最接近人类思维的分类算法-决策树
什么是决策树
决策树说白了就是一棵能够替我们做决策的树,或者说是我们人的脑回路的一种表现形式。比如我看到一个人,然后我会思考这个男人有没有买车。那我的脑回路可能是这样的:
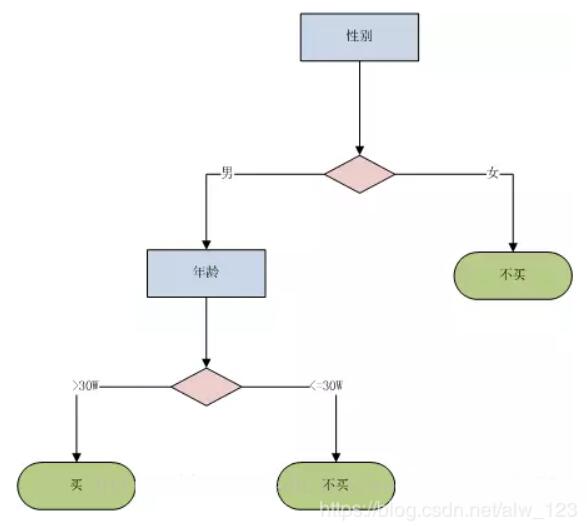
其实这样一种脑回路的形式就是我们所说的决策树。所以从图中能看出决策树是一个类似于人们决策过程的树结构,从根节点开始,每个分枝代表一个新的决策事件,会生成两个或多个分枝,每个叶子代表一个最终判定所属的类别。很明显,如果我现在已经构造好了一颗决策树的话,现在我得到一条数据(男, 29),我就会认为这个人没有买过车。所以呢,关键问题就是怎样来构造决策树了。
构造决策树时会遵循一个指标,有的是按照信息增益来构建,这种叫ID3算法,有的是信息增益比来构建,这种叫C4.5算法,有的是按照基尼系数来构建的,这种叫CART算法。在这里主要介绍一下ID3算法。
ID3算法
整个ID3算法其实主要就是围绕着信息增益来的,所以要弄清楚ID3算法的流程,首先要弄清楚什么是信息增益,但要弄清楚信息增益之前有个概念必须要懂,就是熵。所以先看看什么是熵。
熵、条件熵、信息增益
在信息论和概率统计中呢,为了表示某个随机变量的不确定性,就借用了热力学的一个概念叫熵。如果假设 是一个有限个取值的离散型随机变量的话,很显然它的概率分布或者分布律就是这样的:。
有了概率分布后,则这个随机变量 的熵的计算公式就是(:这里的 是以 为底):
从这个公式也可以看出,如果我概率是 或者是 的时候,我的熵就是 。(因为这种情况下我随机变量的不确定性是最低的),那如果我的概率是 也就是五五开的时候,我的熵是最大也就是 。(就像扔硬币,你永远都猜不透你下次扔到的是正面还是反面,所以它的不确定性非常高)。所以呢,熵越大,不确定性就越高。
在我们实际情况下,我们要研究的随机变量基本上都是多随机变量的情况,所以假设有随便量(X,Y),那么它的联合概率分布是这样的:
那如果我想知道在我事件 发生的前提下,事件 发生的熵是多少的话,这种熵我们叫它条件熵。条件熵 表示随机变量 的条件下随机变量 的不确定性。条件熵的计算公式是这样的:。
当然条件熵的一个性质也熵的性质一样,我概率越确定,条件熵就越小,概率越五五开,条件熵就越大。
OK,现在已经知道了什么是熵,什么是条件熵。接下来就可以看看什么是信息增益了。所谓的信息增益就是表示我已知条件 后能得到信息 的不确定性的减少程度。就好比,我在玩读心术。您心里想一件东西,我来猜。我已开始什么都没问你,我要猜的话,肯定是瞎猜。这个时候我的熵就非常高对不对。然后我接下来我会去试着问你是非题,当我问了是非题之后,我就能减小猜测你心中想到的东西的范围,这样其实就是减小了我的熵。那么我熵的减小程度就是我的信息增益。
所以信息增益如果套上机器学习的话就是,如果把特征 对训练集 的信息增益记为 的话,那么 的计算公式就是:。
如果看到这一堆公式可能会懵逼,那不如举个栗子来看看信息增益怎么算。假设我现在有这一个数据表,第一列是性别,第二列是活跃度, 第三列是客户是否流失的 。
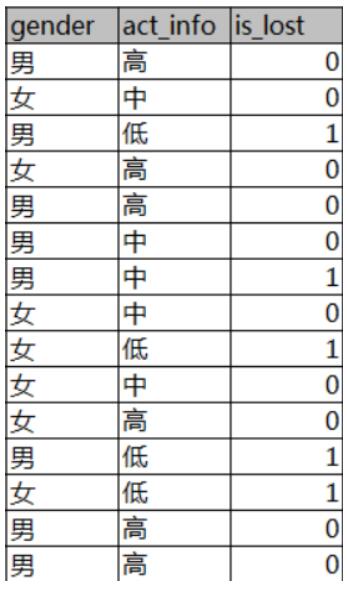
那如果我要算性别和活跃度这两个特征的信息增益的话,首先要先算总的熵和条件熵。( 的意思是总共有 条样本里面 为 的样本有 条, 的意思是性别为男的样本有 条,然后这 条里有 条是 为 ,其他的数值以此类推)
总熵= (-5/15)log(5/15)-(10/15)log(10/15)=0.9182
性别为男的熵= -(3/8)log(3/8)-(5/8)log(5/8)=0.9543
性别为女的熵= -(2/7)log(2/7)-(5/7)log(5/7)=0.8631
活跃度为低的熵= -(4/4)*log(4/4)-0=0
活跃度为中的熵= -(1/5)log(1/5)-(4/5)log(4/5)=0.7219
活跃度为高的熵= -0-(6/6)*log(6/6)=0
现在有了总的熵和条件熵之后我们就能算出性别和活跃度这两个特征的信息增益了。
性别的信息增益=总的熵-(8/15)性别为男的熵-(7/15)性别为女的熵=0.0064
活跃度的信息增益=总的熵-(6/15)活跃度为高的熵-(5/15)活跃度为中的熵-(4/15)*活跃度为低的熵=0.6776
那信息增益算出来之后有什么意义呢?回到读心术的问题,为了我能更加准确的猜出你心中所想,我肯定是问的问题越好就能猜得越准!换句话来说我肯定是要想出一个信息增益最大的问题来问你,对不对?其实ID3算法也是这么想的。ID3算法的思想是从训练集 中计算每个特征的信息增益,然后看哪个最大就选哪个作为当前节点。然后继续重复刚刚的步骤来构建决策树。
决策树构流程
ID3算法其实就是依据特征的信息增益来构建树的。具体套路就是从根节点开始,对节点计算所有可能的特征的信息增益,然后选择信息增益最大的特征作为节点的特征,由该特征的不同取值建立子节点,然后对子节点递归执行上面的套路直到信息增益很小或者没有特征可以继续选择为止。
这样看上去可能会懵,不如用刚刚的数据来构建一颗决策树。
一开始我们已经算过信息增益最大的是活跃度,所以决策树的根节点是活跃度 。所以这个时候树是这样的:

然后发现训练集中的数据表示当我活跃度低的时候一定会流失,活跃度高的时候一定不流失,所以可以先在根节点上接上两个叶子节点。
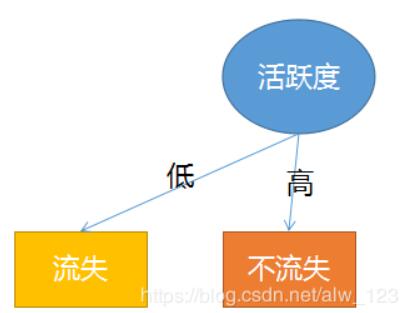
但是活跃度为中的时候就不一定流失了,所以这个时候就可以把活跃度为低和为高的数据屏蔽掉,屏蔽掉之后 条数据,接着把这 条数据当成训练集来继续算哪个特征的信息增益最高,很明显算完之后是性别这个特征,所以这时候树变成了这样:
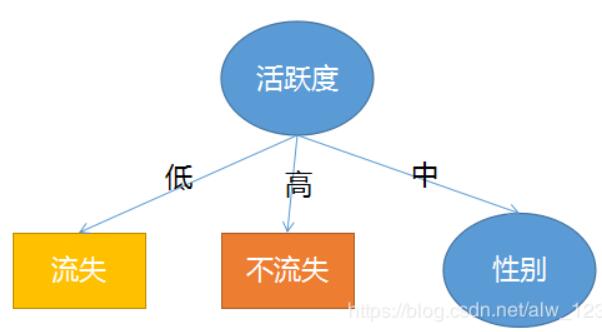
这时候呢,数据集里没有其他特征可以选择了(总共就两个特征,活跃度已经是根节点了),所以就看我性别是男或女的时候那种情况最有可能出现了。此时性别为男的用户中有 个是流失, 个是不流失,五五开。所以可以考虑随机选个结果当输出了。性别为女的用户中有全部都流失,所以性别为女时输出是流失。所以呢,树就成了这样:
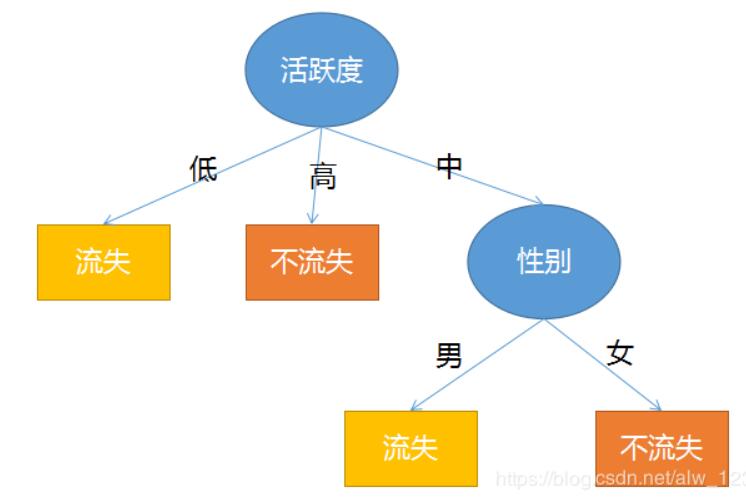
好了,决策树构造好了。从图可以看出决策树有一个非常好的地方就是模型的解释性非常强!!很明显,如果现在来了一条数据(男, 高)的话,输出会是不流失。