8.9 KiB
4. 使用sklearn进行机器学习
4.1 写在前面
这是一个sklearn的hello world级教程,想要更加系统更加全面的学习sklearn建议查阅sklearn的官方网站。
4.2 sklearn简介
scikit-learn(简记sklearn),是用python实现的机器学习算法库。sklearn可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。基本上只需要知道一些python的基础语法知识就能学会怎样使用sklearn了,所以sklearn是一款非常好用的python机器学习库。
4.3 sklearn的安装
和安装其他第三方库一样简单,只需要在命令行中输入 pip install scikit-learn 即可。
4.4 sklearn的目录结构
sklearn提供的接口都封装在不同的目录下的不同的py文件中,所以对sklearn的目录结构有一个大致的了解,有助于我们更加深刻地理解sklearn。目录结构如下:
其实从目录名字可以看出目录中的py文件是干啥的。比如cluster目录下都是聚类算法接口, ensemble目录下都是集成学习算法的接口。
4.5 使用sklearn识别手写数字
接下来不如通过一个实例来感受一下sklearn的强大。
想要识别手写数字,首先需要有数据。sklearn中已经为我们准备好了一些比较经典且质量较高的数据集,其中就包括手写数字数据集。该数据集有1797个样本,每个样本包括8*8 像素(实际上是一条样本有64个特征,每个像素看成是一个特征,每个特征都是float类型的数值)的图像和一个[0, 9]整数的标签。比如下图的标签是2:
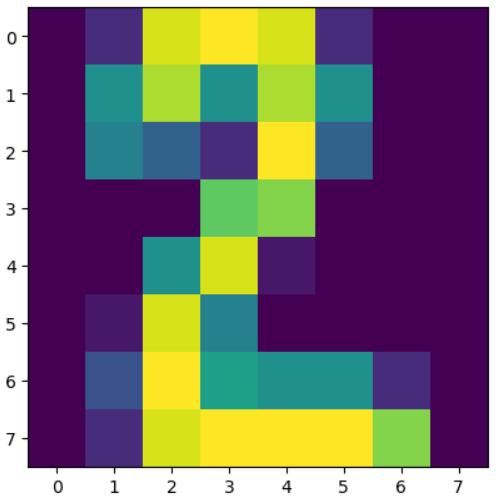
想要使用这个数据很简单,代码如下:
from sklearn import datasets
# 加载手写数字数据集
digits = datasets.load_digits()
# X表示特征,即1797行64列的矩阵
X = digits.data
# Y表示标签,即1797个元素的一维数组
y = digits.target
得到X,y数据之后,还需要将这些数据进行划分,划分成两个部分,一部分是训练集,另一部分是测试集。因为如果没有测试集的话,并不知道手写数字识别程序识别得准不准。数据集划分代码如下:
# 将X,y划分成训练集和测试集,其中训练集的比例为80%,测试集的比例为20%
# X_train表示训练集的特征,X_test表示测试集的特征,y_train表示训练集的标签,y_test表示测试集的标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
接下来,可以使用机器学习算法来实现手写数字识别了,例如想要使用随机森林来进行识别,那么首先要导入随机森林算法接口。
# 由于是分类问题,所以导入的是RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
导入好接口后,就可以创建随机森林对象了。随机森林对象有用来训练的函数 fit 和用来预测的函数 predict。fit函数需要训练集的特征和训练集的标签作为输入,predict函数需要测试集的特征作为输入。所以代码如下:
# 创建一个有50棵决策树的随机森林, n_estimators表示决策树的数量
clf = RandomForestClassifier(n_estimators=50)
# 用训练集训练
clf.fit(X_train, Y_train)
# 用测试集测试,result为预测结果
result = clf.predict(X_test)
得到预测结果后,需要将其与测试集的真实答案进行比对,计算出预测的准确率。sklearn已经提供了计算准确率的接口,使用代码如下:
# 导入计算准确率的接口
from sklearn.metrics import accuracy_score
# 计算预测准确率
acc = accuracy_score(y_test, result)
# 打印准确率
print(acc)
此时你会发现短短的几行代码实现的手写数字识别程序的准确率高于0.95。
而且不仅可以使用随机森林来实现手写数字识别,还可以使用别的机器学习算法实现,比如逻辑回归,代码如下:
from sklearn.linear_model import LogisticRegression
# 创建一个逻辑回归对象
clf = LogisticRegression()
# 用训练集训练
clf.fit(X_train, Y_train)
# 用测试集测试,result为预测结果
result = clf.predict(X_test)
细心的你可能已经发现,不管使用哪种分类算法来进行手写数字识别,不同的只是创建的算法对象不一样而已。有了算法对象后,就可以fit,predict大法了。
下面是使用随机森林识别手写数字的完整代码:
from sklearn import datasets
# 由于是分类问题,所以导入的是RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
# 导入计算准确率的接口
from sklearn.metrics import accuracy_score
# 加载手写数字数据集
digits = datasets.load_digits()
# X表示特征,即1797行64列的矩阵
X = digits.data
# Y表示标签,即1797个元素的一维数组
y = digits.target
# 将X,y划分成训练集和测试集,其中训练集的比例为80%,测试集的比例为20%
# X_train表示训练集的特征,X_test表示测试集的特征,y_train表示训练集的标签,y_test表示测试集的标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建一个有50棵决策树的随机森林, n_estimators表示决策树的数量
clf = RandomForestClassifier(n_estimators=50)
# 用训练集训练
clf.fit(X_train, Y_train)
# 用测试集测试,result为预测结果
result = clf.predict(X_test)
# 计算预测准确率
acc = accuracy_score(y_test, result)
# 打印准确率
print(acc)
4.6 更好地验证算法性能
在划分训练集与测试集时会有这样的情况,可能模型对于数字1的识别准确率比较低 ,而测试集中没多少个数字为1的样本,然后用测试集测试完后得到的准确率为0.96。然后你可能觉得哎呀,我的模型很厉害了,但其实并不然,因为这样的测试集让你的模型的性能有了误解。那有没有更加公正的验证算法性能的方法呢?有,那就是k-折验证!
k-折验证的大体思路是将整个数据集分成k份,然后试图让每一份子集都能成为测试集,并循环k次,总后计算k次模型的性能的平均值作为性能的估计。一般来说k的值为 5或者10。
k-折验证的流程如下:
1. 不重复抽样将整个数据集随机拆分成k份
2. 每一次挑选其中1份作为测试集,剩下的k-1份作为训练集
2.1. 在每个训练集上训练后得到一个模型
2.2. 用这个模型在相应的测试集上测试,计算并保存模型的评估指标
3. 重复第2步k次,这样每份都有一次机会作为测试集,其他机会作为训练集
4. 计算k组测试结果的平均值作为算法性能的估计。
sklearn为我们提供了将数据划分成k份的类KFold,使用示例如下:
# 导入KFold
from sklearn.model_selection import KFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 创建一个将数据集随机划分成5份
kf = KFold(n_splits = 5)
mean_acc = 0
# 将整个数据集划分成5份
# train_index表示从5份中挑出来4份所拼出来的训练集的索引
# test_index表示剩下的一份作为测试集的索引
for train_index, test_index in kf.split(X):
X_train, y_train = X[train_index], y[train_index]
X_test, y_test = X[test_index], y[test_index]
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
result = rf.predict(X_test)
mean_acc = accuracy_score(y_test, result)
# 打印5折验证的平均准确率
print(mean_acc/5)
完整代码如下:
from sklearn import datasets
# 由于是分类问题,所以导入的是RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
# 导入计算准确率的接口
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
# 加载手写数字数据集
digits = datasets.load_digits()
# X表示特征,即1797行64列的矩阵
X = digits.data
# Y表示标签,即1797个元素的一维数组
y = digits.target
# 创建一个将数据集随机划分成5份
kf = KFold(n_splits = 5)
mean_acc = 0
# 将整个数据集划分成5份
# train_index表示从5份中挑出来4份所拼出来的训练集的索引
# test_index表示剩下的一份作为测试集的索引
for train_index, test_index in kf.split(X):
X_train, y_train = X[train_index], y[train_index]
X_test, y_test = X[test_index], y[test_index]
rf = RandomForestClassifier()
rf.fit(X_train, y_train)
result = rf.predict(X_test)
mean_acc = accuracy_score(y_test, result)
# 打印5折验证的平均准确率
print(mean_acc/5)