You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
1.4 KiB
1.4 KiB
13.1 初步分析数据
这一步再熟悉不过了,可能会熟悉地让人心疼。但这又是数据挖掘非常重要也是必不可少的一步。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
datafr = pd.read_csv("./data.csv")
# 查看前10行数据到底长什么样子
datafr.head(10)
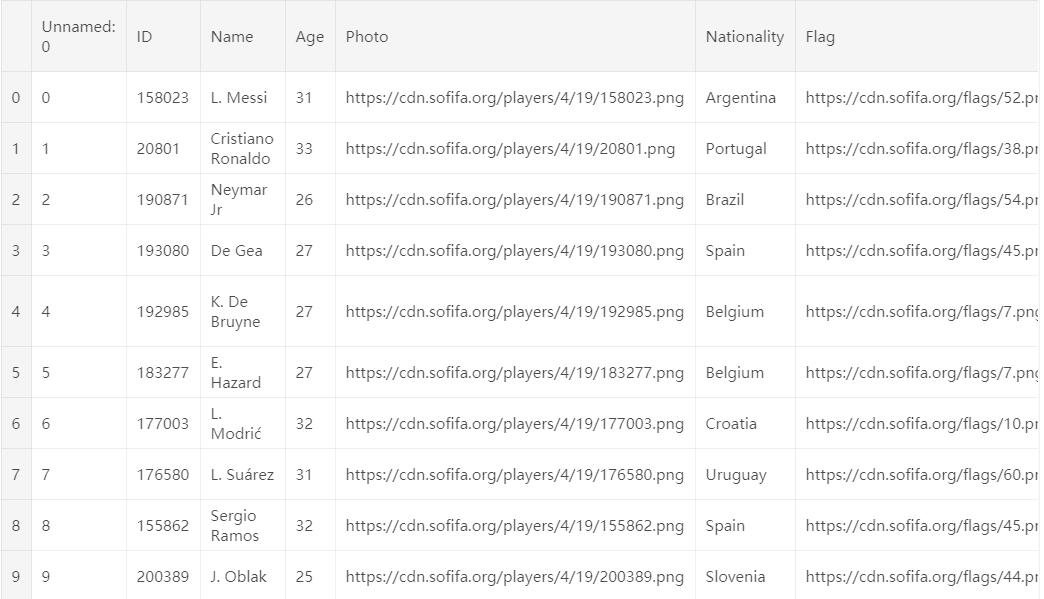
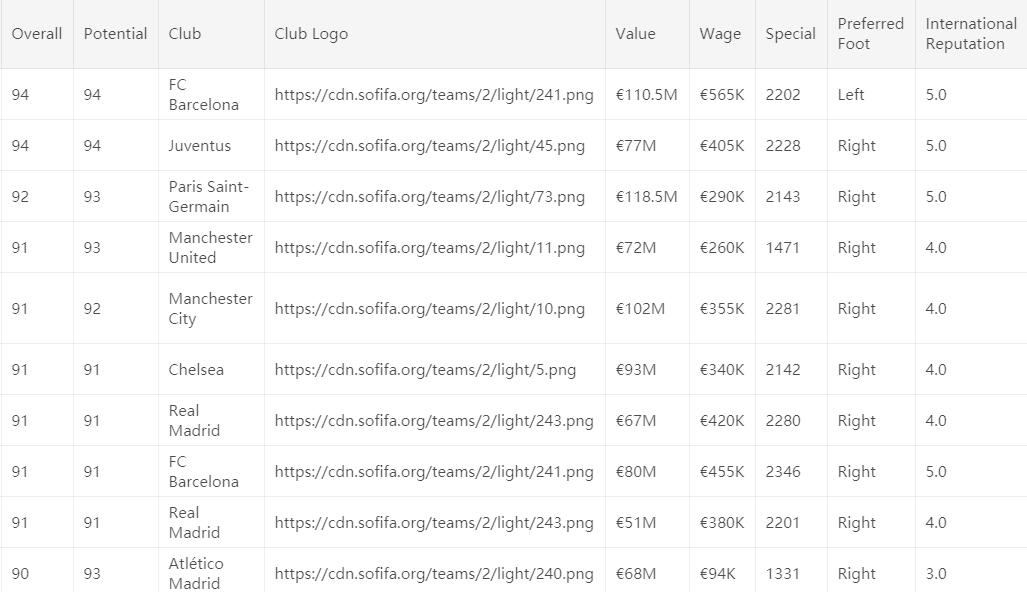
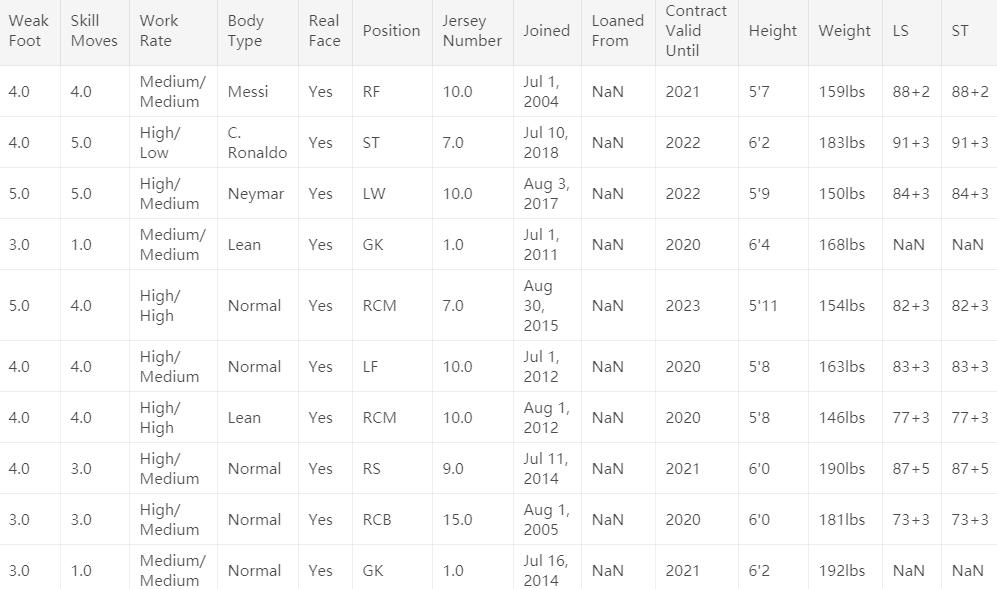
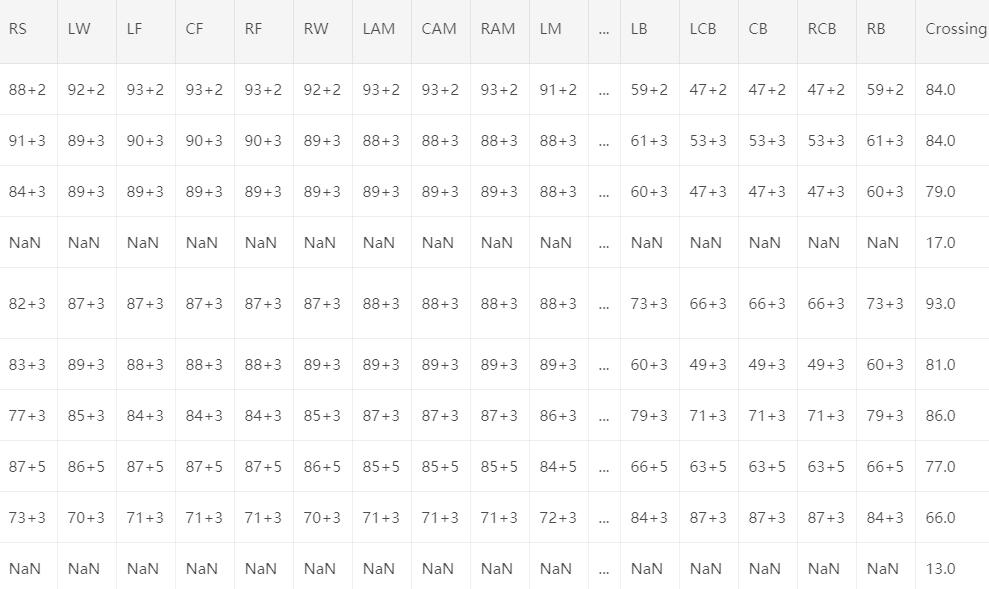

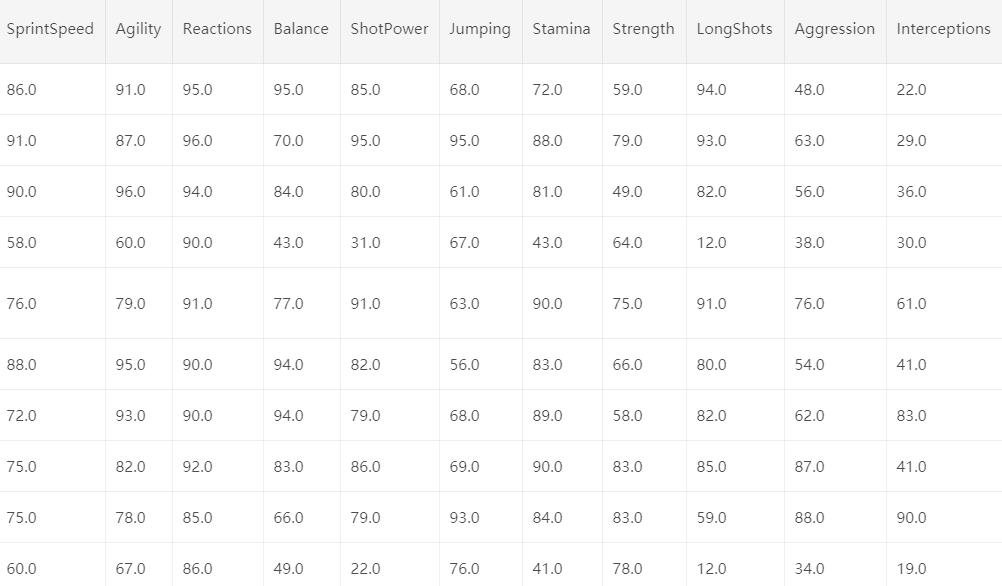
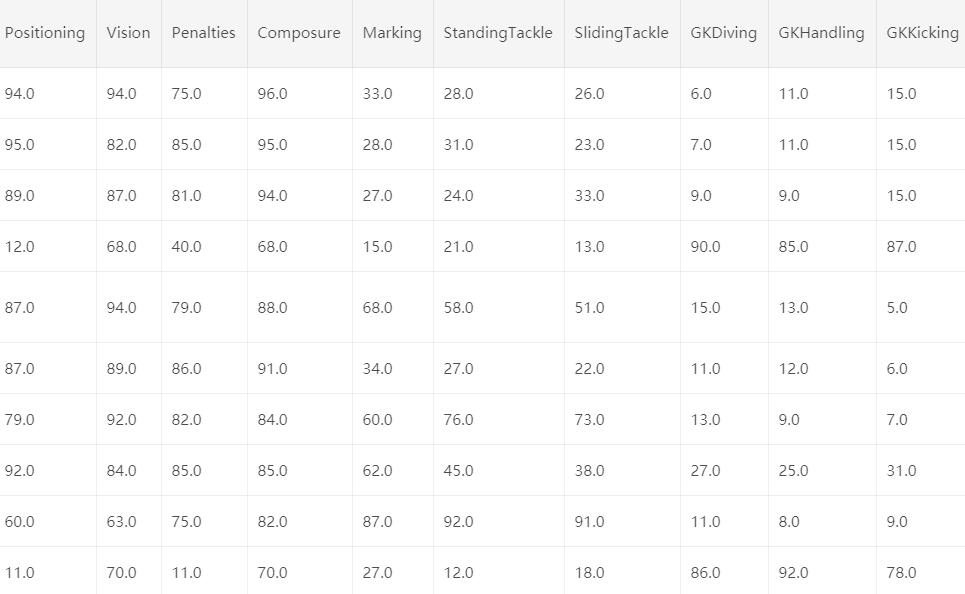
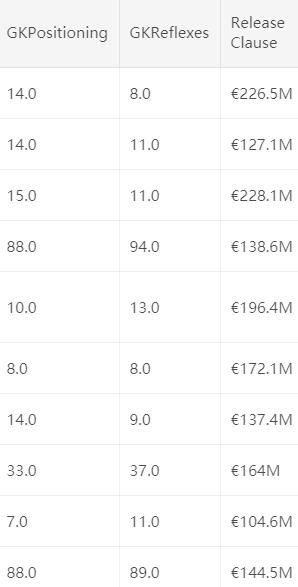
怎么样,是不是感觉有点懵,有这么多特征,还有一些缺失值。看来这个数据集并不是很好处理的样子。是的,我们需要一步一步脚印的来分析它。
还是按照惯例,看一下数据集有多少行多少列。
print("Dimension of the dataset is: ",datafr.shape)

总共 89 个特征!然后再看一下数据缺失的情况。
# 统计出含有缺失值的特征的数量
datafr.isnull().sum().sort_values(ascending=False)
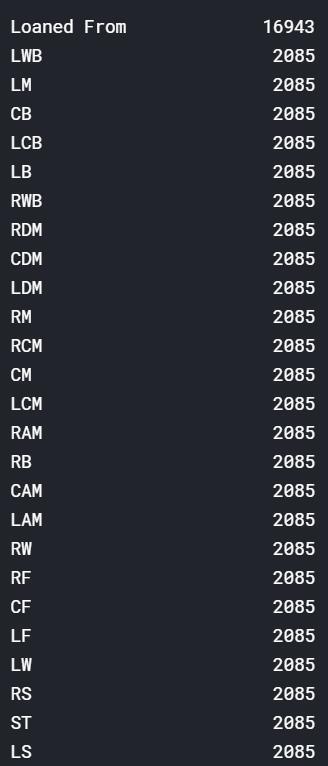
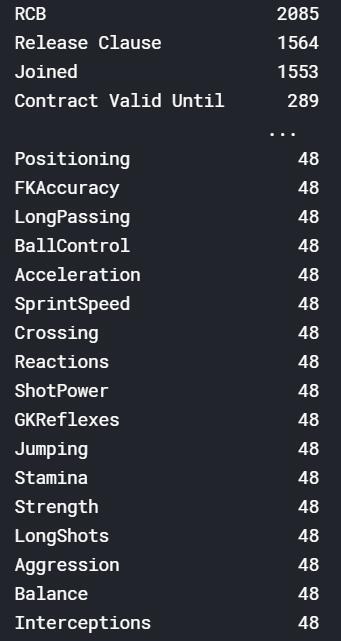

总共 89 个特征,也就只有 13 个特征是完好无损的。不过值得庆幸的是,含有缺失值的特征们的缺失比例并不高,只有 Loaned From 这个特征的缺失严重。所以我们暂且可以认为这个特征没有什么用处,把它删掉就好了。
# 删除Loaned From
datafr.drop('Loaned From',axis=1,inplace=True)