|
|
2 years ago | |
|---|---|---|
| README.md | 2 years ago | |
| comments.xlsx | 2 years ago | |
| content1.txt | 2 years ago | |
| danmu.zip | 2 years ago | |
| danmutongji.xlsx | 2 years ago | |
| python.py | 2 years ago | |
| requirements.txt | 2 years ago | |
| 爬取b站弹幕 | 2 years ago | |
| 附加题 | 2 years ago | |
README.md
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 130 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 240 | 590 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 240 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 10 | 10 |
| · Coding | · 具体编码 | 240 | 300 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 20 | 30 |
| · Test Repor | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 1 | 2 |
| · 合计 | 751 | 902 |
#二、任务要求的实现
##(2.1) 项目设计与技术栈 在完成任务的过程中,我将任务拆分成以下几个阶段: 需求分析 方案设计 数据爬取 数据清洗与处理 数据分析与统计 数据可视化 性能优化 结论报告 使用的技术栈 编程语言:Python 爬虫框架:requests、BeautifulSoup 和json 数据处理:pandas 数据库:MySQL 或 MongoDB(如果需要存储大量数据) 可视化工具:matplotlib、wordcloud 性能分析:VS Code 性能分析插件
##(2.2) 爬虫与数据处理
业务逻辑: 使用python访问多个主流网站并获取与“巴黎奥运会”相关的弹幕数据。 对爬取到的弹幕数据进行清洗和过滤,提取出与 AI 相关的弹幕。 数据分析:统计弹幕中每个关键词出现的次数。
代码设计过程: 实现网页数据的爬取,数据的清洗和关键词提取,最后统计每个关键词的出现频率并生成统计报告。 关键算法说明:
使用 any() 函数检查弹幕中是否包含 AI 相关关键词
使用 Counter库进行频率统计。
##(2.3) 数据统计接口部分的性能改进
性能改进思路:
将数据处理部分的循环由串行改为并行处理(使用 multiprocessing 库)。 优化数据库读写操作,减少多余的 I/O 操作。 使用缓存技术加速重复查询。 性能分析工具:使用了 VS Code 自带的性能分析工具,找到了数据处理部分的瓶颈,并进行了优化。
性能分析图:可以在性能分析工具中生成函数调用栈和消耗时间的报告。
##(2.4) 数据结论的可靠性 结论:
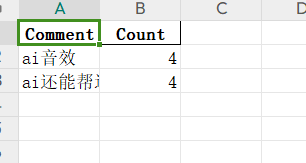
关于巴黎奥运会的AI弹幕,主要集中于'AI给运动员带来的帮助',例如AI能帮助运动员训练
数据依据:
基于爬取到弹幕数据,通过关键词统计得出结论。 ##(2.5) 数据可视化界面的展示 https://file.learnerhub.net/tinymce-image-1726416882778--%E8%AF%8D%E4%BA%91%E5%9B%BE.png https://file.learnerhub.net/tinymce-image-1726416966952--image.png https://file.learnerhub.net/tinymce-image-1726417003114--image.png #三、心得体会 通过这一次的个人编程作业,我对python关于数据爬取的库函数有了深刻的理解,同时我也理解了一个项目从头到尾的开发流程,爬取多个视频的方法我寻找了很久才理解可以通过json来实现,该项目也让我了解到了自身的不足,之前只会根据题目要求去完成代码,现在突然看到这个题目会有些手足无措,但冷静下来分析过后,通过对像request库,panda库这些库的学习,还是顺利完成了此项目
{kind=link}
{kind=link}
{kind=link}