5.9 KiB
逻辑回归
逻辑回归是属于机器学习里面的监督学习,它是以回归的思想来解决分类问题的一种非常经典的二分类分类器。由于其训练后的参数有较强的可解释性,在诸多领域中,逻辑回归通常用作 baseline模型,以方便后期更好的挖掘业务相关信息或提升模型性能。
逻辑回归大体思想
什么是逻辑回归
当一看到“回归”这两个字,可能会认为逻辑回归是一种解决回归问题的算法,然而逻辑回归是通过回归的思想来解决二分类问题的算法。
那么问题来了,回归的算法怎样解决分类问题呢?其实很简单,逻辑回归是将样本特征和样本所属类别的概率联系在一起,假设现在已经训练好了一个逻辑回归的模型为$f(x),模型的输出是样本x的标签是1的概率,则该模型可以表示成\hat p=f(x)。若得到了样本x属于标签1的概率后,很自然的就能想到当\hat p>0.5时x属于标签1,否则属于标签 0$ 。所以就有:
(其中\hat y$为样本 x根据模型预测出的标签结果,标签0和标签1所代表的含义是根据业务决定的,比如在癌细胞识别中可以使0 代表良性肿瘤,1$ 代表恶性肿瘤)。
由于概率是 $0到1$ 的实数,所以逻辑回归若只需要计算出样本所属标签的概率就是一种回归算法,若需要计算出样本所属标签,则就是一种二分类算法。
那么逻辑回归中样本所属标签的概率怎样计算呢?其实和线性回归有关系,学习了线性回归的话肯定知道线性回归就是训练出一组参数 $W和b 来拟合样本数据,线性回归的输出为\hat y=Wx+b 。不过\hat y的值域是(-\infty,+\infty),如果能够将值域为(-\infty,+\infty)的实数转换成(0,1)的概率值的话问题就解决了。**要解决这个问题很自然地就能想到将线性回归的输出作为输入,输入到另一个函数中,这个函数能够进行转换工作,假设函数为\sigma,转换后的概率为\hat p,则逻辑回归在预测时可以看成\hat p=\sigma (Wx+b)**。 \sigma 其实就是接下来要介绍的sigmoid$函数。
sigmoid函数
sigmoid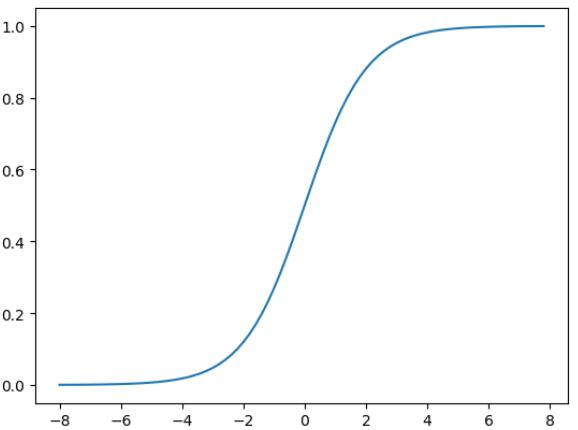
从$sigmoid函数的图像可以看出当t趋近于-\infty时函数值趋近于0,当t趋近于+\infty时函数值趋近于1。可见sigmoid函数的值域是(0,1),满足我们要将(-\infty,+\infty)的实数转换成(0,1)的概率值的需求。因此**逻辑回归**在预测时可以看成\hat p=1/(1+e^{-Wx+b}),如果\hat p>0.5$时预测为一种类别,否则预测为另一种类别。
逻辑回归的损失函数
在预测样本属于哪个类别时取决于算出来的\hat p$。从另外一个角度来说,假设现在有一个样本的真实类别为 1,模型预测样本为类别1的概率为0.9的话,就意味着这个模型认为当前样本的类别有90\%的可能性为1,有10\%的可能性为0。所以从这个角度来看,逻辑回归的损失函数与\hat p$ 有关。
当然逻辑回归的损失函数不仅仅与 \hat p$有关,它还与真实类别有关。假设现在有两种情况,**情况 A** :现在有个样本的真实类别是0,但是模型预测出来该样本是类别1的概率是0.7(也就是说类别 0的概率为0.3);**情况 B** :现在有个样本的真实类别是0,但是模型预测出来该样本是类别1的概率是0.6(也就是说类别 0的概率为0.4);请你思考2秒钟,**AB** 两种情况哪种情况的误差更大?很显然,**情况 A** 的误差更大!因为**情况 A** 中模型认为样本是类别0的可能性只有30\%,而 **情况 B** 有 40\%$。
假设现在又有两种情况,情况A: 现在有个样本的真实类别是 $0,但是模型预测出来该样本是类别1的概率是0.7(也就是说类别 0的概率为0.3);**情况B:**现在有个样本的真实类别是 1,但是模型预测出来该样本是类别 1的概率是0.3(也就是说类别 0的概率为0.7);请你再思考2$ 秒钟,AB两种情况哪种情况的误差更大?很显然,一样大!
所以逻辑回归的损失函数如下,其中 $cost 表示损失函数的值,y$ 表示样本的真实类别:
cost=-ylog(\hat p)-(1-y)log(1-\hat p)
知道了逻辑回归的损失函数之后,逻辑回归的训练流程就很明显了,就是寻找一组合适的 $W和b ,使得损失值最小。找到这组参数后模型就确定下来了。怎么找?很明显,用**梯度下降**,而且不难算出梯度为:(\hat y - y)x$。
所以逻辑回归梯度下降的代码如下:
#loss
def J(theta, X_b, y):
y_hat = self._sigmoid(X_b.dot(theta))
try:
return -np.sum(y*np.log(y_hat)+(1-y)*np.log(1-y_hat)) / len(y)
except:
return float('inf')
# 算theta对loss的偏导
def dJ(theta, X_b, y):
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) / len(y)
# 批量梯度下降
def gradient_descent(X_b, y, initial_theta, leraning_rate, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - leraning_rate * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta