+
+
+ + +
+
+
+##
+
+  +
+
+
+  +
+  +
+  +
+
+ +
+  +
+  +
+
+
+ +
+ + + +
+
+YOLOv5 🚀 is a family of object detection architectures and models pretrained on the COCO dataset, and represents Ultralytics + open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development. +
+ + + +Documentation
+
+See the [YOLOv5 Docs](https://docs.ultralytics.com) for full documentation on training, testing and deployment.
+
+## Quick Start Examples
+
+
+
+
+Install
+ +[**Python>=3.6.0**](https://www.python.org/) is required with all +[requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) installed including +[**PyTorch>=1.7**](https://pytorch.org/get-started/locally/): + + +```bash +$ git clone https://github.com/ultralytics/yolov5 +$ cd yolov5 +$ pip install -r requirements.txt +``` + +
+
+
+
+
+Inference
+ +Inference with YOLOv5 and [PyTorch Hub](https://github.com/ultralytics/yolov5/issues/36). Models automatically download +from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). + +```python +import torch + +# Model +model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5l, yolov5x, custom + +# Images +img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list + +# Inference +results = model(img) + +# Results +results.print() # or .show(), .save(), .crop(), .pandas(), etc. +``` + +
+
+
+Inference with detect.py
+ +`detect.py` runs inference on a variety of sources, downloading models automatically from +the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases) and saving results to `runs/detect`. + +```bash +$ python detect.py --source 0 # webcam + img.jpg # image + vid.mp4 # video + path/ # directory + path/*.jpg # glob + 'https://youtu.be/Zgi9g1ksQHc' # YouTube + 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream +``` + +
+ +
+
+
+
+
+Training
+ +Run commands below to reproduce results +on [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) dataset (dataset auto-downloads on +first use). Training times for YOLOv5s/m/l/x are 2/4/6/8 days on a single V100 (multi-GPU times faster). Use the +largest `--batch-size` your GPU allows (batch sizes shown for 16 GB devices). + +```bash +$ python train.py --data coco.yaml --cfg yolov5s.yaml --weights '' --batch-size 64 + yolov5m 40 + yolov5l 24 + yolov5x 16 +``` + +
+
+
+
+
+## Tutorials
+ +* [Train Custom Data](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data) 🚀 RECOMMENDED +* [Tips for Best Training Results](https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results) ☘️ + RECOMMENDED +* [Weights & Biases Logging](https://github.com/ultralytics/yolov5/issues/1289) 🌟 NEW +* [Roboflow for Datasets, Labeling, and Active Learning](https://github.com/ultralytics/yolov5/issues/4975) 🌟 NEW +* [Multi-GPU Training](https://github.com/ultralytics/yolov5/issues/475) +* [PyTorch Hub](https://github.com/ultralytics/yolov5/issues/36) ⭐ NEW +* [TorchScript, ONNX, CoreML Export](https://github.com/ultralytics/yolov5/issues/251) 🚀 +* [Test-Time Augmentation (TTA)](https://github.com/ultralytics/yolov5/issues/303) +* [Model Ensembling](https://github.com/ultralytics/yolov5/issues/318) +* [Model Pruning/Sparsity](https://github.com/ultralytics/yolov5/issues/304) +* [Hyperparameter Evolution](https://github.com/ultralytics/yolov5/issues/607) +* [Transfer Learning with Frozen Layers](https://github.com/ultralytics/yolov5/issues/1314) ⭐ NEW +* [TensorRT Deployment](https://github.com/wang-xinyu/tensorrtx) + +Environments
+
+Get started in seconds with our verified environments. Click each icon below for details.
+
+
+
+## Integrations
+
+
+
+|Weights and Biases|Roboflow ⭐ NEW|
+|:-:|:-:|
+|Automatically track and visualize all your YOLOv5 training runs in the cloud with [Weights & Biases](https://wandb.ai/site?utm_campaign=repo_yolo_readme)|Label and export your custom datasets directly to YOLOv5 for training with [Roboflow](https://roboflow.com/?ref=ultralytics) |
+
+
+
+
+## Why YOLOv5
+
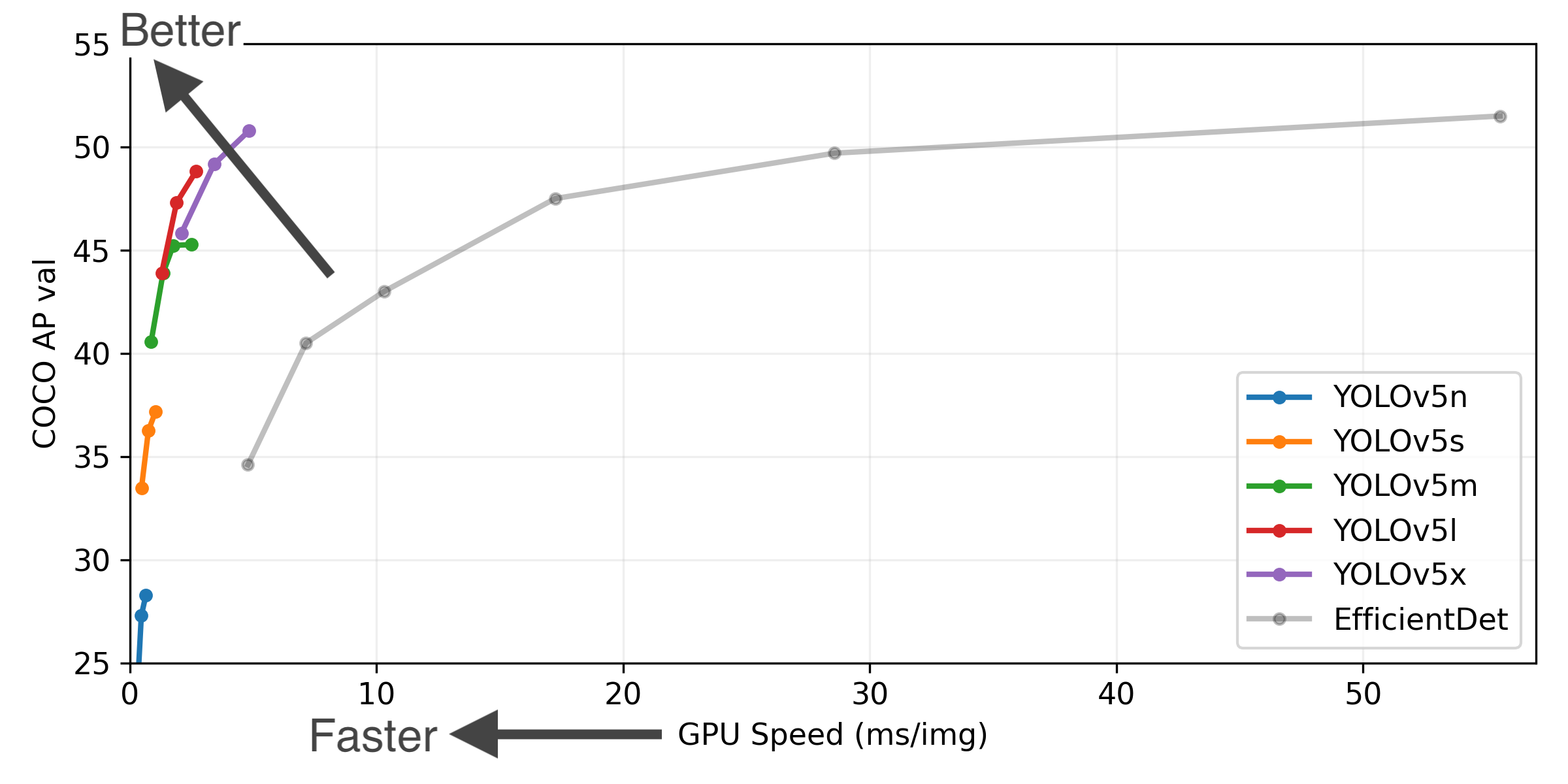
+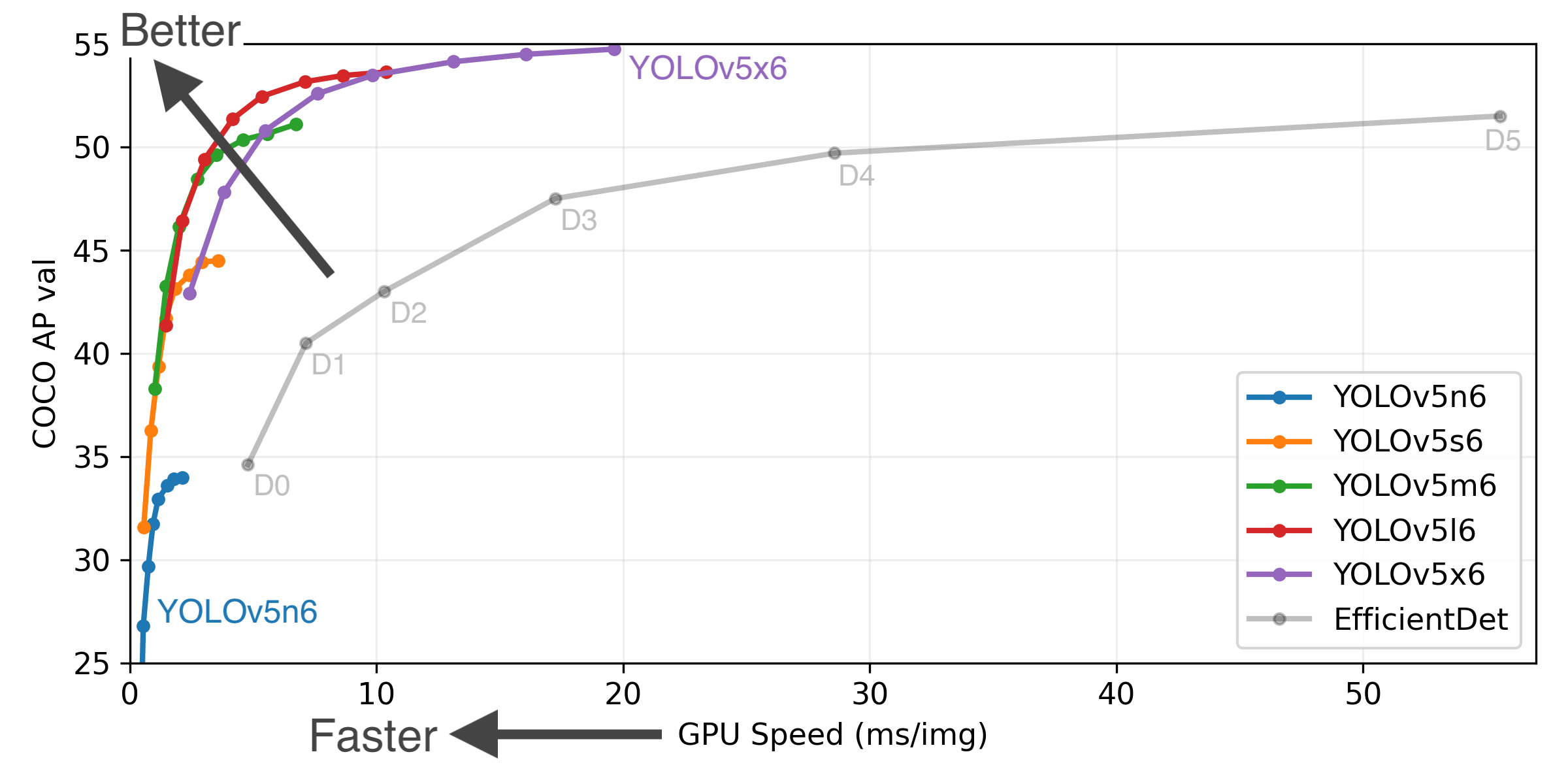
+
+YOLOv5-P5 640 Figure (click to expand)
+ +
+
+
+### Pretrained Checkpoints
+
+[assets]: https://github.com/ultralytics/yolov5/releases
+[TTA]: https://github.com/ultralytics/yolov5/issues/303
+
+|Model |sizeFigure Notes (click to expand)
+ +* **COCO AP val** denotes mAP@0.5:0.95 metric measured on the 5000-image [COCO val2017](http://cocodataset.org) dataset over various inference sizes from 256 to 1536. +* **GPU Speed** measures average inference time per image on [COCO val2017](http://cocodataset.org) dataset using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100 instance at batch-size 32. +* **EfficientDet** data from [google/automl](https://github.com/google/automl) at batch size 8. +* **Reproduce** by `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt` +(pixels) |mAPval
0.5:0.95 |mAPval
0.5 |Speed
CPU b1
(ms) |Speed
V100 b1
(ms) |Speed
V100 b32
(ms) |params
(M) |FLOPs
@640 (B) +|--- |--- |--- |--- |--- |--- |--- |--- |--- +|[YOLOv5n][assets] |640 |28.4 |46.0 |**45** |**6.3**|**0.6**|**1.9**|**4.5** +|[YOLOv5s][assets] |640 |37.2 |56.0 |98 |6.4 |0.9 |7.2 |16.5 +|[YOLOv5m][assets] |640 |45.2 |63.9 |224 |8.2 |1.7 |21.2 |49.0 +|[YOLOv5l][assets] |640 |48.8 |67.2 |430 |10.1 |2.7 |46.5 |109.1 +|[YOLOv5x][assets] |640 |50.7 |68.9 |766 |12.1 |4.8 |86.7 |205.7 +| | | | | | | | | +|[YOLOv5n6][assets] |1280 |34.0 |50.7 |153 |8.1 |2.1 |3.2 |4.6 +|[YOLOv5s6][assets] |1280 |44.5 |63.0 |385 |8.2 |3.6 |16.8 |12.6 +|[YOLOv5m6][assets] |1280 |51.0 |69.0 |887 |11.1 |6.8 |35.7 |50.0 +|[YOLOv5l6][assets] |1280 |53.6 |71.6 |1784 |15.8 |10.5 |76.8 |111.4 +|[YOLOv5x6][assets]
+ [TTA][TTA]|1280
1536 |54.7
**55.4** |**72.4**
72.3 |3136
- |26.2
- |19.4
- |140.7
- |209.8
- + +
+
Reproduce by `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65` +* **Speed** averaged over COCO val images using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) instance. NMS times (~1 ms/img) not included.
Reproduce by `python val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45` +* **TTA** [Test Time Augmentation](https://github.com/ultralytics/yolov5/issues/303) includes reflection and scale augmentations.
Reproduce by `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment` + +
+
+## Table Notes (click to expand)
+ +* All checkpoints are trained to 300 epochs with default settings and hyperparameters. +* **mAPval** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.Reproduce by `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65` +* **Speed** averaged over COCO val images using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) instance. NMS times (~1 ms/img) not included.
Reproduce by `python val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45` +* **TTA** [Test Time Augmentation](https://github.com/ultralytics/yolov5/issues/303) includes reflection and scale augmentations.
Reproduce by `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment` + +
Contribute
+
+We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our [Contributing Guide](CONTRIBUTING.md) to get started, and fill out the [YOLOv5 Survey](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey) to send us feedback on your experiences. Thank you to all our contributors!
+
+ +
+
+##
+
+
+## Contact
+
+For YOLOv5 bugs and feature requests please visit [GitHub Issues](https://github.com/ultralytics/yolov5/issues). For business inquiries or
+professional support requests please visit [https://ultralytics.com/contact](https://ultralytics.com/contact).
+
++ + diff --git a/src/image_recognition/docs/tutorial.ipynb b/src/image_recognition/docs/tutorial.ipynb new file mode 100644 index 0000000..7763a26 --- /dev/null +++ b/src/image_recognition/docs/tutorial.ipynb @@ -0,0 +1,1086 @@ +{ + "nbformat": 4, + "nbformat_minor": 0, + "metadata": { + "colab": { + "name": "YOLOv5 Tutorial", + "provenance": [], + "collapsed_sections": [], + "include_colab_link": true + }, + "kernelspec": { + "name": "python3", + "display_name": "Python 3" + }, + "accelerator": "GPU", + "widgets": { + "application/vnd.jupyter.widget-state+json": { + "eb95db7cae194218b3fcefb439b6352f": { + "model_module": "@jupyter-widgets/controls", + "model_name": "HBoxModel", + "model_module_version": "1.5.0", + "state": { + "_view_name": "HBoxView", + "_dom_classes": [], + "_model_name": "HBoxModel", + "_view_module": "@jupyter-widgets/controls", + "_model_module_version": "1.5.0", + "_view_count": null, + "_view_module_version": "1.5.0", + "box_style": "", + "layout": "IPY_MODEL_769ecde6f2e64bacb596ce972f8d3d2d", + "_model_module": "@jupyter-widgets/controls", + "children": [ + "IPY_MODEL_384a001876054c93b0af45cd1e960bfe", + "IPY_MODEL_dded0aeae74440f7ba2ffa0beb8dd612", + "IPY_MODEL_5296d28be75740b2892ae421bbec3657" + ] + } + }, + "769ecde6f2e64bacb596ce972f8d3d2d": { + "model_module": "@jupyter-widgets/base", + "model_name": "LayoutModel", + "model_module_version": "1.2.0", + "state": { + "_view_name": "LayoutView", + "grid_template_rows": null, + "right": null, + "justify_content": null, + "_view_module": "@jupyter-widgets/base", + "overflow": null, + "_model_module_version": "1.2.0", + "_view_count": null, + "flex_flow": null, + "width": null, + "min_width": null, + "border": null, + "align_items": null, + "bottom": null, + "_model_module": "@jupyter-widgets/base", + "top": null, + "grid_column": null, + "overflow_y": null, + "overflow_x": null, + "grid_auto_flow": null, + "grid_area": null, + "grid_template_columns": null, + "flex": null, + "_model_name": "LayoutModel", + "justify_items": null, + "grid_row": null, + "max_height": null, + "align_content": null, + "visibility": null, + "align_self": null, + "height": null, + "min_height": null, + "padding": null, + "grid_auto_rows": null, + "grid_gap": null, + "max_width": null, + "order": null, + "_view_module_version": "1.2.0", + "grid_template_areas": null, + "object_position": null, + "object_fit": null, + "grid_auto_columns": null, + "margin": null, + "display": null, + "left": null + } + }, + "384a001876054c93b0af45cd1e960bfe": { + "model_module": "@jupyter-widgets/controls", + "model_name": "HTMLModel", + "model_module_version": "1.5.0", + "state": { + "_view_name": "HTMLView", + "style": "IPY_MODEL_9f09facb2a6c4a7096810d327c8b551c", + "_dom_classes": [], + "description": "", + "_model_name": "HTMLModel", + "placeholder": "", + "_view_module": "@jupyter-widgets/controls", + "_model_module_version": "1.5.0", + "value": "100%", + "_view_count": null, + "_view_module_version": "1.5.0", + "description_tooltip": null, + "_model_module": "@jupyter-widgets/controls", + "layout": "IPY_MODEL_25621cff5d16448cb7260e839fd0f543" + } + }, + "dded0aeae74440f7ba2ffa0beb8dd612": { + "model_module": "@jupyter-widgets/controls", + "model_name": "FloatProgressModel", + "model_module_version": "1.5.0", + "state": { + "_view_name": "ProgressView", + "style": "IPY_MODEL_0ce7164fc0c74bb9a2b5c7037375a727", + "_dom_classes": [], + "description": "", + "_model_name": "FloatProgressModel", + "bar_style": "success", + "max": 818322941, + "_view_module": "@jupyter-widgets/controls", + "_model_module_version": "1.5.0", + "value": 818322941, + "_view_count": null, + "_view_module_version": "1.5.0", + "orientation": "horizontal", + "min": 0, + "description_tooltip": null, + "_model_module": "@jupyter-widgets/controls", + "layout": "IPY_MODEL_c4c4593c10904cb5b8a5724d60c7e181" + } + }, + "5296d28be75740b2892ae421bbec3657": { + "model_module": "@jupyter-widgets/controls", + "model_name": "HTMLModel", + "model_module_version": "1.5.0", + "state": { + "_view_name": "HTMLView", + "style": "IPY_MODEL_473371611126476c88d5d42ec7031ed6", + "_dom_classes": [], + "description": "", + "_model_name": "HTMLModel", + "placeholder": "", + "_view_module": "@jupyter-widgets/controls", + "_model_module_version": "1.5.0", + "value": " 780M/780M [00:11<00:00, 91.9MB/s]", + "_view_count": null, + "_view_module_version": "1.5.0", + "description_tooltip": null, + "_model_module": "@jupyter-widgets/controls", + "layout": "IPY_MODEL_65efdfd0d26c46e79c8c5ff3b77126cc" + } + }, + "9f09facb2a6c4a7096810d327c8b551c": { + "model_module": "@jupyter-widgets/controls", + "model_name": "DescriptionStyleModel", + "model_module_version": "1.5.0", + "state": { + "_view_name": "StyleView", + "_model_name": "DescriptionStyleModel", + "description_width": "", + "_view_module": "@jupyter-widgets/base", + "_model_module_version": "1.5.0", + "_view_count": null, + "_view_module_version": "1.2.0", + "_model_module": "@jupyter-widgets/controls" + } + }, + "25621cff5d16448cb7260e839fd0f543": { + "model_module": "@jupyter-widgets/base", + "model_name": "LayoutModel", + "model_module_version": "1.2.0", + "state": { + "_view_name": "LayoutView", + "grid_template_rows": null, + "right": null, + "justify_content": null, + "_view_module": "@jupyter-widgets/base", + "overflow": null, + "_model_module_version": "1.2.0", + "_view_count": null, + "flex_flow": null, + "width": null, + "min_width": null, + "border": null, + "align_items": null, + "bottom": null, + "_model_module": "@jupyter-widgets/base", + "top": null, + "grid_column": null, + "overflow_y": null, + "overflow_x": null, + "grid_auto_flow": null, + "grid_area": null, + "grid_template_columns": null, + "flex": null, + "_model_name": "LayoutModel", + "justify_items": null, + "grid_row": null, + "max_height": null, + "align_content": null, + "visibility": null, + "align_self": null, + "height": null, + "min_height": null, + "padding": null, + "grid_auto_rows": null, + "grid_gap": null, + "max_width": null, + "order": null, + "_view_module_version": "1.2.0", + "grid_template_areas": null, + "object_position": null, + "object_fit": null, + "grid_auto_columns": null, + "margin": null, + "display": null, + "left": null + } + }, + "0ce7164fc0c74bb9a2b5c7037375a727": { + "model_module": "@jupyter-widgets/controls", + "model_name": "ProgressStyleModel", + "model_module_version": "1.5.0", + "state": { + "_view_name": "StyleView", + "_model_name": "ProgressStyleModel", + "description_width": "", + "_view_module": "@jupyter-widgets/base", + "_model_module_version": "1.5.0", + "_view_count": null, + "_view_module_version": "1.2.0", + "bar_color": null, + "_model_module": "@jupyter-widgets/controls" + } + }, + "c4c4593c10904cb5b8a5724d60c7e181": { + "model_module": "@jupyter-widgets/base", + "model_name": "LayoutModel", + "model_module_version": "1.2.0", + "state": { + "_view_name": "LayoutView", + "grid_template_rows": null, + "right": null, + "justify_content": null, + "_view_module": "@jupyter-widgets/base", + "overflow": null, + "_model_module_version": "1.2.0", + "_view_count": null, + "flex_flow": null, + "width": null, + "min_width": null, + "border": null, + "align_items": null, + "bottom": null, + "_model_module": "@jupyter-widgets/base", + "top": null, + "grid_column": null, + "overflow_y": null, + "overflow_x": null, + "grid_auto_flow": null, + "grid_area": null, + "grid_template_columns": null, + "flex": null, + "_model_name": "LayoutModel", + "justify_items": null, + "grid_row": null, + "max_height": null, + "align_content": null, + "visibility": null, + "align_self": null, + "height": null, + "min_height": null, + "padding": null, + "grid_auto_rows": null, + "grid_gap": null, + "max_width": null, + "order": null, + "_view_module_version": "1.2.0", + "grid_template_areas": null, + "object_position": null, + "object_fit": null, + "grid_auto_columns": null, + "margin": null, + "display": null, + "left": null + } + }, + "473371611126476c88d5d42ec7031ed6": { + "model_module": "@jupyter-widgets/controls", + "model_name": "DescriptionStyleModel", + "model_module_version": "1.5.0", + "state": { + "_view_name": "StyleView", + "_model_name": "DescriptionStyleModel", + "description_width": "", + "_view_module": "@jupyter-widgets/base", + "_model_module_version": "1.5.0", + "_view_count": null, + "_view_module_version": "1.2.0", + "_model_module": "@jupyter-widgets/controls" + } + }, + "65efdfd0d26c46e79c8c5ff3b77126cc": { + "model_module": "@jupyter-widgets/base", + "model_name": "LayoutModel", + "model_module_version": "1.2.0", + "state": { + "_view_name": "LayoutView", + "grid_template_rows": null, + "right": null, + "justify_content": null, + "_view_module": "@jupyter-widgets/base", + "overflow": null, + "_model_module_version": "1.2.0", + "_view_count": null, + "flex_flow": null, + "width": null, + "min_width": null, + "border": null, + "align_items": null, + "bottom": null, + "_model_module": "@jupyter-widgets/base", + "top": null, + "grid_column": null, + "overflow_y": null, + "overflow_x": null, + "grid_auto_flow": null, + "grid_area": null, + "grid_template_columns": null, + "flex": null, + "_model_name": "LayoutModel", + "justify_items": null, + "grid_row": null, + "max_height": null, + "align_content": null, + "visibility": null, + "align_self": null, + "height": null, + "min_height": null, + "padding": null, + "grid_auto_rows": null, + "grid_gap": null, + "max_width": null, + "order": null, + "_view_module_version": "1.2.0", + "grid_template_areas": null, + "object_position": null, + "object_fit": null, + "grid_auto_columns": null, + "margin": null, + "display": null, + "left": null + } + } + } + } + }, + "cells": [ + { + "cell_type": "markdown", + "metadata": { + "id": "view-in-github", + "colab_type": "text" + }, + "source": [ + "
 \n",
+ "\n",
+ "This is the **official YOLOv5 🚀 notebook** by **Ultralytics**, and is freely available for redistribution under the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/). \n",
+ "For more information please visit https://github.com/ultralytics/yolov5 and https://ultralytics.com. Thank you!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7mGmQbAO5pQb"
+ },
+ "source": [
+ "# Setup\n",
+ "\n",
+ "Clone repo, install dependencies and check PyTorch and GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wbvMlHd_QwMG",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3809e5a9-dd41-4577-fe62-5531abf7cca2"
+ },
+ "source": [
+ "!git clone https://github.com/ultralytics/yolov5 # clone\n",
+ "%cd yolov5\n",
+ "%pip install -qr requirements.txt # install\n",
+ "\n",
+ "from yolov5 import utils\n",
+ "display = utils.notebook_init() # checks"
+ ],
+ "execution_count": 2,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "Setup complete ✅\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4JnkELT0cIJg"
+ },
+ "source": [
+ "# 1. Inference\n",
+ "\n",
+ "`detect.py` runs YOLOv5 inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/detect`. Example inference sources are:\n",
+ "\n",
+ "```shell\n",
+ "python detect.py --source 0 # webcam\n",
+ " img.jpg # image \n",
+ " vid.mp4 # video\n",
+ " path/ # directory\n",
+ " path/*.jpg # glob\n",
+ " 'https://youtu.be/Zgi9g1ksQHc' # YouTube\n",
+ " 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "zR9ZbuQCH7FX",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "8f7e6588-215d-4ebd-93af-88b871e770a7"
+ },
+ "source": [
+ "!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images\n",
+ "display.Image(filename='runs/detect/exp/zidane.jpg', width=600)"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mdetect: \u001b[0mweights=['yolov5s.pt'], source=data/images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False\n",
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model Summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.007s)\n",
+ "image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.007s)\n",
+ "Speed: 0.5ms pre-process, 6.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/detect/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hkAzDWJ7cWTr"
+ },
+ "source": [
+ " \n",
+ "
\n",
+ "\n",
+ "This is the **official YOLOv5 🚀 notebook** by **Ultralytics**, and is freely available for redistribution under the [GPL-3.0 license](https://choosealicense.com/licenses/gpl-3.0/). \n",
+ "For more information please visit https://github.com/ultralytics/yolov5 and https://ultralytics.com. Thank you!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7mGmQbAO5pQb"
+ },
+ "source": [
+ "# Setup\n",
+ "\n",
+ "Clone repo, install dependencies and check PyTorch and GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "wbvMlHd_QwMG",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3809e5a9-dd41-4577-fe62-5531abf7cca2"
+ },
+ "source": [
+ "!git clone https://github.com/ultralytics/yolov5 # clone\n",
+ "%cd yolov5\n",
+ "%pip install -qr requirements.txt # install\n",
+ "\n",
+ "from yolov5 import utils\n",
+ "display = utils.notebook_init() # checks"
+ ],
+ "execution_count": 2,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "Setup complete ✅\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4JnkELT0cIJg"
+ },
+ "source": [
+ "# 1. Inference\n",
+ "\n",
+ "`detect.py` runs YOLOv5 inference on a variety of sources, downloading models automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases), and saving results to `runs/detect`. Example inference sources are:\n",
+ "\n",
+ "```shell\n",
+ "python detect.py --source 0 # webcam\n",
+ " img.jpg # image \n",
+ " vid.mp4 # video\n",
+ " path/ # directory\n",
+ " path/*.jpg # glob\n",
+ " 'https://youtu.be/Zgi9g1ksQHc' # YouTube\n",
+ " 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "zR9ZbuQCH7FX",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "8f7e6588-215d-4ebd-93af-88b871e770a7"
+ },
+ "source": [
+ "!python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images\n",
+ "display.Image(filename='runs/detect/exp/zidane.jpg', width=600)"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mdetect: \u001b[0mweights=['yolov5s.pt'], source=data/images, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False\n",
+ "YOLOv5 🚀 v6.0-48-g84a8099 torch 1.10.0+cu102 CUDA:0 (Tesla V100-SXM2-16GB, 16160MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "Model Summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "image 1/2 /content/yolov5/data/images/bus.jpg: 640x480 4 persons, 1 bus, Done. (0.007s)\n",
+ "image 2/2 /content/yolov5/data/images/zidane.jpg: 384x640 2 persons, 1 tie, Done. (0.007s)\n",
+ "Speed: 0.5ms pre-process, 6.9ms inference, 1.3ms NMS per image at shape (1, 3, 640, 640)\n",
+ "Results saved to \u001b[1mruns/detect/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "hkAzDWJ7cWTr"
+ },
+ "source": [
+ " \n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on [COCO](https://cocodataset.org/#home) val or test-dev datasets. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag. Note that `pycocotools` metrics may be ~1% better than the equivalent repo metrics, as is visible below, due to slight differences in mAP computation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyTZYGgRjnMc"
+ },
+ "source": [
+ "## COCO val\n",
+ "Download [COCO val 2017](https://github.com/ultralytics/yolov5/blob/74b34872fdf41941cddcf243951cdb090fbac17b/data/coco.yaml#L14) dataset (1GB - 5000 images), and test model accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 48,
+ "referenced_widgets": [
+ "eb95db7cae194218b3fcefb439b6352f",
+ "769ecde6f2e64bacb596ce972f8d3d2d",
+ "384a001876054c93b0af45cd1e960bfe",
+ "dded0aeae74440f7ba2ffa0beb8dd612",
+ "5296d28be75740b2892ae421bbec3657",
+ "9f09facb2a6c4a7096810d327c8b551c",
+ "25621cff5d16448cb7260e839fd0f543",
+ "0ce7164fc0c74bb9a2b5c7037375a727",
+ "c4c4593c10904cb5b8a5724d60c7e181",
+ "473371611126476c88d5d42ec7031ed6",
+ "65efdfd0d26c46e79c8c5ff3b77126cc"
+ ]
+ },
+ "outputId": "bcf9a448-1f9b-4a41-ad49-12f181faf05a"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "eb95db7cae194218b3fcefb439b6352f",
+ "version_minor": 0,
+ "version_major": 2
+ },
+ "text/plain": [
+ " 0%| | 0.00/780M [00:00
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on [COCO](https://cocodataset.org/#home) val or test-dev datasets. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag. Note that `pycocotools` metrics may be ~1% better than the equivalent repo metrics, as is visible below, due to slight differences in mAP computation."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "eyTZYGgRjnMc"
+ },
+ "source": [
+ "## COCO val\n",
+ "Download [COCO val 2017](https://github.com/ultralytics/yolov5/blob/74b34872fdf41941cddcf243951cdb090fbac17b/data/coco.yaml#L14) dataset (1GB - 5000 images), and test model accuracy."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 48,
+ "referenced_widgets": [
+ "eb95db7cae194218b3fcefb439b6352f",
+ "769ecde6f2e64bacb596ce972f8d3d2d",
+ "384a001876054c93b0af45cd1e960bfe",
+ "dded0aeae74440f7ba2ffa0beb8dd612",
+ "5296d28be75740b2892ae421bbec3657",
+ "9f09facb2a6c4a7096810d327c8b551c",
+ "25621cff5d16448cb7260e839fd0f543",
+ "0ce7164fc0c74bb9a2b5c7037375a727",
+ "c4c4593c10904cb5b8a5724d60c7e181",
+ "473371611126476c88d5d42ec7031ed6",
+ "65efdfd0d26c46e79c8c5ff3b77126cc"
+ ]
+ },
+ "outputId": "bcf9a448-1f9b-4a41-ad49-12f181faf05a"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip')\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip"
+ ],
+ "execution_count": null,
+ "outputs": [
+ {
+ "output_type": "display_data",
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "eb95db7cae194218b3fcefb439b6352f",
+ "version_minor": 0,
+ "version_major": 2
+ },
+ "text/plain": [
+ " 0%| | 0.00/780M [00:00 \n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "
\n",
+ "Close the active learning loop by sampling images from your inference conditions with the `roboflow` pip package\n",
+ "\n", + "\n", + "Train a YOLOv5s model on the [COCO128](https://www.kaggle.com/ultralytics/coco128) dataset with `--data coco128.yaml`, starting from pretrained `--weights yolov5s.pt`, or from randomly initialized `--weights '' --cfg yolov5s.yaml`.\n", + "\n", + "- **Pretrained [Models](https://github.com/ultralytics/yolov5/tree/master/models)** are downloaded\n", + "automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases)\n", + "- **[Datasets](https://github.com/ultralytics/yolov5/tree/master/data)** available for autodownload include: [COCO](https://github.com/ultralytics/yolov5/blob/master/data/coco.yaml), [COCO128](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), [VOC](https://github.com/ultralytics/yolov5/blob/master/data/VOC.yaml), [Argoverse](https://github.com/ultralytics/yolov5/blob/master/data/Argoverse.yaml), [VisDrone](https://github.com/ultralytics/yolov5/blob/master/data/VisDrone.yaml), [GlobalWheat](https://github.com/ultralytics/yolov5/blob/master/data/GlobalWheat2020.yaml), [xView](https://github.com/ultralytics/yolov5/blob/master/data/xView.yaml), [Objects365](https://github.com/ultralytics/yolov5/blob/master/data/Objects365.yaml), [SKU-110K](https://github.com/ultralytics/yolov5/blob/master/data/SKU-110K.yaml).\n", + "- **Training Results** are saved to `runs/train/` with incrementing run directories, i.e. `runs/train/exp2`, `runs/train/exp3` etc.\n", + "
\n", + "\n", + "## Train on Custom Data with Roboflow 🌟 NEW\n", + "\n", + "[Roboflow](https://roboflow.com/?ref=ultralytics) enables you to easily **organize, label, and prepare** a high quality dataset with your own custom data. Roboflow also makes it easy to establish an active learning pipeline, collaborate with your team on dataset improvement, and integrate directly into your model building workflow with the `roboflow` pip package.\n", + "\n", + "- Custom Training Example: [https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/](https://blog.roboflow.com/how-to-train-yolov5-on-a-custom-dataset/?ref=ultralytics)\n", + "- Custom Training Notebook: [](https://colab.research.google.com/github/roboflow-ai/yolov5-custom-training-tutorial/blob/main/yolov5-custom-training.ipynb)\n", + "
\n", + "\n", + "

 "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "All results are logged by default to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc. View train and val jpgs to see mosaics, labels, predictions and augmentation effects. Note an Ultralytics **Mosaic Dataloader** is used for training (shown below), which combines 4 images into 1 mosaic during training.\n",
+ "\n",
+ ">
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "All results are logged by default to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc. View train and val jpgs to see mosaics, labels, predictions and augmentation effects. Note an Ultralytics **Mosaic Dataloader** is used for training (shown below), which combines 4 images into 1 mosaic during training.\n",
+ "\n",
+ ">  \n",
+ "`train_batch0.jpg` shows train batch 0 mosaics and labels\n",
+ "\n",
+ ">
\n",
+ "`train_batch0.jpg` shows train batch 0 mosaics and labels\n",
+ "\n",
+ ">  \n",
+ "`test_batch0_labels.jpg` shows val batch 0 labels\n",
+ "\n",
+ ">
\n",
+ "`test_batch0_labels.jpg` shows val batch 0 labels\n",
+ "\n",
+ ">  \n",
+ "`test_batch0_pred.jpg` shows val batch 0 _predictions_\n",
+ "\n",
+ "Training results are automatically logged to [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) as `results.csv`, which is plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:\n",
+ "\n",
+ "```python\n",
+ "from utils.plots import plot_results \n",
+ "plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'\n",
+ "```\n",
+ "\n",
+ "
\n",
+ "`test_batch0_pred.jpg` shows val batch 0 _predictions_\n",
+ "\n",
+ "Training results are automatically logged to [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) as `results.csv`, which is plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:\n",
+ "\n",
+ "```python\n",
+ "from utils.plots import plot_results \n",
+ "plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'\n",
+ "```\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Google Colab and Kaggle** notebooks with free GPU:
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Google Colab and Kaggle** notebooks with free GPU:  \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
\n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)  \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Optional extras below. Unit tests validate repo functionality and should be run on any PRs submitted.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "mcKoSIK2WSzj"
+ },
+ "source": [
+ "# Reproduce\n",
+ "for x in 'yolov5s', 'yolov5m', 'yolov5l', 'yolov5x':\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.25 --iou 0.45 # speed\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "# PyTorch Hub\n",
+ "import torch\n",
+ "\n",
+ "# Model\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n",
+ "\n",
+ "# Images\n",
+ "dir = 'https://ultralytics.com/images/'\n",
+ "imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images\n",
+ "\n",
+ "# Inference\n",
+ "results = model(imgs)\n",
+ "results.print() # or .show(), .save()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "FGH0ZjkGjejy"
+ },
+ "source": [
+ "# CI Checks\n",
+ "%%shell\n",
+ "export PYTHONPATH=\"$PWD\" # to run *.py. files in subdirectories\n",
+ "rm -rf runs # remove runs/\n",
+ "for m in yolov5n; do # models\n",
+ " python train.py --img 64 --batch 32 --weights $m.pt --epochs 1 --device 0 # train pretrained\n",
+ " python train.py --img 64 --batch 32 --weights '' --cfg $m.yaml --epochs 1 --device 0 # train scratch\n",
+ " for d in 0 cpu; do # devices\n",
+ " python val.py --weights $m.pt --device $d # val official\n",
+ " python val.py --weights runs/train/exp/weights/best.pt --device $d # val custom\n",
+ " python detect.py --weights $m.pt --device $d # detect official\n",
+ " python detect.py --weights runs/train/exp/weights/best.pt --device $d # detect custom\n",
+ " done\n",
+ " python hubconf.py # hub\n",
+ " python models/yolo.py --cfg $m.yaml # build PyTorch model\n",
+ " python models/tf.py --weights $m.pt # build TensorFlow model\n",
+ " python export.py --img 64 --batch 1 --weights $m.pt --include torchscript onnx # export\n",
+ "done"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "gogI-kwi3Tye"
+ },
+ "source": [
+ "# Profile\n",
+ "from utils.torch_utils import profile\n",
+ "\n",
+ "m1 = lambda x: x * torch.sigmoid(x)\n",
+ "m2 = torch.nn.SiLU()\n",
+ "results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "RVRSOhEvUdb5"
+ },
+ "source": [
+ "# Evolve\n",
+ "!python train.py --img 640 --batch 64 --epochs 100 --data coco128.yaml --weights yolov5s.pt --cache --noautoanchor --evolve\n",
+ "!d=runs/train/evolve && cp evolve.* $d && zip -r evolve.zip $d && gsutil mv evolve.zip gs://bucket # upload results (optional)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BSgFCAcMbk1R"
+ },
+ "source": [
+ "# VOC\n",
+ "for b, m in zip([64, 48, 32, 16], ['yolov5s', 'yolov5m', 'yolov5l', 'yolov5x']): # zip(batch_size, model)\n",
+ " !python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --cache --img 512 --nosave --hyp hyp.finetune.yaml --project VOC --name {m}"
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/src/image_recognition/export.py b/src/image_recognition/export.py
new file mode 100644
index 0000000..4cf30e3
--- /dev/null
+++ b/src/image_recognition/export.py
@@ -0,0 +1,369 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Export a YOLOv5 PyTorch model to TorchScript, ONNX, CoreML, TensorFlow (saved_model, pb, TFLite, TF.js,) formats
+TensorFlow exports authored by https://github.com/zldrobit
+
+Usage:
+ $ python path/to/export.py --weights yolov5s.pt --include torchscript onnx coreml saved_model pb tflite tfjs
+
+Inference:
+ $ python path/to/detect.py --weights yolov5s.pt
+ yolov5s.onnx (must export with --dynamic)
+ yolov5s_saved_model
+ yolov5s.pb
+ yolov5s.tflite
+
+TensorFlow.js:
+ $ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
+ $ npm install
+ $ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
+ $ npm start
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+import time
+from pathlib import Path
+
+import torch
+import torch.nn as nn
+from torch.utils.mobile_optimizer import optimize_for_mobile
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import Conv
+from models.experimental import attempt_load
+from models.yolo import Detect
+from utils.activations import SiLU
+from utils.datasets import LoadImages
+from utils.general import (LOGGER, check_dataset, check_img_size, check_requirements, colorstr, file_size, print_args,
+ url2file)
+from utils.torch_utils import select_device
+
+
+def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
+ # YOLOv5 TorchScript model export
+ try:
+ LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
+ f = file.with_suffix('.torchscript.pt')
+
+ ts = torch.jit.trace(model, im, strict=False)
+ d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
+ extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
+ (optimize_for_mobile(ts) if optimize else ts).save(f, _extra_files=extra_files)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure: {e}')
+
+
+def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
+ # YOLOv5 ONNX export
+ try:
+ check_requirements(('onnx',))
+ import onnx
+
+ LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
+ f = file.with_suffix('.onnx')
+
+ torch.onnx.export(model, im, f, verbose=False, opset_version=opset,
+ training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
+ do_constant_folding=not train,
+ input_names=['images'],
+ output_names=['output'],
+ dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
+ 'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
+ } if dynamic else None)
+
+ # Checks
+ model_onnx = onnx.load(f) # load onnx model
+ onnx.checker.check_model(model_onnx) # check onnx model
+ # LOGGER.info(onnx.helper.printable_graph(model_onnx.graph)) # print
+
+ # Simplify
+ if simplify:
+ try:
+ check_requirements(('onnx-simplifier',))
+ import onnxsim
+
+ LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
+ model_onnx, check = onnxsim.simplify(
+ model_onnx,
+ dynamic_input_shape=dynamic,
+ input_shapes={'images': list(im.shape)} if dynamic else None)
+ assert check, 'assert check failed'
+ onnx.save(model_onnx, f)
+ except Exception as e:
+ LOGGER.info(f'{prefix} simplifier failure: {e}')
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ LOGGER.info(f"{prefix} run --dynamic ONNX model inference with: 'python detect.py --weights {f}'")
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure: {e}')
+
+
+def export_coreml(model, im, file, prefix=colorstr('CoreML:')):
+ # YOLOv5 CoreML export
+ ct_model = None
+ try:
+ check_requirements(('coremltools',))
+ import coremltools as ct
+
+ LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
+ f = file.with_suffix('.mlmodel')
+
+ model.train() # CoreML exports should be placed in model.train() mode
+ ts = torch.jit.trace(model, im, strict=False) # TorchScript model
+ ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
+ ct_model.save(f)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+ return ct_model
+
+
+def export_saved_model(model, im, file, dynamic,
+ tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
+ conf_thres=0.25, prefix=colorstr('TensorFlow saved_model:')):
+ # YOLOv5 TensorFlow saved_model export
+ keras_model = None
+ try:
+ import tensorflow as tf
+ from tensorflow import keras
+
+ from models.tf import TFDetect, TFModel
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = str(file).replace('.pt', '_saved_model')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ im = tf.zeros((batch_size, *imgsz, 3)) # BHWC order for TensorFlow
+ y = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ inputs = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
+ outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ keras_model = keras.Model(inputs=inputs, outputs=outputs)
+ keras_model.trainable = False
+ keras_model.summary()
+ keras_model.save(f, save_format='tf')
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+ return keras_model
+
+
+def export_pb(keras_model, im, file, prefix=colorstr('TensorFlow GraphDef:')):
+ # YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
+ try:
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = file.with_suffix('.pb')
+
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
+ frozen_func = convert_variables_to_constants_v2(m)
+ frozen_func.graph.as_graph_def()
+ tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_tflite(keras_model, im, file, int8, data, ncalib, prefix=colorstr('TensorFlow Lite:')):
+ # YOLOv5 TensorFlow Lite export
+ try:
+ import tensorflow as tf
+
+ from models.tf import representative_dataset_gen
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+ f = str(file).replace('.pt', '-fp16.tflite')
+
+ converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
+ converter.target_spec.supported_types = [tf.float16]
+ converter.optimizations = [tf.lite.Optimize.DEFAULT]
+ if int8:
+ dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data
+ converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
+ converter.target_spec.supported_types = []
+ converter.inference_input_type = tf.uint8 # or tf.int8
+ converter.inference_output_type = tf.uint8 # or tf.int8
+ converter.experimental_new_quantizer = False
+ f = str(file).replace('.pt', '-int8.tflite')
+
+ tflite_model = converter.convert()
+ open(f, "wb").write(tflite_model)
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_tfjs(keras_model, im, file, prefix=colorstr('TensorFlow.js:')):
+ # YOLOv5 TensorFlow.js export
+ try:
+ check_requirements(('tensorflowjs',))
+ import re
+
+ import tensorflowjs as tfjs
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
+ f = str(file).replace('.pt', '_web_model') # js dir
+ f_pb = file.with_suffix('.pb') # *.pb path
+ f_json = f + '/model.json' # *.json path
+
+ cmd = f"tensorflowjs_converter --input_format=tf_frozen_model " \
+ f"--output_node_names='Identity,Identity_1,Identity_2,Identity_3' {f_pb} {f}"
+ subprocess.run(cmd, shell=True)
+
+ json = open(f_json).read()
+ with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
+ subst = re.sub(
+ r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}}}',
+ r'{"outputs": {"Identity": {"name": "Identity"}, '
+ r'"Identity_1": {"name": "Identity_1"}, '
+ r'"Identity_2": {"name": "Identity_2"}, '
+ r'"Identity_3": {"name": "Identity_3"}}}',
+ json)
+ j.write(subst)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+@torch.no_grad()
+def run(data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # image (height, width)
+ batch_size=1, # batch size
+ device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ include=('torchscript', 'onnx', 'coreml'), # include formats
+ half=False, # FP16 half-precision export
+ inplace=False, # set YOLOv5 Detect() inplace=True
+ train=False, # model.train() mode
+ optimize=False, # TorchScript: optimize for mobile
+ int8=False, # CoreML/TF INT8 quantization
+ dynamic=False, # ONNX/TF: dynamic axes
+ simplify=False, # ONNX: simplify model
+ opset=12, # ONNX: opset version
+ topk_per_class=100, # TF.js NMS: topk per class to keep
+ topk_all=100, # TF.js NMS: topk for all classes to keep
+ iou_thres=0.45, # TF.js NMS: IoU threshold
+ conf_thres=0.25 # TF.js NMS: confidence threshold
+ ):
+ t = time.time()
+ include = [x.lower() for x in include]
+ tf_exports = list(x in include for x in ('saved_model', 'pb', 'tflite', 'tfjs')) # TensorFlow exports
+ imgsz *= 2 if len(imgsz) == 1 else 1 # expand
+ file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights)
+
+ # Load PyTorch model
+ device = select_device(device)
+ assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
+ model = attempt_load(weights, map_location=device, inplace=True, fuse=True) # load FP32 model
+ nc, names = model.nc, model.names # number of classes, class names
+
+ # Input
+ gs = int(max(model.stride)) # grid size (max stride)
+ imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
+ im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
+
+ # Update model
+ if half:
+ im, model = im.half(), model.half() # to FP16
+ model.train() if train else model.eval() # training mode = no Detect() layer grid construction
+ for k, m in model.named_modules():
+ if isinstance(m, Conv): # assign export-friendly activations
+ if isinstance(m.act, nn.SiLU):
+ m.act = SiLU()
+ elif isinstance(m, Detect):
+ m.inplace = inplace
+ m.onnx_dynamic = dynamic
+ # m.forward = m.forward_export # assign forward (optional)
+
+ for _ in range(2):
+ y = model(im) # dry runs
+ LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} ({file_size(file):.1f} MB)")
+
+ # Exports
+ if 'torchscript' in include:
+ export_torchscript(model, im, file, optimize)
+ if 'onnx' in include:
+ export_onnx(model, im, file, opset, train, dynamic, simplify)
+ if 'coreml' in include:
+ export_coreml(model, im, file)
+
+ # TensorFlow Exports
+ if any(tf_exports):
+ pb, tflite, tfjs = tf_exports[1:]
+ assert not (tflite and tfjs), 'TFLite and TF.js models must be exported separately, please pass only one type.'
+ model = export_saved_model(model, im, file, dynamic, tf_nms=tfjs, agnostic_nms=tfjs,
+ topk_per_class=topk_per_class, topk_all=topk_all, conf_thres=conf_thres,
+ iou_thres=iou_thres) # keras model
+ if pb or tfjs: # pb prerequisite to tfjs
+ export_pb(model, im, file)
+ if tflite:
+ export_tflite(model, im, file, int8=int8, data=data, ncalib=100)
+ if tfjs:
+ export_tfjs(model, im, file)
+
+ # Finish
+ LOGGER.info(f'\nExport complete ({time.time() - t:.2f}s)'
+ f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
+ f'\nVisualize with https://netron.app')
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
+ parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
+ parser.add_argument('--train', action='store_true', help='model.train() mode')
+ parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
+ parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
+ parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
+ parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
+ parser.add_argument('--opset', type=int, default=13, help='ONNX: opset version')
+ parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
+ parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
+ parser.add_argument('--include', nargs='+',
+ default=['torchscript', 'onnx'],
+ help='available formats are (torchscript, onnx, coreml, saved_model, pb, tflite, tfjs)')
+ opt = parser.parse_args()
+ print_args(FILE.stem, opt)
+ return opt
+
+
+def main(opt):
+ run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/hubconf.py b/src/image_recognition/hubconf.py
new file mode 100644
index 0000000..3488fef
--- /dev/null
+++ b/src/image_recognition/hubconf.py
@@ -0,0 +1,142 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch Hub models https://pytorch.org/hub/ultralytics_yolov5/
+
+Usage:
+ import torch
+ model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+"""
+
+import torch
+
+
+def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ """Creates a specified YOLOv5 model
+
+ Arguments:
+ name (str): name of model, i.e. 'yolov5s'
+ pretrained (bool): load pretrained weights into the model
+ channels (int): number of input channels
+ classes (int): number of model classes
+ autoshape (bool): apply YOLOv5 .autoshape() wrapper to model
+ verbose (bool): print all information to screen
+ device (str, torch.device, None): device to use for model parameters
+
+ Returns:
+ YOLOv5 pytorch model
+ """
+ from pathlib import Path
+
+ from models.experimental import attempt_load
+ from models.yolo import Model
+ from utils.downloads import attempt_download
+ from utils.general import check_requirements, intersect_dicts, set_logging
+ from utils.torch_utils import select_device
+
+ file = Path(__file__).resolve()
+ check_requirements(exclude=('tensorboard', 'thop', 'opencv-python'))
+ set_logging(verbose=verbose)
+
+ save_dir = Path('') if str(name).endswith('.pt') else file.parent
+ path = (save_dir / name).with_suffix('.pt') # checkpoint path
+ try:
+ device = select_device(('0' if torch.cuda.is_available() else 'cpu') if device is None else device)
+
+ if pretrained and channels == 3 and classes == 80:
+ model = attempt_load(path, map_location=device) # download/load FP32 model
+ else:
+ cfg = list((Path(__file__).parent / 'models').rglob(f'{name}.yaml'))[0] # model.yaml path
+ model = Model(cfg, channels, classes) # create model
+ if pretrained:
+ ckpt = torch.load(attempt_download(path), map_location=device) # load
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=['anchors']) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ if len(ckpt['model'].names) == classes:
+ model.names = ckpt['model'].names # set class names attribute
+ if autoshape:
+ model = model.autoshape() # for file/URI/PIL/cv2/np inputs and NMS
+ return model.to(device)
+
+ except Exception as e:
+ help_url = 'https://github.com/ultralytics/yolov5/issues/36'
+ s = 'Cache may be out of date, try `force_reload=True`. See %s for help.' % help_url
+ raise Exception(s) from e
+
+
+def custom(path='path/to/model.pt', autoshape=True, verbose=True, device=None):
+ # YOLOv5 custom or local model
+ return _create(path, autoshape=autoshape, verbose=verbose, device=device)
+
+
+def yolov5n(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-nano model https://github.com/ultralytics/yolov5
+ return _create('yolov5n', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5s(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-small model https://github.com/ultralytics/yolov5
+ return _create('yolov5s', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5m(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-medium model https://github.com/ultralytics/yolov5
+ return _create('yolov5m', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5l(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-large model https://github.com/ultralytics/yolov5
+ return _create('yolov5l', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5x(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-xlarge model https://github.com/ultralytics/yolov5
+ return _create('yolov5x', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5n6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-nano-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5n6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5s6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-small-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5s6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5m6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-medium-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5m6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5l6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-large-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5l6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5x6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-xlarge-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5x6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+if __name__ == '__main__':
+ model = _create(name='yolov5s', pretrained=True, channels=3, classes=80, autoshape=True, verbose=True) # pretrained
+ # model = custom(path='path/to/model.pt') # custom
+
+ # Verify inference
+ from pathlib import Path
+
+ import cv2
+ import numpy as np
+ from PIL import Image
+
+ imgs = ['data/images/zidane.jpg', # filename
+ Path('data/images/zidane.jpg'), # Path
+ 'https://ultralytics.com/images/zidane.jpg', # URI
+ cv2.imread('data/images/bus.jpg')[:, :, ::-1], # OpenCV
+ Image.open('data/images/bus.jpg'), # PIL
+ np.zeros((320, 640, 3))] # numpy
+
+ results = model(imgs) # batched inference
+ results.print()
+ results.save()
diff --git a/src/image_recognition/images/UI/logo.jpeg b/src/image_recognition/images/UI/logo.jpeg
new file mode 100644
index 0000000..5dd5a31
Binary files /dev/null and b/src/image_recognition/images/UI/logo.jpeg differ
diff --git a/src/image_recognition/images/UI/lufei.png b/src/image_recognition/images/UI/lufei.png
new file mode 100644
index 0000000..54ac3c9
Binary files /dev/null and b/src/image_recognition/images/UI/lufei.png differ
diff --git a/src/image_recognition/images/UI/qq.png b/src/image_recognition/images/UI/qq.png
new file mode 100644
index 0000000..419447c
Binary files /dev/null and b/src/image_recognition/images/UI/qq.png differ
diff --git a/src/image_recognition/images/UI/right.jpeg b/src/image_recognition/images/UI/right.jpeg
new file mode 100644
index 0000000..a90fa90
Binary files /dev/null and b/src/image_recognition/images/UI/right.jpeg differ
diff --git a/src/image_recognition/images/UI/up.jpeg b/src/image_recognition/images/UI/up.jpeg
new file mode 100644
index 0000000..5c8e036
Binary files /dev/null and b/src/image_recognition/images/UI/up.jpeg differ
diff --git a/src/image_recognition/images/right.jpeg b/src/image_recognition/images/right.jpeg
new file mode 100644
index 0000000..e0132cb
Binary files /dev/null and b/src/image_recognition/images/right.jpeg differ
diff --git a/src/image_recognition/images/tmp/single_result.jpg b/src/image_recognition/images/tmp/single_result.jpg
new file mode 100644
index 0000000..4ceed8f
Binary files /dev/null and b/src/image_recognition/images/tmp/single_result.jpg differ
diff --git a/src/image_recognition/images/tmp/single_result_vid.jpg b/src/image_recognition/images/tmp/single_result_vid.jpg
new file mode 100644
index 0000000..659828b
Binary files /dev/null and b/src/image_recognition/images/tmp/single_result_vid.jpg differ
diff --git a/src/image_recognition/images/tmp/tmp_upload.jpeg b/src/image_recognition/images/tmp/tmp_upload.jpeg
new file mode 100644
index 0000000..53469b8
Binary files /dev/null and b/src/image_recognition/images/tmp/tmp_upload.jpeg differ
diff --git a/src/image_recognition/images/tmp/tmp_upload.jpg b/src/image_recognition/images/tmp/tmp_upload.jpg
new file mode 100644
index 0000000..9d79c8d
Binary files /dev/null and b/src/image_recognition/images/tmp/tmp_upload.jpg differ
diff --git a/src/image_recognition/images/tmp/tmp_upload.png b/src/image_recognition/images/tmp/tmp_upload.png
new file mode 100644
index 0000000..d5db4be
Binary files /dev/null and b/src/image_recognition/images/tmp/tmp_upload.png differ
diff --git a/src/image_recognition/images/tmp/upload_show_result.jpg b/src/image_recognition/images/tmp/upload_show_result.jpg
new file mode 100644
index 0000000..50069fa
Binary files /dev/null and b/src/image_recognition/images/tmp/upload_show_result.jpg differ
diff --git a/src/image_recognition/images/up.jpeg b/src/image_recognition/images/up.jpeg
new file mode 100644
index 0000000..53469b8
Binary files /dev/null and b/src/image_recognition/images/up.jpeg differ
diff --git a/src/image_recognition/models/__init__.py b/src/image_recognition/models/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/image_recognition/models/__pycache__/__init__.cpython-38.pyc b/src/image_recognition/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..d1818ef
Binary files /dev/null and b/src/image_recognition/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/image_recognition/models/__pycache__/common.cpython-38.pyc b/src/image_recognition/models/__pycache__/common.cpython-38.pyc
new file mode 100644
index 0000000..2866381
Binary files /dev/null and b/src/image_recognition/models/__pycache__/common.cpython-38.pyc differ
diff --git a/src/image_recognition/models/__pycache__/experimental.cpython-38.pyc b/src/image_recognition/models/__pycache__/experimental.cpython-38.pyc
new file mode 100644
index 0000000..700814a
Binary files /dev/null and b/src/image_recognition/models/__pycache__/experimental.cpython-38.pyc differ
diff --git a/src/image_recognition/models/__pycache__/yolo.cpython-38.pyc b/src/image_recognition/models/__pycache__/yolo.cpython-38.pyc
new file mode 100644
index 0000000..2e9eebb
Binary files /dev/null and b/src/image_recognition/models/__pycache__/yolo.cpython-38.pyc differ
diff --git a/src/image_recognition/models/common.py b/src/image_recognition/models/common.py
new file mode 100644
index 0000000..3930c8e
--- /dev/null
+++ b/src/image_recognition/models/common.py
@@ -0,0 +1,591 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Common modules
+"""
+
+import json
+import math
+import platform
+import warnings
+from copy import copy
+from pathlib import Path
+
+import cv2
+import numpy as np
+import pandas as pd
+import requests
+import torch
+import torch.nn as nn
+from PIL import Image
+from torch.cuda import amp
+
+from utils.datasets import exif_transpose, letterbox
+from utils.general import (LOGGER, check_requirements, check_suffix, colorstr, increment_path, make_divisible,
+ non_max_suppression, scale_coords, xywh2xyxy, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import time_sync
+
+
+def autopad(k, p=None): # kernel, padding
+ # Pad to 'same'
+ if p is None:
+ p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
+ return p
+
+
+class Conv(nn.Module):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
+
+ def forward(self, x):
+ return self.act(self.bn(self.conv(x)))
+
+ def forward_fuse(self, x):
+ return self.act(self.conv(x))
+
+
+class DWConv(Conv):
+ # Depth-wise convolution class
+ def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
+
+
+class TransformerLayer(nn.Module):
+ # Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
+ def __init__(self, c, num_heads):
+ super().__init__()
+ self.q = nn.Linear(c, c, bias=False)
+ self.k = nn.Linear(c, c, bias=False)
+ self.v = nn.Linear(c, c, bias=False)
+ self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
+ self.fc1 = nn.Linear(c, c, bias=False)
+ self.fc2 = nn.Linear(c, c, bias=False)
+
+ def forward(self, x):
+ x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
+ x = self.fc2(self.fc1(x)) + x
+ return x
+
+
+class TransformerBlock(nn.Module):
+ # Vision Transformer https://arxiv.org/abs/2010.11929
+ def __init__(self, c1, c2, num_heads, num_layers):
+ super().__init__()
+ self.conv = None
+ if c1 != c2:
+ self.conv = Conv(c1, c2)
+ self.linear = nn.Linear(c2, c2) # learnable position embedding
+ self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
+ self.c2 = c2
+
+ def forward(self, x):
+ if self.conv is not None:
+ x = self.conv(x)
+ b, _, w, h = x.shape
+ p = x.flatten(2).permute(2, 0, 1)
+ return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
+
+
+class Bottleneck(nn.Module):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_, c2, 3, 1, g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class BottleneckCSP(nn.Module):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
+ self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
+ self.cv4 = Conv(2 * c_, c2, 1, 1)
+ self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
+ self.act = nn.SiLU()
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ y1 = self.cv3(self.m(self.cv1(x)))
+ y2 = self.cv2(x)
+ return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
+
+
+class C3(nn.Module):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c1, c_, 1, 1)
+ self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+ # self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
+
+ def forward(self, x):
+ return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
+
+
+class C3TR(C3):
+ # C3 module with TransformerBlock()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = TransformerBlock(c_, c_, 4, n)
+
+
+class C3SPP(C3):
+ # C3 module with SPP()
+ def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = SPP(c_, c_, k)
+
+
+class C3Ghost(C3):
+ # C3 module with GhostBottleneck()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e) # hidden channels
+ self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
+
+
+class SPP(nn.Module):
+ # Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
+ def __init__(self, c1, c2, k=(5, 9, 13)):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
+ self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
+
+
+class SPPF(nn.Module):
+ # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
+ def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * 4, c2, 1, 1)
+ self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
+
+
+class Focus(nn.Module):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
+ # self.contract = Contract(gain=2)
+
+ def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
+ return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
+ # return self.conv(self.contract(x))
+
+
+class GhostConv(nn.Module):
+ # Ghost Convolution https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
+ super().__init__()
+ c_ = c2 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, k, s, None, g, act)
+ self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
+
+ def forward(self, x):
+ y = self.cv1(x)
+ return torch.cat([y, self.cv2(y)], 1)
+
+
+class GhostBottleneck(nn.Module):
+ # Ghost Bottleneck https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
+ super().__init__()
+ c_ = c2 // 2
+ self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pw
+ DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
+ GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
+ self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False),
+ Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity()
+
+ def forward(self, x):
+ return self.conv(x) + self.shortcut(x)
+
+
+class Contract(nn.Module):
+ # Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
+ x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
+ return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
+
+
+class Expand(nn.Module):
+ # Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
+ x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
+ return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
+
+
+class Concat(nn.Module):
+ # Concatenate a list of tensors along dimension
+ def __init__(self, dimension=1):
+ super().__init__()
+ self.d = dimension
+
+ def forward(self, x):
+ return torch.cat(x, self.d)
+
+
+class DetectMultiBackend(nn.Module):
+ # YOLOv5 MultiBackend class for python inference on various backends
+ def __init__(self, weights='yolov5s.pt', device=None, dnn=True):
+ # Usage:
+ # PyTorch: weights = *.pt
+ # TorchScript: *.torchscript.pt
+ # CoreML: *.mlmodel
+ # TensorFlow: *_saved_model
+ # TensorFlow: *.pb
+ # TensorFlow Lite: *.tflite
+ # ONNX Runtime: *.onnx
+ # OpenCV DNN: *.onnx with dnn=True
+ super().__init__()
+ w = str(weights[0] if isinstance(weights, list) else weights)
+ suffix, suffixes = Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '', '.mlmodel']
+ check_suffix(w, suffixes) # check weights have acceptable suffix
+ pt, onnx, tflite, pb, saved_model, coreml = (suffix == x for x in suffixes) # backend booleans
+ jit = pt and 'torchscript' in w.lower()
+ stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
+
+ if jit: # TorchScript
+ LOGGER.info(f'Loading {w} for TorchScript inference...')
+ extra_files = {'config.txt': ''} # model metadata
+ model = torch.jit.load(w, _extra_files=extra_files)
+ if extra_files['config.txt']:
+ d = json.loads(extra_files['config.txt']) # extra_files dict
+ stride, names = int(d['stride']), d['names']
+ elif pt: # PyTorch
+ from models.experimental import attempt_load # scoped to avoid circular import
+ model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
+ stride = int(model.stride.max()) # model stride
+ names = model.module.names if hasattr(model, 'module') else model.names # get class names
+ elif coreml: # CoreML *.mlmodel
+ import coremltools as ct
+ model = ct.models.MLModel(w)
+ elif dnn: # ONNX OpenCV DNN
+ LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
+ check_requirements(('opencv-python>=4.5.4',))
+ net = cv2.dnn.readNetFromONNX(w)
+ elif onnx: # ONNX Runtime
+ LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
+ check_requirements(('onnx', 'onnxruntime-gpu' if torch.has_cuda else 'onnxruntime'))
+ import onnxruntime
+ session = onnxruntime.InferenceSession(w, None)
+ else: # TensorFlow model (TFLite, pb, saved_model)
+ import tensorflow as tf
+ if pb: # https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
+ def wrap_frozen_graph(gd, inputs, outputs):
+ x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped
+ return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs),
+ tf.nest.map_structure(x.graph.as_graph_element, outputs))
+
+ LOGGER.info(f'Loading {w} for TensorFlow *.pb inference...')
+ graph_def = tf.Graph().as_graph_def()
+ graph_def.ParseFromString(open(w, 'rb').read())
+ frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0")
+ elif saved_model:
+ LOGGER.info(f'Loading {w} for TensorFlow saved_model inference...')
+ model = tf.keras.models.load_model(w)
+ elif tflite: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
+ if 'edgetpu' in w.lower():
+ LOGGER.info(f'Loading {w} for TensorFlow Edge TPU inference...')
+ import tflite_runtime.interpreter as tfli
+ delegate = {'Linux': 'libedgetpu.so.1', # install https://coral.ai/software/#edgetpu-runtime
+ 'Darwin': 'libedgetpu.1.dylib',
+ 'Windows': 'edgetpu.dll'}[platform.system()]
+ interpreter = tfli.Interpreter(model_path=w, experimental_delegates=[tfli.load_delegate(delegate)])
+ else:
+ LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
+ interpreter = tf.lite.Interpreter(model_path=w) # load TFLite model
+ interpreter.allocate_tensors() # allocate
+ input_details = interpreter.get_input_details() # inputs
+ output_details = interpreter.get_output_details() # outputs
+ self.__dict__.update(locals()) # assign all variables to self
+
+ def forward(self, im, augment=False, visualize=False, val=False):
+ # YOLOv5 MultiBackend inference
+ b, ch, h, w = im.shape # batch, channel, height, width
+ if self.pt: # PyTorch
+ y = self.model(im) if self.jit else self.model(im, augment=augment, visualize=visualize)
+ return y if val else y[0]
+ elif self.coreml: # CoreML *.mlmodel
+ im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
+ im = Image.fromarray((im[0] * 255).astype('uint8'))
+ # im = im.resize((192, 320), Image.ANTIALIAS)
+ y = self.model.predict({'image': im}) # coordinates are xywh normalized
+ box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
+ conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
+ y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
+ elif self.onnx: # ONNX
+ im = im.cpu().numpy() # torch to numpy
+ if self.dnn: # ONNX OpenCV DNN
+ self.net.setInput(im)
+ y = self.net.forward()
+ else: # ONNX Runtime
+ y = self.session.run([self.session.get_outputs()[0].name], {self.session.get_inputs()[0].name: im})[0]
+ else: # TensorFlow model (TFLite, pb, saved_model)
+ im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
+ if self.pb:
+ y = self.frozen_func(x=self.tf.constant(im)).numpy()
+ elif self.saved_model:
+ y = self.model(im, training=False).numpy()
+ elif self.tflite:
+ input, output = self.input_details[0], self.output_details[0]
+ int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
+ if int8:
+ scale, zero_point = input['quantization']
+ im = (im / scale + zero_point).astype(np.uint8) # de-scale
+ self.interpreter.set_tensor(input['index'], im)
+ self.interpreter.invoke()
+ y = self.interpreter.get_tensor(output['index'])
+ if int8:
+ scale, zero_point = output['quantization']
+ y = (y.astype(np.float32) - zero_point) * scale # re-scale
+ y[..., 0] *= w # x
+ y[..., 1] *= h # y
+ y[..., 2] *= w # w
+ y[..., 3] *= h # h
+ y = torch.tensor(y)
+ return (y, []) if val else y
+
+
+class AutoShape(nn.Module):
+ # YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
+ conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ multi_label = False # NMS multiple labels per box
+ max_det = 1000 # maximum number of detections per image
+
+ def __init__(self, model):
+ super().__init__()
+ self.model = model.eval()
+
+ def autoshape(self):
+ LOGGER.info('AutoShape already enabled, skipping... ') # model already converted to model.autoshape()
+ return self
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ m = self.model.model[-1] # Detect()
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+ @torch.no_grad()
+ def forward(self, imgs, size=640, augment=False, profile=False):
+ # Inference from various sources. For height=640, width=1280, RGB images example inputs are:
+ # file: imgs = 'data/images/zidane.jpg' # str or PosixPath
+ # URI: = 'https://ultralytics.com/images/zidane.jpg'
+ # OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
+ # PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
+ # numpy: = np.zeros((640,1280,3)) # HWC
+ # torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
+ # multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
+
+ t = [time_sync()]
+ p = next(self.model.parameters()) # for device and type
+ if isinstance(imgs, torch.Tensor): # torch
+ with amp.autocast(enabled=p.device.type != 'cpu'):
+ return self.model(imgs.to(p.device).type_as(p), augment, profile) # inference
+
+ # Pre-process
+ n, imgs = (len(imgs), imgs) if isinstance(imgs, list) else (1, [imgs]) # number of images, list of images
+ shape0, shape1, files = [], [], [] # image and inference shapes, filenames
+ for i, im in enumerate(imgs):
+ f = f'image{i}' # filename
+ if isinstance(im, (str, Path)): # filename or uri
+ im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
+ im = np.asarray(exif_transpose(im))
+ elif isinstance(im, Image.Image): # PIL Image
+ im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
+ files.append(Path(f).with_suffix('.jpg').name)
+ if im.shape[0] < 5: # image in CHW
+ im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
+ im = im[..., :3] if im.ndim == 3 else np.tile(im[..., None], 3) # enforce 3ch input
+ s = im.shape[:2] # HWC
+ shape0.append(s) # image shape
+ g = (size / max(s)) # gain
+ shape1.append([y * g for y in s])
+ imgs[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
+ shape1 = [make_divisible(x, int(self.stride.max())) for x in np.stack(shape1, 0).max(0)] # inference shape
+ x = [letterbox(im, new_shape=shape1, auto=False)[0] for im in imgs] # pad
+ x = np.stack(x, 0) if n > 1 else x[0][None] # stack
+ x = np.ascontiguousarray(x.transpose((0, 3, 1, 2))) # BHWC to BCHW
+ x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
+ t.append(time_sync())
+
+ with amp.autocast(enabled=p.device.type != 'cpu'):
+ # Inference
+ y = self.model(x, augment, profile)[0] # forward
+ t.append(time_sync())
+
+ # Post-process
+ y = non_max_suppression(y, self.conf, iou_thres=self.iou, classes=self.classes,
+ multi_label=self.multi_label, max_det=self.max_det) # NMS
+ for i in range(n):
+ scale_coords(shape1, y[i][:, :4], shape0[i])
+
+ t.append(time_sync())
+ return Detections(imgs, y, files, t, self.names, x.shape)
+
+
+class Detections:
+ # YOLOv5 detections class for inference results
+ def __init__(self, imgs, pred, files, times=None, names=None, shape=None):
+ super().__init__()
+ d = pred[0].device # device
+ gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in imgs] # normalizations
+ self.imgs = imgs # list of images as numpy arrays
+ self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
+ self.names = names # class names
+ self.files = files # image filenames
+ self.xyxy = pred # xyxy pixels
+ self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
+ self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
+ self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
+ self.n = len(self.pred) # number of images (batch size)
+ self.t = tuple((times[i + 1] - times[i]) * 1000 / self.n for i in range(3)) # timestamps (ms)
+ self.s = shape # inference BCHW shape
+
+ def display(self, pprint=False, show=False, save=False, crop=False, render=False, save_dir=Path('')):
+ crops = []
+ for i, (im, pred) in enumerate(zip(self.imgs, self.pred)):
+ s = f'image {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
+ if pred.shape[0]:
+ for c in pred[:, -1].unique():
+ n = (pred[:, -1] == c).sum() # detections per class
+ s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
+ if show or save or render or crop:
+ annotator = Annotator(im, example=str(self.names))
+ for *box, conf, cls in reversed(pred): # xyxy, confidence, class
+ label = f'{self.names[int(cls)]} {conf:.2f}'
+ if crop:
+ file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
+ crops.append({'box': box, 'conf': conf, 'cls': cls, 'label': label,
+ 'im': save_one_box(box, im, file=file, save=save)})
+ else: # all others
+ annotator.box_label(box, label, color=colors(cls))
+ im = annotator.im
+ else:
+ s += '(no detections)'
+
+ im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
+ if pprint:
+ LOGGER.info(s.rstrip(', '))
+ if show:
+ im.show(self.files[i]) # show
+ if save:
+ f = self.files[i]
+ im.save(save_dir / f) # save
+ if i == self.n - 1:
+ LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
+ if render:
+ self.imgs[i] = np.asarray(im)
+ if crop:
+ if save:
+ LOGGER.info(f'Saved results to {save_dir}\n')
+ return crops
+
+ def print(self):
+ self.display(pprint=True) # print results
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {tuple(self.s)}' %
+ self.t)
+
+ def show(self):
+ self.display(show=True) # show results
+
+ def save(self, save_dir='runs/detect/exp'):
+ save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) # increment save_dir
+ self.display(save=True, save_dir=save_dir) # save results
+
+ def crop(self, save=True, save_dir='runs/detect/exp'):
+ save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) if save else None
+ return self.display(crop=True, save=save, save_dir=save_dir) # crop results
+
+ def render(self):
+ self.display(render=True) # render results
+ return self.imgs
+
+ def pandas(self):
+ # return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
+ new = copy(self) # return copy
+ ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
+ cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
+ for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
+ a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
+ setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
+ return new
+
+ def tolist(self):
+ # return a list of Detections objects, i.e. 'for result in results.tolist():'
+ x = [Detections([self.imgs[i]], [self.pred[i]], self.names, self.s) for i in range(self.n)]
+ for d in x:
+ for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
+ setattr(d, k, getattr(d, k)[0]) # pop out of list
+ return x
+
+ def __len__(self):
+ return self.n
+
+
+class Classify(nn.Module):
+ # Classification head, i.e. x(b,c1,20,20) to x(b,c2)
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
+ self.flat = nn.Flatten()
+
+ def forward(self, x):
+ z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
+ return self.flat(self.conv(z)) # flatten to x(b,c2)
diff --git a/src/image_recognition/models/experimental.py b/src/image_recognition/models/experimental.py
new file mode 100644
index 0000000..463e551
--- /dev/null
+++ b/src/image_recognition/models/experimental.py
@@ -0,0 +1,120 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Experimental modules
+"""
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+from models.common import Conv
+from utils.downloads import attempt_download
+
+
+class CrossConv(nn.Module):
+ # Cross Convolution Downsample
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
+ # ch_in, ch_out, kernel, stride, groups, expansion, shortcut
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, (1, k), (1, s))
+ self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class Sum(nn.Module):
+ # Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
+ def __init__(self, n, weight=False): # n: number of inputs
+ super().__init__()
+ self.weight = weight # apply weights boolean
+ self.iter = range(n - 1) # iter object
+ if weight:
+ self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
+
+ def forward(self, x):
+ y = x[0] # no weight
+ if self.weight:
+ w = torch.sigmoid(self.w) * 2
+ for i in self.iter:
+ y = y + x[i + 1] * w[i]
+ else:
+ for i in self.iter:
+ y = y + x[i + 1]
+ return y
+
+
+class MixConv2d(nn.Module):
+ # Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
+ def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
+ super().__init__()
+ n = len(k) # number of convolutions
+ if equal_ch: # equal c_ per group
+ i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
+ c_ = [(i == g).sum() for g in range(n)] # intermediate channels
+ else: # equal weight.numel() per group
+ b = [c2] + [0] * n
+ a = np.eye(n + 1, n, k=-1)
+ a -= np.roll(a, 1, axis=1)
+ a *= np.array(k) ** 2
+ a[0] = 1
+ c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
+
+ self.m = nn.ModuleList(
+ [nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU()
+
+ def forward(self, x):
+ return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
+
+
+class Ensemble(nn.ModuleList):
+ # Ensemble of models
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ y = []
+ for module in self:
+ y.append(module(x, augment, profile, visualize)[0])
+ # y = torch.stack(y).max(0)[0] # max ensemble
+ # y = torch.stack(y).mean(0) # mean ensemble
+ y = torch.cat(y, 1) # nms ensemble
+ return y, None # inference, train output
+
+
+def attempt_load(weights, map_location=None, inplace=True, fuse=True):
+ from models.yolo import Detect, Model
+
+ # Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
+ model = Ensemble()
+ for w in weights if isinstance(weights, list) else [weights]:
+ ckpt = torch.load(attempt_download(w), map_location=map_location) # load
+ if fuse:
+ model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
+ else:
+ model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse
+
+ # Compatibility updates
+ for m in model.modules():
+ if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
+ m.inplace = inplace # pytorch 1.7.0 compatibility
+ if type(m) is Detect:
+ if not isinstance(m.anchor_grid, list): # new Detect Layer compatibility
+ delattr(m, 'anchor_grid')
+ setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
+ elif type(m) is Conv:
+ m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
+
+ if len(model) == 1:
+ return model[-1] # return model
+ else:
+ print(f'Ensemble created with {weights}\n')
+ for k in ['names']:
+ setattr(model, k, getattr(model[-1], k))
+ model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
+ return model # return ensemble
diff --git a/src/image_recognition/models/hub/anchors.yaml b/src/image_recognition/models/hub/anchors.yaml
new file mode 100644
index 0000000..e4d7beb
--- /dev/null
+++ b/src/image_recognition/models/hub/anchors.yaml
@@ -0,0 +1,59 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Default anchors for COCO data
+
+
+# P5 -------------------------------------------------------------------------------------------------------------------
+# P5-640:
+anchors_p5_640:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+
+# P6 -------------------------------------------------------------------------------------------------------------------
+# P6-640: thr=0.25: 0.9964 BPR, 5.54 anchors past thr, n=12, img_size=640, metric_all=0.281/0.716-mean/best, past_thr=0.469-mean: 9,11, 21,19, 17,41, 43,32, 39,70, 86,64, 65,131, 134,130, 120,265, 282,180, 247,354, 512,387
+anchors_p6_640:
+ - [9,11, 21,19, 17,41] # P3/8
+ - [43,32, 39,70, 86,64] # P4/16
+ - [65,131, 134,130, 120,265] # P5/32
+ - [282,180, 247,354, 512,387] # P6/64
+
+# P6-1280: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1280, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 19,27, 44,40, 38,94, 96,68, 86,152, 180,137, 140,301, 303,264, 238,542, 436,615, 739,380, 925,792
+anchors_p6_1280:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# P6-1920: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1920, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 28,41, 67,59, 57,141, 144,103, 129,227, 270,205, 209,452, 455,396, 358,812, 653,922, 1109,570, 1387,1187
+anchors_p6_1920:
+ - [28,41, 67,59, 57,141] # P3/8
+ - [144,103, 129,227, 270,205] # P4/16
+ - [209,452, 455,396, 358,812] # P5/32
+ - [653,922, 1109,570, 1387,1187] # P6/64
+
+
+# P7 -------------------------------------------------------------------------------------------------------------------
+# P7-640: thr=0.25: 0.9962 BPR, 6.76 anchors past thr, n=15, img_size=640, metric_all=0.275/0.733-mean/best, past_thr=0.466-mean: 11,11, 13,30, 29,20, 30,46, 61,38, 39,92, 78,80, 146,66, 79,163, 149,150, 321,143, 157,303, 257,402, 359,290, 524,372
+anchors_p7_640:
+ - [11,11, 13,30, 29,20] # P3/8
+ - [30,46, 61,38, 39,92] # P4/16
+ - [78,80, 146,66, 79,163] # P5/32
+ - [149,150, 321,143, 157,303] # P6/64
+ - [257,402, 359,290, 524,372] # P7/128
+
+# P7-1280: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1280, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 19,22, 54,36, 32,77, 70,83, 138,71, 75,173, 165,159, 148,334, 375,151, 334,317, 251,626, 499,474, 750,326, 534,814, 1079,818
+anchors_p7_1280:
+ - [19,22, 54,36, 32,77] # P3/8
+ - [70,83, 138,71, 75,173] # P4/16
+ - [165,159, 148,334, 375,151] # P5/32
+ - [334,317, 251,626, 499,474] # P6/64
+ - [750,326, 534,814, 1079,818] # P7/128
+
+# P7-1920: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1920, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 29,34, 81,55, 47,115, 105,124, 207,107, 113,259, 247,238, 222,500, 563,227, 501,476, 376,939, 749,711, 1126,489, 801,1222, 1618,1227
+anchors_p7_1920:
+ - [29,34, 81,55, 47,115] # P3/8
+ - [105,124, 207,107, 113,259] # P4/16
+ - [247,238, 222,500, 563,227] # P5/32
+ - [501,476, 376,939, 749,711] # P6/64
+ - [1126,489, 801,1222, 1618,1227] # P7/128
diff --git a/src/image_recognition/models/hub/yolov3-spp.yaml b/src/image_recognition/models/hub/yolov3-spp.yaml
new file mode 100644
index 0000000..c669821
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov3-spp.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3-SPP head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, SPP, [512, [5, 9, 13]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov3-tiny.yaml b/src/image_recognition/models/hub/yolov3-tiny.yaml
new file mode 100644
index 0000000..b28b443
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov3-tiny.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,14, 23,27, 37,58] # P4/16
+ - [81,82, 135,169, 344,319] # P5/32
+
+# YOLOv3-tiny backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [16, 3, 1]], # 0
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2
+ [-1, 1, Conv, [32, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4
+ [-1, 1, Conv, [64, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8
+ [-1, 1, Conv, [128, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16
+ [-1, 1, Conv, [256, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32
+ [-1, 1, Conv, [512, 3, 1]],
+ [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11
+ [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12
+ ]
+
+# YOLOv3-tiny head
+head:
+ [[-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)
+
+ [[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov3.yaml b/src/image_recognition/models/hub/yolov3.yaml
new file mode 100644
index 0000000..4f4b240
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov3.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3 head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, Conv, [512, [1, 1]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-bifpn.yaml b/src/image_recognition/models/hub/yolov5-bifpn.yaml
new file mode 100644
index 0000000..504815f
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-bifpn.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 BiFPN head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14, 6], 1, Concat, [1]], # cat P4 <--- BiFPN change
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-fpn.yaml b/src/image_recognition/models/hub/yolov5-fpn.yaml
new file mode 100644
index 0000000..a23e9c6
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-fpn.yaml
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 FPN head
+head:
+ [[-1, 3, C3, [1024, False]], # 10 (P5/32-large)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 3, C3, [512, False]], # 14 (P4/16-medium)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 3, C3, [256, False]], # 18 (P3/8-small)
+
+ [[18, 14, 10], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-p2.yaml b/src/image_recognition/models/hub/yolov5-p2.yaml
new file mode 100644
index 0000000..ffe26eb
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-p2.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # auto-anchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 2], 1, Concat, [1]], # cat backbone P2
+ [-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
+
+ [-1, 1, Conv, [128, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P3
+ [-1, 3, C3, [256, False]], # 24 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 27 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 30 (P5/32-large)
+
+ [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-p6.yaml b/src/image_recognition/models/hub/yolov5-p6.yaml
new file mode 100644
index 0000000..28f3e43
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-p6.yaml
@@ -0,0 +1,56 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # auto-anchor 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-p7.yaml b/src/image_recognition/models/hub/yolov5-p7.yaml
new file mode 100644
index 0000000..bd2f584
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-p7.yaml
@@ -0,0 +1,67 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # auto-anchor 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, Conv, [1280, 3, 2]], # 11-P7/128
+ [-1, 3, C3, [1280]],
+ [-1, 1, SPPF, [1280, 5]], # 13
+ ]
+
+# YOLOv5 head
+head:
+ [[-1, 1, Conv, [1024, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 10], 1, Concat, [1]], # cat backbone P6
+ [-1, 3, C3, [1024, False]], # 17
+
+ [-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 21
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 25
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 29 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 26], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 32 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 22], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 35 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 38 (P6/64-xlarge)
+
+ [-1, 1, Conv, [1024, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P7
+ [-1, 3, C3, [1280, False]], # 41 (P7/128-xxlarge)
+
+ [[29, 32, 35, 38, 41], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6, P7)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-panet.yaml b/src/image_recognition/models/hub/yolov5-panet.yaml
new file mode 100644
index 0000000..ccfbf90
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-panet.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 PANet head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5l6.yaml b/src/image_recognition/models/hub/yolov5l6.yaml
new file mode 100644
index 0000000..632c2cb
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5l6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5m6.yaml b/src/image_recognition/models/hub/yolov5m6.yaml
new file mode 100644
index 0000000..ecc53fd
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5m6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5n6.yaml b/src/image_recognition/models/hub/yolov5n6.yaml
new file mode 100644
index 0000000..0c0c71d
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5n6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5s-ghost.yaml b/src/image_recognition/models/hub/yolov5s-ghost.yaml
new file mode 100644
index 0000000..ff9519c
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5s-ghost.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, GhostConv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3Ghost, [128]],
+ [-1, 1, GhostConv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3Ghost, [256]],
+ [-1, 1, GhostConv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3Ghost, [512]],
+ [-1, 1, GhostConv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3Ghost, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, GhostConv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3Ghost, [512, False]], # 13
+
+ [-1, 1, GhostConv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3Ghost, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, GhostConv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3Ghost, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, GhostConv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3Ghost, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5s-transformer.yaml b/src/image_recognition/models/hub/yolov5s-transformer.yaml
new file mode 100644
index 0000000..100d7c4
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5s-transformer.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3TR, [1024]], # 9 <--- C3TR() Transformer module
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5s6.yaml b/src/image_recognition/models/hub/yolov5s6.yaml
new file mode 100644
index 0000000..a28fb55
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5s6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5x6.yaml b/src/image_recognition/models/hub/yolov5x6.yaml
new file mode 100644
index 0000000..ba795c4
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5x6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/mask_yolov5l.yaml b/src/image_recognition/models/mask_yolov5l.yaml
new file mode 100644
index 0000000..266180b
--- /dev/null
+++ b/src/image_recognition/models/mask_yolov5l.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/mask_yolov5m.yaml b/src/image_recognition/models/mask_yolov5m.yaml
new file mode 100644
index 0000000..3599293
--- /dev/null
+++ b/src/image_recognition/models/mask_yolov5m.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/mask_yolov5s.yaml b/src/image_recognition/models/mask_yolov5s.yaml
new file mode 100644
index 0000000..4fd7058
--- /dev/null
+++ b/src/image_recognition/models/mask_yolov5s.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/tf.py b/src/image_recognition/models/tf.py
new file mode 100644
index 0000000..96482dd
--- /dev/null
+++ b/src/image_recognition/models/tf.py
@@ -0,0 +1,465 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+TensorFlow, Keras and TFLite versions of YOLOv5
+Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127
+
+Usage:
+ $ python models/tf.py --weights yolov5s.pt
+
+Export:
+ $ python path/to/export.py --weights yolov5s.pt --include saved_model pb tflite tfjs
+"""
+
+import argparse
+import logging
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+import numpy as np
+import tensorflow as tf
+import torch
+import torch.nn as nn
+from tensorflow import keras
+
+from models.common import C3, SPP, SPPF, Bottleneck, BottleneckCSP, Concat, Conv, DWConv, Focus, autopad
+from models.experimental import CrossConv, MixConv2d, attempt_load
+from models.yolo import Detect
+from utils.activations import SiLU
+from utils.general import LOGGER, make_divisible, print_args
+
+
+class TFBN(keras.layers.Layer):
+ # TensorFlow BatchNormalization wrapper
+ def __init__(self, w=None):
+ super().__init__()
+ self.bn = keras.layers.BatchNormalization(
+ beta_initializer=keras.initializers.Constant(w.bias.numpy()),
+ gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
+ moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
+ moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
+ epsilon=w.eps)
+
+ def call(self, inputs):
+ return self.bn(inputs)
+
+
+class TFPad(keras.layers.Layer):
+ def __init__(self, pad):
+ super().__init__()
+ self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]])
+
+ def call(self, inputs):
+ return tf.pad(inputs, self.pad, mode='constant', constant_values=0)
+
+
+class TFConv(keras.layers.Layer):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ assert isinstance(k, int), "Convolution with multiple kernels are not allowed."
+ # TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding)
+ # see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch
+
+ conv = keras.layers.Conv2D(
+ c2, k, s, 'SAME' if s == 1 else 'VALID', use_bias=False if hasattr(w, 'bn') else True,
+ kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+
+ # YOLOv5 activations
+ if isinstance(w.act, nn.LeakyReLU):
+ self.act = (lambda x: keras.activations.relu(x, alpha=0.1)) if act else tf.identity
+ elif isinstance(w.act, nn.Hardswish):
+ self.act = (lambda x: x * tf.nn.relu6(x + 3) * 0.166666667) if act else tf.identity
+ elif isinstance(w.act, (nn.SiLU, SiLU)):
+ self.act = (lambda x: keras.activations.swish(x)) if act else tf.identity
+ else:
+ raise Exception(f'no matching TensorFlow activation found for {w.act}')
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFFocus(keras.layers.Layer):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv)
+
+ def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c)
+ # inputs = inputs / 255 # normalize 0-255 to 0-1
+ return self.conv(tf.concat([inputs[:, ::2, ::2, :],
+ inputs[:, 1::2, ::2, :],
+ inputs[:, ::2, 1::2, :],
+ inputs[:, 1::2, 1::2, :]], 3))
+
+
+class TFBottleneck(keras.layers.Layer):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFConv2d(keras.layers.Layer):
+ # Substitution for PyTorch nn.Conv2D
+ def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None):
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ self.conv = keras.layers.Conv2D(
+ c2, k, s, 'VALID', use_bias=bias,
+ kernel_initializer=keras.initializers.Constant(w.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None, )
+
+ def call(self, inputs):
+ return self.conv(inputs)
+
+
+class TFBottleneckCSP(keras.layers.Layer):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2)
+ self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3)
+ self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4)
+ self.bn = TFBN(w.bn)
+ self.act = lambda x: keras.activations.relu(x, alpha=0.1)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ y1 = self.cv3(self.m(self.cv1(inputs)))
+ y2 = self.cv2(inputs)
+ return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3))))
+
+
+class TFC3(keras.layers.Layer):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFSPP(keras.layers.Layer):
+ # Spatial pyramid pooling layer used in YOLOv3-SPP
+ def __init__(self, c1, c2, k=(5, 9, 13), w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2)
+ self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k]
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3))
+
+
+class TFSPPF(keras.layers.Layer):
+ # Spatial pyramid pooling-Fast layer
+ def __init__(self, c1, c2, k=5, w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2)
+ self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))
+
+
+class TFDetect(keras.layers.Layer):
+ def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer
+ super().__init__()
+ self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32)
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [tf.zeros(1)] * self.nl # init grid
+ self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32)
+ self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]),
+ [self.nl, 1, -1, 1, 2])
+ self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)]
+ self.training = False # set to False after building model
+ self.imgsz = imgsz
+ for i in range(self.nl):
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ self.grid[i] = self._make_grid(nx, ny)
+
+ def call(self, inputs):
+ z = [] # inference output
+ x = []
+ for i in range(self.nl):
+ x.append(self.m[i](inputs[i]))
+ # x(bs,20,20,255) to x(bs,3,20,20,85)
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ x[i] = tf.transpose(tf.reshape(x[i], [-1, ny * nx, self.na, self.no]), [0, 2, 1, 3])
+
+ if not self.training: # inference
+ y = tf.sigmoid(x[i])
+ xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
+ wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]
+ # Normalize xywh to 0-1 to reduce calibration error
+ xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ y = tf.concat([xy, wh, y[..., 4:]], -1)
+ z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no]))
+
+ return x if self.training else (tf.concat(z, 1), x)
+
+ @staticmethod
+ def _make_grid(nx=20, ny=20):
+ # yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
+ # return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
+ xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny))
+ return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32)
+
+
+class TFUpsample(keras.layers.Layer):
+ def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
+ super().__init__()
+ assert scale_factor == 2, "scale_factor must be 2"
+ self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * 2, x.shape[2] * 2), method=mode)
+ # self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
+ # with default arguments: align_corners=False, half_pixel_centers=False
+ # self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
+ # size=(x.shape[1] * 2, x.shape[2] * 2))
+
+ def call(self, inputs):
+ return self.upsample(inputs)
+
+
+class TFConcat(keras.layers.Layer):
+ def __init__(self, dimension=1, w=None):
+ super().__init__()
+ assert dimension == 1, "convert only NCHW to NHWC concat"
+ self.d = 3
+
+ def call(self, inputs):
+ return tf.concat(inputs, self.d)
+
+
+def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m_str = m
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ try:
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+ except NameError:
+ pass
+
+ n = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in [nn.Conv2d, Conv, Bottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
+ c1, c2 = ch[f], args[0]
+ c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3]:
+ args.insert(2, n)
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[-1 if x == -1 else x + 1] for x in f)
+ elif m is Detect:
+ args.append([ch[x + 1] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ args.append(imgsz)
+ else:
+ c2 = ch[f]
+
+ tf_m = eval('TF' + m_str.replace('nn.', ''))
+ m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
+ else tf_m(*args, w=model.model[i]) # module
+
+ torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in torch_m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ ch.append(c2)
+ return keras.Sequential(layers), sorted(save)
+
+
+class TFModel:
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg) as f:
+ self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
+
+ # Define model
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
+
+ def predict(self, inputs, tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
+ conf_thres=0.25):
+ y = [] # outputs
+ x = inputs
+ for i, m in enumerate(self.model.layers):
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+
+ x = m(x) # run
+ y.append(x if m.i in self.savelist else None) # save output
+
+ # Add TensorFlow NMS
+ if tf_nms:
+ boxes = self._xywh2xyxy(x[0][..., :4])
+ probs = x[0][:, :, 4:5]
+ classes = x[0][:, :, 5:]
+ scores = probs * classes
+ if agnostic_nms:
+ nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres)
+ return nms, x[1]
+ else:
+ boxes = tf.expand_dims(boxes, 2)
+ nms = tf.image.combined_non_max_suppression(
+ boxes, scores, topk_per_class, topk_all, iou_thres, conf_thres, clip_boxes=False)
+ return nms, x[1]
+
+ return x[0] # output only first tensor [1,6300,85] = [xywh, conf, class0, class1, ...]
+ # x = x[0][0] # [x(1,6300,85), ...] to x(6300,85)
+ # xywh = x[..., :4] # x(6300,4) boxes
+ # conf = x[..., 4:5] # x(6300,1) confidences
+ # cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes
+ # return tf.concat([conf, cls, xywh], 1)
+
+ @staticmethod
+ def _xywh2xyxy(xywh):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1)
+ return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1)
+
+
+class AgnosticNMS(keras.layers.Layer):
+ # TF Agnostic NMS
+ def call(self, input, topk_all, iou_thres, conf_thres):
+ # wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450
+ return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres), input,
+ fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32),
+ name='agnostic_nms')
+
+ @staticmethod
+ def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS
+ boxes, classes, scores = x
+ class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32)
+ scores_inp = tf.reduce_max(scores, -1)
+ selected_inds = tf.image.non_max_suppression(
+ boxes, scores_inp, max_output_size=topk_all, iou_threshold=iou_thres, score_threshold=conf_thres)
+ selected_boxes = tf.gather(boxes, selected_inds)
+ padded_boxes = tf.pad(selected_boxes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]],
+ mode="CONSTANT", constant_values=0.0)
+ selected_scores = tf.gather(scores_inp, selected_inds)
+ padded_scores = tf.pad(selected_scores,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode="CONSTANT", constant_values=-1.0)
+ selected_classes = tf.gather(class_inds, selected_inds)
+ padded_classes = tf.pad(selected_classes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode="CONSTANT", constant_values=-1.0)
+ valid_detections = tf.shape(selected_inds)[0]
+ return padded_boxes, padded_scores, padded_classes, valid_detections
+
+
+def representative_dataset_gen(dataset, ncalib=100):
+ # Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
+ for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
+ input = np.transpose(img, [1, 2, 0])
+ input = np.expand_dims(input, axis=0).astype(np.float32)
+ input /= 255
+ yield [input]
+ if n >= ncalib:
+ break
+
+
+def run(weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # inference size h,w
+ batch_size=1, # batch size
+ dynamic=False, # dynamic batch size
+ ):
+ # PyTorch model
+ im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image
+ model = attempt_load(weights, map_location=torch.device('cpu'), inplace=True, fuse=False)
+ y = model(im) # inference
+ model.info()
+
+ # TensorFlow model
+ im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ y = tf_model.predict(im) # inference
+
+ # Keras model
+ im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
+ keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im))
+ keras_model.summary()
+
+ LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.')
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--dynamic', action='store_true', help='dynamic batch size')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(FILE.stem, opt)
+ return opt
+
+
+def main(opt):
+ run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/models/yolo.py b/src/image_recognition/models/yolo.py
new file mode 100644
index 0000000..305f0ca
--- /dev/null
+++ b/src/image_recognition/models/yolo.py
@@ -0,0 +1,336 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+YOLO-specific modules
+
+Usage:
+ $ python path/to/models/yolo.py --cfg yolov5s.yaml
+"""
+
+import argparse
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+from models.common import *
+from models.experimental import *
+from utils.autoanchor import check_anchor_order
+from utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
+from utils.plots import feature_visualization
+from utils.torch_utils import (copy_attr, fuse_conv_and_bn, initialize_weights, model_info, scale_img, select_device,
+ time_sync)
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+
+class Detect(nn.Module):
+ stride = None # strides computed during build
+ onnx_dynamic = False # ONNX export parameter
+
+ def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
+ super().__init__()
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [torch.zeros(1)] * self.nl # init grid
+ self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
+ self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
+ self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ self.inplace = inplace # use in-place ops (e.g. slice assignment)
+
+ def forward(self, x):
+ z = [] # inference output
+ for i in range(self.nl):
+ x[i] = self.m[i](x[i]) # conv
+ bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
+ x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
+
+ if not self.training: # inference
+ if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
+ self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
+
+ y = x[i].sigmoid()
+ if self.inplace:
+ y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
+ y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
+ else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
+ xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
+ wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
+ y = torch.cat((xy, wh, y[..., 4:]), -1)
+ z.append(y.view(bs, -1, self.no))
+
+ return x if self.training else (torch.cat(z, 1), x)
+
+ def _make_grid(self, nx=20, ny=20, i=0):
+ d = self.anchors[i].device
+ if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
+ yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')
+ else:
+ yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
+ grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
+ anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
+ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
+ return grid, anchor_grid
+
+
+class Model(nn.Module):
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg, encoding='ascii', errors='ignore') as f:
+ self.yaml = yaml.safe_load(f) # model dict
+
+ # Define model
+ ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ if anchors:
+ LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
+ self.yaml['anchors'] = round(anchors) # override yaml value
+ self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
+ self.names = [str(i) for i in range(self.yaml['nc'])] # default names
+ self.inplace = self.yaml.get('inplace', True)
+
+ # Build strides, anchors
+ m = self.model[-1] # Detect()
+ if isinstance(m, Detect):
+ s = 256 # 2x min stride
+ m.inplace = self.inplace
+ m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
+ m.anchors /= m.stride.view(-1, 1, 1)
+ check_anchor_order(m)
+ self.stride = m.stride
+ self._initialize_biases() # only run once
+
+ # Init weights, biases
+ initialize_weights(self)
+ self.info()
+ LOGGER.info('')
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ if augment:
+ return self._forward_augment(x) # augmented inference, None
+ return self._forward_once(x, profile, visualize) # single-scale inference, train
+
+ def _forward_augment(self, x):
+ img_size = x.shape[-2:] # height, width
+ s = [1, 0.83, 0.67] # scales
+ f = [None, 3, None] # flips (2-ud, 3-lr)
+ y = [] # outputs
+ for si, fi in zip(s, f):
+ xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
+ yi = self._forward_once(xi)[0] # forward
+ # cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
+ yi = self._descale_pred(yi, fi, si, img_size)
+ y.append(yi)
+ y = self._clip_augmented(y) # clip augmented tails
+ return torch.cat(y, 1), None # augmented inference, train
+
+ def _forward_once(self, x, profile=False, visualize=False):
+ y, dt = [], [] # outputs
+ for m in self.model:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+ if profile:
+ self._profile_one_layer(m, x, dt)
+ x = m(x) # run
+ y.append(x if m.i in self.save else None) # save output
+ if visualize:
+ feature_visualization(x, m.type, m.i, save_dir=visualize)
+ return x
+
+ def _descale_pred(self, p, flips, scale, img_size):
+ # de-scale predictions following augmented inference (inverse operation)
+ if self.inplace:
+ p[..., :4] /= scale # de-scale
+ if flips == 2:
+ p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
+ elif flips == 3:
+ p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
+ else:
+ x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
+ if flips == 2:
+ y = img_size[0] - y # de-flip ud
+ elif flips == 3:
+ x = img_size[1] - x # de-flip lr
+ p = torch.cat((x, y, wh, p[..., 4:]), -1)
+ return p
+
+ def _clip_augmented(self, y):
+ # Clip YOLOv5 augmented inference tails
+ nl = self.model[-1].nl # number of detection layers (P3-P5)
+ g = sum(4 ** x for x in range(nl)) # grid points
+ e = 1 # exclude layer count
+ i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
+ y[0] = y[0][:, :-i] # large
+ i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
+ y[-1] = y[-1][:, i:] # small
+ return y
+
+ def _profile_one_layer(self, m, x, dt):
+ c = isinstance(m, Detect) # is final layer, copy input as inplace fix
+ o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
+ t = time_sync()
+ for _ in range(10):
+ m(x.copy() if c else x)
+ dt.append((time_sync() - t) * 100)
+ if m == self.model[0]:
+ LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
+ LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
+ if c:
+ LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
+
+ def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
+ # https://arxiv.org/abs/1708.02002 section 3.3
+ # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
+ m = self.model[-1] # Detect() module
+ for mi, s in zip(m.m, m.stride): # from
+ b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
+ b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
+ b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
+ mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
+
+ def _print_biases(self):
+ m = self.model[-1] # Detect() module
+ for mi in m.m: # from
+ b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
+ LOGGER.info(
+ ('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
+
+ # def _print_weights(self):
+ # for m in self.model.modules():
+ # if type(m) is Bottleneck:
+ # LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
+
+ def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
+ LOGGER.info('Fusing layers... ')
+ for m in self.model.modules():
+ if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
+ m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
+ delattr(m, 'bn') # remove batchnorm
+ m.forward = m.forward_fuse # update forward
+ self.info()
+ return self
+
+ def autoshape(self): # add AutoShape module
+ LOGGER.info('Adding AutoShape... ')
+ m = AutoShape(self) # wrap model
+ copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
+ return m
+
+ def info(self, verbose=False, img_size=640): # print model information
+ model_info(self, verbose, img_size)
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ m = self.model[-1] # Detect()
+ if isinstance(m, Detect):
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+
+def parse_model(d, ch): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ try:
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+ except NameError:
+ pass
+
+ n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
+ c1, c2 = ch[f], args[0]
+ if c2 != no: # if not output
+ c2 = make_divisible(c2 * gw, 8)
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
+ args.insert(2, n) # number of repeats
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[x] for x in f)
+ elif m is Detect:
+ args.append([ch[x] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ elif m is Contract:
+ c2 = ch[f] * args[0] ** 2
+ elif m is Expand:
+ c2 = ch[f] // args[0] ** 2
+ else:
+ c2 = ch[f]
+
+ m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ if i == 0:
+ ch = []
+ ch.append(c2)
+ return nn.Sequential(*layers), sorted(save)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--profile', action='store_true', help='profile model speed')
+ parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
+ opt = parser.parse_args()
+ opt.cfg = check_yaml(opt.cfg) # check YAML
+ print_args(FILE.stem, opt)
+ device = select_device(opt.device)
+
+ # Create model
+ model = Model(opt.cfg).to(device)
+ model.train()
+
+ # Profile
+ if opt.profile:
+ img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
+ y = model(img, profile=True)
+
+ # Test all models
+ if opt.test:
+ for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
+ try:
+ _ = Model(cfg)
+ except Exception as e:
+ print(f'Error in {cfg}: {e}')
+
+ # Tensorboard (not working https://github.com/ultralytics/yolov5/issues/2898)
+ # from torch.utils.tensorboard import SummaryWriter
+ # tb_writer = SummaryWriter('.')
+ # LOGGER.info("Run 'tensorboard --logdir=models' to view tensorboard at http://localhost:6006/")
+ # tb_writer.add_graph(torch.jit.trace(model, img, strict=False), []) # add model graph
diff --git a/src/image_recognition/models/yolov5l.yaml b/src/image_recognition/models/yolov5l.yaml
new file mode 100644
index 0000000..266180b
--- /dev/null
+++ b/src/image_recognition/models/yolov5l.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5m.yaml b/src/image_recognition/models/yolov5m.yaml
new file mode 100644
index 0000000..3599293
--- /dev/null
+++ b/src/image_recognition/models/yolov5m.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5n.yaml b/src/image_recognition/models/yolov5n.yaml
new file mode 100644
index 0000000..fa6b131
--- /dev/null
+++ b/src/image_recognition/models/yolov5n.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5s.yaml b/src/image_recognition/models/yolov5s.yaml
new file mode 100644
index 0000000..4fd7058
--- /dev/null
+++ b/src/image_recognition/models/yolov5s.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5x.yaml b/src/image_recognition/models/yolov5x.yaml
new file mode 100644
index 0000000..2a8dfe6
--- /dev/null
+++ b/src/image_recognition/models/yolov5x.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/pretrained/yolov5l.pt b/src/image_recognition/pretrained/yolov5l.pt
new file mode 100644
index 0000000..6f3fc03
Binary files /dev/null and b/src/image_recognition/pretrained/yolov5l.pt differ
diff --git a/src/image_recognition/pretrained/yolov5m.pt b/src/image_recognition/pretrained/yolov5m.pt
new file mode 100644
index 0000000..6625c38
Binary files /dev/null and b/src/image_recognition/pretrained/yolov5m.pt differ
diff --git a/src/image_recognition/pretrained/yolov5s.pt b/src/image_recognition/pretrained/yolov5s.pt
new file mode 100644
index 0000000..cab379e
Binary files /dev/null and b/src/image_recognition/pretrained/yolov5s.pt differ
diff --git a/src/image_recognition/requirements.txt b/src/image_recognition/requirements.txt
new file mode 100644
index 0000000..9137ed8
--- /dev/null
+++ b/src/image_recognition/requirements.txt
@@ -0,0 +1,36 @@
+# pip install -r requirements.txt
+
+# Base ----------------------------------------
+matplotlib>=3.2.2
+numpy>=1.18.5
+opencv-python>=4.1.2
+Pillow>=7.1.2
+PyYAML>=5.3.1
+requests>=2.23.0
+scipy>=1.4.1
+# torch>=1.7.0
+# torchvision>=0.8.1
+tqdm>=4.41.0
+
+# Logging -------------------------------------
+tensorboard>=2.4.1
+# wandb
+
+# Plotting ------------------------------------
+pandas>=1.1.4
+seaborn>=0.11.0
+
+# Export --------------------------------------
+# coremltools>=4.1 # CoreML export
+# onnx>=1.9.0 # ONNX export
+# onnx-simplifier>=0.3.6 # ONNX simplifier
+# scikit-learn==0.19.2 # CoreML quantization
+# tensorflow>=2.4.1 # TFLite export
+# tensorflowjs>=3.9.0 # TF.js export
+
+# Extras --------------------------------------
+# albumentations>=1.0.3
+# Cython # for pycocotools https://github.com/cocodataset/cocoapi/issues/172
+# pycocotools>=2.0 # COCO mAP
+# roboflow
+thop # FLOPs computation
diff --git a/src/image_recognition/runs/detect/exp/fishman.jpg b/src/image_recognition/runs/detect/exp/fishman.jpg
new file mode 100644
index 0000000..3831716
Binary files /dev/null and b/src/image_recognition/runs/detect/exp/fishman.jpg differ
diff --git a/src/image_recognition/runs/如需要数据集和训练好的模型请在博客自行下载.txt b/src/image_recognition/runs/如需要数据集和训练好的模型请在博客自行下载.txt
new file mode 100644
index 0000000..e69de29
diff --git a/src/image_recognition/setup.cfg b/src/image_recognition/setup.cfg
new file mode 100644
index 0000000..4ca0f0d
--- /dev/null
+++ b/src/image_recognition/setup.cfg
@@ -0,0 +1,51 @@
+# Project-wide configuration file, can be used for package metadata and other toll configurations
+# Example usage: global configuration for PEP8 (via flake8) setting or default pytest arguments
+
+[metadata]
+license_file = LICENSE
+description-file = README.md
+
+
+[tool:pytest]
+norecursedirs =
+ .git
+ dist
+ build
+addopts =
+ --doctest-modules
+ --durations=25
+ --color=yes
+
+
+[flake8]
+max-line-length = 120
+exclude = .tox,*.egg,build,temp
+select = E,W,F
+doctests = True
+verbose = 2
+# https://pep8.readthedocs.io/en/latest/intro.html#error-codes
+format = pylint
+# see: https://www.flake8rules.com/
+ignore =
+ E731 # Do not assign a lambda expression, use a def
+ F405
+ E402
+ F841
+ E741
+ F821
+ E722
+ F401
+ W504
+ E127
+ W504
+ E231
+ E501
+ F403
+ E302
+ F541
+
+
+[isort]
+# https://pycqa.github.io/isort/docs/configuration/options.html
+line_length = 120
+multi_line_output = 0
diff --git a/src/image_recognition/train.py b/src/image_recognition/train.py
new file mode 100644
index 0000000..9d0bd68
--- /dev/null
+++ b/src/image_recognition/train.py
@@ -0,0 +1,630 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Train a YOLOv5 model on a custom dataset
+
+Usage:
+ $ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
+"""
+import argparse
+import math
+import os
+import random
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.cuda import amp
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.optim import SGD, Adam, lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import Model
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.datasets import create_dataloader
+from utils.downloads import attempt_download
+from utils.general import (LOGGER, NCOLS, check_dataset, check_file, check_git_status, check_img_size,
+ check_requirements, check_suffix, check_yaml, colorstr, get_latest_run, increment_path,
+ init_seeds, intersect_dicts, labels_to_class_weights, labels_to_image_weights, methods,
+ one_cycle, print_args, print_mutation, strip_optimizer)
+from utils.loggers import Loggers
+from utils.loggers.wandb.wandb_utils import check_wandb_resume
+from utils.loss import ComputeLoss
+from utils.metrics import fitness
+from utils.plots import plot_evolve, plot_labels
+from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, select_device, torch_distributed_zero_first
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+
+def train(hyp, # path/to/hyp.yaml or hyp dictionary
+ opt,
+ device,
+ callbacks
+ ):
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+
+ # Save run settings
+ with open(save_dir / 'hyp.yaml', 'w') as f:
+ yaml.safe_dump(hyp, f, sort_keys=False)
+ with open(save_dir / 'opt.yaml', 'w') as f:
+ yaml.safe_dump(vars(opt), f, sort_keys=False)
+ data_dict = None
+
+ # Loggers
+ if RANK in [-1, 0]:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+ if loggers.wandb:
+ data_dict = loggers.wandb.data_dict
+ if resume:
+ weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ # Config
+ plots = not evolve # create plots
+ cuda = device.type != 'cpu'
+ init_seeds(1 + RANK)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location=device) # load checkpoint
+ model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz)
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
+
+ g0, g1, g2 = [], [], [] # optimizer parameter groups
+ for v in model.modules():
+ if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
+ g2.append(v.bias)
+ if isinstance(v, nn.BatchNorm2d): # weight (no decay)
+ g0.append(v.weight)
+ elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
+ g1.append(v.weight)
+
+ if opt.adam:
+ optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
+ else:
+ optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
+
+ optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
+ optimizer.add_param_group({'params': g2}) # add g2 (biases)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
+ f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
+ del g0, g1, g2
+
+ # Scheduler
+ if opt.linear_lr:
+ lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ else:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in [-1, 0] else None
+
+ # Resume
+ start_epoch, best_fitness = 0, 0.0
+ if pretrained:
+ # Optimizer
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer'])
+ best_fitness = ckpt['best_fitness']
+
+ # EMA
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
+ ema.updates = ckpt['updates']
+
+ # Epochs
+ start_epoch = ckpt['epoch'] + 1
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
+ hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
+ workers=workers, image_weights=opt.image_weights, quad=opt.quad,
+ prefix=colorstr('train: '), shuffle=True)
+ mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
+ nb = len(train_loader) # number of batches
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in [-1, 0]:
+ val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
+ hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
+ workers=workers, pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ labels = np.concatenate(dataset.labels, 0)
+ # c = torch.tensor(labels[:, 0]) # classes
+ # cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
+ # model._initialize_biases(cf.to(device))
+ if plots:
+ plot_labels(labels, names, save_dir)
+
+ # Anchors
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
+ model.half().float() # pre-reduce anchor precision
+
+ callbacks.run('on_pretrain_routine_end')
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = amp.GradScaler(enabled=cuda)
+ stopper = EarlyStopping(patience=opt.patience)
+ compute_loss = ComputeLoss(model) # init loss class
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(3, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
+ if RANK in [-1, 0]:
+ pbar = tqdm(pbar, total=nb, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with amp.autocast(enabled=cuda):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize
+ if ni - last_opt_step >= accumulate:
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in [-1, 0]:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
+ f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in [-1, 0]:
+ # mAP
+ callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ del ckpt
+ callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # Stop Single-GPU
+ if RANK == -1 and stopper(epoch=epoch, fitness=fi):
+ break
+
+ # Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
+ # stop = stopper(epoch=epoch, fitness=fi)
+ # if RANK == 0:
+ # dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
+
+ # Stop DPP
+ # with torch_distributed_zero_first(RANK):
+ # if stop:
+ # break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in [-1, 0]:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=True,
+ callbacks=callbacks,
+ compute_loss=compute_loss) # val best model with plots
+ if is_coco:
+ callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+
+ callbacks.run('on_train_end', last, best, plots, epoch, results)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ torch.cuda.empty_cache()
+ return results
+
+
+# 明天把这些模型都试试效果先,一波波给他训练完毕,找个公开的数据集测试一下。
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'pretrained/yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300)
+ parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ # parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--multi-scale', default=True, help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--linear-lr', action='store_true', help='linear LR')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ return opt
+
+
+def main(opt, callbacks=Callbacks()):
+
+ # Checks
+ if RANK in [-1, 0]:
+ print_args(FILE.stem, opt)
+ check_git_status()
+ check_requirements(exclude=['thop'])
+
+ # Resume
+ if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
+ ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
+ assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
+ with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
+ opt = argparse.Namespace(**yaml.safe_load(f)) # replace
+ opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
+ LOGGER.info(f'Resuming training from {ckpt}')
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ opt.project = str(ROOT / 'runs/evolve')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
+ assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
+ assert not opt.evolve, '--evolve argument is not compatible with DDP training'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+ if WORLD_SIZE > 1 and RANK == 0:
+ LOGGER.info('Destroying process group... ')
+ dist.destroy_process_group()
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}') # download evolve.csv if exists
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 7] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+
+ # Write mutation results
+ print_mutation(results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+
+
+# python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu
+# python train.py --data mask_data.yaml --cfg mask_yolov5l.yaml --weights pretrained/yolov5l.pt --epoch 100 --batch-size 4
+# python train.py --data mask_data.yaml --cfg mask_yolov5m.yaml --weights pretrained/yolov5m.pt --epoch 100 --batch-size 4
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/utils/__init__.py b/src/image_recognition/utils/__init__.py
new file mode 100644
index 0000000..7ebb57e
--- /dev/null
+++ b/src/image_recognition/utils/__init__.py
@@ -0,0 +1,18 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+utils/initialization
+"""
+
+
+def notebook_init():
+ # For YOLOv5 notebooks
+ print('Checking setup...')
+ from IPython import display # to display images and clear console output
+
+ from utils.general import emojis
+ from utils.torch_utils import select_device # YOLOv5 imports
+
+ display.clear_output()
+ select_device(newline=False)
+ print(emojis('Setup complete ✅'))
+ return display
diff --git a/src/image_recognition/utils/__pycache__/__init__.cpython-38.pyc b/src/image_recognition/utils/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..6277563
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/augmentations.cpython-38.pyc b/src/image_recognition/utils/__pycache__/augmentations.cpython-38.pyc
new file mode 100644
index 0000000..66d4b87
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/augmentations.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/autoanchor.cpython-38.pyc b/src/image_recognition/utils/__pycache__/autoanchor.cpython-38.pyc
new file mode 100644
index 0000000..d6e9e41
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/autoanchor.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/autobatch.cpython-38.pyc b/src/image_recognition/utils/__pycache__/autobatch.cpython-38.pyc
new file mode 100644
index 0000000..0881939
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/autobatch.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/callbacks.cpython-38.pyc b/src/image_recognition/utils/__pycache__/callbacks.cpython-38.pyc
new file mode 100644
index 0000000..1e7c431
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/callbacks.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/datasets.cpython-38.pyc b/src/image_recognition/utils/__pycache__/datasets.cpython-38.pyc
new file mode 100644
index 0000000..06a33b7
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/datasets.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/datasets_not_print.cpython-38.pyc b/src/image_recognition/utils/__pycache__/datasets_not_print.cpython-38.pyc
new file mode 100644
index 0000000..be00221
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/datasets_not_print.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/downloads.cpython-38.pyc b/src/image_recognition/utils/__pycache__/downloads.cpython-38.pyc
new file mode 100644
index 0000000..e689036
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/downloads.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/general.cpython-38.pyc b/src/image_recognition/utils/__pycache__/general.cpython-38.pyc
new file mode 100644
index 0000000..ef8a266
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/general.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/loss.cpython-38.pyc b/src/image_recognition/utils/__pycache__/loss.cpython-38.pyc
new file mode 100644
index 0000000..b3d8d34
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/loss.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/metrics.cpython-38.pyc b/src/image_recognition/utils/__pycache__/metrics.cpython-38.pyc
new file mode 100644
index 0000000..8138867
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/metrics.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/plots.cpython-38.pyc b/src/image_recognition/utils/__pycache__/plots.cpython-38.pyc
new file mode 100644
index 0000000..487e78d
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/plots.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/torch_utils.cpython-38.pyc b/src/image_recognition/utils/__pycache__/torch_utils.cpython-38.pyc
new file mode 100644
index 0000000..4b033d2
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/torch_utils.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/activations.py b/src/image_recognition/utils/activations.py
new file mode 100644
index 0000000..4c7d46c
--- /dev/null
+++ b/src/image_recognition/utils/activations.py
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Activation functions
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+# SiLU https://arxiv.org/pdf/1606.08415.pdf ----------------------------------------------------------------------------
+class SiLU(nn.Module): # export-friendly version of nn.SiLU()
+ @staticmethod
+ def forward(x):
+ return x * torch.sigmoid(x)
+
+
+class Hardswish(nn.Module): # export-friendly version of nn.Hardswish()
+ @staticmethod
+ def forward(x):
+ # return x * F.hardsigmoid(x) # for torchscript and CoreML
+ return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for torchscript, CoreML and ONNX
+
+
+# Mish https://github.com/digantamisra98/Mish --------------------------------------------------------------------------
+class Mish(nn.Module):
+ @staticmethod
+ def forward(x):
+ return x * F.softplus(x).tanh()
+
+
+class MemoryEfficientMish(nn.Module):
+ class F(torch.autograd.Function):
+ @staticmethod
+ def forward(ctx, x):
+ ctx.save_for_backward(x)
+ return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ x = ctx.saved_tensors[0]
+ sx = torch.sigmoid(x)
+ fx = F.softplus(x).tanh()
+ return grad_output * (fx + x * sx * (1 - fx * fx))
+
+ def forward(self, x):
+ return self.F.apply(x)
+
+
+# FReLU https://arxiv.org/abs/2007.11824 -------------------------------------------------------------------------------
+class FReLU(nn.Module):
+ def __init__(self, c1, k=3): # ch_in, kernel
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
+ self.bn = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ return torch.max(x, self.bn(self.conv(x)))
+
+
+# ACON https://arxiv.org/pdf/2009.04759.pdf ----------------------------------------------------------------------------
+class AconC(nn.Module):
+ r""" ACON activation (activate or not).
+ AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
+ according to "Activate or Not: Learning Customized Activation"
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Optional extras below. Unit tests validate repo functionality and should be run on any PRs submitted.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "mcKoSIK2WSzj"
+ },
+ "source": [
+ "# Reproduce\n",
+ "for x in 'yolov5s', 'yolov5m', 'yolov5l', 'yolov5x':\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.25 --iou 0.45 # speed\n",
+ " !python val.py --weights {x}.pt --data coco.yaml --img 640 --conf 0.001 --iou 0.65 # mAP"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "# PyTorch Hub\n",
+ "import torch\n",
+ "\n",
+ "# Model\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s')\n",
+ "\n",
+ "# Images\n",
+ "dir = 'https://ultralytics.com/images/'\n",
+ "imgs = [dir + f for f in ('zidane.jpg', 'bus.jpg')] # batch of images\n",
+ "\n",
+ "# Inference\n",
+ "results = model(imgs)\n",
+ "results.print() # or .show(), .save()"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "FGH0ZjkGjejy"
+ },
+ "source": [
+ "# CI Checks\n",
+ "%%shell\n",
+ "export PYTHONPATH=\"$PWD\" # to run *.py. files in subdirectories\n",
+ "rm -rf runs # remove runs/\n",
+ "for m in yolov5n; do # models\n",
+ " python train.py --img 64 --batch 32 --weights $m.pt --epochs 1 --device 0 # train pretrained\n",
+ " python train.py --img 64 --batch 32 --weights '' --cfg $m.yaml --epochs 1 --device 0 # train scratch\n",
+ " for d in 0 cpu; do # devices\n",
+ " python val.py --weights $m.pt --device $d # val official\n",
+ " python val.py --weights runs/train/exp/weights/best.pt --device $d # val custom\n",
+ " python detect.py --weights $m.pt --device $d # detect official\n",
+ " python detect.py --weights runs/train/exp/weights/best.pt --device $d # detect custom\n",
+ " done\n",
+ " python hubconf.py # hub\n",
+ " python models/yolo.py --cfg $m.yaml # build PyTorch model\n",
+ " python models/tf.py --weights $m.pt # build TensorFlow model\n",
+ " python export.py --img 64 --batch 1 --weights $m.pt --include torchscript onnx # export\n",
+ "done"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "gogI-kwi3Tye"
+ },
+ "source": [
+ "# Profile\n",
+ "from utils.torch_utils import profile\n",
+ "\n",
+ "m1 = lambda x: x * torch.sigmoid(x)\n",
+ "m2 = torch.nn.SiLU()\n",
+ "results = profile(input=torch.randn(16, 3, 640, 640), ops=[m1, m2], n=100)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "RVRSOhEvUdb5"
+ },
+ "source": [
+ "# Evolve\n",
+ "!python train.py --img 640 --batch 64 --epochs 100 --data coco128.yaml --weights yolov5s.pt --cache --noautoanchor --evolve\n",
+ "!d=runs/train/evolve && cp evolve.* $d && zip -r evolve.zip $d && gsutil mv evolve.zip gs://bucket # upload results (optional)"
+ ],
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "BSgFCAcMbk1R"
+ },
+ "source": [
+ "# VOC\n",
+ "for b, m in zip([64, 48, 32, 16], ['yolov5s', 'yolov5m', 'yolov5l', 'yolov5x']): # zip(batch_size, model)\n",
+ " !python train.py --batch {b} --weights {m}.pt --data VOC.yaml --epochs 50 --cache --img 512 --nosave --hyp hyp.finetune.yaml --project VOC --name {m}"
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/src/image_recognition/export.py b/src/image_recognition/export.py
new file mode 100644
index 0000000..4cf30e3
--- /dev/null
+++ b/src/image_recognition/export.py
@@ -0,0 +1,369 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Export a YOLOv5 PyTorch model to TorchScript, ONNX, CoreML, TensorFlow (saved_model, pb, TFLite, TF.js,) formats
+TensorFlow exports authored by https://github.com/zldrobit
+
+Usage:
+ $ python path/to/export.py --weights yolov5s.pt --include torchscript onnx coreml saved_model pb tflite tfjs
+
+Inference:
+ $ python path/to/detect.py --weights yolov5s.pt
+ yolov5s.onnx (must export with --dynamic)
+ yolov5s_saved_model
+ yolov5s.pb
+ yolov5s.tflite
+
+TensorFlow.js:
+ $ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
+ $ npm install
+ $ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
+ $ npm start
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+import time
+from pathlib import Path
+
+import torch
+import torch.nn as nn
+from torch.utils.mobile_optimizer import optimize_for_mobile
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import Conv
+from models.experimental import attempt_load
+from models.yolo import Detect
+from utils.activations import SiLU
+from utils.datasets import LoadImages
+from utils.general import (LOGGER, check_dataset, check_img_size, check_requirements, colorstr, file_size, print_args,
+ url2file)
+from utils.torch_utils import select_device
+
+
+def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
+ # YOLOv5 TorchScript model export
+ try:
+ LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
+ f = file.with_suffix('.torchscript.pt')
+
+ ts = torch.jit.trace(model, im, strict=False)
+ d = {"shape": im.shape, "stride": int(max(model.stride)), "names": model.names}
+ extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
+ (optimize_for_mobile(ts) if optimize else ts).save(f, _extra_files=extra_files)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure: {e}')
+
+
+def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
+ # YOLOv5 ONNX export
+ try:
+ check_requirements(('onnx',))
+ import onnx
+
+ LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
+ f = file.with_suffix('.onnx')
+
+ torch.onnx.export(model, im, f, verbose=False, opset_version=opset,
+ training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
+ do_constant_folding=not train,
+ input_names=['images'],
+ output_names=['output'],
+ dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
+ 'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
+ } if dynamic else None)
+
+ # Checks
+ model_onnx = onnx.load(f) # load onnx model
+ onnx.checker.check_model(model_onnx) # check onnx model
+ # LOGGER.info(onnx.helper.printable_graph(model_onnx.graph)) # print
+
+ # Simplify
+ if simplify:
+ try:
+ check_requirements(('onnx-simplifier',))
+ import onnxsim
+
+ LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
+ model_onnx, check = onnxsim.simplify(
+ model_onnx,
+ dynamic_input_shape=dynamic,
+ input_shapes={'images': list(im.shape)} if dynamic else None)
+ assert check, 'assert check failed'
+ onnx.save(model_onnx, f)
+ except Exception as e:
+ LOGGER.info(f'{prefix} simplifier failure: {e}')
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ LOGGER.info(f"{prefix} run --dynamic ONNX model inference with: 'python detect.py --weights {f}'")
+ except Exception as e:
+ LOGGER.info(f'{prefix} export failure: {e}')
+
+
+def export_coreml(model, im, file, prefix=colorstr('CoreML:')):
+ # YOLOv5 CoreML export
+ ct_model = None
+ try:
+ check_requirements(('coremltools',))
+ import coremltools as ct
+
+ LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
+ f = file.with_suffix('.mlmodel')
+
+ model.train() # CoreML exports should be placed in model.train() mode
+ ts = torch.jit.trace(model, im, strict=False) # TorchScript model
+ ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
+ ct_model.save(f)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+ return ct_model
+
+
+def export_saved_model(model, im, file, dynamic,
+ tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
+ conf_thres=0.25, prefix=colorstr('TensorFlow saved_model:')):
+ # YOLOv5 TensorFlow saved_model export
+ keras_model = None
+ try:
+ import tensorflow as tf
+ from tensorflow import keras
+
+ from models.tf import TFDetect, TFModel
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = str(file).replace('.pt', '_saved_model')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ im = tf.zeros((batch_size, *imgsz, 3)) # BHWC order for TensorFlow
+ y = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ inputs = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
+ outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
+ keras_model = keras.Model(inputs=inputs, outputs=outputs)
+ keras_model.trainable = False
+ keras_model.summary()
+ keras_model.save(f, save_format='tf')
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+ return keras_model
+
+
+def export_pb(keras_model, im, file, prefix=colorstr('TensorFlow GraphDef:')):
+ # YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
+ try:
+ import tensorflow as tf
+ from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ f = file.with_suffix('.pb')
+
+ m = tf.function(lambda x: keras_model(x)) # full model
+ m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
+ frozen_func = convert_variables_to_constants_v2(m)
+ frozen_func.graph.as_graph_def()
+ tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_tflite(keras_model, im, file, int8, data, ncalib, prefix=colorstr('TensorFlow Lite:')):
+ # YOLOv5 TensorFlow Lite export
+ try:
+ import tensorflow as tf
+
+ from models.tf import representative_dataset_gen
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
+ batch_size, ch, *imgsz = list(im.shape) # BCHW
+ f = str(file).replace('.pt', '-fp16.tflite')
+
+ converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
+ converter.target_spec.supported_types = [tf.float16]
+ converter.optimizations = [tf.lite.Optimize.DEFAULT]
+ if int8:
+ dataset = LoadImages(check_dataset(data)['train'], img_size=imgsz, auto=False) # representative data
+ converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib)
+ converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
+ converter.target_spec.supported_types = []
+ converter.inference_input_type = tf.uint8 # or tf.int8
+ converter.inference_output_type = tf.uint8 # or tf.int8
+ converter.experimental_new_quantizer = False
+ f = str(file).replace('.pt', '-int8.tflite')
+
+ tflite_model = converter.convert()
+ open(f, "wb").write(tflite_model)
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+def export_tfjs(keras_model, im, file, prefix=colorstr('TensorFlow.js:')):
+ # YOLOv5 TensorFlow.js export
+ try:
+ check_requirements(('tensorflowjs',))
+ import re
+
+ import tensorflowjs as tfjs
+
+ LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
+ f = str(file).replace('.pt', '_web_model') # js dir
+ f_pb = file.with_suffix('.pb') # *.pb path
+ f_json = f + '/model.json' # *.json path
+
+ cmd = f"tensorflowjs_converter --input_format=tf_frozen_model " \
+ f"--output_node_names='Identity,Identity_1,Identity_2,Identity_3' {f_pb} {f}"
+ subprocess.run(cmd, shell=True)
+
+ json = open(f_json).read()
+ with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
+ subst = re.sub(
+ r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}, '
+ r'"Identity.?.?": {"name": "Identity.?.?"}}}',
+ r'{"outputs": {"Identity": {"name": "Identity"}, '
+ r'"Identity_1": {"name": "Identity_1"}, '
+ r'"Identity_2": {"name": "Identity_2"}, '
+ r'"Identity_3": {"name": "Identity_3"}}}',
+ json)
+ j.write(subst)
+
+ LOGGER.info(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
+ except Exception as e:
+ LOGGER.info(f'\n{prefix} export failure: {e}')
+
+
+@torch.no_grad()
+def run(data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
+ weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # image (height, width)
+ batch_size=1, # batch size
+ device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ include=('torchscript', 'onnx', 'coreml'), # include formats
+ half=False, # FP16 half-precision export
+ inplace=False, # set YOLOv5 Detect() inplace=True
+ train=False, # model.train() mode
+ optimize=False, # TorchScript: optimize for mobile
+ int8=False, # CoreML/TF INT8 quantization
+ dynamic=False, # ONNX/TF: dynamic axes
+ simplify=False, # ONNX: simplify model
+ opset=12, # ONNX: opset version
+ topk_per_class=100, # TF.js NMS: topk per class to keep
+ topk_all=100, # TF.js NMS: topk for all classes to keep
+ iou_thres=0.45, # TF.js NMS: IoU threshold
+ conf_thres=0.25 # TF.js NMS: confidence threshold
+ ):
+ t = time.time()
+ include = [x.lower() for x in include]
+ tf_exports = list(x in include for x in ('saved_model', 'pb', 'tflite', 'tfjs')) # TensorFlow exports
+ imgsz *= 2 if len(imgsz) == 1 else 1 # expand
+ file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights)
+
+ # Load PyTorch model
+ device = select_device(device)
+ assert not (device.type == 'cpu' and half), '--half only compatible with GPU export, i.e. use --device 0'
+ model = attempt_load(weights, map_location=device, inplace=True, fuse=True) # load FP32 model
+ nc, names = model.nc, model.names # number of classes, class names
+
+ # Input
+ gs = int(max(model.stride)) # grid size (max stride)
+ imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
+ im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
+
+ # Update model
+ if half:
+ im, model = im.half(), model.half() # to FP16
+ model.train() if train else model.eval() # training mode = no Detect() layer grid construction
+ for k, m in model.named_modules():
+ if isinstance(m, Conv): # assign export-friendly activations
+ if isinstance(m.act, nn.SiLU):
+ m.act = SiLU()
+ elif isinstance(m, Detect):
+ m.inplace = inplace
+ m.onnx_dynamic = dynamic
+ # m.forward = m.forward_export # assign forward (optional)
+
+ for _ in range(2):
+ y = model(im) # dry runs
+ LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} ({file_size(file):.1f} MB)")
+
+ # Exports
+ if 'torchscript' in include:
+ export_torchscript(model, im, file, optimize)
+ if 'onnx' in include:
+ export_onnx(model, im, file, opset, train, dynamic, simplify)
+ if 'coreml' in include:
+ export_coreml(model, im, file)
+
+ # TensorFlow Exports
+ if any(tf_exports):
+ pb, tflite, tfjs = tf_exports[1:]
+ assert not (tflite and tfjs), 'TFLite and TF.js models must be exported separately, please pass only one type.'
+ model = export_saved_model(model, im, file, dynamic, tf_nms=tfjs, agnostic_nms=tfjs,
+ topk_per_class=topk_per_class, topk_all=topk_all, conf_thres=conf_thres,
+ iou_thres=iou_thres) # keras model
+ if pb or tfjs: # pb prerequisite to tfjs
+ export_pb(model, im, file)
+ if tflite:
+ export_tflite(model, im, file, int8=int8, data=data, ncalib=100)
+ if tfjs:
+ export_tfjs(model, im, file)
+
+ # Finish
+ LOGGER.info(f'\nExport complete ({time.time() - t:.2f}s)'
+ f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
+ f'\nVisualize with https://netron.app')
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
+ parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
+ parser.add_argument('--train', action='store_true', help='model.train() mode')
+ parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
+ parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
+ parser.add_argument('--dynamic', action='store_true', help='ONNX/TF: dynamic axes')
+ parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
+ parser.add_argument('--opset', type=int, default=13, help='ONNX: opset version')
+ parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
+ parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
+ parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
+ parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
+ parser.add_argument('--include', nargs='+',
+ default=['torchscript', 'onnx'],
+ help='available formats are (torchscript, onnx, coreml, saved_model, pb, tflite, tfjs)')
+ opt = parser.parse_args()
+ print_args(FILE.stem, opt)
+ return opt
+
+
+def main(opt):
+ run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/hubconf.py b/src/image_recognition/hubconf.py
new file mode 100644
index 0000000..3488fef
--- /dev/null
+++ b/src/image_recognition/hubconf.py
@@ -0,0 +1,142 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch Hub models https://pytorch.org/hub/ultralytics_yolov5/
+
+Usage:
+ import torch
+ model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
+"""
+
+import torch
+
+
+def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ """Creates a specified YOLOv5 model
+
+ Arguments:
+ name (str): name of model, i.e. 'yolov5s'
+ pretrained (bool): load pretrained weights into the model
+ channels (int): number of input channels
+ classes (int): number of model classes
+ autoshape (bool): apply YOLOv5 .autoshape() wrapper to model
+ verbose (bool): print all information to screen
+ device (str, torch.device, None): device to use for model parameters
+
+ Returns:
+ YOLOv5 pytorch model
+ """
+ from pathlib import Path
+
+ from models.experimental import attempt_load
+ from models.yolo import Model
+ from utils.downloads import attempt_download
+ from utils.general import check_requirements, intersect_dicts, set_logging
+ from utils.torch_utils import select_device
+
+ file = Path(__file__).resolve()
+ check_requirements(exclude=('tensorboard', 'thop', 'opencv-python'))
+ set_logging(verbose=verbose)
+
+ save_dir = Path('') if str(name).endswith('.pt') else file.parent
+ path = (save_dir / name).with_suffix('.pt') # checkpoint path
+ try:
+ device = select_device(('0' if torch.cuda.is_available() else 'cpu') if device is None else device)
+
+ if pretrained and channels == 3 and classes == 80:
+ model = attempt_load(path, map_location=device) # download/load FP32 model
+ else:
+ cfg = list((Path(__file__).parent / 'models').rglob(f'{name}.yaml'))[0] # model.yaml path
+ model = Model(cfg, channels, classes) # create model
+ if pretrained:
+ ckpt = torch.load(attempt_download(path), map_location=device) # load
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=['anchors']) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ if len(ckpt['model'].names) == classes:
+ model.names = ckpt['model'].names # set class names attribute
+ if autoshape:
+ model = model.autoshape() # for file/URI/PIL/cv2/np inputs and NMS
+ return model.to(device)
+
+ except Exception as e:
+ help_url = 'https://github.com/ultralytics/yolov5/issues/36'
+ s = 'Cache may be out of date, try `force_reload=True`. See %s for help.' % help_url
+ raise Exception(s) from e
+
+
+def custom(path='path/to/model.pt', autoshape=True, verbose=True, device=None):
+ # YOLOv5 custom or local model
+ return _create(path, autoshape=autoshape, verbose=verbose, device=device)
+
+
+def yolov5n(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-nano model https://github.com/ultralytics/yolov5
+ return _create('yolov5n', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5s(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-small model https://github.com/ultralytics/yolov5
+ return _create('yolov5s', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5m(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-medium model https://github.com/ultralytics/yolov5
+ return _create('yolov5m', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5l(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-large model https://github.com/ultralytics/yolov5
+ return _create('yolov5l', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5x(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-xlarge model https://github.com/ultralytics/yolov5
+ return _create('yolov5x', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5n6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-nano-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5n6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5s6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-small-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5s6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5m6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-medium-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5m6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5l6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-large-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5l6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+def yolov5x6(pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
+ # YOLOv5-xlarge-P6 model https://github.com/ultralytics/yolov5
+ return _create('yolov5x6', pretrained, channels, classes, autoshape, verbose, device)
+
+
+if __name__ == '__main__':
+ model = _create(name='yolov5s', pretrained=True, channels=3, classes=80, autoshape=True, verbose=True) # pretrained
+ # model = custom(path='path/to/model.pt') # custom
+
+ # Verify inference
+ from pathlib import Path
+
+ import cv2
+ import numpy as np
+ from PIL import Image
+
+ imgs = ['data/images/zidane.jpg', # filename
+ Path('data/images/zidane.jpg'), # Path
+ 'https://ultralytics.com/images/zidane.jpg', # URI
+ cv2.imread('data/images/bus.jpg')[:, :, ::-1], # OpenCV
+ Image.open('data/images/bus.jpg'), # PIL
+ np.zeros((320, 640, 3))] # numpy
+
+ results = model(imgs) # batched inference
+ results.print()
+ results.save()
diff --git a/src/image_recognition/images/UI/logo.jpeg b/src/image_recognition/images/UI/logo.jpeg
new file mode 100644
index 0000000..5dd5a31
Binary files /dev/null and b/src/image_recognition/images/UI/logo.jpeg differ
diff --git a/src/image_recognition/images/UI/lufei.png b/src/image_recognition/images/UI/lufei.png
new file mode 100644
index 0000000..54ac3c9
Binary files /dev/null and b/src/image_recognition/images/UI/lufei.png differ
diff --git a/src/image_recognition/images/UI/qq.png b/src/image_recognition/images/UI/qq.png
new file mode 100644
index 0000000..419447c
Binary files /dev/null and b/src/image_recognition/images/UI/qq.png differ
diff --git a/src/image_recognition/images/UI/right.jpeg b/src/image_recognition/images/UI/right.jpeg
new file mode 100644
index 0000000..a90fa90
Binary files /dev/null and b/src/image_recognition/images/UI/right.jpeg differ
diff --git a/src/image_recognition/images/UI/up.jpeg b/src/image_recognition/images/UI/up.jpeg
new file mode 100644
index 0000000..5c8e036
Binary files /dev/null and b/src/image_recognition/images/UI/up.jpeg differ
diff --git a/src/image_recognition/images/right.jpeg b/src/image_recognition/images/right.jpeg
new file mode 100644
index 0000000..e0132cb
Binary files /dev/null and b/src/image_recognition/images/right.jpeg differ
diff --git a/src/image_recognition/images/tmp/single_result.jpg b/src/image_recognition/images/tmp/single_result.jpg
new file mode 100644
index 0000000..4ceed8f
Binary files /dev/null and b/src/image_recognition/images/tmp/single_result.jpg differ
diff --git a/src/image_recognition/images/tmp/single_result_vid.jpg b/src/image_recognition/images/tmp/single_result_vid.jpg
new file mode 100644
index 0000000..659828b
Binary files /dev/null and b/src/image_recognition/images/tmp/single_result_vid.jpg differ
diff --git a/src/image_recognition/images/tmp/tmp_upload.jpeg b/src/image_recognition/images/tmp/tmp_upload.jpeg
new file mode 100644
index 0000000..53469b8
Binary files /dev/null and b/src/image_recognition/images/tmp/tmp_upload.jpeg differ
diff --git a/src/image_recognition/images/tmp/tmp_upload.jpg b/src/image_recognition/images/tmp/tmp_upload.jpg
new file mode 100644
index 0000000..9d79c8d
Binary files /dev/null and b/src/image_recognition/images/tmp/tmp_upload.jpg differ
diff --git a/src/image_recognition/images/tmp/tmp_upload.png b/src/image_recognition/images/tmp/tmp_upload.png
new file mode 100644
index 0000000..d5db4be
Binary files /dev/null and b/src/image_recognition/images/tmp/tmp_upload.png differ
diff --git a/src/image_recognition/images/tmp/upload_show_result.jpg b/src/image_recognition/images/tmp/upload_show_result.jpg
new file mode 100644
index 0000000..50069fa
Binary files /dev/null and b/src/image_recognition/images/tmp/upload_show_result.jpg differ
diff --git a/src/image_recognition/images/up.jpeg b/src/image_recognition/images/up.jpeg
new file mode 100644
index 0000000..53469b8
Binary files /dev/null and b/src/image_recognition/images/up.jpeg differ
diff --git a/src/image_recognition/models/__init__.py b/src/image_recognition/models/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/image_recognition/models/__pycache__/__init__.cpython-38.pyc b/src/image_recognition/models/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..d1818ef
Binary files /dev/null and b/src/image_recognition/models/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/image_recognition/models/__pycache__/common.cpython-38.pyc b/src/image_recognition/models/__pycache__/common.cpython-38.pyc
new file mode 100644
index 0000000..2866381
Binary files /dev/null and b/src/image_recognition/models/__pycache__/common.cpython-38.pyc differ
diff --git a/src/image_recognition/models/__pycache__/experimental.cpython-38.pyc b/src/image_recognition/models/__pycache__/experimental.cpython-38.pyc
new file mode 100644
index 0000000..700814a
Binary files /dev/null and b/src/image_recognition/models/__pycache__/experimental.cpython-38.pyc differ
diff --git a/src/image_recognition/models/__pycache__/yolo.cpython-38.pyc b/src/image_recognition/models/__pycache__/yolo.cpython-38.pyc
new file mode 100644
index 0000000..2e9eebb
Binary files /dev/null and b/src/image_recognition/models/__pycache__/yolo.cpython-38.pyc differ
diff --git a/src/image_recognition/models/common.py b/src/image_recognition/models/common.py
new file mode 100644
index 0000000..3930c8e
--- /dev/null
+++ b/src/image_recognition/models/common.py
@@ -0,0 +1,591 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Common modules
+"""
+
+import json
+import math
+import platform
+import warnings
+from copy import copy
+from pathlib import Path
+
+import cv2
+import numpy as np
+import pandas as pd
+import requests
+import torch
+import torch.nn as nn
+from PIL import Image
+from torch.cuda import amp
+
+from utils.datasets import exif_transpose, letterbox
+from utils.general import (LOGGER, check_requirements, check_suffix, colorstr, increment_path, make_divisible,
+ non_max_suppression, scale_coords, xywh2xyxy, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import time_sync
+
+
+def autopad(k, p=None): # kernel, padding
+ # Pad to 'same'
+ if p is None:
+ p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
+ return p
+
+
+class Conv(nn.Module):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
+
+ def forward(self, x):
+ return self.act(self.bn(self.conv(x)))
+
+ def forward_fuse(self, x):
+ return self.act(self.conv(x))
+
+
+class DWConv(Conv):
+ # Depth-wise convolution class
+ def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
+
+
+class TransformerLayer(nn.Module):
+ # Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
+ def __init__(self, c, num_heads):
+ super().__init__()
+ self.q = nn.Linear(c, c, bias=False)
+ self.k = nn.Linear(c, c, bias=False)
+ self.v = nn.Linear(c, c, bias=False)
+ self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
+ self.fc1 = nn.Linear(c, c, bias=False)
+ self.fc2 = nn.Linear(c, c, bias=False)
+
+ def forward(self, x):
+ x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
+ x = self.fc2(self.fc1(x)) + x
+ return x
+
+
+class TransformerBlock(nn.Module):
+ # Vision Transformer https://arxiv.org/abs/2010.11929
+ def __init__(self, c1, c2, num_heads, num_layers):
+ super().__init__()
+ self.conv = None
+ if c1 != c2:
+ self.conv = Conv(c1, c2)
+ self.linear = nn.Linear(c2, c2) # learnable position embedding
+ self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
+ self.c2 = c2
+
+ def forward(self, x):
+ if self.conv is not None:
+ x = self.conv(x)
+ b, _, w, h = x.shape
+ p = x.flatten(2).permute(2, 0, 1)
+ return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
+
+
+class Bottleneck(nn.Module):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_, c2, 3, 1, g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class BottleneckCSP(nn.Module):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
+ self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
+ self.cv4 = Conv(2 * c_, c2, 1, 1)
+ self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
+ self.act = nn.SiLU()
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+
+ def forward(self, x):
+ y1 = self.cv3(self.m(self.cv1(x)))
+ y2 = self.cv2(x)
+ return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
+
+
+class C3(nn.Module):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c1, c_, 1, 1)
+ self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
+ self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
+ # self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
+
+ def forward(self, x):
+ return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
+
+
+class C3TR(C3):
+ # C3 module with TransformerBlock()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = TransformerBlock(c_, c_, 4, n)
+
+
+class C3SPP(C3):
+ # C3 module with SPP()
+ def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e)
+ self.m = SPP(c_, c_, k)
+
+
+class C3Ghost(C3):
+ # C3 module with GhostBottleneck()
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
+ super().__init__(c1, c2, n, shortcut, g, e)
+ c_ = int(c2 * e) # hidden channels
+ self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
+
+
+class SPP(nn.Module):
+ # Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
+ def __init__(self, c1, c2, k=(5, 9, 13)):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
+ self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
+
+
+class SPPF(nn.Module):
+ # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
+ def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, 1, 1)
+ self.cv2 = Conv(c_ * 4, c2, 1, 1)
+ self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
+
+ def forward(self, x):
+ x = self.cv1(x)
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
+
+
+class Focus(nn.Module):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
+ # self.contract = Contract(gain=2)
+
+ def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
+ return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
+ # return self.conv(self.contract(x))
+
+
+class GhostConv(nn.Module):
+ # Ghost Convolution https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
+ super().__init__()
+ c_ = c2 // 2 # hidden channels
+ self.cv1 = Conv(c1, c_, k, s, None, g, act)
+ self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
+
+ def forward(self, x):
+ y = self.cv1(x)
+ return torch.cat([y, self.cv2(y)], 1)
+
+
+class GhostBottleneck(nn.Module):
+ # Ghost Bottleneck https://github.com/huawei-noah/ghostnet
+ def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
+ super().__init__()
+ c_ = c2 // 2
+ self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pw
+ DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
+ GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
+ self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False),
+ Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity()
+
+ def forward(self, x):
+ return self.conv(x) + self.shortcut(x)
+
+
+class Contract(nn.Module):
+ # Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
+ x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
+ return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
+
+
+class Expand(nn.Module):
+ # Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
+ def __init__(self, gain=2):
+ super().__init__()
+ self.gain = gain
+
+ def forward(self, x):
+ b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
+ s = self.gain
+ x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
+ x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
+ return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
+
+
+class Concat(nn.Module):
+ # Concatenate a list of tensors along dimension
+ def __init__(self, dimension=1):
+ super().__init__()
+ self.d = dimension
+
+ def forward(self, x):
+ return torch.cat(x, self.d)
+
+
+class DetectMultiBackend(nn.Module):
+ # YOLOv5 MultiBackend class for python inference on various backends
+ def __init__(self, weights='yolov5s.pt', device=None, dnn=True):
+ # Usage:
+ # PyTorch: weights = *.pt
+ # TorchScript: *.torchscript.pt
+ # CoreML: *.mlmodel
+ # TensorFlow: *_saved_model
+ # TensorFlow: *.pb
+ # TensorFlow Lite: *.tflite
+ # ONNX Runtime: *.onnx
+ # OpenCV DNN: *.onnx with dnn=True
+ super().__init__()
+ w = str(weights[0] if isinstance(weights, list) else weights)
+ suffix, suffixes = Path(w).suffix.lower(), ['.pt', '.onnx', '.tflite', '.pb', '', '.mlmodel']
+ check_suffix(w, suffixes) # check weights have acceptable suffix
+ pt, onnx, tflite, pb, saved_model, coreml = (suffix == x for x in suffixes) # backend booleans
+ jit = pt and 'torchscript' in w.lower()
+ stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
+
+ if jit: # TorchScript
+ LOGGER.info(f'Loading {w} for TorchScript inference...')
+ extra_files = {'config.txt': ''} # model metadata
+ model = torch.jit.load(w, _extra_files=extra_files)
+ if extra_files['config.txt']:
+ d = json.loads(extra_files['config.txt']) # extra_files dict
+ stride, names = int(d['stride']), d['names']
+ elif pt: # PyTorch
+ from models.experimental import attempt_load # scoped to avoid circular import
+ model = torch.jit.load(w) if 'torchscript' in w else attempt_load(weights, map_location=device)
+ stride = int(model.stride.max()) # model stride
+ names = model.module.names if hasattr(model, 'module') else model.names # get class names
+ elif coreml: # CoreML *.mlmodel
+ import coremltools as ct
+ model = ct.models.MLModel(w)
+ elif dnn: # ONNX OpenCV DNN
+ LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
+ check_requirements(('opencv-python>=4.5.4',))
+ net = cv2.dnn.readNetFromONNX(w)
+ elif onnx: # ONNX Runtime
+ LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
+ check_requirements(('onnx', 'onnxruntime-gpu' if torch.has_cuda else 'onnxruntime'))
+ import onnxruntime
+ session = onnxruntime.InferenceSession(w, None)
+ else: # TensorFlow model (TFLite, pb, saved_model)
+ import tensorflow as tf
+ if pb: # https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
+ def wrap_frozen_graph(gd, inputs, outputs):
+ x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped
+ return x.prune(tf.nest.map_structure(x.graph.as_graph_element, inputs),
+ tf.nest.map_structure(x.graph.as_graph_element, outputs))
+
+ LOGGER.info(f'Loading {w} for TensorFlow *.pb inference...')
+ graph_def = tf.Graph().as_graph_def()
+ graph_def.ParseFromString(open(w, 'rb').read())
+ frozen_func = wrap_frozen_graph(gd=graph_def, inputs="x:0", outputs="Identity:0")
+ elif saved_model:
+ LOGGER.info(f'Loading {w} for TensorFlow saved_model inference...')
+ model = tf.keras.models.load_model(w)
+ elif tflite: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
+ if 'edgetpu' in w.lower():
+ LOGGER.info(f'Loading {w} for TensorFlow Edge TPU inference...')
+ import tflite_runtime.interpreter as tfli
+ delegate = {'Linux': 'libedgetpu.so.1', # install https://coral.ai/software/#edgetpu-runtime
+ 'Darwin': 'libedgetpu.1.dylib',
+ 'Windows': 'edgetpu.dll'}[platform.system()]
+ interpreter = tfli.Interpreter(model_path=w, experimental_delegates=[tfli.load_delegate(delegate)])
+ else:
+ LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
+ interpreter = tf.lite.Interpreter(model_path=w) # load TFLite model
+ interpreter.allocate_tensors() # allocate
+ input_details = interpreter.get_input_details() # inputs
+ output_details = interpreter.get_output_details() # outputs
+ self.__dict__.update(locals()) # assign all variables to self
+
+ def forward(self, im, augment=False, visualize=False, val=False):
+ # YOLOv5 MultiBackend inference
+ b, ch, h, w = im.shape # batch, channel, height, width
+ if self.pt: # PyTorch
+ y = self.model(im) if self.jit else self.model(im, augment=augment, visualize=visualize)
+ return y if val else y[0]
+ elif self.coreml: # CoreML *.mlmodel
+ im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
+ im = Image.fromarray((im[0] * 255).astype('uint8'))
+ # im = im.resize((192, 320), Image.ANTIALIAS)
+ y = self.model.predict({'image': im}) # coordinates are xywh normalized
+ box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
+ conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
+ y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
+ elif self.onnx: # ONNX
+ im = im.cpu().numpy() # torch to numpy
+ if self.dnn: # ONNX OpenCV DNN
+ self.net.setInput(im)
+ y = self.net.forward()
+ else: # ONNX Runtime
+ y = self.session.run([self.session.get_outputs()[0].name], {self.session.get_inputs()[0].name: im})[0]
+ else: # TensorFlow model (TFLite, pb, saved_model)
+ im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
+ if self.pb:
+ y = self.frozen_func(x=self.tf.constant(im)).numpy()
+ elif self.saved_model:
+ y = self.model(im, training=False).numpy()
+ elif self.tflite:
+ input, output = self.input_details[0], self.output_details[0]
+ int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
+ if int8:
+ scale, zero_point = input['quantization']
+ im = (im / scale + zero_point).astype(np.uint8) # de-scale
+ self.interpreter.set_tensor(input['index'], im)
+ self.interpreter.invoke()
+ y = self.interpreter.get_tensor(output['index'])
+ if int8:
+ scale, zero_point = output['quantization']
+ y = (y.astype(np.float32) - zero_point) * scale # re-scale
+ y[..., 0] *= w # x
+ y[..., 1] *= h # y
+ y[..., 2] *= w # w
+ y[..., 3] *= h # h
+ y = torch.tensor(y)
+ return (y, []) if val else y
+
+
+class AutoShape(nn.Module):
+ # YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
+ conf = 0.25 # NMS confidence threshold
+ iou = 0.45 # NMS IoU threshold
+ classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
+ multi_label = False # NMS multiple labels per box
+ max_det = 1000 # maximum number of detections per image
+
+ def __init__(self, model):
+ super().__init__()
+ self.model = model.eval()
+
+ def autoshape(self):
+ LOGGER.info('AutoShape already enabled, skipping... ') # model already converted to model.autoshape()
+ return self
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ m = self.model.model[-1] # Detect()
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+ @torch.no_grad()
+ def forward(self, imgs, size=640, augment=False, profile=False):
+ # Inference from various sources. For height=640, width=1280, RGB images example inputs are:
+ # file: imgs = 'data/images/zidane.jpg' # str or PosixPath
+ # URI: = 'https://ultralytics.com/images/zidane.jpg'
+ # OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
+ # PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
+ # numpy: = np.zeros((640,1280,3)) # HWC
+ # torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
+ # multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
+
+ t = [time_sync()]
+ p = next(self.model.parameters()) # for device and type
+ if isinstance(imgs, torch.Tensor): # torch
+ with amp.autocast(enabled=p.device.type != 'cpu'):
+ return self.model(imgs.to(p.device).type_as(p), augment, profile) # inference
+
+ # Pre-process
+ n, imgs = (len(imgs), imgs) if isinstance(imgs, list) else (1, [imgs]) # number of images, list of images
+ shape0, shape1, files = [], [], [] # image and inference shapes, filenames
+ for i, im in enumerate(imgs):
+ f = f'image{i}' # filename
+ if isinstance(im, (str, Path)): # filename or uri
+ im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
+ im = np.asarray(exif_transpose(im))
+ elif isinstance(im, Image.Image): # PIL Image
+ im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
+ files.append(Path(f).with_suffix('.jpg').name)
+ if im.shape[0] < 5: # image in CHW
+ im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
+ im = im[..., :3] if im.ndim == 3 else np.tile(im[..., None], 3) # enforce 3ch input
+ s = im.shape[:2] # HWC
+ shape0.append(s) # image shape
+ g = (size / max(s)) # gain
+ shape1.append([y * g for y in s])
+ imgs[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
+ shape1 = [make_divisible(x, int(self.stride.max())) for x in np.stack(shape1, 0).max(0)] # inference shape
+ x = [letterbox(im, new_shape=shape1, auto=False)[0] for im in imgs] # pad
+ x = np.stack(x, 0) if n > 1 else x[0][None] # stack
+ x = np.ascontiguousarray(x.transpose((0, 3, 1, 2))) # BHWC to BCHW
+ x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
+ t.append(time_sync())
+
+ with amp.autocast(enabled=p.device.type != 'cpu'):
+ # Inference
+ y = self.model(x, augment, profile)[0] # forward
+ t.append(time_sync())
+
+ # Post-process
+ y = non_max_suppression(y, self.conf, iou_thres=self.iou, classes=self.classes,
+ multi_label=self.multi_label, max_det=self.max_det) # NMS
+ for i in range(n):
+ scale_coords(shape1, y[i][:, :4], shape0[i])
+
+ t.append(time_sync())
+ return Detections(imgs, y, files, t, self.names, x.shape)
+
+
+class Detections:
+ # YOLOv5 detections class for inference results
+ def __init__(self, imgs, pred, files, times=None, names=None, shape=None):
+ super().__init__()
+ d = pred[0].device # device
+ gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in imgs] # normalizations
+ self.imgs = imgs # list of images as numpy arrays
+ self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
+ self.names = names # class names
+ self.files = files # image filenames
+ self.xyxy = pred # xyxy pixels
+ self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
+ self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
+ self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
+ self.n = len(self.pred) # number of images (batch size)
+ self.t = tuple((times[i + 1] - times[i]) * 1000 / self.n for i in range(3)) # timestamps (ms)
+ self.s = shape # inference BCHW shape
+
+ def display(self, pprint=False, show=False, save=False, crop=False, render=False, save_dir=Path('')):
+ crops = []
+ for i, (im, pred) in enumerate(zip(self.imgs, self.pred)):
+ s = f'image {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
+ if pred.shape[0]:
+ for c in pred[:, -1].unique():
+ n = (pred[:, -1] == c).sum() # detections per class
+ s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
+ if show or save or render or crop:
+ annotator = Annotator(im, example=str(self.names))
+ for *box, conf, cls in reversed(pred): # xyxy, confidence, class
+ label = f'{self.names[int(cls)]} {conf:.2f}'
+ if crop:
+ file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
+ crops.append({'box': box, 'conf': conf, 'cls': cls, 'label': label,
+ 'im': save_one_box(box, im, file=file, save=save)})
+ else: # all others
+ annotator.box_label(box, label, color=colors(cls))
+ im = annotator.im
+ else:
+ s += '(no detections)'
+
+ im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
+ if pprint:
+ LOGGER.info(s.rstrip(', '))
+ if show:
+ im.show(self.files[i]) # show
+ if save:
+ f = self.files[i]
+ im.save(save_dir / f) # save
+ if i == self.n - 1:
+ LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
+ if render:
+ self.imgs[i] = np.asarray(im)
+ if crop:
+ if save:
+ LOGGER.info(f'Saved results to {save_dir}\n')
+ return crops
+
+ def print(self):
+ self.display(pprint=True) # print results
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {tuple(self.s)}' %
+ self.t)
+
+ def show(self):
+ self.display(show=True) # show results
+
+ def save(self, save_dir='runs/detect/exp'):
+ save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) # increment save_dir
+ self.display(save=True, save_dir=save_dir) # save results
+
+ def crop(self, save=True, save_dir='runs/detect/exp'):
+ save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) if save else None
+ return self.display(crop=True, save=save, save_dir=save_dir) # crop results
+
+ def render(self):
+ self.display(render=True) # render results
+ return self.imgs
+
+ def pandas(self):
+ # return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
+ new = copy(self) # return copy
+ ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
+ cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
+ for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
+ a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
+ setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
+ return new
+
+ def tolist(self):
+ # return a list of Detections objects, i.e. 'for result in results.tolist():'
+ x = [Detections([self.imgs[i]], [self.pred[i]], self.names, self.s) for i in range(self.n)]
+ for d in x:
+ for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
+ setattr(d, k, getattr(d, k)[0]) # pop out of list
+ return x
+
+ def __len__(self):
+ return self.n
+
+
+class Classify(nn.Module):
+ # Classification head, i.e. x(b,c1,20,20) to x(b,c2)
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
+ self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
+ self.flat = nn.Flatten()
+
+ def forward(self, x):
+ z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
+ return self.flat(self.conv(z)) # flatten to x(b,c2)
diff --git a/src/image_recognition/models/experimental.py b/src/image_recognition/models/experimental.py
new file mode 100644
index 0000000..463e551
--- /dev/null
+++ b/src/image_recognition/models/experimental.py
@@ -0,0 +1,120 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Experimental modules
+"""
+import math
+
+import numpy as np
+import torch
+import torch.nn as nn
+
+from models.common import Conv
+from utils.downloads import attempt_download
+
+
+class CrossConv(nn.Module):
+ # Cross Convolution Downsample
+ def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
+ # ch_in, ch_out, kernel, stride, groups, expansion, shortcut
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = Conv(c1, c_, (1, k), (1, s))
+ self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
+ self.add = shortcut and c1 == c2
+
+ def forward(self, x):
+ return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
+
+
+class Sum(nn.Module):
+ # Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
+ def __init__(self, n, weight=False): # n: number of inputs
+ super().__init__()
+ self.weight = weight # apply weights boolean
+ self.iter = range(n - 1) # iter object
+ if weight:
+ self.w = nn.Parameter(-torch.arange(1.0, n) / 2, requires_grad=True) # layer weights
+
+ def forward(self, x):
+ y = x[0] # no weight
+ if self.weight:
+ w = torch.sigmoid(self.w) * 2
+ for i in self.iter:
+ y = y + x[i + 1] * w[i]
+ else:
+ for i in self.iter:
+ y = y + x[i + 1]
+ return y
+
+
+class MixConv2d(nn.Module):
+ # Mixed Depth-wise Conv https://arxiv.org/abs/1907.09595
+ def __init__(self, c1, c2, k=(1, 3), s=1, equal_ch=True): # ch_in, ch_out, kernel, stride, ch_strategy
+ super().__init__()
+ n = len(k) # number of convolutions
+ if equal_ch: # equal c_ per group
+ i = torch.linspace(0, n - 1E-6, c2).floor() # c2 indices
+ c_ = [(i == g).sum() for g in range(n)] # intermediate channels
+ else: # equal weight.numel() per group
+ b = [c2] + [0] * n
+ a = np.eye(n + 1, n, k=-1)
+ a -= np.roll(a, 1, axis=1)
+ a *= np.array(k) ** 2
+ a[0] = 1
+ c_ = np.linalg.lstsq(a, b, rcond=None)[0].round() # solve for equal weight indices, ax = b
+
+ self.m = nn.ModuleList(
+ [nn.Conv2d(c1, int(c_), k, s, k // 2, groups=math.gcd(c1, int(c_)), bias=False) for k, c_ in zip(k, c_)])
+ self.bn = nn.BatchNorm2d(c2)
+ self.act = nn.SiLU()
+
+ def forward(self, x):
+ return self.act(self.bn(torch.cat([m(x) for m in self.m], 1)))
+
+
+class Ensemble(nn.ModuleList):
+ # Ensemble of models
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ y = []
+ for module in self:
+ y.append(module(x, augment, profile, visualize)[0])
+ # y = torch.stack(y).max(0)[0] # max ensemble
+ # y = torch.stack(y).mean(0) # mean ensemble
+ y = torch.cat(y, 1) # nms ensemble
+ return y, None # inference, train output
+
+
+def attempt_load(weights, map_location=None, inplace=True, fuse=True):
+ from models.yolo import Detect, Model
+
+ # Loads an ensemble of models weights=[a,b,c] or a single model weights=[a] or weights=a
+ model = Ensemble()
+ for w in weights if isinstance(weights, list) else [weights]:
+ ckpt = torch.load(attempt_download(w), map_location=map_location) # load
+ if fuse:
+ model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().fuse().eval()) # FP32 model
+ else:
+ model.append(ckpt['ema' if ckpt.get('ema') else 'model'].float().eval()) # without layer fuse
+
+ # Compatibility updates
+ for m in model.modules():
+ if type(m) in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU, Detect, Model]:
+ m.inplace = inplace # pytorch 1.7.0 compatibility
+ if type(m) is Detect:
+ if not isinstance(m.anchor_grid, list): # new Detect Layer compatibility
+ delattr(m, 'anchor_grid')
+ setattr(m, 'anchor_grid', [torch.zeros(1)] * m.nl)
+ elif type(m) is Conv:
+ m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
+
+ if len(model) == 1:
+ return model[-1] # return model
+ else:
+ print(f'Ensemble created with {weights}\n')
+ for k in ['names']:
+ setattr(model, k, getattr(model[-1], k))
+ model.stride = model[torch.argmax(torch.tensor([m.stride.max() for m in model])).int()].stride # max stride
+ return model # return ensemble
diff --git a/src/image_recognition/models/hub/anchors.yaml b/src/image_recognition/models/hub/anchors.yaml
new file mode 100644
index 0000000..e4d7beb
--- /dev/null
+++ b/src/image_recognition/models/hub/anchors.yaml
@@ -0,0 +1,59 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+# Default anchors for COCO data
+
+
+# P5 -------------------------------------------------------------------------------------------------------------------
+# P5-640:
+anchors_p5_640:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+
+# P6 -------------------------------------------------------------------------------------------------------------------
+# P6-640: thr=0.25: 0.9964 BPR, 5.54 anchors past thr, n=12, img_size=640, metric_all=0.281/0.716-mean/best, past_thr=0.469-mean: 9,11, 21,19, 17,41, 43,32, 39,70, 86,64, 65,131, 134,130, 120,265, 282,180, 247,354, 512,387
+anchors_p6_640:
+ - [9,11, 21,19, 17,41] # P3/8
+ - [43,32, 39,70, 86,64] # P4/16
+ - [65,131, 134,130, 120,265] # P5/32
+ - [282,180, 247,354, 512,387] # P6/64
+
+# P6-1280: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1280, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 19,27, 44,40, 38,94, 96,68, 86,152, 180,137, 140,301, 303,264, 238,542, 436,615, 739,380, 925,792
+anchors_p6_1280:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# P6-1920: thr=0.25: 0.9950 BPR, 5.55 anchors past thr, n=12, img_size=1920, metric_all=0.281/0.714-mean/best, past_thr=0.468-mean: 28,41, 67,59, 57,141, 144,103, 129,227, 270,205, 209,452, 455,396, 358,812, 653,922, 1109,570, 1387,1187
+anchors_p6_1920:
+ - [28,41, 67,59, 57,141] # P3/8
+ - [144,103, 129,227, 270,205] # P4/16
+ - [209,452, 455,396, 358,812] # P5/32
+ - [653,922, 1109,570, 1387,1187] # P6/64
+
+
+# P7 -------------------------------------------------------------------------------------------------------------------
+# P7-640: thr=0.25: 0.9962 BPR, 6.76 anchors past thr, n=15, img_size=640, metric_all=0.275/0.733-mean/best, past_thr=0.466-mean: 11,11, 13,30, 29,20, 30,46, 61,38, 39,92, 78,80, 146,66, 79,163, 149,150, 321,143, 157,303, 257,402, 359,290, 524,372
+anchors_p7_640:
+ - [11,11, 13,30, 29,20] # P3/8
+ - [30,46, 61,38, 39,92] # P4/16
+ - [78,80, 146,66, 79,163] # P5/32
+ - [149,150, 321,143, 157,303] # P6/64
+ - [257,402, 359,290, 524,372] # P7/128
+
+# P7-1280: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1280, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 19,22, 54,36, 32,77, 70,83, 138,71, 75,173, 165,159, 148,334, 375,151, 334,317, 251,626, 499,474, 750,326, 534,814, 1079,818
+anchors_p7_1280:
+ - [19,22, 54,36, 32,77] # P3/8
+ - [70,83, 138,71, 75,173] # P4/16
+ - [165,159, 148,334, 375,151] # P5/32
+ - [334,317, 251,626, 499,474] # P6/64
+ - [750,326, 534,814, 1079,818] # P7/128
+
+# P7-1920: thr=0.25: 0.9968 BPR, 6.71 anchors past thr, n=15, img_size=1920, metric_all=0.273/0.732-mean/best, past_thr=0.463-mean: 29,34, 81,55, 47,115, 105,124, 207,107, 113,259, 247,238, 222,500, 563,227, 501,476, 376,939, 749,711, 1126,489, 801,1222, 1618,1227
+anchors_p7_1920:
+ - [29,34, 81,55, 47,115] # P3/8
+ - [105,124, 207,107, 113,259] # P4/16
+ - [247,238, 222,500, 563,227] # P5/32
+ - [501,476, 376,939, 749,711] # P6/64
+ - [1126,489, 801,1222, 1618,1227] # P7/128
diff --git a/src/image_recognition/models/hub/yolov3-spp.yaml b/src/image_recognition/models/hub/yolov3-spp.yaml
new file mode 100644
index 0000000..c669821
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov3-spp.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3-SPP head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, SPP, [512, [5, 9, 13]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov3-tiny.yaml b/src/image_recognition/models/hub/yolov3-tiny.yaml
new file mode 100644
index 0000000..b28b443
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov3-tiny.yaml
@@ -0,0 +1,41 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,14, 23,27, 37,58] # P4/16
+ - [81,82, 135,169, 344,319] # P5/32
+
+# YOLOv3-tiny backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [16, 3, 1]], # 0
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2
+ [-1, 1, Conv, [32, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4
+ [-1, 1, Conv, [64, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8
+ [-1, 1, Conv, [128, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16
+ [-1, 1, Conv, [256, 3, 1]],
+ [-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32
+ [-1, 1, Conv, [512, 3, 1]],
+ [-1, 1, nn.ZeroPad2d, [[0, 1, 0, 1]]], # 11
+ [-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12
+ ]
+
+# YOLOv3-tiny head
+head:
+ [[-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)
+
+ [[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov3.yaml b/src/image_recognition/models/hub/yolov3.yaml
new file mode 100644
index 0000000..4f4b240
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov3.yaml
@@ -0,0 +1,51 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# darknet53 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [32, 3, 1]], # 0
+ [-1, 1, Conv, [64, 3, 2]], # 1-P1/2
+ [-1, 1, Bottleneck, [64]],
+ [-1, 1, Conv, [128, 3, 2]], # 3-P2/4
+ [-1, 2, Bottleneck, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 5-P3/8
+ [-1, 8, Bottleneck, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 7-P4/16
+ [-1, 8, Bottleneck, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
+ [-1, 4, Bottleneck, [1024]], # 10
+ ]
+
+# YOLOv3 head
+head:
+ [[-1, 1, Bottleneck, [1024, False]],
+ [-1, 1, Conv, [512, [1, 1]]],
+ [-1, 1, Conv, [1024, 3, 1]],
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
+
+ [-2, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Bottleneck, [512, False]],
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
+
+ [-2, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Bottleneck, [256, False]],
+ [-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
+
+ [[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-bifpn.yaml b/src/image_recognition/models/hub/yolov5-bifpn.yaml
new file mode 100644
index 0000000..504815f
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-bifpn.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 BiFPN head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14, 6], 1, Concat, [1]], # cat P4 <--- BiFPN change
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-fpn.yaml b/src/image_recognition/models/hub/yolov5-fpn.yaml
new file mode 100644
index 0000000..a23e9c6
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-fpn.yaml
@@ -0,0 +1,42 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 FPN head
+head:
+ [[-1, 3, C3, [1024, False]], # 10 (P5/32-large)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 3, C3, [512, False]], # 14 (P4/16-medium)
+
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 3, C3, [256, False]], # 18 (P3/8-small)
+
+ [[18, 14, 10], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-p2.yaml b/src/image_recognition/models/hub/yolov5-p2.yaml
new file mode 100644
index 0000000..ffe26eb
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-p2.yaml
@@ -0,0 +1,54 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # auto-anchor evolves 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [128, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 2], 1, Concat, [1]], # cat backbone P2
+ [-1, 1, C3, [128, False]], # 21 (P2/4-xsmall)
+
+ [-1, 1, Conv, [128, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P3
+ [-1, 3, C3, [256, False]], # 24 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 27 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 30 (P5/32-large)
+
+ [[21, 24, 27, 30], 1, Detect, [nc, anchors]], # Detect(P2, P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-p6.yaml b/src/image_recognition/models/hub/yolov5-p6.yaml
new file mode 100644
index 0000000..28f3e43
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-p6.yaml
@@ -0,0 +1,56 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # auto-anchor 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-p7.yaml b/src/image_recognition/models/hub/yolov5-p7.yaml
new file mode 100644
index 0000000..bd2f584
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-p7.yaml
@@ -0,0 +1,67 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors: 3 # auto-anchor 3 anchors per P output layer
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, Conv, [1280, 3, 2]], # 11-P7/128
+ [-1, 3, C3, [1280]],
+ [-1, 1, SPPF, [1280, 5]], # 13
+ ]
+
+# YOLOv5 head
+head:
+ [[-1, 1, Conv, [1024, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 10], 1, Concat, [1]], # cat backbone P6
+ [-1, 3, C3, [1024, False]], # 17
+
+ [-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 21
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 25
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 29 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 26], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 32 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 22], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 35 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 18], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 38 (P6/64-xlarge)
+
+ [-1, 1, Conv, [1024, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P7
+ [-1, 3, C3, [1280, False]], # 41 (P7/128-xxlarge)
+
+ [[29, 32, 35, 38, 41], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6, P7)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5-panet.yaml b/src/image_recognition/models/hub/yolov5-panet.yaml
new file mode 100644
index 0000000..ccfbf90
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5-panet.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 PANet head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5l6.yaml b/src/image_recognition/models/hub/yolov5l6.yaml
new file mode 100644
index 0000000..632c2cb
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5l6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5m6.yaml b/src/image_recognition/models/hub/yolov5m6.yaml
new file mode 100644
index 0000000..ecc53fd
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5m6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5n6.yaml b/src/image_recognition/models/hub/yolov5n6.yaml
new file mode 100644
index 0000000..0c0c71d
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5n6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5s-ghost.yaml b/src/image_recognition/models/hub/yolov5s-ghost.yaml
new file mode 100644
index 0000000..ff9519c
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5s-ghost.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, GhostConv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3Ghost, [128]],
+ [-1, 1, GhostConv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3Ghost, [256]],
+ [-1, 1, GhostConv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3Ghost, [512]],
+ [-1, 1, GhostConv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3Ghost, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, GhostConv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3Ghost, [512, False]], # 13
+
+ [-1, 1, GhostConv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3Ghost, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, GhostConv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3Ghost, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, GhostConv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3Ghost, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5s-transformer.yaml b/src/image_recognition/models/hub/yolov5s-transformer.yaml
new file mode 100644
index 0000000..100d7c4
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5s-transformer.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3TR, [1024]], # 9 <--- C3TR() Transformer module
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5s6.yaml b/src/image_recognition/models/hub/yolov5s6.yaml
new file mode 100644
index 0000000..a28fb55
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5s6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/hub/yolov5x6.yaml b/src/image_recognition/models/hub/yolov5x6.yaml
new file mode 100644
index 0000000..ba795c4
--- /dev/null
+++ b/src/image_recognition/models/hub/yolov5x6.yaml
@@ -0,0 +1,60 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 80 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [19,27, 44,40, 38,94] # P3/8
+ - [96,68, 86,152, 180,137] # P4/16
+ - [140,301, 303,264, 238,542] # P5/32
+ - [436,615, 739,380, 925,792] # P6/64
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [768, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [768]],
+ [-1, 1, Conv, [1024, 3, 2]], # 9-P6/64
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 11
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [768, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 8], 1, Concat, [1]], # cat backbone P5
+ [-1, 3, C3, [768, False]], # 15
+
+ [-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 19
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 23 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 20], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 26 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 16], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [768, False]], # 29 (P5/32-large)
+
+ [-1, 1, Conv, [768, 3, 2]],
+ [[-1, 12], 1, Concat, [1]], # cat head P6
+ [-1, 3, C3, [1024, False]], # 32 (P6/64-xlarge)
+
+ [[23, 26, 29, 32], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5, P6)
+ ]
diff --git a/src/image_recognition/models/mask_yolov5l.yaml b/src/image_recognition/models/mask_yolov5l.yaml
new file mode 100644
index 0000000..266180b
--- /dev/null
+++ b/src/image_recognition/models/mask_yolov5l.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/mask_yolov5m.yaml b/src/image_recognition/models/mask_yolov5m.yaml
new file mode 100644
index 0000000..3599293
--- /dev/null
+++ b/src/image_recognition/models/mask_yolov5m.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/mask_yolov5s.yaml b/src/image_recognition/models/mask_yolov5s.yaml
new file mode 100644
index 0000000..4fd7058
--- /dev/null
+++ b/src/image_recognition/models/mask_yolov5s.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/tf.py b/src/image_recognition/models/tf.py
new file mode 100644
index 0000000..96482dd
--- /dev/null
+++ b/src/image_recognition/models/tf.py
@@ -0,0 +1,465 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+TensorFlow, Keras and TFLite versions of YOLOv5
+Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127
+
+Usage:
+ $ python models/tf.py --weights yolov5s.pt
+
+Export:
+ $ python path/to/export.py --weights yolov5s.pt --include saved_model pb tflite tfjs
+"""
+
+import argparse
+import logging
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+import numpy as np
+import tensorflow as tf
+import torch
+import torch.nn as nn
+from tensorflow import keras
+
+from models.common import C3, SPP, SPPF, Bottleneck, BottleneckCSP, Concat, Conv, DWConv, Focus, autopad
+from models.experimental import CrossConv, MixConv2d, attempt_load
+from models.yolo import Detect
+from utils.activations import SiLU
+from utils.general import LOGGER, make_divisible, print_args
+
+
+class TFBN(keras.layers.Layer):
+ # TensorFlow BatchNormalization wrapper
+ def __init__(self, w=None):
+ super().__init__()
+ self.bn = keras.layers.BatchNormalization(
+ beta_initializer=keras.initializers.Constant(w.bias.numpy()),
+ gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
+ moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
+ moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
+ epsilon=w.eps)
+
+ def call(self, inputs):
+ return self.bn(inputs)
+
+
+class TFPad(keras.layers.Layer):
+ def __init__(self, pad):
+ super().__init__()
+ self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]])
+
+ def call(self, inputs):
+ return tf.pad(inputs, self.pad, mode='constant', constant_values=0)
+
+
+class TFConv(keras.layers.Layer):
+ # Standard convolution
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, weights, kernel, stride, padding, groups
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ assert isinstance(k, int), "Convolution with multiple kernels are not allowed."
+ # TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding)
+ # see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch
+
+ conv = keras.layers.Conv2D(
+ c2, k, s, 'SAME' if s == 1 else 'VALID', use_bias=False if hasattr(w, 'bn') else True,
+ kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
+ self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
+ self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
+
+ # YOLOv5 activations
+ if isinstance(w.act, nn.LeakyReLU):
+ self.act = (lambda x: keras.activations.relu(x, alpha=0.1)) if act else tf.identity
+ elif isinstance(w.act, nn.Hardswish):
+ self.act = (lambda x: x * tf.nn.relu6(x + 3) * 0.166666667) if act else tf.identity
+ elif isinstance(w.act, (nn.SiLU, SiLU)):
+ self.act = (lambda x: keras.activations.swish(x)) if act else tf.identity
+ else:
+ raise Exception(f'no matching TensorFlow activation found for {w.act}')
+
+ def call(self, inputs):
+ return self.act(self.bn(self.conv(inputs)))
+
+
+class TFFocus(keras.layers.Layer):
+ # Focus wh information into c-space
+ def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
+ # ch_in, ch_out, kernel, stride, padding, groups
+ super().__init__()
+ self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv)
+
+ def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c)
+ # inputs = inputs / 255 # normalize 0-255 to 0-1
+ return self.conv(tf.concat([inputs[:, ::2, ::2, :],
+ inputs[:, 1::2, ::2, :],
+ inputs[:, ::2, 1::2, :],
+ inputs[:, 1::2, 1::2, :]], 3))
+
+
+class TFBottleneck(keras.layers.Layer):
+ # Standard bottleneck
+ def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2)
+ self.add = shortcut and c1 == c2
+
+ def call(self, inputs):
+ return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
+
+
+class TFConv2d(keras.layers.Layer):
+ # Substitution for PyTorch nn.Conv2D
+ def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None):
+ super().__init__()
+ assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
+ self.conv = keras.layers.Conv2D(
+ c2, k, s, 'VALID', use_bias=bias,
+ kernel_initializer=keras.initializers.Constant(w.weight.permute(2, 3, 1, 0).numpy()),
+ bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None, )
+
+ def call(self, inputs):
+ return self.conv(inputs)
+
+
+class TFBottleneckCSP(keras.layers.Layer):
+ # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2)
+ self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3)
+ self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4)
+ self.bn = TFBN(w.bn)
+ self.act = lambda x: keras.activations.relu(x, alpha=0.1)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ y1 = self.cv3(self.m(self.cv1(inputs)))
+ y2 = self.cv2(inputs)
+ return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3))))
+
+
+class TFC3(keras.layers.Layer):
+ # CSP Bottleneck with 3 convolutions
+ def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
+ # ch_in, ch_out, number, shortcut, groups, expansion
+ super().__init__()
+ c_ = int(c2 * e) # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
+ self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
+ self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
+
+ def call(self, inputs):
+ return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
+
+
+class TFSPP(keras.layers.Layer):
+ # Spatial pyramid pooling layer used in YOLOv3-SPP
+ def __init__(self, c1, c2, k=(5, 9, 13), w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2)
+ self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k]
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3))
+
+
+class TFSPPF(keras.layers.Layer):
+ # Spatial pyramid pooling-Fast layer
+ def __init__(self, c1, c2, k=5, w=None):
+ super().__init__()
+ c_ = c1 // 2 # hidden channels
+ self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
+ self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2)
+ self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
+
+ def call(self, inputs):
+ x = self.cv1(inputs)
+ y1 = self.m(x)
+ y2 = self.m(y1)
+ return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))
+
+
+class TFDetect(keras.layers.Layer):
+ def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer
+ super().__init__()
+ self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32)
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [tf.zeros(1)] * self.nl # init grid
+ self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32)
+ self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]),
+ [self.nl, 1, -1, 1, 2])
+ self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)]
+ self.training = False # set to False after building model
+ self.imgsz = imgsz
+ for i in range(self.nl):
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ self.grid[i] = self._make_grid(nx, ny)
+
+ def call(self, inputs):
+ z = [] # inference output
+ x = []
+ for i in range(self.nl):
+ x.append(self.m[i](inputs[i]))
+ # x(bs,20,20,255) to x(bs,3,20,20,85)
+ ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
+ x[i] = tf.transpose(tf.reshape(x[i], [-1, ny * nx, self.na, self.no]), [0, 2, 1, 3])
+
+ if not self.training: # inference
+ y = tf.sigmoid(x[i])
+ xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
+ wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i]
+ # Normalize xywh to 0-1 to reduce calibration error
+ xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
+ y = tf.concat([xy, wh, y[..., 4:]], -1)
+ z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no]))
+
+ return x if self.training else (tf.concat(z, 1), x)
+
+ @staticmethod
+ def _make_grid(nx=20, ny=20):
+ # yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
+ # return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
+ xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny))
+ return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32)
+
+
+class TFUpsample(keras.layers.Layer):
+ def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
+ super().__init__()
+ assert scale_factor == 2, "scale_factor must be 2"
+ self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * 2, x.shape[2] * 2), method=mode)
+ # self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
+ # with default arguments: align_corners=False, half_pixel_centers=False
+ # self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
+ # size=(x.shape[1] * 2, x.shape[2] * 2))
+
+ def call(self, inputs):
+ return self.upsample(inputs)
+
+
+class TFConcat(keras.layers.Layer):
+ def __init__(self, dimension=1, w=None):
+ super().__init__()
+ assert dimension == 1, "convert only NCHW to NHWC concat"
+ self.d = 3
+
+ def call(self, inputs):
+ return tf.concat(inputs, self.d)
+
+
+def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m_str = m
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ try:
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+ except NameError:
+ pass
+
+ n = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in [nn.Conv2d, Conv, Bottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
+ c1, c2 = ch[f], args[0]
+ c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3]:
+ args.insert(2, n)
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[-1 if x == -1 else x + 1] for x in f)
+ elif m is Detect:
+ args.append([ch[x + 1] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ args.append(imgsz)
+ else:
+ c2 = ch[f]
+
+ tf_m = eval('TF' + m_str.replace('nn.', ''))
+ m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
+ else tf_m(*args, w=model.model[i]) # module
+
+ torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in torch_m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ ch.append(c2)
+ return keras.Sequential(layers), sorted(save)
+
+
+class TFModel:
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg) as f:
+ self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
+
+ # Define model
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
+
+ def predict(self, inputs, tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
+ conf_thres=0.25):
+ y = [] # outputs
+ x = inputs
+ for i, m in enumerate(self.model.layers):
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+
+ x = m(x) # run
+ y.append(x if m.i in self.savelist else None) # save output
+
+ # Add TensorFlow NMS
+ if tf_nms:
+ boxes = self._xywh2xyxy(x[0][..., :4])
+ probs = x[0][:, :, 4:5]
+ classes = x[0][:, :, 5:]
+ scores = probs * classes
+ if agnostic_nms:
+ nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres)
+ return nms, x[1]
+ else:
+ boxes = tf.expand_dims(boxes, 2)
+ nms = tf.image.combined_non_max_suppression(
+ boxes, scores, topk_per_class, topk_all, iou_thres, conf_thres, clip_boxes=False)
+ return nms, x[1]
+
+ return x[0] # output only first tensor [1,6300,85] = [xywh, conf, class0, class1, ...]
+ # x = x[0][0] # [x(1,6300,85), ...] to x(6300,85)
+ # xywh = x[..., :4] # x(6300,4) boxes
+ # conf = x[..., 4:5] # x(6300,1) confidences
+ # cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes
+ # return tf.concat([conf, cls, xywh], 1)
+
+ @staticmethod
+ def _xywh2xyxy(xywh):
+ # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
+ x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1)
+ return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1)
+
+
+class AgnosticNMS(keras.layers.Layer):
+ # TF Agnostic NMS
+ def call(self, input, topk_all, iou_thres, conf_thres):
+ # wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450
+ return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres), input,
+ fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32),
+ name='agnostic_nms')
+
+ @staticmethod
+ def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS
+ boxes, classes, scores = x
+ class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32)
+ scores_inp = tf.reduce_max(scores, -1)
+ selected_inds = tf.image.non_max_suppression(
+ boxes, scores_inp, max_output_size=topk_all, iou_threshold=iou_thres, score_threshold=conf_thres)
+ selected_boxes = tf.gather(boxes, selected_inds)
+ padded_boxes = tf.pad(selected_boxes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]],
+ mode="CONSTANT", constant_values=0.0)
+ selected_scores = tf.gather(scores_inp, selected_inds)
+ padded_scores = tf.pad(selected_scores,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode="CONSTANT", constant_values=-1.0)
+ selected_classes = tf.gather(class_inds, selected_inds)
+ padded_classes = tf.pad(selected_classes,
+ paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
+ mode="CONSTANT", constant_values=-1.0)
+ valid_detections = tf.shape(selected_inds)[0]
+ return padded_boxes, padded_scores, padded_classes, valid_detections
+
+
+def representative_dataset_gen(dataset, ncalib=100):
+ # Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
+ for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
+ input = np.transpose(img, [1, 2, 0])
+ input = np.expand_dims(input, axis=0).astype(np.float32)
+ input /= 255
+ yield [input]
+ if n >= ncalib:
+ break
+
+
+def run(weights=ROOT / 'yolov5s.pt', # weights path
+ imgsz=(640, 640), # inference size h,w
+ batch_size=1, # batch size
+ dynamic=False, # dynamic batch size
+ ):
+ # PyTorch model
+ im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image
+ model = attempt_load(weights, map_location=torch.device('cpu'), inplace=True, fuse=False)
+ y = model(im) # inference
+ model.info()
+
+ # TensorFlow model
+ im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image
+ tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
+ y = tf_model.predict(im) # inference
+
+ # Keras model
+ im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
+ keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im))
+ keras_model.summary()
+
+ LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.')
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
+ parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
+ parser.add_argument('--batch-size', type=int, default=1, help='batch size')
+ parser.add_argument('--dynamic', action='store_true', help='dynamic batch size')
+ opt = parser.parse_args()
+ opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
+ print_args(FILE.stem, opt)
+ return opt
+
+
+def main(opt):
+ run(**vars(opt))
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/models/yolo.py b/src/image_recognition/models/yolo.py
new file mode 100644
index 0000000..305f0ca
--- /dev/null
+++ b/src/image_recognition/models/yolo.py
@@ -0,0 +1,336 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+YOLO-specific modules
+
+Usage:
+ $ python path/to/models/yolo.py --cfg yolov5s.yaml
+"""
+
+import argparse
+import sys
+from copy import deepcopy
+from pathlib import Path
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[1] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+# ROOT = ROOT.relative_to(Path.cwd()) # relative
+
+from models.common import *
+from models.experimental import *
+from utils.autoanchor import check_anchor_order
+from utils.general import LOGGER, check_version, check_yaml, make_divisible, print_args
+from utils.plots import feature_visualization
+from utils.torch_utils import (copy_attr, fuse_conv_and_bn, initialize_weights, model_info, scale_img, select_device,
+ time_sync)
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+
+class Detect(nn.Module):
+ stride = None # strides computed during build
+ onnx_dynamic = False # ONNX export parameter
+
+ def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
+ super().__init__()
+ self.nc = nc # number of classes
+ self.no = nc + 5 # number of outputs per anchor
+ self.nl = len(anchors) # number of detection layers
+ self.na = len(anchors[0]) // 2 # number of anchors
+ self.grid = [torch.zeros(1)] * self.nl # init grid
+ self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
+ self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
+ self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
+ self.inplace = inplace # use in-place ops (e.g. slice assignment)
+
+ def forward(self, x):
+ z = [] # inference output
+ for i in range(self.nl):
+ x[i] = self.m[i](x[i]) # conv
+ bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
+ x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
+
+ if not self.training: # inference
+ if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
+ self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
+
+ y = x[i].sigmoid()
+ if self.inplace:
+ y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
+ y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
+ else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
+ xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
+ wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
+ y = torch.cat((xy, wh, y[..., 4:]), -1)
+ z.append(y.view(bs, -1, self.no))
+
+ return x if self.training else (torch.cat(z, 1), x)
+
+ def _make_grid(self, nx=20, ny=20, i=0):
+ d = self.anchors[i].device
+ if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
+ yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')
+ else:
+ yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
+ grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
+ anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
+ .view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
+ return grid, anchor_grid
+
+
+class Model(nn.Module):
+ def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
+ super().__init__()
+ if isinstance(cfg, dict):
+ self.yaml = cfg # model dict
+ else: # is *.yaml
+ import yaml # for torch hub
+ self.yaml_file = Path(cfg).name
+ with open(cfg, encoding='ascii', errors='ignore') as f:
+ self.yaml = yaml.safe_load(f) # model dict
+
+ # Define model
+ ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
+ if nc and nc != self.yaml['nc']:
+ LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
+ self.yaml['nc'] = nc # override yaml value
+ if anchors:
+ LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
+ self.yaml['anchors'] = round(anchors) # override yaml value
+ self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
+ self.names = [str(i) for i in range(self.yaml['nc'])] # default names
+ self.inplace = self.yaml.get('inplace', True)
+
+ # Build strides, anchors
+ m = self.model[-1] # Detect()
+ if isinstance(m, Detect):
+ s = 256 # 2x min stride
+ m.inplace = self.inplace
+ m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
+ m.anchors /= m.stride.view(-1, 1, 1)
+ check_anchor_order(m)
+ self.stride = m.stride
+ self._initialize_biases() # only run once
+
+ # Init weights, biases
+ initialize_weights(self)
+ self.info()
+ LOGGER.info('')
+
+ def forward(self, x, augment=False, profile=False, visualize=False):
+ if augment:
+ return self._forward_augment(x) # augmented inference, None
+ return self._forward_once(x, profile, visualize) # single-scale inference, train
+
+ def _forward_augment(self, x):
+ img_size = x.shape[-2:] # height, width
+ s = [1, 0.83, 0.67] # scales
+ f = [None, 3, None] # flips (2-ud, 3-lr)
+ y = [] # outputs
+ for si, fi in zip(s, f):
+ xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
+ yi = self._forward_once(xi)[0] # forward
+ # cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
+ yi = self._descale_pred(yi, fi, si, img_size)
+ y.append(yi)
+ y = self._clip_augmented(y) # clip augmented tails
+ return torch.cat(y, 1), None # augmented inference, train
+
+ def _forward_once(self, x, profile=False, visualize=False):
+ y, dt = [], [] # outputs
+ for m in self.model:
+ if m.f != -1: # if not from previous layer
+ x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
+ if profile:
+ self._profile_one_layer(m, x, dt)
+ x = m(x) # run
+ y.append(x if m.i in self.save else None) # save output
+ if visualize:
+ feature_visualization(x, m.type, m.i, save_dir=visualize)
+ return x
+
+ def _descale_pred(self, p, flips, scale, img_size):
+ # de-scale predictions following augmented inference (inverse operation)
+ if self.inplace:
+ p[..., :4] /= scale # de-scale
+ if flips == 2:
+ p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
+ elif flips == 3:
+ p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
+ else:
+ x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
+ if flips == 2:
+ y = img_size[0] - y # de-flip ud
+ elif flips == 3:
+ x = img_size[1] - x # de-flip lr
+ p = torch.cat((x, y, wh, p[..., 4:]), -1)
+ return p
+
+ def _clip_augmented(self, y):
+ # Clip YOLOv5 augmented inference tails
+ nl = self.model[-1].nl # number of detection layers (P3-P5)
+ g = sum(4 ** x for x in range(nl)) # grid points
+ e = 1 # exclude layer count
+ i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
+ y[0] = y[0][:, :-i] # large
+ i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
+ y[-1] = y[-1][:, i:] # small
+ return y
+
+ def _profile_one_layer(self, m, x, dt):
+ c = isinstance(m, Detect) # is final layer, copy input as inplace fix
+ o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
+ t = time_sync()
+ for _ in range(10):
+ m(x.copy() if c else x)
+ dt.append((time_sync() - t) * 100)
+ if m == self.model[0]:
+ LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
+ LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
+ if c:
+ LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
+
+ def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
+ # https://arxiv.org/abs/1708.02002 section 3.3
+ # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
+ m = self.model[-1] # Detect() module
+ for mi, s in zip(m.m, m.stride): # from
+ b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
+ b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
+ b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
+ mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
+
+ def _print_biases(self):
+ m = self.model[-1] # Detect() module
+ for mi in m.m: # from
+ b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
+ LOGGER.info(
+ ('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
+
+ # def _print_weights(self):
+ # for m in self.model.modules():
+ # if type(m) is Bottleneck:
+ # LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
+
+ def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
+ LOGGER.info('Fusing layers... ')
+ for m in self.model.modules():
+ if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
+ m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
+ delattr(m, 'bn') # remove batchnorm
+ m.forward = m.forward_fuse # update forward
+ self.info()
+ return self
+
+ def autoshape(self): # add AutoShape module
+ LOGGER.info('Adding AutoShape... ')
+ m = AutoShape(self) # wrap model
+ copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
+ return m
+
+ def info(self, verbose=False, img_size=640): # print model information
+ model_info(self, verbose, img_size)
+
+ def _apply(self, fn):
+ # Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
+ self = super()._apply(fn)
+ m = self.model[-1] # Detect()
+ if isinstance(m, Detect):
+ m.stride = fn(m.stride)
+ m.grid = list(map(fn, m.grid))
+ if isinstance(m.anchor_grid, list):
+ m.anchor_grid = list(map(fn, m.anchor_grid))
+ return self
+
+
+def parse_model(d, ch): # model_dict, input_channels(3)
+ LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
+ anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
+ na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
+ no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
+
+ layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
+ for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
+ m = eval(m) if isinstance(m, str) else m # eval strings
+ for j, a in enumerate(args):
+ try:
+ args[j] = eval(a) if isinstance(a, str) else a # eval strings
+ except NameError:
+ pass
+
+ n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
+ if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
+ BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
+ c1, c2 = ch[f], args[0]
+ if c2 != no: # if not output
+ c2 = make_divisible(c2 * gw, 8)
+
+ args = [c1, c2, *args[1:]]
+ if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
+ args.insert(2, n) # number of repeats
+ n = 1
+ elif m is nn.BatchNorm2d:
+ args = [ch[f]]
+ elif m is Concat:
+ c2 = sum(ch[x] for x in f)
+ elif m is Detect:
+ args.append([ch[x] for x in f])
+ if isinstance(args[1], int): # number of anchors
+ args[1] = [list(range(args[1] * 2))] * len(f)
+ elif m is Contract:
+ c2 = ch[f] * args[0] ** 2
+ elif m is Expand:
+ c2 = ch[f] // args[0] ** 2
+ else:
+ c2 = ch[f]
+
+ m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
+ t = str(m)[8:-2].replace('__main__.', '') # module type
+ np = sum(x.numel() for x in m_.parameters()) # number params
+ m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
+ LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
+ save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
+ layers.append(m_)
+ if i == 0:
+ ch = []
+ ch.append(c2)
+ return nn.Sequential(*layers), sorted(save)
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--profile', action='store_true', help='profile model speed')
+ parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
+ opt = parser.parse_args()
+ opt.cfg = check_yaml(opt.cfg) # check YAML
+ print_args(FILE.stem, opt)
+ device = select_device(opt.device)
+
+ # Create model
+ model = Model(opt.cfg).to(device)
+ model.train()
+
+ # Profile
+ if opt.profile:
+ img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
+ y = model(img, profile=True)
+
+ # Test all models
+ if opt.test:
+ for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
+ try:
+ _ = Model(cfg)
+ except Exception as e:
+ print(f'Error in {cfg}: {e}')
+
+ # Tensorboard (not working https://github.com/ultralytics/yolov5/issues/2898)
+ # from torch.utils.tensorboard import SummaryWriter
+ # tb_writer = SummaryWriter('.')
+ # LOGGER.info("Run 'tensorboard --logdir=models' to view tensorboard at http://localhost:6006/")
+ # tb_writer.add_graph(torch.jit.trace(model, img, strict=False), []) # add model graph
diff --git a/src/image_recognition/models/yolov5l.yaml b/src/image_recognition/models/yolov5l.yaml
new file mode 100644
index 0000000..266180b
--- /dev/null
+++ b/src/image_recognition/models/yolov5l.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 1.0 # model depth multiple
+width_multiple: 1.0 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5m.yaml b/src/image_recognition/models/yolov5m.yaml
new file mode 100644
index 0000000..3599293
--- /dev/null
+++ b/src/image_recognition/models/yolov5m.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.67 # model depth multiple
+width_multiple: 0.75 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5n.yaml b/src/image_recognition/models/yolov5n.yaml
new file mode 100644
index 0000000..fa6b131
--- /dev/null
+++ b/src/image_recognition/models/yolov5n.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5s.yaml b/src/image_recognition/models/yolov5s.yaml
new file mode 100644
index 0000000..4fd7058
--- /dev/null
+++ b/src/image_recognition/models/yolov5s.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 0.33 # model depth multiple
+width_multiple: 0.50 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/models/yolov5x.yaml b/src/image_recognition/models/yolov5x.yaml
new file mode 100644
index 0000000..2a8dfe6
--- /dev/null
+++ b/src/image_recognition/models/yolov5x.yaml
@@ -0,0 +1,48 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+
+# Parameters
+nc: 2 # number of classes
+depth_multiple: 1.33 # model depth multiple
+width_multiple: 1.25 # layer channel multiple
+anchors:
+ - [10,13, 16,30, 33,23] # P3/8
+ - [30,61, 62,45, 59,119] # P4/16
+ - [116,90, 156,198, 373,326] # P5/32
+
+# YOLOv5 v6.0 backbone
+backbone:
+ # [from, number, module, args]
+ [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
+ [-1, 1, Conv, [128, 3, 2]], # 1-P2/4
+ [-1, 3, C3, [128]],
+ [-1, 1, Conv, [256, 3, 2]], # 3-P3/8
+ [-1, 6, C3, [256]],
+ [-1, 1, Conv, [512, 3, 2]], # 5-P4/16
+ [-1, 9, C3, [512]],
+ [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
+ [-1, 3, C3, [1024]],
+ [-1, 1, SPPF, [1024, 5]], # 9
+ ]
+
+# YOLOv5 v6.0 head
+head:
+ [[-1, 1, Conv, [512, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 6], 1, Concat, [1]], # cat backbone P4
+ [-1, 3, C3, [512, False]], # 13
+
+ [-1, 1, Conv, [256, 1, 1]],
+ [-1, 1, nn.Upsample, [None, 2, 'nearest']],
+ [[-1, 4], 1, Concat, [1]], # cat backbone P3
+ [-1, 3, C3, [256, False]], # 17 (P3/8-small)
+
+ [-1, 1, Conv, [256, 3, 2]],
+ [[-1, 14], 1, Concat, [1]], # cat head P4
+ [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
+
+ [-1, 1, Conv, [512, 3, 2]],
+ [[-1, 10], 1, Concat, [1]], # cat head P5
+ [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
+
+ [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
+ ]
diff --git a/src/image_recognition/pretrained/yolov5l.pt b/src/image_recognition/pretrained/yolov5l.pt
new file mode 100644
index 0000000..6f3fc03
Binary files /dev/null and b/src/image_recognition/pretrained/yolov5l.pt differ
diff --git a/src/image_recognition/pretrained/yolov5m.pt b/src/image_recognition/pretrained/yolov5m.pt
new file mode 100644
index 0000000..6625c38
Binary files /dev/null and b/src/image_recognition/pretrained/yolov5m.pt differ
diff --git a/src/image_recognition/pretrained/yolov5s.pt b/src/image_recognition/pretrained/yolov5s.pt
new file mode 100644
index 0000000..cab379e
Binary files /dev/null and b/src/image_recognition/pretrained/yolov5s.pt differ
diff --git a/src/image_recognition/requirements.txt b/src/image_recognition/requirements.txt
new file mode 100644
index 0000000..9137ed8
--- /dev/null
+++ b/src/image_recognition/requirements.txt
@@ -0,0 +1,36 @@
+# pip install -r requirements.txt
+
+# Base ----------------------------------------
+matplotlib>=3.2.2
+numpy>=1.18.5
+opencv-python>=4.1.2
+Pillow>=7.1.2
+PyYAML>=5.3.1
+requests>=2.23.0
+scipy>=1.4.1
+# torch>=1.7.0
+# torchvision>=0.8.1
+tqdm>=4.41.0
+
+# Logging -------------------------------------
+tensorboard>=2.4.1
+# wandb
+
+# Plotting ------------------------------------
+pandas>=1.1.4
+seaborn>=0.11.0
+
+# Export --------------------------------------
+# coremltools>=4.1 # CoreML export
+# onnx>=1.9.0 # ONNX export
+# onnx-simplifier>=0.3.6 # ONNX simplifier
+# scikit-learn==0.19.2 # CoreML quantization
+# tensorflow>=2.4.1 # TFLite export
+# tensorflowjs>=3.9.0 # TF.js export
+
+# Extras --------------------------------------
+# albumentations>=1.0.3
+# Cython # for pycocotools https://github.com/cocodataset/cocoapi/issues/172
+# pycocotools>=2.0 # COCO mAP
+# roboflow
+thop # FLOPs computation
diff --git a/src/image_recognition/runs/detect/exp/fishman.jpg b/src/image_recognition/runs/detect/exp/fishman.jpg
new file mode 100644
index 0000000..3831716
Binary files /dev/null and b/src/image_recognition/runs/detect/exp/fishman.jpg differ
diff --git a/src/image_recognition/runs/如需要数据集和训练好的模型请在博客自行下载.txt b/src/image_recognition/runs/如需要数据集和训练好的模型请在博客自行下载.txt
new file mode 100644
index 0000000..e69de29
diff --git a/src/image_recognition/setup.cfg b/src/image_recognition/setup.cfg
new file mode 100644
index 0000000..4ca0f0d
--- /dev/null
+++ b/src/image_recognition/setup.cfg
@@ -0,0 +1,51 @@
+# Project-wide configuration file, can be used for package metadata and other toll configurations
+# Example usage: global configuration for PEP8 (via flake8) setting or default pytest arguments
+
+[metadata]
+license_file = LICENSE
+description-file = README.md
+
+
+[tool:pytest]
+norecursedirs =
+ .git
+ dist
+ build
+addopts =
+ --doctest-modules
+ --durations=25
+ --color=yes
+
+
+[flake8]
+max-line-length = 120
+exclude = .tox,*.egg,build,temp
+select = E,W,F
+doctests = True
+verbose = 2
+# https://pep8.readthedocs.io/en/latest/intro.html#error-codes
+format = pylint
+# see: https://www.flake8rules.com/
+ignore =
+ E731 # Do not assign a lambda expression, use a def
+ F405
+ E402
+ F841
+ E741
+ F821
+ E722
+ F401
+ W504
+ E127
+ W504
+ E231
+ E501
+ F403
+ E302
+ F541
+
+
+[isort]
+# https://pycqa.github.io/isort/docs/configuration/options.html
+line_length = 120
+multi_line_output = 0
diff --git a/src/image_recognition/train.py b/src/image_recognition/train.py
new file mode 100644
index 0000000..9d0bd68
--- /dev/null
+++ b/src/image_recognition/train.py
@@ -0,0 +1,630 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Train a YOLOv5 model on a custom dataset
+
+Usage:
+ $ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
+"""
+import argparse
+import math
+import os
+import random
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.cuda import amp
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.optim import SGD, Adam, lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import Model
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.datasets import create_dataloader
+from utils.downloads import attempt_download
+from utils.general import (LOGGER, NCOLS, check_dataset, check_file, check_git_status, check_img_size,
+ check_requirements, check_suffix, check_yaml, colorstr, get_latest_run, increment_path,
+ init_seeds, intersect_dicts, labels_to_class_weights, labels_to_image_weights, methods,
+ one_cycle, print_args, print_mutation, strip_optimizer)
+from utils.loggers import Loggers
+from utils.loggers.wandb.wandb_utils import check_wandb_resume
+from utils.loss import ComputeLoss
+from utils.metrics import fitness
+from utils.plots import plot_evolve, plot_labels
+from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, select_device, torch_distributed_zero_first
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+
+def train(hyp, # path/to/hyp.yaml or hyp dictionary
+ opt,
+ device,
+ callbacks
+ ):
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
+
+ # Directories
+ w = save_dir / 'weights' # weights dir
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+
+ # Save run settings
+ with open(save_dir / 'hyp.yaml', 'w') as f:
+ yaml.safe_dump(hyp, f, sort_keys=False)
+ with open(save_dir / 'opt.yaml', 'w') as f:
+ yaml.safe_dump(vars(opt), f, sort_keys=False)
+ data_dict = None
+
+ # Loggers
+ if RANK in [-1, 0]:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+ if loggers.wandb:
+ data_dict = loggers.wandb.data_dict
+ if resume:
+ weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ # Config
+ plots = not evolve # create plots
+ cuda = device.type != 'cpu'
+ init_seeds(1 + RANK)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location=device) # load checkpoint
+ model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz)
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
+
+ g0, g1, g2 = [], [], [] # optimizer parameter groups
+ for v in model.modules():
+ if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
+ g2.append(v.bias)
+ if isinstance(v, nn.BatchNorm2d): # weight (no decay)
+ g0.append(v.weight)
+ elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
+ g1.append(v.weight)
+
+ if opt.adam:
+ optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
+ else:
+ optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
+
+ optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
+ optimizer.add_param_group({'params': g2}) # add g2 (biases)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
+ f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
+ del g0, g1, g2
+
+ # Scheduler
+ if opt.linear_lr:
+ lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ else:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in [-1, 0] else None
+
+ # Resume
+ start_epoch, best_fitness = 0, 0.0
+ if pretrained:
+ # Optimizer
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer'])
+ best_fitness = ckpt['best_fitness']
+
+ # EMA
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
+ ema.updates = ckpt['updates']
+
+ # Epochs
+ start_epoch = ckpt['epoch'] + 1
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
+ hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
+ workers=workers, image_weights=opt.image_weights, quad=opt.quad,
+ prefix=colorstr('train: '), shuffle=True)
+ mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
+ nb = len(train_loader) # number of batches
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in [-1, 0]:
+ val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
+ hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
+ workers=workers, pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ labels = np.concatenate(dataset.labels, 0)
+ # c = torch.tensor(labels[:, 0]) # classes
+ # cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
+ # model._initialize_biases(cf.to(device))
+ if plots:
+ plot_labels(labels, names, save_dir)
+
+ # Anchors
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
+ model.half().float() # pre-reduce anchor precision
+
+ callbacks.run('on_pretrain_routine_end')
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = amp.GradScaler(enabled=cuda)
+ stopper = EarlyStopping(patience=opt.patience)
+ compute_loss = ComputeLoss(model) # init loss class
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(3, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
+ if RANK in [-1, 0]:
+ pbar = tqdm(pbar, total=nb, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with amp.autocast(enabled=cuda):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize
+ if ni - last_opt_step >= accumulate:
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in [-1, 0]:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
+ f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in [-1, 0]:
+ # mAP
+ callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ del ckpt
+ callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # Stop Single-GPU
+ if RANK == -1 and stopper(epoch=epoch, fitness=fi):
+ break
+
+ # Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
+ # stop = stopper(epoch=epoch, fitness=fi)
+ # if RANK == 0:
+ # dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
+
+ # Stop DPP
+ # with torch_distributed_zero_first(RANK):
+ # if stop:
+ # break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in [-1, 0]:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=True,
+ callbacks=callbacks,
+ compute_loss=compute_loss) # val best model with plots
+ if is_coco:
+ callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+
+ callbacks.run('on_train_end', last, best, plots, epoch, results)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ torch.cuda.empty_cache()
+ return results
+
+
+# 明天把这些模型都试试效果先,一波波给他训练完毕,找个公开的数据集测试一下。
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'pretrained/yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=300)
+ parser.add_argument('--batch-size', type=int, default=4, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ # parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--multi-scale', default=True, help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=0, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--linear-lr', action='store_true', help='linear LR')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ return opt
+
+
+def main(opt, callbacks=Callbacks()):
+
+ # Checks
+ if RANK in [-1, 0]:
+ print_args(FILE.stem, opt)
+ check_git_status()
+ check_requirements(exclude=['thop'])
+
+ # Resume
+ if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
+ ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
+ assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
+ with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
+ opt = argparse.Namespace(**yaml.safe_load(f)) # replace
+ opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
+ LOGGER.info(f'Resuming training from {ckpt}')
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ opt.project = str(ROOT / 'runs/evolve')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
+ assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
+ assert not opt.evolve, '--evolve argument is not compatible with DDP training'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+ if WORLD_SIZE > 1 and RANK == 0:
+ LOGGER.info('Destroying process group... ')
+ dist.destroy_process_group()
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}') # download evolve.csv if exists
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 7] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+
+ # Write mutation results
+ print_mutation(results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+
+
+# python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu
+# python train.py --data mask_data.yaml --cfg mask_yolov5l.yaml --weights pretrained/yolov5l.pt --epoch 100 --batch-size 4
+# python train.py --data mask_data.yaml --cfg mask_yolov5m.yaml --weights pretrained/yolov5m.pt --epoch 100 --batch-size 4
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/utils/__init__.py b/src/image_recognition/utils/__init__.py
new file mode 100644
index 0000000..7ebb57e
--- /dev/null
+++ b/src/image_recognition/utils/__init__.py
@@ -0,0 +1,18 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+utils/initialization
+"""
+
+
+def notebook_init():
+ # For YOLOv5 notebooks
+ print('Checking setup...')
+ from IPython import display # to display images and clear console output
+
+ from utils.general import emojis
+ from utils.torch_utils import select_device # YOLOv5 imports
+
+ display.clear_output()
+ select_device(newline=False)
+ print(emojis('Setup complete ✅'))
+ return display
diff --git a/src/image_recognition/utils/__pycache__/__init__.cpython-38.pyc b/src/image_recognition/utils/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..6277563
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/augmentations.cpython-38.pyc b/src/image_recognition/utils/__pycache__/augmentations.cpython-38.pyc
new file mode 100644
index 0000000..66d4b87
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/augmentations.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/autoanchor.cpython-38.pyc b/src/image_recognition/utils/__pycache__/autoanchor.cpython-38.pyc
new file mode 100644
index 0000000..d6e9e41
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/autoanchor.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/autobatch.cpython-38.pyc b/src/image_recognition/utils/__pycache__/autobatch.cpython-38.pyc
new file mode 100644
index 0000000..0881939
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/autobatch.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/callbacks.cpython-38.pyc b/src/image_recognition/utils/__pycache__/callbacks.cpython-38.pyc
new file mode 100644
index 0000000..1e7c431
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/callbacks.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/datasets.cpython-38.pyc b/src/image_recognition/utils/__pycache__/datasets.cpython-38.pyc
new file mode 100644
index 0000000..06a33b7
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/datasets.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/datasets_not_print.cpython-38.pyc b/src/image_recognition/utils/__pycache__/datasets_not_print.cpython-38.pyc
new file mode 100644
index 0000000..be00221
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/datasets_not_print.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/downloads.cpython-38.pyc b/src/image_recognition/utils/__pycache__/downloads.cpython-38.pyc
new file mode 100644
index 0000000..e689036
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/downloads.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/general.cpython-38.pyc b/src/image_recognition/utils/__pycache__/general.cpython-38.pyc
new file mode 100644
index 0000000..ef8a266
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/general.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/loss.cpython-38.pyc b/src/image_recognition/utils/__pycache__/loss.cpython-38.pyc
new file mode 100644
index 0000000..b3d8d34
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/loss.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/metrics.cpython-38.pyc b/src/image_recognition/utils/__pycache__/metrics.cpython-38.pyc
new file mode 100644
index 0000000..8138867
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/metrics.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/plots.cpython-38.pyc b/src/image_recognition/utils/__pycache__/plots.cpython-38.pyc
new file mode 100644
index 0000000..487e78d
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/plots.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/__pycache__/torch_utils.cpython-38.pyc b/src/image_recognition/utils/__pycache__/torch_utils.cpython-38.pyc
new file mode 100644
index 0000000..4b033d2
Binary files /dev/null and b/src/image_recognition/utils/__pycache__/torch_utils.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/activations.py b/src/image_recognition/utils/activations.py
new file mode 100644
index 0000000..4c7d46c
--- /dev/null
+++ b/src/image_recognition/utils/activations.py
@@ -0,0 +1,101 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Activation functions
+"""
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+# SiLU https://arxiv.org/pdf/1606.08415.pdf ----------------------------------------------------------------------------
+class SiLU(nn.Module): # export-friendly version of nn.SiLU()
+ @staticmethod
+ def forward(x):
+ return x * torch.sigmoid(x)
+
+
+class Hardswish(nn.Module): # export-friendly version of nn.Hardswish()
+ @staticmethod
+ def forward(x):
+ # return x * F.hardsigmoid(x) # for torchscript and CoreML
+ return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for torchscript, CoreML and ONNX
+
+
+# Mish https://github.com/digantamisra98/Mish --------------------------------------------------------------------------
+class Mish(nn.Module):
+ @staticmethod
+ def forward(x):
+ return x * F.softplus(x).tanh()
+
+
+class MemoryEfficientMish(nn.Module):
+ class F(torch.autograd.Function):
+ @staticmethod
+ def forward(ctx, x):
+ ctx.save_for_backward(x)
+ return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ x = ctx.saved_tensors[0]
+ sx = torch.sigmoid(x)
+ fx = F.softplus(x).tanh()
+ return grad_output * (fx + x * sx * (1 - fx * fx))
+
+ def forward(self, x):
+ return self.F.apply(x)
+
+
+# FReLU https://arxiv.org/abs/2007.11824 -------------------------------------------------------------------------------
+class FReLU(nn.Module):
+ def __init__(self, c1, k=3): # ch_in, kernel
+ super().__init__()
+ self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
+ self.bn = nn.BatchNorm2d(c1)
+
+ def forward(self, x):
+ return torch.max(x, self.bn(self.conv(x)))
+
+
+# ACON https://arxiv.org/pdf/2009.04759.pdf ----------------------------------------------------------------------------
+class AconC(nn.Module):
+ r""" ACON activation (activate or not).
+ AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
+ according to "Activate or Not: Learning Customized Activation"
+
+ +
+
+
+
+
+
+
+## Viewing Runs
+Toggle Details
+When you first train, W&B will prompt you to create a new account and will generate an **API key** for you. If you are an existing user you can retrieve your key from https://wandb.ai/authorize. This key is used to tell W&B where to log your data. You only need to supply your key once, and then it is remembered on the same device. + +W&B will create a cloud **project** (default is 'YOLOv5') for your training runs, and each new training run will be provided a unique run **name** within that project as project/name. You can also manually set your project and run name as: + + ```shell + $ python train.py --project ... --name ... + ``` + +YOLOv5 notebook example:
+
+
+
+
+
+
+## Advanced Usage
+You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
+Toggle Details
+Run information streams from your environment to the W&B cloud console as you train. This allows you to monitor and even cancel runs in realtime . All important information is logged: + + * Training & Validation losses + * Metrics: Precision, Recall, mAP@0.5, mAP@0.5:0.95 + * Learning Rate over time + * A bounding box debugging panel, showing the training progress over time + * GPU: Type, **GPU Utilization**, power, temperature, **CUDA memory usage** + * System: Disk I/0, CPU utilization, RAM memory usage + * Your trained model as W&B Artifact + * Environment: OS and Python types, Git repository and state, **training command** + +
+
+
+ 1. Visualize and Version Datasets
+ Log, visualize, dynamically query, and understand your data with W&B Tables. You can use the following command to log your dataset as a W&B Table. This will generate a{dataset}_wandb.yaml file which can be used to train from dataset artifact.
+
+
+
+ Usage
+ Code $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data ..
+
+ 
+ 2: Train and Log Evaluation simultaneousy
+ This is an extension of the previous section, but it'll also training after uploading the dataset. This also evaluation Table + Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets, + so no images will be uploaded from your system more than once. +
+
+
+ Usage
+ Code $ python utils/logger/wandb/log_dataset.py --data .. --upload_data
+
+
+ 3: Train using dataset artifact
+ When you upload a dataset as described in the first section, you get a new config file with an added `_wandb` to its name. This file contains the information that + can be used to train a model directly from the dataset artifact. This also logs evaluation +
+
+
+ Usage
+ Code $ python utils/logger/wandb/log_dataset.py --data {data}_wandb.yaml
+
+
+ 4: Save model checkpoints as artifacts
+ To enable saving and versioning checkpoints of your experiment, pass `--save_period n` with the base cammand, where `n` represents checkpoint interval. + You can also log both the dataset and model checkpoints simultaneously. If not passed, only the final model will be logged + +
+
+
+Usage
+ Code $ python train.py --save_period 1
+
+
+ 5: Resume runs from checkpoint artifacts.
+Any run can be resumed using artifacts if the--resume argument starts with wandb-artifact:// prefix followed by the run path, i.e, wandb-artifact://username/project/runid . This doesn't require the model checkpoint to be present on the local system.
+
+
+
+
+ Usage
+ Code $ python train.py --resume wandb-artifact://{run_path}
+
+
+ 6: Resume runs from dataset artifact & checkpoint artifacts.
+ Local dataset or model checkpoints are not required. This can be used to resume runs directly on a different device + The syntax is same as the previous section, but you'll need to lof both the dataset and model checkpoints as artifacts, i.e, set bot--upload_dataset or
+ train from _wandb.yaml file and set --save_period
+
+
+
+
+
+
+
+ Usage
+ Code $ python train.py --resume wandb-artifact://{run_path}
+
+
+ Reports
+W&B Reports can be created from your saved runs for sharing online. Once a report is created you will receive a link you can use to publically share your results. Here is an example report created from the COCO128 tutorial trainings of all four YOLOv5 models ([link](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY)). + + +
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/src/image_recognition/utils/loggers/wandb/__init__.py b/src/image_recognition/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/image_recognition/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc b/src/image_recognition/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..ea07ec0
Binary files /dev/null and b/src/image_recognition/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc b/src/image_recognition/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc
new file mode 100644
index 0000000..b6081e8
Binary files /dev/null and b/src/image_recognition/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/loggers/wandb/log_dataset.py b/src/image_recognition/utils/loggers/wandb/log_dataset.py
new file mode 100644
index 0000000..06e81fb
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/src/image_recognition/utils/loggers/wandb/sweep.py b/src/image_recognition/utils/loggers/wandb/sweep.py
new file mode 100644
index 0000000..206059b
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent
+ hyp_dict = vars(wandb.config).get("_items")
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/src/image_recognition/utils/loggers/wandb/sweep.yaml b/src/image_recognition/utils/loggers/wandb/sweep.yaml
new file mode 100644
index 0000000..c7790d7
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/src/image_recognition/utils/loggers/wandb/wandb_utils.py b/src/image_recognition/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000..47757dd
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,532 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import pkg_resources as pkg
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.datasets import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = (isinstance(data_dict['train'], str) and
+ data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX))
+ is_valset_wandb_artifact = (isinstance(data_dict['val'], str) and
+ data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX))
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup trainig processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict},
+ allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data,
+ opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ LOGGER.info(f"Created dataset config file {config_path}")
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs, \
+ config.hyp
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(data_dict.get('train'),
+ opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(data_dict.get('val'),
+ opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model', type='model', metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score
+ })
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
+ self.val_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+ path = Path(data_file).stem
+ path = (path if overwrite_config else path + '_wandb') + '.yaml' # updated data.yaml path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.wandb_run.use_artifact(self.train_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int,str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.img_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file),
+ name='data/labels/' + label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({"position": {"middle": [xywh[0], xywh[1]], "width": xywh[2], "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ total_conf = 0
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ box_data.append(
+ {"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"})
+ total_conf += conf
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch,
+ id,
+ self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ total_conf / max(1, len(box_data))
+ )
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact, aliases=['latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/src/image_recognition/utils/loss.py b/src/image_recognition/utils/loss.py
new file mode 100644
index 0000000..194c8e5
--- /dev/null
+++ b/src/image_recognition/utils/loss.py
@@ -0,0 +1,222 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import is_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ self.sort_obj_iou = False
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ for k in 'na', 'nc', 'nl', 'anchors':
+ setattr(self, k, getattr(det, k))
+
+ def __call__(self, p, targets): # predictions, targets, model
+ device = targets.device
+ lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
+
+ # Regression
+ pxy = ps[:, :2].sigmoid() * 2 - 0.5
+ pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ score_iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ sort_id = torch.argsort(score_iou)
+ b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
+ tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(ps[:, 5:], t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0],
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ b, c = t[:, :2].long().T # image, class
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, 6].long() # anchor indices
+ indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/src/image_recognition/utils/metrics.py b/src/image_recognition/utils/metrics.py
new file mode 100644
index 0000000..2e0e0c6
--- /dev/null
+++ b/src/image_recognition/utils/metrics.py
@@ -0,0 +1,335 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=()):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes = np.unique(target_cls)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = (target_cls == c).sum() # number of labels
+ n_p = i.sum() # number of predictions
+
+ if n_p == 0 or n_l == 0:
+ continue
+ else:
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + 1e-16) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + 1e-16)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = {i: v for i, v in enumerate(names)} # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
+
+ i = f1.mean(0).argmax() # max F1 index
+ return p[:, i], r[:, i], ap, f1[:, i], unique_classes.astype('int32')
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(np.int16)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # background FP
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # background FN
+
+ def matrix(self):
+ return self.matrix
+
+ def plot(self, normalize=True, save_dir='', names=()):
+ try:
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-6) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig = plt.figure(figsize=(12, 9), tight_layout=True)
+ sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
+ labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
+ xticklabels=names + ['background FP'] if labels else "auto",
+ yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
+ fig.axes[0].set_xlabel('True')
+ fig.axes[0].set_ylabel('Predicted')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close()
+ except Exception as e:
+ print(f'WARNING: ConfusionMatrix plot failure: {e}')
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
+ box2 = box2.T
+
+ # Get the coordinates of bounding boxes
+ if x1y1x2y2: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+ else: # transform from xywh to xyxy
+ b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
+ b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
+ b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
+ b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ iou = inter / union
+ if GIoU or DIoU or CIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
+ (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
+ if DIoU:
+ return iou - rho2 / c2 # DIoU
+ elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU
+ else:
+ return iou # IoU
+
+
+def box_iou(box1, box2):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ def box_area(box):
+ # box = 4xn
+ return (box[2] - box[0]) * (box[3] - box[1])
+
+ area1 = box_area(box1.T)
+ area2 = box_area(box2.T)
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
+ return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
+
+
+def bbox_ioa(box1, box2, eps=1E-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ box2 = box2.transpose()
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
+
+
+def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = py.mean(0)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
diff --git a/src/image_recognition/utils/plots.py b/src/image_recognition/utils/plots.py
new file mode 100644
index 0000000..9919e4d
--- /dev/null
+++ b/src/image_recognition/utils/plots.py
@@ -0,0 +1,469 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import math
+import os
+from copy import copy
+from pathlib import Path
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils.general import (LOGGER, Timeout, check_requirements, clip_coords, increment_path, is_ascii, is_chinese,
+ try_except, user_config_dir, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+
+# Settings
+CONFIG_DIR = user_config_dir() # Ultralytics settings dir
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb('#' + c) for c in hex]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_font(font='Arial.ttf', size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception as e: # download if missing
+ url = "https://ultralytics.com/assets/" + font.name
+ print(f'Downloading {url} to {font}...')
+ torch.hub.download_url_to_file(url, str(font), progress=False)
+ try:
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+
+
+class Annotator:
+ if RANK in (-1, 0):
+ check_font() # download TTF if necessary
+
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ self.pil = pil or not is_ascii(example) or is_chinese(example)
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_font(font='Arial.Unicode.ttf' if is_chinese(example) else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle([box[0],
+ box[1] - h if outside else box[1],
+ box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1], fill=color)
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h - 3 >= 0 # label fits outside box
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, self.lw / 3, txt_color,
+ thickness=tf, lineType=cv2.LINE_AA)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255)):
+ # Add text to image (PIL-only)
+ w, h = self.font.getsize(text) # text width, height
+ self.draw.text((xy[0], xy[1] - h + 1), text, fill=txt_color, font=self.font)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ print(f'Saving {save_dir / f}... ({n}/{channels})')
+ plt.savefig(save_dir / f, dpi=300, bbox_inches='tight')
+ plt.close()
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf]
+ targets = []
+ for i, o in enumerate(output):
+ for *box, conf, cls in o.cpu().numpy():
+ targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf])
+ return np.array(targets)
+
+
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None, max_size=1920, max_subplots=16):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5 + h), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j], y[3, 1:j] * 1E2, '.-', linewidth=2, markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-', linewidth=2, markersize=8, alpha=.25, label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@try_except # known issue https://github.com/ultralytics/yolov5/issues/5395
+@Timeout(30) # known issue https://github.com/ultralytics/yolov5/issues/5611
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ # [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # update colors bug #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(names, rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for fi, f in enumerate(files):
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file='image.jpg', gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_coords(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ cv2.imwrite(str(increment_path(file).with_suffix('.jpg')), crop)
+ return crop
diff --git a/src/image_recognition/utils/torch_utils.py b/src/image_recognition/utils/torch_utils.py
new file mode 100644
index 0000000..1628910
--- /dev/null
+++ b/src/image_recognition/utils/torch_utils.py
@@ -0,0 +1,318 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import datetime
+import math
+import os
+import platform
+import subprocess
+import time
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+
+from utils.general import LOGGER
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ """
+ Decorator to make all processes in distributed training wait for each local_master to do something.
+ """
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def date_modified(path=__file__):
+ # return human-readable file modification date, i.e. '2021-3-26'
+ t = datetime.datetime.fromtimestamp(Path(path).stat().st_mtime)
+ return f'{t.year}-{t.month}-{t.day}'
+
+
+def git_describe(path=Path(__file__).parent): # path must be a directory
+ # return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
+ s = f'git -C {path} describe --tags --long --always'
+ try:
+ return subprocess.check_output(s, shell=True, stderr=subprocess.STDOUT).decode()[:-1]
+ except subprocess.CalledProcessError as e:
+ return '' # not a git repository
+
+
+def select_device(device='', batch_size=None, newline=True):
+ # device = 'cpu' or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or date_modified()} torch {torch.__version__} ' # string
+ device = str(device).strip().lower().replace('cuda:', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ if cpu:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable
+ assert torch.cuda.is_available(), f'CUDA unavailable, invalid device {device} requested' # check availability
+
+ cuda = not cpu and torch.cuda.is_available()
+ if cuda:
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / 1024 ** 2:.0f}MiB)\n" # bytes to MB
+ else:
+ s += 'CPU\n'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
+ return torch.device('cuda:0' if cuda else 'cpu')
+
+
+def time_sync():
+ # pytorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ # YOLOv5 speed/memory/FLOPs profiler
+ #
+ # Usage:
+ # input = torch.randn(16, 3, 640, 640)
+ # m1 = lambda x: x * torch.sigmoid(x)
+ # m2 = nn.SiLU()
+ # profile(input, [m1, m2], n=100) # profile over 100 iterations
+
+ results = []
+ device = device or select_device()
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception as e: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in = tuple(x.shape) if isinstance(x, torch.Tensor) else 'list'
+ s_out = tuple(y.shape) if isinstance(y, torch.Tensor) else 'list'
+ p = sum(list(x.numel() for x in m.parameters())) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ print('Pruning model... ', end='')
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ print(' %.3g global sparsity' % sparsity(model))
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse convolution and batchnorm layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, img_size=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ from thop import profile
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32
+ img = torch.zeros((1, model.yaml.get('ch', 3), stride, stride), device=next(model.parameters()).device) # input
+ flops = profile(deepcopy(model), inputs=(img,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ img_size = img_size if isinstance(img_size, list) else [img_size, img_size] # expand if int/float
+ fs = ', %.1f GFLOPs' % (flops * img_size[0] / stride * img_size[1] / stride) # 640x640 GFLOPs
+ except (ImportError, Exception):
+ fs = ''
+
+ LOGGER.info(f"Model Summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ else:
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Model Exponential Moving Average from https://github.com/rwightman/pytorch-image-models
+ Keep a moving average of everything in the model state_dict (parameters and buffers).
+ This is intended to allow functionality like
+ https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ A smoothed version of the weights is necessary for some training schemes to perform well.
+ This class is sensitive where it is initialized in the sequence of model init,
+ GPU assignment and distributed training wrappers.
+ """
+
+ def __init__(self, model, decay=0.9999, updates=0):
+ # Create EMA
+ self.ema = deepcopy(model.module if is_parallel(model) else model).eval() # FP32 EMA
+ # if next(model.parameters()).device.type != 'cpu':
+ # self.ema.half() # FP16 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / 2000)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ with torch.no_grad():
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = model.module.state_dict() if is_parallel(model) else model.state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point:
+ v *= d
+ v += (1 - d) * msd[k].detach()
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/src/image_recognition/utils/ui/__init__.py b/src/image_recognition/utils/ui/__init__.py
new file mode 100644
index 0000000..2691d65
--- /dev/null
+++ b/src/image_recognition/utils/ui/__init__.py
@@ -0,0 +1,9 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+'''
+@Project :yolov5-60
+@File :__init__.py.py
+@Author :ChenmingSong
+@Date :2021/12/12 16:55
+@Description:
+'''
diff --git a/src/image_recognition/utils/ui/ji.py b/src/image_recognition/utils/ui/ji.py
new file mode 100644
index 0000000..bb24b83
--- /dev/null
+++ b/src/image_recognition/utils/ui/ji.py
@@ -0,0 +1,173 @@
+# -*- coding: utf-8 -*-
+"""
+-------------------------------------------------
+Project Name: yolov5-60
+File Name: ji.py
+Author: chenming
+Create Date: 2021/11/18
+Description:
+-------------------------------------------------
+"""
+import argparse
+import os
+os.chdir("/home/chenming/scm/xianyu/det/yolov5-60/yolov5-60")
+import sys
+from pathlib import Path
+import cv2
+import torch
+import torch.backends.cudnn as cudnn
+import json
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+from models.common import DetectMultiBackend
+from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
+from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
+ increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import select_device, time_sync
+from utils.augmentations import letterbox
+import numpy as np
+
+
+@torch.no_grad()
+def init():
+ weights = "runs/train/exp2/weights/best.pt" # model.pt path(s)
+ device = '' # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half = False # use FP16 half-precision inference
+ dnn = False # use OpenCV DNN for ONNX inference
+ device = select_device(device)
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ # Load model
+ # Load model
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn)
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ # Half
+ half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
+ if pt:
+ model.model.half() if half else model.model.float()
+ print("模型加载完成!")
+ return model
+
+
+@torch.no_grad()
+def process_image(handle=None, input_image=None, args=None, **kwargs):
+ '''Do inference to analysis input_image and get output
+ Attributes:
+ handle: algorithm handle returned by init()
+ input_image (numpy.ndarray): image to be process, format: (h, w, c), BGR
+ Returns: process result
+ '''
+
+ # Process image here
+ fake_result = {
+ 'objects': []
+ }
+
+ # Padded resize
+ net = handle
+ device = ''
+ device = select_device(device)
+ half = False
+ augment = True
+ visualize = False
+ img_size = (640, 640)
+ img0 = input_image
+ stride = net.stride
+ names = net.names
+ img = letterbox(img0, img_size, stride=stride)[0]
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ # pred
+ im = torch.from_numpy(img).to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ # Inference
+
+ pred = net(im, augment=augment, visualize=visualize)
+ conf_thres = 0.25
+ iou_thres = 0.45
+ classes = None
+ max_det = 1000
+ agnostic_nms = False
+ save_crop = False
+
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+
+ for i, det in enumerate(pred): # per image
+ # seen += 1
+ # if webcam: # batch_size >= 1
+ # p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ # s += f'{i}: '
+ # else:
+ # p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+ im0 = img0.copy()
+
+ # p = Path(p) # to Path
+ # save_path = str(save_dir / p.name) # im.jpg
+ # txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ # s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=3, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, -1].unique():
+ n = (det[:, -1] == c).sum() # detections per class
+ # s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ # if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ c = int(cls) # integer class
+ label = f'{names[c]} {conf:.2f}'
+ annotator.box_label(xyxy, label, color=colors(c, True))
+
+ xyxy = [x.cpu().numpy().item() for x in xyxy]
+ conf = conf.cpu().numpy()
+ name = names[c]
+ # print(cls)
+ # print(conf)
+ # print(xyxy)
+ # print(xywh)
+ fake_result['objects'].append({
+ 'xmin': int(xyxy[0]),
+ 'ymin': int(xyxy[1]),
+ 'xmax': int(xyxy[2]),
+ 'ymax': int(xyxy[3]),
+ 'name': str(name),
+ 'confidence': float(conf)
+ })
+ # line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ # with open(txt_path + '.txt', 'a') as f:
+ # f.write(('%g ' * len(line)).rstrip() % line + '\n')
+ # if save_img or save_crop or view_img: # Add bbox to image
+ #
+ #
+ # im0 = annotator.result()
+ # # print(im0)
+ # # if view_img:
+ # cv2.imshow("test", im0)
+ # cv2.waitKey(0) # 1 millisecond
+ # cv2.destroyAllWindows()
+ return json.dumps(fake_result, indent=4)
+
+# 现在的任务就是走通训练的流程,包括使用cpu进行训练和将日志文件以及模型输出到对应的位置中去
+if __name__ == '__main__':
+ """Test python api
+ """
+ img = cv2.imread('data/images/phone/phone_419.jpg')
+ predictor = init()
+ result = process_image(predictor, img)
+ print(result)
diff --git a/src/image_recognition/utils/ui/server_main.py b/src/image_recognition/utils/ui/server_main.py
new file mode 100644
index 0000000..f5e9663
--- /dev/null
+++ b/src/image_recognition/utils/ui/server_main.py
@@ -0,0 +1,17 @@
+# -*- coding: utf-8 -*-
+"""
+-------------------------------------------------
+Project Name: yolov5-v1.0
+File Name: main.py
+Author: chenming
+Create Date: 2021/11/9
+Description:
+-------------------------------------------------
+"""
+# 首先检查文件,把存在的目录删除
+import os
+os.chdir("/project/train/src_repo/")
+# 启动数据处理
+os.system("python server_data_gen.py")
+os.system("python train_server.py >> /project/train/log/log.txt")
+# 启动训练
diff --git a/src/image_recognition/utils/ui/train_server.py b/src/image_recognition/utils/ui/train_server.py
new file mode 100644
index 0000000..700b350
--- /dev/null
+++ b/src/image_recognition/utils/ui/train_server.py
@@ -0,0 +1,630 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Train a YOLOv5 model on a custom dataset
+
+Usage:
+ $ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
+"""
+import argparse
+import math
+import os
+import random
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.cuda import amp
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.optim import SGD, Adam, lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import Model
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.datasets import create_dataloader
+from utils.downloads import attempt_download
+from utils.general import (LOGGER, NCOLS, check_dataset, check_file, check_git_status, check_img_size,
+ check_requirements, check_suffix, check_yaml, colorstr, get_latest_run, increment_path,
+ init_seeds, intersect_dicts, labels_to_class_weights, labels_to_image_weights, methods,
+ one_cycle, print_args, print_mutation, strip_optimizer)
+from utils.loggers import Loggers
+from utils.loggers.wandb.wandb_utils import check_wandb_resume
+from utils.loss import ComputeLoss
+from utils.metrics import fitness
+from utils.plots import plot_evolve, plot_labels
+from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, select_device, torch_distributed_zero_first
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+
+def train(hyp, # path/to/hyp.yaml or hyp dictionary
+ opt,
+ device,
+ callbacks
+ ):
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
+
+ # Directories
+ # w = save_dir / 'weights' # weights dir?
+ # todo weight dir
+ save_dir = Path("/project/train/log")
+ # w = os.path.join("/runs/models/", "exp1")
+ w = Path("/project/train/models") / 'exp1'
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+
+ # Save run settings
+ with open(save_dir / 'hyp.yaml', 'w') as f:
+ yaml.safe_dump(hyp, f, sort_keys=False)
+ with open(save_dir / 'opt.yaml', 'w') as f:
+ yaml.safe_dump(vars(opt), f, sort_keys=False)
+ data_dict = None
+
+ # Loggers
+ if RANK in [-1, 0]:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+ if loggers.wandb:
+ data_dict = loggers.wandb.data_dict
+ if resume:
+ weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ # Config
+ plots = not evolve # create plots
+ cuda = device.type != 'cpu'
+ init_seeds(1 + RANK)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location=device) # load checkpoint
+ model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz)
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
+
+ g0, g1, g2 = [], [], [] # optimizer parameter groups
+ for v in model.modules():
+ if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
+ g2.append(v.bias)
+ if isinstance(v, nn.BatchNorm2d): # weight (no decay)
+ g0.append(v.weight)
+ elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
+ g1.append(v.weight)
+
+ if opt.adam:
+ optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
+ else:
+ optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
+
+ optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
+ optimizer.add_param_group({'params': g2}) # add g2 (biases)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
+ f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
+ del g0, g1, g2
+
+ # Scheduler
+ if opt.linear_lr:
+ lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ else:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in [-1, 0] else None
+
+ # Resume
+ start_epoch, best_fitness = 0, 0.0
+ if pretrained:
+ # Optimizer
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer'])
+ best_fitness = ckpt['best_fitness']
+
+ # EMA
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
+ ema.updates = ckpt['updates']
+
+ # Epochs
+ start_epoch = ckpt['epoch'] + 1
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
+ hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
+ workers=workers, image_weights=opt.image_weights, quad=opt.quad,
+ prefix=colorstr('train: '), shuffle=True)
+ mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
+ nb = len(train_loader) # number of batches
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in [-1, 0]:
+ val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
+ hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
+ workers=workers, pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ labels = np.concatenate(dataset.labels, 0)
+ # c = torch.tensor(labels[:, 0]) # classes
+ # cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
+ # model._initialize_biases(cf.to(device))
+ if plots:
+ plot_labels(labels, names, save_dir)
+
+ # Anchors
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
+ model.half().float() # pre-reduce anchor precision
+
+ callbacks.run('on_pretrain_routine_end')
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = amp.GradScaler(enabled=cuda)
+ stopper = EarlyStopping(patience=opt.patience)
+ compute_loss = ComputeLoss(model) # init loss class
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(3, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
+ if RANK in [-1, 0]:
+ pbar = tqdm(pbar, total=nb, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with amp.autocast(enabled=cuda):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize
+ if ni - last_opt_step >= accumulate:
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in [-1, 0]:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
+ f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in [-1, 0]:
+ # mAP
+ callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ del ckpt
+ callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # Stop Single-GPU
+ if RANK == -1 and stopper(epoch=epoch, fitness=fi):
+ break
+
+ # Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
+ # stop = stopper(epoch=epoch, fitness=fi)
+ # if RANK == 0:
+ # dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
+
+ # Stop DPP
+ # with torch_distributed_zero_first(RANK):
+ # if stop:
+ # break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in [-1, 0]:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=True,
+ callbacks=callbacks,
+ compute_loss=compute_loss) # val best model with plots
+ if is_coco:
+ callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+
+ callbacks.run('on_train_end', last, best, plots, epoch, results)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ torch.cuda.empty_cache()
+ return results
+
+
+# 明天把这些模型都试试效果先,一波波给他训练完毕,找个公开的数据集测试一下。
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'pretrained/yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=150)
+ parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ # parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--multi-scale', default=True, help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--linear-lr', action='store_true', help='linear LR')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ return opt
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ if RANK in [-1, 0]:
+ print_args(FILE.stem, opt)
+ check_git_status()
+ check_requirements(exclude=['thop'])
+
+ # Resume
+ if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
+ ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
+ assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
+ with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
+ opt = argparse.Namespace(**yaml.safe_load(f)) # replace
+ opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
+ LOGGER.info(f'Resuming training from {ckpt}')
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ opt.project = str(ROOT / 'runs/evolve')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
+ assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
+ assert not opt.evolve, '--evolve argument is not compatible with DDP training'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+ if WORLD_SIZE > 1 and RANK == 0:
+ LOGGER.info('Destroying process group... ')
+ dist.destroy_process_group()
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}') # download evolve.csv if exists
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 7] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+
+ # Write mutation results
+ print_mutation(results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/utils/ui/x.py b/src/image_recognition/utils/ui/x.py
new file mode 100644
index 0000000..bb259f1
--- /dev/null
+++ b/src/image_recognition/utils/ui/x.py
@@ -0,0 +1,100 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+'''
+@Project :yolov5-60
+@File :x.py
+@Author :ChenmingSong
+@Date :2021/12/12 16:04
+@Description:
+'''
+import cv2
+import sys
+# import DisplayUI
+from PyQt5.QtWidgets import QApplication, QMainWindow
+import threading
+from PyQt5.QtCore import QFile
+from PyQt5.QtWidgets import QFileDialog, QMessageBox
+from PyQt5.QtGui import QImage, QPixmap
+
+
+class Display:
+ def __init__(self, ui, mainWnd):
+ self.ui = ui
+ self.mainWnd = mainWnd
+
+ # 默认视频源为相机
+ self.ui.radioButtonCam.setChecked(True)
+ self.isCamera = True
+
+ # 信号槽设置
+ ui.Open.clicked.connect(self.Open)
+ ui.Close.clicked.connect(self.Close)
+ ui.radioButtonCam.clicked.connect(self.radioButtonCam)
+ ui.radioButtonFile.clicked.connect(self.radioButtonFile)
+
+ # 创建一个关闭事件并设为未触发
+ self.stopEvent = threading.Event()
+ self.stopEvent.clear()
+
+ def radioButtonCam(self):
+ self.isCamera = True
+
+ def radioButtonFile(self):
+ self.isCamera = False
+
+ def Open(self):
+ if not self.isCamera:
+ self.fileName, self.fileType = QFileDialog.getOpenFileName(self.mainWnd, 'Choose file', '', '*.mp4')
+ self.cap = cv2.VideoCapture(self.fileName)
+ self.frameRate = self.cap.get(cv2.CAP_PROP_FPS)
+ else:
+ # 下面两种rtsp格式都是支持的
+ # cap = cv2.VideoCapture("rtsp://admin:Supcon1304@172.20.1.126/main/Channels/1")
+ self.cap = cv2.VideoCapture("rtsp://admin:Supcon1304@172.20.1.126:554/h264/ch1/main/av_stream")
+
+ # 创建视频显示线程
+ th = threading.Thread(target=self.Display)
+ th.start()
+
+ def Close(self):
+ # 关闭事件设为触发,关闭视频播放
+ self.stopEvent.set()
+
+ def Display(self):
+ self.ui.Open.setEnabled(False)
+ self.ui.Close.setEnabled(True)
+
+ while self.cap.isOpened():
+ success, frame = self.cap.read()
+ # RGB转BGR
+ frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
+ img = QImage(frame.data, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
+ self.ui.DispalyLabel.setPixmap(QPixmap.fromImage(img))
+
+ if self.isCamera:
+ cv2.waitKey(1)
+ else:
+ cv2.waitKey(int(1000 / self.frameRate))
+
+ # 判断关闭事件是否已触发
+ if True == self.stopEvent.is_set():
+ # 关闭事件置为未触发,清空显示label
+ self.stopEvent.clear()
+ self.ui.DispalyLabel.clear()
+ self.ui.Close.setEnabled(False)
+ self.ui.Open.setEnabled(True)
+ break
+
+if __name__ == '__main__':
+ app = QApplication(sys.argv)
+ mainWnd = QMainWindow()
+ ui = DisplayUI.Ui_MainWindow()
+
+ # 可以理解成将创建的 ui 绑定到新建的 mainWnd 上
+ ui.setupUi(mainWnd)
+
+ display = Display(ui, mainWnd)
+
+ mainWnd.show()
+
+ sys.exit(app.exec_())
diff --git a/src/image_recognition/val.py b/src/image_recognition/val.py
new file mode 100644
index 0000000..251e9a1
--- /dev/null
+++ b/src/image_recognition/val.py
@@ -0,0 +1,367 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 model accuracy on a custom dataset
+
+Usage:
+ $ python path/to/val.py --data coco128.yaml --weights yolov5s.pt --img 640
+"""
+
+import argparse
+import json
+import os
+import sys
+from pathlib import Path
+from threading import Thread
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.datasets import create_dataloader
+from utils.general import (LOGGER, NCOLS, box_iou, check_dataset, check_img_size, check_requirements, check_yaml,
+ coco80_to_coco91_class, colorstr, increment_path, non_max_suppression, print_args,
+ scale_coords, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, time_sync
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct predictions matrix. Both sets of boxes are in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (Array[N, 10]), for 10 IoU levels
+ """
+ correct = torch.zeros(detections.shape[0], iouv.shape[0], dtype=torch.bool, device=iouv.device)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ x = torch.where((iou >= iouv[0]) & (labels[:, 0:1] == detections[:, 5])) # IoU above threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detection, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ matches = torch.Tensor(matches).to(iouv.device)
+ correct[matches[:, 1].long()] = matches[:, 2:3] >= iouv
+ return correct
+
+
+@torch.no_grad()
+def run(data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+ ):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt = next(model.parameters()).device, True # get model device, PyTorch model
+
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn)
+ stride, pt = model.stride, model.pt
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
+ if pt:
+ model.model.half() if half else model.model.float()
+ else:
+ half = False
+ batch_size = 1 # export.py models default to batch-size 1
+ device = torch.device('cpu')
+ LOGGER.info(f'Forcing --batch-size 1 square inference shape(1,3,{imgsz},{imgsz}) for non-PyTorch backends')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith('coco/val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10).to(device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and device.type != 'cpu':
+ model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
+ pad = 0.0 if task == 'speed' else 0.5
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task], imgsz, batch_size, stride, single_cls, pad=pad, rect=pt,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = {k: v for k, v in enumerate(model.names if hasattr(model, 'names') else model.module.names)}
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%20s' + '%11s' * 6) % ('Class', 'Images', 'Labels', 'P', 'R', 'mAP@.5', 'mAP@.5:.95')
+ dt, p, r, f1, mp, mr, map50, map = [0.0, 0.0, 0.0], 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ pbar = tqdm(dataloader, desc=s, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ t1 = time_sync()
+ if pt:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+ t2 = time_sync()
+ dt[0] += t2 - t1
+
+ # Inference
+ out, train_out = model(im) if training else model(im, augment=augment, val=True) # inference, loss outputs
+ dt[1] += time_sync() - t2
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss([x.float() for x in train_out], targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.Tensor([width, height, width, height]).to(device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ t3 = time_sync()
+ out = non_max_suppression(out, conf_thres, iou_thres, labels=lb, multi_label=True, agnostic=single_cls)
+ dt[2] += time_sync() - t3
+
+ # Metrics
+ for si, pred in enumerate(out):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl = len(labels)
+ tcls = labels[:, 0].tolist() if nl else [] # target class
+ path, shape = Path(paths[si]), shapes[si][0]
+ seen += 1
+
+ if len(pred) == 0:
+ if nl:
+ stats.append((torch.zeros(0, niou, dtype=torch.bool), torch.Tensor(), torch.Tensor(), tcls))
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_coords(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_coords(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ else:
+ correct = torch.zeros(pred.shape[0], niou, dtype=torch.bool)
+ stats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls)) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / (path.stem + '.txt'))
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ f = save_dir / f'val_batch{batch_i}_labels.jpg' # labels
+ Thread(target=plot_images, args=(im, targets, paths, f, names), daemon=True).start()
+ f = save_dir / f'val_batch{batch_i}_pred.jpg' # predictions
+ Thread(target=plot_images, args=(im, output_to_target(out), paths, f, names), daemon=True).start()
+
+ # Compute metrics
+ stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ p, r, ap, f1, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per class
+ else:
+ nt = torch.zeros(1)
+
+ # Print results
+ pf = '%20s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end')
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path(data.get('path', '../coco')) / 'annotations/instances_val2017.json') # annotations json
+ pred_json = str(save_dir / f"{w}_predictions.json") # predictions json
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements(['pycocotools'])
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.img_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(FILE.stem, opt)
+ return opt
+
+
+def main(opt):
+ check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING: confidence threshold {opt.conf_thres} >> 0.001 will produce invalid mAP values.')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = True # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ os.system('zip -r study.zip study_*.txt')
+ plot_val_study(x=x) # plot
+
+# python val.py --data data/mask_data.yaml --weights runs/train/exp_yolov5s/weights/best.pt --img 640
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/window.py b/src/image_recognition/window.py
new file mode 100644
index 0000000..64d4b68
--- /dev/null
+++ b/src/image_recognition/window.py
@@ -0,0 +1,561 @@
+# -*- coding: utf-8 -*-
+"""
+-------------------------------------------------
+Project Name: yolov5-jungong
+File Name: window.py.py
+Author: chenming
+Create Date: 2021/11/8
+Description:图形化界面,可以检测摄像头、视频和图片文件
+-------------------------------------------------
+"""
+# 应该在界面启动的时候就将模型加载出来,设置tmp的目录来放中间的处理结果
+import shutil
+import PyQt5.QtCore
+from PyQt5.QtGui import *
+from PyQt5.QtCore import *
+from PyQt5.QtWidgets import *
+import threading
+import argparse
+import os
+import sys
+from pathlib import Path
+import cv2
+import torch
+import torch.backends.cudnn as cudnn
+import os.path as osp
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
+from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
+ increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import select_device, time_sync
+
+
+# 添加一个关于界面
+# 窗口主类
+class MainWindow(QTabWidget):
+ # 基本配置不动,然后只动第三个界面
+ def __init__(self):
+ # 初始化界面
+ super().__init__()
+ self.setWindowTitle('Target detection system')
+ self.resize(1200, 800)
+ self.setWindowIcon(QIcon("images/UI/lufei.png"))
+ # 图片读取进程
+ self.output_size = 480
+ self.img2predict = ""
+ self.device = 'cpu'
+ # # 初始化视频读取线程
+ self.vid_source = '0' # 初始设置为摄像头
+ self.stopEvent = threading.Event()
+ self.webcam = True
+ self.stopEvent.clear()
+ self.model = self.model_load(weights="runs/train/exp_yolov5s/weights/best.pt",
+ device=self.device) # todo 指明模型加载的位置的设备
+ self.initUI()
+ self.reset_vid()
+
+ '''
+ ***模型初始化***
+ '''
+ @torch.no_grad()
+ def model_load(self, weights="", # model.pt path(s)
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ ):
+ device = select_device(device)
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn)
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ # Half
+ half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
+ if pt:
+ model.model.half() if half else model.model.float()
+ print("模型加载完成!")
+ return model
+
+ '''
+ ***界面初始化***
+ '''
+ def initUI(self):
+ # 图片检测子界面
+ font_title = QFont('楷体', 16)
+ font_main = QFont('楷体', 14)
+ # 图片识别界面, 两个按钮,上传图片和显示结果
+ img_detection_widget = QWidget()
+ img_detection_layout = QVBoxLayout()
+ img_detection_title = QLabel("图片识别功能")
+ img_detection_title.setFont(font_title)
+ mid_img_widget = QWidget()
+ mid_img_layout = QHBoxLayout()
+ self.left_img = QLabel()
+ self.right_img = QLabel()
+ self.left_img.setPixmap(QPixmap("images/UI/up.jpeg"))
+ self.right_img.setPixmap(QPixmap("images/UI/right.jpeg"))
+ self.left_img.setAlignment(Qt.AlignCenter)
+ self.right_img.setAlignment(Qt.AlignCenter)
+ mid_img_layout.addWidget(self.left_img)
+ mid_img_layout.addStretch(0)
+ mid_img_layout.addWidget(self.right_img)
+ mid_img_widget.setLayout(mid_img_layout)
+ up_img_button = QPushButton("上传图片")
+ det_img_button = QPushButton("开始检测")
+ up_img_button.clicked.connect(self.upload_img)
+ det_img_button.clicked.connect(self.detect_img)
+ up_img_button.setFont(font_main)
+ det_img_button.setFont(font_main)
+ up_img_button.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ det_img_button.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ img_detection_layout.addWidget(img_detection_title, alignment=Qt.AlignCenter)
+ img_detection_layout.addWidget(mid_img_widget, alignment=Qt.AlignCenter)
+ img_detection_layout.addWidget(up_img_button)
+ img_detection_layout.addWidget(det_img_button)
+ img_detection_widget.setLayout(img_detection_layout)
+
+ # todo 视频识别界面
+ # 视频识别界面的逻辑比较简单,基本就从上到下的逻辑
+ vid_detection_widget = QWidget()
+ vid_detection_layout = QVBoxLayout()
+ vid_title = QLabel("视频检测功能")
+ vid_title.setFont(font_title)
+ self.vid_img = QLabel()
+ self.vid_img.setPixmap(QPixmap("images/UI/up.jpeg"))
+ vid_title.setAlignment(Qt.AlignCenter)
+ self.vid_img.setAlignment(Qt.AlignCenter)
+ self.webcam_detection_btn = QPushButton("摄像头实时监测")
+ self.mp4_detection_btn = QPushButton("视频文件检测")
+ self.vid_stop_btn = QPushButton("停止检测")
+ self.webcam_detection_btn.setFont(font_main)
+ self.mp4_detection_btn.setFont(font_main)
+ self.vid_stop_btn.setFont(font_main)
+ self.webcam_detection_btn.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ self.mp4_detection_btn.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ self.vid_stop_btn.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ self.webcam_detection_btn.clicked.connect(self.open_cam)
+ self.mp4_detection_btn.clicked.connect(self.open_mp4)
+ self.vid_stop_btn.clicked.connect(self.close_vid)
+ # 添加组件到布局上
+ vid_detection_layout.addWidget(vid_title)
+ vid_detection_layout.addWidget(self.vid_img)
+ vid_detection_layout.addWidget(self.webcam_detection_btn)
+ vid_detection_layout.addWidget(self.mp4_detection_btn)
+ vid_detection_layout.addWidget(self.vid_stop_btn)
+ vid_detection_widget.setLayout(vid_detection_layout)
+
+ # todo 关于界面
+ about_widget = QWidget()
+ about_layout = QVBoxLayout()
+ about_title = QLabel('欢迎使用目标检测系统\n\n 提供付费指导:有需要的好兄弟加下面的QQ即可') # todo 修改欢迎词语
+ about_title.setFont(QFont('楷体', 18))
+ about_title.setAlignment(Qt.AlignCenter)
+ about_img = QLabel()
+ about_img.setPixmap(QPixmap('images/UI/qq.png'))
+ about_img.setAlignment(Qt.AlignCenter)
+
+ # label4.setText("如何调整学习率")
+ label_super = QLabel() # todo 更换作者信息
+ label_super.setText("或者你可以在这里找到我-->肆十二")
+ label_super.setFont(QFont('楷体', 16))
+ label_super.setOpenExternalLinks(True)
+ # label_super.setOpenExternalLinks(True)
+ label_super.setAlignment(Qt.AlignRight)
+ about_layout.addWidget(about_title)
+ about_layout.addStretch()
+ about_layout.addWidget(about_img)
+ about_layout.addStretch()
+ about_layout.addWidget(label_super)
+ about_widget.setLayout(about_layout)
+
+ self.left_img.setAlignment(Qt.AlignCenter)
+ self.addTab(img_detection_widget, '图片检测')
+ self.addTab(vid_detection_widget, '视频检测')
+ self.addTab(about_widget, '联系我')
+ self.setTabIcon(0, QIcon('images/UI/lufei.png'))
+ self.setTabIcon(1, QIcon('images/UI/lufei.png'))
+ self.setTabIcon(2, QIcon('images/UI/lufei.png'))
+
+ '''
+ ***上传图片***
+ '''
+ def upload_img(self):
+ # 选择录像文件进行读取
+ fileName, fileType = QFileDialog.getOpenFileName(self, 'Choose file', '', '*.jpg *.png *.tif *.jpeg')
+ if fileName:
+ suffix = fileName.split(".")[-1]
+ save_path = osp.join("images/tmp", "tmp_upload." + suffix)
+ shutil.copy(fileName, save_path)
+ # 应该调整一下图片的大小,然后统一防在一起
+ im0 = cv2.imread(save_path)
+ resize_scale = self.output_size / im0.shape[0]
+ im0 = cv2.resize(im0, (0, 0), fx=resize_scale, fy=resize_scale)
+ cv2.imwrite("images/tmp/upload_show_result.jpg", im0)
+ # self.right_img.setPixmap(QPixmap("images/tmp/single_result.jpg"))
+ self.img2predict = fileName
+ self.left_img.setPixmap(QPixmap("images/tmp/upload_show_result.jpg"))
+ # todo 上传图片之后右侧的图片重置,
+ self.right_img.setPixmap(QPixmap("images/UI/right.jpeg"))
+
+ '''
+ ***检测图片***
+ '''
+ def detect_img(self):
+ model = self.model
+ output_size = self.output_size
+ source = self.img2predict # file/dir/URL/glob, 0 for webcam
+ imgsz = [640,640] # inference size (pixels)
+ conf_thres = 0.25 # confidence threshold
+ iou_thres = 0.45 # NMS IOU threshold
+ max_det = 1000 # maximum detections per image
+ device = self.device # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img = False # show results
+ save_txt = False # save results to *.txt
+ save_conf = False # save confidences in --save-txt labels
+ save_crop = False # save cropped prediction boxes
+ nosave = False # do not save images/videos
+ classes = None # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms = False # class-agnostic NMS
+ augment = False # ugmented inference
+ visualize = False # visualize features
+ line_thickness = 3 # bounding box thickness (pixels)
+ hide_labels = False # hide labels
+ hide_conf = False # hide confidences
+ half = False # use FP16 half-precision inference
+ dnn = False # use OpenCV DNN for ONNX inference
+ print(source)
+ if source == "":
+ QMessageBox.warning(self, "请上传", "请先上传图片再进行检测")
+ else:
+ source = str(source)
+ device = select_device(self.device)
+ webcam = False
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ # Dataloader
+ if webcam:
+ view_img = check_imshow()
+ cudnn.benchmark = True # set True to speed up constant image size inference
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = len(dataset) # batch_size
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = 1 # batch_size
+ vid_path, vid_writer = [None] * bs, [None] * bs
+ # Run inference
+ if pt and device.type != 'cpu':
+ model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
+ dt, seen = [0.0, 0.0, 0.0], 0
+ for path, im, im0s, vid_cap, s in dataset:
+ t1 = time_sync()
+ im = torch.from_numpy(im).to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ t2 = time_sync()
+ dt[0] += t2 - t1
+ # Inference
+ # visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred = model(im, augment=augment, visualize=visualize)
+ t3 = time_sync()
+ dt[1] += t3 - t2
+ # NMS
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+ dt[2] += time_sync() - t3
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+ p = Path(p) # to Path
+ s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, -1].unique():
+ n = (det[:, -1] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(
+ -1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ # with open(txt_path + '.txt', 'a') as f:
+ # f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ # if save_crop:
+ # save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg',
+ # BGR=True)
+ # Print time (inference-only)
+ LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
+ # Stream results
+ im0 = annotator.result()
+ # if view_img:
+ # cv2.imshow(str(p), im0)
+ # cv2.waitKey(1) # 1 millisecond
+ # Save results (image with detections)
+ resize_scale = output_size / im0.shape[0]
+ im0 = cv2.resize(im0, (0, 0), fx=resize_scale, fy=resize_scale)
+ cv2.imwrite("images/tmp/single_result.jpg", im0)
+ # 目前的情况来看,应该只是ubuntu下会出问题,但是在windows下是完整的,所以继续
+ self.right_img.setPixmap(QPixmap("images/tmp/single_result.jpg"))
+
+ # 视频检测,逻辑基本一致,有两个功能,分别是检测摄像头的功能和检测视频文件的功能,先做检测摄像头的功能。
+
+ '''
+ ### 界面关闭事件 ###
+ '''
+ def closeEvent(self, event):
+ reply = QMessageBox.question(self,
+ 'quit',
+ "Are you sure?",
+ QMessageBox.Yes | QMessageBox.No,
+ QMessageBox.No)
+ if reply == QMessageBox.Yes:
+ self.close()
+ event.accept()
+ else:
+ event.ignore()
+
+ '''
+ ### 视频关闭事件 ###
+ '''
+
+ def open_cam(self):
+ self.webcam_detection_btn.setEnabled(False)
+ self.mp4_detection_btn.setEnabled(False)
+ self.vid_stop_btn.setEnabled(True)
+ self.vid_source = '0'
+ self.webcam = True
+ # 把按钮给他重置了
+ # print("GOGOGO")
+ th = threading.Thread(target=self.detect_vid)
+ th.start()
+
+ '''
+ ### 开启视频文件检测事件 ###
+ '''
+
+ def open_mp4(self):
+ fileName, fileType = QFileDialog.getOpenFileName(self, 'Choose file', '', '*.mp4 *.avi')
+ if fileName:
+ self.webcam_detection_btn.setEnabled(False)
+ self.mp4_detection_btn.setEnabled(False)
+ # self.vid_stop_btn.setEnabled(True)
+ self.vid_source = fileName
+ self.webcam = False
+ th = threading.Thread(target=self.detect_vid)
+ th.start()
+
+ '''
+ ### 视频开启事件 ###
+ '''
+
+ # 视频和摄像头的主函数是一样的,不过是传入的source不同罢了
+ def detect_vid(self):
+ # pass
+ model = self.model
+ output_size = self.output_size
+ # source = self.img2predict # file/dir/URL/glob, 0 for webcam
+ imgsz = [640, 640] # inference size (pixels)
+ conf_thres = 0.25 # confidence threshold
+ iou_thres = 0.45 # NMS IOU threshold
+ max_det = 1000 # maximum detections per image
+ # device = self.device # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img = False # show results
+ save_txt = False # save results to *.txt
+ save_conf = False # save confidences in --save-txt labels
+ save_crop = False # save cropped prediction boxes
+ nosave = False # do not save images/videos
+ classes = None # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms = False # class-agnostic NMS
+ augment = False # ugmented inference
+ visualize = False # visualize features
+ line_thickness = 3 # bounding box thickness (pixels)
+ hide_labels = False # hide labels
+ hide_conf = False # hide confidences
+ half = False # use FP16 half-precision inference
+ dnn = False # use OpenCV DNN for ONNX inference
+ source = str(self.vid_source)
+ webcam = self.webcam
+ device = select_device(self.device)
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ # Dataloader
+ if webcam:
+ view_img = check_imshow()
+ cudnn.benchmark = True # set True to speed up constant image size inference
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = len(dataset) # batch_size
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = 1 # batch_size
+ vid_path, vid_writer = [None] * bs, [None] * bs
+ # Run inference
+ if pt and device.type != 'cpu':
+ model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
+ dt, seen = [0.0, 0.0, 0.0], 0
+ for path, im, im0s, vid_cap, s in dataset:
+ t1 = time_sync()
+ im = torch.from_numpy(im).to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ t2 = time_sync()
+ dt[0] += t2 - t1
+ # Inference
+ # visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred = model(im, augment=augment, visualize=visualize)
+ t3 = time_sync()
+ dt[1] += t3 - t2
+ # NMS
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+ dt[2] += time_sync() - t3
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+ p = Path(p) # to Path
+ # save_path = str(save_dir / p.name) # im.jpg
+ # txt_path = str(save_dir / 'labels' / p.stem) + (
+ # '' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, -1].unique():
+ n = (det[:, -1] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(
+ -1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ # with open(txt_path + '.txt', 'a') as f:
+ # f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ # if save_crop:
+ # save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg',
+ # BGR=True)
+ # Print time (inference-only)
+ LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
+ # Stream results
+ # Save results (image with detections)
+ im0 = annotator.result()
+ frame = im0
+ resize_scale = output_size / frame.shape[0]
+ frame_resized = cv2.resize(frame, (0, 0), fx=resize_scale, fy=resize_scale)
+ cv2.imwrite("images/tmp/single_result_vid.jpg", frame_resized)
+ self.vid_img.setPixmap(QPixmap("images/tmp/single_result_vid.jpg"))
+ # self.vid_img
+ # if view_img:
+ # cv2.imshow(str(p), im0)
+ # self.vid_img.setPixmap(QPixmap("images/tmp/single_result_vid.jpg"))
+ # cv2.waitKey(1) # 1 millisecond
+ if cv2.waitKey(25) & self.stopEvent.is_set() == True:
+ self.stopEvent.clear()
+ self.webcam_detection_btn.setEnabled(True)
+ self.mp4_detection_btn.setEnabled(True)
+ self.reset_vid()
+ break
+ # self.reset_vid()
+
+ '''
+ ### 界面重置事件 ###
+ '''
+
+ def reset_vid(self):
+ self.webcam_detection_btn.setEnabled(True)
+ self.mp4_detection_btn.setEnabled(True)
+ self.vid_img.setPixmap(QPixmap("images/UI/up.jpeg"))
+ self.vid_source = '0'
+ self.webcam = True
+
+ '''
+ ### 视频重置事件 ###
+ '''
+
+ def close_vid(self):
+ self.stopEvent.set()
+ self.reset_vid()
+
+
+if __name__ == "__main__":
+ app = QApplication(sys.argv)
+ mainWindow = MainWindow()
+ mainWindow.show()
+ sys.exit(app.exec_())
diff --git a/src/资源.txt b/src/资源.txt
deleted file mode 100644
index 0d3cd98..0000000
--- a/src/资源.txt
+++ /dev/null
@@ -1 +0,0 @@
-资源目录
\ No newline at end of file
+
+
+## Environments
+
+YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
+
+- **Google Colab and Kaggle** notebooks with free GPU:
+- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
+- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
+- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
+
+
+## Status
+
+
+
+If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/src/image_recognition/utils/loggers/wandb/__init__.py b/src/image_recognition/utils/loggers/wandb/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/image_recognition/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc b/src/image_recognition/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc
new file mode 100644
index 0000000..ea07ec0
Binary files /dev/null and b/src/image_recognition/utils/loggers/wandb/__pycache__/__init__.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc b/src/image_recognition/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc
new file mode 100644
index 0000000..b6081e8
Binary files /dev/null and b/src/image_recognition/utils/loggers/wandb/__pycache__/wandb_utils.cpython-38.pyc differ
diff --git a/src/image_recognition/utils/loggers/wandb/log_dataset.py b/src/image_recognition/utils/loggers/wandb/log_dataset.py
new file mode 100644
index 0000000..06e81fb
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/log_dataset.py
@@ -0,0 +1,27 @@
+import argparse
+
+from wandb_utils import WandbLogger
+
+from utils.general import LOGGER
+
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def create_dataset_artifact(opt):
+ logger = WandbLogger(opt, None, job_type='Dataset Creation') # TODO: return value unused
+ if not logger.wandb:
+ LOGGER.info("install wandb using `pip install wandb` to log the dataset")
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')
+ parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')
+ parser.add_argument('--project', type=str, default='YOLOv5', help='name of W&B Project')
+ parser.add_argument('--entity', default=None, help='W&B entity')
+ parser.add_argument('--name', type=str, default='log dataset', help='name of W&B run')
+
+ opt = parser.parse_args()
+ opt.resume = False # Explicitly disallow resume check for dataset upload job
+
+ create_dataset_artifact(opt)
diff --git a/src/image_recognition/utils/loggers/wandb/sweep.py b/src/image_recognition/utils/loggers/wandb/sweep.py
new file mode 100644
index 0000000..206059b
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/sweep.py
@@ -0,0 +1,41 @@
+import sys
+from pathlib import Path
+
+import wandb
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from train import parse_opt, train
+from utils.callbacks import Callbacks
+from utils.general import increment_path
+from utils.torch_utils import select_device
+
+
+def sweep():
+ wandb.init()
+ # Get hyp dict from sweep agent
+ hyp_dict = vars(wandb.config).get("_items")
+
+ # Workaround: get necessary opt args
+ opt = parse_opt(known=True)
+ opt.batch_size = hyp_dict.get("batch_size")
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
+ opt.epochs = hyp_dict.get("epochs")
+ opt.nosave = True
+ opt.data = hyp_dict.get("data")
+ opt.weights = str(opt.weights)
+ opt.cfg = str(opt.cfg)
+ opt.data = str(opt.data)
+ opt.hyp = str(opt.hyp)
+ opt.project = str(opt.project)
+ device = select_device(opt.device, batch_size=opt.batch_size)
+
+ # train
+ train(hyp_dict, opt, device, callbacks=Callbacks())
+
+
+if __name__ == "__main__":
+ sweep()
diff --git a/src/image_recognition/utils/loggers/wandb/sweep.yaml b/src/image_recognition/utils/loggers/wandb/sweep.yaml
new file mode 100644
index 0000000..c7790d7
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/sweep.yaml
@@ -0,0 +1,143 @@
+# Hyperparameters for training
+# To set range-
+# Provide min and max values as:
+# parameter:
+#
+# min: scalar
+# max: scalar
+# OR
+#
+# Set a specific list of search space-
+# parameter:
+# values: [scalar1, scalar2, scalar3...]
+#
+# You can use grid, bayesian and hyperopt search strategy
+# For more info on configuring sweeps visit - https://docs.wandb.ai/guides/sweeps/configuration
+
+program: utils/loggers/wandb/sweep.py
+method: random
+metric:
+ name: metrics/mAP_0.5
+ goal: maximize
+
+parameters:
+ # hyperparameters: set either min, max range or values list
+ data:
+ value: "data/coco128.yaml"
+ batch_size:
+ values: [64]
+ epochs:
+ values: [10]
+
+ lr0:
+ distribution: uniform
+ min: 1e-5
+ max: 1e-1
+ lrf:
+ distribution: uniform
+ min: 0.01
+ max: 1.0
+ momentum:
+ distribution: uniform
+ min: 0.6
+ max: 0.98
+ weight_decay:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ warmup_epochs:
+ distribution: uniform
+ min: 0.0
+ max: 5.0
+ warmup_momentum:
+ distribution: uniform
+ min: 0.0
+ max: 0.95
+ warmup_bias_lr:
+ distribution: uniform
+ min: 0.0
+ max: 0.2
+ box:
+ distribution: uniform
+ min: 0.02
+ max: 0.2
+ cls:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ cls_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ obj:
+ distribution: uniform
+ min: 0.2
+ max: 4.0
+ obj_pw:
+ distribution: uniform
+ min: 0.5
+ max: 2.0
+ iou_t:
+ distribution: uniform
+ min: 0.1
+ max: 0.7
+ anchor_t:
+ distribution: uniform
+ min: 2.0
+ max: 8.0
+ fl_gamma:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_h:
+ distribution: uniform
+ min: 0.0
+ max: 0.1
+ hsv_s:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ hsv_v:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ degrees:
+ distribution: uniform
+ min: 0.0
+ max: 45.0
+ translate:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ scale:
+ distribution: uniform
+ min: 0.0
+ max: 0.9
+ shear:
+ distribution: uniform
+ min: 0.0
+ max: 10.0
+ perspective:
+ distribution: uniform
+ min: 0.0
+ max: 0.001
+ flipud:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ fliplr:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mosaic:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ mixup:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
+ copy_paste:
+ distribution: uniform
+ min: 0.0
+ max: 1.0
diff --git a/src/image_recognition/utils/loggers/wandb/wandb_utils.py b/src/image_recognition/utils/loggers/wandb/wandb_utils.py
new file mode 100644
index 0000000..47757dd
--- /dev/null
+++ b/src/image_recognition/utils/loggers/wandb/wandb_utils.py
@@ -0,0 +1,532 @@
+"""Utilities and tools for tracking runs with Weights & Biases."""
+
+import logging
+import os
+import sys
+from contextlib import contextmanager
+from pathlib import Path
+from typing import Dict
+
+import pkg_resources as pkg
+import yaml
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[3] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+
+from utils.datasets import LoadImagesAndLabels, img2label_paths
+from utils.general import LOGGER, check_dataset, check_file
+
+try:
+ import wandb
+
+ assert hasattr(wandb, '__version__') # verify package import not local dir
+except (ImportError, AssertionError):
+ wandb = None
+
+RANK = int(os.getenv('RANK', -1))
+WANDB_ARTIFACT_PREFIX = 'wandb-artifact://'
+
+
+def remove_prefix(from_string, prefix=WANDB_ARTIFACT_PREFIX):
+ return from_string[len(prefix):]
+
+
+def check_wandb_config_file(data_config_file):
+ wandb_config = '_wandb.'.join(data_config_file.rsplit('.', 1)) # updated data.yaml path
+ if Path(wandb_config).is_file():
+ return wandb_config
+ return data_config_file
+
+
+def check_wandb_dataset(data_file):
+ is_trainset_wandb_artifact = False
+ is_valset_wandb_artifact = False
+ if check_file(data_file) and data_file.endswith('.yaml'):
+ with open(data_file, errors='ignore') as f:
+ data_dict = yaml.safe_load(f)
+ is_trainset_wandb_artifact = (isinstance(data_dict['train'], str) and
+ data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX))
+ is_valset_wandb_artifact = (isinstance(data_dict['val'], str) and
+ data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX))
+ if is_trainset_wandb_artifact or is_valset_wandb_artifact:
+ return data_dict
+ else:
+ return check_dataset(data_file)
+
+
+def get_run_info(run_path):
+ run_path = Path(remove_prefix(run_path, WANDB_ARTIFACT_PREFIX))
+ run_id = run_path.stem
+ project = run_path.parent.stem
+ entity = run_path.parent.parent.stem
+ model_artifact_name = 'run_' + run_id + '_model'
+ return entity, project, run_id, model_artifact_name
+
+
+def check_wandb_resume(opt):
+ process_wandb_config_ddp_mode(opt) if RANK not in [-1, 0] else None
+ if isinstance(opt.resume, str):
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ if RANK not in [-1, 0]: # For resuming DDP runs
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ api = wandb.Api()
+ artifact = api.artifact(entity + '/' + project + '/' + model_artifact_name + ':latest')
+ modeldir = artifact.download()
+ opt.weights = str(Path(modeldir) / "last.pt")
+ return True
+ return None
+
+
+def process_wandb_config_ddp_mode(opt):
+ with open(check_file(opt.data), errors='ignore') as f:
+ data_dict = yaml.safe_load(f) # data dict
+ train_dir, val_dir = None, None
+ if isinstance(data_dict['train'], str) and data_dict['train'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ train_artifact = api.artifact(remove_prefix(data_dict['train']) + ':' + opt.artifact_alias)
+ train_dir = train_artifact.download()
+ train_path = Path(train_dir) / 'data/images/'
+ data_dict['train'] = str(train_path)
+
+ if isinstance(data_dict['val'], str) and data_dict['val'].startswith(WANDB_ARTIFACT_PREFIX):
+ api = wandb.Api()
+ val_artifact = api.artifact(remove_prefix(data_dict['val']) + ':' + opt.artifact_alias)
+ val_dir = val_artifact.download()
+ val_path = Path(val_dir) / 'data/images/'
+ data_dict['val'] = str(val_path)
+ if train_dir or val_dir:
+ ddp_data_path = str(Path(val_dir) / 'wandb_local_data.yaml')
+ with open(ddp_data_path, 'w') as f:
+ yaml.safe_dump(data_dict, f)
+ opt.data = ddp_data_path
+
+
+class WandbLogger():
+ """Log training runs, datasets, models, and predictions to Weights & Biases.
+
+ This logger sends information to W&B at wandb.ai. By default, this information
+ includes hyperparameters, system configuration and metrics, model metrics,
+ and basic data metrics and analyses.
+
+ By providing additional command line arguments to train.py, datasets,
+ models and predictions can also be logged.
+
+ For more on how this logger is used, see the Weights & Biases documentation:
+ https://docs.wandb.com/guides/integrations/yolov5
+ """
+
+ def __init__(self, opt, run_id=None, job_type='Training'):
+ """
+ - Initialize WandbLogger instance
+ - Upload dataset if opt.upload_dataset is True
+ - Setup trainig processes if job_type is 'Training'
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ run_id (str) -- Run ID of W&B run to be resumed
+ job_type (str) -- To set the job_type for this run
+
+ """
+ # Pre-training routine --
+ self.job_type = job_type
+ self.wandb, self.wandb_run = wandb, None if not wandb else wandb.run
+ self.val_artifact, self.train_artifact = None, None
+ self.train_artifact_path, self.val_artifact_path = None, None
+ self.result_artifact = None
+ self.val_table, self.result_table = None, None
+ self.bbox_media_panel_images = []
+ self.val_table_path_map = None
+ self.max_imgs_to_log = 16
+ self.wandb_artifact_data_dict = None
+ self.data_dict = None
+ # It's more elegant to stick to 1 wandb.init call,
+ # but useful config data is overwritten in the WandbLogger's wandb.init call
+ if isinstance(opt.resume, str): # checks resume from artifact
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ entity, project, run_id, model_artifact_name = get_run_info(opt.resume)
+ model_artifact_name = WANDB_ARTIFACT_PREFIX + model_artifact_name
+ assert wandb, 'install wandb to resume wandb runs'
+ # Resume wandb-artifact:// runs here| workaround for not overwriting wandb.config
+ self.wandb_run = wandb.init(id=run_id,
+ project=project,
+ entity=entity,
+ resume='allow',
+ allow_val_change=True)
+ opt.resume = model_artifact_name
+ elif self.wandb:
+ self.wandb_run = wandb.init(config=opt,
+ resume="allow",
+ project='YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem,
+ entity=opt.entity,
+ name=opt.name if opt.name != 'exp' else None,
+ job_type=job_type,
+ id=run_id,
+ allow_val_change=True) if not wandb.run else wandb.run
+ if self.wandb_run:
+ if self.job_type == 'Training':
+ if opt.upload_dataset:
+ if not opt.resume:
+ self.wandb_artifact_data_dict = self.check_and_upload_dataset(opt)
+
+ if opt.resume:
+ # resume from artifact
+ if isinstance(opt.resume, str) and opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ self.data_dict = dict(self.wandb_run.config.data_dict)
+ else: # local resume
+ self.data_dict = check_wandb_dataset(opt.data)
+ else:
+ self.data_dict = check_wandb_dataset(opt.data)
+ self.wandb_artifact_data_dict = self.wandb_artifact_data_dict or self.data_dict
+
+ # write data_dict to config. useful for resuming from artifacts. Do this only when not resuming.
+ self.wandb_run.config.update({'data_dict': self.wandb_artifact_data_dict},
+ allow_val_change=True)
+ self.setup_training(opt)
+
+ if self.job_type == 'Dataset Creation':
+ self.data_dict = self.check_and_upload_dataset(opt)
+
+ def check_and_upload_dataset(self, opt):
+ """
+ Check if the dataset format is compatible and upload it as W&B artifact
+
+ arguments:
+ opt (namespace)-- Commandline arguments for current run
+
+ returns:
+ Updated dataset info dictionary where local dataset paths are replaced by WAND_ARFACT_PREFIX links.
+ """
+ assert wandb, 'Install wandb to upload dataset'
+ config_path = self.log_dataset_artifact(opt.data,
+ opt.single_cls,
+ 'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
+ LOGGER.info(f"Created dataset config file {config_path}")
+ with open(config_path, errors='ignore') as f:
+ wandb_data_dict = yaml.safe_load(f)
+ return wandb_data_dict
+
+ def setup_training(self, opt):
+ """
+ Setup the necessary processes for training YOLO models:
+ - Attempt to download model checkpoint and dataset artifacts if opt.resume stats with WANDB_ARTIFACT_PREFIX
+ - Update data_dict, to contain info of previous run if resumed and the paths of dataset artifact if downloaded
+ - Setup log_dict, initialize bbox_interval
+
+ arguments:
+ opt (namespace) -- commandline arguments for this run
+
+ """
+ self.log_dict, self.current_epoch = {}, 0
+ self.bbox_interval = opt.bbox_interval
+ if isinstance(opt.resume, str):
+ modeldir, _ = self.download_model_artifact(opt)
+ if modeldir:
+ self.weights = Path(modeldir) / "last.pt"
+ config = self.wandb_run.config
+ opt.weights, opt.save_period, opt.batch_size, opt.bbox_interval, opt.epochs, opt.hyp = str(
+ self.weights), config.save_period, config.batch_size, config.bbox_interval, config.epochs, \
+ config.hyp
+ data_dict = self.data_dict
+ if self.val_artifact is None: # If --upload_dataset is set, use the existing artifact, don't download
+ self.train_artifact_path, self.train_artifact = self.download_dataset_artifact(data_dict.get('train'),
+ opt.artifact_alias)
+ self.val_artifact_path, self.val_artifact = self.download_dataset_artifact(data_dict.get('val'),
+ opt.artifact_alias)
+
+ if self.train_artifact_path is not None:
+ train_path = Path(self.train_artifact_path) / 'data/images/'
+ data_dict['train'] = str(train_path)
+ if self.val_artifact_path is not None:
+ val_path = Path(self.val_artifact_path) / 'data/images/'
+ data_dict['val'] = str(val_path)
+
+ if self.val_artifact is not None:
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+ self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
+ self.val_table = self.val_artifact.get("val")
+ if self.val_table_path_map is None:
+ self.map_val_table_path()
+ if opt.bbox_interval == -1:
+ self.bbox_interval = opt.bbox_interval = (opt.epochs // 10) if opt.epochs > 10 else 1
+ train_from_artifact = self.train_artifact_path is not None and self.val_artifact_path is not None
+ # Update the the data_dict to point to local artifacts dir
+ if train_from_artifact:
+ self.data_dict = data_dict
+
+ def download_dataset_artifact(self, path, alias):
+ """
+ download the model checkpoint artifact if the path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ path -- path of the dataset to be used for training
+ alias (str)-- alias of the artifact to be download/used for training
+
+ returns:
+ (str, wandb.Artifact) -- path of the downladed dataset and it's corresponding artifact object if dataset
+ is found otherwise returns (None, None)
+ """
+ if isinstance(path, str) and path.startswith(WANDB_ARTIFACT_PREFIX):
+ artifact_path = Path(remove_prefix(path, WANDB_ARTIFACT_PREFIX) + ":" + alias)
+ dataset_artifact = wandb.use_artifact(artifact_path.as_posix().replace("\\", "/"))
+ assert dataset_artifact is not None, "'Error: W&B dataset artifact doesn\'t exist'"
+ datadir = dataset_artifact.download()
+ return datadir, dataset_artifact
+ return None, None
+
+ def download_model_artifact(self, opt):
+ """
+ download the model checkpoint artifact if the resume path starts with WANDB_ARTIFACT_PREFIX
+
+ arguments:
+ opt (namespace) -- Commandline arguments for this run
+ """
+ if opt.resume.startswith(WANDB_ARTIFACT_PREFIX):
+ model_artifact = wandb.use_artifact(remove_prefix(opt.resume, WANDB_ARTIFACT_PREFIX) + ":latest")
+ assert model_artifact is not None, 'Error: W&B model artifact doesn\'t exist'
+ modeldir = model_artifact.download()
+ epochs_trained = model_artifact.metadata.get('epochs_trained')
+ total_epochs = model_artifact.metadata.get('total_epochs')
+ is_finished = total_epochs is None
+ assert not is_finished, 'training is finished, can only resume incomplete runs.'
+ return modeldir, model_artifact
+ return None, None
+
+ def log_model(self, path, opt, epoch, fitness_score, best_model=False):
+ """
+ Log the model checkpoint as W&B artifact
+
+ arguments:
+ path (Path) -- Path of directory containing the checkpoints
+ opt (namespace) -- Command line arguments for this run
+ epoch (int) -- Current epoch number
+ fitness_score (float) -- fitness score for current epoch
+ best_model (boolean) -- Boolean representing if the current checkpoint is the best yet.
+ """
+ model_artifact = wandb.Artifact('run_' + wandb.run.id + '_model', type='model', metadata={
+ 'original_url': str(path),
+ 'epochs_trained': epoch + 1,
+ 'save period': opt.save_period,
+ 'project': opt.project,
+ 'total_epochs': opt.epochs,
+ 'fitness_score': fitness_score
+ })
+ model_artifact.add_file(str(path / 'last.pt'), name='last.pt')
+ wandb.log_artifact(model_artifact,
+ aliases=['latest', 'last', 'epoch ' + str(self.current_epoch), 'best' if best_model else ''])
+ LOGGER.info(f"Saving model artifact on epoch {epoch + 1}")
+
+ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=False):
+ """
+ Log the dataset as W&B artifact and return the new data file with W&B links
+
+ arguments:
+ data_file (str) -- the .yaml file with information about the dataset like - path, classes etc.
+ single_class (boolean) -- train multi-class data as single-class
+ project (str) -- project name. Used to construct the artifact path
+ overwrite_config (boolean) -- overwrites the data.yaml file if set to true otherwise creates a new
+ file with _wandb postfix. Eg -> data_wandb.yaml
+
+ returns:
+ the new .yaml file with artifact links. it can be used to start training directly from artifacts
+ """
+ self.data_dict = check_dataset(data_file) # parse and check
+ data = dict(self.data_dict)
+ nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
+ names = {k: v for k, v in enumerate(names)} # to index dictionary
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
+ self.val_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+ if data.get('val'):
+ data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
+ path = Path(data_file).stem
+ path = (path if overwrite_config else path + '_wandb') + '.yaml' # updated data.yaml path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+
+ if self.job_type == 'Training': # builds correct artifact pipeline graph
+ self.wandb_run.use_artifact(self.val_artifact)
+ self.wandb_run.use_artifact(self.train_artifact)
+ self.val_artifact.wait()
+ self.val_table = self.val_artifact.get('val')
+ self.map_val_table_path()
+ else:
+ self.wandb_run.log_artifact(self.train_artifact)
+ self.wandb_run.log_artifact(self.val_artifact)
+ return path
+
+ def map_val_table_path(self):
+ """
+ Map the validation dataset Table like name of file -> it's id in the W&B Table.
+ Useful for - referencing artifacts for evaluation.
+ """
+ self.val_table_path_map = {}
+ LOGGER.info("Mapping dataset")
+ for i, data in enumerate(tqdm(self.val_table.data)):
+ self.val_table_path_map[data[3]] = data[0]
+
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int,str], name: str = 'dataset'):
+ """
+ Create and return W&B artifact containing W&B Table of the dataset.
+
+ arguments:
+ dataset -- instance of LoadImagesAndLabels class used to iterate over the data to build Table
+ class_to_id -- hash map that maps class ids to labels
+ name -- name of the artifact
+
+ returns:
+ dataset artifact to be logged or used
+ """
+ # TODO: Explore multiprocessing to slpit this loop parallely| This is essential for speeding up the the logging
+ artifact = wandb.Artifact(name=name, type="dataset")
+ img_files = tqdm([dataset.path]) if isinstance(dataset.path, str) and Path(dataset.path).is_dir() else None
+ img_files = tqdm(dataset.img_files) if not img_files else img_files
+ for img_file in img_files:
+ if Path(img_file).is_dir():
+ artifact.add_dir(img_file, name='data/images')
+ labels_path = 'labels'.join(dataset.path.rsplit('images', 1))
+ artifact.add_dir(labels_path, name='data/labels')
+ else:
+ artifact.add_file(img_file, name='data/images/' + Path(img_file).name)
+ label_file = Path(img2label_paths([img_file])[0])
+ artifact.add_file(str(label_file),
+ name='data/labels/' + label_file.name) if label_file.exists() else None
+ table = wandb.Table(columns=["id", "train_image", "Classes", "name"])
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in class_to_id.items()])
+ for si, (img, labels, paths, shapes) in enumerate(tqdm(dataset)):
+ box_data, img_classes = [], {}
+ for cls, *xywh in labels[:, 1:].tolist():
+ cls = int(cls)
+ box_data.append({"position": {"middle": [xywh[0], xywh[1]], "width": xywh[2], "height": xywh[3]},
+ "class_id": cls,
+ "box_caption": "%s" % (class_to_id[cls])})
+ img_classes[cls] = class_to_id[cls]
+ boxes = {"ground_truth": {"box_data": box_data, "class_labels": class_to_id}} # inference-space
+ table.add_data(si, wandb.Image(paths, classes=class_set, boxes=boxes), list(img_classes.values()),
+ Path(paths).name)
+ artifact.add(table, name)
+ return artifact
+
+ def log_training_progress(self, predn, path, names):
+ """
+ Build evaluation Table. Uses reference from validation dataset table.
+
+ arguments:
+ predn (list): list of predictions in the native space in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ names (dict(int, str)): hash map that maps class ids to labels
+ """
+ class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
+ box_data = []
+ total_conf = 0
+ for *xyxy, conf, cls in predn.tolist():
+ if conf >= 0.25:
+ box_data.append(
+ {"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"})
+ total_conf += conf
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ id = self.val_table_path_map[Path(path).name]
+ self.result_table.add_data(self.current_epoch,
+ id,
+ self.val_table.data[id][1],
+ wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
+ total_conf / max(1, len(box_data))
+ )
+
+ def val_one_image(self, pred, predn, path, names, im):
+ """
+ Log validation data for one image. updates the result Table if validation dataset is uploaded and log bbox media panel
+
+ arguments:
+ pred (list): list of scaled predictions in the format - [xmin, ymin, xmax, ymax, confidence, class]
+ predn (list): list of predictions in the native space - [xmin, ymin, xmax, ymax, confidence, class]
+ path (str): local path of the current evaluation image
+ """
+ if self.val_table and self.result_table: # Log Table if Val dataset is uploaded as artifact
+ self.log_training_progress(predn, path, names)
+
+ if len(self.bbox_media_panel_images) < self.max_imgs_to_log and self.current_epoch > 0:
+ if self.current_epoch % self.bbox_interval == 0:
+ box_data = [{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
+ "class_id": int(cls),
+ "box_caption": f"{names[cls]} {conf:.3f}",
+ "scores": {"class_score": conf},
+ "domain": "pixel"} for *xyxy, conf, cls in pred.tolist()]
+ boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
+ self.bbox_media_panel_images.append(wandb.Image(im, boxes=boxes, caption=path.name))
+
+ def log(self, log_dict):
+ """
+ save the metrics to the logging dictionary
+
+ arguments:
+ log_dict (Dict) -- metrics/media to be logged in current step
+ """
+ if self.wandb_run:
+ for key, value in log_dict.items():
+ self.log_dict[key] = value
+
+ def end_epoch(self, best_result=False):
+ """
+ commit the log_dict, model artifacts and Tables to W&B and flush the log_dict.
+
+ arguments:
+ best_result (boolean): Boolean representing if the result of this evaluation is best or not
+ """
+ if self.wandb_run:
+ with all_logging_disabled():
+ if self.bbox_media_panel_images:
+ self.log_dict["BoundingBoxDebugger"] = self.bbox_media_panel_images
+ try:
+ wandb.log(self.log_dict)
+ except BaseException as e:
+ LOGGER.info(f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
+ self.wandb_run.finish()
+ self.wandb_run = None
+
+ self.log_dict = {}
+ self.bbox_media_panel_images = []
+ if self.result_artifact:
+ self.result_artifact.add(self.result_table, 'result')
+ wandb.log_artifact(self.result_artifact, aliases=['latest', 'last', 'epoch ' + str(self.current_epoch),
+ ('best' if best_result else '')])
+
+ wandb.log({"evaluation": self.result_table})
+ self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
+ self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
+
+ def finish_run(self):
+ """
+ Log metrics if any and finish the current W&B run
+ """
+ if self.wandb_run:
+ if self.log_dict:
+ with all_logging_disabled():
+ wandb.log(self.log_dict)
+ wandb.run.finish()
+
+
+@contextmanager
+def all_logging_disabled(highest_level=logging.CRITICAL):
+ """ source - https://gist.github.com/simon-weber/7853144
+ A context manager that will prevent any logging messages triggered during the body from being processed.
+ :param highest_level: the maximum logging level in use.
+ This would only need to be changed if a custom level greater than CRITICAL is defined.
+ """
+ previous_level = logging.root.manager.disable
+ logging.disable(highest_level)
+ try:
+ yield
+ finally:
+ logging.disable(previous_level)
diff --git a/src/image_recognition/utils/loss.py b/src/image_recognition/utils/loss.py
new file mode 100644
index 0000000..194c8e5
--- /dev/null
+++ b/src/image_recognition/utils/loss.py
@@ -0,0 +1,222 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Loss functions
+"""
+
+import torch
+import torch.nn as nn
+
+from utils.metrics import bbox_iou
+from utils.torch_utils import is_parallel
+
+
+def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
+ # return positive, negative label smoothing BCE targets
+ return 1.0 - 0.5 * eps, 0.5 * eps
+
+
+class BCEBlurWithLogitsLoss(nn.Module):
+ # BCEwithLogitLoss() with reduced missing label effects.
+ def __init__(self, alpha=0.05):
+ super().__init__()
+ self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
+ self.alpha = alpha
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ pred = torch.sigmoid(pred) # prob from logits
+ dx = pred - true # reduce only missing label effects
+ # dx = (pred - true).abs() # reduce missing label and false label effects
+ alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
+ loss *= alpha_factor
+ return loss.mean()
+
+
+class FocalLoss(nn.Module):
+ # Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+ # p_t = torch.exp(-loss)
+ # loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
+
+ # TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = (1.0 - p_t) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class QFocalLoss(nn.Module):
+ # Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
+ def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
+ super().__init__()
+ self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
+ self.gamma = gamma
+ self.alpha = alpha
+ self.reduction = loss_fcn.reduction
+ self.loss_fcn.reduction = 'none' # required to apply FL to each element
+
+ def forward(self, pred, true):
+ loss = self.loss_fcn(pred, true)
+
+ pred_prob = torch.sigmoid(pred) # prob from logits
+ alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
+ modulating_factor = torch.abs(true - pred_prob) ** self.gamma
+ loss *= alpha_factor * modulating_factor
+
+ if self.reduction == 'mean':
+ return loss.mean()
+ elif self.reduction == 'sum':
+ return loss.sum()
+ else: # 'none'
+ return loss
+
+
+class ComputeLoss:
+ # Compute losses
+ def __init__(self, model, autobalance=False):
+ self.sort_obj_iou = False
+ device = next(model.parameters()).device # get model device
+ h = model.hyp # hyperparameters
+
+ # Define criteria
+ BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
+ BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
+
+ # Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
+ self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
+
+ # Focal loss
+ g = h['fl_gamma'] # focal loss gamma
+ if g > 0:
+ BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
+
+ det = model.module.model[-1] if is_parallel(model) else model.model[-1] # Detect() module
+ self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
+ self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
+ self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
+ for k in 'na', 'nc', 'nl', 'anchors':
+ setattr(self, k, getattr(det, k))
+
+ def __call__(self, p, targets): # predictions, targets, model
+ device = targets.device
+ lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
+ tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
+
+ # Losses
+ for i, pi in enumerate(p): # layer index, layer predictions
+ b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
+ tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
+
+ n = b.shape[0] # number of targets
+ if n:
+ ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
+
+ # Regression
+ pxy = ps[:, :2].sigmoid() * 2 - 0.5
+ pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
+ pbox = torch.cat((pxy, pwh), 1) # predicted box
+ iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
+ lbox += (1.0 - iou).mean() # iou loss
+
+ # Objectness
+ score_iou = iou.detach().clamp(0).type(tobj.dtype)
+ if self.sort_obj_iou:
+ sort_id = torch.argsort(score_iou)
+ b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
+ tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
+
+ # Classification
+ if self.nc > 1: # cls loss (only if multiple classes)
+ t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
+ t[range(n), tcls[i]] = self.cp
+ lcls += self.BCEcls(ps[:, 5:], t) # BCE
+
+ # Append targets to text file
+ # with open('targets.txt', 'a') as file:
+ # [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
+
+ obji = self.BCEobj(pi[..., 4], tobj)
+ lobj += obji * self.balance[i] # obj loss
+ if self.autobalance:
+ self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
+
+ if self.autobalance:
+ self.balance = [x / self.balance[self.ssi] for x in self.balance]
+ lbox *= self.hyp['box']
+ lobj *= self.hyp['obj']
+ lcls *= self.hyp['cls']
+ bs = tobj.shape[0] # batch size
+
+ return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
+
+ def build_targets(self, p, targets):
+ # Build targets for compute_loss(), input targets(image,class,x,y,w,h)
+ na, nt = self.na, targets.shape[0] # number of anchors, targets
+ tcls, tbox, indices, anch = [], [], [], []
+ gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
+ ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
+ targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
+
+ g = 0.5 # bias
+ off = torch.tensor([[0, 0],
+ [1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
+ # [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
+ ], device=targets.device).float() * g # offsets
+
+ for i in range(self.nl):
+ anchors = self.anchors[i]
+ gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
+
+ # Match targets to anchors
+ t = targets * gain
+ if nt:
+ # Matches
+ r = t[:, :, 4:6] / anchors[:, None] # wh ratio
+ j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
+ # j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
+ t = t[j] # filter
+
+ # Offsets
+ gxy = t[:, 2:4] # grid xy
+ gxi = gain[[2, 3]] - gxy # inverse
+ j, k = ((gxy % 1 < g) & (gxy > 1)).T
+ l, m = ((gxi % 1 < g) & (gxi > 1)).T
+ j = torch.stack((torch.ones_like(j), j, k, l, m))
+ t = t.repeat((5, 1, 1))[j]
+ offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
+ else:
+ t = targets[0]
+ offsets = 0
+
+ # Define
+ b, c = t[:, :2].long().T # image, class
+ gxy = t[:, 2:4] # grid xy
+ gwh = t[:, 4:6] # grid wh
+ gij = (gxy - offsets).long()
+ gi, gj = gij.T # grid xy indices
+
+ # Append
+ a = t[:, 6].long() # anchor indices
+ indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
+ tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
+ anch.append(anchors[a]) # anchors
+ tcls.append(c) # class
+
+ return tcls, tbox, indices, anch
diff --git a/src/image_recognition/utils/metrics.py b/src/image_recognition/utils/metrics.py
new file mode 100644
index 0000000..2e0e0c6
--- /dev/null
+++ b/src/image_recognition/utils/metrics.py
@@ -0,0 +1,335 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Model validation metrics
+"""
+
+import math
+import warnings
+from pathlib import Path
+
+import matplotlib.pyplot as plt
+import numpy as np
+import torch
+
+
+def fitness(x):
+ # Model fitness as a weighted combination of metrics
+ w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
+ return (x[:, :4] * w).sum(1)
+
+
+def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=()):
+ """ Compute the average precision, given the recall and precision curves.
+ Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
+ # Arguments
+ tp: True positives (nparray, nx1 or nx10).
+ conf: Objectness value from 0-1 (nparray).
+ pred_cls: Predicted object classes (nparray).
+ target_cls: True object classes (nparray).
+ plot: Plot precision-recall curve at mAP@0.5
+ save_dir: Plot save directory
+ # Returns
+ The average precision as computed in py-faster-rcnn.
+ """
+
+ # Sort by objectness
+ i = np.argsort(-conf)
+ tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
+
+ # Find unique classes
+ unique_classes = np.unique(target_cls)
+ nc = unique_classes.shape[0] # number of classes, number of detections
+
+ # Create Precision-Recall curve and compute AP for each class
+ px, py = np.linspace(0, 1, 1000), [] # for plotting
+ ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
+ for ci, c in enumerate(unique_classes):
+ i = pred_cls == c
+ n_l = (target_cls == c).sum() # number of labels
+ n_p = i.sum() # number of predictions
+
+ if n_p == 0 or n_l == 0:
+ continue
+ else:
+ # Accumulate FPs and TPs
+ fpc = (1 - tp[i]).cumsum(0)
+ tpc = tp[i].cumsum(0)
+
+ # Recall
+ recall = tpc / (n_l + 1e-16) # recall curve
+ r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
+
+ # Precision
+ precision = tpc / (tpc + fpc) # precision curve
+ p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
+
+ # AP from recall-precision curve
+ for j in range(tp.shape[1]):
+ ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
+ if plot and j == 0:
+ py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
+
+ # Compute F1 (harmonic mean of precision and recall)
+ f1 = 2 * p * r / (p + r + 1e-16)
+ names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
+ names = {i: v for i, v in enumerate(names)} # to dict
+ if plot:
+ plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
+ plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
+ plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
+ plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
+
+ i = f1.mean(0).argmax() # max F1 index
+ return p[:, i], r[:, i], ap, f1[:, i], unique_classes.astype('int32')
+
+
+def compute_ap(recall, precision):
+ """ Compute the average precision, given the recall and precision curves
+ # Arguments
+ recall: The recall curve (list)
+ precision: The precision curve (list)
+ # Returns
+ Average precision, precision curve, recall curve
+ """
+
+ # Append sentinel values to beginning and end
+ mrec = np.concatenate(([0.0], recall, [1.0]))
+ mpre = np.concatenate(([1.0], precision, [0.0]))
+
+ # Compute the precision envelope
+ mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
+
+ # Integrate area under curve
+ method = 'interp' # methods: 'continuous', 'interp'
+ if method == 'interp':
+ x = np.linspace(0, 1, 101) # 101-point interp (COCO)
+ ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
+ else: # 'continuous'
+ i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
+ ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
+
+ return ap, mpre, mrec
+
+
+class ConfusionMatrix:
+ # Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
+ def __init__(self, nc, conf=0.25, iou_thres=0.45):
+ self.matrix = np.zeros((nc + 1, nc + 1))
+ self.nc = nc # number of classes
+ self.conf = conf
+ self.iou_thres = iou_thres
+
+ def process_batch(self, detections, labels):
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ None, updates confusion matrix accordingly
+ """
+ detections = detections[detections[:, 4] > self.conf]
+ gt_classes = labels[:, 0].int()
+ detection_classes = detections[:, 5].int()
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+
+ x = torch.where(iou > self.iou_thres)
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ else:
+ matches = np.zeros((0, 3))
+
+ n = matches.shape[0] > 0
+ m0, m1, _ = matches.transpose().astype(np.int16)
+ for i, gc in enumerate(gt_classes):
+ j = m0 == i
+ if n and sum(j) == 1:
+ self.matrix[detection_classes[m1[j]], gc] += 1 # correct
+ else:
+ self.matrix[self.nc, gc] += 1 # background FP
+
+ if n:
+ for i, dc in enumerate(detection_classes):
+ if not any(m1 == i):
+ self.matrix[dc, self.nc] += 1 # background FN
+
+ def matrix(self):
+ return self.matrix
+
+ def plot(self, normalize=True, save_dir='', names=()):
+ try:
+ import seaborn as sn
+
+ array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-6) if normalize else 1) # normalize columns
+ array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
+
+ fig = plt.figure(figsize=(12, 9), tight_layout=True)
+ sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
+ labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
+ with warnings.catch_warnings():
+ warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
+ sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
+ xticklabels=names + ['background FP'] if labels else "auto",
+ yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
+ fig.axes[0].set_xlabel('True')
+ fig.axes[0].set_ylabel('Predicted')
+ fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
+ plt.close()
+ except Exception as e:
+ print(f'WARNING: ConfusionMatrix plot failure: {e}')
+
+ def print(self):
+ for i in range(self.nc + 1):
+ print(' '.join(map(str, self.matrix[i])))
+
+
+def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
+ # Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
+ box2 = box2.T
+
+ # Get the coordinates of bounding boxes
+ if x1y1x2y2: # x1, y1, x2, y2 = box1
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+ else: # transform from xywh to xyxy
+ b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
+ b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
+ b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
+ b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
+
+ # Intersection area
+ inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
+ (torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
+
+ # Union Area
+ w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
+ w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
+ union = w1 * h1 + w2 * h2 - inter + eps
+
+ iou = inter / union
+ if GIoU or DIoU or CIoU:
+ cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
+ ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
+ if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
+ c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
+ rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
+ (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
+ if DIoU:
+ return iou - rho2 / c2 # DIoU
+ elif CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
+ v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
+ with torch.no_grad():
+ alpha = v / (v - iou + (1 + eps))
+ return iou - (rho2 / c2 + v * alpha) # CIoU
+ else: # GIoU https://arxiv.org/pdf/1902.09630.pdf
+ c_area = cw * ch + eps # convex area
+ return iou - (c_area - union) / c_area # GIoU
+ else:
+ return iou # IoU
+
+
+def box_iou(box1, box2):
+ # https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
+ """
+ Return intersection-over-union (Jaccard index) of boxes.
+ Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
+ Arguments:
+ box1 (Tensor[N, 4])
+ box2 (Tensor[M, 4])
+ Returns:
+ iou (Tensor[N, M]): the NxM matrix containing the pairwise
+ IoU values for every element in boxes1 and boxes2
+ """
+
+ def box_area(box):
+ # box = 4xn
+ return (box[2] - box[0]) * (box[3] - box[1])
+
+ area1 = box_area(box1.T)
+ area2 = box_area(box2.T)
+
+ # inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
+ inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
+ return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
+
+
+def bbox_ioa(box1, box2, eps=1E-7):
+ """ Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
+ box1: np.array of shape(4)
+ box2: np.array of shape(nx4)
+ returns: np.array of shape(n)
+ """
+
+ box2 = box2.transpose()
+
+ # Get the coordinates of bounding boxes
+ b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
+ b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
+
+ # Intersection area
+ inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
+ (np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
+
+ # box2 area
+ box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
+
+ # Intersection over box2 area
+ return inter_area / box2_area
+
+
+def wh_iou(wh1, wh2):
+ # Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
+ wh1 = wh1[:, None] # [N,1,2]
+ wh2 = wh2[None] # [1,M,2]
+ inter = torch.min(wh1, wh2).prod(2) # [N,M]
+ return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
+
+
+# Plots ----------------------------------------------------------------------------------------------------------------
+
+def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
+ # Precision-recall curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+ py = np.stack(py, axis=1)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py.T):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
+ else:
+ ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
+
+ ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
+ ax.set_xlabel('Recall')
+ ax.set_ylabel('Precision')
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
+
+
+def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
+ # Metric-confidence curve
+ fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
+
+ if 0 < len(names) < 21: # display per-class legend if < 21 classes
+ for i, y in enumerate(py):
+ ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
+ else:
+ ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
+
+ y = py.mean(0)
+ ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
+ ax.set_xlabel(xlabel)
+ ax.set_ylabel(ylabel)
+ ax.set_xlim(0, 1)
+ ax.set_ylim(0, 1)
+ plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
+ fig.savefig(Path(save_dir), dpi=250)
+ plt.close()
diff --git a/src/image_recognition/utils/plots.py b/src/image_recognition/utils/plots.py
new file mode 100644
index 0000000..9919e4d
--- /dev/null
+++ b/src/image_recognition/utils/plots.py
@@ -0,0 +1,469 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Plotting utils
+"""
+
+import math
+import os
+from copy import copy
+from pathlib import Path
+
+import cv2
+import matplotlib
+import matplotlib.pyplot as plt
+import numpy as np
+import pandas as pd
+import seaborn as sn
+import torch
+from PIL import Image, ImageDraw, ImageFont
+
+from utils.general import (LOGGER, Timeout, check_requirements, clip_coords, increment_path, is_ascii, is_chinese,
+ try_except, user_config_dir, xywh2xyxy, xyxy2xywh)
+from utils.metrics import fitness
+
+# Settings
+CONFIG_DIR = user_config_dir() # Ultralytics settings dir
+RANK = int(os.getenv('RANK', -1))
+matplotlib.rc('font', **{'size': 11})
+matplotlib.use('Agg') # for writing to files only
+
+
+class Colors:
+ # Ultralytics color palette https://ultralytics.com/
+ def __init__(self):
+ # hex = matplotlib.colors.TABLEAU_COLORS.values()
+ hex = ('FF3838', 'FF9D97', 'FF701F', 'FFB21D', 'CFD231', '48F90A', '92CC17', '3DDB86', '1A9334', '00D4BB',
+ '2C99A8', '00C2FF', '344593', '6473FF', '0018EC', '8438FF', '520085', 'CB38FF', 'FF95C8', 'FF37C7')
+ self.palette = [self.hex2rgb('#' + c) for c in hex]
+ self.n = len(self.palette)
+
+ def __call__(self, i, bgr=False):
+ c = self.palette[int(i) % self.n]
+ return (c[2], c[1], c[0]) if bgr else c
+
+ @staticmethod
+ def hex2rgb(h): # rgb order (PIL)
+ return tuple(int(h[1 + i:1 + i + 2], 16) for i in (0, 2, 4))
+
+
+colors = Colors() # create instance for 'from utils.plots import colors'
+
+
+def check_font(font='Arial.ttf', size=10):
+ # Return a PIL TrueType Font, downloading to CONFIG_DIR if necessary
+ font = Path(font)
+ font = font if font.exists() else (CONFIG_DIR / font.name)
+ try:
+ return ImageFont.truetype(str(font) if font.exists() else font.name, size)
+ except Exception as e: # download if missing
+ url = "https://ultralytics.com/assets/" + font.name
+ print(f'Downloading {url} to {font}...')
+ torch.hub.download_url_to_file(url, str(font), progress=False)
+ try:
+ return ImageFont.truetype(str(font), size)
+ except TypeError:
+ check_requirements('Pillow>=8.4.0') # known issue https://github.com/ultralytics/yolov5/issues/5374
+
+
+class Annotator:
+ if RANK in (-1, 0):
+ check_font() # download TTF if necessary
+
+ # YOLOv5 Annotator for train/val mosaics and jpgs and detect/hub inference annotations
+ def __init__(self, im, line_width=None, font_size=None, font='Arial.ttf', pil=False, example='abc'):
+ assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to Annotator() input images.'
+ self.pil = pil or not is_ascii(example) or is_chinese(example)
+ if self.pil: # use PIL
+ self.im = im if isinstance(im, Image.Image) else Image.fromarray(im)
+ self.draw = ImageDraw.Draw(self.im)
+ self.font = check_font(font='Arial.Unicode.ttf' if is_chinese(example) else font,
+ size=font_size or max(round(sum(self.im.size) / 2 * 0.035), 12))
+ else: # use cv2
+ self.im = im
+ self.lw = line_width or max(round(sum(im.shape) / 2 * 0.003), 2) # line width
+
+ def box_label(self, box, label='', color=(128, 128, 128), txt_color=(255, 255, 255)):
+ # Add one xyxy box to image with label
+ if self.pil or not is_ascii(label):
+ self.draw.rectangle(box, width=self.lw, outline=color) # box
+ if label:
+ w, h = self.font.getsize(label) # text width, height
+ outside = box[1] - h >= 0 # label fits outside box
+ self.draw.rectangle([box[0],
+ box[1] - h if outside else box[1],
+ box[0] + w + 1,
+ box[1] + 1 if outside else box[1] + h + 1], fill=color)
+ # self.draw.text((box[0], box[1]), label, fill=txt_color, font=self.font, anchor='ls') # for PIL>8.0
+ self.draw.text((box[0], box[1] - h if outside else box[1]), label, fill=txt_color, font=self.font)
+ else: # cv2
+ p1, p2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
+ cv2.rectangle(self.im, p1, p2, color, thickness=self.lw, lineType=cv2.LINE_AA)
+ if label:
+ tf = max(self.lw - 1, 1) # font thickness
+ w, h = cv2.getTextSize(label, 0, fontScale=self.lw / 3, thickness=tf)[0] # text width, height
+ outside = p1[1] - h - 3 >= 0 # label fits outside box
+ p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
+ cv2.rectangle(self.im, p1, p2, color, -1, cv2.LINE_AA) # filled
+ cv2.putText(self.im, label, (p1[0], p1[1] - 2 if outside else p1[1] + h + 2), 0, self.lw / 3, txt_color,
+ thickness=tf, lineType=cv2.LINE_AA)
+
+ def rectangle(self, xy, fill=None, outline=None, width=1):
+ # Add rectangle to image (PIL-only)
+ self.draw.rectangle(xy, fill, outline, width)
+
+ def text(self, xy, text, txt_color=(255, 255, 255)):
+ # Add text to image (PIL-only)
+ w, h = self.font.getsize(text) # text width, height
+ self.draw.text((xy[0], xy[1] - h + 1), text, fill=txt_color, font=self.font)
+
+ def result(self):
+ # Return annotated image as array
+ return np.asarray(self.im)
+
+
+def feature_visualization(x, module_type, stage, n=32, save_dir=Path('runs/detect/exp')):
+ """
+ x: Features to be visualized
+ module_type: Module type
+ stage: Module stage within model
+ n: Maximum number of feature maps to plot
+ save_dir: Directory to save results
+ """
+ if 'Detect' not in module_type:
+ batch, channels, height, width = x.shape # batch, channels, height, width
+ if height > 1 and width > 1:
+ f = f"stage{stage}_{module_type.split('.')[-1]}_features.png" # filename
+
+ blocks = torch.chunk(x[0].cpu(), channels, dim=0) # select batch index 0, block by channels
+ n = min(n, channels) # number of plots
+ fig, ax = plt.subplots(math.ceil(n / 8), 8, tight_layout=True) # 8 rows x n/8 cols
+ ax = ax.ravel()
+ plt.subplots_adjust(wspace=0.05, hspace=0.05)
+ for i in range(n):
+ ax[i].imshow(blocks[i].squeeze()) # cmap='gray'
+ ax[i].axis('off')
+
+ print(f'Saving {save_dir / f}... ({n}/{channels})')
+ plt.savefig(save_dir / f, dpi=300, bbox_inches='tight')
+ plt.close()
+
+
+def hist2d(x, y, n=100):
+ # 2d histogram used in labels.png and evolve.png
+ xedges, yedges = np.linspace(x.min(), x.max(), n), np.linspace(y.min(), y.max(), n)
+ hist, xedges, yedges = np.histogram2d(x, y, (xedges, yedges))
+ xidx = np.clip(np.digitize(x, xedges) - 1, 0, hist.shape[0] - 1)
+ yidx = np.clip(np.digitize(y, yedges) - 1, 0, hist.shape[1] - 1)
+ return np.log(hist[xidx, yidx])
+
+
+def butter_lowpass_filtfilt(data, cutoff=1500, fs=50000, order=5):
+ from scipy.signal import butter, filtfilt
+
+ # https://stackoverflow.com/questions/28536191/how-to-filter-smooth-with-scipy-numpy
+ def butter_lowpass(cutoff, fs, order):
+ nyq = 0.5 * fs
+ normal_cutoff = cutoff / nyq
+ return butter(order, normal_cutoff, btype='low', analog=False)
+
+ b, a = butter_lowpass(cutoff, fs, order=order)
+ return filtfilt(b, a, data) # forward-backward filter
+
+
+def output_to_target(output):
+ # Convert model output to target format [batch_id, class_id, x, y, w, h, conf]
+ targets = []
+ for i, o in enumerate(output):
+ for *box, conf, cls in o.cpu().numpy():
+ targets.append([i, cls, *list(*xyxy2xywh(np.array(box)[None])), conf])
+ return np.array(targets)
+
+
+def plot_images(images, targets, paths=None, fname='images.jpg', names=None, max_size=1920, max_subplots=16):
+ # Plot image grid with labels
+ if isinstance(images, torch.Tensor):
+ images = images.cpu().float().numpy()
+ if isinstance(targets, torch.Tensor):
+ targets = targets.cpu().numpy()
+ if np.max(images[0]) <= 1:
+ images *= 255 # de-normalise (optional)
+ bs, _, h, w = images.shape # batch size, _, height, width
+ bs = min(bs, max_subplots) # limit plot images
+ ns = np.ceil(bs ** 0.5) # number of subplots (square)
+
+ # Build Image
+ mosaic = np.full((int(ns * h), int(ns * w), 3), 255, dtype=np.uint8) # init
+ for i, im in enumerate(images):
+ if i == max_subplots: # if last batch has fewer images than we expect
+ break
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ im = im.transpose(1, 2, 0)
+ mosaic[y:y + h, x:x + w, :] = im
+
+ # Resize (optional)
+ scale = max_size / ns / max(h, w)
+ if scale < 1:
+ h = math.ceil(scale * h)
+ w = math.ceil(scale * w)
+ mosaic = cv2.resize(mosaic, tuple(int(x * ns) for x in (w, h)))
+
+ # Annotate
+ fs = int((h + w) * ns * 0.01) # font size
+ annotator = Annotator(mosaic, line_width=round(fs / 10), font_size=fs, pil=True)
+ for i in range(i + 1):
+ x, y = int(w * (i // ns)), int(h * (i % ns)) # block origin
+ annotator.rectangle([x, y, x + w, y + h], None, (255, 255, 255), width=2) # borders
+ if paths:
+ annotator.text((x + 5, y + 5 + h), text=Path(paths[i]).name[:40], txt_color=(220, 220, 220)) # filenames
+ if len(targets) > 0:
+ ti = targets[targets[:, 0] == i] # image targets
+ boxes = xywh2xyxy(ti[:, 2:6]).T
+ classes = ti[:, 1].astype('int')
+ labels = ti.shape[1] == 6 # labels if no conf column
+ conf = None if labels else ti[:, 6] # check for confidence presence (label vs pred)
+
+ if boxes.shape[1]:
+ if boxes.max() <= 1.01: # if normalized with tolerance 0.01
+ boxes[[0, 2]] *= w # scale to pixels
+ boxes[[1, 3]] *= h
+ elif scale < 1: # absolute coords need scale if image scales
+ boxes *= scale
+ boxes[[0, 2]] += x
+ boxes[[1, 3]] += y
+ for j, box in enumerate(boxes.T.tolist()):
+ cls = classes[j]
+ color = colors(cls)
+ cls = names[cls] if names else cls
+ if labels or conf[j] > 0.25: # 0.25 conf thresh
+ label = f'{cls}' if labels else f'{cls} {conf[j]:.1f}'
+ annotator.box_label(box, label, color=color)
+ annotator.im.save(fname) # save
+
+
+def plot_lr_scheduler(optimizer, scheduler, epochs=300, save_dir=''):
+ # Plot LR simulating training for full epochs
+ optimizer, scheduler = copy(optimizer), copy(scheduler) # do not modify originals
+ y = []
+ for _ in range(epochs):
+ scheduler.step()
+ y.append(optimizer.param_groups[0]['lr'])
+ plt.plot(y, '.-', label='LR')
+ plt.xlabel('epoch')
+ plt.ylabel('LR')
+ plt.grid()
+ plt.xlim(0, epochs)
+ plt.ylim(0)
+ plt.savefig(Path(save_dir) / 'LR.png', dpi=200)
+ plt.close()
+
+
+def plot_val_txt(): # from utils.plots import *; plot_val()
+ # Plot val.txt histograms
+ x = np.loadtxt('val.txt', dtype=np.float32)
+ box = xyxy2xywh(x[:, :4])
+ cx, cy = box[:, 0], box[:, 1]
+
+ fig, ax = plt.subplots(1, 1, figsize=(6, 6), tight_layout=True)
+ ax.hist2d(cx, cy, bins=600, cmax=10, cmin=0)
+ ax.set_aspect('equal')
+ plt.savefig('hist2d.png', dpi=300)
+
+ fig, ax = plt.subplots(1, 2, figsize=(12, 6), tight_layout=True)
+ ax[0].hist(cx, bins=600)
+ ax[1].hist(cy, bins=600)
+ plt.savefig('hist1d.png', dpi=200)
+
+
+def plot_targets_txt(): # from utils.plots import *; plot_targets_txt()
+ # Plot targets.txt histograms
+ x = np.loadtxt('targets.txt', dtype=np.float32).T
+ s = ['x targets', 'y targets', 'width targets', 'height targets']
+ fig, ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)
+ ax = ax.ravel()
+ for i in range(4):
+ ax[i].hist(x[i], bins=100, label=f'{x[i].mean():.3g} +/- {x[i].std():.3g}')
+ ax[i].legend()
+ ax[i].set_title(s[i])
+ plt.savefig('targets.jpg', dpi=200)
+
+
+def plot_val_study(file='', dir='', x=None): # from utils.plots import *; plot_val_study()
+ # Plot file=study.txt generated by val.py (or plot all study*.txt in dir)
+ save_dir = Path(file).parent if file else Path(dir)
+ plot2 = False # plot additional results
+ if plot2:
+ ax = plt.subplots(2, 4, figsize=(10, 6), tight_layout=True)[1].ravel()
+
+ fig2, ax2 = plt.subplots(1, 1, figsize=(8, 4), tight_layout=True)
+ # for f in [save_dir / f'study_coco_{x}.txt' for x in ['yolov5n6', 'yolov5s6', 'yolov5m6', 'yolov5l6', 'yolov5x6']]:
+ for f in sorted(save_dir.glob('study*.txt')):
+ y = np.loadtxt(f, dtype=np.float32, usecols=[0, 1, 2, 3, 7, 8, 9], ndmin=2).T
+ x = np.arange(y.shape[1]) if x is None else np.array(x)
+ if plot2:
+ s = ['P', 'R', 'mAP@.5', 'mAP@.5:.95', 't_preprocess (ms/img)', 't_inference (ms/img)', 't_NMS (ms/img)']
+ for i in range(7):
+ ax[i].plot(x, y[i], '.-', linewidth=2, markersize=8)
+ ax[i].set_title(s[i])
+
+ j = y[3].argmax() + 1
+ ax2.plot(y[5, 1:j], y[3, 1:j] * 1E2, '.-', linewidth=2, markersize=8,
+ label=f.stem.replace('study_coco_', '').replace('yolo', 'YOLO'))
+
+ ax2.plot(1E3 / np.array([209, 140, 97, 58, 35, 18]), [34.6, 40.5, 43.0, 47.5, 49.7, 51.5],
+ 'k.-', linewidth=2, markersize=8, alpha=.25, label='EfficientDet')
+
+ ax2.grid(alpha=0.2)
+ ax2.set_yticks(np.arange(20, 60, 5))
+ ax2.set_xlim(0, 57)
+ ax2.set_ylim(25, 55)
+ ax2.set_xlabel('GPU Speed (ms/img)')
+ ax2.set_ylabel('COCO AP val')
+ ax2.legend(loc='lower right')
+ f = save_dir / 'study.png'
+ print(f'Saving {f}...')
+ plt.savefig(f, dpi=300)
+
+
+@try_except # known issue https://github.com/ultralytics/yolov5/issues/5395
+@Timeout(30) # known issue https://github.com/ultralytics/yolov5/issues/5611
+def plot_labels(labels, names=(), save_dir=Path('')):
+ # plot dataset labels
+ LOGGER.info(f"Plotting labels to {save_dir / 'labels.jpg'}... ")
+ c, b = labels[:, 0], labels[:, 1:].transpose() # classes, boxes
+ nc = int(c.max() + 1) # number of classes
+ x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
+
+ # seaborn correlogram
+ sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
+ plt.savefig(save_dir / 'labels_correlogram.jpg', dpi=200)
+ plt.close()
+
+ # matplotlib labels
+ matplotlib.use('svg') # faster
+ ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
+ y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
+ # [y[2].patches[i].set_color([x / 255 for x in colors(i)]) for i in range(nc)] # update colors bug #3195
+ ax[0].set_ylabel('instances')
+ if 0 < len(names) < 30:
+ ax[0].set_xticks(range(len(names)))
+ ax[0].set_xticklabels(names, rotation=90, fontsize=10)
+ else:
+ ax[0].set_xlabel('classes')
+ sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
+ sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
+
+ # rectangles
+ labels[:, 1:3] = 0.5 # center
+ labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
+ img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
+ for cls, *box in labels[:1000]:
+ ImageDraw.Draw(img).rectangle(box, width=1, outline=colors(cls)) # plot
+ ax[1].imshow(img)
+ ax[1].axis('off')
+
+ for a in [0, 1, 2, 3]:
+ for s in ['top', 'right', 'left', 'bottom']:
+ ax[a].spines[s].set_visible(False)
+
+ plt.savefig(save_dir / 'labels.jpg', dpi=200)
+ matplotlib.use('Agg')
+ plt.close()
+
+
+def plot_evolve(evolve_csv='path/to/evolve.csv'): # from utils.plots import *; plot_evolve()
+ # Plot evolve.csv hyp evolution results
+ evolve_csv = Path(evolve_csv)
+ data = pd.read_csv(evolve_csv)
+ keys = [x.strip() for x in data.columns]
+ x = data.values
+ f = fitness(x)
+ j = np.argmax(f) # max fitness index
+ plt.figure(figsize=(10, 12), tight_layout=True)
+ matplotlib.rc('font', **{'size': 8})
+ for i, k in enumerate(keys[7:]):
+ v = x[:, 7 + i]
+ mu = v[j] # best single result
+ plt.subplot(6, 5, i + 1)
+ plt.scatter(v, f, c=hist2d(v, f, 20), cmap='viridis', alpha=.8, edgecolors='none')
+ plt.plot(mu, f.max(), 'k+', markersize=15)
+ plt.title(f'{k} = {mu:.3g}', fontdict={'size': 9}) # limit to 40 characters
+ if i % 5 != 0:
+ plt.yticks([])
+ print(f'{k:>15}: {mu:.3g}')
+ f = evolve_csv.with_suffix('.png') # filename
+ plt.savefig(f, dpi=200)
+ plt.close()
+ print(f'Saved {f}')
+
+
+def plot_results(file='path/to/results.csv', dir=''):
+ # Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')
+ save_dir = Path(file).parent if file else Path(dir)
+ fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)
+ ax = ax.ravel()
+ files = list(save_dir.glob('results*.csv'))
+ assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'
+ for fi, f in enumerate(files):
+ try:
+ data = pd.read_csv(f)
+ s = [x.strip() for x in data.columns]
+ x = data.values[:, 0]
+ for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):
+ y = data.values[:, j]
+ # y[y == 0] = np.nan # don't show zero values
+ ax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)
+ ax[i].set_title(s[j], fontsize=12)
+ # if j in [8, 9, 10]: # share train and val loss y axes
+ # ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}: {e}')
+ ax[1].legend()
+ fig.savefig(save_dir / 'results.png', dpi=200)
+ plt.close()
+
+
+def profile_idetection(start=0, stop=0, labels=(), save_dir=''):
+ # Plot iDetection '*.txt' per-image logs. from utils.plots import *; profile_idetection()
+ ax = plt.subplots(2, 4, figsize=(12, 6), tight_layout=True)[1].ravel()
+ s = ['Images', 'Free Storage (GB)', 'RAM Usage (GB)', 'Battery', 'dt_raw (ms)', 'dt_smooth (ms)', 'real-world FPS']
+ files = list(Path(save_dir).glob('frames*.txt'))
+ for fi, f in enumerate(files):
+ try:
+ results = np.loadtxt(f, ndmin=2).T[:, 90:-30] # clip first and last rows
+ n = results.shape[1] # number of rows
+ x = np.arange(start, min(stop, n) if stop else n)
+ results = results[:, x]
+ t = (results[0] - results[0].min()) # set t0=0s
+ results[0] = x
+ for i, a in enumerate(ax):
+ if i < len(results):
+ label = labels[fi] if len(labels) else f.stem.replace('frames_', '')
+ a.plot(t, results[i], marker='.', label=label, linewidth=1, markersize=5)
+ a.set_title(s[i])
+ a.set_xlabel('time (s)')
+ # if fi == len(files) - 1:
+ # a.set_ylim(bottom=0)
+ for side in ['top', 'right']:
+ a.spines[side].set_visible(False)
+ else:
+ a.remove()
+ except Exception as e:
+ print(f'Warning: Plotting error for {f}; {e}')
+ ax[1].legend()
+ plt.savefig(Path(save_dir) / 'idetection_profile.png', dpi=200)
+
+
+def save_one_box(xyxy, im, file='image.jpg', gain=1.02, pad=10, square=False, BGR=False, save=True):
+ # Save image crop as {file} with crop size multiple {gain} and {pad} pixels. Save and/or return crop
+ xyxy = torch.tensor(xyxy).view(-1, 4)
+ b = xyxy2xywh(xyxy) # boxes
+ if square:
+ b[:, 2:] = b[:, 2:].max(1)[0].unsqueeze(1) # attempt rectangle to square
+ b[:, 2:] = b[:, 2:] * gain + pad # box wh * gain + pad
+ xyxy = xywh2xyxy(b).long()
+ clip_coords(xyxy, im.shape)
+ crop = im[int(xyxy[0, 1]):int(xyxy[0, 3]), int(xyxy[0, 0]):int(xyxy[0, 2]), ::(1 if BGR else -1)]
+ if save:
+ file.parent.mkdir(parents=True, exist_ok=True) # make directory
+ cv2.imwrite(str(increment_path(file).with_suffix('.jpg')), crop)
+ return crop
diff --git a/src/image_recognition/utils/torch_utils.py b/src/image_recognition/utils/torch_utils.py
new file mode 100644
index 0000000..1628910
--- /dev/null
+++ b/src/image_recognition/utils/torch_utils.py
@@ -0,0 +1,318 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+PyTorch utils
+"""
+
+import datetime
+import math
+import os
+import platform
+import subprocess
+import time
+from contextlib import contextmanager
+from copy import deepcopy
+from pathlib import Path
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import torch.nn.functional as F
+
+from utils.general import LOGGER
+
+try:
+ import thop # for FLOPs computation
+except ImportError:
+ thop = None
+
+
+@contextmanager
+def torch_distributed_zero_first(local_rank: int):
+ """
+ Decorator to make all processes in distributed training wait for each local_master to do something.
+ """
+ if local_rank not in [-1, 0]:
+ dist.barrier(device_ids=[local_rank])
+ yield
+ if local_rank == 0:
+ dist.barrier(device_ids=[0])
+
+
+def date_modified(path=__file__):
+ # return human-readable file modification date, i.e. '2021-3-26'
+ t = datetime.datetime.fromtimestamp(Path(path).stat().st_mtime)
+ return f'{t.year}-{t.month}-{t.day}'
+
+
+def git_describe(path=Path(__file__).parent): # path must be a directory
+ # return human-readable git description, i.e. v5.0-5-g3e25f1e https://git-scm.com/docs/git-describe
+ s = f'git -C {path} describe --tags --long --always'
+ try:
+ return subprocess.check_output(s, shell=True, stderr=subprocess.STDOUT).decode()[:-1]
+ except subprocess.CalledProcessError as e:
+ return '' # not a git repository
+
+
+def select_device(device='', batch_size=None, newline=True):
+ # device = 'cpu' or '0' or '0,1,2,3'
+ s = f'YOLOv5 🚀 {git_describe() or date_modified()} torch {torch.__version__} ' # string
+ device = str(device).strip().lower().replace('cuda:', '') # to string, 'cuda:0' to '0'
+ cpu = device == 'cpu'
+ if cpu:
+ os.environ['CUDA_VISIBLE_DEVICES'] = '-1' # force torch.cuda.is_available() = False
+ elif device: # non-cpu device requested
+ os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable
+ assert torch.cuda.is_available(), f'CUDA unavailable, invalid device {device} requested' # check availability
+
+ cuda = not cpu and torch.cuda.is_available()
+ if cuda:
+ devices = device.split(',') if device else '0' # range(torch.cuda.device_count()) # i.e. 0,1,6,7
+ n = len(devices) # device count
+ if n > 1 and batch_size: # check batch_size is divisible by device_count
+ assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
+ space = ' ' * (len(s) + 1)
+ for i, d in enumerate(devices):
+ p = torch.cuda.get_device_properties(i)
+ s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / 1024 ** 2:.0f}MiB)\n" # bytes to MB
+ else:
+ s += 'CPU\n'
+
+ if not newline:
+ s = s.rstrip()
+ LOGGER.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
+ return torch.device('cuda:0' if cuda else 'cpu')
+
+
+def time_sync():
+ # pytorch-accurate time
+ if torch.cuda.is_available():
+ torch.cuda.synchronize()
+ return time.time()
+
+
+def profile(input, ops, n=10, device=None):
+ # YOLOv5 speed/memory/FLOPs profiler
+ #
+ # Usage:
+ # input = torch.randn(16, 3, 640, 640)
+ # m1 = lambda x: x * torch.sigmoid(x)
+ # m2 = nn.SiLU()
+ # profile(input, [m1, m2], n=100) # profile over 100 iterations
+
+ results = []
+ device = device or select_device()
+ print(f"{'Params':>12s}{'GFLOPs':>12s}{'GPU_mem (GB)':>14s}{'forward (ms)':>14s}{'backward (ms)':>14s}"
+ f"{'input':>24s}{'output':>24s}")
+
+ for x in input if isinstance(input, list) else [input]:
+ x = x.to(device)
+ x.requires_grad = True
+ for m in ops if isinstance(ops, list) else [ops]:
+ m = m.to(device) if hasattr(m, 'to') else m # device
+ m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m
+ tf, tb, t = 0, 0, [0, 0, 0] # dt forward, backward
+ try:
+ flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # GFLOPs
+ except:
+ flops = 0
+
+ try:
+ for _ in range(n):
+ t[0] = time_sync()
+ y = m(x)
+ t[1] = time_sync()
+ try:
+ _ = (sum(yi.sum() for yi in y) if isinstance(y, list) else y).sum().backward()
+ t[2] = time_sync()
+ except Exception as e: # no backward method
+ # print(e) # for debug
+ t[2] = float('nan')
+ tf += (t[1] - t[0]) * 1000 / n # ms per op forward
+ tb += (t[2] - t[1]) * 1000 / n # ms per op backward
+ mem = torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0 # (GB)
+ s_in = tuple(x.shape) if isinstance(x, torch.Tensor) else 'list'
+ s_out = tuple(y.shape) if isinstance(y, torch.Tensor) else 'list'
+ p = sum(list(x.numel() for x in m.parameters())) if isinstance(m, nn.Module) else 0 # parameters
+ print(f'{p:12}{flops:12.4g}{mem:>14.3f}{tf:14.4g}{tb:14.4g}{str(s_in):>24s}{str(s_out):>24s}')
+ results.append([p, flops, mem, tf, tb, s_in, s_out])
+ except Exception as e:
+ print(e)
+ results.append(None)
+ torch.cuda.empty_cache()
+ return results
+
+
+def is_parallel(model):
+ # Returns True if model is of type DP or DDP
+ return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
+
+
+def de_parallel(model):
+ # De-parallelize a model: returns single-GPU model if model is of type DP or DDP
+ return model.module if is_parallel(model) else model
+
+
+def initialize_weights(model):
+ for m in model.modules():
+ t = type(m)
+ if t is nn.Conv2d:
+ pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
+ elif t is nn.BatchNorm2d:
+ m.eps = 1e-3
+ m.momentum = 0.03
+ elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6, nn.SiLU]:
+ m.inplace = True
+
+
+def find_modules(model, mclass=nn.Conv2d):
+ # Finds layer indices matching module class 'mclass'
+ return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
+
+
+def sparsity(model):
+ # Return global model sparsity
+ a, b = 0, 0
+ for p in model.parameters():
+ a += p.numel()
+ b += (p == 0).sum()
+ return b / a
+
+
+def prune(model, amount=0.3):
+ # Prune model to requested global sparsity
+ import torch.nn.utils.prune as prune
+ print('Pruning model... ', end='')
+ for name, m in model.named_modules():
+ if isinstance(m, nn.Conv2d):
+ prune.l1_unstructured(m, name='weight', amount=amount) # prune
+ prune.remove(m, 'weight') # make permanent
+ print(' %.3g global sparsity' % sparsity(model))
+
+
+def fuse_conv_and_bn(conv, bn):
+ # Fuse convolution and batchnorm layers https://tehnokv.com/posts/fusing-batchnorm-and-conv/
+ fusedconv = nn.Conv2d(conv.in_channels,
+ conv.out_channels,
+ kernel_size=conv.kernel_size,
+ stride=conv.stride,
+ padding=conv.padding,
+ groups=conv.groups,
+ bias=True).requires_grad_(False).to(conv.weight.device)
+
+ # prepare filters
+ w_conv = conv.weight.clone().view(conv.out_channels, -1)
+ w_bn = torch.diag(bn.weight.div(torch.sqrt(bn.eps + bn.running_var)))
+ fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
+
+ # prepare spatial bias
+ b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
+ b_bn = bn.bias - bn.weight.mul(bn.running_mean).div(torch.sqrt(bn.running_var + bn.eps))
+ fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
+
+ return fusedconv
+
+
+def model_info(model, verbose=False, img_size=640):
+ # Model information. img_size may be int or list, i.e. img_size=640 or img_size=[640, 320]
+ n_p = sum(x.numel() for x in model.parameters()) # number parameters
+ n_g = sum(x.numel() for x in model.parameters() if x.requires_grad) # number gradients
+ if verbose:
+ print(f"{'layer':>5} {'name':>40} {'gradient':>9} {'parameters':>12} {'shape':>20} {'mu':>10} {'sigma':>10}")
+ for i, (name, p) in enumerate(model.named_parameters()):
+ name = name.replace('module_list.', '')
+ print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
+ (i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
+
+ try: # FLOPs
+ from thop import profile
+ stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32
+ img = torch.zeros((1, model.yaml.get('ch', 3), stride, stride), device=next(model.parameters()).device) # input
+ flops = profile(deepcopy(model), inputs=(img,), verbose=False)[0] / 1E9 * 2 # stride GFLOPs
+ img_size = img_size if isinstance(img_size, list) else [img_size, img_size] # expand if int/float
+ fs = ', %.1f GFLOPs' % (flops * img_size[0] / stride * img_size[1] / stride) # 640x640 GFLOPs
+ except (ImportError, Exception):
+ fs = ''
+
+ LOGGER.info(f"Model Summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
+
+
+def scale_img(img, ratio=1.0, same_shape=False, gs=32): # img(16,3,256,416)
+ # scales img(bs,3,y,x) by ratio constrained to gs-multiple
+ if ratio == 1.0:
+ return img
+ else:
+ h, w = img.shape[2:]
+ s = (int(h * ratio), int(w * ratio)) # new size
+ img = F.interpolate(img, size=s, mode='bilinear', align_corners=False) # resize
+ if not same_shape: # pad/crop img
+ h, w = (math.ceil(x * ratio / gs) * gs for x in (h, w))
+ return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447) # value = imagenet mean
+
+
+def copy_attr(a, b, include=(), exclude=()):
+ # Copy attributes from b to a, options to only include [...] and to exclude [...]
+ for k, v in b.__dict__.items():
+ if (len(include) and k not in include) or k.startswith('_') or k in exclude:
+ continue
+ else:
+ setattr(a, k, v)
+
+
+class EarlyStopping:
+ # YOLOv5 simple early stopper
+ def __init__(self, patience=30):
+ self.best_fitness = 0.0 # i.e. mAP
+ self.best_epoch = 0
+ self.patience = patience or float('inf') # epochs to wait after fitness stops improving to stop
+ self.possible_stop = False # possible stop may occur next epoch
+
+ def __call__(self, epoch, fitness):
+ if fitness >= self.best_fitness: # >= 0 to allow for early zero-fitness stage of training
+ self.best_epoch = epoch
+ self.best_fitness = fitness
+ delta = epoch - self.best_epoch # epochs without improvement
+ self.possible_stop = delta >= (self.patience - 1) # possible stop may occur next epoch
+ stop = delta >= self.patience # stop training if patience exceeded
+ if stop:
+ LOGGER.info(f'Stopping training early as no improvement observed in last {self.patience} epochs. '
+ f'Best results observed at epoch {self.best_epoch}, best model saved as best.pt.\n'
+ f'To update EarlyStopping(patience={self.patience}) pass a new patience value, '
+ f'i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.')
+ return stop
+
+
+class ModelEMA:
+ """ Model Exponential Moving Average from https://github.com/rwightman/pytorch-image-models
+ Keep a moving average of everything in the model state_dict (parameters and buffers).
+ This is intended to allow functionality like
+ https://www.tensorflow.org/api_docs/python/tf/train/ExponentialMovingAverage
+ A smoothed version of the weights is necessary for some training schemes to perform well.
+ This class is sensitive where it is initialized in the sequence of model init,
+ GPU assignment and distributed training wrappers.
+ """
+
+ def __init__(self, model, decay=0.9999, updates=0):
+ # Create EMA
+ self.ema = deepcopy(model.module if is_parallel(model) else model).eval() # FP32 EMA
+ # if next(model.parameters()).device.type != 'cpu':
+ # self.ema.half() # FP16 EMA
+ self.updates = updates # number of EMA updates
+ self.decay = lambda x: decay * (1 - math.exp(-x / 2000)) # decay exponential ramp (to help early epochs)
+ for p in self.ema.parameters():
+ p.requires_grad_(False)
+
+ def update(self, model):
+ # Update EMA parameters
+ with torch.no_grad():
+ self.updates += 1
+ d = self.decay(self.updates)
+
+ msd = model.module.state_dict() if is_parallel(model) else model.state_dict() # model state_dict
+ for k, v in self.ema.state_dict().items():
+ if v.dtype.is_floating_point:
+ v *= d
+ v += (1 - d) * msd[k].detach()
+
+ def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
+ # Update EMA attributes
+ copy_attr(self.ema, model, include, exclude)
diff --git a/src/image_recognition/utils/ui/__init__.py b/src/image_recognition/utils/ui/__init__.py
new file mode 100644
index 0000000..2691d65
--- /dev/null
+++ b/src/image_recognition/utils/ui/__init__.py
@@ -0,0 +1,9 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+'''
+@Project :yolov5-60
+@File :__init__.py.py
+@Author :ChenmingSong
+@Date :2021/12/12 16:55
+@Description:
+'''
diff --git a/src/image_recognition/utils/ui/ji.py b/src/image_recognition/utils/ui/ji.py
new file mode 100644
index 0000000..bb24b83
--- /dev/null
+++ b/src/image_recognition/utils/ui/ji.py
@@ -0,0 +1,173 @@
+# -*- coding: utf-8 -*-
+"""
+-------------------------------------------------
+Project Name: yolov5-60
+File Name: ji.py
+Author: chenming
+Create Date: 2021/11/18
+Description:
+-------------------------------------------------
+"""
+import argparse
+import os
+os.chdir("/home/chenming/scm/xianyu/det/yolov5-60/yolov5-60")
+import sys
+from pathlib import Path
+import cv2
+import torch
+import torch.backends.cudnn as cudnn
+import json
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+from models.common import DetectMultiBackend
+from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
+from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
+ increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import select_device, time_sync
+from utils.augmentations import letterbox
+import numpy as np
+
+
+@torch.no_grad()
+def init():
+ weights = "runs/train/exp2/weights/best.pt" # model.pt path(s)
+ device = '' # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half = False # use FP16 half-precision inference
+ dnn = False # use OpenCV DNN for ONNX inference
+ device = select_device(device)
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ # Load model
+ # Load model
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn)
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ # Half
+ half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
+ if pt:
+ model.model.half() if half else model.model.float()
+ print("模型加载完成!")
+ return model
+
+
+@torch.no_grad()
+def process_image(handle=None, input_image=None, args=None, **kwargs):
+ '''Do inference to analysis input_image and get output
+ Attributes:
+ handle: algorithm handle returned by init()
+ input_image (numpy.ndarray): image to be process, format: (h, w, c), BGR
+ Returns: process result
+ '''
+
+ # Process image here
+ fake_result = {
+ 'objects': []
+ }
+
+ # Padded resize
+ net = handle
+ device = ''
+ device = select_device(device)
+ half = False
+ augment = True
+ visualize = False
+ img_size = (640, 640)
+ img0 = input_image
+ stride = net.stride
+ names = net.names
+ img = letterbox(img0, img_size, stride=stride)[0]
+ # Convert
+ img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
+ img = np.ascontiguousarray(img)
+
+ # pred
+ im = torch.from_numpy(img).to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ # Inference
+
+ pred = net(im, augment=augment, visualize=visualize)
+ conf_thres = 0.25
+ iou_thres = 0.45
+ classes = None
+ max_det = 1000
+ agnostic_nms = False
+ save_crop = False
+
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+
+ for i, det in enumerate(pred): # per image
+ # seen += 1
+ # if webcam: # batch_size >= 1
+ # p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ # s += f'{i}: '
+ # else:
+ # p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+ im0 = img0.copy()
+
+ # p = Path(p) # to Path
+ # save_path = str(save_dir / p.name) # im.jpg
+ # txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ # s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=3, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, -1].unique():
+ n = (det[:, -1] == c).sum() # detections per class
+ # s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ # if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ c = int(cls) # integer class
+ label = f'{names[c]} {conf:.2f}'
+ annotator.box_label(xyxy, label, color=colors(c, True))
+
+ xyxy = [x.cpu().numpy().item() for x in xyxy]
+ conf = conf.cpu().numpy()
+ name = names[c]
+ # print(cls)
+ # print(conf)
+ # print(xyxy)
+ # print(xywh)
+ fake_result['objects'].append({
+ 'xmin': int(xyxy[0]),
+ 'ymin': int(xyxy[1]),
+ 'xmax': int(xyxy[2]),
+ 'ymax': int(xyxy[3]),
+ 'name': str(name),
+ 'confidence': float(conf)
+ })
+ # line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ # with open(txt_path + '.txt', 'a') as f:
+ # f.write(('%g ' * len(line)).rstrip() % line + '\n')
+ # if save_img or save_crop or view_img: # Add bbox to image
+ #
+ #
+ # im0 = annotator.result()
+ # # print(im0)
+ # # if view_img:
+ # cv2.imshow("test", im0)
+ # cv2.waitKey(0) # 1 millisecond
+ # cv2.destroyAllWindows()
+ return json.dumps(fake_result, indent=4)
+
+# 现在的任务就是走通训练的流程,包括使用cpu进行训练和将日志文件以及模型输出到对应的位置中去
+if __name__ == '__main__':
+ """Test python api
+ """
+ img = cv2.imread('data/images/phone/phone_419.jpg')
+ predictor = init()
+ result = process_image(predictor, img)
+ print(result)
diff --git a/src/image_recognition/utils/ui/server_main.py b/src/image_recognition/utils/ui/server_main.py
new file mode 100644
index 0000000..f5e9663
--- /dev/null
+++ b/src/image_recognition/utils/ui/server_main.py
@@ -0,0 +1,17 @@
+# -*- coding: utf-8 -*-
+"""
+-------------------------------------------------
+Project Name: yolov5-v1.0
+File Name: main.py
+Author: chenming
+Create Date: 2021/11/9
+Description:
+-------------------------------------------------
+"""
+# 首先检查文件,把存在的目录删除
+import os
+os.chdir("/project/train/src_repo/")
+# 启动数据处理
+os.system("python server_data_gen.py")
+os.system("python train_server.py >> /project/train/log/log.txt")
+# 启动训练
diff --git a/src/image_recognition/utils/ui/train_server.py b/src/image_recognition/utils/ui/train_server.py
new file mode 100644
index 0000000..700b350
--- /dev/null
+++ b/src/image_recognition/utils/ui/train_server.py
@@ -0,0 +1,630 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Train a YOLOv5 model on a custom dataset
+
+Usage:
+ $ python path/to/train.py --data coco128.yaml --weights yolov5s.pt --img 640
+"""
+import argparse
+import math
+import os
+import random
+import sys
+import time
+from copy import deepcopy
+from datetime import datetime
+from pathlib import Path
+
+import numpy as np
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+import yaml
+from torch.cuda import amp
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.optim import SGD, Adam, lr_scheduler
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+import val # for end-of-epoch mAP
+from models.experimental import attempt_load
+from models.yolo import Model
+from utils.autoanchor import check_anchors
+from utils.autobatch import check_train_batch_size
+from utils.callbacks import Callbacks
+from utils.datasets import create_dataloader
+from utils.downloads import attempt_download
+from utils.general import (LOGGER, NCOLS, check_dataset, check_file, check_git_status, check_img_size,
+ check_requirements, check_suffix, check_yaml, colorstr, get_latest_run, increment_path,
+ init_seeds, intersect_dicts, labels_to_class_weights, labels_to_image_weights, methods,
+ one_cycle, print_args, print_mutation, strip_optimizer)
+from utils.loggers import Loggers
+from utils.loggers.wandb.wandb_utils import check_wandb_resume
+from utils.loss import ComputeLoss
+from utils.metrics import fitness
+from utils.plots import plot_evolve, plot_labels
+from utils.torch_utils import EarlyStopping, ModelEMA, de_parallel, select_device, torch_distributed_zero_first
+
+LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
+RANK = int(os.getenv('RANK', -1))
+WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
+
+
+def train(hyp, # path/to/hyp.yaml or hyp dictionary
+ opt,
+ device,
+ callbacks
+ ):
+ save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
+ Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
+ opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
+
+ # Directories
+ # w = save_dir / 'weights' # weights dir?
+ # todo weight dir
+ save_dir = Path("/project/train/log")
+ # w = os.path.join("/runs/models/", "exp1")
+ w = Path("/project/train/models") / 'exp1'
+ (w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
+ last, best = w / 'last.pt', w / 'best.pt'
+
+ # Hyperparameters
+ if isinstance(hyp, str):
+ with open(hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
+
+ # Save run settings
+ with open(save_dir / 'hyp.yaml', 'w') as f:
+ yaml.safe_dump(hyp, f, sort_keys=False)
+ with open(save_dir / 'opt.yaml', 'w') as f:
+ yaml.safe_dump(vars(opt), f, sort_keys=False)
+ data_dict = None
+
+ # Loggers
+ if RANK in [-1, 0]:
+ loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
+ if loggers.wandb:
+ data_dict = loggers.wandb.data_dict
+ if resume:
+ weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
+
+ # Register actions
+ for k in methods(loggers):
+ callbacks.register_action(k, callback=getattr(loggers, k))
+
+ # Config
+ plots = not evolve # create plots
+ cuda = device.type != 'cpu'
+ init_seeds(1 + RANK)
+ with torch_distributed_zero_first(LOCAL_RANK):
+ data_dict = data_dict or check_dataset(data) # check if None
+ train_path, val_path = data_dict['train'], data_dict['val']
+ nc = 1 if single_cls else int(data_dict['nc']) # number of classes
+ names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
+ assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
+ is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
+
+ # Model
+ check_suffix(weights, '.pt') # check weights
+ pretrained = weights.endswith('.pt')
+ if pretrained:
+ with torch_distributed_zero_first(LOCAL_RANK):
+ weights = attempt_download(weights) # download if not found locally
+ ckpt = torch.load(weights, map_location=device) # load checkpoint
+ model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+ exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
+ csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
+ csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
+ model.load_state_dict(csd, strict=False) # load
+ LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
+ else:
+ model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
+
+ # Freeze
+ freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
+ for k, v in model.named_parameters():
+ v.requires_grad = True # train all layers
+ if any(x in k for x in freeze):
+ LOGGER.info(f'freezing {k}')
+ v.requires_grad = False
+
+ # Image size
+ gs = max(int(model.stride.max()), 32) # grid size (max stride)
+ imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
+
+ # Batch size
+ if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
+ batch_size = check_train_batch_size(model, imgsz)
+
+ # Optimizer
+ nbs = 64 # nominal batch size
+ accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
+ hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
+ LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
+
+ g0, g1, g2 = [], [], [] # optimizer parameter groups
+ for v in model.modules():
+ if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
+ g2.append(v.bias)
+ if isinstance(v, nn.BatchNorm2d): # weight (no decay)
+ g0.append(v.weight)
+ elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
+ g1.append(v.weight)
+
+ if opt.adam:
+ optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
+ else:
+ optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
+
+ optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
+ optimizer.add_param_group({'params': g2}) # add g2 (biases)
+ LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
+ f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
+ del g0, g1, g2
+
+ # Scheduler
+ if opt.linear_lr:
+ lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
+ else:
+ lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
+ scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
+
+ # EMA
+ ema = ModelEMA(model) if RANK in [-1, 0] else None
+
+ # Resume
+ start_epoch, best_fitness = 0, 0.0
+ if pretrained:
+ # Optimizer
+ if ckpt['optimizer'] is not None:
+ optimizer.load_state_dict(ckpt['optimizer'])
+ best_fitness = ckpt['best_fitness']
+
+ # EMA
+ if ema and ckpt.get('ema'):
+ ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
+ ema.updates = ckpt['updates']
+
+ # Epochs
+ start_epoch = ckpt['epoch'] + 1
+ if resume:
+ assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
+ if epochs < start_epoch:
+ LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
+ epochs += ckpt['epoch'] # finetune additional epochs
+
+ del ckpt, csd
+
+ # DP mode
+ if cuda and RANK == -1 and torch.cuda.device_count() > 1:
+ LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
+ 'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
+ model = torch.nn.DataParallel(model)
+
+ # SyncBatchNorm
+ if opt.sync_bn and cuda and RANK != -1:
+ model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
+ LOGGER.info('Using SyncBatchNorm()')
+
+ # Trainloader
+ train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
+ hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
+ workers=workers, image_weights=opt.image_weights, quad=opt.quad,
+ prefix=colorstr('train: '), shuffle=True)
+ mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
+ nb = len(train_loader) # number of batches
+ assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
+
+ # Process 0
+ if RANK in [-1, 0]:
+ val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
+ hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
+ workers=workers, pad=0.5,
+ prefix=colorstr('val: '))[0]
+
+ if not resume:
+ labels = np.concatenate(dataset.labels, 0)
+ # c = torch.tensor(labels[:, 0]) # classes
+ # cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
+ # model._initialize_biases(cf.to(device))
+ if plots:
+ plot_labels(labels, names, save_dir)
+
+ # Anchors
+ if not opt.noautoanchor:
+ check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
+ model.half().float() # pre-reduce anchor precision
+
+ callbacks.run('on_pretrain_routine_end')
+
+ # DDP mode
+ if cuda and RANK != -1:
+ model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
+
+ # Model attributes
+ nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
+ hyp['box'] *= 3 / nl # scale to layers
+ hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
+ hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
+ hyp['label_smoothing'] = opt.label_smoothing
+ model.nc = nc # attach number of classes to model
+ model.hyp = hyp # attach hyperparameters to model
+ model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
+ model.names = names
+
+ # Start training
+ t0 = time.time()
+ nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
+ # nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
+ last_opt_step = -1
+ maps = np.zeros(nc) # mAP per class
+ results = (0, 0, 0, 0, 0, 0, 0) # P, R, mAP@.5, mAP@.5-.95, val_loss(box, obj, cls)
+ scheduler.last_epoch = start_epoch - 1 # do not move
+ scaler = amp.GradScaler(enabled=cuda)
+ stopper = EarlyStopping(patience=opt.patience)
+ compute_loss = ComputeLoss(model) # init loss class
+ LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
+ f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
+ f"Logging results to {colorstr('bold', save_dir)}\n"
+ f'Starting training for {epochs} epochs...')
+ for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
+ model.train()
+
+ # Update image weights (optional, single-GPU only)
+ if opt.image_weights:
+ cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
+ iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
+ dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
+
+ # Update mosaic border (optional)
+ # b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
+ # dataset.mosaic_border = [b - imgsz, -b] # height, width borders
+
+ mloss = torch.zeros(3, device=device) # mean losses
+ if RANK != -1:
+ train_loader.sampler.set_epoch(epoch)
+ pbar = enumerate(train_loader)
+ LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
+ if RANK in [-1, 0]:
+ pbar = tqdm(pbar, total=nb, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ optimizer.zero_grad()
+ for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
+ ni = i + nb * epoch # number integrated batches (since train start)
+ imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
+
+ # Warmup
+ if ni <= nw:
+ xi = [0, nw] # x interp
+ # compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
+ accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
+ for j, x in enumerate(optimizer.param_groups):
+ # bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
+ x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
+ if 'momentum' in x:
+ x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
+
+ # Multi-scale
+ if opt.multi_scale:
+ sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
+ sf = sz / max(imgs.shape[2:]) # scale factor
+ if sf != 1:
+ ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
+ imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
+
+ # Forward
+ with amp.autocast(enabled=cuda):
+ pred = model(imgs) # forward
+ loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
+ if RANK != -1:
+ loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
+ if opt.quad:
+ loss *= 4.
+
+ # Backward
+ scaler.scale(loss).backward()
+
+ # Optimize
+ if ni - last_opt_step >= accumulate:
+ scaler.step(optimizer) # optimizer.step
+ scaler.update()
+ optimizer.zero_grad()
+ if ema:
+ ema.update(model)
+ last_opt_step = ni
+
+ # Log
+ if RANK in [-1, 0]:
+ mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
+ mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
+ pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
+ f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
+ callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
+ # end batch ------------------------------------------------------------------------------------------------
+
+ # Scheduler
+ lr = [x['lr'] for x in optimizer.param_groups] # for loggers
+ scheduler.step()
+
+ if RANK in [-1, 0]:
+ # mAP
+ callbacks.run('on_train_epoch_end', epoch=epoch)
+ ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
+ final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
+ if not noval or final_epoch: # Calculate mAP
+ results, maps, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=ema.ema,
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ plots=False,
+ callbacks=callbacks,
+ compute_loss=compute_loss)
+
+ # Update best mAP
+ fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, mAP@.5, mAP@.5-.95]
+ if fi > best_fitness:
+ best_fitness = fi
+ log_vals = list(mloss) + list(results) + lr
+ callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
+
+ # Save model
+ if (not nosave) or (final_epoch and not evolve): # if save
+ ckpt = {'epoch': epoch,
+ 'best_fitness': best_fitness,
+ 'model': deepcopy(de_parallel(model)).half(),
+ 'ema': deepcopy(ema.ema).half(),
+ 'updates': ema.updates,
+ 'optimizer': optimizer.state_dict(),
+ 'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
+ 'date': datetime.now().isoformat()}
+
+ # Save last, best and delete
+ torch.save(ckpt, last)
+ if best_fitness == fi:
+ torch.save(ckpt, best)
+ if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
+ torch.save(ckpt, w / f'epoch{epoch}.pt')
+ del ckpt
+ callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
+
+ # Stop Single-GPU
+ if RANK == -1 and stopper(epoch=epoch, fitness=fi):
+ break
+
+ # Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
+ # stop = stopper(epoch=epoch, fitness=fi)
+ # if RANK == 0:
+ # dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
+
+ # Stop DPP
+ # with torch_distributed_zero_first(RANK):
+ # if stop:
+ # break # must break all DDP ranks
+
+ # end epoch ----------------------------------------------------------------------------------------------------
+ # end training -----------------------------------------------------------------------------------------------------
+ if RANK in [-1, 0]:
+ LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
+ for f in last, best:
+ if f.exists():
+ strip_optimizer(f) # strip optimizers
+ if f is best:
+ LOGGER.info(f'\nValidating {f}...')
+ results, _, _ = val.run(data_dict,
+ batch_size=batch_size // WORLD_SIZE * 2,
+ imgsz=imgsz,
+ model=attempt_load(f, device).half(),
+ iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
+ single_cls=single_cls,
+ dataloader=val_loader,
+ save_dir=save_dir,
+ save_json=is_coco,
+ verbose=True,
+ plots=True,
+ callbacks=callbacks,
+ compute_loss=compute_loss) # val best model with plots
+ if is_coco:
+ callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
+
+ callbacks.run('on_train_end', last, best, plots, epoch, results)
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
+
+ torch.cuda.empty_cache()
+ return results
+
+
+# 明天把这些模型都试试效果先,一波波给他训练完毕,找个公开的数据集测试一下。
+def parse_opt(known=False):
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--weights', type=str, default=ROOT / 'pretrained/yolov5s.pt', help='initial weights path')
+ parser.add_argument('--cfg', type=str, default=ROOT / 'models/yolov5s.yaml', help='model.yaml path')
+ parser.add_argument('--data', type=str, default=ROOT / 'data/data.yaml', help='dataset.yaml path')
+ parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
+ parser.add_argument('--epochs', type=int, default=150)
+ parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs, -1 for autobatch')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
+ parser.add_argument('--rect', action='store_true', help='rectangular training')
+ parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
+ parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
+ parser.add_argument('--noval', action='store_true', help='only validate final epoch')
+ parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
+ parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
+ parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
+ parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
+ parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ # parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
+ parser.add_argument('--multi-scale', default=True, help='vary img-size +/- 50%%')
+ parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
+ parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
+ parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--quad', action='store_true', help='quad dataloader')
+ parser.add_argument('--linear-lr', action='store_true', help='linear LR')
+ parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
+ parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
+ parser.add_argument('--freeze', type=int, default=0, help='Number of layers to freeze. backbone=10, all=24')
+ parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
+ parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
+ # Weights & Biases arguments
+ parser.add_argument('--entity', default=None, help='W&B: Entity')
+ parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
+ parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
+ parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
+
+ opt = parser.parse_known_args()[0] if known else parser.parse_args()
+ return opt
+
+
+def main(opt, callbacks=Callbacks()):
+ # Checks
+ if RANK in [-1, 0]:
+ print_args(FILE.stem, opt)
+ check_git_status()
+ check_requirements(exclude=['thop'])
+
+ # Resume
+ if opt.resume and not check_wandb_resume(opt) and not opt.evolve: # resume an interrupted run
+ ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
+ assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
+ with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
+ opt = argparse.Namespace(**yaml.safe_load(f)) # replace
+ opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
+ LOGGER.info(f'Resuming training from {ckpt}')
+ else:
+ opt.data, opt.cfg, opt.hyp, opt.weights, opt.project = \
+ check_file(opt.data), check_yaml(opt.cfg), check_yaml(opt.hyp), str(opt.weights), str(opt.project) # checks
+ assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
+ if opt.evolve:
+ opt.project = str(ROOT / 'runs/evolve')
+ opt.exist_ok, opt.resume = opt.resume, False # pass resume to exist_ok and disable resume
+ opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok))
+
+ # DDP mode
+ device = select_device(opt.device, batch_size=opt.batch_size)
+ if LOCAL_RANK != -1:
+ assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
+ assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
+ assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
+ assert not opt.evolve, '--evolve argument is not compatible with DDP training'
+ torch.cuda.set_device(LOCAL_RANK)
+ device = torch.device('cuda', LOCAL_RANK)
+ dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo")
+
+ # Train
+ if not opt.evolve:
+ train(opt.hyp, opt, device, callbacks)
+ if WORLD_SIZE > 1 and RANK == 0:
+ LOGGER.info('Destroying process group... ')
+ dist.destroy_process_group()
+
+ # Evolve hyperparameters (optional)
+ else:
+ # Hyperparameter evolution metadata (mutation scale 0-1, lower_limit, upper_limit)
+ meta = {'lr0': (1, 1e-5, 1e-1), # initial learning rate (SGD=1E-2, Adam=1E-3)
+ 'lrf': (1, 0.01, 1.0), # final OneCycleLR learning rate (lr0 * lrf)
+ 'momentum': (0.3, 0.6, 0.98), # SGD momentum/Adam beta1
+ 'weight_decay': (1, 0.0, 0.001), # optimizer weight decay
+ 'warmup_epochs': (1, 0.0, 5.0), # warmup epochs (fractions ok)
+ 'warmup_momentum': (1, 0.0, 0.95), # warmup initial momentum
+ 'warmup_bias_lr': (1, 0.0, 0.2), # warmup initial bias lr
+ 'box': (1, 0.02, 0.2), # box loss gain
+ 'cls': (1, 0.2, 4.0), # cls loss gain
+ 'cls_pw': (1, 0.5, 2.0), # cls BCELoss positive_weight
+ 'obj': (1, 0.2, 4.0), # obj loss gain (scale with pixels)
+ 'obj_pw': (1, 0.5, 2.0), # obj BCELoss positive_weight
+ 'iou_t': (0, 0.1, 0.7), # IoU training threshold
+ 'anchor_t': (1, 2.0, 8.0), # anchor-multiple threshold
+ 'anchors': (2, 2.0, 10.0), # anchors per output grid (0 to ignore)
+ 'fl_gamma': (0, 0.0, 2.0), # focal loss gamma (efficientDet default gamma=1.5)
+ 'hsv_h': (1, 0.0, 0.1), # image HSV-Hue augmentation (fraction)
+ 'hsv_s': (1, 0.0, 0.9), # image HSV-Saturation augmentation (fraction)
+ 'hsv_v': (1, 0.0, 0.9), # image HSV-Value augmentation (fraction)
+ 'degrees': (1, 0.0, 45.0), # image rotation (+/- deg)
+ 'translate': (1, 0.0, 0.9), # image translation (+/- fraction)
+ 'scale': (1, 0.0, 0.9), # image scale (+/- gain)
+ 'shear': (1, 0.0, 10.0), # image shear (+/- deg)
+ 'perspective': (0, 0.0, 0.001), # image perspective (+/- fraction), range 0-0.001
+ 'flipud': (1, 0.0, 1.0), # image flip up-down (probability)
+ 'fliplr': (0, 0.0, 1.0), # image flip left-right (probability)
+ 'mosaic': (1, 0.0, 1.0), # image mixup (probability)
+ 'mixup': (1, 0.0, 1.0), # image mixup (probability)
+ 'copy_paste': (1, 0.0, 1.0)} # segment copy-paste (probability)
+
+ with open(opt.hyp, errors='ignore') as f:
+ hyp = yaml.safe_load(f) # load hyps dict
+ if 'anchors' not in hyp: # anchors commented in hyp.yaml
+ hyp['anchors'] = 3
+ opt.noval, opt.nosave, save_dir = True, True, Path(opt.save_dir) # only val/save final epoch
+ # ei = [isinstance(x, (int, float)) for x in hyp.values()] # evolvable indices
+ evolve_yaml, evolve_csv = save_dir / 'hyp_evolve.yaml', save_dir / 'evolve.csv'
+ if opt.bucket:
+ os.system(f'gsutil cp gs://{opt.bucket}/evolve.csv {save_dir}') # download evolve.csv if exists
+
+ for _ in range(opt.evolve): # generations to evolve
+ if evolve_csv.exists(): # if evolve.csv exists: select best hyps and mutate
+ # Select parent(s)
+ parent = 'single' # parent selection method: 'single' or 'weighted'
+ x = np.loadtxt(evolve_csv, ndmin=2, delimiter=',', skiprows=1)
+ n = min(5, len(x)) # number of previous results to consider
+ x = x[np.argsort(-fitness(x))][:n] # top n mutations
+ w = fitness(x) - fitness(x).min() + 1E-6 # weights (sum > 0)
+ if parent == 'single' or len(x) == 1:
+ # x = x[random.randint(0, n - 1)] # random selection
+ x = x[random.choices(range(n), weights=w)[0]] # weighted selection
+ elif parent == 'weighted':
+ x = (x * w.reshape(n, 1)).sum(0) / w.sum() # weighted combination
+
+ # Mutate
+ mp, s = 0.8, 0.2 # mutation probability, sigma
+ npr = np.random
+ npr.seed(int(time.time()))
+ g = np.array([meta[k][0] for k in hyp.keys()]) # gains 0-1
+ ng = len(meta)
+ v = np.ones(ng)
+ while all(v == 1): # mutate until a change occurs (prevent duplicates)
+ v = (g * (npr.random(ng) < mp) * npr.randn(ng) * npr.random() * s + 1).clip(0.3, 3.0)
+ for i, k in enumerate(hyp.keys()): # plt.hist(v.ravel(), 300)
+ hyp[k] = float(x[i + 7] * v[i]) # mutate
+
+ # Constrain to limits
+ for k, v in meta.items():
+ hyp[k] = max(hyp[k], v[1]) # lower limit
+ hyp[k] = min(hyp[k], v[2]) # upper limit
+ hyp[k] = round(hyp[k], 5) # significant digits
+
+ # Train mutation
+ results = train(hyp.copy(), opt, device, callbacks)
+
+ # Write mutation results
+ print_mutation(results, hyp.copy(), save_dir, opt.bucket)
+
+ # Plot results
+ plot_evolve(evolve_csv)
+ LOGGER.info(f'Hyperparameter evolution finished\n'
+ f"Results saved to {colorstr('bold', save_dir)}\n"
+ f'Use best hyperparameters example: $ python train.py --hyp {evolve_yaml}')
+
+
+def run(**kwargs):
+ # Usage: import train; train.run(data='coco128.yaml', imgsz=320, weights='yolov5m.pt')
+ opt = parse_opt(True)
+ for k, v in kwargs.items():
+ setattr(opt, k, v)
+ main(opt)
+
+
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/utils/ui/x.py b/src/image_recognition/utils/ui/x.py
new file mode 100644
index 0000000..bb259f1
--- /dev/null
+++ b/src/image_recognition/utils/ui/x.py
@@ -0,0 +1,100 @@
+#!/usr/bin/env python
+# -*- coding: UTF-8 -*-
+'''
+@Project :yolov5-60
+@File :x.py
+@Author :ChenmingSong
+@Date :2021/12/12 16:04
+@Description:
+'''
+import cv2
+import sys
+# import DisplayUI
+from PyQt5.QtWidgets import QApplication, QMainWindow
+import threading
+from PyQt5.QtCore import QFile
+from PyQt5.QtWidgets import QFileDialog, QMessageBox
+from PyQt5.QtGui import QImage, QPixmap
+
+
+class Display:
+ def __init__(self, ui, mainWnd):
+ self.ui = ui
+ self.mainWnd = mainWnd
+
+ # 默认视频源为相机
+ self.ui.radioButtonCam.setChecked(True)
+ self.isCamera = True
+
+ # 信号槽设置
+ ui.Open.clicked.connect(self.Open)
+ ui.Close.clicked.connect(self.Close)
+ ui.radioButtonCam.clicked.connect(self.radioButtonCam)
+ ui.radioButtonFile.clicked.connect(self.radioButtonFile)
+
+ # 创建一个关闭事件并设为未触发
+ self.stopEvent = threading.Event()
+ self.stopEvent.clear()
+
+ def radioButtonCam(self):
+ self.isCamera = True
+
+ def radioButtonFile(self):
+ self.isCamera = False
+
+ def Open(self):
+ if not self.isCamera:
+ self.fileName, self.fileType = QFileDialog.getOpenFileName(self.mainWnd, 'Choose file', '', '*.mp4')
+ self.cap = cv2.VideoCapture(self.fileName)
+ self.frameRate = self.cap.get(cv2.CAP_PROP_FPS)
+ else:
+ # 下面两种rtsp格式都是支持的
+ # cap = cv2.VideoCapture("rtsp://admin:Supcon1304@172.20.1.126/main/Channels/1")
+ self.cap = cv2.VideoCapture("rtsp://admin:Supcon1304@172.20.1.126:554/h264/ch1/main/av_stream")
+
+ # 创建视频显示线程
+ th = threading.Thread(target=self.Display)
+ th.start()
+
+ def Close(self):
+ # 关闭事件设为触发,关闭视频播放
+ self.stopEvent.set()
+
+ def Display(self):
+ self.ui.Open.setEnabled(False)
+ self.ui.Close.setEnabled(True)
+
+ while self.cap.isOpened():
+ success, frame = self.cap.read()
+ # RGB转BGR
+ frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
+ img = QImage(frame.data, frame.shape[1], frame.shape[0], QImage.Format_RGB888)
+ self.ui.DispalyLabel.setPixmap(QPixmap.fromImage(img))
+
+ if self.isCamera:
+ cv2.waitKey(1)
+ else:
+ cv2.waitKey(int(1000 / self.frameRate))
+
+ # 判断关闭事件是否已触发
+ if True == self.stopEvent.is_set():
+ # 关闭事件置为未触发,清空显示label
+ self.stopEvent.clear()
+ self.ui.DispalyLabel.clear()
+ self.ui.Close.setEnabled(False)
+ self.ui.Open.setEnabled(True)
+ break
+
+if __name__ == '__main__':
+ app = QApplication(sys.argv)
+ mainWnd = QMainWindow()
+ ui = DisplayUI.Ui_MainWindow()
+
+ # 可以理解成将创建的 ui 绑定到新建的 mainWnd 上
+ ui.setupUi(mainWnd)
+
+ display = Display(ui, mainWnd)
+
+ mainWnd.show()
+
+ sys.exit(app.exec_())
diff --git a/src/image_recognition/val.py b/src/image_recognition/val.py
new file mode 100644
index 0000000..251e9a1
--- /dev/null
+++ b/src/image_recognition/val.py
@@ -0,0 +1,367 @@
+# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
+"""
+Validate a trained YOLOv5 model accuracy on a custom dataset
+
+Usage:
+ $ python path/to/val.py --data coco128.yaml --weights yolov5s.pt --img 640
+"""
+
+import argparse
+import json
+import os
+import sys
+from pathlib import Path
+from threading import Thread
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.datasets import create_dataloader
+from utils.general import (LOGGER, NCOLS, box_iou, check_dataset, check_img_size, check_requirements, check_yaml,
+ coco80_to_coco91_class, colorstr, increment_path, non_max_suppression, print_args,
+ scale_coords, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, time_sync
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct predictions matrix. Both sets of boxes are in (x1, y1, x2, y2) format.
+ Arguments:
+ detections (Array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (Array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (Array[N, 10]), for 10 IoU levels
+ """
+ correct = torch.zeros(detections.shape[0], iouv.shape[0], dtype=torch.bool, device=iouv.device)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ x = torch.where((iou >= iouv[0]) & (labels[:, 0:1] == detections[:, 5])) # IoU above threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detection, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ matches = torch.Tensor(matches).to(iouv.device)
+ correct[matches[:, 1].long()] = matches[:, 2:3] >= iouv
+ return correct
+
+
+@torch.no_grad()
+def run(data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+ ):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt = next(model.parameters()).device, True # get model device, PyTorch model
+
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn)
+ stride, pt = model.stride, model.pt
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
+ if pt:
+ model.model.half() if half else model.model.float()
+ else:
+ half = False
+ batch_size = 1 # export.py models default to batch-size 1
+ device = torch.device('cpu')
+ LOGGER.info(f'Forcing --batch-size 1 square inference shape(1,3,{imgsz},{imgsz}) for non-PyTorch backends')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith('coco/val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10).to(device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and device.type != 'cpu':
+ model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
+ pad = 0.0 if task == 'speed' else 0.5
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task], imgsz, batch_size, stride, single_cls, pad=pad, rect=pt,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = {k: v for k, v in enumerate(model.names if hasattr(model, 'names') else model.module.names)}
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%20s' + '%11s' * 6) % ('Class', 'Images', 'Labels', 'P', 'R', 'mAP@.5', 'mAP@.5:.95')
+ dt, p, r, f1, mp, mr, map50, map = [0.0, 0.0, 0.0], 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ pbar = tqdm(dataloader, desc=s, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ t1 = time_sync()
+ if pt:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+ t2 = time_sync()
+ dt[0] += t2 - t1
+
+ # Inference
+ out, train_out = model(im) if training else model(im, augment=augment, val=True) # inference, loss outputs
+ dt[1] += time_sync() - t2
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss([x.float() for x in train_out], targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.Tensor([width, height, width, height]).to(device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ t3 = time_sync()
+ out = non_max_suppression(out, conf_thres, iou_thres, labels=lb, multi_label=True, agnostic=single_cls)
+ dt[2] += time_sync() - t3
+
+ # Metrics
+ for si, pred in enumerate(out):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl = len(labels)
+ tcls = labels[:, 0].tolist() if nl else [] # target class
+ path, shape = Path(paths[si]), shapes[si][0]
+ seen += 1
+
+ if len(pred) == 0:
+ if nl:
+ stats.append((torch.zeros(0, niou, dtype=torch.bool), torch.Tensor(), torch.Tensor(), tcls))
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_coords(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_coords(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ else:
+ correct = torch.zeros(pred.shape[0], niou, dtype=torch.bool)
+ stats.append((correct.cpu(), pred[:, 4].cpu(), pred[:, 5].cpu(), tcls)) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / (path.stem + '.txt'))
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ f = save_dir / f'val_batch{batch_i}_labels.jpg' # labels
+ Thread(target=plot_images, args=(im, targets, paths, f, names), daemon=True).start()
+ f = save_dir / f'val_batch{batch_i}_pred.jpg' # predictions
+ Thread(target=plot_images, args=(im, output_to_target(out), paths, f, names), daemon=True).start()
+
+ # Compute metrics
+ stats = [np.concatenate(x, 0) for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ p, r, ap, f1, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(np.int64), minlength=nc) # number of targets per class
+ else:
+ nt = torch.zeros(1)
+
+ # Print results
+ pf = '%20s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end')
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path(data.get('path', '../coco')) / 'annotations/instances_val2017.json') # annotations json
+ pred_json = str(save_dir / f"{w}_predictions.json") # predictions json
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements(['pycocotools'])
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.img_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(FILE.stem, opt)
+ return opt
+
+
+def main(opt):
+ check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING: confidence threshold {opt.conf_thres} >> 0.001 will produce invalid mAP values.')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = True # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ os.system('zip -r study.zip study_*.txt')
+ plot_val_study(x=x) # plot
+
+# python val.py --data data/mask_data.yaml --weights runs/train/exp_yolov5s/weights/best.pt --img 640
+if __name__ == "__main__":
+ opt = parse_opt()
+ main(opt)
diff --git a/src/image_recognition/window.py b/src/image_recognition/window.py
new file mode 100644
index 0000000..64d4b68
--- /dev/null
+++ b/src/image_recognition/window.py
@@ -0,0 +1,561 @@
+# -*- coding: utf-8 -*-
+"""
+-------------------------------------------------
+Project Name: yolov5-jungong
+File Name: window.py.py
+Author: chenming
+Create Date: 2021/11/8
+Description:图形化界面,可以检测摄像头、视频和图片文件
+-------------------------------------------------
+"""
+# 应该在界面启动的时候就将模型加载出来,设置tmp的目录来放中间的处理结果
+import shutil
+import PyQt5.QtCore
+from PyQt5.QtGui import *
+from PyQt5.QtCore import *
+from PyQt5.QtWidgets import *
+import threading
+import argparse
+import os
+import sys
+from pathlib import Path
+import cv2
+import torch
+import torch.backends.cudnn as cudnn
+import os.path as osp
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.datasets import IMG_FORMATS, VID_FORMATS, LoadImages, LoadStreams
+from utils.general import (LOGGER, check_file, check_img_size, check_imshow, check_requirements, colorstr,
+ increment_path, non_max_suppression, print_args, scale_coords, strip_optimizer, xyxy2xywh)
+from utils.plots import Annotator, colors, save_one_box
+from utils.torch_utils import select_device, time_sync
+
+
+# 添加一个关于界面
+# 窗口主类
+class MainWindow(QTabWidget):
+ # 基本配置不动,然后只动第三个界面
+ def __init__(self):
+ # 初始化界面
+ super().__init__()
+ self.setWindowTitle('Target detection system')
+ self.resize(1200, 800)
+ self.setWindowIcon(QIcon("images/UI/lufei.png"))
+ # 图片读取进程
+ self.output_size = 480
+ self.img2predict = ""
+ self.device = 'cpu'
+ # # 初始化视频读取线程
+ self.vid_source = '0' # 初始设置为摄像头
+ self.stopEvent = threading.Event()
+ self.webcam = True
+ self.stopEvent.clear()
+ self.model = self.model_load(weights="runs/train/exp_yolov5s/weights/best.pt",
+ device=self.device) # todo 指明模型加载的位置的设备
+ self.initUI()
+ self.reset_vid()
+
+ '''
+ ***模型初始化***
+ '''
+ @torch.no_grad()
+ def model_load(self, weights="", # model.pt path(s)
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ half=False, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ ):
+ device = select_device(device)
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ device = select_device(device)
+ model = DetectMultiBackend(weights, device=device, dnn=dnn)
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ # Half
+ half &= pt and device.type != 'cpu' # half precision only supported by PyTorch on CUDA
+ if pt:
+ model.model.half() if half else model.model.float()
+ print("模型加载完成!")
+ return model
+
+ '''
+ ***界面初始化***
+ '''
+ def initUI(self):
+ # 图片检测子界面
+ font_title = QFont('楷体', 16)
+ font_main = QFont('楷体', 14)
+ # 图片识别界面, 两个按钮,上传图片和显示结果
+ img_detection_widget = QWidget()
+ img_detection_layout = QVBoxLayout()
+ img_detection_title = QLabel("图片识别功能")
+ img_detection_title.setFont(font_title)
+ mid_img_widget = QWidget()
+ mid_img_layout = QHBoxLayout()
+ self.left_img = QLabel()
+ self.right_img = QLabel()
+ self.left_img.setPixmap(QPixmap("images/UI/up.jpeg"))
+ self.right_img.setPixmap(QPixmap("images/UI/right.jpeg"))
+ self.left_img.setAlignment(Qt.AlignCenter)
+ self.right_img.setAlignment(Qt.AlignCenter)
+ mid_img_layout.addWidget(self.left_img)
+ mid_img_layout.addStretch(0)
+ mid_img_layout.addWidget(self.right_img)
+ mid_img_widget.setLayout(mid_img_layout)
+ up_img_button = QPushButton("上传图片")
+ det_img_button = QPushButton("开始检测")
+ up_img_button.clicked.connect(self.upload_img)
+ det_img_button.clicked.connect(self.detect_img)
+ up_img_button.setFont(font_main)
+ det_img_button.setFont(font_main)
+ up_img_button.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ det_img_button.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ img_detection_layout.addWidget(img_detection_title, alignment=Qt.AlignCenter)
+ img_detection_layout.addWidget(mid_img_widget, alignment=Qt.AlignCenter)
+ img_detection_layout.addWidget(up_img_button)
+ img_detection_layout.addWidget(det_img_button)
+ img_detection_widget.setLayout(img_detection_layout)
+
+ # todo 视频识别界面
+ # 视频识别界面的逻辑比较简单,基本就从上到下的逻辑
+ vid_detection_widget = QWidget()
+ vid_detection_layout = QVBoxLayout()
+ vid_title = QLabel("视频检测功能")
+ vid_title.setFont(font_title)
+ self.vid_img = QLabel()
+ self.vid_img.setPixmap(QPixmap("images/UI/up.jpeg"))
+ vid_title.setAlignment(Qt.AlignCenter)
+ self.vid_img.setAlignment(Qt.AlignCenter)
+ self.webcam_detection_btn = QPushButton("摄像头实时监测")
+ self.mp4_detection_btn = QPushButton("视频文件检测")
+ self.vid_stop_btn = QPushButton("停止检测")
+ self.webcam_detection_btn.setFont(font_main)
+ self.mp4_detection_btn.setFont(font_main)
+ self.vid_stop_btn.setFont(font_main)
+ self.webcam_detection_btn.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ self.mp4_detection_btn.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ self.vid_stop_btn.setStyleSheet("QPushButton{color:white}"
+ "QPushButton:hover{background-color: rgb(2,110,180);}"
+ "QPushButton{background-color:rgb(48,124,208)}"
+ "QPushButton{border:2px}"
+ "QPushButton{border-radius:5px}"
+ "QPushButton{padding:5px 5px}"
+ "QPushButton{margin:5px 5px}")
+ self.webcam_detection_btn.clicked.connect(self.open_cam)
+ self.mp4_detection_btn.clicked.connect(self.open_mp4)
+ self.vid_stop_btn.clicked.connect(self.close_vid)
+ # 添加组件到布局上
+ vid_detection_layout.addWidget(vid_title)
+ vid_detection_layout.addWidget(self.vid_img)
+ vid_detection_layout.addWidget(self.webcam_detection_btn)
+ vid_detection_layout.addWidget(self.mp4_detection_btn)
+ vid_detection_layout.addWidget(self.vid_stop_btn)
+ vid_detection_widget.setLayout(vid_detection_layout)
+
+ # todo 关于界面
+ about_widget = QWidget()
+ about_layout = QVBoxLayout()
+ about_title = QLabel('欢迎使用目标检测系统\n\n 提供付费指导:有需要的好兄弟加下面的QQ即可') # todo 修改欢迎词语
+ about_title.setFont(QFont('楷体', 18))
+ about_title.setAlignment(Qt.AlignCenter)
+ about_img = QLabel()
+ about_img.setPixmap(QPixmap('images/UI/qq.png'))
+ about_img.setAlignment(Qt.AlignCenter)
+
+ # label4.setText("如何调整学习率")
+ label_super = QLabel() # todo 更换作者信息
+ label_super.setText("或者你可以在这里找到我-->肆十二")
+ label_super.setFont(QFont('楷体', 16))
+ label_super.setOpenExternalLinks(True)
+ # label_super.setOpenExternalLinks(True)
+ label_super.setAlignment(Qt.AlignRight)
+ about_layout.addWidget(about_title)
+ about_layout.addStretch()
+ about_layout.addWidget(about_img)
+ about_layout.addStretch()
+ about_layout.addWidget(label_super)
+ about_widget.setLayout(about_layout)
+
+ self.left_img.setAlignment(Qt.AlignCenter)
+ self.addTab(img_detection_widget, '图片检测')
+ self.addTab(vid_detection_widget, '视频检测')
+ self.addTab(about_widget, '联系我')
+ self.setTabIcon(0, QIcon('images/UI/lufei.png'))
+ self.setTabIcon(1, QIcon('images/UI/lufei.png'))
+ self.setTabIcon(2, QIcon('images/UI/lufei.png'))
+
+ '''
+ ***上传图片***
+ '''
+ def upload_img(self):
+ # 选择录像文件进行读取
+ fileName, fileType = QFileDialog.getOpenFileName(self, 'Choose file', '', '*.jpg *.png *.tif *.jpeg')
+ if fileName:
+ suffix = fileName.split(".")[-1]
+ save_path = osp.join("images/tmp", "tmp_upload." + suffix)
+ shutil.copy(fileName, save_path)
+ # 应该调整一下图片的大小,然后统一防在一起
+ im0 = cv2.imread(save_path)
+ resize_scale = self.output_size / im0.shape[0]
+ im0 = cv2.resize(im0, (0, 0), fx=resize_scale, fy=resize_scale)
+ cv2.imwrite("images/tmp/upload_show_result.jpg", im0)
+ # self.right_img.setPixmap(QPixmap("images/tmp/single_result.jpg"))
+ self.img2predict = fileName
+ self.left_img.setPixmap(QPixmap("images/tmp/upload_show_result.jpg"))
+ # todo 上传图片之后右侧的图片重置,
+ self.right_img.setPixmap(QPixmap("images/UI/right.jpeg"))
+
+ '''
+ ***检测图片***
+ '''
+ def detect_img(self):
+ model = self.model
+ output_size = self.output_size
+ source = self.img2predict # file/dir/URL/glob, 0 for webcam
+ imgsz = [640,640] # inference size (pixels)
+ conf_thres = 0.25 # confidence threshold
+ iou_thres = 0.45 # NMS IOU threshold
+ max_det = 1000 # maximum detections per image
+ device = self.device # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img = False # show results
+ save_txt = False # save results to *.txt
+ save_conf = False # save confidences in --save-txt labels
+ save_crop = False # save cropped prediction boxes
+ nosave = False # do not save images/videos
+ classes = None # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms = False # class-agnostic NMS
+ augment = False # ugmented inference
+ visualize = False # visualize features
+ line_thickness = 3 # bounding box thickness (pixels)
+ hide_labels = False # hide labels
+ hide_conf = False # hide confidences
+ half = False # use FP16 half-precision inference
+ dnn = False # use OpenCV DNN for ONNX inference
+ print(source)
+ if source == "":
+ QMessageBox.warning(self, "请上传", "请先上传图片再进行检测")
+ else:
+ source = str(source)
+ device = select_device(self.device)
+ webcam = False
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ # Dataloader
+ if webcam:
+ view_img = check_imshow()
+ cudnn.benchmark = True # set True to speed up constant image size inference
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = len(dataset) # batch_size
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = 1 # batch_size
+ vid_path, vid_writer = [None] * bs, [None] * bs
+ # Run inference
+ if pt and device.type != 'cpu':
+ model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
+ dt, seen = [0.0, 0.0, 0.0], 0
+ for path, im, im0s, vid_cap, s in dataset:
+ t1 = time_sync()
+ im = torch.from_numpy(im).to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ t2 = time_sync()
+ dt[0] += t2 - t1
+ # Inference
+ # visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred = model(im, augment=augment, visualize=visualize)
+ t3 = time_sync()
+ dt[1] += t3 - t2
+ # NMS
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+ dt[2] += time_sync() - t3
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+ p = Path(p) # to Path
+ s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, -1].unique():
+ n = (det[:, -1] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(
+ -1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ # with open(txt_path + '.txt', 'a') as f:
+ # f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ # if save_crop:
+ # save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg',
+ # BGR=True)
+ # Print time (inference-only)
+ LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
+ # Stream results
+ im0 = annotator.result()
+ # if view_img:
+ # cv2.imshow(str(p), im0)
+ # cv2.waitKey(1) # 1 millisecond
+ # Save results (image with detections)
+ resize_scale = output_size / im0.shape[0]
+ im0 = cv2.resize(im0, (0, 0), fx=resize_scale, fy=resize_scale)
+ cv2.imwrite("images/tmp/single_result.jpg", im0)
+ # 目前的情况来看,应该只是ubuntu下会出问题,但是在windows下是完整的,所以继续
+ self.right_img.setPixmap(QPixmap("images/tmp/single_result.jpg"))
+
+ # 视频检测,逻辑基本一致,有两个功能,分别是检测摄像头的功能和检测视频文件的功能,先做检测摄像头的功能。
+
+ '''
+ ### 界面关闭事件 ###
+ '''
+ def closeEvent(self, event):
+ reply = QMessageBox.question(self,
+ 'quit',
+ "Are you sure?",
+ QMessageBox.Yes | QMessageBox.No,
+ QMessageBox.No)
+ if reply == QMessageBox.Yes:
+ self.close()
+ event.accept()
+ else:
+ event.ignore()
+
+ '''
+ ### 视频关闭事件 ###
+ '''
+
+ def open_cam(self):
+ self.webcam_detection_btn.setEnabled(False)
+ self.mp4_detection_btn.setEnabled(False)
+ self.vid_stop_btn.setEnabled(True)
+ self.vid_source = '0'
+ self.webcam = True
+ # 把按钮给他重置了
+ # print("GOGOGO")
+ th = threading.Thread(target=self.detect_vid)
+ th.start()
+
+ '''
+ ### 开启视频文件检测事件 ###
+ '''
+
+ def open_mp4(self):
+ fileName, fileType = QFileDialog.getOpenFileName(self, 'Choose file', '', '*.mp4 *.avi')
+ if fileName:
+ self.webcam_detection_btn.setEnabled(False)
+ self.mp4_detection_btn.setEnabled(False)
+ # self.vid_stop_btn.setEnabled(True)
+ self.vid_source = fileName
+ self.webcam = False
+ th = threading.Thread(target=self.detect_vid)
+ th.start()
+
+ '''
+ ### 视频开启事件 ###
+ '''
+
+ # 视频和摄像头的主函数是一样的,不过是传入的source不同罢了
+ def detect_vid(self):
+ # pass
+ model = self.model
+ output_size = self.output_size
+ # source = self.img2predict # file/dir/URL/glob, 0 for webcam
+ imgsz = [640, 640] # inference size (pixels)
+ conf_thres = 0.25 # confidence threshold
+ iou_thres = 0.45 # NMS IOU threshold
+ max_det = 1000 # maximum detections per image
+ # device = self.device # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ view_img = False # show results
+ save_txt = False # save results to *.txt
+ save_conf = False # save confidences in --save-txt labels
+ save_crop = False # save cropped prediction boxes
+ nosave = False # do not save images/videos
+ classes = None # filter by class: --class 0, or --class 0 2 3
+ agnostic_nms = False # class-agnostic NMS
+ augment = False # ugmented inference
+ visualize = False # visualize features
+ line_thickness = 3 # bounding box thickness (pixels)
+ hide_labels = False # hide labels
+ hide_conf = False # hide confidences
+ half = False # use FP16 half-precision inference
+ dnn = False # use OpenCV DNN for ONNX inference
+ source = str(self.vid_source)
+ webcam = self.webcam
+ device = select_device(self.device)
+ stride, names, pt, jit, onnx = model.stride, model.names, model.pt, model.jit, model.onnx
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ save_img = not nosave and not source.endswith('.txt') # save inference images
+ # Dataloader
+ if webcam:
+ view_img = check_imshow()
+ cudnn.benchmark = True # set True to speed up constant image size inference
+ dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = len(dataset) # batch_size
+ else:
+ dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt and not jit)
+ bs = 1 # batch_size
+ vid_path, vid_writer = [None] * bs, [None] * bs
+ # Run inference
+ if pt and device.type != 'cpu':
+ model(torch.zeros(1, 3, *imgsz).to(device).type_as(next(model.model.parameters()))) # warmup
+ dt, seen = [0.0, 0.0, 0.0], 0
+ for path, im, im0s, vid_cap, s in dataset:
+ t1 = time_sync()
+ im = torch.from_numpy(im).to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ if len(im.shape) == 3:
+ im = im[None] # expand for batch dim
+ t2 = time_sync()
+ dt[0] += t2 - t1
+ # Inference
+ # visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
+ pred = model(im, augment=augment, visualize=visualize)
+ t3 = time_sync()
+ dt[1] += t3 - t2
+ # NMS
+ pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
+ dt[2] += time_sync() - t3
+ # Second-stage classifier (optional)
+ # pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
+ # Process predictions
+ for i, det in enumerate(pred): # per image
+ seen += 1
+ if webcam: # batch_size >= 1
+ p, im0, frame = path[i], im0s[i].copy(), dataset.count
+ s += f'{i}: '
+ else:
+ p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
+ p = Path(p) # to Path
+ # save_path = str(save_dir / p.name) # im.jpg
+ # txt_path = str(save_dir / 'labels' / p.stem) + (
+ # '' if dataset.mode == 'image' else f'_{frame}') # im.txt
+ s += '%gx%g ' % im.shape[2:] # print string
+ gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
+ imc = im0.copy() if save_crop else im0 # for save_crop
+ annotator = Annotator(im0, line_width=line_thickness, example=str(names))
+ if len(det):
+ # Rescale boxes from img_size to im0 size
+ det[:, :4] = scale_coords(im.shape[2:], det[:, :4], im0.shape).round()
+
+ # Print results
+ for c in det[:, -1].unique():
+ n = (det[:, -1] == c).sum() # detections per class
+ s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
+
+ # Write results
+ for *xyxy, conf, cls in reversed(det):
+ if save_txt: # Write to file
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(
+ -1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ # with open(txt_path + '.txt', 'a') as f:
+ # f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+ if save_img or save_crop or view_img: # Add bbox to image
+ c = int(cls) # integer class
+ label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
+ annotator.box_label(xyxy, label, color=colors(c, True))
+ # if save_crop:
+ # save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg',
+ # BGR=True)
+ # Print time (inference-only)
+ LOGGER.info(f'{s}Done. ({t3 - t2:.3f}s)')
+ # Stream results
+ # Save results (image with detections)
+ im0 = annotator.result()
+ frame = im0
+ resize_scale = output_size / frame.shape[0]
+ frame_resized = cv2.resize(frame, (0, 0), fx=resize_scale, fy=resize_scale)
+ cv2.imwrite("images/tmp/single_result_vid.jpg", frame_resized)
+ self.vid_img.setPixmap(QPixmap("images/tmp/single_result_vid.jpg"))
+ # self.vid_img
+ # if view_img:
+ # cv2.imshow(str(p), im0)
+ # self.vid_img.setPixmap(QPixmap("images/tmp/single_result_vid.jpg"))
+ # cv2.waitKey(1) # 1 millisecond
+ if cv2.waitKey(25) & self.stopEvent.is_set() == True:
+ self.stopEvent.clear()
+ self.webcam_detection_btn.setEnabled(True)
+ self.mp4_detection_btn.setEnabled(True)
+ self.reset_vid()
+ break
+ # self.reset_vid()
+
+ '''
+ ### 界面重置事件 ###
+ '''
+
+ def reset_vid(self):
+ self.webcam_detection_btn.setEnabled(True)
+ self.mp4_detection_btn.setEnabled(True)
+ self.vid_img.setPixmap(QPixmap("images/UI/up.jpeg"))
+ self.vid_source = '0'
+ self.webcam = True
+
+ '''
+ ### 视频重置事件 ###
+ '''
+
+ def close_vid(self):
+ self.stopEvent.set()
+ self.reset_vid()
+
+
+if __name__ == "__main__":
+ app = QApplication(sys.argv)
+ mainWindow = MainWindow()
+ mainWindow.show()
+ sys.exit(app.exec_())
diff --git a/src/资源.txt b/src/资源.txt
deleted file mode 100644
index 0d3cd98..0000000
--- a/src/资源.txt
+++ /dev/null
@@ -1 +0,0 @@
-资源目录
\ No newline at end of file