7.9 KiB
线性回归
什么是线性回归
线性回归是什么意思?可以拆字释义。回归肯定不用我多说了,那什么是线性呢?我们可以回忆一下初中时学过的直线方程:$y=k*x+b$
这个式子表达的是,当我知道k(参数)和b(参数)的情况下,我随便给一个x我都能通过这个方程算出y来。而且呢,这个式子是线性的,为什么呢?因为从直觉上来说,你都知道,这个式子的函数图像是条直线。
从理论上来说,这式子满足线性系统的性质(至于线性系统是什么,可以查阅相关资料,这里就不多做赘述了,不然没完没了)。你可能会觉得疑惑,这一节要说的是线性回归,我说个这么low直线方程干啥?其实,说白了,线性回归就是在N维空间中找一个形式像直线方程一样的函数来拟合数据而已。比如说,我现在有这么一张图,横坐标代表房子的面积,纵坐标代表房价。
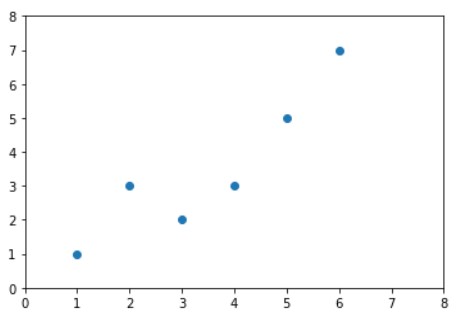
然后呢,线性回归就是要找一条直线,并且让这条直线尽可能地拟合图中的数据点。
那如果让1000位朋友来找这条直线就可能找出1000种直线来,比如这样
这样
或者这样
喏,其实找直线的过程就是在做线性回归,只不过这个叫法更有高大上而已。
损失函数
那既然是找直线,那肯定是要有一个评判的标准,来评判哪条直线才是最好的。道理我们都懂,那咋评判呢?其实只要算一下实际房价和我找出的直线根据房子大小预测出来的房价之间的差距就行了。说白了就是算两点的距离。当把所有实际房价和预测出来的房价的差距(距离)算出来然后做个加和,就能量化出现在预测的房价和实际房价之间的误差。例如下图中我画了很多条小数线,每一条小数线就是实际房价和预测房价的差距(距离)。
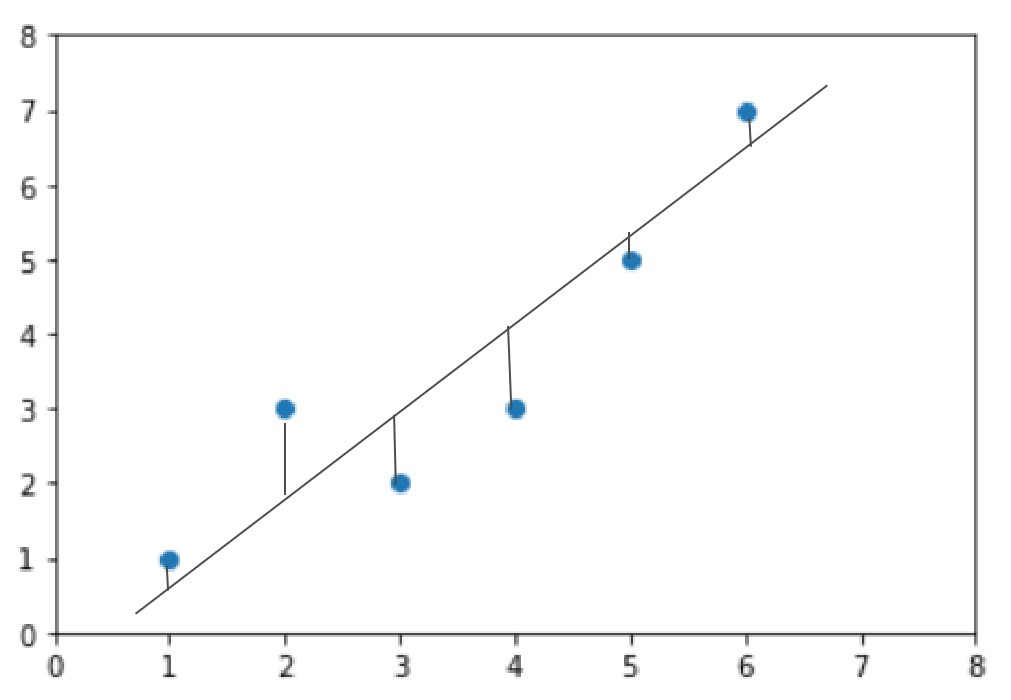
然后把每条小竖线的长度加起来就等于现在通过这条直线预测出的房价与实际房价之间的差距。那每条小竖线的长度的加和怎么算?其实就是欧式距离加和,公式为:\sum_{i=1}^m(y^{(i)}-y\hat{^{(i)}})^2$(其中y(i)表示的是实际房价,y \hat (i)$表示的是预测房价)。
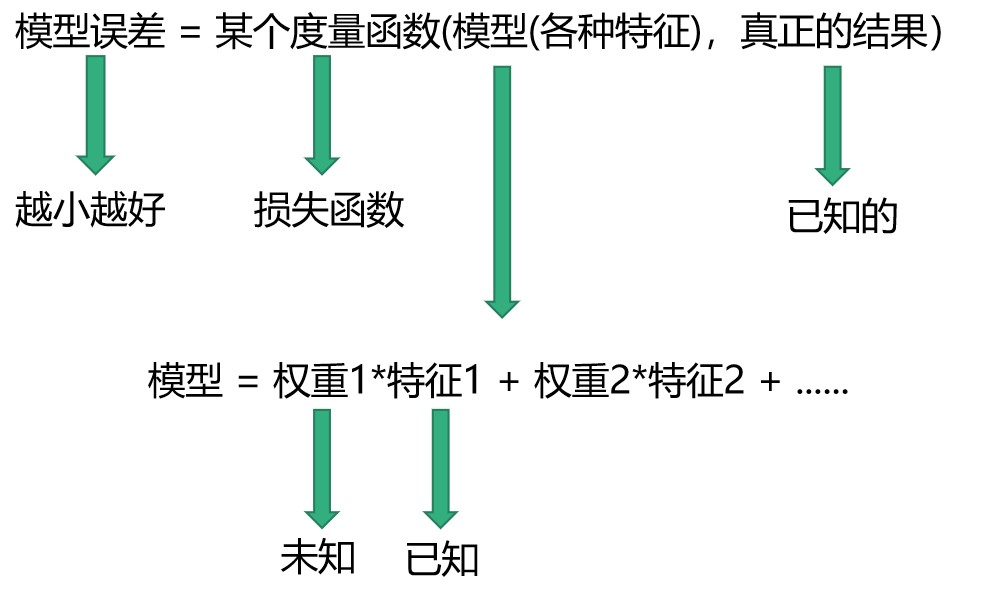
这个欧氏距离加和其实就是用来量化预测结果和真实结果的误差的一个函数。在机器学习中称它为损失函数(说白了就是计算误差的函数)。那有了这个函数,就相当于有了一个评判标准,当这个函数的值越小,就越说明找到的这条直线越能拟合房价数据。所以说啊,线性回归就是通过这个损失函数做为评判标准来找出一条直线。
如果假设$h_{(\theta)}(x)表示当权重为\theta,输入为x时计算出来的y \hat (i),那么线性回归的损失函数J(\theta)$就是:
怎样计算出线性回归的解?
现在你应该已经弄明白了一个事实,那就是我只要找到一组参数(也就是线性方程每一项上的系数)能让我的损失函数的值最小,那我这一组参数就能最好的拟合我现在的训练数据。
那怎么来找到这一组参数呢?其实有两种套路,一种就是用大名鼎鼎的梯度下降,其大概思想就是根据每个参数对损失函数的偏导来更新参数。另一种是线性回归的正规方程解,这名字听起来高大上,其实本质就是根据一个固定的式子计算出参数。由于正规方程解在数据量比较大的时候时间复杂度比较高,所以在这一部分中,主要聊聊怎样使用梯度下降的方法来更新参数。
什么是梯度下降
其实梯度下降不是一个机器学习算法,而是一种基于搜索的最优化方法。因为很多算法都没有正规解的,所以需要通过一次一次的迭代来找到找到一组参数能让损失函数最小。损失函数的大概套路可以参看这个图:
所以说,梯度下降的作用是不断的寻找靠谱的权重是多少。
现在已经知道了梯度下降就是用来找权重的,那怎么找权重呢?瞎猜?不可能的....这辈子都不可能猜的。想想都知道,权重的取值范围可以看成是个实数空间,那100个特征就对应着 100个权重,10000个特征就对应着10000个权重。如果靠瞎猜权重的话,应该这辈子都猜不中了。所以找权重的找个套路来找,这个套路就是梯度。梯度其实就是让函数值为 0 时其中各个变量的偏导所组成的向量,而且梯度方向是使得函数值增长最快的方向。
这个性质怎么理解呢?举个栗子。假如我是个想要成为英雄联盟郊区王者的死肥宅,然后要成为郊区王者可能有这么几个因素,一个是英雄池的深浅,一个是大局观,还有一个是骚操作。他们对我成为王者来说都有一定的权重。如图所示,每一个因素的箭头都有方向(也就是因素对于我成为王者的偏导的方向)和长度(偏导的值的大小)。然后在这些因素的共同作用下,我最终会朝着一个方向来训练(好比物理中分力和合力的关系),这个时候我就能以最快的速度向郊区王者更进一步。
也就是说我如果一直朝着最终的那个方向努力的话,理论上来说我就能以最快的速度成为郊区王者。
现在你知道了梯度的方向是函数增长最快的方向,那我在梯度前面取个负号(反方向),那不就是函数下降最快的方向了么。所以,梯度下降它的本质就是更新权重的时候是沿着梯度的反方向更新。好比下面这个图,假如我是个瞎子,然后莫名其妙的来到了一个山谷里。现在我要做的事情就是走到山谷的谷底。因为我是瞎子,所以我只能一点一点的挪。要挪的话,那我肯定是那我的脚在我四周扫一遍,觉得哪里感觉起来更像是在下山那我就往哪里走。然后这样循环反复一发我最终就能走到山谷的谷底。

所以,梯度下降的伪代码如下:
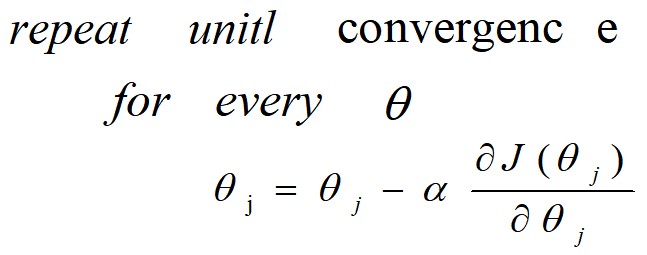
循环干的事情就相当于我下山的时候在迈步子,代码里的 \alpha$$ 高端点叫学习率,实际上就是代表我下山的时候步子迈多大。值越小就代表我步子迈得小,害怕一脚下去掉坑里。值越大就代表我胆子越大,步子迈得越大,但是有可能会越过山谷的谷底。
使用梯度下降求解线性回归的解
线性回归的损失函数 $J 为:J(\theta)=\frac{1}{2}\sum^m_{i=1}(h_\theta(x^i)-y^i)^2,其中\theta为线性回归的解。使用梯度下降来求解,最关键的一步是算梯度(也就是算偏导),通过计算可知第j$个权重的偏导为:
所以很自然的可以想到,使用梯度下降求解线性回归的解的流程如下:
循环若干次
计算当前参数theta对损失函数的梯度 gradient
theta = theta - alpha * gradient
当\theta$$更新好了之后,就相当于得到了一个线性回归模型。也就是说只要将数据放到模型中进行计算就能得到预测输出了。