forked from p3t2ja9zs/dcs
You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
|
|
3 years ago | |
|---|---|---|
| .idea | 3 years ago | |
| bin | 3 years ago | |
| conf | 3 years ago | |
| dcs | 3 years ago | |
| docs/pictures | 3 years ago | |
| ui | 3 years ago | |
| .gitignore | 3 years ago | |
| README.md | 3 years ago | |
| requirements.txt | 3 years ago | |
| setup.py | 4 years ago | |
README.md
分布式爬虫系统
下载&安装
爬虫
安装selenium
pip3 install selenium
安装 mysql,pymysql 并配置
下载edge浏览器引擎
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/

浏览器 --> 设置 --> 关于 Microsoft Edge --> 版本信息。和上面对应(浏览器图标也要对应上,是这个带 绿色 的)
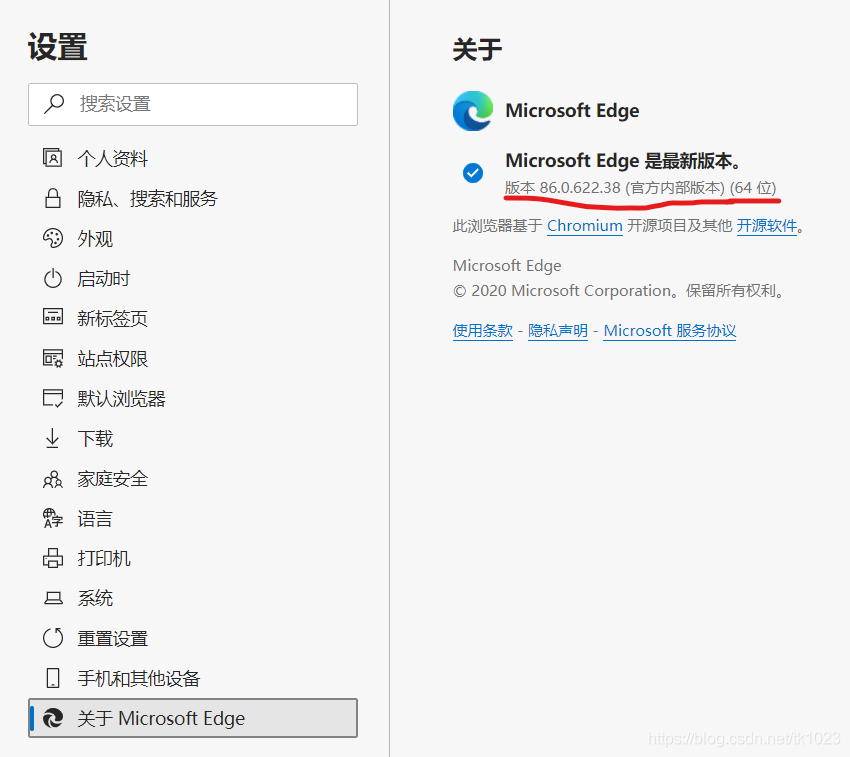
把下载的浏览器引擎程序放在 dcs/bin 目录下
可以用下面的脚本测试
from time import sleep
from selenium import webdriver
driverfile_path = r'G:\Users\god\PycharmProjects\dcs\bin\msedgedriver.exe'
driver = webdriver.Edge(executable_path=driverfile_path)
driver.get(r'https://www.baidu.com/')
sleep(5)
driver.close()
上面的路径需要自己对应改一下
运行
python3 运行 main.py 文件,开启 server、spider、user_process、requester、communicate 五个服务线程,分布式爬虫系统服务端开始运行和监测。
node 运行 login.js,即可开启web服务器,可接收浏览器请求,之后与爬虫服务器通信,取得结果后返回浏览器。
再运行 client.py 文件,运行客户端,开始请求爬虫任务,服务端即可接收、分配并执行、组合,最终返回结果到客户端。
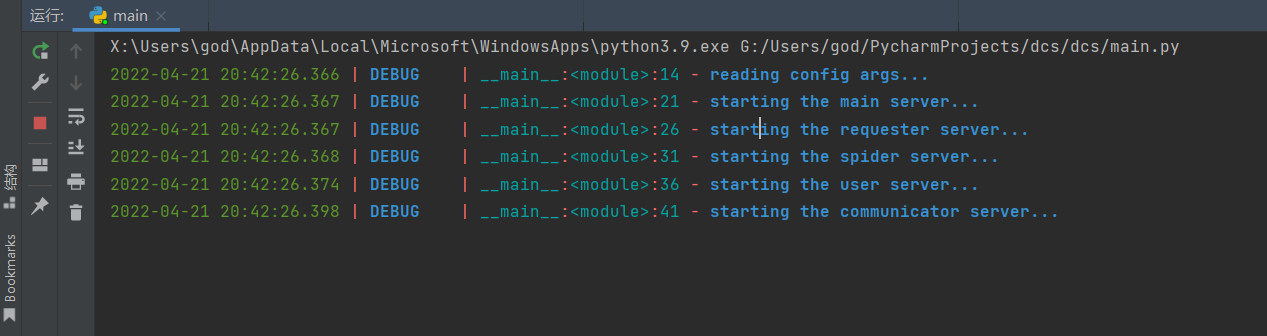
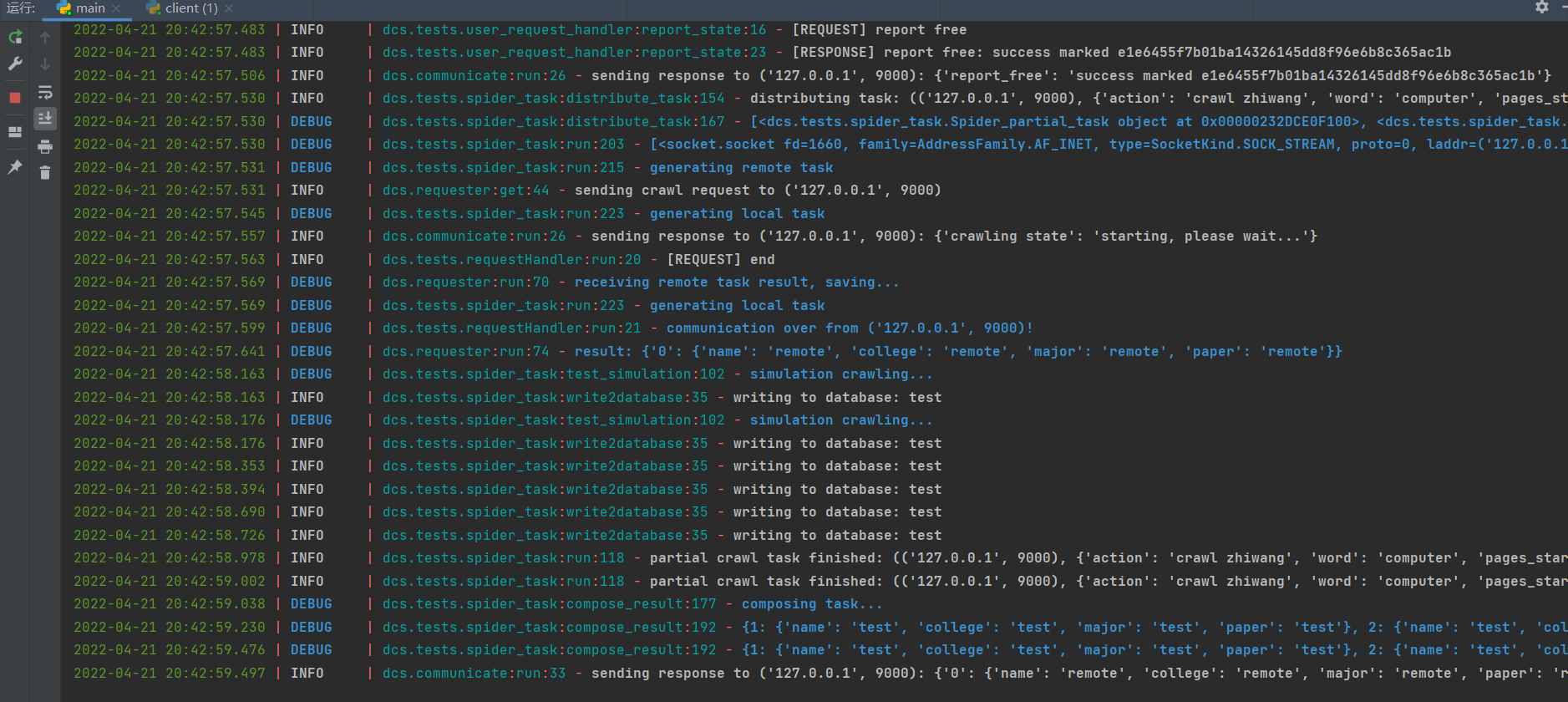
运行截图

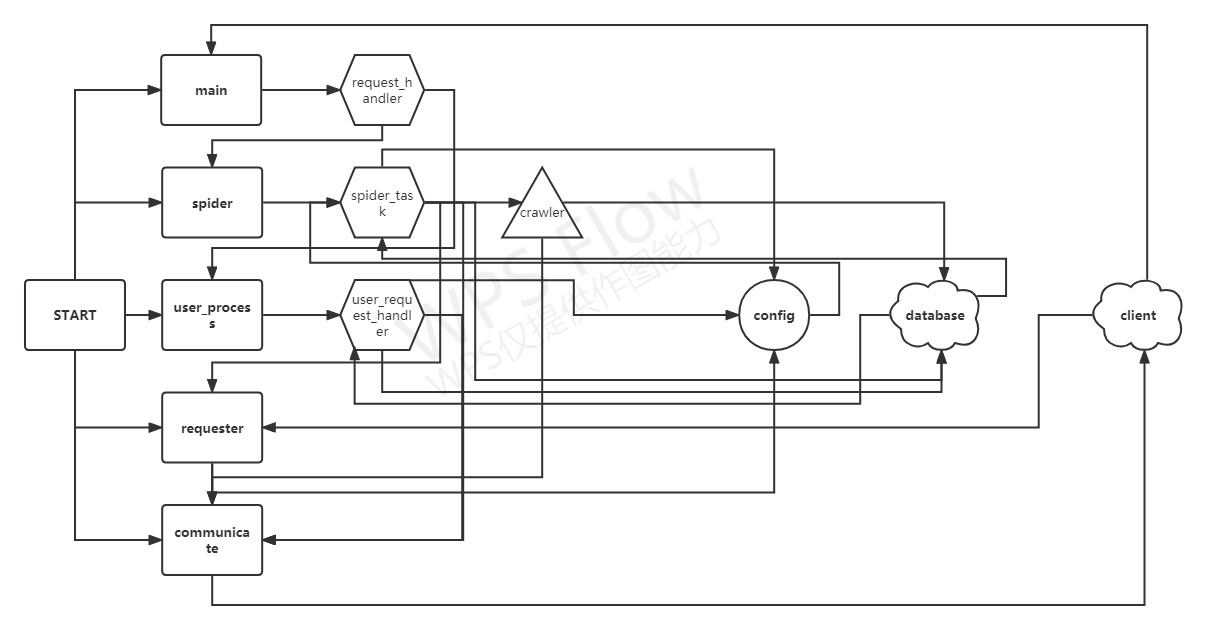
项目结构图
服务器运行日志
更新日志
V1.0
基本框架搭建完毕,实现核心的类“P2P”机制