "offline":
+ if experiment_id is not None:
+ return comet_ml.ExistingOfflineExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.OfflineExperiment(**self.default_experiment_kwargs,)
+
+ else:
+ try:
+ if experiment_id is not None:
+ return comet_ml.ExistingExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.Experiment(**self.default_experiment_kwargs)
+
+ except ValueError:
+ logger.warning("COMET WARNING: "
+ "Comet credentials have not been set. "
+ "Comet will default to offline logging. "
+ "Please set your credentials to enable online logging.")
+ return self._get_experiment("offline", experiment_id)
+
+ return
+
+ def log_metrics(self, log_dict, **kwargs):
+ self.experiment.log_metrics(log_dict, **kwargs)
+
+ def log_parameters(self, log_dict, **kwargs):
+ self.experiment.log_parameters(log_dict, **kwargs)
+
+ def log_asset(self, asset_path, **kwargs):
+ self.experiment.log_asset(asset_path, **kwargs)
+
+ def log_asset_data(self, asset, **kwargs):
+ self.experiment.log_asset_data(asset, **kwargs)
+
+ def log_image(self, img, **kwargs):
+ self.experiment.log_image(img, **kwargs)
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ if not self.save_model:
+ return
+
+ model_metadata = {
+ "fitness_score": fitness_score[-1],
+ "epochs_trained": epoch + 1,
+ "save_period": opt.save_period,
+ "total_epochs": opt.epochs,}
+
+ model_files = glob.glob(f"{path}/*.pt")
+ for model_path in model_files:
+ name = Path(model_path).name
+
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ metadata=model_metadata,
+ overwrite=True,
+ )
+
+ def check_dataset(self, data_file):
+ with open(data_file) as f:
+ data_config = yaml.safe_load(f)
+
+ if data_config['path'].startswith(COMET_PREFIX):
+ path = data_config['path'].replace(COMET_PREFIX, "")
+ data_dict = self.download_dataset_artifact(path)
+
+ return data_dict
+
+ self.log_asset(self.opt.data, metadata={"type": "data-config-file"})
+
+ return check_dataset(data_file)
+
+ def log_predictions(self, image, labelsn, path, shape, predn):
+ if self.logged_images_count >= self.max_images:
+ return
+ detections = predn[predn[:, 4] > self.conf_thres]
+ iou = box_iou(labelsn[:, 1:], detections[:, :4])
+ mask, _ = torch.where(iou > self.iou_thres)
+ if len(mask) == 0:
+ return
+
+ filtered_detections = detections[mask]
+ filtered_labels = labelsn[mask]
+
+ image_id = path.split("/")[-1].split(".")[0]
+ image_name = f"{image_id}_curr_epoch_{self.experiment.curr_epoch}"
+ if image_name not in self.logged_image_names:
+ native_scale_image = PIL.Image.open(path)
+ self.log_image(native_scale_image, name=image_name)
+ self.logged_image_names.append(image_name)
+
+ metadata = []
+ for cls, *xyxy in filtered_labels.tolist():
+ metadata.append({
+ "label": f"{self.class_names[int(cls)]}-gt",
+ "score": 100,
+ "box": {
+ "x": xyxy[0],
+ "y": xyxy[1],
+ "x2": xyxy[2],
+ "y2": xyxy[3]},})
+ for *xyxy, conf, cls in filtered_detections.tolist():
+ metadata.append({
+ "label": f"{self.class_names[int(cls)]}",
+ "score": conf * 100,
+ "box": {
+ "x": xyxy[0],
+ "y": xyxy[1],
+ "x2": xyxy[2],
+ "y2": xyxy[3]},})
+
+ self.metadata_dict[image_name] = metadata
+ self.logged_images_count += 1
+
+ return
+
+ def preprocess_prediction(self, image, labels, shape, pred):
+ nl, _ = labels.shape[0], pred.shape[0]
+
+ # Predictions
+ if self.opt.single_cls:
+ pred[:, 5] = 0
+
+ predn = pred.clone()
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1])
+
+ labelsn = None
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(image.shape[1:], tbox, shape[0], shape[1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1]) # native-space pred
+
+ return predn, labelsn
+
+ def add_assets_to_artifact(self, artifact, path, asset_path, split):
+ img_paths = sorted(glob.glob(f"{asset_path}/*"))
+ label_paths = img2label_paths(img_paths)
+
+ for image_file, label_file in zip(img_paths, label_paths):
+ image_logical_path, label_logical_path = map(lambda x: os.path.relpath(x, path), [image_file, label_file])
+
+ try:
+ artifact.add(image_file, logical_path=image_logical_path, metadata={"split": split})
+ artifact.add(label_file, logical_path=label_logical_path, metadata={"split": split})
+ except ValueError as e:
+ logger.error('COMET ERROR: Error adding file to Artifact. Skipping file.')
+ logger.error(f"COMET ERROR: {e}")
+ continue
+
+ return artifact
+
+ def upload_dataset_artifact(self):
+ dataset_name = self.data_dict.get("dataset_name", "yolov5-dataset")
+ path = str((ROOT / Path(self.data_dict["path"])).resolve())
+
+ metadata = self.data_dict.copy()
+ for key in ["train", "val", "test"]:
+ split_path = metadata.get(key)
+ if split_path is not None:
+ metadata[key] = split_path.replace(path, "")
+
+ artifact = comet_ml.Artifact(name=dataset_name, artifact_type="dataset", metadata=metadata)
+ for key in metadata.keys():
+ if key in ["train", "val", "test"]:
+ if isinstance(self.upload_dataset, str) and (key != self.upload_dataset):
+ continue
+
+ asset_path = self.data_dict.get(key)
+ if asset_path is not None:
+ artifact = self.add_assets_to_artifact(artifact, path, asset_path, key)
+
+ self.experiment.log_artifact(artifact)
+
+ return
+
+ def download_dataset_artifact(self, artifact_path):
+ logged_artifact = self.experiment.get_artifact(artifact_path)
+ artifact_save_dir = str(Path(self.opt.save_dir) / logged_artifact.name)
+ logged_artifact.download(artifact_save_dir)
+
+ metadata = logged_artifact.metadata
+ data_dict = metadata.copy()
+ data_dict["path"] = artifact_save_dir
+
+ metadata_names = metadata.get("names")
+ if type(metadata_names) == dict:
+ data_dict["names"] = {int(k): v for k, v in metadata.get("names").items()}
+ elif type(metadata_names) == list:
+ data_dict["names"] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
+
+ data_dict = self.update_data_paths(data_dict)
+ return data_dict
+
+ def update_data_paths(self, data_dict):
+ path = data_dict.get("path", "")
+
+ for split in ["train", "val", "test"]:
+ if data_dict.get(split):
+ split_path = data_dict.get(split)
+ data_dict[split] = (f"{path}/{split_path}" if isinstance(split, str) else [
+ f"{path}/{x}" for x in split_path])
+
+ return data_dict
+
+ def on_pretrain_routine_end(self, paths):
+ if self.opt.resume:
+ return
+
+ for path in paths:
+ self.log_asset(str(path))
+
+ if self.upload_dataset:
+ if not self.resume:
+ self.upload_dataset_artifact()
+
+ return
+
+ def on_train_start(self):
+ self.log_parameters(self.hyp)
+
+ def on_train_epoch_start(self):
+ return
+
+ def on_train_epoch_end(self, epoch):
+ self.experiment.curr_epoch = epoch
+
+ return
+
+ def on_train_batch_start(self):
+ return
+
+ def on_train_batch_end(self, log_dict, step):
+ self.experiment.curr_step = step
+ if self.log_batch_metrics and (step % self.comet_log_batch_interval == 0):
+ self.log_metrics(log_dict, step=step)
+
+ return
+
+ def on_train_end(self, files, save_dir, last, best, epoch, results):
+ if self.comet_log_predictions:
+ curr_epoch = self.experiment.curr_epoch
+ self.experiment.log_asset_data(self.metadata_dict, "image-metadata.json", epoch=curr_epoch)
+
+ for f in files:
+ self.log_asset(f, metadata={"epoch": epoch})
+ self.log_asset(f"{save_dir}/results.csv", metadata={"epoch": epoch})
+
+ if not self.opt.evolve:
+ model_path = str(best if best.exists() else last)
+ name = Path(model_path).name
+ if self.save_model:
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ overwrite=True,
+ )
+
+ # Check if running Experiment with Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ metric = results.get(self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_metric_value', metric)
+
+ self.finish_run()
+
+ def on_val_start(self):
+ return
+
+ def on_val_batch_start(self):
+ return
+
+ def on_val_batch_end(self, batch_i, images, targets, paths, shapes, outputs):
+ if not (self.comet_log_predictions and ((batch_i + 1) % self.comet_log_prediction_interval == 0)):
+ return
+
+ for si, pred in enumerate(outputs):
+ if len(pred) == 0:
+ continue
+
+ image = images[si]
+ labels = targets[targets[:, 0] == si, 1:]
+ shape = shapes[si]
+ path = paths[si]
+ predn, labelsn = self.preprocess_prediction(image, labels, shape, pred)
+ if labelsn is not None:
+ self.log_predictions(image, labelsn, path, shape, predn)
+
+ return
+
+ def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
+ if self.comet_log_per_class_metrics:
+ if self.num_classes > 1:
+ for i, c in enumerate(ap_class):
+ class_name = self.class_names[c]
+ self.experiment.log_metrics(
+ {
+ 'mAP@.5': ap50[i],
+ 'mAP@.5:.95': ap[i],
+ 'precision': p[i],
+ 'recall': r[i],
+ 'f1': f1[i],
+ 'true_positives': tp[i],
+ 'false_positives': fp[i],
+ 'support': nt[c]},
+ prefix=class_name)
+
+ if self.comet_log_confusion_matrix:
+ epoch = self.experiment.curr_epoch
+ class_names = list(self.class_names.values())
+ class_names.append("background")
+ num_classes = len(class_names)
+
+ self.experiment.log_confusion_matrix(
+ matrix=confusion_matrix.matrix,
+ max_categories=num_classes,
+ labels=class_names,
+ epoch=epoch,
+ column_label='Actual Category',
+ row_label='Predicted Category',
+ file_name=f"confusion-matrix-epoch-{epoch}.json",
+ )
+
+ def on_fit_epoch_end(self, result, epoch):
+ self.log_metrics(result, epoch=epoch)
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ def on_params_update(self, params):
+ self.log_parameters(params)
+
+ def finish_run(self):
+ self.experiment.end()
diff --git a/src/FireDetect/utils/loggers/comet/comet_utils.py b/src/FireDetect/utils/loggers/comet/comet_utils.py
new file mode 100644
index 0000000..3cbd451
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/comet_utils.py
@@ -0,0 +1,150 @@
+import logging
+import os
+from urllib.parse import urlparse
+
+try:
+ import comet_ml
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+
+import yaml
+
+logger = logging.getLogger(__name__)
+
+COMET_PREFIX = "comet://"
+COMET_MODEL_NAME = os.getenv("COMET_MODEL_NAME", "yolov5")
+COMET_DEFAULT_CHECKPOINT_FILENAME = os.getenv("COMET_DEFAULT_CHECKPOINT_FILENAME", "last.pt")
+
+
+def download_model_checkpoint(opt, experiment):
+ model_dir = f"{opt.project}/{experiment.name}"
+ os.makedirs(model_dir, exist_ok=True)
+
+ model_name = COMET_MODEL_NAME
+ model_asset_list = experiment.get_model_asset_list(model_name)
+
+ if len(model_asset_list) == 0:
+ logger.error(f"COMET ERROR: No checkpoints found for model name : {model_name}")
+ return
+
+ model_asset_list = sorted(
+ model_asset_list,
+ key=lambda x: x["step"],
+ reverse=True,
+ )
+ logged_checkpoint_map = {asset["fileName"]: asset["assetId"] for asset in model_asset_list}
+
+ resource_url = urlparse(opt.weights)
+ checkpoint_filename = resource_url.query
+
+ if checkpoint_filename:
+ asset_id = logged_checkpoint_map.get(checkpoint_filename)
+ else:
+ asset_id = logged_checkpoint_map.get(COMET_DEFAULT_CHECKPOINT_FILENAME)
+ checkpoint_filename = COMET_DEFAULT_CHECKPOINT_FILENAME
+
+ if asset_id is None:
+ logger.error(f"COMET ERROR: Checkpoint {checkpoint_filename} not found in the given Experiment")
+ return
+
+ try:
+ logger.info(f"COMET INFO: Downloading checkpoint {checkpoint_filename}")
+ asset_filename = checkpoint_filename
+
+ model_binary = experiment.get_asset(asset_id, return_type="binary", stream=False)
+ model_download_path = f"{model_dir}/{asset_filename}"
+ with open(model_download_path, "wb") as f:
+ f.write(model_binary)
+
+ opt.weights = model_download_path
+
+ except Exception as e:
+ logger.warning("COMET WARNING: Unable to download checkpoint from Comet")
+ logger.exception(e)
+
+
+def set_opt_parameters(opt, experiment):
+ """Update the opts Namespace with parameters
+ from Comet's ExistingExperiment when resuming a run
+
+ Args:
+ opt (argparse.Namespace): Namespace of command line options
+ experiment (comet_ml.APIExperiment): Comet API Experiment object
+ """
+ asset_list = experiment.get_asset_list()
+ resume_string = opt.resume
+
+ for asset in asset_list:
+ if asset["fileName"] == "opt.yaml":
+ asset_id = asset["assetId"]
+ asset_binary = experiment.get_asset(asset_id, return_type="binary", stream=False)
+ opt_dict = yaml.safe_load(asset_binary)
+ for key, value in opt_dict.items():
+ setattr(opt, key, value)
+ opt.resume = resume_string
+
+ # Save hyperparameters to YAML file
+ # Necessary to pass checks in training script
+ save_dir = f"{opt.project}/{experiment.name}"
+ os.makedirs(save_dir, exist_ok=True)
+
+ hyp_yaml_path = f"{save_dir}/hyp.yaml"
+ with open(hyp_yaml_path, "w") as f:
+ yaml.dump(opt.hyp, f)
+ opt.hyp = hyp_yaml_path
+
+
+def check_comet_weights(opt):
+ """Downloads model weights from Comet and updates the
+ weights path to point to saved weights location
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if weights are successfully downloaded
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.weights, str):
+ if opt.weights.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.weights)
+ experiment_path = f"{resource.netloc}{resource.path}"
+ experiment = api.get(experiment_path)
+ download_model_checkpoint(opt, experiment)
+ return True
+
+ return None
+
+
+def check_comet_resume(opt):
+ """Restores run parameters to its original state based on the model checkpoint
+ and logged Experiment parameters.
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if the run is restored successfully
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.resume)
+ experiment_path = f"{resource.netloc}{resource.path}"
+ experiment = api.get(experiment_path)
+ set_opt_parameters(opt, experiment)
+ download_model_checkpoint(opt, experiment)
+
+ return True
+
+ return None
diff --git a/src/FireDetect/utils/loggers/comet/hpo.py b/src/FireDetect/utils/loggers/comet/hpo.py
new file mode 100644
index 0000000..7dd5c92
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/hpo.py
@@ -0,0 +1,118 @@
+import argparse
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+import comet_ml
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+# Project Configuration
+config = comet_ml.config.get_config()
+COMET_PROJECT_NAME = config.get_string(os.getenv("COMET_PROJECT_NAME"), "comet.project_name", default="yolov5")
+
+
+def get_args(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ # Comet Arguments
+ parser.add_argument("--comet_optimizer_config", type=str, help="Comet: Path to a Comet Optimizer Config File.")
+ parser.add_argument("--comet_optimizer_id", type=str, help="Comet: ID of the Comet Optimizer sweep.")
+ parser.add_argument("--comet_optimizer_objective", type=str, help="Comet: Set to 'minimize' or 'maximize'.")
+ parser.add_argument("--comet_optimizer_metric", type=str, help="Comet: Metric to Optimize.")
+ parser.add_argument("--comet_optimizer_workers",
+ type=int,
+ default=1,
+ help="Comet: Number of Parallel Workers to use with the Comet Optimizer.")
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def run(parameters, opt):
+ hyp_dict = {k: v for k, v in parameters.items() if k not in ["epochs", "batch_size"]}
+
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.batch_size = parameters.get("batch_size")
+ opt.epochs = parameters.get("epochs")
+
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ opt = get_args(known=True)
+
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.project = str(opt.project)
+
+ optimizer_id = os.getenv("COMET_OPTIMIZER_ID")
+ if optimizer_id is None:
+ with open(opt.comet_optimizer_config) as f:
+ optimizer_config = json.load(f)
+ optimizer = comet_ml.Optimizer(optimizer_config)
+ else:
+ optimizer = comet_ml.Optimizer(optimizer_id)
+
+ opt.comet_optimizer_id = optimizer.id
+ status = optimizer.status()
+
+ opt.comet_optimizer_objective = status["spec"]["objective"]
+ opt.comet_optimizer_metric = status["spec"]["metric"]
+
+ logger.info("COMET INFO: Starting Hyperparameter Sweep")
+ for parameter in optimizer.get_parameters():
+ run(parameter["parameters"], opt)
diff --git a/src/FireDetect/utils/loggers/comet/optimizer_config.json b/src/FireDetect/utils/loggers/comet/optimizer_config.json
new file mode 100644
index 0000000..83dddda
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/optimizer_config.json
@@ -0,0 +1,209 @@
+{
+ "algorithm": "random",
+ "parameters": {
+ "anchor_t": {
+ "type": "discrete",
+ "values": [
+ 2,
+ 8
+ ]
+ },
+ "batch_size": {
+ "type": "discrete",
+ "values": [
+ 16,
+ 32,
+ 64
+ ]
+ },
+ "box": {
+ "type": "discrete",
+ "values": [
+ 0.02,
+ 0.2
+ ]
+ },
+ "cls": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "cls_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "copy_paste": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "degrees": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 45
+ ]
+ },
+ "epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "fl_gamma": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "fliplr": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "flipud": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_h": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_s": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_v": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "iou_t": {
+ "type": "discrete",
+ "values": [
+ 0.7
+ ]
+ },
+ "lr0": {
+ "type": "discrete",
+ "values": [
+ 1e-05,
+ 0.1
+ ]
+ },
+ "lrf": {
+ "type": "discrete",
+ "values": [
+ 0.01,
+ 1
+ ]
+ },
+ "mixup": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "momentum": {
+ "type": "discrete",
+ "values": [
+ 0.6
+ ]
+ },
+ "mosaic": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "obj": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "obj_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "optimizer": {
+ "type": "categorical",
+ "values": [
+ "SGD",
+ "Adam",
+ "AdamW"
+ ]
+ },
+ "perspective": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "scale": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "shear": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "translate": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "warmup_bias_lr": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.2
+ ]
+ },
+ "warmup_epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "warmup_momentum": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.95
+ ]
+ },
+ "weight_decay": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.001
+ ]
+ }
+ },
+ "spec": {
+ "maxCombo": 0,
+ "metric": "metrics/mAP_0.5",
+ "objective": "maximize"
+ },
+ "trials": 1
+}
diff --git a/src/FireDetect/utils/loggers/wandb/README.md b/src/FireDetect/utils/loggers/wandb/README.md
new file mode 100644
index 0000000..d78324b
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/README.md
@@ -0,0 +1,162 @@
+📚 This guide explains how to use **Weights & Biases** (W&B) with YOLOv5 🚀. UPDATED 29 September 2021.
+
+- [About Weights & Biases](#about-weights-&-biases)
+- [First-Time Setup](#first-time-setup)
+- [Viewing runs](#viewing-runs)
+- [Disabling wandb](#disabling-wandb)
+- [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
+- [Reports: Share your work with the world!](#reports)
+
+## About Weights & Biases
+
+Think of [W&B](https://wandb.ai/site?utm_campaign=repo_yolo_wandbtutorial) like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models — architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
+
+Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
+
+- [Debug](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Free-2) model performance in real time
+- [GPU usage](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#System-4) visualized automatically
+- [Custom charts](https://wandb.ai/wandb/customizable-charts/reports/Powerful-Custom-Charts-To-Debug-Model-Peformance--VmlldzoyNzY4ODI) for powerful, extensible visualization
+- [Share insights](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Share-8) interactively with collaborators
+- [Optimize hyperparameters](https://docs.wandb.com/sweeps) efficiently
+- [Track](https://docs.wandb.com/artifacts) datasets, pipelines, and production models
+
+## First-Time Setup
+
+
+
diff --git a/src/FireDetect/utils/loggers/comet/__init__.py b/src/FireDetect/utils/loggers/comet/__init__.py
new file mode 100644
index 0000000..b0318f8
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/__init__.py
@@ -0,0 +1,508 @@
+import glob
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+try:
+ import comet_ml
+
+ # Project Configuration
+ config = comet_ml.config.get_config()
+ COMET_PROJECT_NAME = config.get_string(os.getenv("COMET_PROJECT_NAME"), "comet.project_name", default="yolov5")
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+ COMET_PROJECT_NAME = None
+
+import PIL
+import torch
+import torchvision.transforms as T
+import yaml
+
+from utils.dataloaders import img2label_paths
+from utils.general import check_dataset, scale_boxes, xywh2xyxy
+from utils.metrics import box_iou
+
+COMET_PREFIX = "comet://"
+
+COMET_MODE = os.getenv("COMET_MODE", "online")
+
+# Model Saving Settings
+COMET_MODEL_NAME = os.getenv("COMET_MODEL_NAME", "yolov5")
+
+# Dataset Artifact Settings
+COMET_UPLOAD_DATASET = os.getenv("COMET_UPLOAD_DATASET", "false").lower() == "true"
+
+# Evaluation Settings
+COMET_LOG_CONFUSION_MATRIX = os.getenv("COMET_LOG_CONFUSION_MATRIX", "true").lower() == "true"
+COMET_LOG_PREDICTIONS = os.getenv("COMET_LOG_PREDICTIONS", "true").lower() == "true"
+COMET_MAX_IMAGE_UPLOADS = int(os.getenv("COMET_MAX_IMAGE_UPLOADS", 100))
+
+# Confusion Matrix Settings
+CONF_THRES = float(os.getenv("CONF_THRES", 0.001))
+IOU_THRES = float(os.getenv("IOU_THRES", 0.6))
+
+# Batch Logging Settings
+COMET_LOG_BATCH_METRICS = os.getenv("COMET_LOG_BATCH_METRICS", "false").lower() == "true"
+COMET_BATCH_LOGGING_INTERVAL = os.getenv("COMET_BATCH_LOGGING_INTERVAL", 1)
+COMET_PREDICTION_LOGGING_INTERVAL = os.getenv("COMET_PREDICTION_LOGGING_INTERVAL", 1)
+COMET_LOG_PER_CLASS_METRICS = os.getenv("COMET_LOG_PER_CLASS_METRICS", "false").lower() == "true"
+
+RANK = int(os.getenv("RANK", -1))
+
+to_pil = T.ToPILImage()
+
+
+class CometLogger:
+ """Log metrics, parameters, source code, models and much more
+ with Comet
+ """
+
+ def __init__(self, opt, hyp, run_id=None, job_type="Training", **experiment_kwargs) -> None:
+ self.job_type = job_type
+ self.opt = opt
+ self.hyp = hyp
+
+ # Comet Flags
+ self.comet_mode = COMET_MODE
+
+ self.save_model = opt.save_period > -1
+ self.model_name = COMET_MODEL_NAME
+
+ # Batch Logging Settings
+ self.log_batch_metrics = COMET_LOG_BATCH_METRICS
+ self.comet_log_batch_interval = COMET_BATCH_LOGGING_INTERVAL
+
+ # Dataset Artifact Settings
+ self.upload_dataset = self.opt.upload_dataset if self.opt.upload_dataset else COMET_UPLOAD_DATASET
+ self.resume = self.opt.resume
+
+ # Default parameters to pass to Experiment objects
+ self.default_experiment_kwargs = {
+ "log_code": False,
+ "log_env_gpu": True,
+ "log_env_cpu": True,
+ "project_name": COMET_PROJECT_NAME,}
+ self.default_experiment_kwargs.update(experiment_kwargs)
+ self.experiment = self._get_experiment(self.comet_mode, run_id)
+
+ self.data_dict = self.check_dataset(self.opt.data)
+ self.class_names = self.data_dict["names"]
+ self.num_classes = self.data_dict["nc"]
+
+ self.logged_images_count = 0
+ self.max_images = COMET_MAX_IMAGE_UPLOADS
+
+ if run_id is None:
+ self.experiment.log_other("Created from", "YOLOv5")
+ if not isinstance(self.experiment, comet_ml.OfflineExperiment):
+ workspace, project_name, experiment_id = self.experiment.url.split("/")[-3:]
+ self.experiment.log_other(
+ "Run Path",
+ f"{workspace}/{project_name}/{experiment_id}",
+ )
+ self.log_parameters(vars(opt))
+ self.log_parameters(self.opt.hyp)
+ self.log_asset_data(
+ self.opt.hyp,
+ name="hyperparameters.json",
+ metadata={"type": "hyp-config-file"},
+ )
+ self.log_asset(
+ f"{self.opt.save_dir}/opt.yaml",
+ metadata={"type": "opt-config-file"},
+ )
+
+ self.comet_log_confusion_matrix = COMET_LOG_CONFUSION_MATRIX
+
+ if hasattr(self.opt, "conf_thres"):
+ self.conf_thres = self.opt.conf_thres
+ else:
+ self.conf_thres = CONF_THRES
+ if hasattr(self.opt, "iou_thres"):
+ self.iou_thres = self.opt.iou_thres
+ else:
+ self.iou_thres = IOU_THRES
+
+ self.log_parameters({"val_iou_threshold": self.iou_thres, "val_conf_threshold": self.conf_thres})
+
+ self.comet_log_predictions = COMET_LOG_PREDICTIONS
+ if self.opt.bbox_interval == -1:
+ self.comet_log_prediction_interval = 1 if self.opt.epochs < 10 else self.opt.epochs // 10
+ else:
+ self.comet_log_prediction_interval = self.opt.bbox_interval
+
+ if self.comet_log_predictions:
+ self.metadata_dict = {}
+ self.logged_image_names = []
+
+ self.comet_log_per_class_metrics = COMET_LOG_PER_CLASS_METRICS
+
+ self.experiment.log_others({
+ "comet_mode": COMET_MODE,
+ "comet_max_image_uploads": COMET_MAX_IMAGE_UPLOADS,
+ "comet_log_per_class_metrics": COMET_LOG_PER_CLASS_METRICS,
+ "comet_log_batch_metrics": COMET_LOG_BATCH_METRICS,
+ "comet_log_confusion_matrix": COMET_LOG_CONFUSION_MATRIX,
+ "comet_model_name": COMET_MODEL_NAME,})
+
+ # Check if running the Experiment with the Comet Optimizer
+ if hasattr(self.opt, "comet_optimizer_id"):
+ self.experiment.log_other("optimizer_id", self.opt.comet_optimizer_id)
+ self.experiment.log_other("optimizer_objective", self.opt.comet_optimizer_objective)
+ self.experiment.log_other("optimizer_metric", self.opt.comet_optimizer_metric)
+ self.experiment.log_other("optimizer_parameters", json.dumps(self.hyp))
+
+ def _get_experiment(self, mode, experiment_id=None):
+ if mode == "offline":
+ if experiment_id is not None:
+ return comet_ml.ExistingOfflineExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.OfflineExperiment(**self.default_experiment_kwargs,)
+
+ else:
+ try:
+ if experiment_id is not None:
+ return comet_ml.ExistingExperiment(
+ previous_experiment=experiment_id,
+ **self.default_experiment_kwargs,
+ )
+
+ return comet_ml.Experiment(**self.default_experiment_kwargs)
+
+ except ValueError:
+ logger.warning("COMET WARNING: "
+ "Comet credentials have not been set. "
+ "Comet will default to offline logging. "
+ "Please set your credentials to enable online logging.")
+ return self._get_experiment("offline", experiment_id)
+
+ return
+
+ def log_metrics(self, log_dict, **kwargs):
+ self.experiment.log_metrics(log_dict, **kwargs)
+
+ def log_parameters(self, log_dict, **kwargs):
+ self.experiment.log_parameters(log_dict, **kwargs)
+
+ def log_asset(self, asset_path, **kwargs):
+ self.experiment.log_asset(asset_path, **kwargs)
+
+ def log_asset_data(self, asset, **kwargs):
+ self.experiment.log_asset_data(asset, **kwargs)
+
+ def log_image(self, img, **kwargs):
+ self.experiment.log_image(img, **kwargs)
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ if not self.save_model:
+ return
+
+ model_metadata = {
+ "fitness_score": fitness_score[-1],
+ "epochs_trained": epoch + 1,
+ "save_period": opt.save_period,
+ "total_epochs": opt.epochs,}
+
+ model_files = glob.glob(f"{path}/*.pt")
+ for model_path in model_files:
+ name = Path(model_path).name
+
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ metadata=model_metadata,
+ overwrite=True,
+ )
+
+ def check_dataset(self, data_file):
+ with open(data_file) as f:
+ data_config = yaml.safe_load(f)
+
+ if data_config['path'].startswith(COMET_PREFIX):
+ path = data_config['path'].replace(COMET_PREFIX, "")
+ data_dict = self.download_dataset_artifact(path)
+
+ return data_dict
+
+ self.log_asset(self.opt.data, metadata={"type": "data-config-file"})
+
+ return check_dataset(data_file)
+
+ def log_predictions(self, image, labelsn, path, shape, predn):
+ if self.logged_images_count >= self.max_images:
+ return
+ detections = predn[predn[:, 4] > self.conf_thres]
+ iou = box_iou(labelsn[:, 1:], detections[:, :4])
+ mask, _ = torch.where(iou > self.iou_thres)
+ if len(mask) == 0:
+ return
+
+ filtered_detections = detections[mask]
+ filtered_labels = labelsn[mask]
+
+ image_id = path.split("/")[-1].split(".")[0]
+ image_name = f"{image_id}_curr_epoch_{self.experiment.curr_epoch}"
+ if image_name not in self.logged_image_names:
+ native_scale_image = PIL.Image.open(path)
+ self.log_image(native_scale_image, name=image_name)
+ self.logged_image_names.append(image_name)
+
+ metadata = []
+ for cls, *xyxy in filtered_labels.tolist():
+ metadata.append({
+ "label": f"{self.class_names[int(cls)]}-gt",
+ "score": 100,
+ "box": {
+ "x": xyxy[0],
+ "y": xyxy[1],
+ "x2": xyxy[2],
+ "y2": xyxy[3]},})
+ for *xyxy, conf, cls in filtered_detections.tolist():
+ metadata.append({
+ "label": f"{self.class_names[int(cls)]}",
+ "score": conf * 100,
+ "box": {
+ "x": xyxy[0],
+ "y": xyxy[1],
+ "x2": xyxy[2],
+ "y2": xyxy[3]},})
+
+ self.metadata_dict[image_name] = metadata
+ self.logged_images_count += 1
+
+ return
+
+ def preprocess_prediction(self, image, labels, shape, pred):
+ nl, _ = labels.shape[0], pred.shape[0]
+
+ # Predictions
+ if self.opt.single_cls:
+ pred[:, 5] = 0
+
+ predn = pred.clone()
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1])
+
+ labelsn = None
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(image.shape[1:], tbox, shape[0], shape[1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ scale_boxes(image.shape[1:], predn[:, :4], shape[0], shape[1]) # native-space pred
+
+ return predn, labelsn
+
+ def add_assets_to_artifact(self, artifact, path, asset_path, split):
+ img_paths = sorted(glob.glob(f"{asset_path}/*"))
+ label_paths = img2label_paths(img_paths)
+
+ for image_file, label_file in zip(img_paths, label_paths):
+ image_logical_path, label_logical_path = map(lambda x: os.path.relpath(x, path), [image_file, label_file])
+
+ try:
+ artifact.add(image_file, logical_path=image_logical_path, metadata={"split": split})
+ artifact.add(label_file, logical_path=label_logical_path, metadata={"split": split})
+ except ValueError as e:
+ logger.error('COMET ERROR: Error adding file to Artifact. Skipping file.')
+ logger.error(f"COMET ERROR: {e}")
+ continue
+
+ return artifact
+
+ def upload_dataset_artifact(self):
+ dataset_name = self.data_dict.get("dataset_name", "yolov5-dataset")
+ path = str((ROOT / Path(self.data_dict["path"])).resolve())
+
+ metadata = self.data_dict.copy()
+ for key in ["train", "val", "test"]:
+ split_path = metadata.get(key)
+ if split_path is not None:
+ metadata[key] = split_path.replace(path, "")
+
+ artifact = comet_ml.Artifact(name=dataset_name, artifact_type="dataset", metadata=metadata)
+ for key in metadata.keys():
+ if key in ["train", "val", "test"]:
+ if isinstance(self.upload_dataset, str) and (key != self.upload_dataset):
+ continue
+
+ asset_path = self.data_dict.get(key)
+ if asset_path is not None:
+ artifact = self.add_assets_to_artifact(artifact, path, asset_path, key)
+
+ self.experiment.log_artifact(artifact)
+
+ return
+
+ def download_dataset_artifact(self, artifact_path):
+ logged_artifact = self.experiment.get_artifact(artifact_path)
+ artifact_save_dir = str(Path(self.opt.save_dir) / logged_artifact.name)
+ logged_artifact.download(artifact_save_dir)
+
+ metadata = logged_artifact.metadata
+ data_dict = metadata.copy()
+ data_dict["path"] = artifact_save_dir
+
+ metadata_names = metadata.get("names")
+ if type(metadata_names) == dict:
+ data_dict["names"] = {int(k): v for k, v in metadata.get("names").items()}
+ elif type(metadata_names) == list:
+ data_dict["names"] = {int(k): v for k, v in zip(range(len(metadata_names)), metadata_names)}
+ else:
+ raise "Invalid 'names' field in dataset yaml file. Please use a list or dictionary"
+
+ data_dict = self.update_data_paths(data_dict)
+ return data_dict
+
+ def update_data_paths(self, data_dict):
+ path = data_dict.get("path", "")
+
+ for split in ["train", "val", "test"]:
+ if data_dict.get(split):
+ split_path = data_dict.get(split)
+ data_dict[split] = (f"{path}/{split_path}" if isinstance(split, str) else [
+ f"{path}/{x}" for x in split_path])
+
+ return data_dict
+
+ def on_pretrain_routine_end(self, paths):
+ if self.opt.resume:
+ return
+
+ for path in paths:
+ self.log_asset(str(path))
+
+ if self.upload_dataset:
+ if not self.resume:
+ self.upload_dataset_artifact()
+
+ return
+
+ def on_train_start(self):
+ self.log_parameters(self.hyp)
+
+ def on_train_epoch_start(self):
+ return
+
+ def on_train_epoch_end(self, epoch):
+ self.experiment.curr_epoch = epoch
+
+ return
+
+ def on_train_batch_start(self):
+ return
+
+ def on_train_batch_end(self, log_dict, step):
+ self.experiment.curr_step = step
+ if self.log_batch_metrics and (step % self.comet_log_batch_interval == 0):
+ self.log_metrics(log_dict, step=step)
+
+ return
+
+ def on_train_end(self, files, save_dir, last, best, epoch, results):
+ if self.comet_log_predictions:
+ curr_epoch = self.experiment.curr_epoch
+ self.experiment.log_asset_data(self.metadata_dict, "image-metadata.json", epoch=curr_epoch)
+
+ for f in files:
+ self.log_asset(f, metadata={"epoch": epoch})
+ self.log_asset(f"{save_dir}/results.csv", metadata={"epoch": epoch})
+
+ if not self.opt.evolve:
+ model_path = str(best if best.exists() else last)
+ name = Path(model_path).name
+ if self.save_model:
+ self.experiment.log_model(
+ self.model_name,
+ file_or_folder=model_path,
+ file_name=name,
+ overwrite=True,
+ )
+
+ # Check if running Experiment with Comet Optimizer
+ if hasattr(self.opt, 'comet_optimizer_id'):
+ metric = results.get(self.opt.comet_optimizer_metric)
+ self.experiment.log_other('optimizer_metric_value', metric)
+
+ self.finish_run()
+
+ def on_val_start(self):
+ return
+
+ def on_val_batch_start(self):
+ return
+
+ def on_val_batch_end(self, batch_i, images, targets, paths, shapes, outputs):
+ if not (self.comet_log_predictions and ((batch_i + 1) % self.comet_log_prediction_interval == 0)):
+ return
+
+ for si, pred in enumerate(outputs):
+ if len(pred) == 0:
+ continue
+
+ image = images[si]
+ labels = targets[targets[:, 0] == si, 1:]
+ shape = shapes[si]
+ path = paths[si]
+ predn, labelsn = self.preprocess_prediction(image, labels, shape, pred)
+ if labelsn is not None:
+ self.log_predictions(image, labelsn, path, shape, predn)
+
+ return
+
+ def on_val_end(self, nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix):
+ if self.comet_log_per_class_metrics:
+ if self.num_classes > 1:
+ for i, c in enumerate(ap_class):
+ class_name = self.class_names[c]
+ self.experiment.log_metrics(
+ {
+ 'mAP@.5': ap50[i],
+ 'mAP@.5:.95': ap[i],
+ 'precision': p[i],
+ 'recall': r[i],
+ 'f1': f1[i],
+ 'true_positives': tp[i],
+ 'false_positives': fp[i],
+ 'support': nt[c]},
+ prefix=class_name)
+
+ if self.comet_log_confusion_matrix:
+ epoch = self.experiment.curr_epoch
+ class_names = list(self.class_names.values())
+ class_names.append("background")
+ num_classes = len(class_names)
+
+ self.experiment.log_confusion_matrix(
+ matrix=confusion_matrix.matrix,
+ max_categories=num_classes,
+ labels=class_names,
+ epoch=epoch,
+ column_label='Actual Category',
+ row_label='Predicted Category',
+ file_name=f"confusion-matrix-epoch-{epoch}.json",
+ )
+
+ def on_fit_epoch_end(self, result, epoch):
+ self.log_metrics(result, epoch=epoch)
+
+ def on_model_save(self, last, epoch, final_epoch, best_fitness, fi):
+ if ((epoch + 1) % self.opt.save_period == 0 and not final_epoch) and self.opt.save_period != -1:
+ self.log_model(last.parent, self.opt, epoch, fi, best_model=best_fitness == fi)
+
+ def on_params_update(self, params):
+ self.log_parameters(params)
+
+ def finish_run(self):
+ self.experiment.end()
diff --git a/src/FireDetect/utils/loggers/comet/comet_utils.py b/src/FireDetect/utils/loggers/comet/comet_utils.py
new file mode 100644
index 0000000..3cbd451
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/comet_utils.py
@@ -0,0 +1,150 @@
+import logging
+import os
+from urllib.parse import urlparse
+
+try:
+ import comet_ml
+except (ModuleNotFoundError, ImportError):
+ comet_ml = None
+
+import yaml
+
+logger = logging.getLogger(__name__)
+
+COMET_PREFIX = "comet://"
+COMET_MODEL_NAME = os.getenv("COMET_MODEL_NAME", "yolov5")
+COMET_DEFAULT_CHECKPOINT_FILENAME = os.getenv("COMET_DEFAULT_CHECKPOINT_FILENAME", "last.pt")
+
+
+def download_model_checkpoint(opt, experiment):
+ model_dir = f"{opt.project}/{experiment.name}"
+ os.makedirs(model_dir, exist_ok=True)
+
+ model_name = COMET_MODEL_NAME
+ model_asset_list = experiment.get_model_asset_list(model_name)
+
+ if len(model_asset_list) == 0:
+ logger.error(f"COMET ERROR: No checkpoints found for model name : {model_name}")
+ return
+
+ model_asset_list = sorted(
+ model_asset_list,
+ key=lambda x: x["step"],
+ reverse=True,
+ )
+ logged_checkpoint_map = {asset["fileName"]: asset["assetId"] for asset in model_asset_list}
+
+ resource_url = urlparse(opt.weights)
+ checkpoint_filename = resource_url.query
+
+ if checkpoint_filename:
+ asset_id = logged_checkpoint_map.get(checkpoint_filename)
+ else:
+ asset_id = logged_checkpoint_map.get(COMET_DEFAULT_CHECKPOINT_FILENAME)
+ checkpoint_filename = COMET_DEFAULT_CHECKPOINT_FILENAME
+
+ if asset_id is None:
+ logger.error(f"COMET ERROR: Checkpoint {checkpoint_filename} not found in the given Experiment")
+ return
+
+ try:
+ logger.info(f"COMET INFO: Downloading checkpoint {checkpoint_filename}")
+ asset_filename = checkpoint_filename
+
+ model_binary = experiment.get_asset(asset_id, return_type="binary", stream=False)
+ model_download_path = f"{model_dir}/{asset_filename}"
+ with open(model_download_path, "wb") as f:
+ f.write(model_binary)
+
+ opt.weights = model_download_path
+
+ except Exception as e:
+ logger.warning("COMET WARNING: Unable to download checkpoint from Comet")
+ logger.exception(e)
+
+
+def set_opt_parameters(opt, experiment):
+ """Update the opts Namespace with parameters
+ from Comet's ExistingExperiment when resuming a run
+
+ Args:
+ opt (argparse.Namespace): Namespace of command line options
+ experiment (comet_ml.APIExperiment): Comet API Experiment object
+ """
+ asset_list = experiment.get_asset_list()
+ resume_string = opt.resume
+
+ for asset in asset_list:
+ if asset["fileName"] == "opt.yaml":
+ asset_id = asset["assetId"]
+ asset_binary = experiment.get_asset(asset_id, return_type="binary", stream=False)
+ opt_dict = yaml.safe_load(asset_binary)
+ for key, value in opt_dict.items():
+ setattr(opt, key, value)
+ opt.resume = resume_string
+
+ # Save hyperparameters to YAML file
+ # Necessary to pass checks in training script
+ save_dir = f"{opt.project}/{experiment.name}"
+ os.makedirs(save_dir, exist_ok=True)
+
+ hyp_yaml_path = f"{save_dir}/hyp.yaml"
+ with open(hyp_yaml_path, "w") as f:
+ yaml.dump(opt.hyp, f)
+ opt.hyp = hyp_yaml_path
+
+
+def check_comet_weights(opt):
+ """Downloads model weights from Comet and updates the
+ weights path to point to saved weights location
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if weights are successfully downloaded
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.weights, str):
+ if opt.weights.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.weights)
+ experiment_path = f"{resource.netloc}{resource.path}"
+ experiment = api.get(experiment_path)
+ download_model_checkpoint(opt, experiment)
+ return True
+
+ return None
+
+
+def check_comet_resume(opt):
+ """Restores run parameters to its original state based on the model checkpoint
+ and logged Experiment parameters.
+
+ Args:
+ opt (argparse.Namespace): Command Line arguments passed
+ to YOLOv5 training script
+
+ Returns:
+ None/bool: Return True if the run is restored successfully
+ else return None
+ """
+ if comet_ml is None:
+ return
+
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(COMET_PREFIX):
+ api = comet_ml.API()
+ resource = urlparse(opt.resume)
+ experiment_path = f"{resource.netloc}{resource.path}"
+ experiment = api.get(experiment_path)
+ set_opt_parameters(opt, experiment)
+ download_model_checkpoint(opt, experiment)
+
+ return True
+
+ return None
diff --git a/src/FireDetect/utils/loggers/comet/hpo.py b/src/FireDetect/utils/loggers/comet/hpo.py
new file mode 100644
index 0000000..7dd5c92
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/hpo.py
@@ -0,0 +1,118 @@
+import argparse
+import json
+import logging
+import os
+import sys
+from pathlib import Path
+
+import comet_ml
+
+logger = logging.getLogger(__name__)
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+# Project Configuration
+config = comet_ml.config.get_config()
+COMET_PROJECT_NAME = config.get_string(os.getenv("COMET_PROJECT_NAME"), "comet.project_name", default="yolov5")
+
+
+def get_args(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300, help='total training epochs')
+ parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
+ parser.add_argument('--noplots', action='store_true', help='save no plot files')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--seed', type=int, default=0, help='Global training seed')
+ parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
+
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ # Comet Arguments
+ parser.add_argument("--comet_optimizer_config", type=str, help="Comet: Path to a Comet Optimizer Config File.")
+ parser.add_argument("--comet_optimizer_id", type=str, help="Comet: ID of the Comet Optimizer sweep.")
+ parser.add_argument("--comet_optimizer_objective", type=str, help="Comet: Set to 'minimize' or 'maximize'.")
+ parser.add_argument("--comet_optimizer_metric", type=str, help="Comet: Metric to Optimize.")
+ parser.add_argument("--comet_optimizer_workers",
+ type=int,
+ default=1,
+ help="Comet: Number of Parallel Workers to use with the Comet Optimizer.")
+
+ return parser.parse_known_args()[0] if known else parser.parse_args()
+
+
+def run(parameters, opt):
+ hyp_dict = {k: v for k, v in parameters.items() if k not in ["epochs", "batch_size"]}
+
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.batch_size = parameters.get("batch_size")
+ opt.epochs = parameters.get("epochs")
+
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ opt = get_args(known=True)
+
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.project = str(opt.project)
+
+ optimizer_id = os.getenv("COMET_OPTIMIZER_ID")
+ if optimizer_id is None:
+ with open(opt.comet_optimizer_config) as f:
+ optimizer_config = json.load(f)
+ optimizer = comet_ml.Optimizer(optimizer_config)
+ else:
+ optimizer = comet_ml.Optimizer(optimizer_id)
+
+ opt.comet_optimizer_id = optimizer.id
+ status = optimizer.status()
+
+ opt.comet_optimizer_objective = status["spec"]["objective"]
+ opt.comet_optimizer_metric = status["spec"]["metric"]
+
+ logger.info("COMET INFO: Starting Hyperparameter Sweep")
+ for parameter in optimizer.get_parameters():
+ run(parameter["parameters"], opt)
diff --git a/src/FireDetect/utils/loggers/comet/optimizer_config.json b/src/FireDetect/utils/loggers/comet/optimizer_config.json
new file mode 100644
index 0000000..83dddda
--- /dev/null
+++ b/src/FireDetect/utils/loggers/comet/optimizer_config.json
@@ -0,0 +1,209 @@
+{
+ "algorithm": "random",
+ "parameters": {
+ "anchor_t": {
+ "type": "discrete",
+ "values": [
+ 2,
+ 8
+ ]
+ },
+ "batch_size": {
+ "type": "discrete",
+ "values": [
+ 16,
+ 32,
+ 64
+ ]
+ },
+ "box": {
+ "type": "discrete",
+ "values": [
+ 0.02,
+ 0.2
+ ]
+ },
+ "cls": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "cls_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "copy_paste": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "degrees": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 45
+ ]
+ },
+ "epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "fl_gamma": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "fliplr": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "flipud": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_h": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_s": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "hsv_v": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "iou_t": {
+ "type": "discrete",
+ "values": [
+ 0.7
+ ]
+ },
+ "lr0": {
+ "type": "discrete",
+ "values": [
+ 1e-05,
+ 0.1
+ ]
+ },
+ "lrf": {
+ "type": "discrete",
+ "values": [
+ 0.01,
+ 1
+ ]
+ },
+ "mixup": {
+ "type": "discrete",
+ "values": [
+ 1
+ ]
+ },
+ "momentum": {
+ "type": "discrete",
+ "values": [
+ 0.6
+ ]
+ },
+ "mosaic": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "obj": {
+ "type": "discrete",
+ "values": [
+ 0.2
+ ]
+ },
+ "obj_pw": {
+ "type": "discrete",
+ "values": [
+ 0.5
+ ]
+ },
+ "optimizer": {
+ "type": "categorical",
+ "values": [
+ "SGD",
+ "Adam",
+ "AdamW"
+ ]
+ },
+ "perspective": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "scale": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "shear": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "translate": {
+ "type": "discrete",
+ "values": [
+ 0
+ ]
+ },
+ "warmup_bias_lr": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.2
+ ]
+ },
+ "warmup_epochs": {
+ "type": "discrete",
+ "values": [
+ 5
+ ]
+ },
+ "warmup_momentum": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.95
+ ]
+ },
+ "weight_decay": {
+ "type": "discrete",
+ "values": [
+ 0,
+ 0.001
+ ]
+ }
+ },
+ "spec": {
+ "maxCombo": 0,
+ "metric": "metrics/mAP_0.5",
+ "objective": "maximize"
+ },
+ "trials": 1
+}
diff --git a/src/FireDetect/utils/loggers/wandb/README.md b/src/FireDetect/utils/loggers/wandb/README.md
new file mode 100644
index 0000000..d78324b
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/README.md
@@ -0,0 +1,162 @@
+📚 This guide explains how to use **Weights & Biases** (W&B) with YOLOv5 🚀. UPDATED 29 September 2021.
+
+- [About Weights & Biases](#about-weights-&-biases)
+- [First-Time Setup](#first-time-setup)
+- [Viewing runs](#viewing-runs)
+- [Disabling wandb](#disabling-wandb)
+- [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
+- [Reports: Share your work with the world!](#reports)
+
+## About Weights & Biases
+
+Think of [W&B](https://wandb.ai/site?utm_campaign=repo_yolo_wandbtutorial) like GitHub for machine learning models. With a few lines of code, save everything you need to debug, compare and reproduce your models — architecture, hyperparameters, git commits, model weights, GPU usage, and even datasets and predictions.
+
+Used by top researchers including teams at OpenAI, Lyft, Github, and MILA, W&B is part of the new standard of best practices for machine learning. How W&B can help you optimize your machine learning workflows:
+
+- [Debug](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Free-2) model performance in real time
+- [GPU usage](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#System-4) visualized automatically
+- [Custom charts](https://wandb.ai/wandb/customizable-charts/reports/Powerful-Custom-Charts-To-Debug-Model-Peformance--VmlldzoyNzY4ODI) for powerful, extensible visualization
+- [Share insights](https://wandb.ai/wandb/getting-started/reports/Visualize-Debug-Machine-Learning-Models--VmlldzoyNzY5MDk#Share-8) interactively with collaborators
+- [Optimize hyperparameters](https://docs.wandb.com/sweeps) efficiently
+- [Track](https://docs.wandb.com/artifacts) datasets, pipelines, and production models
+
+## First-Time Setup
+
+
+ +
+
+
+
$ python train.py --upload_data val
+
+
+
+{dataset}_wandb.yaml file which can be used to train from dataset artifact.
+ $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data ..
+
+
+
+ $ python train.py --data {data}_wandb.yaml
+
+
+
+ $ python train.py --save_period 1
+
+
+
+--resume argument starts with wandb-artifact:// prefix followed by the run path, i.e, wandb-artifact://username/project/runid . This doesn't require the model checkpoint to be present on the local system.
+
+ $ python train.py --resume wandb-artifact://{run_path}
+
+
+
+--upload_dataset or
+ train from _wandb.yaml file and set --save_period
+
+ $ python train.py --resume wandb-artifact://{run_path}
+
+
+
+ +
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/src/FireDetect/utils/loggers/wandb/__init__.py b/src/FireDetect/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/FireDetect/utils/loggers/wandb/log_dataset.py b/src/FireDetect/utils/loggers/wandb/log_dataset.py
new file mode 100644
index 0000000..06e81fb
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/src/FireDetect/utils/loggers/wandb/sweep.py b/src/FireDetect/utils/loggers/wandb/sweep.py
new file mode 100644
index 0000000..d49ea6f
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent. Copy because train() modifies parameters which confused wandb.
+ hyp_dict = vars(wandb.config).get("_items").copy()
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/src/FireDetect/utils/loggers/wandb/sweep.yaml b/src/FireDetect/utils/loggers/wandb/sweep.yaml
new file mode 100644
index 0000000..688b1ea
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 4.0
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/src/FireDetect/utils/loggers/wandb/wandb_utils.py b/src/FireDetect/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000..238f4ed
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,589 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.dataloaders import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if isinstance(data_file, dict):
+ # In that case another dataset manager has already processed it and we don't have to
+ return data_file
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = isinstance(data_dict['train'],
+ str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX)
+ is_valset_wandb_artifact = isinstance(data_dict['val'],
+ str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX)
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup training processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Temporary-fix
+ if opt.upload_dataset:
+ opt.upload_dataset = False
+ # LOGGER.info("Uploading Dataset functionality is not being supported temporarily due to a bug.")
+
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if isinstance(opt.data, dict):
+ # This means another dataset manager has already processed the dataset info (e.g. ClearML)
+ # and they will have stored the already processed dict in opt.data
+ self.data_dict = opt.data
+ elif opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict}, allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.wandb_run.config.update({"upload_dataset": True})
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data, opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp, opt.imgsz = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs,\
+ config.hyp, config.imgsz
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(
+ data_dict.get('train'), opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(
+ data_dict.get('val'), opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ if opt.evolve or opt.noplots:
+ self.bbox_interval = opt.bbox_interval = opt.epochs + 1 # disable bbox_interval
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ # epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model',
+ type='model',
+ metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score})
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ upload_dataset = self.wandb_run.config.upload_dataset
+ log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+
+ # log train set
+ if not log_val_only:
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(data['train'], rect=True, batch_size=1),
+ names,
+ name='train') if data.get('train') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+
+ self.val_artifact = self.create_dataset_table(
+ LoadImagesAndLabels(data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+
+ path = Path(data_file)
+ # create a _wandb.yaml file with artifacts links if both train and test set are logged
+ if not log_val_only:
+ path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
+ path = ROOT / 'data' / path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+ LOGGER.info(f"Created dataset config file {path}")
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ if not log_val_only:
+ self.wandb_run.log_artifact(
+ self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.im_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file), name='data/labels/' +
+ label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "middle": [xywh[0], xywh[1]],
+ "width": xywh[2],
+ "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ avg_conf_per_class = [0] * len(self.data_dict['names'])
+ pred_class_count = {}
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": cls,
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"})
+ avg_conf_per_class[cls] += conf
+
+ if cls in pred_class_count:
+ pred_class_count[cls] += 1
+ else:
+ pred_class_count[cls] = 1
+
+ for pred_class in pred_class_count.keys():
+ avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
+
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch, id, self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ *avg_conf_per_class)
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[int(cls)]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}"
+ )
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact,
+ aliases=[
+ 'latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/src/FireDetect/utils/loss.py b/src/FireDetect/utils/loss.py
new file mode 100644
index 0000000..9b9c3d9
--- /dev/null
+++ b/src/FireDetect/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/src/FireDetect/utils/metrics.py b/src/FireDetect/utils/metrics.py
new file mode 100644
index 0000000..65ea463
--- /dev/null
+++ b/src/FireDetect/utils/metrics.py
@@ -0,0 +1,363 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+from utils import TryExcept, threaded
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=""):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for gc in gt_classes:
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # true background
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # predicted background
+
+ def matrix(self):
+ return self.matrix
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
+ def plot(self, normalize=True, save_dir='', names=()):
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ ticklabels = (names + ['background']) if labels else "auto"
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ ax=ax,
+ annot=nc < 30,
+ annot_kws={
+ "size": 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=ticklabels,
+ yticklabels=ticklabels).set_facecolor((1, 1, 1))
+ ax.set_ylabel('True')
+ ax.set_ylabel('Predicted')
+ ax.set_title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close(fig)
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+@threaded
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ ax.set_title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+
+
+@threaded
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ ax.set_title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
diff --git a/src/FireDetect/utils/plots.py b/src/FireDetect/utils/plots.py
new file mode 100644
index 0000000..36df271
--- /dev/null
+++ b/src/FireDetect/utils/plots.py
@@ -0,0 +1,575 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import contextlib
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils import TryExcept, threaded
+from utils.general import (CONFIG_DIR, FONT, LOGGER, check_font, check_requirements, clip_boxes, increment_path,
+ is_ascii, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+from utils.segment.general import scale_image
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def masks(self, masks, colors, im_gpu=None, alpha=0.5):
+ """Plot masks at once.
+ Args:
+ masks (tensor): predicted masks on cuda, shape: [n, h, w]
+ colors (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
+ im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
+ alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
+ """
+ if self.pil:
+ # convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ if im_gpu is None:
+ # Add multiple masks of shape(h,w,n) with colors list([r,g,b], [r,g,b], ...)
+ if len(masks) == 0:
+ return
+ if isinstance(masks, torch.Tensor):
+ masks = torch.as_tensor(masks, dtype=torch.uint8)
+ masks = masks.permute(1, 2, 0).contiguous()
+ masks = masks.cpu().numpy()
+ # masks = np.ascontiguousarray(masks.transpose(1, 2, 0))
+ masks = scale_image(masks.shape[:2], masks, self.im.shape)
+ masks = np.asarray(masks, dtype=np.float32)
+ colors = np.asarray(colors, dtype=np.float32) # shape(n,3)
+ s = masks.sum(2, keepdims=True).clip(0, 1) # add all masks together
+ masks = (masks @ colors).clip(0, 255) # (h,w,n) @ (n,3) = (h,w,3)
+ self.im[:] = masks * alpha + self.im * (1 - s * alpha)
+ else:
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = scale_image(im_gpu.shape, im_mask, self.im.shape)
+ if self.pil:
+ # convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255), anchor='top'):
+ # Add text to image (PIL-only)
+ if anchor == 'bottom': # start y from font bottom
+ w, h = self.font.getsize(text) # text width, height
+ xy[1] += 1 - h
+ self.draw.text(xy, text, fill=txt_color, font=self.font)
+
+ def fromarray(self, im):
+ # Update self.im from a numpy array
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output, max_det=300):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf] for plotting
+ targets = []
+ for i, o in enumerate(output):
+ box, conf, cls = o[:max_det, :6].cpu().split((4, 1, 1), 1)
+ j = torch.full((conf.shape[0], 1), i)
+ targets.append(torch.cat((j, cls, xyxy2xywh(box), conf), 1))
+ return torch.cat(targets, 0).numpy()
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j],
+ y[3, 1:j] * 1E2,
+ '.-',
+ linewidth=2,
+ markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-',
+ linewidth=2,
+ markersize=8,
+ alpha=.25,
+ label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@TryExcept() # known issue https://github.com/ultralytics/yolov5/issues/5395
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ with contextlib.suppress(Exception): # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(list(names.values()), rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def imshow_cls(im, labels=None, pred=None, names=None, nmax=25, verbose=False, f=Path('images.jpg')):
+ # Show classification image grid with labels (optional) and predictions (optional)
+ from utils.augmentations import denormalize
+
+ names = names or [f'class{i}' for i in range(1000)]
+ blocks = torch.chunk(denormalize(im.clone()).cpu().float(), len(im),
+ dim=0) # select batch index 0, block by channels
+ n = min(len(blocks), nmax) # number of plots
+ m = min(8, round(n ** 0.5)) # 8 x 8 default
+ fig, ax = plt.subplots(math.ceil(n / m), m) # 8 rows x n/8 cols
+ ax = ax.ravel() if m > 1 else [ax]
+ # plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze().permute((1, 2, 0)).numpy().clip(0.0, 1.0))
+ ax[i].axis('off')
+ if labels is not None:
+ s = names[labels[i]] + (f'—{names[pred[i]]}' if pred is not None else '')
+ ax[i].set_title(s, fontsize=8, verticalalignment='top')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ if verbose:
+ LOGGER.info(f"Saving {f}")
+ if labels is not None:
+ LOGGER.info('True: ' + ' '.join(f'{names[i]:3s}' for i in labels[:nmax]))
+ if pred is not None:
+ LOGGER.info('Predicted:' + ' '.join(f'{names[i]:3s}' for i in pred[:nmax]))
+ return f
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_boxes(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/src/FireDetect/utils/segment/__init__.py b/src/FireDetect/utils/segment/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/FireDetect/utils/segment/__pycache__/__init__.cpython-38.pyc b/src/FireDetect/utils/segment/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..172f6fa
Binary files /dev/null and b/src/FireDetect/utils/segment/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/FireDetect/utils/segment/__pycache__/general.cpython-38.pyc b/src/FireDetect/utils/segment/__pycache__/general.cpython-38.pyc
new file mode 100644
index 0000000..6241328
Binary files /dev/null and b/src/FireDetect/utils/segment/__pycache__/general.cpython-38.pyc differ
diff --git a/src/FireDetect/utils/segment/augmentations.py b/src/FireDetect/utils/segment/augmentations.py
new file mode 100644
index 0000000..169adde
--- /dev/null
+++ b/src/FireDetect/utils/segment/augmentations.py
@@ -0,0 +1,104 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from ..augmentations import box_candidates
+from ..general import resample_segments, segment2box
+
+
+def mixup(im, labels, segments, im2, labels2, segments2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ segments = np.concatenate((segments, segments2), 0)
+ return im, labels, segments
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ a = random.uniform(-degrees, degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * width) # x translation (pixels)
+ T[1, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * height) # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ new_segments = []
+ if n:
+ new = np.zeros((n, 4))
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]) # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+ new_segments.append(xy)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+ new_segments = np.array(new_segments)[i]
+
+ return im, targets, new_segments
diff --git a/src/FireDetect/utils/segment/dataloaders.py b/src/FireDetect/utils/segment/dataloaders.py
new file mode 100644
index 0000000..9de6f0f
--- /dev/null
+++ b/src/FireDetect/utils/segment/dataloaders.py
@@ -0,0 +1,331 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Dataloaders
+"""
+
+import os
+import random
+
+import cv2
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, distributed
+
+from ..augmentations import augment_hsv, copy_paste, letterbox
+from ..dataloaders import InfiniteDataLoader, LoadImagesAndLabels, seed_worker
+from ..general import LOGGER, xyn2xy, xywhn2xyxy, xyxy2xywhn
+from ..torch_utils import torch_distributed_zero_first
+from .augmentations import mixup, random_perspective
+
+RANK = int(os.getenv('RANK', -1))
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False,
+ mask_downsample_ratio=1,
+ overlap_mask=False):
+ if rect and shuffle:
+ LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabelsAndMasks(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix,
+ downsample_ratio=mask_downsample_ratio,
+ overlap=overlap_mask)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + RANK)
+ return loader(
+ dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=True,
+ collate_fn=LoadImagesAndLabelsAndMasks.collate_fn4 if quad else LoadImagesAndLabelsAndMasks.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ ), dataset
+
+
+class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
+
+ def __init__(
+ self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0,
+ min_items=0,
+ prefix="",
+ downsample_ratio=1,
+ overlap=False,
+ ):
+ super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
+ stride, pad, min_items, prefix)
+ self.downsample_ratio = downsample_ratio
+ self.overlap = overlap
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ masks = []
+ if mosaic:
+ # Load mosaic
+ img, labels, segments = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp["mixup"]:
+ img, labels, segments = mixup(img, labels, segments, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ # [array, array, ....], array.shape=(num_points, 2), xyxyxyxy
+ segments = self.segments[index].copy()
+ if len(segments):
+ for i_s in range(len(segments)):
+ segments[i_s] = xyn2xy(
+ segments[i_s],
+ ratio[0] * w,
+ ratio[1] * h,
+ padw=pad[0],
+ padh=pad[1],
+ )
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels, segments = random_perspective(img,
+ labels,
+ segments=segments,
+ degrees=hyp["degrees"],
+ translate=hyp["translate"],
+ scale=hyp["scale"],
+ shear=hyp["shear"],
+ perspective=hyp["perspective"])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1e-3)
+ if self.overlap:
+ masks, sorted_idx = polygons2masks_overlap(img.shape[:2],
+ segments,
+ downsample_ratio=self.downsample_ratio)
+ masks = masks[None] # (640, 640) -> (1, 640, 640)
+ labels = labels[sorted_idx]
+ else:
+ masks = polygons2masks(img.shape[:2], segments, color=1, downsample_ratio=self.downsample_ratio)
+
+ masks = (torch.from_numpy(masks) if len(masks) else torch.zeros(1 if self.overlap else nl, img.shape[0] //
+ self.downsample_ratio, img.shape[1] //
+ self.downsample_ratio))
+ # TODO: albumentations support
+ if self.augment:
+ # Albumentations
+ # there are some augmentation that won't change boxes and masks,
+ # so just be it for now.
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp["hsv_h"], sgain=hyp["hsv_s"], vgain=hyp["hsv_v"])
+
+ # Flip up-down
+ if random.random() < hyp["flipud"]:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+ masks = torch.flip(masks, dims=[1])
+
+ # Flip left-right
+ if random.random() < hyp["fliplr"]:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+ masks = torch.flip(masks, dims=[2])
+
+ # Cutouts # labels = cutout(img, labels, p=0.5)
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return (torch.from_numpy(img), labels_out, self.im_files[index], shapes, masks)
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+
+ # 3 additional image indices
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp["copy_paste"])
+ img4, labels4, segments4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp["degrees"],
+ translate=self.hyp["translate"],
+ scale=self.hyp["scale"],
+ shear=self.hyp["shear"],
+ perspective=self.hyp["perspective"],
+ border=self.mosaic_border) # border to remove
+ return img4, labels4, segments4
+
+ @staticmethod
+ def collate_fn(batch):
+ img, label, path, shapes, masks = zip(*batch) # transposed
+ batched_masks = torch.cat(masks, 0)
+ for i, l in enumerate(label):
+ l[:, 0] = i # add target image index for build_targets()
+ return torch.stack(img, 0), torch.cat(label, 0), path, shapes, batched_masks
+
+
+def polygon2mask(img_size, polygons, color=1, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (np.ndarray): [N, M], N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ mask = np.zeros(img_size, dtype=np.uint8)
+ polygons = np.asarray(polygons)
+ polygons = polygons.astype(np.int32)
+ shape = polygons.shape
+ polygons = polygons.reshape(shape[0], -1, 2)
+ cv2.fillPoly(mask, polygons, color=color)
+ nh, nw = (img_size[0] // downsample_ratio, img_size[1] // downsample_ratio)
+ # NOTE: fillPoly firstly then resize is trying the keep the same way
+ # of loss calculation when mask-ratio=1.
+ mask = cv2.resize(mask, (nw, nh))
+ return mask
+
+
+def polygons2masks(img_size, polygons, color, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (list[np.ndarray]): each polygon is [N, M],
+ N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ masks = []
+ for si in range(len(polygons)):
+ mask = polygon2mask(img_size, [polygons[si].reshape(-1)], color, downsample_ratio)
+ masks.append(mask)
+ return np.array(masks)
+
+
+def polygons2masks_overlap(img_size, segments, downsample_ratio=1):
+ """Return a (640, 640) overlap mask."""
+ masks = np.zeros((img_size[0] // downsample_ratio, img_size[1] // downsample_ratio),
+ dtype=np.int32 if len(segments) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(segments)):
+ mask = polygon2mask(
+ img_size,
+ [segments[si].reshape(-1)],
+ downsample_ratio=downsample_ratio,
+ color=1,
+ )
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(segments)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
diff --git a/src/FireDetect/utils/segment/general.py b/src/FireDetect/utils/segment/general.py
new file mode 100644
index 0000000..b526333
--- /dev/null
+++ b/src/FireDetect/utils/segment/general.py
@@ -0,0 +1,137 @@
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+
+def crop_mask(masks, boxes):
+ """
+ "Crop" predicted masks by zeroing out everything not in the predicted bbox.
+ Vectorized by Chong (thanks Chong).
+
+ Args:
+ - masks should be a size [h, w, n] tensor of masks
+ - boxes should be a size [n, 4] tensor of bbox coords in relative point form
+ """
+
+ n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(1,1,n)
+ r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
+ c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
+
+
+def process_mask_upsample(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask(protos, masks_in, bboxes, shape, upsample=False):
+ """
+ Crop before upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ ih, iw = shape
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
+
+ downsampled_bboxes = bboxes.clone()
+ downsampled_bboxes[:, 0] *= mw / iw
+ downsampled_bboxes[:, 2] *= mw / iw
+ downsampled_bboxes[:, 3] *= mh / ih
+ downsampled_bboxes[:, 1] *= mh / ih
+
+ masks = crop_mask(masks, downsampled_bboxes) # CHW
+ if upsample:
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ return masks.gt_(0.5)
+
+
+def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
+ """
+ img1_shape: model input shape, [h, w]
+ img0_shape: origin pic shape, [h, w, 3]
+ masks: [h, w, num]
+ """
+ # Rescale coordinates (xyxy) from im1_shape to im0_shape
+ if ratio_pad is None: # calculate from im0_shape
+ gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
+ pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
+ else:
+ pad = ratio_pad[1]
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
+
+ if len(masks.shape) < 2:
+ raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
+ masks = masks[top:bottom, left:right]
+ # masks = masks.permute(2, 0, 1).contiguous()
+ # masks = F.interpolate(masks[None], im0_shape[:2], mode='bilinear', align_corners=False)[0]
+ # masks = masks.permute(1, 2, 0).contiguous()
+ masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
+
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+ return masks
+
+
+def mask_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [M, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, [N, M]
+ """
+ intersection = torch.matmul(mask1, mask2.t()).clamp(0)
+ union = (mask1.sum(1)[:, None] + mask2.sum(1)[None]) - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [N, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, (N, )
+ """
+ intersection = (mask1 * mask2).sum(1).clamp(0) # (N, )
+ union = (mask1.sum(1) + mask2.sum(1))[None] - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks2segments(masks, strategy='largest'):
+ # Convert masks(n,160,160) into segments(n,xy)
+ segments = []
+ for x in masks.int().cpu().numpy().astype('uint8'):
+ c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
+ segments.append(c.astype('float32'))
+ return segments
diff --git a/src/FireDetect/utils/segment/loss.py b/src/FireDetect/utils/segment/loss.py
new file mode 100644
index 0000000..b45b2c2
--- /dev/null
+++ b/src/FireDetect/utils/segment/loss.py
@@ -0,0 +1,186 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..general import xywh2xyxy
+from ..loss import FocalLoss, smooth_BCE
+from ..metrics import bbox_iou
+from ..torch_utils import de_parallel
+from .general import crop_mask
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False, overlap=False):
+ self.sort_obj_iou = False
+ self.overlap = overlap
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+ self.device = device
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.nm = m.nm # number of masks
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, preds, targets, masks): # predictions, targets, model
+ p, proto = preds
+ bs, nm, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
+ lcls = torch.zeros(1, device=self.device)
+ lbox = torch.zeros(1, device=self.device)
+ lobj = torch.zeros(1, device=self.device)
+ lseg = torch.zeros(1, device=self.device)
+ tcls, tbox, indices, anchors, tidxs, xywhn = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ pxy, pwh, _, pcls, pmask = pi[b, a, gj, gi].split((2, 2, 1, self.nc, nm), 1) # subset of predictions
+
+ # Box regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Mask regression
+ if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
+ masks = F.interpolate(masks[None], (mask_h, mask_w), mode="nearest")[0]
+ marea = xywhn[i][:, 2:].prod(1) # mask width, height normalized
+ mxyxy = xywh2xyxy(xywhn[i] * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device))
+ for bi in b.unique():
+ j = b == bi # matching index
+ if self.overlap:
+ mask_gti = torch.where(masks[bi][None] == tidxs[i][j].view(-1, 1, 1), 1.0, 0.0)
+ else:
+ mask_gti = masks[tidxs[i]][j]
+ lseg += self.single_mask_loss(mask_gti, pmask[j], proto[bi], mxyxy[j], marea[j])
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp["box"]
+ lobj *= self.hyp["obj"]
+ lcls *= self.hyp["cls"]
+ lseg *= self.hyp["box"] / bs
+
+ loss = lbox + lobj + lcls + lseg
+ return loss * bs, torch.cat((lbox, lseg, lobj, lcls)).detach()
+
+ def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):
+ # Mask loss for one image
+ pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n,32) @ (32,80,80) -> (n,80,80)
+ loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction="none")
+ return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch, tidxs, xywhn = [], [], [], [], [], []
+ gain = torch.ones(8, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ if self.overlap:
+ batch = p[0].shape[0]
+ ti = []
+ for i in range(batch):
+ num = (targets[:, 0] == i).sum() # find number of targets of each image
+ ti.append(torch.arange(num, device=self.device).float().view(1, num).repeat(na, 1) + 1) # (na, num)
+ ti = torch.cat(ti, 1) # (na, nt)
+ else:
+ ti = torch.arange(nt, device=self.device).float().view(1, nt).repeat(na, 1)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None], ti[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, at = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ (a, tidx), (b, c) = at.long().T, bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ tidxs.append(tidx)
+ xywhn.append(torch.cat((gxy, gwh), 1) / gain[2:6]) # xywh normalized
+
+ return tcls, tbox, indices, anch, tidxs, xywhn
diff --git a/src/FireDetect/utils/segment/metrics.py b/src/FireDetect/utils/segment/metrics.py
new file mode 100644
index 0000000..b09ce23
--- /dev/null
+++ b/src/FireDetect/utils/segment/metrics.py
@@ -0,0 +1,210 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import numpy as np
+
+from ..metrics import ap_per_class
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9, 0.0, 0.0, 0.1, 0.9]
+ return (x[:, :8] * w).sum(1)
+
+
+def ap_per_class_box_and_mask(
+ tp_m,
+ tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=False,
+ save_dir=".",
+ names=(),
+):
+ """
+ Args:
+ tp_b: tp of boxes.
+ tp_m: tp of masks.
+ other arguments see `func: ap_per_class`.
+ """
+ results_boxes = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix="Box")[2:]
+ results_masks = ap_per_class(tp_m,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix="Mask")[2:]
+
+ results = {
+ "boxes": {
+ "p": results_boxes[0],
+ "r": results_boxes[1],
+ "ap": results_boxes[3],
+ "f1": results_boxes[2],
+ "ap_class": results_boxes[4]},
+ "masks": {
+ "p": results_masks[0],
+ "r": results_masks[1],
+ "ap": results_masks[3],
+ "f1": results_masks[2],
+ "ap_class": results_masks[4]}}
+ return results
+
+
+class Metric:
+
+ def __init__(self) -> None:
+ self.p = [] # (nc, )
+ self.r = [] # (nc, )
+ self.f1 = [] # (nc, )
+ self.all_ap = [] # (nc, 10)
+ self.ap_class_index = [] # (nc, )
+
+ @property
+ def ap50(self):
+ """AP@0.5 of all classes.
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap[:, 0] if len(self.all_ap) else []
+
+ @property
+ def ap(self):
+ """AP@0.5:0.95
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap.mean(1) if len(self.all_ap) else []
+
+ @property
+ def mp(self):
+ """mean precision of all classes.
+ Return:
+ float.
+ """
+ return self.p.mean() if len(self.p) else 0.0
+
+ @property
+ def mr(self):
+ """mean recall of all classes.
+ Return:
+ float.
+ """
+ return self.r.mean() if len(self.r) else 0.0
+
+ @property
+ def map50(self):
+ """Mean AP@0.5 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap[:, 0].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map(self):
+ """Mean AP@0.5:0.95 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap.mean() if len(self.all_ap) else 0.0
+
+ def mean_results(self):
+ """Mean of results, return mp, mr, map50, map"""
+ return (self.mp, self.mr, self.map50, self.map)
+
+ def class_result(self, i):
+ """class-aware result, return p[i], r[i], ap50[i], ap[i]"""
+ return (self.p[i], self.r[i], self.ap50[i], self.ap[i])
+
+ def get_maps(self, nc):
+ maps = np.zeros(nc) + self.map
+ for i, c in enumerate(self.ap_class_index):
+ maps[c] = self.ap[i]
+ return maps
+
+ def update(self, results):
+ """
+ Args:
+ results: tuple(p, r, ap, f1, ap_class)
+ """
+ p, r, all_ap, f1, ap_class_index = results
+ self.p = p
+ self.r = r
+ self.all_ap = all_ap
+ self.f1 = f1
+ self.ap_class_index = ap_class_index
+
+
+class Metrics:
+ """Metric for boxes and masks."""
+
+ def __init__(self) -> None:
+ self.metric_box = Metric()
+ self.metric_mask = Metric()
+
+ def update(self, results):
+ """
+ Args:
+ results: Dict{'boxes': Dict{}, 'masks': Dict{}}
+ """
+ self.metric_box.update(list(results["boxes"].values()))
+ self.metric_mask.update(list(results["masks"].values()))
+
+ def mean_results(self):
+ return self.metric_box.mean_results() + self.metric_mask.mean_results()
+
+ def class_result(self, i):
+ return self.metric_box.class_result(i) + self.metric_mask.class_result(i)
+
+ def get_maps(self, nc):
+ return self.metric_box.get_maps(nc) + self.metric_mask.get_maps(nc)
+
+ @property
+ def ap_class_index(self):
+ # boxes and masks have the same ap_class_index
+ return self.metric_box.ap_class_index
+
+
+KEYS = [
+ "train/box_loss",
+ "train/seg_loss", # train loss
+ "train/obj_loss",
+ "train/cls_loss",
+ "metrics/precision(B)",
+ "metrics/recall(B)",
+ "metrics/mAP_0.5(B)",
+ "metrics/mAP_0.5:0.95(B)", # metrics
+ "metrics/precision(M)",
+ "metrics/recall(M)",
+ "metrics/mAP_0.5(M)",
+ "metrics/mAP_0.5:0.95(M)", # metrics
+ "val/box_loss",
+ "val/seg_loss", # val loss
+ "val/obj_loss",
+ "val/cls_loss",
+ "x/lr0",
+ "x/lr1",
+ "x/lr2",]
+
+BEST_KEYS = [
+ "best/epoch",
+ "best/precision(B)",
+ "best/recall(B)",
+ "best/mAP_0.5(B)",
+ "best/mAP_0.5:0.95(B)",
+ "best/precision(M)",
+ "best/recall(M)",
+ "best/mAP_0.5(M)",
+ "best/mAP_0.5:0.95(M)",]
diff --git a/src/FireDetect/utils/segment/plots.py b/src/FireDetect/utils/segment/plots.py
new file mode 100644
index 0000000..9b90900
--- /dev/null
+++ b/src/FireDetect/utils/segment/plots.py
@@ -0,0 +1,143 @@
+import contextlib
+import math
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import torch
+
+from .. import threaded
+from ..general import xywh2xyxy
+from ..plots import Annotator, colors
+
+
+@threaded
+def plot_images_and_masks(images, targets, masks, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if isinstance(masks, torch.Tensor):
+ masks = masks.cpu().numpy().astype(int)
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5 + h), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ idx = targets[:, 0] == i
+ ti = targets[idx] # image targets
+
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+
+ # Plot masks
+ if len(masks):
+ if masks.max() > 1.0: # mean that masks are overlap
+ image_masks = masks[[i]] # (1, 640, 640)
+ nl = len(ti)
+ index = np.arange(nl).reshape(nl, 1, 1) + 1
+ image_masks = np.repeat(image_masks, nl, axis=0)
+ image_masks = np.where(image_masks == index, 1.0, 0.0)
+ else:
+ image_masks = masks[idx]
+
+ im = np.asarray(annotator.im).copy()
+ for j, box in enumerate(boxes.T.tolist()):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ color = colors(classes[j])
+ mh, mw = image_masks[j].shape
+ if mh != h or mw != w:
+ mask = image_masks[j].astype(np.uint8)
+ mask = cv2.resize(mask, (w, h))
+ mask = mask.astype(bool)
+ else:
+ mask = image_masks[j].astype(bool)
+ with contextlib.suppress(Exception):
+ im[y:y + h, x:x + w, :][mask] = im[y:y + h, x:x + w, :][mask] * 0.4 + np.array(color) * 0.6
+ annotator.fromarray(im)
+ annotator.im.save(fname) # save
+
+
+def plot_results_with_masks(file="path/to/results.csv", dir="", best=True):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 8, figsize=(18, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob("results*.csv"))
+ assert len(files), f"No results.csv files found in {save_dir.resolve()}, nothing to plot."
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ index = np.argmax(0.9 * data.values[:, 8] + 0.1 * data.values[:, 7] + 0.9 * data.values[:, 12] +
+ 0.1 * data.values[:, 11])
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 6, 9, 10, 13, 14, 15, 16, 7, 8, 11, 12]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker=".", label=f.stem, linewidth=2, markersize=2)
+ if best:
+ # best
+ ax[i].scatter(index, y[index], color="r", label=f"best:{index}", marker="*", linewidth=3)
+ ax[i].set_title(s[j] + f"\n{round(y[index], 5)}")
+ else:
+ # last
+ ax[i].scatter(x[-1], y[-1], color="r", label="last", marker="*", linewidth=3)
+ ax[i].set_title(s[j] + f"\n{round(y[-1], 5)}")
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f"Warning: Plotting error for {f}: {e}")
+ ax[1].legend()
+ fig.savefig(save_dir / "results.png", dpi=200)
+ plt.close()
diff --git a/src/FireDetect/utils/torch_utils.py b/src/FireDetect/utils/torch_utils.py
new file mode 100644
index 0000000..77549b0
--- /dev/null
+++ b/src/FireDetect/utils/torch_utils.py
@@ -0,0 +1,432 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return (torch.inference_mode if torch_1_9 else torch.no_grad)()(fn)
+
+ return decorate
+
+
+def smartCrossEntropyLoss(label_smoothing=0.0):
+ # Returns nn.CrossEntropyLoss with label smoothing enabled for torch>=1.10.0
+ if check_version(torch.__version__, '1.10.0'):
+ return nn.CrossEntropyLoss(label_smoothing=label_smoothing)
+ if label_smoothing > 0:
+ LOGGER.warning(f'WARNING ⚠️ label smoothing {label_smoothing} requires torch>=1.10.0')
+ return nn.CrossEntropyLoss()
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+def reshape_classifier_output(model, n=1000):
+ # Update a TorchVision classification model to class count 'n' if required
+ from models.common import Classify
+ name, m = list((model.model if hasattr(model, 'model') else model).named_children())[-1] # last module
+ if isinstance(m, Classify): # YOLOv5 Classify() head
+ if m.linear.out_features != n:
+ m.linear = nn.Linear(m.linear.in_features, n)
+ elif isinstance(m, nn.Linear): # ResNet, EfficientNet
+ if m.out_features != n:
+ setattr(model, name, nn.Linear(m.in_features, n))
+ elif isinstance(m, nn.Sequential):
+ types = [type(x) for x in m]
+ if nn.Linear in types:
+ i = types.index(nn.Linear) # nn.Linear index
+ if m[i].out_features != n:
+ m[i] = nn.Linear(m[i].in_features, n)
+ elif nn.Conv2d in types:
+ i = types.index(nn.Conv2d) # nn.Conv2d index
+ if m[i].out_channels != n:
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not cpu and not mps and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ """ YOLOv5 speed/memory/FLOPs profiler
+ Usage:
+ input = torch.randn(16, 3, 640, 640)
+ m1 = lambda x: x * torch.sigmoid(x)
+ m2 = nn.SiLU()
+ profile(input, [m1, m2], n=100) # profile over 100 iterations
+ """
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ dilation=conv.dilation,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.empty((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f"{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f"{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias")
+ return optimizer
+
+
+def smart_hub_load(repo='ultralytics/yolov5', model='yolov5s', **kwargs):
+ # YOLOv5 torch.hub.load() wrapper with smart error/issue handling
+ if check_version(torch.__version__, '1.9.1'):
+ kwargs['skip_validation'] = True # validation causes GitHub API rate limit errors
+ if check_version(torch.__version__, '1.12.0'):
+ kwargs['trust_repo'] = True # argument required starting in torch 0.12
+ try:
+ return torch.hub.load(repo, model, **kwargs)
+ except Exception:
+ return torch.hub.load(repo, model, force_reload=True, **kwargs)
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point: # true for FP16 and FP32
+ v *= d
+ v += (1 - d) * msd[k].detach()
+ # assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/src/FireDetect/utils/triton.py b/src/FireDetect/utils/triton.py
new file mode 100644
index 0000000..a94ef0a
--- /dev/null
+++ b/src/FireDetect/utils/triton.py
@@ -0,0 +1,85 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+""" Utils to interact with the Triton Inference Server
+"""
+
+import typing
+from urllib.parse import urlparse
+
+import torch
+
+
+class TritonRemoteModel:
+ """ A wrapper over a model served by the Triton Inference Server. It can
+ be configured to communicate over GRPC or HTTP. It accepts Torch Tensors
+ as input and returns them as outputs.
+ """
+
+ def __init__(self, url: str):
+ """
+ Keyword arguments:
+ url: Fully qualified address of the Triton server - for e.g. grpc://localhost:8000
+ """
+
+ parsed_url = urlparse(url)
+ if parsed_url.scheme == "grpc":
+ from tritonclient.grpc import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton GRPC client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository.models[0].name
+ self.metadata = self.client.get_model_metadata(self.model_name, as_json=True)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i["shape"]], i['datatype']) for i in self.metadata['inputs']]
+
+ else:
+ from tritonclient.http import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton HTTP client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository[0]['name']
+ self.metadata = self.client.get_model_metadata(self.model_name)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i["shape"]], i['datatype']) for i in self.metadata['inputs']]
+
+ self._create_input_placeholders_fn = create_input_placeholders
+
+ @property
+ def runtime(self):
+ """Returns the model runtime"""
+ return self.metadata.get("backend", self.metadata.get("platform"))
+
+ def __call__(self, *args, **kwargs) -> typing.Union[torch.Tensor, typing.Tuple[torch.Tensor, ...]]:
+ """ Invokes the model. Parameters can be provided via args or kwargs.
+ args, if provided, are assumed to match the order of inputs of the model.
+ kwargs are matched with the model input names.
+ """
+ inputs = self._create_inputs(*args, **kwargs)
+ response = self.client.infer(model_name=self.model_name, inputs=inputs)
+ result = []
+ for output in self.metadata['outputs']:
+ tensor = torch.as_tensor(response.as_numpy(output['name']))
+ result.append(tensor)
+ return result[0] if len(result) == 1 else result
+
+ def _create_inputs(self, *args, **kwargs):
+ args_len, kwargs_len = len(args), len(kwargs)
+ if not args_len and not kwargs_len:
+ raise RuntimeError("No inputs provided.")
+ if args_len and kwargs_len:
+ raise RuntimeError("Cannot specify args and kwargs at the same time")
+
+ placeholders = self._create_input_placeholders_fn()
+ if args_len:
+ if args_len != len(placeholders):
+ raise RuntimeError(f"Expected {len(placeholders)} inputs, got {args_len}.")
+ for input, value in zip(placeholders, args):
+ input.set_data_from_numpy(value.cpu().numpy())
+ else:
+ for input in placeholders:
+ value = kwargs[input.name]
+ input.set_data_from_numpy(value.cpu().numpy())
+ return placeholders
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/src/FireDetect/utils/loggers/wandb/__init__.py b/src/FireDetect/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/FireDetect/utils/loggers/wandb/log_dataset.py b/src/FireDetect/utils/loggers/wandb/log_dataset.py
new file mode 100644
index 0000000..06e81fb
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/src/FireDetect/utils/loggers/wandb/sweep.py b/src/FireDetect/utils/loggers/wandb/sweep.py
new file mode 100644
index 0000000..d49ea6f
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent. Copy because train() modifies parameters which confused wandb.
+ hyp_dict = vars(wandb.config).get("_items").copy()
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/src/FireDetect/utils/loggers/wandb/sweep.yaml b/src/FireDetect/utils/loggers/wandb/sweep.yaml
new file mode 100644
index 0000000..688b1ea
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 4.0
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/src/FireDetect/utils/loggers/wandb/wandb_utils.py b/src/FireDetect/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000..238f4ed
--- /dev/null
+++ b/src/FireDetect/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,589 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.dataloaders import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if isinstance(data_file, dict):
+ # In that case another dataset manager has already processed it and we don't have to
+ return data_file
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = isinstance(data_dict['train'],
+ str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX)
+ is_valset_wandb_artifact = isinstance(data_dict['val'],
+ str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX)
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup training processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Temporary-fix
+ if opt.upload_dataset:
+ opt.upload_dataset = False
+ # LOGGER.info("Uploading Dataset functionality is not being supported temporarily due to a bug.")
+
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if isinstance(opt.data, dict):
+ # This means another dataset manager has already processed the dataset info (e.g. ClearML)
+ # and they will have stored the already processed dict in opt.data
+ self.data_dict = opt.data
+ elif opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict}, allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.wandb_run.config.update({"upload_dataset": True})
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data, opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp, opt.imgsz = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs,\
+ config.hyp, config.imgsz
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(
+ data_dict.get('train'), opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(
+ data_dict.get('val'), opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ if opt.evolve or opt.noplots:
+ self.bbox_interval = opt.bbox_interval = opt.epochs + 1 # disable bbox_interval
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ # epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model',
+ type='model',
+ metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score})
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ upload_dataset = self.wandb_run.config.upload_dataset
+ log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+
+ # log train set
+ if not log_val_only:
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(data['train'], rect=True, batch_size=1),
+ names,
+ name='train') if data.get('train') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+
+ self.val_artifact = self.create_dataset_table(
+ LoadImagesAndLabels(data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+
+ path = Path(data_file)
+ # create a _wandb.yaml file with artifacts links if both train and test set are logged
+ if not log_val_only:
+ path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
+ path = ROOT / 'data' / path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+ LOGGER.info(f"Created dataset config file {path}")
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ if not log_val_only:
+ self.wandb_run.log_artifact(
+ self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.im_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file), name='data/labels/' +
+ label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "middle": [xywh[0], xywh[1]],
+ "width": xywh[2],
+ "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ avg_conf_per_class = [0] * len(self.data_dict['names'])
+ pred_class_count = {}
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ cls = int(cls)
+ box_data.append({
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": cls,
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"})
+ avg_conf_per_class[cls] += conf
+
+ if cls in pred_class_count:
+ pred_class_count[cls] += 1
+ else:
+ pred_class_count[cls] = 1
+
+ for pred_class in pred_class_count.keys():
+ avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
+
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch, id, self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ *avg_conf_per_class)
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{
+ "position": {
+ "minX": xyxy[0],
+ "minY": xyxy[1],
+ "maxX": xyxy[2],
+ "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[int(cls)]} {conf:.3f}",
+ "scores": {
+ "class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(
+ f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}"
+ )
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact,
+ aliases=[
+ 'latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/src/FireDetect/utils/loss.py b/src/FireDetect/utils/loss.py
new file mode 100644
index 0000000..9b9c3d9
--- /dev/null
+++ b/src/FireDetect/utils/loss.py
@@ -0,0 +1,234 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import de_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ sort_obj_iou = False
+
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, p, targets): # predictions, targets
+ lcls = torch.zeros(1, device=self.device) # class loss
+ lbox = torch.zeros(1, device=self.device) # box loss
+ lobj = torch.zeros(1, device=self.device) # object loss
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ # pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
+ pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
+
+ # Regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/src/FireDetect/utils/metrics.py b/src/FireDetect/utils/metrics.py
new file mode 100644
index 0000000..65ea463
--- /dev/null
+++ b/src/FireDetect/utils/metrics.py
@@ -0,0 +1,363 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+from utils import TryExcept, threaded
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def smooth(y, f=0.05):
+ # Box filter of fraction f
+ nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
+ p = np.ones(nf // 2) # ones padding
+ yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
+ return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=""):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes, nt = np.unique(target_cls, return_counts=True)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = nt[ci] # number of labels
+ n_p = i.sum() # number of predictions
+ if n_p == 0 or n_l == 0:
+ continue
+
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + eps) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + eps)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = dict(enumerate(names)) # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')
+
+ i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
+ p, r, f1 = p[:, i], r[:, i], f1[:, i]
+ tp = (r * nt).round() # true positives
+ fp = (tp / (p + eps) - tp).round() # false positives
+ return tp, fp, p, r, f1, ap, unique_classes.astype(int)
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ if detections is None:
+ gt_classes = labels.int()
+ for gc in gt_classes:
+ self.matrix[self.nc, gc] += 1 # background FN
+ return
+
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(int)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # true background
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # predicted background
+
+ def matrix(self):
+ return self.matrix
+
+ def tp_fp(self):
+ tp = self.matrix.diagonal() # true positives
+ fp = self.matrix.sum(1) - tp # false positives
+ # fn = self.matrix.sum(0) - tp # false negatives (missed detections)
+ return tp[:-1], fp[:-1] # remove background class
+
+ @TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
+ def plot(self, normalize=True, save_dir='', names=()):
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
+ nc, nn = self.nc, len(names) # number of classes, names
+ sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
+ labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
+ ticklabels = (names + ['background']) if labels else "auto"
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array,
+ ax=ax,
+ annot=nc < 30,
+ annot_kws={
+ "size": 8},
+ cmap='Blues',
+ fmt='.2f',
+ square=True,
+ vmin=0.0,
+ xticklabels=ticklabels,
+ yticklabels=ticklabels).set_facecolor((1, 1, 1))
+ ax.set_ylabel('True')
+ ax.set_ylabel('Predicted')
+ ax.set_title('Confusion Matrix')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close(fig)
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
+
+ # Get the coordinates of bounding boxes
+ if xywh: # transform from xywh to xyxy
+ (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
+ w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
+ b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
+ b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
+ else: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ # IoU
+ iou = inter / union
+ if CIoU or DIoU or GIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
+ if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ return iou - rho2 / c2 # DIoU
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ return iou # IoU
+
+
+def box_iou(box1, box2, eps=1e-7):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ (a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
+ inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
+
+ # IoU = inter / (area1 + area2 - inter)
+ return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
+
+
+def bbox_ioa(box1, box2, eps=1e-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2, eps=1e-7):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+
+@threaded
+def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ ax.set_title('Precision-Recall Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
+
+
+@threaded
+def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = smooth(py.mean(0), 0.05)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ ax.set_title(f'{ylabel}-Confidence Curve')
+ fig.savefig(save_dir, dpi=250)
+ plt.close(fig)
diff --git a/src/FireDetect/utils/plots.py b/src/FireDetect/utils/plots.py
new file mode 100644
index 0000000..36df271
--- /dev/null
+++ b/src/FireDetect/utils/plots.py
@@ -0,0 +1,575 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import contextlib
+import math
+import os
+from copy import copy
+from pathlib import Path
+from urllib.error import URLError
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils import TryExcept, threaded
+from utils.general import (CONFIG_DIR, FONT, LOGGER, check_font, check_requirements, clip_boxes, increment_path,
+ is_ascii, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+from utils.segment.general import scale_image
+
+# Settings
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hexs = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb(f'#{c}') for c in hexs]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_pil_font(font=FONT, size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception: # download if missing
+ try:
+ check_font(font)
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+ except URLError: # not online
+ return ImageFont.load_default()
+
+
+class Annotator:
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ non_ascii = not is_ascii(example) # non-latin labels, i.e. asian, arabic, cyrillic
+ self.pil = pil or non_ascii
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_pil_font(font='Arial.Unicode.ttf' if non_ascii else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle(
+ (box[0], box[1] - h if outside else box[1], box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1),
+ fill=color,
+ )
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h >= 3
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im,
+ label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2),
+ 0,
+ self.lw / 3,
+ txt_color,
+ thickness=tf,
+ lineType=cv2.LINE_AA)
+
+ def masks(self, masks, colors, im_gpu=None, alpha=0.5):
+ """Plot masks at once.
+ Args:
+ masks (tensor): predicted masks on cuda, shape: [n, h, w]
+ colors (List[List[Int]]): colors for predicted masks, [[r, g, b] * n]
+ im_gpu (tensor): img is in cuda, shape: [3, h, w], range: [0, 1]
+ alpha (float): mask transparency: 0.0 fully transparent, 1.0 opaque
+ """
+ if self.pil:
+ # convert to numpy first
+ self.im = np.asarray(self.im).copy()
+ if im_gpu is None:
+ # Add multiple masks of shape(h,w,n) with colors list([r,g,b], [r,g,b], ...)
+ if len(masks) == 0:
+ return
+ if isinstance(masks, torch.Tensor):
+ masks = torch.as_tensor(masks, dtype=torch.uint8)
+ masks = masks.permute(1, 2, 0).contiguous()
+ masks = masks.cpu().numpy()
+ # masks = np.ascontiguousarray(masks.transpose(1, 2, 0))
+ masks = scale_image(masks.shape[:2], masks, self.im.shape)
+ masks = np.asarray(masks, dtype=np.float32)
+ colors = np.asarray(colors, dtype=np.float32) # shape(n,3)
+ s = masks.sum(2, keepdims=True).clip(0, 1) # add all masks together
+ masks = (masks @ colors).clip(0, 255) # (h,w,n) @ (n,3) = (h,w,3)
+ self.im[:] = masks * alpha + self.im * (1 - s * alpha)
+ else:
+ if len(masks) == 0:
+ self.im[:] = im_gpu.permute(1, 2, 0).contiguous().cpu().numpy() * 255
+ colors = torch.tensor(colors, device=im_gpu.device, dtype=torch.float32) / 255.0
+ colors = colors[:, None, None] # shape(n,1,1,3)
+ masks = masks.unsqueeze(3) # shape(n,h,w,1)
+ masks_color = masks * (colors * alpha) # shape(n,h,w,3)
+
+ inv_alph_masks = (1 - masks * alpha).cumprod(0) # shape(n,h,w,1)
+ mcs = (masks_color * inv_alph_masks).sum(0) * 2 # mask color summand shape(n,h,w,3)
+
+ im_gpu = im_gpu.flip(dims=[0]) # flip channel
+ im_gpu = im_gpu.permute(1, 2, 0).contiguous() # shape(h,w,3)
+ im_gpu = im_gpu * inv_alph_masks[-1] + mcs
+ im_mask = (im_gpu * 255).byte().cpu().numpy()
+ self.im[:] = scale_image(im_gpu.shape, im_mask, self.im.shape)
+ if self.pil:
+ # convert im back to PIL and update draw
+ self.fromarray(self.im)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255), anchor='top'):
+ # Add text to image (PIL-only)
+ if anchor == 'bottom': # start y from font bottom
+ w, h = self.font.getsize(text) # text width, height
+ xy[1] += 1 - h
+ self.draw.text(xy, text, fill=txt_color, font=self.font)
+
+ def fromarray(self, im):
+ # Update self.im from a numpy array
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = save_dir / f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ LOGGER.info(f'Saving {f}... ({n}/{channels})')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ np.save(str(f.with_suffix('.npy')), x[0].cpu().numpy()) # npy save
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output, max_det=300):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf] for plotting
+ targets = []
+ for i, o in enumerate(output):
+ box, conf, cls = o[:max_det, :6].cpu().split((4, 1, 1), 1)
+ j = torch.full((conf.shape[0], 1), i)
+ targets.append(torch.cat((j, cls, xyxy2xywh(box), conf), 1))
+ return torch.cat(targets, 0).numpy()
+
+
+@threaded
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j],
+ y[3, 1:j] * 1E2,
+ '.-',
+ linewidth=2,
+ markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-',
+ linewidth=2,
+ markersize=8,
+ alpha=.25,
+ label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@TryExcept() # known issue https://github.com/ultralytics/yolov5/issues/5395
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ with contextlib.suppress(Exception): # color histogram bars by class
+ [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # known issue #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(list(names.values()), rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def imshow_cls(im, labels=None, pred=None, names=None, nmax=25, verbose=False, f=Path('images.jpg')):
+ # Show classification image grid with labels (optional) and predictions (optional)
+ from utils.augmentations import denormalize
+
+ names = names or [f'class{i}' for i in range(1000)]
+ blocks = torch.chunk(denormalize(im.clone()).cpu().float(), len(im),
+ dim=0) # select batch index 0, block by channels
+ n = min(len(blocks), nmax) # number of plots
+ m = min(8, round(n ** 0.5)) # 8 x 8 default
+ fig, ax = plt.subplots(math.ceil(n / m), m) # 8 rows x n/8 cols
+ ax = ax.ravel() if m > 1 else [ax]
+ # plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze().permute((1, 2, 0)).numpy().clip(0.0, 1.0))
+ ax[i].axis('off')
+ if labels is not None:
+ s = names[labels[i]] + (f'—{names[pred[i]]}' if pred is not None else '')
+ ax[i].set_title(s, fontsize=8, verticalalignment='top')
+ plt.savefig(f, dpi=300, bbox_inches='tight')
+ plt.close()
+ if verbose:
+ LOGGER.info(f"Saving {f}")
+ if labels is not None:
+ LOGGER.info('True: ' + ' '.join(f'{names[i]:3s}' for i in labels[:nmax]))
+ if pred is not None:
+ LOGGER.info('Predicted:' + ' '.join(f'{names[i]:3s}' for i in pred[:nmax]))
+ return f
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ print(f'Best results from row {j} of {evolve_csv}:')
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j].astype('float')
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ LOGGER.info(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file=Path('im.jpg'), gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_boxes(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ f = str(increment_path(file).with_suffix('.jpg'))
+ # cv2.imwrite(f, crop) # save BGR, https://github.com/ultralytics/yolov5/issues/7007 chroma subsampling issue
+ Image.fromarray(crop[..., ::-1]).save(f, quality=95, subsampling=0) # save RGB
+ return crop
diff --git a/src/FireDetect/utils/segment/__init__.py b/src/FireDetect/utils/segment/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/FireDetect/utils/segment/__pycache__/__init__.cpython-38.pyc b/src/FireDetect/utils/segment/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..172f6fa
Binary files /dev/null and b/src/FireDetect/utils/segment/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/FireDetect/utils/segment/__pycache__/general.cpython-38.pyc b/src/FireDetect/utils/segment/__pycache__/general.cpython-38.pyc
new file mode 100644
index 0000000..6241328
Binary files /dev/null and b/src/FireDetect/utils/segment/__pycache__/general.cpython-38.pyc differ
diff --git a/src/FireDetect/utils/segment/augmentations.py b/src/FireDetect/utils/segment/augmentations.py
new file mode 100644
index 0000000..169adde
--- /dev/null
+++ b/src/FireDetect/utils/segment/augmentations.py
@@ -0,0 +1,104 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Image augmentation functions
+"""
+
+import math
+import random
+
+import cv2
+import numpy as np
+
+from ..augmentations import box_candidates
+from ..general import resample_segments, segment2box
+
+
+def mixup(im, labels, segments, im2, labels2, segments2):
+ # Applies MixUp augmentation https://arxiv.org/pdf/1710.09412.pdf
+ r = np.random.beta(32.0, 32.0) # mixup ratio, alpha=beta=32.0
+ im = (im * r + im2 * (1 - r)).astype(np.uint8)
+ labels = np.concatenate((labels, labels2), 0)
+ segments = np.concatenate((segments, segments2), 0)
+ return im, labels, segments
+
+
+def random_perspective(im,
+ targets=(),
+ segments=(),
+ degrees=10,
+ translate=.1,
+ scale=.1,
+ shear=10,
+ perspective=0.0,
+ border=(0, 0)):
+ # torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
+ # targets = [cls, xyxy]
+
+ height = im.shape[0] + border[0] * 2 # shape(h,w,c)
+ width = im.shape[1] + border[1] * 2
+
+ # Center
+ C = np.eye(3)
+ C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
+ C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
+
+ # Perspective
+ P = np.eye(3)
+ P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
+ P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
+
+ # Rotation and Scale
+ R = np.eye(3)
+ a = random.uniform(-degrees, degrees)
+ # a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
+ s = random.uniform(1 - scale, 1 + scale)
+ # s = 2 ** random.uniform(-scale, scale)
+ R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
+
+ # Shear
+ S = np.eye(3)
+ S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
+ S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
+
+ # Translation
+ T = np.eye(3)
+ T[0, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * width) # x translation (pixels)
+ T[1, 2] = (random.uniform(0.5 - translate, 0.5 + translate) * height) # y translation (pixels)
+
+ # Combined rotation matrix
+ M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
+ if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
+ if perspective:
+ im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
+ else: # affine
+ im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
+
+ # Visualize
+ # import matplotlib.pyplot as plt
+ # ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
+ # ax[0].imshow(im[:, :, ::-1]) # base
+ # ax[1].imshow(im2[:, :, ::-1]) # warped
+
+ # Transform label coordinates
+ n = len(targets)
+ new_segments = []
+ if n:
+ new = np.zeros((n, 4))
+ segments = resample_segments(segments) # upsample
+ for i, segment in enumerate(segments):
+ xy = np.ones((len(segment), 3))
+ xy[:, :2] = segment
+ xy = xy @ M.T # transform
+ xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]) # perspective rescale or affine
+
+ # clip
+ new[i] = segment2box(xy, width, height)
+ new_segments.append(xy)
+
+ # filter candidates
+ i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01)
+ targets = targets[i]
+ targets[:, 1:5] = new[i]
+ new_segments = np.array(new_segments)[i]
+
+ return im, targets, new_segments
diff --git a/src/FireDetect/utils/segment/dataloaders.py b/src/FireDetect/utils/segment/dataloaders.py
new file mode 100644
index 0000000..9de6f0f
--- /dev/null
+++ b/src/FireDetect/utils/segment/dataloaders.py
@@ -0,0 +1,331 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Dataloaders
+"""
+
+import os
+import random
+
+import cv2
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, distributed
+
+from ..augmentations import augment_hsv, copy_paste, letterbox
+from ..dataloaders import InfiniteDataLoader, LoadImagesAndLabels, seed_worker
+from ..general import LOGGER, xyn2xy, xywhn2xyxy, xyxy2xywhn
+from ..torch_utils import torch_distributed_zero_first
+from .augmentations import mixup, random_perspective
+
+RANK = int(os.getenv('RANK', -1))
+
+
+def create_dataloader(path,
+ imgsz,
+ batch_size,
+ stride,
+ single_cls=False,
+ hyp=None,
+ augment=False,
+ cache=False,
+ pad=0.0,
+ rect=False,
+ rank=-1,
+ workers=8,
+ image_weights=False,
+ quad=False,
+ prefix='',
+ shuffle=False,
+ mask_downsample_ratio=1,
+ overlap_mask=False):
+ if rect and shuffle:
+ LOGGER.warning('WARNING ⚠️ --rect is incompatible with DataLoader shuffle, setting shuffle=False')
+ shuffle = False
+ with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
+ dataset = LoadImagesAndLabelsAndMasks(
+ path,
+ imgsz,
+ batch_size,
+ augment=augment, # augmentation
+ hyp=hyp, # hyperparameters
+ rect=rect, # rectangular batches
+ cache_images=cache,
+ single_cls=single_cls,
+ stride=int(stride),
+ pad=pad,
+ image_weights=image_weights,
+ prefix=prefix,
+ downsample_ratio=mask_downsample_ratio,
+ overlap=overlap_mask)
+
+ batch_size = min(batch_size, len(dataset))
+ nd = torch.cuda.device_count() # number of CUDA devices
+ nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
+ sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
+ loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
+ generator = torch.Generator()
+ generator.manual_seed(6148914691236517205 + RANK)
+ return loader(
+ dataset,
+ batch_size=batch_size,
+ shuffle=shuffle and sampler is None,
+ num_workers=nw,
+ sampler=sampler,
+ pin_memory=True,
+ collate_fn=LoadImagesAndLabelsAndMasks.collate_fn4 if quad else LoadImagesAndLabelsAndMasks.collate_fn,
+ worker_init_fn=seed_worker,
+ generator=generator,
+ ), dataset
+
+
+class LoadImagesAndLabelsAndMasks(LoadImagesAndLabels): # for training/testing
+
+ def __init__(
+ self,
+ path,
+ img_size=640,
+ batch_size=16,
+ augment=False,
+ hyp=None,
+ rect=False,
+ image_weights=False,
+ cache_images=False,
+ single_cls=False,
+ stride=32,
+ pad=0,
+ min_items=0,
+ prefix="",
+ downsample_ratio=1,
+ overlap=False,
+ ):
+ super().__init__(path, img_size, batch_size, augment, hyp, rect, image_weights, cache_images, single_cls,
+ stride, pad, min_items, prefix)
+ self.downsample_ratio = downsample_ratio
+ self.overlap = overlap
+
+ def __getitem__(self, index):
+ index = self.indices[index] # linear, shuffled, or image_weights
+
+ hyp = self.hyp
+ mosaic = self.mosaic and random.random() < hyp['mosaic']
+ masks = []
+ if mosaic:
+ # Load mosaic
+ img, labels, segments = self.load_mosaic(index)
+ shapes = None
+
+ # MixUp augmentation
+ if random.random() < hyp["mixup"]:
+ img, labels, segments = mixup(img, labels, segments, *self.load_mosaic(random.randint(0, self.n - 1)))
+
+ else:
+ # Load image
+ img, (h0, w0), (h, w) = self.load_image(index)
+
+ # Letterbox
+ shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
+ img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
+ shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
+
+ labels = self.labels[index].copy()
+ # [array, array, ....], array.shape=(num_points, 2), xyxyxyxy
+ segments = self.segments[index].copy()
+ if len(segments):
+ for i_s in range(len(segments)):
+ segments[i_s] = xyn2xy(
+ segments[i_s],
+ ratio[0] * w,
+ ratio[1] * h,
+ padw=pad[0],
+ padh=pad[1],
+ )
+ if labels.size: # normalized xywh to pixel xyxy format
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
+
+ if self.augment:
+ img, labels, segments = random_perspective(img,
+ labels,
+ segments=segments,
+ degrees=hyp["degrees"],
+ translate=hyp["translate"],
+ scale=hyp["scale"],
+ shear=hyp["shear"],
+ perspective=hyp["perspective"])
+
+ nl = len(labels) # number of labels
+ if nl:
+ labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1e-3)
+ if self.overlap:
+ masks, sorted_idx = polygons2masks_overlap(img.shape[:2],
+ segments,
+ downsample_ratio=self.downsample_ratio)
+ masks = masks[None] # (640, 640) -> (1, 640, 640)
+ labels = labels[sorted_idx]
+ else:
+ masks = polygons2masks(img.shape[:2], segments, color=1, downsample_ratio=self.downsample_ratio)
+
+ masks = (torch.from_numpy(masks) if len(masks) else torch.zeros(1 if self.overlap else nl, img.shape[0] //
+ self.downsample_ratio, img.shape[1] //
+ self.downsample_ratio))
+ # TODO: albumentations support
+ if self.augment:
+ # Albumentations
+ # there are some augmentation that won't change boxes and masks,
+ # so just be it for now.
+ img, labels = self.albumentations(img, labels)
+ nl = len(labels) # update after albumentations
+
+ # HSV color-space
+ augment_hsv(img, hgain=hyp["hsv_h"], sgain=hyp["hsv_s"], vgain=hyp["hsv_v"])
+
+ # Flip up-down
+ if random.random() < hyp["flipud"]:
+ img = np.flipud(img)
+ if nl:
+ labels[:, 2] = 1 - labels[:, 2]
+ masks = torch.flip(masks, dims=[1])
+
+ # Flip left-right
+ if random.random() < hyp["fliplr"]:
+ img = np.fliplr(img)
+ if nl:
+ labels[:, 1] = 1 - labels[:, 1]
+ masks = torch.flip(masks, dims=[2])
+
+ # Cutouts # labels = cutout(img, labels, p=0.5)
+
+ labels_out = torch.zeros((nl, 6))
+ if nl:
+ labels_out[:, 1:] = torch.from_numpy(labels)
+
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ return (torch.from_numpy(img), labels_out, self.im_files[index], shapes, masks)
+
+ def load_mosaic(self, index):
+ # YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
+ labels4, segments4 = [], []
+ s = self.img_size
+ yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
+
+ # 3 additional image indices
+ indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
+ for i, index in enumerate(indices):
+ # Load image
+ img, _, (h, w) = self.load_image(index)
+
+ # place img in img4
+ if i == 0: # top left
+ img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
+ x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
+ elif i == 1: # top right
+ x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
+ x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
+ elif i == 2: # bottom left
+ x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
+ elif i == 3: # bottom right
+ x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
+ x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
+
+ img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
+ padw = x1a - x1b
+ padh = y1a - y1b
+
+ labels, segments = self.labels[index].copy(), self.segments[index].copy()
+
+ if labels.size:
+ labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
+ segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
+ labels4.append(labels)
+ segments4.extend(segments)
+
+ # Concat/clip labels
+ labels4 = np.concatenate(labels4, 0)
+ for x in (labels4[:, 1:], *segments4):
+ np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
+ # img4, labels4 = replicate(img4, labels4) # replicate
+
+ # Augment
+ img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp["copy_paste"])
+ img4, labels4, segments4 = random_perspective(img4,
+ labels4,
+ segments4,
+ degrees=self.hyp["degrees"],
+ translate=self.hyp["translate"],
+ scale=self.hyp["scale"],
+ shear=self.hyp["shear"],
+ perspective=self.hyp["perspective"],
+ border=self.mosaic_border) # border to remove
+ return img4, labels4, segments4
+
+ @staticmethod
+ def collate_fn(batch):
+ img, label, path, shapes, masks = zip(*batch) # transposed
+ batched_masks = torch.cat(masks, 0)
+ for i, l in enumerate(label):
+ l[:, 0] = i # add target image index for build_targets()
+ return torch.stack(img, 0), torch.cat(label, 0), path, shapes, batched_masks
+
+
+def polygon2mask(img_size, polygons, color=1, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (np.ndarray): [N, M], N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ mask = np.zeros(img_size, dtype=np.uint8)
+ polygons = np.asarray(polygons)
+ polygons = polygons.astype(np.int32)
+ shape = polygons.shape
+ polygons = polygons.reshape(shape[0], -1, 2)
+ cv2.fillPoly(mask, polygons, color=color)
+ nh, nw = (img_size[0] // downsample_ratio, img_size[1] // downsample_ratio)
+ # NOTE: fillPoly firstly then resize is trying the keep the same way
+ # of loss calculation when mask-ratio=1.
+ mask = cv2.resize(mask, (nw, nh))
+ return mask
+
+
+def polygons2masks(img_size, polygons, color, downsample_ratio=1):
+ """
+ Args:
+ img_size (tuple): The image size.
+ polygons (list[np.ndarray]): each polygon is [N, M],
+ N is the number of polygons,
+ M is the number of points(Be divided by 2).
+ """
+ masks = []
+ for si in range(len(polygons)):
+ mask = polygon2mask(img_size, [polygons[si].reshape(-1)], color, downsample_ratio)
+ masks.append(mask)
+ return np.array(masks)
+
+
+def polygons2masks_overlap(img_size, segments, downsample_ratio=1):
+ """Return a (640, 640) overlap mask."""
+ masks = np.zeros((img_size[0] // downsample_ratio, img_size[1] // downsample_ratio),
+ dtype=np.int32 if len(segments) > 255 else np.uint8)
+ areas = []
+ ms = []
+ for si in range(len(segments)):
+ mask = polygon2mask(
+ img_size,
+ [segments[si].reshape(-1)],
+ downsample_ratio=downsample_ratio,
+ color=1,
+ )
+ ms.append(mask)
+ areas.append(mask.sum())
+ areas = np.asarray(areas)
+ index = np.argsort(-areas)
+ ms = np.array(ms)[index]
+ for i in range(len(segments)):
+ mask = ms[i] * (i + 1)
+ masks = masks + mask
+ masks = np.clip(masks, a_min=0, a_max=i + 1)
+ return masks, index
diff --git a/src/FireDetect/utils/segment/general.py b/src/FireDetect/utils/segment/general.py
new file mode 100644
index 0000000..b526333
--- /dev/null
+++ b/src/FireDetect/utils/segment/general.py
@@ -0,0 +1,137 @@
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+
+def crop_mask(masks, boxes):
+ """
+ "Crop" predicted masks by zeroing out everything not in the predicted bbox.
+ Vectorized by Chong (thanks Chong).
+
+ Args:
+ - masks should be a size [h, w, n] tensor of masks
+ - boxes should be a size [n, 4] tensor of bbox coords in relative point form
+ """
+
+ n, h, w = masks.shape
+ x1, y1, x2, y2 = torch.chunk(boxes[:, :, None], 4, 1) # x1 shape(1,1,n)
+ r = torch.arange(w, device=masks.device, dtype=x1.dtype)[None, None, :] # rows shape(1,w,1)
+ c = torch.arange(h, device=masks.device, dtype=x1.dtype)[None, :, None] # cols shape(h,1,1)
+
+ return masks * ((r >= x1) * (r < x2) * (c >= y1) * (c < y2))
+
+
+def process_mask_upsample(protos, masks_in, bboxes, shape):
+ """
+ Crop after upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw)
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ masks = crop_mask(masks, bboxes) # CHW
+ return masks.gt_(0.5)
+
+
+def process_mask(protos, masks_in, bboxes, shape, upsample=False):
+ """
+ Crop before upsample.
+ proto_out: [mask_dim, mask_h, mask_w]
+ out_masks: [n, mask_dim], n is number of masks after nms
+ bboxes: [n, 4], n is number of masks after nms
+ shape:input_image_size, (h, w)
+
+ return: h, w, n
+ """
+
+ c, mh, mw = protos.shape # CHW
+ ih, iw = shape
+ masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
+
+ downsampled_bboxes = bboxes.clone()
+ downsampled_bboxes[:, 0] *= mw / iw
+ downsampled_bboxes[:, 2] *= mw / iw
+ downsampled_bboxes[:, 3] *= mh / ih
+ downsampled_bboxes[:, 1] *= mh / ih
+
+ masks = crop_mask(masks, downsampled_bboxes) # CHW
+ if upsample:
+ masks = F.interpolate(masks[None], shape, mode='bilinear', align_corners=False)[0] # CHW
+ return masks.gt_(0.5)
+
+
+def scale_image(im1_shape, masks, im0_shape, ratio_pad=None):
+ """
+ img1_shape: model input shape, [h, w]
+ img0_shape: origin pic shape, [h, w, 3]
+ masks: [h, w, num]
+ """
+ # Rescale coordinates (xyxy) from im1_shape to im0_shape
+ if ratio_pad is None: # calculate from im0_shape
+ gain = min(im1_shape[0] / im0_shape[0], im1_shape[1] / im0_shape[1]) # gain = old / new
+ pad = (im1_shape[1] - im0_shape[1] * gain) / 2, (im1_shape[0] - im0_shape[0] * gain) / 2 # wh padding
+ else:
+ pad = ratio_pad[1]
+ top, left = int(pad[1]), int(pad[0]) # y, x
+ bottom, right = int(im1_shape[0] - pad[1]), int(im1_shape[1] - pad[0])
+
+ if len(masks.shape) < 2:
+ raise ValueError(f'"len of masks shape" should be 2 or 3, but got {len(masks.shape)}')
+ masks = masks[top:bottom, left:right]
+ # masks = masks.permute(2, 0, 1).contiguous()
+ # masks = F.interpolate(masks[None], im0_shape[:2], mode='bilinear', align_corners=False)[0]
+ # masks = masks.permute(1, 2, 0).contiguous()
+ masks = cv2.resize(masks, (im0_shape[1], im0_shape[0]))
+
+ if len(masks.shape) == 2:
+ masks = masks[:, :, None]
+ return masks
+
+
+def mask_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [M, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, [N, M]
+ """
+ intersection = torch.matmul(mask1, mask2.t()).clamp(0)
+ union = (mask1.sum(1)[:, None] + mask2.sum(1)[None]) - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks_iou(mask1, mask2, eps=1e-7):
+ """
+ mask1: [N, n] m1 means number of predicted objects
+ mask2: [N, n] m2 means number of gt objects
+ Note: n means image_w x image_h
+
+ return: masks iou, (N, )
+ """
+ intersection = (mask1 * mask2).sum(1).clamp(0) # (N, )
+ union = (mask1.sum(1) + mask2.sum(1))[None] - intersection # (area1 + area2) - intersection
+ return intersection / (union + eps)
+
+
+def masks2segments(masks, strategy='largest'):
+ # Convert masks(n,160,160) into segments(n,xy)
+ segments = []
+ for x in masks.int().cpu().numpy().astype('uint8'):
+ c = cv2.findContours(x, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
+ if c:
+ if strategy == 'concat': # concatenate all segments
+ c = np.concatenate([x.reshape(-1, 2) for x in c])
+ elif strategy == 'largest': # select largest segment
+ c = np.array(c[np.array([len(x) for x in c]).argmax()]).reshape(-1, 2)
+ else:
+ c = np.zeros((0, 2)) # no segments found
+ segments.append(c.astype('float32'))
+ return segments
diff --git a/src/FireDetect/utils/segment/loss.py b/src/FireDetect/utils/segment/loss.py
new file mode 100644
index 0000000..b45b2c2
--- /dev/null
+++ b/src/FireDetect/utils/segment/loss.py
@@ -0,0 +1,186 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from ..general import xywh2xyxy
+from ..loss import FocalLoss, smooth_BCE
+from ..metrics import bbox_iou
+from ..torch_utils import de_parallel
+from .general import crop_mask
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False, overlap=False):
+ self.sort_obj_iou = False
+ self.overlap = overlap
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+ self.device = device
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ m = de_parallel(model).model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ self.na = m.na # number of anchors
+ self.nc = m.nc # number of classes
+ self.nl = m.nl # number of layers
+ self.nm = m.nm # number of masks
+ self.anchors = m.anchors
+ self.device = device
+
+ def __call__(self, preds, targets, masks): # predictions, targets, model
+ p, proto = preds
+ bs, nm, mask_h, mask_w = proto.shape # batch size, number of masks, mask height, mask width
+ lcls = torch.zeros(1, device=self.device)
+ lbox = torch.zeros(1, device=self.device)
+ lobj = torch.zeros(1, device=self.device)
+ lseg = torch.zeros(1, device=self.device)
+ tcls, tbox, indices, anchors, tidxs, xywhn = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ pxy, pwh, _, pcls, pmask = pi[b, a, gj, gi].split((2, 2, 1, self.nc, nm), 1) # subset of predictions
+
+ # Box regression
+ pxy = pxy.sigmoid() * 2 - 0.5
+ pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ j = iou.argsort()
+ b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
+ if self.gr < 1:
+ iou = (1.0 - self.gr) + self.gr * iou
+ tobj[b, a, gj, gi] = iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(pcls, self.cn, device=self.device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(pcls, t) # BCE
+
+ # Mask regression
+ if tuple(masks.shape[-2:]) != (mask_h, mask_w): # downsample
+ masks = F.interpolate(masks[None], (mask_h, mask_w), mode="nearest")[0]
+ marea = xywhn[i][:, 2:].prod(1) # mask width, height normalized
+ mxyxy = xywh2xyxy(xywhn[i] * torch.tensor([mask_w, mask_h, mask_w, mask_h], device=self.device))
+ for bi in b.unique():
+ j = b == bi # matching index
+ if self.overlap:
+ mask_gti = torch.where(masks[bi][None] == tidxs[i][j].view(-1, 1, 1), 1.0, 0.0)
+ else:
+ mask_gti = masks[tidxs[i]][j]
+ lseg += self.single_mask_loss(mask_gti, pmask[j], proto[bi], mxyxy[j], marea[j])
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp["box"]
+ lobj *= self.hyp["obj"]
+ lcls *= self.hyp["cls"]
+ lseg *= self.hyp["box"] / bs
+
+ loss = lbox + lobj + lcls + lseg
+ return loss * bs, torch.cat((lbox, lseg, lobj, lcls)).detach()
+
+ def single_mask_loss(self, gt_mask, pred, proto, xyxy, area):
+ # Mask loss for one image
+ pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n,32) @ (32,80,80) -> (n,80,80)
+ loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction="none")
+ return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch, tidxs, xywhn = [], [], [], [], [], []
+ gain = torch.ones(8, device=self.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ if self.overlap:
+ batch = p[0].shape[0]
+ ti = []
+ for i in range(batch):
+ num = (targets[:, 0] == i).sum() # find number of targets of each image
+ ti.append(torch.arange(num, device=self.device).float().view(1, num).repeat(na, 1) + 1) # (na, num)
+ ti = torch.cat(ti, 1) # (na, nt)
+ else:
+ ti = torch.arange(nt, device=self.device).float().view(1, nt).repeat(na, 1)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None], ti[..., None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor(
+ [
+ [0, 0],
+ [1, 0],
+ [0, 1],
+ [-1, 0],
+ [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ],
+ device=self.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors, shape = self.anchors[i], p[i].shape
+ gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain # shape(3,n,7)
+ if nt:
+ # Matches
+ r = t[..., 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ bc, gxy, gwh, at = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
+ (a, tidx), (b, c) = at.long().T, bc.long().T # anchors, image, class
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid indices
+
+ # Append
+ indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+ tidxs.append(tidx)
+ xywhn.append(torch.cat((gxy, gwh), 1) / gain[2:6]) # xywh normalized
+
+ return tcls, tbox, indices, anch, tidxs, xywhn
diff --git a/src/FireDetect/utils/segment/metrics.py b/src/FireDetect/utils/segment/metrics.py
new file mode 100644
index 0000000..b09ce23
--- /dev/null
+++ b/src/FireDetect/utils/segment/metrics.py
@@ -0,0 +1,210 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import numpy as np
+
+from ..metrics import ap_per_class
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9, 0.0, 0.0, 0.1, 0.9]
+ return (x[:, :8] * w).sum(1)
+
+
+def ap_per_class_box_and_mask(
+ tp_m,
+ tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=False,
+ save_dir=".",
+ names=(),
+):
+ """
+ Args:
+ tp_b: tp of boxes.
+ tp_m: tp of masks.
+ other arguments see `func: ap_per_class`.
+ """
+ results_boxes = ap_per_class(tp_b,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix="Box")[2:]
+ results_masks = ap_per_class(tp_m,
+ conf,
+ pred_cls,
+ target_cls,
+ plot=plot,
+ save_dir=save_dir,
+ names=names,
+ prefix="Mask")[2:]
+
+ results = {
+ "boxes": {
+ "p": results_boxes[0],
+ "r": results_boxes[1],
+ "ap": results_boxes[3],
+ "f1": results_boxes[2],
+ "ap_class": results_boxes[4]},
+ "masks": {
+ "p": results_masks[0],
+ "r": results_masks[1],
+ "ap": results_masks[3],
+ "f1": results_masks[2],
+ "ap_class": results_masks[4]}}
+ return results
+
+
+class Metric:
+
+ def __init__(self) -> None:
+ self.p = [] # (nc, )
+ self.r = [] # (nc, )
+ self.f1 = [] # (nc, )
+ self.all_ap = [] # (nc, 10)
+ self.ap_class_index = [] # (nc, )
+
+ @property
+ def ap50(self):
+ """AP@0.5 of all classes.
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap[:, 0] if len(self.all_ap) else []
+
+ @property
+ def ap(self):
+ """AP@0.5:0.95
+ Return:
+ (nc, ) or [].
+ """
+ return self.all_ap.mean(1) if len(self.all_ap) else []
+
+ @property
+ def mp(self):
+ """mean precision of all classes.
+ Return:
+ float.
+ """
+ return self.p.mean() if len(self.p) else 0.0
+
+ @property
+ def mr(self):
+ """mean recall of all classes.
+ Return:
+ float.
+ """
+ return self.r.mean() if len(self.r) else 0.0
+
+ @property
+ def map50(self):
+ """Mean AP@0.5 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap[:, 0].mean() if len(self.all_ap) else 0.0
+
+ @property
+ def map(self):
+ """Mean AP@0.5:0.95 of all classes.
+ Return:
+ float.
+ """
+ return self.all_ap.mean() if len(self.all_ap) else 0.0
+
+ def mean_results(self):
+ """Mean of results, return mp, mr, map50, map"""
+ return (self.mp, self.mr, self.map50, self.map)
+
+ def class_result(self, i):
+ """class-aware result, return p[i], r[i], ap50[i], ap[i]"""
+ return (self.p[i], self.r[i], self.ap50[i], self.ap[i])
+
+ def get_maps(self, nc):
+ maps = np.zeros(nc) + self.map
+ for i, c in enumerate(self.ap_class_index):
+ maps[c] = self.ap[i]
+ return maps
+
+ def update(self, results):
+ """
+ Args:
+ results: tuple(p, r, ap, f1, ap_class)
+ """
+ p, r, all_ap, f1, ap_class_index = results
+ self.p = p
+ self.r = r
+ self.all_ap = all_ap
+ self.f1 = f1
+ self.ap_class_index = ap_class_index
+
+
+class Metrics:
+ """Metric for boxes and masks."""
+
+ def __init__(self) -> None:
+ self.metric_box = Metric()
+ self.metric_mask = Metric()
+
+ def update(self, results):
+ """
+ Args:
+ results: Dict{'boxes': Dict{}, 'masks': Dict{}}
+ """
+ self.metric_box.update(list(results["boxes"].values()))
+ self.metric_mask.update(list(results["masks"].values()))
+
+ def mean_results(self):
+ return self.metric_box.mean_results() + self.metric_mask.mean_results()
+
+ def class_result(self, i):
+ return self.metric_box.class_result(i) + self.metric_mask.class_result(i)
+
+ def get_maps(self, nc):
+ return self.metric_box.get_maps(nc) + self.metric_mask.get_maps(nc)
+
+ @property
+ def ap_class_index(self):
+ # boxes and masks have the same ap_class_index
+ return self.metric_box.ap_class_index
+
+
+KEYS = [
+ "train/box_loss",
+ "train/seg_loss", # train loss
+ "train/obj_loss",
+ "train/cls_loss",
+ "metrics/precision(B)",
+ "metrics/recall(B)",
+ "metrics/mAP_0.5(B)",
+ "metrics/mAP_0.5:0.95(B)", # metrics
+ "metrics/precision(M)",
+ "metrics/recall(M)",
+ "metrics/mAP_0.5(M)",
+ "metrics/mAP_0.5:0.95(M)", # metrics
+ "val/box_loss",
+ "val/seg_loss", # val loss
+ "val/obj_loss",
+ "val/cls_loss",
+ "x/lr0",
+ "x/lr1",
+ "x/lr2",]
+
+BEST_KEYS = [
+ "best/epoch",
+ "best/precision(B)",
+ "best/recall(B)",
+ "best/mAP_0.5(B)",
+ "best/mAP_0.5:0.95(B)",
+ "best/precision(M)",
+ "best/recall(M)",
+ "best/mAP_0.5(M)",
+ "best/mAP_0.5:0.95(M)",]
diff --git a/src/FireDetect/utils/segment/plots.py b/src/FireDetect/utils/segment/plots.py
new file mode 100644
index 0000000..9b90900
--- /dev/null
+++ b/src/FireDetect/utils/segment/plots.py
@@ -0,0 +1,143 @@
+import contextlib
+import math
+from pathlib import Path
+
+import cv2
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import torch
+
+from .. import threaded
+from ..general import xywh2xyxy
+from ..plots import Annotator, colors
+
+
+@threaded
+def plot_images_and_masks(images, targets, masks, paths=None, fname='images.jpg', names=None):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if isinstance(masks, torch.Tensor):
+ masks = masks.cpu().numpy().astype(int)
+
+ max_size = 1920 # max image size
+ max_subplots = 16 # max image subplots, i.e. 4x4
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True, example=names)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5 + h), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ idx = targets[:, 0] == i
+ ti = targets[idx] # image targets
+
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+
+ # Plot masks
+ if len(masks):
+ if masks.max() > 1.0: # mean that masks are overlap
+ image_masks = masks[[i]] # (1, 640, 640)
+ nl = len(ti)
+ index = np.arange(nl).reshape(nl, 1, 1) + 1
+ image_masks = np.repeat(image_masks, nl, axis=0)
+ image_masks = np.where(image_masks == index, 1.0, 0.0)
+ else:
+ image_masks = masks[idx]
+
+ im = np.asarray(annotator.im).copy()
+ for j, box in enumerate(boxes.T.tolist()):
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ color = colors(classes[j])
+ mh, mw = image_masks[j].shape
+ if mh != h or mw != w:
+ mask = image_masks[j].astype(np.uint8)
+ mask = cv2.resize(mask, (w, h))
+ mask = mask.astype(bool)
+ else:
+ mask = image_masks[j].astype(bool)
+ with contextlib.suppress(Exception):
+ im[y:y + h, x:x + w, :][mask] = im[y:y + h, x:x + w, :][mask] * 0.4 + np.array(color) * 0.6
+ annotator.fromarray(im)
+ annotator.im.save(fname) # save
+
+
+def plot_results_with_masks(file="path/to/results.csv", dir="", best=True):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 8, figsize=(18, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob("results*.csv"))
+ assert len(files), f"No results.csv files found in {save_dir.resolve()}, nothing to plot."
+ for f in files:
+ try:
+ data = pd.read_csv(f)
+ index = np.argmax(0.9 * data.values[:, 8] + 0.1 * data.values[:, 7] + 0.9 * data.values[:, 12] +
+ 0.1 * data.values[:, 11])
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 6, 9, 10, 13, 14, 15, 16, 7, 8, 11, 12]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker=".", label=f.stem, linewidth=2, markersize=2)
+ if best:
+ # best
+ ax[i].scatter(index, y[index], color="r", label=f"best:{index}", marker="*", linewidth=3)
+ ax[i].set_title(s[j] + f"\n{round(y[index], 5)}")
+ else:
+ # last
+ ax[i].scatter(x[-1], y[-1], color="r", label="last", marker="*", linewidth=3)
+ ax[i].set_title(s[j] + f"\n{round(y[-1], 5)}")
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f"Warning: Plotting error for {f}: {e}")
+ ax[1].legend()
+ fig.savefig(save_dir / "results.png", dpi=200)
+ plt.close()
diff --git a/src/FireDetect/utils/torch_utils.py b/src/FireDetect/utils/torch_utils.py
new file mode 100644
index 0000000..77549b0
--- /dev/null
+++ b/src/FireDetect/utils/torch_utils.py
@@ -0,0 +1,432 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import math
+import os
+import platform
+import subprocess
+import time
+import warnings
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+from utils.general import LOGGER, check_version, colorstr, file_date, git_describe
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+# Suppress PyTorch warnings
+warnings.filterwarnings('ignore', message='User provided device_type of \'cuda\', but CUDA is not available. Disabling')
+warnings.filterwarnings('ignore', category=UserWarning)
+
+
+def smart_inference_mode(torch_1_9=check_version(torch.__version__, '1.9.0')):
+ # Applies torch.inference_mode() decorator if torch>=1.9.0 else torch.no_grad() decorator
+ def decorate(fn):
+ return (torch.inference_mode if torch_1_9 else torch.no_grad)()(fn)
+
+ return decorate
+
+
+def smartCrossEntropyLoss(label_smoothing=0.0):
+ # Returns nn.CrossEntropyLoss with label smoothing enabled for torch>=1.10.0
+ if check_version(torch.__version__, '1.10.0'):
+ return nn.CrossEntropyLoss(label_smoothing=label_smoothing)
+ if label_smoothing > 0:
+ LOGGER.warning(f'WARNING ⚠️ label smoothing {label_smoothing} requires torch>=1.10.0')
+ return nn.CrossEntropyLoss()
+
+
+def smart_DDP(model):
+ # Model DDP creation with checks
+ assert not check_version(torch.__version__, '1.12.0', pinned=True), \
+ 'torch==1.12.0 torchvision==0.13.0 DDP training is not supported due to a known issue. ' \
+ 'Please upgrade or downgrade torch to use DDP. See https://github.com/ultralytics/yolov5/issues/8395'
+ if check_version(torch.__version__, '1.11.0'):
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, static_graph=True)
+ else:
+ return DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+
+def reshape_classifier_output(model, n=1000):
+ # Update a TorchVision classification model to class count 'n' if required
+ from models.common import Classify
+ name, m = list((model.model if hasattr(model, 'model') else model).named_children())[-1] # last module
+ if isinstance(m, Classify): # YOLOv5 Classify() head
+ if m.linear.out_features != n:
+ m.linear = nn.Linear(m.linear.in_features, n)
+ elif isinstance(m, nn.Linear): # ResNet, EfficientNet
+ if m.out_features != n:
+ setattr(model, name, nn.Linear(m.in_features, n))
+ elif isinstance(m, nn.Sequential):
+ types = [type(x) for x in m]
+ if nn.Linear in types:
+ i = types.index(nn.Linear) # nn.Linear index
+ if m[i].out_features != n:
+ m[i] = nn.Linear(m[i].in_features, n)
+ elif nn.Conv2d in types:
+ i = types.index(nn.Conv2d) # nn.Conv2d index
+ if m[i].out_channels != n:
+ m[i] = nn.Conv2d(m[i].in_channels, n, m[i].kernel_size, m[i].stride, bias=m[i].bias is not None)
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ # Decorator to make all processes in distributed training wait for each local_master to do something
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def device_count():
+ # Returns number of CUDA devices available. Safe version of torch.cuda.device_count(). Supports Linux and Windows
+ assert platform.system() in ('Linux', 'Windows'), 'device_count() only supported on Linux or Windows'
+ try:
+ cmd = 'nvidia-smi -L | wc -l' if platform.system() == 'Linux' else 'nvidia-smi -L | find /c /v ""' # Windows
+ return int(subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1])
+ except Exception:
+ return 0
+
+
+def select_device(device='', batch_size=0, newline=True):
+ # device = None or 'cpu' or 0 or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or file_date()} Python-{platform.python_version()} torch-{torch.__version__} '
+ device = str(device).strip().lower().replace('cuda:', '').replace('none', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ mps = device == 'mps' # Apple Metal Performance Shaders (MPS)
+ if cpu or mps:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable - must be before assert is_available()
+ assert torch.cuda.is_available() and torch.cuda.device_count() >= len(device.replace(',', '')), \
+ f"Invalid CUDA '--device {device}' requested, use '--device cpu' or pass valid CUDA device(s)"
+
+ if not cpu and not mps and torch.cuda.is_available(): # prefer GPU if available
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size > 0: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / (1 << 20):.0f}MiB)\n" # bytes to MB
+ arg = 'cuda:0'
+ elif mps and getattr(torch, 'has_mps', False) and torch.backends.mps.is_available(): # prefer MPS if available
+ s += 'MPS\n'
+ arg = 'mps'
+ else: # revert to CPU
+ s += 'CPU\n'
+ arg = 'cpu'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s)
+ return torch.device(arg)
+
+
+def time_sync():
+ # PyTorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ """ YOLOv5 speed/memory/FLOPs profiler
+ Usage:
+ input = torch.randn(16, 3, 640, 640)
+ m1 = lambda x: x * torch.sigmoid(x)
+ m2 = nn.SiLU()
+ profile(input, [m1, m2], n=100) # profile over 100 iterations
+ """
+ results = []
+ if not isinstance(device, torch.device):
+ device = select_device(device)
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except Exception:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in, s_out = (tuple(x.shape) if isinstance(x, torch.Tensor) else 'list' for x in (x, y)) # shapes
+ p = sum(x.numel() for x in m.parameters()) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ LOGGER.info(f'Model pruned to {sparsity(model):.3g} global sparsity')
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse Conv2d() and BatchNorm2d() layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ dilation=conv.dilation,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # Prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # Prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, imgsz=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ p = next(model.parameters())
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32 # max stride
+ im = torch.empty((1, p.shape[1], stride, stride), device=p.device) # input image in BCHW format
+ flops = thop.profile(deepcopy(model), inputs=(im,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ imgsz = imgsz if isinstance(imgsz, list) else [imgsz, imgsz] # expand if int/float
+ fs = f', {flops * imgsz[0] / stride * imgsz[1] / stride:.1f} GFLOPs' # 640x640 GFLOPs
+ except Exception:
+ fs = ''
+
+ name = Path(model.yaml_file).stem.replace('yolov5', 'YOLOv5') if hasattr(model, 'yaml_file') else 'Model'
+ LOGGER.info(f"{name} summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # Scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+def smart_optimizer(model, name='Adam', lr=0.001, momentum=0.9, decay=1e-5):
+ # YOLOv5 3-param group optimizer: 0) weights with decay, 1) weights no decay, 2) biases no decay
+ g = [], [], [] # optimizer parameter groups
+ bn = tuple(v for k, v in nn.__dict__.items() if 'Norm' in k) # normalization layers, i.e. BatchNorm2d()
+ for v in model.modules():
+ for p_name, p in v.named_parameters(recurse=0):
+ if p_name == 'bias': # bias (no decay)
+ g[2].append(p)
+ elif p_name == 'weight' and isinstance(v, bn): # weight (no decay)
+ g[1].append(p)
+ else:
+ g[0].append(p) # weight (with decay)
+
+ if name == 'Adam':
+ optimizer = torch.optim.Adam(g[2], lr=lr, betas=(momentum, 0.999)) # adjust beta1 to momentum
+ elif name == 'AdamW':
+ optimizer = torch.optim.AdamW(g[2], lr=lr, betas=(momentum, 0.999), weight_decay=0.0)
+ elif name == 'RMSProp':
+ optimizer = torch.optim.RMSprop(g[2], lr=lr, momentum=momentum)
+ elif name == 'SGD':
+ optimizer = torch.optim.SGD(g[2], lr=lr, momentum=momentum, nesterov=True)
+ else:
+ raise NotImplementedError(f'Optimizer {name} not implemented.')
+
+ optimizer.add_param_group({'params': g[0], 'weight_decay': decay}) # add g0 with weight_decay
+ optimizer.add_param_group({'params': g[1], 'weight_decay': 0.0}) # add g1 (BatchNorm2d weights)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__}(lr={lr}) with parameter groups "
+ f"{len(g[1])} weight(decay=0.0), {len(g[0])} weight(decay={decay}), {len(g[2])} bias")
+ return optimizer
+
+
+def smart_hub_load(repo='ultralytics/yolov5', model='yolov5s', **kwargs):
+ # YOLOv5 torch.hub.load() wrapper with smart error/issue handling
+ if check_version(torch.__version__, '1.9.1'):
+ kwargs['skip_validation'] = True # validation causes GitHub API rate limit errors
+ if check_version(torch.__version__, '1.12.0'):
+ kwargs['trust_repo'] = True # argument required starting in torch 0.12
+ try:
+ return torch.hub.load(repo, model, **kwargs)
+ except Exception:
+ return torch.hub.load(repo, model, force_reload=True, **kwargs)
+
+
+def smart_resume(ckpt, optimizer, ema=None, weights='yolov5s.pt', epochs=300, resume=True):
+ # Resume training from a partially trained checkpoint
+ best_fitness = 0.0
+ start_epoch = ckpt['epoch'] + 1
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer']) # optimizer
+ best_fitness = ckpt['best_fitness']
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict()) # EMA
+ ema.updates = ckpt['updates']
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.\n' \
+ f"Start a new training without --resume, i.e. 'python train.py --weights {weights}'"
+ LOGGER.info(f'Resuming training from {weights} from epoch {start_epoch} to {epochs} total epochs')
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+ return best_fitness, start_epoch, epochs
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Updated Exponential Moving Average (EMA) from https://github.com/rwightman/pytorch-image-models
+ Keeps a moving average of everything in the model state_dict (parameters and buffers)
+ For EMA details see https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ """
+
+ def __init__(self, model, decay=0.9999, tau=2000, updates=0):
+ # Create EMA
+ self.ema = deepcopy(de_parallel(model)).eval() # FP32 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / tau)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = de_parallel(model).state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point: # true for FP16 and FP32
+ v *= d
+ v += (1 - d) * msd[k].detach()
+ # assert v.dtype == msd[k].dtype == torch.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/src/FireDetect/utils/triton.py b/src/FireDetect/utils/triton.py
new file mode 100644
index 0000000..a94ef0a
--- /dev/null
+++ b/src/FireDetect/utils/triton.py
@@ -0,0 +1,85 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+""" Utils to interact with the Triton Inference Server
+"""
+
+import typing
+from urllib.parse import urlparse
+
+import torch
+
+
+class TritonRemoteModel:
+ """ A wrapper over a model served by the Triton Inference Server. It can
+ be configured to communicate over GRPC or HTTP. It accepts Torch Tensors
+ as input and returns them as outputs.
+ """
+
+ def __init__(self, url: str):
+ """
+ Keyword arguments:
+ url: Fully qualified address of the Triton server - for e.g. grpc://localhost:8000
+ """
+
+ parsed_url = urlparse(url)
+ if parsed_url.scheme == "grpc":
+ from tritonclient.grpc import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton GRPC client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository.models[0].name
+ self.metadata = self.client.get_model_metadata(self.model_name, as_json=True)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i["shape"]], i['datatype']) for i in self.metadata['inputs']]
+
+ else:
+ from tritonclient.http import InferenceServerClient, InferInput
+
+ self.client = InferenceServerClient(parsed_url.netloc) # Triton HTTP client
+ model_repository = self.client.get_model_repository_index()
+ self.model_name = model_repository[0]['name']
+ self.metadata = self.client.get_model_metadata(self.model_name)
+
+ def create_input_placeholders() -> typing.List[InferInput]:
+ return [
+ InferInput(i['name'], [int(s) for s in i["shape"]], i['datatype']) for i in self.metadata['inputs']]
+
+ self._create_input_placeholders_fn = create_input_placeholders
+
+ @property
+ def runtime(self):
+ """Returns the model runtime"""
+ return self.metadata.get("backend", self.metadata.get("platform"))
+
+ def __call__(self, *args, **kwargs) -> typing.Union[torch.Tensor, typing.Tuple[torch.Tensor, ...]]:
+ """ Invokes the model. Parameters can be provided via args or kwargs.
+ args, if provided, are assumed to match the order of inputs of the model.
+ kwargs are matched with the model input names.
+ """
+ inputs = self._create_inputs(*args, **kwargs)
+ response = self.client.infer(model_name=self.model_name, inputs=inputs)
+ result = []
+ for output in self.metadata['outputs']:
+ tensor = torch.as_tensor(response.as_numpy(output['name']))
+ result.append(tensor)
+ return result[0] if len(result) == 1 else result
+
+ def _create_inputs(self, *args, **kwargs):
+ args_len, kwargs_len = len(args), len(kwargs)
+ if not args_len and not kwargs_len:
+ raise RuntimeError("No inputs provided.")
+ if args_len and kwargs_len:
+ raise RuntimeError("Cannot specify args and kwargs at the same time")
+
+ placeholders = self._create_input_placeholders_fn()
+ if args_len:
+ if args_len != len(placeholders):
+ raise RuntimeError(f"Expected {len(placeholders)} inputs, got {args_len}.")
+ for input, value in zip(placeholders, args):
+ input.set_data_from_numpy(value.cpu().numpy())
+ else:
+ for input in placeholders:
+ value = kwargs[input.name]
+ input.set_data_from_numpy(value.cpu().numpy())
+ return placeholders