You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
4.1 KiB
4.1 KiB
特征工程
什么是特征工程?其实每当我们拿到数据时,并不是所有的特征都是有用的,可能有许多冗余的特征需要删掉,或者根据EDA的结果,我们可以根据已有的特征来添加新的特征,这其实就是特征工程。
接下来我们来尝试对一些特征进行处理。
年龄离散化
年龄是一个连续型的数值特征,有的机器学习算法对于连续性数值特征不太友好,例如决策树、随机森林等tree-base model。所以我们可以考虑将年龄转换成年龄段。例如将年龄小于16的船客置为0 ,16到32岁之间的置为1等。
data['Age_band']=0
data.loc[data['Age']<=16,'Age_band']=0
data.loc[(data['Age']>16)&(data['Age']<=32),'Age_band']=1
data.loc[(data['Age']>32)&(data['Age']<=48),'Age_band']=2
data.loc[(data['Age']>48)&(data['Age']<=64),'Age_band']=3
data.loc[data['Age']>64,'Age_band']=4
我们可以看一下转换成年龄段后,年龄段与生还率的关系。
sns.factorplot('Age_band','Survived',data=data,col='Pclass')
plt.show()
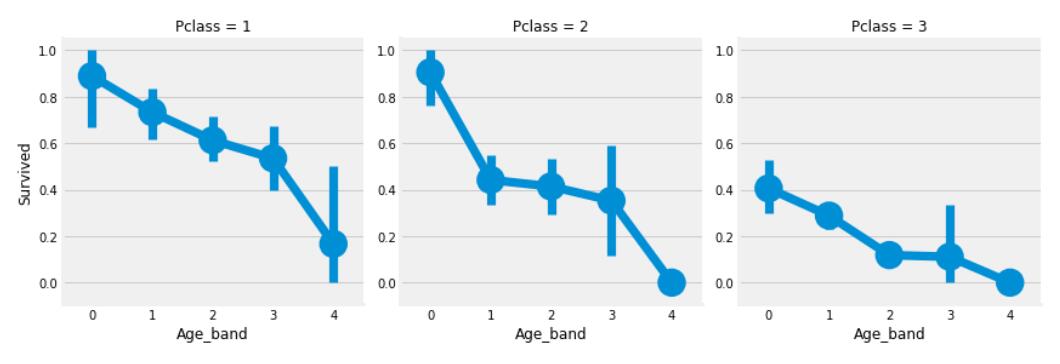
可以看出和我们之前EDA的结果相符,年龄越大,生还率越低。
家庭成员数量与是否孤身一人
由于家庭成员数量和是否孤身一人好想对于是否生还有影响,所以我们不妨添加新的特征。
data['Family_Size']=0
data['Family_Size']=data['Parch']+data['SibSp']
data['Alone']=0
data.loc[data.Family_Size==0,'Alone']=1
然后再可视化看一下
f,ax=plt.subplots(1,2,figsize=(18,6))
sns.factorplot('Family_Size','Survived',data=data,ax=ax[0])
ax[0].set_title('Family_Size vs Survived')
sns.factorplot('Alone','Survived',data=data,ax=ax[1])
ax[1].set_title('Alone vs Survived')
plt.close(2)
plt.close(3)
plt.show()
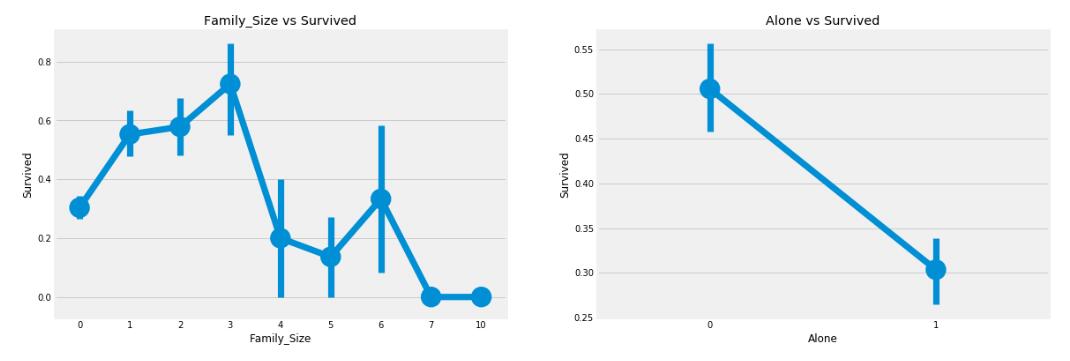
从图中可以很明显的看出,如果你是一个人,那么生还的几率比较低,而且对于人数大于4人的家庭来说生还率也比较低。感觉,这可能也是一个比较好的特征,可以再深入的看一下。
sns.factorplot('Alone','Survived',data=data,hue='Sex',col='Pclass')
plt.show()
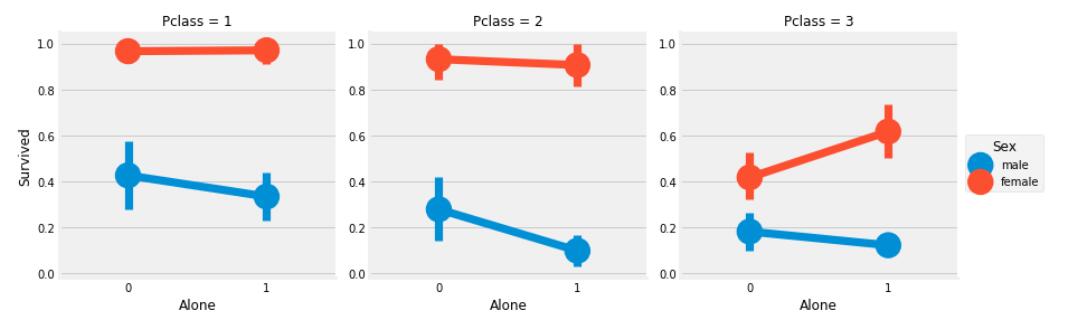
可以看出,除了三等舱的单身女性的生还率比非单身女性的生还率高外,单身并不是什么好事。
花费离散化
和年龄一样,花费也是一个连续性的数值特征,所以我们不妨将其离散化。
data['Fare_cat']=0
data.loc[data['Fare']<=7.91,'Fare_cat']=0
data.loc[(data['Fare']>7.91)&(data['Fare']<=14.454),'Fare_cat']=1
data.loc[(data['Fare']>14.454)&(data['Fare']<=31),'Fare_cat']=2
data.loc[(data['Fare']>31)&(data['Fare']<=513),'Fare_cat']=3
sns.factorplot('Fare_cat','Survived',data=data,hue='Sex')
plt.show()
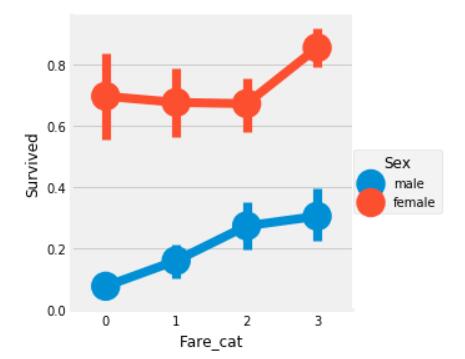
很明显,花费越多生还率越高,金钱决定命运。
将字符串特征转换为数值型特征
由于我们的机器学习模型不支持字符串,所以需要将一些有用的字符串类型的特征转换成数值型的特征,比如:性别,口岸,姓名前缀。
data['Sex'].replace(['male','female'],[0,1],inplace=True)
data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True)
删掉没多大用处的特征
- 姓名:难道姓名和生死有关系?这也太玄乎了,我不信,所以把它删掉
- 年龄:由于已经根据年龄生成了新的特征“年龄段”,所以这个特征也需要删除。
- 票:票这个特征感觉是一堆随机的字符串,所以删掉。
- 花费:和年龄一样,删掉。
- 船舱:由于有很多缺失值,不好填充,所以可以考虑删掉。
- 船客
ID:ID和生死应该没啥关系,所以删掉。
data.drop(['Name','Age','Ticket','Fare','Cabin','PassengerId'],axis=1,inplace=True)