5.2:线性回归算法原理
线性回归训练流程
我们已经知道线性回归模型如下:
y=b+w1x1+w2x2+...+wnxn
为了方便,我们稍微将模型进行变换:
y=w0x0+w1x1+w2x2+...+wnxn
其中x0=1,w0=b,通过向量化公式可写成如下形式:
Y=X.W
W=(w0,w1,...,wn)
X=(1,x1,...,xn)
而我们的目的就是找出能够正确预测的多元线性回归模型,即找出正确的W(即权重与偏置)。那么如何寻找呢?通常在监督学习里面都会使用这么一个套路,构造一个损失函数,用来衡量真实值与预测值之间的差异,然后将问题转化为最优化损失函数。既然损失函数是用来衡量真实值与预测值之间的差异那么很多人自然而然的想到了用所有真实值与预测值的差的绝对值来表示损失函数。不过带绝对值的函数不容易求导,所以采用MSE(均方误差)作为损失函数,公式如下:
loss=m1i=1∑m(y(i)−p(i))2
其中p表示预测值,y表示真实值,m为样本总个数,i表示第i个样本。最后,我们再使用正规方程解来求得我们所需要的参数。
线性回归模型训练流程图如下:
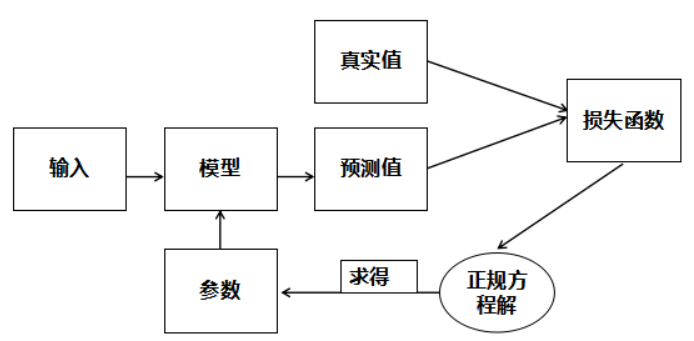
正规方程解
对线性回归模型,假设训练集中m个训练样本,每个训练样本中有n个特征,可以使用矩阵的表示方法,预测函数可以写为:
Y=X.W
其损失函数可以表示为
loss=m1(Y−X.W)T(Y−X.W)
其中,标签Y为m行1列的矩阵,训练特征X为m行(n+1)列的矩阵,回归系数W为(n+1)行1列的矩阵,对W求导,并令其导数为零可解得:
W=(XTX)−1XTY
这个就是正规方程解,我们可以通过正规方程解直接求得我们所需要的参数。