2.7 KiB
什么是强化学习
强化学习是一类算法,是让计算机实现从一开始完全随机的进行操作,通过不断地尝试,从错误中学习,最后找到规律,学会了达到目的的方法。
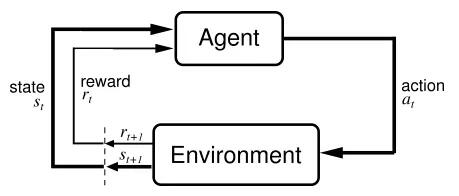
它主要包含四个元素,Agent、环境状态、行动、奖励,强化学习的目标就是获得最多的累计奖励。
让我们想象一下比赛现场:
计算机有一位虚拟的裁判,这个裁判他不会告诉你如何行动,如何做决定,他为你做的事只有给你的行为打分,最开始,计算机完全不知道该怎么做,行为完全是随机的,那计算机应该以什么形式学习这些现有的资源,或者说怎么样只从分数中学习到我应该怎样做决定呢?很简单,只需要记住那些高分,低分对应的行为,下次用同样的行为拿高分,并避免低分的行为。
计算机就是Agent,他试图通过采取行动来操纵环境,并且从一个状态转变到另一个状态,当他完成任务时给高分(奖励),但是当他没完成任务时,给低分(无奖励)。这也是强化学习的核心思想。
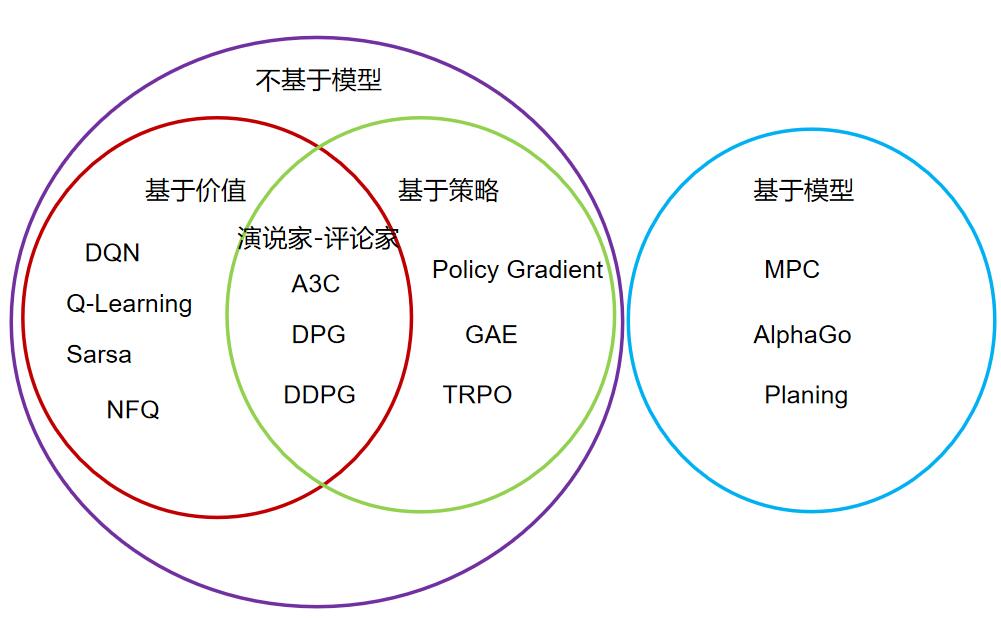
在强化学习中有很多算法,如果按类别划分可以划分成 model-based(基于模型)和model-free(不基于模型)两大类。
如果我们的Agent不理解环境,环境给了什么就是什么,我们就把这种方法叫做model-free,这里的model就是用模型来表示环境,理解环境就是学会了用一个模型来代表环境,所以这种就是 model-based方法。
Model-free的方法有很多, 像Q learning、Sarsa、Policy Gradients都是从环境中得到反馈然后从中学习。而 model-based只是多了一道程序,为真实世界建模,也可以说他们都是model-free的强化学习, 只是Model-based多出了一个虚拟环境,我们可以先在虚拟环境中尝试,如果没问题,再拿到现实环境中来。
model-free中, Agent只能按部就班,一步一步等待真实世界的反馈,再根据反馈采取下一步行动。而model-based,能通过想象来预判断接下来将要发生的所有情况,然后选择这些想象情况中最好的那种,并依据这种情况来采取下一步的策略,这也就是围棋场上AlphaGo能够超越人类的原因。
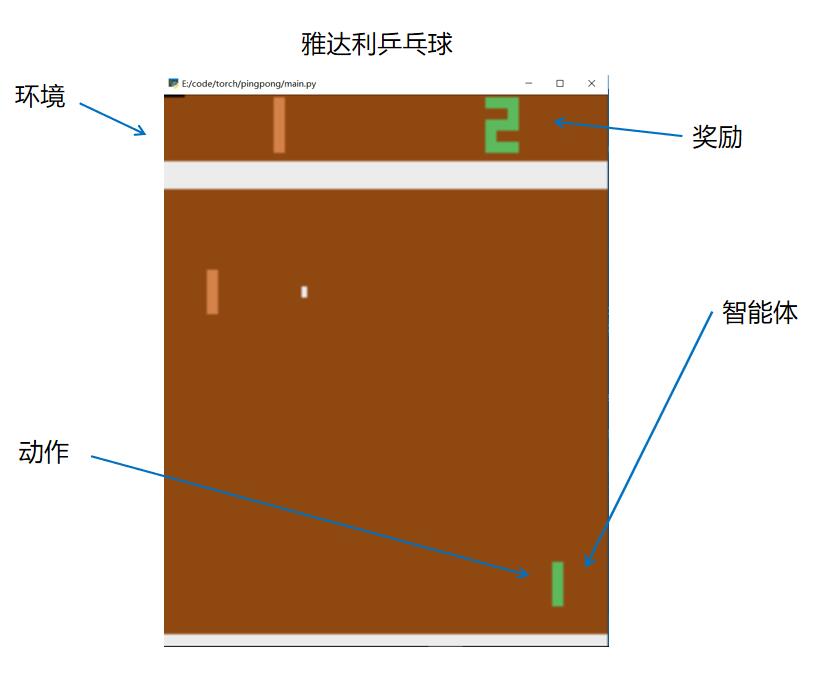
在这里主要介绍一下model-free中基于策略的一种算法,Policy Gradient。在介绍该算法之前,我们先要明确一下这个雅达利乒乓球游戏中的环境状态是游戏画面,Agent是我们操作的挡板,奖励是分数,动作是上或者下。