You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
1.8 KiB
1.8 KiB
4.1 问题的本质
红酒鉴定家的烦恼
身为一为红酒鉴定师,每天打交道打得最多的肯定就是红酒啦。一为合格的红酒鉴定师能根据红酒的颜色、气味、口感、酿造时间、木桶的材质等一系列信息准确的推测出该红酒的品质。
但是人总是喜欢偷懒,当需要在短时间内鉴定大量红酒的品质时,就算是久经沙场的红酒鉴定师,也会觉得心有余而力不足。
如果我们能够使用一种方法,该方法能够根据红酒品质的历史数据来推测出现在需要鉴定的红酒的品质的话,那么红酒鉴定师就可以悠闲地坐在沙发上喝咖啡了。
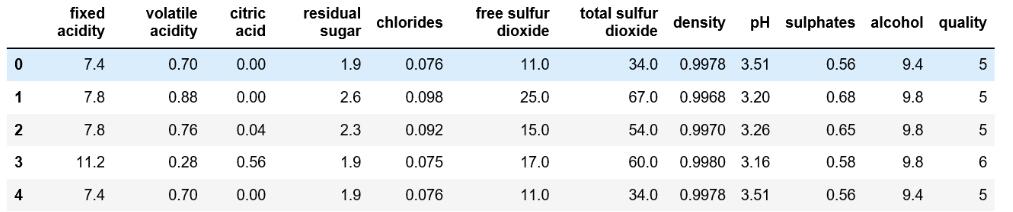
下面是红酒鉴定师收藏多年的红酒数据中的冰山一角,数据中包含了红酒的颜色,酸碱度,酒精度等信息。其中quality表示红酒的品质(该特征是离散特征),数字的值越大,表示红酒的品质越高。
抓住主要矛盾
现在我们想要得到一种算法,自动的能根据红酒的颜色、酸碱度、酒精度等信息来推算出该红酒的品质。而品质这一属性是一种离散值。假设红酒的品质分为 1 到 9 ,9 个等级。那么我们的算法要的事情就是输出 1 到 9 之间的一个数字即可。像这种需要输出离散值的算法,我们通常称之为分类算法。(如果将 9 个等级看成是 9 种类别,可以思考一下算法的输出是不是相当于在做分类的事情。)
作为正式接触数据挖掘算法的第一章,本章的算法应该尽量简单,有效。所以本章将使用k近邻算法来完成红酒品质检测的功能。因为k近邻算法的思想是众多数据挖掘算法中最简单的,非常适合入门。如果你准备好了,请继续往下看。