3.9 KiB
6.2.2 人脸位置检测
OpenCV的人脸检测,使用Harr分类器。该分类器采用的Viola-Jones人脸检测算法。它是在 2001年由Viola和Jones提出的基于机器学习的人脸检测算法。
算法首先需要大量的积极图片(包含人脸的图片)和消极图片(不包含人脸的图片)。然后从中提取类Harr特征( Harr-like features),之所以称为Harr分类器,是正是因为它使用了类Harr特征。最后,训练出一个级联检测器,用其来检测人脸。
类Harr特征
图像中的特征通常是指,图片的像素点经过一系列的运算之后得到的结果,这些结果可能是向量、矩阵和多维数据等等。类Harr特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。
Harr特征类别
它分为三类:边缘特征、线性特征、中心特征和对角线特征。用黑色两种矩形框组成为特征模板。
1.边缘特征

2.线性特征

3.中心特征和对角线特征

特征值计算
特征模板的特征值计算的方式,是用黑色矩形像素总和的均值减去白色矩形像素总和的均值。
\Delta = \frac{1}{n}\sum_{dark}^{n}I(x)-\frac{1}{n}\sum_{white}^{n}I(x) 例如,对于4x4的像素块。
理想情况下,黑色和白色的像素块分布如下:
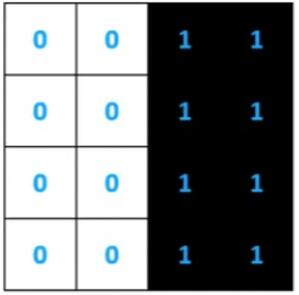
符合边缘特征的情况(a)。
但是通常情况,一张灰阶照片的黑白分布并非如此的明显,例如:

根据公式,第一张图特征值为1,第二张图特征值为0.75-0.18=0.56。
一张图中,对于识别人脸,只有部分特征是有效的。例如,用下图中的特征模板可以看出,眉毛区域比额头要亮,鼻梁区域比眼镜区域要亮。嘴唇区域比牙齿区域要暗。这样的类Harr特征能很好的识别出人脸。

为简化特征值计算,可以使用积分图算法。得到类Harr特征后,使用AdaBoost的方法选择出有效特征。最后再使用瀑布型级联检测器提高检测速度。其中,瀑布的每一层都是一个由Adaboost算法训练得到的强分类器。
Harr人脸检测一个简单的动画过程如下:

红色的搜索框不断移动,检测出是否包含人脸。一般来说,输入的图片会大于样本,为了检索出不同大小的目标,分类器可以按比例的改变自己的尺寸,对输入图片进行多次的扫描。
训练Harr分类器
训练Harr分类器的主要步骤如下:
- 搜集制作大量的“消极”图像
- 搜集制作大量“积极”图像,确保这些图像中包含要检测的对象
- 创建“积极”向量文件
- 使用
OpenCV训练Harr分类器
因为训练需要花费较多的资源和时间,所以我们学习时,先使用OpenCV中已经训练好的Harr分类器。
使用Harr分类器检测人脸
声明分类器:
CascadeClassifier(模型文件路径)
调用分类函数:
detectMultiScale(图片对象,scaleFactor, minNeighbors, minSize)
参数说明:
- 图片对象:待识别图片对象;
scaleFactor:图像缩放比例;minNeighbors:对特征检测点周边多少有效点同时检测,这样可避免因选取的特征检测点太小而导致遗漏;minSize:特征检测点的最小尺寸,可选参数。
示例如下:
import numpy as np
import cv2 as cv
# 读取图片
img = cv.imread('face.jpg')
# 转换为灰度图片
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 人脸检测器
face_cascade = cv.CascadeClassifier('Harrcascade_frontalface_default.xml')
# 识别人脸
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
print(x,y,w,h)
其中,图片坐标系以左上角为原点,x,y代表人脸区域左上角坐标,w代表宽度,h代表高度。
