27 KiB
操作系统原理课程设计
扩充proxy kernel的代码,使你的内核可以支持以下应用程序:
实验一 多进程支持
应用:
App5_1的代码如下:
int main(){
int a=10;
int ret=-1;
printf("print proc app5_1\n");
if((ret=fork()) == 0) {
printf("print proc this is child process;my pid = %d\n",getpid());
a=a-1;
printf("print proc a=%d\n",a);
}else {
int wait_ret = -1;
wait_ret=wait(ret);
a=a-2;
printf("print proc this is farther process;my pid = %d\n",getpid());
printf("print proc a=%d\n",a);
}
if((ret=fork()) == 0) {
a=a-3;
printf("print proc this is child process;my pid = %d\n",getpid());
printf("print proc a=%d\n",a);
}else {
a=a-4;
int wait_ret = -1;
wait_ret=wait(ret);
printf("print proc this is farther process;my pid = %d\n",getpid());
printf("print proc a=%d\n",a);
}
return 0;
}
实验一任务:
任务一 : proc_pagetable/ vmcopy
实验任务描述:
实现pk/proc.c中的proc_pagetable与vmcopy函数,为进程创建用户页表,并映射用户内存,确保你的代码仍可以保证app5的正确运行。
实验预期输出:
$ spike obj/pke app/elf/app5
得到输出:
PKE IS RUNNING
to host 10
from host 0
elf name app/elf/app5
sched class: RR_scheduler
++ setup timer interrupts
log: proc init
father process
this is father process;my pid = 1
this is child process;my pid = 2
任务二:do_wait
实验任务描述:
实现do_wait函数,支持app5_1.c的运行
$ spike obj/pke app/elf/app5_1
预期得到输出:
PKE IS RUNNING
to host 10
from host 0
elf name app/elf/app5_1
sched class: RR_scheduler
++ setup timer interrupts
log: proc init
print proc app5_1
print proc this is child process;my pid = 2
print proc a=9
print proc this is child process;my pid = 3
print proc a=6
print proc this is farther process;my pid = 2
print proc a=5
print proc this is farther process;my pid = 1
print proc a=8
print proc this is child process;my pid = 4
print proc a=5
print proc this is farther process;my pid = 1
此时运行测试脚本:
$ python3 ./pke-final-1
预期得到输出:
build pk : OK
running app5_1 : OK
test fork : OK
Score: 20/20
实验一提示:
app5_1.c是一段多进程的代码,我们可以结合下图进行分析:
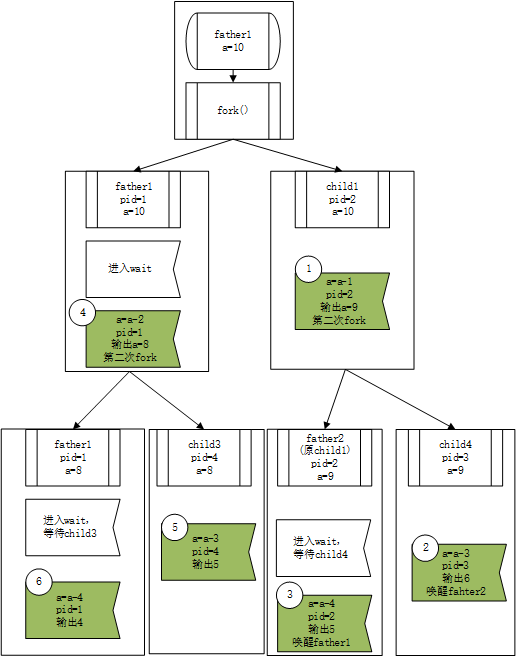
首先对app的内容进行分析,程序首先在父进程father1中调用了fork(),产生子进程child1,父进程father1进入等待状态。而子进程child1此时打印出a=9随机再次调用fork(),产生子进程child4,child4打印输出6后退出,此时child1结束等待输出5,随即father1被唤醒,输出8。Father1进行第二次fork,产生child3。Child3输出5后返回,父进程father1再次被唤醒,最后输出4。故而,正确的打印顺序为9、6、5、8、5、4。
现在,我们要支持上述app,就需要完善pke的进程支持。
在实验五的代码中,函数do_fork()中我们需要实现函数copy_mm(),即复制虚拟内存。该函数的本质实际上是对页表进程操作。由于实验五中只需要实现父子进程的切换,所以我们可以直接复制内核页表作为进程页表,并且再复制后的内核页表上为每个进程映射其用户地址空间。
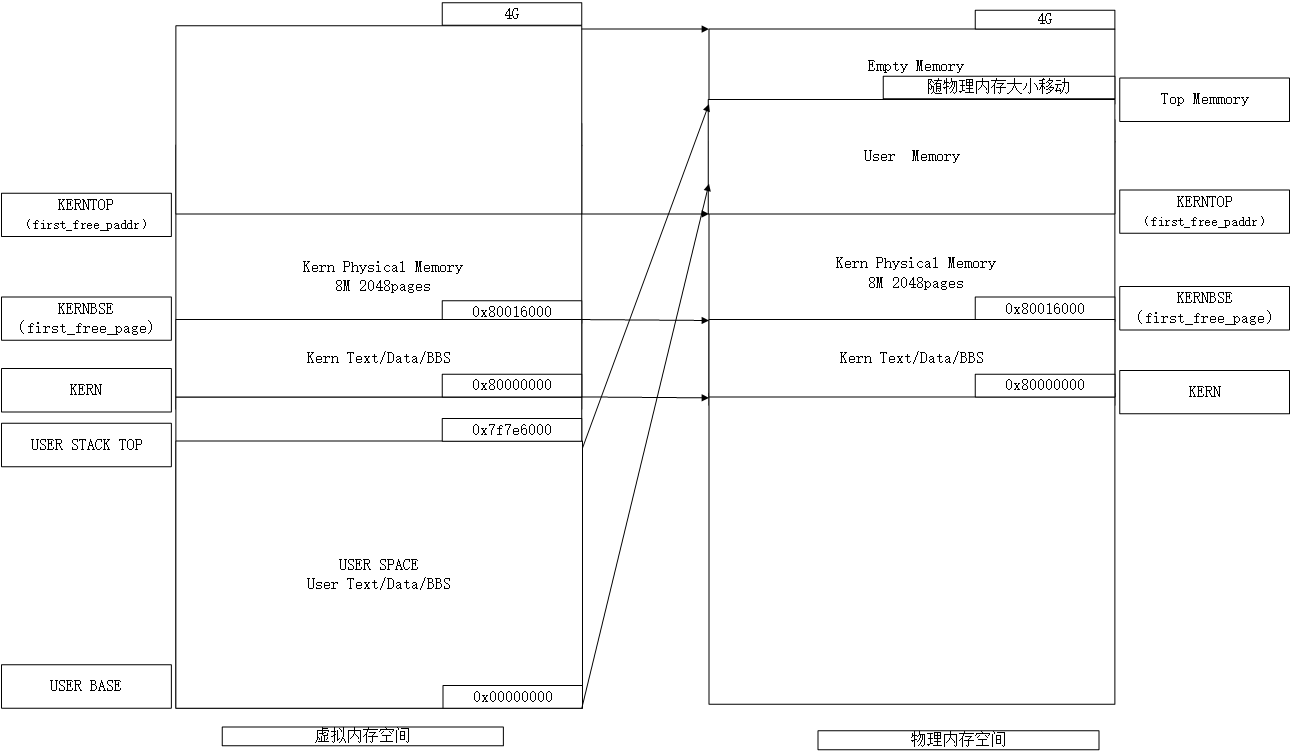
上图为pke的虚实映射关系。其中内核空间采用对等映射,即令物理地址等于虚拟地址,这样做使我们在内核下操作虚拟地址时无需再进行地址转换,例如我们使用__page_alloc分配了一段物理内存,并且要使用memset函数设置这段内存的值时,我们可以直接将分配得到的物理地址传入memset函数,注意,此时memset中,这个地址会被当作虚拟地址。结合实验三的知识,我们知道,这里必然会经由页表进行地址转化,但由于内核页表中物理地址与虚拟地址采用了对等的映射,我们实际上得到了和这个虚拟地址相同的物理地址,从而完成了写的操作。
虚拟地址空间中用户地址空间从零开始到USER STACK TOP结束,RISCV中物理地址从0x80000000开始,这一部分用户地址自然不存在对等映射的物理地址空间。如图所示,它映射至first_free_paddr到Top Memory之间的内存。
我们知道每个用户进程都有它独立的用户代码,而所有用户都共享内核代码。所以,一种更为清晰的设计如下,每个用户进程维护一张属于该进程的用户页表,所有进程共享内核页表。我们为进程结构体proc_struct添加upagetable属性,用以维护用户页表,其结构如下:
struct proc_struct {
list_entry_t run_link;
struct run_queue *rq;
int time_slice;
enum proc_state state; // Process state
int pid; // Process ID
int runs; // the running times of Proces
int exit_code;
uintptr_t kstack; // Process kernel stack
volatile bool need_resched; // bool value: need to be rescheduled to release CPU?
struct proc_struct *parent; // the parent process
struct context context; // Switch here to run process
trapframe_t *tf; // Trap frame for current interrupt
++ uintptr_t upagetable; // the base addr of Page Directroy Table
uint32_t flags; // Process flag
char name[PROC_NAME_LEN + 1]; // Process name
list_entry_t list_link; // Process link list
uint32_t wait_state; // waiting state
struct proc_struct *cptr, *yptr, *optr; // relations between processes
list_entry_t hash_link; // Process hash list
};
这样我们拥有了一张属于每个进程的用户页表,现在我们来看如何对其进行分配与维护。首先是进程间共性的部分,我们知道在用户态发生异常时,代码会跳转到stvec控制状态寄存器所指向的位置继续进行,所以所有用户页表中都需要对这部分代码进行映射。
pke中stvec指向trap_entry,我们可以对其内容进行简要的分析:
.global trap_entry
trap_entry:
#将sp与sscratch中的值互换
csrrw sp, sscratch, sp
bnez sp, write_stap
csrr sp, sscratch
addi sp,sp,-320
save_tf
jal 1f
write_stap:
addi sp,sp,-320
save_tf
进入trap_entry后,首先交换sp和sscratch寄存器,此时分为两个情况,第一是由内核空间跳转至trap_entry,第二种则是由用户空间跳转至trap_entry。
在pk.c中的boot_loader函数中sscratch于内核态被设置为0。而在proc.c的forkret函数中,forkret函数模拟上次调用是由用户态进入内核态的假象,将ssctatch写为内核栈的栈帧。综上可以得出结论,从用户态进入trap_entry后,sscratch值为该进程内核栈顶trapframe的指针;而从内核态进入trapframe后,sscratch的值为0。
所以在交换sscratch与sp后,代码对sp(即原sscratch的值)的值进行判断,如果sp中的值为0,表示其从内核态进入trap,代码顺序向下执行后跳转1f。如果不是0,则表示其从用户态进入trap,代码跳转write_satp。
我们先看sp为0即内核态进入的情况,首先sp作为栈指针寄存器自然是不能为0的,我们需要将sscratch的值(即原sp的值)再次写回sp寄存器。此时sp指向内核栈,接着调用宏save_tf将当前trap的trapframe保存在该内核栈中。
接着是sp为1即用户态进入的情况。它直接使用当前sp(即原sscratch中的值)作为内核栈地址,注意,由于forkret在进入用户态时向sscratch中写入了即将进入用户态运行的进程的内核栈,此时我们从用户态进入内核态,从sscratch中得到内核栈的自然也同运行的进程所一致。
接着,无论是哪种进入内核的状态都为欲存储的栈帧分配了栈空间,且都调用了宏save_tf:
.macro save_tf
# save gprs
STORE x1,1*REGBYTES(x2)
STORE x3,3*REGBYTES(x2)
STORE x4,4*REGBYTES(x2)
STORE x5,5*REGBYTES(x2)
STORE x6,6*REGBYTES(x2)
STORE x7,7*REGBYTES(x2)
STORE x8,8*REGBYTES(x2)
STORE x9,9*REGBYTES(x2)
STORE x10,10*REGBYTES(x2)
STORE x11,11*REGBYTES(x2)
STORE x12,12*REGBYTES(x2)
STORE x13,13*REGBYTES(x2)
STORE x14,14*REGBYTES(x2)
STORE x15,15*REGBYTES(x2)
STORE x16,16*REGBYTES(x2)
STORE x17,17*REGBYTES(x2)
STORE x18,18*REGBYTES(x2)
STORE x19,19*REGBYTES(x2)
STORE x20,20*REGBYTES(x2)
STORE x21,21*REGBYTES(x2)
STORE x22,22*REGBYTES(x2)
STORE x23,23*REGBYTES(x2)
STORE x24,24*REGBYTES(x2)
STORE x25,25*REGBYTES(x2)
STORE x26,26*REGBYTES(x2)
STORE x27,27*REGBYTES(x2)
STORE x28,28*REGBYTES(x2)
STORE x29,29*REGBYTES(x2)
STORE x30,30*REGBYTES(x2)
STORE x31,31*REGBYTES(x2)
csrrw t0,sscratch,x0
csrr s0,sstatus
csrr t1,sepc
csrr t2,sbadaddr
csrr t3,scause
STORE t0,2*REGBYTES(x2)
STORE s0,32*REGBYTES(x2)
STORE t1,33*REGBYTES(x2)
STORE t2,34*REGBYTES(x2)
STORE t3,35*REGBYTES(x2)
# get faulting insn, if it wasn't a fetch-related trap
li x5,-1
STORE x5,36*REGBYTES(x2)
简单来说,它用来保存栈帧。X2即sp寄存器,此时存储的是进程内核栈的指针。故而save_tf在预留出的栈帧中首先存储了除sp以外的31个通用寄存器,接着将sscratch中的值(即用户栈指针)存入t0、sstatus存入s0、sepc存入t1、sbadaddr存入t2、scause存入t3并保存。注意,由于csrrw 将x0写入sscratch,sscratch置位为0。
接下来,由用户态进入的trap需要将在用户态时使用的用户页表更换为内核态的内核页表:
write_stap:
addi sp,sp,-320
save_tf
move a0,sp
ld t1, 37*REGBYTES(a0)
csrw satp, t1
sfence.vma zero, zero
这里内核页表被加载入t1中,然后将t1写入satp寄存器,并刷新当前CPU的TLB。在RISCV中架构下,每个CPU都会将页表条目缓冲在转译后备缓冲区(Translation Lookaside Buffer)中,当页表更改时,必须告诉CPU使缓存的TLB条目无效。如果没有这样做,那么在以后的某个时间,TLB可能依旧会使用旧的缓存映射,这将可能导致某个进程在某些页面上乱写其他进程的内存。RISC-V提供指令sfence.vma刷新当前CPU的TLB。故而每次更换页表时,调用sfence.vma指令是必要的。
最后将sp作为参数传递给handle_trap,进入中断处理:
move a0,sp
j al handle_trap
同样,当代码从forkrets返回时,则执行了相反的逻辑:
forkrets:
andi s0,s0,SSTATUS_SPP
bnez s0,start_user
move sp, a0
csrw sptbr, a1
sfence.vma zero, zero
addi sp,sp,320
csrw sscratch,sp
j start_user
这里我们首先对sstatus寄存器进行介绍,sstatus作为状态控制寄存器,其中的SIE位控制是否允许设备中断。如果内核清除了SIE,则RISC-V将推迟设备中断,直到内核设置SIE。SPP位指示tarp是来自用户模式还是主管模式,并且sret将返回该种模式。当异常发生时,硬件将自动将sstatus的SIE位置零以禁用中断,并且将发生异常之前的特权模式保存在SPP中。而当调用sret时,机器会将SPIE的值写入SIE来恢复异常发生之前的中断使能情况,并且按照SPP中的值恢复特权模式。
故而,在forkrets中,代码先判断了SSTATUS_SPP的值是否为零,若其为零,则表示异常发生之前是处于用户态,若不为零,则表示异常发生之前是处于内核态。对于用户态,我们重新将用户页表写入satp寄存器,并且将内核栈地址写入sscratch,以备下一次异常发生时使用。对于内核态,则直接进入start_user:
.globl start_user
start_user:
LOAD t0, 32*REGBYTES(a0)
LOAD t1, 33*REGBYTES(a0)
csrw sstatus, t0
csrw sepc, t1
# restore x registers
LOAD x1,1*REGBYTES(a0)
LOAD x2,2*REGBYTES(a0)
LOAD x3,3*REGBYTES(a0)
LOAD x4,4*REGBYTES(a0)
LOAD x5,5*REGBYTES(a0)
LOAD x6,6*REGBYTES(a0)
LOAD x7,7*REGBYTES(a0)
LOAD x8,8*REGBYTES(a0)
LOAD x9,9*REGBYTES(a0)
LOAD x11,11*REGBYTES(a0)
LOAD x12,12*REGBYTES(a0)
LOAD x13,13*REGBYTES(a0)
LOAD x14,14*REGBYTES(a0)
LOAD x15,15*REGBYTES(a0)
LOAD x16,16*REGBYTES(a0)
LOAD x17,17*REGBYTES(a0)
LOAD x18,18*REGBYTES(a0)
LOAD x19,19*REGBYTES(a0)
LOAD x20,20*REGBYTES(a0)
LOAD x21,21*REGBYTES(a0)
LOAD x22,22*REGBYTES(a0)
LOAD x23,23*REGBYTES(a0)
LOAD x24,24*REGBYTES(a0)
LOAD x25,25*REGBYTES(a0)
LOAD x26,26*REGBYTES(a0)
LOAD x27,27*REGBYTES(a0)
LOAD x28,28*REGBYTES(a0)
LOAD x29,29*REGBYTES(a0)
LOAD x30,30*REGBYTES(a0)
LOAD x31,31*REGBYTES(a0)
# restore a0 last
LOAD x10,10*REGBYTES(a0)
# gtfo
sret
start_user中首先恢复sstatus以及sepc,然后加载32个通用寄存器,并调用sret返回。
综上,为了用户态的代码能够跳转进入中断处理程序,上述由用户态进入内核态的代码需要在所有进程的用户页表中进行映射。
同样每个用户页表中都应该维护自己的用户堆栈,需要对虚拟地址current.stack_top-RISCV_PGSIZE进行映射。
以上功能均由proc_pagetable函数实现。
现在,我们已经完成了用户页表的创建,不过目前页表中除了我们映射的异常入口与用户栈还是一片空白,接下来我们需要对用户内存进程映射。
还记得fork函数中的copy_mm吗?我们需要在该函数中将父进程的用户内存拷贝给子进程,或者说复制父进程的用户页表。对于用户进程空间中的虚拟地址,这里有几种情况需要考虑:
- 其一、该虚拟地址对应的页表项不存在,则无需在子进程中进程映射
- 其二、该虚拟地址对应的页表项存在且
PTE_V位有效,则需要为子进程分配内存,并复制父进程对应的物理页,最后将该虚拟地址与新分配的物理内存映射进子进程的用户页表 - 其三、该虚拟地址对应的页表项存在且但
PTE_V位无效,这是因为pke中采用了预映射的机制,此时父进程的页表项中所描述的地址不是真实的物理地址而是一个vmr_t结构体,该结构体描述着该段物理内存在对应文件中的位置,会在page_fault中被使用。在此,只需要将父进程页表项所描述的vmr_t结构体地址赋值给子页表项。 - 其四、该虚拟地址对应着用户栈,由于我们在proc_pagetable函数中已近为其分配了内存,此时只需要复制父进程的用户栈。
至此,我们进一步完善了对fork的支持。接下来,我们来看进程间的同步。
wait是最为基础的同步操作。wait函数在进程列表中进行遍历,寻找该进程为尚未完成的任意子进程/或pid指定的子进程,若存在且子进程处于PROC_ZOMBIE状态,则释放该子进程资源并返回。若子进程不处于PROC_ZOMBIE状态,则将父进程的状态设为PROC_SLEEPING,将父进程的等待状态设为WT_CHILD,继而调用schedule。
从父进程调用wait开始,进程是如何调度与切换的呢?下面我们一起一探究竟。如下是一张wait调用的流程图:
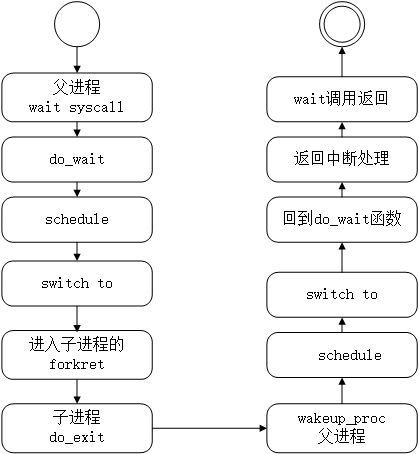
首先,wait的本质仍是系统调用,父进程会进入trap_entry并在属于他的内核栈中保存trapframe,在上文中我们对该段代码进行过讨论,这里需要记住的是该trapframe中保存了父进程的sepc,而当使用sret从管理员模式下返回时,pc会被设置为sepc的值。
接着进入do_wait的代码,这里不妨假其子进程状态不处于PROC_ZOMBIE,故而在将父进程状态设置完成后,进入schedule代码:
void
schedule(void) {
bool intr_flag;
struct proc_struct *next;
local_intr_save(intr_flag);
{
currentproc->need_resched = 0;
if (currentproc->state == PROC_RUNNABLE) {
sched_class_enqueue(currentproc);
}
if ((next = sched_class_pick_next()) != NULL) {
sched_class_dequeue(next);
}
if (next == NULL) {
next = idleproc;
shutdown(0);
}
next->runs ++;
if (next != currentproc) {
proc_run(next);
}
}
local_intr_restore(intr_flag);
}
Schedule会选取下一个进程,随即进入switch_to,这又是一段汇编代码:
# void switch_to(struct proc_struct* from, struct proc_struct* to)
.globl switch_to
switch_to:
# save from's registers
STORE ra, 0*REGBYTES(a0)
STORE sp, 1*REGBYTES(a0)
STORE s0, 2*REGBYTES(a0)
STORE s1, 3*REGBYTES(a0)
STORE s2, 4*REGBYTES(a0)
STORE s3, 5*REGBYTES(a0)
STORE s4, 6*REGBYTES(a0)
STORE s5, 7*REGBYTES(a0)
STORE s6, 8*REGBYTES(a0)
STORE s7, 9*REGBYTES(a0)
STORE s8, 10*REGBYTES(a0)
STORE s9, 11*REGBYTES(a0)
STORE s10, 12*REGBYTES(a0)
STORE s11, 13*REGBYTES(a0)
# restore to's registers
LOAD ra, 0*REGBYTES(a1)
LOAD sp, 1*REGBYTES(a1)
LOAD s0, 2*REGBYTES(a1)
LOAD s1, 3*REGBYTES(a1)
LOAD s2, 4*REGBYTES(a1)
LOAD s3, 5*REGBYTES(a1)
LOAD s4, 6*REGBYTES(a1)
LOAD s5, 7*REGBYTES(a1)
LOAD s6, 8*REGBYTES(a1)
LOAD s7, 9*REGBYTES(a1)
LOAD s8, 10*REGBYTES(a1)
LOAD s9, 11*REGBYTES(a1)
LOAD s10, 12*REGBYTES(a1)
LOAD s11, 13*REGBYTES(a1)
ret
这段代码保存了切换所前运行进程的14个寄存器到当前进程的上下文(context),此时当前进程的ra中存储的返回地址为函数schedule中proc_run下一行的地址。同时将下一个需要运行的进程的上下文装入各个寄存器中。若下一个进程为才被fork出来的子进程,则由于在之前copy_thread中所设置的proc->context.ra = (uintptr_t)forkret;被加载的进程将进入函数forkret,就此切换至另一进程运行。
当子进程执行完毕,它将执行do_exit,在do_exit中,会将当前子进程的状态设置为PROC_ZOMBIE,并且对其父进程的等待状态进行判断,若父进程处于等待状态,则使用wakeup_proc函数唤醒父进程。若当前执行exit进程存在子进程,需要为其重新指定父进程。
当父进程被唤醒后,进入wakeup_proc的代码,在wakeup_proc函数中恢复了父进程的运行状态,随即再次调用schedule函数。如上文所述,schedule再次加载父进程的上下文,还记的方才父进程上下文中的ra寄存器的值吗?父进程将根据此值返回schedule中proc_run的下一行地址继续上次的代码,并返回schedule的调用函数do_wait。do_wait里我们将再次查看子进程的state,若为PROC_ZOMBIE则返回。至此wait系统调用执行完毕。
实验二 信号量
实验二应用输入:
到目前为止,我们已近实现了进程间的简单同步。接下来,我们更进一步,考虑信号量的实现。App5_2的代码如下:
#include<stdio.h>
#include "libuser.h"
#define N 2
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
int items=0;
void producer(void)
{
while(1)
{
if(items==5*N) break;
produce_item();
down(&empty); //空槽数目减1,相当于P(empty)
down(&mutex); //进入临界区,相当于P(mutex)
insert_item(); //将新数据放到缓冲区中
up(&mutex); //离开临界区,相当于V(mutex)
up(&full); //满槽数目加1,相当于V(full)
}
}
void consumer()
{
while(1)
{
down(&full); //将满槽数目减1,相当于P(full)
down(&mutex); //进入临界区,相当于P(mutex)
remove_item(); //从缓冲区中取出数据
up(&mutex); //离开临界区,相当于V(mutex)
up(&empty); //将空槽数目加1 ,相当于V(empty)
consume_item(); //处理取出的数据项
}
}
int main(){
int pid;
int i;
for(i=0; i<2; i++){
pid=fork();
if(pid==0||pid==-1) //子进程或创建进程失败均退出
{
break;
}
}
if(pid==0) {
//
printf("printf 5_2 child %d\n",getpid());
consumer(getpid());
}else{
//
printf("printf 5_2 father %d \n",getpid());
producer();
}
return 0;
}
上述代码是一个简单的生产者消费者程序,由一个父进程创建两个子进程,父进程作为producer而子进程作为consumer。这里维护了三个信号量,mutex作为互斥信号量,为临界区提供互斥访问,empty用来维护空闲缓冲区,full则用来维护被填充的缓存区。
实验二任务:
实验二任务描述:
实现__down函数,支持app5_2.c的运行
实验二预期输出:
$ spike obj/pke app/elf/app5_2
预期得到输出中,父进程生产的数量等于两个子进程消费的数量之和。运行脚本:
$ python3 ./pke-final-2
预期得到输出:
build pk : OK
running app5_2 : OK
test sema : OK
Score: 20/20
实验二提示:
在程序执行的过程中,任务常常会因为某一条件没有达成而进入等待状态,具到的上述的例子,当producer发现没有空闲的缓存区即empty不足时,或者consumer发现full不足时,二者均会进入等待状态。等待条件得到满足,然后继续运行。这种机制,我们可以使用等待队列来实现,等待某一条件的进程在条件未满足时加入到等待队列当中,当条件满足时在遍历对应的队列唤醒进程,并且将进程从队列中删除。
在此,我们定义结构体wait_t如下:
typedef struct {
struct proc_struct *proc;
uint64_t wakeup_flags;
wait_queue_t * wait_queue;
list_entry_t wait_link;
}wait_t;
proc指向因条件不满足而被加入队列的进程,wakeup_flags对该未满足的条件进行描述,wait_queue指向此wait_t单元所属于的等待队列,wait_link同之前实验中的各类link一样用来组织链表的链接。
对于一个等待队列,封装了一系列的操作,我们对如下几个操作的代码进行阅读。
首先,初始化wait_t,将一个进程封装入wait_t结构体:
void
wait_init(wait_t *wait, struct proc_struct *proc) {
wait->proc = proc;
wait->wakeup_flags = WT_INTERRUPTED;
list_init(&(wait->wait_link));
}
然后是wakeup_wait:首先将指定的wait单元从等待队列中删除,为其赋值新的wakeup_flags,最后唤醒进程。
void
wakeup_wait(wait_queue_t *queue, wait_t *wait, uint64_t wakeup_flags, bool del) {
if (del) {
wait_queue_del(queue, wait);
}
wait->wakeup_flags = wakeup_flags;
wakeup_proc(wait->proc);
}
wait_current_set,修改当前进程的状态,并加入等待队列。
void
wait_current_set(wait_queue_t *queue, wait_t *wait, uint64_t wait_state) {
kassert(currentproc != NULL);
wait_init(wait, currentproc);
currentproc->state = PROC_SLEEPING;
currentproc->wait_state = wait_state;
wait_queue_add(queue, wait);
}
有了这些基本操作,我们就能在等待队列的基础上实现信号量,对于信号量,我们定义如下:
typedef struct semaphore{
intptr_t vaddr;
int value;
wait_queue_t wait_queue;
} semaphore_t;
vaddr是信号量在用户空间的地址,即&empty的值。这里我们将信号量的数组sema_q维护在内核空间中,并通过vaddr将它与用户变量唯一关联。value为信号量的值,wait_queue为信号量对应的等待队列。
当用户程序中调用down/up时会调用至系统调用sys_sema_down/sys_sema_up,以sys_sema_down为例:
void sys_sema_down(intptr_t sema_va){
semaphore_t * se;
if((se=find_sema(sema_va))==NULL){
se=alloc_sema(sema_va);
}
down(se);
}
首先,它会查看该用户变量是否已经有对应的信号量,若不存在,则为其分配信号量。alloc_sema的代码如下:
semaphore_t* alloc_sema(intptr_t sema_va){
int found=0;
semaphore_t * se;
int value=0;
copyin((pte_t *)currentproc->upagetable,(char *)&value,sema_va,sizeof(int));
for(se=sema_q;se<&sema_q[NSEMA];se++){
if(se->vaddr==0){
se->vaddr=sema_va;
sem_init(se,value);
found=1;
break;
}else
{
continue;
}
}
if(found==0){
panic("no sema alloc\n");
}
return se;
}
它使用函数copyin,利用用户页表,得到用户变量所对应的值,并用该值初始化信号量。至此,完成信号量的分配。
接下来,我们来关注对于信号量的操作up的实现:
static __noinline void __up(semaphore_t *sem, uint64_t wait_state) {
bool intr_flag;
local_intr_save(intr_flag);
{
wait_t *wait;
if ((wait = wait_queue_first(&(sem->wait_queue))) == NULL) {
sem->value ++;
}
else {
kassert(wait->proc->wait_state == wait_state);
wakeup_wait(&(sem->wait_queue), wait, wait_state, 1);
}
}
local_intr_restore(intr_flag);
}
首先,它从等待队列中取出头节点,若不存在,则说明没有进程在等待,那么直接增加信号量的值。若取出的头节点不为空,则判断该节点是否处于等待状态,然后唤醒该节点。
相应的,在down的代码中需要执行相反的逻辑,首先,需要判断value的值是否大于0,若value值大于0,则可以直接进行减操作。若否则需要将当前进程加入等待队列,并设置其state与wait_state。接着需要调用schedule。当schedule返回时,需要对唤醒标准进行判断,并将进程从等待队列中删除。
提交课设
至此为止,你已经完成了本实验的所有代码,运行脚本./pke-final:
$ python3 ./pke-final
预期得到如下输出,然后提交你的代码吧!
build pk : OK
running app5_1 : OK
test fork : OK
running app5_2 : OK
test sema : OK
Score: 40/40