You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
1.9 KiB
1.9 KiB
2.9 k Means
k Means是属于机器学习里面的非监督学习,通常是大家接触到的第一个聚类算法,其原理非常简单,是一种典型的基于距离的聚类算法。距离指的是每个样本到质心的距离。那么,这里所说的质心是什么呢?
其实,质心指的是样本每个特征的均值所构成的一个坐标。举个例子:假如有两个数据 (1,1) 和(2,2) 则这两个样本的质心为 (1.5,1.5)。
同样的,如果一份数据有 $m个样本,每个样本有n个特征,用x_i^j来表示第j个样本的第i 个特征,则它们的质心为:Cmass=(\frac{\sum_{j=1}^mx_1^j}{m},\frac{\sum_{j=1}^mx_2^j}{m},...,\frac{\sum_{j=1}^mx_n^j}{m})$。
知道什么是质心后,就可以看看k Means算法的流程了。
k Means算法流程
使用k Means来聚类时需要首先定义参数k,k的意思是我想将数据聚成几个类别。假设k=3,就是将数据划分成3个类别。接下来就可以开始k Means算法的流程了,流程如下:
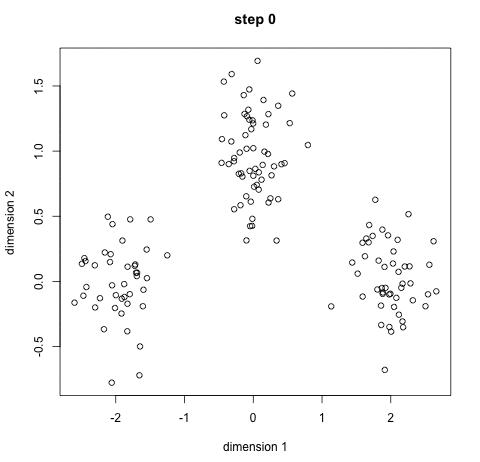
1.随机初始k个样本,作为类别中心。
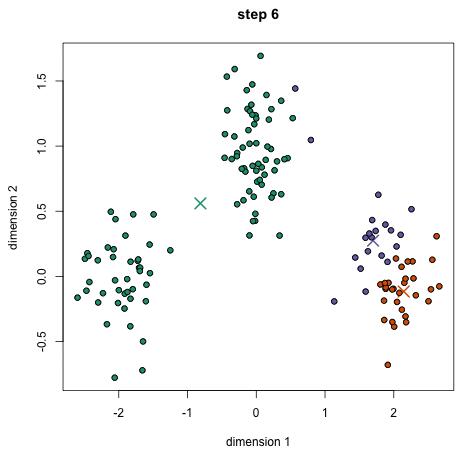
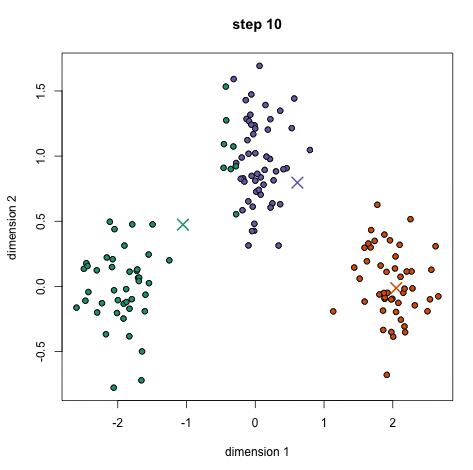
2.对每个样本将其标记为距离类别中心最近的类别。
3.将每个类别的质心更新为新的类别中心。
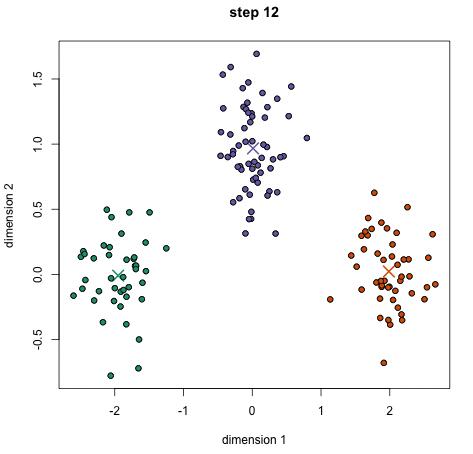
4.重复步骤2、3,直到类别中心的变化小于阈值。
过程示意图如下(其中 X 表示类别的中心,数据点的颜色代表不同的类别,总共迭代12次,下图为部分迭代的结果):