3.9 KiB
机器学习常用术语
训练集,测试集,样本,特征
假设收集了一份西瓜数据:
| 色泽 | 纹理 | 声音 | 甜不甜 |
|---|---|---|---|
| 青绿 | 清晰 | 清脆 | 不甜 |
| 青绿 | 模糊 | 浑浊 | 甜 |
| 乌黑 | 清晰 | 清脆 | 不甜 |
| 乌黑 | 模糊 | 浑浊 | 甜 |
并假设现在已经使用机器学习算法根据这份数据的特点训练出了一个很厉害的模型,成为了一个挑瓜好手,只需告诉它这个西瓜的色泽,纹理和声音就能告诉你这个西瓜甜不甜。
通常将这种喂给机器学习算法来训练模型的数据称为训练集,用来让机器学习算法预测的数据称为测试集。
训练集中的所有行称为样本。由于我们的挑瓜好手需要的西瓜信息是色泽、纹理和声音,所以此训练集中每个样本的前3列称为特征。挑瓜好手给出的结果是甜或不甜,所以最后1列称为标签。
因此,这份数据是一个有4个样本,3个特征的训练集,训练集的标签是“甜不甜”。
欠拟合与过拟合
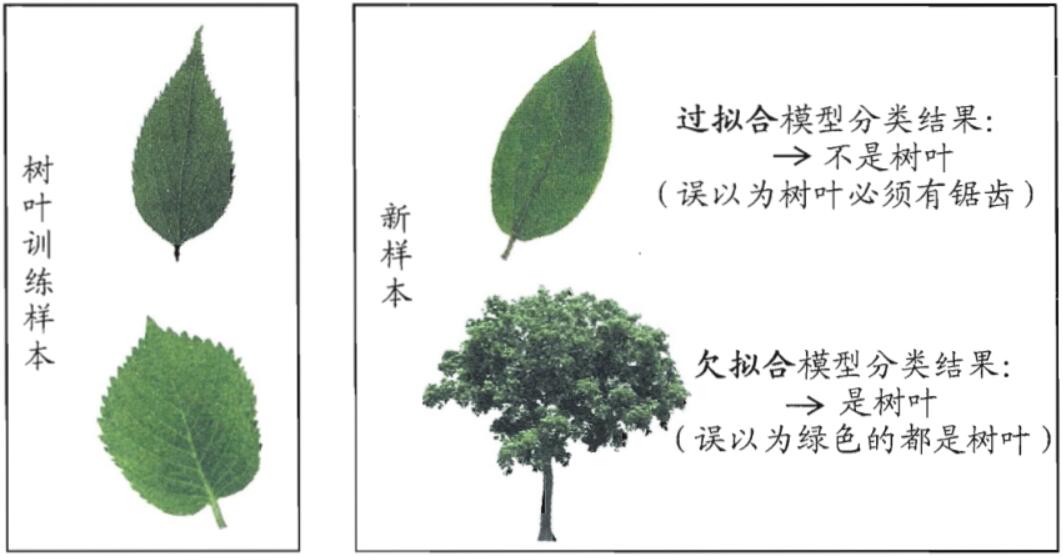
最好的情况下,模型应该不管在训练集上还是测试集上,它的性能都不错。但是有的时候,我模型在训练集上的性能比较差,那么这种情况我们称为欠拟合。那如果模型在训练集上的性能好到爆炸,但在测试集上的性能却不尽人意,那么这种情况我们称为过拟合。
其实欠拟合与过拟合的区别和生活中学生考试的例子很像。如果一个学生在平时的练习中题目的正确率都不高,那么说明这个学生可能基础不牢或者心思没花在学习上,所以这位学生可能欠缺基础知识或者智商可能不太高或者其他种种原因,像这种情况可以看成是欠拟合。那如果这位学生平时练习的正确率非常高,但是他不怎么灵光,喜欢死记硬背,只会做已经做过的题,一碰到没见过的新题就不知所措了。像这种情况可以看成是过拟合。
那么是什么原因导致了欠拟合和过拟合呢?
当模型过于简单,很可能会导致欠拟合。如果模型过于复杂,就很可能会导致过拟合。
验证集与交叉验证
在真实业务中,我们可能没有真正意义上的测试集,或者说不知道测试集中的数据长什么样子。那么怎样在没有测试集的情况下来验证模型好还是不好呢?这个时候就需要验证集了。
那么验证集从何而来,很明显,可以从训练集中抽取一小部分的数据作为验证集,用来验证模型的性能。
但如果仅仅是从训练集中抽取一小部分作为验证集的话,有可能会让对模型的性能有一种偏见或者误解。
比如现在要对手写数字进行识别,那么我就可能会训练一个分类模型。但可能模型对于数字1的识别准确率比较低 ,而验证集中没多少个数字为1的样本,然后用验证集测试完后得到的准确率为0.96。然后您可能觉得哎呀,我的模型很厉害了,但其实并不然,因为这样的验证集让您的模型的性能有了误解。那有没有更加公正的验证算法性能的方法呢?有,那就是k-折交叉验证!
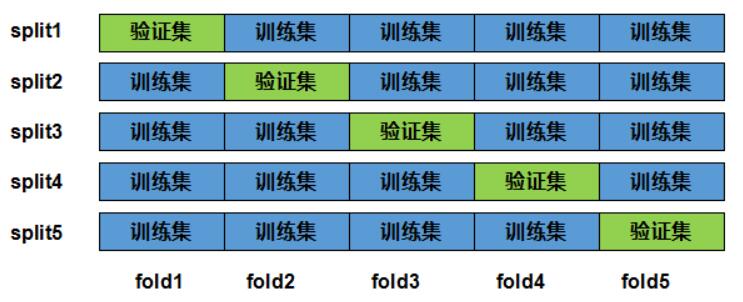
在K-折交叉验证中,把原始训练数据集分割成K个不重合的⼦数据集,然后做K次模型训练和验证。每⼀次,使⽤⼀个⼦数据集验证模型,并使⽤其它K−1个⼦数据集来训练模型。在这K次训练和验证中,每次⽤来验证模型的⼦数据集都不同。最后,对这K次在验证集上的性能求平均。
K的值由我们自己来指定,如以下为5折交叉验证。