10 KiB
朴素贝叶斯分类器
朴素贝叶斯分类算法是基于贝叶斯理论和特征条件独立假设的分类算法。对于给定的训练集,首先基于特征条件独立假设学习数据的概率分布。然后基于此模型,对于给定的特征数据x,利用贝叶斯定理计算出标签y。朴素贝叶斯分类算法实现简单,预测的效率很高,是一种常用的分类算法。
##条件概率
朴素贝叶斯分类算法是基于贝叶斯定理与特征条件独立假设的分类方法,因此想要了解朴素贝叶斯分类算法背后的算法原理,就不得不用到概率论的一些知识,首当其冲就是条件概率。
###什么是条件概率
概率指的是某一事件A发生的可能性,表示为P(A)。而条件概率指的是某一事件A已经发生了条件下,另一事件B发生的可能性,表示为P(B|A),举个例子:
今天有25%的可能性下雨,即P(下雨)=0.25;
今天75%的可能性是晴天,即P(晴天)=0.75;
如果下雨,我有75%的可能性穿外套,即P(穿外套|下雨)=0.75;
如果下雨,我有25%的可能性穿T恤,即P(穿T恤|下雨)=0.25;
从上述例子可以看出,条件概率描述的是|右边的事件已经发生之后,左边的事件发生的可能性,而不是两个事件同时发生的可能性!
###怎样计算条件概率
设A,B是两个事件,且P(A)>0,称P(B|A)=P(AB)/P(A)为在事件A发生的条件下,事件B发生的条件概率。(其中P(AB)表示事件A和事件B同时发生的概率)
举个例子,现在有一个表格,表格中统计了甲乙两个厂生产的产品中合格品数量、次品数量的数据。数据如下:
| 甲厂 | 乙厂 | 合计 | |
|---|---|---|---|
| 合格品 | 475 | 644 | 1119 |
| 次品 | 25 | 56 | 81 |
| 合计 | 500 | 700 | 1200 |
现在想要算一下已知产品是甲厂生产的,那么产品是次品的概率是多少。这个时候其实就是在算条件概率,计算非常简单。
假设事件A为产品是甲厂生产的,事件B为产品是次品。则根据表中数据可知P(AB)=25/1200,P(A)=500/1200。则P(B|A)=P(AB)/P(A)=25/500。
###乘法定理
将条件概率的公式两边同时乘以P(A),就变成了乘法定理,即P(AB)=P(B|A)*P(A)。那么乘法定理怎么用呢?举个例子:
现在有一批产品共100件,次品有10件,从中不放回地抽取2次,每次取1件。现在想要算一下第一次为次品,第二次为正品的概率。
从问题来看,这个问题问的是第一次为次品,第二次为正品这两个事件同时发生的概率。所以可以用乘法定理来解决这个问题。
假设事件A为第一次为次品,事件B为第二次为正品。则P(AB)=P(A)*P(B|A)=(10/100)*(90/99)=0.091。
##全概率公式
贝叶斯公式是朴素贝叶斯分类算法的核心数学理论,在了解贝叶斯公式之前,我们需要先了解全概率公式的相关知识。
###引例
小明从家到公司上班总共有三条路可以直达,如下图:
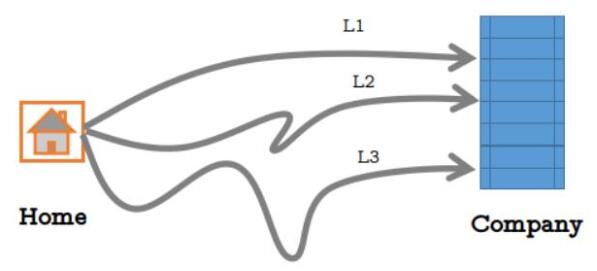
但是每条路每天拥堵的可能性不太一样,由于路的远近不同,选择每条路的概率如下表所示:
| L1 | L2 | L3 |
|---|---|---|
| 0.5 | 0.3 | 0.2 |
每天从上述三条路去公司时不堵车的概率如下表所示:
| L1不堵车 | L2不堵车 | L3不堵车 |
|---|---|---|
| 0.2 | 0.4 | 0.7 |
如果不堵车就不会迟到,现在小明想要算一算去公司上班不会迟到的概率是多少,应该怎么办呢?
其实很简单,假设事件C为小明不迟到,事件A1为小明选L1这条路并且不堵车,事件A2为小明选L2这条路并且不堵车,事件A3为小明选L3这条路并且不堵车。那么很显然P(C)=P(A1)+P(A2)+P(A3)。
那么问题来了,P(A1)、P(A2)和P(A3)怎么算呢?其实只要会算P(A1)其他的就都会算了。我们同样可以假设事件D1为小明选择L1路,事件E1为不堵车。那么P(A1)=P(D1)*P(E1)。但是在从表格中我们只知道P(D1)=0.5,怎么办呢?
回忆一下上面介绍的乘法定理,不难想到P(A1)=P(D1)*P(E1|D1)。从表格中可以看出P(E1|D1)=0.2。因此P(A1)=0.5*0.2=0.1。
然后依葫芦画瓢可以很快算出,P(A2)=0.3*0.4=0.12,P(A3)=0.2*0.7=0.14。所以P(C)=0.1+0.12+0.14=0.36。
###全概率公式
当为了达到某种目的,但是达到目的有很多种方式,如果想知道通过所有方式能够达到目的的概率是多少的话,就需要用到全概率公式(上面的例子就是这种情况!)。全概率公式的定义如下:
若事件$B_1,B_2,...,B_n$两两互不相容,并且其概率和为1。那么对于任意一个事件C都满足:
引例中小明选择哪条路去公司的概率是两两互不相容的(只能选其中一条路去公司),并且和为1。所以小明不迟到的概率可以通过全概率公式来计算,而引例中的计算过程就是用的全概率公式。
##贝叶斯公式
当已知引发事件发生的各种原因的概率,想要算该事件发生的概率时,我们可以用全概率公式。但如果现在反过来,已知事件已经发生了,但想要计算引发该事件的各种原因的概率时,我们就需要用到贝叶斯公式了。
贝叶斯公式定义如下,其中$A表示已经发生的事件,B_i为导致事件A发生的第i$个原因:
贝叶斯公式看起来比较复杂,其实非常简单,分子部分是乘法定理,分母部分是全概率公式(分母等于$P(A)$)。
如果我们对贝叶斯公式进行一个简单的数学变换(两边同时乘以分母,再两边同时除以$P(B_i)$)。就能够得到如下公式:
##贝叶斯算法流程
在炎热的夏天你可能需要买一个大西瓜来解暑,但虽然你的挑西瓜的经验很老道,但还是会有挑错的时候。尽管如此,你可能还是更愿意相信自己经验。假设现在在你面前有一个纹路清晰,拍打西瓜后声音浑厚,按照你的经验来看这个西瓜是好瓜的概率有80%,不是好瓜的概率有20%。那么在这个时候你下意识会认为这个西瓜是好瓜,因为它是好瓜的概率大于不是好瓜的概率。
###朴素贝叶斯分类算法的预测流程
朴素贝叶斯分类算法的预测思想和引例中挑西瓜的思想一样,会根据以往的经验计算出待预测数据分别为所有类别的概率,然后挑选其中概率最高的类别作为分类结果。
假如现在一个西瓜的数据如下表所示:
| 颜色 | 声音 | 纹理 | 是否为好瓜 |
|---|---|---|---|
| 绿 | 清脆 | 清晰 | ? |
若想使用朴素贝叶斯分类算法的思想,根据这条数据中颜色、声音和纹理这三个特征来推断是不是好瓜,我们需要计算出这个西瓜是好瓜的概率和不是好瓜的概率。
假设事件A1为好瓜,事件B为绿,事件C为清脆,事件D为清晰,则这个西瓜是好瓜的概率为P(A1|BCD)。根据贝叶斯公式可知:
同样,假设事件A2为好瓜,事件B为绿,事件C为清脆,事件D为清晰,则这个西瓜不是好瓜的概率为P(A2|BCD)。根据贝叶斯公式可知:
朴素贝叶斯分类算法的思想是取概率最大的类别作为预测结果,所以如果满足下面的式子,则认为这个西瓜是好瓜,否则就不是好瓜:
$$ \frac{P(A_1)P(B|A_1)P(C|A_1)P(D|A_1)}{P(BCD)}>\frac{P(A_2)P(B|A_2)P(C|A_2)P(D|A_2)}{P(BCD)} $$从上面的式子可以看出,P(BCD)是多少对于判断哪个类别的概率高没有影响,所以式子可以简化成如下形式:
所以在预测时,需要知道P(A1),P(A2),P(B|A_1),P(C|A_1),P(D|A_1)等于多少。而这些概率在训练阶段可以计算出来。
###朴素贝叶斯分类算法的训练流程
训练的流程非常简单,主要是计算各种条件概率。假设现在有一组西瓜的数据,如下表所示:
| 编号 | 颜色 | 声音 | 纹理 | 是否为好瓜 |
|---|---|---|---|---|
| 1 | 绿 | 清脆 | 清晰 | 是 |
| 2 | 黄 | 浑厚 | 模糊 | 否 |
| 3 | 绿 | 浑厚 | 模糊 | 是 |
| 4 | 绿 | 清脆 | 清晰 | 是 |
| 5 | 黄 | 浑厚 | 模糊 | 是 |
| 6 | 绿 | 清脆 | 清晰 | 否 |
从表中数据可以看出:
P(是好瓜)=4/6
P(颜色绿|是好瓜)=3/4
P(颜色黄|是好瓜)=1/4
P(声音清脆|是好瓜)=1/2
P(声音浑厚|是好瓜)=1/2
P(纹理清晰|是好瓜)=1/2
P(纹理模糊|是好瓜)=1/2
P(不是好瓜)=2/6
P(颜色绿|不是好瓜)=1/2
P(颜色黄|是好瓜)=1/2
P(声音清脆|不是好瓜)=1/2
P(声音浑厚|不是好瓜)=1/2
P(纹理清晰|不是好瓜)=1/2
P(纹理模糊|不是好瓜)=1/2
当得到以上概率后,训练阶段的任务就已经完成了。我们不妨再回过头来预测一下这个西瓜是不是好瓜。
| 颜色 | 声音 | 纹理 | 是否为好瓜 |
|---|---|---|---|
| 绿 | 清脆 | 清晰 | ? |
假设事件A1为好瓜,事件B为绿,事件C为清脆,事件D为清晰。则有:
假设事件A2为不是瓜,事件B为绿,事件C为清脆,事件D为清晰。则有:
由于\frac{1}{8}>\frac{1}{24},所以这个西瓜是好瓜。